Как устроены системы оперативной аналитики данных, почему для BI больше подходит многомерный анализ и какие базы данных используют в OLAP.
В IT-системах компаний обычно есть приложения для комплексного анализа данных. Чаще всего их использует топ-менеджмент, чтобы принимать решения, основанные на данных, а не на интуиции.
Чтобы получить информацию, нужную для принятия взвешенного решения, надо собрать данные из различных источников, обработать и проанализировать. Для этого корпоративное хранилище данных должно быть организовано особым образом, в частности с использованием технологии OLAP. Ее мы и рассмотрим в статье.
Что такое OLAP и зачем нужны такие системы
OLAP — это online analytical processing, оно же — оперативный анализ данных. Давайте попробуем определить это понятие на человеческом языке.
В IT-системах данные хранятся в разных источниках — это несвязанные между собой базы данных, хранилища событий, файлы, быстрые хранилища, системы статистики. В этой куче информации прячется то, что важно знать для эффективного управления IT-продуктом и бизнесом. Но достать нужные сведения из столь разнородной структуры и представить в виде, удобном для менеджеров и аналитиков — проблематично.
Поэтому инженеры придумали системы, которые сами следят за всеми поставщиками данных и собирают всё, что надо знать менеджерам, в одном месте. Это и есть «анализ данных».
А почему «оперативный»? Допустим, вы управляете большим интернет-магазином и прямо сейчас тестируете на эффективность несколько рекламных кампаний. Из всех кампаний нужно отобрать самую эффективную и уже с ней работать дальше. Система обработки данных, конечно, позволит увидеть нужные цифры и принять правильные решения. Но данные из нее надо достать быстро — если построение отчета займет недели, то с такой задержкой хорошие решения принять нельзя.
Поэтому инженеры сделали не просто систему обработки и анализа данных из разнородных источников — они сделали ее быстрой, чтобы вся нужная информация попадала на стол менеджеров практически в режиме реального времени.
Весь этот подход и программы, которые задействованы в таком быстром сборе и анализе информации, и называется OLAP.
OLAP и многомерный анализ данных
Работа OLAP-систем опирается на многомерную модель данных, то есть такие системы позволяют анализировать множество разных параметров с разных сторон. Они обрабатывают многомерные массивы данных, то есть такие, в которых каждый элемент массива связан с другими элементами.
Поэтому OLAP позволяет строить гипотезы, выявлять причинно-следственные связи между разными параметрами, моделировать поведение системы при изменениях.
Данные при этом организованы в виде многомерных кубов — осями будут отслеживаемые параметры, на их пересечении находятся данные. Пользователи могут выбирать нужные параметры и получать информацию по разным измерениям.
Например, для продаж осями куба могут быть товары, тип покупателя, регион, частота покупки и так далее. Пользователь может получить данные о том, какие товары, в каких регионах чаще покупают, или какие типы покупателей чаще делают покупки, или сколько товаров продано в каждом регионе за месяц.
OLAP-система собирает информацию из баз данных, ERP, CRM и других источников, а затем формирует многомерный массив данных. В общем виде структура OLAP выглядит так:
- Источники данных — реляционные или многомерные базы данных, хранилище данных.
- OLAP-сервер, управляющий многомерными массивами данных.
- Приложения, которые формируют отчеты, графики, диаграммы для пользователей.
Как можно реализовать OLAP на практике: виды таких систем
Самый простой и очевидный подход — создать систему, которая напрямую ничего не хранит, но умеет быстро вынимать разные записи из разных мест и в правильном виде показывать данные менеджерам. Такие системы хорошо работают, когда данные разложены по однотипным СУБД. Например, все подразделения сидят на реляционной СУБД PostgreSQL.
OLAP с такой архитектурой будет называться Relational OLAP (ROLAP) — OLAP, построенный на отношениях таблиц и баз данных между собой. Такая система не требует предварительной подготовки записей в таблицах для анализа — можно брать все нужные значения напрямую и в режиме онлайн.
Если же данные лежат не только в однотипных корпоративных базах данных, то надо собирать информацию по разным источникам и сводить всё это вместе. Появляется этап предварительной подготовки данных на отдельном сервере. И такая система — это уже Multidimensional OLAP (MOLAP), или многомерный OLAP. Такую штуку построить сложнее, но иногда без нее никак — чем больше ваша компания, тем больше разнородных систем хранения данных в ней будет задействовано. Это наиболее эффективный тип для аналитической обработки, так как позволяет структурировать данные под разные запросы пользователей.
И третий вид — гибрид первых двух типов систем. В очень-очень больших компаниях часть данных проще достать через запросы в базы данных, а часть нужно предварительно готовить средствами многомерной OLAP, работающей с различными источниками.
Самое интересное: многомерный анализ данных
Самая интересная технология из всех этих — многомерный OLAP и многомерные системы, которые применяют для сбора информации из всех подразделений компании. Софт для таких систем чертовски сложен и интересен, он умеет работать с различными источниками, при этом делать это быстро и эффективно, одновременно опрашивая десятки многотерабайтных таблиц.
Однако впечатляющая способность опрашивать разных поставщиков — не самое главное, у таких систем есть еще крутейший набор инструментов для работы с самими данными.
Давайте бросим взгляд на несколько представителей рынка многомерных БД для OLAP:
- Vertica — неплохая база, появившаяся в 2005 году. Самая крутая фишка этой системы — встроенные в нее алгоритмы машинного обучения. Можно применять регрессии и считать кластеры на данных с помощью SQL-запросов, не написав ни строчки кода для создания моделей машинного обучения.
- Greenplum — профессиональная база данных, которая работает на основе PostgreSQL. Огромная производительность, надежность и масштабируемость для тех, кому надо ворочать гигабайтами записей в режиме реального времени. Пожалуй, трудно найти что-то гибче и мощнее этой штуки. А еще она доступна в готовом и настроенном виде в облаке — в виде СУБД Arenadata DB. Облачный сервис поможет развернуть сложную многомерную базу данных в максимально короткие сроки.
- Hadoop. Штука, в общем-то, не предназначенная для OLAP-процессов. Но, тем не менее, может выполнять роль ядра OLAP-системы. Качество и скорость, понятное дело, будут страдать, но зато этот инструмент всегда под рукой, он прост и умеет справляться со своими задачами. То есть вариант для быстрого прототипирования OLAP-систем. Также может интегрироваться с Greenplum, и в этом случае такая система подходит для работы с big data.
Кто пользуется OLAP-системами
Практически все, у кого много данных и надо принимать оперативные управленческие решения. Такие системы предоставляют почти безграничные возможности по составлению отчетов, сложной аналитике, прогнозированию и планированию.
Например, агрегаторы такси — ситуация с клиентами и водителями меняется быстро, нужно понимать, что происходит. Даже задержка в 15 минут на этом рынке имеет критическое значение.
Или большие онлайн-магазины и ритейлеры. Наличие запасов на складе и показателей выручки важно знать здесь и сейчас — ведь даже за 10 минут торгового дня эти значения меняются очень быстро.
Думаю, на этих примерах вы мысленно примерили OLAP на свой бизнес. И уже поняли, насколько вам нужна такая система.
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
В
ведение
OLAP — это не отдельно взятый программный продукт, не язык программирования и даже не конкретная технология. Если постараться охватить OLAP во всех его проявлениях, то это совокупность концепций, принципов и требований, лежащих в основе программных продуктов, облегчающих аналитикам доступ к данным.
Для начала мы выясним, зачем аналитикам надо как-то специально облегчать
доступ к данным. Дело в том, что аналитики — это особые потребители
корпоративной информации. Задача аналитика — находить закономерности в
больших массивах данных. Поэтому аналитик не будет обращать внимания на отдельно взятый факт, что в четверг четвертого числа контрагенту Чернову была продана партия черных чернил — ему нужна информация о сотнях и тысячах подобных событий. Одиночные факты в базе данных могут заинтересовать, к примеру, бухгалтера или начальника отдела продаж, в компетенции которого находится сделка. Аналитику одной записи мало — ему, к примеру, могут понадобиться все сделки данного филиала или представительства за месяц, год. Заодно аналитик отбрасывает ненужные ему подробности вроде ИНН покупателя, его точного адреса и номера телефона, индекса контракта и тому подобного. В то же время данные, которые требуются аналитику для работы, обязательно содержат числовые значения — это обусловлено самой сущностью его деятельности.
Централизация и удобное структурирование — это далеко не все, что нужно
аналитику. Ему ведь еще требуется инструмент для просмотра, визуализации
информации. Традиционные отчеты, даже построенные на основе единого
хранилища, лишены одного — гибкости. Их нельзя “покрутить”, “развернуть” или “свернуть”, чтобы получить желаемое представление данных. Конечно, можно вызвать программиста, и он сделает новый отчет достаточно быстро — скажем, в течение часа. Получается, что аналитик может проверить за день не более двух идей. А ему (если он хороший аналитик) таких идей может приходить в голову по нескольку в час. И чем больше “срезов” и “разрезов” данных аналитик видит, тем больше у него идей, которые, в свою очередь, для проверки требуют все новых и новых “срезов”.В качестве такого инструмента и выступает OLAP.
Хотя OLAP и не представляет собой необходимый атрибут хранилища данных, он все чаще и чаще применяется для анализа накопленных в этом хранилище сведений.
Чтотакое OLAP- технологии
OLAP (On-Line Analytical Processing) –
-
это класс приложений и технологий, предназначенных для оперативной аналитической обработки многомерных данных (сбор, хранение, анализ) для анализа деятельности корпорации и прогнозирования будущего состояния с целью поддержки принятия управленческих решений.
-
набор технологий для оперативной обработки информации, включающих динамическое построение отчётов в различных разрезах, анализ данных, мониторинг и прогнозирование ключевых показателей бизнеса.
Технология OLAP применяется, чтобы упростить работу с многоцелевыми накопленными данными о деятельности корпорации в прошлом и не погрязнуть в их большом объеме, а также превратить набор количественных показателей в качественные, позволяет аналитикам, менеджерам и управляющим сформировать свое собственное видение данных, используя быстрый, единообразный, оперативный доступ к разнообразным формам представления информации. Такие формы, полученные на основании первичных данных, позволяют пользователю сформировать полноценное представление о деятельности предприятия.
OLAP-технология является альтернативой традиционным методам анализа данных, основанным на различных системах реализации SQL-запросов к реляционной БД. OLAP-системы играют важнейшую роль в анализе и планировании деятельности крупных предприятий и являются одним из направлений развития ИТ. В основу кладутся требования людей принимающих решения к предоставляемой информации, сложившейся индивидуальные особенности ведения дел и принятый механизм принятия решения. С точки зрения пользователя основное отличие OLAP-системы заключается: в предметной структурированности информации (именно предметной, а не технической). Работая с OLAP-приложением, пользователь применяет привычные категории и показатели – виды материалов и готовой продукции, регионы продаж, объем реализации, себестоимость, прибыль и т. п. А для того чтобы сформировать любой, даже довольно сложный запрос, пользователю не придется изучать SQL. При этом ответ на запрос будет получен в течение всего нескольких секунд. Кроме того, работая с OLAP-системой, экономист может пользоваться такими привычными для себя инструментами, как электронные таблицы или специальные средства построения отчетов.
Есть характеристики, которые должны соблюдаться во всех OLAP-продуктах, в которых и заключается идеал технологии. Это 5 ключевых определений, так называемый, тестFASMI:
Быстрый — означает, что система должна обеспечивать выдачу большинства ответов пользователям в пределах приблизительно пяти секунд. Даже если система предупредит, что процесс будет длиться существенно дольше, пользователи, могут отвлечься и потерять мысль, при этом качество анализа страдает. Такую скорость не просто достигнуть с большими количествами данных, особенно, если требуются специальные вычисления «на лету». Поставщики прибегают к широкому разнообразию методов, чтобы достигнуть этой цели, включая специализированные формы хранения данных, обширные предварительные вычисления, или же ужесточая аппаратные требования. Однако полностью оптимизированных решений на сегодняшний день нет. На первый взгляд может казаться удивительным, что при получении отчета за минуту, на который не так давно требовались дни, пользователь очень быстро начинает скучать во время ожиданий, и проект оказывается намного менее успешным, чем в случае мгновенного ответа, даже ценой менее детального анализа.
Разделяемой означает, что система дает возможность выполнять все требования защиты данных и реализовывать распределенный и одновременный доступ к данным для различных уровней пользователей. Система должна быть способна обработать множественные изменения данных своевременным, безопасным способом. Это — главная слабость многих OLAP продуктов, которые имеют тенденцию предполагать, что во всех приложениях OLAP требуется только чтение, и предоставляют упрощенные средства защиты.
Многомерной — ключевое требование. Если бы необходимо было определить OLAP одним словом, то выбрали бы его. Система должна обеспечить многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий, поскольку это определяет наиболее логичный способ анализировать бизнес. Минимальное число измерений, которые должны быть обработаны, не устанавливается, поскольку это также зависит от приложения, и большинство продуктов OLAP, имеет достаточное количество измерений для тех рынков, на которые они нацелены. И опять же, мы не определяем, какая основная технология базы данных должна использоваться, если пользователь получает действительно многомерное концептуальное представление информации. Эта особенность — сердцевина OLAP.
Информации. Необходимая информация должна быть получена там, где она необходима, независимо от ее объема и места хранения. Однако многое зависит от приложения. Мощность различных продуктов измеряется в терминах того, сколько входных данных они могут обрабатывать, но не сколько гигабайт они могут хранить. Мощность продуктов весьма различна — самые большие OLAP продукты могут оперировать, по крайней мере, в тысячу раз большим количеством данных по сравнению с самыми маленькими. По этому поводу следует учитывать много факторов, включая дублирование данных, требуемую оперативную память, использование дискового пространства, эксплуатационные показатели, интеграцию с информационными хранилищами и т. п.
Анализ означает, что система может справляться с любым логическим и статистическим анализом, характерным для данного приложения, и обеспечивает его сохранение в виде, доступном для конечного пользователя. Пользователь должен иметь возможность задавать новые специальные вычисления как часть анализа без необходимости программирования. То есть все требуемые функциональные возможности анализа должны обеспечиваться интуитивным способом для конечных пользователей. Средства анализа могли бы включать определенные процедуры, типа анализа временных рядов, распределения затрат, валютных переводов, поиска целей и др. Такие возможности широко отличаются среди продуктов, в зависимости от целевой ориентации.
Важно отметить, что OLAP один из способов реализации Business Intelligence, который является процессом превращения данных в знания, а знаний в действия бизнеса для получения выгоды. Является деятельностью конечного пользователя, которую облегчают различные аналитические и групповые инструменты и приложения, а также инфраструктура хранилища данных.
Способ представления
В основе OLAP-технологий лежит представление информации в виде OLAP-кубов.
OLAP-кубы содержат бизнес-показатели, используемые для анализа и принятия управленческих решений, например: прибыль, рентабельность продукции, совокупные средства (активы), собственные средства, заемные средства и т.д.
Бизнес-показатели хранятся в кубах не в виде простых таблиц, как в обычных системах учета или бухгалтерских программах, а в разрезах, представляющих собой основные бизнес-категории деятельности организации: товары, магазины, клиенты, время продаж и т. д.
Благодаря детальному структурированию информации OLAP-кубы позволяют оперативно осуществлять анализ данных и формировать отчёты в различных разрезах и с произвольной глубиной детализации. Отчёты могут создаваться аналитиками, менеджерами, финансистами, руководителями подразделений в интерактивном режиме для того, чтобы быстро получить ответы, на возникающие ежедневно вопросы, и принять правильное решение. При этом сотрудникам, для создания отчетов не нужно прибегать к услугам программистов, на что обычно уходит немало времени.
Из OLAP-куба может быть составлен обычный плоский отчёт. По столбикам и строчкам отчёта будут бизнес-категории (грани куба), а в ячейках показатели.
Этапы построения OLAP-системы
1. Хранилище данных
Хранилище данных является основой OLAP-системы. Процедуры загрузки с определённой периодичностью пополняют хранилище из различных источников (базы данных, документы Excel, Web и т.д.), выполняя проверку и предварительную обработку. Механизмы загрузки данных проектируются таким образом, чтобы хранилище содержало в хронологическом порядке в едином формате всю необходимую информацию о предметной области для поддержки принятия решений.
2. Многомерные OLAP-кубы
На основе хранилища данных строятся многомерные OLAP-кубы, позволяющие в реальном времени осуществлять анализ данных и формировать отчёты в различных разрезах и произвольной глубиной детализации.
При работе с OLAP-кубами пользователь оперирует привычными категориями и показателями: виды готовой продукции, материалы, регионы, время продаж, объём реализации, себестоимость, прибыль и т. п. Отчёты создаются сотрудниками в интерактивном режиме (нет необходимости прибегать к помощи программистов).
3. Система ключевых показателей (KPI) — показатели деятельности подразделения (предприятия), которые помогают организации в достижении стратегических и тактических (операционных) целей, создаётся на базе OLAP-кубов для мониторинга и оценки бизнес-процессов, а также для оповещения ответственных сотрудников о фактах отклонения.
4. Интеллектуальный анализ данных (Data Mining)
Модели интеллектуального анализа данных проектируются для автоматического прогнозирования наиболее важных показателей бизнеса, а также извлечения скрытых закономерностей из накопленной информации.
5. Доступ через web-интерфейс
Для работы с OLAP-системой могут быть использованы различные приложения, например Excel. Чаще всего доступ осуществляется через специализированный web-портал, позволяющий работать с OLAP-кубами и отчётами, обладающий административным интерфейсом и возможностью разграничения прав доступа к данным и инструментам.
Преимущества OLAP-систем
Ключевую роль в управлении компанией играет информация. Как правило, даже небольшие компании используют несколько информационных систем для автоматизации различных сфер деятельности. Получение аналитической отчётности в информационных системах, основанных на традиционных базах данных сопряжено с рядом ограничений:
-
Разработка каждого отчёта требует работы программиста;
-
Отчёты формируются очень медленно (зачастую несколько часов), замедляя при этом работу всей информационной системы;
-
Данные, получаемые от различных структурных элементов компании не унифицированы и часто противоречивы.
OLAP-системы, самой идеологией своего построения предназначены для анализа больших объёмов информации, позволяют преодолеть ограничения традиционных информационных систем. Создание OLAP-системы на предприятии позволит:
-
Интегрировать данные различных информационных систем, создав единую версию правды;
-
Проектировать новые отчеты несколькими щелчками мыши без участия программистов;
-
В реальном времени анализировать данные по любым категориям и показателям бизнеса на любом уровне детализации;
-
Производить мониторинг и прогнозирование ключевых показателей бизнеса.
Недостатки OLAP
Как и любая технология OLAP также имеет свои недостатки: высокие требования к аппаратному обеспечению, подготовке и знаниям административного персонала и конечных пользователей, высокие затраты на реализацию проекта внедрения (как денежные, так и временные, интеллектуальные).
Заключение
Эффект от правильной организации, стратегического и оперативного планирования развития бизнеса трудно заранее оценить в цифрах, но очевидно, что он в десятки и даже сотни раз может превзойти затраты на реализацию таких систем. Однако не следует и заблуждаться. Эффект обеспечивает не сама система, а люди с ней работающие. Поэтому не совсем корректны декларации типа: «система Хранилищ Данных и OLAP-технологий будет помогать менеджеру принимать правильные решения». Современные аналитические системы не являются системами искусственного интеллекта и они не могут ни помочь, ни помешать в принятии решения. Их цель своевременно обеспечить менеджера всей информацией необходимой для принятия решения в удобном виде. А какая информация будет запрошена и какое решение будет принято на её основе, зависит только от конкретного человека ее использующего
Список источников
[1]Применение OLAP-технологий для учетных систем на платформе 1С. — специалисты компании «Абис Софт»
http://www.cfin.ru/itm/olap/1c.shtml
[2]Что такое Business Intelligence? — Валерий Артемьев
http://citforum.ru/consulting/BI/whatis/
[3] http://www.interface.ru/home.asp?artId=9228
[4] Способ извлечь данные из 1С. – movsb
http://habrahabr.ru/post/191660//
[5] http://www.lavelin.ru/articles/18-1s/razrabotka-i-administrirovanie/328-sposob-izvlech-dannye-iz-bazy-1s.html

