Постановка задач машинного обучения математически очень проста. Любая задача классификации, регрессии или кластеризации – это по сути обычная оптимизационная задача с ограничениями. Несмотря на это, существующее многообразие алгоритмов и методов их решения делает профессию аналитика данных одной из наиболее творческих IT-профессий. Чтобы решение задачи не превратилось в бесконечный поиск «золотого» решения, а было прогнозируемым процессом, необходимо придерживаться довольно четкой последовательности действий. Эту последовательность действий описывают такие методологии, как CRISP-DM.
Методология анализа данных CRISP-DM упоминается во многих постах на Хабре, но я не смог найти ее подробных русскоязычных описаний и решил своей статьей восполнить этот пробел. В основе моего материала – оригинальное описание и адаптированное описание от IBM. Обзорную лекцию о преимуществах использования CRISP-DM можно посмотреть, например, здесь.

* Crisp (англ.) — хрустящий картофель, чипсы
Я работаю в компании CleverDATA (входит в группу ЛАНИТ) на позиции дата-сайентиста с 2015 года. Мы занимаемся проектами в области больших данных и машинного обучения, преимущественно в сфере data-driven маркетинга (то есть маркетинга, построенного на «глубоком» анализе клиентских данных). Также развиваем платформу управления данными 1DMP и биржу данных 1DMC. Наши типичные проекты по машинному обучению – это разработка и внедрение предиктивных (прогнозирующих) и прескриптивных (рекомендующих наилучшее действие) моделей для оптимизации ключевых бизнес-показателей заказчика. В ряде подобных проектов мы использовали методологию CRISP-DM.
CRoss Industry Standard Process for Data Mining (CRISP-DM) – стандарт, описывающий общие процессы и подходы к аналитике данных, используемые в промышленных data-mining проектах независимо от конкретной задачи и индустрии.
На известном аналитическом портале kdnuggets.org периодически публикуется опрос (например, здесь), согласно которому среди методологий анализа данных первое место по популярности регулярно занимает именно CRISP-DM, дальше с большим отрывом идет SEMMA и реже всего используется KDD Process.
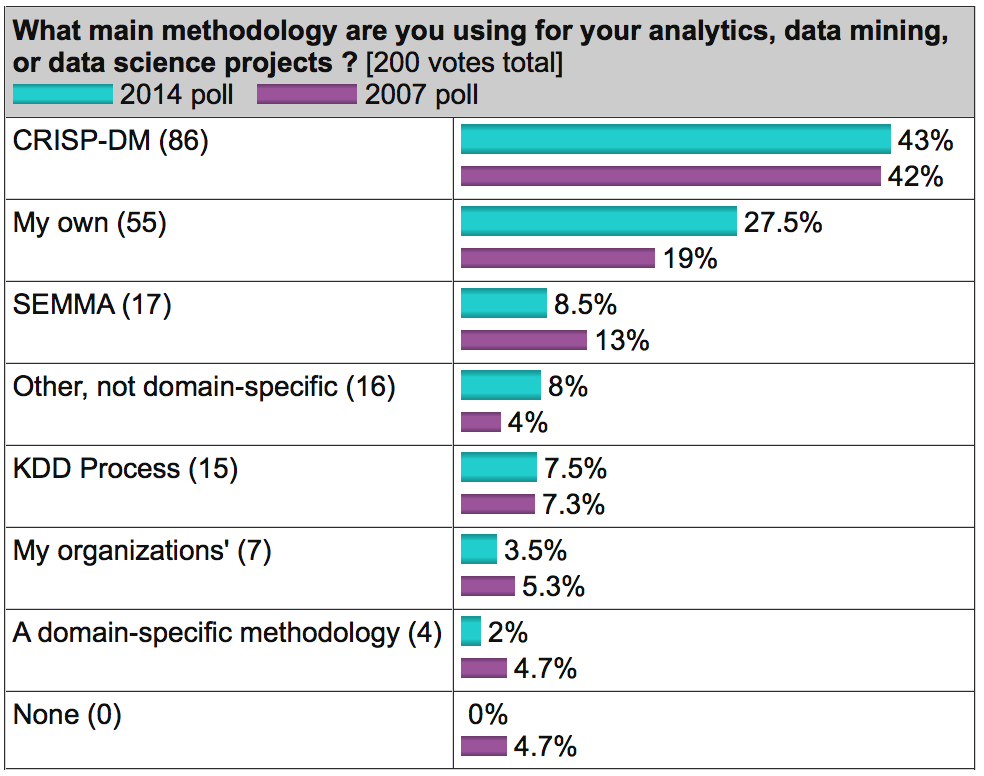
Источник: kdnuggets.com
В целом, эти три методологии очень похожи друг на друга (здесь сложно придумать что-то принципиально новое). Однако CRISP-DM заслужила популярность как наиболее полная и детальная. По сравнению с ней KDD является более общей и теоретической, а SEMMA – это просто организация функций по целевому предназначению в инструменте SAS Enterprise Miner и затрагивает исключительно технические аспекты моделирования, никак не касаясь бизнес-постановки задачи.
О методологии
Методология разработана в 1996 году по инициативе трех компаний (нынешние DaimlerChrysler, SPSS и Teradata) и далее дорабатывалась при участии 200 компаний различных индустрий, имеющих опыт data-mining проектов. Все эти компании использовали разные аналитические инструменты, но процесс у всех был построен очень похоже.
Методология активно продвигается компанией IBM. Например, она интегрирована в продукт IBM SPSS Modeler (бывший SPSS Clementine).
Важное свойство методологии – уделение внимания бизнес-целям компании. Это позволяет руководству воспринимать проекты по анализу данных не как «песочницу» для экспериментов, а как полноценный элемент бизнес-процессов компании.
Вторая особенность — это довольно детальное документирование каждого шага. По мнению авторов, хорошо задокументированный процесс позволяет менеджменту лучше понимать суть проекта, а аналитикам – больше влиять на принятие решений.
Согласно CRISP-DM, аналитический проект состоит из шести основных этапов, выполняемых последовательно:
- Бизнес-анализ (Business understanding)
- Анализ данных (Data understanding)
- Подготовка данных (Data preparation)
- Моделирование (Modeling)
- Оценка результата (Evaluation)
- Внедрение (Deployment)
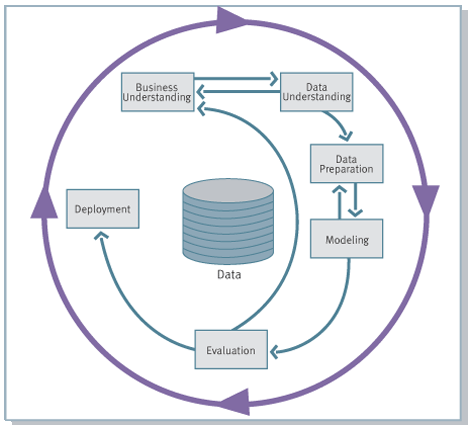
Методология не жесткая. Она допускает вариацию в зависимости от конкретного проекта – можно возвращаться к предыдущим шагам, можно какие-то шаги пропускать, если для решаемой задачи они не важны:
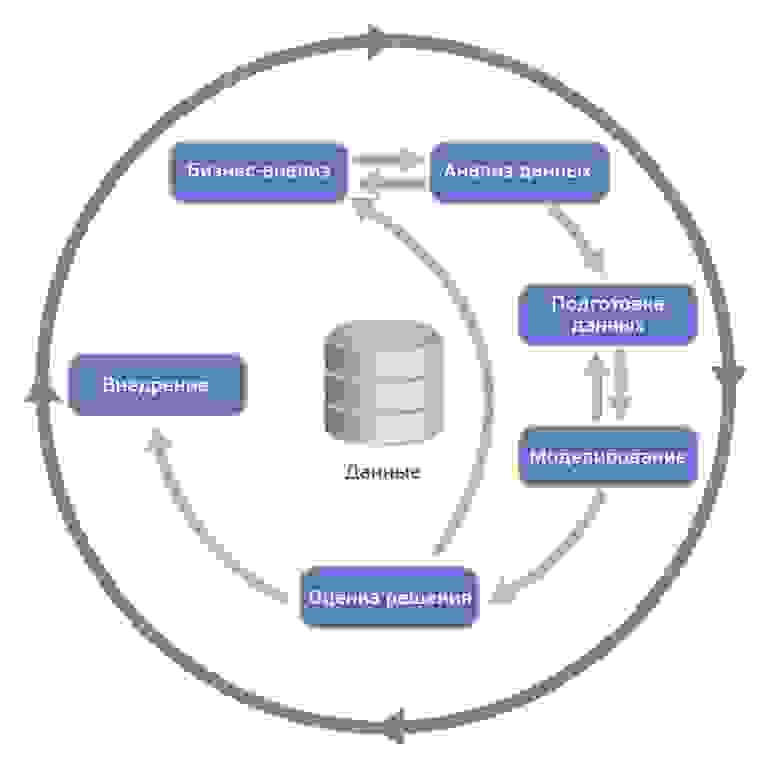
Источник Wikipedia
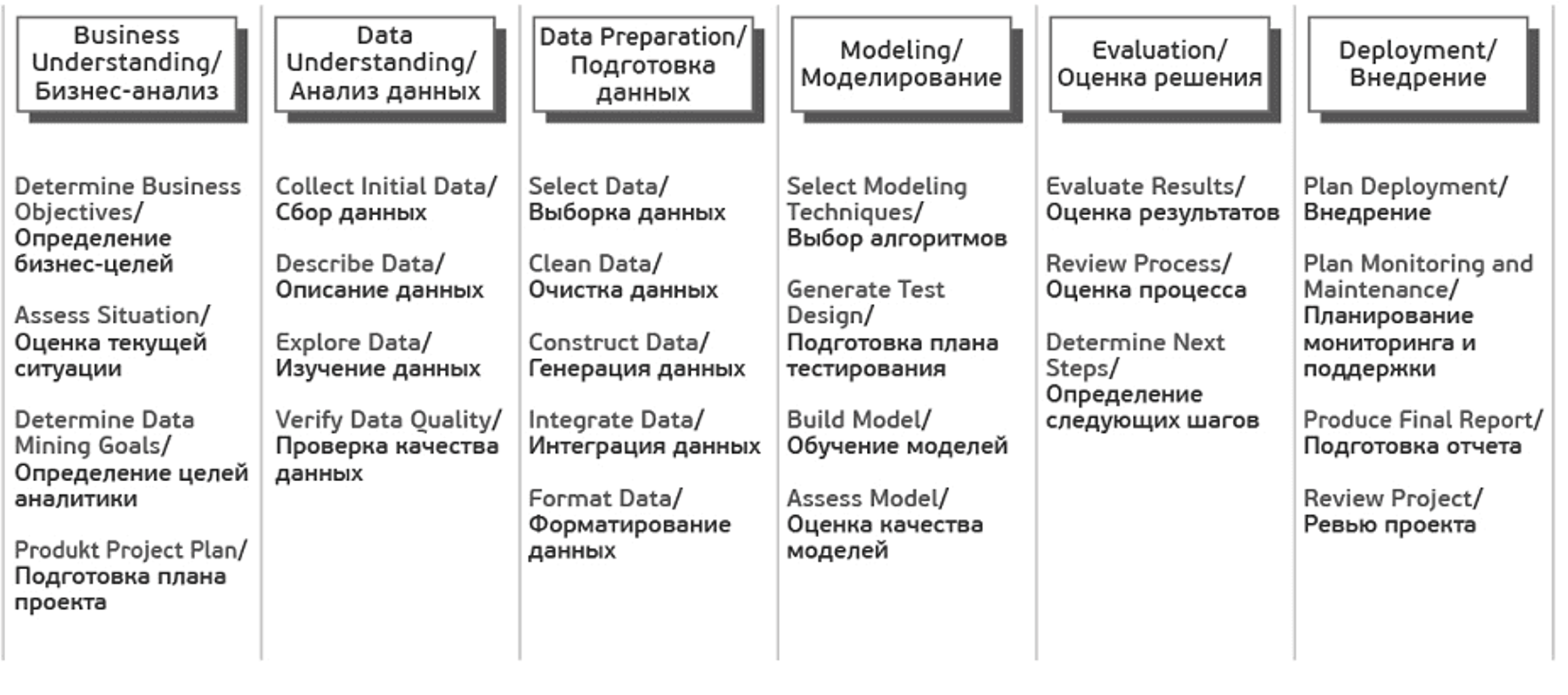
Каждый из этих этапов в свою очередь делится на задачи. На выходе каждой задачи должен получаться определенный результат. Задачи следующие:
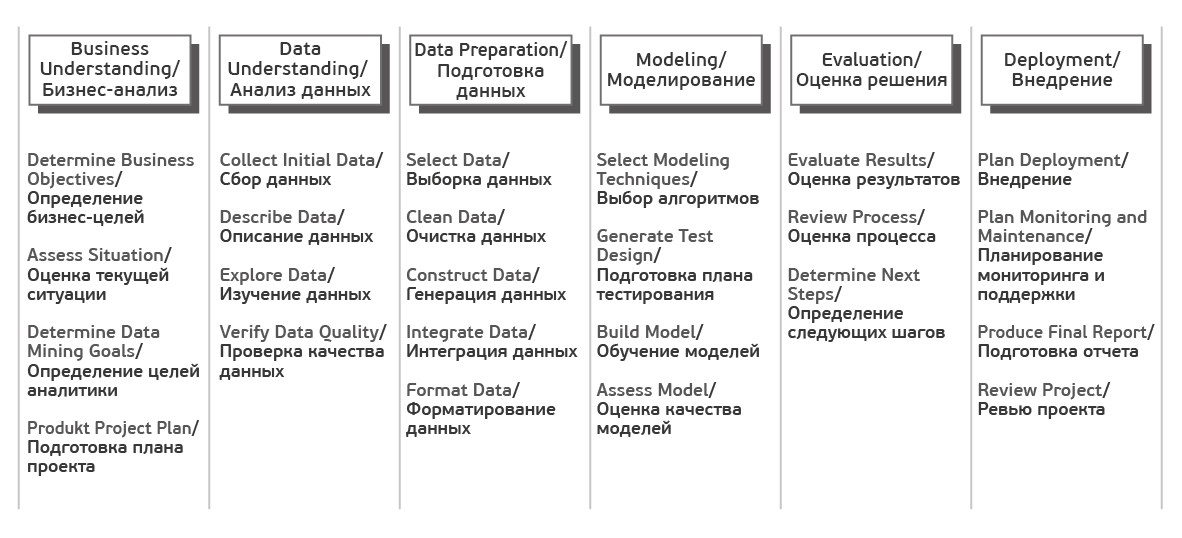
Источник Crisp_DM Documentation
В описании шагов я сознательно не буду углубляться в математику и алгоритмы, поскольку в статье фокус делается именно на процесс. Предполагаю, что читатель знаком с основами машинного обучения, но на всякий случай в следующем параграфе приводится описание базовых терминов.
