Резюме урока Архитектура компьютера
Каталог статьи
- Резюме урока Архитектура компьютера
- Уравнение производительности процессора
- Комплекс набор команд и сокращенный набор команд
- Самый короткий код: наименьшее время среднее время доступа
- Везде в кэш, принцип локальности
Уравнение производительности процессора
Компьютерная архитектура, в дополнение к исследованиям абстрактную и универсальный структурный уровень системы, но также необходимо рассмотреть, является «производительность» вопросы.
Измерить производительность компьютера, как правило, имеет два критерия:
-
Время выполнения (Время выполнения)
 CPU) выполняет программу, сколько времени это занимает;
CPU) выполняет программу, сколько времени это занимает; -
Пропускная способность (пропускная способность): в течение определенного периода времени, (ЦП), в конце концов к количеству выполняемых команд.
 CPU) выполняет программу, сколько времени это занимает;
CPU) выполняет программу, сколько времени это занимает;В этих двух важных показателях, чтобы повысить производительность, ядро оптимизировано для выполнения первого [времени], и время выполнения формула выглядит следующим образом:
- Время выполнения = тактовых циклов × часы реального времени цикла (тактовая частота)
Часы время цикла (называемое частотой или частоты), такие как формат: xxGHz,

Например, карта 1.6GHz.
Если операция должна быть 1,6 * 1 миллиард операций в секунду.
1 ГГц = 1 миллиард операций в секунду, 1,6 ГГц тактовой частоты процессора, частота
1
16
frac{1}{16}
Сто миллионов секунд.
Можно сказать, что количество команд, количество простых инструкций, которые могут быть выполнены на второй полосы 1.6G, 1G фактически один миллиард раз.
Сократите время цикла часы, самый простой способ изменить немного лучше или процессор, такие как закон Мура оптимизировать.
Тем не менее, это наши разработчики программного обеспечения не могут контролировать эти вещи.
Таким образом, мы можем видеть только их глаза [к] числу тактов.
Если процессор может быть уменьшено количество тактов требуется по программе, как это возможно, чтобы улучшить работу программы.
Так что да, [] число тактов является ключевым для нас, чтобы улучшить производительность компьютера, поэтому количество тактов, а затем внимательно посмотреть на разделение.
Количество тактов: среднее число тактов на значение инструкции × (CPI)
Количество команд хорошо понимают, количество инструкций.
Среднее количество тактов на команду, набор инструкций есть много инструкций, такие как сложение, умножение и т.д., добавления, конечно, медленнее, чем умножение … время отличается.
- Время выполнения =] × [число тактов времени тактового цикла (частота)
Превратиться в:
- Время выполнения = [среднее число тактов на значение инструкции ×] × Частота
Если мы хотим решить проблемы с производительностью, на самом деле, это оптимизировать эти три:
- Частота: Закон Мура, производительность процессора, годовой прирост составил 60%.
- Среднее количество тактов на команду (CPI): Искусство дизайна процессора, чем PIPELINING ее.
- Количество инструкций: сколько инструкций необходимо выполнить программу, в конце концов, с помощью которого инструкции, в основном оптимизации компилятора.
Мы можем думать о себе как центральный процессор, сидя там писать программы.
- Скорость компьютера часы, как набрав скорость, набрав быстрее и более естественно написать небольшую программу.
- CPI эквивалентен процедурам записи, знаком со всеми видами ярлыков, тем больше играть то же содержание, тем меньше количества нажатий клавиш требуется.
- В соответствии с номером программы инструкций, разработанных, чтобы быть разумным, та же самая процедура, чтобы написать число строк кода меньше.
Если три Jieneng естественно может быстро написать хорошую программу, «Performance» взгляд со стороны хорошо.
Комплекс набор команд и сокращенный набор команд
В реальной жизни, набор команд делятся с полным набором команд CISC [] и [сокращенный набор команд RISC].
| Сравнить Свойства | CISC | RISC |
|---|---|---|
| Набор инструкций | Комплекс, переменная | Простая, фиксированная длина |
| Количество инструкций | Более 200 | Менее 100 |
| формат команды | Более 4 | Менее 4 |
| адресация | Более 4 | Менее 4 |
| Может принести инструкции | неограниченный | Только команды загрузки / STORE |
| Заданная частота | Большая разница | Почти то же самое |
| время выполнения команды | Большая разница | цикл |
| Оптимизация компилятора | сложно | легкий |
| Длина кода программы | короткая | длинный |
| реализация контроллера | микропрограмма | Проводные |
| время разработки системы программного обеспечения | короткая | длинный |
Мы теперь окна компьютеры с CISC, в то время как мобильный процессор, Apple является RISC, поддерживаемый набор инструкций процессора разные.
В ранней истории вычислительной техники, на самом деле, нет ничего CISC и RISC-точка, все CPU на самом деле являются CISC.
В 1974 год Дэвид Паттерсон (David Patterson) , профессор [^ Профессор Дэвид Паттерсон написал «ЭВМ и дизайн: Оборудование / Программное обеспечение Интерфейс», «Компьютерная архитектура: Количественные методы исследования» два учебников. ] Доказано, что, в реальной программе центрального процессора, работающего в 80% времени при 20% простых инструкций.
Поэтому он предложил идею РНЦ, содержит только 20% простых, часто используемых команд.
В архитектуре внутри RISC ЦП выберите команду «обтекаемую» до 20% простых инструкций. Оригинальный комплекс инструкция реализуется путем объединения простой инструкции, чтобы программное обеспечение для аппаратных функций. Таким образом, вся конструкция оборудования CPU будет легче, и повысить производительность на аппаратном уровне станет легче.
RISC-процессор в полной команде схемы становится простым, так что она высвобождает больше места. Это пространство часто используется для размещения регистров общего назначения. Поскольку RISC выполняют ту же функцию, число выполняемых инструкций, чем CISC много, так что если вам нужно несколько раз прочитать из памяти инструкции или внутри данных для регистрации здесь, то много времени будет потрачено на доступ к памяти. Таким образом, архитектура RISC CPU часто имеют больше регистров общего назначения. В дополнении к таким регистрам хранения, RISC-процессор может поместить больше транзисторов, для улучшения функций, связанных с предсказанием ветвлений, для дальнейшего повышения эффективности фактического CPU.
В общем, для CISC и RISC сравнения:
- Время выполнения = [Количество инструкций × Среднее количество тактов на инструкцию] × частота
Архитектура CISC на самом деле сокращение времени выполнения процессора за счет оптимизации количества инструкций. Архитектура RISC фактически оптимизирована CPI. Так как инструкция относительно проста, Нужный такт является относительно небольшим. Поскольку RISC снижает проектирование и разработку трудности аппаратного процессора, с 1980 года, большинство новых процессоров начали принимать RISC-архитектур. От PowerPC от IBM, СПАРК Sun является архитектура RISC, кроме Intel.
Хотя RISC очень мала, преимущества очень много, но RISC означает , что количество команд поддерживается аппаратными или схемных уровней является относительно небольшим, что означает , что многие сложные операции должны выполнять более вместо менее, с инструкциями RISC развития программного обеспечения воли есть много времени …
Минимальный код: кратчайшее среднее время доступа
Базовый мир компьютера 0 и 1, но это потому, что только 0 и 1 можно повторить и повторно использовать только.
Существует закон, в теории информации (первый закон Шеннона), что свидетельствует о том, что есть как минимум в теории коды.
Позже профессор MIT сделал дальнейшее развитие на основе первого закона Xiangnong, образуя кодирование Hawman.
