Рассматривая
различные алгоритмы решения одной и
той же задачи, полезно проанализировать,
сколько вычислительных ресурсов они
требуют (время работы, память), и выбрать
наиболее эффективный. Конечно, надо
договориться о том, какая модель
вычислений используется. В данном
учебном пособии в качестве модели по
большей части используется обычная
однопроцессорная машина
с произвольным доступом
(random—access
machine,
RAM),
не предусматривающая параллельного
выполнения операций.
Под
временем
работы
(running
time)
алгоритма будем подразумевать число
элементарных шагов, которые он
выполняет. Положим, что одна строка
псевдокода требует не более чем
фиксированного числа операций (если
только это не словесное описание каких-то
сложных действий – типа «отсортировать
все точки по x-координате»).
Следует также различать вызов
(call)
процедуры (на который уходит фиксированное
число операций) и её исполнение
(execution),
которое может быть долгим.
Сложность
алгоритма – это величина, отражающая
порядок величины требуемого ресурса
(времени или дополнительной памяти) в
зависимости от размерности задачи.
Таким
образом, будем различать временную T(n)
и пространственную V(n)
сложности алгоритма. При рассмотрении
оценок сложности, будем использовать
только временную сложность. Пространственная
сложность оценивается аналогично. Самый
простой способ оценки – экспериментальный,
то есть запрограммировать алгоритм и
выполнить полученную программу на
нескольких задачах, оценивая время
выполнения программ. Однако, этот способ
имеет ряд недостатков. Во-первых,
экспериментальное программирование –
это, возможно, дорогостоящий процесс.
Во-вторых, необходимо учитывать, что на
время выполнения программ влияют
следующие факторы:
-
Временная
сложность алгоритма программы; -
Качество
скомпилированного кода исполняемой
программы; -
Машинные
инструкции, используемые для выполнения
программы.
Наличие
второго и третьего факторов не позволяют
применять типовые единицы измерения
временной сложности алгоритма (секунды,
миллисекунды и т.п.), так как можно
получить самые различные оценки для
одного и того же алгоритма, если
использовать разных программистов
(которые программируют алгоритм каждый
по-своему), разные компиляторы и разные
вычислительные машины.
Часто,
временная сложность алгоритма зависит
от количества входных данных. Обычно
говорят, что временная сложность
алгоритма имеет порядок T(n)
от входных данных размера n.
Точно определить величину T(n)
на практике представляется довольно
трудно. Поэтому прибегают к асимптотическим
отношениям с использованием
O-символики.
Существует
метод, позволяющий теоретически оценить
время выполнения алгоритма, который
будет рассмотрен далее.

Листинг
1.3 – Псевдокод алгоритма сортировки
вставками с оценками времени выполнения
Для
вычисления суммарного времени выполнения
процедуры Insertion-Sort
отметим
около каждой строки её стоимость
(число операций) и число раз, которое
эта строка исполняется. Для каждого j
от
2 до п
(здесь
п
=
length[A]
–
размер массива) требуется подсчитать,
сколько раз будет исполнена строка 5,
обозначим это число через tj.
Строки
внутри цикла выполняются на один раз
меньше, чем проверка, поскольку последняя
проверка выводит из цикла. Строка
стоимостью c,
повторённая т
раз,
даёт вклад c
m
в
общее число операций (однако, это
выражение нельзя использовать для
оценки количества использованной
памяти). Сложив вклады всех строк, получим
![]()
Время
работы процедуры зависит не только от
п
но
и от того, какой именно массив размера
п
подан
ей на вход. Для процедуры Insertion-Sort
наиболее
благоприятен случай, когда массив уже
отсортирован. Тогда цикл в строке 5
завершается после первой же проверки
(поскольку A[i]
≤
key
при
i
=
j
–
1), так что все tj
равны
1, и общее время есть
![]()
Таким
образом, в наиболее благоприятном случае
время T(n),
необходимое для сортировки массива
размера п,
является
линейной функцией (linear
function)
от n,
т.е. имеет вид Т(п)
=
a n + b
для некоторых констант a
и
b.
