Информационный подход к анализу базируется на различных алгоритмах извлечения закономерностей из исходных данных, результатом работы которых являются модели. Таких алгоритмов довольно много, но они не способны гарантировать качественное решение. Никакой, даже весьма изощрённый, метод сам по себе не даст хорошего результата, так как критически важным является качество исходных
данных. Чаще всего именно оно становится причиной неудачи. Несмотря на то что существуют специальные методы очистки данных, понимание и соблюдение
принципов сбора и подготовки данных значительно облегчит построение моделей и позволит получить хорошие результаты.
Данные, которые накапливают предприятия и организации в базах данных и прочих источниках (так называемые бизнес-данные), имеют свои особенности. Рассмотрим их.
Бизнес-данные редко накапливаются специально для решения задач анализа.
Предприятия и организации собирают данные для коммерческих целей: ведения учета, проведения финансового анализа, составления отчетности, принятия решений и т, п. Этим бизнес-данные отличаются от экспериментальных данных, которые
собираются для исследовательских целей. Основными потребителями бизнес-данных обычно являются лица, принимающие решения в компаниях.
Бизнес-данные, как правило, содержат ошибки, аномалии, противоречия и пропуски. Это следствие того, что компании не собирают данные с целью анализа. В них появляются ошибки различной природы, что снижает качество данных.
С точки зрения анализа объемы хранимых данных очень велики. Современные
базы данных содержат мегабайты и гигабайты информации. Для ресурсоемких
алгоритмов анализа данных таблицу объемом 50 тыс. записей можно считать большой, поэтому при построении моделей важно применять процедуры сэмплинга, сокращения записей и отбора информативных признаков либо использовать специальные масштабируемые алгоритмы, способные работать на больших наборах данных.
Отмеченные особенности бизнес-данных влияют как на сам процесс анализа, так и на подготовку и систематизацию данных.
При сборе данных нужно придерживаться следующих принципов.
1. Абстрагироваться от существующих информационных систем и имеющихся в наличии данных. Большие объемы накопленных данных совершенно не говорят о том, что их достаточно для анализа в конкретной компании, Необходимо
отталкиваться от задачи и подбирать данные для ее решения, а не брать имеющуюся информацию. К примеру, при построении моделей прогноза продаж
опрос экспертов показал, что на спрос очень влияет цветовая характеристика товара. Анализ имеющихся данных продемонстрировал, что информация о цвете товарной позиции отсутствует в учетной системе. Значит, нужно каким-то образом добавить эти данные, иначе не стоит рассчитывать на хороший результат использования моделей.
2. Описать все факторы, потенциально влияющие на анализируемый процесс/объект. Основным инструментом здесь становится опрос экспертов и людей, непосредственно владеющих проблемной ситуацией. Необходимо максимально использовать знания экспертов о предметной области и, полагаясь на здравый смысл, постараться собрать и систематизировать максимум возможных предположений и гипотез.
3. Экспертно оценить значимость каждого фактора. Эта оценка не является окончательной, она будет отправной точкой. В процессе анализа вполне может
выяснится, что фактор, который эксперты посчитали очень важным, таковым не является, и наоборот, незначимый, с их точки зрения, фактор может оказывать значительное влияние на результат.
4. Определить способ представления информации — число, дата, да/нет, категория (то есть тип данных). Определить способ представления, то есть формализовать некоторые данные, просто. Например, объем продаж в рублях — это определенное число. Но довольно часто бывает непонятно, как представить фактор. Чаще всего такие проблемы возникают с качественными характеристиками. Например, на объемы продаж влияет качество товара. Качество — сложное понятие, но если этот показатель действительно важен, то нужно придумать способ его
формализации. Скажем, качество можно определять по количеству брака на тысячу единиц продукции либо оценивать экспертно, разбив на несколько категорий — отлично/хорошо/удовлетворительно/плохо.
5. Собрать все легкодоступные факторы. Они содержатся в первую очередь в источниках структурированной информации — учетных системах, базах данных и т. п.
6. Обязательно собрать наиболее значимые, с точки зрения экспертов, факторы. Вполне возможно, что без них не удастся построить качественную модель.
7. Оценить сложность и стоимость сбора средних и наименее важных по значимости факторов. Некоторые данные легкодоступны, их можно извлечь из существующих информационных систем. Но есть информация, которую непросто собрать, например сведения о конкурентах, поэтому необходимо оценить, во что обойдется сбор данных. Сбор данных не является самоцелью. Если информацию получить легко, то, естественно, нужно ее собрать. Если сложно, то необходимо соизмерить затраты на ее сбор и систематизацию с ожидаемыми результатами.
Рассмотрим эти принципы на примере формализации данных при решении задачи прогнозирования спроса. На этапе описания факторов, влияющих на продажи, и выдвижения гипотез полезно составить таблицу факторов и их значимости (табл. 1.3).
Таблица 1.3. Факторы, влияющие на продажи, и их значимость
Фактор Экспертная оценка
значимости (1—109)
Сезон 100
День недели 80
Объем продаж за предыдущие недели 190
Объем продаж за аналогичный период
прошлого года 95
При создании подобной таблицы следуют принципам 1—3 формализации данных. Далее необходимо определить способ представления данных и оценить
стоимость их сбора. К таблице добавятся еще два столбца (табл. 1.4). (добавили: Способ представления (Число, Дата, Число и т.д.), Экспертная оценка сложности получения (Низкая, Высокая и т.д.)) И уже после этого можно принимать решение о том, какие факторы включать в анализ, а какими пренебречь. Очевидно, что все легкодоступные показатели с высокой экспертной значимостью требуется включать в рассмотрение. А фактором «Качество продукции», например, можно пренебречь: по мнению экспертов, он малозначим, а стоимость его сбора велика.
Есть несколько методов сбора необходимых для анализа данных.
1. Получение из учетных систем. Обычно в учетных системах есть различные механизмы построения отчетов и экспорта данных, поэтому извлечение нужной информации из них чаще всего относительно несложная операция.
2. Получение данных из косвенных источников информации. О многих показателях можно судить по косвенным признакам, и этим нужно воспользоваться. Например, можно оценить реальное финансовое положение жителей определенного региона следующим образом. В большинстве случаев имеется несколько товаров, предназначенных для выполнения одной и той же функции, но отличающихся по цене: товары для бедных, средних и богатых. Если получить отчет о продажах товара в интересующем регионе и проанализировать пропорции, в которых продаются товары для бедных, средних и богатых, то можно предположить, что чем больше доля дорогих изделий из одной товарной группы, тем более состоятельны в среднем жители данного региона.
3. Использование открытых источников. Большое количество данных присутствует в таких открытых источниках, как статистические сборники, отчеты
корпораций, опубликованные результаты маркетинговых исследований и пр.
4. Приобретение аналитических отчетов у специализированных компаний. На рынке работает множество компаний, которые профессионально занимаются сбором данных и представлением результатов клиентам для последующего анализа. Собираемая информация обычно представляется в виде различных таблиц и сводок, которые с успехом можно применять при анализе. Стоимость получения подобной информации чаще всего относительно
невысока.
5. Проведение собственных маркетинговых исследований и аналогичных мероприятий по сбору данных. Этот вариант сбора данных может быть достаточно дорогостоящим, но в любом случае он существует.
6. Ввод данных вручную. Данные вводятся по различного рода экспертным оценкам сотрудниками организации. Такой метод является наиболее трудоемким.
Методы сбора информации существенно отличаются по стоимости и необходимому времени, поэтому следует соизмерять затраты с результатами. Возможно, от сбора некоторых данных придется отказаться, но факторы, которые эксперты оценили как наиболее значимые, нужно собрать обязательно, несмотря на стоимость этих работ, либо вообще не проводить анализ.
Данные должны быть собраны в единую таблицу в формате Excel, DBase, в текстовые файлы с разделителями или в набор таблиц в любой реляционной СУБД (системе управления базами данных), то есть должны быть представлены в структурированном виде, Кроме того, необходимо унифицировать представление данных: один и тот же объект должен везде описываться одинаково.
Аналитические инструменты пытаются построить модели на основе предложенных данных, поэтому чем ближе данные к действительности, тем лучше. Необходимо понимать: модель не может «знать» о том, что находится за пределами собранных для анализа данных. Например, если при создании системы диагностики больных использовать только сведения о больных людях, то модель не будет знать о существовании в природе здоровых людей.
Существуют требования к минимальным объемам данных для возможности построения моделей на их основе. В зависимости от представления данных и решаемой задачи эти требования различны.
Для временных рядов, которые относятся к упорядоченным данным, требования следующие. Если для моделируемого бизнес-процесса (например, продажи) характерна сезонность/цикличность, то необходимо иметь данные хотя бы за один
полный сезон/цикл с возможностью варьирования интервалов (понедельное, помесячное ит. д.). Максимальный горизонт прогнозирования зависит от объема данных: данные за 1,5 года — прогноз возможен максимум на 1 месяц; данные за 2-3 года — на 2 месяца.
Для неупорядоченных данных требования следующие.
— Количество примеров (прецедентов) должно быть значительно больше количества факторов.
— Желательно, чтобы данные покрывали как можно больше ситуаций реального процесса.
— Пропорции различных примеров (прецедентов) должны примерно соответствовать реальному процессу.
Транзакционные данные. Анализ транзакций целесообразно производить на большом объеме данных, иначе могут быть выявлены статистически необоснованные правила. Алгоритмы поиска ассоциативных связей способны быстро перерабатывать огромные массивы данных. Примерное соотношение между количеством
объектов и объемом данных следующее:
— 300-500 объектов — не менее 10 тыс. транзакций;
— 500-1000 объектов — более 300 тыс. транзакций.
Одной из распространенных ошибок при сборе данных из структурированных источников является стремление взять для анализа как можно больше признаков, описывающих объекты. Между тем предварительная оценка данных, которая проводится визуально при помощи таблиц и базовой статистической информации по набору данных, существенно помогает в определении информативности признаков с точки зрения анализа.
Среди неинформативных признаков выделяется четыре типа:
— признаки, содержащие только одно значение;
— признаки, содержащие в основном одно значение;
— признаки с уникальными значениями;
— признаки, между которыми имеет место сильная корреляция, — в этом случае для анализа можно взять один столбец.
Признаки, содержащие в основном одно значение, не всегда могут быть неинформативными, многое зависит от целей анализа Например, при решении задачи
анализа отклонений такие признаки могут существенно повлиять на построение моделей.
![]()
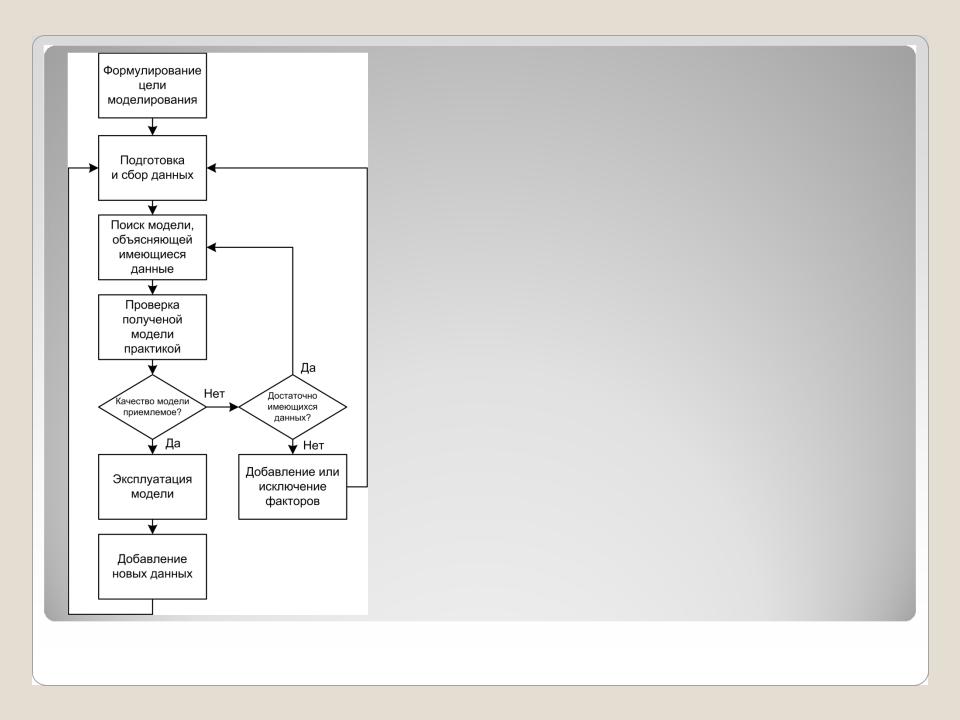
Процесс построения моделей состоит из нескольких шагов:
1. Формулирование цели моделирования. При построении модели следует отталкиваться от задачи, которую можно рассматривать как получение ответа на интересующий нас вопрос.
|
07.03.13 Доцент С.Т. Касюк |
3 |