Также обращу внимание, что методология одинаково применима как для внутренних проектов, так и для ситуаций, когда проект делается консультантами.
Несколько базовых понятий машинного обучения
Как правило, основным результатом аналитического проекта является математическая модель. Что такое модель?
Пусть у бизнеса есть некая интересующая его величина — y (например, вероятность оттока клиента). А также есть данные — x (например, обращения клиента в техподдержку), от которых может зависеть y. Бизнес хочет понимать, как именно y зависит от x, чтобы в дальнейшем через настройку x он мог влиять на y. Таким образом, задача проекта — найти функцию f, которая лучше всего моделирует исследуемую зависимость y = f(x).
Под моделью мы будем понимать формулу f(x) либо программу, реализующую эту формулу. Любая модель описывается, во-первых, своим алгоритмом обучения (это может быть регрессия, дерево решений, градиентный бустинг и прочее), а во-вторых, набором своих параметров (которые у каждого алгоритма свои). Обучение модели – процесс поиска таких параметров, при которых модель лучше всего аппроксимирует наблюдаемые данные.
Обучающая выборка – таблица, содержащая пары x и y. Строки в этой таблице называются кейсами, а столбцы – атрибутами. Атрибуты, обладающие достаточной предсказательной способностью, будем называть предикторами. В случае с обучением «без учителя» (например, в задачах кластеризации), обучающая выборка состоит только из x. Скоринг – это применение найденной функции f(x) к новым данным, по которым y пока неизвестен. Например, в задаче кредитного скоринга сначала моделируется вероятность несвоевременной оплаты долга клиентом, а затем разработанная модель применяется к новым заявителям для оценки их кредитоспособности.
Пошаговое описание методологии

Источник
1. Бизнес-анализ (Business Understanding)
На первом шаге нам нужно определиться с целями и скоупом проекта.
Цель проекта (Business objectives)
Первым делом знакомимся с заказчиком и пытаемся понять, что же он на самом деле хочет (или рассказываем ему). На следующие вопросы хорошо бы получить ответ.
- Организационная структура: кто участвует в проекте со стороны заказчика, кто выделяет деньги под проект, кто принимает ключевые решения, кто будет основным пользователем? Собираем контакты.
- Какова бизнес-цель проекта?
Например, уменьшение оттока клиентов. - Существуют ли какие-то уже разработанные решения? Если существуют, то какие и чем именно текущее решение не устраивает?
1.2 Текущая ситуация (Assessing current solution)

Источник
Когда вместе с заказчиком разобрались, что мы хотим, нужно оценить, что мы можем предложить с учетом текущих реалий.
Оцениваем, хватает ли ресурсов для проекта.
- Есть ли доступное железо или его необходимо закупать?
- Где и как хранятся данные, будет ли предоставлен доступ в эти системы, нужно ли дополнительно докупать/собирать внешние данные?
- Сможет ли заказчик выделить своих экспертов для консультаций на данный проект?
Нужно описать вероятные риски проекта, а также определить план действий по их уменьшению.
Типичные риски следующие.
- Не уложиться в сроки.
- Финансовые риски (например, если спонсор потеряет заинтересованность в проекте).
- Малое количество или плохое качество данных, которые не позволят получить эффективную модель.
- Данные качественные, но закономерности в принципе отсутствуют и, как следствие, полученные результаты не интересны заказчику.
Важно, чтобы заказчик и исполнитель говорили на одном языке, поэтому перед началом проекта лучше составить глоссарий и договориться об используемой в рамках проекта терминологии. Так, если мы делаем модель оттока для телекома, необходимо сразу договориться, что именно мы будем считать оттоком – например, отсутствие значительных начислений по счету в течение 4 недель подряд.
Далее стоит (хотя бы грубо) оценить ROI. В machine-learning проектах обоснованную оценку окупаемости часто можно получить только по завершению проекта (либо пилотного моделирования), но понимание потенциальной выгоды может стать хорошим драйвером для всех.
1.3 Решаемые задачи с точки зрения аналитики (Data Mining goals)
После того, как задача поставлена в бизнес-терминах, необходимо описать ее в технических терминах. В частности, отвечаем на следующие вопросы.
- Какую метрику мы будем использовать для оценки результата моделирования (а выбрать есть из чего: Accuracy, RMSE, AUC, Precision, Recall, F-мера, R2, Lift, Logloss и т.д.)?
- Каков критерий успешности модели (например, считаем AUC равный 0.65 — минимальным порогом, 0.75 — оптимальным)?
- Если объективный критерий качества использовать не будем, то как будут оцениваться результаты?
1.4 План проекта (Project Plan)
Как только получены ответы на все основные вопросы и ясна цель проекта, время составить план проекта. План должен содержать оценку всех шести фаз внедрения.
2. Анализ данных (Data Understanding)
Начинаем реализацию проекта и для начала смотрим на данные. На этом шаге никакого моделирования нет, используется только описательная аналитика.
Цель шага – понять слабые и сильные стороны предоставленных данных, определить их достаточность, предложить идеи, как их использовать, и лучше понять процессы заказчика. Для этого мы строим графики, делаем выборки и рассчитываем статистики.
2.1 Сбор данных (Data collection)

Источник
Для начала нужно понимать, какими данными располагает заказчик. Данные могут быть:
- собственные (1st party data),
- сторонние данные (3rd party),
- «потенциальные» данные (для получения которых необходимо организовать сбор).
Необходимо проанализировать все источники, доступ к которым предоставляет заказчик. Если собственных данных недостаточно, возможно, стоит закупить сторонние или организовать сбор новых данных.
2.2 Описание данных (Data description)
Далее смотрим на доступные нам данные.
- Необходимо описать данные во всех источниках (таблица, ключ, количество строк, количество столбцов, объем на диске).
- Если объем слишком велик для используемого ПО, создаем сэмпл данных.
- Считаем ключевые статистики по атрибутам (минимум, максимум, разброс, кардинальность и т.д.).
2.3 Исследование данных (Data exploration)
С помощью графиков и таблиц исследуем данные, чтобы сформулировать гипотезы относительно того, как эти данные помогут решить задачу.
В мини-отчете фиксируем, что интересного нашли в данных, а также список атрибутов, которые потенциально полезны.
2.4 Качество данных (Data quality)
Важно еще до моделирования оценить качество данных, так как любые несоответствия могут повлиять на ход проекта. Какие могут быть сложности с данными?
- Пропущенные значения.
К примеру, мы делаем модель классификации клиентов банка по их продуктовым предпочтениям, но, поскольку анкеты заполняют только клиенты-заемщики, атрибут «уровень з/п» у клиентов-вкладчиков не заполнен. - Ошибки данных (опечатки)
- Неконсистентная кодировка значений (например «M» и «male» в разных системах)
3. Подготовка данных (Data Preparation)

Источник
Подготовка данных – это традиционно наиболее затратный по времени этап machine learning проекта (в описании говорится о 50-70% времени проекта, по нашему опыту может быть еще больше). Цель этапа – подготовить обучающую выборку для использования в моделировании.
3.1 Отбор данных (Data Selection)
Для начала нужно отобрать данные, которые мы будем использовать для обучения модели.
Отбираются как атрибуты, так и кейсы.
Например, если мы делаем продуктовые рекомендации посетителям сайта, мы ограничиваемся анализом только зарегистрированных пользователей.
При выборе данных аналитик отвечает на следующие вопросы.
- Какова потенциальная релевантность атрибута решаемой задаче?
Так, электронная почта или номер телефона клиента как предикторы для прогнозирования явно бесполезны. А вот домен почты (mail.ru, gmail.com) или код оператора в теории уже могут обладать предсказательной способностью. - Достаточно ли качественный атрибут для использования в модели?
Если видим, что большая часть значений атрибута пуста, то атрибут, скорее всего, бесполезен. - Стоит ли включать коррелирующие друг с другом атрибуты?
- Есть ли ограничения на использование атрибутов?
Например, политика компании может запрещать использование атрибутов с персональной информацией в качестве предикторов.
3.2 Очистка данных (Data Cleaning)
Когда отобрали потенциально интересные данные, проверяем их качество.
- Пропущенные значения => нужно либо их заполнить, либо удалить из рассмотрения
- Ошибки в данных => попробовать исправить вручную либо удалить из рассмотрения
- Несоответствующая кодировка => привести к единой кодировке
На выходе получается 3 списка атрибутов – качественные атрибуты, исправленные атрибуты и забракованные.
3.3 Генерация данных (Constructing new data)
Часто генерация признаков (feature engineering) – это наиболее важный этап в подготовке данных: грамотно составленный признак может существенно улучшить качество модели.
К генерации данных можно отнести:
- агрегацию атрибутов (расчет sum, avg, min, max, var и т.д.),
- генерацию кейсов (например, oversampling или алгоритм SMOTE),
- конвертацию типов данных для использования в разных моделях (например, SVM традиционно работает с интервальными данными, а CHAID с номинальными),
- нормализацию атрибутов (feature scaling),
- заполнение пропущенных данных (missing data imputation).
3.4 Интеграция данных (Integrating data)
Хорошо, когда данные берутся из корпоративного хранилища (КХД) или заранее подготовленной витрины. Однако часто данные необходимо загружать из нескольких источников и для подготовки обучающей выборки требуется их интеграция. Под интеграцией понимается как «горизонтальное» соединение (Merge), так и «вертикальное» объединение (Append), а также агрегация данных. На выходе, как правило, имеем единую аналитическую таблицу, пригодную для поставки в аналитическое ПО в качестве обучающей выборки.