Кубы данных — не самая простая тема в дата-инжиниринге. Это тот самый случай, когда на пять запросов об определении приходятся пять разных вариантов ответа. Эта неоднозначность породила неудачную универсальную метафору, с помощью которой описываются кубы данных, — схему трехмерного куба. При этом в объяснениях нет примеров, рассказывающих, как в дата-пайплайне реализуется эта концепция.
Команда VK Cloud перевела статью, в которой заполняются пробелы и развенчиваются мифы, окружающие тему кубов данных.
Что такое куб данных
В общих чертах куб данных — это дизайн-паттерн, в котором показатели, например продажи, агрегируются по разным разрезам: региону, магазину или продукту.
Дизайн-паттерн реализован в основном в двух контекстах:
- Как предварительно агрегированная таблица в реляционной базе данных.
- Как объект данных в специализированной OLAP-системе.
В обоих контекстах кубы данных должны помогать бизнес-аналитикам предварительно упаковывать и агрегировать важные для стейкхолдеров показатели. Если вкратце, с 1980 по 2010 год специалисты прибегали к предварительной упаковке и агрегированию. Это помогало избежать оперативных агрегатных запросов, из-за которых резко снижалась доступная на тот момент пропускная способность обработки.
Сегодня эти проблемы стоят не так остро. Но к этой теме мы вернёмся позже.
Кубы данных в реляционных БД
Рассмотрим пример — таблицу с данными по продажам по региону, магазину и продукту:

Чтобы создать куб данных из взятого для примера дата-сета, нужно агрегировать сумму цен по каждой комбинации разрезов. В PostgreSQL и MS SQL имеется подблок GROUP BY под названием CUBE, который сделает эту работу за вас.
Вот как выглядит запрос CUBE с этими данными:
SELECT SUM(price) as total_sales,
region,
store,
product
FROM sales
GROUP BY CUBE(region, store, product);Поскольку у взятого для примера дата-сета есть три разреза: регион, магазин, продукт, — вышеуказанный запрос выдаст восемь сгруппированных множеств и 29 строк данных (исходя из количества уникальных значений по разрезам).
Чтобы рассчитать общее количество сгруппированных множеств, созданных кубом данных, воспользуйтесь формулой: 2^number_of_dimensions.
Сгруппированные множества для этого примера:
(region, store, product),
(region, store),
(region, product),
(store, product),
(region),
(store),
(product),
()В этом кубе данных нет ничего чрезмерно сложного: мы просто обобщили данные по каждому сочетанию разрезов. В прошлом дата-инженер создавал похожую таблицу и передавал её аналитику в виде общего представления по продажам.
Кубы данных в OLAP-системах
Как мы показали выше, куб данных можно реализовать в таблице стандартной БД, но их чаще используют в приложении Online Analytical Processing (OLAP).
Кубы — важная характеристика ядра традиционных OLAP-систем. Пожалуй, не будет преувеличением сказать, что OLAP и кубы данных — это в каком-то смысле синонимы.
Краткий исторический экскурс
Сейчас давайте ненадолго вернёмся в прошлое и разберёмся, что такое OLAP-системы и почему их вообще создали.
Сегодня, как и в 1970-х, бизнес-аналитика служит одной и той же цели: стейкхолдеры направляют запросы к данным и обобщают результаты по разным разрезам. К сожалению, десятилетия назад для выполнения этих запросов мог подойти только интерфейс используемых в компании рабочих баз данных SQL — тех самых, которые поддерживали цифровые бизнес-транзакции.
По современным меркам, компьютеры той эпохи работали очень медленно. Выполнять анализ непосредственно в рабочей базе данных было долго и дорого в плане затрат вычислительных ресурсов. Что ещё хуже, это мешало выполнять повседневные операции, для которых базы данных, собственно, и предназначались.
Приход OLAP-систем
В качестве решения этой проблемы разработчики ПО придумали отдельные хранилища, в которые загружали рабочие данные для анализа. Эти специализированные OLAP-системы хранили в предварительно агрегированном виде многомерную информацию, которую инженеры и аналитики называли OLAP-кубами.
Постепенно эти OLAP-системы доросли до полноценных приложений. В них аналитики или стейкхолдеры могли изучать OLAP-кубы, используя специальный синтаксис запросов или графический пользовательский интерфейс. Это позволяло выполнять нескольких функций, характерных для сводных таблиц:
- Roll up: объединить показатели в категории разрезов уровнем выше (город => область).
- Drill Down: разбить обобщённые категории на категории уровнем ниже (область => город).
- Slice and Dice: выбрать сегмент данных из одного или нескольких разрезов.
- Pivot: поменять оси табличного представления.
В этом контексте OLAP-куб — это агрегат многомерных данных, а OLAP-система — интерфейс сводных таблиц, предназначенный для исследования куба с помощью языка запросов или GUI. Современные версии OLAP-систем — это IMB Cognos, Oracle Olap и Oracle Essbase.
Если искать в интернете, что такое OLAP-куб, Google будет раз за разом выводить описания в виде трёхмерного изображения куба, который состоит из кубиков поменьше. Суть таких схем — наглядно представить, как вышеописанные функции работают в OLAP-системе и как выглядят сегменты агрегированных данных, созданных пересекающимися разрезами.
Но поскольку этому визуальному представлению не хватает контекста, оно скорее запутывает, чем проясняет дело. Зато теперь, когда мы разобрались с основами, эта схема может нам пригодиться.

OLAP drill up&down en.png со страницы Wikipedia
Вчера и сегодня
С тех пор как разработчики разворачивали кубы данных и OLAP-системы в качестве решения для бизнес-аналитики, технологический ландшафт кардинально изменился. Эффективность обработки данных экспоненциально выросла, а благодаря облачным платформам вроде AWS, GCP и VK Cloud, ещё и существенно подешевела. Кроме того, колоночные хранилища упростили доступ к большому объёму данных при стандартных нагрузках.
Благодаря этим переменам необходимость в кубах и OLAP-системах заметно снизилась.
Сегодня аналитики могут безо всяких проблем на лету агрегировать данные по разным разрезам с помощью платформ типа BigQuery и Snowflake. Да и использование GUI для сведения воедино больших объёмов данных уже не вызывает трудностей. Такие инструменты, как DOMO и PowerBI, позволяют аналитикам с лёгкостью фрагментировать и анализировать данные вдоль и поперёк.
Заключение
Вернёмся к исходному вопросу — так что же такое OLAP-куб? Если очень коротко, это многомерная сводная таблица в OLAP-системе. Если не брать в расчёт особенности технической реализации, она похожа на сводную таблицу Excel.
Команда VK Cloud развивает собственные Big Data-решения. Будем признательны, если вы их протестируете и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3000 бонусных рублей.

26.05.2020
OLAP-технологии — это технологии обработки данных, с помощью которых из больших многомерных информационных массивов извлекается и подготавливается для анализа необходимая агрегированная (то есть объединенная в «пакет») информация.
Подробнее о специфике этих технологий и об их использовании в бизнесе будет рассказано в представленной статье.

