Основы правил проектирования базы данных
Время на прочтение
11 мин
Количество просмотров 161K
Введение
Как это часто бывает, архитектору БД нужно разработать базу данных под конкретное решение.
Однажды в пятницу вечером, возвращаясь на электричке домой с работы, я подумал о том, как бы я создал сервис по найму сотрудников в разные компании. Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
В данной статье я позволю себе немного разбавить строгое изложение материала, смешав техническую информацию с не техническими примерами из жизни.
Для начала, разберем создание базы данных в MS SQL Server для сервиса поиска соискателей на работу.
Этот материал можно перенести и на другую СУБД такую как MySQL или PostgreSQL.
Основы правил проектирования
Для проектирования схемы базы данных, нужно вспомнить 7 формальных правил и саму концепцию нормализации и денормализации. Они и лежат в основе всех правил проектирования.
Опишем более детально 7 формальных правил:
- отношение один к одному:
1.1) с обязательной связью:
примером может выступать гражданин и его паспорт: у любого гражданина должен быть паспорт; паспорт один для каждого гражданина
Реализовать данную связь можно двумя способами:
1.1.1) в одной сущности (таблице):

Рис.1. Сущность CitizenЗдесь таблица Citizen представляет собой сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (NOT NULL).
1.1.2) в двух разных сущностях (таблицах):
Рис.2. Отношение сущностей Citizen и PassportDataЗдесь таблица Citizen представляет собой сущность гражданина, а таблица PassportData — сущность паспортных данных гражданина (самого паспорта). Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL). Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
1.2) с необязательной связью:
примером может выступать человек, имеющий или не имеющий паспорт конкретной страны. В первом случае он будет являться гражданином рассматриваемой страны, а во втором — нет.
Реализовать данную связь можно двумя способами:
1.2.1) в одной сущности (таблице):
Рис.3. Сущность PersonТаблица Person представляет собой сущность человека, а атрибут (поле) PassportData содержит все его паспортные данные и может быть пустым (NULL).
1.2.2) в двух сущностях (таблицах):
Рис.4. Отношение сущностей Person и PassportData
Таблица Person представляет собой сущность человека, а таблица PassportData — сущность паспортных данных человека (самого паспорта). Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL. - отношение один ко многим:
2.1) с обязательной связью:
примером могут выступать родитель и его дети. У каждого родителя есть как минимум один ребенок.
Реализовать данную связь можно двумя способами:
2.1.1) в одной сущности (таблице):
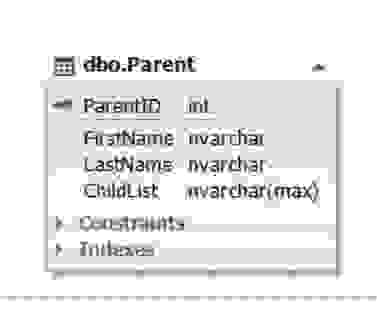
Рис.5. Сущность ParentТаблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.1.2) в двух сущностях (таблицах):
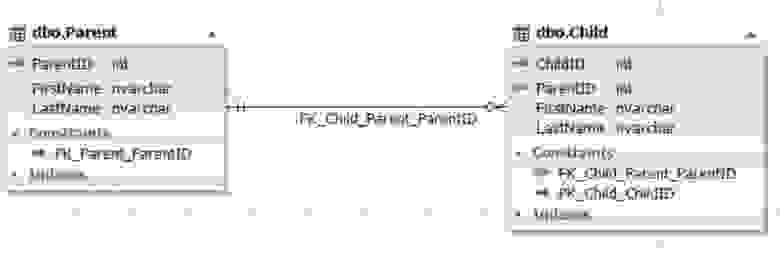
Рис.6. Отношение сущностей Parent и ChildТаблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child не может быть пустым (NOT NULL).
2.2) с необязательной связью:
примером может выступать человек, у которого могут быть дети или их может не быть.
Реализовать данную связь можно двумя способами:
2.2.1) в одной сущности (таблице):
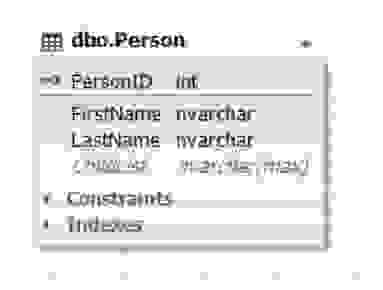
Рис.7. Сущность Person
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле может быть пустым (NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.2.2.2) в двух сущностях (таблицах):
Рис.8. Отношение сущностей Person и ChildТаблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child может быть пустым (NULL).
2.2.3) в одной сущности со ссылкой на саму себя при условии, что у сущностей (таблиц) родителя и ребенка будут одинаковые наборы атрибутов (полей) без учета ссылки на родителя:
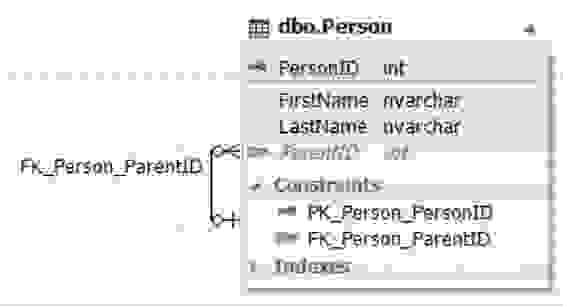
Рис.9. Сущность Person со связью на саму себя
Сущность (таблица) Person содержит атрибут (поле) ParentID, который ссылается на первичный ключ PersonID этой же таблицы Person и может содержать пустое значение (NULL).Также данная реализация является примером реализации отношения «многие к одному» с необязательной связью.
- отношение многие к одному:
Эту связь можно рассмотреть зеркально к приведенной выше связи один ко многим. Иными словами, отношение сущности «дети» к сущности «родители», где обязательная связь будет при условии, что у ребенка есть хотя бы один родитель. Если же участвуют все дети, в том числе и находящиеся в детских домах, отношение будет с необязательной связью.
- отношение многие ко многим:
Примером может выступить недвижимость: она может быть в собственности как одного человека, так и нескольких. С другой стороны, один человек может владеть несколькими домами или долями нескольких домов.
Реализовать данное отношение, с привлечением NoSQL, можно так же, как в описанных выше отношениях. Однако, в рамках реляционной модели обычно такое отношение реализуют через 3 сущности (таблицы):
Рис.10. Отношение сущностей Person и RealEstate Таблицы Person и RealEstate представляют соответственно сущности человека и недвижимости. Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.Также данное отношение можно реализовать через более чем три сущности. Для этого добавляются нужные атрибуты, которые ссылаются на первичные ключи необходимых соответствующих сущностей. Такая реализация схожа с примерами, описанными выше в пунктах 1.1.2 и 1.2.2.





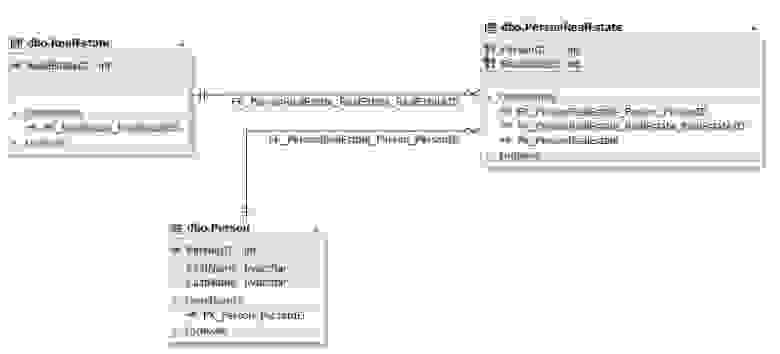
Отношения один ко многим и многие к одному можно реализовать через более чем две сущности. Для этого добавляются нужные атрибуты, которые ссылаются на первичные ключи необходимых соответствующих сущностей. Такая реализация схожа с примерами, описанными выше в пунктах 1.1.2 и 1.2.2.
А где же семь формальных правил?
Вот они:
- п.1 (п.1.1 и п.1.2) — первое и второе формальные правила
- п.2 (п.2.1 и п.2.2) — третье и четвертое формальные правила
- п.3 (аналогично п.2) — пятое и шестое формальные правила
- п.4 — седьмое формальное правило
В тексте выше эти семь формальных правил объединены в четыре блока по функционалу.
Говоря о нормализации, нужно понимать ее суть. Нормализация ведет к уменьшению повторяемости хранения информации, а следовательно и к уменьшению возможности появления аномалий в данных. Однако, нормализация при дроблении сущностей приводит к более сложным построениям запросов для манипуляций с данными (вставки, модификации, выборки и удаления).
Обратным процессом нормализации называется денормализация. Это упрощение построения запросов доступа к данным за счет укрупнения и вложенности сущностей (например, как было показано выше в пунктах 2.1.1 и 2.2.1 с помощью неполно-структурированных данных (NoSQL)).
Вот и вся суть правил проектирования баз данных.
А вы уверены, что поняли отношения в семи формальных правилах? Именно поняли, а не узнали? Ведь знать и понимать — две совершенно разных концепции.
Объясню более детально. Спросите себя, можете ли вы за пару часов набросать пусть и укрупненную по сущностям, но модель базы данных для любой предметной области и для любой информационной системы? (тонкости и детали можно достроить, поспрашивав аналитиков и представителей заказчиков). Если вопрос вас удивил, и вы думаете, что это невозможно, значит вы знаете семь формальных правил, но не понимаете их.
Почему-то многие источники игнорируют тот факт, что эти отношения были не придуманы, а выявлены. Они изначально существуют в реальном мире как между субъектами, так и между субъектами и объектами.
Также, эти отношения могут меняться, переходя из один к одному к одному ко многим, многие к одному или многие ко многим. Обязательность связи может меняться или остаться неизменной.
Позволю себе рассказать об одном случае, когда от знания семи формальных правил я пришел именно к пониманию этих отношений.
В свое время меня смущало то, что в ВУЗе я знал эти семь формальных правил, но на производственной практике (ВУЗ отправляет студентов в различные компании для приобретения профессионального опыта) очень долго строил модели баз для разных предметных областей. Я задумался и понял, что не понимаю этих отношений.
Мне помогло наблюдение за людьми, а суть отношений раскрылась в сновидении. Этот сон я перескажу в упрощенной форме: только то, что позволяет лучше понять именно эти семь формальных правил — без детализации всего остального.
Сон был про семью, в которой есть отец, мать и дети. Отец погибает в автомобильной катастрофе, а мать начинает пить, и детей в итоге забирают в детский дом. Эти дети надолго остаются без родителей. Затем у некоторых детей появляются попечители, их тоже несколько.
Вы проследили, какие отношения были между субъектами, и как менялись эти отношения?
Давайте присмотримся внимательнее.
- Когда семья была полной, с несколькими детьми, отношение между родителями и детьми имело вид многие ко многим.
- Когда остались мать и дети, отношение между родителем и детьми стало один ко многим с обязательной связью. Однако, в любой семье, где может и не быть детей, это отношение будет таким же, но уже с необязательной связью.
- А вот со стороны детей отношение к родителю было как многие к одному с обязательной связью пока родителя не лишили родительских прав.