3.5 Форматирование данных (Formatting Data)
Наконец, нужно привести данные к формату, пригодному для моделирования (только для тех алгоритмов, которые работают с определенным форматом данных). Так, если речь идет об анализе временного ряда – к примеру, прогнозируем ежемесячные продажи торговой сети – возможно, его нужно предварительно отсортировать.
4. Моделирование (Modeling)
На четвертом шаге наконец-то начинается самое интересное — обучение моделей. Как правило, оно выполняется итерационно – мы пробуем различные модели, сравниваем их качество, делаем перебор гиперпараметров и выбираем лучшую комбинацию. Это наиболее приятный этап проекта.
4.1 Выбор алгоритмов (Selecting the modeling technique)
Необходимо определиться, какие модели будем использовать (благо, их множество). Выбор модели зависит от решаемой задачи, типов атрибутов и требований по сложности (например, если модель будет дальше внедряться в Excel, то RandomForest и XGBoost явно не подойдут). При выборе следует обратить внимание на следующее.
- Достаточно ли данных, поскольку сложные модели как правило требуют большей выборки?
- Сможет ли модель обработать пропуски данных (какие-то реализации алгоритмов умеют работать с пропусками, какие-то нет)?
- Сможет ли модель работать с имеющимися типами данных или необходима конвертация?
4.2 Планирование тестирования (Generating a test design)
Далее надо решить, на чем мы будем обучать, а на чем тестировать нашу модель.
Традиционный подход – это разделение выборки на 3 части (обучение, валидацию и тест) в примерной пропорции 60/20/20. В этом случае обучающая выборка используется для подгонки параметров модели, а валидация и тест для получения очищенной от эффекта переобучения оценки ее качества. Более сложные стратегии предполагают использование различных вариантов кросс-валидации.
Здесь же прикидываем, как будем делать оптимизацию гиперпараметров моделей – сколько будет итераций по каждому алгоритму, будем ли делать grid-search или random-search.
4.3 Обучение моделей (Building the models)
Запускаем цикл обучения и после каждой итерации фиксируем результат. На выходе получаем несколько обученных моделей.
Кроме того, для каждой обученной модели фиксируем следующее.
- Показывает ли модель какие-то интересные закономерности?
Например, что точность предсказания на 99% объясняется всего одним атрибутом. - Какова скорость обучения/применения модели?
Если модель обучается 2 дня, возможно, стоит поискать более эффективный алгоритм или уменьшить обучающую выборку. - Были ли проблемы с качеством данных?
Например, в тестовую выборку попали кейсы с пропущенными значениями, и из-за этого не вся выборка проскорилась.
4.4 Оценка результатов (Assessing the model)

Источник
После того, как был сформирован пул моделей, нужно их еще раз детально проанализировать и выбрать модели-победители. На выходе неплохо иметь список моделей, отсортированный по объективному и/или субъективному критерию.
Задачи шага:
- провести технический анализ качества модели (ROC, Gain, Lift и т.д.),
- оценить, готова ли модель к внедрению в КХД (или куда нужно),
- достигаются ли заданные критерии качества,
- оценить результаты с точки зрения достижения бизнес-целей. Это можно обсудить с аналитиками заказчика.
Если критерий успеха не достигнут, то можно либо улучшать текущую модель, либо пробовать новую.
Прежде чем переходить к внедрению нужно убедиться, что:
- результат моделирования понятен (модель, атрибуты, точность)
- результат моделирования логичен
Например, мы прогнозируем отток клиентов и получили ROC AUC, равный 95%. Слишком хороший результат – повод проверить модель еще раз. - мы попробовали все доступные модели
- инфраструктура готова к внедрению модели
Заказчик: «Давайте внедрять! Только у нас места нет в витрине…».
5. Оценка результата (Evaluation)

Источник
Результатом предыдущего шага является построенная математическая модель (model), а также найденные закономерности (findings). На пятом шаге мы оцениваем результаты проекта.
5.1 Оценка результатов моделирования (Evaluating the results)
Если на предыдущем этапе мы оценивали результаты моделирования с технической точки зрения, то здесь мы оцениваем результаты с точки зрения достижения бизнес-целей.
Адресуем следующие вопросы:
- Формулировка результата в бизнес-терминах. Бизнесу гораздо легче общаться в терминах $ и ROI, чем в абстрактных Lift или R2
Классический пример диалога
Аналитик: Наша модель показывает десятикратный lift!
Бизнес: Я не впечатлён…
Аналитик: Вы заработаете дополнительных 100K$ в год!
Бизнес: С этого надо было начинать! Поподробнее, пожалуйста… - В целом насколько хорошо полученные результаты решают бизнес-задачу?
- Найдена ли какая-то новая ценная информация, которую стоит выделить отдельно?
К примеру, компания-ритейлер фокусировала свои маркетинговые усилия на сегменте «активная молодежь», но, занявшись прогнозированием вероятности отклика, с удивлением обнаружила, что их целевой сегмент совсем другой – «обеспеченные дамы 40+».
5.2 Разбор полетов (Review the process)
Стоит собраться
за кружкой пива
за столом, проанализировать ход проекта и сформулировать его сильные и слабые стороны. Для этого нужно пройтись по всем шагам:
- Можно ли было какие-то шаги сделать более эффективными?
Например, из-за неповоротливости IT-отдела заказчика целый месяц ушел на согласование доступов. Не гуд! - Какие были допущены ошибки и как их избежать в будущем?
На этапе планирования недооценили сложность выгрузки данных из источников и в результате не уложились в сроки. - Были ли не сработавшие гипотезы? Если да, стоит ли их повторять?
Аналитик: «А давайте теперь попробуем сверточную нейронную сеть… Всё становится лучше с нейросетями!» - Были ли неожиданности при реализации шагов? Как их предусмотреть в будущем?
Заказчик: «Ok. А мы думали, что обучающая выборка для разработки модели не нужна…»
5.3 Принятие решения (Determining the next steps)
Далее нужно либо внедрять модель, если она устраивает заказчика, либо, если виден потенциал для улучшения, попытаться еще ее улучшить.
Если на данном этапе у нас несколько удовлетворяющих моделей, то отбираем те, которые будем дальше внедрять.
6. Внедрение (Deployment)

Источник
Перед началом проекта с заказчиком всегда оговаривается способ поставки модели. В одном случае это может быть просто проскоренная база клиентов, в другом – SQL-формула, в третьем – полностью проработанное аналитическое решение, интегрированное в информационную систему.
На данном шаге осуществляется внедрение модели (если проект предполагает этап внедрения). Причем под внедрением может пониматься как физическое добавление функционала, так и инициирование изменений в бизнес-процессах компании.
6.1 Планирование развертывания (Planning Deployment)
Наконец собрали в кучу все полученные результаты. Что теперь?
- Важно зафиксировать, что именно и в каком виде мы будем внедрять, а также подготовить технический план внедрения (пароли, явки и прочее)
- Продумать, как с внедряемой моделью будут работать пользователи
Например, на экране сотрудника колл-центра показываем склонность клиента к подключению дополнительных услуг. - Определить принцип мониторинга решения. Если нужно, подготовиться к опытно-промышленной эксплуатации.
Например, договариваемся об использовании модели в течение года и тюнинге модели раз в 3 месяца.
6.2 Настройка мониторинга модели (Planning Monitoring)
Очень часто в проект включаются работы по поддержке решения. Вот что оговаривается.
- Какие показатели качества модели будут отслеживаться?
В своих банковских проектах мы часто используем популярный в банках показатель population stability index PSI. - Как понимаем, что модель устарела?
Например, если PSI больше 0.15, либо просто договариваемся о регулярном пересчете раз в 3 месяца. - Если модель устарела, достаточно ли будет ее переобучить или нужно организовывать новый проект?
При существенных изменениях в бизнес-процессах тюнинга модели недостаточно, нужен полный цикл переобучения – с добавлением новых атрибутов, отбором предикторов и.т.д.
6.3 Отчет по результатам моделирования (Final Report)
По окончании проекта, как правило, пишется отчет о результатах моделирования, в который добавляются результаты по каждому шагу, начиная от первичного анализа данных и заканчивая внедрением модели. В этот отчет также можно включить рекомендации по дальнейшему развитию модели.
Написанный отчет презентуется заказчику и всем заинтересованным лицам. В отсутствие ТЗ этот отчет является главным документом проекта. Также важно поговорить с задействованными в проекте сотрудниками (как со стороны заказчика, так и со стороны исполнителя) и собрать их мнение о проекте.
Как насчет практики?
Важно понимать, что методология не является универсальным рецептом. Это просто попытка формально описать последовательность действий, которую в той или иной степени выполняет любой аналитик, занимающийся анализом данных.
У нас в CleverDATA следование методологии на дата-майнинговых проектах не является жестким требованием, но, как правило, при составлении плана проекта наша детализация довольно точно укладывается в данную последовательность шагов.
Методология применима к совершенно разным задачам. Мы следовали ей в ряде маркетинговых проектов, в том числе, когда предсказывали вероятность отклика клиента торговой сети на рекламное предложение, делали модель оценки кредитоспособности заемщика для коммерческого банка и разрабатывали сервис рекомендаций товаров для интернет-магазина.
Сто и один отчет

Источник
По задумке авторов, после каждого шага должен писаться некий отчет. Однако на практике это не очень реалистично. Как и у всех, у нас бывают проекты, когда заказчик ставит очень сжатые сроки и необходимо быстро получить результат. Понятно, что в таких условиях нет смысла тратить время на детальное документирование каждого шага. Всю промежуточную информацию, если она нужна, мы в таких случаях фиксируем карандашом «на салфетке». Это позволяет максимально быстро заняться реализацией модели и уложиться в сроки.
На практике многие вещи делаются куда менее формально, чем требует методология. Мы, например, обычно не тратим время на выбор и согласование используемых моделей, а тестируем сразу все доступные алгоритмы (конечно, если ресурсы позволяют). Аналогично поступаем с атрибутами – готовим сразу несколько вариантов каждого атрибута, чтобы можно было опробовать максимальное количество вариантов. Нерелевантные атрибуты при таком подходе отсеиваются автоматически с помощью алгоритмов feature selection – автоматическом определении предсказательной способности атрибутов.
Полагаю, формализм методологии объясняется тем, что она писалась еще в 90-е, когда не было такого количества вычислительнных мощностей и важно было грамотно спланировать каждое действие. Сейчас доступность и дешевизна «железа» упрощает многие вещи.
О важности планирования
Всегда есть соблазн «пробежать» первые два этапа и перейти сразу к реализации. Практика показывает, что это не всегда оправдано.
На этапе постановки бизнес-целей (business understanding) важно как можно детальнее проговорить с заказчиком предлагаемое решение и убедиться, что ваши с ним ожидания совпадают. Бывает так, что бизнес рассчитывает получить в результате некоего «волшебного» робота, который сходу решит все его проблемы и мгновенно увеличит вдвое выручку. Поэтому, чтобы ни у кого не было разочарований по итогам проекта, всегда стоит четко проговаривать, какой именно результат получит заказчик и что он даст бизнесу.
Кроме того, не всегда заказчик может дать правильную оценку точности модели. В качестве примера: предположим, мы анализируем отклик на рекламную кампанию в интернете. Знаем, что по ссылке переходят примерно 10% клиентов. Разработанная нами модель отбирает 1000 наиболее склонных к отклику клиентов, и мы видим, что среди них переходит по ссылке каждый четвертый – получаем точность (precision) в 25%. Модель показывает неплохой результат (в 2.5 раза лучше «случайной» модели), но для заказчика точность в 25% слишком мала (он ждет цифр в районе 80-90%). И наоборот, совершенно бессмысленная модель, которая относит всех в один класс, покажет точность (accuracy), равную 90%, и формально будет удовлетворять заявленному критерию успеха. Т.е. важно вместе с заказчиком выбирать правильную меру качества модели и правильно ее интерпретировать.
Этап исследования (data understanding) важен тем, что позволяет и нам, и заказчику лучше понять его данные. У нас были примеры, когда после презентации результатов шага мы параллельно с основным проектом договаривались о новых, так как заказчик видел потенциал в найденных на этом этапе закономерностях.
В качестве другого примера приведу один из наших проектов, когда мы положились на диалог с заказчиком, ограничились поверхностным изучением данных и на этапе моделирования обнаружили, что часть данных оказалась неприменима из-за многочисленных пропусков. Поэтому всегда стоит заранее изучить данные, с которыми предстоит работать.