Специфика OLAP-технологий
OLAP-технологии в бизнесе (преимущественно в e-commerce, IT и финтехе) применяются по трем направлениям:
- для аналитики данных;
- для планирования бюджета;
- для составления финансовой консолидированной отчетности.
При этом чаще всего эти технологии применяются как инструмент анализа. Использование OLAP-технологий в данной сфере предоставляет возможность быстро обрабатывать запросы при постановке задач с большим количеством исходных данных. С их помощью можно решать вопросы, связанные с:
- динамикой развития бизнеса;
- определением структуры реализуемых товаров или оказываемых услуг;
- определением структуры продаж по территориально-географическому принципу.
При этом результаты обработки и подготовки консолидированных данных при работе по данным технологиям представляются в виде OLAP-кубов, содержащих необходимые для принятия управленческих решений бизнес-показатели.
Сферы применения OLAP-технологий в бизнесе
Наиболее востребованными OLAP-технологии являются в сферах анализа:
- продаж. Анализ структуры реализации товаров позволяет принимать управленческие решения, касающиеся изменений товарного ассортимента и ценообразования, проведения рекламных акций, заключения договоров с контрагентами и открытии новых торговых точек;
- закупок. В данном случае с помощью средств аналитики наиболее часто выполняются планирование денежных средств и контроль за выбором поставщиков;
- ценообразования — в данной сфере анализ данных с применением OLAP-технологий проводится для оптимизации расходов и создания наиболее выгодных предложений при изучении рыночных цен;
- маркетинга. В этой области бизнеса исследуется и анализируется поведение покупателей и клиентов для правильного позиционирования товаров, выявления целевой аудитории для проведения рекламных акций и для оптимизации ассортимента;
- посещаемости сайтов. Данная область применения OLAP-технологий позволяет проанализировать количество посещений, количество просмотренных страниц и времени, проведенного на сайте.
Обучиться применению OLAP-технологий в бизнесе каждый желающий сможет, пройдя курс профессиональной переподготовки по программе«Инструментальные средства бизнес-аналитики», которую проводит ВШБИ НИУ ВШЭ. Записаться на обучение по данному курсу можно на нашем сайте.
← Назад к списку
С точки зрения пользователя, OLAP-системы представляют средства гибкого просмотра информации в различных срезах, автоматического получения агрегированных данных, выполнения аналитических операций свёртки, детализации, сравнения во времени. Всё это делает OLAP-системы решением с очевидными преимуществами в области подготовки данных для всех видов бизнес-отчетности, предполагающих представление данных в различных разрезах и разных уровнях иерархии — например, отчетов по продажам, различных форм бюджетов и так далее. Очевидны плюсы подобного представления и в других формах анализа данных, в том числе для прогнозирования.
Требования к OLAP-системам. FASMI
Ключевое требование, предъявляемое к OLAP-системам — скорость, позволяющая использовать их в процессе интерактивной работы аналитика с информацией. В этом смысле OLAP-системы противопоставляются, во-первых, традиционным РСУБД, выборки из которых с типовыми для аналитиков запросами, использующими группировку и агрегирование данных, обычно затратны по времени ожидания и загрузке РСУБД, поэтому интерактивная работа с ними при сколько-нибудь значительных объемах данных сложна. Во-вторых, OLAP-системы противопоставляются и обычному плоскофайловому представлению данных, например, в виде часто используемых традиционных электронных таблиц, представление многомерных данных в которых сложно и не интуитивно, а операции по смене среза — точки зрения на данные — также требуют временных затрат и усложняют интерактивную работу с данными.
Термин OLAP, предложенный Эдгаром Коддом (Edgar Codd) для разграничения таких систем с OLTP-системами (от англ. OnLine Transaction Processing — обработка транзакций в реальном времени), некоторые эксперты считают слишком широким. Поэтому Найджел Пендс (Nigel Pendse) предложил использовать для описания этой концепции и взамен предложенных Коддом 12-ти правил OLAP так называемый тест FASMI (от англ. Fast Analysis of Shared Multidimensional Information — быстрый анализ доступной многомерной информации), более точно харакетеризующую требования к этим системам.
Fast (быстрый) в отражает упомянутое выше требование к скорости реакции системы. По Пендсу, интервалы с момента инициации запроса до получения результата должен измеряться секундами. Важность этого требования возрастает при использовании таких систем в качестве инструмента оперативного представления данных для аналитика, так как длительное время ожидания может пагубно влиять на цепочку рассуждений аналитика.
Analysis (анализ) предполагает приспособленность системы к использованию в релевантной для задачи и пользователя бизнес-логике с сохранением доступной «обычному» пользователю легкости оперирования данными без использования низкоуровневого специального инструментария.
Shared (доступность, общедоступность) описывает очевидное требование к возможности одновременного многопользовательского доступа к информации с интегрированной системой разграничения прав доступа вплоть до уровня конкретной ячейки данных.
Multidimensional (многомерность) является ключевым требованием концепции. Предполагается, что система должна обеспечивать полную поддержку многомерного иерархического представления как «наиболее логичного пути анализа бизнеса и организаций». Отметим, что многомерность указывает на модель концептуального представления данных, то есть на то, как пользователь должен представлять организацию данных при формулировании запросов, а не на то, в каких структурах хранятся данные физически.
Многомерность в рамках OLAP предполагает концептуальное представление данных в виде многомерной структуры данных — гиперкуба (OLAP-куба), рёбрами в котором выступают измерения(dimension), а данные (facts — факты; measures — меры, показатели) расположены на пересечении осей измерений.
При этом измерение обычно представляет собой плоский или иерархический список. Например, измерение «Партнёры» может включать список партнёров компании, измерение «Время» — список филиалов с географической группировкой (регион мира, страна, регион, город, филиал). Если в качестве меры определён объём продаж, то на срезе по измерениям «Партнёры» и «Время» будем иметь таблицу с данными об изменении объема продажа по партнёрам во времени, в качестве заголовков строк и столбцов которой будут выступать наши измерения — «Время» и «Партнёры», а в ячейках на пересечении строк и столбцов будут расположены значений меры, т. е. данные об объеме продаж в конкретный период времени для конкретного партнёра.
Information (информация) — это все релевантные целям пользователя данные, при этом наличие «лишних» данных негативно сказывается на требовании к скорости реакции системы.
Особенности архитектуры. Классификация OLAP-систем
На архитектуру конкретных OLAP-систем оказывают влияние несколько факторов. Среди них — взаимодействие с источниками данных, особенности организации хранения данных в самой OLAP-системе и подход к обработке данных в ней.
Источники данных
OLAP-системы редко используются как средство непосредственного хранения и модификации данных (за исключением некоторых простых и маломасштабных систем бюджетирования, учета и анализа продаж и т. п.), так как большинство данных, используемых в OLAP для анализа, генерируются в других информационных системах (ERP, CRM, HRM и т. д.).
При этом, с одной стороны, специфичные для OLAP-систем требования к данным обычно подразумевают хранение данных в специальных оптимизированных под типовые задачи OLAP структурах, с другой сторны, непосредственное извлечение данных из существующих систем в процессе анализа привело бы к существенному падению их производительности.
Следовательно, важным требованием является обеспечение макимально гибкой связки импорта-экспорта между существующими системами, выступающими в качестве источника данных и OLAP-системой, а также OLAP-системой и внешними приложениями анализа данных и отчетности.
При этом такая связка должна удовлетворять очевидным требованиям поддержки импорта-экспорта из нескольких источников данных, осуществления процедур очистки и трансформации данных, унификации используемых классификаторов и справочников. Кроме того, к этим требованиям добавляется необходимость учёта различных циклов обновления данных в существующих информационных системах и унификации требуемого уровня детализации данных. Сложность и многогранность этой проблемы привела к появлению концепции хранилищ данных, и, в узком смысле, к выделению отдельного класса утилит конвертации и преобразования данных — ETL (Extract Transform Load).
Модели хранения активных данных
Выше мы указали, что OLAP предполагает многомерное иерархическое представление данных, и, в каком-то смысле, противопоставляется базирующимся на РСУБД системам.
Это, однако, не значит, что все OLAP-системы используют многомерную модель для хранения активных, «рабочих» данных системы.
Так как модель хранения активных данных оказывает влияние на все диктуемые FASMI-тестом требования, её важность подчёркивается тем, что именно по этому признаку традиционно выделяют подтипы OLAP — многомерный (MOLAP), реляционный (ROLAP) и гибридный (HOLAP).
