Предисловие
Данный материал является конспектом темы «Архитектура Oracle Database». В первую очередь составлял его для себя. В книге «Oracle для профессионалов» Том Кайт (на момент написания актуально 3 издание) идет дублирование информации с разным уровнем детализации. Конспект позволяет быстро вспомнить опорные точки в повествовании, вернуться к ним и при необходимости перечитать заново.
Нужно ли разработчику базы данных понимать как устроен Oracle DB?
Ответ: да!
Для чего?
1. Разработчик баз данных (DBD) – должен иметь представление об устройстве инструмента с которым он работает. Это знание поможет ему создавать более эффективные приложения, понять почему работает так, а не иначе.
2. Для общения на одном языке с администраторами баз данных (DBA). Когда совместно разбирается какая-то проблема, то DBA начинают сыпать непонятными словами, с которыми разработчик БД в повседневной жизни обычно не сталкивается.
Определение базы данных и экземпляра
Существуют два термина, которые при использовании в контексте Oracle вызывают наибольшую путаницу: база данных и экземпляр. В терминологии Oracle они определяются следующим образом.
База данных. Коллекция физических файлов операционной системы. Начиная с версии Oracle Database 12с существуют три типа баз данных (об этом далее).
Экземпляр. Набор фоновых процессов и область разделяемой памяти Oracle, которая совместно используется этими процессами. Это место для изменяющихся, непостоянных данных, часть которых сбрасывается на диск. Экземпляр базы данных может существовать вообще без какого-либо дискового хранилища.
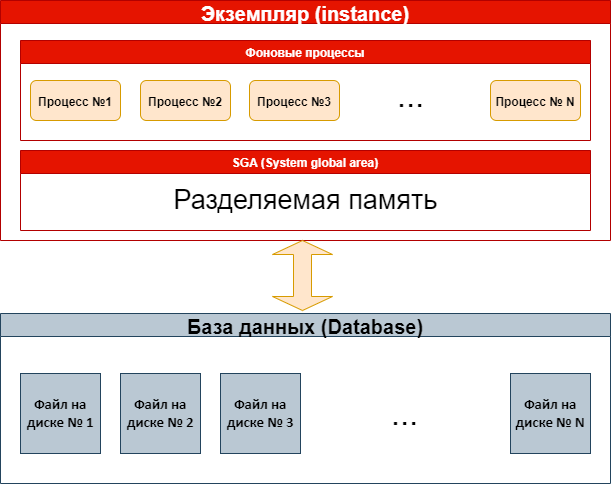
Рис. 1. Схема экземпляра и базы данных.
База данных
Три типа базы данных
С версии Oracle 12с существенно изменилась архитектура. Мы получили три типа базы данных:
База данных с единственным владельцем (single tenant). Это обособленный набор файлов данных, управляющих файлов, журнальных файлов для восстановления, файлов параметров и т.д. Этот набор содержит метаданные (например, определение ALL_OBJECTS), программный код (такой как код для DBMS_OUTPUT) необходимый для работы самого движка Оракл. Плюс здесь же содержатся метаданные, программный код необходимый для работы бизнес-приложения. В версиях, предшествующих 12с, это был единственный тип базы данных.
Контейнерная (container) или корневая (root) база данных. Это обособленный набор файлов данных, управляющих файлов, журнальных файлов для восстановления, файлов параметров и т.д. Этот набор содержит ТОЛЬКО метаданные (например, определение ALL_OBJECTS), программный код (такой как код для DBMS_OUTPUT) необходимый для работы самого движка Оракл. Здесь отсутствуют данные бизнес-приложения. База данных является обособленной в том смысле, что она может быть смонтирована и открыта без дополнительных поддерживающих физических структур.
Подключаемая (pluggable) база данных. Это набор одних лишь файлов данных. Такая база данных не является обособленной. Чтобы появилась возможность открытия и доступа, подключаемая база данных должна быть » вставлена» в контейнерную базу данных. Файлы данных содержат только метаданные для объектов бизнес-приложений, данные приложений и код для приложений.
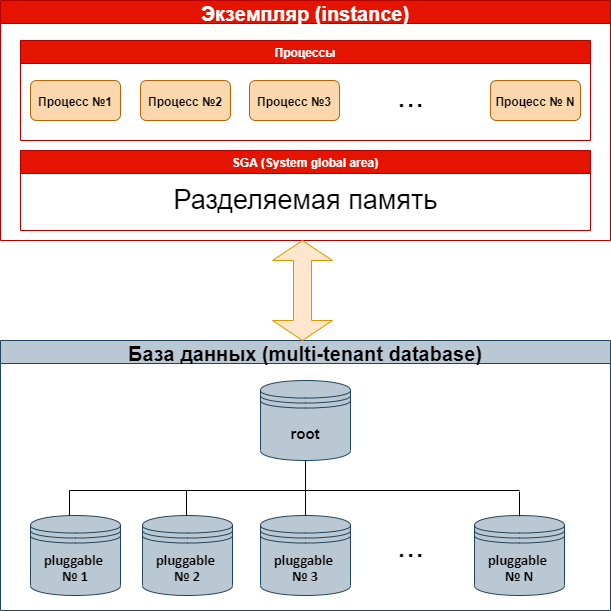
Рис. 2. Схема экземпляра и базы данных (multitenant database).
Плюсы подключаемых БД
1.Для заметного уменьшения объема ресурсов, необходимых при размещении многих баз данных — многих приложений — на единственном хосте
2.Для сокращения объема работ по обслуживанию, выполняемых администратором баз данных в отношении множества баз данных — множества приложений — на единственном хосте.
3.С точки зрения разработчика подключаемая база данных ничем не отличается базы с единственным владельцем.
Основные типы файлов
1. Файлы данных (data file). Эти файлы предназначены для базы данных: они хранят таблицы, индексы и все остальные сегменты.
2.Временные файлы (temp file). Эти файлы используются для выполнения дисковых сортировок и в качестве временного хранилища.
3.Управляющие файлы (control file). Эти файлы указывают местоположение файлов данных, временных файлов, журнальных файлов повторения действий (файлов с измененными данными), а также содержат другие важные метаданные об их состоянии.
4.Журнальные файлы повторения действий (redo log file). Эти файлы представляют собой журналы транзакций. Основное назначение: восстановления данный после сбоя, например аварийного выключения питания. Дополнительное: используются при обслуживании резервных копий, в Goden Gate. Как обслуживаются журналы транзакций-это отдельная интересная тема, рассмотрим ее позже.
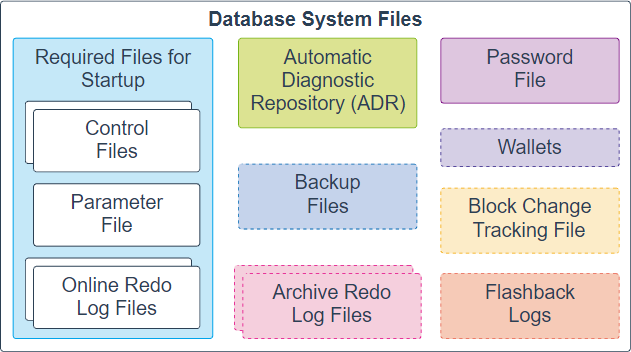
Прочие файлы:
1.Файлы параметров (parameter file). Эти файлы указывают экземпляру базы данных Oracle, где искать управляющие файлы, а также задают набор параметров инициализации, которые определяют размеры ряда структур памяти и т.д. Например tnsname.ora, listener.ora, spfile<ORACLE_SID>. ora и init.ora (файл параметров БД)
2.Трассировочные файлы (trace file). Эти диагностические файлы создаются процессом сервера по большей части в ответ на возникновение некоторых необычных ошибок. Являются источником отладочной информации.
3.Сигнальный файл (alert file). Этот файл подобен трассировочным файлам, но содержит информацию об «ожидаемых» событиях, а также служит единым централизованным файлом для хранения оповещений администратора базы данных о многих событиях, связанных с базой данных.
4.Файлы паролей (password file). Эти файлы применяются для аутентификации пользователей(SYSDBA, SYSOPER), выполняющих административные действия.
Из всех перечисленных файлов наиболее важными являются файлы данных и журнальные файлы повторения действий, т.к. они содержат бизнес-данные. Утеря любых или даже всех остальных файлов не приведет к безвозвратной утрате данных. Утеря журнальных файлов может привести к потере некоторых данных. Утеря файлов данных и их резервных копий неизбежно приведет к безвозвратной потере данных.
Логическая и физическая структура данных
Логическая структура введена для удобства управления. База данных может состоять из одного или большего числа табличных пространств.
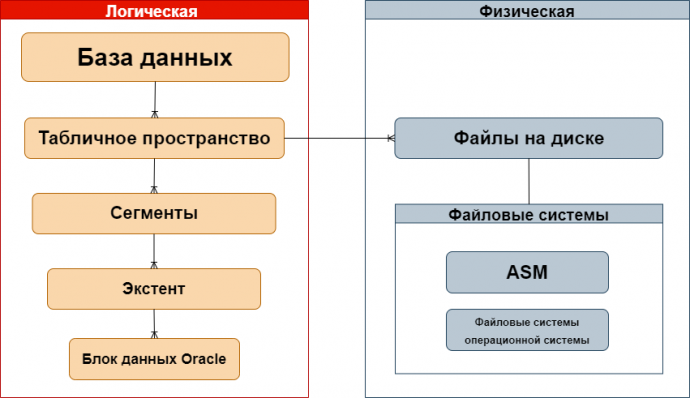
Рис. 3. Логическая и физическая структура Oracle Database.
Табличное пространство
Табличное пространство содержит в себя сегменты. Логически группирует физические файлы на диске. Табличное пространство является точкой соединения логической и физической структуры.
Табличное пространство данных бизнес приложения
CREATE TABLESPACE userdata
DATAFILE #ff0000;">'data/file_userdata_01.dbf'
SIZE 500M -- начальный размер
AUTOEXTEND ON
NEXT 10M
MAXSIZE 1000M
EXTENT MANAGEMENT LOCAL;
Временное табличное пространство
CREATE TEMPORARY TABLESPACE temp01 DATAFILE #ff0000;">'temp/temp01.dbf';
Табличное пространство для хранения информации отмены
CREATE UNDO TABLESPACE undo01 DATAFILE #ff0000;">'undo/undo01.dbf';
Сегмент, экстент, блок данных
Сегмент (таблица, индекс, партиция и т.д.) формируется одним или большим количеством экстентов.
Экстент – состоит из непрерывистого набор блоков на диске. Расширение пространства в сегменте происходит экстентами.
Блок — это наименьшая единица данных в базе данных. Блок является наименьшим элементом ввода-вывода, используемым базой данных при взаимодействии с файлами данных.
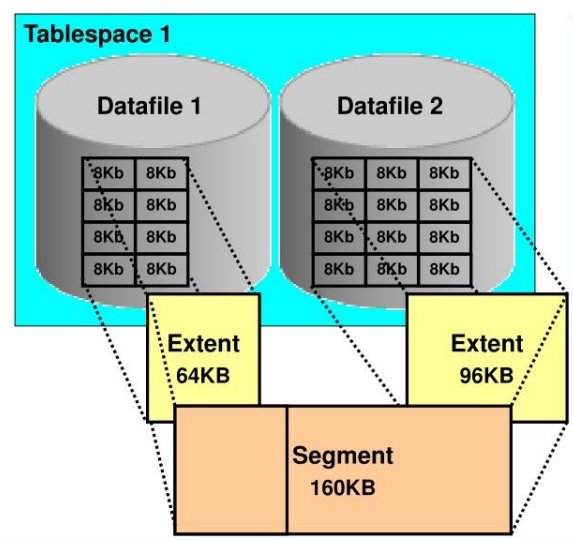
Рис. 4. Структура блока данных Oracle Database.

Рис. 5. Структура блока данных Oracle Database.
Экземпляр – основные структуры памяти и процессы
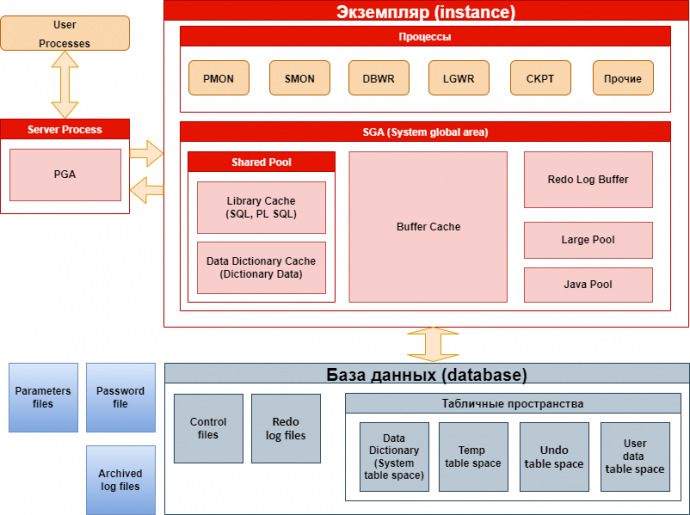
Рис. 6. Схема экземпляра и базы данных с детализацией.
Структура памяти
Глобальная область системы (System Global Area — SGA). Это большой совместно используемый сегмент памяти, к которому в тот или иной момент времени будут обращаться практически все процессы Oracle. Выделяется при старте, обслуживает экземпляр Oracle.
Глобальная область процесса (или проrраммы) (Process (Prorgam) Global Area PGA). Это закрытая область отдельного процесса или потока; из других процессов или потоков она не доступна. Создается в режиме выделенного сервера. Содержит области памяти для хранения информации о сеансе, а также области для сортировок.
Глобальная область пользователя (User Global Area — UGA). Эта область памяти связана с конкретным сеансом. Она располагается либо в области SGA (если подключение к базе данных выполнено посредством разделяемого сервера), либо в области PGA (если подключение к базе данных осуществлено через выделенный сервер).
Структура памяти SGA
1.Разделяемый пул (Shared Pool) состоит из:
- Библиотечного кеша (library cache) – содержит информацию о последних выполненных операторах SQL и PL/SQL (план разбора, откомпилированные процедуры и функции и пр)
- Кеша словаря (data dictionary cache) — сдержит информацию о определениях объектов базы данных (нужно для синтаксического разбора для получения метаданных о запрашиваемых объектах)
2. Буферный кеш Buffer Cache. Буферный кеш содержит блоки данных, запрошенные пользователями. Дает большой выигрыш в производительности т.к. позволяет избежать обращений к диску. Работает по принципу LRU (самые горячие блоки живут дольше).Каждый блок запрошенный или измененный пользователем сперва помещается в буферный кеш (кроме CREATE T ABLE AS). Состоит из трех независимых подкешей, определяемых параметрами:
DB_CACHE_SIZE – основной размер кеша
DB_KEEP_CACHE_SIZE – данных, которые принудительно запихнули в кеш, часто-используемые блоки.
DB_RECYCLE_CACHE_SIZE – для редко-используемых блоков, которые после использования сразу могут быть удалены из кеша
3. Журнальный кеш(Redo log buffer cache). Журнальный кеш перезаписывается по кругу. Содержит изменения, которые происходят во время транзакции и сбрасываются потом в файлы журнала повтора.
4. Большой пул (Large Pool). Большой пул необязательная область. Содержит области памяти, которые без него сдержались бы в SGA и тем самым снимает нагрузку. Например, используется для хранения области UGA в режиме разделяемого сервера. Используется RMAN-ом.
Основные процессы
Каждый процесс в Oracle выполняет отдельную задачу или набор задач, и каждый из них имеет внутреннюю память (память PGA), выделенную им для выполнения своего задания.
FOREGRAUND – процесс обслуживающий пользователей (серверный процесс)
BACKGRAUND – процессы самого движка Oracle (фоновые процессы)
Основные фоновые процессы BACKGRAUND.
PMON — очищает ресурсы после сбоев процессов. Откатывает транзакции пользователя, снимает блокировки, перезапускает сбойнувшие диспетчеры.
SMON — восстанавливает базу после сбоев. Накатывает успешные транзакции, либо откатывает незавершенные транзакции. Выполняет также объединение пирлегающих свободных экстентов и освобождает пространство временных сегментов.
DBWn — означает №. Т.е. их может быть несколько. Сбрасывает измененные блоки из кеша буферов в базу данных при заполнении кеша, либо срабатывании контрольной точки и др. событиях. Обновляет контрольную точку в контрольных файлах.
LGWn — пишет буфера из кеша буферов в журналы при фиксации транзакции, а также через каждые 3 секунды, а также если журнальный буфер заполнен более чем на 1/3 либо >1 Мб. Всегда срабатывает перед DBWn и даже может его вызывать. Успешная запись подтверждает успешную транзакцию.
CKPT — обновляет информацию о контрольной точке в заголовках файлов данных и в управляющих файлах. Делает это каждые 3 секунды. Задача контрольной точки в том, чтобы гарантировать, что все изменные в кеше буфера до срабатывания контрольной точки были записаны на диск.
Посмотреть фоновые процессы можно запросом:
SELECT paddr, name , description FROM v$bgprocess ORDER bу paddr DESC;
Или
SELECT * FROM v$PROCE t WHERE t.РNАМЕ IS NULL;
Прочие фоновые процессы BACKGRAUND:
ARCn — процесс архивирования журнальный файлов.
RECO — процесс завершения транзакций в распределенной базе данных.
Dnnn — диспетчер в многопотоковом сервере.
Pnnn — подчиненные процессы параллельного сервера.
Тезисы, которые надо запомнить:
1.Экземпляр может монтировать и открывать только одну базу данных (с единственным владельцем или контейнерную) в каждый момент времени.
2.Подключаемая база данных может быть ассоциирована с одной контейнерной базой данных за раз. Подключаемую базу данных обслуживает экземпляр, связанный с контейнерной БД.
3.База данных может обслуживаться несколькими экземплярами. В таком случае мы получаем RAC ( Real Application Clusters).
Подключение к Oracle
Основной протокол, по которому происходит подключение к Oracle является TCP/IP.
1.Каждый клиент(любое клиентское приложение), который хочет подключиться к Oracle, создает пользовательский процесс и пробует подключиться использую host + port + sid.
2.Подключение происходит через посредника – LISTENER. Именно он принимает запрос на подключение и соединяет нас с серверным процессом базы данных.
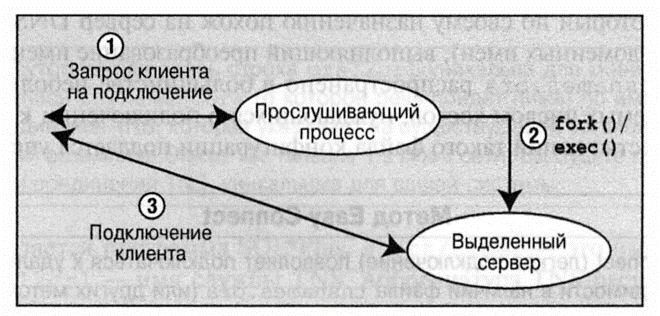
Рис. 7. Место LISTENER-а в схеме подключения.
3.Для каждой новой сессии Oracle создает серверный процесс (есть нюансы), который и будет обслуживать запросы пользовательского процесса.
Сеанс и подключение
В терминологии Oracle: подключение — это не синоним сеанса.
1.Физический канал связи между клиентом и сервером – это подключение.
2.Oracle NET – протокол по которому связывается процесс клиента с процессом сервера.
3.Сеанс(session) — это логическая идентификация запросов конкретной сессии.
4.В рамках одного подключения может быть 0 и более сеансов.
Демонстрация общего примера подключения

Рис. 8. Этапы подключения на примере SQLPLUS.
Виды подключения
DEDICATED – подключение (выделенный сервер). При таком подключении на один сеанс создается персональный серверный процесс. Он обслуживает этот сеанс от начала и до конца, ни на какие другие сеансы не переключается, т.е. выделен под этот сеанс. После того как сеанс завершен, серверный процесс тоже завершается. Такой способ подключения обычно используют в случае когда мало клиентов и время ожидания отклика некритично (например OLAP — системы).
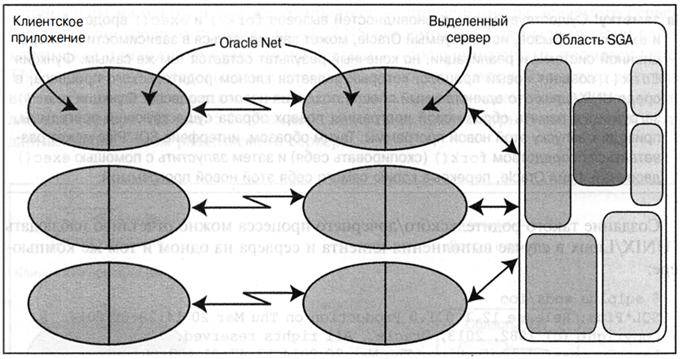
Рис. 9. Схема подключения с выделенным сервером — DEDICATED.
SHARED — подключение (разделяемый сервер). При таком подключении создается пул серверных процессов (далее разделяемый сервер) и появляется диспетчер процессов. Клиентский процесс здесь обмениваться данными с диспетчером. Диспетчер помещает запрос клиента в очередь запросов внутри области SGA. Первый незанятый разделяемый сервер примет этот запрос и обработает его (например, запросом мог бы служить UPDATE т S ET Х=Х+5 WHERE У=2 ). По завершении этой команды разделяемый сервер поместит ответ в очередь ответов вызывающего диспетчера. Диспетчера будет отслеживать эту очередь и, обнаружив результат, переправит его клиенту. Такой тип систем применим к OLTP системам.
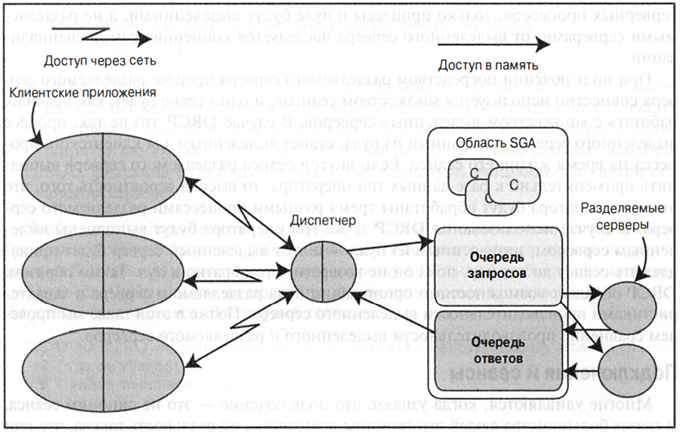
Рис. 10. Схема подключения с разделяемым сервером — SHARED.
Резидентный пул соединений с базой данных (DRCP — Database Resident Connection Pooling). Новый режим соединения (появился в 11g), который объединяет в себе преимущества выделенного и разделяемого сервера. Суть сводится к тому, что заранее создает пул серверных процессов и каждому подключению выделяется свободный процесс в режиме выделенного сервера.
Запросом можно посмотреть тип подключения:
SELECT username , sid, serial#, server, paddr , STATUS FROM v$session WHERE username = USER;
Отключение пользователя
1.Команда DISCONNECT.
2.ALTER SYSTEM KILL SESSION ‘SID,SERIAL#’ помечает сессию на удаление. Все транзакции откатываются. Сессия живет пока все не откатится.
3.ALTER SYSTEM DISCONNECT SESSION ‘SID,SERIAL#’ IMMEDIATE немедленное отключение сессии. За ней потом приберет PMON.
Системные представления
- DBA_TABLESPACES – информация о ТС
- DBA_DATA_FILES – инф. о файлах данных
- DBA_SEGMENTS – инф. о сегментах
- V$VERSION – инф. о версии ПО
- V$INSTANCE – инф. о экземпляре
- V$DATABASE – инф. о БД
- V$PROCESS – инф. о процессах
- V$SESSION – инф. о сессиях
и много других здесь:
SELECT * FROM dictionary;
Summary: in this tutorial, you will learn about the Oracle Database architecture and its components.
Oracle Database is an object-relational database management system developed and marketed by Oracle Corporation. Oracle Database is commonly referred to as Oracle RDBMS or simply Oracle.
Database and Instance
An Oracle Database consists of a database and at least one instance.
An instance, or database instance, is the combination of memory and processes that are a part of a running installation and a database is a set of files that store data.
The following picture illustrates the Oracle Database server architecture.
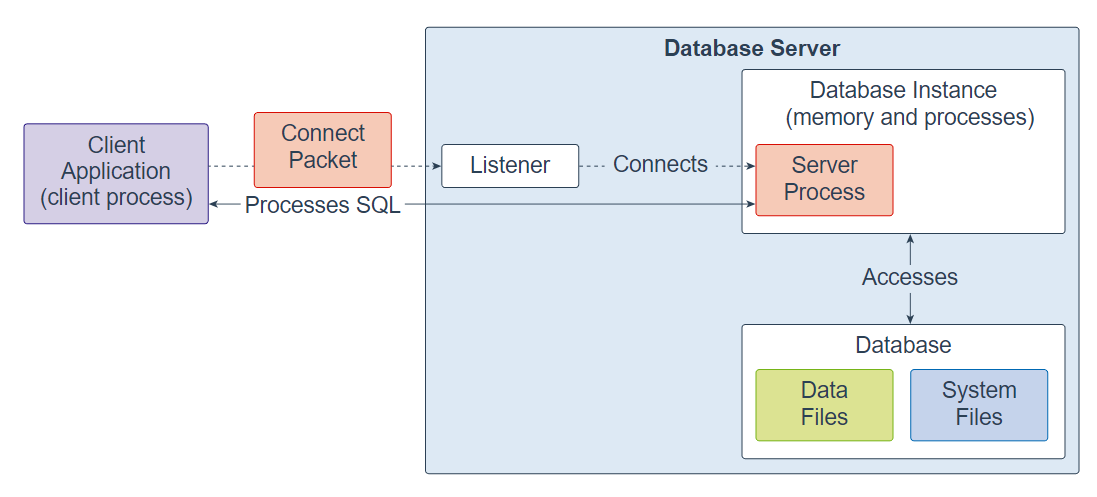
Sometimes, a database instance is referred to as an entire running database. However, it is important to understand the distinctions between the two.
First, you can start a database instance without having it accessing any database files. This is how you create a database, starting an instance first and creating the database from within the instance.
Second, an instance can access only one database at a time. When you start an instance, the next step is to mount that instance to a database. And an instance can mount only one database at a single point in time.
Third, multiple database instances can access the same database. In a clustering environment, many instances on several servers can access a central database to enable high availability and scalability.
Finally, a database can exist without an instance. However, it would be unusable because it is just a set of files.
One of the essential tasks of the Oracle Database is to store data. The following section briefly describes the physical and logical storage structure of an Oracle Database.
Physical storage structures
The physical storage structures are simply files that store data. When you execute a CREATE DATABASE statement to create a new database, Oracle creates the following files:
- Data files: data files contain real data, e.g., sales order and customer data. The data of logical database structures such as tables and indexes are physically stored in the data files.
- Control files: every database has a control file that contains metadata. The metadata describes the physical structure of the database including the database name and the locations of data files.
- Online redo log files: every database has an online redo log that consists of two or more online redo log files. An online redo log is made up of redo entries that record all changes made to the data.
Besides these files, an Oracle database includes other important files such as parameter files, network files, backup files, and archived redo log files for backup and recovery.
Logical Storage Structures
Oracle Database uses a logical storage structure for fine-grained control of disk space usage. The following are logical storage structures in an Oracle Database:
- Data blocks: a data block corresponds to a number of bytes on the disk. Oracle stores data in data blocks. Data blocks are also referred to as logical blocks, Oracle blocks or pages.
- Extents: An extent is a specific number of logically contiguous data blocks used to store the particular type of information.
- Segments: a segment is a set of extents allocated for storing database objects, e.g., a table or an index.
- Tablespaces: a database is divided into logical storage units called tablespaces. A tablespace is a logical container for a segment. Each tablespace consists of at least one data file.