Например, в спорте к таким вопросам относятся следующие. Каких результатов добились спортсмены за определенный период?
У каких спортсменов лучшие результаты?
Из каких спортсменов необходимо набирать команду? Как оптимизировать процесс тренировок?
В этом случае можно говорить о создании модели прогнозирования в спорте.
|
07.03.13 Доцент С.Т. Касюк |
4 |

2. Подготовка и сбор данных.
Информационный подход к моделированию основан на использовании данных, подготовить и систематизировать которые — отдельная сложная задача.
|
07.03.13 Доцент С.Т. Касюк |
5 |

3. Поиск модели. После сбора и систематизации данных переходят к поиску модели, которая объясняла бы имеющиеся данные, позволила бы добиться эмпирически обоснованных ответов на интересующие вопросы. В промышленном анализе данных предпочтение отдается самообучающимся алгоритмам, машинному обучению, методам
Data Mining.
|
07.03.13 Доцент С.Т. Касюк |
6 |

4.Проверка полученной модели. Если построенная модель показывает приемлемые результаты на практике, еѐ запускают эксплуатацию.
5.Если качество модели неудовлетворительное, то процесс построения модели повторяется.
|
07.03.13 Доцент С.Т. Касюк |
7 |

Моделирование позволяет получать новые знания, которые невозможно извлечь каким-либо другим способом. Кроме того, полученные результаты представляют собой формализованное описание некоего процесса, вследствие чего поддаются автоматической обработке.
|
07.03.13 Доцент С.Т. Касюк |
8 |
Однако результаты, полученные при использовании моделей,
очень чувствительны к качеству данных, к знаниям аналитика и экспертов и к формализации самого изучаемого процесса. К тому же почти всегда имеются случаи, не укладывающиеся ни в какие модели.
|
07.03.13 Доцент С.Т. Касюк |
9 |

КОМПЬЮТЕРНАЯ ОБРАБОТКА ДАННЫХ ЭКСПЕРИМЕНТАЛЬНЫХ ИССЛЕДОВАНИЙ
§5. Подготовка и сбор данных

Информационный подход к анализу базируется на различных алгоритмах извлечения закономерностей из исходных данных, результатом работы которых являются модели. Таких алгоритмов довольно много, но они не способны гарантировать качественное решение. Никакой, даже весьма изощренный, метод сам по себе не даст хорошего результата, так как критически важным является качество исходных данных. Чаще всего именно оно становится причиной неудачи.
|
07.03.13 Доцент С.Т. Касюк |
2 |