Наконец, хочу отметить, что, несмотря на свою полноту, методология все-таки достаточно общая. Она ничего не говорит о выборе конкретных алгоритмов и не дает готовых решений. Возможно, это и хорошо, так как всегда остается пространство для творческого поиска, ведь, повторюсь, сегодня профессия data scientist по-прежнему остается одной из наиболее творческих в IT-сфере.
Метод обработки данных, полученных в процессе продажи людьми (звонки/встречи), с целью оптимизации воронки, сокращения цикла сделки и увеличения конверсии.
Это лучшая работа, которую я видел — очень все хорошо структурировано. И бизнес у вас суперинтересный. Надеюсь, у вас получится что-то сделать и на международном рынке. — Владимир Горовой, Yandex.Cloud, преподаватель Skillbox, дисциплина “Большие данные и AI в бизнесе”.
Основной процесс
Звонки/встречи проводятся с подключением SalesAI. Интеграция с CRM системой позволяет собрать чистые и точные данные, которые можно анализировать инструментами Big Data: Process Mining, Spaghetti Diagram, Reverse Engineering и тд.
Если у нас сформирован качественный и объемный массив чистых данных, мы можем провести операцию Reverse Engineering для оптимизации процесса продаж, например, пересобрать воронку продаж или определить наиболее короткий процесс, или собрать наиболее эффективные тактические приемы/фразы, которые приводят к конверсии с высокой долей вероятности. Обратную задачу тоже можно решить: выявить эпик фейлы в процессе.
Рассказываем подробно, как это выглядит по шагам и какой результат от этого мы можем получить.
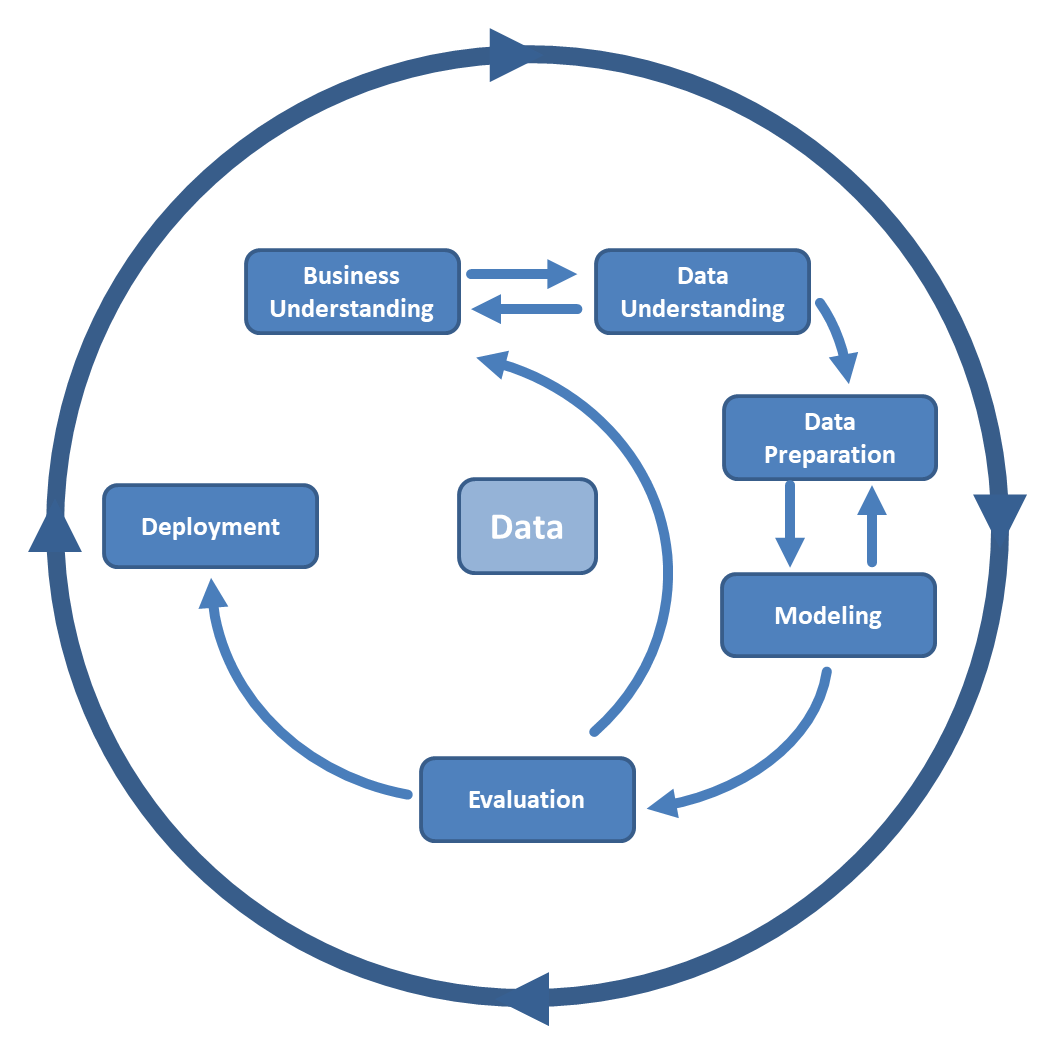
Рис.1 Методология CRISP-DM
Разобьем процесс на этапы, в соответствии с методологией CRISP-DM
|
Этап |
Цели этапа |
Выход |
Проблемы/риски |
|
Business Understanding |
Цель проекта — определить точки роста конверсии продаж. В зависимости от продуктов/регионов и др переменных, за счет глубокого анализа имеющихся внутренних данных. Второстепенная цель — определить внешние данные, которые необходимо учитывать для более точного результата. |
Задачи: • Определить зоны роста • Определить зоны потерь • Описать новый эффективный процесс • Определить метрики эффективности процесса |
Объем выборки может быть недостаточен для однозначных выводов. Хранение данных, возможность их получения. Отсутствие интересующих инсайтов для заказчика. |
|
Data Understanding |
В идеале, тк все диалоги пропущены через SalesAI и есть интеграция с CRM, то все необходимые данные хранятся в CRM: список событий по каждой сделке, Некоторые записи разговоров/встреч, Записи статусов сделки и связанных с ней объектов, Возможно протоколы встреч, Эл письма, Договоры/НДА, ТЗ, КП (все версии), пресейл документация и тд. Понять сильные и слабые стороны имеющегося набора документов. |
Понимание общего объема и категорий данных, доступных для анализа. Обогащение данных с помощью сторонних источников. Определение начальных гипотез для анализа: Оценка: — достаточности данных — релевантности данных Рассчитаны описательные статистики данных (целевых метрик), построены их графики Корректировка бизнес целей исходя из состояния данных |
Проблемы консистентности данных состоят в том, что может быть очень мало полного набора данных, объединенных одним ID сделки: нет исторических данных, данные в CRM с ошибками (90%), не полные, несвоевременно измененные, пропущенные кирпичики, не сохранились документы, или хранятся в разных местах, нечитабельные, коммуникация велась не в санкционированных каналах, которые не подлежат учету и тд. Основная проблема постфактум будет состоять в сборе полной цепочки событий по каждой сделке (Data Evidence). Иначе точность анализа будет слишком низкой. Именно поэтому сложно сделать ретроспективный анализ, потому что необходимо долго ковыряться в архивах, чтобы все найти. Для наиболее эффективного пути, сначала внедряется Политика управления Данными и SalesAI, потом собираются данные, затем проводится анализ по собранным данным. |
|
Data Preparation |
Допустим, у нас не сложные сделки, которые проводятся по телефону и нет долгих переписок и обменов документами. КП переделывается максимум один раз. Допустим, надо разобраться, что и как говорить по телефону менеджеру, чтобы конверсия росла сама. Тогда нам необходимо взять весь объем имеющихся записей звонков за последние 3-24 месяца и провести подготовительную работу. |
Подготовка датасетов: 1. Выстраивание звонков (событий) в хронологические цепочки в привязке к каждому ID сделки, тк в рамках одной сделки у нас может быть несколько этапов переговоров. 2. Транскрибирование/распознавание голоса в текст. 3. Разметка данных этап 1. нам необходимо определить цель каждого звонка и каждому разговору присвоить лейбл. Если звонок был полезный. Например, у нас могут быть звонки с целью квалификации лида, могут быть с целью закрытия сделки и тд. Также инициатором звонка может быть клиент, или менеджер, это тоже нам необходимо отразить в свойствах. 4. Разметка данных этап 2, более глубокого уровня: разложить каждый звонок на элементы контекста, что происходило внутри. Здесь, возможно, придется использовать гипотезу, в рамках которой определить набор сущностей и разложить все в рамках заданного набора сущностей, либо набор гипотез и у каждой гипотезы будет свой набор сущностей. В дальнейшем можно будет определить, какая гипотеза оказалось наиболее успешной. 5. Провести Кластеризацию моделью и сравнить результаты с используемыми гипотезами. |
• Качество распознавания • набор гипотез может быть ложным и дать фейковые срабатывания • выбор не тех сущностей и тд • мало неразорванных цепочек |
|
Modeling |
Визуализация данных и создание скоринговой модели |
1. Определить репрезентативность выборки: Диаграмма Спагетти, которая позволит показать: • количество полных цепей • количество успешных цепей • кол-во разорванных цепей событий 2. Детализация успешных цепей: • цепочки событий на временном графике, которые увеличивали скоринг лида. С указанием скоринга • КФУ в каждом мейлстоуне • Детализация до ключевых фраз • Успешные фреймворки проведения переговоров 3. Аналогично по неуспешным цепям 4. Общие характеристики клиентов, с которыми сделки закрыты успехом: критерии квалификации. 5. Сколько сделок можно было бы закрыть на том массиве по новому процессу. 6. Как выглядит новый процесс на графике время/скор |
Сложность сделать zoomin/zoomout процесса красиво |
|
Evaluation |
Оценка качества модели Проведение тестовой симуляции (ретроспективный анализ) или пилота в виде А/В-тестирования, например, сколько мы смогли бы продать в прошлом (на том же датасете), если бы применили новый процесс. |
Определяем метрики эффективности нового процесса (возможно лучше: оценка эффективности нового процесса определенными заранее метриками) Разработан дизайн эксперимента в виде А/В-тестирования: — определен объем контрольной и целевой выборок — длительность проведения эксперимента — критерии остановки эксперимента — определены ресурсы и технологии, необходимые для проведения эксперимента. Запущен пилот Вносим еще итерацию изменений, если необходимо. Повторяем эксперимент, если необходимо, если результат достигнут (метрики изменились), то приступаем к внедрению |
Влияние внешней среды Человеческий фактор Сезонность |
|
Deployment |
План внедрения: — Внедрение автоматизации сбора данных с помощью SalesAI. — Презентация команде результатов анализа. — Гиперболизация разницы: сколько потратили и сколько могли бы заработать, если бы работали по другому. — Объяснение, как теперь будет выглядеть новый процесс. — Какой рутины у них больше не будет — Подсказки сейлам в режиме реального времени. |
Пайплайн сбора чистых данных и петля обратной связи, которая позволяет изменять элементы процесса и фактически адаптировать процесс под каждый сегмент клиентов или под каждого целевого клиента (ABM в действии). |
Человеческий фактор/инстинкт самосохранения Привычки UI/UX Нежелание перестраиваться Изменения внешней среды Сезонность Кривая обучения |
Результаты
- Одноразовые улучшения процесса на той глубине, на какой у вас есть кластеризация. Это можно сделать вручную, если есть чистые данные.
- Непрерывный процесс улучшений процесса вкупе с постоянным получением чистых данных — при использовании SalesAI.
Скачайте бесплатную книгу про Process Mining, каким образом он позволяет выстроить более эффективный процесс продаж. Заполняйте форму и мы пришлем вам бесплатный экземпляр этой книги:
Материал из CDTOwiki
Перейти к: навигация, поиск
Цикл работы с данными
этапы и виды работ, которые необходимо проделать, чтобы получить новую информацию на их основе
Сегмент
Рекомендовано
Сложность
Один из подходов работы с данными – это методология исследования данных CRISP, которая включает в себя шесть этапов: понимание бизнеса, начальное изучение данных, подготовка данных, моделирование, оценка решения и внедрение.
