Improve Article
Save Article
Improve Article
Save Article
In this article, we will get into detail about the three-tier client-server architecture. The most common type of multi-tier architecture in distributed systems is a three-tier client-server architecture. In this architecture, the entire application is organized into three computing tiers
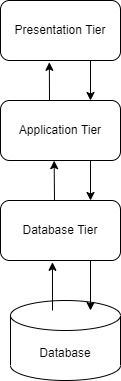
- Presentation tier
- Application tier
- Data-tier
The major benefit of the three tiers in client-server architecture is that these tiers are developed and maintained independently and this would not impact the other tiers in case of any modification. It allows for better performance and even more scalability in architecture can be made as with the increasing demand, more servers can be added.
Three-tier client-server architecture in a distributed system:
- Presentation Tier: It is the user interface and topmost tier in the architecture. Its purpose is to take request from the client and displays information to the client. It communicates with other tiers using a web browser as it gives output on the browser. If we talk about Web-based tiers then these are developed using languages like- HTML, CSS, JavaScript.
- Application Tier: It is the middle tier of the architecture also known as the logic tier as the information/request gathered through the presentation tier is processed in detail here. It also interacts with the server that stores the data. It processes the client’s request, formats, it and sends it back to the client. It is developed using languages like- Python, Java, PHP, etc.
- Data Tier: It is the last tier of the architecture also known as the Database Tier. It is used to store the processed information so that it can be retrieved later on when required. It consists of Database Servers like- Oracle, MySQL, DB2, etc. The communication between the Presentation Tier and Data-Tier is done using middle-tier i.e. Application Tier.
Advantages:
- Logical separation is maintained between Presentation Tier, Application Tier, and Database Tier.
- Enhancement of Performance as the task is divided on multiple machines in distributed machines and moreover, each tier is independent of other tiers.
- Increasing demand for adding more servers can also be handled in the architecture as tiers can be scaled independently.
- Developers are independent to update the technology of one tier as it would not impact the other tiers.
- Reliability is improved with the independence of the tiers as issues of one tier would not affect the other ones.
- Programmers can easily maintain the database, presentation code, and business/application logic separately. If any change is required in business/application logic then it does not impact the presentation code and codebase.
- Load is balanced as the presentation tier task is separated from the server of the data tier.
- Security is improved as the client cannot communicate directly with Database Tier. Moreover, the data is validated at Application Tier before passing to Database Tier.
- The integrity of data is maintained.
- Provision of deployment to a variety of databases rather than restraining yourself to one particular technology.
Disadvantages:
- The Presentation Tier cannot communicate directly with Database Tier.
- Complexity also increases with the increase in tiers in architecture.
- There is an increase in the number of resources as codebase, presentation code, and application code need to be maintained separately.
Определение
Архитектура «Клиент-Сервер» (также используются термины «сеть Клиент-Сервер» или «модель Клиент-Сервер») предусматривает разделение процессов предоставление услуг и отправки запросов на них на разных компьютерах в сети, каждый из которых выполняют свои задачи независимо от других.
В архитектуре «Клиент-Сервер» несколько компьютеров-клиентов (удалённые системы) посылают запросы и получают услуги от централизованной служебной машины – сервера (server – англ. «официант, обслуга»), которая также может называться хост-системой (host system, от host – англ. «хозяин», обычно гостиницы).
Клиентская машина предоставляет пользователю т.н. «дружественный интерфейс» (user-friendly interface), чтобы облегчить его взаимодействие с сервером.

Рис. 1. Архитектура «Клиент-Сервер».
Типы клиент-серверной архитектуры
Архитектуру «клиент-сервер» принято разделять на три класса: одно-, двух- и трёхуровневую. Однако, нельзя сказать, что в вопросе о таком разделении в сообществе ИТ-специалистов существует полный консенсус. Многие называют одноуровневую архитектуру двухуровневой и наоборот, то же можно сказать о соотношении двух- и трёхуровневой архитектур.
Постараемся внести ясность в этот вопрос.
Одноуровневая архитектура (1-Tier)
Одноуровневая архитектура «клиент-сервер» (1-Tier) – такая, где все прикладные программы рассредоточены по рабочим станциям, которые обращаются к общему серверу баз данных или к общему файловому серверу. Никаких прикладных программ сервер при этом не исполняет, только предоставляет данные.
")
Рис. 2. Одноуровневая архитектура «клиент-сервер» (1-Tier).
В целом, такая архитектура очень надёжна, однако, ей сложно управлять, поскольку в каждой рабочей станции данные будут присутствовать в разных вариантах. Поэтому возникает проблема их синхронизации на отдельных машинах. В общем, как можно видеть из рисунка, в этой архитектуре просматривается ещё один уровень – базы данных, что даёт повод во многих случаях называть её двухуровневой.
Двухуровневая архитектура (2-Tier)
К двухуровневой архитектуре «клиент-сервер» следует относить такую, в которой прикладные программы сосредоточены на сервере приложений (Application Server), например, сервере 1С или сервере CRM, а в рабочих станциях находятся программы-клиенты, которые предоставляют для пользователей интерфейс для работы с приложениями на общем сервере.
")
Рис. 3. Двухуровневая архитектура «клиент-сервер» (2-Tier).
Такая архитектура представляется наиболее логичной для архитектуры «клиент-сервер». В ней, однако, можно выделить два варианта. Когда общие данные хранятся на сервере, а логика их обработки и бизнес-данные хранятся на клиентской машине, то такая архитектура носит название “fat client thin server” (толстый клиент, тонкий сервер). Когда не только данные, но и логика их обработки и бизнес-данные хранятся на сервере, то это называется “thin client fat server” (тонкий клиент, толстый сервер). Такая архитектура послужила прообразом облачных вычислений (Cloud Computing).
Преимущества двухуровневой архитектуры:
- Легко конфигурировать и модифицировать приложения;
- Пользователю обычно легко работать в такой среде;
- Хорошая производительность и масштабируемость.
Однако, у двухуровневой архитектуры есть и ограничения:
- Производительность может падать при увеличении числа пользователей;
- Потенциальные проблемы с безопасностью, поскольку все данные и программы находятся на центральном сервере;
- Все клиенты зависимы от базы данных одного производителя;
Трёхуровневая архитектура (3-Tier)
В трёхуровневой архитектуре сервер баз данных, файловый сервер и другие представляют собой отдельный уровень, результаты работы которого использует сервер приложений. Логика данных и бизнес-логика находятся в сервере приложений. Все обращения клиентов к базе данных происходят через промежуточное программное обеспечение (middleware), которое находится на сервере приложений. Вследствие этого, повышается гибкость работы и производительность.
")
Рис. 4. Трёхуровневая архитектура «клиент-сервер» (3-Tier).
Преимущества трёхуровневой архитектуры:
- Целостность данных;
- Более высокая безопасность, по сравнению с двухуровневой архитектурой;
- Защищённость базы данных от несанкционированного проникновения.
Ограничения:
- Более сложная структура коммуникаций между клиентов и сервером, поскольку в нём также находится middleware.
Многоуровневая архитектура (N-Tier)
В отдельный класс архитектуры «клиент-сервер» можно вынести многоуровневую архитектуру, в которой несколько серверов приложений используют результаты работы друг друга, а также данные от различных серверов баз данных, файловых серверов и других видов серверов.
По сути, предыдущий вариант, трёхуровневая архитектура – не более, чем частный случай многоуровневой архитектуры.
")
Рис. 5. Многоуровневая архитектура «клиент-сервер» (N-Tier).
Преимуществом многоуровневой архитектуры является гибкость предоставления услуг, которые могут являться комбинацией работы различных приложений серверов разных уровней и элементов этих приложений.
Очевидным недостатком является сложность, многокомпонентность такой архитектуры.
Характеристики архитектуры «клиент-сервер»
- Асимметричность протоколов. Между клиентами и сервером существуют отношения «один ко многим». Инициатором диалога с сервером обычно является клиент.
- Инкапсуляция услуг. После получения запроса на услугу от клиента, сервер решает, как должна быть выполнена данная услуга. Модификация («апгрейд») сервера может производиться без влияния на работу клиентов, поскольку это не влияет на опубликованный интерфейс взаимодействия между ними. Иными словами, максимум, что может при этом почувствовать пользователь – незначительная задержка отклика сервера в течение небольшого времени апгрейда.
- Целостность. Программы и общие данные для сервера управляются централизованно, что снижает стоимость обслуживания и защищает целостность данных. В то же время, данные клиентов остаются персонифицированными и независимыми.
- Местная прозрачность. Сервер – это программный процесс, который может исполняться на той же машине, что и клиент, либо на другой машине, подключенной по сети. Программное обеспечение «клиент-сервер» обычно скрывает местоположение сервера от клиентов, перенаправляя запрос на услуги через сеть.
- Обмен на основе сообщений. Клиенты и сервер являются нежёстко связанными («loosely-coupled») процессами, которые обмениваются сообщениями: запросами на услуги и ответами на них.
- Модульный дизайн, способный к расширению. Модульный дизайн программной платформы «клиент-сервер» придаёт ей устойчивость к отказам, то есть, отказ в каком-то модуле не вызывает отказа всего приложения. В такой системе, один или больше серверов могут отказать без остановки всей системы в целом, до тех пор, пока услуги отказавшего сервера могут быть предоставлены с резервного сервера. Другое преимущество модульности в том, что приложение «клиент-сервер» может автоматически реагировать на повышение или понижение нагрузки на систему, путём добавления или отключения услуг или серверов.
- Независимость от платформы. Идеальное приложение «клиент-сервер» не зависит от платформ оборудования или операционной системы. Клиенты и серверы могут развёртываться на различных аппаратных платформах и разных операционных системах.
- Масштабируемость. Системы «клиент-сервер» могут масштабироваться как горизонтально (по числу серверов и клиентов), так и вертикально (по производительности и спектру услуг).
- Разделение функционала. Система «клиент-сервер» — это соотношение между процессами, работающими на одной или на разных машинах. Сервер – это процесс предоставления услуг. Клиент – это потребитель услуг.
- Общее использование ресурсов. Один сервер может предоставлять услуги множеству клиентов одновременно, и регулировать их доступ к совместно используемым ресурсам.
Практические применения архитектуры «клиент-сервер»
Архитектуры «клиент-сервер» — один из основных принципов работы сети Интернет. Любой веб-сайт, или приложение в Интернет работает на сервере, а его пользователи являются клиентами. Социальные сети (Фейсбук, ВК и пр.), сайты электронной коммерции (Amazon, Озон и др.) , мобильные приложения (Instagram и т.д.), устройства Интернета вещей (умные колонки или смарт-часы) работают на основе клиент-серверной архитектуры.
Хорошим примером работы системы «клиент-сервер» является автомобильный навигатор. Приложение навигации на сервере собирает данные с многих смартфонов пользователей, на которых установлены клиенты приложения. Кроме того, приложение навигации использует ещё и данные с сервера базы данных – геоинформационной системы, который предоставляет данные, например, о текущих ремонтах дорог, о появлении новых дорог и пр. Данные со многих клиентов (местоположение, скорость) обрабатывается сервером навигации и выдаётся на смартфоны пользователей в виде информации о средней скорости движения по тому или иному участку маршрута.
Практически любая корпоративная сеть или ИТ-система предприятия, как правило, строится по архитектуре «клиент-сервер». В небольших сетях (3-5 компьютеров в компании) функции сервера может выполнять один из рабочих компьютеров. Если число машин в организации более 10, то лучше сделать выделенный сервер (почтовый сервер, приложений, баз данных и пр.), который будет заниматься обслуживанием клиентов – компьютеров и телефонов сотрудников организации.
В домашних сетях архитектура «клиент-сервер» тоже используется довольно часто. Например, в домашнюю сеть могут быть объединены компьютеры членов семьи, один из которых выполняет функции сервера. В домашнюю сеть также могут быть включены такие устройства, как умные колонки, умные домашние устройства (пылесосы-роботы, фотоаппараты, DVD-плееры и пр.), а также «умные» счётчики (вода, электричество) и т.д. Тогда в системе управления сервера, будут видны все параметры, данные и медифайлы (музыка, видео, фото), а также «умные устройства».
Преимущества и недостатки архитектуры «клиент-сервер»
К преимуществам архитектуры «клиент-сервер» можно отнести:
- Централизованность, поскольку все данные и управление сосредоточены в центральном сервере;
- Информационная безопасность, поскольку ресурсы общего пользования администрируются централизованно;
- Производительность, использование выделенного сервера повышает скорость работы ресурсов общего пользования;
- Масштабируемость, количество клиентов и серверов можно увеличивать независимо друг от друга.