Особенности данных, накопленных в компаниях
Данные, которые накапливают предприятия и организации в базах данных и прочих источниках, имеют свои особенности:
1. Данные редко накапливаются
специально для решения задач анализа.
Компании часто собирают данные для коммерческих целей: ведения учета, проведения финансового анализа, составления отчетности, принятия решений и т.п. Этим бизнес-данные отличаются от экспериментальных данных, которые собираются для исследовательских целей.
|
07.03.13 Доцент С.Т. Касюк |
3 |
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
1. Современные компьютерные технологии сбора, хранения, обработки, анализа и передачи информации для решения профессиональных
задач
«Информационные технологии в науке и производстве»,
тема 3
Д.т.н., доц. Ханова А.А.
2. Анализ данных
исследования, связанные с обсчетом многомерной системы
данных, имеющей множество параметров
Обработка
информации
после ее
сбора
Средство
проверки
гипотез и
решения
задач
исследовател
я
анализ данных тесно связан с моделированием
3.
4. Подходы к моделированию
Аналитический
При аналитическом подходе мы пытаемся подобрать
существующую аналитическую модель таким образом, чтобы она
адекватно отражала реальность
Информационный
при информационном подходе отправной точкой являются данные,
характеризующие исследуемый объект, и модель «подстраивается»
под действительность.
5.
6. Процесс анализа
Эксперт — специалист в предметной области,
профессионал, который за годы обучения и практической
деятельности научился эффективно решать задачи,
относящиеся к конкретной предметной области
Гипотеза — предположение о влиянии какого-либо фактора
или группы факторов на результат.
Аналитик — специалист в области анализа и
моделирования:
владеет инструментальными и программными средствами
анализа данных,
систематизирует данные, проводит опрос мнений
экспертов,
координирует действий всех участников проекта по анализу
данных.
7. Общая схема анализа
8. Извлечение и визуализация данных
Способы визуализации:
многомерные кубы;
таблицы;
диаграммы, гистограммы;
карты, проекции, срезы и т.п.
+ простота
— люди не могут обнаруживать сложные и нетривиальные зависимости,
невозможно отделить знания от эксперта и тиражировать знания
9. Этапы моделирования
10. Формы представления данных
Данные – сведения, характеризующие систему, явление, процесс
или объект, представленные в определенной форме и
предназначенные для дальнейшего использования
По степени структурированности:
Неструктурированные данные — произвольные по форме,
включают тексты и графику,
мультимедиа (видео, речь, аудио).
Структурированные данные отражают
отдельные факты предметной области.
Это основная форма представления сведений
в базах данных.
Слабоструктурированные данные — это данные, для которых
определены некоторые правила и форматы, но в самом общем виде.
Например, строка с адресом, строка в прайс-листе, ФИО и т. п.
11. Типы структурированных данных
целый (количество товара, код товара и т. п.);
вещественный (цена, скидка и т. п.);
строковый (фамилия, наименование, адрес, пол, образование и т.п.);
логический;
дата/время.
Виды структурированных данных
Непрерывные данные — данные, значения которых могут принимать какое угодно
значение в некотором интервале. Над непрерывными данными можно производить
арифметические операции сложения, вычитания, умножения, деления, и они имеют
смысл.
Дискретные данные — значения признака, общее число которых конечно либо
бесконечно, но может быть подсчитано при помощи натуральных чисел от одного до
бесконечности. С дискретными данными не могут быть произведены никакие
арифметические действия, либо они не имеют смысла.
Соответствие между
типами и видами
данных
12. Представления наборов данных
Упорядоченный набор данных — каждому столбцу соответствует один фактор, а в
каждую строку заносятся упорядоченные по какому-либо признаку (например, время)
события с интервалом периода между строками.
Неупорядоченный набор — каждому столбцу соответствует фактор, а в каждую строку
заносится пример (ситуация, прецедент), упорядоченность строк не требуется.
Транзакционные данные — любые связанные объекты или действия.
13. Подготовка данных к анализу
Особенности данных, накопленных в организациях
Данные редко накапливаются специально для решения задач анализа.
Данные, как правило, содержат ошибки, аномалии, противоречия и пропуски.
С точки зрения анализа объемы хранимых данных очень велики.
Принципы формализации данных
1.
Абстрагироваться от существующих ИС и имеющихся в наличии данных.
2.
Описать все факторы, потенциально влияющие на анализируемый процесс/объект.
3.
Экспертно оценить значимость каждого фактора.
4.
Определить способ представления информации — число, дата, да/нет, категория
(то есть тип данных).
5.
Собрать все легкодоступные факторы.
6.
Обязательно собрать наиболее значимые, с точки зрения экспертов, факторы.
7.
Оценить сложность и стоимость сбора средних и наименее важных по значимости
факторов.
14.
Таблица 1
Решение задачи
прогнозирования спроса
При создании таблицы 1
следуют принципам 1–3
формализации данных.
Таблица 2
Далее необходимо определить способ
представления данных и оценить
стоимость их сбора. К
таблице добавятся еще два столбца
(таблица 2). И уже после этого можно
принимать решение
о том, какие факторы включать в анализ,
а какими пренебречь. Очевидно, что все
легкодоступные показатели с высокой
экспертной значимостью требуется
включать в рассмотрение. А фактором
Качество продукции, например, можно
пренебречь: по мнению экспертов, он
малозначим, а стоимость его сбора
велика
15. Методы сбора данных
1.
Получение из учетных систем.
2.
Получение данных из косвенных
источников информации.
3.
Использование открытых источников
(статистические сборники, отчеты
корпораций, опубликованные
результаты маркетинговых
исследований и пр.).
4.
Приобретение аналитических отчетов у
специализированных компаний
5.
Проведение собственных
маркетинговых исследований и
аналогичных мероприятий по сбору
данных.
6.
Ввод данных вручную.
соизмерение затрат с
результатами
представление в
структурированном виде (MS
Excel, DBase, текстовые
файлы с разделителями или в
набор таблиц в любой
реляционной СУБД )
унифицированное
представление данных
16. Информативность данных
неинформативные признаки:
признаки, содержащие только одно значение (а);
признаки, содержащие в основном одно значение (б);
признаки с уникальными значениями (в);
признаки, между которыми имеет место сильная корреляция, — в
этом случае для анализа можно взять один столбец (г).
17. Требования к данным
Для временных рядов, которые относятся к упорядоченным данным.
Если для моделируемого бизнес-процесса (например, продажи) характерна
сезонность/цикличность, то необходимо иметь данные хотя бы за один полный
сезон/цикл с возможностью варьирования интервалов (понедельное,
помесячное и т. д.).
Максимальный горизонт прогнозирования зависит от объема данных:
данные за 1,5 года — прогноз возможен максимум на 1 месяц;
данные за 2–3 года — на 2 месяца.
Для неупорядоченных данных :
Количество примеров (прецедентов) должно быть значительно больше
количества факторов.
Желательно, чтобы данные покрывали как можно больше ситуаций реального
процесса.
Пропорции различных примеров (прецедентов) должны примерно
соответствовать реальному процессу.
Для Транзакционных данных.
Анализ транзакций целесообразно производить на большом объеме данных,
иначе могут быть выявлены статистически необоснованные правила. Алгоритмы
поиска ассоциативных связей способны быстро перерабатывать огромные
массивы данных.
300–500 объектов — не менее 10 тыс. транзакций;
500–1000 объектов — более 300 тыс. транзакций.
18. Методика извлечения знаний
Knowledge Discovery in Databases — процесс получения из данных
знаний в виде зависимостей, правил, моделей, обычно состоящий из
таких этапов, как выборка данных, их очистка и трансформация,
моделирование и интерпретация полученных результатов.
19. Data Mining
обнаружение в «сырых» данных ранее неизвестных,
нетривиальных, практически полезных и доступных
интерпретации знаний, необходимых для принятия решений в
различных сферах человеческой деятельности.
Кассы задач:
1.
Классификация – установление зависимости дискретной выходной
переменной от входных переменных.
2.
Регрессия – установление зависимости непрерывной выходной
переменной от входных переменных.
3.
Кластеризация – группировка объектов (наблюдений, событий) на
основе данных, описывающих свойства объектов. Объекты внутри
кластера должны быть похожими друг на друга и отличаться от
других, которые вошли в другие кластеры.
4.
Ассоциация – выявление закономерностей между связанными
событиями. Примером такой закономерности служит правило,
указывающее, что из события X следует событие Y. Такие правила
называются ассоциативными.
5.
Анализ отклонений (deviation detection).
6.
Связей (link analysis).
7.
Отбор значимых признаков (feature selection).
20.
Отнесение нового товара к той или иной
товарной группе, клиента к какой-либо
категории
При кредитовании – по каким-то признакам к
одной из групп риска
Зависимость между суммой продаж, и
факторами, влияющими на нее, (предыдущие
объемы продаж, изменение курсов валют,
активность конкурентов)
При кредитовании физических лиц вероятность
возврата кредита зависит от личных
характеристик человека, сферы его
деятельности, наличия имущества
При достаточно большом количестве клиентов
становится трудно подходить к каждому
индивидуально, поэтому их удобно объединять
в группы — сегменты с однородными
признаками. Например по сфере деятельности,
по географическому расположению. После
кластеризации можно узнать, какие сегменты
наиболее активны, какие приносят наибольшую
прибыль, выделить характерные для них
признаки. Эффективность работы с клиентами
повышается благодаря учету их персональных
предпочтений.
21.
22. Машинное обучение
Машинное обучение (machine learning) — обширный подраздел
искусственного интеллекта, изучающий методы построения алгоритмов,
способных обучаться на данных.
Имеется множество объектов (ситуаций) и множество возможных
ответов (откликов, реакций).
Между ответами и объектами существует некоторая зависимость,
но она неизвестна. Известна только конечная совокупность
прецедентов — пар вида «объект — ответ», — называемая
обучающей выборкой.
На основе этих данных требуется обнаружить зависимость, то есть
построить модель, способную для любого объекта выдать достаточно
точный ответ. Чтобы измерить точность ответов, вводится критерий
качества.
23. Причины распространения KDD и Data Mining
1.
Развитие технологий автоматизированной обработки информации
создало основу для учета сколь угодно большого количества факторов
и достаточного объема данных.
2.
Возникла острая нехватка высококвалифицированных специалистов
в области статистики и анализа данных. Поэтому потребовались
технологии обработки и анализа, доступные для специалистов любого
профиля за счет применения методов визуализации и
самообучающихся алгоритмов.
3.
Возникла объективная потребность в тиражировании знаний.
Полученные в процессе KDD и Data Mining результаты являются
формализованным описанием некоего процесса, а следовательно,
поддаются автоматической обработке и повторному использованию на
новых данных.
4.
На рынке появились программные продукты, поддерживающие
технологии KDD и Data Mining, – аналитические платформы. С их
помощью можно создавать полноценные аналитические решения и
быстро получать первые результаты.
24.
25. Программное обеспечение в области анализа данных
26. Статистические пакеты с возможностями Data Mining и настольные Data Mining пакеты
1.
слабая интеграция с промышленными источниками данных;
2.
бедные средства очистки, предобработки и трансформации
данных;
3.
отсутствие гибких возможностей консолидации
информации, например, в специализированном хранилище
данных;
4.
конвейерная (поточная) обработка новых данных
затруднительна или реализуется встроенными языками
программирования и требует высокой квалификации;
5.
из-за использования пакетов на локальных рабочих
станциях обработка больших объемов данных затруднена.
27.
СУБД с элементами Data Mining:
высокая производительность;
алгоритмы анализа данных по максимуму используют
преимущества СУБД;
жесткая привязка всех технологий анализа к одной СУБД;
сложность в создании прикладных решений, поскольку работа с
СУБД ориентирована на программистов и администраторов баз
данных.
Аналитическая платформа –
Специализированное программное решение (или набор
решений), которое содержит в себе все инструменты для
извлечения закономерностей из «сырых» данных:
средства консолидации информации в едином источнике
(хранилище данных),
извлечения, преобразования,
трансформации данных,
алгоритмы Data Mining,
средства визуализации и распространения результатов среди
пользователей,
возможности конвейерной» обработки новых данных.
28.
Типовая схема системы на базе аналитической платформы
29. Языки визуального моделирования
!важно освободить аналитика от необходимости углубленного
понимания сложных математических алгоритмов.
Формы представления
диаграмм:
в виде дерева
и в виде графа
30. Общие особенности языков моделирования в аналитических платформах
1.
Базовым узлом, с которого начинается диаграмма, является
узел импорта, поскольку в аналитических платформах обычно
отсутствуют средства для ручного ввода данных;
предполагается, что данные уже имеются в каких-либо
источниках.
2.
Графическое изображение, соответствующее какому-либо
узлу, несет в себе большой семантический смысл. Оно
помогает аналитику различать узлы по функциям и определять
их активность (часто еще не выполненный узел обозначается
иконкой серого цвета, а выполненный — цветной).
3.
Диаграмма описывает формализованную последовательность
действий над данными, и эти действия можно повторить на
совершенно других данных, предварительно настроив
соответствие колонок.
1
Первый слайд презентации: Современные компьютерные технологии сбора, хранения, обработки, анализа и передачи информации для решения профессиональных задач
«Информационные технологии в науке и производстве», тема 3
Д.т.н., доц. Ханова А.А.