Hawwmann код: Поместите [кратчайший код] в [максимуме информации]. Это делает среднее время доступа короткое, но должно заранее знать частоту каждого кода.
Как passwordologist, текст на катушке полки, помещение знать частоту каждого письма:

В реальной жизни, количество информации больше, чем одно сообщение, и его распределение вероятности больше, поэтому он сжимается с использованием Hafman кодирования, и степень сжатия будет выше. Так, например, по-китайски, если частота китайских иероглифов статистически, сжатое, статья, как правило, сжимает более чем на 50%, но если статистики частот выполняются в соответствии со словами, а затем использовать Hafman код для сжатия, может сжимать более 70 %.
Обтекаемый набор команд, возьмите 20% инструкции для завершения 80% вещей.
- [Самый короткий код] / [самый ценный ресурс] слон на [80% время]
- [Самая большая информация] слон стать [20% инструкция]
В реальной жизни, мы можем улучшить оптимальную эффективность, еще несколько выходов, в основном, наблюдая великолепие Hafman мышления! Действительно
Если вы преследуете более короткое кодирование, вы должны попробовать [Hawman Метод], найти общую точку между разными вещами, и наркоманией или иконичностью.
Нежелательный кэш, частичный принцип
Причина, почему все считают, что RISC лучше, чем CISC, из доказательства Дэвида Паттерсона, в реальной процедуре, 80% кода работающего кода с 20% инструкций общего.
Это означает , что код реализован в процессоре имеет сильный местный [^ В период времени, выполнение всей программы ограничиваются какой — либо часть программы], и есть общее решение для сильной частичной проблемы. Это является использование кэш-памяти.
Пристрастность делятся на [время местность] и [космической часть].
- Время местное: Если данные доступны, то он будет вновь доступен в течение короткого времени.
Например, «Разорвать небо» Этот роман, я прочитал его на некоторое время сегодня, я не закончил читать, я буду продолжать читать завтра.
- Пространственное местонахождение: Если данные доступны данные, примыкающие к ней также будут доступны.
Например, после прочтения «разобьет Sky», написанную картофелем, я чувствую, что эта книга хороша, так что я буду видеть другие работы.
В реальной компьютерной ежедневной разработке и приложениях, доступ к базе данных всегда будет иметь некоторые населенные пункты.
Иногда эта местность время местное, то есть, наши последние данные будут неоднократно обращались.
Иногда эта местность представляет собой пространство локального, которое данные мы недавно посетили данные будут в скором времени будет доступ.
И местное существование позволяет использовать кэш этого благоприятного оружия в разработке приложений.
Предположение:
- Память, 0.015MB / юаней (1 Мб, 0,015 юаней)
- Механический жесткий диск, 0.00004MB / юаней (1 МБ, 0,00004 юаней)
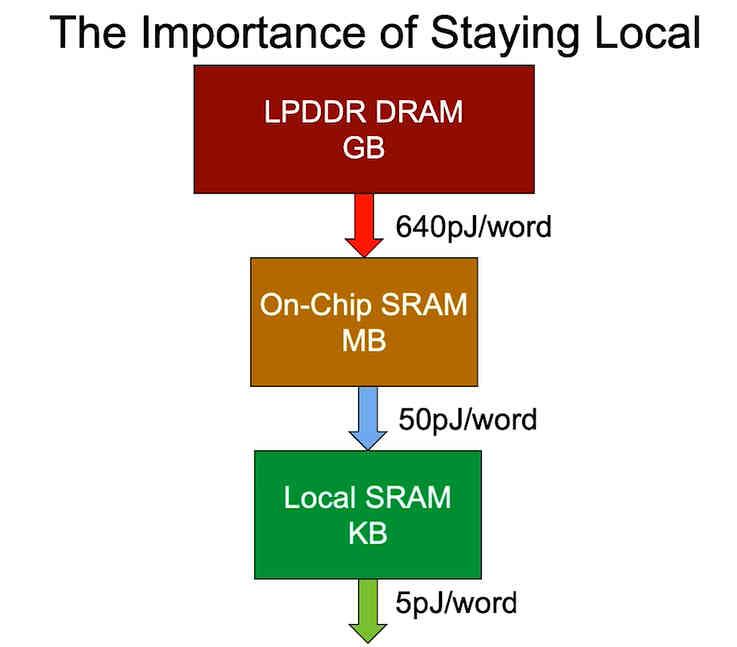
Мы можем использовать локальные принципы для загрузки горячих точек данных для загрузки и сохранения скорости быстрее устройств хранения данных (например, внутреннее хранилище), мы можем поддерживать серверы (exteriorities) с меньшими затратами.
Предположим, что Taobao имеет количество 1,2 миллиарда элементов, каждый элемент требует 4 Мб дискового пространства, которое требует 4800TB хранения данных (=> 1,2 млрд × 4 МБ). В этом 1,2 млрд штук, не вполне доступны.
Если только 1% горячих данных кэш-памяти, 48TB памяти требуется 720,000 юаней (=> 48TB / 1MB × 0,015 = 720,000 юаней юаней)
Кроме того, 99% от жесткого диска 190000 юаней (=> 4752TB / 1MB × 0,00004 = 190000 юаней юаней)
При этом используется кэш + память + жесткий диск + скорость доступа к диску и размер емкости, в соответствии с местными принципами, иерархия памяти предназначена.
Это имеет скорость процессора кэш-памяти, и наслаждаться памяти, огромный потенциал и низкую цену.

Сегодня скорость доступа процессора и памяти уже был промежуток между 120 раз. Со временем этот разрыв будет по-прежнему большой в течение долгого времени.
Скорость процессора лучше, чем высокоскоростные железные дороги ветра. Однако, память может ждать только для старой женщины, которая не является слишком слабой, рядом с ногами.
Для того, чтобы компенсировать разницу в производительности между этими двумя, мы действительно можем использовать производительность процессора для повышения производительности процессора, а не позволяя ему идти туда, и мы вводим кэш в современном процессоре.

От процессора кэша к существующему CPU, инструкции в памяти запускаются, и данные будут загружены в кэш L1-L3, а не непосредственно из ЦП. В 95%, процессор должен получить доступ к L1-L3 кэш, прочитать инструкции и данные из внутренней памяти без доступа только.
Компьютеры кэширование не только в CPU (Cache, TLB делает более эффективным CPU),
- Кэш операционной системы: Page Coke, горбыль, так что система является более эффективной
- кэш уровня приложений: управление памятью, кэш приложений IO, сделать приложение более эффективным
Кэш представляет собой современный компьютер функция, которая использует идею алгоритма: «Пространство для времени». В обмен на быстрее вычисления скорости в ограниченном пространстве, то мы должны учитывать кэш при замене расчет.
Компьютерные решения, как правило, систематическая задача оптимизации, а простая часть улучшения может вызвать другую частичную проблему.
Наш мозг, как центральный процессор компьютера, нет времени, ограничение пространства, и тело, душа не хорошо. Если мозг используется , как он сам, мозг работает в полном диапазоне (вы также можете понять «себялюбие») ,
В этом всестороннем режиме, мозг будет считать себя мастером, души и тела рассматриваются как подчиненные. Отказ Отказ Отказ Отказ Отказ В это время, я заставил мое тело и мой разум, чтобы делать то, что ТЕ люди, которые не желают, тело, душа будет выбрать задержки, ленивый, мозг будет сердиться, вы также будете сердиться …
Есть ли эта идея знает, что это возможно, я думаю, вы должны добавить [кэш], все roomlifting, и все это не слишком верно.