К недостаткам архитектуры «клиент-сервер» следует отнести:
- Перегрузку трафика в сети, что является главной проблемой в сетях «клиент-сервер». Когда большое число клиентов одновременно запрашивают одну услугу на сервере, то число запросов может создать перегрузку в сети;
- Наличие единой точки отказа в небольших сетях с одним сервером. Если он отказывает, все клиенты остаются без обслуживания;
- Превышение пределов ресурсов сервера, когда новые клиенты, запрашивающие услугу, остаются без обслуживания. В таких случаях, требуется срочное расширение ресурсов сервера;
- Иногда клиентские программы могут не работать на терминалах пользователей, если не установлены соответствующие драйверы. Например, пользователь посылает запрос на печать документа, а на сервере нет подходящего драйвера для печати данного формата документа на определённом принтере.
Заключение
В настоящее время можно встретить термин Serverless Architecture, т.н. «бессерверная архитектура». Однако, по сути, она представляет собой процесс получения функций сервера в виде облачной услуги. То есть, серверы в облаке тоже есть, но для конечного пользователя они не видны, и он получает их сервисы в виде абстрактной «функции как услуги» FaaS (Function as a Service).
Архитектура «клиент-сервер» является основой большинства корпоративных сетей и берёт свое начало от самых первых вычислительных машин, т.н. «мэйнфреймов». Программное обеспечение для локальных компьютерных сетей, подавляющее большинство которых основано на архитектуре «клиент-сервер», начало создаваться около 50 лет назад.
Дальнейшее развитие информационных технологий также будет происходить в значительной степени с использованием архитектуры «клиент-сервер».
Содержание:

ВВЕДЕНИЕ
Как и любая другая сложно организованная инфраструктура, программное обеспечение должно основываться на прочном фундаменте. Неверное определение ключевых принципов, некорректное определение общих вопросов или отсутствие возможности выявить отдаленные последствия основных решение способны вызвать критические нарушения в работе системы. Современные средства разработки и платформы ускоряют рутинные процессы создания приложений, но не лишают необходимости тщательного проектирования в строгом соответствии с требованиями и на основании конкретных сценариев. Неверно определенная архитектура приложения вызывает нестабильность в работе программного обеспечения, обуславливает невозможность поддержки существующих или перспективных бизнес-процессов, создает сложности при развертывании и администрировании в среде эксплуатации. В процессе выбора оптимального решения проектировщик системы обязан ориентироваться на потребности пользователя, возможности инфраструктуры и поставленные бизнес-задачи.
Востребованность информационных технологий в сфере бизнеса и в повседневной жизни способствует дальнейшему совершенствованию технологий, а также их усложнению в попытке решить поставленные задачи в максимально возможном объеме. Данные преобразования происходят как в области программного, так и аппаратного обеспечения.
Наступление эры персональных компьютеров сделало доступным применение вычислительных технологий не только крупном, но и среднем и малом бизнесе, отодвинув на второй план применение мейнфреймов, популярных на заре информационных технологий. Однако это не уменьшило необходимость обмена накопленными данными, их анализа, обеспечения совместной работы.
Архитектура «клиент-сервер» является одним из вариантов решения этих задач в современных условиях, чья успешность определила ее популярность во всех сферах деятельности. По сей день она остается динамично развивающейся технологией, с каждым днем предоставляющей все больше возможностей для успешного решения бизнес-задач.
В связи с этим, изучение и анализ данной технологии представляются актуальными.
Целью данной работы является детальное рассмотрение вариантов архитектуры «клиент-сервер».
Обозначенная цель определяет следующие задачи курсовой работы:
- Изучить главные характеристики технологии «клиент-сервер»;
- Ознакомиться с основными моделями архитектуры «клиент-сервер»;
3.Детально рассмотреть варианты архитектуры «клиент-сервер», в зависимости от количества уровней, а также типов применяемого программного обеспечения.
ГЛАВА.1 ИСТОРИЯ РАЗВИТИЯ ТЕХНОЛОГИЙ ОБРАБОТКИ ИНФОРМАЦИИ.
1.1.Централизованная модель обработки информации.
Исторически первой наибольшее распространение получила централизованная модель. Ее расцвет связывают с появлением первых мэйнфреймов IBM System/360 в 1964 году и их последующих поколений.
Данная модель предусматривает использование одного или нескольких вычислительных устройств высокой производительности. Данные устройства обеспечивают выполнение большого количества различных приложений. При этом происходит совместное использование приложениями одних и тех же аппаратных ресурсов: оперативной памяти, дисковых и вычислительных систем. Все пользователи имеют непосредственное подключение к системе.
Для работы данных систем применяются специализированные операционные системы, такие как IBM Z/OS, Sun Solaris, HP-UX.
Централизованная модель обработки информации имеет ряд преимуществ, среди которых одним из наиболее важных является уменьшение затрат на передачу данных и сравнительно высокий уровень безопасности за счет нахождения приложений непосредственно рядом с данными. Также к преимуществом данной модели принято относить наличие интегрированных средств администрирования [11].
К недостаткам данных систем относят высокую стоимость оборудования, сложности масштабирования, трудности в настройках под меняющиеся потребности (пользователь зависит от администратора и лишен возможности настроить в полной мере рабочую среду под свои потребности). Компания Gartner предоставила прогноз, что последний мэйнфрейм будет выключен в 1993 году. Однако, несмотря на имеющиеся недостатки, системы централизованной обработки на основе мэйнфреймов продолжают использоваться и в наше время.
Несколько позже, примерно в 1980-х годах, появилась новая модель обработки информации, получившая название клиент-серверной.
1.2.«Клиент-серверная» модель обработки информации.
Клиент-сервер — форма вычислительной или сетевой архитектуры, подразумевающая распределение заданий или сетевой нагрузки между поставщиками услуг (серверами) и заказчиками (клиентами) [6].
Данная модель предусматривает распределение вычислительных ресурсов по большому количеству вычислительных систем, не имеющих совместно используемых ресурсов. При этом каждый отдельный узел обеспечивает функционирования одного или нескольких приложений, а их общее взаимодействие обеспечивается посредством сети. Данная модель возникла с целью получить возможность отказаться от применения мощных вычислительных систем, в связи с их высокой стоимостью и низким уровнем «гибкости».
В основе данной архитектуры лежит программное обеспечение, расположенное, как правило, на различных вычислительных системах и взаимодействующее через вычислительную сеть с помощью стандартизированных сетевых протоколов.
Серверное программное обеспечение выполняет функцию провайдера услуг и предоставляет свои ресурсы, как в виде вычислений, так и в виде данных и их обработки [1].
Высокие требования к серверному программному обеспечению обуславливают характеристики аппаратной платформы, подразумевающие в зависимости от предоставляемых возможностей, повышенную производительность, большой обрабатываемых объем данных, либо их сочетание.
В качестве клиента в наши дни используются, как правило, персональные компьютеры (так называемые «интеллектуальные терминалы», способные запускать собственное программное обеспечение, в отличие от классических терминалов, обеспечивающих только отображение предоставленной сервером информации). Подобная реализация архитектуры клиент-сервер позволяет обеспечить распределенную обработку информации, при которой часть работы выполняется на клиентской машине (например, отображение пользовательского интерфейса, заключительная обработка), а часть на сервере. Такая организация снижает нагрузку на серверное аппаратное обеспечение, позволяя увеличить производительность, либо количество клиентов одновременно работающих с данным сервером.
Поскольку в рамках аппаратного представления компьютеры классифицируются также на клиентов (вычислительные системы, запрашивающие ресурсы) и серверы (вычислительные системы, предоставляющие ресурсы), то одна и та же машина может выполнять функции сервера и клиента одновременно [4].
Применение технологии клиент-сервер допускает использование различных аппаратных платформ и операционных систем в пределах единого окружения. Целостность системы достигается путем применения стандартизированных сетевых протоколов и единых интерфейсов приложений.
Развитие парадигмы объектно-ориентированного программирования позволило унифицировать подход к созданию клиент-серверных приложений, разбив их на три основных компонента [8]:
- Компонент представления, обеспечивающий пользовательский интерфейс.
- Компонент прикладного назначения, предназначенный для решения конкретных задач в рамках приложения.
- Компонент управления, реализующий доступ к требуемым ресурсам (Рис.1).

Рисунок 1. Компоненты приложений.
Архитектура проектируемого приложения подразумевает объединение прикладных требований, с точки зрения решаемой задачи, и технических требований через поиск различных вариантов применения с последующей их реализацией в виде конечного программного обеспечения. Задача на этапе проектирования — выявление требований, влияющих на архитектуру приложения. Правильно построенная архитектура в значительной степени снижает бизнес-риски, связанные с разработкой и внедрением технического решения. Под хорошей архитектурой подразумевается наличие такого свойства, как гибкость, позволяющая адаптироваться к развитию технологий как в области аппаратного и программного обеспечения, так и пользовательских сценариев и требований [6].
На этапе проектирования следует учитывать эффект от принимаемых решений, неизбежно возникающие компромиссы между критериями качества (например между производительностью и безопасностью) и компромиссы, необходимые для решения системных, пользовательских и бизнес-задач. Необходимо принимать во внимание, что архитектура приложения должна [9]:
- раскрывать структуру системы, но скрывать детали реализации.
- Предоставлять возможность реализации всех вариантов использования и сценариев.
- Максимально возможно отвечать требованием всех заинтересованных сторон.
- Соответствовать требованиям как по качеству, так и по функциональности.
ГЛАВА.2 ДВУХУРОВНЕВЫЙ И МНОГОУРОВНЕВЫЙ ВАРИАНТЫ АРХИТЕКТУРЫ «КЛИЕНТ — СЕРВЕР»
2.1.Двухуровневый вариант архитектуры «клиент-сервер».
При анализе любой сети (включая одноранговые), построенной с применением современных сетевых технологий можно обнаружить компоненты клиент-серверного взаимодействия, как правило относящегося к двухзвенной архитектуре. Данное название (two-tier, 2-tier) подобная архитектура получила из-за особенностей реализации, при которой три базовых компонента распределяются между двумя узлами (клиентом и сервером).
Подобная реализация применяется в клиент-серверных системах, предусматривающих предоставление сервером ответа на клиентские запросы напрямую и в полном объеме, с задействованием исключительно собственных ресурсов сервера. Соответственно при этом не выполняются сторонние сетевые приложения и не происходит обращения к сторонним ресурсам для реализации некой части запроса [5].
В зависимости от расположения компонентов системы на стороне сервера или клиента выделяют несколько основных моделей их взаимодействия (в рамках двухзвенной организации архитектуры):
- сервер терминалов — распределенное представление данных
- файл сервер — доступ к удаленной базе данных и файловым ресурсам
- сервер БД — удаленное представление данных
- сервер приложений — удаленное приложение
Двухзвенная организация клиент-серверного приложения считается самой простой. При подобной реализации модели приложение состоит из сервера (иди группы идентичных серверов) и группы клиентов.
Существует два варианта реализации двухзвенного приложения: модель «толстого» клиента и модель тонкого клиента.
Модель «тонкого» клиента подразумевает работу компонента приложения и компонента управления на стороне сервера (Рис.2). На клиентское аппаратное обеспечение возлагается функция работы компонента представления.
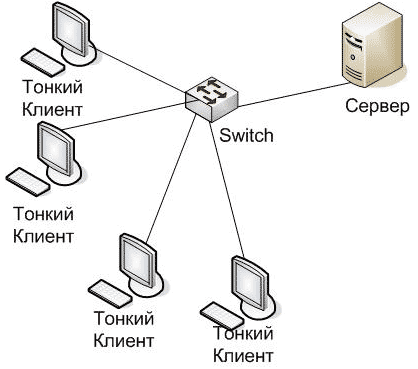
Рисунок 2. «Тонкий» клиент.
Реализация модели толстого клиента подразумевает выполнение компонента представления и прикладного компонента на стороне клиента. На сервер возлагается управление данными. [4]
В первоначальных реализациях двухзвенной архитектуры основная часть прикладных задач решалась на стороне клиента, в то время как на сервер возлагалась задача обработки SQL-запросов (модель «толстый клиент — тонкий сервер»). Впоследствии была создана архитектура, при которой на сервере располагаются хранимые процедуры — откомпилированные программы, реализующие внутреннюю логику работы. Благодаря этом возникла возможность все большую часть задач выполнять на стороне сервера.
«Тонкий» клиент — это самый простой и очевидный способ реализации архитектуры «клиент-сервер», логически происходящий от централизованных систем обработки информации. При этом происходит лишь перенос компонента представления на клиентский компьютер, при этом на само программное приложение возлагаются функции сервера (т. е. оно реализует управленческий и прикладной компоненты). [8]
Тонкий клиент — это самый легкий способ перевода существующих централизованных систем на архитектуру «клиент — сервер». Достаточно перенести пользовательский интерфейс на компьютер пользователя, а само программное приложение будет осуществлять функции сервера (выполнять все процессы приложения и управлять данными).