Изображение слайда
2
Слайд 2: Анализ данных
исследования, связанные с обсчетом многомерной системы данных, имеющей множество параметров
анализ данных тесно связан с моделированием

Изображение слайда

Изображение слайда
4
Слайд 4: Подходы к моделированию
Аналитический
При аналитическом подходе мы пытаемся подобрать существующую аналитическую модель таким образом, чтобы она адекватно отражала реальность
Информационный
при информационном подходе отправной точкой являются данные, характеризующие исследуемый объект, и модель «подстраивается» под действительность.

Изображение слайда

Изображение слайда
6
Слайд 6: Процесс анализа
Эксперт — специалист в предметной области, профессионал, который за годы обучения и практической деятельности научился эффективно решать задачи, относящиеся к конкретной предметной области
Гипотеза — предположение о влиянии какого-либо фактора или группы факторов на результат.
Аналитик — специалист в области анализа и моделирования:
владеет инструментальными и программными средствами анализа данных,
систематизирует данные, проводит опрос мнений экспертов,
координирует действий всех участников проекта по анализу данных.

Изображение слайда
7
Слайд 7: Общая схема анализа

Изображение слайда
8
Слайд 8: Извлечение и визуализация данных
Способы визуализации:
многомерные кубы;
таблицы;
диаграммы, гистограммы;
карты, проекции, срезы и т.п.
+ простота
— люди не могут обнаруживать сложные и нетривиальные зависимости, невозможно отделить знания от эксперта и тиражировать знания

Изображение слайда
9
Слайд 9: Этапы моделирования

Изображение слайда
10
Слайд 10: Формы представления данных
Данные – сведения, характеризующие систему, явление, процесс или объект, представленные в определенной форме и предназначенные для дальнейшего использования
По степени структурированности:
Неструктурированные данные — произвольные по форме,
включают тексты и графику,
мультимедиа (видео, речь, аудио).
Структурированные данные отражают
отдельные факты предметной области.
Это основная форма представления сведений
в базах данных.
Слабоструктурированные данные — это данные, для которых определены некоторые правила и форматы, но в самом общем виде. Например, строка с адресом, строка в прайс-листе, ФИО и т. п.

Изображение слайда
11
Слайд 11: Типы структурированных данных
целый (количество товара, код товара и т. п.);
вещественный (цена, скидка и т. п.);
строковый (фамилия, наименование, адрес, пол, образование и т.п.);
логический;
дата/время.
Виды структурированных данных
Непрерывные данные — данные, значения которых могут принимать какое угодно значение в некотором интервале. Над непрерывными данными можно производить арифметические операции сложения, вычитания, умножения, деления, и они имеют смысл.
Дискретные данные — значения признака, общее число которых конечно либо бесконечно, но может быть подсчитано при помощи натуральных чисел от одного до бесконечности. С дискретными данными не могут быть произведены никакие арифметические действия, либо они не имеют смысла.
Соответствие между типами и видами данных

Изображение слайда
12
Слайд 12: Представления наборов данных
Упорядоченный набор данных — каждому столбцу соответствует один фактор, а в каждую строку заносятся упорядоченные по какому-либо признаку (например, время) события с интервалом периода между строками.
Неупорядоченный набор — каждому столбцу соответствует фактор, а в каждую строку заносится пример (ситуация, прецедент), упорядоченность строк не требуется.
Транзакционные данные — любые связанные объекты или действия.

Изображение слайда
13
Слайд 13: Подготовка данных к анализу
Особенности данных, накопленных в организациях
Данные редко накапливаются специально для решения задач анализа.
Данные, как правило, содержат ошибки, аномалии, противоречия и пропуски.
С точки зрения анализа объемы хранимых данных очень велики.
Принципы формализации данных
Абстрагироваться от существующих ИС и имеющихся в наличии данных.
Описать все факторы, потенциально влияющие на анализируемый процесс/объект.
Экспертно оценить значимость каждого фактора.
Определить способ представления информации — число, дата, да/нет, категория (то есть тип данных).
Собрать все легкодоступные факторы.
Обязательно собрать наиболее значимые, с точки зрения экспертов, факторы.
Оценить сложность и стоимость сбора средних и наименее важных по значимости факторов.

Изображение слайда
При создании таблицы 1 следуют принципам 1–3 формализации данных.
Решение задачи
прогнозирования спроса
Далее необходимо определить способ представления данных и оценить стоимость их сбора. К
таблице добавятся еще два столбца (таблица 2). И уже после этого можно принимать решение
о том, какие факторы включать в анализ, а какими пренебречь. Очевидно, что все
легкодоступные показатели с высокой экспертной значимостью требуется включать в рассмотрение. А фактором Качество продукции, например, можно пренебречь: по мнению экспертов, он малозначим, а стоимость его сбора велика
Таблица 1
Таблица 2

Изображение слайда
15
Слайд 15: Методы сбора данных
Получение из учетных систем.
Получение данных из косвенных источников информации.
Использование открытых источников (статистические сборники, отчеты корпораций, опубликованные результаты маркетинговых исследований и пр.).
Приобретение аналитических отчетов у специализированных компаний
Проведение собственных маркетинговых исследований и аналогичных мероприятий по сбору данных.
Ввод данных вручную.
соизмерение затрат с результатами
представление в структурированном виде (MS Excel, DBase, текстовые файлы с разделителями или в набор таблиц в любой реляционной СУБД )
унифицированное представление данных

Изображение слайда
16
Слайд 16: Информативность данных
неинформативные признаки:
признаки, содержащие только одно значение (а);
признаки, содержащие в основном одно значение (б);
признаки с уникальными значениями (в);
признаки, между которыми имеет место сильная корреляция, — в этом случае для анализа можно взять один столбец ( г ).

Изображение слайда
17
Слайд 17: Требования к данным
Для временных рядов, которые относятся к упорядоченным данным.
Если для моделируемого бизнес-процесса (например, продажи) характерна сезонность/цикличность, то необходимо иметь данные хотя бы за один полный сезон/цикл с возможностью варьирования интервалов (понедельное, помесячное и т. д.).
Максимальный горизонт прогнозирования зависит от объема данных:
данные за 1,5 года — прогноз возможен максимум на 1 месяц;
данные за 2–3 года — на 2 месяца.
Для неупорядоченных данных :
Количество примеров (прецедентов) должно быть значительно больше количества факторов.
Желательно, чтобы данные покрывали как можно больше ситуаций реального процесса.
Пропорции различных примеров (прецедентов) должны примерно соответствовать реальному процессу.
Для Транзакционных данных.
Анализ транзакций целесообразно производить на большом объеме данных, иначе могут быть выявлены статистически необоснованные правила. Алгоритмы поиска ассоциативных связей способны быстро перерабатывать огромные массивы данных.
300–500 объектов — не менее 10 тыс. транзакций;
500–1000 объектов — более 300 тыс. транзакций.

Изображение слайда
18
Слайд 18: Методика извлечения знаний
Knowledge Discovery in Databases — процесс получения из данных знаний в виде зависимостей, правил, моделей, обычно состоящий из таких этапов, как выборка данных, их очистка и трансформация, моделирование и интерпретация полученных результатов.

Изображение слайда
обнаружение в «сырых» данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Кассы задач:
Классификация – установление зависимости дискретной выходной переменной от входных переменных.
Регрессия – установление зависимости непрерывной выходной переменной от входных переменных.
Кластеризация – группировка объектов (наблюдений, событий) на основе данных, описывающих свойства объектов. Объекты внутри кластера должны быть похожими друг на друга и отличаться от других, которые вошли в другие кластеры.
Ассоциация – выявление закономерностей между связанными событиями. Примером такой закономерности служит правило, указывающее, что из события X следует событие Y. Такие правила называются ассоциативными.
Анализ отклонений ( deviation detection ).
Связей ( link analysis ).
Отбор значимых признаков ( feature selection ).