Кэширование, это легко сказать, что это не так просто.
Наконец, я дам вам полезный способ работы, который называется: Баффет метод внутреннего контроля.
Баффет сказал, что если он не записан на листе бумаги, он никогда не будет торговать. Эта сделка может быть неправильно, но вы должны иметь «сделки» ответ.
Например, написать на бумаге: «Я должен потратить 50 миллиардов долларов сегодня, чтобы купить Apple, потому что …»
Если вы не можете ответить на этот вопрос, не покупайте его.
Что я могу использовать на бумаге?
На самом деле, это, чтобы построитькэш, Искусственно создали «»точка кэша»Предотвратить любовь обмануть собственный мозг слишком импульсивны.
Сброс настроек:
Каталог статьи
- Краткое описание структуры системы компьютера
- Формула процессора Производительность
- Комплекс набор команд и обтекаемый набор команд
- Минимальный код: кратчайшее среднее время доступа
- Нежелательный кэш, частичный принцип
Производительность одного процессора по сравнению с другим измеряется временем, необходимым для решения одной и той же программы. Этого можно добиться разными способами, и есть разные способы повысить производительность и тем самым сократить время, необходимое для запуска. Один из них — сократить время ожидания выполняемых инструкций. Но из чего именно он состоит?

Что мы подразумеваем под задержкой выполнения инструкций?
Задержка — это время, которое требуется процессору для выполнения инструкции, и это зависит от того, где находятся данные, поскольку чем дальше, тем больше времени требуется, чтобы они были помещены в соответствующие регистры. По этой причине, а также из-за того, что память не масштабируется с той же скоростью, что и процессоры, пришлось создать такие механизмы, как кэш, и даже интегрировать контроллер памяти в процессор, чтобы уменьшить задержку выполнения инструкций.
Однако это обычно не принимается во внимание при продаже ЦП и даже ГП, часто используются другие показатели производительности, чтобы сказать, что одна архитектура превосходит другую. Но задержка инструкций обычно не используется при продвижении процессора, когда это еще один способ понять производительность.
Тактовые циклы на инструкцию и задержку

Первым показателем производительности является количество циклов на инструкцию, поскольку существуют инструкции, достаточно сложные, чтобы их можно было выполнять в нескольких разных циклах команд. Много раз при разработке новых процессоров архитекторы часто вносят изменения в способ решения инструкций по отношению к предыдущим процессорам с тем же ISA, говорим ли мы о процессорах, графических процессорах или любом другом типе процессора.
Что никогда не меняется, так это форма инструкции, но что делается, так это сокращается количество тактовых циклов, необходимых для ее шифрования. Например, у нас может быть инструкция, отвечающая за вычисление среднего между двумя числами, которая занимает 4 тактовых цикла в процессоре с тем же ISA и которая улучшается на 20% по сравнению с предыдущей версией той же инструкции, которая занимает 5 циклов.
Идея состоит в том, чтобы сократить время, необходимое для выполнения части инструкций, чтобы сократить время, необходимое для выполнения программы. Таким образом, с небольшими ускорениями в инструкциях достигается общая производительность.
Кэш и задержка инструкций

В кэш-памяти хранится копия Оперативная память память, в которой выполняются инструкции в этот момент, это позволяет процессору получить доступ к памяти без необходимости доступа к ОЗУ, и, поскольку кеш находится ближе к модулям ЦП, память в конечном итоге может выполнять инструкцию за меньшее время, так как сбор инструкций требует меньше времени.
Тот факт, что мы говорим о разных уровнях кэша, не означает, что все кэши первого, второго и даже третьего уровня имеют одинаковое расстояние и, следовательно, задержку, а скорее то, что они различаются от одной архитектуры к другой. Например, в текущем Intel Core от Intel, латентность с кешами ниже, чем у аналогов у конкурентов, AMDAMD Zen.
Чтобы улучшить архитектуру от одной версии к другой, одно из обычно вносимых изменений — это уменьшение задержки по отношению к кешу. Особенно при переносе одной и той же архитектуры с одного узла на другой благодаря уменьшению размера процессора и расстояния между модулями и кешем.
Дилемма чиплета и задержки

Идея чиплетов не что иное, как использование нескольких чипов вместо одного для одной и той же функции, поэтому это увеличивает расстояние связи между различными частями и, следовательно, задержку. Это приводит к снижению производительности по сравнению с монолитной версией процессора.
В случае AMD Ryzen, которые являются наиболее известным случаем, один из способов сократить разницу между версиями, основанными на чиплетах, и версиями, которые являются монолитными процессорами, — это сократить кэш последнего уровня за секунды. Причина? Если бы у них был одинаковый объем кеша, то версии с использованием чиплета только из-за расстояния от контроллера памяти имели бы меньшую задержку в инструкциях и, как следствие, более высокую производительность.
Задержка инструкций — ключ к 3DIC

Еще одним ключевым моментом являются интегрированные в трех измерениях микросхемы, особенно те, которые объединяют память в процессор. Причина этого в том, что они помещают память так близко к процессору, что только это увеличивает производительность. Компромиссом здесь является тепловое дросселирование между памятью и процессором, которое приводит к падению тактовой частоты, и в некоторых конструкциях может случиться так, что размещение процессора и памяти отдельно позволяет получить более высокие тактовые частоты, чем в дизайне 3DIC.
Если память находится достаточно близко к процессору, это может создать любопытный эффект, при котором для доступа к данным во встроенной памяти требуется меньше времени, чем для прохождения различных уровней кэш-памяти в архитектуре один за другим. Это полностью меняет способ проектирования процессора, поскольку кэш-память — это способ уменьшить задержку, когда данные, подлежащие обработке, находятся слишком далеко друг от друга.
Расстояние и потребление связаны
Последний пункт — это потребление энергии, которое зависит от того, где находятся данные. Вот почему при разработке более оптимизированной версии с точки зрения потребления процессора стремятся сократить расстояние, на котором находятся данные, поскольку потребление энергии процессором увеличивается с увеличением расстояния, в котором данные могут быть найдены, а не просто задержка, к сожалению, мы не можем вместить огромные объемы данных, которые нам нужны для запуска программы в пространстве чипа.
В мире, где потребление энергии из-за изменения климата стало одним из самых важных моментов, а портативность и низкое потребление являются аргументом в пользу продажи и, следовательно, ценностью для многих продуктов, факт поиска способов приблизить память к процессору и, следовательно, уменьшить задержку инструкций, что становится чрезвычайно важным для увеличения производительности на ватт.
Введение в технику оптимизации циклов
Время на прочтение
4 мин
Количество просмотров 53K
Большая часть времени исполнения программы приходится на циклы: это могут быть вычисления, прием и обработка информации и т.д. Правильное применение техник оптимизации циклов позволит увеличить скорость работы программы. Но прежде, чем приступать к оптимизациям необходимо выделить «узкие» места программы и попытаться найти причины падения быстродействия.
Время исполнения кода в циклах зависит от организации памяти, архитектуры процессора, в том числе, поддерживаемого набора инструкций, конвейеров, кэшей и опыта программиста.
Рассмотрим некоторые методы оптимизаций циклов: развертка циклов (loop unrolling), объединение циклов (loop fusion), разрезание циклов (loop distribution), выравнивание циклов (loop alignment), перестановка циклов (loop interchange), разделение на блоки (loop blocking).
Перед применением какой-либо оптимизации сделайте самое простое: вынесите из цикла все переменные, которые в нем не изменяются.