- Когда дети оказались в детском доме — отношение изменилось на многие к одному с необязательной связью.
- Когда у детей появились попечители, связь между ними стала многие ко многим: у каждого попечителя могут быть другие подопечные дети, а у каждого ребенка могут быть другие попечители (родители).
Отношение между мужем и женой один к одному с обязательной связью при официальной брака или один к одному с необязательной связью до регистрации. Жена может быть только одна, как и муж может быть только один. По крайней мере, в России. Но в другой стране возможно многоженство, и тогда связь между мужем и женами будет один ко многим, а между женами и мужем — многие к одному.
Надеюсь, теперь вы значительно приблизились к пониманию этих семи формальных правил.
Стоит постоянно практиковаться: наблюдать за людьми и выявлять существующие отношения как между субъектами, так и между субъектами и объектами. Выше описывался гражданин и его паспорт как отношение один к одному с обязательной связью. В тоже время, пример человека и его паспорта — это отношение один к одному с необязательной связью.
Поняв семь формальных правил, вы сможете без труда спроектировать модель базы данных любой сложности для любой информационной системы.
Также вы увидите, что реализовать отношение можно разными способами, а сами отношения могут меняться. Модель (схема) базы данных — это «снимок» отношений между сущностями в определенный момент времени. Именно поэтому важно определить как сами сущности — образы объектов из реального мира или предметной области, так и их отношения между собой с учетом изменений в будущем.
Хорошо спроектированную модель базы данных с учетом изменения отношений в реальности или в предметной области не понадобится менять годами или даже десятилетия. Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Важно запомнить, что таблицы в реляционной модели — это отношения сущностей, а строки (кортежи) — это экземпляры этих отношений. Но чтобы было проще, под таблицами часто понимаются сущности, а под строками таблицы — экземпляры сущностей. Их отношения выражаются через связи в форме внешних ключей.
Проектирование схемы базы данных для поиска соискателей на работу
После того, как мы описали основы правил проектирования БД в первой части, давайте создадим схему базы данных для поиска соискателей на работу.
Для начала, определим, что важно для сотрудников из компании, которые ищут кандидатов:
- для HR:
1.1) компании, где работал соискатель
1.2) позиции, которые ранее занимал соискатель в данных компаниях
1.3) навыки и умения, которыми соискатель пользовался в работе;
а также продолжительность работы соискателя в каждой компании на каждой позиции и длительность использования каждого навыка и умения - для технического специалиста:
2.1) позиции, которые занимал соискатель в данных компаниях
2.2) навыки и умения, которыми соискатель пользовался в работе
2.3) проекты, в которых участвовал соискатель;
а также продолжительность работы соискателя на каждой позиции и в каждом проекте, длительность использования каждого навыка и умения
Для начала выявим нужные сущности:
- Сотрудник (Employee)
- Компания (Company)
- Позиция (должность) (Position)
- Проект (Project)
- Навык (Skill)
- Компании и сотрудники относятся как многие ко многим, так как сотрудник мог работать в нескольких компаниях, а в компании работают многие люди.
- Аналогично относятся позиции и сотрудники: несколько сотрудников могут занимать одну позицию как в рамках как одной, так и нескольких компаний.
- С другой стороны, сотрудник мог работать на разных позициях как в рамках одной, так разных компаний. Таким образом, отношение между позициями и компаниями — многие ко многим.
- Аналогично и по проектам: проекты относятся ко всем выше рассмотренным сущностям как многие ко многим.
- Для простоты будем считать, что в проекте сотрудник использует один набор навыков.
- Тогда проекты и навык относятся как многие ко многим.
Поскольку очень важно зафиксировать, как долго сотрудник работал на той или иной позиции в той или иной компании, а также на каждом проекте, схема нашей базы данных может быть следующей:
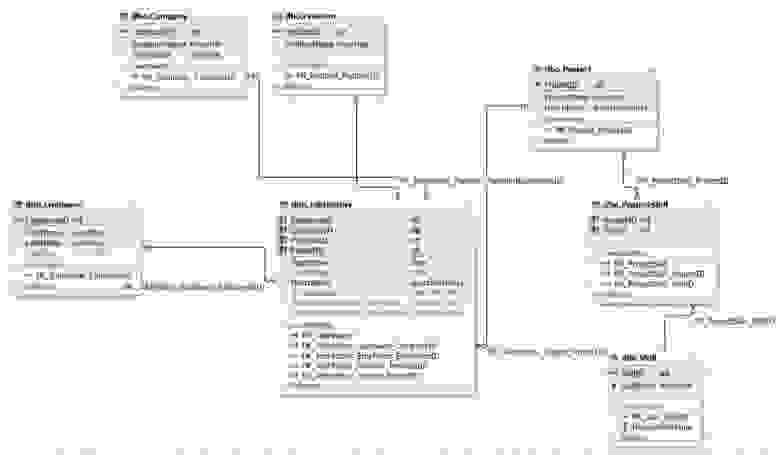
Рис.11. Схема базы данных для поиска соискателей на работу
Здесь таблица JobHistory выступает как сущность истории работы каждого соискателя. То есть, это резюме, которое педставляет отношения многие ко многим между сущностями сотрудник, компания, позиция и проект.
Проекты и навыки относятся друг другу как многие ко многим и потому связываются между собой через сущность (таблицу) ProjectSkill.
Когда вы понимаете отношения между субъектами и между субъектами и объектами — уже упомянутые семь формальных правил — эту или схожую схему можно реализовать «на коленке»: на листке бумаги, мене чем за час. И это еще с учетом усталости после плодотворного рабочего дня.
Здесь можно было упростить схему добавления данных, если «навыки» вложить в сущность «проекты» через неполно структурированные данные (NoSQL) в виде XML, JSON или просто перечислять названия навыков через точку с запятой. Но это бы усложнило выборку с группировкой по навыкам и фильтрацию по отдельным навыкам.
Подобная модель лежит в основе базы данных проекта Geecko.
Как видите, ничего сложного в проектировании информационных систем в части проектирования базы данных нет. Это всего лишь отражение объектов и субъектов из реальности, перенесенное в «сущности» схемы базы данных. Отношения между этими сущностями фиксируются на определенный момент времени, с учетом будущих изменений.
Что именно мы возьмем из реальности и вложим в сущность схемы, и какие отношения построим в модели, будет зависеть от того, что мы хотим от информационной системы в общем, здесь и в будущем. Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Немного лирики
После того, как вы внедрите модель в работу, остановитесь на миг и подумайте: только что был создан новый маленький мир. В нем есть свои сущности из реального мира и свои отношения. Да, это цифровой мир, но он теперь будет развиваться своей дорогой. Он будет общаться (интегрироваться) с другими системами (мирами), тоже созданными по своим правилам. Данные будут течь в этих системах, как кровь в живом организме.
А перед сном подумайте о том, что семь формальных правил были всегда, и что они окружают нас всюду. Не больше и не меньше, всегда семь. Все отношения реальной жизни можно разложить на эти семь формальных правил. А когда вы думаете или видите сны, как там сущности относятся друг к другу — не по тем же семи формальным правилам?
Вообще, я уверен, что эти отношения (семь формальных правил) выявил очень хороший психотерапевт, возможно — женщина. Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Но мы немного отошли от темы. Я лишь призываю в момент создания новой системы подойти к этому процессу с душой. И тогда поверьте, случится момент творения. Спроектированная таким образом система будет живее всех живых в цифровом мире.
Послесловие
Диаграммы для примеров были реализованы с помощью инструмента Database Diagram Tool for SQL Server. Однако, подобный функционал есть и в DBeaver.
Источники
- SQL Database Design Basics with Example
- Geecko
- Microsoft SQL documentation
- SSMS
- Database Diagram Tool for SQL Server
Типовая бизнес-модель процесса проектирования базы данных
Процесс проектирования базы данных может быть представлен в виде модели бизнес-процессов. Обычно проектировщики не создают бизнес-модель процесса проектирования базы данных. А напрасно! Бизнес-модель процесса проектирования позволяет:
- отобразить субъективное мнение проектировщика баз данных на процесс проектирования конкретной базы данных;
- учесть особенности ИТ-проекта, в рамках которого проектируется база данных;
- достаточно быстро составить план проектирования конкретной базы данных;
- просчитать длительность проектных работ (создать временную модель проектирования).
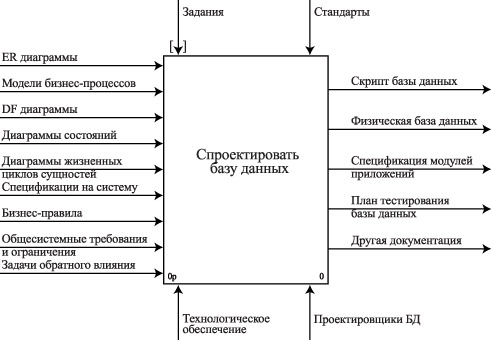
Рассмотрим типовую бизнес-модель процесса проектирования базы данных. На рис. 3.1 приведена контекстная диаграмма процесса проектирования базы данных.
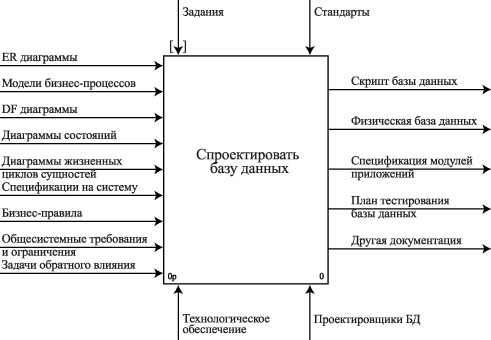
Рис.
3.1.
Контекстная диаграмма процесса проектирования базы данных
Как видно из рисунка, на вход процесса проектирования базы данных подаются:
- информационная модель предметной области базы данных: диаграммы «сущность-связь» ( ER -диаграммы);
- функциональная модель предметной области базы данных: бизнес-модель процессов, диаграммы потока данных ( DF -диаграммы), диаграммы состояний, — диаграммы жизненных циклов сущностей, спецификации на системы (требования), бизнес-правила;
- общесистемные требования и ограничения;
- задачи обратного влияния.
Могут быть представлены и другие документы.
Примечание. Под задачами обратного влияния здесь понимается совокупность проблем, которые возникают в процессе разработки приложений базы данных, ее тестирования, опытной и промышленной эксплуатации и приводят к модификации физической модели базы данных. Примером такой задачи является настройка операторов SELECT с целью увеличения производительности выборки.
На выходе процесса проектирования базы данных формируются следующие результаты:
- физическая модель базы данных, которая может быть преобразована в скрипт для создания базы данных;
- физическая база данных;
- спецификация модулей приложений базы данных;
- план тестирования базы данных.
По требованию может быть разработана и другая документация.
Продолжим функциональную декомпозицию процесса проектирования базы данных. На рис. 3.2 приведена диаграмма декомпозиции процесса проектирования базы данных первого уровня, отражающая основные наиболее крупные профессиональные задачи (этапы) проектирования базы данных.
Внимание! В настоящем курсе рассматривается минимально необходимый, с точки зрения автора, набор задач, позволяющий спроектировать реляционную базу данных.