Как и любая реализация, модель «тонкого клиента» обладает своими недостатками, наиболее ярким из которых является высокая нагрузка на сервер и сеть, вследствие того, что именно на серверной стороне производятся все вычисления, что требует интенсивного обмена данными между клиентским компьютером и сервером. [5]
Наиболее рациональным представляется применение подобной модели организации в системах, наследуемых от центральной модели обработки информации, в которых разделение прикладного компонента и управления данными представляется нецелесообразным.
Кроме того, имеет смысл применять архитектуру «тонкого клиента» в приложениях, подразумевающих интенсивные вычисления и ограниченный объем управления данными, либо наоборот — приложения, подразумевающие обработку больших объемов данных, но не требующие интенсивных вычислений. При этом к аппаратному обеспечению будут предоставляться соответствующие специфические требования, подразумевающие либо высокую вычислительную мощность, либо наличие производительных систем хранения и передачи данных.
К недостаткам подобной реализации архитектуры также относят:
- Трудности реализации, обусловленные низким уровнем гибкости языков типа PL/SQL и отсутствием удобных средств отладки.
- Невысокий уровень производительности программ, написанных на языках типа PL/SQL, в сравнении с приложениями, реализованных на других языках.
- Низкий уровень безопасности программ, созданных с применением языков СУБД; высокая стоимость ошибок.
- Сложности с переносом данных программ на другие платформы
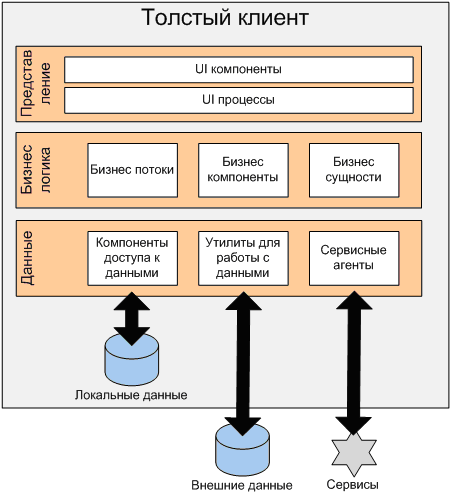 Модель «толстого клиента» позволяет использовать вычислительные мощности клиентских машин, что является актуальным в эпоху распространения персональных компьютеров (Рис.3).
Модель «толстого клиента» позволяет использовать вычислительные мощности клиентских машин, что является актуальным в эпоху распространения персональных компьютеров (Рис.3).
Рисунок 3. «Толстый» клиент.
При этом на стороне клиента происходит выполнения и компонента представления, и компонента прикладного назначения. На стороне сервера реализуется работа компонента управления транзакциями баз данных.
Реализация приложения в форме модели «толстого» клиента позволяет более рационально использовать имеющиеся вычислительные ресурсы. При этом функции приложения распределены между разными компьютерами, что повышает сложность администрирования подобной системы. Рост количества компьютеров в системе вызывает соответствующее повышение уровня сложности. В целом это повышает затраты на обслуживание системы, как временные, так и финансовые [7].
К другим недостаткам данной модели относят:
- Трудности в разграничении прав доступа, в связи с тем, что оно проводится по таблицам, а не действиям.
- Сложности обеспечения защиты данных, обусловленные сложностью формирования правильного распределения полномочий.
- Высокая нагрузка на коммуникационные каналы, обусловленная передачей необработанных данных.
Распространение языка программирования Java появление загружаемых «апплетов» предоставили возможность создавать клиент-серверные модели, представляющие собой нечто среднее между указанными моделями толстого и тонкого клиентов. Часть функций компонента прикладного назначения стало возможным загружать на клиентский компьютер в форме апплетов Java, что позволяет снижать нагрузку на сервер. При этом пользовательское окружение строилось на основе web-браузера, имеющего возможность запускать апплеты. Но такой подход имеет свои сложности, обусловленные, во многом, дополнительными трудностями администрирования и разработки приложений. Это связано с недостаточной стандартизированностью технологий, применяемых в браузерах [7]. Например, устаревшие версии браузеров, установленные на старых клиентских компьютерах, порой не имеют возможность исполнения апплетов Java.
Таким образом можно сказать, что двухуровневую модель организации клиент-серверного приложения целесообразно применять при обеспечении доступа к серверу приложений, а также при создании приложения по взаимодействию клиента с сервером баз данных [6]. Подобная архитектура может оказаться оптимальной в случае функциональной неизменности клиентской части приложения, при наличии эффективного системного управления.
Один из основных вопросов, встающих перед разработчиком двухуровневого приложения является расположение трех основных программных компонентов (представления, прикладного и управления) на двух аппаратных уровнях. Неизбежные компромиссы могут вызывать сложности с уровнем производительности и масштабируемости (при использовании архитектуры «тонкого клиента»), либо с администрированием системы (при использовании «толстого клиента»). [7]
2.2.Трехуровневый вариант архитектуры «клиент — сервер».
В связи с наличием ряда серьезных проблем при реализации двухуровневой модели «клиент-сервер» было продолжено развитие данной архитектуры, благодаря чему была сформирована трехуровневый вариант.
Его активное развитие началось с середины 90-х годов. При этом информационная система по-прежнему представлена тремя компонентами (представления, прикладной и доступа к данным), но реализация данной модели представлена клиентским приложением («тонкий клиент»), взаимодействующим с сервером приложений, подключенным к серверу базы данных [10].
Первое звено данной модели представлено тонким клиентом, с работающим на нем компонентом представления. У него отсутствует прямая связь с базой данных, что повышает уровень безопасности. На данном уровне выполняются операции авторизации, валидации, шифрования, а также элементарные операции с данными. Вынесение прикладного компонента за пределы клиентского компьютера позволяет повысить масштабируемость информационной системы.
Основная часть бизнес-логики приложения располагается на уровне сервера приложений, представляющего второй уровень модели. Программное обеспечение данного звена выполняет задачи, требующие высокой вычислительной мощности, что позволяет снизить нагрузку на клиентские компьютеры, которые отправляют запросы не напрямую в базу данных, а к промежуточному слою. [9]
Сервер базы данных, представленный, как правило стандартной реляционной или объектно-ориентированной СУБД, является третьим уровнем модели.
Данный уровень также содержит хранимые процедуры, триггеры и схемы, представляющие приложение в терминах реляционной модели.
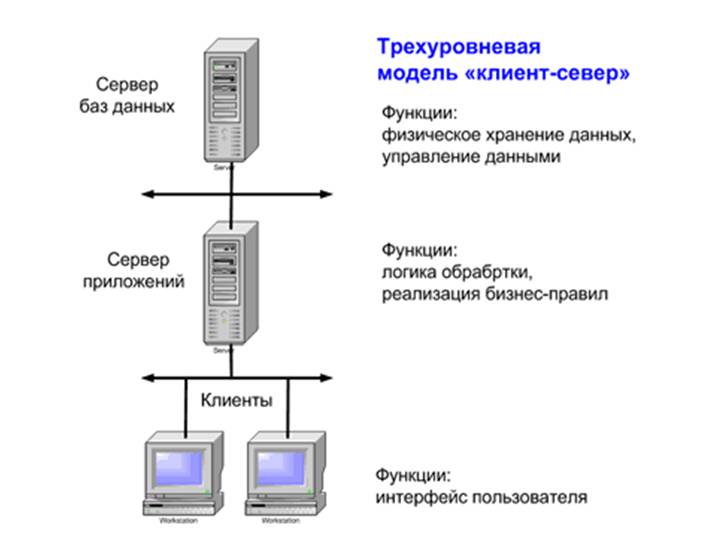
Рисунок 4. Трехуровневая модель архитектуры «клиент-сервер»
Основным отличием трехзвенной модели клиент-сервер является наличие промежуточного программного обеспечения (middleware), детальный разбор которого будет проведен в отдельной главе (Рис.4).
При использовании трехуровневой архитектуры снижается нагрузка на клиентское приложение, связанная с обработкой данных, его основной задачей становится исполнение компонента представления для информации, поступающей в обработанном виде с сервера приложения. Это снижает интенсивность обмена данными между клиентом и серверной частью, что позволяет разгружать каналы связи. При этом его реализация может быть выполнена на основе универсального браузера, с использованием унифицированных коммуникационных протоколов и общедоступных библиотек [8].
Интенсивный обмен данными, при использовании трехзвенной архитектуры, предполагается между сервером приложений и СУБД. Поскольку оба они могут располагаться в одном помещении, или быть развернутыми в виде логических модулей на одном физическом сервере это не вызывает перегрузки сети передачи информации.
При этом следует учитывать, что приложения, предъявляющие высокие требования с точки зрения безопасности, предусматривают выделение отдельного компьютера для выполнения функций сервера баз данных, который будет соединен с одним или несколькими серверами приложений, к которым подключены клиентские компьютеры.
Трехуровневую модель можно развернуть как в пределах корпоративной интранет-сети, так и распределенного интернет-приложения, в котором функции сервера приложений выполняет удаленный web-сервер.
2.3.Многоуровневый вариант архитектуры «клиент-сервер».
Дальнейшим развитием клиент-серверной архитектуры является многоуровневая модель, которая предусматривает использование нескольких серверов обработки данных.
Данная организация нацелена на дальнейшее разделение систем исполнения компонентов с целью более эффективного использования аппаратных ресурсов, снижения нагрузки на сеть передачи данных и повышения возможностей масштабирования. При этом следует учитывать, что трехуровневая модель является частным случаем многоуровневой, которую выделяют отдельно в связи с ее распространенностью и простотой организации.
Применение многоуровневой архитектуры целесообразно при использовании информации, хранящейся в нескольких источниках данных. При этом сервер, находящийся между серверами баз данных и сервером с реализованной бизнес-логикой выполняет задачу сбора разрозненных данных и их предоставления в целостном виде серверу приложений (Рис. 5) [9].
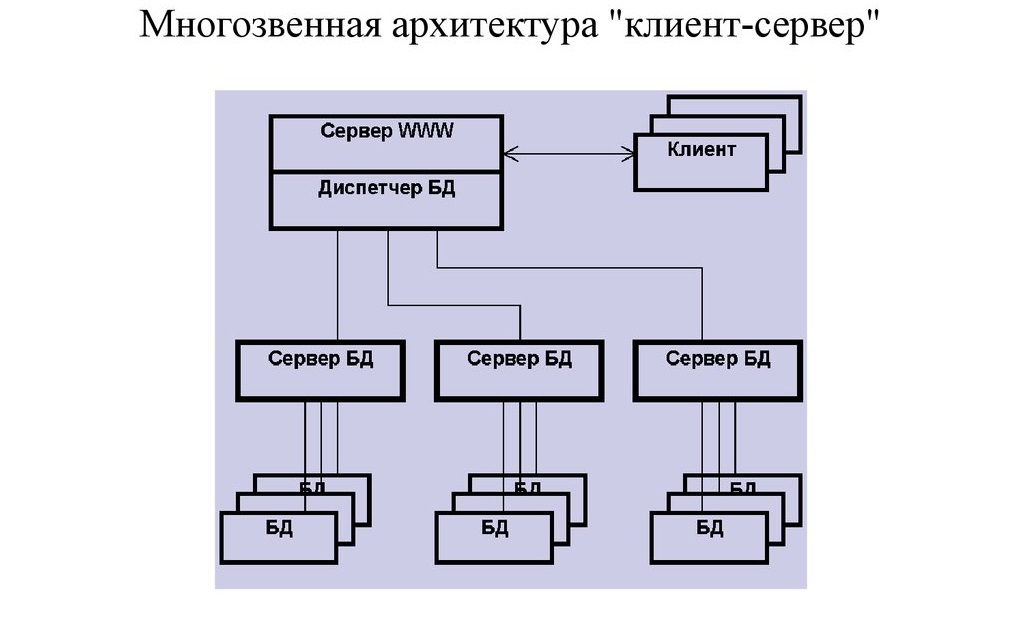
Рисунок 5. Многоуровневая архитектура «клиент-сервер».
При этом многоуровневое клиент-серверное приложение достаточно просто разворачивается на базе web-технологий. При этом в качестве клиентской части приложения используется универсальный браузер, а сервер приложений дополняется web-сервером. Вызов процедур сервера приложений создают с помощью технологий Java или Common Gateway Interface (CGI).
CGI – стандарт интерфейса, применяемый для обеспечения связи внешней программы с web-сервером. Программу, работающую по такому интерфейсу совместно с web-сервером, принято называть шлюзом.
Существует классификация, согласно которой в многоуровневой архитектуре выделяют пять уровней [9]:
- Представление
- Уровень представления
- Уровень логики
- Уровень данных
- Данные
Представлению соответствует та информация, которую непосредственно видит пользователь. К ней относятся изображения, сгенерированные html-страницы, таблицы стилей.
К уровню представления относятся элементы, реализующие общение с системой. Задачи приложения на этом уровне — отображение информации и интерпретация вводимых пользователем команд с их модификацией в соответствующие операции, представленные на уровне логики и данных.