Какие причины могут привести к уменьшению скорости работы программы в циклах?
- Итерации цикла зависимы и не могут исполняться параллельно.
- Тело цикла большое и требуется слишком много регистров.
- Тело цикла или количество итераций мало и выгоднее совсем отказаться от использования цикла.
- Цикл содержит вызовы функций и процедур из сторонних библиотек.
- Цикл интенсивно использует какое-то одно исполняющее устройство процессора.
- В цикле имеются условные переходы.
Развертка циклов
Такая оптимизация выполняется, когда тело цикла мало. Необходимо более эффективно использовать исполняющие устройства на каждой итерации. Поэтому многократно дублируют тело цикла в зависимости от количества исполняющих устройств. Но такая оптимизация может вызвать зависимость по данным, чтобы от нее избавиться вводятся дополнительные переменные.
| До | После | После №2 |
for (int i = 0; i < iN; i++){ |
for (int i = 0; i < iN; i+=3){ |
for (int i = 0; i < iN; i+=3){ |
В gcc можно применить следующие ключи: -funroll-all-loops -funroll-loops.
Объединение циклов
В цикле может быть долго выполняющиеся инструкции, например, извлечение квадратных корней. Или есть несколько циклов, которые выполняются по одинаковому интервалу индексов. Поэтому целесообразно объединить циклы для более сбалансированной нагрузки исполняющих устройств.
| До | После |
for(int i = 0; i < iN; i++){ |
for(int i = 0; i < iN-1; i++){ |
Разрезание циклов
Данная оптимизация применяется, когда тело цикла большое и переменным не хватает регистров. Поэтому данные сначала вытесняются в кэш, а если совсем все плохо, то и в оперативную память. А доступ к оперативной памяти занимает ~300 тактов процессора, а доступ к L2 всего ~10. Доступ к памяти с большим шагом еще больше замедляет программу. Оптимально «ходить» по памяти с шагом 2n, где n — достаточно маленькое число (<7).
| До | После |
for (int j = 0; j < jN; j++){ |
for (int j = 0; j < jN; j++){ |
Перестановка циклов
Во вложенных циклах важен порядок вложения. Поэтому необходимо помнить как хранятся массивы в памяти. Классический пример: c/c++ хранят матрицы построчно, а fortran — по столбцам.
| До | После |
for(int i = 0; i < iN; i++){ |
for(int i = 0; i < iN; i++){ |
Теперь обращения к массиву a идут последовательно.
Разделение циклов на блоки
Если тело цикла сложное, то можно применить эту оптимизацию для более лучшего расположения данных в памяти и улучшения использования кэшей. Результат оптимизации сильно зависит от архитектуры процессора.
| До | После |
for(int i = 0; i < iN; i++){ |
// размер блоков зависит от размера исходных массивов |
Примерно по такому принципу работает технология MPI: делит большие массивы на блоки и рассылает отдельным процессорам.
Разрешение зависимостей
Лучшее решение — избавиться. Но не со всеми зависимостями это получится.
for (int i = 1; i < N; i++){
a[i] = a[i-1] + 1;
}
Для этого примера лучше применить развертку, т.к. результат вычислений будет оставаться на регистрах. Но большинство таких циклов не могут быть полностью оптимизированы (или распараллелены), результат все равно зависит от предыдущего витка цикла.
Чтобы проверить цикл на независимость, измените направление движения в цикле на обратное. Если результат вычислений не изменился, то итерации цикла — независимы.
Относительно условных переходов
Потери времени возникают из-за ошибок в предсказании переходов, т. к. приходиться откатывать конвейер. Поэтому лучше всего отказаться от условных конструкций. Но, если это невозможно нужно постараться облегчить работу модулю предсказания переходов. Для этого разместите наиболее вероятные ветви в начале ветвления и, если возможно, вынесите условные конструкции за пределы цикла.
Вместо заключения
Если Вы создаете сложную программу, которая будет занимать много процессорного времени, то
- Ознакомтесь с архитектурой процессора (узнайте сколько и каких исполняющих устройств у него есть, сколько конвейеров, размеры кэшей L1 и L2).
- Попробуйте компилировать программу разными компиляторами и с различными ключами.
- Учитывайте влияние операционной системы.
Также советую ознакомиться с этой статьей.
По своему опыту могу сказать, что грамотное применение оптимизаций может улучшить быстродействие программы в разы.
Если хотите сами потренироваться в оптимизации, то попробуйте вычислить число Пи:

Ниже приведен «плохой» код.
long N = 10000000;
double dx, sum, x;
sum = 0.0;
x = 0.0;
dx = 1.0 / (double) N;
for (long i = 0; i < N; i++){
sum += 4.0 / (1.0 + x * x);
x += dx;
}
double pi = dx * sum;
О чем я не рассказал: о векторизации вычислений (инструкции SSE); о prefetch’ах, облегчающих работу с памятью. Если будут люди «которым интересно», то напишу отдельную статью про векторизацию циклов.
Подсветка исходных кодов Source Code Highlighter.
Управление использованием времени центрального процессора.
1.
У меня есть большое количество задач
или программ, требующих большого объема
вычислительных мощностей системы.
Алгоритм планирования времени ЦП в
этом случае будет следующий: если ЦП
выделен одному из процессов, то этот
процесс будет занимать ЦП до наступления
одной из следующих ситуаций: 1. Обращение
к внешнему устройству. 2. Завершение
процесса. 3. Зафиксированный факт
зацикливания процесса.
Количество
передач управления от одного процесса
к другому минимизировано. Это пакетная
ОС.
2.
ОС
раздел. врем.
Для такой системы подойдет критерий
времени ожидания пользователя: с
момента, как он послал заказ на выполнение
какого-то действия, до момента ответа
системы на этот заказ. Чем эффективнее
работает система, тем это среднестатистическое
время ожидания в системе меньше. В
системе используется некоторый параметр
t,
который называют квантом времени (в
общем случае, квант времени — это
некоторое значение, которое может
изменяться при настройке системы). Все
множество процессов, которое находится
в мультипрограммной обработке,
подразделяется на два подмножества:
не готовые к продолжению выполнения и
готовые.1. Обращение с заказом на обмен.
2. Завершение процесса. 3. Исчерпание
кванта времени t.
3.
ОС реального времени
основным критерием является время
гарантированная реакции системы на
возникновение того или иного события
из набора заранее предопределенных
событий. То есть в системе есть набор
событий, на которые система в любой
ситуации прореагирует и обработает их
за некоторое наперед заданное время.
Управление
подкачкой и буфером ввода.
Самый
простейший вариант заключается в
использовании времени нахождения в
том или ином состоянии. Или все задачи
подразделены на различные категории,
т. е. могут быть задачи ОС — в этом случае
они рассматриваются в первую очередь
и все остальные задачи. Управление
разделяемыми ресурсами.
См.
на примере Unix.
Билет №7.
Мультипрограммирование, требования к
аппаратуре. Обработка прерываний.
Режим
работы программного обеспечения и
аппаратуры, обеспечивающий одновременное
выполнение нескольких программ, наз.
мультипрограммным режимом. Аппаратные
требования:
защита
памяти, привелигерованный режим,
наличие аппарата прерывания.
В
каждой вычислительной машине имеется
предопределенный, заданный при разработке
и производстве, набор некоторых событий
и аппаратных реакций на возникновение
каждого из этих событий. Эти события
называются прерываниями. Прерывания
используются для управления внешними
устройствами и для получения возможности
асинхронной работы с внешними
устройствами. В момент возникновения
прерывания: 1. В некоторые специальные
регистры аппаратно заносится информация
о выполняемой в данный момент программе.