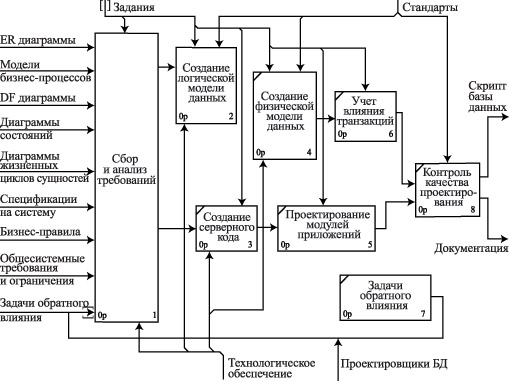
Рис.
3.2.
Диаграмма декомпозиция процесса проектирования базы данных: первый уровень
Такими задачами (этапами) являются:
- сбор и анализ входных данных;
- создание логической модели базы данных ;
- создание физической модели базы данных: внутренняя схема;
- создание физической модели базы данных: учет влияния транзакций ;
- создание серверного кода ;
- проектирование модулей приложений базы данных;
- контроль качества проектирования базы данных ;
- задачи обратного влияния.
Сбор и анализ входных данных — это начальный этап проектирования, на котором осуществляется сбор и контроль качества результатов анализа предметной области базы данных, готовится план проектирования базы данных.
Создание логической модели базы данных — это этап, на котором на основании информационной модели предметной области базы данных создается логическая структура базы данных, независимая от ее реализации.
Создание физической модели базы данных: внутренняя схема — это этап, на котором на основании логической модели базы данных создается физическая структура базы данных, зависимая от ее реализации. На этом этапе выполняется преобразование отношений логической модели реляционной базы данных в команды создания объектов физической базы данных, в результате чего создается так называемая внутренняя схема базы данных. Дополнительно может быть создана так называемая внешняя схема базы данных, которая отражает точку зрения пользователей на данные в базе данных. Полученный скрипт может быть применен для создания физической базы данных.
Создание физической модели базы данных: учет влияния транзакций — это этап, на котором анализируются возможные транзакции системы, выполняется, в случае необходимости, денормализация отношений для обеспечения более высокой производительности базы данных. На этом этапе создается скрипт создания физической базы данных.
Создание серверного кода — это этап, на котором на основании функциональной модели предметной области базы данных создается серверный код базы данных в виде триггеров, хранимых процедур и пакетов. Эти модули создаются проектировщиком базы данных и выполняются сервером.
Проектирование модулей приложений — это этап, на котором создаются спецификации модулей приложений, разрабатываются стратегии тестирования базы данных и приложений, создается план тестирования приложений базы данных и готовятся тестовые данные.
Контроль качества проектирования базы данных заключается в проверке качества результатов проектирования на каждом его этапе.
Учет задач обратного влияния заключается в настройке некоторых транзакций к базе данных и локальном перепроектировании базы данных согласно требованиям, поступающим с других этапов создания базы данных.
Как правило, последние четыре из сформулированных нами задач решаются в соответствии с правилами и стандартами, принятыми в конкретной организации.
Поэтому мы не будем строить для них детальной бизнес-модели в настоящей лекции, а в лекциях, посвященных рассмотрению этих задач, мы ограничимся понятийным материалом и установочными рекомендациями. В частности, задача контроля качества проектирования базы данных упомянута в настоящем курсе для полноты представления материала и как самостоятельная задача в настоящих лекциях не изучается. Это предмет отдельного курса лекций.
Содержание:

1. Введение
Значительная часть проектов в области информационных технологий (далее ИТ-проектов) направлена на разработку и создание информационных систем, в рамках которых осуществляется обработка данных различной сложности. Целью таких проектов является разработка и создание информационной системы с базами данных. Практически во всех таких проектах решается задача проектирования баз данных определенного типа. Решение задачи проектирования повышает вероятность того, что разрабатываемая информационная система (далее — система) будет удовлетворять заданным функциональным и информационным требованиям с учетом заданных ограничений.
Примеры функциональных требований: выдача отчетов по продажам по регионам; выдача отчетов по продажам по кварталам; автоматический расчет скидок на товары при увеличении объема закупаемой партии и т.п.
Примеры ограничений: максимальное время, отпущенное на проект; количество денежных средств, которое можно на него потратить. Следует также учитывать технологические средства, доступные при реализации проекта, например требование реализации базы данных в архитектуре «файл-сервер».
В эксплуатации база данных и ее окружение должны удовлетворять набору требований по ряду укрупненных (интегрированных) параметров, таких как:
- функциональность и адаптируемость;
- производительность обработки транзакций;
- пропускная способность;
- время реакции;
- безопасность.
Это далеко не полный перечень параметров, по которым выставляются требования к базам данных, однако он содержит параметры, требования по которым выставляются наиболее часто.
Такие параметры иногда находятся в противоречии друг к другу. Так, высокие требования по функциональности на данном конкретном оборудовании могут вступать в конфликт с высокими требованиями по
в достижении компромиссов между функциональными, информационными, аппаратными, архитектурными и технологическими требованиями к базе данных и строится на информированном принятии решений по структуре базы данных.
2. Проектирование базы данных
Проектирование базы данных — это поиск способов удовлетворения функциональных требований средствами имеющейся компьютерной технологии с учетом заданных ограничений.
Как правило, ИТ-проекты по созданию базы данных включают в себя следующие этапы: определение стратегии построения системы, анализ требований к базе данных, проектирование базы данных, реализация базы, тестирование и внедрение базы данных. Этап проектирования базы данных считается одним из самых сложных «размытых» этапов создания базы данных, который не имеет явно выраженного начала и окончания. По сравнению с анализом требований.
Процесс проектирования базы данных охватывает несколько основных сфер.
Проектирование объектов базы данных (таблицы, представления, индексы, триггеры, хранимые процедуры, функции, пакеты) для представления данных предметной области в базе данных.
Проектирование интерфейса взаимодействия с базой данных (формы, отчеты и т.д.), т.е. проектирование приложений, которые будут сопровождать данные в базе данных и реализовывать вопросно-
- платформе;
- поддерживается в рамках определенных организационно-технологических мероприятий.
Таким образом, база данных является сложным многокомпонентным объектом, объединяющим аппаратное обеспечение, программное обеспечение, информацию в виде данных и персонал. Основной задачей проектировщика базы данных является обоснованный выбор такой ее структуры, которая обеспечит согласованное взаимодействие всех ее компонентов согласно заданным функциональным требованиям в рамках заданных ограничений.
Типовая бизнес-модель процесса проектирования базы данных
Процесс проектирования базы данных может быть представлен в виде модели бизнес-процессов. Бизнес-модель процесса проектирования позволяет:
- отобразить субъективное мнение проектировщика баз данных на процесс проектирования конкретной базы данных;
- учесть особенности ИТ-проекта, в рамках которого проектируется база данных;
- достаточно быстро составить план проектирования конкретной базы данных;
- просчитать длительность проектных работ (создать временную модель проектирования).
Рассмотрим типовую бизнес-модель процесса проектирования базы данных. На рис. 3.1 приведена контекстная диаграмма процесса проектирования базы данных.
Контекстная диаграмма процесса проектирования базы данных
Как видно из рисунка, на вход процесса проектирования базы данных подаются:
- информационная модель предметной области базы данных: диаграммы «сущность-связь» (ER-диаграммы);
- функциональная модель предметной области базы данных: бизнес-модель процессов, диаграммы потока данных (DF-диаграммы), диаграммы состояний, — диаграммы жизненных циклов сущностей, спецификации на системы (требования), бизнес-правила;
- общесистемные требования и ограничения;
- задачи обратного влияния.
Могут быть представлены и другие документы.
На выходе процесса проектирования базы данных формируются следующие результаты:
- физическая модель базы данных, которая может быть преобразована в скрипт для создания базы данных;
- физическая база данных;
- спецификация модулей приложений базы данных;
- план тестирования базы данных.
По требованию может быть разработана и другая документация.
На рис. 3.2 приведена диаграмма декомпозиции процесса проектирования базы данных первого уровня, отражающая основные наиболее крупные профессиональные задачи (этапы) проектирования базы данных.
анализ входных данных — это начальный этап проектирования, на котором осуществляется сбор и контроль качества результатов анализа предметной области базы данных, готовится план проектирования базы данных.
Создание логической модели базы данных — это этап, на котором на основании информационной модели предметной области базы данных
Создание физической модели базы данных: учет влияния транзакций — это этап, на котором анализируются возможные транзакции системы, выполняется, в случае необходимости, денормализация отношений для обеспечения более высокой производительности базы данных. На этом этапе создается скрипт создания физической базы данных.
Создание серверного кода — это этап, на котором на основании функциональной модели предметной области базы данных создается серверный код базы данных в виде триггеров, хранимых процедур и пакетов. Эти модули создаются проектировщиком базы данных и выполняются сервером.
Проектирование модулей приложений — это этап, на котором создаются спецификации модулей приложений, разрабатываются стратегии тестирования базы данных и приложений, создается план тестирования приложений базы данных и готовятся тестовые данные.
Контроль качества проектирования базы данных заключается в проверке качества результатов проектирования на каждом его этапе.
Учет задач обратного влияния заключается в настройке некоторых транзакций к базе данных и локальном перепроектировании базы данных согласно требованиям, поступающим с других этапов создания базы данных.
3. Бизнес-модель процесса проектирования базы данных: сбор и анализ входных данных
На рис. 3.3 представлена диаграмма декомпозиции процесса проектирования базы данных второго уровня, отражающая основные задачи этапа сбора и анализа входных данных.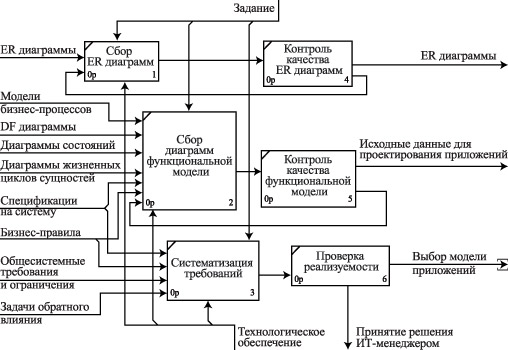 Диаграмма декомпозициии процесса проектирования базы данных: второй уровень. Сбор и анализ входных данных
Диаграмма декомпозициии процесса проектирования базы данных: второй уровень. Сбор и анализ входных данных
Такими задачами являются:
- сбор документации с результатами анализа предметной области базы данных в виде диаграмм, спецификаций и требований;
- контроль качества результатов анализа предметной области базы данных;
- систематизация требований и спецификаций заказчика к базе данных;
- подготовка плана проектирования базы данных.
В ходе контроля качества основными моментами деятельности являются контроль ER-диаграмм и контроль диаграмм функциональной
и состава команды проекта, объема проекта, проектных рисков и т.д.