Вместе с тем, некоторые эксперты, во главе с вышеупомянутым Найджелом Пендсом, указывают, что классификация, базирующаяся на одном критерии недостаточно полна. Тем более, что подавляющее большинство существующих OLAP-систем будут относиться к гибридному типу. Поэтому мы более подробно остановимся именно на моделях хранения активных данных, упомянув, какие из них соответствуют каким из традиционных подтипов OLAP.
Хранение активных данных в многомерной БД
В этом случае данные OLAP хранятся в многомерных СУБД, использующих оптимизированные для такого типа данных конструкции. Обычно многомерные СУБД поддерживают и все типовые для OLAP операции, включая агрегацию по требуемым уровням иерархии и так далее.
Этот тип хранения данных в каком-то смысле можно назвать классическим для OLAP. Для него, впрочем, в полной мере необходимы все шаги по предварительной подготовке данных. Обычно данные многомерной СУБД хранятся на диске, однако, в некоторых случаях, для ускорения обработки данных такие системы позволяют хранить данные в оперативной памяти. Для тех же целей иногда применяется и хранение в БД заранее рассчитанных агрегатных значений и прочих расчётных величин.
Многомерные СУБД, полностью поддерживающие многопользовательский доступ с конкурирующими транзакциями чтения и записи достаточно редки, обычным режимом для таких СУБД является однопользовательский с доступом на запись при многопользовательском на чтение, либо многопользовательский только на чтение.
Среди условных недостатков, характерных для некоторых реализаций многомерных СУБД и базирующихся на них OLAP-систем можно отметить их подверженность непредсказуемому с пользовательской точки зрения росту объёмов занимаемого БД места. Этот эффект вызван желанием максимально уменьшить время реакции системы, диктующим хранить заранее рассчитанные значения агрегатных показателей и иных величин в БД, что вызывает нелинейный рост объёма хранящейся в БД информации с добавлением в неё новых значений данных или измерений.
Степень проявления этой проблемы, а также связанных с ней проблем эффективного хранения разреженных кубов данных, определяется качеством применяемых подходов и алгоритмов конкретных реализаций OLAP-систем.
Хранение активных данных в реляционной БД
Могут храниться данные OLAP и в традиционной РСУБД. В большинстве случаев этот подход используется при попытке «безболезненной» интеграции OLAP с существующими учётными системами, либо базирующимися на РСУБД хранилищами данных. Вместе с тем, этот подход требует от РСУБД для обеспечения эффективного выполнения требований FASMI-теста (в частности, обеспечения минимального времени реакции системы) некоторых дополнительных возможностей. Обычно данные OLAP хранятся в денормализованном виде, а часть заранее рассчитанных агрегатов и значений хранится в специальных таблицах. При хранении же в нормализованном виде эффективность РСУБД в качестве метода хранения активных данных снижается.
Проблема выбора эффективных подходов и алгоритмов хранения предрассчитанных данных также актуальна для OLAP-систем, базирующихся на РСУБД, поэтому производители таких систем обычно акцентируют внимание на достоинствах применяемых подходов.
В целом считается, что базирующиеся на РСУБД OLAP-системы медленнее систем, базирующихся на многомерных СУБД, в том числе за счет менее эффективных для задач OLAP структур хранения данных, однако на практике это зависит от особенностей конкретной системы.
Среди достоинств хранения данных в РСУБД обычно называют большую масштабируемость таких систем.
Хранение активных данных в «плоских» файлах
Этот подход предполагает хранение порций данных в обычных файлах. Обычно он используется как дополнение к одному из двух основных подходов с целью ускорения работы за счет кэширования актуальных данных на диске или в оперативной памяти клиентского ПК.
Гибридный подход к хранению данных
Большинство производителей OLAP-систем, продвигающих свои комплексные решения, часто включающие помимо собственно OLAP-системы СУБД, инструменты ETL (Extract Transform Load) и отчетности, в настоящее время используют гибридный подход к организации хранения активных данных системы, распределяя их тем или иным образом между РСУБД и специализированным хранилищем, а также между дисковыми структурами и кэшированием в оперативной памяти.
Так как эффективность такого решения зависит от конкретных подходов и алгоритмов, применяемых производителем для определения того, какие данные и где хранить, то поспешно делать выводы о изначально большей эффективности таких решений как класса без оценки конкретных особенностей рассматриваемой системы.
OLAP (англ. on-line analytical processing) – совокупность методов динамической обработки многомерных запросов в аналитических базах данных. Такие источники данных обычно имеют довольно большой объем, и в применяемых для их обработки средствах одним из наиболее важных требований является высокая скорость. В реляционных БД информация хранится в отдельных таблицах, которые хорошо нормализованы. Но сложные многотабличные запросы в них выполняются довольно медленно. Значительно лучшие показатели по скорости обработки в OLAP-системах достигаются за счет особенности структуры хранения данных. Вся информация четко организована, и применяются два типа хранилищ данных: измерения (содержат справочники, разделенные по категориям, например, точки продаж, клиенты, сотрудники, услуги и т.д.) и факты (характеризуют взаимодействие элементов различных измерений, например, 3 марта 2010 г. продавец A оказал услугу клиенту Б в магазине В на сумму Г денежных единиц). Для вычисления результатов в аналитическом кубе применяются меры. Меры представляют собой совокупности фактов, агрегированных по соответствующим выбранным измерениям и их элементам. Благодаря этим особенностям на сложные запросы с многомерными данными затрачивается гораздо меньшее время, чем в реляционных источниках.
Одним из основных вендоров OLAP-систем является корпорация Microsoft. Рассмотрим реализацию принципов OLAP на практических примерах создания аналитического куба в приложениях Microsoft SQL Server Business Intelligence Development Studio (BIDS) и Microsoft Office PerformancePoint Server Planning Business Modeler (PPS) и ознакомимся с возможностями визуального представления многомерных данных в виде графиков, диаграмм и таблиц.
Например, в BIDS необходимо создать OLAP-куб по данным о страховой компании, ее работниках, партнерах (клиентах) и точках продаж. Допустим предположение, что компания предоставляет один вид услуг, поэтому измерение услуг не понадобится.
Сначала определим измерения. С деятельности компании связаны следующие сущности (категории данных):
- Точки продаж
— Сотрудники
— Партнеры
Также создаются измерения Время и Сценарий, которые являются обязательными для любого куба.
Далее необходима одна таблица для хранения фактов (таблица фактов).
Информация в таблицы может вноситься вручную, но наиболее распространена загрузка данных с применением мастера импорта из различных источников.
На следующем рисунке представлена последовательность процесса создания и заполнения таблиц измерений и фактов вручную:
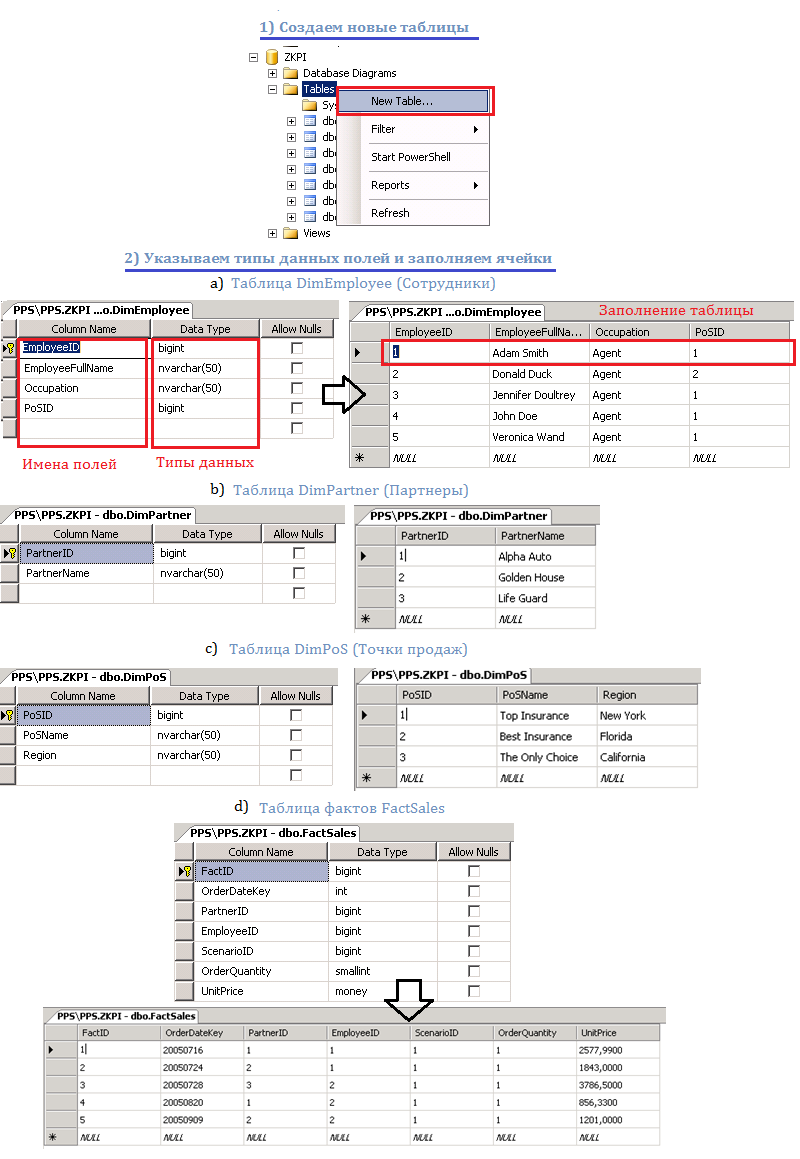
Рис.1. Таблицы измерений и фактов в аналитической БД. Последовательность создания
После создания многомерного источника данных в BIDS имеется возможность просмотреть его представление (Data Source View). В нашем примере получится схема, представленная на рисунке ниже.
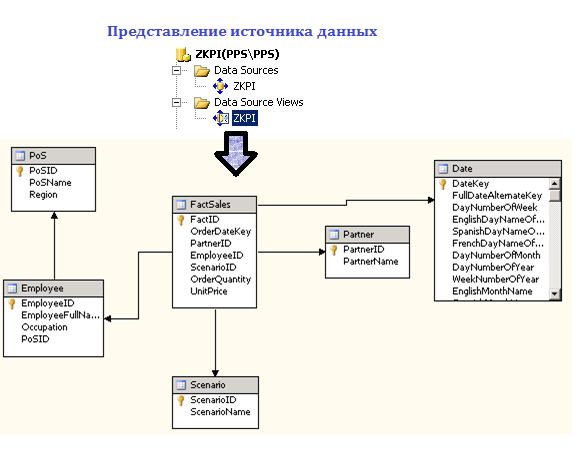
Рис.2. Представление источника данных (Data Source View) в Business Intellingence Development Studio (BIDS)
Как видим, таблица фактов связана с таблицами измерений посредством однозначного соответствия полей-идентификаторов (PartnerID, EmployeeID и т.д.).
Далее производится развертывание куба. Кроме того, при необходимости дополнительно настраиваются иерархии, атрибуты измерений, создаются вычисляемые меры.
Посмотрим на результат. На вкладке обозревателя куба, перетаскивая меры и измерения в поля итогов, строк, столбцов и фильтров, можем получить представление интересующих данных (к примеру, заключенные сделки по страховым договорам, заключенные определенным работником в 2005 году):
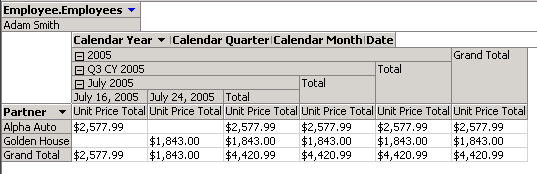
Рис.3. Просмотр аналитического куба
Основные игроки и решения
OLAP-системы входят в состав подавляющего большинства решений для бизнес-аналитики, «корпоративных» редакций СУБД основных поставщиков (IBM, Microsoft, Oracle). В той или иной мере технологии OLAP используются в существенной части современных ERP-систем. В государственном секторе РФ отдается предпочтение OLAP-инструментарию, предложенному Группой компаний БАРС Груп.
Внешние ссылки
Ознакомиться с примерами визуализации данных на основе куба BIDS, а также узнать о возможностях создания многомерных моделей в Microsoft Office PerformancePoint Server можно здесь
Источники
Codd E.F., Codd S.B., Salley C.T. «Providing OLAP (On-line Analytical Processing) to User-Analysts: An IT Mandate». Codd & Date, Inc, 1993. Retrieved on 2008-12-11.
Nigel Pendse. «What is OLAP? An analysis of what the often misused OLAP term is supposed to mean. Retrieved on 2008-12-11.
Nigel Pendse. «OLAP architectures». Retrieved on 2008-12-15.
Слайд 2
OLTP и OLAP
Значительная часть корпоративной информации ~ 90%