Уровень логики реализует прикладные функции системы, необходимые для выполнения поставленной пользователем цели. К ним относятся вычисления на основании вводимых и хранимых данных, обеспечение проверки элементов данных, обработка команд, приходящих от уровня представления, и передача информации на уровень данных.
Уровень доступа к данным представлен компонентами, обеспечивающими взаимодействие со сторонними системами, выполняющими задачи, необходимые приложению [5].
Данные системы — данные которыми оперирует система, и которые, как правило, хранятся в базе данных.
Как и любая архитектура приложения, многоуровневая имеет смови преимущества и недостатки.
К достоинствами многоуровневой архитектуры относятся: [8]
- масштабируемость
- облегченная конфигурируемость вследствие изолированности уровней
- возможность быстро переконфигурировать систему при возникновении сбоев, а также при плановом обслуживании на одном из уровней
- повышенный уровень безопасности
- повышенный уровень надежности
- упрщение администрирования клиентского ПО
- сниженные требования к скорости передачи данных между сервером приложений и терминалами
- невысокие требования к вычислительным возможностям терминалов, что позволяет снизить их стоимость.
К недостаткам относится [7]:
- увеличение сложности серверной части приложения и, как следствие, рост расходов на администрирование и обслуживание
- увеличение сложности создания приложений
- высокие требования к производительности серверов приложений и сервера базы данных, соответственно, их высокая стоимость
- высокие требования к скорости канала между серверами приложений и сервером базы данных.
Несмотря на ряд недостатков, распределенные приложения реализованные в виде многоуровневой архитектуры завоевывают все большую популярность на рынке программного обеспечения в самых различных областях: от банковских систем до приложений в игровой сфере.
ГЛАВА.3 ОСНОВНЫЕ ХАРАКТЕРИСТИКИ ПРОМЕЖУТОЧНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
3.1.Общая характеристика промежуточного программного обеспечения.
Компания International System Group дает следующее определение этому звену клиент-серверного приложения: это специальный уровень прикладной системы, который расположен между бизнес-приложением и коммуникационным уровнем и изолирует приложение от сетевых протоколов и деталей операционных систем [12].
Вычислительная среда клиент-серверного приложения может быть основана на различных операционных системах, аппаратных платформах, протоколах передачи данных, систем управления баз данных и средствах разработки.
Наличие общих прикладных интерфейсов промежуточного ПО обеспечивает взаимодействие между отдельными частями системы, не раскрывая подробности реализации архитектуры. При этом изменения в системе, связанные, к примеру, с масштабируемостью, не требуют внесения изменений в приложение, при условии что API промежуточного ПО остается неизменным.
Данный уровень предоставляет возможность передачи и анализа разнородной информации. К примеру, формат представления данных, применяемый в мэйнфремах, отличается от того, что используется в Unix- или Windows- системах, но эта проблема нивелируется путем применения промежуточного программного обеспечения. Можно сказать, что данное звено играет роль «информационной шины», построенное над сетевым уровнем и предоставляющей доступ приложениям к разнородным ресурсам, а также обеспечивающей платформонезависимую связь отдельных прикладных компонентов [14].
Существующее промежуточное программное обеспечение можно классифицировать на две группы: реализующее доступ к базам данных и реализующее межпрограммное взаимодействие.
Вторая группа включает в себя:
- ПО, обеспечивающее вызов удаленных процедур (RPC)
- мониторы обработки транзакций
- средства интеграции распределенных объектов
- ПО, реализующее обработку сообщений
Поскольку множество прикладных задач имеет большое разнообразие, то создание универсального промежуточного программного обеспечения невозможно. Тем не менее на рынке наблюдается тенденция интеграции различных видов ПО внутри одного пакета, например брокеров объектных запросов и мониторов обработки транзакций.
Рассмотрим отдельные типы промежуточного ПО.
3.2.Системы доступа к БД.
Системы доступа к БД — один из наиболее распространенных типов ПО. Необходимость в подобных решениях возникает в разнородных системах, обеспечивающих одновременный доступ к различным источникам данных, включая СУБД и хранилища данных от разных поставщиков [12]. При этом на сервере приложений развертывается SQL-шлюз, представляющий собой комплекс интерфейсов приложений, предоставляющих возможность построения унифицированных запросов к разнородным данным. Промежуточное ПО данного типа проводит анализ запроса с последующим его преобразованием в SQL-диалект требуемой СУБД. При этом используется синхронный механизм коммуникации, при котором исполнение приложения, осуществившего запрос, приостанавливается до получения данных. Подобный механизм коммуникации может создавать сложности с масштабированием приложения [14]. Применение подобного ПО востребовано в системах поддержки принятия решений, которые агрегируют данные из большого количества разнородных источников, но при этом не требуют управления оперативными транзакциями, например система, выстраивающая прогноз уровня продаж.
3.3.Вызов удаленных процедур.
Вызов удаленных процедур (remote procedure call) — программно обеспечение, реализующее организацию взаимодействия удаленных прикладных компонентов. Данный тип ПО организует синхронный тип коммуникации между прикладными модулями на клиентской и серверной сторонах. Чтобы обеспечить связь, вызов функции и передачу результата создаются специальные модули, называемые суррогатами (клиентский и серверный), к которым и происходит обращение. Суррогаты не содержат компонентов, реализующих бизнес-логику, и служат для обеспечения взаимодействия прикладных компонентов [12]. Любая функция, к которой может произойти обращение из удаленного клиента, обязана иметь реализацию подобного суррогатного процесса. При выполнении вызова клиентской программой удаленной процедуры он, включая параметры, поступает к клиентскокму суррогату. Тот выполняет преобразование вызова в форму сетевого сообщения и передает на сторону серверного суррогата. Тот производит распаковку полученных данных и их передачу прикладному серверу, выполняя затем обратную операцию с полученными результатами. Таким образом происходит изоляция прикладных модулей как на стороне сервера, так и клиента от уровня сетевых коммуникаций.
Таким образом происходит реализация принципов структурного программирования в распределенной среде. Клиентская часть приложения обращается к процессу-суррогату как к действительному серверному приложению, причем этот вызов абсолютно идентичен вызову локальной функции. При этом за вызовом удаленной процедуры следует передача управления той же процедуре, и, как следствие, приостановка выполнения клиентского приложения на период реализации вызова.
Данный механизм имеет свои недостатки, в частности клиентская часть привязана к конкретным серверным суррогатам с этапа компиляции приложения, и не имеет возможности изменения в период выполнения [14].
Подобных недостатков лишены более новые решения, вроде ПО, ориентированного на обработку сообщений предоставляющих возможность динамического выбора сервера, или мониторов обработки транзакций, имеющих поддержку оптимального распределения нагрузки между серверами и средства восстановления.
В основе ПО вызова удаленных процедур лежит язык описания интерфейсов (interface definition language), посредством которого создаются интерфейсы, определяющие контрактные отношения между клиентской и серверной сторонами. Интерфейс включает определение имени функции, а также описание параметров вызова и результатов его обработки. Подобный инструмент обеспечивает независимость механизма вызова удаленных процедур от конкретных языков программирования: при вызове удаленной процедуры на стороне клиента могут применять свои языковые конструкции, которые модифицируются IDL-компилятором в собственный формат. Соответственно, на стороне сервера происходят преобразования в форму языка программирования, с помощью которого реализована серверная часть приложения [12].
В основе некоторой части программного обеспечения этого типа лежит стандарт Open Group DCT RPC.
DCE (Distributed Computer Environment) относится к категории свободно распространяемого программного обеспечения и представлено в виде нескольких реализаций, предназначенных под конкретные операционные системы. Кроме основного механизма обеспечения взаимодействия компонентов распределенного приложения, DCE включает в себя реализацию некоторых востребованных в подобной среде служб, таких как распределенная файловая система, служба каталогов, средства обеспечения безопасности (Рис.6).
DCE имеет свои ограничения, в частности синхронные механизм коммуникации обуславливает сложности масштабируемости системы и снижают производительность, потому на сегодняшний день востребованы конкурирующие технологии промежуточного ПО, такие как архитектура распределенных объектов CORBA, или ПО, ориентированное на передачу сообщений. При этом DCE может служить дополнительным компонентом новейшего ПО этой сферы [14].
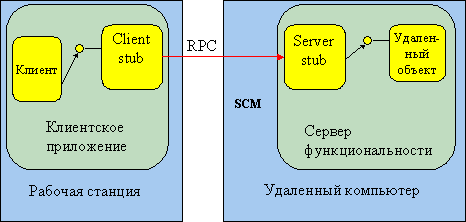
Рисунок 6. Служба вызова удаленных процедур
Кроме того на рынке существуют реализации вызова удаленных процедур на основе асинхронного механизма коммуникации. Подобная реализация не останавливает исполнение клиентского процесса в период выполнения запроса, что позволяет сократить объем поддерживаемой информации о коммуникации между клиентом и сервером, как следствие это обеспечивает лучшую масштабируемость подобных систем.
3.4.Мониторы обработки транзакций.
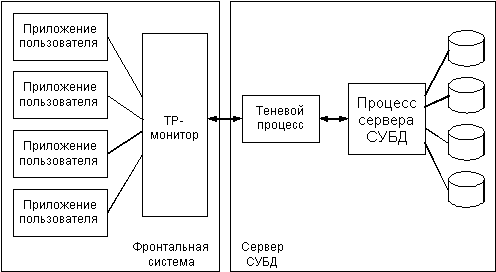
Мониторы обработки транзакций — тип промежуточного программного обеспечения, который широко применялся на мэйнфреймах для развертывания банковских и страховых систем, и использовал специфическое окружение, предназначенное для этих машин [13]. В 90-х годах прошлого столетия появились реализации данного ПО в среде Unix и Windows (Рис.7).
Основной задачей этого ПО в период появления было снижения числа соединений терминалов с базами данных. При этом, обращение клиентского приложения к серверу базы данных вызывает запуск отдельного процесса. Мониторы обработки транзакций брали на себя посреднический функции между терминалом и базой данных, становясь таким образом концентратором соединений. Со временем мониторы обработки транзакций расширили свою функциональность, став одним из наиболее сложноорганизованных приложений промежуточного программного обеспечения.
Как следует из названия, их основное предназначение — автоматизированная поддержка приложений, созданных в форме последовательности транзакций.
Каждая транзакция представляет собой некий комплекс обращений к базе данных (или иному ресурсу) и некоторых действий над ней, который характеризуется наличием четырех свойств: атомарность, согласованность, изолированность и долговременность (ACID: Atomicity, Consistency, Isolation, Durability) [12].
- Атомарность — операции транзакции представлены минимальным неделимым блоком, у которого определены начало и конец. Данный блок либо выполняется в полном объеме, либо не исполняется вовсе. В случае возникновения сбоя в процессе исполнения транзакции, выполняется откат к исходному состоянию.
- Согласованность — после исполнения блока транзакции все используемые ресурсы имеют согласованное состояние.
- Изолированность — механизм монитора обработки транзакций реализован таким образом, что при одновременном доступе транзакций, поступающих от различных приложений к разделяемым ресурсам не происходит их взаимного влияния.
 Долговременность — изменения ресурсов, произошедшие в ходе исполнения транзакции являются долговременными.
Долговременность — изменения ресурсов, произошедшие в ходе исполнения транзакции являются долговременными.
 Долговременность — изменения ресурсов, произошедшие в ходе исполнения транзакции являются долговременными.
Долговременность — изменения ресурсов, произошедшие в ходе исполнения транзакции являются долговременными.Рисунок 7. Монитор обработки транзакций.
Те системы, в которых не реализован механизм монитора обработки транзакций, выполнение принципа ACID возлагается на серверы распределенной базы данных, использующей протокол 2PC.
Данный протокол определяет двухфазный процесс, при котором в первой фазе все задействованные ресурсы опрашиваются о готовности к выполнению запрошенных действий. В случае. Если от каждого из серверов получен положительный ответ, происходит исполнение транзакции. В случае возникновения сбоя на любом из уровней, выполняется откат всей транзакции с возвращением системы в исходное состояние.
Но исполнение протокола P2C может быть гарантированно исполнено в системе с распределенными базами данных лишь при условии, что все источники данных относятся к одному поставщику. Поэтому в масштабных распределенных средах, включающих тысячи терминалов и работающих с множеством разнородных источников данных возникает необходимость в использовании мониторов обработки транзакций [14]. Они обеспечивают эффективную координацию при работе с разнородными данными от различных поставщиков за счет применения транзакционной архитектуры XA, являющейся стандартом для этого типа промежуточного программного обеспечения. Данная архитектура предоставляет интерфейс для обеспечения взаимодействия монитора транзакций с менеджеров ресурсов, таким как СУБД.
Спецификация XA входит в общий стандарт распределенной обработки транзакций (DTP — distributed transaction processing), разработанного группой X/Open [13].
Данный стандарт обеспечивает совместную работу с ресурсами множества клиентских программ, сохраняя согласованность системы.