Изображение слайда
Отнесение нового товара к той или иной товарной группе, клиента к какой-либо категории
При кредитовании – по каким-то признакам к одной из групп риска
Зависимость между суммой продаж, и факторами, влияющими на нее, (предыдущие объемы продаж, изменение курсов валют, активность конкурентов)
При кредитовании физических лиц вероятность возврата кредита зависит от личных характеристик человека, сферы его деятельности, наличия имущества
При достаточно большом количестве клиентов становится трудно подходить к каждому индивидуально, поэтому их удобно объединять в группы — сегменты с однородными признаками. Например по сфере деятельности, по географическому расположению. После кластеризации можно узнать, какие сегменты наиболее активны, какие приносят наибольшую прибыль, выделить характерные для них признаки. Эффективность работы с клиентами повышается благодаря учету их персональных предпочтений.

Изображение слайда

Изображение слайда
22
Слайд 22: Машинное обучение
Машинное обучение (machine learning) — обширный подраздел искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться на данных.
Имеется множество объектов ( ситуаций ) и множество возможных ответов ( откликов, реакций ).
Между ответами и объектами существует некоторая зависимость, но она неизвестна. Известна только конечная совокупность прецедентов — пар вида «объект — ответ», — называемая обучающей выборкой.
На основе этих данных требуется обнаружить зависимость, то есть построить модель, способную для любого объекта выдать достаточно точный ответ. Чтобы измерить точность ответов, вводится критерий качества.

Изображение слайда
23
Слайд 23: Причины распространения KDD и Data Mining
Развитие технологий автоматизированной обработки информации создало основу для учета сколь угодно большого количества факторов и достаточного объема данных.
Возникла острая нехватка высококвалифицированных специалистов в области статистики и анализа данных. Поэтому потребовались технологии обработки и анализа, доступные для специалистов любого профиля за счет применения методов визуализации и самообучающихся алгоритмов.
Возникла объективная потребность в тиражировании знаний. Полученные в процессе KDD и Data Mining результаты являются формализованным описанием некоего процесса, а следовательно, поддаются автоматической обработке и повторному использованию на новых данных.
На рынке появились программные продукты, поддерживающие технологии KDD и Data Mining, – аналитические платформы. С их помощью можно создавать полноценные аналитические решения и быстро получать первые результаты.

Изображение слайда

Изображение слайда
25
Слайд 25: Программное обеспечение в области анализа данных

Изображение слайда
26
Слайд 26: Статистические пакеты с возможностями Data Mining и настольные Data Mining пакеты
слабая интеграция с промышленными источниками данных;
бедные средства очистки, предобработки и трансформации данных;
отсутствие гибких возможностей консолидации информации, например, в специализированном хранилище данных;
конвейерная (поточная) обработка новых данных затруднительна или реализуется встроенными языками программирования и требует высокой квалификации;
из-за использования пакетов на локальных рабочих станциях обработка больших объемов данных затруднена.

Изображение слайда
СУБД с элементами Data Mining:
высокая производительность;
алгоритмы анализа данных по максимуму используют преимущества СУБД;
жесткая привязка всех технологий анализа к одной СУБД;
сложность в создании прикладных решений, поскольку работа с СУБД ориентирована на программистов и администраторов баз данных.
Аналитическая платформа –
Специализированное программное решение (или набор решений), которое содержит в себе все инструменты для извлечения закономерностей из «сырых» данных:
средства консолидации информации в едином источнике (хранилище данных),
извлечения, преобразования,
трансформации данных,
алгоритмы Data Mining,
средства визуализации и распространения результатов среди пользователей,
возможности конвейерной» обработки новых данных.

Изображение слайда
Типовая схема системы на базе аналитической платформы

Изображение слайда
29
Слайд 29: Языки визуального моделирования
!важно освободить аналитика от необходимости углубленного понимания сложных математических алгоритмов.
Формы представления диаграмм:
в виде дерева
и в виде графа

Изображение слайда
30
Последний слайд презентации: Современные компьютерные технологии сбора, хранения, обработки, анализа и: Общие особенности языков моделирования в аналитических платформах
Базовым узлом, с которого начинается диаграмма, является узел импорта, поскольку в аналитических платформах обычно отсутствуют средства для ручного ввода данных; предполагается, что данные уже имеются в каких-либо источниках.
Графическое изображение, соответствующее какому-либо узлу, несет в себе большой семантический смысл. Оно помогает аналитику различать узлы по функциям и определять их активность (часто еще не выполненный узел обозначается иконкой серого цвета, а выполненный — цветной).
Диаграмма описывает формализованную последовательность действий над данными, и эти действия можно повторить на совершенно других данных, предварительно настроив соответствие колонок.

Изображение слайда
Предложите, как улучшить StudyLib
(Для жалоб на нарушения авторских прав, используйте
другую форму
)
Ваш е-мэйл
Заполните, если хотите получить ответ
Оцените наш проект
1
2
3
4
5
Слайд 1Современные компьютерные технологии сбора, хранения, обработки, анализа и передачи информации
для решения профессиональных задач
«Информационные технологии в науке и производстве», тема
3
Д.т.н., доц. Ханова А.А.

Слайд 2Анализ данных
исследования, связанные с обсчетом многомерной системы данных, имеющей множество
параметров
анализ данных тесно связан с моделированием

Слайд 4Подходы к моделированию
Аналитический
При аналитическом подходе мы пытаемся подобрать существующую аналитическую
модель таким образом, чтобы она адекватно отражала реальность
Информационный
при информационном подходе
отправной точкой являются данные, характеризующие исследуемый объект, и модель «подстраивается» под действительность.

Слайд 6Процесс анализа
Эксперт — специалист в предметной области, профессионал, который за
годы обучения и практической деятельности научился эффективно решать задачи, относящиеся
к конкретной предметной области
Гипотеза — предположение о влиянии какого-либо фактора или группы факторов на результат.
Аналитик — специалист в области анализа и моделирования:
владеет инструментальными и программными средствами анализа данных,
систематизирует данные, проводит опрос мнений экспертов,
координирует действий всех участников проекта по анализу данных.

Слайд 8Извлечение и визуализация данных
Способы визуализации:
многомерные кубы;
таблицы;
диаграммы, гистограммы;
карты, проекции, срезы и
т.п.
+ простота
— люди не могут обнаруживать сложные и нетривиальные зависимости,
невозможно отделить знания от эксперта и тиражировать знания

Слайд 10Формы представления данных
Данные – сведения, характеризующие систему, явление, процесс или
объект, представленные в определенной форме и предназначенные для дальнейшего использования
По
степени структурированности:
Неструктурированные данные — произвольные по форме,
включают тексты и графику,
мультимедиа (видео, речь, аудио).
Структурированные данные отражают
отдельные факты предметной области.
Это основная форма представления сведений
в базах данных.
Слабоструктурированные данные — это данные, для которых определены некоторые правила и форматы, но в самом общем виде. Например, строка с адресом, строка в прайс-листе, ФИО и т. п.

Слайд 11Типы структурированных данных
целый (количество товара, код товара и т. п.);
вещественный
(цена, скидка и т. п.);
строковый (фамилия, наименование, адрес, пол, образование
и т.п.);
логический;
дата/время.
Виды структурированных данных
Непрерывные данные — данные, значения которых могут принимать какое угодно значение в некотором интервале. Над непрерывными данными можно производить арифметические операции сложения, вычитания, умножения, деления, и они имеют смысл.
Дискретные данные — значения признака, общее число которых конечно либо бесконечно, но может быть подсчитано при помощи натуральных чисел от одного до бесконечности. С дискретными данными не могут быть произведены никакие арифметические действия, либо они не имеют смысла.
Соответствие между типами и видами данных
;вещественный (цена,")
Слайд 12Представления наборов данных
Упорядоченный набор данных — каждому столбцу соответствует один
фактор, а в каждую строку заносятся упорядоченные по какому-либо признаку
(например, время) события с интервалом периода между строками.
Неупорядоченный набор — каждому столбцу соответствует фактор, а в каждую строку заносится пример (ситуация, прецедент), упорядоченность строк не требуется.
Транзакционные данные — любые связанные объекты или действия.

Слайд 13Подготовка данных к анализу
Особенности данных, накопленных в организациях
Данные редко накапливаются
специально для решения задач анализа.
Данные, как правило, содержат ошибки,
аномалии, противоречия и пропуски.
С точки зрения анализа объемы хранимых данных очень велики.
Принципы формализации данных
Абстрагироваться от существующих ИС и имеющихся в наличии данных.
Описать все факторы, потенциально влияющие на анализируемый процесс/объект.
Экспертно оценить значимость каждого фактора.
Определить способ представления информации — число, дата, да/нет, категория (то есть тип данных).
Собрать все легкодоступные факторы.
Обязательно собрать наиболее значимые, с точки зрения экспертов, факторы.
Оценить сложность и стоимость сбора средних и наименее важных по значимости факторов.