4. Бизнес-модель процесса проектирования реляционной базы данных: создание логической модели базы данных
Основной целью этапа создания логической модели базы данных является преобразование информационной модели предметной области базы данных в логическую модель реляционной базы данных. Создание логической модели базы данных предполагает решение следующих основных задач и выполнения операций в рамках таких задач:
- нормализация сущностей предметной области:
- получить список атрибутов сущности;
- определить функциональные зависимости (ФЗ) в сущности;
- определить детерминанты сущности;
- определить возможные ключи отношения, в частности,
- из уникального идентификатора связи и процедуры миграции ключей при нормализации;
- определить атрибуты связывающих отношений, если необходимо;
- сформировать бизнес-правила поддержки целостности связей;
- проверка правильности логической модели реляционной базы данных:
- проверка отношений на соответствие нормальной форме Бойса-Кодда;
- проверка отношений на свойства соединения без потерь и сохранения функциональных зависимостей;
- предотвращение потери данных путем миграции первичных ключей отношения и назначения внешних ключей;
- проверка на отсутствие незамкнутых связей;
- проверка на отсутствие одиночных отношений;
- формулировка части исходных данных для решения задачи управления ссылочной целостностью;
- документирование логической модели реляционной базы данных;
- принятие решения о реализуемости построенной логической модели реляционной базы данных;
- принятие решения о разработке физической модели реляционной базы данных.
Результатом проектирования логической модели базы данных является нормализованная схема отношений базы данных. Отметим, что в ходе выполнения этапа создания логической модели базы данных могут быть созданы новые объекты базы данных, не предусмотренные в информационной модели предметной области, например связывающая сущность при нормализации отношения со степенью связи «многие-ко-многим». Иногда на этом этапе принимается решение о выборочной денормализации отношений.
На рис. 3.4-рис. 3.6 представлены бизнес-модели процессов создания логической модели базы данных, нормализации сущности предметной области и нормализации отношений логической модели базы данных соответственно.
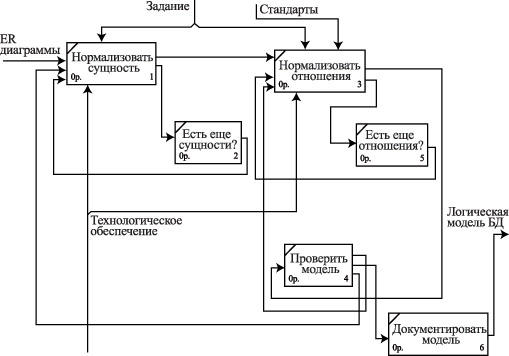
Бизнес-модель процесса создания логической модели базы данных
. Бизнес-модель процесса нормализации сущности
Бизнес-модель процесса нормализации отношения
Представленные задачи составляют минимально необходимый набор задач, позволяющих спроектировать логическую модель базы данных, и могут рассматриваться как один из возможных способов организации работ в этой области.
5. Бизнес-модель этапа проектирования — создание физической модели реляционной базы данных
Организационная сторона решения профессиональной задачи проектировщика баз данных — задача создания физической модели реляционной базы данных. Основная цель решения этой задачи: преобразовать логическую модель реляционной базы данных в последовательность команд SQL для создания объектов реляционной базы данных. Таким образом, проектировщик базы данных отображает отношения логической модели реляционной базы данных (сущности предметной области, представленные в нормализованной форме на ER-диаграммах) в таблицы и индексы реляционной базы данных.
Эта задача включает выполнение ряда обязательных последовательных процедур.
Создание базовых таблиц. Они представляют основные блоки хранения данных и выводятся из сущностей логической модели данных. При создании каждой таблицы проектировщик должен рассмотреть и учесть ряд факторов:
- определить список колонок в таблице. Колонки выводятся из атрибутов сущности логической модели данных;
- определить типы данных для каждой колонки. Типы данных колонок либо заданы спецификацией домена атрибута логической модели, либо определяются проектировщиком самостоятельно;
- определить имя таблицы. Оно может быть выведено из имени сущности логической модели базы данных или задано проектировщиком самостоятельно. Желательно в этот момент определить собственника таблицы — пользователя, который будет иметь все права доступа на таблицу, а также потенциальных пользователей таблицы;
- определить ряд параметров, связанных с характером хранения таблицы в физической базе данных;
- определить ограничения на значения колонок, исходя из ряда бизнес-правил.
Создание связывающих таблиц, необходимых для разрешения отношения «многие-ко-многим», если они имеют место в логической модели базы данных. В рамках ER-диаграмм это отношение может быть уже разрешено. Тогда речь пойдет только о его реализации в командах SQL.
Принять решение о способе поддержки ссылочной целостности в базе данных. Если будет решено поддерживать ссылочную целостность на уровне команд SQL, то специфицировать ограничения ссылочной целостности. Эта задача решается в четыре этапа:
- идентифицировать первичные ключи каждой таблицы;
- построить индексы первичного ключа;
- определить внешние ключи в дочерних таблицах, если необходимо;
- построить команды SQL, которые идентифицируют внешние ключи в дочерних таблицах и правила поддержки ссылочной целостности;
- Если необходимо, построить представления внешней схемы базы данных.
В результате решения данной задачи делается важный вывод о правильности полученной первой итерации физической модели базы данных, осуществляется документирование физической модели данных в виде скрипта, принимается решение о характере дальнейшей разработки физической модели данных.
6. Бизнес-модель этапа проектирования — создание физической модели реляционной базы данных: учет влияния транзакций
Решая профессиональную задачу создания физической модели данных — учет влияния транзакций, — проектировщик базы данных стремиться создать такую физическую модель данных, которая, по его мнению, давала бы наибольшую производительность обработки запросов базы данных. На практике, особенно при создании и разработке новых баз данных, такая задача вряд ли может быть решена полностью. Ясно, что для ее решения необходимо иметь список всех запросов к базе данных, их частоте и объеме выборок по каждому, что в принципе невозможно. Поэтому проектировщики базы данных на основе анализа исходной документации и опросов потенциальных пользователей пытаются систематизировать транзакции к базе данных, оценить кардинальность таблиц в целом и отдельных колонок в частности. На основе таких оценок проектировщик базы данных пытается определить критические транзакции и настроить структуры таблиц, задействованных в таких транзакциях, на достижение, с его точки зрения, максимальной производительности. При этом он выдвигает гипотезы о применимости того или иного способа повышения производительности обработки запросов и умозрительно проверяет их. Далее он принимает решение о применении наиболее подходящего, с его точки зрения, способа увеличения производительности запросов.
Следует понимать, что задача обеспечения высокой производительности базы данных — это задача, которую постоянно решает администратор базы данных в процессе ее эксплуатации. На этом этапе проектирования базы данных проектировщик, по мере возможности, готовит успешное решение этой задачи. Этот этап является очень ответственным в физическом проектировании базы данных, поэтому следует соблюдать при решении этой задачи разумный прагматизм и документировать свои решения. Должно действовать эмпирическое правило: если проектировщик базы данных не имеет достаточно данных для надежного решения задачи повышения производительности базы данных, то решение этой задачи должно быть передано администратору базы данных.
На этом этапе проектирования физической модели реляционной базы данных проектировщик базы данных:
- исходя из требований к характеру обработки данных, определяет тип приложения базы данных;
- по имеющимся требованиям и описаниям выполняет систематизацию и описание по возможности всех транзакций к базе данных;
- отталкиваясь от исходной документации, определяет возможные размеры таблиц, а если это невозможно, делает предположения об их возможном размере;
- исходя из фактических размеров таблиц и требований к производительности выполнения транзакций, определяет критические транзакции;
- транзакции и таблицы, которые в них участвуют, проектировщик базы данных принимает субъективные решения по изменению структуры таблиц внутренней схемы базы данных, исходя из тех механизмов, которые ему предоставляет конкретная СУБД;
- по завершении изменения структур таблиц проектировщик базы данных документирует эти изменения, приводя обоснование своих решений для администратора базы данных.
В результате проектировщик базы данных создает физическую модель базы данных, которая учитывает характер обработки данных в базе данных, выраженный через учет влияния транзакций.
7. Краткое рассмотрение задач создания серверного кода и подготовки скрипта
Профессиональная задача проектирования баз данных — разработка серверного кода базы данных — возникает, как правило, в многопользовательской вычислительной среде.
В многопользовательских системах пользователи совместно используют вычислительные ресурсы, в частности ресурсы дисковой памяти и оперативной памяти процессора. Вычислительные ресурсы могут быть сконцентрированы в одном месте (централизованные вычисления) или быть рассредоточенными в различных узлах, объединенных в компьютерную сеть (распределенные вычисления). СУБД в любом случае призвана координировать и осуществлять доступ пользователей к базам данных и их объектам.
Большинство современных СУБД поддерживают концепцию клиент-
создания таких объектов с целью сокращения сетевого трафика или принять решение о переносе определенного объема обработки на сервер, особенно в тех случаях, когда эта обработка выполняется очень интенсивно. Например, несколько строк разных таблиц проверяются перед вставкой новой строки.
Таким образом, разработка серверного кода сводится к решению следующих подзадач:
- принятие решения и создание хранимых процедур;
- принятие решения и создание функций;
- принятие решения и создание пакетов;
- принятие решения и создание триггеров.
Задача проектирования базы данных — подготовка инсталляционного скрипта для создания базы данных — в определенной степени завершающая для самостоятельной работы проектировщика базы данных. Такой скрипт — это один из главных результатов его работы.
как проанализировать и проверить проделанную работу, отредактировать окончательный вариант скрипта и создать физическую базу данных? Принято считать, что задача создания базы данных, так же как и управление базой данных, является задачей администратора базы данных.
вопросов в рамках этого курса.
Таким образом, задача создания скрипта базы данных состоит из решения крупных подзадач:
- создание пользователей, их идентификация и назначение им привилегий;
- привязка разработанных объектов реляционной базы данных к параметрам физического хранения базы данных с помощью создания специальных объектов базы данных;
- создание инсталляционного скрипта;
- документирование базы данных.
Заключение.
Широко известные методы проектирования баз данных (БД) появились в процессе разработки все более сложных Информационных Систем (ИС), которые должны были рассматривать потребности не одного пользователя, но больших групп и коллективов. Одна такая интегрированная БД создавалась для решения многих задач, каждая из которых использовала только «свою» часть данных, обычно, пересекающуюся с частями, используемыми в других задачах. Поэтому главнейшими методами проектирования стали методы исключения избыточности в данных. Эти методы связывались с другими средствами обеспечения логической целостности данных.
Было сформулировано принципиальное требование отделения программ от интегрированных данных. Этот принцип направлен на отчуждение данных в качестве ресурса предприятия, важен также тем, что консервативные по характеру данные отделялись от прикладных программ, которые могли часто подвергаться изменениям.
Другой важной проблемой проектирования БД явилось обеспечение нужных эксплуатационных параметров, таких как объем внешней памяти или время выполнения различных операций.

- Макроэкономические модели: их сущность и классификация.
- Особенности привлечения инвестиций для малого и среднего бизнеса
- Лауреаты нобелевской премии по экономике в области макроэкономике
- Классификация долевых ценных бумаг
- Организационно-административная работа в приютах для несовершеннолетних.
- БЭМ-методология (БЭМ — МЕТОДОЛОГИЯ)
- Основные цели в управлении организацией
- Общие тенденции развития web по иерархическим уровням и поколениям.