— лежит невостребованной и никак не анализируется.
=> Необходимы технологии,
которые бы позволили анализировать накопленную информацию и предоставили бы возможность
оперативно принимать решения.
Зачастую имеет место серьезное недопонимание различий в возможностях, назначении и роли технологий, предназначенных для сбора данных, — OLTP-систем и технологий анализа данных.
Слайд 3
Задачи OLTP-системы – это быстрый сбор и оптимальное

размещение данных в БД, а также обеспечение их полноты,
актуальности и согласованности.
Однако такие системы не предназначены для эффективного,
быстрого и многоаспектного анализа.
По собранным данным можно строить отчеты, но это требует от бизнес-аналитика или постоянного взаимодействия с IT-специалистом, или специальной подготовки в области программирования и вычислительной техники.
Слайд 4
Традиционный процесс принятия решений в российской компании, использующей

информационную систему, построенную на OLTP-технологии:
Менеджер дает задание специалисту информационного
отдела в соответствии со своим пониманием вопроса.
Специалист информационного отдела, по-своему
осознав задачу, строит запрос оперативной системе, получает электронный отчет и доводит его до сведения руководителя.
Слайд 5
Недостатки такой схемы принятия решений:
используется малое количество данных;
процесс

занимает длительное время;
требуется повторение цикла в случае необходимости уточнения
данных или рассмотрения данных в другом разрезе, а также при
возникновении дополнительных вопросов;
ИТ специалист и руководитель мыслят разными категориями => непонимание
сложность электронных отчетов (в цифровом виде) для восприятия => ИТ специалист вынужден отвлекаться на рутинную работу по составлению таблиц, диаграмм и т.д.
Слайд 6
Выход из этой ситуации – исходная информация должна

быть доступна ее непосредственному потребителю – аналитику (Билл Гейтс
– «Информация на кончиках пальцев»).
OLAP-технология и предназначена для этого.
Инструменты OLAP-технологии
позволяют бизнес-аналитикам даже без специальной подготовки самостоятельно (непосредственно) и оперативно получать всю необходимую для исследования закономерностей бизнеса информацию в различных комбинациях и срезах.
При этом максимальный отклик любого отчета не превышает ~5 секунд.
Слайд 7
Основы OLAP
OLAP – технологии интерактивной аналитической обработки данных

в системах БД, предназначенные для поддержки принятия решений и
ориентированные гл. образом на нерегламентированные интерактивные запросы.
Термин OLAP был введен
Э. Коддом в 1993г.
По способам организации источников данных систем OLAP различают технологии:
ROLAP (Relational OLAP),
MOLAP (Multi-Dimensional OLAP),
HOLAP (Hybrid OLAP).
Слайд 8
В качестве источников данных часто используют хранилища данных.
Обеспечивает

многомерный анализ данных (с т. зр. их концептуального представления).
Основная
структура – N-мерный куб данных.
Куб данных обладает 2-мя или более
независимыми измерениями (атрибутами) => система координат пространства данных.
Совокупности координат соответствуют значения данных в точках куба, называемые элементами (Item) или ячейками (Cell).
Для анализа на многомерном кубе делают «срезы» (обычные двумерные таблицы)
Слайд 9
OLAP (On-Line Analytical Processing)
OLAP – это совокупность концепций,

принципов и требований, лежащих в основе программных продуктов, облегчающих
аналитикам доступ к данным.
Аналитика не интересует одиночный факт — ему
нужна информация о сотнях и тысячах подобных событий (причем, без лишних подробностей).
Задача аналитика – находить закономерности в больших массивах данных.
Данные, которые требуются аналитику, обязательно содержат числовые значения.
Слайд 10
Итак, аналитику нужно много данных, эти данные являются

выборочными, а также носят характер «набор атрибутов – число»:
Слайд 11
В общем случае куб может быть многомерным (~

до 20 измерений) – «система координат»
В принципе, все измерения
равноправны
Трехмерное представление таблицы (куб OLAP):
Слайд 12
Измерения OLAP-кубов (например: страна, товар, год) состоят из

т.н. меток или членов (members). Например: измерение «Страна» состоит
из меток «Аргентина», «Бразилия», «Венесуэла» и так далее.
Элементы куба м.б.
не заполнены (нет данных) – «вакуум».
Куб (гиперкуб) – это логическое представление данных (для пользователя). Данные физически не обязательно хранятся в многомерной структуре. Благодаря спец. способам компактного хранения многомерных данных решается проблема «вакуума» (бесполезной траты памяти)
Слайд 13
Куб сам по себе не пригоден для восприятия

и анализа человеком (нельзя адекватно представить более 3-х измерений).
Перед
употреблением из n-мерного куба извлекают обычные двумерные таблицы. Эта операция
называется «разрезанием» (slice) куба.
При «разрезании» куба оставляются только необходимые измерения (обычно не больше двух), остальные измерения – фиксируются на интересующих аналитика метках.
Пример: фиксируем измерение «Товары» на метке «Бытовая электроника» и анализируем объемы продаж по странам и годам.
Слайд 14
Данные в таблице не являются первичными, а получены

в результате агрегирования более мелких элементов:
Год => кварталы =>
месяцы => недели => дни.
Страна => регионы => населенные
пункты =>. районы => конкретные торговые точки.
Слайд 15
Такие многоуровневые объединения значений атрибутов-измерений называется иерархиями
Пример иерархии:

Слайд 16
Исходные данные берутся из нижних уровней иерархий, а

затем суммируются для получения значений более высоких уровней.
Средства
OLAP дают возможность в любой момент перейти на нужный уровень
иерархии с помощью операций агрегации (aggregation) и детализации (drill-down).
Для ускорения процесса перехода, просуммированные значения для разных уровней хранятся в кубе.
Операция поворота (rotation) позволяет изменить порядок измерений в кубе данных нужным для пользователя образом.
Слайд 17
Средства OLAP позволяют значительно повысить эффективность работы аналитика

с данными по сравнению с OLTP-системами.
Аналитик непосредственно работает с
заранее подготовленными (загруженными из OLTP БД) данными, оптимизированными для быстрой
аналитической обработки (нет необходимости каждый раз обрабатывать тысячи и миллионы первичных данных).
Кубы OLAP представляют собой, по сути, многомерные отчеты. Разрезая многомерные кубы по измерениям, аналитик получает интересующие его «обычные» двумерные отчеты.
Слайд 18
Тест FASMI (требования к продуктам OLAP):
Fast (Быстрый) —

время доступа к аналитическим данным — порядка 5 секунд;
Analysis
(Анализ) — возможность осуществлять числовой и статистический анализ;
Shared (Разделяемый доступ)
— возможность работы с информацией многим пользователям одновременно;
Multidimensional (Многомерность) — см. выше;
Information (Информация) — возможность получать нужную информацию, в каком бы электронном хранилище данных она не находилась.
Слайд 19
Хранилища данных (Data Warehouse)
Хранилище данных (ХД) и OLAP