Обычно, в этот набор данных входит
счетчик команд, регистр результата,
указатель стека и несколько регистров
общего назначения. (Эти действия
называются малым упрятыванием). 2. В
некоторый специальный управляющий
регистр, условно будем его называть
регистром прерываний, помещается код
возникшего прерывания. 3. Запускается
программа обработки прерываний
операционной системы.
Запущенная
программа в начале потребляет столько
ресурсов (не более), сколько освобождено
при аппаратном упрятывании информации.
Эта программа производит анализ причины
прерывания. Если это прерывание было
фатальным то продолжать выполнение
программы бессмысленно. Если нет,
происходит дополнительный анализ.
Можно ли оперативно обработать
прерывание? Прерывание, связанное с
приходом информации по линии связи
нельзя обработать оперативно, т.к.
происходит расчищение в системе места
для программы операционной системы,
которая займется обработкой этого
прерывания. Происходит т.н. полное
упрятывание. Теперь прячется не только
информация о некоторых регистрах
исполнявшейся программы, теперь все
регистры сохраняются в таблицах системы
(а не в аппаратных регистрах, как раньше)
и фиксируется то, что пространство
оперативной памяти, занимаемое
программой, может быть перенесено (при
необходимости) на внешнее устройство.
Дальше идет обработка прерывания и
возврат из прерывания. Прерывания могут
быть инициированы схемами контроля
процессора или внешним устройством.
Если бы все обмены с внешними устройствами
происходили в синхронном режиме, то
производительность ВС была бы очень
низкой.
Билет
№9. Особенности ОС UNIX.
1.
Используется древовидная структура
ФС.
2.
Базовые объекты: процесс и файл.
3.
Грамотно организована работа с внешними
устройствами: байт-ориентированные и
блок-ориентированные. ВУ накрыто именем
файла. Вся системная информация хранится
в текстовых файлах.
4.
Концепция процессов в ОС. Есть некоторые
унифицированные средства формирования
процессов.
5.
Переносимость системы (т.к. 90% системы
написано на СИ)
6.Удобный
интерфейс СИ и UNIXа.
Можно создать свое программное окружение
и систему команд.
7.ОС
UNIX
решает проблему сглаживания скорости
ЦП и ОП, за счет глубокой многоуровневой
буферизации и за счет оптимизации
доступа к информации в ФС. Буферизация
идет через КЭШ-буфера, следовательно
минимальное количество обменов, снижение
нагрузки на механику дисков. С другой
стороны, реальное содержимое ФС может
не соответствовать тому, что там
концептуально должно находиться.
Билет
№10. Организация планировщика и свопинга
в Unix.
Планирование
процессов в UNIX.
Чем выше числовое значение приоритета,
тем меньше приоритет. Приоритет процесса
— это параметр, который размещен в
контексте процесса, и по его значению
осуществляется выбор очередного
процесса для продолжения работы или
выбор процесса для его приостановки.
В вычислении приоритета используются
— P_NICE
и
P_CPU.
P_NICE
— пользовательская составляющая
приоритета. Она наследуется от родителя
и может изменяться по воле процесса.
Изменяться она может только в сторону
увеличения значения. Т.е. пользователь
может снижать приоритет своих процессов.
P_CPU
— системная составляющая, а формируется
системой следующим образом: по таймеру
через предопределенные периоды времени
P_CPU
увеличивается на единицу для процесса,
работающего с процессором.
Процессор
выделяется тому процессу, у которого
приоритет является наименьшим. Упрощенная
формула вычисления приоритета:
ПРИОРИТЕТ
=
P_USER + P_NICE + P_CPU.
Константа P_USER
для процессов операционной системы
она равна нулю, для процессов пользователей
она равна некоторому значению (т.е.
«навешиваются
гирьки на ноги»
процессам пользователя). Схема
планирования свопинга.
Мы
говорили о том, что в системе определенным
образом выделяется пространство для
области свопинга. Имеется проблема.
Есть пространство оперативной памяти,
в котором находятся процессы,
обрабатываемые системой в режиме
мультипрограммирования. Есть область
на ВЗУ, предназначенная для откачки
этих процессов. В ОС UNIX
(в модельном варианте) свопирование
осуществляется всем процессом, т.е.
откачивается не часть процесса, а весь.
Это правило действует в подавляющем
числе UNIX-ов,
т.е. свопинг в UNIX-е
в общем не эффективен. Упрощенная схема
планирования подкачки основывается
на использовании некоторого приоритета,
который называется P_TIME
и также находится в контексте процесса.
В этом параметре аккумулируется время
пребывания процесса в состоянии
мультипрограммной обработки, или в
области свопинга. При перемещении
процесса из оперативной памяти в область
свопинга или обратно система обнуляет
значение параметра P_TIME.
Для загрузки процесса в память из
области свопинга выбирается процесс
с максимальным значением P_TIME.
Если для загрузки этого процесса нет
свободного пространства оперативной
памяти, то система ищет среди процессов
в оперативной памяти процесс, ожидающий
ввода/вывода и имеющий максимальное
значение P_TIME (т.е. тот, который находился
в оперативной памяти дольше всех). Если
такого процесса нет, то выбирается
просто процесс с максимальным значением
P_TIME.
Эта схема не совсем эффективна. Первая
неэффективность — это то, что обмены из
оперативной памяти в область свопинга
происходят всем процессом. Вторая
неэффективность (связанная с первой)
заключается в том, что если процесс
закрыт по причине заказа на обмен, то
этот обмен реально происходит не со
свопированным процессом, т.е. для того
чтобы обмен нормально завершился, весь
процесс должен быть возвращен в
оперативную память. Это тоже плохо
потому, что, если бы свопинг происходил
блоками памяти, то можно было бы откачать
процесс без той страницы, с которой
надо меняться, а после обмена докачать
из области свопинга весь процесс обратно
в оперативную память. Современные
UNIX-ы
имеют возможность свопирования не
всего процесса, а какой-то его части.
Билет
№11. Файловая система Unix.
Файловая
система — это компонент операционной
системы, обеспечивающий организацию
создания, хранения и доступа к именованным
наборам данных
(файлам).
Файловая система:
Блок
начальной загрузки, Суперблок файловой
системы, Область индексных дескрипторов,
Блоки файлов, Область сохранения.
Индексный
дескриптор содержит следующую информацию:
1. Тип файла (каталог или нет). 2. Поле
кода защиты. 3. Количество ссылок к
данному ИД из каталогов. Если значение
этого поля равно нулю, то считается что
этот индексный дескриптор свободен.
4. Длина файла. 5. Статистика: поля, дата,
время и т.п. 6. Поле адресации блоков
файлов. Суперблок.Содерж.
данные о параметрах настройки ФС, кол-во
индексных дескрипторов, кол-во и
информацию о свободных блоках файлов,
о свободных индексных дескрипторах, и
проч. Массив свободных блоков файлов
состоит из пятидесяти элементов. В нем
записаны номера свободных блоков. Эти
номера записаны с 2 по 49. Первый элемент
массива содержит номер последней записи
в этом массиве. Нулевой элемент этого
списка содержит ссылку на блок
пространства блоков файлов, в котором
этот список
продолжен,
и т.д. 2-й массив сост. из ста элементов
и содержит номера свободных ИД. Пока
есть место в этом массиве, то при
освобождении индексных дескрипторов
свободные индексные дескрипторы
записываются на свободные места массива.