На уровне прикладных программ взаимодействие с монитором транзакций выполняется путем применения интерфейса TX, обеспечивающего реализацию семантики транзакций, разделяя запросы на логические составляющие.
Кроме указанного, современные мониторы обработки транзакций берут на себя функции планирования, распределения ресурсов и определения приоритетов нескольких приложений одновременно, за счет чего достигается снижение вычислительной нагрузки и сокращается время отклика системы. При этом обеспечивается более эффективное использование многопоточности.
Мониторы транзакций предоставляют мультиплексирование запросов от нескольких терминалов к ресурсам. Для большинства приложений непосредственный доступ клиентского приложения к базе данных составляет лишь некоторую часть от общего времени соединения. С применением мониторов транзакций становится возможным обслуживание 100 клиентских терминалов за счет 10 активных соединений с сервером, на котором развернуты требуемые ресурсы. Это позволяет преодолевать одно из наиболее «узких мест» в обеспечении производительности и масштабируемости распредленных приложений — необходимости поддержки индивидуального соединения с ресурсом для каждого из клиентских приложений. Часть современных мониторов транзакций содержат функционал, позволяющий оптимизировать нагрузку на серверы и обеспечивающий восстановление после сбоя.
Резюмируя, можно сказать, что мониторы обработки транзакций являются эффективным механизмом, позволяющим реализовать распределенное приложение со сложной бизнес-логикой.
3.5.Интеграция распределенных объектов.
Интеграция распределенных объектов — механизм, реализуемый промежуточным программным обеспечением, позволяющий интегрировать объекты, расположенные на удаленных платформах [12].
В результате развития объектно ориентированной-парадигмы возникло два стандарта, имеющих отношение к распределенным приложениям — общая архитектура брокеров объектных запросов CORBA (Common Object Request Broker Architecture), разработанная группой OMG и COM/DCOM (Common Object Model/Distributed COM), созданный компанией Microsoft.
Данные стандарты определяют принципы вызова удаленных процедур на объектные распределенные приложения и обеспечивают прозрачность реализации и физического размещения серверного объекта для клиентской части приложения. Кроме того они предоставляют возможность взаимодействия объектов, созданных на различных объектно-ориентированных языках, не раскрывая при этом детали сетевого взаимодействия.
В DCOM взаимодействие удаленных объектов основано на спецификации DCE RPC, в то время как CORBA содержит представление брокера объектных запросов (ORB), в котором реализован синхронный механизм, имеющий сходство с механизмом вызова удаленных процедур (RPC).
ORB реализует отправку объектных запросов, обеспечивает поиск требуемых сервисов и возврат результата. Одним из базовых компонентов стандарта CORBA является язык описания интерфейсов IDL, который обеспечивает «контрактные» отношения между терминалом и сервером и реализуется независимость от конкретного объектно-ориентированного языка [14].
В CORBA IDL реализованы основные принципы объектно-ориентированной парадигмы: инкапсуляция, полиморфизм, наследование. DCOM также предполагает использование собственной версии IDL разработанной Microsoft, но в рамках этой модели он выполняет вспомогательную функцию и применяется для упрощения описания объектов. Реальная интеграция, при применении данной технологии, происходит на уровне бинарных кодов, а не абстрактных интерфейсов, что составляет одно из основных отличий между двумя стандартами.
В соответствие с объектно-ориентированной парадигмой обе модели предоставляют возможность динамического связывания удаленных объектов, при этом клиентское приложение может выполнить обращение к серверному объекту на этапе исполнения, не обладая информацией о данном объекте на этапе компиляции). С этой целью в CORBA реализован интерфейс динамического вызова DII, в модели COM существует механизм OLE Automation [13]. При необходимости предоставляется информация о доступных объектах сервера из хранилища метаданных об объектах: Type Library при использовании стандарта COM и Interface Repositary в случае применения CORBA. Данный механизм обладает особой ценностью при реализации больших распределенных приложений, поскольку предоставляет возможность изменять функциональность серверов без существенной модификации клиентской части приложения.
Одно из основных преимуществ CORBA заключается в кроссплатформенности данного решения и поддержке гетерогенных окружений, в то время как DCOM является разработкой одной компании, и оптимизировано под использование в системах построенных на ОС Windows. Так же следует отметить более широкую поддержку CORBA в средствах разработки от различных поставщиков.
3.6.Промежуточное ПО, ориентированное на обработку сообщений.
Промежуточное ПО, ориентированное на обработку сообщений — сравнительно новая технология, при использовании которой между приложениями происходит обмен байтовыми строками, называемыми сообщениями, путем обращения к API- интерфейсу Message Oriented Middleware (MOM) [12]. Это позволяет изолировать приложения от операционной системы и сетевых протоколов. Данный тип промежуточного программного обеспечения поддерживает не только клиент-серверную модель, но и приносит элементы равноправного взаимодействия (модель peer-to-peer) между отдельными компонентами архитектуры.
Данная модель реализует как синхронную, так и асинхронную связь на основе сетевых протоколов как с установлением соединения, так и без него, что обеспечивает высокий уровень гибкости и адаптируемости системы под меняющиеся условия.
Все примеры данной архитектуры принято классифицировать на три типа, в зависимости от выбранного типа обмена сообщениями:
- очереди сообщений,
- подписка/публикация,
- передача сообщений
Для реализации взаимодействия приложений системы с передачей сообщений устанавливается логическое соединение между отдельными программными компонентами. Подобное решение плохо подходит для слабо связанных программ.
Модели иного типа представляет асинхронный механизм очереди сообщений (Рис.8). Подобная реализация не требует поддержки непосредственного соединения одного компонента с другим, при этом осуществляет гарантированную доставку сообщения, даже при условии, что конечное приложение на данный момент недоступно. Приложение-отправитель передает сообщение механизму очереди и продолжает свое выполнение. Сообщение помещается при этом в промежуточное хранилище, расположенное на диске или в оперативной памяти, откуда передается приложению получателю немедленно, или спустя какое-то время, когда получатель будет доступен.
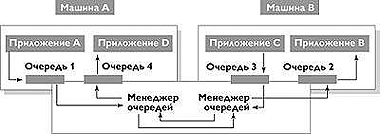
Рисунок 8. Механизм очереди сообщений.
Соответственно, модули, применяющие подобную организацию связи, могут работать независимо друг от друга, не нуждаясь во временной синхронизации, что является подходящим решением для приложений, ориентированных на мобильных пользователей, а также для поддержки приложений, развернутых в среде с медленными либо ненадежными соединениями [12].
Значительная часть подобных систем включают в себя менеджер очереди, который предназначен для управления локальными очередями, обеспечивает гарантированную передачу сообщения приложению-адресату, и путем коммуникации с менеджерами других узлов контролирует маршрут передачи сообщения по сети, выбирая иной путь при необходимости.
Очереди сообщений могут быть долговременного типа. В этом случае, при возникновении сбоя в работе менеджера сообщения восстанавливаются после его перезапуска. Подобный тип менеджера предпочтителен для систем с критичными данными, например банковских распределенных приложений [14].
Кроме того системы на основе очередей сообщений можно разделить на следующие три типа:
- обеспечивающие надежную доставку сообщений — подобная система гарантирует, ни одно сообщение не будет потеряно в процессе функционирования
- обеспечивающие гарантированную доставку сообщений: сообщение доставляется приложению-адресату немедленно, или через промежуток времени, не превышающий заданное значение в случае недоступности каналов передачи сообщений
- обеспечивающие застрахованную доставку сообщений — при этом каждое сообщение доставляется только один раз
В основе систем на базе очереди сообщений лежит новая парадигма создания приложений — программы, управляемые событиями. Возникновения события в одном приложении в форме сообщения вызывает определенное действие в другом. Такая модель взаимодействия наиболее приближена к реальной бизнес-логике. По этой причине именно системы на базе очередей сообщений представляют собой большинство среди всех систем, ориентированных на обработку сообщений.
Последняя модель, представленная среди систем данного типа определяется как модель подписки/публикации. При данном варианте архитектуры одно приложение публикует сообщение в сети, а другое оформляет подписку на интересующую его информацию. При подобной организации взаимодействия различные приложения абсолютно независимы и в общем случае не обладают информацией о взаимном существовании, физическом расположении и состоянии друг друга. Это позволяет обеспечить динамическую конфигурацию системы с возможностью произвольного добавления и изменения клиентов и серверов при прерывании работы системы и позволяет добиться полной изоляции прикладных компонентов от любых деталей реализации других модулей системы.
Для обеспечения стандартизации в области промежуточного программного обеспечения ориентированного на обработку сообщений с целью эффективного взаимодействия решений от разных поставщиков в 1994 году был создан консорциум Message-Oriented Middleware Association (MOMA), в кторый вошли такие компании, как IBM и Sun Microsystems. Позже она была переименована в Iternational Middleware Association, которая занимается общим развитием систем промежуточного слоя [12].
ЗАКЛЮЧЕНИЕ
В данной работе было дано определение понятия «архитектура «клиент-сервер», рассмотрены факторы, способствующие ее возникновению, история развития, приведены ее основные характеристики и компоненты. Были изучены типы серверов и основные клиент-серверные технологии.
Это позволило рассмотреть различные виды архитектуры «клиент-сервер», сравнить их между собой, определив достоинства и недостатки. Были рассмотрены различные варианты архитектуры, в зависимости от количества уровней, а также используемого промежуточного программного обеспечения.
Цели и задачи курсовой работы считаю выполненными.
Подводя итоги, можно сделать вывод, применение многоуровневой модели архитектуры «клиент-сервер» является наиболее рациональным при решении большинства бизнес-задач. Свойства системы, ее преимущества и ограничения во много определяются не только количеством звеньев, но и используемым типом промежуточного программного обеспечения. Его дальнейшее совершенствование во многом определит последующее развитие всей технологии и позволит более точно соответствовать заявленным требованиям.
В целом, технология «клиент-сервер» является перспективной, поскольку позволяет обеспечить совместную работу множества клиентских приложений с использованием разнородных распределенных данных, что является востребованным решением для множества современных бизнес-задач.
БИБЛИОГРАФИЯ
- Баканов В.М. Программное обеспечение компьютерных сетей и информационных систем.— М., 2003.
- Дуглас Камер Сети TCP/IP, том 1. Принципы, протоколы и структура.
М.: Вильямс, 2003. — 851 с. - Когаловский М.Р. Энциклопедия технологий баз данных.—М.:Финансы и статистика, 2005. — 800 с.
- Программное обеспечение компьютерных сетей: Учебное пособие / О. В. Исаченко. — М.: ИНФРА-М, 2012. — 117 с.
- Руденков Н.А., Долинер Л.И. Основы сетевых технологий: Учебник для вузов. Екатеринбург: Изд-во Уральского Федерального ун-та, 2011 – 300 с.
- Руководство Microsoft по проектированию архитектуры приложений. 2-е издание. — 2009. 529 с.
- Соммервилл Иан. Инженерия программного обеспечения 6-е изд., пер. с англ. — М.: Вильямс, 2002. — 624 с.
- Таненбаум Э., М. ван Стеен. Распределенные системы. Принципы и парадигмы/ — СПб.: Питер, 2003. — 877 с.
- Фаулер, Мартин. Архитектура корпоративных программных приложений.: Пер. с англ. — М.: Издательский дом «Вильямс», 2006 — 544 с.
- Хьюз Камерон. Параллельное и распределенное программирование на С++ Издательский дом ISBN, 2004.
- Эбберс М. Введение в современные мейнфреймы: основы z/OS., пер. с англ. — М.: 2007
- Дубова Наталья. Все про промежуточное ПО. // Открытые системы. СУБД. — 1999. — NN 07-08.
- Касаткин Александр. Средства Middleware и их классификация. // PCWeek, 1999. — N19.
- Эйнджел Джонатан. Промежуточное программное обеспечение. // Журнал сетевых решений. — 1999. — N11

- Процессор персонального компьютера. Назначение, функции, классификация процессора (Архитектура микропроцессора)
- Анализ и оценка средств реализации объектно-ориентированных методов анализа и проектирования экономической информационной системы.
- Сетевая форма организации бизнеса.
- Эффективность менеджмента организации (Понятие и сущность эффективности менеджмента предприятия)
- Налоги и налогообложение
- Организационная культура и ее роль в современных организациях
- Применение объектно-ориентированного подхода при проектировании информационной системы (Теоретические основы)
- Ценовые войны в теории и на практике.
- Методы кодирования данных (Общие принципы кодирования данных)
- Анализ и оценка средств реализации структурных методов анализа и проектирования экономической информационной системы..
- Рынок ценных бумаг
- Применение процессного подхода для оптимизации бизнес-процессов
Обновлено: 22.03.2023
Как правило, третьим звеном в трехзвенной архитектуре становится сервер приложений, т.е. компоненты распределяются следующим образом: представление данных — на стороне клиента. Прикладной компонент — на выделенном сервере приложений (как вариант, выполняющем функции промежуточного ПО). Управление ресурсами — на сервере БД, который и представляет запрашиваемые данные.