The following picture illustrates segments, extents and data blocks within a tablespace:
And the next figure shows the relationship between logical and physical storage structures:
Database Instance
A Database Instance is an interface between client applications (users) and the database. An Oracle instance consists of three main parts: System Global Area (SGA), Program Global Area (PGA), and background processes.
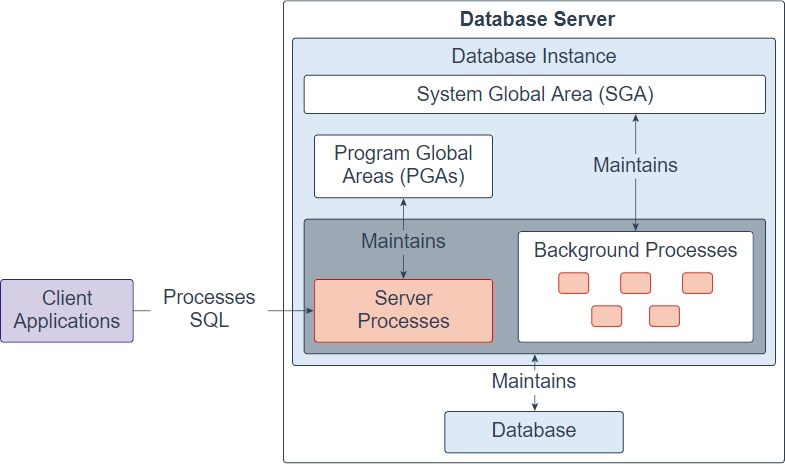
The SGA is a shared memory structure allocated when the instance started up and released when it is shut down. The SGA is a group of shared memory structures that contain data and control information for one database instance.
Different from the SGA, which is available to all processes, PGA is a private memory area allocated to each session when the session started and released when the session ends.
Major Oracle Database’s background processes
The following are the major background processes of an Oracle instance:
- PMON is the process monitor that regulates all other processes. PMON cleans up abnormally connected database connections and automatically registers a database instance with the listener process. PMON is a process that must be alive in an Oracle database.
- SMON is the system monitor process that performs system-level clean-up operation. It has two primary responsibilities including automatically instance recovery in the event of a failed instance, e.g., power failure and cleaning up of temporary files.
- DBWn is the database writer. Oracle performs every operation in memory instead of the disk because processing in memory is faster and more efficient than on disk. The DBWn process reads data from disk and writes it back to the disk. An Oracle instance has many database writers DBW0, DBW1, DBW2, and so on.
- CKPT is the checkpoint process. In Oracle, data that is on disk is called block and the data which in memory is called buffer. When a block is written to the buffer and changed, the buffer becomes dirty, and it needs to be written down to the disk. The CKPT process updates the control and data file headers with checkpoint information and signals writing of dirty buffers to disk. Note that Oracle 12c allows both full and incremental checkpoints.

- LGWR is the log writer process which is the key to the recoverability architecture. Every change occurs in the database is written out to a file called redo log for recovery purposes. And these changes are written and logged by LGWR process. The LGWR process first writes the changes to memory and then disk as redo logs which then can be used for recovery.
- ARCn is the archiver process that copies the content of redo logs to archive redo log files. The archiver process can have multiple processes such as ARC0, ARC1, and ARC3, which allow the archiver to write to various destinations such as D: drive, E drive or other storage.
- MMON is the manageability monitor process that gathers performance metrics.
- MMAN is the memory manager that automatically manages memory in an Oracle database.
- LREG is the listener registration process that registers information on the database instance and dispatcher processes with the Oracle Net Listener.
Now, you should have a good overview of the Oracle Database architecture and its components.
Was this tutorial helpful?
Система управления базами данных (СУБД) Oracle предназначена для одновременного доступа к большим объемам хранимой информации и манипуляции с ними. В СУБД есть два основных понятия, которые необходимо усвоить для понимания некоторых последующих моментов с точки зрения безопасности и защиты СУБД, – это база данных и экземпляр. Если в двух словах, то база данных – это набор файлов в ОС, а экземпляр – процессы и память, причем одна база данных может быть доступна в нескольких экземплярах, а экземпляр единовременно обеспечивает доступ только к одной базе данных. Теперь рассмотрим эти понятия подробнее.
База данных Oracle
В базе данных Oracle есть два уровня представления данных: физический и логический. Физический уровень включает файлы баз данных, которые хранятся на диске, а логический уровень включает в себя табличное пространство, схемы пользователей. Рассмотрим эти уровни более подробно.
Физический уровень базы данных
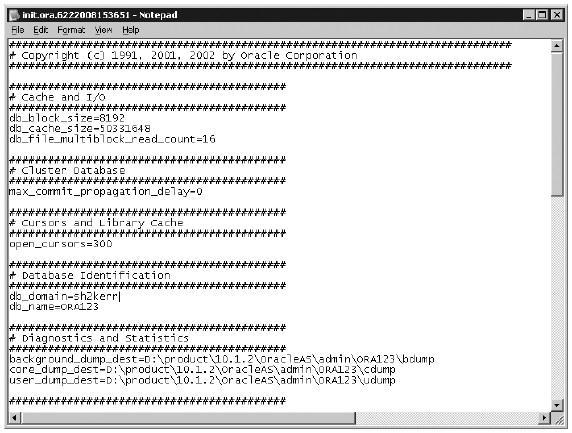
База данных и экземпляр на физическом уровне представлены шестью типами файлов. К экземпляру относятся файлы параметров, в которых прописываются его характеристики. Основной файл – это файл init.ora, отвечающий за параметры инициализации экземпляра, такие как имя базы данных, ссылку на управляющие файлы и пр. Пример файла инициализации представлен на рис. 1
Файлы базы данных
База данных как таковая представлена набором файлов разных типов, в которых собственно хранятся различные данные. Ниже кратко рассказано о том, что представляют собой эти типы файлов и чем файлы каждого типа могут быть нам полезны:
- Файлы данных. В этих файлах хранятся собственно сами данные в виде таблиц, индексов, триггеров и прочих объектов. Файлы данных являются наиболее важными во всей базе данных. В стандартной базе должно присутствовать минимум два файла данных: для системных данных (табличное пространство SYSTEM) и для пользовательских данных (табличное пространство USER). В табличном пространстве SYSTEM хранятся пароли всех пользователей в зашифрованном виде.
- Файлы журнала повторного выполнения (redo logs). Файлы журнала повторного выполнения очень важны для базы данных Oracle. В них записываются все транзакции базы данных. Они используются только для восстановления данных в самой базе при сбое экземпляра. В журналах повторного выполнения можно обнаружить множество критичной информации, о существовании которой рядовой администратор мог и не задуматься, в том числе и пароли пользователей.
- Управляющие файлы. В этих файлах определено местонахождение файлов данных и другая информация о состоянии базы данных. Управляющие файлы должны быть хорошо защищены. Наиболее важным является файл параметров инициализации экземпляра, потому что без него не удастся запустить экземпляр. Остальные файлы, такие как LISTENER.ORA, SQLNET.ORA, PROTOCOL.ORA, NAMES.ORA и пр., связаны с поддержкой сети и так же очень важны. В этих файлах можно обнаружить множество полезной информации для проникновения в СУБД.
- Временные файлы. Временные файлы используются для хранения промежуточных результатов действий над большим объемом данных в случае, если в оперативной памяти для этого не хватает места. Во временных файлах можно обнаружить содержимое временных таблиц и построенных по ним индексов. Временные файлы могут оказаться полезными в процессе расследования инцидентов или при восстановлении важной информации, удаленной из базы данных.
- Файлы паролей. Используются для аутентификации пользователей, выполняющих удаленное администрирование СУБД по сети. Более детально о них мы будем говорить позже.
Как видно, с точки зрения безопасности каждый приведенный выше тип файлов имеет большое значение.
Логический уровень базы данных
На логическом уровне находятся табличные пространства и схема БД, состоящая из таблиц, индексов, представлений, хранимых процедур и пр.
База данных разделяется на несколько логических частей, называемых табличными пространствами. Табличные пространства используются для логической группировки данных между собой для упрощения администрирования.
Каждое табличное пространство состоит из одного или более файлов данных, которые физически могут располагаться на разных дисках.
В табличных пространствах, в свою очередь, находятся схемы – это своеобразные контейнеры хранимых в БД объектов. Каждая схема однозначно ассоциируется с определенным пользователем – владельцем этой схемы. В этих схемах уже находятся такие логические единицы, как таблицы, индексы, представления и хранимые процедуры.
Вас заинтересует / Intresting for you:
2005 г.
Предисловие переводчика
Издательство «ДиаСофт» любезно
разрешило мне опубликовать переводы нескольких глав знаменитой книги Тома Кайта
«Expert one-on-one Oracle» в формате HTML. Я с удовольствием пользуюсь
предоставленной возможностью, и предлагаю вашему вниманию перевод второй главы.
В этой главе достаточно много схем и иллюстраций. Некоторые я попытался
«перерисовать», используя ASCII-графику. Остальные просто описаны в
комментариях.
Учтите, что в этом тексте используется терминология, соответствующая третьему,
исправленному изданию, которое должно выйти в свет в ближайшее время.
С наилучшими пожеланиями,
В.К.
Архитектура
Oracle проектировалась как максимально переносимая СУБД, — она доступна на всех
распространенных платформах. Поэтому физическая архитектура Oracle различна в разных
операционных системах. Например, в ОС UNIX СУБД Oracle реализована в виде нескольких
отдельных процессов операционной системы — практически каждая существенная функция
реализована отдельным процессом. Для UNIX такая реализация подходит, поскольку основой
многозадачности в ней является процесс. Для Windows, однако, подобная реализация не
подходит и работала бы не слишком хорошо (система получилась бы медленной и плохо
масштабируемой). На этой платформе СУБД Oracle реализована как один многопоточный
процесс, т.е. с использованием подходящих для этой платформы механизмов реализации.
На мэйнфреймах IBM, работающих под управлением OS/390 и zOS, СУБД Oracle использует
несколько адресных пространств OS/390, совместно образующих экземпляр Oracle. Для одного
экземпляра базы данных можно сконфигурировать до 255 адресных пространств. Более того, СУБД
Oracle взаимодействует с диспетчером загрузки OS/390 WorkLoad Manager (WLM) для установки
приоритетности выполнения определенных компонентов Oracle по отношению друг к другу и
к другим задачам, работающим в системе OS/390. В ОС Netware тоже используется многопоточная
модель. Хотя физические средства реализации СУБД Oracle на разных платформах могут
отличаться, архитектура системы — достаточно общая, чтобы можно было понять,
как СУБД Oracle работает на всех платформах.
В этой главе мы рассмотрим три основных компонента архитектуры Oracle.
- Файлы. Будут рассмотрены пять видов файлов, образующих базу данных и поддерживающих
экземпляр. Это файлы параметров, сообщений, данных, временных данных и журналов повторного
выполнения. - Структуры памяти, в частности системная глобальная область (System Global
Area — SGA). Мы рассмотрим взаимодействие SGA, PGA и UGA. Будут также рассмотрены
входящие в SGA Java-пул, разделяемый пул и большой пул. - Физические процессы или потоки. Будут описаны три типа процессов, образующих
экземпляр: серверные процессы, фоновые процессы и подчиненные процессы.
Сервер
Трудно решить, с какого компонента сервера начать описание. Процессы используют
область SGA, поэтому рассматривать SGA до процессов не имеет смысла. С другой стороны,
при описании процессов и их функционирования придется ссылаться на компоненты SGA.
Они тесно взаимосвязаны. С файлами работают процессы, и их нет смысла описывать, пока не
объяснено, что делают процессы. Ниже определены некоторые термины и сделан общий обзор
сервера Oracle, после чего подробно рассматриваются отдельные компоненты.
Два термина в контексте Oracle вызывают большую путаницу. Речь идет о терминах
«база данных» и «экземпляр». В соответствии с принятой в Oracle терминологией, эти
понятия определяются так:
- база данных — набор физических файлов операционной системы;
- экземпляр — набор процессов Oracle и область SGA.
Эти два термина иногда взаимозаменяемы, но представляют принципиально разные
концепции. Взаимосвязь между ними такова, что база данных может быть смонтирована
и открыта в нескольких экземплярах. Экземпляр может смонтировать и открыть только
одну базу данных в каждый момент времени. Не обязательно отрывать и монтировать одну
и ту же базу данных при каждом запуске экземпляра.
Стало еще непонятнее? Вот ряд примеров, которые помогут прояснить ситуацию.
Экземпляр — это набор процессов операционной системы и используемая ими память.
Все эти процессы могут работать с базой данных, которая представляет собой просто набор
файлов (файлов данных, временных файлов, файлов журнала повторного выполнения, управляющих
файлов). В каждый момент времени с экземпляром связан только один набор файлов. В
большинстве случаев обратное утверждение тоже верно; с базой данных работает только
один экземпляр. В случае же использования параллельного сервера Oracle
(Oracle Parallel Server — OPS), опции Oracle, позволяющей серверу функционировать
на нескольких компьютерах в кластерной среде, одна и та же база данных может быть
одновременно смонтирована и открыта несколькими экземплярами. Это делает возможным
доступ к базе данных одновременно с нескольких компьютеров. Oracle Parallel Server
позволяет создавать системы с высокой доступностью данных и, при условии правильной
реализации, очень масштабируемые. Рассмотрение опции OPS здесь не предусмотрено,
поскольку для описания особенностей ее реализации потребовалась бы отдельная книга.
Итак, в большинстве случаев между базой данных и экземпляром имеется отношение
один к одному. Это, вероятно, и является причиной путаницы при использовании этих
терминов. По опыту большинства пользователей, база данных — это экземпляр, а
экземпляр — это база данных.
Во многих тестовых средах это, однако, не так. На моем диске, например, может
быть пять отдельных баз данных. На тестовой машине СУБД Oracle установлена в одном
экземпляре. В каждый момент времени работает только один экземпляр, но обращаться
он может к разным базам данных, в зависимости от задач, которые я решаю. Создав
несколько конфигурационных файлов, я могу монтировать и открывать любую из этих
баз данных. В данном случае у меня один «экземпляр», но несколько баз данных,
лишь одна из которых доступна в каждый момент времени.
Итак, теперь под термином «экземпляр» мы будем понимать процессы и память сервера
Oracle. Термин «база данных» означает физические файлы, в которых находятся данные.
База данных может быть доступна многим экземплярам, но экземпляр в каждый момент
времени обеспечивает доступ только к одной базе данных.
Теперь можно приступать к рассмотрению абстрактной схемы СУБД
Oracle1.
Упрощенно, СУБД Oracle включает большую область памяти — SGA, —
содержащую внутренние структуры данных, доступ к которым необходим всем процессам для
кеширования данных с диска, кеширования данных повторного выполнения перед записью
на диск, хранения планов выполнения разобранных операторов SQL и т.д. Имеется также
набор процессов, подключенных к этой области SGA, причем механизм подключения в каждой
операционной системе другой. В среде UNIX процессы физически подключаются к большому
сегменту разделяемой памяти — выделенному ОС фрагменту памяти, к которому может
одновременно обращаться несколько процессов. В ОС Windows для выделения памяти
процессы используют библиотечную функцию malloc() языка C, поскольку они сами
являются потоками одного большого процесса. В СУБД Oracle также имеется набор файлов,
читаемых и записываемых процессами/потоками базы данных (причем читать и записывать
эти файлы имеют право только процессы Oracle). В этих файлах хранятся данные таблиц,
индексов, временное пространство, журналы повторного выполнения и т.д.
Если запустить СУБД Oracle в UNIX-системе и выполнить команду ps (для
просмотра состояния процессов), можно увидеть количество работающих процессов
и их имена. Например:
$ /bin/ps -aef | grep ora816 ora816 20827 1 0 Feb 09 ? 0:00 ora_d000_ora816dev ora816 20821 1 0 Feb 09 ? 0:06 ora_smon_ora816dev ora816 20817 1 0 Feb 09 ? 0:57 ora_lgwr_ora816dev ora816 20813 1 0 Feb 09 ? 0:00 ora_pmon_ora816dev ora816 20819 1 0 Feb 09 ? 0:45 ora_ckpt_ora816dev ora816 20815 1 0 Feb 09 ? 0:27 ora_dbw0_ora816dev ora816 20825 1 0 Feb 09 ? 0:00 ora_s000_ora816dev ora816 20823 1 0 Feb 09 ? 0:00 ora_reco_ora816dev
Я еще опишу назначение каждого из этих процессов, но часто их в совокупности
называют просто фоновыми процессами Oracle. Это — постоянно работающие
процессы, образующие экземпляр; они появляются при запуске СУБД и работают до тех пор,
пока она не будет остановлена. Интересно отметить, что все это — процессы, а не
программы. СУБД Oracle реализуется одной программой в UNIX, но программа эта многолика.
Программа, которая запускалась для реализации процесса ora_lgwr_ora816dev,
была использована и для запуска процесса ora_ckpt_ora816dev. Есть только один
двоичный файл с именем oracle. Просто он выполняется несколько раз с разными
именами. В ОС Windows с помощью программы tlist, входящей в Windows resource
toolkit, можно обнаружить только один процесс — Oracle.exe. В случае
NT тоже есть всего одна двоичная программа. Этот процесс создает несколько потоков,
представляющих фоновые процессы Oracle. С помощью утилиты tlist (или любого из
множества подобных средств) можно увидеть эти потоки:
C:Documents and SettingsThomas KyteDesktop>tlist 1072
1072 ORACLE.EXE
CWD: C:oracleDATABASE
CmdLine: c:oraclebinORACLE.EXE TKYTE816
VirtualSize: 144780 KB PeakVirtualSize: 154616 KB
WorkingSetSize: 69424 KB PeakWorkingSetSize: 71208 KB
NumberOfThreads: 11
0 Win32StartAddr:0x00000000 LastErr:0x00000000 State:Initialized
5 Win32StartAddr:0x00000000 LastErr:0x00000000 State:Initialized
5 Win32StartAddr:0x00000000 LastErr:0x00000000 State:Initialized
5 Win32StartAddr:0x00000000 LastErr:0x00000000 State:Initialized
5 Win32StartAddr:0x00000000 LastErr:0x00000000 State:Initialized
5 Win32StartAddr:0x00000000 LastErr:0x00000000 State:Initialized
5 Win32StartAddr:0x00000000 LastErr:0x00000000 State:Initialized
5 Win32StartAddr:0x00000000 LastErr:0x00000000 State:Initialized
5 Win32StartAddr:0x00000000 LastErr:0x00000000 State:Initialized
5 Win32StartAddr:0x00000000 LastErr:0x00000000 State:Initialized
5 Win32StartAddr:0x00000000 LastErr:0x00000000 State:Initialized
0.0.0.0 shp 0x00400000 ORACLE.EXE
5.0.2163.1 shp 0x77f80000 ntdll.dll
0.0.0.0 shp 0x60400000 oraclient8.dll
0.0.0.0 shp 0x60600000 oracore8.dll
0.0.0.0 shp 0x60800000 oranls8.dll
...
В данном случае имеется 11 потоков, выполняющихся в рамках одного процесса
Oracle. Если подключиться к базе данных, количество потоков увеличится до 12.
В ОС UNIX к существующим процессам oracle просто добавился бы еще один.
Теперь можно представить следующую схему. Предыдущая схема представляла
концептуальный вид СУБД Oracle сразу после запуска. Теперь, если подключиться к
СУБД Oracle в наиболее типичной конфигурации, схема будет выглядеть примерно
так2:
…
Обычно СУБД Oracle при подключении пользователя создает новый процесс. Это
принято называть конфигурацией выделенного сервера, поскольку на все время
сеанса ему выделяется отдельный серверный процесс. Сеансы и выделенные серверы
находятся в отношении один к одному. Клиентский процесс (любая программа,
пытающаяся подключиться к СУБД) будет непосредственно взаимодействовать с
соответствующим выделенным сервером по сети, например, через сокет TCP/IP.
Именно этот сервер будет получать и выполнять SQL-операторы. Он будет читать
файлы данных, а также искать необходимые данные в кеше. Он будет выполнять
операторы UPDATE и PL/SQL-код. Единственное его назначение —
отвечать на получаемые SQL-запросы.
СУБД Oracle также может работать в режиме многопоточного сервера
(multi-threaded server — MTS), в котором при подключении не создается
дополнительный поток или процесс UNIX. В режиме MTS СУБД Oracle использует пул
«разделяемых серверов» для поддержки большого количества пользователей.
Разделяемые серверы — это просто механизм организации пула подключений.
Вместо запуска 10000 выделенных серверов (это действительно много, если речь идет
о процессах или потоках) для 10000 сеансов режим MTS позволяет обслуживать их с
помощью гораздо меньшего количества разделяемых серверов, которые (как следует
из названия) будут совместно использоваться всеми сеансами. Это позволяет
СУБД Oracle поддерживать намного больше сеансов, чем в режиме выделенного
сервера. Машина, на которой работает сервер, может не справиться с поддержкой
10000 процессов, но управление 100 или 1000 процессами для нее вполне реально.
В режиме MTS разделяемые серверные процессы обычно запускаются сразу при старте
СУБД и отображаются в списке, выдаваемом командой ps (в представленных
выше результатах выполнения команды ps процесс ora_s000_ora816dev
представляет собой разделяемый серверный процесс).
Принципиальное отличие режима MTS от режима выделенного сервера состоит в том,
что клиентский процесс, подключившийся к СУБД, никогда не взаимодействует
непосредственно с разделяемым сервером, как это происходит в случае выделенного
сервера. Он не может взаимодействовать с разделяемым сервером, так как
соответствующий процесс используется совместно. Чтобы обеспечить совместное
использование этих процессов, необходим другой механизм взаимодействия. Для
этого в СУБД Oracle используется процесс (или набор процессов), которые
называют диспетчерами. Клиентский процесс взаимодействует по сети с
процессом-диспетчером. Процесс-диспетчер помещает запрос клиента в очередь
запросов в SGA (это одно из многих назначений области SGA). Первый же
свободный разделяемый сервер выберет и обработает этот запрос (например, запрос
может иметь вид UPDATE T SET X = X+5 WHERE Y = 2). По завершении выполнения
команды разделяемый сервер поместит ответ в очередь ответов. Процесс-диспетчер
следит за очередью и немедленно передает полученный результат клиенту.
Концептуально поток информации в режиме MTS выглядит следующим
образом3:
…
Клиентское подключение посылает запрос диспетчеру. Диспетчер поместит этот запрос
в очередь запросов в области SGA (1). Первый свободный разделяемый сервер выберет
этот запрос (2) из очереди и обработает его. Когда разделяемый сервер закончит
выполнение, ответ (коды возврата, данные и т.д.) помещается в очередь ответов (3),
после чего выбирается диспетчером (4) и возвращается клиенту.
С точки зрения разработчика нет никакой разницы между подключением к серверу
в режиме MTS и подключением к выделенному серверу. Теперь, когда стало понятно,
как происходит подключение к выделенному и разделяемому серверу, возникают
вопросы: а как вообще подключиться; как запускается выделенный сервер и как
связываться с процессом-диспетчером? Ответы зависят от платформы, но в
принципе все происходит так, как описано ниже.
Мы рассмотрим наиболее общий случай: запрос на подключение по сети с использованием
протоколов TCP/IP. В этом случае клиент находится на одной машине, а сервер —
на другой, причем эти машины связаны сетью на базе семейства протоколов TCP/IP.
Все начинается с клиента. Он посылает запрос клиентскому ПО Oracle на подключение
к базе данных. Например, выполняется команда:
C:> sqlplus scott/tiger@ora816.us.oracle.com
Здесь клиентом является утилита SQL*Plus. scott/tiger — имя пользователя
и пароль, а ora816.us.oracle.com — имя службы TNS. TNS — сокращение
от Transparent Network Substrate (прозрачная сетевая среда), которое обозначает
«базовое» программное обеспечение, встроенное в клиент Oracle и обеспечивающее
удаленное подключение (двухточечное взаимодействие клиента и сервера). Строка
подключения TNS указывает программному обеспечению Oracle, как подключаться к
удаленной базе данных. В общем случае клиентское программное обеспечение обращается
к файлу TNSNAMES.ORA. Это обычный текстовый файл конфигурации, обычно
находящийся в каталоге [ORACLE_HOME]networkadmin и содержащий записи вида:
ORA816.US.ORACLE.COM =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = aria.us.oracle.com)(PORT = 1521))
)
(CONNECT_DATA =
(ORACLE_SID = ora816)
)
)
Именно эти параметры конфигурации позволяют клиентскому ПО Oracle преобразовать
строку ora816.us.oracle.com в необходимые для подключения данные: имя хоста;
порт на этом хосте, прослушиваемый процессом, который принимает подключения;
идентификатор SID (Site IDentifier) базы данных на хосте, к которой необходимо
подключиться, и т.д. Эта строка, ora816.us.oracle.com, может преобразовываться
в необходимые данные и по-другому. Например, она может преобразовываться с помощью службы
Oracle Names — распределенного сервера имен для СУБД, аналогичного по назначению
службе DNS, используемой для преобразования имен хостов в IP-адреса. Однако в
большинстве небольших и средних серверов, где количество копий конфигурационных файлов
невелико, чаще всего используется именно файл TNSNAMES.ORA.
Теперь, когда клиентскому ПО известно, куда подключаться, оно открывает соединение
через сокет TCP/IP к порту 1521 машины aria.us.oracle.com. Если администратор
базы данных соответствующего сервера настроил службу Net8 и запустил процесс
прослушивания, это подключение может быть принято. В сетевой среде на сервере
работает процесс TNS Listener. Это процесс прослушивания, обеспечивающий физическое
подключение к базе данных. Получив запрос на подключение, он проверяет его, используя
собственные файлы конфигурации, и либо отвечает отказом (например, не существует
запрашиваемой базы данных или IP-адрес подключающегося содержится в списке тех,
кому не разрешено подключение к хосту), либо обеспечивает подключение клиента.
При подключении к выделенному серверу процесс прослушивания автоматически
запустит выделенный сервер. В ОС UNIX это делается с помощью системных вызовов
fork() и exec() (единственный способ создать новый процесс после
инициализации ОС UNIX — использовать системный вызов fork()). Теперь
мы физически подключены к базе данных. В Windows процесс прослушивания требует
от серверного процесса создания нового потока для подключения. После создания
этого потока клиент «перенаправляется» на него, и тем самым обеспечивается
физическое подключение. В случае ОС UNIX это можно представить следующей
схемой4:
…
В режиме MTS процесс прослушивания работает иначе. Ему известно, какие
процессы-диспетчеры работают в составе экземпляра. При получении запроса на
подключение процесс прослушивания выбирает процесс-диспетчер из пула доступных
диспетчеров. Затем он посылает клиенту информацию, позволяющую подключиться к
процессу-диспетчеру. Это необходимо, поскольку процесс прослушивания работает
на известном порту соответствующего хоста, а вот диспетчеры будут принимать
подключения через произвольно выделенные порты. Процессу прослушивания известны
эти выделенные порты, поэтому он автоматически выбирает свободный диспетчер.
Затем клиент отключается от процесса прослушивания и подключается непосредственно
к диспетчеру. В результате устанавливается физическое соединение с СУБД. Графически
это можно представить так5:
…
Итак, обзор архитектуры Oracle закончен. Мы описали, что такое экземпляр Oracle,
что такое база данных и как можно подключиться к базе данных через выделенный и
разделяемый сервер. На следующей схеме показано взаимодействие с сервером Oracle клиента,
подключенного к разделяемому серверу, и клиента, работающего с выделенным серверным
процессом. Один экземпляр Oracle может поддерживать оба типа подключений
одновременно6:
…
Теперь подробно рассмотрим процессы, образующие сервер, их назначение и
взаимодействие друг с другом, а также содержимое области SGA и назначение ее
компонентов. Но начнем мы с описания различных типов файлов, которые сервер
Oracle использует для управления данными.
Файлы
В состав базы данных и экземпляра входит шесть типов файлов. С экземпляром
связаны файлы параметров. По этим файлам экземпляр при запуске определяет свои
характеристики, например размер структур в памяти и местонахождение управляющих
файлов.