- Характеристика основных фондов предприятия (Показатели и пути улучшения использования основных фондов предприятия)
- Виды инвестиционных проектов и требования к их разработке
- Структура общественного воспроизводства (типы воспроизводства)
- Экономическое обоснование стандартизации
Прим. перев. Предполагается, что вы уже имеете начальные знания по SQL. Если вы плохо понимаете, что такое таблицы, строки, индексы, первичные ключи и ссылочная целостность, то лучше сначала изучить их, например по этим видео:
А если вы знакомы с SQL и вас не остановили предыдущие термины, на всякий случай напомним, что:
- атомарность предполагает, что значение нельзя разделить на несколько атрибутов;
- под кортежем понимается запись (строка) в таблице базы данных;
- атрибут — это колонка таблицы;
- неключевой атрибут — это атрибут, не входящий в состав никакого потенциального ключа.
***
Есть минимум два требования, которые должны быть соблюдены при проектировании структуры БД:
- Сохранить всю информацию после разделения её на таблицы.
- Минимизировать избыточность того, как эта информация хранится.
Примечание Второй пункт важен не только из-за того, что избыточность влияет на размер БД. Чаще всего при обновлении данных нужно обработать много строк. В таком случае вы рискуете просто забыть обновить некоторые из них, что приведёт к коллизиям внутри БД.
Ниже перечислены некоторые рекомендации, которые помогут добиться эффективной структуры:
- используйте хотя бы третью нормальную форму;
- создавайте ограничения для входных данных;
- не храните ФИО в одном поле, также как и полный адрес;
- установите для себя правила именования таблиц и полей.
Используйте хотя бы третью нормальную форму
Нормальные формы — это требования, которые должны соблюдаться при правильной проектировке базы данных.
Нормальных форм существует целых 6 штук, однако обычно соблюдают всего лишь 3 и для начала этого более чем достаточно.
Первая нормальная форма
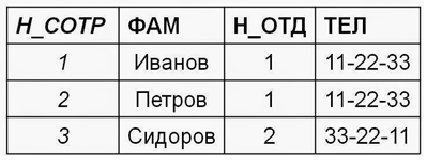
Для примера будем использовать отношение сотрудники_отделы_проекты. В нём есть информация о номере сотрудника, его фамилии, номере отдела, в котором он работает, номере телефона отдела и так далее.

Это отношение, как и любое другое, автоматически находится в первой нормальной форме:
- в отношении нет одинаковых кортежей;
- кортежи не упорядочены;
- атрибуты не упорядочены и различаются по наименованию;
- все значения атрибутов атомарны.
Вторая нормальная форма
В нашем случае у таблицы выше имеется сложный (составной) ключ {Н_СОТР, Н_ПРО}. От части ключа Н_СОТР зависят неключевые атрибуты ФАМ, Н_ОТД, ТЕЛ. От части ключа Н_ПРО зависит неключевой атрибут ПРОЕКТ. А вот атрибут Н_ЗАДАН зависит от всего составного ключа, так как сотрудник может выполнять одно задание в одном проекте.
Поэтому для приведения отношения ко второй нормальной форме из отношения сотрудники_отделы_проекты нужно выделить два отношения сотрудники_отделы и проекты, а исходное отношение оставим отношением задания.
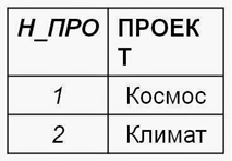

Наконец, третья нормальная форма
Отношение находится в третьей нормальной форме, когда отношение находится во второй нормальной форме и все неключевые атрибуты взаимно независимы.
Для того, чтобы устранить зависимость неключевых атрибутов, нужно произвести декомпозицию отношения ещё на несколько отношений. При этом те неключевые атрибуты, которые являются зависимыми, выносятся в отдельное отношение.
Отношение сотрудники_отделы не находится в третьей нормальной форме, так как имеется зависимость неключевых атрибутов, таких как зависимость номера телефона от номера отдела. Поэтому декомпозируем отношение сотрудники_отделы на два отношения — сотрудники и отделы:
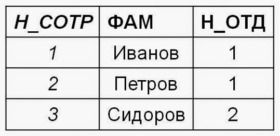
Используйте проверочные ограничения
База данных — это не просто набор таблиц. В неё встроено много инструментов, которые помогут с сохранностью и качеством данных.
В первую очередь БД поможет с ограничением значений, которые принимают поля.
Внешние ключи регламентируют отношения между таблицами. Благодаря им сильно упрощается контроль за структурой базы, уменьшается и упрощается код приложения. Правильно настроенные внешние ключи — это гарант того, что увеличится целостность данных за счёт уменьшения избыточности. Поэтому обязательно применяйте ограничение внешнего ключа при определении связей между таблицами.
Выражения ON DELETE и ON UPDATE внешних ключей используются для указания действий, которые будут выполняться при удалении строк родительской таблицы (ON DELETE) или изменении родительского ключа (ON UPDATE). Не пренебрегайте ими.
Стоит убедиться, что обязательность заполнения (NOT NULL) проверяется для полей, которые строго не должны оставаться пустыми.
Используйте CHECK, чтобы убедиться, что значения входят в диапазон (например чтобы цена не была отрицательной).
Не храните ФИО в одном поле, также как и полный адрес
Представим ситуацию, когда вам понадобится узнать, в каком городе продукт более популярен. В таком случае, если полный адрес хранится в виде цельной строки, сделать это будет очень тяжело, ведь вам нужно будет каким-то образом выделить из этой строки город. Учитывая все возможные форматы и варианты адресов, эта задача становится практически невыполнимой. Похожая ситуация и с ФИО. Даже если кажется, что это ни к чему, храните эти данные в разных полях, и в будущем вы поблагодарите себя.
Установите для себя правила именования таблиц и полей
Сложно работать с данными, которые выглядят как-то так: user.firstName, user.last_name, user.birthDate. Конечно, каждый программист в праве сам выбирать для себя стиль наименования, но для SQL рекомендуется выбрать наименование с подчёркиванием. Потому что не все SQL-движки одинаково работают с заглавными буквами, а помещать всё в кавычки бывает утомительно.
Ещё нужно определиться как будут называться таблицы — во множественном числе (users) или в единственном (user). Каждая базовая структура в БД обычно настроена на множественное число, поэтому и именовать таблицы стоит соответственно.
Не упускайте возможность сложить побольше обязанностей на базу данных, чтобы облегчить себе работу над приложением и думать о его структуре, а не о контроле табличных связей.
Всё приходит с опытом. Спроектируйте две-три схемы, и картинка сама сложится у вас в голове. Отталкивайтесь от задачи —некоторыми рекомендациями иногда можно пренебречь.
Перевод статьи «A humble guide to database schema design»
Библиографическое описание:
Иванов, К. К. Проектирование базы данных. Роль процесса в создании информационной системы / К. К. Иванов, А. А. Ефремов, И. А. Ващенко. — Текст : непосредственный // Молодой ученый. — 2016. — № 18 (122). — С. 40-42. — URL: https://moluch.ru/archive/122/33704/ (дата обращения: 22.03.2023).
На сегодняшний день ни одна сложная система не разрабатывается в «лоб». В первую очередь, она проектируется. База данных, являющаяся одной из важнейших частей информационной системы, конечно же, представляет собой сложный объект, который также подлежит проектированию. Именно о процессе проектирования базы данных, его особенностях, методах, этапах и роли в создании информационной системы и пойдет речь.
Для начала необходимо разобраться, какой смысл вкладывается в понятия информационная система и база данных. Информационная система, в общем случае, предназначена для хранения, поиска и обработки информации (также с некоторыми оговорками к функциям можно добавить и процесс передачи). База данных, в свою очередь, представляет собой подобие электронной картотеки, то есть хранилище или контейнер для некоторого набора файлов данных, занесенных в компьютер [1]. Таким образом, в информационной системе база данных отвечает за процесс хранения информации, при этом поиск данной информации, соответственно, система осуществляет в этой базе данных.
Цель проектирования базы данных — это правильное отображение выбранной для автоматизации предметной области [2]. В связи с этим выделяют два основных подхода к данному процессу [4]: нисходящий (сверху-вниз) и восходящий (снизу-вверх). Они отличаются, как понятно из названия, тем, как происходит процесс проектирования. Так, при нисходящем проектировании сначала происходит изучение целого, или описание предметной области, а затем уже осуществляется разделение целого на составные части, каждая из которых после этого также последовательно изучается. В свою очередь, при восходящем проектировании сначала происходит описание составных частей, после чего собирается общая картина. У каждого из этих способов есть свои отличительные черты, свои плюсы и минусы.
Нисходящее проектирование также называют анализом. Стоит отметить, что им пользуются чаще, чем восходящим. Нисходящее проектирование включает в себя пять этапов [3]:
1) Анализ предметной области. Отличительной чертой анализа в нисходящем проектировании является то, что сначала проводится анализ предметной области в целом с последующей декомпозицией на отдельные элементы. В результате получается описание внешнего уровня базы данных, при этом внешняя модель создается для пользователей и абстрагируется от особенностей реализации.
2) Разработка информационно-логической модели предметной области. Данная модель отражает предметную область в виде совокупности информационных объектов и их структурных связей. Её разработка начинается с построения инфологической модели (она обеспечивает наиболее естественные для человека способы сбора и представления той информации, которую предполагается хранить в создаваемой базе данных, а основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства или атрибуты), затем на ее основе строится концептуальная модель данных (представляет объекты и их взаимосвязи без указания способов их физического хранения).
3) Формирование даталогической модели базы данных. Под даталогической моделью базы данных понимается модель, отражающая логические взаимосвязи между элементами данных безотносительно их содержания и физической организации. При этом даталогическая модель разрабатывается на основе информационно-логической модели предметной области с учётом конкретной реализации системы управления базой данных, а также с учётом специфики конкретной предметной области на основе ее концептуальной модели, определенной в процессе разработки информационно-логической модели предметной области.
4) Нормализация. Благодаря последовательному построению нескольких моделей и проектированию сверху при нисходящем проектировании необходима незначительная нормализация. Для нормализации выбирается сформированная на предыдущем этапе даталогическая модель.
5) Формирование физической модели базы данных. Физическая модель определяет размещение данных, методы доступа и технику индексирования. Она также называется внутренней моделью системы.
Особенностями нисходящего проектирования являются высокая степень описания семантики предметной области, низкая вероятность появления ошибок в последующей работе информационной системы, высокая степень формализации процесса (также обуславливает возможность автоматизации процесса) и небольшой объем трудозатрат при привидении даталогической модели базы данных к заданной нормальной форме.
Восходящее проектирование также называют синтезом. Оно тоже включает в себя пять этапов [3]:
1) Анализ предметной области. Несмотря на то, что название первого этапа восходящего проектирования полностью совпадает с названием первого этапа нисходящего проектирования, они обладают очень большими различиями. Так, происходит анализ не задач и работы выбранной области в целом, а анализ небольших частей для определения их потребностей и проблем.
2) Формирование даталогической модели базы данных. Особенностью данного этапа в восходящем подходе является то, что работа ведется на основании требований, определенных в ходе анализа предметной области.