Двухуровневая архитектура проще, так как все запросы обслуживаются одним сервером, но именно из-за этого она менее надежна и предъявляет повышенные требования к производительности сервера.
Трехуровневая архитектура сложнее, но благодаря тому, что функции распределены между серверами второго и третьего уровня, эта архитектура представляет высокую степень гибкости и масштабируемости, высокую безопасность, высокую производительность (т.к. задачи распределены между серверами).
По сравнению с клиент-серверной или файл-серверной архитектурой трёхуровневая архитектура обеспечивает, как правило, бо́льшую масштабируемость (за счёт горизонтальной масштабируемости сервера приложений и мультиплексирования соединений, бо́льшую конфигурируемость, более широкие возможности по обеспечению безопасности и отказоустойчивости. Кроме того, в сравнении с клиент-серверными приложениями, использующими прямые подключения к серверам баз данных, снижаются требования к скорости и стабильности каналов связи между клиентом и серверной частью. Реализация приложений, доступных из веб-браузера или из тонкого клиента, как правило, подразумевает развёртывание программного комплекса в трёхуровневой архитектуре. При этом обычно разработка приложений для трёхуровневых программных комплексов сложнее, чем для клиент-серверных приложений, также наличие дополнительного связующего программного обеспечения может налагать дополнительные издержки в администрировании таких комплексов.
Как правило, третьим звеном в трехзвенной архитектуре становится сервер приложений, т.е. компоненты распределяются следующим образом: представление данных — на стороне клиента. Прикладной компонент — на выделенном сервере приложений (как вариант, выполняющем функции промежуточного ПО). Управление ресурсами — на сервере БД, который и представляет запрашиваемые данные.
Двухуровневая архитектура проще, так как все запросы обслуживаются одним сервером, но именно из-за этого она менее надежна и предъявляет повышенные требования к производительности сервера.
Трехуровневая архитектура сложнее, но благодаря тому, что функции распределены между серверами второго и третьего уровня, эта архитектура представляет высокую степень гибкости и масштабируемости, высокую безопасность, высокую производительность (т.к. задачи распределены между серверами).
По сравнению с клиент-серверной или файл-серверной архитектурой трёхуровневая архитектура обеспечивает, как правило, бо́льшую масштабируемость (за счёт горизонтальной масштабируемости сервера приложений и мультиплексирования соединений, бо́льшую конфигурируемость, более широкие возможности по обеспечению безопасности и отказоустойчивости. Кроме того, в сравнении с клиент-серверными приложениями, использующими прямые подключения к серверам баз данных, снижаются требования к скорости и стабильности каналов связи между клиентом и серверной частью. Реализация приложений, доступных из веб-браузера или из тонкого клиента, как правило, подразумевает развёртывание программного комплекса в трёхуровневой архитектуре. При этом обычно разработка приложений для трёхуровневых программных комплексов сложнее, чем для клиент-серверных приложений, также наличие дополнительного связующего программного обеспечения может налагать дополнительные издержки в администрировании таких комплексов.
В компьютерных технологиях трёхуровневая архитектура, синоним трёхзвенная архитектура (по англ. three-tier или Multitier architecture) предполагает наличие следующих компонентов приложения: клиентское приложение (обычно говорят «тонкий клиент» или терминал), подключенное к серверу приложений, который в свою очередь подключен к серверу базы данных.
Содержание
Обзор архитектуры
- Терминал — это интерфейсный (обычно графический) компонент, который представляет первый уровень, собственно приложение для конечного пользователя. Первый уровень не должен иметь прямых связей с базой данных (по требованиям безопасности), быть нагруженным основной бизнес-логикой (по требованиям масштабируемости) и хранить состояние приложения (по требованиям надежности). На первый уровень может быть вынесена и обычно выносится простейшая бизнес-логика: интерфейс авторизации, алгоритмы шифрования, проверка вводимых значений на допустимость и соответствие формату, несложные операции (сортировка, группировка, подсчет значений) с данными, уже загруженными на терминал.
- Сервер приложений располагается на втором уровне. На втором уровне сосредоточена большая часть бизнес-логики. Вне его остаются фрагменты, экспортируемые на терминалы (см.выше), а также погруженные в третий уровень хранимые процедуры и триггеры.
- Сервер базы данных обеспечивает хранение данных и выносится на третий уровень. Обычно это стандартная реляционная или объектно-ориентированнаяСУБД. Если третий уровень представляет собой базу данных вместе с хранимыми процедурами, триггерами и схемой, описывающей приложение в терминах реляционной модели, то второй уровень строится как программный интерфейс, связывающий клиентские компоненты с прикладной логикой базы данных.
В простейшей конфигурации физически сервер приложений может быть совмещен с сервером базы данных на одном компьютере, к которому по сети подключается один или несколько терминалов.
В «правильной» (с точки зрения безопасности, надежности, масштабирования) конфигурации сервер базы данных находится на выделенном компьютере (или кластере), к которому по сети подключены один или несколько серверов приложений, к которым, в свою очередь, по сети подключаются терминалы.
Достоинства
По сравнению с клиент-серверной или файл-серверной архитектурой можно выделить следующие достоинства трёхуровневой архитектуры:
- масштабируемость
- конфигурируемость — изолированность уровней друг от друга позволяет (при правильном развертывании архитектуры) быстро и простыми средствами переконфигурировать систему при возникновении сбоев или при плановом обслуживании на одном из уровней
- высокая безопасность
- высокая надежность
- низкие требования к скорости канала (сети) между терминалами и сервером приложений
- низкие требования к производительности и техническим характеристикам терминалов, как следствие снижение их стоимости. Терминалом может выступать не только компьютер, но и мобильный телефон к примеру.
Недостатки
Недостатки вытекают из достоинств. По сравнению c клиент-серверной или файл-серверной архитектурой можно выделить следующие недостатки трёхуровневой архитектуры:
Трехуровневая архитектура приложений — это модульная клиент-серверная архитектура, которая состоит из уровня представления, уровня приложения и уровня данных. Уровень данных обеспечивает хранение информации, уровень приложений обрабатывает логику, а уровень представления являет собой графический интерфейс пользователя (GUI), который взаимодействует с двумя другими уровнями. Эти три уровня являются логическими, а не физическими, и могут работать как на одном физическом сервере, так и на разных машинах.
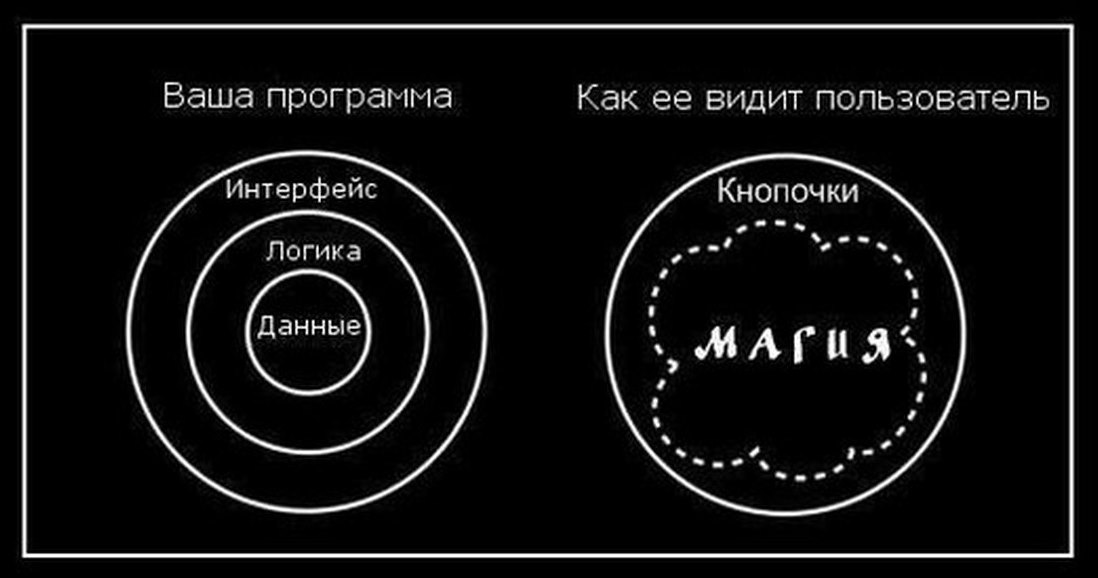
Уровень представления. Этот уровень, созданный с использованием HTML5, JavaScript и каскадных таблиц стилей (CSS), развертывается на вычислительном устройстве через веб-браузер или веб-приложение. Уровень представления связывается с другими уровнями посредством вызовов интерфейса прикладных программ (API).
Уровень приложения. Уровень приложения, который также можно назвать логическим уровнем, написан на языке программирования, таком как Java, Python или Ruby, и содержит бизнес-логику, которая поддерживает основные функции приложения. Базовый уровень приложений может быть размещен на распределенных серверах в облаке или на выделенном внутреннем сервере, в зависимости от того, сколько вычислительной мощности требуется приложению.
Уровень данных. Уровень данных состоит из базы данных и программы для управления доступом для чтения и записи в базе данных. Этот уровень также может называться уровнем хранения и может быть размещен локально или в облаке. Популярные системы баз данных для управления доступом для чтения / записи включают MySQL, Oracle, PostgreSQL, Microsoft SQL Server и MongoDB.
Преимущества использования треуровневой архитектуры
Преимущества использования 3-уровневой архитектуры включают улучшенную масштабируемость, производительность и доступность. При использовании подхода к разработке приложений с тремя уровнями или частями, все эти части могут разрабатываться одновременно несколькими командами программистов, кодирующих на разных языках, при этом каждая из команд не зависит от других разработчиков, которые занимаются созданием другого уровня. Поскольку процесс создания программного кода для каждого уровня может претерпевать изменения, не затрагивая другие уровни, 3-уровневая модель облегчает непрерывное развитие приложения для предприятия или программного пакета по мере появления новых потребностей и возможностей. Существующие приложения или критические части могут быть постоянно или временно сохранены и инкапсулированы в новый уровень, компонентом которого они становятся.
Содержание

Обзор архитектуры
- Клиент — это интерфейсный (обычно графический) компонент, который представляет первый уровень, собственно приложение для конечного пользователя. Первый уровень не должен иметь прямых связей с базой данных (по требованиям безопасности), быть нагруженным основной бизнес-логикой (по требованиям масштабируемости) и хранить состояние приложения (по требованиям надежности). На первый уровень может быть вынесена и обычно выносится простейшая бизнес-логика: интерфейс авторизации, алгоритмы шифрования, проверка вводимых значений на допустимость и соответствие формату, несложные операции (сортировка, группировка, подсчет значений) с данными, уже загруженными на терминал.
- Сервер приложений располагается на втором уровне. На втором уровне сосредоточена бо́льшая часть бизнес-логики. Вне его остаются фрагменты, экспортируемые на терминалы (см.выше), а также погруженные в третий уровень хранимые процедуры и триггеры.
- Сервер базы данных обеспечивает хранение данных и выносится на третий уровень. Обычно это стандартная реляционная или объектно-ориентированнаяСУБД. Если третий уровень представляет собой базу данных вместе с хранимыми процедурами, триггерами и схемой, описывающей приложение в терминах реляционной модели, то второй уровень строится как программный интерфейс, связывающий клиентские компоненты с прикладной логикой базы данных.
В простейшей конфигурации физически сервер приложений может быть совмещён с сервером базы данных на одном компьютере, к которому по сети подключается один или несколько терминалов.
Достоинства
По сравнению с клиент-серверной или файл-серверной архитектурой можно выделить следующие достоинства трёхуровневой архитектуры:
Недостатки
Недостатки вытекают из достоинств. По сравнению c клиент-серверной или файл-серверной архитектурой можно выделить следующие недостатки трёхуровневой архитектуры:
Читайте также:
- Определение способов контроля за состоянием здоровья детей в доу
- Школа боев без правил в уфе
- Методы семейного воспитания кратко
- Сценарий мама папа я спортивная семья в детском саду во второй младшей группе
- Принципы построения программы воспитания и обучения в детском саду кратко
На верхнем
уровне абстрагирования взаимодействия
клиента и сервера достаточно четко
можно выделить следующие компоненты:
*презентационная
логика (Presentation Layer — PL), предназначенная
для работы с данными пользователя;
*бизнес-логика
(Business Layer — BL), предназначенная для
проверки правильности данных, поддержки
ссылочной целостности;
*логика доступа
к ресурсам (Access Layer — AL), предназначенная
для хранения данных;
Таким образом
можно, можно придти к нескольким моделям
клиент-серверного взаимодействия:
1. «Толстый»
клиент. (fat client)
Сервер БД
Пользовательский интерфейс
Данные
Бизнес-логика
Пользовательский
интерфейс
Бизнес-логика
Наиболее часто
встречающийся вариант реализации
архитектуры клиент-сервер в уже
внедренных и активно используемых
системах. Такая модель подразумевает
объединение в клиентском приложении
как PL, так и BL, таким образом обеспечивается
полная децентрализация управления
бизнес-логикой. Однако в случае
необходимости выполнения каких-либо
изменений в клиентском приложении
придется менять исходный код. Серверная
часть, при описанном подходе, представляет
собой сервер баз данных, реализующий
AL. К описанной модели часто применяют
аббревиатуру RDA — Remote Data Access.