Базу данных образуют следующие файлы.
- Файлы данных. Собственно данные (в этих файлах хранятся таблицы, индексы и
все остальные сегменты). - Файлы журнала повторного выполнения. Журналы транзакций.
- Управляющие файлы. Определяют местонахождение файлов данных и содержат
другую необходимую информацию о состоянии базы данных. - Временные файлы. Используются при сортировке больших объемов данных и
для хранения временных объектов. - Файлы паролей.
Используются для аутентификации пользователей,
выполняющих администрирование удаленно, по сети. Мы не будем их подробно рассматривать.
Наиболее важны первые два типа файлов, поскольку именно в них хранятся накопленные
данные. В случае потери остальных файлов хранящиеся данные не пострадают. Если будут
потеряны файлы журнала повторного выполнения, некоторые данные могут быть потеряны.
Если же будут потеряны файлы данных и все их резервные копии, данные, безусловно,
будут потеряны навсегда.
Теперь давайте детально рассмотрим все типы файлов и их содержимое.
Файлы параметров
С базой данных Oracle связано много файлов параметров: от файла TNSNAMES.ORA
на клиентской рабочей станции (используемого для поиска сервера) и файла
LISTENER.ORA на сервере (для запуска процесса прослушивания Net8) до файлов
SQLNET.ORA, PROTOCOL.ORA, NAMES.ORA, CMAN.ORA и
LDAP.ORA. Наиболее важным является файл параметров инициализации экземпляра,
потому что без него не удастся запустить экземпляр. Остальные файлы тоже важны;
они связаны с поддержкой сети и обеспечением подключения к базе данных. Однако
рассматриваться в этом разделе они не будут. Сведения об их конфигурировании
и настройке можно найти в руководстве Oracle Net8 Administrators Guide.
Обычно разработчик не настраивает эти файлы — они создаются администратором.
Файл параметров инициализации экземпляра обычно называют файлом init или
файлом init.ora. Это название происходит от стандартного имени этого файла, —
init<ORACLE_SID>.ora. Например, экземпляр со значением SID, равным
tkyte816, обычно имеет файл параметров инициализации inittkyte816.ora.
Без файла параметров инициализации нельзя запустить экземпляр Oracle. Поэтому файл
этот достаточно важен. Однако, поскольку это обычный текстовый файл, который можно
создать в любом текстовом редакторе, сохранять его ценой собственной жизни не стоит.
Для тех, кому незнаком термин SID или параметр ORACLE_SID, представлю
полное определение. SID — это идентификатор экземпляра (сайта). В ОС UNIX
он хешируется совместно со значением ORACLE_HOME (задающим каталог, в котором
установлено ПО Oracle) для создания уникального ключа при подсоединении области SGA.
Если значение ORACLE_SID или ORACLE_HOME задано неправильно, выдается
сообщение об ошибке ORACLE NOT AVAILABLE, поскольку невозможно подключиться
к сегменту разделяемой памяти, определяемому этим «магическим» ключом. В ОС Windows
разделяемая память используется не так, как в ОС UNIX, но параметр SID все
равно важен. В одном и том же базовом каталоге ORACLE_HOME может быть несколько
баз данных, так что необходимо иметь возможность уникально идентифицировать их и
соответствующие конфигурационные файлы.
В Oracle файл init.ora имеет очень простую конструкцию. Он представляет
собой набор пар имя параметра/значение. Файл init.ora может иметь такой вид:
db_name = "tkyte816"
db_block_size = 8192
control_files = ("C:oradatacontrol01.ctl", "C:oradatacontrol02.ctl")
Фактически это почти минимальный файл init.ora, с которым уже можно
работать. В нем указан размер блока, стандартный для моей платформы (стандартный
размер блока различен для разных платформ), так что я могу эту строку удалить.
Файл параметров инициализации используется для получения имени базы данных и
местонахождения управляющих файлов. Управляющие файлы содержат информацию о
местонахождении всех остальных файлов, так что они нужны в процессе начальной
загрузки при запуске экземпляра.
В файле параметров инициализации обычно содержится и много других параметров.
Количество и имена параметров меняются с каждой новой версией. Например, в
Oracle 8.1.5 был параметр plsql_load_without_compile. Его не было ни в
одной из предыдущих версий и нет в последующих. В моих базах данных версий
8.1.5, 8.1.6 и 8.1.7 имеется, соответственно, 199, 201 и 203 различных параметра
инициализации. Большинство параметров, например db_block_size, существует
очень давно (они были во всех версиях), но со временем необходимость во многих
параметрах отпадает, так как меняется реализация. Если захочется прочитать об
этих параметрах и разобраться, что они позволяют установить, обратитесь к
руководству Oracle8i Reference. В первой главе этого руководства
представлены официально поддерживаемые параметры инициализации.
Обратите внимание на слова «официально поддерживаемые» в предыдущем абзаце.
Не поддерживаются (и не описаны в руководстве) параметры, имена которых начинаются
с символа подчеркивания. Вокруг этих параметров много спекуляций: поскольку они не
поддерживаются официально, значит, имеют «магические» свойства. Многие полагают,
что эти параметры хорошо известны «посвященным» сотрудникам корпорации Oracle и
используются ими. По моему мнению, все как раз наоборот. Их мало кто вообще знает
и редко использует. Большинство из неописанных параметров — лишние,
представляют устаревшие возможности или обеспечивают обратную совместимость.
Другие помогают при восстановлении данных, но не всей базы данных: они позволяют
запустить экземпляр в определенных экстремальных ситуациях, но лишь для
извлечения данных — базу данных затем придется пересоздавать.
Я не вижу смысла использовать неописанные параметры файла init.ora
в реальной базе данных, если только этого не требует служба технической
поддержки. Многие из них имеют побочные эффекты, которые могут оказаться
разрушительными. В базе данных, которую я использую для разработки,
установлен только один неописанный параметр:
_TRACE_FILES_PUBLIC = TRUE
Это делает трассировочные файлы доступными всем, а не только членам
группы dba. Я хочу, чтобы разработчики как можно чаще использовали
установки SQL_TRACE, TIMED_STATISTICS и утилиту TKPROF (более того,
я это требую), поэтому всем им необходимо читать трассировочные файлы.
В производственной базе данных я неописанных параметров не использую.
Неописанные параметры должны использоваться только по указанию службы
технической поддержки Oracle. При их использовании можно повредить базу
данных, да и реализация меняется от версии к версии.
Теперь, когда известно, что представляют собой файлы параметров и где можно
более подробно прочитать о параметрах, которые в них можно устанавливать,
осталось узнать, где эти файлы искать на диске. Файлы параметров инициализации
экземпляра принято именовать так:
init$ORACLE_SID.ora (переменная среды Unix) init%ORACLE_SID%.ora (переменная среды Windows)
Как правило, они находятся в каталогах
$ORACLE_HOME/dbs (в ОС Unix) %ORACLE_HOME%DATABASE (в ОС Windows)
Часто в файле параметров содержится всего одна строка примерно такого вида:
IFILE='C:oracleadmintkyte816pfileinit.ora'
Директива IFILE работает аналогично директиве препроцессора
#include в языке C. Она вставляет в данном месте текущего файла
содержимое указанного файла. В данном случае включается содержимое файла
init.ora из нестандартного каталога.
Следует отметить, что файл параметров не обязательно должен находится в
одном и том же стандартном месте. При запуске экземпляра можно использовать
параметр pfile = имя_файла. Это особенно полезно при попытке проверить
результаты установки других значений для параметров.
Файлы данных
Файлы данных вместе с файлами журнала повторного выполнения являются наиболее
важными в базе данных. Именно в них хранятся все данные. В каждой базе данных
есть хотя бы один файл данных, но обычно их намного больше. Только самые простые,
«тестовые» базы данных имеют один файл данных. В любой реальной базе данных
должно быть минимум два файла данных: один — для системных данных (табличное
пространство SYSTEM), другой — для пользовательских (табличное пространство
USER). В этом разделе мы рассмотрим организацию файлов данных в Oracle и
способы хранения данных в этих файлах. Но прежде надо разобраться, что такое
табличное пространство, сегмент, экстент и блок. Все это — единицы выделения
пространства под объекты в базе данных Oracle.
Начнем с сегментов. Сегменты — это области на диске,
выделяемые под объекты — таблицы, индексы, сегменты отката и т.д. При
создании таблицы создается сегмент таблицы. При создании секционированной таблицы
создается по сегменту для каждой секции. При создании индекса создается сегмент
индекса и т.д. Каждый объект, занимающий место на диске, хранится в одном сегменте.
Есть сегменты отката, временные сегменты, сегменты кластеров, сегменты индексов и т.д.
Сегменты, в свою очередь, состоят из одного или нескольких экстентов.
Экстент — это непрерывный фрагмент пространства в файле. Каждый сегмент
первоначально состоит хотя бы из одного экстента, причем для некоторых объектов
требуется минимум два экстента (в качестве примера можно назвать сегменты отката).
Чтобы объект мог вырасти за пределы исходного экстента, ему необходимо выделить
следующий экстент. Этот экстент не обязательно должен выделяться рядом с первым;
он может находиться достаточно далеко от первого, но в пределах экстента в файле
пространство всегда непрерывно. Размер экстента варьируется от одного блока до 2 Гбайт.
Экстенты состоят из блоков. Блок — наименьшая единица выделения
пространства в Oracle. В блоках и хранятся строки данных, индексов или промежуточные
результаты сортировок. Именно блоками сервер Oracle обычно выполняет чтение и запись
на диск. Блоки в Oracle бывают размером 2 Кбайта, 4 Кбайта или 8 Кбайт (хотя
допустимы также блоки размером 16 Кбайт и 32 Кбайта).
Сегмент состоит из одного или более экстентов, а экстент — это группа
следующих подряд блоков.
Размер блока в базе данных с момента ее создания — величина постоянная,
поэтому все блоки в базе данных одного размера. Формат блока представлен ниже.
+---------------+ | | <---- заголовок +---------------+ | | <---- каталог таблиц +---------------+ |\\\\\\\| <---- каталог строк +---------------+ | | | | <---- свободное пространство | ... | +---------------+ |010101010101010| |010101010101010| |010101010101010| <---- данные |010101010101010| |010101010101010| +---------------+
Заголовок блока содержит информацию о типе блока (блок таблицы, блок индекса
и т.д.), информацию о текущих и прежних транзакциях, затронувших блок, а также адрес
(местонахождение) блока на диске. Каталог таблиц содержит информацию о таблицах,
строки которых хранятся в этом блоке (в блоке могут храниться данные нескольких таблиц).
Каталог строк содержит описание хранящихся в блоке строк. Это массив указателей
на строки, хранящиеся в области данных блока. Вместе эти три части блока называются
служебным пространством блока. Это пространство недоступно для данных и
используется сервером Oracle для управления блоком. Остальные две части блока вполне
понятны: в блоке имеется занятое пространство, в котором хранятся данные,
и может быть свободное пространство.
Теперь, получив общее представление о сегментах, состоящих из экстентов, которые,
в свою очередь, состоят из блоков, можно переходить к понятию «табличное пространство»
и разбираться, где же в этой структуре место для файлов. Табличное пространство —
это контейнер с сегментами. Каждый сегмент принадлежит к одному табличному пространству.
В табличном пространстве может быть много сегментов. Все экстенты сегмента находятся
в табличном пространстве, где создан сегмент. Сегменты никогда не переходят границ
табличного пространства. С табличным пространством, в свою очередь, связан один или
несколько файлов данных. Экстент любого сегмента табличного пространства целиком
помещается в одном файле данных. Однако экстенты сегмента могут находиться в нескольких
различных файлах данных. Графически это можно представить следующим
образом7:
…
Итак, здесь представлено табличное пространство USER_DATA. Оно состоит из
двух файлов данных — user_data01 и user_data02. В нем выделено
три сегмента: T1, T2 и I1 (вероятно, две таблицы и индекс).
В табличном пространстве выделены четыре экстента, причем каждый показан как
непрерывный набор блоков базы данных. Сегмент T1 состоит из двух экстентов
(по одному экстенту в каждом файле). Сегменты T2 и I1 состоят из одного
экстента. Если для табличного пространства понадобится больше места, можно либо
увеличить размер файлов данных, уже выделенных ему, либо добавить третий файл данных.
Табличные пространства в Oracle — это логические структуры хранения данных.
Разработчики создают сегменты в табличных пространствах. Они никогда не переходят на
уровень файлов — нельзя указать, что экстенты должны выделяться из определенного
файла. Объекты создаются в табличных пространствах, а об остальном заботится сервер
Oracle. Если в дальнейшем администратор базы данных решит перенести файлы данных
на другой диск для более равномерного распределения операций ввода-вывода
по дискам, никаких проблем для приложения это не создаст. На работе приложения
это никак не отразится.
Итак, иерархия объектов, обеспечивающих хранение данных в Oracle, выглядит так.
- База данных, состоящая из одного или нескольких табличных пространств.
- Табличное пространство, состоящее из одного или нескольких файлов данных.
Табличное пространство содержит сегменты. - Сегмент (TABLE, INDEX и т.д.), состоящий из одного и более экстентов.
Сегмент привязан к табличному пространству, но его данные могут находиться в разных
файлах данных, образующих это табличное пространство. - Экстент — набор расположенных рядом на диске блоков. Экстент целиком
находится в одном табличном пространстве и, более того, в одном файле данных
этого табличного пространства. - Блок — наименьшая единица управления пространством в базе данных.
Блок — наименьшая единица ввода-вывода, используемая сервером.
Прежде чем завершить описание файлов данных, давайте разберемся, как происходит
управление экстентами в табличном пространстве. До версии 8.1.5 в Oracle был только
один метод управления выделением экстентов в табличном пространстве. Этот метод
называется управление табличным пространством по словарю. Т.е. место в
табличном пространстве отслеживается в таблицах словаря данных (аналогично тому,
как отслеживаются движения средств на банковских счетах с помощью пары таблиц
DEBIT и CREDIT). В качестве дебета можно рассматривать выделенные
объектам экстенты, в качестве кредита — свободные для использования экстенты.
Когда для объекта необходим очередной экстент, он запрашивается у системы. При
получении такого запроса сервер Oracle обращается к соответствующим таблицам
словаря данных, выполняет ряд запросов, находит (или не находит) свободное место
нужного размера, а затем изменяет строку в одной таблице (или удаляет ее)
и вставляет строку в другую. При этом сервер Oracle управляет пространством
примерно так же, как работают обычные приложения: он изменяет данные в таблицах.
Соответствующие SQL-операторы для получения дополнительного пространства,
выполняемые в фоновом режиме от имени пользователя, называют рекурсивными.
Выполненный пользователем SQL-оператор INSERT вызывает выполнение других
рекурсивных SQL-операторов для получения пространства на диске. При частом
выполнении рекурсивные SQL-операторы создают весьма существенную дополнительную
нагрузку на систему. Подобные изменения словаря данных должны выполняться
последовательно, делать их одновременно нельзя. По возможности их следует избегать.
В прежних версиях Oracle этот метод управления пространством (и связанные с
ним дополнительные расходы ресурсов на выполнение рекурсивных SQL-операторов)
приводил к проблемам при работе с временными табличными пространствами (до появления
«настоящих» временных табличных пространств). Речь идет о табличных пространствах,
в которых необходимо часто выделять место (при этом надо удалить строку из одной
таблицы словаря данных и вставить в другую) и освобождать его (помещая только что
перенесенные строки туда, где они ранее были). Эти операции выполняются
последовательно, что существенно снижает возможности одновременной работы и
увеличивает время ожидания. В версии 7.3 СУБД Oracle для решения этой проблемы
добавили временные пространства. Во временном табличном пространстве пользователь
не мог создавать постоянные объекты. Это было единственным новшеством: управление
пространством все равно выполнялось с помощью таблиц словаря данных. Однако после
выделения экстента во временном табличном пространстве система его уже не
освобождала. При следующем запросе экстента из временного табличного пространства
сервер Oracle искал уже выделенный экстент в соответствующей структуре данных
в памяти и, найдя, использовал повторно. В противном случае экстент выделялся
как обычно. При этом после запуска и работы СУБД в течение некоторого времени
соответствующий временный сегмент выглядел как заполненный, но фактически был просто
«выделен». Свободными экстентами в нем управляли по-другому. При запросе сеансом
временного пространства сервер Oracle искал его в структурах данных в памяти,
а не выполнял дорогостоящие рекурсивные SQL-операторы.
В версиях Oracle, начиная с 8.1.5, был сделан следующий шаг по сокращению
расхода ресурсов на управление пространством. Кроме табличных пространств,
управляемых по словарю данных, появились локально управляемые табличные
пространства. Для всех табличных пространств стало можно делать то, что в
Oracle 7.3 делалось для временных, т.е. не использовать словарь данных для
управления свободным местом в табличном пространстве. В локально управляемом
табличном пространстве для отслеживания экстентов используется битовая карта,
хранящаяся в каждом файле данных. Теперь для получения экстента достаточно
установить значение 1 для соответствующего бита в битовой карте. Для освобождения
экстента — сбросить бит обратно в 0. По сравнению с обращениями к словарю
данных, это выполняется молниеносно. Больше не требуется ждать завершения
длительно выполняемой операции, на уровне базы данных последовательно выделяющей
место во всех табличных пространствах. Очередность на уровне табличного
пространства остается только для очень быстро выполняемой операции.
Локально управляемые табличные пространства имеют и другие положительные
качества, например устанавливают одинаковый размер всех экстентов, но это
имеет значение только для администраторов баз данных.
Временные файлы
Временные файлы в Oracle — это специальный тип файлов данных.
Сервер Oracle использует временные файлы для хранения промежуточных результатов
сортировки большого объема данных или результирующих множеств, если для них не
хватает оперативной памяти. Постоянные объекты данных, такие как таблицы или
индексы, во временных файлах никогда не хранятся, в отличие от содержимого
временных таблиц и построенных по ним индексов. Так что создать таблицы приложения
во временном файле данных нельзя, а вот хранить в нем данные можно, если использовать
временную таблицу.
Сервер Oracle обрабатывает временные файлы специальным образом. Обычно все
изменения объектов записываются в журналы повторного выполнения. Эти журналы
транзакций в дальнейшем можно использовать для повторного выполнения транзакций.
Это делается, например, при восстановлении после сбоя. Временные файлы в этом
процессе не участвуют. Для них не генерируются данные повторного выполнения,
хотя и генерируются данные отмены (UNDO) при работе с глобальными временными
таблицами, чтобы можно было откатить изменения, сделанные в ходе сеанса. Создавать
резервные копии временных файлов данных нет необходимости, а если кто-то это
делает, то напрасно теряет время, поскольку данные во временном файле восстановить
все равно нельзя.
Рекомендуется конфигурировать базу данных так, чтобы временные табличные
пространства управлялись локально. Убедитесь, что ваш администратор базы данных
использует команду CREATE TEMPORARY TABLESPACE. Никому не нужно еще одно обычное
табличное пространство, используемое под временные данные, поскольку не удастся
получить преимущества временных файлов данных. Убедитесь также, что в качестве
временного используется локально управляемое табличное пространство с экстентами
одинакового размера, соответствующего значению параметра инициализации
sort_area_size. Создаются такие временные табличные пространства примерно так:
tkyte@TKYTE816> create temporary tablespace temp 2 tempfile 'c:oracleoradatatkyte816temp.dbf' 3 size 5m 4 extent management local 5 uniform size 64k; Tablespace created.
Поскольку мы опять вторгаемся в сферу деятельности администратора базы данных,
переходим к следующей теме.
Управляющие файлы
Управляющий файл — это сравнительно небольшой файл (в редких случаях
он может увеличиваться до 64 Мбайт), содержащий информацию обо всех файлах,
необходимых серверу Oracle. Из файла параметров инициализации (init.ora)
экземпляр может узнать, где находятся управляющие файлы, а в управляющем файле
описано местонахождение файлов данных и файлов журнала повторного выполнения.
В управляющих файлах хранится и другие необходимые серверу Oracle сведения, в
частности время обработки контрольной точки, имя базы данных (которое должно
совпадать со значением параметра инициализации db_name), дата и время
создания базы данных, хронология архивирования журналов повторного выполнения
(именно она приводит к увеличению размера управляющего файла в некоторых случаях)
и т.д.
Управляющие файлы надо мультиплексировать либо аппаратно (располагать на
RAID-массиве), либо с помощью средств сервера Oracle, когда RAID-массив или
зеркалирование использовать нельзя. Необходимо поддерживать несколько копий
этих файлов, желательно на разных дисках, чтобы предотвратить потерю управляющих
файлов в случае сбоя диска. Потеря управляющих файлов — не фатальное событие,
она только существенно усложнит восстановление.
С управляющими файлами разработчику скорее всего сталкиваться никогда не придется.
Для администратора базы данных это — важная часть базы данных, но для
разработчика эти файлы не особенно нужны.
Файлы журнала повторного выполнения
Файлы журнала повторного выполнения принципиально важны для базы данных Oracle.
Это журналы транзакций базы данных. Они используются только для восстановления
при сбое экземпляра или носителя или при поддержке резервной базы данных на случай
сбоев. Если на сервере, где работает СУБД, отключится питание и вследствие этого
произойдет сбой экземпляра, для восстановления системы в состояние,
непосредственно предшествующее отключению питания, сервер Oracle при повторном
запуске будет использовать оперативные журналы повторного выполнения. Если диск,
содержащий файлы данных, полностью выйдет из строя, для восстановления резервной
копии этого диска на соответствующий момент времени сервер Oracle, помимо оперативных
журналов повторного выполнения, будет использовать также архивные. Кроме того,
при случайном удалении таблицы или какой-то принципиально важной информации,
если эта операция зафиксирована, с помощью оперативных и архивных журналов повторного
выполнения можно восстановить данные из резервной копии на момент времени,
непосредственно предшествующий удалению.
Практически каждое действие, выполняемое в СУБД Oracle, генерирует определенные
данные повторного выполнения, которые надо записать в оперативные файлы журнала
повторного выполнения. При вставке строки в таблицу конечный результат этой операции
записывается в журналы повторного выполнения. При удалении строки записывается факт
удаления. При удалении таблицы в журнал повторного выполнения записываются
последствия этого удаления. Данные из удаленной таблицы не записываются,
но рекурсивные SQL-операторы, выполняемые сервером Oracle при удалении таблицы,
генерируют определенные данные повторного выполнения. Например, при этом сервер
Oracle удалит строку из таблицы SYS.OBJ$, и это удаление будет отражено в журнале.
Некоторые операции могут выполняться в режиме с минимальной генерацией данных
повторного выполнения. Например, можно создать индекс с атрибутом NOLOGGING.
Это означает, что первоначальное создание этого индекса не будет записываться в журнал,
но любые инициированные при этом рекурсивные SQL-операторы, выполняемые сервером
Oracle, — будут. Например, вставка в таблицу SYS.OBJ$ строки,
соответствующей индексу, в журнал записываться не будет. Однако последующие
изменения индекса при выполнении SQL-операторов INSERT, UPDATE и
DELETE, будут записываться в журнал.
Есть два типа файлов журнала повторного выполнения: оперативные и архивные.
В главе 5 мы еще раз затронем тему журналов повторного выполнения и сегментов
отката, чтобы понять, как они влияют на разработку приложений. Пока же мы опишем,
что собой представляют журналы повторного выполнения и их назначение.
Оперативный журнал повторного выполнения
В каждой базе данных Oracle есть как минимум два оперативных файла журнала
повторного выполнения. Эти оперативные файлы журнала повторного выполнения
имеют фиксированный размер и используются циклически. Сервер Oracle выполняет
запись в файл журнала 1, а когда доходит до конца этого файла, —
переключается на файл журнала 2 и переписывает его содержимое от начала
до конца. Когда заполнен файл журнала 2, сервер переключается снова на
файл журнала 1 (если имеется всего два файла журнала повторного выполнения;
если их три, сервер, разумеется, переключится на третий файл).
Переход с одного файла журнала на другой называется переключением журнала.
Важно отметить, что переключение журнала может вызвать временное «зависание»
плохо настроенной базы данных. Поскольку журналы повторного выполнения
используются для восстановления транзакций в случае сбоя, перед повторным
использованием файла журнала необходимо убедиться, что его содержимое не
понадобится в случае сбоя. Если сервер Oracle «не уверен», что содержимое
файла журнала не понадобится, он приостанавливает на время изменения в базе
данных и убеждается, что данные, «защищаемые» этой информацией повторного
выполнения, записаны на диск. После этого обработка возобновляется,
и файл журнала переписывается. Мы затронули ключевое понятие баз данных —
обработку контрольной точки. Чтобы понять, как используются оперативные
журналы повторного выполнения, надо разобраться с обработкой контрольной
точки, использованием буферного кеша базы данных и рассмотреть функции
процесса записи блоков базы данных (Database Block Writer — DBWn).
Буферный кеш и процесс DBWn подробно рассматриваются ниже, но мы все
равно забегаем вперед, так что имеет смысл поговорить о них.
В буферном кеше базы данных временно хранятся блоки базы данных. Это
структура в области SGA разделяемой памяти экземпляра Oracle. При чтении
блоки запоминаются в этом кеше (предполагается, что в дальнейшем их не
придется читать с диска). Буферный кеш — первое и основное средство
настройки производительности сервера. Он существует исключительно для
ускорения очень медленного процесса ввода-вывода. При изменении блока путем
обновления одной из его строк изменения выполняются в памяти, в блоках
буферного кеша. Информация, достаточная для повторного выполнения этого
изменения, записывается в буфер журнала повторного выполнения —
еще одну структуру данных в области SGA. При фиксации изменений с помощью
оператора COMMIT сервер Oracle не записывает на диск все измененные
блоки в области SGA. Он только записывает в оперативные журналы повторного
выполнения содержимое буфера журнала повторного выполнения. Пока измененный
блок находится в кеше, а не на диске, содержимое соответствующего оперативного
журнала может быть использовано в случае сбоя экземпляра. Если сразу после
фиксации изменения отключится питание, содержимое буферного кеша пропадет.
Если это произойдет, единственная запись о выполненном изменении останется
в файле журнала повторного выполнения. После перезапуска экземпляра сервер
Oracle будет по сути повторно выполнять транзакцию, изменяя блок точно так
же, как мы это делали ранее, и фиксируя это изменение автоматически. Итак,
если измененный блок находится в кеше и не записан на диск, мы не можем
повторно записывать соответствующий файл журнала повторного выполнения.
Тут и вступает в игру процесс DBWn. Это фоновый процесс сервера
Oracle, отвечающий за освобождение буферного кеша при заполнении и
обработку контрольных точек. Обработка контрольной точки состоит в
сбросе грязных (измененных) блоков из буферного кеша на диск. Сервер
Oracle делает это автоматически, в фоновом режиме. Обработка контрольной
точки может быть вызвана многими событиями, но чаще всего — переключением
журнала повторного выполнения. При заполнении файла журнала 1, перед переходом
на файл журнала 2, сервер Oracle инициирует обработку контрольной точки.
В этот момент процесс DBWn начинает сбрасывать на диск все грязные блоки,
защищенные файлом журнала 1. Пока процесс DBWn не сбросит все блоки,
защищаемые этим файлом, сервер Oracle не сможет его повторно использовать.
Если попытаться использовать его прежде, чем процесс DBWn завершит
обработку контрольной точки, в журнал сообщений (alert log) будет выдано
следующее сообщение:
... Thread 1 cannot allocate new log, sequence 66 Checkpoint not complete Current log# 2 seq# 65 mem# 0: C:ORACLEORADATATKYTE816REDO02.LOG ...
Журнал сообщений — это файл на сервере, содержащий информационные
сообщения сервера, например, о запуске и останове, а также уведомления об
исключительных ситуациях, вроде незавершенной обработки контрольной точки.