Эти константы определяются выбранными
значениями с1,…,
с8.
Если же массив
расположен в обратном (убывающем)
порядке, время работы
процедуры
будет максимальным: каждый элемент A[j]
придётся
сравнить со всеми элементами А[1],…,
A[j
–
1]. При этом tj
= j.
Поскольку
![]()
![]()
получаем, что в
худшем случае время работы процедуры
равно
![]()
![]()
В
данном
случае
T(n)
– квадратичная
(quadratic
function),
т.е.
имеет
вид
Т(п) = an2
+ bn
+ с.
Константы
a, b и
с здесь
также определяются значениями с1,…,с8.
Обычно
говорят, что временная сложность
алгоритма имеет порядок T(n)
от входных данных размера n.
Точно определить величину T(n)
на практике представляется довольно
трудно. Поэтому прибегают к асимптотическим
отношениям с использованием O-символики.
Например,
если число тактов (действий), необходимое
для работы алгоритма, выражается как
16n2 + 12n log n + 2n + 3,
то это алгоритм, для которого T(n)
имеет порядок O(n2).
При формировании асимптотической
O-оценки
из всех слагаемых исходного выражения
оставляется одно, вносящее наибольший
вклад при больших n
(остальными слагаемыми можно пренебречь)
и игнорируется коэффициент перед ним
(так как все асимптотические оценки
даются с точностью до константы).
Когда
используют обозначение O(),
имеют в виду не точное время исполнения,
а только его предел сверху, причем с
точностью до постоянного множителя.
Когда говорят, например, что алгоритму
требуется время порядка O(n2),
имеют в виду, что время исполнения задачи
растет не быстрее, чем квадрат количества
элементов.
Таблица 1.2
– Сравнительный анализ скорости роста
функций
|
|
|
|
|
|
1 |
0 |
0 |
1 |
|
16 |
4 |
64 |
256 |
|
256 |
8 |
2 048 |
65 536 |
|
4 096 |
12 |
49 152 |
16 777 216 |
|
65 536 |
16 |
1 048 565 |
4 294 967 296 |
|
1 048 476 |
20 |
20 969 520 |
1 099 301 922 576 |
|
16 775 616 |
24 |
402 614 784 |
281 421 292 179 456 |

Рисунок
1.1 – Примеры различных функциональных
зависимостей
Если
считать, что числа, приведенные в
таблице 1.2,
соответствуют микросекундам, то для
задачи с 1048476 элементами алгоритму со
временем работы T(log n)
потребуется 20 микросекунд, а алгоритму
со временем работы T(n2)
– более 12 дней.
Если
операция выполняется за фиксированное
число шагов, не зависящее от количества
данных, то принято писать O(1).
Следует
обратить внимание, что основание
логарифма в асимптотических оценках
не пишется. Причина этого весьма проста.
Пусть есть O(log2 n).
Но log2 n = log3 n / log3 2,
а log3 2,
как и любую константу, символ О()
не учитывает. Таким образом, O(log2 n)
= O(log3 n).
К любому основанию можно перейти
аналогично, а, значит, и писать его не
имеет смысла.
Практически
время выполнения алгоритма зависит не
только от количества входных данных,
но и от их значений, например, время
работы некоторых алгоритмов сортировки
значительно сокращается, если первоначально
данные частично упорядочены, тогда как
другие методы оказываются нечувствительными
к этому свойству. Чтобы учитывать этот
факт, полностью сохраняя при этом
возможность анализировать алгоритмы
независимо от данных, различают:
-
максимальную
сложность Tmax(n),
или сложность наиболее неблагоприятного
случая, когда алгоритм работает дольше
всего; -
среднюю
сложность Tmid(n)
– сложность алгоритма в среднем; -
минимальную
сложность Tmin(n)
– сложность в наиболее благоприятном
случае, когда алгоритм справляется
быстрее всего.
Теоретическая
оценка временной сложности алгоритма
осуществляется с использованием
следующих базовых принципов:
-
Время
выполнения операций присваивания,
чтения, записи обычно имеют порядок
O(1).