2. «Тонкий»
клиент. (thin client)
Бизнес- Логика
Пользовательский интерфейс
Данные
Пользовательский
интерфейс
Модель,
начинающая активно использоваться в
корпоративной среде в связи с
распространением Internet-технологий и, в
первую очередь, Web-браузеров. В этом
случае клиентское приложение обеспечивает
реализацию PL, поэтому клиент может
довольствоваться довольно скромной
аппаратной платформой, а сервер
объединяет BL и AL. Максимальная загрузка
сервера предусматривает выполнение
бизнес-логики только с помощью хранимых
процедур сервера (Хранимые процедуры
— откомпилированные SQL-инструкции,
хранящиеся на сервере). Это позволяет
максимально централизовать контроль
над данными и легко изменять правила
работы сразу для целого предприятия.
С другой стороны, незначительная
корректировка правил, касающаяся только
части пользователей, потребует длительной
процедуры согласования. В этом случае
невозможно реализовать какие-то
исключения из общих правил для некоторых
пользователей или приложений. В принципе,
это хорошо и является залогом безопасности
и целостности данных.
3. Сервер
бизнес-логики. (трехуровневая архитектура)
Промежуточный сервер
Пользовательский
Бизнес-логика
интерфейс
второго уровня
Сервер БД
Пользовательский
Бизнес-логика
интерфейс
сервера
Данные
Модель с
физически выделенным в отдельное
приложение блоком BL, таким образом
получаем трехуровневую архитектуру
“клиент-сервер”. На сервере БД может
функционировать “универсальная”
часть бизнес-логики (правила на уровне
предприятия или группы связанных
приложений). Такая схема позволяет
поддерживать тонких клиентов на
пользовательских компьютерах и в то
же время разгрузить сервер БД от
чрезмерной загрузки при сохранении
гибкой системы работы с бизнес-правилами.
В качестве промежуточного сервера
может использоваться второй SQL-сервер,
но чаще рациональней задействовать
персональную СУБД, которая менее
требовательна к аппаратным ресурсам
и может обеспечить удобные средства
построения и поддержки бизнес-логики.
3. Программные средства разработки
Универсальные
средства
Для разработки
клиентских приложений существует
громадное число универсальных пакетов
программ, которые позволяют выполнить
соединение с сервером и разработать
для пользователя удобный графический
интерфейс, позволяющий эффективно
работать с данными. Некоторые из этих
средств для разработки приложений в
архитектуре “клиент-сервер” перечислены
в таблице.
|
Наименование |
Краткая характеристика |
|
|
CA-OpenROAD |
Полнофункциональная объектно-ориентированная |
|
|
Delphi Client/Server |
Универсальный пакет для разработки |
|
|
Magic 6.0 |
Таблично-управляемый инструментарий |
|
|
MS Visual Basic 5.0 |
Универсальный пакет разработки |
|
|
PowerBuilder 4.0 |
Объектно-ориентированное средство |
|
|
Progress 8 |
Пакет поддерживает компонентную |
|
|
SAS System |
Обеспечивает инструментарий для |
|
|
Uniface Six |
Независимая среда разработки. |
|
Персональные
СУБД
Для разработки
клиентских приложений в большинстве
случаев вместо универсальных средств
разработки удобнее использовать
персональные СУБД. Использование
персональных СУБД позволяет не только
эффективно организовывать работу с
бизнес-правилами, но и поддержать
независимую работу клиентского
приложения за счет наличия собственных
форматов хранения данных. Краткая
характеристика некоторых персональных
СУБД приведена в таблице.
|
Наименование |
Краткая характеристика |
|
|
Lotus Approach 97 |
Позволяет выполнять все виды обработки |
|
|
MS Access 97 |
Полнофункциональная СУБД, обладающая |
|
|
MS Visual FoxPro 5 |
Одна из наиболее быстрых персональных |
|
|
Paradox 7 |
Поддерживает все виды работы с данными. |
|
4. Intranet и архитектура
“клиент-сервер”
Двухуровневая
архитектура “клиент-сервер”
Web-броузер Источник
данных
Web-сервер
NOS (Network Operation
System)
Разграничение
функций между Web-броузером и Web-сервером
является очень четким. Web-сервер
предоставляет HTML-страницы, а броузер
отображает эти страницы путем
интерпретации тегов HTML.
Трехуровневая
архитектура “клиент-сервер”
Web-броузер Источник
данных
Третий уровень
Программа
расширения
сервера
HTML
Web-сервер
NOS
Клиентский уровень
занимает броузер, на уровне сервера
находится сервер БД, а на промежуточном
уровне располагаются Web-сервер и
программа расширения сервера. Такое
архитектурное решение позволяет
уменьшить сетевой трафик, делает
компоненты взаимозаменяемыми и повышает
уровень безопасности. Однако такая
архитектура также затрудняет обработку
транзакций БД ввиду природы протокола
HTTP, не запоминающего состояния (этот
протокол использует для передачи данных
между броузером и сервером БД).
Броузер посылает
Web-серверу запросы на доставку Web-страниц
или данных. Web-сервер обслуживает заявки
на Web-страницы, а запросы отправляет
программе-расширению серверной части.
Последняя принимает передаваемые ей
запросы, преобразует их в форму, понятную
серверу БД, и передает их серверу БД.
Затем сервер БД
выполняет работу по обслуживанию
запроса и возвращает результат
программе-расширению серверной части.
Наконец та преобразует результаты в
формат, приемлемый для броузера, и
передает их Web-серверу, а тот в свою
очередь — броузеру.
Программы
расширения серверной части
Одной из главных
причин использования программ-расширений
серверной части на промежуточном уровне
является возможность использовать
стандарты, существующих для двух крайних
уровней, путем осуществления трансляции
между ними. Другие применения расширений
серверной части состоят в поддержании
соединений между БД с целью уменьшить
трафик в сети и в поддержании резерва
соединений между БД для уменьшения
затрат ресурсов на открытие/закрытие
БД. Расширения серверной части также
поддерживают взаимозаменяемость в
своих стандартных интерфейсах. Поэтому
Web-серверы и серверы БД можно сравнительно
легко заменять или наращивать.
Цель
лекции: дать общее представление об
основных задачах программного обеспечения
баз данных, существующих подходов к
решению этих задач, в том числе и о
структурированном языке запросов SQL.
11.1.
Основные задачи программного обеспечения
баз данных
При работе
с реляционными базами данных можно
условно выделить две основные задачи:
-
собственно работа с базой данных ,
включающая создание и ведение базы
данных (создание структур таблиц,
добавление записи в таблицу, удаление
записи, обновление, выборка нужной
записи ); -
создание
пользовательских приложений, включающих
разработку пользовательского интерфейса
по работе с базой данных.
Для решения указанных задач современные
СУБД в своем составе могут содержать
следующие программные средства: языки
процедурного пошагового программирования,
средства визуального программирования
(графический интерфейс, диспетчер
проекта, мастера и построители), средства
создания объектно-ориентированных
приложений. Кроме этого, при разработке
пользовательских программ во многих
СУБД допускается использование других
языков программирования, а также
использование библиотек разного рода.
Так, например, при работе с СУБД ACCESS
можно использовать язык программирования
ACCESS , мастер ACCESS и язык программирования
VISUAL BASIC.
При работе с клиент-серверными системами
ситуация немного сложнее. Здесь в работе
участвуют два типа компьютеров (сервер
и клиент) и, соответственно, различают
клиентское и серверное программное
обеспечение. Серверное программное
обеспечение включает язык программирования,
поддерживающий создание и ведение базы
данных, также реализацию поступающих
от клиентов запросов пользователей к
базе данных. Пользовательские приложения
создаются и работают на компьютерах-клиентах.
Именно эти компьютеры должны иметь,
наряду со средствами формирования
запросов к базе данных, средства
разработки интерфейса. В связи с этим,
для клиент-серверных СУБД программное
обеспечение разделяется на две части:
программное обеспечение – клиент и
программное обеспечение – сервер.
Заметим, что наряду с программным
обеспечением – клиент, при разработке
пользовательских программ в конкретной
СУБД могут использоваться другие языки
программирования, специальные библиотеки,
другие системы программирования
(определенные для этой СУБД). В качестве
примера в таблице приводятся возможные
варианты использования программного
обеспечения для организации
клиент-серверного взаимодействия в
СУБД Microsoft SQL Server.
Таблица 11.1. Возможные варианты
использования программного обеспечения
в СУБД MS SQL Server
|
Средства ведения баз данных на |
Средства разработки клиентских |
|
Службы SQL-сервер (MS SQL server и др.) |
|
Полное рассмотрение всего спектра
программного обеспечения работы СУБД
очень обширно и выходит за рамки данного
пособия. Поэтому в данной работе будет
рассмотрены только средства создания
и ведения базы данных.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Клиент — серверная архитектура (Client-Server Architecture)
Клиент — сервер — вычислительная или сетевая архитектура, в которой задания или сетевая нагрузка распределены между поставщиками услуг, называемыми серверами, и заказчиками услуг, называемыми клиентами. Фактически клиент и сервер — это программное обеспечение. Обычно эти программы расположены на разных вычислительных машинах и взаимодействуют между собой через вычислительную сеть посредством сетевых протоколов, но они могут быть расположены также и на одной машине. Программы-серверы ожидают от клиентских программ запросы и предоставляют им свои ресурсы в виде:
- данных (например, загрузка файлов посредством HTTP, FTP, BitTorrent, потоковое мультимедиа или работа с базами данных);
- сервисных функций (например, работа с электронной почтой, общение посредством систем мгновенного обмена сообщениями или просмотр web-страниц во всемирной паутине).
Поскольку одна программа-сервер может выполнять запросы от множества программ-клиентов, ее размещают на специально выделенной вычислительной машине, настроенной особым образом, как правило, совместно с другими программами-серверами, поэтому производительность этой машины должна быть высокой. Из-за особой роли такой машины в сети, специфики ее оборудования и программного обеспечения, её также называют сервером, а машины, выполняющие клиентские программы, соответственно, клиентами.
Архитектуру «клиент-сервер» принято разделять на три класса: одно-, двух- и трехуровневую. Однако, нельзя сказать, что в вопросе о таком разделении в сообществе ИТ-специалистов существует полный консенсус. Многие называют одноуровневую архитектуру двухуровневой и наоборот, то же можно сказать о соотношении двух- и трёхуровневой архитектур.
Одноуровневая архитектура (1-Tier)
Одноуровневая архитектура «клиент-сервер» (1-Tier) — такая, где все прикладные программы рассредоточены по рабочим станциям, которые обращаются к общему серверу баз данных или к общему файловому серверу. Никаких прикладных программ сервер при этом не исполняет, только предоставляет данные.
В целом, такая архитектура очень надежна, однако, ей сложно управлять, поскольку в каждой рабочей станции данные будут присутствовать в разных вариантах. Поэтому возникает проблема их синхронизации на отдельных машинах. В общем, как можно видеть из рисунка, в этой архитектуре просматривается еще один уровень — базы данных, что дает повод во многих случаях называть её двухуровневой.
Двухуровневая архитектура (2-Tier)
К двухуровневой архитектуре «клиент-сервер» следует относить такую, в которой прикладные программы сосредоточены на сервере приложений (Application Server), например, сервере 1С или сервере CRM, а в рабочих станциях находятся программы-клиенты, которые предоставляют для пользователей интерфейс для работы с приложениями на общем сервере.
Такая архитектура представляется наиболее логичной для архитектуры «клиент-сервер». В ней, однако, можно выделить два варианта. Когда общие данные хранятся на сервере, а логика их обработки и бизнес-данные хранятся на клиентской машине, то такая архитектура носит название “fat client thin server” (толстый клиент, тонкий сервер). Когда не только данные, но и логика их обработки и бизнес-данные хранятся на сервере, то это называется “thin client fat server” (тонкий клиент, толстый сервер). Такая архитектура послужила прообразом облачных вычислений (Cloud Computing).
Трехуровневая архитектура (3-Tier)
В трехуровневой архитектуре сервер баз данных, файловый сервер и другие представляют собой отдельный уровень, результаты работы которого использует сервер приложений. Логика данных и бизнес-логика находятся в сервере приложений. Все обращения клиентов к базе данных происходят через промежуточное программное обеспечение (middleware), которое находится на сервере приложений. Вследствие этого, повышается гибкость работы и производительность.