— две разные технологии. Однако, в комплексных решениях обе
технологии применяются совместно.
Задача ХД – интеграция, актуализация и согласование оперативных
данных из разнородных источников для формирования единого непротиворечивого взгляда на объект управления в целом.
ХД используются для составления отчетности, проведения оперативной аналитической обработки и глубинного анализа данных (Data Mining).
Слайд 20
Понятие хранилища данных:
Хранилище данных — система, содержащая непротиворечивую

интегрированную предметно-ориентированную совокупность исторических данных крупной корпорации или иной
организации с целью поддержки принятия стратегических решений.
Хранилище:
(1) собирает, (2)
очищает, (3) загружает, (4) агрегирует, (5) хранит данные и (6) предоставляет к ним быстрый доступ.
Основной источник данных — учетные системы (OLTP)
Слайд 21
Билл Инмон («отец» хранилищ данных):
Хранилища данных —

«предметно ориентированные, интегрированные, неизменчивые, поддерживающие хронологию наборы данных, организованные
с целью поддержки управления» и призванные выступать в роли «единого
и единственного источника истины», который обеспечивает менеджеров и аналитиков достоверной информацией, необходимой для оперативного анализа и принятия решений.
Слайд 22
Предметная ориентация – данные объединены в категории и

сохраняются соответственно областям, которые они описывают, а не применениям,
их использующим.
Интегрированность – данные удовлетворяют требованиям всего предприятия, а не
одной функции бизнеса (одинаковые отчеты, сгенерированные для разных аналитиков, будут содержать одинаковые результаты).
Неизменность – попав один раз в хранилище, данные там сохраняются и не изменяются. Данные могут лишь добавляться.
Слайд 23
Привязка ко времени – хранилище можно рассматривать как
совокупность «исторических» данных: возможно восстановление данных на любой момент
времени. Атрибут времени явно присутствует в структурах хранилища данных.
Т.о., хранилище
данных представляет собой своеобразный накопитель информации о деятельности предприятия.
ХД изначально технологически оптимизированы не для ввода, а для быстрого поиска и анализа информации => имеют другую архитектуру БД (структура часто денормализована)
Слайд 24
В дополнение к единому ХД могут создаваться т.н.

витрины данных
Витрина данных (Data Mart) – хранилище данных, связанных
с какими-либо конкретными аспектами деятельности организации.
Используется для поддержки принятия
решений в интересах какого-либо подразделения организации или обеспечения какой-либо сферы ее деятельности.
Источником данных может быть общее хранилище данных организации.
Слайд 26
Хранилище данных
(OLAP, Data Mining)
OLTP DB
сбор, очистка, загрузка
OLTP DB
OLTP

DB
Витрина данных
Внешняя среда
Витрина данных
Data Mining
OLAP
OLAP
OLAP
Слайд 27
Контрольные вопросы:
Сущность и назначение операции разрезания (slice) куба