Исключением являются операторы
присваивания, в которых операнды
представляют собой массивы или вызовы
функций; -
Время
выполнения последовательности операций
совпадает с наибольшим временем
выполнения операции в данной
последовательности (правило сумм: если
T1(n)
имеет порядок O(f(n)),
а T2(n)
– порядок O(g(n)),
то T1(n)
+ T2(n)
имеет порядок O(max(f(n),
g(n))); -
Время
выполнения конструкции ветвления
(if-then-else)
состоит из времени вычисления логического
выражения (обычно имеет порядок O(1))
и наибольшего из времени, необходимого
для выполнения операций, исполняемых
при истинном значении логического
выражения и при ложном значении
логического выражения; -
Время
выполнения цикла состоит из времени
вычисления условия прекращения цикла
(обычно имеет порядок O(1) )
и произведения количества выполненных
итераций цикла на наибольшее возможное
время выполнения операций тела цикла. -
Время
выполнения операции вызова процедур
определяется как время выполнения
вызываемой процедуры; -
При
наличии в алгоритме операции безусловного
перехода, необходимо учитывать изменения
последовательности операций,
осуществляемых с использованием этих
операции безусловного перехода.
Итак,
время работы в худшем случае и в лучшем
случае могут
сильно
различаться. При анализе алгоритмов
наиболее часто используется время
работы в худшем случае
(worst—case
running
time),
которое определяется как максимальное
время работы для входов данного размера.
Почему? Вот несколько причин.
-
Зная
время работы в худшем случае можно
гарантировать, что выполнение
алгоритма
закончится за некоторое время при любом
входе данного размера; -
На
практике «плохие» входы (для которых
время работы близко к максимуму)
встречаются наиболее часто. Например,
для базы данных плохим запросом может
быть поиск отсутствующего элемента
(очень распространенная ситуация); -
Время
работы в среднем может быть довольно
близко к времени работы в худшем случае.
Пусть, например, сортируется массив
из п
случайных
чисел
с помощью процедуры Insertion-Sort.Сколько
раз придётся выполнить цикл в строках
5-8 (листинг 1.3)? В среднем около половины
элементов массива A[1..j
– 1]
больше A[j],
так
что tj
в
среднем можно считать равным j/2,
и
время Т(п)
квадратично
зависит от n.
В
некоторых случаях требуется также
среднее время
работы
(average—case
running
time,
expected
running
time)
алгоритма на входах данной длины.
Конечно, эта величина зависит от
выбранного распределения вероятностей,
и на практике реальное распределение
входов может отличаться от предполагаемого,
которое обычно считают равномерным.
Иногда можно добиться равномерности
распределения, используя датчик случайных
чисел.
Аннотация: Рассматривается конвейерная организация работы идеального микропроцессора, сравнение производительности его работы с последовательной обработкой команд, типы и причины конфликтов в конвейере и пути уменьшения их влияния на работу микропроцессора.
Оценка производительности идеального конвейера
Выполнение каждой команды складывается из ряда последовательных этапов (шагов, стадий), суть которых не меняется от команды к команде. С целью увеличения быстродействия процессора и максимального использования всех его возможностей в современных микропроцессорах используется конвейерный принцип обработки информации. Этот принцип подразумевает, что в каждый момент времени процессор работает над различными стадиями выполнения нескольких команд, причем на выполнение каждой стадии выделяются отдельные аппаратные ресурсы. По очередному тактовому импульсу каждая команда в конвейере продвигается на следующую стадию обработки, выполненная команда покидает конвейер, а новая поступает в него.
В различных процессорах количество и суть этапов различаются. Рассмотрим принципы конвейерной обработки информации на примере пятиступенчатого конвейера, в котором выполнение команды складывается из следующих этапов:
- IF ( Instruction Fetch ) — считывание команды в процессор;
- ID ( Instruction Decoding ) — декодирование команды;
- OR ( Operand Reading ) — считывание операндов;
- EX ( Executing ) — выполнение команды;
- WB ( Write Back ) — запись результата.