Многоуровневая архитектура (N-Tier)
В отдельный класс архитектуры «клиент-сервер» можно вынести многоуровневую архитектуру, в которой несколько серверов приложений используют результаты работы друг друга, а также данные от различных серверов баз данных, файловых серверов и других видов серверов.
По сути, предыдущий вариант, трехуровневая архитектура — не более, чем частный случай многоуровневой архитектуры.
Преимуществом многоуровневой архитектуры является гибкость предоставления услуг, которые могут являться комбинацией работы различных приложений серверов разных уровней и элементов этих приложений.
Очевидным недостатком является сложность, многокомпонентность такой архитектуры.
Характеристики архитектуры «клиент-сервер»
- Асимметричность протоколов. Между клиентами и сервером существуют отношения «один ко многим». Инициатором диалога с сервером обычно является клиент.
- Инкапсуляция услуг. После получения запроса на услугу от клиента, сервер решает, как должна быть выполнена данная услуга. Модификация («апгрейд») сервера может производиться без влияния на работу клиентов, поскольку это не влияет на опубликованный интерфейс взаимодействия между ними. Иными словами, максимум, что может при этом почувствовать пользователь — незначительная задержка отклика сервера в течение небольшого времени апгрейда.
- Целостность. Программы и общие данные для сервера управляются централизованно, что снижает стоимость обслуживания и защищает целостность данных. В то же время, данные клиентов остаются персонифицированными и независимыми.
- Местная прозрачность. Сервер — это программный процесс, который может исполняться на той же машине, что и клиент, либо на другой машине, подключенной по сети. Программное обеспечение «клиент-сервер» обычно скрывает местоположение сервера от клиентов, перенаправляя запрос на услуги через сеть.
- Обмен на основе сообщений. Клиенты и сервер являются нежёстко связанными («loosely-coupled») процессами, которые обмениваются сообщениями: запросами на услуги и ответами на них.
- Модульный дизайн, способный к расширению. Модульный дизайн программной платформы «клиент-сервер» придаёт ей устойчивость к отказам, то есть, отказ в каком-то модуле не вызывает отказа всего приложения. В такой системе, один или больше серверов могут отказать без остановки всей системы в целом, до тех пор, пока услуги отказавшего сервера могут быть предоставлены с резервного сервера. Другое преимущество модульности в том, что приложение «клиент-сервер» может автоматически реагировать на повышение или понижение нагрузки на систему, путем добавления или отключения услуг или серверов.
- Независимость от платформы. Идеальное приложение «клиент-сервер» не зависит от платформ оборудования или операционной системы. Клиенты и серверы могут развертываться на различных аппаратных платформах и разных операционных системах.
- Масштабируемость. Системы «клиент-сервер» могут масштабироваться как горизонтально (по числу серверов и клиентов), так и вертикально (по производительности и спектру услуг).
- Разделение функционала. Система «клиент-сервер» — это соотношение между процессами, работающими на одной или на разных машинах. Сервер — это процесс предоставления услуг. Клиент — это потребитель услуг.
- Общее использование ресурсов. Один сервер может предоставлять услуги множеству клиентов одновременно, и регулировать их доступ к совместно используемым ресурсам.
Практические применения архитектуры «клиент-сервер»
Архитектура «клиент-сервер» — один из основных принципов работы сети Интернет. Любой веб-сайт, или приложение в Интернет работает на сервере, а его пользователи являются клиентами. Социальные сети (Фейсбук, ВК и пр.), сайты электронной коммерции (Amazon, Озон и др.) , мобильные приложения (Instagram и т.д.), устройства Интернета вещей (умные колонки или смарт-часы) работают на основе клиент-серверной архитектуры.
Хорошим примером работы системы «клиент-сервер» является автомобильный навигатор. Приложение навигации на сервере собирает данные с многих смартфонов пользователей, на которых установлены клиенты приложения. Кроме того, приложение навигации использует ещё и данные с сервера базы данных — геоинформационной системы, который предоставляет данные, например, о текущих ремонтах дорог, о появлении новых дорог и пр. Данные со многих клиентов (местоположение, скорость) обрабатывается сервером навигации и выдаётся на смартфоны пользователей в виде информации о средней скорости движения по тому или иному участку маршрута.
Практически любая корпоративная сеть или ИТ-система предприятия, как правило, строится по архитектуре «клиент-сервер». В небольших сетях (3-5 компьютеров в компании) функции сервера может выполнять один из рабочих компьютеров. Если число машин в организации более 10, то лучше сделать выделенный сервер (почтовый сервер, приложений, баз данных и пр.), который будет заниматься обслуживанием клиентов — компьютеров и телефонов сотрудников организации.
В домашних сетях архитектура «клиент-сервер» тоже используется довольно часто. Например, в домашнюю сеть могут быть объединены компьютеры членов семьи, один из которых выполняет функции сервера. В домашнюю сеть также могут быть включены такие устройства, как умные колонки, умные домашние устройства (пылесосы-роботы, фотоаппараты, DVD-плееры и пр.), а также «умные» счётчики (вода, электричество) и т.д. Тогда в системе управления сервера, будут видны все параметры, данные и медиа файлы (музыка, видео, фото), а также «умные устройства».
В настоящее время можно встретить термин Serverless Architecture, т.н. «бессерверная архитектура». Однако, по сути, она представляет собой процесс получения функций сервера в виде облачной услуги. То есть, серверы в облаке тоже есть, но для конечного пользователя они не видны, и он получает их сервисы в виде абстрактной «функции как услуги» FaaS (Function as a Service).
Архитектура «клиент-сервер» является основой большинства корпоративных сетей и берет свое начало от самых первых вычислительных машин, т.н. «мэйнфреймов».
Статические и динамические сайты
Статический сайт — это тот, который возвращает тот же жёсткий кодированный контент с сервера всякий раз, когда запрашивается конкретный ресурс. Например, если у вас есть страница о товаре в /static/myproduct1.html, эта же страница будет возвращена каждому пользователю. Если вы добавите еще один подобный товар на свой сайт, вам нужно будет добавить ещё одну страницу (например, myproduct2.html) и так далее. Это может стать действительно неэффективным — что происходит, когда вы попадаете на тысячи страниц товаров? Вы повторяли бы много кода на каждой странице (основной шаблон страницы, структуру и т. д.), И если бы вы захотели изменить что-либо в структуре страницы — например, добавить новый раздел «связанные товары» — тогда вам придётся менять каждую страницу отдельно.
На заметку: Статические сайты превосходны, когда у вас небольшое количество страниц и вы хотите отправить один и тот же контент каждому пользователю. Однако их обслуживание может потребовать значительных затрат по мере увеличения количества страниц.
Когда пользователь хочет перейти на страницу, браузер отправляет HTTP-запрос GET с указанием URL-адреса его HTML-страницы. Сервер извлекает запрошенный документ из своей файловой системы и возвращает HTTP-ответ, содержащий документ и код состояния HTTP Response status code 200 OK (успех). Сервер может вернуть другой код состояния, например, «404 Not Found», если файл отсутствует на сервере или «301 Moved Permanently», если файл существует, но был перемещён в другое место.
Серверу для статического сайта нужно будет только обрабатывать GET-запросы, потому что сервер не сохраняет никаких модифицируемых данных. Он также не изменяет свои ответы на основе данных HTTP-запроса (например, URL-параметров или файлов cookie).
Понимание того, как работают статические сайты, тем не менее полезно при изучении программирования на стороне сервера, поскольку динамические сайты точно так же обрабатывают запросы для статических файлов (CSS, JavaScript, статические изображения и т. д.).
Динамический сайт — это тот, который может генерировать и возвращать контент на основе конкретного URL-адреса запроса и данных (а не всегда возвращать один и тот же жёсткий код для определенного URL-адреса). Используя пример сайта товара, сервер будет хранить «данные» товара в базе данных, а не отдельные HTML-файлы. При получении GET-запроса для товара сервер определяет идентификатор товара, извлекает данные из базы данных и затем создает HTML-страницу для ответа, вставляя данные в HTML-шаблон. Это имеет большие преимущества перед статическим сайтом:
- Использование базы данных позволяет эффективно хранить информацию о товаре с помощью легко расширяемого, изменяемого и доступного для поиска способа.
- Использование HTML-шаблонов позволяет очень легко изменить структуру HTML, потому что это нужно делать только в одном месте, в одном шаблоне, а не через потенциально тысячи статических страниц.
Анатомия динамического запроса: чтобы не отдаляться от практики, мы будем использовать контекст веб-сайта менеджера спортивной команды, где тренер может выбрать имя своей команды и размер команды в HTML-форме и вернуться к предлагаемому «лучшему составу» для своей следующей игры.
На приведённой ниже диаграмме показаны основные элементы веб-сайта «team coach», а также пронумерованные ярлыки для последовательности операций, когда тренер обращается к списку «лучших команд». Частями сайта, которые делают его динамичным, являются веб-приложение (так мы будем ссылаться на серверный код, обрабатывающий HTTP-запросы и возвращающие HTTP-ответы), база данных, которая содержит информацию об игроках, командах, тренерах и их отношениях, и HTML-шаблоны.
После того, как тренер отправит форму с именем команды и количеством игроков, последовательность операций будет следующей:
- Веб-браузер отправит HTTP-запрос GET на сервер с использованием базового URL-адреса ресурса (/best) и кодирования номера команды и игрока в форме URL-параметров (например, /best?team=my_team_name&show=11) или как часть URL-адреса (например, /best/my_team_name/11/). Запрос GET используется, потому что речь идёт только о запросе выборки данных (а не об их изменении).
- Веб-сервер определяет, что запрос является «динамическим» и пересылает его в веб-приложение для обработки (веб-сервер определяет, как обрабатывать разные URL-адреса на основе правил сопоставления шаблонов, определённых в его конфигурации).
- Веб-приложение определяет, что цель запроса состоит в том, чтобы получить «лучший список команд» на основе URL (/best/) и узнать имя команды и количество игроков из URL-адреса. Затем веб-приложение получает требуемую информацию из базы данных (используя дополнительные «внутренние» параметры, чтобы определить, какие игроки являются «лучшими», и, возможно, определяя личность зарегистрированного тренера из файла cookie на стороне клиента).
- Веб-приложение динамически создаёт HTML-страницу, помещая данные (из базы данных) в заполнители внутри HTML-шаблона.
- Веб-приложение возвращает сгенерированный HTML в веб-браузер (через веб-сервер) вместе с кодом состояния HTTP 200 («успех»). Если что-либо препятствует возврату HTML, веб-приложение вернёт другой код, например, «404», чтобы указать, что команда не существует.
- Затем веб-браузер начнёт обрабатывать возвращённый HTML, отправив отдельные запросы, чтобы получить любые другие файлы CSS или JavaScript, на которые он ссылается (см. шаг 7).
- Веб-сервер загружает статические файлы из файловой системы и возвращает их непосредственно в браузер (опять же, правильная обработка файлов основана на правилах конфигурации и сопоставлении шаблонов URL).
Операция по обновлению записи в базе данных будет обрабатываться аналогичным образом, за исключением того, что, как и любое обновление базы данных, HTTP-запрос из браузера должен быть закодирован как запрос POST.
Выполнение другой работы: задача веб-приложения — получать HTTP-запросы и возвращать HTTP-ответы. Хотя взаимодействие с базой данных для получения или обновления информации является очень распространённой задачей, код может делать другие вещи одновременно или вообще не взаимодействовать с базой данных.
Хорошим примером дополнительной задачи, которую может выполнять веб-приложение, является отправка электронной почты пользователям для подтверждения их регистрации на сайте. Сайт также может выполнять протоколирование или другие операции.
Возвращение чего-то другого, кроме HTML: серверный код сайта может возвращать не только HTML-фрагменты и файлы в ответе. Он может динамически создавать и возвращать другие типы файлов (текст, PDF, CSV и т. д.) или даже данные (JSON, XML и т. д.).
Идея вернуть данные в веб-браузер, чтобы он мог динамически обновлять свой собственный контент (AJAX) существует довольно давно. Совсем недавно «Одностраничные приложения» стали популярными, где весь сайт написан с одним HTML-файлом, который динамически обновляется по мере необходимости. Веб-сайты, созданные с использованием приложений такого рода, переносят большие вычислительные затраты с сервера на веб-браузер и приводят к тому, что веб-сайты, ведут себя больше как нативные приложения (очень отзывчивые и т. д.).
Источники:
- Клиент — сервер
- Архитектура «Клиент-Сервер»
- Клиент-сервер
Доп. материал:
- Computer Networking Tutorial: The Ultimate Guide
- Web Server vs. Application Server
- Что такое сервер приложения
- Клиент-серверная архитектура в картинках
- Тестировщик с нуля / Урок 11. Клиент-серверная архитектура. Веб-сайт, веб-приложение и веб-сервис
- Клиент-серверная архитектура