Итак, в момент выдачи этого сообщения обработка изменений была приостановлена
до завершения процессом DBWn обработки контрольной точки. Для ускорения
обработки сервер Oracle отдал все вычислительные мощности процессу DBWn.
При соответствующей настройке сервера это сообщение в журнале появляться
не должно. Если оно все же есть, значит, имеют место искусственные, ненужные
ожидания, которых можно избежать. Цель (в большей степени администратора базы
данных, чем разработчика) — иметь достаточно оперативных файлов журнала
повторного выполнения. Это предотвратит попытки сервера использовать файл
журнала, прежде чем будет закончена обработка контрольной точки. Если это
сообщение выдается часто, значит, администратор базы данных не выделил для
приложения достаточного количества оперативных журналов повторного выполнения
или процесс DBWn не настроен как следует. Разные приложения генерируют
различные объемы информации повторного выполнения. Системы класса DSS (системы
поддержки принятия решений, выполняющие только запросы), естественно, будут
генерировать намного меньше информации повторного выполнения, чем системы OLTP
(системы оперативной обработки транзакций). Система, манипулирующая изображениями
в больших двоичных объектах базы данных, может генерировать во много раз больше
информации повторного выполнения, чем простая система ввода заказов. В системе
ввода заказов со 100 пользователями генерируется в десять раз меньше информации
повторного выполнения, чем в системе с 1000 пользователей. «Правильного»
размера для журналов повторного выполнения нет, — он просто должен быть
достаточным.
При определении размера и количества оперативных журналов повторного
выполнения необходимо учитывать много факторов. Они, в общем, выходят
за рамки книги, но я перечислю хотя бы отдельные, чтобы вы поняли, о чем речь.
- Резервная база данных. Когда заполненные журналы повторного
выполнения посылаются на другую машину и там применяются к копии текущей
базы данных, необходимо много небольших файлов журнала. Это поможет уменьшить
рассинхронизацию резервной базы данных с основной. - Множество пользователей, изменяющих одни и те же блоки. Здесь могут
понадобиться большие файлы журнала повторного выполнения. Поскольку все изменяют
одни и те же блоки, желательно, чтобы до того как блоки будут сброшены на
диск, было выполнено как можно больше изменений. Каждое переключение журнала
инициирует обработку контрольной точки, так что желательно переключать
журналы как можно реже. Это, однако, может замедлить восстановление. - Среднее время восстановления. Если необходимо обеспечить максимально
быстрое восстановление, придется использовать файлы журнала меньшего размера,
даже если одни и те же блоки изменяются множеством пользователей. Один или
два небольших файла журнала повторного выполнения будут обработаны при
восстановлении намного быстрее, чем один гигантский. Система в целом будет
работать медленнее, чем могла бы (из-за слишком частой обработки контрольных
точек), но восстановление будет выполняться быстрее. Для сокращения времени
восстановления можно изменять и другие параметры базы данных, а не только
уменьшать размер файлов журнала повторного выполнения.
Архивный журнал повторного выполнения
База данных Oracle может работать в двух режимах — NOARCHIVELOG
и ARCHIVELOG. Я считаю, что система, используемая в производственных
условиях, обязательно должна работать в режиме ARCHIVELOG. Если база
данных не работает в режиме ARCHIVELOG, данные рано или поздно будут
потеряны. Работать в режиме NOARCHIVELOG можно только в среде разработки или
тестирования.
Эти режимы отличаются тем, что происходит с файлом журнала повторного
выполнения до того как сервер Oracle его перепишет. Сохранять ли копию
информации повторного выполнения или разрешить серверу Oracle переписать ее,
потеряв при этом навсегда — очень важный вопрос. Если не сохранить
этот файл, мы не сможем восстановить данные с резервной копии до текущего
момента. Предположим, резервное копирование выполняется раз в неделю,
по субботам. В пятницу вечером, после того как за неделю было сгенерировано
несколько сотен журналов повторного выполнения, происходит сбой диска. Если
база данных не работала в режиме ARCHIVELOG, остается только два варианта
дальнейших действий.
- Удалить табличное пространство/пространства, связанные со сбойным диском.
Любое табличное пространство, имеющее файлы данных на этом диске, должно
быть удалено, включая его содержимое. Если затронуто табличное пространство
SYSTEM (словарь данных Oracle), этого сделать нельзя. - Восстановить данные за субботу и потерять все изменения за неделю.
Оба варианта непривлекательны, поскольку приводят к потере данных.
Работая же в режиме ARCHIVELOG, достаточно найти другой диск и восстановить
на него соответствующие файлы с субботней резервной копии. Затем применить
к ним архивные журналы повторного выполнения и, наконец, —
оперативные журналы повторного выполнения (то есть повторить все накопленные
за неделю транзакции в режиме быстрого наката). При этом ничего не
теряется. Данные восстанавливаются на момент сбоя.
Часто приходится слышать, что в производственных системах режим
ARCHIVELOG не нужен. Это глубочайшее заблуждение. Если не хотите
в один момент потерять данные, сервер должен работать в режиме
ARCHIVELOG. «Мы используем дисковый массив RAID-5 и абсолютно защищены» —
вот типичное оправдание. Я сталкивался с ситуациями, когда по вине изготовителя
все пять дисков массива одновременно останавливались. Я видел поврежденные
аппаратным контроллером файлы данных, которые в поврежденном виде надежно
защищались дисковым массивом. Если имеется резервная копия данных на момент,
предшествующий сбою оборудования, и архивы не повреждены, — восстановление
возможно. Поэтому нет разумных оснований для того, чтобы не использовать режим
ARCHIVELOG в системе, где данные представляют хоть какую-нибудь ценность.
Производительность — не основание. При правильной настройке на архивирование
расходуется незначительное количество ресурсов системы. Это, а также тот факт,
что быстро работающая система, в которой данные теряются, — бесполезна,
заставляет сделать вывод, что, даже если бы архивирование журналов замедляло
работу системы в два раза, оно в любом случае должно выполняться.
Не поддавайтесь ни на какие уговоры и не отказывайтесь от режима
ARCHIVELOG. Вы потратили много времени на разработку приложения, поэтому
надо, чтобы пользователи ему доверяли. О доверии можно забыть, если их данные
будут потеряны.
Итак, мы рассмотрели основные типы файлов, используемых сервером Oracle:
от небольших файлов параметров инициализации (без которых не удастся даже
запустить экземпляр) до принципиально важных файлов журнала повторного
выполнения и файлов данных. Обсудили структуры хранения данных в Oracle:
от табличных пространств, сегментов и экстентов до блоков базы данных —
наименьшей единицы хранения. Была описана обработка контрольной точки в
базе данных и даже (несколько преждевременно) затронута работа физических
процессов или потоков, составляющих экземпляр Oracle. В последующих разделах
этой главы мы более детально рассмотрим эти процессы и структуры памяти.
Структуры памяти
Теперь пришло время рассмотреть основные структуры памяти сервера Oracle.
Их три.
- SGA, System Global Area — глобальная область системы. Это большой
совместно используемый сегмент памяти, к которому обращаются все процессы
Oracle. - PGA, Process Global Area — глобальная область процесса. Это
приватная область памяти процесса или потока, недоступная другим
процессам/потокам. - UGA, User Global Area — глобальная область пользователя.
Это область памяти, связанная с сеансом. Глобальная область памяти может
находиться в SGA либо в PGA. Если сервер работает в режиме MTS, она
располагается в области SGA, если в режиме выделенного сервера, —
в области PGA.
Рассмотрим кратко области PGA и UGA, затем перейдем к действительно
большой структуре — области SGA.
Области PGA и UGA
Как уже было сказано, PGA — это область памяти процесса. Эта область
памяти используется одним процессом или одним потоком. Она недоступна ни
одному из остальных процессов/потоков в системе. Область PGA обычно выделяется
с помощью библиотечного вызова malloc() языка C и со временем может расти
(или уменьшаться). Область PGA никогда не входит в состав области SGA —
она всегда локально выделяется процессом или потоком.
Область памяти UGA хранит состояние сеанса, поэтому всегда должна быть
ему доступна. Местонахождение области UGA зависит исключительно от конфигурации
сервера Oracle. Если сконфигурирован режим MTS, область UGA должна находиться в
структуре памяти, доступной всем процессам, следовательно, в SGA. В этом случае
сеанс сможет использовать любой разделяемый сервер, так как каждый из них сможет
прочитать и записать данные сеанса. При подключении к выделенному серверу это
требование общего доступа к информации о состоянии сеанса снимается, и область
UGA становится почти синонимом PGA, — именно там информация о состоянии
сеанса и будет располагаться. Просматривая статистическую информацию о системе,
можно обнаружить, что при работе в режиме выделенного сервера область UGA
входит в PGA (размер области PGA будет больше или равен размеру используемой
памяти UGA — размер UGA будет учитываться при определении размера области
PGA).
Размер области PGA/UGA определяют параметры уровня сеанса в файле
init.ora: SORT_AREA_SIZE и SORT_AREA_RETAINED_SIZE. Эти два
параметра управляют объемом пространства, используемым сервером Oracle для
сортировки данных перед сбросом на диск, и определяют объем сегмента памяти,
который не будет освобожден по завершении сортировки. SORT_AREA_SIZE обычно
выделяется в области PGA, а SORT_AREA_RETAINED_SIZE — в UGA.
Управлять размером областей UGA/PGA можно с помощью запроса к специальному
представлению V$ сервера Oracle. Эти представления называют также
представлениями динамической производительности. Подробнее эти представления V$
рассматриваются в главе 10. С помощью представлений V$ можно определить
текущее использование памяти под области PGA и UGA. Например, запущен небольшой
тестовый пример, требующий сортировки большого объема данных. Просмотрев несколько
первых строк данных, я решил не извлекать остальное результирующее множество.
После этого можно сравнить использование памяти «до» и «после»:
tkyte@TKYTE816> select a.name, b.value 2 from v$statname a, v$mystat b 3 where a.statistic# = b.statistic# 4 and a.name like '%ga %' 5 / NAME VALUE ------------------------------ ---------- session uga memory 67532 session uga memory max 71972 session pga memory 144688 session pga memory max 144688 4 rows selected.
Итак, перед началом сортировки в области UGA было около 70 Кбайт данных,
а в PGA — порядка 140 Кбайт. Первый вопрос: сколько памяти используется в
области PGA помимо UGA? Вопрос нетривиальный и на него нельзя ответить, не зная,
подключен ли сеанс к выделенному или к разделяемому серверу; но даже зная это
нельзя ответить однозначно. В режиме выделенного сервера область UGA входит в
состав PGA. В этом случае порядка 140 Кбайт выделено в области памяти процесса
или потока. В режиме MTS область UGA выделяется из SGA, а область PGA относится
к разделяемому серверу. Поэтому при работе в режиме MTS к моменту получения
последней строки из представленного выше запроса разделяемый серверный процесс
уже может использоваться другим сеансом. Соответственно, область PGA уже не
принадлежит нам, так что мы используем всего 70 Кбайт памяти (если только не
находимся в процессе выполнения запроса, когда областями PGA и UGA суммарно
используется 210 Кбайт памяти).
Теперь разберемся, что происходит в областях PGA/UGA нашего сеанса:
tkyte@TKYTE816> show parameter sort_area NAME TYPE VALUE ------------------------------------ ------- -------------------------- sort_area_retained_size integer 65536 sort_area_size integer 65536 tkyte@TKYTE816> set pagesize 10 tkyte@TKYTE816> set pause on tkyte@TKYTE816> select * from all_objects order by 1, 2, 3, 4; ...(Нажмите Control-C после первой страницы данных) ... tkyte@TKYTE816> set pause off tkyte@TKYTE816> select a.name, b.value 2 from v$statname a, v$mystat b 3 where a.statistic# = b.statistic# 4 and a.name like '%ga %' 5 / NAME VALUE ------------------------------ ---------- session uga memory 67524 session uga memory max 174968 session pga memory 291336 session pga memory max 291336 4 rows selected.
Как видите, памяти использовано больше, поскольку данные сортировались.
Область UGA временно увеличилась примерно на размер SORT_AREA_RETAINED_SIZE,
а область PGA — немного больше. Для выполнения запроса и сортировки сервер
Oracle выделил дополнительные структуры, которые оставлены в памяти сеанса для
других запросов. Давайте выполним ту же операцию, изменив значение
SORT_AREA_SIZE:
tkyte@TKYTE816> alter session set sort_area_size=1000000; Session altered. tkyte@TKYTE816> select a.name, b.value 2 from v$statname a, v$mystat b 3 where a.statistic# = b.statistic# 4 and a.name like '%ga %' 5 / NAME VALUE ------------------------------ ---------- session uga memory 63288 session uga memory max 174968 session pga memory 291336 session pga memory max 291336 4 rows selected. tkyte@TKYTE816> show parameter sort_area NAME TYPE VALUE ------------------------------------ ------- -------------------------- sort_area_retained_size integer 65536 sort_area_size integer 1000000 tkyte@TKYTE816> select * from all_objects order by 1, 2, 3, 4; ...(Нажмите Control-C после первой страницы данных) ... tkyte@TKYTE816> set pause off tkyte@TKYTE816> select a.name, b.value 2 from v$statname a, v$mystat b 3 where a.statistic# = b.statistic# 4 and a.name like '%ga %' 5 / NAME VALUE ------------------------------ ---------- session uga memory 67528 session uga memory max 174968 session pga memory 1307580 session pga memory max 1307580 4 rows selected.
Как видите, в этот раз область PGA увеличилась существенно. Примерно на
1000000 байт, в соответствии с заданным значением SORT_AREA_SIZE.
Интересно отметить, что в этот раз размер области UGA вообще не изменился.
Для ее изменения надо задать другое значение SORT_AREA_RETAINED_SIZE,
как показано ниже:
tkyte@TKYTE816> alter session set sort_area_retained_size=1000000; Session altered. tkyte@TKYTE816> select a.name, b.value 2 from v$statname a, v$mystat b 3 where a.statistic# = b.statistic# 4 and a.name like '%ga %' 5 / NAME VALUE ------------------------------ ---------- session uga memory 63288 session uga memory max 174968 session pga memory 1307580 session pga memory max 1307580 4 rows selected. tkyte@TKYTE816> show parameter sort_area NAME TYPE VALUE ------------------------------------ ------- -------------------------- sort_area_retained_size integer 1000000 sort_area_size integer 1000000 tkyte@TKYTE816> select * from all_objects order by 1, 2, 3, 4; ...(Нажмите Control-C после первой страницы данных) ... tkyte@TKYTE816> select a.name, b.value 2 from v$statname a, v$mystat b 3 where a.statistic# = b.statistic# 4 and a.name like '%ga %' 5 / NAME VALUE ------------------------------ ---------- session uga memory 66344 session uga memory max 1086120 session pga memory 1469192 session pga memory max 1469192 4 rows selected.
Теперь мы видим, что существенное увеличение размера области UGA связано с
необходимостью дополнительно принять данные размером SORT_AREA_RETAINED_SIZE.
В ходе обработки запроса 1 Мбайт сортируемых данных «кеширован в памяти».
Остальные данные были на диске (где-то во временном сегменте). По завершении
выполнения запроса это дисковое пространство возвращено для использования
другими сеансами. Обратите внимание, что область PGA не уменьшилась до прежнего
размера. Этого следовало ожидать, поскольку область PGA используется как «куча»
и состоит из фрагментов, выделенных с помощью вызовов malloc(). Некоторые
процессы в сервере Oracle явно освобождают память PGA, другие же оставляют
выделенную память в куче (область для сортировки, например, остается в куче).
Сжатие кучи при этом обычно ничего не дает (размер используемой процессами
памяти только растет). Поскольку область UGA является своего рода «подкучей»
(ее «родительской» кучей является область PGA либо SGA), она может сжиматься.
При необходимости можно принудительно сжать область PGA:
tkyte@TKYTE816> exec dbms_session.free_unused_user_memory; PL/SQL procedure successfully completed. tkyte@TKYTE816> select a.name, b.value 2 from v$statname a, v$mystat b 3 where a.statistic# = b.statistic# 4 and a.name like '%ga %' 5 / NAME VALUE ------------------------------ ---------- session uga memory 73748 session uga memory max 1086120 session pga memory 183360 session pga memory max 1469192
Учтите, однако, что в большинстве систем это действие — пустая трата
времени. Можно уменьшить размер кучи PGA в рамках экземпляра Oracle, но память
при этом операционной системе не возвращается. В зависимости от принятого
в ОС метода управления памятью, суммарное количество используемой памяти
даже увеличится. Все зависит от того, как на данной платформе реализованы
функции malloc(), free(), realloc(), brk() и
sbrk() (стандартные функции управления памятью в языке C).
Итак, мы рассмотрели две структуры памяти, области PGA и UGA. Теперь понятно,
что область PGA принадлежит процессу. Она представляет собой набор переменных,
необходимых выделенному или разделяемому серверному процессу Oracle для
поддержки сеанса. Область PGA — это «куча» памяти, в которой могут
выделяться другие структуры. Область UGA также является кучей, в которой
определяются связанные с сеансом структуры. Область UGA выделяется из PGA
при подключении к выделенному серверу Oracle и — из области SGA при
подключении в режиме MTS. Это означает, что при работе в режиме MTS необходимо
задать такой размер области SGA, чтобы в ней хватило места под области UGA
для предполагаемого максимального количества одновременно подключенных к базе
данных пользователей. Поэтому область SGA в экземпляре, работающем в режиме
MTS, обычно намного больше, чем область SGA аналогично сконфигурированного
экземпляра, работающего в режиме выделенного сервера.
Область SGA
Каждый экземпляр Oracle имеет одну большую область памяти, которая
называется SGA, System Global Area — глобальная область системы.
Это большая разделяемая структура, к которой обращаются все процессы Oracle.
Ее размер варьируется от нескольких мегабайт в небольших тестовых системах до
сотен мегабайт в системах среднего размера и множества гигабайт в больших
системах.
В ОС UNIX область SGA — это физический объект, которую можно «увидеть»
с помощью утилит командной строки. Физически область SGA реализована как сегмент
разделяемой памяти — отдельный фрагмент памяти, к которому могут
подключаться процессы. При отсутствии процессов Oracle вполне допустимо иметь
в системе область SGA; память существует отдельно от них. Однако наличие
области SGA при отсутствии процессов Oracle означает, что произошел тот или
иной сбой экземпляра. Эта ситуация — нештатная, но она бывает. Вот
как «выглядит» область SGA в ОС UNIX:
$ ipcs -mb IPC status from <running system> as of Mon Feb 19 14:48:26 EST 2001 T ID KEY MODE OWNER GROUP SEGSZ Shared Memory: m 105 0xf223dfc8 --rw-r----- ora816 dba 186802176
В ОС Windows увидеть область SGA, как в ОС UNIX, нельзя. Поскольку на
этой платформе экземпляр Oracle работает как единый процесс с одним адресным
пространством, область SGA выделяется как приватная память процесса
ORACLE.EXE. С помощью диспетчера задач Windows (Task Manager) или другого
средства контроля производительности можно узнать, сколько памяти выделено
процессу ORACLE.EXE, но нельзя определить, какую часть по отношению к
другим выделенным структурам памяти занимает область SGA.
В самой СУБД Oracle можно определить размер области SGA независимо от
платформы. Есть еще одно «магическое» представление V$, именуемое
V$SGASTAT. Вот как его можно использовать:
tkyte@TKYTE816> compute sum of bytes on pool
tkyte@TKYTE816> break on pool skip 1
tkyte@TKYTE816> select pool, name, bytes
2 from v$sgastat
3 order by pool, name;
POOL NAME BYTES
----------- ------------------------------ ----------
java pool free memory 18366464
memory in use 2605056
*********** ----------
sum 20971520
large pool free memory 6079520
session heap 64480
*********** ----------
sum 6144000
shared pool Checkpoint queue 73764
KGFF heap 5900
KGK heap 17556
KQLS heap 554560
PL/SQL DIANA 364292
PL/SQL MPCODE 138396
PLS non-lib hp 2096
SYSTEM PARAMETERS 61856
State objects 125464
VIRTUAL CIRCUITS 97752
character set object 58936
db_block_buffers 408000
db_block_hash_buckets 179128
db_files 370988
dictionary cache 319604
distributed_transactions- 180152
dlo fib struct 40980
enqueue_resources 94176
event statistics per sess 201600
file # translation table 65572
fixed allocation callback 320
free memory 9973964
joxlod: in ehe 52556
joxlod: in phe 4144
joxs heap init 356
library cache 1403012
message pool freequeue 231152
miscellaneous 562744
processes 40000
sessions 127920
sql area 2115092
table columns 19812
transaction_branches 368000
transactions 58872
trigger defini 2792
trigger inform 520
*********** ----------
sum 18322028
db_block_buffers 24576000
fixed_sga 70924
log_buffer 66560
*********** ----------
sum 24713484
43 rows selected.
Область SGA разбита на несколько пулов.
- Java-пул. Java-пул представляет собой фиксированный пул памяти,
выделенный виртуальной машине JVM, которая работает в составе сервера. - Большой пул. Большой пул (large pool) используется сервером в
режиме MTS для размещения памяти сеанса, средствами распараллеливания
Parallel Execution для буферов сообщений и при резервном копировании
с помощью RMAN для буферов дискового ввода-вывода. - Разделяемый пул. Разделяемый пул (shared pool) содержит разделяемые
курсоры, хранимые процедуры, объекты состояния, кеш словаря данных и десятки
других компонентов данных. - «Неопределенный» («Null») пул. Этот пул не имеет имени. Это память,
выделенная под буферы блоков (кеш блоков базы данных, буферный кеш), буфер
журнала повторного выполнения и «фиксированную область SGA».
Поэтому графически область SGA можно представить следующим образом:
+----------------------------------------------------------------------+ | SGA | | +-----------------+ +----------+ +---------------+ +---------------+ | | | | | Java-пул | | Фиксированная | | Буфер журнала | | | | Разделяемый пул | | | | область SGA | | повторного | | | | | +----------+ +---------------+ | выполнения | | | +-----------------+ +---------------+ | | +-----------------------------------------+ +----------------------+ | | | Буферный кеш | | Большой пул | | | +-----------------------------------------+ +----------------------+ | +----------------------------------------------------------------------+
На общий размер SGA наиболее существенно влияют следующие параметры
init.ora.
- JAVA_POOL_SIZE. Управляет размером Java-пула.
- SHARED_POOL_SIZE. Управляет (до некоторой степени) размером
разделяемого пула. - LARGE_POOL_SIZE. Управляет размером большого пула.
- DB_BLOCK_BUFFERS. Управляет размером буферного кеша.
- LOG_BUFFER. Управляет (отчасти) размером буфера журнала повторного
выполнения.
За исключением параметров SHARED_POOL_SIZE и LOG_BUFFER,
имеется однозначное соответствие между значением параметров в файле init.ora
и объемом памяти, выделяемой соответствующей структуре в области SGA. Например,
если умножить DB_BLOCK_BUFFERS на размер буфера, получится значение,
совпадающее с размером в строке DB_BLOCK_BUFFERS для пула NULL в
представлении V$SGASTAT (добавляется определенный объем памяти на поддержку
защелок). Суммарное количество байтов, вычисленное из строк представления
V$SGASTAT для большого пула, совпадет со значением параметра инициализации
LARGE_POOL_SIZE.
Фиксированная область SGA
Фиксированная область SGA — это часть области SGA, размер которой зависит
от платформы и версии. Она «компилируется» в двоичный модуль сервера
Oracle при установке (отсюда и название — «фиксированная»). Фиксированная
область SGA содержит переменные, которые указывают на другие части SGA, а также
переменные, содержащие значения различных параметров. Размером фиксированной
области SGA (как правило, очень небольшой) управлять нельзя. Можно рассматривать
эту область как «загрузочную» часть SGA, используемую сервером Oracle для
поиска других компонентов SGA.
Буфер журнала повторного выполнения
Буфер журнала повторного выполнения используется для временного кеширования
данных оперативного журнала повторного выполнения перед записью на диск.
Поскольку перенос данных из памяти в память намного быстрее, чем из памяти —
на диск, использование буфера журнала повторного выполнения позволяет существенно
ускорить работу сервера. Данные не задерживаются в буфере журнала повторного
выполнения надолго. Содержимое этого буфера сбрасывается на диск:
- раз в три секунды;
- при фиксации транзакции;
- при заполнении буфера на треть или когда в нем оказывается 1 Мбайт
данных журнала повторного выполнения.
Поэтому создание буфера журнала повторного выполнения размером в десятки
Мбайт — напрасное расходование памяти. Чтобы использовать буфер журнала
повторного выполнения размером 6 Мбайт, например, надо выполнять продолжительные
транзакции, генерирующие по 2 Мбайта информации повторного выполнения не более
чем за три секунды. Если кто-либо в системе зафиксирует транзакцию в течение
этих трех секунд, в буфере не будет использовано и 2 Мбайт, — содержимое
буфера будет регулярно сбрасываться на диск. Лишь очень немногие приложения
выиграют от использования буфера журнала повторного выполнения размером
в несколько мегабайт.
Стандартный размер буфера журнала повторного выполнения, задаваемый параметром
LOG_BUFFER в файле init.ora, определяется как максимальное из
значений 512 и (128 * количество_процессоров) Кбайт. Минимальный
размер этой области равен максимальному размеру блока базы данных для
соответствующей платформы, умноженному на четыре. Если необходимо узнать это
значение, установите LOG_BUFFER равным 1 байту и перезапустите сервер.
Например, на моем сервере под Windows 2000 я получил следующий результат:
SVRMGR> show parameter log_buffer
NAME TYPE VALUE
----------------------------------- ------- --------------------------
log_buffer integer 1
SVRMGR> select * from v$sgastat where name = 'log_buffer';
POOL NAME BYTES
----------- -------------------------- ----------
log_buffer 66560
Теоретически минимальный размер буфера журнала повторного выполнения,
независимо от установок в файле init.ora, в данном случае — 65 Кбайт.
Фактически он немного больше:
tkyte@TKYTE816> select * from v$sga where name = 'Redo Buffers'; NAME VALUE ------------------------------ ---------- Redo Buffers 77824
То есть размер буфера — 76 Кбайт. Дополнительное пространство
выделено из соображений безопасности, как «резервные» страницы, защищающие
страницы буфера журнала повторного выполнения.
Буферный кеш
До сих пор мы рассматривали небольшие компоненты области SGA. Теперь переходим
к составляющей, которая достигает огромных размеров. В буферном кеше сервер
Oracle хранит блоки базы данных перед их записью на диск, а также после
считывания с диска. Это принципиально важный компонент SGA. Если сделать его
слишком маленьким, запросы будут выполняться годами. Если же он будет
чрезмерно большим, пострадают другие процессы (например, выделенному серверу
не хватит пространства для создания области PGA, и он просто не запустится).
Блоки в буферном кеше контролируются двумя списками. Это список «грязных»
блоков, которые должны быть записаны процессом записи блоков базы данных
(это DBWn; его мы рассмотрим несколько позже). Есть еще список «чистых»
блоков, организованный в Oracle 8.0 и предыдущих версиях в виде очереди
(LRU — Least Recently Used). Блоки упорядочивались по времени последнего
использования. Этот алгоритм был немного изменен в Oracle 8i и последующих
версиях. Вместо физического упорядочения списка блоков, сервер Oracle с помощью
счетчика, связанного с блоком, подсчитывает количество обращений («touch count»)
при каждом обращении (hit) к этому блоку в буферном кеше. Это можно увидеть в
одной из действительно «магических» таблиц X$. Эти таблицы не описаны в
документации Oracle, но информация о них периодически просачивается.
Таблица X$BH содержит информацию о блоках в буферном кеше. В ней можно
увидеть, как «счетчик обращений» увеличивается при каждом обращении к блоку.