Слайд 14При создании таблицы 1 следуют принципам 1–3 формализации данных.
Решение задачи
прогнозирования
спроса
Далее необходимо определить способ представления данных и оценить стоимость их
сбора. К
таблице добавятся еще два столбца (таблица 2). И уже после этого можно принимать решение
о том, какие факторы включать в анализ, а какими пренебречь. Очевидно, что все
легкодоступные показатели с высокой экспертной значимостью требуется включать в рассмотрение. А фактором Качество продукции, например, можно пренебречь: по мнению экспертов, он малозначим, а стоимость его сбора велика
Таблица 1
Таблица 2

Слайд 15Методы сбора данных
Получение из учетных систем.
Получение данных из косвенных источников
информации.
Использование открытых источников (статистические сборники, отчеты корпораций, опубликованные результаты
маркетинговых исследований и пр.).
Приобретение аналитических отчетов у специализированных компаний
Проведение собственных маркетинговых исследований и аналогичных мероприятий по сбору данных.
Ввод данных вручную.
соизмерение затрат с результатами
представление в структурированном виде (MS Excel, DBase, текстовые файлы с разделителями или в набор таблиц в любой реляционной СУБД )
унифицированное представление данных

Слайд 16Информативность данных
неинформативные признаки:
признаки, содержащие только одно значение (а);
признаки, содержащие в
основном одно значение (б);
признаки с уникальными значениями (в);
признаки, между которыми
имеет место сильная корреляция, — в этом случае для анализа можно взять один столбец (г).
;признаки, содержащие в основном")
Слайд 17Требования к данным
Для временных рядов, которые относятся к упорядоченным данным.
Если
для моделируемого бизнес-процесса (например, продажи) характерна сезонность/цикличность, то необходимо иметь
данные хотя бы за один полный сезон/цикл с возможностью варьирования интервалов (понедельное, помесячное и т. д.).
Максимальный горизонт прогнозирования зависит от объема данных:
данные за 1,5 года — прогноз возможен максимум на 1 месяц;
данные за 2–3 года — на 2 месяца.
Для неупорядоченных данных :
Количество примеров (прецедентов) должно быть значительно больше количества факторов.
Желательно, чтобы данные покрывали как можно больше ситуаций реального процесса.
Пропорции различных примеров (прецедентов) должны примерно соответствовать реальному процессу.
Для Транзакционных данных.
Анализ транзакций целесообразно производить на большом объеме данных, иначе могут быть выявлены статистически необоснованные правила. Алгоритмы поиска ассоциативных связей способны быстро перерабатывать огромные массивы данных.
300–500 объектов — не менее 10 тыс. транзакций;
500–1000 объектов — более 300 тыс. транзакций.

Слайд 18Методика извлечения знаний
Knowledge Discovery in Databases — процесс получения из
данных знаний в виде зависимостей, правил, моделей, обычно состоящий из
таких этапов, как выборка данных, их очистка и трансформация, моделирование и интерпретация полученных результатов.

Слайд 19Data Mining
обнаружение в «сырых» данных ранее неизвестных, нетривиальных, практически полезных
и доступных интерпретации знаний, необходимых для принятия решений в различных
сферах человеческой деятельности.
Кассы задач:
Классификация – установление зависимости дискретной выходной переменной от входных переменных.
Регрессия – установление зависимости непрерывной выходной переменной от входных переменных.
Кластеризация – группировка объектов (наблюдений, событий) на основе данных, описывающих свойства объектов. Объекты внутри кластера должны быть похожими друг на друга и отличаться от других, которые вошли в другие кластеры.
Ассоциация – выявление закономерностей между связанными событиями. Примером такой закономерности служит правило, указывающее, что из события X следует событие Y. Такие правила называются ассоциативными.
Анализ отклонений (deviation detection).
Связей (link analysis).
Отбор значимых признаков (feature selection).

Слайд 20Отнесение нового товара к той или иной товарной группе, клиента
к какой-либо категории
При кредитовании – по каким-то признакам к
одной из групп риска
Зависимость между суммой продаж, и факторами, влияющими на нее, (предыдущие объемы продаж, изменение курсов валют, активность конкурентов)
При кредитовании физических лиц вероятность возврата кредита зависит от личных характеристик человека, сферы его деятельности, наличия имущества
При достаточно большом количестве клиентов становится трудно подходить к каждому индивидуально, поэтому их удобно объединять в группы — сегменты с однородными признаками. Например по сфере деятельности, по географическому расположению. После кластеризации можно узнать, какие сегменты наиболее активны, какие приносят наибольшую прибыль, выделить характерные для них признаки. Эффективность работы с клиентами повышается благодаря учету их персональных предпочтений.

Слайд 22Машинное обучение
Машинное обучение (machine learning) — обширный подраздел искусственного интеллекта,
изучающий методы построения алгоритмов, способных обучаться на данных.
Имеется множество объектов
(ситуаций) и множество возможных ответов (откликов, реакций).
Между ответами и объектами существует некоторая зависимость, но она неизвестна. Известна только конечная совокупность прецедентов — пар вида «объект — ответ», — называемая обучающей выборкой.
На основе этих данных требуется обнаружить зависимость, то есть построить модель, способную для любого объекта выдать достаточно точный ответ. Чтобы измерить точность ответов, вводится критерий качества.
 — обширный подраздел искусственного интеллекта, изучающий")
Слайд 23Причины распространения KDD и Data Mining
Развитие технологий автоматизированной обработки информации
создало основу для учета сколь угодно большого количества факторов и
достаточного объема данных.
Возникла острая нехватка высококвалифицированных специалистов в области статистики и анализа данных. Поэтому потребовались технологии обработки и анализа, доступные для специалистов любого профиля за счет применения методов визуализации и самообучающихся алгоритмов.
Возникла объективная потребность в тиражировании знаний. Полученные в процессе KDD и Data Mining результаты являются формализованным описанием некоего процесса, а следовательно, поддаются автоматической обработке и повторному использованию на новых данных.
На рынке появились программные продукты, поддерживающие технологии KDD и Data Mining, – аналитические платформы. С их помощью можно создавать полноценные аналитические решения и быстро получать первые результаты.

Слайд 25Программное обеспечение в области анализа данных

Слайд 26Статистические пакеты с возможностями Data Mining и настольные Data Mining
пакеты
слабая интеграция с промышленными источниками данных;
бедные средства очистки, предобработки и
трансформации данных;
отсутствие гибких возможностей консолидации информации, например, в специализированном хранилище данных;
конвейерная (поточная) обработка новых данных затруднительна или реализуется встроенными языками программирования и требует высокой квалификации;
из-за использования пакетов на локальных рабочих станциях обработка больших объемов данных затруднена.

Слайд 27СУБД с элементами Data Mining:
высокая производительность;
алгоритмы анализа данных по максимуму
используют преимущества СУБД;
жесткая привязка всех технологий анализа к одной СУБД;
сложность
в создании прикладных решений, поскольку работа с СУБД ориентирована на программистов и администраторов баз данных.
Аналитическая платформа –
Специализированное программное решение (или набор решений), которое содержит в себе все инструменты для извлечения закономерностей из «сырых» данных:
средства консолидации информации в едином источнике (хранилище данных),
извлечения, преобразования,
трансформации данных,
алгоритмы Data Mining,
средства визуализации и распространения результатов среди пользователей,
возможности конвейерной» обработки новых данных.

Слайд 28Типовая схема системы на базе аналитической платформы

Слайд 29Языки визуального моделирования
!важно освободить аналитика от необходимости углубленного понимания сложных
математических алгоритмов.
Формы представления диаграмм:
в виде дерева
и в виде графа

Слайд 30Общие особенности языков моделирования в аналитических платформах
Базовым узлом, с которого
начинается диаграмма, является узел импорта, поскольку в аналитических платформах обычно
отсутствуют средства для ручного ввода данных; предполагается, что данные уже имеются в каких-либо источниках.
Графическое изображение, соответствующее какому-либо узлу, несет в себе большой семантический смысл. Оно помогает аналитику различать узлы по функциям и определять их активность (часто еще не выполненный узел обозначается иконкой серого цвета, а выполненный — цветной).
Диаграмма описывает формализованную последовательность действий над данными, и эти действия можно повторить на совершенно других данных, предварительно настроив соответствие колонок.