Выполнение команд в таком конвейере представлено в табл. 11.1.
Так как в каждом такте могут выполняться различные стадии обработки команд, то длительность такта выбирается исходя из максимального времени выполнения всех стадий. Кроме того, следует учитывать, что для передачи команды с одной стадии на другую требуется определенное дополнительное время (  t), связанное с записью промежуточных результатов обработки в буферные регистры.
t), связанное с записью промежуточных результатов обработки в буферные регистры.
| Команда | Такт | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| i | IF | ID | OR | EX | WB | ||||
| i+1 | IF | ID | OR | EX | WB | ||||
| i+2 | IF | ID | OR | EX | WB | ||||
| i+3 | IF | ID | OR | EX | WB | ||||
| i+4 | IF | ID | OR | EX | WB |
Пусть для выполнения отдельных стадий обработки требуются следующие затраты времени (в некоторых условных единицах):
TIF = 20, TID = 15, TOR = 20, TEX = 25, TWB = 20.
Тогда, предполагая, что дополнительные расходы времени составляют dt = 5 единиц, получим время такта:
 .
.
Оценим время выполнения одной команды и некоторой группы команд при последовательной и конвейерной обработке.
При последовательной обработке время выполнения N команд составит:
Tпосл = N*(TIF + TID + TOR + TEX + TWB) = 100N.
Анализ табл. 11.1 показывает, что при конвейерной обработке после того, как получен результат выполнения первой команды, результат очередной команды появляется в следующем такте работы процессора. Следовательно,
Tконв = 5T + (N-1) * T.
Примеры длительности выполнения некоторого количества команд при последовательной и конвейерной обработке приведены в табл. 11.2.
| Количество команд | Время | |
|---|---|---|
| при последовательном выполнении | при конвейерном выполнении | |
| 1 | 100 | 150 |
| 2 | 200 | 240 |
| 10 | 1000 | 420 |
| 100 | 10000 | 3120 |
Очевидно, что при достаточно длительной работе конвейера его быстродействие будет существенно превышать быстродействие, достигаемое при последовательной обработке команд. Это увеличение будет тем больше, чем меньше длительность такта конвейера и чем больше количество выполненных команд. Сокращение длительности такта достигается, в частности, разбиением выполнения команды на большое число этапов, каждый из которых включает в себя относительно простые операции и поэтому может выполняться за короткий промежуток времени. Так, если в микропроцессоре Pentium длина конвейера составляла 5 ступеней (при максимальной тактовой частоте 200 МГц), то в Pentium-4 — уже 20 ступеней (при максимальной тактовой частоте на сегодняшний день 3,4 ГГц).
УДК 004.054
МЕТОДЫ ИЗМЕРЕНИЯ ВРЕМЕНИ РАБОТЫ ПРОГРАММЫ
Лохматов Степан Юрьевич1, Светлов Сергей Викторович2, Калач Геннадий Петрович3
1Московский технологический университет, студент 4 курса
2Московский технологический университет, студент 4 курса
3Московский технологический университет, кандидат военных наук, доцент военной кафедры
Аннотация
Данная статья посвящена обзору и описанию некоторых методов измерения времени работы программ. Произведено тестирование таймеров.
Ключевые слова: clock_get_time, rdtsc, методы измерения, программа
Рубрика: 05.00.00 ТЕХНИЧЕСКИЕ НАУКИ
Библиографическая ссылка на статью:
Лохматов С.Ю., Светлов С.В., Калач Г.П. Методы измерения времени работы программы // Современные научные исследования и инновации. 2017. № 5 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2017/05/83188 (дата обращения: 25.02.2023).
Методология и способы измерений
Одним из главных способов проверки характеристик программного и аппаратного обеспечения касательно быстродействия является измерение времени прикладной программы или ее составных частей.
Подобная проверка целесообразна для нахождения мест в программе или ее алгоритме, которым необходима оптимизация, а также помогает судить о реальных производительных качествах компьютера. На время работы программы влияют различные факторы: характеристики программы, ОС компьютера, работающие процессы и пр.