3) Нормализация схемы базы данных. Из-за проектирования снизу для восходящего проектирования необходимо проводить полную операцию нормализации [1]. Сначала путем удаления повторяющихся элементов добиваются того, чтобы каждый кортеж содержал только одно значение для каждого из атрибутов. Тогда говорят, что переменная отношения находится в первой нормальной форме. После этого необходимо сделать так, чтобы каждый неключевой атрибут переменной отношения неприводимо зависел от ее первичного ключа. Тогда говорят, что переменная отношения находится во второй нормальной форме. Затем достигается, чтобы ни один неключевой атрибут переменной отношения не являлся транзитивно зависимым от ее первичного ключа. Тогда говорят, что переменная отношения находится в третьей нормальной форме. Благодаря удалению из функциональных зависимостей оставшихся аномалий переменная отношения переходит в нормальную форму Бойса-Кодда. На следующем этапе удаляются нетривиальные многозначные зависимости, а переменная отношения переходит в четвертую нормальную форму. В конце из переменной отношения удаляются зависимости соединения. В итоге переменная отношения переходит в конечную пятую нормальную форму и получается даталогическая модель базы данных в заданной нормальной форме.
4) Формирование физической модели базы данных. Физическая модель данных строится на основе нормализованной даталогической модели. Её характеристики соответствуют характеристикам физической модели, получаемой при нисходящем проектировании.
5) Реинжиниринг [5]. Данный процесс является фундаментальным переосмыслением и радикальным перепроектированием базы данных для ее наиболее эффективной работы. Наличие данного процесса среди этапов восходящего проектирования обусловлено проектированием снизу-вверх, так как решаются, в первую очередь, не глобальные проблемы выбранной области, а ее составных частей. В итоге получается информационно-логическая модель предметной области.
В свою очередь, особенностями восходящего проектирования являются низкая степень описания семантики предметной области, высокая вероятность появления ошибок в последующей работе информационной системы, отсутствует формализация процесса, а объем трудозатрат при приведении даталогической модели базы данных к заданной нормальной форме является очень большим.
Как видно из описания этапов, нисходящее и восходящее проектирование имеют как общие черты, так и заметные отличия. Например, для обоих методов сначала проводится анализ предметной области (но их суть несколько различается из-за особенностей выбранного метода проектирования), а также после формирования даталогической модели данных проводится нормализация (после которой формируется физическая модель данных), однако если для нисходящего проектирования проводится незначительная нормализация, то для восходящего — полная. Важным отличием является то, что при нисходящем проектировании перед формированием даталогической модели данных разрабатывается информационно-логическая модель данных, а при восходящем проектировании данная модель строится только после проведения особенного для данного метода проектирования процесса реинжиниринга.
Необходимо отметить, что наиболее правильным является не использование какого-то одного из представленных методов, а их комбинирование. При таком подходе удается решить как проблемы всей предметной области в целом (использование нисходящего подхода), так и проблемы конечных составных частей (использование восходящего подхода), например, работников определенного предприятия. При выборе данного комбинированного метода определяется участок, на котором произойдет встреча двух этих методов.
В процессе создания информационной системы проектирование базы данных имеет очень важную роль, так как база данных является фундаментом информационной системы [1]. Проектирование базы данных выполняется после анализа требований к будущей системе (анализ носит неформальный характер, однако очень важно сохранить полученную информацию, поскольку она должна входить в документацию системы). А уже после того, как выработана общая схема базы данных, происходит процесс определения архитектуры будущей информационной системы. Так, решаются вопросы о том, какой будет база данных (централизованной или распределенной), производится соответствующая декомпозиция и другие необходимые работы.
Таким образом, проектирование базы данных играет огромную роль в создании будущей информационной системы, являясь её фундаментом. Также нельзя забывать о том, что наиболее правильным является двухстороннее проектирование, когда работа одновременно идет как сверху, так и снизу.
Литература:
- Дейт, К.Дж. Введение в системы баз данных, 8-е издание.: Пер. с англ. / К.Дж. Дейт. — М.: Издательский дом «Вильямс», 2008. — 1328 с.: ил. — Парал. тит. англ.
- Зеленков, Ю. А. Введение в базы данных. // Электронный ресурс. URL: http://www.mstu.edu.ru/study/materials/zelenkov/toc.html (дата обращения: 10.09.2016).
- Анализ методов проектирования БД. // Shpargalum.ru. Электронный ресурс. URL: http://shpargalum.ru/shpora-gos-povtas/proektirovanie-avtomatizirovannyix-sistem-na-osnove-bd/analiz-metodov-proektirovaniya-bd.html (дата обращения: 10.09.2016).
- Коваленко, Т. Работа с базами данных. / Т. Коваленко, О. Сирант. — Электронный ресурс. URL: http://www.intuit.ru/studies/courses/3439/681/lecture/14021 (дата обращения 10.09.2016).
- Реинжиниринг бизнес-процессов: сущность и методология. // Центр дистанционного «Элитариум». Электронный ресурс. URL: http://www.elitarium.ru/reinzhiniring-biznes-process-kompanija-sotrudniki-rukovodstvo-izmenenija/ (дата обращения 10.09.2016).
Основные термины (генерируются автоматически): предметная область, нисходящее проектирование, информационная система, восходящее проектирование, база данных, модель базы данных, нормальная форма, информационно-логическая модель, проектирование базы данных, заданная нормальная форма.
Чтобы помочь начинающим аналитикам разобраться с основами SQL и реляционных баз данных, сегодня рассмотрим практический пример построения модели данных, заполнения таблиц значениями и генерации запросов к полученной базе. DDL-запросы для создания таблиц и примеры DML-запросов для наполнения их данными, а также выборки с условиями WHERE, GROUP BY, HAVING, операторы работы с датами и временем.
Проектирование реляционной модели (схемы базы данных)
Как я уже рассказывала здесь, системные и бизнес-аналитики часто сталкиваются с моделированием данных в рамках задачи разработки требований к ИС. Однако, зачастую простого концептуального моделирования, которое переводит ключевые сущности домена (предметной области) в плоскость программной системы, бывает недостаточно для разработки или более детального проектирования базы данных на физическом уровне. Основным фактором, определяющим ценность концептуальной модели, является возможность ее использования для дальнейшей работы. И чтобы повысить эту ценность, аналитику полезно понимать, какие именно потребности бизнеса позволит обеспечить разработанная им модель. Применительно к моделированию данных это примеры SQL-запросов.
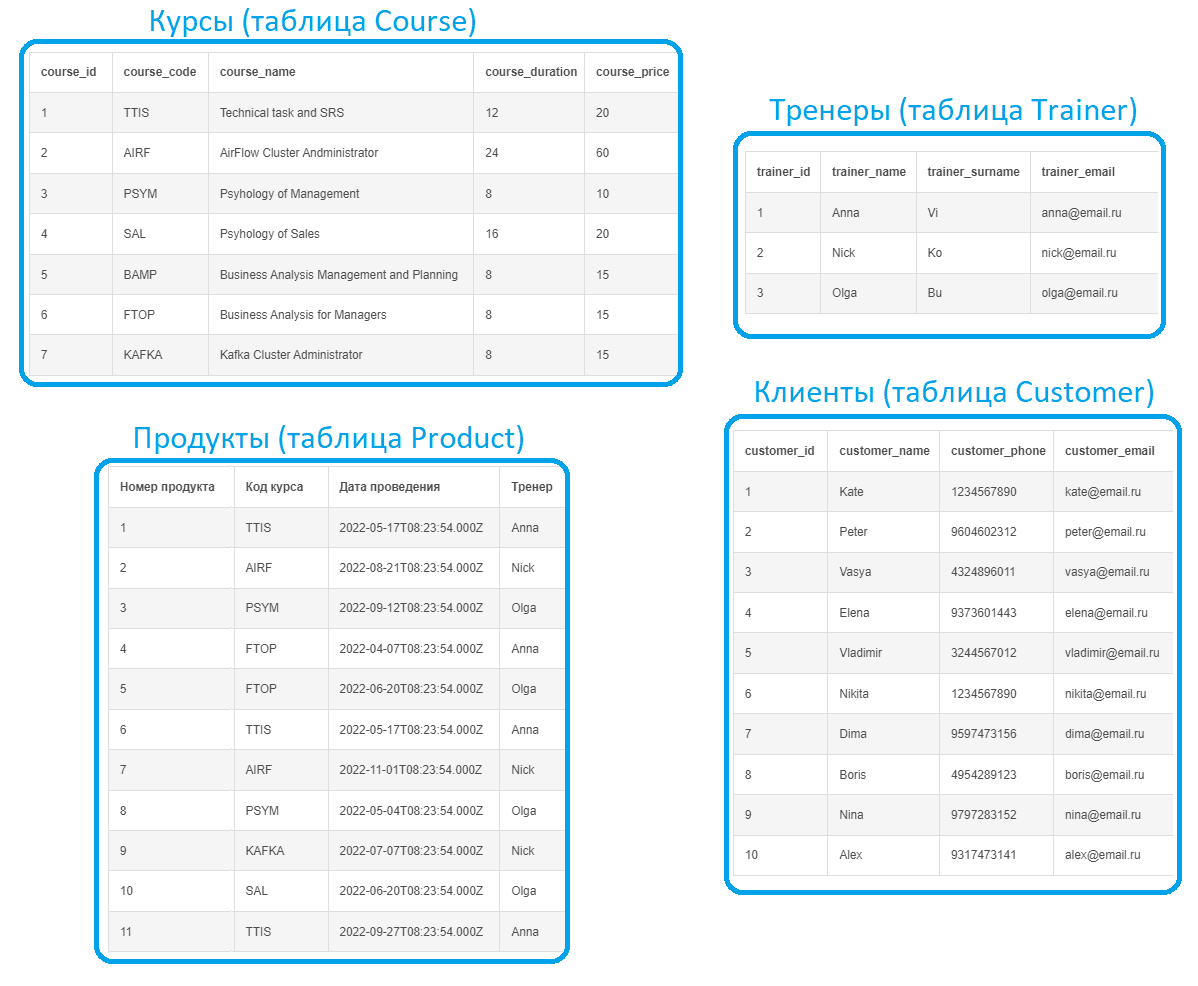
Предположим, учебный центр, который предлагает курсы по 3-м направлениям: системный и бизнес-анализ, технологии Big Data, а также менеджмент, имеет данные о заявках слушателей на разные курсы.