В статье рассказываем про основные этапы сбора информации, следуя которым, можно подготовить качественные данные в нужном для анализа объеме. Данная методика — не жесткий набор инструкций, а список рекомендаций, которых желательно придерживаться.
- Выдвижение гипотез
- Формализация и сбор данных
- Представление и минимальные объемы
- Упорядоченные данные
- Неупорядоченные данные
- Транзакционные данные
- Построение моделей — анализ
B процессе анализа данных (Data Mining) используются алгоритмы машинного обучения, позволяющие прогнозировать развитие ситуации, выявлять закономерности, оценивать значимость факторов и т.п.
Подобных алгоритмов разработано множество, но даже самые мощные из них не способны гарантировать качественный результат. Алгоритмы машинного обучения могут найти закономерности в данных, только если сведения корректно собраны. На практике чаще всего именно проблемы с данными являются причиной неудач.
Ниже описаны этапы сбора информации, следуя которым, можно подготовить качественные данные в нужном для анализа объеме. В предлагаемой методике все достаточно просто и логично, но, несмотря на это, неопытные аналитики почти всегда допускают одни и те же тривиальные ошибки. Следование описанным правилам повысит вероятность получения качественного результата. Данные методика — не жесткий набор инструкций, а, скорее, список рекомендаций, которых желательно придерживаться.
Общая схема применения алгоритмов Data Mining состоит из следующих шагов (подробнее в статье «Методика анализа данных»):
- Выдвижение гипотез
- Сбор и систематизация данных
- Подбор модели, объясняющей собранные данные
- Тестирование и интерпретация результатов
- Использование модели
При этом на любом из этапов возможен возврат на один или несколько шагов назад.
Данная последовательность действий не зависит от предметной области, поэтому ее можно использовать для любой сферы деятельности.
Выдвижение гипотез
Гипотезой считается предположение о влиянии определенных факторов на исследуемый процесс. Форма зависимости значения не имеет. Т.е. в процессе выдвижения гипотезы можно сказать, например, что на продажи влияет отклонение нашей цены на товар от среднерыночной, но при этом не указывать, как именно этот фактор влияет на продажи. Для определения формы и степени выявления зависимостей и используется машинное обучение.
Автоматизировать процесс выдвижения гипотез не представляется возможным, по крайней мере, на современном уровне развития технологий. Эту задачу должны решать эксперты — специалисты в предметной области. Полагаться можно и нужно на их опыт и здравый смысл. Необходимо максимально использовать их знание о предмете и собрать как можно больше гипотез/предположений.
Для этих целей хорошо зарекомендовала себя тактика мозгового штурма, в процессе которого собираются и систематизируются все идеи без попытки произвести оценку их адекватности. Результатом данного шага должен быть список с описанием всех предложенных экспертами факторов.
Например, для задачи прогнозирования спроса это может быть список следующего вида: сезон, день недели, объемы продаж за предыдущие недели, объем продаж за аналогичный период прошлого года, рекламная компания, маркетинговые мероприятия, качество продукции, бренд, отклонение цены от среднерыночной, наличие товара у конкурентов.
В процессе подбора влияющих факторов необходимо абстрагироваться от существующих информационных систем и имеющихся в наличии данных. Очень часто аналитики за отправную точку хотят взять данные из существующих учетных систем. Звучит это примерно следующим образом: «У нас есть такие-то данные: что можно на них получить?».
На первый взгляд, это выглядит логично, но является порочной практикой. В процессе анализа надо отталкиваться от решаемой задачи и подбирать под нее данные, а не брать имеющуюся информацию и придумывать, что из них можно «выжать». Надо учитывать, что учетные системы собирают информацию, необходимую для выполнения своих задач, например, то, что важно для составления бухгалтерского баланса бессмысленно для решения задачи сегментации клиентов.
После подготовки таблицы с описанием факторов нужно экспертно оценить значимость каждого из них. Эта оценка не является окончательной — она будет считаться отправной точкой. В процессе анализа может оказаться, что фактор, который эксперты посчитали важным, таковым не является, и, наоборот, незначимый с их точки зрения атрибут оказывает значительное влияние.
Чаще всего количество гипотез велико, поэтому собрать и проанализировать все данные не представляется возможным. Необходимо взять за основу разумно ограниченный список факторов. Самое простое — отталкиваться от экспертной оценки значимости атрибутов. Тем более, что довольно часто реальные данные подтверждают их мнение.
Результатом этого шага может быть таблица следующего вида:
Формализация и сбор данных
Далее необходимо определить способ представления данных, выбрав один из 4-х типов: – число, строка, дата, логическая переменная (да/нет).
Некоторые данные достаточно просто формализовать, т.е. определить способ их представления. Например, объем продаж в рублях — это число. Но часто возникают ситуации, когда непонятно, как представить фактор.
Чаще всего такие проблемы возникают с качественными характеристиками. Например, на объемы продаж влияет качество товара, но это довольно сложное понятие, которое не понятно как представить. Однако если данный атрибут действительно важен, то нужно придумать способ его формализации. Например, определять качество по количеству брака на тысячу единиц продукции, либо экспертно оценивать, разбив на несколько категорий – отлично/хорошо/удовлетворительно/плохо.
Далее необходимо оценить стоимость сбора нужных для анализа данных. Некоторые данные легко доступны, например, их можно выгрузить из существующих информационных систем. Но есть информация, которую сложно собрать, например, сведения о наличии товара у конкурентов. Поэтому необходимо оценить, во что обойдется сбор данных.
Чем больше данных для анализа, тем лучше. Их проще отбросить на следующих этапах, чем собрать новые сведения. К тому же необходимо учитывать, что не всегда экспертная оценка значимости факторов будет совпадать с реальной, т. е. в начале не известно, что на самом деле является значимым, а что нет. Из-за большой неопределенности, приходится отталкиваться от мнения экспертов относительно значимости факторов, но в действительности эти гипотезы могут не подтвердиться. Поэтому желательно собрать больше данных, чтобы иметь возможность оценить влияние максимального количества показателей.
Однако сбор данных не является самоцелью. Если информацию получить легко, то, естественно, нужно ее собрать. Если данные получить сложно, то необходимо соизмерить затраты на ее сбор и систематизацию с ожидаемыми результатами.
Есть несколько методов сбора, необходимых для анализа данных. Они перечислены в порядке увеличения стоимости:
- Выгрузка из учетных систем. Обычно в учетных системах имеются механизмы экспорта данных или существует API для доступа к ним. Поэтому извлечение нужной информации из систем учета чаще всего относительно несложная операция.
- Получение сведений из косвенных данных. О многих показателях можно судить по косвенным признакам. Например, можно оценить реальное финансовое положение жителей определенного региона. В большинстве случаев имеется несколько товаров, предназначенных для выполнения одной и той же функции, но отличающихся по цене: товары для бедных, среднеобеспеченных и состоятельных. При наличии данных о продажах по регионам, можно проанализировать пропорции, в которых продаются товары для каждой из категорий клиентов: чем больше доля дорогой продукции, тем более состоятельны в среднем жители данного региона.
- Использование открытых источников. Большое количество данных присутствует в открытых источниках, таких как статистические сборники, отчеты корпораций, опубликованные результаты маркетинговых исследований и прочее.
- Покупка сведений у соцсетей, мобильных операторов и дата-брокеров. На рынке работает много компаний, которые занимаются сбором и продажей данных. Они предоставляют посредством API систематизированную информацию различного плана: кредитоспособность, клиентские предпочтения, цены на продукцию, геолокация и т.д.
- Проведение собственных маркетинговых исследований и аналогичных мероприятий по сбору данных. Это может быть достаточно дорогостоящим мероприятием, но, в любом случае, такой вариант сбора данных возможен.
- Ввод данных «вручную», когда данные вводится по различного рода экспертным оценкам сотрудниками организации. Данный метод достаточно трудоемкий и требует постоянного выделения ресурсов для обеспечения актуальности сведений.
Стоимость сбора информации различными методами существенно отличается по цене и времени, которое необходимо для этого. Поэтому нужно соизмерять затраты с ожидаемыми результатами. Возможно, от сбора некоторых данных придется отказаться, но факторы, которые эксперты оценили как наиболее значимые, нужно собрать обязательно, не смотря на стоимость этих работ, либо вообще отказаться от анализа.
Очевидно, что если эксперт указал некоторый фактор как важный, то исключать его неразумно. Мы рискуем провести анализ, ориентируясь на второстепенные малозначащие факторы, и, следовательно, получить модель, которая будет давать плохие и нестабильные результаты. Такая модель не представляет практической ценности.
Собранные данные нужно преобразовать к единому формату. Идеальный случай — загрузка в базу или витрину данных. Но можно использовать и более легковесные форматы, например, Excel или текстовой файл с разделителями.
Данные обязательно необходимо стандартизировать, т.е. одна и та же информация везде должна описываться одинаково. Обычно проблемы с единообразным представлением возникают при сборе информации из разнородных источников. В этом случае стандартизация является серьезной самостоятельной задачей, но ее обсуждение выходит за рамки данной статьи.
Представление и минимальные объемы
Для анализируемых процессов различной природы данные должны быть подготовлены специальным образом. Для простоты можно считать, что собранные данные могут быть трех видов:
- Упорядоченные
- Неупорядоченные
- Транзакционные
Упорядоченные данные
Упорядоченные данные нужны для решения задач прогнозирования, когда необходимо на основе имеющихся исторических сведений определить, каким образом, скорее всего, поведет себя тот или иной процесс в будущем. Чаще всего в качестве одного из атрибутов выступает дата или время, хотя это и не обязательно. Речь может идти и о неких отсчетах, например, данные, собираемые с датчиков через фиксированное расстояние.