Для выявления интересующих характеристик существуют некоторые приемы, которые позволяют снизить воздействие нежелательных факторов. Время выполнения тестируемой программы определяется по показаниям таймера (в начале выполнения и после завершения программы). Стоит отметить, что замер времени всегда происходит с некоторой погрешностью.
Теперь подробно рассмотрим способы снижения влияния подобных нежелательных факторов.
-
Многократное измерение. Время выполнения программы измеряется несколько раз. Обычно, из-за влияния сторонних факторов, измерения отличаются, а время работы самой программы не изменяется. Наиболее точным из всех полученных измерений будет являться минимальное значение.
-
Исключение из измерения стадий инициализации и завершения. Если необходимо измерить время выполнения некоторой части кода, то будет рационально вынести весь код, предшествующий вызову этой части, за первый замер времени, а следующий замер провести сразу после завершения работы программы.
-
Снижение влияния кода функции измерения времени. Код снятия показаний таймера выполняется не мгновенно, т.е. в измеряемый интервал времени частично попадает и время его исполнения, такое влияние следует уменьшить. Для этого достаточно снимать временные показания в начале и в конце работы измеряемого фрагмента, а не постоянно. А также следить за тем, чтобы время работы функции, измеряющей время, было меньше измеряемого интервала.
-
Снижение влияния посторонних процессов. Часто процессор загружен другими процессами. В таких случаях рационально использовать таймер времени выполнения процесса.
В данной работе выбран метод многократного измерения. ВС имеет несколько различных таймеров, которые отражают течение времени с разных аспектов. Следует различать следующие таймеры:
1) Таймер системного времени – аппаратный счетчик, отражающий течение времени с позиции ВС. Совпадает с реальным временем. Системное время одинаково для всех работающих на компьютере программ. Значение временного интервала, который измерен таким таймером, включает в себя кроме времени выполнения процесса замера еще и другие процессы. Функции для получения системного времени:
-
ОС Windows: time(); GetTickCount(); GetSystemTime(); clock() (системное время, которое прошло с запуска процесса).
-
ОС Linux: clock_gettime(); time(); times(); gettimeofday().
2) Счетчик тактов процессора – аппаратный счетчик, величина которого возрастает на каждом такте процессора. Позволяет с наибольшей точностью замерять малые промежутки времени. Данный счетчик стоит использовать для измерения интервалов времени, которые меньше кванта времени, выделенного процессу ОС. Специальные команды процессора для получения значения счетчика тактов:
-
Alpha: rpcc;
-
PowerPC: mftbu, mftb;
-
x86/x86-64: rdtsc;
-
Itanium: ar.itc.
Библиотечная функция clock_gettime
Для получения значения системного таймера в ОС Linux/UNIX используется библиотечная функция clock_gettime. Данная функция с параметром CLOCK_MONOTONIC_RAW записывает значение системного таймера в структуру struct timespec, которая состоит из двух полей – tv_sec и tv_nsec, задающих значение секунд и наносекунд, прошедших с некоторого момента времени. В примере записывается значение таймера перед выполнением фрагмента кода и после него. Разница показаний в секундах выводится на экран. Кроме того, функция дает возможность получать значения и с других таймеров.

Листинг 1: clock_gettime
Точность: Обычно в ОС Windows составляет 55 мс (55 ∗ 10−3 с), в ОС GNU Linux/UNIX – 1 нс (1 ∗ 10−9 с).
Достоинство: является переносимой, т.е. функция доступна пользователю независимо от аппаратного обеспечения.
Недостатки: сравнительно низкая точность, и измеренный интервал включает время выполнения и других процессов, работавших в измеряемый период.
Машинная команда rdtsc
Машинная команда rdtsc (Read Time Stamp Counter) берет показания счетчика тактов в виде 64-разрядного беззнакового целого числа, которое равно количеству тактов, прошедших с момента запуска процессора. Делением количества тактов на тактовую частоту процессора получается время в секундах. В этом примере используется ассемблерная вставка команды процессора rdtsc, результат выполнения который записывается в объединение (union) ticks.