OLAP
Сущность и назначение иерархий значений в измерениях куба OLAP
Сущность
и назначение Хранилищ данных
Приведите схемы реализации многомерного представления данных с
помощью реляционных таблиц (использовать доп. литературу)
Что такое OLAP сегодня, в общем-то знает каждый специалист. По крайней мере, понятия “OLAP” и “многомерные данные” устойчиво связаны в нашем сознании. Тем не менее тот факт, что эта тема вновь поднимается, надеюсь, будет одобрен большинством читателей, т. к. для того, чтобы представление о чем-либо с течением времени не устаревало, нужно периодически общаться с умными людьми или читать статьи в хорошем издании…
- Аналитика бизнеса
- Методы анализа данных Ответы на вопросы
- Введение в OLAP и многомерные базы данных
Оглавление
Что такое OLAP сегодня, в общем-то знает каждый специалист. По крайней мере, понятия “OLAP” и “многомерные данные” устойчиво связаны в нашем сознании. Тем не менее тот факт, что эта тема вновь поднимается, надеюсь, будет одобрен большинством читателей, т. к. для того, чтобы представление о чем-либо с течением времени не устаревало, нужно периодически общаться с умными людьми или читать статьи в хорошем издании…
Хранилища данных (место OLAP в информационной структуре предприятия)
Термин “OLAP” неразрывно связан с термином “хранилище данных” (Data Warehouse).
Приведем определение, сформулированное “отцом-основателем” хранилищ данных Биллом Инмоном: “Хранилище данных – это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений”.
Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Зачем строить хранилища данных – ведь они содержат заведомо избыточную информацию, которая и так “живет” в базах или файлах оперативных систем? Ответить можно кратко: анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется различными причинами, в том числе разрозненностью данных, хранением их в форматах различных СУБД и в разных “уголках” корпоративной сети. Но даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах. Автор имеет достаточно печальный опыт попыток “накормить” голодных аналитиков “сырыми” данными из оперативных систем – им это оказалось “не по зубам”.
Таким образом, задача хранилища – предоставить “сырье” для анализа в одном месте и в простой, понятной структуре. Ральф Кимбалл в предисловии к своей книге “The Data Warehouse Toolkit” пишет, что если по прочтении всей книги читатель поймет только одну вещь, а именно: структура хранилища должна быть простой, – автор будет считать свою задачу выполненной.
Есть и еще одна причина, оправдывающая появление отдельного хранилища – сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
На мой взгляд, под хранилищем можно понимать не обязательно гигантское скопление данных – главное, чтобы оно было удобно для анализа. Вообще говоря, для маленьких хранилищ предназначается отдельный термин – Data Marts (киоски данных), но в нашей российской практике его не часто услышишь.
OLAP – удобный инструмент анализа
Централизация и удобное структурирование – это далеко не все, что нужно аналитику. Ему ведь еще требуется инструмент для просмотра, визуализации информации. Традиционные отчеты, даже построенные на основе единого хранилища, лишены одного – гибкости. Их нельзя “покрутить”, “развернуть” или “свернуть”, чтобы получить желаемое представление данных. Конечно, можно вызвать программиста (если он захочет придти), и он (если не занят) сделает новый отчет достаточно быстро – скажем, в течение часа (пишу и сам не верю – так быстро в жизни не бывает; давайте дадим ему часа три). Получается, что аналитик может проверить за день не более двух идей. А ему (если он хороший аналитик) таких идей может приходить в голову по нескольку в час. И чем больше “срезов” и “разрезов” данных аналитик видит, тем больше у него идей, которые, в свою очередь, для проверки требуют все новых и новых “срезов”. Вот бы ему такой инструмент, который позволил бы разворачивать и сворачивать данные просто и удобно! В качестве такого инструмента и выступает OLAP.
Хотя OLAP и не представляет собой необходимый атрибут хранилища данных, он все чаще и чаще применяется для анализа накопленных в этом хранилище сведений.
Компоненты, входящие в типичное хранилище, представлены на рис. 1.
Рис. 1. Структура хранилища данных
Оперативные данные собираются из различных источников, очищаются, интегрируются и складываются в реляционное хранилище. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они могут быть загружены в специальную БД OLAP или оставлены в реляционном хранилище. Важнейшим его элементом являются метаданные, т. е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Подытоживая, можно определить OLAP как совокупность средств многомерного анализа данных, накопленных в хранилище. Теоретически средства OLAP можно применять и непосредственно к оперативным данным или их точным копиям (чтобы не мешать оперативным пользователям). Но мы тем самым рискуем наступить на уже описанные выше грабли, т. е. начать анализировать оперативные данные, которые напрямую для анализа непригодны.
Определение и основные понятия OLAP
Для начала расшифруем: OLAP – это Online Analytical Processing, т. е. оперативный анализ данных. 12 определяющих принципов OLAP сформулировал в 1993 г. Е. Ф. Кодд – “изобретатель” реляционных БД. Позже его определение было переработано в так называемый тест FASMI, требующий, чтобы OLAP-приложение предоставляло возможности быстрого анализа разделяемой многомерной информации.
Тест FASMI
Fast (Быстрый) – анализ должен производиться одинаково быстро по всем аспектам информации. Приемлемое время отклика – 5 с или менее.
Analysis (Анализ) – должна быть возможность осуществлять основные типы числового и статистического анализа, предопределенного разработчиком приложения или произвольно определяемого пользователем.
Shared (Разделяемой) – множество пользователей должно иметь доступ к данным, при этом необходимо контролировать доступ к конфиденциальной информации.
Multidimensional (Многомерной) – это основная, наиболее существенная характеристика OLAP.
Information (Информации) – приложение должно иметь возможность обращаться к любой нужной информации, независимо от ее объема и места хранения.
OLAP = многомерное представление = Куб
OLAP предоставляет удобные быстродействующие средства доступа, просмотра и анализа деловой информации. Пользователь получает естественную, интуитивно понятную модель данных, организуя их в виде многомерных кубов (Cubes). Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса. Например, для продаж это могут быть товар, регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей – измерений (Dimensions) – находятся данные, количественно характеризующие процесс – меры (Measures). Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т. п. Пользователь, анализирующий информацию, может “разрезать” куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие манипуляции, которые ему придут в голову в процессе анализа.
В качестве мер в трехмерном кубе, изображенном на рис. 2, использованы суммы продаж, а в качестве измерений – время, товар и магазин. Измерения представлены на определенных уровнях группировки: товары группируются по категориям, магазины – по странам, а данные о времени совершения операций – по месяцам. Чуть позже мы рассмотрим уровни группировки (иерархии) подробнее.
“Разрезание” куба
Даже трехмерный куб сложно отобразить на экране компьютера так, чтобы были видны значения интересующих мер. Что уж говорить о кубах с количеством измерений, большим трех? Для визуализации данных, хранящихся в кубе, применяются, как правило, привычные двумерные, т. е. табличные, представления, имеющие сложные иерархические заголовки строк и столбцов.
Двумерное представление куба можно получить, “разрезав” его поперек одной или нескольких осей (измерений): мы фиксируем значения всех измерений, кроме двух, – и получаем обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов) представлено одно измерение, в вертикальной (заголовки строк) – другое, а в ячейках таблицы – значения мер. При этом набор мер фактически рассматривается как одно из измерений – мы либо выбираем для показа одну меру (и тогда можем разместить в заголовках строк и столбцов два измерения), либо показываем несколько мер (и тогда одну из осей таблицы займут названия мер, а другую – значения единственного “неразрезанного” измерения).
Взгляните на рис. 3 – здесь изображен двумерный срез куба для одной меры – Unit Sales (продано штук) и двух “неразрезанных” измерений – Store (Магазин) и Время (Time).
Рис. 3. Двумерный срез куба для одной меры
На рис. 4 представлено лишь одно “неразрезанное” измерение – Store, но зато здесь отображаются значения нескольких мер – Unit Sales (продано штук), Store Sales (сумма продажи) и Store Cost (расходы магазина).
Рис. 4. Двумерный срез куба для нескольких мер
Двумерное представление куба возможно и тогда, когда “неразрезанными” остаются и более двух измерений. При этом на осях среза (строках и столбцах) будут размещены два или более измерений “разрезаемого” куба – см. рис. 5.
Рис. 5. Двумерный срез куба с несколькими измерениями на одной оси
Метки
Значения, “откладываемые” вдоль измерений, называются членами или метками (members). Метки используются как для “разрезания” куба, так и для ограничения (фильтрации) выбираемых данных – когда в измерении, остающемся “неразрезанным”, нас интересуют не все значения, а их подмножество, например три города из нескольких десятков. Значения меток отображаются в двумерном представлении куба как заголовки строк и столбцов.
Иерархии и уровни
Метки могут объединяться в иерархии, состоящие из одного или нескольких уровней (levels). Например, метки измерения “Магазин” (Store) естественно объединяются в иерархию с уровнями:
- All (Мир)
- Country (Страна)
- State (Штат)
- City (Город)
- Store (Магазин).
В соответствии с уровнями иерархии вычисляются агрегатные значения, например объем продаж для USA (уровень “Country”) или для штата California (уровень “State”). В одном измерении можно реализовать более одной иерархии – скажем, для времени: {Год, Квартал, Месяц, День} и {Год, Неделя, День}.
Архитектура OLAP-приложений
Все, что говорилось выше про OLAP, по сути, относилось к многомерному представлению данных. То, как данные хранятся, грубо говоря, не волнует ни конечного пользователя, ни разработчиков инструмента, которым клиент пользуется.
Многомерность в OLAP-приложениях может быть разделена на три уровня:
- Многомерное представление данных – средства конечного пользователя, обеспечивающие многомерную визуализацию и манипулирование данными; слой многомерного представления абстрагирован от физической структуры данных и воспринимает данные как многомерные.
- Многомерная обработка – средство (язык) формулирования многомерных запросов (традиционный реляционный язык SQL здесь оказывается непригодным) и процессор, умеющий обработать и выполнить такой запрос.
- Многомерное хранение – средства физической организации данных, обеспечивающие эффективное выполнение многомерных запросов.
Первые два уровня в обязательном порядке присутствуют во всех OLAP-средствах. Третий уровень, хотя и является широко распространенным, не обязателен, так как данные для многомерного представления могут извлекаться и из обычных реляционных структур; процессор многомерных запросов в этом случае транслирует многомерные запросы в SQL-запросы, которые выполняются реляционной СУБД.
Конкретные OLAP-продукты, как правило, представляют собой либо средство многомерного представления данных, OLAP-клиент (например, Pivot Tables в Excel 2000 фирмы Microsoft или ProClarity фирмы Knosys), либо многомерную серверную СУБД, OLAP-сервер (например, Oracle Express Server или Microsoft OLAP Services).
Слой многомерной обработки обычно бывает встроен в OLAP-клиент и/или в OLAP-сервер, но может быть выделен в чистом виде, как, например, компонент Pivot Table Service фирмы Microsoft.
Технические аспекты многомерного хранения данных
Как уже говорилось выше, средства OLAP-анализа могут извлекать данные и непосредственно из реляционных систем. Такой подход был более привлекательным в те времена, когда OLAP-серверы отсутствовали в прайс-листах ведущих производителей СУБД. Но сегодня и Oracle, и Informix, и Microsoft предлагают полноценные OLAP-серверы, и даже те IT-менеджеры, которые не любят разводить в своих сетях “зоопарк” из ПО разных производителей, могут купить (точнее, обратиться с соответствующей просьбой к руководству компании) OLAP-сервер той же марки, что и основной сервер баз данных.
OLAP-серверы, или серверы многомерных БД, могут хранить свои многомерные данные по-разному. Прежде чем рассмотреть эти способы, нам нужно поговорить о таком важном аспекте, как хранение агрегатов. Дело в том, что в любом хранилище данных – и в обычном, и в многомерном – наряду с детальными данными, извлекаемыми из оперативных систем, хранятся и суммарные показатели (агрегированные показатели, агрегаты), такие, как суммы объемов продаж по месяцам, по категориям товаров и т. п. Агрегаты хранятся в явном виде с единственной целью – ускорить выполнение запросов. Ведь, с одной стороны, в хранилище накапливается, как правило, очень большой объем данных, а с другой – аналитиков в большинстве случаев интересуют не детальные, а обобщенные показатели. И если каждый раз для вычисления суммы продаж за год пришлось бы суммировать миллионы индивидуальных продаж, скорость, скорее всего, была бы неприемлемой. Поэтому при загрузке данных в многомерную БД вычисляются и сохраняются все суммарные показатели или их часть.
Но, как известно, за все надо платить. И за скорость обработки запросов к суммарным данным приходится платить увеличением объемов данных и времени на их загрузку. Причем увеличение объема может стать буквально катастрофическим – в одном из опубликованных стандартных тестов полный подсчет агрегатов для 10 Мб исходных данных потребовал 2,4 Гб, т. е. данные выросли в 240 раз! Степень “разбухания” данных при вычислении агрегатов зависит от количества измерений куба и структуры этих измерений, т. е. соотношения количества “отцов” и “детей” на разных уровнях измерения. Для решения проблемы хранения агрегатов применяются подчас сложные схемы, позволяющие при вычислении далеко не всех возможных агрегатов достигать значительного повышения производительности выполнения запросов.
Теперь о различных вариантах хранения информации. Как детальные данные, так и агрегаты могут храниться либо в реляционных, либо в многомерных структурах. Многомерное хранение позволяет обращаться с данными как с многомерным массивом, благодаря чему обеспечиваются одинаково быстрые вычисления суммарных показателей и различные многомерные преобразования по любому из измерений. Некоторое время назад OLAP-продукты поддерживали либо реляционное, либо многомерное хранение. Сегодня, как правило, один и тот же продукт обеспечивает оба этих вида хранения, а также третий вид – смешанный. Применяются следующие термины:
- MOLAP (Multidimensional OLAP) – и детальные данные, и агрегаты хранятся в многомерной БД. В этом случае получается наибольшая избыточность, так как многомерные данные полностью содержат реляционные.
- ROLAP (Relational OLAP) – детальные данные остаются там, где они “жили” изначально – в реляционной БД; агрегаты хранятся в той же БД в специально созданных служебных таблицах.
- HOLAP (Hybrid OLAP) – детальные данные остаются на месте (в реляционной БД), а агрегаты хранятся в многомерной БД.
Каждый из этих способов имеет свои преимущества и недостатки и должен применяться в зависимости от условий – объема данных, мощности реляционной СУБД и т. д.
При хранении данных в многомерных структурах возникает потенциальная проблема “разбухания” за счет хранения пустых значений. Ведь если в многомерном массиве зарезервировано место под все возможные комбинации меток измерений, а реально заполнена лишь малая часть (например, ряд продуктов продается только в небольшом числе регионов), то большая часть куба будет пустовать, хотя место будет занято. Современные OLAP-продукты умеют справляться с этой проблемой.
Почитать еще

Что такое нейронные сети (ANN)
Человеческий мозг является сложным и интеллектуальным “компьютером”. Взяв за основу принцип образования нейронных связей в







Что такое отток клиентов
Тема оттока клиентов достаточно обширная и многогранная. В данной статье мы попытались в сжатой форме

Что такое виртуализация данных?
Программное обеспечение для виртуализации данных действует как мост между множеством разнообразных источников данных, объединяя критически важные
Несколько видео о наших продуктах

Проиграть видео
Презентация аналитической платформы Tibco Spotfire

Проиграть видео
Отличительные особенности Tibco Spotfire 10X

Проиграть видео
Как аналитика данных помогает менеджерам компании