Для упорядоченных данных (обычно это временные ряды) каждому столбцу соответствует один фактор, а в каждую строку заносятся упорядоченные по времени события с единым интервалом между строками. Интервал между строками должен быть одинаковым, пропуски не допускаются. Кроме того, необходимо исключить группировки, промежуточные итоги и прочее, т. е. нужна обычная таблица.
Если для процесса характерна сезонность/цикличность, необходимо иметь данные хотя бы за один полный сезон/цикл с возможность варьирования интервалов (понедельное, помесячное…). Т.к. цикличность может быть сложной, например, внутри годового цикла квартальные, а внутри кварталов недельные, то необходимо иметь полные данные как минимум за один самый длительный цикл.
Максимальный горизонт прогнозирования зависит от объема данных:
- Данные на 1.5 года – прогноз максимум на 1 месяц;
- Данные за 2-3 года – прогноз максимум на 2 месяца;
Тут указана минимальная глубина погружения (история) для соответствующего горизонта прогнозирования, т.е. времени, на которое можно строить достаточно достоверные прогнозы. В случае отсутствия хотя бы такого объема прогнозирование, основанное на данных, будет невозможно. При этом надо учитывать, что при указанном минимальном объеме данных работают только самые простые алгоритмы. Сложный математический аппарат требует большего объема данных для построения модели.
В общем случае максимальный горизонт прогнозирования ограничивается не только объемом данных. Прогнозные модели исходят из предположения, что факторы, определяющие развитие процесса, будут в будущем оказывать примерно такое же влияние, что и на текущий момент. Данное предположение справедливо не всегда. Например, в случае слишком быстрого изменения ситуации, появления новых значимых факторов и т.п. это правило не работает.
Поэтому в зависимости от задачи требования к объему могут сильно изменяться. Однако необходимо принимать во внимание и то, что использование слишком большой глубины погружения так же нецелесообразно. В этом случае мы будем строить модель по старой не актуальной истории, и, следовательно, могут учитываться факторы, возможно уже утратившие свою значимость.
Неупорядоченные данные
Неупорядоченные данные нужны для задач, где временной фактор не имеет значения, например, кредитный скоринг, диагностика, сегментация потребителей. В таких случаях мы считаем информацию о том, что одно событие произошло раньше другого несущественной.
Для неупорядоченных данных каждому столбцу соответствует фактор, а в каждую строку заносится пример (ситуация, прецедент). Упорядоченность строк не требуется. Не допускается наличие группировок, итогов и прочее — нужна обычная плоская таблица.
В собранных данных количество примеров (прецедентов), т.е. строк таблицы должно быть значительно больше количества факторов, т.е. столбцов. В противном случае высока вероятность, что случайный фактор окажет серьезное влияние на результат. Если нет возможности увеличить количество данных, то придется уменьшить количество анализируемых факторов, оставив наиболее значимые.
Желательно, чтобы данные были репрезентативными, т.е. покрывали как можно больше ситуаций реального процесса, а пропорции различных примеров (прецедентов) примерно соответствовали действительности. Цель Data Mining — выявить закономерности в имеющихся данных, поэтому, чем ближе данные к действительности, тем лучше.
Необходимо понимать, что алгоритмы машинного обучения не могут знать о чем-либо, что находится за пределами поданных на вход данных. Например, если при создании системы медицинской диагностики подавать только сведения о больных, то система не будет знать о существовании здоровых людей, и, соответственно, любой человек с ее точки зрения будет обязательно чем-то болен.
Транзакционные данные
Транзакционные данные используются в алгоритмах поиска ассоциативных правил, этот метод часто называют «анализом потребительской корзины». Под транзакцией подразумевается несколько объектов или действий, сгруппированных в логически связанную единицу.
Часто данный механизм используется для анализа покупок (чеков) в супермаркетах. Но вообще речь может идти о любых связанных объектах или действиях, например, продажа туристических туров с набором сопутствующих услуг (оформление виз, доставка в аэропорт, услуги гида и прочее). Используя данный метод анализа, находятся зависимости вида, «если произошло событие А, то с определенной вероятностью произойдет событие Б».
Транзакционные данные для анализа необходимо подготовить в следующем виде:
Код транзакции соответствует номеру чека, счета, накладной. Товары с одинаковым кодом входят в разовую покупку.
Описанного представления данных достаточно для работы обычных ассоциативных правил, где находятся связи между каждым объектом в отдельности. Пример, «Если купили «Йогурт «Чудо» 0.4», то приобретут и Батон «Рязанский»».
Существует еще алгоритм поиска обобщенных ассоциативных правил, когда имеется возможность найти связи не только между объектами, но и группами объектов. Например, при наличии информации о товарных группах, к которым относятся объекты, можно находить зависимости типа «Если купили Батон «Рязанский», то купят и что-нибудь из йогуртов». Для поиска обобщенных ассоциативных правил необходимо подготовить дополнительную информацию с деревом отношений между объектами — иерархией групп в следующем виде:
ID – уникальный номер объекта. ID предка – номер родительского объекта. Если объект корневой, то это поле должно быть пустым. В поле «Объекты» находятся как группы, так и товар.
Таблица с иерархией объектов соответствует следующей диаграмме.
Рисунок 1. Иерархия товаров
Для анализа транзакционных данных помимо поиска ассоциативных правил могут применяться алгоритмы выявления последовательных шаблонов, т.е. определения закономерностей, что «после события А с определенной вероятностью произойдет событие Б». Данные для этого собираются так же, как и для поиска ассоциативных правил, но с добавлением временной метки события.
Анализ транзакций целесообразно производить на больших наборах данных, иначе могут быть выявлены статистически необоснованные правила. Алгоритмы поиска ассоциативных связей и последовательных шаблонов способны быстро перерабатывать огромные массивы информации. Их основное достоинство заключается именно в масштабируемости, т.е. способности обрабатывать большие объемы.
Примерное соотношение между количеством объектов и объемом данных:
- 300-500 объектов – более 10 тыс. транзакций;
- 500-1000 объектов – более 300 тысяч транзакций;
При недостаточном количестве транзакций целесообразно уменьшить количество анализируемых объектов, например, сгруппировать их.
Построение моделей — анализ
Существует большое количество алгоритмов машинного обучения и их описание выходит за рамки данной статьи. Каждый из них имеет свои ограничения и решает определенный класс задач. На практике, чаще всего добиться успеха можно, комбинируя методы анализа.
В целом, можно дать следующие, не зависящие от Data Mining алгоритма, рекомендации по построению моделей:
- Уделить большое внимание очистке данных. Собрав данные в нужном объеме, нельзя быть уверенным, что они будут хорошего качества. Чаще всего, оно оставляет желать лучшего, поэтому необходимо их предобработать. Для этого есть множество методов: удаление шумов, сглаживание, редактирование аномалий и прочее.
- Комбинировать методики анализа. Это позволяет шире смотреть на проблему. Более того, использование различных методов для решения одной и той же задачи может помочь выявить интересные закономерности, выходящие за рамки применимости одного алгоритма;
- Не гнаться за абсолютной точностью. Желательно начать использование при получении первых приемлемых результатов. Все равно идеальную модель построить невозможно. Полезный, пусть не идеальный результат, позволяет раньше получать выгоду от применения машинного обучения. При этом можно и нужно параллельно работать над совершенствованием модели с учетом полученных на практике результатов;
- Начинать с более простых моделей. Правильно собранные данные позволяют получить выгоду от применения даже самых простых моделей. Если несколько методов анализа дают примерно одинаковый результат, всегда стоит выбрать наиболее простой из них. Простые методы более надежны, они менее требовательны к качеству данных, их легче интерпретировать и модифицировать. Применение сложных алгоритмов должно быть обосновано достаточной выгодой, оправдывающей повышенные затраты на их построение и развитие.
При невозможности построения качественной модели следует вернуться на предыдущие шаги Data Mining процесса. К сожалению, ошибки могут быть допущены на любом шаге: может быть некорректно сформулирована первоначальная гипотеза, могут возникнуть проблемы со сбором необходимых данных и прочее. К этому нужно быть готовым, т.к. Data Mining — это исследование, т.е. процесс поиска ранее неизвестных закономерностей.
Для оценки адекватности полученных результатов необходимо привлекать экспертов в предметной области. Интерпретация модели, так же как и выдвижение гипотез, может и должно делаться экспертом, т.к. для этого нужно глубокое понимание процесса, выходящее за пределы анализируемых данных.
Кроме того, нужно воспользоваться и формальными способами оценки качества модели: тестировать построенные модели на различных выборках для оценки их обобщающих способностей, т.е. способности выдавать приемлемые результаты на данных, которые не предоставлялись системе при построении модели.
Дело в том, что некоторые механизмы анализа могут «запоминать» предъявленные ей данные и на них демонстрировать прекрасные результаты, но при этом полностью терять способность к обобщению и на тестовых (из неизвестных системе ранее) данных выдавать очень плохие результаты. При формальной оценке можно отталкиваться от идеи, что если на тестовых данных модель дает приемлемые результаты значит она имеет право на жизнь.
При получении приемлемых результатов нужно начать использование полученных моделей, но необходимо понимать, что начало применения не является завершением Data Mining проекта. Работать над совершенствованием моделей нужно всегда, т.к. по прошествии времени обязательно наступит момент, когда придется опять проходить описанный цикл. К тому же, после получения первых удовлетворительных результатов, обычно встает вопрос о повышении точности.
Необходимо периодически оценивать адекватность модели текущей ситуации, потому что даже самая удачная модель со временем перестает соответствовать действительности.
Другие материалы по теме:
Алгоритмы кластеризации на службе Data Mining
Loginom Community Edition — аналитика, доступная каждому