Разница данных счётчика тактов преобразовывается в секунды в зависимости от тактовой частоты.

Листинг 2: rdtsc
Точность: один такт.
Достоинство: максимально точность измерения времени.
Недостатки: привязка к архитектуре x86. Затруднительно преобразование в секунды в процессорах с динамическим изменением частоты.
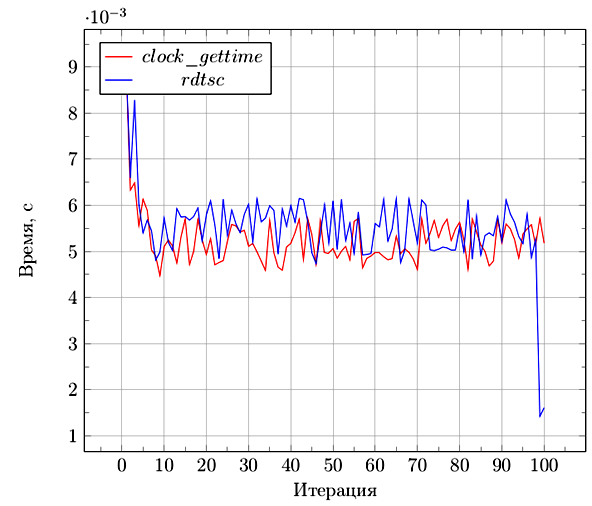
Тестирование
Тестирование данных таймеров было произведено на алгоритме, представляющим из себя сложение двух чисел, повторяющееся 1000000 раз. Для уменьшения влияния посторонних факторов на результаты, измерения будет проведены 100 раз.
Эксперименты проводились на персональной ЭВМ с процессором Intel Core i3-2625M CPU с тактовой частотой 1.3 ГГц. Полученные результаты изображены на графике.
Библиографический список
- Supercomputer Software Department, Institute of Computational Mathematics and Mathematics Geophysics “Определение времени работы прикладных программ” http://ssd.sscc.ru/sites/default/les/content/attach/310/computerlab1.pdf
Количество просмотров публикации: Please wait
Все статьи автора «Лохматов Степан Юрьевич»
Improve Article
Save Article
Improve Article
Save Article
Execution time : The execution time or CPU time of a given task is defined as the time spent by the system executing that task in other way you can say the time during which a program is running.
There are multiple way to measure execution time of a program, in this article i will discuss 5 different way to
measure execution time of a program.
- Using
time()function in C & C++.
time() : time() function returns the time since the Epoch(jan 1 1970) in seconds.
Header File : “time.h”
Prototype / Syntax : time_t time(time_t *tloc);
Return Value : On success, the value of time in seconds since the Epoch is returned, on error -1 is returned.Below program to demonstrate how to measure execution time using
time()function.#include <bits/stdc++.h>usingnamespacestd;voidfun(){for(inti=0; i<10; i++){}}intmain(){time_tstart, end;time(&start);ios_base::sync_with_stdio(false);fun();time(&end);doubletime_taken =double(end - start);cout <<"Time taken by program is : "<< fixed<< time_taken << setprecision(5);cout <<" sec "<< endl;return0;}Output:
Time taken by program is : 0.000000 sec
- Using
clock()function in C & C++.
clock() : clock() returns the number of clock ticks elapsed since the program was launched.
Header File : “time.h”
Prototype / Syntax : clock_t clock(void);
Return Value : On success, the value returned is the CPU time used so far as a clock_t; To get the number of seconds used, divide by CLOCKS_PER_SEC.on error -1 is returned.Below program to demonstrate how to measure execution time using
clock()function.you can also see this#include <bits/stdc++.h>usingnamespacestd;voidfun(){for(inti=0; i<10; i++){}}intmain(){clock_tstart, end;start =clock();fun();end =clock();doubletime_taken =double(end - start) /double(CLOCKS_PER_SEC);cout <<"Time taken by program is : "<< fixed<< time_taken << setprecision(5);cout <<" sec "<< endl;return0;}Output:
Time taken by program is : 0.000001 sec
- using
gettimeofday()function in C & C++.
gettimeofday() : The function gettimeofday() can get the time as well as timezone.