Сначала необходимо найти блок. Мы используем блок таблицы DUAL —
специальной таблицы, состоящей из одной строки и одного столбца, которая есть
во всех базах данных Oracle. Необходимо найти соответствующий номер файла
и номер блока в файле:
tkyte@TKYTE816> select file_id, block_id
2 from dba_extents
3 where segment_name = 'DUAL' and owner = 'SYS';
FILE_ID BLOCK_ID
---------- ----------
1 465
Теперь можно использовать эту информацию для получения «счетчика обращений»
для этого блока:
sys@TKYTE816> select tch from x$bh where file# = 1 and dbablk = 465;
TCH
----------
10
sys@TKYTE816> select * from dual;
D
-
X
sys@TKYTE816> select tch from x$bh where file# = 1 and dbablk = 465;
TCH
----------
11
sys@TKYTE816> select * from dual;
D
-
X
sys@TKYTE816> select tch from x$bh where file# = 1 and dbablk = 465;
TCH
----------
12
При каждом обращении к блоку увеличивается значение счетчика. Использованный
буфер больше не переносится в начало списка. Он остается на месте, а его «счетчик
обращений» увеличивается. Блоки со временем перемещаются по списку естественным
путем, поскольку измененные блоки переносятся в список «грязных» (для записи на
диск процессом DBWn). Кроме того, если несмотря на повторное использование
блоков буферный кеш заполнился, и блок с небольшим значением «счетчика обращений»
удаляется из списка, он возвращается с новыми данными примерно в середину списка.
Полный алгоритм управления списком довольно сложный и меняется с каждой новой
версией Oracle. Подробности его работы несущественны для разработчиков,
достаточно помнить, что интенсивно используемые блоки кешируются надолго,
а редко используемые — долго в кеше не задерживаются.
Буферный кеш в версиях до Oracle 8.0 представлял собой один большой кеш.
Все блоки кешировались одинаково, никаких средств деления пространства буферного
кеша на части не существовало. В Oracle 8.0 добавлена возможность создания
буферных пулов. С ее помощью можно зарезервировать в буферном кеше место для
сегментов (как вы помните, сегменты соответствуют таблицам, индексам и т.д.).
Появилась возможность выделить место (буферный пул) достаточного размера для
размещения целиком в памяти, например, таблиц-«справочников». При чтении
сервером Oracle блоков из этих таблиц они кешируются в этом специальном пуле.
Они будут конфликтовать за место в пуле только с другими помещаемыми в него
сегментами. Остальные сегменты в системе будут «сражаться» за место в
стандартном буферном пуле. При этом повышается вероятность их кеширования:
они не выбрасываются из кеша как устаревшие при считывании других, не связанных
с ними блоков. Буферный пул, обеспечивающий подобное кеширование, называется пулом
KEEP. Блоками в пуле KEEP сервер управляет так же, как в обычном
буферном кеше. Если блок используется часто, он остается в кеше; если к блоку
некоторое время не обращались и в буферном пуле не осталось места, этот блок
выбрасывается из пула как устаревший.
Можно выделить еще один буферный пул. Он называется пулом RECYCLE.
В нем блоки выбрасываются иначе, чем в пуле KEEP. Пул KEEP
предназначен для продолжительного кеширования «горячих» блоков. Из пула
RECYCLE блок выбрасывается сразу после использования. Это эффективно
в случае «больших» таблиц, которые читаются случайным образом. (Понятие
«большая таблица» очень относительно; нет эталона для определения того,
что считать «большим».) Если в течение разумного времени вероятность повторного
считывания блока мала, нет смысла долго держать такой блок в кеше. Поэтому
в пуле RECYCLE блоки регулярно перечитываются.
…
Разделяемый пул
Разделяемый пул — один из наиболее важных фрагментов памяти в области
SGA, особенно для обеспечения производительности и масштабируемости. Слишком
маленький разделяемый пул может снизить производительность настолько, что
система будет казаться зависшей. Слишком большой разделяемый пул может привести
к такому же результату. Неправильное использование разделяемого пула грозит
катастрофой.
Итак, что же такое разделяемый пул? В разделяемом пуле сервер Oracle кеширует
различные «программные» данные. Здесь кешируются результаты разбора запроса.
Перед повторным разбором запроса сервер Oracle просматривает разделяемый пул
в поисках готового результата. Выполняемый сеансом PL/SQL-код тоже кешируется
здесь, так что при следующем выполнении не придется снова читать его с диска.
PL/SQL-код в разделяемом пуле не просто кешируется, — появляется возможность
его совместного использования сеансами. Если 1000 сеансов выполняют тот же
код, загружается и совместно используется всеми сеансами лишь одна копия
этого кода. Сервер Oracle хранит в разделяемом пуле параметры системы.
Здесь же хранится кеш словаря данных, содержащий информацию об объектах
базы данных. Короче, в разделяемом пуле хранится все, кроме продуктов питания.
Разделяемый пул состоит из множества маленьких (около 4 Кбайт) фрагментов
памяти. Память в разделяемом пуле управляется по принципу давности
использования (LRU). В этом отношении она похожа на буферный кеш: если
фрагмент не используется, он теряется. Стандартный пакет DBMS_SHARED_POOL
позволяет изменить это и принудительно закрепить объекты в разделяемом пуле.
Это позволяет загрузить часто используемые процедуры и пакеты при запуске
сервера и сделать так, чтобы они не выбрасывались из пула как устаревшие.
Обычно, если в течение определенного периода времени фрагмент памяти в
разделяемом пуле не использовался, он выбрасывается как устаревший. Даже
PL/SQL-код, который может иметь весьма большой размер, управляется механизмом
постраничного устаревания, так что при выполнении кода очень большого пакета
необходимый код загружается в разделяемый пул небольшими фрагментами. Если
в течение продолжительного времени он не используется, то в случае переполнения
выбрасывается из разделяемого пула, а пространство выделяется для других
объектов.
Самый простой способ поломать механизм разделяемого пула Oracle —
не использовать связываемые переменные. Как было показано в главе 1,
отказавшись от использования связываемых переменных, можно «поставить на
колени» любую систему, поскольку:
- система будет тратить много процессорного времени на разбор запросов;
- система будет тратить очень много ресурсов на управление объектами в
разделяемом пуле, т.к. не предусмотрено повторное использование планов
выполнения запросов.
Если каждый переданный серверу Oracle запрос специфичен, с жестко заданными
константами, это вступает в противоречие с назначением разделяемого пула.
Разделяемый пул создавался для того, чтобы хранящиеся в нем планы выполнения
запросов использовались многократно. Если каждый запрос — абсолютно новый
и никогда ранее не встречался, в результате кеширования только расходуются
дополнительные ресурсы. Разделяемый пул начинает снижать производительность.
Обычно эту проблему пытаются решить, увеличивая разделяемый пул, но в
результате становится еще хуже. Разделяемый пул снова неизбежно заполняется,
и его поддержка требует больших ресурсов, чем поддержка маленького
разделяемого пула, поскольку при управлении большим заполненным пулом приходится
выполнять больше действий, чем при управлении маленьким заполненным пулом.
Единственным решением этой проблемы является применение разделяемых
операторов SQL, которые используются повторно. В главе 10 мы опишем параметр
инициализации CURSOR_SHARING, который можно использовать для частичного
решения подобных проблем, но наиболее эффективное решение — применять
повторно используемые SQL-операторы. Даже самые большие из крупных систем
требуют от 10000 до 20000 уникальных SQL-операторов. В большинстве систем
используется лишь несколько сотен уникальных запросов.
Следующий практический пример показывает, насколько все осложняется при
неправильном использовании разделяемого пула. Меня пригласили поработать над
системой, стандартной процедурой обслуживания которой была остановка экземпляра
каждую ночь для очистки области SGA и последующий перезапуск. Это приходилось
делать, поскольку в течение дня в системе возникали проблемы, связанные с
избыточной загрузкой процессора, и, если сервер работал больше одного дня,
производительность начинала падать. Единственная причина этого была в том,
что за период с 9 утра до 5 вечера они полностью заполняли разделяемый пул
размером 1 Гбайт в области SGA общим размером 1,1 Гбайт. Да, именно так:
0,1 Гбайта было выделено под буферный кеш и другие компоненты, а 1 Гбайт —
для кеширования запросов, которые никогда не выполнялись повторно. Систему
приходилось перезапускать, потому что свободная память в разделяемом пуле
исчерпывалась в течение одного дня. На поиск и удаление устаревших структур
(особенно из такого большого разделяемого пула) расходовалось столько
ресурсов, что производительность резко падала (хотя она и до этого была
далека от оптимальной, ведь приходилось управлять разделяемым пулом в 1 Гбайт).
Кроме того, пользователи этой системы постоянно требовали добавления новых
процессоров, поскольку полный разбор SQL-операторов требовал больших
вычислительных ресурсов. Когда, после внесения исправлений, в приложении
стали использоваться связываемые переменные, удалось не только снизить
требования к ресурсам машины (у них и так вычислительные мощности намного
превышали необходимые), но и появилась возможность пересмотреть распределение
памяти. Вместо разделяемого пула размером в 1 Гбайт оказалось достаточно
выделить 100 Мбайт, причем за много недель непрерывной работы он не заполнился.
И последнее, что хотелось бы сказать о разделяемом пуле и параметре
инициализации SHARED_POOL_SIZE. Нет никакой связи между результатами
выполнения запроса:
sys@TKYTE816> select sum(bytes) from v$sgastat where pool = 'shared pool'; SUM(BYTES) ---------- 18322028 1 row selected.
и значением параметра инициализации SHARED_POOL_SIZE:
sys@TKYTE816> show parameter shared_pool_size NAME TYPE VALUE ----------------------------------- ------- -------------------------- shared_pool_size string 15360000
кроме того, что значение SUM(BYTES) FROM V$SGASTAT всегда больше, чем
значение параметра SHARED_POOL_SIZE. В разделяемом пуле хранится много
других структур, не охватываемых соответствующим параметром инициализации.
Значение SHARED_POOL_SIZE обычно является основным, но не единственным
фактором, определяющим размер разделяемого пула SUM(BYTES). Например,
параметр инициализации CONTROL_FILES задает управляющие файлы, а для
каждого управляющего файла в разделе «прочее» разделяемого пула требуется
264 байта. Жаль, что показатель ‘shared pool’ в представлении
V$SGASTAT и параметр инициализации SHARED_POOL_SIZE получили похожие
названия, поскольку параметр инициализации влияет на размер разделяемого пула,
но не задает его полностью.
Большой пул
Большой пул назван так не потому, что это «большая» структура (хотя его размер
вполне может быть большим), а потому, что используется для выделения больших
фрагментов памяти — больших, чем те, для управления которыми
создавался разделяемый пул. До его появления в Oracle 8.0, выделение памяти
выполнялось в рамках разделяемого пула. Это было неэффективно при использовании
средств, выделяющих «большие» объемы памяти, например, при работе в режиме MTS.
Проблема осложнялась еще и тем, что при обработке, требующей больших объемов
памяти, эта память используется не так, как предполагает управление памятью в
разделяемом пуле. Память в разделяемом пуле управляется на основе давности
использования, что отлично подходит для кеширования и повторного использования
данных. При выделении же больших объемов памяти фрагмент выделяется,
используется и после этого он не нужен, т.е. нет смысла его кешировать.
Серверу Oracle требовался аналог буферных пулов RECYCLE и KEEP
в буферном кеше. Именно в таком качестве сейчас и выступают большой пул и
разделяемый пул. Большой пул — это область памяти, управляемая по принципу
пула RECYCLE, а разделяемый пул скорее похож на буферный пул KEEP:
если фрагмент в нем используется часто, он кешируется надолго.
Память в большом пуле организована по принципу «кучи» и управляется с помощью
алгоритмов, аналогичных используемым функциями malloc() и free()
в языке C. После освобождения фрагмента памяти он может использоваться другими
процессами. В разделяемом пуле отсутствует понятие освобождения фрагмента памяти.
Память выделяется, используется, а затем перестает использоваться. Через некоторое
время, если эту память необходимо использовать повторно, сервер Oracle позволит
изменить содержимое устаревшего фрагмента. Проблема при использовании только
разделяемого пула состоит в том, что все потребности в памяти нельзя подогнать
под одну мерку.
Большой пул, в частности, используется:
- сервером в режиме MTS для размещения области UGA в SGA;
- при распараллеливании выполнения операторов — для буферов сообщений,
которыми обмениваются процессы для координации работы серверов; - в ходе резервного копирования для буферизации дискового ввода-вывода
утилиты RMAN.
Как видите, ни одну из описанных выше областей памяти нельзя помещать в
буферный пул с вытеснением небольших фрагментов памяти на основе давности
использования. Область UGA, например, не будет использоваться повторно по
завершении сеанса, поэтому ее немедленно надо возвращать в пул. Кроме того,
область UGA обычно — достаточно большая. Как было показано на примере, где
изменялось значение параметра SORT_AREA_RETAINED_SIZE, область UGA может
быть очень большой, и, конечно, больше, чем фрагмент в 4 Кбайта. При помещении
области UGA в разделяемый пул она фрагментируется на части одинакового размера
и, что хуже всего, выделение больших областей памяти, никогда не используемых
повторно, приведет к выбрасыванию из пула фрагментов, которые могли бы повторно
использоваться. В дальнейшем на перестройку этих фрагментов памяти расходуются
ресурсы сервера.
То же самое справедливо и для буферов сообщений. После того как сообщение
доставлено, в них уже нет необходимости. С буферами, создаваемыми в процессе
резервного копирования, все еще сложнее: они большие и сразу после использования
сервером Oracle должны «исчезать».
Использовать большой пул при работе в режиме MTS не обязательно, но желательно.
Если сервер работает в режиме MTS в отсутствие большого пула, вся память
выделяется из разделяемого пула, как это и было в версиях Oracle вплоть до
7.3. Из-за этого производительность со временем будет падать, поэтому такой
конфигурации надо избегать. Большой пул стандартного размера будет создаваться
при установке одного из следующих параметров инициализации: DBWn_IO_SLAVES
или PARALLEL_AUTOMATIC_TUNING. Рекомендуется задавать размер большого
пула явно. Однако стандартное значение не может использоваться во всех без
исключения случаях.
Java-пул
Java-пул — это самый новый пул памяти в Oracle 8i. Он был добавлен в версии
8.1.5 для поддержки работы Java-машины в базе данных. Если поместить хранимую
процедуру на языке Java или компонент EJB (Enterprise JavaBean) в базу данных,
сервер Oracle будет использовать этот фрагмент памяти при обработке
соответствующего кода. Одним из недостатков первоначальной реализации Java-пула в
Oracle 8.1.5 было то, что он не отображался командой SHOW SGA и не был
представлен строками в представлении V$SGASTAT. В то время это особенно
сбивало с толку, поскольку параметр инициализации JAVA_POOL_SIZE,
определяющий размер этой структуры, имел стандартное значение 20 Мбайт.
Это заставляло людей гадать, почему область SGA занимает оперативной памяти
на 20 Мбайт больше, чем следует.
Начиная с версии 8.1.6, однако, Java-пул виден в представлении V$SGASTAT,
а также в результатах выполнения команды SHOW SGA. Параметр инициализации
JAVA_POOL_SIZE используется для определения фиксированного объема
памяти, отводящегося для Java-кода и данных сеансов. В Oracle 8.1.5 этот параметр
мог иметь значения от 1 Мбайта до 1 Гбайт. В Oracle 8.1.6 и последующих версиях
диапазон допустимых значений уже 32 Кбайта-1 Гбайт. Это противоречит документации,
где по-прежнему указан устаревший минимум — 1 Мбайт.
Java-пул используется по-разному, в зависимости от режима работы сервера
Oracle. В режиме выделенного сервера Java-пул включает разделяемую часть
каждого Java-класса, использованного хоть в одном сеансе. Эти части только
читаются (векторы выполнения, методы и т.д.) и имеют для типичных классов
размер от 4 до 8 Кбайт.
Таким образом, в режиме выделенного сервера (который, как правило,
и используется, если в приложениях применяются хранимые процедуры на языке Java)
объем общей памяти для Java-пула имеет весьма невелик; его можно определить
исходя из количества используемых Java-классов. Учтите, что информация
о состоянии сеансов при работе в режиме разделяемого сервера в области SGA
не сохраняется, поскольку эти данные находятся в области UGA, а она,
если вы помните, в режиме разделяемого сервера является частью области PGA.
При работе в режиме MTS Java-пул включает:
- разделяемую часть каждого Java-класса и
- часть области UGA для каждого сеанса, используемую для хранения информации
о состоянии сеансов.
Оставшаяся часть области UGA выделяется как обычно — из разделяемого
пула или из большого пула, если он выделен.
Поскольку общий размер Java-пула фиксирован, разработчикам приложений
необходимо оценить общий объем памяти для приложения и умножить на
предполагаемое количество одновременно поддерживаемых сеансов. Полученное
значение будет определять общий размер Java-пула. Каждая Java-часть области
UGA будет увеличиваться и уменьшаться при необходимости, но помните, что
размер пула должен быть таким, чтобы части всех областей UGA могли
поместиться в нем одновременно.
В режиме MTS, который обычно используется для приложений, использующих
архитектуру CORBA или компоненты EJB (об этом говорилось в главе 1), может
потребоваться очень большой Java-пул., Его размер будет зависеть не от
количества используемых классов, а от количества одновременно работающих
пользователей. Как и большой пул, размеры которого становятся очень
большими в режиме MTS, Java-пул тоже может разрастаться до огромных размеров.
Итак, в этом разделе была рассмотрена структура памяти сервера Oracle.
Мы начали с уровня процессов и сеансов, поговорили об областях
PGA (Process Global Area — глобальная область процесса) и UGA
(User Global Area — глобальная область пользователя) и разобрались
в их взаимосвязи. Было показано, как режим, в котором пользователь подключается
к серверу Oracle, определяет организацию памяти. Подключение к выделенному
серверу предполагает использование памяти серверным процессом в большем
объеме, чем подключение в режиме MTS, но работа в режиме MTS требует создания
намного большей области SGA. Затем мы описали компоненты самой области SGA,
выделив в ней шесть основных структур. Были описаны различия между разделяемым
и большим пулом, и показано, почему большой пул необходим для «сохранения»
разделяемого пула. Мы описали Java-пул и его использование в различных
условиях. Был рассмотрен буферный кеш и способ деления его на меньшие, более
специализированные пулы.
Теперь можно переходить к физическим процессам экземпляра Oracle.
Процессы
Осталось рассмотреть последний элемент «головоломки». Мы изучили организацию
базы данных и набор образующих ее физических файлов. Разбираясь с использованием
памяти сервером Oracle, рассмотрели половину экземпляра. Оставшийся компонент
архитектуры — набор процессов, образующий вторую половину экземпляра.
Некоторые из этих процессов, например процесс записи блоков в базу данных
(DBWn) и процесс записи журнала (LGWR), уже упоминались. Здесь
мы более детально рассмотрим функцию каждого процесса: что и почему они делают.
В этом разделе «процесс» будет использоваться как синоним «потока» в
операционных системах, где сервер Oracle реализован с помощью потоков.
Так, например, если описывается процесс DBWn, в среде Windows ему
соответствует поток DBWn.
В экземпляре Oracle есть три класса процессов.
- Серверные процессы. Они выполняют запросы клиентов. Мы уже затрагивали
тему выделенных и разделяемых серверов. И те, и другие относятся к серверным
процессам. - Фоновые процессы. Это процессы, которые начинают выполняться при
запуске экземпляра и решают различные задачи поддержки базы данных, такие
как запись блоков на диск, поддержка оперативного журнала повторного
выполнения, удаление прекративших работу процессов и т.д. - Подчиненные процессы. Они подобны фоновым процессам, но выполняют,
кроме того, действия от имени фонового или серверного процесса.
Мы рассмотрим все эти процессы и постараемся выяснить, какую роль они
играют в экземпляре.
Серверные процессы
Мы уже бегло рассматривали эти процессы ранее при обсуждении выделенных и
разделяемых серверов. Здесь мы еще раз опишем два вида серверных процессов
и более детально рассмотрим их архитектуру.
Выделенные и разделяемые серверы решают одну и ту же задачу: обрабатывают
передаваемые им SQL-операторы. При получении запроса SELECT * FROM EMP
именно выделенный/разделяемый сервер Oracle будет разбирать его и помещать в
разделяемый пул (или находить соответствующий запрос в разделяемом пуле). Именно
этот процесс создает план выполнения запроса. Этот процесс реализует план
запроса, находя необходимые данные в буферном кеше или считывая данные в
буферный кеш с диска. Такие серверные процессы можно назвать
«рабочими лошадками» СУБД. Часто именно они потребляют основную часть
процессорного времени в системе, поскольку выполняют сортировку, суммирование,
соединения — в общем, почти все.
В режиме выделенного сервера имеется однозначное соответствие между
клиентскими сеансами и серверными процессами (или потоками). Если имеется
100 сеансов на UNIX-машине, будет 100 процессов, работающих от их имени.
Графически это можно представить так8:
…
С клиентским приложением скомпонованы библиотеки Oracle. Они обеспечивают
функциональный интерфейс (Application Program Interface — API) для
взаимодействия с базой данных. Функции API «знают», как передавать запрос
к базе данных и обрабатывать возвращаемый курсор. Они обеспечивают преобразование
запросов пользователя в передаваемые по сети пакеты, обрабатываемые выделенным
сервером. Эти функции обеспечивает компонент Net8 — сетевое программное
обеспечение/протокол, используемое Oracle для клиент-серверной обработки (даже в
n-звенной архитектуре есть место для клиент-серверного взаимодействия). Сервер
Oracle использует такую архитектуру, даже если протокол Net8 не нужен.
То есть, когда клиент и сервер работают на одной и той же машине,
используется эта двухпроцессная (известная также как двухзадачная — two-task)
архитектура. Эта архитектура обеспечивает два преимущества.
- Удаленное выполнение. Клиентское приложение, естественно, может
работать не на той машине, где работает СУБД. - Изолирование адресных пространств. Серверный процесс имеет доступ для
чтения и записи к области SGA. Ошибочный указатель в клиентском процессе может
повредить структуры данных в области SGA, если клиентский и серверный процессы
физически взаимосвязаны.
Ранее в этой главе мы рассматривали «порождение», или создание, этих серверных
процессов процессом прослушивания Oracle Net8 Listener. Не будем снова возвращаться
к этому процессу, но коротко рассмотрим, что происходит, если процесс прослушивания
не задействован. Механизм во многом аналогичен, но вместо создания выделенного
сервера процессом прослушивания с помощью вызовов fork()/exec()
в ОС UNIX или вызова IPC (Inter Process Communication),
как это происходит в Windows, процесс создается непосредственно клиентским
процессом. Это можно четко увидеть в ОС UNIX:
ops$tkyte@ORA8I.WORLD> select a.spid dedicated_server,
2 b.process clientpid
3 from v$process a, v$session b
4 where a.addr = b.paddr
5 and b.audsid = userenv('sessionid')
6 /
DEDICATED CLIENTPID
--------- ---------
7055 7054
ops$tkyte@ORA8I.WORLD> !/bin/ps -lp 7055
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
8 S 30174 7055 7054 0 41 20 61ac4230 36815 639b1998 ? 0:00 oracle
ops$tkyte@ORA8I.WORLD> !/bin/ps -lp 7054
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
8 S 12997 7054 6783 0 51 20 63eece30 1087 63eecea0 pts/7 0:00 sqlplus
Я использовал запрос для определения идентификатора процесса (PID) моего
выделенного сервера (столбец SPID в представлении V$PROCESS — это
идентификатор процесса операционной системы, использовавшегося для выполнения
запроса). Кроме того, в столбце PROCESS представления V$SESSION
находится идентификатор клиентского процесса, подключившегося к базе данных.
С помощью команды ps можно явно показать, что PPID (Parent Process
ID — идентификатор родительского процесса) моего выделенного
сервера соответствует процессу SQL*Plus. В данном случае именно утилита
SQL*Plus создала выделенный сервер с помощью системных вызовов fork()
и exec().
Теперь давайте более детально рассмотрим другой тип серверных процессов —
разделяемый серверный процесс. Для подключения к серверному процессу этого типа
обязательно используется протокол Net8, даже если клиент и сервер работают на одной
машине, — нельзя использовать режим MTS без процесса прослушивания Net8.
Как уже описывалось ранее в этом разделе, клиентское приложение подключается
к процессу прослушивания Net8 и перенаправляется на процесс-диспетчер.
Диспетчер играет роль канала передачи информации между клиентским приложением
и разделяемым серверным процессом. Ниже представлена схема подключения к базе данных
через разделяемый сервер9:
…
Как видите, клиентские приложения со скомпонованными в них библиотеками Oracle
физически подключаются к диспетчеру MTS. Диспетчеров MTS для любого экземпляра
можно сгенерировать несколько, но часто для сотен и даже тысяч пользователей
используется один диспетчер. Диспетчер отвечает за получение входящих запросов
от клиентских приложений и их размещение в очереди запросов в области SGA.
Первый свободный разделяемый серверный процесс, по сути, ничем не отличающийся
от выделенного серверного процесса, выберет запрос из очереди и подключится к
области UGA соответствующего сеанса. Разделяемый сервер обработает запрос и
поместит полученный при его выполнении результат в очередь ответов. Диспетчер
постоянно следит за появлением результатов в очереди и передает их клиентскому
приложению. С точки зрения клиента нет никакой разницы между подключением к
выделенному серверу и подключением в режиме MTS, — они работают одинаково.
Различие возникает только на уровне экземпляра.
Выделенный и разделяемый сервер
Прежде чем перейти к остальным процессам, давайте обсудим, почему поддерживается
два режима подключения и когда лучше использовать каждый из них. Режим выделенного
сервера — наиболее широко используемый способ подключения к СУБД Oracle
для всех приложений, использующих SQL-запросы. Режим выделенного сервера проще
настроить и он обеспечивает самый простой способ подключения. При этом требуется
минимальное конфигурирование. Настройка и конфигурирование режима MTS, хотя и
несложный, но дополнительный шаг. Основное различие между этими режимами,
однако, не в настройке. Оно связано с особенностями работы. При использовании
выделенного сервера имеется соответствие один к одному между клиентским сеансом
и серверным процессом. В режиме MTS соответствие — многие к одному (много
клиентов и один разделяемый сервер). Как следует из названия, разделяемый
сервер — общий ресурс, а выделенный — нет. При использовании общего
ресурса необходимо стараться не монополизировать его надолго. Как было показано
в главе 1, в примере с компонентами EJB, запускавшими продолжительную хранимую
процедуру, монополизация этого ресурса может приводить как бы к зависанию
системы. На представленной выше схеме имеется два разделяемых сервера. При
наличии трех клиентов, более-менее одновременно пытающихся запустить 45-секундный
процесс, два из них получат результат через 45 секунд, а третий — через 90
секунд. Правило номер один для режима MTS: убедитесь, что транзакции выполняются
быстро. Они могут выполняться часто, но должны быть короткими (что обычно и
бывает в системах OLTP). В противном случае будут наблюдаться все признаки
замедления работы системы из-за монополизации общих ресурсов несколькими
процессами. В экстремальных случаях, если все разделяемые серверы заняты,
система «зависает».
Поэтому режим MTS очень хорошо подходит для систем класса OLTP, характеризующихся
короткими, но частыми транзакциями. В системе класса OLTP транзакции выполняются
за миллисекунды, — ни одно действие не требует для выполнения более чем доли
секунды. Режим MTS не подходит, однако, для хранилища данных. В такой системе
выполняются запросы продолжительностью одна, две, пять и более минут. Для
режима MTS это «смертельно». В системе, где 90 процентов задач относятся к
классу OLTP, а 10 процентов — «не совсем OLTP», можно поддерживать
одновременно выделенные и разделяемые серверы в одном экземпляре. В этом случае
существенно сокращается количество процессов для пользователей OLTP, а
«не совсем OLTP»-задачи не монополизируют надолго разделяемые серверы.
Итак, какие же преимущества дает режим MTS, если учитывать, для какого типа
транзакций он предназначен? Режим MTS позволяет добиться следующего.