Если заполнен — запись прекращается.
Если массив
исчерпался
— запускает процесс, который просматривает
обл. ИД и заполняет массив новыми
значениями. Индексные
дескрипторы.
В поле адресации находятся номера
первых десяти блоков файлов. Если файл
превышает десять блоков, то одиннадцатый
элемент поля адресации содержит номер
блока из пространства блоков файлов,
в котором размещены 128 ссылок на блоки
данного файла. Если файл еще больше, то
двенадцатый элемент поля адресации
содержит номер блока, в котором содержится
128 записей о номерах блоков, содержащих
по 128 номеров блоков файловой системы.
Если файл еще больше, то используется
тринадцатый элемент и используется
тройная косвенность. Предельный размер
файла (при размере блока 512) будет равен
(128 + 1282
+ 1283)
* 512 байт = 1Гб + 8Мб + 64Кб >
1Гб. Каталоги.
Каталог, с точки зрения файловой системы,
— это файл, в котором размещены данные
о тех файлах, которые принадлежат
каталогу.
Каталог состоит из элементов, которые
содержат два поля. Первое поле — номер
индексного дескриптора, второе поле
— имя файла.
Файлы
устройств.
Тип указан в ИД. Содержимого нет, а есть
только ИД и имя. В ИД указывается
информация о типе устройства:
байт-ориентированное (напр.,
клавиатура)
или
блок-ориентированное. Имеется поле,
определяющее номер драйвера, связанного
с этим устройством и некоторый цифровой
параметр, который может быть передан
драйверу в качестве уточняющего
информацию о работе.
Билет
№??
Отладка.
Ф-я ptrace()
Осн.
Задачи при отладке:
1. Установка
контрольной точки.
2.
Обработка ситуации, связанной с приходом
в контрольную точку. 3. Чтение/запись
информации в отлаживаемой программе.
4. Остановка/продолжение выполнения
отлаживаемого процесса. 5. Шаговый режим
отладки (остановка отлаживаемой
программы после выполнения каждой
инструкции). 6. Передача управления на
произвольную точку отлаживаемой
программы. 7. Обработка аварийных
остановок (АВОСТ).
ptrace(int op, int pid, int addr, int data);
ptrace
— в
отцовском процессе, и через возможности
этой функции организуется управление
процессом сыном. Для того чтобы процесс
можно было трассировать, процесс-сын
должен подтвердить разрешение на его
трассировку т.е. выполнить обращение
к функции ptrace
с
op=0.
op=1
или op=2
—
ptrace
возвращает
значение слова, адрес которого задан
параметром addr.
Два значения op
на
случай, если есть самостоятельные
адресные пространства в сегментах
данных и кода. op=3
— читать
информацию из контекста процесса.
addr
указывает смещение относительно начала
этой структуры.( регистры, текущее
состояние процесса, счетчик адреса и
т.д.) op=4
или
op=5
— запись данных, размещенных в параметре
data,
по
адресу addr.
op=6
— запись
данных из data
в контекст по смещению addr.
(изм-е регистров).
op=7
— продолжение выполнения трассируемого
процесса. Если data=0,
то процесс, который к этому моменту был
приостановлен (сыновий), продолжит свое
выполнение, и при этом все пришедшие
(и необработанные еще) к нему сигналы
будут проигнорированы. Если значение
параметра data
равно
номеру сигнала, то это означает, что
процесс (сыновий) возобновит свое
выполнение, и при этом будет смоделирована
ситуация прихода сигнала с этим номером.
Все остальные сигналы будут проигнорированы.
Кроме
того, если addr=1,
то процесс продолжит свое выполнение
с того места, на котором он быт
приостановлен. Если addr>1,
то осуществиться переход по адресу
addr
(goto addr).
op=8
— завершение
трассируемого процесса. op=9
— установка
бита трассировки. Это тот самый код,
который обеспечивает пошаговое
выполнение машинных команд. После
каждой машинной команды в процессе
происходит событие, связанное с сигналом
SIG_TRAP.
Все
вышеописанные действия с функцией
ptrace
выполняются
при остановленном отлаживаемом процессе.
(Отцовский процесс посылает сыну сигнал
(в сыне уже ранее выполнена ptrace
c op=0),
предположим SIG_TRAP,
и после отправки сигнала отцовский
процесс выполняет функцию wait.)
Пример
к ptrace()
Отлаживаемый
процесс
int
main()
/*
эта
программа находится в процессе-сыне
SON */
{
int
i;
return
i/0;
}
Процесс
— отладчик
#iinclude
<stdio.h>
#iinclude
<unistd.h>
#iinclude
<signal.h>
#iinclude
<sys/types.h>
#iinclude
<sys/ptrace.h>
#iinclude
<sys/wait.h>
#iinclude
<machine/reg.h>
int
main(int argc, char *argv[])
{
pid_f
pid;
int
status;
struct
reg REG;
switch
(pid=fork()){
/*
формируем
процесс, в pid
— код ответа
*/
сase
-1: perror(«Ошибка
fork»);
exit(25);
/*
Обработка
ошибки
*/
case
0: ptrace( PT_TRACE_ME, 0, 0, 0); execl(«SON»,»SON»,0);
/*
В сыне: разрешаем отладку и загружаем
процесс SON.
При этом произойдет приостановка сына
перед выполнением первойкоманды нового
тела процесса (а точнее в нем возникнет
событие, связанное с сигналом SIG_TRAP)
*/
default:
break; /*
В отце: выход из switch
*/
}
for(;;)
{
wait(&status);
/*
ждем
возникновения события в сыне (сигнала
SIG_TRAP)
*/
ptrace(PT_GETREGS,pid,(caddr_t)®,0);
/*
Читаем регистры, например, чтобы их
распечатать */
printf(«EIP=%0.8x
+ ESP=%0.8xn»,REG.r_eip,
REG.r_esp);
/*
печатаем
регистры EIP
и
ESP */
if(WIFSTOPPED(status)||WIFSIGNALED(status)){
/*
проверяем
с помощью макросов условия функции
wait,
и если все нормально, продолжаем
разбирать причину остановки программы
*/
printf(«Сигналы:
«);
switch(WSTOPSIG(status)){
/*анализируем
код сигнала, по которому произошла
остановка */
case
SIGINT: printf(«INT n»); break;/*
выводим
причину остановки
*/
case
SIGTRAP: . . . . . . break;
…
default:
printf(«%d»,
WSTOPSIG(status));
}
if
(WSTOPSIG(status)!=SIGTRAP) exit(1);
/*
Если
процесс остановился не по SIGTRAP
тогда выходим
*/
if
(WIFEXITED(status)){ /*проверяем
случай, если процесс завершился нормально
*/
printf(«Процесс
завершился, код завершения = %d
n«,
WEXITSTATUS(status)); exit(0);
}
ptrace(PT_CONTINUE,
pid, (caddr_t) 1, 0);
/*
Если
был
SIGTRAP,
продолжаем процесс
*/
}
/*
End for(;;) */
exit(0);
}
Билет
№18. Разделяемая память.
int
shmget (key_t key, int size, int shmemflg);
key
— ключ,
size
— размер
раздела памяти, который должен быть
создан, shmemflg
— флаги
(напр. IPC_CREAT,
?IPC_EXCL?).
Функция возвращает идентификатор
ресурса, который ассоциируется с
созданным по данному запросу разделяемым
ресурсом.