Цикл работы с данными по методологии CRISP
CRISP-DM (Cross-Industry Standard Process for Data Mining — межотраслевой стандартный процесс для исследования данных) — это проверенная в промышленности и наиболее распространённая методология по исследованию данных.
Данная схема включает в себя шесть этапов
Понимание бизнеса (Business Understanding) – на первом этапе работы с данными вам нужно понять, зачем вам собирать и анализировать данные, а также какие данные вам необходимы. Определение целей и предварительные гипотезы на данных затем лягут в основу вашего проекта.
Задачи фазы Business Understanding:
- Определить цели вашей организации
- Оценить текущую ситуацию
- Определить цели анализа данных
- Составить план проекта
Начальное изучение данных (Data Understanding) – на втором этапе работы с данными вам нужно оценить качество ваших данных: насколько данные полные, есть ли в них ошибки, пробелы и пропуски. Нужно понять, какими сведениями вы обладаете, сформулировать к ним вопросы и итоговые гипотезы о скрытых закономерностях
Задачи фазы Data Understanding:
- Собрать исходные данные
- Описать данные
- Исследовать данные
- Проверить качество данных
Подготовка данных (Data Preparation) – на этом этапе вам нужно сформировать итоговый набор данных для анализа, “очистить” данные, привести их в единых формат из исходных разнородных и разноформатных данных.
Задачи фазы Data Preparation могут выполняться много раз без какого-то заранее определенного порядка:
- Отобрать данные (таблицы, записи и атрибуты)
- Очистить данные, в т.ч. выполнить их конвертацию и подготовку к моделированию
- Сделать производные данные
- Объединить данные
- Привести данные в нужный формат
Моделирование (Modeling) – на этом этапе вам нужно выбрать методику, каким образом анализировать данные, построить модель анализа. Модель должна отражать весь их процесс анализа (что вы хотите выяснить с помощью анализа данных, какие данные вы используете, как они организованы, как они обработаны, и так далее). У вас может возникнуть необходимость вернуться к фазе подготовки данных, так как разные методы анализа требуют различных форматов данных.
Задачи фазы Modeling:
- Выбрать методику моделирования
- Сделать тесты для модели
- Построить модель
- Оценить модель
Оценка (Evaluation) – определение, удалось ли достигнуть целей с помощью разработанной модели и полученных результатов анализа. Данный этап позволяет понять, действительно ли те шаги, которые вы запланировали, позволяют получить те результаты, которые вы хотели. На данном этапе могут быть выявлены более важные задачи организации, которые не были учтены.
Задачи фазы Evaluation:
- Оценить результаты
- Сделать ревью процесса
- Определить следующие шаги
Внедрение (Deployment) – этот этап может быть простым или сложным, в зависимости от целей организации. Обычно это — разработка и внедрение решений на основе анализа данных. Это может быть как составление отчета, так и автоматизация процессов для решения ваших целей.
Задачи фазы Deployment:
- Запланировать развертывание
- Запланировать поддержку и мониторинг развернутого решения
- Сделать финальный отчет
- Сделать ревью проекта
Рассмотрим подробнее некоторые аспекты этапов подготовки и моделирования данных, инструменты подготовки данных и способы их моделирования
Сбор данных
Важный вопрос на этом этапе — поиск данных. Согласно И.В. Бегтину поиск данных осуществляется по следующей схеме:
- формулировка запроса — что ищем;
- запрос консультаций с целью помощи в поиске источников поиска;
- самостоятельный поиск;
- запрос и получение данных.
Хранение данных
Хранение данных — это процесс обеспечения доступности, целостности, защищенности данных. Данные можно хранить разным способом:
- твердотельный съемный или несъемный носитель — нужен доступ к самому носителю или устройству, в которое он помещается, для получения данных;
- сервера баз данных;
- облачное хранилище данных — доступ к данным возможен из любой локации и др.
Выбор способа хранения данных зависит от объема данных, необходимой скорости доступа к ней, частоте обновлений данных, количества лиц, которым будет разрешен доступ к данным, стоимости хранения нужного объема данных.
Основной формой хранения данных является база данных. С помощью СУБД можно получить доступ к данным, записать их, переместить, изменить, удалить.

Обработка данных
Под обработкой данных понимается определенная последовательность операций с данными, выполненных для получения новой информации путем пересмотра и уточнения имеющейся результатов анализа данных, вычислений и пр. На первом этапе осуществляется первичная обработка данных — приведение данных к единому формату, выделение общих признаков, структурирование данных. Затем выбирается наиболее актуальная для решения задачи модель работы:
- точечная обработка активных задач — операции только с выбранными категориями;
- потоковая обработка в реальном времени — операции с большим объемом данных, поступающих непрерывно, в процессе чего результаты анализа меняются каждый раз когда поступают новые данные;
- пакетная обработка исторических данных — обработка данных, накопленных за определенный срок.
В зависимости от выбранной модели, решаемой задачи подбираются технологии, тип базы данных, которые будут наиболее эффективны в конкретном случае.
К процедурам обработки данных относятся: создание данных, модификация данных, поиск информации, принятие решений, создание отчетов, создание документов, повышение безопасности данных.
При обработке данных обращают внимание на их качество. Выделяют чистые и грязные данные. Грязные данные отличает наличие обработки, дополнительной, не связанных с первоначальными данными, информации, недостаток первичных данных. Все это мешает полному анализу данных, так как грязные данные уже содержат в себе некоторые критерии анализа, “обнулить” значение которых нельзя.
Визуализация данных
Визуализация данных — процесс представления данных в агрегированном, понятном для восприятия человеком виде. Визуализация может быть презентационной — готовой для демонстрации аудитории, исследовательской — готовой для получения некоторых промежуточных результатов обработки данных.
Визуализация может быть использована на всех этапах работы с данными: визуализация результатов первичной обработки, визуализация промежуточных результатов, визуализация окончательных результатов.
В связи с объемом анализируемых данных визуализация – это необходимый способ оформления данных в понятный человеку вид. Поэтому инструменты визуализации важны в работе с данными.
Вид визуализации данных:
- Графики: линейный, график рассеивания и др.
- Диаграммы: столбиковая, круговая, гистограмма, кольцевая, лепестковая, облако тегов и др.
- Инфографика.
- Схемы.
- Презентации.
- Карты: фотографическая, географическая, дорожная, тематическая, картограмма.
- Дашборды.
- Иллюстрации.
Выводы
- Методология исследования данных CRISP включается шесть этапов: понимание бизнеса, начальное изучение данных, подготовка данных, моделирование, оценка решения и внедрение.
- Поиск данных включает четыре этапа: формулировка запроса, консультации, самостоятельный поиск, запрос и получение данный
- Хранить данные можно на твердых носителях, серверах или в облачных хранилищах.
- Обработка данных включает в себя: первичную обработку и очистку, выделение общих признаков, уплотнение данных, выбор модели для анализа.
- Анализ данных — совокупность действий исследователя, направленных на получение определенных представлений о характере явления, описываемых этими данными.
- Визуализация данных — процесс представления данных в агрегированном, понятном для восприятия человеком виде.
Дата последней редакции 29 мая 2020
Материал из MachineLearning.
Перейти к: навигация, поиск
CRISP-DM (CRoss Industry Standard Process for Data Mining) наиболее распространенная и популярная методология ведения проектов интеллектуального анализа данных[1]. Опросы, проводившиеся в 2002, 2004 и 2007 годах, показывают, что эта методология часто применяется исследователями данных.[1] [1] [1]
Содержание
- 1 Зачем нужна методология?
- 2 Инструменты методологии
- 2.1 Иерархическая декомпозиция
- 2.2 Применение общей модели в конкретном проекте
- 2.3 База знаний
- 3 Основные этапы проекта
- 3.1 Понимание бизнеса (Business Understanding)
- 3.2 Понимание данных (Data Understanding)
- 3.3 Подготовка данных (Data Preparation)
- 3.4 Моделирование (Modeling)
- 3.5 Оценка (Evaluation)
- 3.6 Развертывание (Deployment)
- 4 История
- 5 Преимущества методологии
- 6 Ссылки
- 6.1 Сноски
- 6.2 Смотри также
- 6.3 Внешние ссылки
Зачем нужна методология?
Проекты анализа данных должны:
- надежно исполняться испытанными средствами с предсказуемыми результатом (Reliable);
- быть повторяемыми, особенно людьми с малым опытом в анализе данных (Repeatable).
Следование методике дает нам:
- Средства для сохранения опыта проектов, накопленный опыт позволяет нам успешно повторять проекты;
- Упрощение планирования и управления проектами, известная и привычная последовательность действий и набор необходимых артефактов;
- Простоту включения в работу новых членов команды, уменьшение зависимости от «звезд».
Инструменты методологии
Иерархическая декомпозиция
Применение общей модели в конкретном проекте
База знаний
- (TODO: рекомендации по накоплению базы знаний)
В базе знаний сохраняются хорошо зарекомендовавшие себя методы для последующего применения в других проектах.
Основные этапы проекта
CRISP-DM разбивает процесс анализа данных на шесть основных этапов[1]:
Понимание бизнеса (Business Understanding)
Первая фаза процесса направлена на определение целей проекта и требований со стороны бизнеса. Затем эти знания конвертируются в постановку задачи интеллектуального анализа данных и предварительный план достижения целей проекта.
- Определить бизнес цели
- Оценить ситуацию
- Определить цели анализа данных
- Составить план проекта
Понимание данных (Data Understanding)
Вторая фаза начинается со сбора данных и ставит целью познакомиться с данными как можно ближе. Для этого необходимо выявить проблемы с качеством данных такие как ошибки или пропуски, понять что за данные имеются в наличии, попробовать отыскать интересные наборы данных или сформировать гипотезы о наличии скрытых закономерностей в данных.
- Собрать исходные данные
- Описать данные
- Исследовать данные
- Проверить качество данных
Подготовка данных (Data Preparation)
Фаза подготовки данных ставит целью получить итоговый набор данных, которые будут использоваться при моделировании, из исходных разнородных и разноформатных данных. Задачи подготовки данных могут выполняться много раз без какого-либо наперед заданного порядка. Они включают в себя отбор таблиц, записей и атрибутов, а также конвертацию и очистку данных для моделирования.
- Отобрать данные
- Очистить данные
- Сделать производные данные
- Объединить данные
- Привести данные в нужный формат
Моделирование (Modeling)
В этой фазе к данным применяются разнообразные методики моделирования, строятся модели и их параметры настраиваются на оптимальные значения. Обычно для решения любой задачи анализа данных существует несколько различных подходов. Некоторые подходы накладывают особые требования на представление данных. Таким образом часто бывает нужен возврат на шаг назад к фазе подготовки данных.
- Выбрать методику моделирования
- Сделать тесты для модели
- Построить модель
- Оценить модель
Оценка (Evaluation)
На этом этапе проекта уже построена модель и получены количественные оценки её качества. Перед тем, как внедрять эту модель, необходимо убедиться, что мы достигли всех поставленных бизнес-целей. Основной целью этапа является поиск важных бизнес-задач, которым не было уделено должного внимания.
- Оценить результаты
- Сделать ревью процесса
- Определить следующие шаги
Развертывание (Deployment)
В зависимости от требований фаза развертывания может быть простой, например, составление финального отчета, или сложной, например, автоматизация процесса анализа данных для решения бизнес-задач. Обычно развертывание — это забота клиента. Однако, даже если аналитик не принимает участие в развертывании, важно дать понять клиенту, что ему нужно сделать для того, чтобы начать использовать полученные модели.
- Запланировать развертывание
- Запланировать поддержку и мониторинг развернутого решения
- Сделать финальный отчет
- Сделать ревью проекта
Перемещение вперед и назад между фазами — обычное дело. В зависимости от результата фазы или её подзадачи принимается решение, в какую фазу переходить дальше. Стрелками обозначены наиболее важные и частые переходы между фазами.
Внешний круг символизирует циклическую природу анализа данных. Процесс анализа данных продолжается и после развертывания решения. Знания, полученные во время процесса, могут породить новые более тонкие вопросы бизнеса. Последующий процесс анализа данных выгодно проводить, используя знания, полученные ранее. [1]
История
Идея CRISP-DM зародилась в 1996. В 1997 была начата разработка проекта в Европейском Содружестве под эгидой фонда ESPRIT (European Strategic Program on Research in Information Technology). Проект возглавили четыре компании: ISL, NCR Corporation, Daimler-Benz и OHRA.