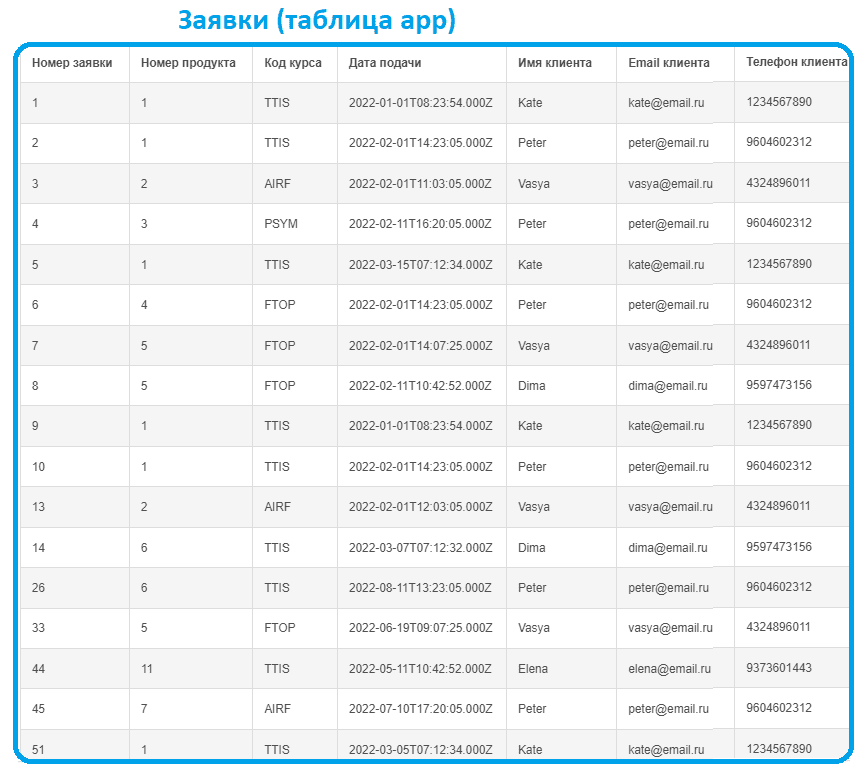
Имеется каталог курсов и расписание их проведение, а также данные по потенциальным клиентам, подавшим заявки и тренерам, которые проводят курсы.
Реляционная модель данных, спроектированная для рассматриваемого случая, будет выглядеть следующим образом:
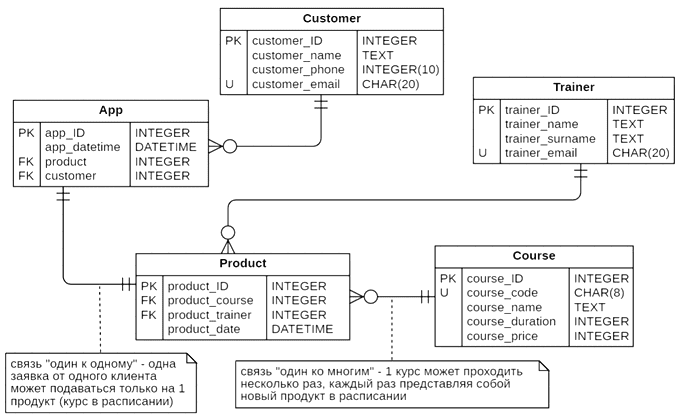
Выделено 5 сущностей, которые связаны между собой разными типами отношений. Каждая сущность в итоге представляет собой таблицу реляционной базы данных с набором столбцов, т.е. атрибутов или полей, каждое из которых содержит данные определенного типа. Поскольку база данных является реляционной, таблицы связаны между собой по ключам. Например, один тренер может вести несколько курсов. Таблица Course представляет собой каталог курсов, каждый из которых может проводиться несколько раз в разное время разными тренерами, что хранится в таблице Product. Один клиент (Customer) может подать много заявок, но каждая заявка может быть только по одному продукту.
Чтобы сократить избыточность данных в разных таблицах, проведена нормализация, т.е. приведение структуры данных к нормальной форме. В частности, данные клиентов хранятся не в таблице заявки, а выделены в отдельную таблицу Customer. Аналогичным образом данные о курсах и тренерах, которые их проводят содержатся не в таблице с расписанием (Product), а в отдельных таблицах. Это исключает транзитивную зависимость полей друг от друга. Чаще всего ER-модель приводят к 3-ей нормальной форме, когда каждая таблица атомарна и любой не ключевой атрибут в ней зависит только от первичного ключа.
В каждой таблице определен первичный ключ (Primary Key, PK),– столбец, каждое значение которого уникально и однозначно идентифицирует запись (строку) этой таблицы. Для ускорения работы базы данных в качестве первичного ключа обычно принимается целочисленный идентификатор, который реализуется автоматической генерацией поля ID с автоинкрементом, т.е. увеличением на 1 при создании новой записи. Большинство современных СУБД сами следят за этим, т.е. на уровне концептуального проектирования при описании модели предметной области, этот атрибут не обязательно добавлять в словарь данных.
Связи между таблицами реализованы с помощью внешних ключей (Foreign Key, FK). Внешний (ссылочный) ключ показывает, что поведение записи в одной таблице (зависимой сущности) меняется при изменении или удалении записей из другой связанной таблицы (независимой сущности). Внешний ключ также нужен для объединения двух таблиц. Можно сказать, FK в одной таблице – это один или несколько столбцов, значения которых соответствуют PK в другой таблице. Связь между двумя таблицами задается через соответствие PK в одной таблице FK во второй. Например, в таблице App внешними ключами будут поля product и customer, соответствующие первичным ключам (id) в таблицах Product и Customer соответственно.
После проектирования схемы модели данных в редакторе StarUML, который я часто использую для разработки UML-диаграмм, с помощью расширения Postgresql DDL Extension for StarUML 2 для создания DDL-запросов к СУБД PostgreSQL, я получила набор SQL-команд по созданию таблиц:
CREATE TABLE public.course (
course_id integer NOT NULL,
course_code char(8) NOT NULL,
course_name text NOT NULL,
course_duration integer NOT NULL,
course_price integer NOT NULL,
PRIMARY KEY (course_id)
);
ALTER TABLE public.course
ADD UNIQUE (course_code);
CREATE TABLE public.customer (
customer_id integer NOT NULL,
customer_name text NOT NULL,
customer_phone char(10) NOT NULL,
customer_email char(20) NOT NULL,
PRIMARY KEY (customer_id)
);
ALTER TABLE public.customer
ADD UNIQUE (customer_email);
CREATE TABLE public.app (
app_id integer NOT NULL,
app_datetime timestamp with time zone NOT NULL,
product integer NOT NULL,
customer integer NOT NULL,
PRIMARY KEY (app_id)
);
CREATE INDEX ON public.app
(product);
CREATE INDEX ON public.app
(customer);
CREATE TABLE public.trainer (
trainer_id integer NOT NULL,
trainer_name text NOT NULL,
trainer_surname text NOT NULL,
trainer_email char(20) NOT NULL,
PRIMARY KEY (trainer_id)
);
ALTER TABLE public.trainer
ADD UNIQUE (trainer_email);
CREATE TABLE public.product (
product_id integer NOT NULL,
product_course integer NOT NULL,
product_trainer integer NOT NULL,
product_date timestamp with time zone NOT NULL,
PRIMARY KEY (product_id)
);
CREATE INDEX ON public.product
(product_course);
CREATE INDEX ON public.product
(product_trainer);
Автоматическая генерация DDL-запросов по спроектированной схеме сэкономила мне время на прописывание SQL-команд вручную, чтобы создать нужные таблицы, определить их атрибуты и связи между таблицами. Полученный код я внесла в бесплатный веб-движок тестирования SQL-запросов https://www.db-fiddle.com/, определив схему SQL. Там же внесла данные в мои таблицы с помощью следующих DML-запросов:
INSERT INTO app VALUES (1, '2022-01-01 10:23:54', 1, 1); INSERT INTO app VALUES (2, '2022-02-01 16:23:05', 1, 2); INSERT INTO app VALUES (3, '2022-02-01 13:03:05', 2, 3); INSERT INTO app VALUES (4, '2022-02-11 18:20:05', 3, 2); INSERT INTO app VALUES (5, '2022-03-15 09:12:34', 1, 1); INSERT INTO app VALUES (6, '2022-02-01 16:23:05', 4, 2); INSERT INTO app VALUES (7, '2022-02-01 16:07:25', 5, 3); INSERT INTO app VALUES (8, '2022-02-11 12:42:52', 5, 7); INSERT INTO app VALUES (9, '2022-01-01 10:23:54', 1, 1); INSERT INTO app VALUES (10, '2022-02-01 16:23:05', 1, 2); INSERT INTO app VALUES (13, '2022-02-01 14:03:05', 2, 3); INSERT INTO app VALUES (45, '2022-07-10 19:20:05', 7, 2); INSERT INTO app VALUES (51, '2022-03-05 09:12:34', 1, 1); INSERT INTO app VALUES (26, '2022-08-11 15:23:05', 6, 2); INSERT INTO app VALUES (33, '2022-06-19 11:07:25', 5, 3); INSERT INTO app VALUES (44, '2022-05-11 12:42:52', 11, 4); INSERT INTO app VALUES (14, '2022-03-07 09:12:32', 6, 7); INSERT INTO customer VALUES (1, 'Kate', 1234567890, 'kate@email.ru'); INSERT INTO customer VALUES (2, 'Peter', 9604602312, 'peter@email.ru'); INSERT INTO customer VALUES (3, 'Vasya', 4324896011, 'vasya@email.ru'); INSERT INTO customer VALUES (4, 'Elena', 9373601443, 'elena@email.ru'); INSERT INTO customer VALUES (5, 'Vladimir', 3244567012, 'vladimir@email.ru'); INSERT INTO customer VALUES (6, 'Nikita', 1234567890, 'nikita@email.ru'); INSERT INTO customer VALUES (7, 'Dima', 9597473156, 'dima@email.ru'); INSERT INTO customer VALUES (8, 'Boris', 4954289123, 'boris@email.ru'); INSERT INTO customer VALUES (9, 'Nina', 9797283152, 'nina@email.ru'); INSERT INTO customer VALUES (10, 'Alex', 9317473141, 'alex@email.ru'); INSERT INTO trainer VALUES (1, 'Anna', 'Vi', 'anna@email.ru'); INSERT INTO trainer VALUES (2, 'Nick', 'Ko', 'nick@email.ru'); INSERT INTO trainer VALUES (3, 'Olga', 'Bu', 'olga@email.ru'); INSERT INTO course VALUES (1, 'TTIS', 'Technical task and SRS', 12, 20); INSERT INTO course VALUES (2, 'AIRF', 'AirFlow Cluster Andministrator', 24, 60); INSERT INTO course VALUES (3, 'PSYM', 'Psyhology of Management', 8, 10); INSERT INTO course VALUES (4, 'SAL', 'Psyhology of Sales', 16, 20); INSERT INTO course VALUES (5, 'BAMP', 'Business Analysis Management and Planning', 8, 15); INSERT INTO course VALUES (6, 'FTOP', 'Business Analysis for Managers', 8, 15); INSERT INTO course VALUES (7, 'KAFKA', 'Kafka Cluster Administrator', 8, 15); INSERT INTO product VALUES (1, 1, 1, '2022-05-17 10:23:54'); INSERT INTO product VALUES (2, 2, 2, '2022-08-21 10:23:54'); INSERT INTO product VALUES (3, 3, 3, '2022-09-12 10:23:54'); INSERT INTO product VALUES (4, 6, 1, '2022-04-07 10:23:54'); INSERT INTO product VALUES (5, 6, 3, '2022-06-20 10:23:54'); INSERT INTO product VALUES (6, 1, 1, '2022-05-17 10:23:54'); INSERT INTO product VALUES (7, 2, 2, '2022-11-01 10:23:54'); INSERT INTO product VALUES (8, 3, 3, '2022-05-04 10:23:54'); INSERT INTO product VALUES (9, 7, 2, '2022-07-07 10:23:54'); INSERT INTO product VALUES (10, 4, 3, '2022-06-20 10:23:54'); INSERT INTO product VALUES (11, 1, 1, '2022-09-27 10:23:54');
Когда схема данных создана и таблицы наполнены, можно приступить к самому интересному: SQL-запросам на выборку нужных данных.