Доступ.
char
*shmat(int shmid, char *shmaddr, int shmflg);
shmid
— идентификатор
разделяемого ресурса, shmaddr
— адрес,
с которого размещать разделяемую
память. Если shmaddr
—
адрес, то память будет подключена с
этого адреса, если его значение — нуль,
то система сама подберет адрес начала.
Могут быть указаны предопределенные
константы, которые позволяют организовать,
в частности, выравнивание адреса по
странице или началу сегмента памяти.
shmflg
— флаги.
Они определяют разные режимы доступа,
в частности, есть флаг SHM_RDONLY.
Открепление.
int shmdt(char *shmaddr);
shmaddr
— адрес
прикрепленной к процессу памяти, который
был получен при подключении памяти в
начале работы. Управление
разделяемой памятью:
int
shmctl(int shmid, int cmd, struct shmid_ds *buf);
shmid
— идентификатор;
cmd — команда.
Могут быть
команды:
IPC_SET
(сменить
права доступа и владельца ресурса),
IPC_STAT
(запросить
состояние ресурса — в этом случае
заполняется информация в структуру,
указатель на которую передается третьим
параметром, IPC_RMID
(уничтожение
ресурса — после того, как автор создал
процесс — с ним работают процессы,
которые подключаются и отключаются,
но не уничтожают ресурс, а с помощью
данной команды мы уничтожаем ресурс в
системе). Пример
— см. “Семафоры”.
Соседние файлы в папке Материал
- #
- #
- #
30.04.2013203 б12descript.ion
- #
- #
30.04.2013392.69 Кб14SPO.HTM
- #
- #
- #
- #
Executing an instruction requires a set of operations. For the sake of simplicity assume there are 5:
fetch-instruction decode-execute-memory access-write back.
This can be implemented with several schemes.
A/ Mono cycle processor
The scheme is the following:
The processor fetches an instruction, directs it to a decoder that controls a bank of multiplexers that will configure a large combinatorial datapath that will implement the instruction.
In this model, every instruction requires one cycle, and, assuming all the 5 «stages» require an equal time t, the period will be 5t.
Hence CPI=1, T=5
Actually, this was more or less the underlying model of the earlier computers in the late 40’s. Besides that, no real processor has be done like that, but it is theorically quite doable.
B/ Multi cycle processor
Compared to the previous model, you introduce registers on the datapath. First one fetches the instruction and sends it to the inputs of an automaton that will sequentially apply the computation «stages».
In that case, instructions require 5 cycles (maybe slightly less as some instructions may be simpler and, for instance, skip the memory access). Period is 1t (or maybe slighly more to take into account the registers traversal time).
CPI=5, T=1
The first «true» computers were implemented like that and this was the main architectural model up to the early 80’s. Nowadays several microcontrollers or, for instance, the simpler version of NIOS, are still relying on this scheme.
C/ pipeline processor
You add extra registers between the stages in order to keep track of the instruction and of all the partial results. In that case, the execution of every stage can be independent and you can execute several instructions simutaneously in different stages.
CPI becomes 1, as you can start a new instruction at every clock cycle (probably a bit more because of the hazards, but that is another story).
And T=1.
So CPI=1, T=1
(the CPI reflects the throughput increase but the execution time of a single instruction is not reduced)
So pipeline can be seen as either reducing the cycle time wrt scheme A, or reducing the CPI, wrt to scheme B. And you can also imagine an intermediate scheme (say 3 stages, with a period of 2) where pipeline will reduce both.
Аннотация: Рассматривается конвейерная организация работы идеального микропроцессора, сравнение производительности его работы с последовательной обработкой команд, типы и причины конфликтов в конвейере и пути уменьшения их влияния на работу микропроцессора.
Оценка производительности идеального конвейера
Выполнение каждой команды складывается из ряда последовательных этапов (шагов, стадий), суть которых не меняется от команды к команде. С целью увеличения быстродействия процессора и максимального использования всех его возможностей в современных микропроцессорах используется конвейерный принцип обработки информации. Этот принцип подразумевает, что в каждый момент времени процессор работает над различными стадиями выполнения нескольких команд, причем на выполнение каждой стадии выделяются отдельные аппаратные ресурсы. По очередному тактовому импульсу каждая команда в конвейере продвигается на следующую стадию обработки, выполненная команда покидает конвейер, а новая поступает в него.
В различных процессорах количество и суть этапов различаются. Рассмотрим принципы конвейерной обработки информации на примере пятиступенчатого конвейера, в котором выполнение команды складывается из следующих этапов:
- IF ( Instruction Fetch ) — считывание команды в процессор;
- ID ( Instruction Decoding ) — декодирование команды;
- OR ( Operand Reading ) — считывание операндов;
- EX ( Executing ) — выполнение команды;
- WB ( Write Back ) — запись результата.
Выполнение команд в таком конвейере представлено в табл. 11.1.
Так как в каждом такте могут выполняться различные стадии обработки команд, то длительность такта выбирается исходя из максимального времени выполнения всех стадий. Кроме того, следует учитывать, что для передачи команды с одной стадии на другую требуется определенное дополнительное время (  t), связанное с записью промежуточных результатов обработки в буферные регистры.
t), связанное с записью промежуточных результатов обработки в буферные регистры.
| Команда | Такт | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| i | IF | ID | OR | EX | WB | ||||
| i+1 | IF | ID | OR | EX | WB | ||||
| i+2 | IF | ID | OR | EX | WB | ||||
| i+3 | IF | ID | OR | EX | WB | ||||
| i+4 | IF | ID | OR | EX | WB |
Пусть для выполнения отдельных стадий обработки требуются следующие затраты времени (в некоторых условных единицах):
TIF = 20, TID = 15, TOR = 20, TEX = 25, TWB = 20.
Тогда, предполагая, что дополнительные расходы времени составляют dt = 5 единиц, получим время такта:
 .
.
Оценим время выполнения одной команды и некоторой группы команд при последовательной и конвейерной обработке.
При последовательной обработке время выполнения N команд составит:
Tпосл = N*(TIF + TID + TOR + TEX + TWB) = 100N.
Анализ табл. 11.1 показывает, что при конвейерной обработке после того, как получен результат выполнения первой команды, результат очередной команды появляется в следующем такте работы процессора. Следовательно,
Tконв = 5T + (N-1) * T.
Примеры длительности выполнения некоторого количества команд при последовательной и конвейерной обработке приведены в табл. 11.2.
| Количество команд | Время | |
|---|---|---|
| при последовательном выполнении | при конвейерном выполнении | |
| 1 | 100 | 150 |
| 2 | 200 | 240 |
| 10 | 1000 | 420 |
| 100 | 10000 | 3120 |
Очевидно, что при достаточно длительной работе конвейера его быстродействие будет существенно превышать быстродействие, достигаемое при последовательной обработке команд. Это увеличение будет тем больше, чем меньше длительность такта конвейера и чем больше количество выполненных команд. Сокращение длительности такта достигается, в частности, разбиением выполнения команды на большое число этапов, каждый из которых включает в себя относительно простые операции и поэтому может выполняться за короткий промежуток времени. Так, если в микропроцессоре Pentium длина конвейера составляла 5 ступеней (при максимальной тактовой частоте 200 МГц), то в Pentium-4 — уже 20 ступеней (при максимальной тактовой частоте на сегодняшний день 3,4 ГГц).