Сократить количество процессов/потоков операционной системы
В системе с тысячами пользователей ОС может быстро оказаться перегруженной
при попытке управлять тысячами процессов. В обычной системе одновременно активна
лишь небольшая часть этих тысяч пользователей. Например, я недавно работал над
системой с 5000 одновременно работающих пользователей. В каждый момент времени
в среднем активны были не более 50. Эта система могла бы работать с 50
разделяемыми серверными процессами, на два порядка (в 100 раз) сокращая
количество процессов в операционной системе. При этом существенно сокращается
количество переключений контекстов на уровне операционной системы.
Искусственно ограничить степень параллелизма
Как человеку, участвовавшему во многих тестированиях производительности,
преимущества ограничения степени параллелизма мне очевидны. При тестировании
клиенты просят запустить как можно больше пользователей, пока система не
перестанет работать. Одним из результатов такого рода тестирования является
диаграмма, показывающая зависимость количества транзакций от количества
одновременно работающих пользователей:
Транзакции в секунду ^ | Максимальный параллелизм | | | __ | - - | / | / | / | / | | / | / |/ +---------------------------------> Одновременно работающие пользователи
Сначала при добавлении одновременно работающих пользователей количество
транзакций растет. С какого-то момента, однако, добавление новых пользователей
не увеличивает количества выполняемых в секунду транзакций: оно стабилизируется.
Пропускная способность достигла максимума, и время ожидания ответа начинает
расти (каждую секунду выполняется то же количество транзакций, но пользователи
получают результаты со все возрастающей задержкой. При дальнейшем добавлении
пользователей пропускная способность начинает падать. Количество одновременно
работающих пользователей перед началом этого падения и является максимально
допустимой степенью параллелизма в системе. Дальше система переполняется
запросами, и образуются очереди. С этого момента система не справляется с
нагрузкой. Не только существенно увеличивается время ответа, но и начинает
падать пропускная способность системы. Если ограничить количество одновременно
работающих пользователей до числа, непосредственно предшествующего падению,
можно обеспечить максимальную пропускную способность и приемлемое время ответа
для большинства пользователей. Режим MTS позволяет ограничить максимальную
степень параллелизма в системе до этого количества одновременно работающих
пользователей.
Сократить объем памяти, необходимый системе
Это одна из наиболее часто упоминаемых причин использования режима MTS:
сокращается объем памяти, необходимой для поддержки определенного количества
пользователей. Да, сокращается, но не настолько, как можно было бы ожидать.
Помните, что при использовании режима MTS область UGA помещается в SGA.
Это означает, что при переходе на режим MTS необходимо точно оценить суммарный
объем областей UGA и выделить место в области SGA с помощью параметра
инициализации LARGE_POOL. Поэтому размер области SGA при использовании
режима MTS обычно очень большой. Эта память выделяется заранее и поэтому может
использоваться только СУБД. Сравните это с режимом разделяемого сервера, когда
процессы могут использовать любую область памяти, не выделенную под SGA. Итак,
если область SGA становится намного больше вследствие размещения в ней областей
UGA, каким же образом экономится память? Экономия связана с уменьшением
количества выделяемых областей PGA. Каждый выделенный/разделяемый сервер
имеет область PGA. В ней хранится информация процесса. В ней располагаются
области сортировки, области хешей и другие структуры процесса. Именно этой
памяти для системы надо меньше, если используется режим MTS. При переходе
с 5000 выделенных серверов на 100 разделяемых освобождается 4900 областей
PGA — именно такой объем памяти и экономится в режиме MTS.
Конечно, используют в этих целях режим MTS только при отсутствии выбора.
Если необходимо взаимодействовать с компонентами EJB в базе данных, придется
использовать режим MTS. Есть и другие расширенные возможности подключения,
требующие использования режима MTS. Если необходимо централизовать связи
нескольких баз данных, например, также придется использовать режим MTS.
Рекомендация
Если система не перегружена и нет необходимости использовать режим MTS для
обеспечения необходимой функциональности, лучше использовать выделенный сервер.
Выделенный сервер проще устанавливать, и упрощается настройка производительности.
Есть ряд операций, которые можно выполнять только при подключении в режиме
выделенного сервера, так что в любом экземпляре надо поддерживать либо оба
режима, либо только режим выделенного сервера.
С другой стороны, если необходимо поддерживать большое количество
пользователей и известно, что эксплуатировать систему придется в режиме MTS,
я рекомендую разрабатывать и тестировать ее тоже в режиме MTS. Если система
разрабатывалась в режиме разделяемого сервера и никогда не тестировалась
в режиме MTS, вероятность неудачи повышается. Испытывайте систему в рабочих
условиях; тестируйте ее производительность; проверьте, хорошо ли она работает
в режиме MTS. То есть, проверьте, не монополизирует ли она надолго разделяемые
серверы. Обнаруженные на стадии разработки недостатки устранить гораздо проще,
чем при внедрении. Для сокращения времени работы процесса можно использовать
средства расширенной обработки очередей (Advanced Queues — AQ),
но это надо учесть в проекте приложения. Такие вещи лучше делать на этапе
разработки.
Если в приложении уже используется пул подключений (например, пул подключений
компонентов J2EE) и размер этого пула определен верно, использование режима
MTS только снизит производительность. Размер пула подключений уже рассчитан
с учетом максимального количества одновременных подключений, поэтому необходимо,
чтобы каждое из этих подключений выполнялось непосредственно к выделенному
серверу. Иначе один пул подключений будет просто подключаться к другому пулу
подключений.
Фоновые процессы
Экземпляр Oracle состоит из двух частей: области SGA и набора фоновых
процессов. Фоновые процессы выполняют рутинные задачи сопровождения,
обеспечивающие работу СУБД. Есть, например, процесс, автоматически поддерживающий
буферный кеш и при необходимости записывающий блоки данных на диск. Есть процесс,
копирующий заполненный файл оперативного журнала повторного выполнения в архив.
Еще один процесс отвечает за очистку всех структур, которые использовались
завершившимися процессами, и т.д. Каждый из этих процессов решает конкретную
задачу, но работает в координации с остальными. Например, когда процесс,
записывающий файлы журнала, заполняет один журнал и переходит на следующий,
он уведомляет процесс, отвечающий за архивирование заполненного журнала,
что для него есть работа.
Есть два класса фоновых процессов: предназначенные исключительно для решения
конкретных задач (как только что описанные) и решающие множество различных задач.
Например, есть фоновый процесс, обеспечивающий работу внутренних очередей заданий
в Oracle. Этот процесс контролирует очередь заданий и выполняет находящиеся в ней
задания. Во многом он похож на выделенный сервер, но без подключения к клиенту.
Сейчас мы рассмотрим все эти фоновые процессы, начиная с тех, которые выполняют
конкретную задачу, а затем перейдем к процессам «общего назначения».
Фоновые процессы, предназначенные для решения конкретных задач
На следующей схеме представлены фоновые процессы экземпляра Oracle,
имеющие конкретное назначение:
+------------+
[LMD0]--------------------------->| кластерные |+
^ [LCKn]------------------->| экземпляры ||
| ^ [BSP]----------->+------------+|
| | ^ [LMON]--> +------------+
| | | ^
| | | |
v | | v
+--------------------------------------------+
PMON<----------->| SGA |
| +--------------+ +---------------+ |
SMON<----------->| | буферный кеш | | буфер журнала | |
| +--------------+ +---------------+ |
[RECO]<--------->| | | |
| +-------+---------------------+--------------+
| ^ | | ^
| | | | |
| v v v v
| CKPT DBWn LGWR [ARCn]----+
| | | | ^ |
v v v v | v
+-------------+ +-------------------+ +-------------+ | +----------+
| удаленная | | файлы базы данных |+ | оперативный | | | архивные |
| база данных | | ||+ | журнал | | | журналы |
+-------------+ +-------------------+|| +-------------+ -+-+ +----------+
+------------------+| |0101010101010|
+-----------------+ |1010101010101|
+-------------+
Вы не обязательно увидите все эти процессы сразу после запуска своего экземпляра,
но большинство из них работает в каждом экземпляре. Процесс ARCn (архиватор)
запускается только при работе в режиме архивирования журналов (Archive Log Mode)
при включенном автоматическом архивировании. Процессы LMD0, LCKn,
LMON и BSP (подробнее о них — ниже) запускаются только при
работе с Oracle Parallel Server (конфигурация сервера Oracle, поддерживающая
несколько экземпляров на различных машинах в кластерной среде), если открывается
одна и та же база данных. Для простоты на схеме не показаны процессы диспетчеров
MTS (Dnnn) и разделяемых серверов (Snnn). Поскольку мы только что
детально их рассмотрели, они не показаны, чтобы упростить схему. Предыдущая схема
показывает, что можно «увидеть» при запуске экземпляра Oracle, если база данных
смонтирована и открыта. Например, в моей UNIX-системе сразу после запуска экземпляра
имеются следующие процессы:
$ /bin/ps -aef | grep 'ora_.*_ora8i$' ora816 20642 1 0 Jan 17 ? 5:02 ora_arc0_ora8i ora816 20636 1 0 Jan 17 ? 265:44 ora_snp0_ora8i ora816 20628 1 0 Jan 17 ? 92:17 ora_lgwr_ora8i ora816 20626 1 0 Jan 17 ? 9:23 ora_dbw0_ora8i ora816 20638 1 0 Jan 17 ? 0:00 ora_s000_ora8i ora816 20634 1 0 Jan 17 ? 0:04 ora_reco_ora8i ora816 20630 1 0 Jan 17 ? 6:56 ora_ckpt_ora8i ora816 20632 1 0 Jan 17 ? 186:44 ora_smon_ora8i ora816 20640 1 0 Jan 17 ? 0:00 ora_d000_ora8i ora816 20624 1 0 Jan 17 ? 0:05 ora_pmon_ora8i
Они соответствуют процессам, представленным на схеме, за исключением процесса
SNPn (о нем будет рассказано позже, т.к. он не является фоновым процессом,
выполняющим «конкретной» задачу). Обратите внимание на соглашение по именованию
этих процессов. Имя процесса начинается с префикса ora_. Затем следуют
четыре символа, представляющие фактическое имя процесса, а затем суффикс —
_ora8i. Дело в том, что у меня параметр инициализации ORACLE_SID
(идентификатор сайта) имеет значение ora8i. В ОС UNIX это существенно
упрощает идентификацию фоновых процессов Oracle и их привязку к определенному
экземпляру (в Windows простого способа для этого нет, поскольку фоновые процессы
реализованы как потоки одного большого процесса). Но что самое интересное, хотя
это и не очевидно по представленным результатам, — все эти процессы
реализуются одним и тем же двоичным файлом. Вы не найдете на диске двоичный
выполняемый файл arc0, точно так же, как не найдете файлов LGWR
и DBW0. Все эти процессы реализуются файлом oracle (именно этот
выполняемый двоичный файл запускается). Просто при запуске процессы получают
такие псевдонимы, чтобы проще было идентифицировать их назначение. Это
позволяет совместно использовать большую часть объектного кода на платформе
UNIX. В среде Windows это вообще не имеет значения, поскольку процессы
Oracle — всего лишь потоки в одном физическом процессе, поэтому все
они — один большой двоичный файл.
Давайте теперь рассмотрим функции каждого процесса.
PMON — монитор процессов
Этот процесс отвечает за очистку после нештатного прекращения подключений.
Например, если выделенный сервер «падает» или, получив сигнал,
прекращает работу, именно процесс PMON освобождает ресурсы. Процесс PMON
откатит незафиксированные изменения, снимет блокировки и освободит ресурсы
в области SGA, выделенные прекратившему работу процессу.
Помимо очистки после прерванных подключений, процесс PMON контролирует другие
фоновые процессы сервера Oracle и перезапускает их при необходимости (если это
возможно). Если разделяемый сервер или диспетчер сбоит (прекращает работу),
процесс PMON запускает новый процесс (после очистки структур сбойного процесса).
Процесс PMON следит за всеми процессами Oracle и либо перезапускает их, либо
прекращает работу экземпляра, в зависимости от ситуации. Например, в случае
сбоя процесса записи журнала повторного выполнения (LGWR) экземпляр надо
перезапускать. Это серьезная ошибка и самое безопасное — немедленно прекратить
работу экземпляра, предоставив исправление данных штатному процессу
восстановления. Это происходит очень редко, и о случившемся надо немедленно
сообщить службе поддержки Oracle.
Еще одна функция процесса PMON в экземпляре (версия Oracle 8i) —
регистрировать экземпляр в процессе прослушивания протокола Net8. При запуске
экземпляра процесс PMON опрашивает известный порт (если явно не указан
другой), чтобы убедиться, запущен и работает ли процесс прослушивания.
Известный/стандартный порт, используемый сервером Oracle, — порт 1521.
А что произойдет, если процесс прослушивания запущен на другом порту? В этом
случае используется тот же механизм, но адрес процесса прослушивания необходимо
указать явно с помощью параметра инициализации LOCAL_LISTENER. Если процесс
прослушивания запущен, процесс PMON связывается с ним и передает
соответствующие параметры, например имя службы.
SMON — монитор системы
SMON — это процесс, занимающийся всем тем, от чего «отказываются»
остальные процессы. Это своего рода «сборщик мусора» для базы данных. Вот
некоторые из решаемых им задач.
- Очистка временного пространства. С появлением по-настоящему временных
табличных пространств эта задача упростилась, но она не снята с повестки дня
полностью. Например, при построении индекса выделяемые ему в ходе создания
экстенты помечаются как временные (TEMPORARY). Если выполнение оператора
CREATE INDEX прекращено досрочно по какой-либо причине, процесс SMON
должен эти экстенты освободить. Есть и другие операции, создающие временные
экстенты, за очистку которых также отвечает процесс SMON. - Восстановление после сбоев. Процесс SMON после сбоя
восстанавливает экземпляр при перезапуске. - Дефрагментация свободного пространства. При использовании табличных
пространств, управляемых по словарю, процесс SMON заменяет расположенные
подряд свободные экстенты одним «большим» свободным экстентом. Это происходит
только в табличном пространстве, управляемом по словарю и имеющем стандартную
конструкцию хранения с ненулевым значением параметра PCTINCREASE. - Восстановление транзакций, затрагивающих недоступные файлы. Эта задача
аналогична той, которая возникает при запуске базы данных. Процесс SMON
восстанавливает сбойные транзакции, пропущенные при восстановлении экземпляра
после сбоя по причине недоступности файлов для восстановления. Например, файл
мог быть на недоступном или на не смонтированном диске. Когда файл будет
доступен, процесс SMON восстановит его. - Восстановление сбойного экземпляра в OPS. В конфигурации Oracle
Parallel Server, если одна из машин кластера останавливается (на ней
происходит сбой), другая машина в экземпляре откроет файлы журнала
повторного выполнения этой сбойной машины и восстановит все данные
этой машины. - Очистка таблицы OBJ$. OBJ$ — низкоуровневая таблица
словаря данных, содержащая записи практически для каждого объекта (таблицы,
индекса, триггера, представления и т.д.) базы данных. Часто там встречаются
записи, представляющие удаленные или «отсутствующие» объекты, используемые
механизмом поддержки зависимостей Oracle. Процесс SMON удаляет эти
ненужные строки. - Сжатие сегментов отката. Процесс SMON автоматически сжимает
сегмент отката до заданного размера. - «Отключение» сегментов отката. Администратор базы данных может
«отключить» или сделать недоступным сегмент отката с активными транзакциями.
Активные транзакции могут продолжать использование такого отключенного
сегмента отката. В этом случае сегмент отката фактически не отключается:
он помечается для «отложенного отключения». Процесс SMON периодически
пытается «действительно» отключить его, пока это не получится.
Этот список дает представление о том, что делает процесс SMON. Как
видно из представленной выше информации о процессах, полученной с помощью
команды ps, процесс SMON может со временем потребовать существенных
вычислительных ресурсов (команда ps выполнялась на машине, где экземпляр
проработал около месяца). Процесс SMON периодически «пробуждается» (или
его «будят» другие фоновые процессы) для выполнения задач сопровождения.
RECO — восстановление распределенной базы данных
Процесс RECO имеет очень конкретную задачу: он восстанавливает
транзакции, оставшиеся в готовом состоянии из-за сбоя или потери связи в ходе
двухэтапной фиксации (2PC). 2PC — это распределенный протокол,
позволяющий неделимо фиксировать изменения в нескольких удаленных базах данных.
Он пытается максимально снизить вероятность распределенного сбоя перед
фиксацией. При использовании протокола 2PC между N базами данных одна из баз
данных обычно (но не всегда) та, к которой первоначально подключился клиент,
становится координатором. Соответствующий сервер опрашивает остальные N -1
серверов, готовы ли они фиксировать транзакцию. Фактически, этот сервер
связывается с остальными N — 1 серверами и просит их подготовиться к
фиксации. Каждый из N -1 серверов сообщает о своем состоянии готовности
как да (YES) или нет (NO). Если любой из серверов вернул NO,
вся транзакция откатывается. Если все серверы вернули YES, координатор
рассылает всем N — 1 серверам сообщение о постоянной фиксации.
Если серверы ответили YES и подготовились к фиксации, но до
получения директивы о фактической фиксации от координатора происходит сбой
сети или возникает какая-то другая ошибка, транзакция становится сомнительной
(in-doubt) распределенной транзакцией. Протокол 2PC старается сократить до
минимума время, в течение которого это может произойти, но не может
полностью предотвратить сомнительные транзакции. Если сбой произойдет в
определенном месте и в определенное время, дальнейшую обработку сомнительной
транзакции выполняет процесс RECO. Он пытается связаться с координатором
транзакции, чтобы узнать ее исход. До этого транзакция остается незафиксированной.
Связавшись с координатором транзакции, процесс RECO восстановит либо
откатит ее.
Если связаться с координатором долго не удается и имеется ряд сомнительных
транзакций, их можно зафиксировать или откатить вручную. Это приходится делать,
поскольку сомнительная распределенная транзакция может вызвать блокирование
читающих пишущими (единственный случай в СУБД Oracle). Ваш администратор
базы данных должен связаться с администратором другой базы данных и попросить
его определить состояние сомнительных транзакций. Затем администратор базы
данных может зафиксировать или откатить их, предоставив все остальное
процессу RECO.
CKPT — обработка контрольной точки
Процесс обработки контрольной точки вовсе не обрабатывает ее, как можно
предположить по названию, — это делает процесс DBWn. Процесс
CKPT просто содействует обработке контрольной точки, обновляя
заголовки файлов данных. Раньше процесс CKPT был необязательным, но,
начиная с версии 8.0, он запускается всегда, так что он представлен в
результатах выполнения команды ps в ОС UNIX. Ранее заголовки файлов данных
обновлялись в соответствии с информацией о контрольной точке процессом записи
журнала LGWR (Log Writer). Однако с ростом размеров баз данных и
увеличением количества файлов это стало невыполнимой задачей для процесса
LGWR. Если процессу LGWR надо обновлять десятки, сотни, а то и
тысячи файлов, увеличивается вероятность того, что ожидающие фиксации
транзакций сеансы будут ждать слишком долго. Процесс CKPT снимает эту
задачу с процесса LGWR.
DBWn — запись блоков базы данных
Процесс записи блоков базы данных (Database Block Writer — DBWn)
— фоновый процесс, отвечающий за запись измененных блоков на диск. Процесс
DBWn записывает измененные блоки из буферного кеша, чтобы освободить
пространство в кеше (чтобы освободить буферы для чтения других данных) или в ходе
обработки контрольной точки (чтобы перенести вперед позицию в оперативном файле
журнала повторного выполнения, с которой сервер Oracle начнет чтение при
восстановлении экземпляра после сбоя). Как было описано ранее, при переключении
журнальных файлов сервером Oracle запрашивается обработка контрольной точки.
Серверу Oracle нужно перенести отметку контрольной точки, чтобы не было
необходимости в только что заполненном оперативном файле журнала повторного
выполнения. Если ему не удастся это сделать до того, как возникнет необходимость
в файле журнала повторного выполнения, выдается сообщение, что обработка
контрольной точки не завершена (checkpoint not complete), и придется ждать
завершения обработки.
Как видите, производительность процесса DBWn может иметь принципиальное
значение. Если он недостаточно быстро записывает блоки для освобождения буферов,
сеансам приходится ждать события FREE_BUFFER_WAITS, и показатель
‘Write Complete Waits‘ начинает расти.
Можно сконфигурировать несколько (до десяти) процессов DBWn
(DBW0 … DBW9). В большинстве систем работает только один процесс
записи блоков базы данных, но в больших, многопроцессорных системах имеет смысл
использовать несколько. Если сконфигурировано более одного процесса DBWn,
не забудьте также увеличить значение параметра инициализации
DB_BLOCK_LRU_LATCHES. Он определяет количество защелок списков по
давности использования, LRU lists (теперь, в версии 8i, их называют списками
количества обращений — touch lists). Каждый процесс DBWn
должен иметь собственный список. Если несколько процессов DBWn совместно
используют один список блоков для записи на диск, они будут конфликтовать друг
с другом при доступе к списку.
Обычно процесс DBWn использует асинхронный ввод-вывод для записи
блоков на диск. При использовании асинхронного ввода-вывода процесс DBWn
собирает пакет блоков для записи и передает его операционной системе. Процесс
DBWn не ждет, пока ОС запишет блоки, — он собирает следующий пакет
для записи. Завершив асинхронную запись, ОС уведомляет об этом процесс DBWn.
Это позволяет процессу DBWn работать намного быстрее, чем при
последовательном выполнении действий. В разделе «Подчиненные процессы»
будет показано, как с помощью подчиненных процессов ввода-вывода можно
эмулировать асинхронный ввод-вывод на платформах, где он не поддерживается.
И последнее замечание о процессе DBWn. Он, по определению, записывает
блоки, разбросанные по всему диску, — процесс DBWn выполняет множество
записей вразброс. В случае изменений будут изменяться разбросанные блоки индекса
и блоки данных, достаточно случайно распределенные по диску. Процесс LGWR,
напротив, выполняет в основном запись последовательных блоков в журнал повторного
выполнения. Это — важное отличие и одна из причин, почему сервер Oracle
имеет журнал повторного выполнения и отдельный процесс LGWR. Записи вразброс
выполняются намного медленнее, чем последовательные записи. Имея грязные блоки в
буферном кеше в SGA и процесс LGWR, записывающий большое количество
последовательных блоков информации для восстановления измененных буферов, можно
повысить производительность. Сочетание работы двух процессов — процесс
DBWn медленно работает в фоновом режиме, тогда как процесс LGWR
быстро выполняет работу для ожидающего пользователя — позволяет повысить
общую производительность. Это верно даже несмотря на то, что сервер Oracle может
выполнять больший объем ввода-вывода, чем надо (записывает в журнал и в файл
данных), — записи в оперативный журнал повторного выполнения можно
пропустить, если в ходе обработки контрольной точки сервер Oracle уже
записал измененные блоки на диск.
LGWR — запись журнала
Процесс LGWR отвечает за сброс на диск содержимого буфера журнала
повторного выполнения, находящегося в области SGA. Он делает это:
- раз в три секунды;
- при фиксации транзакции;
- при заполнении буфера журнала повторного выполнения на треть или при
записи в него 1 Мбайта данных.
Поэтому создание слишком большого буфера журнала повторного выполнения
не имеет смысла: сервер Oracle никогда не сможет использовать его целиком.
Все журналы записываются последовательно, а не вразброс, как вынужден
выполнять ввод-вывод процесс DBWn. Запись большими пакетами, как в
этом случае, намного эффективнее, чем запись множества отдельных блоков
в разные части файла. Это одна из главных причин выделения процесса LGWR
и журнала повторного выполнения. Эффективность последовательной записи измененных
байтов перевешивает расход ресурсов на дополнительный ввод-вывод. Сервер
Oracle мог бы записывать блоки данных непосредственно на диск при фиксации,
но это потребовало бы записи множества разбросанных блоков, а это существенно
медленнее, чем последовательная запись изменений процессом LGWR.
ARCn — архивирование
Задача процесса ARCn — копировать в другое место оперативный файл
журнала повторного выполнения, когда он заполняется процессом LGWR.
Эти архивные файлы журнала повторного выполнения затем можно использовать для
восстановления носителя. Тогда как оперативный журнал повторного выполнения
используется для «исправления» файлов данных в случае сбоя питания (когда
прекращается работа экземпляра), архивные журналы повторного выполнения
используются для восстановления файлов данных в случае сбоя диска. Если будет
потерян диск, содержащий файл данных /d01/oradata/ora8i/system.dbf,
можно взять резервные копии за прошлую неделю, восстановить из них старую
копию файла и попросить сервер применить оперативный журнал повторного
выполнения и все архивные журналы, сгенерированные с момента создания
этой резервной копии. Это «подтянет» файл по времени к остальным файлам
в базе данных, и можно будет продолжить работу без потери данных.
Процесс ARCn обычно копирует оперативный журнал повторного
выполнения в несколько мест (избыточность — гарантия сохранности данных!).
Это могут быть диски на локальной машине или, что лучше, на другой машине,
на случай катастрофического сбоя. Во многих случаях архивные файлы журнала
повторного выполнения копируются затем другим процессом на третье устройство
хранения, например на ленту. Они также могут отправляться на другую машину для
применения к резервной базе данных (это одно из средств защиты от сбоев,
предлагаемое Oracle).
BSP — сервер блоков
Этот процесс используется исключительно в среде Oracle Parallel Server (OPS).
OPS — конфигурация Oracle, при которой несколько экземпляров монтируют
и открывают одну и ту же базу данных. Каждый экземпляр Oracle в этом случае
работает на своей машине в кластере, и все они имеют доступ для чтения и
записи к одному и тому же набору файлов базы данных.
При этом буферные кеши в SGA экземпляров должны поддерживаться в согласованном
состоянии. Для этого и предназначен процесс BSP. В ранних версиях OPS
согласование достигалось с помощью выгрузки блока из кеша (‘ping‘).
Если машине в кластере требовалось согласованное по чтению представление
блока данных, заблокированного в исключительном режиме другой машиной,
выполнялся обмен данными с помощью сброса на диск. В результате получалась
очень дорогостоящая операция чтения данных. Сейчас, при наличии процесса
BSP, обмен происходит из кеша в кеш через высокоскоростное
соединение машин в кластере.
LMON — контроль блокировок
Этот процесс используется исключительно в среде OPS. Процесс LMON
контролирует все экземпляры кластера для выявления сбоя экземпляра. Затем
он вместе с диспетчером распределенных блокировок (Distributed Lock
Manager — DLM), используемым аппаратным обеспечением кластера,
восстанавливает глобальные блокировки, которые удерживаются сбойным
экземпляром.
LMD — демон диспетчера блокировок
Этот процесс используется исключительно в среде OPS. Процесс LMD управляет
глобальными блокировками и глобальными ресурсами для буферного кеша в
кластерной среде. Другие экземпляры посылают локальному процессу LMD
запросы с требованием снять блокировку или определить, кто ее установил.
Процесс LMD также выявляет и снимает глобальные взаимные блокировки.
LCKn — блокирование
Процесс LCKn используется исключительно в среде OPS. Он подобен
по функциям описанному выше процессу LMD, но обрабатывает запросы ко всем
остальным глобальным ресурсам, кроме буферного кеша.
Служебные фоновые процессы
Эти фоновые процессы необязательны — они запускаются в случае
необходимости. Они реализуют средства, необязательные для штатного
функционирования базы данных. Использование этих средств инициируется явно или
косвенно, при использовании возможности, требующей их запуска.
Служебных фоновых процессов — два. Один из них запускает посланные на
выполнение задания. В СУБД Oracle встроена очередь пакетных заданий, позволяющая
выполнять по расписанию однократные или периодические задания. Другой процесс
поддерживает и обрабатывает таблицы очереди, используемые средствами расширенной
поддержки очередей (Advanced Queuing — AQ). Средства AQ обеспечивают
встроенные возможности обмена сообщениями между сеансами базы данных.
Эти процессы можно увидеть в среде ОС UNIX, как и любой другой фоновый
процесс, с помощью команды ps. В представленных ранее результатах выполнения
команды ps можно видеть, что у меня в экземпляре работает один процесс
очереди заданий (ora_snp0_ora8I) и ни одного процесса очереди.