Разработка ТЗ на информационную систему по ГОСТ и SRS
Код курса
TTIS
Ближайшая дата курса
24 апреля, 2023
Длительность обучения
12 ак.часов
Стоимость обучения
20 000 руб.
SQL-запросы для анализа данных
Напомню, для доступа к данным в реляционных СУБД используется язык структурированных запросов SQL (Structured Query Language) – декларативный язык программирования. Он содержит операторы определения данных (DDL), манипулирования данными (DML), определения доступа к данным (DCL) и управления транзакциями (TCL). Все эти операторы реализуют не только базовые CRUDL-операции, но и обеспечивают целостность и непротиворечивость информации. В рамках этой статьи мы рассматриваем только самые распространенные DDL- и DML-запросы. Например, следующий запрос покажет, сколько заявок подано на каждый курс:
SELECT course.course_code AS "Код курса",
course.course_name AS "Название курса",
count(*) AS aps_number
FROM app
JOIN product ON product.product_id=app.product
JOIN course ON course.course_id=product.product_course
GROUP BY app.product,
course.course_code,
course.course_name
ORDER BY aps_number DESC;
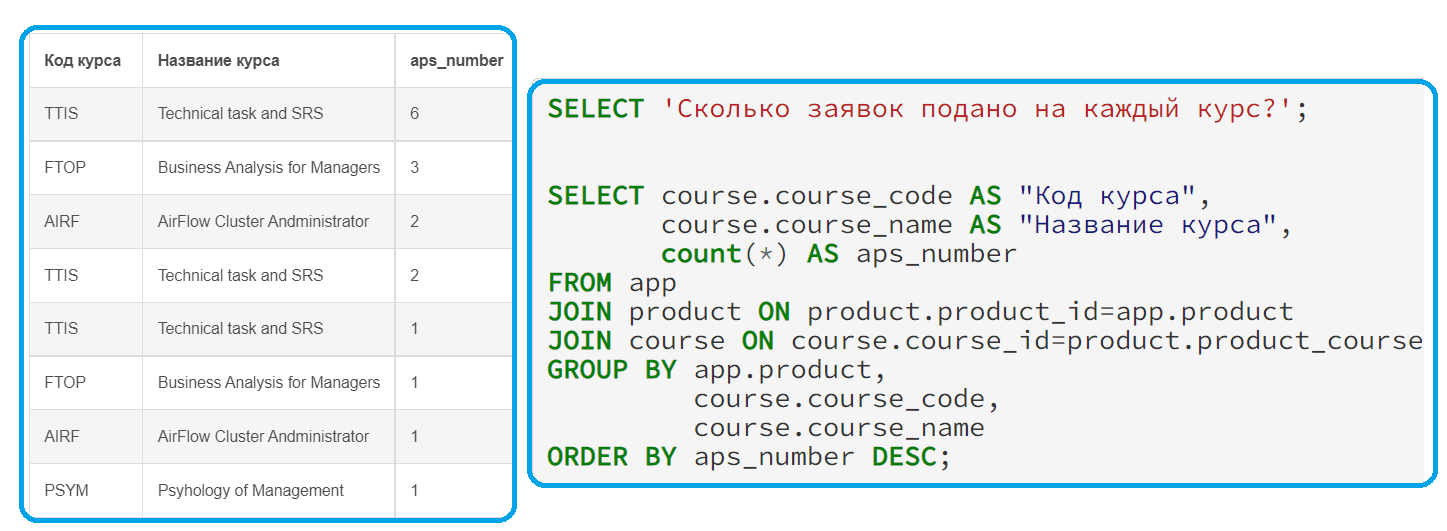
В этом запросе выполнено несколько соединений таблиц через оператор JOIN. Например, чтобы получить код и название курса, таблицу с заявками app нужно было соединить с таблицей продуктов, где указаны внешние ключи курсов, а не сами курсы. А чтобы получить название и код курса, пришлось выполнять соединение с таблицей курсов по внешним ключам, что указывается после ключевого слова ON. Для группировки заявок, поданных по одному и тому же курсу, в конце запроса добавлено выражение GROUP BY, в котором указаны поля группировки. В нашем случае некоторые из них совпадают с теми, что указаны в выборке после ключевого слова SELECT. Оператор COUNT(*) считает все строки таблицы с заявками. За сортировку по убыванию отвечает оператор ORDER BY с уточнением DESC.
Рассмотрим другой бизнес-запрос. Например, нужно определить, сколько денег на каком курсе заработает каждый тренер. На это ответит следующий SQL-запрос:
SELECT course.course_code AS "Код курса",
trainer.trainer_name AS "Тренер",
count(*)*(course.course_price) AS income
FROM product
JOIN app ON app.product=product.product_id
JOIN course ON course.course_id=product.product_course
JOIN trainer ON trainer.trainer_id=product.product_trainer
GROUP BY course.course_code,
trainer.trainer_name,
course.course_price
ORDER BY income DESC;

В этом SQL-запросе тоже появилась группировка, поскольку здесь выполняется агрегация строк по курсу. Поэтому встречается оператор GROUP BY с указанием полей, по которым выполняется группировка. Агрегатные функции, такие как расчет суммы, среднего или количества строк, выполняют вычисление на наборе ненулевых значений и возвращают одиночное значение. Исключением из этого правила является функция подсчета количества значений COUNT().
Также в запрос добавлен оператор сортировки по убыванию дохода от проведения курса, который вычисляется как произведение стоимости курса на количество поданных заявок. В свою очередь, количество заявок по определенному продукту, с которым связан курс, определяется через соединение с таблицей заявок.
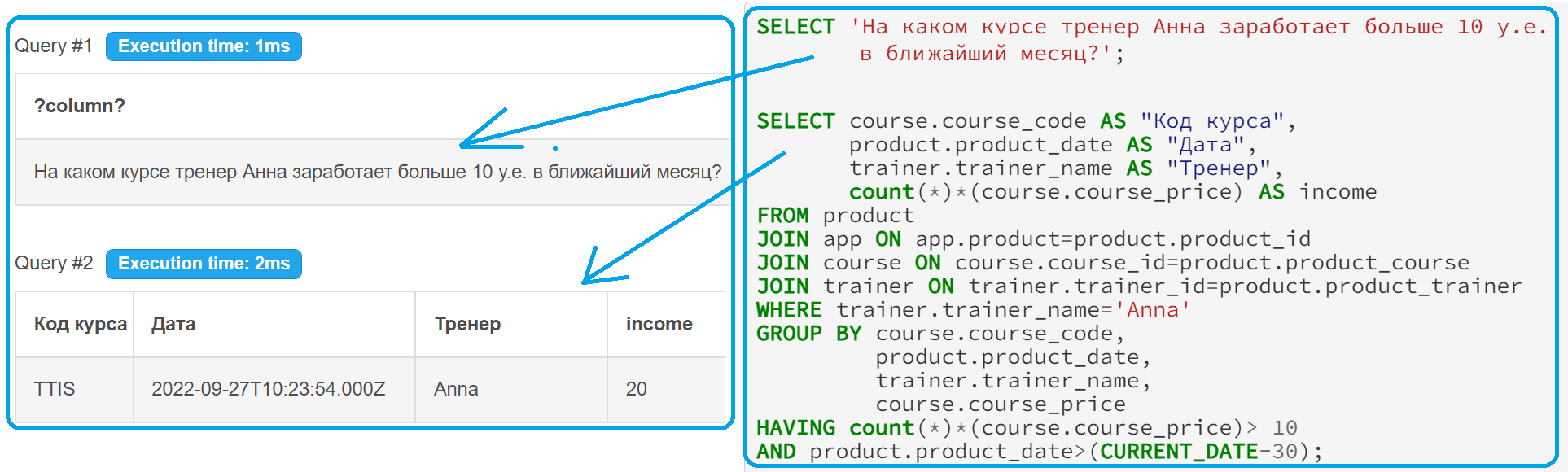
В заключение рассмотрим еще один пример с использованием группировки и фильтрации значений по агрегатным функциям через добавление HAVING после GROUP BY. Например, на каком курсе тренер Anna заработает больше 10 в ближайший месяц от текущей даты? Для этого используем следующий SQL-запрос:
SELECT 'На каком курсе тренер Анна заработает больше 10 у.е. в ближайший месяц?';
SELECT course.course_code AS "Код курса",
product.product_date AS "Дата",
trainer.trainer_name AS "Тренер",
count(*)*(course.course_price) AS income
FROM product
JOIN app ON app.product=product.product_id
JOIN course ON course.course_id=product.product_course
JOIN trainer ON trainer.trainer_id=product.product_trainer
WHERE trainer.trainer_name='Anna'
GROUP BY course.course_code,
product.product_date,
trainer.trainer_name,
course.course_price
HAVING count(*)*(course.course_price)> 10
AND product.product_date>(CURRENT_DATE-30);
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
27 апреля, 2023
Длительность обучения
8 ак.часов
Стоимость обучения
15 000 руб.
Разумеется, в рамках это статьи не рассматривались все типы SQL-запросов и возможности этого языка. Наиболее эффективным способом освоить их будет самостоятельная работа с выполнением упражнений. Для этого есть множество открытых ресурсов, платных и бесплатных курсов, а также свободных и проприетарных инструментов. В частности, очень советую следующие онлайн-учебники и тренажеры:
- https://sql-academy.org/ru/guide
- https://learndb.ru/articles
- https://www.sql-ex.ru/
- https://stepik.org/course/63054/promo?search=882582677
Чтобы освоить все нюансы проектирования реляционных моделей и написания SQL-запросов к ним, также необходимо читать документацию и выполнять упражнения в соответствующей среде, развернув ее на своем компьютере. Например, для MySQL отлично подходит платформа MySQL Workbench (>https://www.mysql.com/products/workbench/), а для PostgreSQL можно использовать pgAdmin (>https://www.pgadmin.org/). Эти инструменты поддерживают как визуальное проектирование ER-модели, так и выполнение SQL-запросов. Они способны заменить целый набор инструментов, которые использовались при подготовке этой статьи:
- StarUML – среда разработки UML и ER-диаграмм;
- расширение Postgresql DDL Extension for StarUML 2 для создания DDL-запросов к СУБД PostgreSQL по спроектированной диаграмме;
- https://www.db-fiddle.com/ – онлайн-движок реляционных баз данных для тестирования, отладки и обмена фрагментами SQL-запросов;
- https://sqlformat.org/ – онлайн-форматер для операторов SQL, который делает код более читаемым;
- https://postgrespro.ru/docs/postgrespro/14/index – документация по Postgres Pro Standard, популярной объектно-реляционной СУБД.
В заключение отмечу, что проверить, как вы усвоили материал этой статьи можно бесплатно прямо на нашем сайте, выполнив интерактивный тест по основам баз данных и языку запросов SQL.
10 вопросов по основам теории баз данных и SQL: тест для начинающих
А подробнее познакомиться с основами реляционных СУБД и моделированием данных вам помогут курсы Школы прикладного бизнес-анализа в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Основы архитектуры и интеграции информационных систем
- Разработка ТЗ на информационную систему по ГОСТ и SRS