Какой бы ни была операционная система, перед ней стоит целый комплекс задач. И нам понадобится не раз возвращаться к этой теме, чтобы рассмотреть их все хотя бы в самых общих чертах. Темой нашего сегодняшнего повествования станет распределение операционной системой времени центрального процессора между различными задачами. Сегодня мы получим ответ на вопрос, который рано или поздно возникает у каждого любознательного пользователя: как операционная система распределяет время процессора для решения нескольких задач одновременно? Ведь под красочными обоями рабочего стола таится неутомимая труженица, способная день и ночь решать поставленные перед ней пользователем задачи. За ее плечами нелегкий груз забот, но обычно она несет его с легкостью, кроме некоторых ситуаций, когда пользователь требует от своей помощницы невозможного.


Все выполняемые операционной системой задачи можно сгруппировать по шести категориям:
- Управление процессором (Processor management)
- Управление памятью (Memory management)
- Управление устройством (Device management)
- Управление накопителем (Storage management)
- Интерфейс приложения (Application interface)
- Интерфейс пользователя (User interface)
Читатели могут отметить, что современная операционная система умеет много такого, что не вмещается ни в одну из этих шести групп. И будут правы. Разработчики операционных систем оснащают их множеством вспомогательных утилит и дополнительных функций. Но эти шесть категорий, которые нам предстоит рассмотреть, составляют саму суть того, что положено делать операционной системе.
Управление процессором

Управление процессором компьютера сводится к решению двух, теснейшим образом связанных между собою проблем:
- Обеспечение каждого программного процесса и приложения достаточным для корректного функционирования временем процессора
- Использование циклов процессора в том объеме, который реально необходим для работы
Основной единицей программного обеспечения, которой операционная система выделяет процессорное время, является процесс или поток (тред). Это зависит от конкретной операционной системы.
Можно даже сказать, что операционная система склонна воспринимать процесс в качестве приложения. Но это упрощение не описывает всей сложности взаимодействия процессов с операционной системой и аппаратным обеспечением компьютера. Процессом является любое приложение: текстовый редактор, электронная таблица или игра. Но приложение может вести к запуску дополнительных процессов, обеспечивающих взаимодействие с устройствами или другими компьютерами.
Когда операционная система работает, в ней запущено множество процессов, которые даже не дают вам знать о своем существовании. Например, в Windows XP или UNIX работают десятки фоновых процессов. В список их задач входят: обеспечение работы сети, управление памятью компьютера и его дисками, проверка системы на вирусы. Разумеется, этим круг их задач не исчерпывается.
Процессом называется программное обеспечение, выполняющее некую работу. Каждый процесс должен кем-то или чем-то контролироваться: операционной системой, другим приложением или непосредственно пользователем.
Операционная система управляет скорее процессами, чем приложениями и именно их она ставит в расписание центрального процессора. В однозадачных операционных системах это расписание линейно. Операционная система позволяет приложению запуститься, прерывая его выполнение только на те промежутки времени, которые требуются пользователю на ввод данных или другие прерывания.
Прерываниями называют специальные сигналы, исходящие от аппаратного и программного обеспечения. Они происходят тогда, когда та или иная часть компьютера неожиданно требует к себе внимания со стороны центрального процессора. Порой операционная система определяет приоритет процессов и маскирует некоторые прерывания. То есть она игнорирует прерывания от некоторых источников, позволяя процессору сначала справиться с уже выполняемой им работой.
Но некоторые прерывания крайне важны и не игнорируются. Речь идет о проблемах памяти и ошибках. Эти прерывания называют немаскируемыми и они обрабатываются немедленно, вне зависимости от того, над какими задачами в данный момент работает процессор. В качестве наиболее яркого (но, разумеется, не единственного) примера немаскируемого прерывания можно привести прерывание по прекращению подачи питания. Нетрудно понять, что такое прерывание всегда ведет к прекращению работы процессора по весьма уважительной причине.
Прерывания усложняют работу даже однозадачной операционной системы. Каждодневный труд многозадачной операционной системы еще сложнее. Сегодня операционная система должна выполнять приложения таким образом, чтобы для вас это выглядело в качестве событий, происходящих одновременно. Современные многоядерные процессоры и многопроцессорные компьютеры, разумеется, очень работоспособны, но каждое ядро процессора до сих пор может выполнять лишь одну задачу в один момент времени.
Чтобы создавалось впечатление одновременно происходящих событий, операционной системе приходится переключаться между процессами тысячи раз за одну только секунду. Теперь рассмотрим то, как все это происходит в реальности:
- Процесс занимает определенный объем в оперативной памяти (ОЗУ, RAM). Он также может использовать регистры, стеки и очереди в рамках памяти процессора и операционной системы
- Когда два процесса выполняются одновременно в многозадачном режиме, операционная система выделяет одной программе определенное количество исполнительных циклов процессора
- После выполнения этой последовательности циклов, операционная система копирует состояние всех регистров, стеков и очередей, использованных в ходе работы над выполнением процесса и отмечает точку, в которой выполнение процесса было приостановлено
- Затем загружает все регистры, стеки и очереди, используемые вторым процессом и позволяет процессору уделить ему некоторое количество циклов
- Когда все это уже произошло, она вновь копирует состояние всех регистров, стеков и очередей, использованных второй программой и в очередной раз загружает первую программу
Управляющий блок процесса

Вся информация, необходимая для отслеживания процесса, содержится в пакете данных, именуемом управляющим блоком процесса (process control block). Таким образом состояние процесса не теряется при переключении между задачами. В общем случае, управляющий блок процесса содержит:
- Номер-идентификатор (ID), идентифицирующий данный процесс
- Указатели и положения программы и ее данных на момент последней обработки процесса
- Контент регистра
- Состояния различных признаков и переключателей
- Список открытых процессом файлов
- Приоритет процесса
- Статус всех необходимых данному процессу устройств ввода и вывода
Каждый процесс характеризуется связанным с ним статусом (состоянием). Многие процессы в определенных ситуациях не требуют времени центрального процессора. К примеру, процесс может находиться в состоянии ожидания нажатия пользователем клавиши. В этом состоянии процесс называют приостановленным (suspended). Когда поступает информация о нажатии клавиши, операционная система меняет его статус. В данном конкретном примере речь идет о том, что статус ожидания сменяется статусом исполнения. Для продолжения выполнения процесса используется информация из его управляющего блока.
Подкачка процессов не требует непосредственного вмешательства пользователя. Каждый процесс получает в свое распоряжение достаточно циклов процессора, чтобы выполнить свою задачу за разумный промежуток времени. Проблемы наступают, когда пользователь начинает одновременно работать со слишком большим числом процессов. Операционная система и сама требует определенного количества циклов процессора на сохранение всех регистров и очередей и переключение между задачами. Операционная система не идеальна, и может случиться так, что она начнет использовать большую часть отведенных ей циклов процессора на переключение между процессами, а не на их запуск. Это называется пробуксовкой и обычно требует вмешательства пользователя. Ему необходимо завершить некоторые процессы и навести порядок в работе системы.
Все рассмотренное нами выше касается тех случаев, когда компьютер располагает всего одним процессором. На машинах, располагающих двумя и более процессорами, операционной системе приходится распределять между ними свою рабочую нагрузку. И при этом стараться поддержать баланс между потребностями процессов и количеством доступных циклов разных процессоров. Асимметричные операционные системы выделяют один из процессоров под свои собственные нужды, а процессы приложений распределяют между остальными. Симметричные операционные системы распределяют свои нужды между несколькими процессорами даже в тех случаях, если никаких других задач больше не запущено.
В дальнейшем нам предстоит поговорить еще о пяти категориях задач, которые постоянно «держит в уме» самая обычная операционная система любого компьютера.
Продолжение следует…
По материалам computer.howstuffworks.com