Эти компании объединили свой опыт в проекте. ISL впоследствии была поглощена SPSS Inc. на тот момент имела программный продукт для анализа данных Clementine. Компьютерный гигант NCR Corporation, породивший Teradata — СУБД для хранения сверхбольших данных, имел штат консультантов и собственное программное обеспечение по анализу данных. В Daimler-Benz была большая команда интеллектуального анализа данных для удовлетворения нужд собственного бизнеса. Страховая компания OHRA начала исследовать потенциал интеллектуального анализа данных.
Первая версия методологии была выпущена CRISP-DM 1.0 в 1999.
В июле 2006 консорциум анонсировал желание начать работу над второй версией CRISP-DM. 26 сентября 2006, инициативная группа CRISP-DM собрались для обсуждения потенциальных улучшений в CRISP-DM 2.0 и последующего плана работ. Однако, этим начинаниям не суждено было быть завершенными. С начала 2007 года инициативная группа больше не собиралась, вебсайт CRISP не обновлялся и не появлялось какой-либо новой информации.
Преимущества методологии
- Пригодна для любой индустрии.
- Можно использовать любые инструменты.
- Близка по духу к KDD Process Model.
- Делает основной упор на интеллектуальном анализе данных.
Ссылки
Сноски
Смотри также
- Численные методы обучения по прецедентам
- Автоматизация и стандартизация научных исследований
- Отчет о выполнении исследовательского проекта
Внешние ссылки
- CRoss Industry Standard Process for Data Mining
- CRoss Industry Standard Process for Data Mining Blog
- Le site des dataminers Article publié par Pascal BIZZARI, Mai 2009
- The Data Mining Group (DMG): The DMG is an independent, vendor led group which develops data mining standards, such as the Predictive Model Markup Language (PMML)
Постановка задач машинного обучения математически очень проста. Любая задача классификации, регрессии или кластеризации – это по сути обычная оптимизационная задача с ограничениями. Несмотря на это, существующее многообразие алгоритмов и методов их решения делает профессию аналитика данных одной из наиболее творческих IT-профессий. Чтобы решение задачи не превратилось в бесконечный поиск «золотого» решения, а было прогнозируемым процессом, необходимо придерживаться довольно четкой последовательности действий. Эту последовательность действий описывают такие методологии, как CRISP-DM.
Методология анализа данных CRISP-DM упоминается во многих постах на Хабре, но я не смог найти ее подробных русскоязычных описаний и решил своей статьей восполнить этот пробел. В основе моего материала – оригинальное описание и адаптированное описание от IBM. Обзорную лекцию о преимуществах использования CRISP-DM можно посмотреть, например, здесь.
* Crisp (англ.) — хрустящий картофель, чипсы
Я работаю в компании CleverDATA (входит в группу ЛАНИТ) на позиции дата-сайентиста с 2015 года. Мы занимаемся проектами в области больших данных и машинного обучения, преимущественно в сфере data-driven маркетинга (то есть маркетинга, построенного на «глубоком» анализе клиентских данных). Также развиваем платформу управления данными 1DMP и биржу данных 1DMC. Наши типичные проекты по машинному обучению – это разработка и внедрение предиктивных (прогнозирующих) и прескриптивных (рекомендующих наилучшее действие) моделей для оптимизации ключевых бизнес-показателей заказчика. В ряде подобных проектов мы использовали методологию CRISP-DM.
CRoss Industry Standard Process for Data Mining (CRISP-DM) – стандарт, описывающий общие процессы и подходы к аналитике данных, используемые в промышленных data-mining проектах независимо от конкретной задачи и индустрии.
На известном аналитическом портале kdnuggets.org периодически публикуется опрос (например, здесь), согласно которому среди методологий анализа данных первое место по популярности регулярно занимает именно CRISP-DM, дальше с большим отрывом идет SEMMA и реже всего используется KDD Process.
Источник: kdnuggets.com
В целом, эти три методологии очень похожи друг на друга (здесь сложно придумать что-то принципиально новое). Однако CRISP-DM заслужила популярность как наиболее полная и детальная. По сравнению с ней KDD является более общей и теоретической, а SEMMA – это просто организация функций по целевому предназначению в инструменте SAS Enterprise Miner и затрагивает исключительно технические аспекты моделирования, никак не касаясь бизнес-постановки задачи.
О методологии
Методология разработана в 1996 году по инициативе трех компаний (нынешние DaimlerChrysler, SPSS и Teradata) и далее дорабатывалась при участии 200 компаний различных индустрий, имеющих опыт data-mining проектов. Все эти компании использовали разные аналитические инструменты, но процесс у всех был построен очень похоже.
Методология активно продвигается компанией IBM. Например, она интегрирована в продукт IBM SPSS Modeler (бывший SPSS Clementine).
Важное свойство методологии – уделение внимания бизнес-целям компании. Это позволяет руководству воспринимать проекты по анализу данных не как «песочницу» для экспериментов, а как полноценный элемент бизнес-процессов компании.
Вторая особенность — это довольно детальное документирование каждого шага. По мнению авторов, хорошо задокументированный процесс позволяет менеджменту лучше понимать суть проекта, а аналитикам – больше влиять на принятие решений.
Согласно CRISP-DM, аналитический проект состоит из шести основных этапов, выполняемых последовательно:
- Бизнес-анализ (Business understanding)
- Анализ данных (Data understanding)
- Подготовка данных (Data preparation)
- Моделирование (Modeling)
- Оценка результата (Evaluation)
- Внедрение (Deployment)
Методология не жесткая. Она допускает вариацию в зависимости от конкретного проекта – можно возвращаться к предыдущим шагам, можно какие-то шаги пропускать, если для решаемой задачи они не важны:

Источник Wikipedia
Каждый из этих этапов в свою очередь делится на задачи. На выходе каждой задачи должен получаться определенный результат. Задачи следующие:
Источник Crisp_DM Documentation
В описании шагов я сознательно не буду углубляться в математику и алгоритмы, поскольку в статье фокус делается именно на процесс. Предполагаю, что читатель знаком с основами машинного обучения, но на всякий случай в следующем параграфе приводится описание базовых терминов.
Также обращу внимание, что методология одинаково применима как для внутренних проектов, так и для ситуаций, когда проект делается консультантами.
Несколько базовых понятий машинного обучения
Как правило, основным результатом аналитического проекта является математическая модель. Что такое модель?
Пусть у бизнеса есть некая интересующая его величина — y (например, вероятность оттока клиента). А также есть данные — x (например, обращения клиента в техподдержку), от которых может зависеть y. Бизнес хочет понимать, как именно y зависит от x, чтобы в дальнейшем через настройку x он мог влиять на y. Таким образом, задача проекта — найти функцию f, которая лучше всего моделирует исследуемую зависимость y = f(x).
Под моделью мы будем понимать формулу f(x) либо программу, реализующую эту формулу. Любая модель описывается, во-первых, своим алгоритмом обучения (это может быть регрессия, дерево решений, градиентный бустинг и прочее), а во-вторых, набором своих параметров (которые у каждого алгоритма свои). Обучение модели – процесс поиска таких параметров, при которых модель лучше всего аппроксимирует наблюдаемые данные.
Обучающая выборка – таблица, содержащая пары x и y. Строки в этой таблице называются кейсами, а столбцы – атрибутами. Атрибуты, обладающие достаточной предсказательной способностью, будем называть предикторами. В случае с обучением «без учителя» (например, в задачах кластеризации), обучающая выборка состоит только из x. Скоринг – это применение найденной функции f(x) к новым данным, по которым y пока неизвестен. Например, в задаче кредитного скоринга сначала моделируется вероятность несвоевременной оплаты долга клиентом, а затем разработанная модель применяется к новым заявителям для оценки их кредитоспособности.
Пошаговое описание методологии
Источник
1. Бизнес-анализ (Business Understanding)
На первом шаге нам нужно определиться с целями и скоупом проекта.
Цель проекта (Business objectives)
Первым делом знакомимся с заказчиком и пытаемся понять, что же он на самом деле хочет (или рассказываем ему). На следующие вопросы хорошо бы получить ответ.
- Организационная структура: кто участвует в проекте со стороны заказчика, кто выделяет деньги под проект, кто принимает ключевые решения, кто будет основным пользователем? Собираем контакты.
- Какова бизнес-цель проекта?
Например, уменьшение оттока клиентов. - Существуют ли какие-то уже разработанные решения? Если существуют, то какие и чем именно текущее решение не устраивает?
1.2 Текущая ситуация (Assessing current solution)
Источник
Когда вместе с заказчиком разобрались, что мы хотим, нужно оценить, что мы можем предложить с учетом текущих реалий.
Оцениваем, хватает ли ресурсов для проекта.
- Есть ли доступное железо или его необходимо закупать?
- Где и как хранятся данные, будет ли предоставлен доступ в эти системы, нужно ли дополнительно докупать/собирать внешние данные?
- Сможет ли заказчик выделить своих экспертов для консультаций на данный проект?
Нужно описать вероятные риски проекта, а также определить план действий по их уменьшению.
Типичные риски следующие.
- Не уложиться в сроки.
- Финансовые риски (например, если спонсор потеряет заинтересованность в проекте).
- Малое количество или плохое качество данных, которые не позволят получить эффективную модель.
- Данные качественные, но закономерности в принципе отсутствуют и, как следствие, полученные результаты не интересны заказчику.
Важно, чтобы заказчик и исполнитель говорили на одном языке, поэтому перед началом проекта лучше составить глоссарий и договориться об используемой в рамках проекта терминологии. Так, если мы делаем модель оттока для телекома, необходимо сразу договориться, что именно мы будем считать оттоком – например, отсутствие значительных начислений по счету в течение 4 недель подряд.
Далее стоит (хотя бы грубо) оценить ROI. В machine-learning проектах обоснованную оценку окупаемости часто можно получить только по завершению проекта (либо пилотного моделирования), но понимание потенциальной выгоды может стать хорошим драйвером для всех.
1.3 Решаемые задачи с точки зрения аналитики (Data Mining goals)
После того, как задача поставлена в бизнес-терминах, необходимо описать ее в технических терминах. В частности, отвечаем на следующие вопросы.
- Какую метрику мы будем использовать для оценки результата моделирования (а выбрать есть из чего: Accuracy, RMSE, AUC, Precision, Recall, F-мера, R2, Lift, Logloss и т.д.)?
- Каков критерий успешности модели (например, считаем AUC равный 0.65 — минимальным порогом, 0.75 — оптимальным)?
- Если объективный критерий качества использовать не будем, то как будут оцениваться результаты?
1.4 План проекта (Project Plan)
Как только получены ответы на все основные вопросы и ясна цель проекта, время составить план проекта. План должен содержать оценку всех шести фаз внедрения.
2. Анализ данных (Data Understanding)
Начинаем реализацию проекта и для начала смотрим на данные. На этом шаге никакого моделирования нет, используется только описательная аналитика.
Цель шага – понять слабые и сильные стороны предоставленных данных, определить их достаточность, предложить идеи, как их использовать, и лучше понять процессы заказчика. Для этого мы строим графики, делаем выборки и рассчитываем статистики.
2.1 Сбор данных (Data collection)
Источник
Для начала нужно понимать, какими данными располагает заказчик. Данные могут быть:
- собственные (1st party data),
- сторонние данные (3rd party),
- «потенциальные» данные (для получения которых необходимо организовать сбор).
Необходимо проанализировать все источники, доступ к которым предоставляет заказчик. Если собственных данных недостаточно, возможно, стоит закупить сторонние или организовать сбор новых данных.
2.2 Описание данных (Data description)
Далее смотрим на доступные нам данные.
- Необходимо описать данные во всех источниках (таблица, ключ, количество строк, количество столбцов, объем на диске).
- Если объем слишком велик для используемого ПО, создаем сэмпл данных.
- Считаем ключевые статистики по атрибутам (минимум, максимум, разброс, кардинальность и т.д.).
2.3 Исследование данных (Data exploration)
С помощью графиков и таблиц исследуем данные, чтобы сформулировать гипотезы относительно того, как эти данные помогут решить задачу.
В мини-отчете фиксируем, что интересного нашли в данных, а также список атрибутов, которые потенциально полезны.