SNPn — обработка снимков (очереди заданий)
Сейчас можно сказать, что имя для процесса SNPn выбрано неудачно. В
версии 7.0 сервера Oracle впервые появилась поддержка репликации. Это делалось с
помощью объекта базы данных, известного как моментальный снимок
(snapshot). Внутренним механизмом для обновления или приведения к текущему
состоянию моментальных снимков был SNPn — процесс обработки
снимков (snapshot process). Этот процесс контролировал таблицу заданий,
по которой определял, когда необходимо обновлять моментальные снимки
в системе. В Oracle 7.1 корпорация Oracle открыла это средство для общего
доступа через пакет DBMS_JOB. То, что было связано с моментальными
снимками в версии 7.0, стало «очередью заданий» в версии 7.1 и последующих.
Со временем имена параметров для управления очередью (как часто ее надо
проверять и сколько процессов может быть в очереди) изменились со
SNAPSHOT_REFRESH_INTERVAL и SNAPSHOT_REFRESH_PROCESSES на
JOB_QUEUE_INTERVAL и JOB_QUEUE_PROCESSES. А вот имя процесса
операционной системы не изменилось.
Можно запускать до 36 процессов очереди заданий. Они именуются
SNP0, SNP1, …, SNP9, SNPA, …, SNPZ.
Эти процессы очередей заданий интенсивно используются при репликации в ходе
обновления моментального снимка или материализованного представления.
Разработчики также часто используют их для запуска отдельных (фоновых)
или периодически выполняющихся заданий. Например, далее в книге будет
показано, как использовать очереди заданий для существенного ускорения
обработки: за счет дополнительной работы можно сделать намного
приятнее среду для пользователя (аналогично тому, как сделано в самом
сервере Oracle при использовании процессов LGWR и DBWn).
Процессы SNPn сочетают в себе особенности как разделяемого, так
и выделенного сервера: обрабатывают несколько заданий, но памятью управляют
как выделенный сервер (область UGA находится в области PGA процесса).
Процесс очереди заданий выполняет в каждый момент времени только одно задание.
Вот почему необходимо несколько процессов, если требуется выполнять несколько
заданий одновременно. На уровне заданий не поддерживаются потоки или
вытеснение. Запущенное задание выполняется, пока не будет выполнено
(или не произойдет сбой). В приложении А мы более детально рассмотрим
пакет DBMS_JOB и нетрадиционное использование очереди заданий.
QMNn — контроль очередей
Процесс QMNn по отношению к таблицам AQ выполняет ту же роль, что и
процесс SNPn по отношению к таблице заданий. Этот процесс контролирует
очереди и уведомляет ожидающие сообщений процессы о том, что доступно сообщение.
Он также отвечает за распространение очередей — возможность переместить
сообщение, поставленное в очередь в одной базе данных, в другую базу данных для
извлечения из очереди.
Монитор очередей — это необязательный фоновый процесс. Параметр
инициализации AQ_TM_PROCESS позволяет создать до десяти таких процессов
с именами QMN0, …, QMN9. По умолчанию процессы QMNn
не запускаются.
EMNn — монитор событий
Процессы EMNn — часть подсистемы расширенной поддержки очередей.
Они используются для уведомления подписчиков очереди о сообщениях, в которых
они могут быть заинтересованы. Это уведомление выполняется асинхронно.
Имеются функции Oracle Call Interface (OCI) для регистрации обратного вызова,
уведомляющего о сообщении. Обратный вызов (callback) — это функция
в программе OCI, которая вызывается автоматически при появлении в очереди
определенного сообщения. Фоновый процесс EMNn используется для
уведомления подписчика. Процесс EMNn запускается автоматически при выдаче
первого уведомления в экземпляре. После этого приложение может явно вызвать
message_receive(dequeue) для извлечения сообщения из очереди.
Подчиненные процессы
Теперь мы готовы рассмотреть последний класс процессов Oracle —
подчиненные процессы. В сервере Oracle есть два типа подчиненных процессов —
ввода-вывода (I/O slaves) и параллельных запросов (Parallel Query slaves).
Подчиненные процессы ввода-вывода
Подчиненные процессы ввода-вывода используются для эмуляции асинхронного
ввода-вывода в системах или на устройствах, которые его не поддерживают.
Например, ленточные устройства (чрезвычайно медленно работающие) не
поддерживают асинхронный ввод-вывод. Используя подчиненные процессы
ввода-вывода, можно сымитировать для ленточных устройств такой способ работы,
который операционная система обычно обеспечивает для дисков. Как и в случае
действительно асинхронного ввода-вывода, процесс, записывающий на устройство,
накапливает большой объем данных в виде пакета и отправляет их на запись.
Об их успешной записи процесс (на этот раз — подчиненный процесс
ввода-вывода, а не ОС) сигнализирует исходному вызвавшему процессу,
который удаляет этот пакет из списка данных, ожидающих записи. Таким образом,
можно существенно повысить производительность, поскольку именно подчиненные
процессы ввода-вывода ожидают завершения работы медленно работающего
устройства, а вызвавший их процесс продолжает выполнять другие важные действия,
собирая данные для следующей операции записи.
Подчиненные процессы ввода-вывода используются в нескольких компонентах
Oracle 8i — процессы DBWn и LGWR используют их для имитации
асинхронного ввода-вывода, а утилита RMAN (Recovery
MANager — диспетчер восстановления) использует их при записи
на ленту.
Использование подчиненных процессов ввода-вывода управляется двумя
параметрами инициализации.
- BACKUP_TAPE_IO_SLAVES. Этот параметр указывает, используются ли
подчиненные процессы ввода-вывода утилитой RMAN для резервного копирования
или восстановления данных с ленты. Поскольку этот параметр предназначен для
ленточных устройств, а к ленточным устройствам в каждый момент времени может
обращаться только один процесс, он — булева типа, а не задает количество
используемых подчиненных процессов, как можно было ожидать. Утилита RMAN
запускает необходимое количество подчиненных процессов, в соответствии с
количеством используемых физических устройств. Если параметр
BACKUP_TAPE_IO_SLAVES имеет значение TRUE, то для записи или
чтения с ленточного устройства используется подчиненный процесс ввода-вывода.
Если этот параметр имеет (стандартное) значение FALSE, подчиненные
процессы ввода-вывода не используются при резервном копировании. К ленточному
устройству тогда обращается фоновый процесс, выполняющий резервное копирование. - DBWn_IO_SLAVES. Задает количество подчиненных процессов
ввода-вывода, используемых процессом DBWn. Процесс DBWn и
его подчиненные процессы всегда записывают на диск измененные буфера
буферного кеша. По умолчанию этот параметр имеет значение 0, и подчиненные
процессы ввода-вывода не используются.
Подчиненные процессы параллельных запросов
В Oracle 7.1 появились средства распараллеливания запросов к базе данных.
Речь идет о возможности создавать для SQL-операторов типа SELECT,
CREATE TABLE, CREATE INDEX, UPDATE и т.д. план выполнения,
состоящий из нескольких планов, которые можно выполнять одновременно.
Результаты выполнения этих планов объединяются. Это позволяет выполнить
операцию за меньшее время, чем при последовательном выполнении. Например,
если имеется большая таблица, разбросанная по десяти различным файлам
данных, 16-процессорный сервер, и необходимо выполнить к этой таблице запрос,
имеет смысл разбить план выполнения этого запроса на 16 небольших частей
и полностью использовать возможности сервера. Это принципиально отличается от
использования одного процесса для последовательного чтения и обработки всех
данных.
Резюме
Вот и все компоненты СУБД Oracle. Мы рассмотрели файлы, используемые в СУБД
Oracle: небольшой, но важный файл параметров инициализации init.ora,
файлы данных, файлы журнала повторного выполнения и т.д. Мы изучили структуры
памяти, используемые экземпляром Oracle как в серверных процессах, так и в
области SGA. Было показано, как различные конфигурации сервера, например
подключение в режиме MTS и к выделенному серверу, принципиально влияют на
использование памяти в системе. Наконец, мы рассмотрели процессы
(или потоки — в зависимости от базовой ОС), обеспечивающие выполнение
функций сервера Oracle. Теперь мы готовы к рассмотрению других возможностей
сервера Oracle — управления блокированием и одновременным доступом,
и поддержки транзакций.
Примечания переводчика
1. Здесь в книге идет простая схема, вид которой понятен из
дальнейшего текста. Я не счел нужным включать ее при публикации в формате HTML.
2. Здесь в книге идет дополненная версия предыдущей схемы. На ней
появился отдельный процесс — выделенный сервер, обслуживающий клиентское подключение
и выполняющий доступ к памяти (SGA) и дисковый ввод-вывод в файлы базы данных.
3. Можете нарисовать эту схему самостоятельно, на основе
предлагаемого в следующем абзаце главы описания. Схема состоит из следующих
компонентов:
- shared server — разделяемый сервер
- request queue — очередь запросов
- response queue — очередь ответов
- dispatcher — диспетчер
- client connection — клиентское подключение
4. Здесь в книге идет простая схема, иллюстрирующая предыдущий
абзац.
5. Здесь в книге идет простая схема, иллюстрирующая предыдущий
абзац. На ней — два процесса-диспетчера, работающие на портах 24536 и 12754.
6. Дополненная версия схемы СУБД Oracle, учитывающая два типа
подключений: к выделенному и разделяемому серверному процессу.
7. Здесь в книге идет простая схема, подробно описанная
в следующем абзаце.
8. Здесь в книге идет простая схема, иллюстрирующая
взаимодействие каждого клиентского приложения с соответствующим выделенным
сервером по протоколу Net8.
9. Здесь в книге идет простая схема, иллюстрирующая
взаимодействие всех клиентских приложений с диспетчером MTS, который
помещает их запросы в очередь запросов. Оттуда они выбираются разделяемыми
серверами, которые помещают результаты в очередь ответов. Диспетчер MTS
выбирает результат из очереди и отправляет соответствующему клиентскому
приложению.
Один, архитектура Oracle
Архитектура базы данных относится к составу базы данных, рабочему процессу, а также к механизму организации и управления данными в базе данных.Чтобы понять архитектуру базы данных Oracle, вы должны понимать основные компоненты и важные концепции системы Oracle.
1. Обзор архитектуры Oracle
Архитектура Oracle включает ряд компонентов, как показано на следующем рисунке, который показывает основные компоненты в архитектуре Oracle, включая экземпляры, пользовательские процессы, серверные процессы, файлы данных и другие файлы, такие как файлы параметров, файлы паролей и файлы архивных журналов. Подождите. Как видно из рисунка, экземпляр и база данных являются основными компонентами архитектуры базы данных Oracle и двумя наиболее важными концепциями; очень важной задачей администратора базы данных является поддержание нормальной работы экземпляра и самой базы данных.
1) Примеры
Экземпляр Oracle — это набор фоновых процессов и структур памяти. Экземпляр должен быть запущен для доступа к данным в базе данных. Когда экземпляр Oracle запускается, он выделяет системную глобальную область (SGA) и запускает ряд фоновых процессов Oracle. Существует два типа экземпляров Oracle: однопроцессные экземпляры и многопроцессорные экземпляры. Однопроцессные экземпляры Oracle используют один процесс для выполнения всех операций Oracle. В однопроцессной среде только один пользователь может получить доступ к экземпляру Oracle; многопроцессорные экземпляры Oracle (также Называется многопользовательский Oracle) использует несколько процессов для выполнения разных частей Oracle, и для каждого подключенного пользователя существует один процесс.
2) База данных
База данных — это набор данных, который физически относится к набору файлов операционной системы, в которых хранится информация о базе данных.Каждая база данных имеет логическую структуру и физическую структуру. Физическая структура относится к набору файлов операционной системы, составляющих базу данных, которая в основном состоит из трех типов файлов: файлов данных, управляющих файлов и файлов журнала повторного выполнения. Логическая структура базы данных относится к логической структуре хранения данных базы данных (таких как табличные пространства, сегменты) и объектов схемы (таких как таблицы, представления и т. Д.).
3) Подключаемая база данных
Начиная с версии Oracle 12c, Oracle представила концепцию подключаемой базы данных, которая родилась для облачных вычислений. Подключаемая структура состоит из контейнерной базы данных (CDB) и нескольких собираемых баз данных (PDB). Каждая PDB может действовать как независимая прикладная программа базы данных. Она может содержать свои собственные файлы данных, но все PDB. Делитесь файлами управления CDB и файлами журналов. Так называемый подключаемый модуль означает, что PDB может быть вставлен в CDB в любое время, как USB, и может быть отключен в любое время, когда он не используется. CDB может вставлять до 250 PDB. В PDB seedPDB является шаблоном PDB, который предоставляет шаблон для вновь созданного PDB. Другие PDB могут быть созданы или удалены по мере необходимости. Подключаемая функция может ускорить развертывание базы данных.Заключение CDB может быть синхронизировано со всеми PDB в ней через все обновления.
В версиях до Oracle 12c экземпляры и базы данных могут иметь отношения только один к одному или многие к одному (RAC, реальные кластеры приложений, кластер приложений реального времени), то есть только один экземпляр может соответствовать одной базе данных, или несколько экземпляров могут соответствовать База данных. Но в версии Oracle 12c, введя CDB и PDB, один экземпляр может соответствовать нескольким подключаемым базам данных.
Используйте сценарии для подключаемых баз данных:
На предприятии есть несколько приложений, которым необходимо использовать базу данных Oracle, они используют только очень небольшое количество аппаратных ресурсов, но им необходимо создать для них несколько экземпляров;
Для некоторых баз данных, которые не особенно важны, упаковка требует, чтобы администратор баз данных тратил много энергии на обслуживание;
- Чтобы лучше использовать аппаратные ресурсы и снизить накладные расходы на управление, необходимо интегрировать большое количество приложений уровня отдела в несколько реляционных баз данных Oracle для развертывания и управления;
За счет развертывания нескольких баз данных на централизованной платформе и одновременного совместного использования экземпляра базы данных можно значительно снизить затраты, то есть уменьшить потери экземпляров и технологии хранения сельскохозяйственных угодий.
Если вам нужна только одна база данных в производственной среде и вы не хотите использовать подключаемую базу данных, вы можете снять флажок «Создать как базу данных контейнера» во время процесса установки, чтобы установить обычную базу данных.
2. Сервер Oracle
Сервер Oracle в основном состоит из файлов мощности и базы данных, которые часто называют системой управления базами данных (СУБД). Состав сервера Oracle следующий:
Помимо поддержки файлов экземпляра и базы данных, сервер Oracle также запускает серверный процесс и выделяет PGA (область программы), когда пользователь устанавливает соединение с сервером.
3. Структура хранилища Oracle
Структура хранения Oracle делится на физическую структуру и логическую структуру, эти две структуры хранения взаимно независимы и взаимосвязаны. Как показано ниже:
-
Физическая структура в основном описывает структуру внешнего хранилища базы данных Oracle, то есть способы организации данных в операционной системе и управления ими.
- Логическая структура в основном описывает внутреннюю структуру хранения базы данных Oracle, то есть то, как организовать данные в базе данных Oracle и управлять ими, исходя из логической концепции.
1) Физическая структура Oracle
Физическая структура — это физические файлы операционной системы, используемые после создания базы данных Oracle.Физические файлы базы данных Oracle делятся на следующие две категории:
(1) Основные документы
①Файл данных:Расширением файла данных (файла данных) обычно является .dbf, который представляет собой файл, в котором физически хранятся данные базы данных Oracle.
Особенности файла данных:
Каждый файл данных связан только с одной базой данных;
Табличное пространство может содержать один или несколько файлов данных;
- Файл данных может принадлежать только одному табличному пространству;
②Redo файл журнала:Файл журнала повторов имеет расширение .log, в котором записываются все изменения данных и обеспечивается механизм восстановления данных, гарантирующий восстановление базы данных после сбоя системы или других аварий.
В базе данных Oracle файлы журнала повторного выполнения используются в группах, и каждая группа файлов журнала повторного выполнения может иметь один или несколько файлов журнала повторного выполнения. В процессе работы циклически используются несколько групп файлов журнала повторного выполнения.Когда одна группа файлов журнала повторного выполнения заполняется, она переключается на следующую группу файлов журнала. Файлы журнала повтора используются для записи изменений в базе данных и представляют собой журналы обработки пользовательских транзакций.
③Контрольные документы:Расширение управляющего файла (Control File) — .ctl, это двоичный файл. В контрольном файле хранится много информации, включая имена и расположение файлов данных и файлов журнала повторного выполнения. Контрольный файл является необходимым файлом для запуска и работы базы данных. Когда Oracle читает и записывает данные, ему необходимо найти файл данных на основе информации в контрольном файле.
В связи с важностью контрольных документов в базе данных должно быть не менее двух контрольных документов. Oracle 12c по умолчанию содержит два управляющих файла, и содержимое каждого управляющего файла одинаково, что позволяет избежать ситуации, когда база данных не может быть запущена из-за повреждения одного управляющего файла.
В контрольном файле записана следующая ключевая информация:
Расположение и размер файла данных;
Расположение и размер файла журнала повторного выполнения;
Имя базы данных и время создания;
- Порядковый номер журнала;
(2) Прочие документы
Другие файлы включают файлы параметров, файлы архивных журналов, файлы паролей и т. Д.
2) Логическая структура Oracle
Логическая структура базы данных предназначена для анализа состава базы данных с логической точки зрения. Логическая структура базы данных Oracle включает табличные пространства, сегменты, регионы, блоки и шаблоны. Как показано:
(1) Табличное пространство
Каждая база данных Oracle состоит из нескольких табличных пространств, и все содержимое, созданное пользователем в базе данных, хранится в табличном пространстве. Табличное пространство может состоять из нескольких файлов данных, но файл данных может принадлежать только одному табличному пространству. В отличие от физической структуры файла данных, табличное пространство принадлежит логической структуре базы данных.
В каждой базе данных есть табличное пространство с именем «SYSTEM», то есть системное табличное пространство, и есть табличные пространства, такие как SYSAUX, UNDO, USERS и т. Д., Которые автоматически создаются при создании базы данных. Администраторы могут создавать собственные табличные пространства и назначать их назначенным пользователям, а также добавлять и удалять файлы данных для табличного пространства.
В основном есть три типа табличных пространств:
①Постоянное табличное пространство: обычно хранят данные базовых таблиц, попыток, процедур и индексов. Табличные пространства SYSTEM, SYSAUX и USERS устанавливаются по умолчанию;
②Временное табличное пространство: используется только для хранения данных о краткосрочных действиях в системе, таких как данные сортировки и т. Д .;
- ③ Табличное пространство для отзыва: используется для отката незафиксированных данных транзакции, отправленные данные здесь не могут быть восстановлены;
Как правило, вам не нужно создавать временные табличные пространства и табличные пространства отмены, если вы не хотите перенести их на другие диски для повышения производительности.
Назначение табличного пространства:
① Выделять разные табличные пространства разным пользователям и выделять разные табличные пространства для разных объектов модели, чтобы облегчить работу пользователей и управление объектами модели;
- ②На разных дисках можно создавать разные файлы данных, что полезно для управления дисковым пространством, повышения производительности ввода-вывода, резервного копирования и восстановления данных и т. Д .;
Обычно после установки системы Oracle и создания экземпляра Oracle система Oracle автоматически создает несколько табличных пространств, таких как SYSTEM, SYSAUX и USRS.
Следующие сведения о табличном пространстве SYSTEM, табличном пространстве SYSAUX, табличном пространстве TEMP и табличном пространстве TEMP:
-
Табличное пространство SYSTEM: используется для хранения данных внутренних таблиц и словаря данных системы Oracle, таких как имена таблиц, имена столбцов и имена пользователей. Не рекомендуется хранить созданные пользователем таблицы, индексы и другие объекты в табличном пространстве SYSTEM.
-
Табличное пространство SYSAUX: в качестве вспомогательного табличного пространства SYSTEM оно используется для хранения данных различных пользователей инструментов базы данных; оно также используется для хранения данных объектов различных режимов, таких как пользователь интеллектуального агента DBSNMP и т. Д. Эти режимы устанавливаются после установки базы данных. Соответствующие объекты хранятся в табличном пространстве SYSAUX.
-
Табличное пространство USERS: обычно в качестве табличного пространства, используемого пользователями, в этом табличном пространстве могут быть созданы различные объекты, такие как таблицы, индексы и т. Д.
- Табличное пространство TEMP: специальное табличное пространство, используемое системой Oracle для хранения временных данных. Например: когда операцию нужно отсортировать, система Oracle временно сохраняет отсортированные данные в табличном пространстве. После завершения процесса сортировки пространство, занятое отсортированными данными, может быть освобождено, поэтому оно становится временным табличным пространством.
В дополнение к табличным пространствам, создаваемым системой Oracle по умолчанию, пользователи могут создавать несколько табличных пространств в соответствии с режимом прикладной системы и типами объектов, которые должны быть сохранены, чтобы различать пользовательские данные и системные данные.
Создайте язык определения данных данных табличного пространства, синтаксис следующий:
SQL> create tablespace benet datafile'/u01/app/oracle/oradata/benet.DBF' size 10M
autoextend on;В синтаксисе:
tablespacename — это имя табличного пространства.
DATAFILE определяет один или несколько файлов данных, составляющих табличное пространство. Если файлов данных несколько, используйте запятые для их разделения.
filename — это путь и имя файла данных в табличном пространстве.
SIZE указывает размер файла, K указывает размер в килобайтах, а M указывает размер в мегабайтах.
- Предложение AUTOEXTEND используется для включения или отключения автоматического расширения файлов данных. Если для параметра AUTOEXTEND установлено значение ON, пространство будет автоматически расширяться при его исчерпании; если для параметра AUTOEXTEND установлено значение OFF, легко получить оставшуюся емкость табличного пространства равной 0, что приведет к ситуации, когда данные не могут быть сохранены в базе данных.
После создания табличного пространства вы можете соответствующим образом управлять табличным пространством, в основном включая следующие операции.
Отрегулируйте размер табличного пространства. Если при вставке данных произошел сбой, а табличное пространство заполнено, вы можете настроить размер табличного пространства с помощью оператора ALTER. На данный момент есть два способа изменить размер табличного пространства.
Метод 1. Измените размер файла данных и укажите путь хранения файла данных. Ключевое слово RESIZE также используется для указания размера скорректированного файла данных. Код выглядит следующим образом:
SQL> alter database datafile'/u01/app/oracle/oradata/benet.DBF' resize 50M;
Database altered.
Метод 2: Добавьте файлы данных в табличное пространство. Код для добавления нового файла данных в табличное пространство выглядит следующим образом:
SQL> alter tablespace benet add datafile '/u01/app/oracle/oradata/benet01.DBF' size 20M autoextend no;
Tablespace altered.
Измените статус чтения и записи табличного пространства. Если данные представляют собой исторические данные, разрешить только запрос, не нужно изменять, вы можете установить табличное пространство в состояние только для чтения. READ ONLY указывает, что табличное пространство доступно только для чтения, а READ WRITE указывает, что табличное пространство доступно для чтения и записи. Конкретный формат синтаксиса следующий:
SQL> изменить табличное пространство только для чтения; <! - Изменить табличное пространство только для чтения ->
Tablespace altered.
SQL> изменить табличное пространство для чтения и записи; <! - Изменить табличное пространство для чтения и записи файлов ->
Tablespace altered.
Удалите табличное пространство. Вы можете удалить табличное пространство с помощью оператора DROP, просто добавьте имя табличного пространства. Конкретный формат синтаксиса следующий:
SQL> drop tablespace benet including contents;
Tablespace dropped.
(2) Сегмент
Сегмент (Segment) существует в табличном пространстве, представляет собой определенный тип логической структуры хранения, сегмент состоит из группы областей. Сегменты можно разделить на четыре категории: сегмент данных, сегмент индекса, сегмент отката и временный сегмент. Например, есть один сегмент данных для каждой некластеризованной таблицы, и все данные таблицы хранятся в этом сегменте; и есть сегмент индекса для каждого индекса.
(3) Район
Площадь (Экстент) — это наименьшая единица распределения дискового пространства. Диски разделены на зоны, и одновременно выделяется как минимум одна зона. Область состоит из последовательных блоков данных. Сегмент в основном состоит из одной или нескольких областей. Когда сегмент создается, он содержит как минимум одну область. Когда все пространство в сегменте будет полностью использовано, система автоматически выделит для сегмента новую область. Зоны не могут существовать в файлах данных, они могут существовать только в одном файле данных.
(4) Блок данных
Блок данных — это наименьшая единица организации данных и единица управления в базе данных. Данные в базе данных Oracle хранятся в блоках данных. Блок данных — это наименьшая единица хранения, которая может быть прочитана или записана сервером Oracle. Сервер Oracle управляет пространством хранения файлов данных в единицах блоков данных. Диапазон значений блока данных составляет 2 ~ 64 КБ, а его размер по умолчанию зависит от версии Oracle.
(5) Режим
Схема — это набор объектов базы данных (также известных как объекты схемы). Объекты схемы включают таблицы, представления, индексы, синонимы, последовательности, процедуры и пакеты. Каждый раз, когда создается пользователь, Oracle автоматически создает шаблон с тем же именем, что и у пользователя, поэтому шаблон также называется шаблоном пользователя. После входа пользователя в систему доступ по умолчанию осуществляется к объекту базы данных в схеме с тем же именем, что и его собственное.
4. Структура памяти Oracle
Структура памяти является наиболее важной частью системы баз данных Oracle, а память также является первым элементом, влияющим на производительность базы данных.
Основное содержимое хранилища памяти Oacle:
код;
Информация о подключенных сеансах, включая все текущие активные сеансы и неактивные сеансы;
Связанная информация, необходимая для запуска программы, например план запроса;
- Информация, передаваемая и совместно используемая между процессами Oracle, например, блокировки;
Согласно различным методам использования памяти, память базы данных Oracle также может быть разделена на SGA, PGA и UGA (глобальная область пользователя, глобальная область пользователя).
-
SGA: общая область памяти экземпляра, к которой имеют доступ все пользователи. Блоки данных, журналы обработки транзакций, информация словаря данных и т.д. — все это хранится в SGA.
- PGA: тип не разделяемой памяти, выделенной для определенного серверного процесса, доступ к которой может получить только этот процесс.
UGA: область памяти, в которой хранится состояние сеанса для пользовательских процессов. В зависимости от того, настроена ли база данных пользователей как режим выделенного сервера или как режим общего сервера, UGA может использоваться как часть SGA или PGA. В нем хранятся данные для пользовательских сессий. Далее я сосредоточусь на SGA и PGA:
1)SGA
SGA экземпляра Oracle также хранит информацию о базе данных и используется несколькими процессами базы данных. При запуске экземпляра базы данных автоматически выделяется память SGA. SAG — это область, которая занимает самую большую память сервера в базе данных, а также важный показатель, влияющий на производительность базы данных. SGA можно разделить на общий пул, буфер данных, буфер журнала повторного выполнения, большой пул и пул Java в соответствии с его различными функциями.
①Общий пул
Общий пул — это область памяти, используемая для синтаксического анализа, компиляции и выполнения программ SQL и PL / SQL. Общий пул состоит из кеша библиотеки и кеша словаря данных.
-
Кэш библиотеки содержит код анализа и план выполнения последних выполненных операторов SQL и PL / SQL.
- Кэш словаря данных содержит определения таблиц, индексов, определения столбцов, информацию о разрешениях и другие объекты базы данных, полученные из словаря данных.Если Oracle кэширует эту информацию, это, несомненно, сократит время ответа на запрос.
②Буфер данных
Буфер данных используется для хранения данных, считанных из файла данных на диске, для совместного использования всеми пользователями. При изменении данных сначала извлеките данные из файла данных и сохраните их в буфере данных. Все измененные данные и вставленные данные сохраняются в буфере данных, и данные записываются в файл данных, когда модификация завершена и выполнены другие условия.