Header File : “sys/time.h”.
Prototype / Syntax : int gettimeofday(struct timeval *tv, struct timezone *tz);
The tv argument is a struct timeval and gives the number of seconds and micro seconds since the
Epoch.
struct timeval {
time_t tv_sec; // seconds
suseconds_t tv_usec; // microseconds
};
Return Value : return 0 for success, or -1 for failure.Below program to demonstrate how to measure execution time using
gettimeofday()function.#include <bits/stdc++.h>#include <sys/time.h>usingnamespacestd;voidfun(){for(inti=0; i<10; i++){}}intmain(){structtimeval start, end;gettimeofday(&start, NULL);ios_base::sync_with_stdio(false);fun();gettimeofday(&end, NULL);doubletime_taken;time_taken = (end.tv_sec - start.tv_sec) * 1e6;time_taken = (time_taken + (end.tv_usec -start.tv_usec)) * 1e-6;cout <<"Time taken by program is : "<< fixed<< time_taken << setprecision(6);cout <<" sec"<< endl;return0;}Output:
Time taken by program is : 0.000029 sec
- Using
clock_gettime()function in C & C++.
clock_gettime() : The clock_gettime() function gets the current time of the clock specified by clock_id, and puts it into the buffer pointed to by tp.
Header File : “time.h”.
Prototype / Syntax : int clock_gettime( clockid_t clock_id, struct timespec *tp );
tp parameter points to a structure containing atleast the following members :
struct timespec {
time_t tv_sec; //seconds
long tv_nsec; //nanoseconds
};
Return Value : return 0 for success, or -1 for failure.
clock_id : clock id = CLOCK_REALTIME,
CLOCK_PROCESS_CPUTIME_ID, CLOCK_MONOTONIC … etc.
CLOCK_REALTIME : clock that measures real i.e., wall-clock) time.
CLOCK_PROCESS_CPUTIME_ID : High-resolution per-process timer from the CPU.
CLOCK_MONOTONIC : High resolution timer that is unaffected by system date changes (e.g. NTP daemons).Below program to demonstrate how to measure execution time using
clock_gettime()function.#include <bits/stdc++.h>#include <sys/time.h>usingnamespacestd;voidfun(){for(inti=0; i<10; i++){}}intmain(){structtimespec start, end;clock_gettime(CLOCK_MONOTONIC, &start);ios_base::sync_with_stdio(false);fun();clock_gettime(CLOCK_MONOTONIC, &end);doubletime_taken;time_taken = (end.tv_sec - start.tv_sec) * 1e9;time_taken = (time_taken + (end.tv_nsec - start.tv_nsec)) * 1e-9;cout <<"Time taken by program is : "<< fixed<< time_taken << setprecision(9);cout <<" sec"<< endl;return0;}Output:
Time taken by program is : 0.000028 sec
- Using
chrono::high_resolution_clockin C++.
chrono : Chrono library is used to deal with date and time. This library was designed to deal with the fact that timers and clocks might be different on different systems and thus to improve over time in terms of precision.chrono is the name of a header, but also of a sub-namespace, All the elements in this header are not defined directly under the std namespace (like most of the standard library) but under the std::chrono namespace.
Below program to demonstrate how to measure execution time using
high_resolution_clockfunction. For detail info on chrono library see this and this#include <bits/stdc++.h>#include <chrono>usingnamespacestd;voidfun(){for(inti=0; i<10; i++){}}intmain(){autostart = chrono::high_resolution_clock::now();ios_base::sync_with_stdio(false);fun();autoend = chrono::high_resolution_clock::now();doubletime_taken =chrono::duration_cast<chrono::nanoseconds>(end - start).count();time_taken *= 1e-9;cout <<"Time taken by program is : "<< fixed<< time_taken << setprecision(9);cout <<" sec"<< endl;return0;}Output:
Time taken by program is : 0.000024 sec