2.4 Качество данных (Data quality)
Важно еще до моделирования оценить качество данных, так как любые несоответствия могут повлиять на ход проекта. Какие могут быть сложности с данными?
- Пропущенные значения.
К примеру, мы делаем модель классификации клиентов банка по их продуктовым предпочтениям, но, поскольку анкеты заполняют только клиенты-заемщики, атрибут «уровень з/п» у клиентов-вкладчиков не заполнен. - Ошибки данных (опечатки)
- Неконсистентная кодировка значений (например «M» и «male» в разных системах)
3. Подготовка данных (Data Preparation)
Источник
Подготовка данных – это традиционно наиболее затратный по времени этап machine learning проекта (в описании говорится о 50-70% времени проекта, по нашему опыту может быть еще больше). Цель этапа – подготовить обучающую выборку для использования в моделировании.
3.1 Отбор данных (Data Selection)
Для начала нужно отобрать данные, которые мы будем использовать для обучения модели.
Отбираются как атрибуты, так и кейсы.
Например, если мы делаем продуктовые рекомендации посетителям сайта, мы ограничиваемся анализом только зарегистрированных пользователей.
При выборе данных аналитик отвечает на следующие вопросы.
- Какова потенциальная релевантность атрибута решаемой задаче?
Так, электронная почта или номер телефона клиента как предикторы для прогнозирования явно бесполезны. А вот домен почты (mail.ru, gmail.com) или код оператора в теории уже могут обладать предсказательной способностью. - Достаточно ли качественный атрибут для использования в модели?
Если видим, что большая часть значений атрибута пуста, то атрибут, скорее всего, бесполезен. - Стоит ли включать коррелирующие друг с другом атрибуты?
- Есть ли ограничения на использование атрибутов?
Например, политика компании может запрещать использование атрибутов с персональной информацией в качестве предикторов.
3.2 Очистка данных (Data Cleaning)
Когда отобрали потенциально интересные данные, проверяем их качество.
- Пропущенные значения => нужно либо их заполнить, либо удалить из рассмотрения
- Ошибки в данных => попробовать исправить вручную либо удалить из рассмотрения
- Несоответствующая кодировка => привести к единой кодировке
На выходе получается 3 списка атрибутов – качественные атрибуты, исправленные атрибуты и забракованные.
3.3 Генерация данных (Constructing new data)
Часто генерация признаков (feature engineering) – это наиболее важный этап в подготовке данных: грамотно составленный признак может существенно улучшить качество модели.
К генерации данных можно отнести:
- агрегацию атрибутов (расчет sum, avg, min, max, var и т.д.),
- генерацию кейсов (например, oversampling или алгоритм SMOTE),
- конвертацию типов данных для использования в разных моделях (например, SVM традиционно работает с интервальными данными, а CHAID с номинальными),
- нормализацию атрибутов (feature scaling),
- заполнение пропущенных данных (missing data imputation).
3.4 Интеграция данных (Integrating data)
Хорошо, когда данные берутся из корпоративного хранилища (КХД) или заранее подготовленной витрины. Однако часто данные необходимо загружать из нескольких источников и для подготовки обучающей выборки требуется их интеграция. Под интеграцией понимается как «горизонтальное» соединение (Merge), так и «вертикальное» объединение (Append), а также агрегация данных. На выходе, как правило, имеем единую аналитическую таблицу, пригодную для поставки в аналитическое ПО в качестве обучающей выборки.
3.5 Форматирование данных (Formatting Data)
Наконец, нужно привести данные к формату, пригодному для моделирования (только для тех алгоритмов, которые работают с определенным форматом данных). Так, если речь идет об анализе временного ряда – к примеру, прогнозируем ежемесячные продажи торговой сети – возможно, его нужно предварительно отсортировать.
4. Моделирование (Modeling)
На четвертом шаге наконец-то начинается самое интересное — обучение моделей. Как правило, оно выполняется итерационно – мы пробуем различные модели, сравниваем их качество, делаем перебор гиперпараметров и выбираем лучшую комбинацию. Это наиболее приятный этап проекта.
4.1 Выбор алгоритмов (Selecting the modeling technique)
Необходимо определиться, какие модели будем использовать (благо, их множество). Выбор модели зависит от решаемой задачи, типов атрибутов и требований по сложности (например, если модель будет дальше внедряться в Excel, то RandomForest и XGBoost явно не подойдут). При выборе следует обратить внимание на следующее.
- Достаточно ли данных, поскольку сложные модели как правило требуют большей выборки?
- Сможет ли модель обработать пропуски данных (какие-то реализации алгоритмов умеют работать с пропусками, какие-то нет)?
- Сможет ли модель работать с имеющимися типами данных или необходима конвертация?
4.2 Планирование тестирования (Generating a test design)
Далее надо решить, на чем мы будем обучать, а на чем тестировать нашу модель.
Традиционный подход – это разделение выборки на 3 части (обучение, валидацию и тест) в примерной пропорции 60/20/20. В этом случае обучающая выборка используется для подгонки параметров модели, а валидация и тест для получения очищенной от эффекта переобучения оценки ее качества. Более сложные стратегии предполагают использование различных вариантов кросс-валидации.
Здесь же прикидываем, как будем делать оптимизацию гиперпараметров моделей – сколько будет итераций по каждому алгоритму, будем ли делать grid-search или random-search.
4.3 Обучение моделей (Building the models)
Запускаем цикл обучения и после каждой итерации фиксируем результат. На выходе получаем несколько обученных моделей.
Кроме того, для каждой обученной модели фиксируем следующее.
- Показывает ли модель какие-то интересные закономерности?
Например, что точность предсказания на 99% объясняется всего одним атрибутом. - Какова скорость обучения/применения модели?
Если модель обучается 2 дня, возможно, стоит поискать более эффективный алгоритм или уменьшить обучающую выборку. - Были ли проблемы с качеством данных?
Например, в тестовую выборку попали кейсы с пропущенными значениями, и из-за этого не вся выборка проскорилась.
4.4 Оценка результатов (Assessing the model)
Источник
После того, как был сформирован пул моделей, нужно их еще раз детально проанализировать и выбрать модели-победители. На выходе неплохо иметь список моделей, отсортированный по объективному и/или субъективному критерию.
Задачи шага:
- провести технический анализ качества модели (ROC, Gain, Lift и т.д.),
- оценить, готова ли модель к внедрению в КХД (или куда нужно),
- достигаются ли заданные критерии качества,
- оценить результаты с точки зрения достижения бизнес-целей. Это можно обсудить с аналитиками заказчика.
Если критерий успеха не достигнут, то можно либо улучшать текущую модель, либо пробовать новую.
Прежде чем переходить к внедрению нужно убедиться, что:
- результат моделирования понятен (модель, атрибуты, точность)
- результат моделирования логичен
Например, мы прогнозируем отток клиентов и получили ROC AUC, равный 95%. Слишком хороший результат – повод проверить модель еще раз. - мы попробовали все доступные модели
- инфраструктура готова к внедрению модели
Заказчик: «Давайте внедрять! Только у нас места нет в витрине…».
5. Оценка результата (Evaluation)
Источник
Результатом предыдущего шага является построенная математическая модель (model), а также найденные закономерности (findings). На пятом шаге мы оцениваем результаты проекта.
5.1 Оценка результатов моделирования (Evaluating the results)
Если на предыдущем этапе мы оценивали результаты моделирования с технической точки зрения, то здесь мы оцениваем результаты с точки зрения достижения бизнес-целей.
Адресуем следующие вопросы:
- Формулировка результата в бизнес-терминах. Бизнесу гораздо легче общаться в терминах $ и ROI, чем в абстрактных Lift или R2
Классический пример диалога
Аналитик: Наша модель показывает десятикратный lift!
Бизнес: Я не впечатлён…
Аналитик: Вы заработаете дополнительных 100K$ в год!
Бизнес: С этого надо было начинать! Поподробнее, пожалуйста… - В целом насколько хорошо полученные результаты решают бизнес-задачу?
- Найдена ли какая-то новая ценная информация, которую стоит выделить отдельно?
К примеру, компания-ритейлер фокусировала свои маркетинговые усилия на сегменте «активная молодежь», но, занявшись прогнозированием вероятности отклика, с удивлением обнаружила, что их целевой сегмент совсем другой – «обеспеченные дамы 40+».
5.2 Разбор полетов (Review the process)
Стоит собраться за кружкой пива за столом, проанализировать ход проекта и сформулировать его сильные и слабые стороны. Для этого нужно пройтись по всем шагам:
- Можно ли было какие-то шаги сделать более эффективными?
Например, из-за неповоротливости IT-отдела заказчика целый месяц ушел на согласование доступов. Не гуд! - Какие были допущены ошибки и как их избежать в будущем?
На этапе планирования недооценили сложность выгрузки данных из источников и в результате не уложились в сроки. - Были ли не сработавшие гипотезы? Если да, стоит ли их повторять?
Аналитик: «А давайте теперь попробуем сверточную нейронную сеть… Всё становится лучше с нейросетями!» - Были ли неожиданности при реализации шагов? Как их предусмотреть в будущем?
Заказчик: «Ok. А мы думали, что обучающая выборка для разработки модели не нужна…»
5.3 Принятие решения (Determining the next steps)
Далее нужно либо внедрять модель, если она устраивает заказчика, либо, если виден потенциал для улучшения, попытаться еще ее улучшить.
Если на данном этапе у нас несколько удовлетворяющих моделей, то отбираем те, которые будем дальше внедрять.
6. Внедрение (Deployment)
Источник
Перед началом проекта с заказчиком всегда оговаривается способ поставки модели. В одном случае это может быть просто проскоренная база клиентов, в другом – SQL-формула, в третьем – полностью проработанное аналитическое решение, интегрированное в информационную систему.
На данном шаге осуществляется внедрение модели (если проект предполагает этап внедрения). Причем под внедрением может пониматься как физическое добавление функционала, так и инициирование изменений в бизнес-процессах компании.
6.1 Планирование развертывания (Planning Deployment)
Наконец собрали в кучу все полученные результаты. Что теперь?
- Важно зафиксировать, что именно и в каком виде мы будем внедрять, а также подготовить технический план внедрения (пароли, явки и прочее)
- Продумать, как с внедряемой моделью будут работать пользователи
Например, на экране сотрудника колл-центра показываем склонность клиента к подключению дополнительных услуг. - Определить принцип мониторинга решения. Если нужно, подготовиться к опытно-промышленной эксплуатации.
Например, договариваемся об использовании модели в течение года и тюнинге модели раз в 3 месяца.
6.2 Настройка мониторинга модели (Planning Monitoring)
Очень часто в проект включаются работы по поддержке решения. Вот что оговаривается.
- Какие показатели качества модели будут отслеживаться?
В своих банковских проектах мы часто используем популярный в банках показатель population stability index PSI. - Как понимаем, что модель устарела?
Например, если PSI больше 0.15, либо просто договариваемся о регулярном пересчете раз в 3 месяца. - Если модель устарела, достаточно ли будет ее переобучить или нужно организовывать новый проект?
При существенных изменениях в бизнес-процессах тюнинга модели недостаточно, нужен полный цикл переобучения – с добавлением новых атрибутов, отбором предикторов и.т.д.
6.3 Отчет по результатам моделирования (Final Report)
По окончании проекта, как правило, пишется отчет о результатах моделирования, в который добавляются результаты по каждому шагу, начиная от первичного анализа данных и заканчивая внедрением модели. В этот отчет также можно включить рекомендации по дальнейшему развитию модели.
Написанный отчет презентуется заказчику и всем заинтересованным лицам. В отсутствие ТЗ этот отчет является главным документом проекта. Также важно поговорить с задействованными в проекте сотрудниками (как со стороны заказчика, так и со стороны исполнителя) и собрать их мнение о проекте.
Как насчет практики?
Важно понимать, что методология не является универсальным рецептом. Это просто попытка формально описать последовательность действий, которую в той или иной степени выполняет любой аналитик, занимающийся анализом данных.
У нас в CleverDATA следование методологии на дата-майнинговых проектах не является жестким требованием, но, как правило, при составлении плана проекта наша детализация довольно точно укладывается в данную последовательность шагов.
Методология применима к совершенно разным задачам. Мы следовали ей в ряде маркетинговых проектов, в том числе, когда предсказывали вероятность отклика клиента торговой сети на рекламное предложение, делали модель оценки кредитоспособности заемщика для коммерческого банка и разрабатывали сервис рекомендаций товаров для интернет-магазина.
Сто и один отчет

Источник
По задумке авторов, после каждого шага должен писаться некий отчет. Однако на практике это не очень реалистично. Как и у всех, у нас бывают проекты, когда заказчик ставит очень сжатые сроки и необходимо быстро получить результат. Понятно, что в таких условиях нет смысла тратить время на детальное документирование каждого шага. Всю промежуточную информацию, если она нужна, мы в таких случаях фиксируем карандашом «на салфетке». Это позволяет максимально быстро заняться реализацией модели и уложиться в сроки.
На практике многие вещи делаются куда менее формально, чем требует методология. Мы, например, обычно не тратим время на выбор и согласование используемых моделей, а тестируем сразу все доступные алгоритмы (конечно, если ресурсы позволяют). Аналогично поступаем с атрибутами – готовим сразу несколько вариантов каждого атрибута, чтобы можно было опробовать максимальное количество вариантов. Нерелевантные атрибуты при таком подходе отсеиваются автоматически с помощью алгоритмов feature selection – автоматическом определении предсказательной способности атрибутов.
Полагаю, формализм методологии объясняется тем, что она писалась еще в 90-е, когда не было такого количества вычислительнных мощностей и важно было грамотно спланировать каждое действие. Сейчас доступность и дешевизна «железа» упрощает многие вещи.
О важности планирования
Всегда есть соблазн «пробежать» первые два этапа и перейти сразу к реализации. Практика показывает, что это не всегда оправдано.
На этапе постановки бизнес-целей (business understanding) важно как можно детальнее проговорить с заказчиком предлагаемое решение и убедиться, что ваши с ним ожидания совпадают. Бывает так, что бизнес рассчитывает получить в результате некоего «волшебного» робота, который сходу решит все его проблемы и мгновенно увеличит вдвое выручку. Поэтому, чтобы ни у кого не было разочарований по итогам проекта, всегда стоит четко проговаривать, какой именно результат получит заказчик и что он даст бизнесу.
Кроме того, не всегда заказчик может дать правильную оценку точности модели. В качестве примера: предположим, мы анализируем отклик на рекламную кампанию в интернете. Знаем, что по ссылке переходят примерно 10% клиентов. Разработанная нами модель отбирает 1000 наиболее склонных к отклику клиентов, и мы видим, что среди них переходит по ссылке каждый четвертый – получаем точность (precision) в 25%. Модель показывает неплохой результат (в 2.5 раза лучше «случайной» модели), но для заказчика точность в 25% слишком мала (он ждет цифр в районе 80-90%). И наоборот, совершенно бессмысленная модель, которая относит всех в один класс, покажет точность (accuracy), равную 90%, и формально будет удовлетворять заявленному критерию успеха. Т.е. важно вместе с заказчиком выбирать правильную меру качества модели и правильно ее интерпретировать.
Этап исследования (data understanding) важен тем, что позволяет и нам, и заказчику лучше понять его данные. У нас были примеры, когда после презентации результатов шага мы параллельно с основным проектом договаривались о новых, так как заказчик видел потенциал в найденных на этом этапе закономерностях.
В качестве другого примера приведу один из наших проектов, когда мы положились на диалог с заказчиком, ограничились поверхностным изучением данных и на этапе моделирования обнаружили, что часть данных оказалась неприменима из-за многочисленных пропусков. Поэтому всегда стоит заранее изучить данные, с которыми предстоит работать.
Наконец, хочу отметить, что, несмотря на свою полноту, методология все-таки достаточно общая. Она ничего не говорит о выборе конкретных алгоритмов и не дает готовых решений. Возможно, это и хорошо, так как всегда остается пространство для творческого поиска, ведь, повторюсь, сегодня профессия data scientist по-прежнему остается одной из наиболее творческих в IT-сфере.
Просмотры: 510
Если у вас завалялись где-то в облаках записи разговоров ваших сейлов с лидами-клиентами, даже если вы их ни разу не переслушивали, не спешите их выбрасывать: Из них можно извлечь немалую пользу. Например, сократить цикл сделки на 26%, или поднять конверсию на 18%, или просто понять, что же происходит с лидом/клиентом между стадией MQL и ClosedWon/ClosedLost. Уже давно существуют инструменты, которые позволяют провести такой анализ. Один из них CRISP-DM.
Метод обработки данных, полученных в процессе продажи людьми (звонки/встречи), с целью оптимизации воронки, сокращения цикла сделки и увеличения конверсии.
Это лучшая работа, которую я видел — очень все хорошо структурировано. И бизнес у вас суперинтересный. Надеюсь, у вас получится что-то сделать и на международном рынке.
Владимир Горовой, Yandex.Cloud, преподаватель Skillbox, дисциплина Big Data.
Ретроспективный анализ
Если у нас сформирован качественный и объемный массив чистых данных, мы можем провести операцию Reverse Engineering для оптимизации процесса продаж, например, пересобрать воронку продаж или определить наиболее короткий процесс, или собрать наиболее эффективные тактические приемы/фразы, которые приводят к конверсии с высокой долей вероятности. Обратную задачу тоже можно решить: выявить эпик фейлы в процессе.
Разобьем процесс на этапы, в соответствии с методологией CRISP-DM
Рассказываем подробно, как это выглядит по шагам и какой результат от этого мы можем получить:
Прямой процесс
Звонки/встречи проводятся с подключением SalesAI. Интеграция с CRM системой позволяет собрать чистые и точные данные, которые можно анализировать инструментами Big Data: Process Mining, Spaghetti Diagram, Reverse Engineering в режиме реального времени.
Результаты
- Одноразовые улучшения процесса на той глубине, на какой у вас есть кластеризация. Это можно сделать вручную, если есть чистые данные.
- Непрерывный процесс улучшений процесса вкупе с постоянным получением чистых данных — при использовании SalesAI.
Оригинал статьи опубликован тут:
From Wikipedia, the free encyclopedia
Cross-industry standard process for data mining, known as CRISP-DM,[1] is an open standard process model that describes common approaches used by data mining experts. It is the most widely-used analytics model.[2]
In 2015, IBM released a new methodology called Analytics Solutions Unified Method for Data Mining/Predictive Analytics[3][4] (also known as ASUM-DM) which refines and extends CRISP-DM.
History[edit]
CRISP-DM was conceived in 1996 and became a European Union project under the ESPRIT funding initiative in 1997. The project was led by five companies: Integral Solutions Ltd (ISL), Teradata, Daimler AG, NCR Corporation and OHRA, an insurance company.
This core consortium brought different experiences to the project. ISL, later acquired and merged into SPSS. The computer giant NCR Corporation produced the Teradata data warehouse and its own data mining software. Daimler-Benz had a significant data mining team. OHRA was just starting to explore the potential use of data mining.
The first version of the methodology was presented at the 4th CRISP-DM SIG Workshop in Brussels in March 1999,[5] and published as a step-by-step data mining guide later that year.[6]
Between 2006 and 2008, a CRISP-DM 2.0 SIG was formed and there were discussions about updating the CRISP-DM process model.[7] The current status of these efforts is not known. However, the original crisp-dm.org website cited in the reviews,[8][9] and the CRISP-DM 2.0 SIG website are both no longer active.[7]
While many non-IBM data mining practitioners use CRISP-DM,[10][11][12] IBM is the primary corporation that currently uses the CRISP-DM process model. It makes some of the old CRISP-DM documents available for download and it has incorporated it into its SPSS Modeler product.[6]
Based on current research, CRISP-DM is the most widely used form of data-mining model because of its various advantages which solved the existing problems in the data mining industries. Some of the drawbacks of this model is that it does not perform project management activities. The success of CRISP-DM is largely attributable to that fact that it is industry, tool, and application neutral.[13]
Major phases[edit]
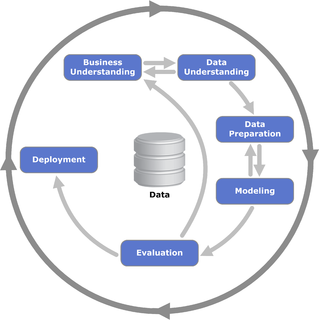
Process diagram showing the relationship between the different phases of CRISP-DM
CRISP-DM breaks the process of data mining into six major phases:[14]
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
The sequence of the phases is not strict and moving back and forth between different phases is usually required. The arrows in the process diagram indicate the most important and frequent dependencies between phases. The outer circle in the diagram symbolizes the cyclic nature of data mining itself. A data mining process continues after a solution has been deployed. The lessons learned during the process can trigger new, often more focused business questions, and subsequent data mining processes will benefit from the experiences of previous ones.
Polls[edit]
Polls conducted at the same website (KDNuggets) in 2002, 2004, 2007, and 2014 show that it was the leading methodology used by industry data miners who decided to respond to the survey.[10][11][12][15] The only other data mining approach named in these polls was SEMMA. However, SAS Institute clearly states that SEMMA is not a data mining methodology, but rather a «logical organization of the functional toolset of SAS Enterprise Miner.» A review and critique of data mining process models in 2009 called the CRISP-DM the «de facto standard for developing data mining and knowledge discovery projects.»[16] Other reviews of CRISP-DM and data mining process models include Kurgan and Musilek’s 2006 review,[8] and Azevedo and Santos’ 2008 comparison of CRISP-DM and SEMMA.[9] Efforts to update the methodology started in 2006, but have, as of June 2015, not led to a new version, and the «Special Interest Group» (SIG) responsible along with the website has long disappeared (see History of CRISP-DM).
References[edit]
- ^ Shearer C., The CRISP-DM model: the new blueprint for data mining, J Data Warehousing (2000); 5:13—22.
- ^ What IT Needs To Know About The Data Mining Process Published by Forbes, 29 July 2015, retrieved June 24, 2018
- ^ Have you seen ASUM-DM?, By Jason Haffar, 16 October 2015, SPSS Predictive Analytics, IBM Archived 8 March 2016 at the Wayback Machine
- ^ Analytics Solutions Unified Method — Implementations with Agile principles Published by IBM, 1 March 2016, retrieved October 5, 2018
- ^ Pete Chapman (1999); The CRISP-DM User Guide.
- ^ a b Pete Chapman, Julian Clinton, Randy Kerber, Thomas Khabaza, Thomas Reinartz, Colin Shearer, and Rüdiger Wirth (2000); The CRISP-DM User Guide (entry on semantic scholar, including links to PDFs), (PDF version with high-resolution graphics).
- ^ a b Colin Shearer (2006); First CRISP-DM 2.0 Workshop Held
- ^ a b Lukasz Kurgan and Petr Musilek (2006); A survey of Knowledge Discovery and Data Mining process models. The Knowledge Engineering Review. Volume 21 Issue 1, March 2006, pp 1–24, Cambridge University Press, New York, NY, USA doi: 10.1017/S0269888906000737.
- ^ a b Azevedo, A. and Santos, M. F. (2008); KDD, SEMMA and CRISP-DM: a parallel overview. In Proceedings of the IADIS European Conference on Data Mining 2008, pp 182–185.
- ^ a b Gregory Piatetsky-Shapiro (2002); KDnuggets Methodology Poll
- ^ a b Gregory Piatetsky-Shapiro (2004); KDnuggets Methodology Poll
- ^ a b Gregory Piatetsky-Shapiro (2007); KDnuggets Methodology Poll
- ^ Mariscal,G.,Marban,O.,Fernandez,C. (2010). «A Survey of Data Mining and knowledge discovery process Models and methodologies». The Knowledge Engineering Review. 25 (2): 137–166. doi:10.1017/S0269888910000032. S2CID 31359633.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - ^ Harper, Gavin; Stephen D. Pickett (August 2006). «Methods for mining HTS data». Drug Discovery Today. 11 (15–16): 694–699. doi:10.1016/j.drudis.2006.06.006. PMID 16846796.
- ^ Gregory Piatetsky-Shapiro (2014); KDnuggets Methodology Poll
- ^ Martínez-Plumed, Fernando; Contreras-Ochando, Lidia; Ferri, Cèsar; Flach, Peter; Hernández-Orallo, José; Kull, Meelis; Lachiche, Nicolas; Ramírez-Quintana, María José (19 September 2017). «CASP-DM: Context Aware Standard Process for Data Mining». arXiv:1709.09003 [cs.DB].