Когда серверный процесс Oracle обрабатывает запрос, он сначала проверяет, существует ли требуемый блок данных в памяти. Если требуемый блок не найден в буфере данных, серверный процесс считывает блок из файла данных и сохраняет его в буфере. Когда последующим запросам необходимо прочитать эти блоки, их можно найти в памяти, поэтому эти запросы не нужно читать с диска, тем самым увеличивая скорость чтения. Размер буфера данных напрямую влияет на скорость чтения базы данных.
③ Восстановить буфер журнала
Когда пользователь выполняет такие операции, как INSERT, UPDATE, DELETE, CREATE, ALTER, DROP и т. Д., Данные были изменены. Эти измененные данные должны быть записаны в буфер журнала повторов перед записью в кэш данных, а предыдущие изменения Данные также помещаются в кэш журнала повторного выполнения, чтобы Oracle знала, какие ресурсы необходимо отправить, а какие — отозвать во время восстановления данных. По сравнению с буфером данных, буфер журнала меньше влияет на производительность базы данных.
④Oike
В SGA большой пул является дополнительным буфером, и администратор может настроить его по мере необходимости. Большие пулы также необходимы в качестве буферного пространства во время крупномасштабных процессов ввода, вывода и резервного копирования, таких как операции с большими данными, резервное копирование и восстановление базы данных.
⑤Java бассейн
В SGA пул Java также является необязательным буфером, но пул Java должен быть установлен при установке Java или использовании программ Java для компиляции инструкций, написанных на языке Java.
2)PGA
PGA не является частью экземпляра, он содержит данные и управляющую информацию, необходимые для одного серверного процесса или одного фонового процесса. PGA автоматически выделяется, когда пользовательский процесс подключается к базе данных и создает сеанс.Раздел резервирует память, необходимую для каждого пользовательского процесса, подключенного к базе данных Oracle. После того, как пользователь завершит сеанс, PGA будет выпущен.
5. Структура процессов Oracle
В Oracle есть несколько различных типов процессов: пользовательские процессы, серверные процессы и фоновые процессы.
Пользовательский процесс: запускается, когда пользователь базы данных запрашивает соединение с сервером Oracle;
Серверный процесс: запускается, когда пользователь устанавливает сеанс и подключается к экземпляру Oracle;
- Фоновый процесс: запускается при запуске экземпляра Oracle;
-
Пользовательский процесс — это программа, которая должна взаимодействовать с серверным процессом Oracle. Когда пользователь базы данных запускает приложение и готовится отправить запрос на сервер базы данных, создается пользовательский процесс. Например: когда пользователь запускает инструмент базы данных Sqlplus, система автоматически устанавливает пользовательский процесс.
- Серверный процесс используется для обработки запросов от пользовательских процессов, подключенных к экземпляру. Когда пользователь устанавливает соединение с базой данных, создается серверный процесс. Серверный процесс взаимодействует с пользовательским процессом и запрашивает услуги для подключенного пользователя. Серверный процесс напрямую взаимодействует с базой данных Oracle для достижения цели вызова и возврата результатов. Серверный процесс может обрабатывать запрос от одного пользовательского процесса или он может обрабатывать запросы от нескольких пользовательских процессов.
В базе данных Oracle, чтобы повысить производительность системы, координировать работу нескольких пользователей, некоторые дополнительные процессы, используемые в системе экземпляра, называются фоновыми процессами. Эти фоновые процессы существуют в операционной системе и автоматически запускаются при запуске экземпляра. Необходимо запустить пять процессов, иначе экземпляр базы данных не может быть запущен. Пять важных и необходимых фоновых процессов: процесс мониторинга (Process Monitor, PMON), процесс системного мониторинга (System Monitor, SMON), процесс записи данных (Database Writer, DBWR) и запись журнала (Log Writer, LGWR). Процесс, процесс Check Point (CKPT).
1) процесс PMON
Процесс PMON выполняет очистку ресурсов после неожиданного прерывания пользовательского соединения, включая следующие задачи:
Освободить все приостановленные в настоящее время блокировки;
Откатить обработку текущей транзакции пользователя;
Освободить ресурсы, используемые в данный момент пользователем;
- Следите за процессами сервера и другими фоновыми процессами, перезапускайте их в случае сбоя;
2) процесс SMON
Процесс SMON выполняет следующие задачи:
- Выполните восстановление экземпляра при запуске экземпляра. Восстановление экземпляра включает три этапа:
① Поверните для восстановления данных, которые не были записаны в файл данных, но были записаны в файл онлайн-журнала;
②Открыть базу данных, чтобы пользователи могли войти в систему и получить доступ к данным;
③ Отменить отправленную обработку транзакции;
Организовать свободное пространство файлов данных;
- Освободите временные сегменты, которые больше не используются;
3) процесс DBWR
Процесс DBWR выполняет следующие задачи:
Управляйте буфером данных, чтобы вы могли найти свободный буфер для чтения данных в файл данных;
Записать все измененные данные буфера в файл данных;
Используйте алгоритм LRU, чтобы сохранить в памяти самый последний использованный блок;
- Оптимизировать чтение и запись дискового ввода-вывода за счет отложенной записи;
4) процесс LGWR
Процесс LGWR отвечает за запись данных журнала из буфера журнала повторного выполнения в группу файлов журнала. Если во время работы базы данных изменяются данные, генерируется информация журнала, которая сначала создается в буфере журнала повторного выполнения. Этот буфер работает в соответствии с принципом «первым пришел — первым ушел». Когда информация журнала соответствует определенным условиям, процесс LGWR записывает данные журнала в файл журнала. В системе обычно имеется несколько файлов журнала, и процесс записи журнала записывает данные в файлы циклически.
5) процесс CKPT
Процесс CKPT — это механизм, обеспечивающий запись всех измененных блоков данных в буфере данных в файл данных. Когда контрольная точка завершена, процесс CKPT отвечает за обновление заголовка файла данных и контрольного файла, а также за сохранение информации контрольной точки, чтобы гарантировать синхронизацию файла журнала базы данных и файла данных. Во время восстановления базы данных вам нужно только найти последнюю контрольную точку, сохраненную CKPT, вы можете определить начальную позицию восстановленных данных в файле журнала на ее основе, а затем повторно выполнить последующие записи журнала.
6) процесс ARCn
Процесс ARCn — это процесс архивирования журнала, который является необязательным, и этот процесс существует только тогда, когда архивирование журнала включено. Основная функция этого процесса — копирование полных файлов онлайн-журнала в каталог архива при переключении журнала.
2. Основные операции CDB и PDB
В отличие от предыдущей версии Oracle, Oracle 12c можно использовать как единую базу данных (сняв флажок «Создать как базу данных контейнера» во время переустановки), или он может предоставить несколько подключаемых баз данных PDB в соответствии с потребностями предприятия. Каждую PDB может обслуживать другой администратор базы данных. Ниже описывается базовое обслуживание CDB и PDB.
[[email protected] ~]$ source .bash_profile
[oracle @ oracle ~] $ sqlplus / as sysdba <! - Войдите в базу данных как пользователь sys ->
SQL*Plus: Release 12.2.0.1.0 Production on Tue Jan 7 14:58:04 2020
Copyright (c) 1982, 2016, Oracle. All rights reserved.
Connected to:
Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production
SQL> startup; <! - Запустить базу данных ->
ORACLE instance started.
Total System Global Area 1660944384 bytes
Fixed Size 8793448 bytes
Variable Size 1056965272 bytes
Database Buffers 587202560 bytes
Redo Buffers 7983104 bytes
Database mounted.
Database opened.
SQL>
SQL> show con_name; <! - Просмотреть текущий контейнер ->
CON_NAME
------------------------------
CDB $ ROOT <! - CDB $ ROOT в настоящее время находится в CDB ->
SQL>
SQL> show pdbs; <! - Просмотреть все контейнеры базы данных ->
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 ORCLPDB MOUNTED <! - Состояние примонтировано (не открыто) ->
SQL>
SQL> alter pluggable database orclpdb open;
<! - Измените подключаемую базу данных orclpdb в CDB в открытое состояние ->
Pluggable database altered.
SQL>
SQL> alter session set container=orclpdb;
<! - Переключить сеанс из CDB в PDB (orclpdb) ->
Session altered.
SQL>
SQL> show con_name; <! - Убедитесь, что текущая позиция уже находится в orclpdb ->
CON_NAME
------------------------------
ORCLPDB
SQL> Переключение с CDB на PDB и связанные с ним операции следующие:
SQL> show con_name; <! - Просмотр текущего местоположения ->
CON_NAME
------------------------------
CDB$ROOT
SQL>
SQL> alter session set container = orclpdb; <! - Переключить сеанс на PDB ->
Session altered.
SQL>
SQL> show con_name; <! - Запросить текущий контейнер ->
CON_NAME
------------------------------
ORCLPDB
SQL>
SQL> немедленно завершить работу; <! - Закройте подключаемую базу данных в PDB ->
Pluggable Database closed.
SQL>
SQL> startup; <! - Открыть подключаемую базу данных в PDB ->
Pluggable Database opened.
SQL>
SQL> alter session set container = cdb $ root; <! - Переключить сеанс на CDB ->
Session altered.
SQL>
SQL> show con_name; <! - Проверить текущую позицию еще раз ->
CON_NAME
------------------------------
CDB$ROOT
SQL> С помощью описанной выше операции можно обнаружить, что PDB может управляться в CDB.Например, в CDB данные PDB могут быть установлены в открытое состояние с помощью команды «alter pluggable database orclpdb open». Конечно, это также может поддерживаться в PDB, например, выполнение команды «немедленное завершение работы» и команды «запуска» для закрытия и открытия базы данных PDB соответственно. Переключение между CDB и PDB также очень удобно, просто выполните команду «alter session set container = xxx».
Существует два способа подключения к подключаемой базе данных PDB: один — выполнить команду sqlplus / as sysdba для входа в CDB, а затем переключиться на PDB с помощью команды «alter session set container = xxx»; второй — выполнить команду sqlplus sys Команда / oracle @ orclpdb sa sysdba «напрямую входит в базу данных PDB, где orclpdb — это имя контейнера pdb, и его необходимо добавить в файл /u01/app/oracle/product/12.2.0/dbhome_1/network/admin/tnsnames.ora Последующий:
[[email protected] ~]$ vim /u01/app/oracle/product/12.2.0/dbhome_1/
network/admin/tnsnames.ora
# Generated by Oracle configuration tools.
LISTENER_ORCL =
(ADDRESS = (PROTOCOL = TCP)(HOST = oracle)(PORT = 1521))
# Generated by Oracle configuration tools.
LISTENER_ORCL =
(ADDRESS = (PROTOCOL = TCP)(HOST = oracle)(PORT = 1521))
ORCL =
ORCL =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = oracle)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = orcl)
)
)
----------------------------------------------------
<! - Разделительная линия, вышеуказанное делать не нужно ->
ORCLPDB =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = Oracle)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = orclpdb)
)
)Три, управление пользователями
При создании новой базы данных Oracle создаст некоторых пользователей базы данных по умолчанию, таких как: SYS, SYSTEM и других пользователей. Пользователи SYS и SYSTEM являются администраторами Oracle. Если вы решите установить образец базы данных во время процесса установки, пользователь HR будет создан автоматически. Пользователь HR является примером пользователя базы данных Oracle. При необходимости вы также можете импортировать другие образцы баз данных. База данных примеров содержит несколько примеров таблиц для демонстрации тестов. Далее кратко представлены SYS, SYSTEM и пользовательские пользователи.
1、SYS
Пользователь SYS — это суперпользователь в Oracle, который в основном используется для обслуживания системной информации и управления экземплярами. Все словари данных и представления в базе данных хранятся в режиме SYS. Словарь данных хранит всю информацию, используемую для управления объектами базы данных, которая является очень важной системной информацией в базе данных Oracle. Пользователь SYS может войти в систему базы данных только с ролью SYSOPER или SYSDBA.
2、SYSTEM
Пользователь SYSTEM является администратором базы данных в Oracle по умолчанию и имеет права администратора баз данных. В этом пользовательском режиме хранятся внутренние таблицы и представления, используемые инструментами управления Oracle. Пользователь SYSTEM обычно используется для управления пользователями, разрешениями и хранилищем базы данных Oracle. Не рекомендуется создавать пользовательские таблицы в режиме SYSTEM. Пользователь SYSTEM не может войти в систему с ролью SYSOPER или SYSDBA и может только войти в систему, используя метод по умолчанию (метод аутентификации базы данных).
3. Пользовательский пользователь
Oracle 12c поддерживает создание настраиваемых пользователей.В связи с введением PDB объем настраиваемых пользователей отличается от предыдущей версии. В режиме CDB есть два типа пользователей: публичные пользователи и локальные пользователи. Общедоступных пользователей можно использовать в CDB и PDB, в то время как локальных пользователей можно использовать только в PDB. В среде CDB создание локальных пользователей запрещено. Oracle оговаривает, что при создании общедоступного пользователя в CDB имя пользователя должно начинаться с c ##.
Обычно из соображений безопасности для разных таблиц данных пользователей требуются разные права доступа, поэтому необходимо создавать разных пользователей. Команда CREATE USER в Oracle используется для создания новых пользователей. У каждого пользователя есть пространство по умолчанию и временное табличное пространство. Если не указано иное, Oracle устанавливает ПОЛЬЗОВАТЕЛИ в качестве табличного пространства по умолчанию, а TEMP — как временное табличное пространство. Синтаксис для создания пользователя следующий:

1) Войдите в CDB базы данных orcl как системный пользователь, создайте пользователя tom с паролем 123, табличное пространство по умолчанию — users, а временное табличное пространство — temp. Откройте квоту табличного пространства и измените пароль при следующем входе в систему.
SQL> create user c##tom identified by 123 default tablespace users temporary tablespace temp quota unlimited on users password expire;
User created.2) Измените пароль пользователя tom на 123456
SQL> alter user c##tom identified by 123456;
User altered.3) Удалить неиспользуемую учетную запись тома
SQL> drop user c##tom cascade;
User dropped.Четыре, управление полномочиями базы данных
Разрешение — это право выполнять определенные типы операторов SQL и получать доступ к другим объектам пользовательской базы данных. В Oracle разрешения делятся на системные разрешения и разрешения на объекты.
1. Системные разрешения
Системные полномочия относятся к полномочиям выполнять определенную операцию системного уровня в базе данных или выполнять определенную операцию с определенным типом объекта. Например, полномочия по созданию табличного пространства в базе данных или полномочия по созданию таблицы в базе данных относятся к системным разрешениям. Пример системных разрешений показан ниже:
Общие системные разрешения следующие:
СОЗДАТЬ СЕССИЮ: подключиться к базе данных;
CREATE TABLE: создать таблицу;
СОЗДАТЬ ВИД: создать представление;
- CREATE SEQUENCE: создать последовательность;
После создания нового пользователя желательно предоставить разрешение CREATE SESSION, чтобы он мог войти в базу данных.
2. Права доступа к объекту
Полномочия объекта относятся к праву выполнять операции с объектом определенного режима. Вы можете устанавливать разрешения на объекты и управлять ими только для объектов схемы, включая таблицы, представления, последовательности и хранимые процедуры в базе данных. Как показано ниже:
Пользователи базы данных Oracle могут получить разрешения двумя способами:: напрямую предоставить разрешения пользователям; ② предоставить разрешения ролям, а затем предоставить роли одному или нескольким пользователям. Используйте роли для более удобного и эффективного управления разрешениями. Таким образом, администратор базы данных предоставляет разрешения пользователям с помощью ролей вместо того, чтобы напрямую предоставлять разрешения пользователям. В системе баз данных Oracle есть много предопределенных ролей, среди которых наиболее часто используются CONNECT, RESOURCE, DBA и т. Д.
Обычно используемые системные предопределенные роли в Oracle следующие:
ПОДКЛЮЧИТЬСЯ: иметь право подключаться к базе данных;
РЕСУРС: иметь право создавать таблицы, триггеры, процедуры и т.д .;
- Администратор базы данных: роль администратора базы данных имеет наивысшие полномочия по управлению базой данных; пользователь с ролью администратора базы данных может авторизовать любого другого пользователя или даже другие разрешения администратора базы данных, что очень опасно, поэтому не давайте эту роль легкомысленно;
Вновь созданным пользователям должны быть предоставлены определенные разрешения для выполнения связанных операций с базой данных. Авторизация осуществляется с помощью оператора CRANT, а авторизация — с помощью оператора REVOKE.
1) Пример синтаксиса базовой операции для создания учетной записи bob, авторизации и отзыва авторизации
SQL> alter session set container = orclpdb; <! - Переключиться на базу данных orclpdb ->
Session altered.
SQL> создать пользователя bob с идентификатором 123456; <! - Создать учетную запись bob ->
User created.
SQL> grant connect,resource to bob;
<! - Авторизованный пользователь bob имеет разрешение на подключение к базе данных и создание таблиц, триггеров, процедур и т. Д. ->
Grant succeeded.
SQL> отменить соединение, ресурс от bob; <! - Отменить авторизацию ->
Revoke succeeded.Принципы проектирования безопасности пользователей баз данных следующие:
Куда поступают пользователи базы данных в первую очередь в соответствии с принципом наименьшего распределения;
Пользователи базы данных можно разделить на четыре типа пользователей: управление, приложение, обслуживание и резервное копирование;
Не разрешается использовать sys и системных пользователей для создания объектов приложения базы данных;
Запрещено предоставлять права доступа к dba обычным пользователям;
Для запросов пользователей могут быть открыты только разрешения запросов;
- Для вновь созданных пользователей для первого входа в базу данных для принудительной смены пароля;
Обычным разработчикам программ нужно только предоставить две роли CONNECT и RESOURCE. В частности, предоставление этих двух ролей включает предоставление пользователям неограниченного доступа к табличному пространству по умолчанию.
———————— На этом статья завершается, спасибо за чтение ————————
Oracle Database — это объектно-реляционная СУБД (система управления базами данных), созданная компанией Oracle. В настоящее время она имеет множество разных версий и типов. Однако в этой статье мы поговорим не о видах баз данных Oracle, а о структуре и основных концепциях, которые относятся к СУБД Oracle Database. Поняв архитектуру СУБД Oracle, вы заложите фундамент, необходимый для понимания прочих средств (а они весьма обширны), предоставляемых базой данных Oracle.

Базы данных Oracle: экземпляры и сущности
СУБД Oracle Database включает в себя физические и логические компоненты. Особого упоминания заслуживает понятие экземпляра. Замечено, что некоторые используют термины «база данных» и «экземпляр» в качестве синонимов. Да, это взаимосвязанные, но всё же разные вещи. База данных в терминологии Oracle — это физическое хранилище информации, а экземпляр — это программное обеспечение, которое работает на сервере и предоставляет доступ к информации, содержащейся в базе данных Oracle. Экземпляр исполняется на конкретном сервере либо компьютере, в то самое время как база данных хранится на дисках, подключённых к этому серверу:
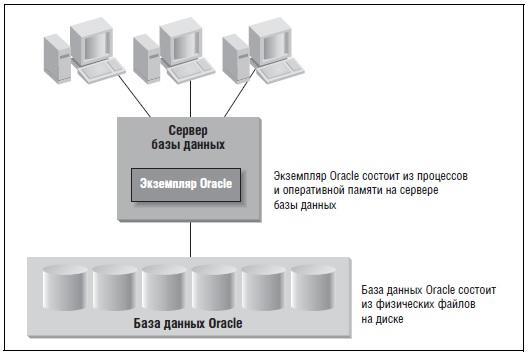
При этом база данных Oracle является физической сущностью, состоящей из файлов, которые хранятся на дисках. В то же самое время, экземпляр – это сущность логическая, состоящая из структур в оперативной памяти и процессов, которые работают на сервере. Экземпляр может являться частью только одной базы данных. При этом с одной базой данных бывает ассоциировано несколько экземпляров. Экземпляр ограничен по времени жизни, тогда как БД, условно говоря, может существовать вечно.
Также стоит заметить, что у пользователей нет прямого доступа к информации, которая хранится в базе данных Oracle — они должны запрашивать эту информацию у экземпляра Oracle.
Если упрощённо, то экземпляр — это мост к базе данных, а сама БД – это остров. Когда экземпляр запущен, мост работает, а данные способны попадать в базу данных Oracle и покидать её. Если мост перекрыт (экземпляр остановлен), пользователи не могут обращаться к базе данных, несмотря на то, что физически она никуда не исчезла.
Структура базы данных Oracle
База данных Oracle включает в себя:
— табличные пространства;
— управляющие файлы;
— журналы;
— архивные журналы;
— файлы трассировки изменения блоков;
— ретроспективные журналы;
— файлы резервных копий (RMAN).
Табличные пространства Oracle
Любые данные, которые хранятся в базе данных Oracle, просто обязаны существовать в каком-либо табличном пространстве. Под табличным пространством (tablespace) понимают логическую структуру, то есть вы не сможете попросить ОС показать вам табличное пространство Oracle.
При этом каждое табличное пространство включает в себя физические структуры, называемые файлами данных (data files). Одно табличное пространство Oracle способно содержать один либо несколько файлов данных, в то время как каждый файл данных может принадлежать лишь одному tablespace. Создавая таблицу, мы можем указать, в какое именно табличное пространство мы её поместим — Oracle находит для неё место в каком-нибудь из файлов данных, которые составляют указанное табличное пространство.
На рисунке ниже вы можете посмотреть на соотношение между файлами данных и табличными пространствами в базе данных Oracle.
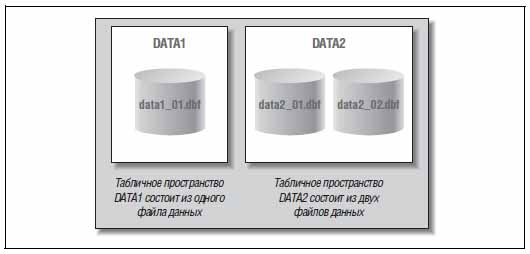
Создавая новую таблицу, мы можем поместить её в табличное пространство DATA1 либо DATA2. Таким образом, физически наша таблица окажется в одном из файлов данных, которые составляют указанное табличное пространство.
Файлы базы данных Oracle
База данных Oracle может включать в себя физические файлы 3-х основных типов:
• control files — управляющие файлы;
• data files — файлы данных;
• redo log files — журнальные файлы либо журналы.
Посмотрим на отношения между ними:
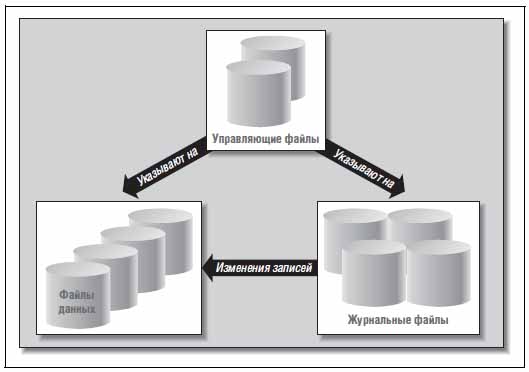
В управляющих файлах содержится информация о местонахождении других физических файлов, которые составляют базу данных Oracle, — речь идёт о файлах данных и журналов. Также там хранится важная информация о содержимом и состоянии БД Oracle. Что это за информация:
• имя базы данных Oracle;
• время создания БД;
• имена и местонахождение журнальных файлов и файлов данных;
• информация о табличных пространствах;
• информация об архивных журналах;
• история журналов, порядковый номер текущего журнала;
• информация о файлах данных в автономном режиме;
• информация о резервных копиях, контрольных точках, копиях файлов данных.
При этом функция управляющих файлов не ограничивается хранением важной информации, нужной при запуске экземпляра, — полезны они и в процессе удалении БД Oracle. К примеру, уже с версии Oracle Database 10g можно посредством команды DROP DATABASE удалить все файлы, которые перечислены в управляющем файле БД, включая сам управляющий файл.
Инициализация СУБД Oracle
Когда вы запускаете экземпляр Oracle, происходит считывание параметров инициализации. Параметры определяют, каким образом базе данных Oracle следует использовать физическую инфраструктуру и прочую конфигурационную информацию об экземпляре.
Как правило, инициализационные параметры хранятся в файле параметров инициализации экземпляра (обычно это INIT.ORA) либо, начиная с Oracle9i, в репозитории, называемом файлом параметров сервера (SPFILE). С выходом каждой новой версии Oracle число обязательных параметров инициализации уменьшается.
Кстати, в дистрибутиве Oracle можно найти пример файла инициализации, который пригоден для запуска базы данных. Также можно воспользоваться специальной программой Database Configuration Assistant (DCA) — она подскажет обязательные значения.
Вот, к примеру, как выглядит список обязательных параметров инициализации для СУБД Oracle Database 11g:
1. Местонахождение управляющих файлов — CONTROLFILES.
2. Локальное имя БД — DB_NAME.
3. Имя домена БД Oracle — DBDOMAIN.
4. Местонахождение архивного журнала — LOGARCHIVEDEST.
5. Параметр, который включает архивирование журналов — LOG_ARCHIVE_DEST_STATE.
6. Местонахождение области быстрого восстановления — DBRECOVERYFILEDEST.
7. Наибольший размер области быстрого восстановления БД Oracle в байтах —DBRECOVERYFILEDESTSIZE.
8. Размер блока БД в байтах — DBBLOCKSIZE.
9. Наибольшее количество процессов ОС, которые обслуживают одновременный доступ к СУБД Oracle — PROCESSES.
10. Наибольшее число сеансов работы с БД — SESSIONS.
11. Наибольшее количество открытых курсоров в базе данных — OPEN_CURSORS.
12. Наименьшее количество разделяемых серверов базы данных Oracle — SHARED_SERVERS.
13. Имя удалённого прослушивателя — REM O TE_LI S TENER.
14. Версия СУБД Oracle, с которой должна поддерживаться совместимость — COMPATIBLE.
15. Размер области памяти, которая автоматически выделяется для PGA и SGA экземпляра — MEMORY_TARGET.
16. Время ожидания возможности установить монопольную блокировку до отправки сообщения об ошибке (для команд DDL) — DDLLOCKTIMEOUT.
17. Язык, который определён в подсистеме поддержки национальных языков для базы данных Oracle — NLS_LANGUAGE.
18. Территория, которая определена в подсистеме поддержки национальных языков для БД — NLS_TERRITORY.

Более подробную информацию смотрите в официальной документации для СУБД Oracle Database.
Думаю пришло время, поговорить о том, как вообще устроена СУРБД Oracle. Когда речь идет о БД Oracle, то обычно имеется в виду система управления БД. Но, для профессиональных пользователей БД Oracle необходимо понимание разницы между собственно Базой Данных и экземпляром. Иногда эти два понятия вводят в заблуждение администраторов БД других фирм разработчиков. Высокий уровень сервиса гибкость и производительность, которую БД Oracle предоставляет клиентам обеспечивается сложным комплексом структур памяти и процессов операционной системы. Все эти понятия в совокупности называются «экземпляром» (instance). Любая БД Oracle имеет связанный с ней экземпляр. Тот самый, который мы с вами получили при инсталляции. Сама по себе организация экземпляра позволяет СУРБД обслуживать множество типов транзакций, инициируемых одновременно большим количеством пользователей, в то же время обеспечивая высокую производительность, целостность данных и безопасность. При работе БД Oracle одновременно присутствует множество процессов, выполняющих специфические задачи, в рамках СУРБД. Каждый процесс имеет отдельный блок памяти, в котором сохраняются локальные переменные, стек адресов и другая информация. Все эти процессы используют так называемую — «разделяемую область памяти». В ней хранятся данные общего пользования. Доступ к этой памяти, как для записи, так и для чтения, могут получить одновременно различные процессы и программы. Этот блок памяти вообще называется — «Глобальной Системной Областью» или ГСО. По-английски в документации это звучит как System Global Area — SGA. Еще можно уточнить, так как ГСО находится в разделяемом сегменте памяти, ее еще часто называют «Разделяемой Глобальной Областью» Shared Global Area. Вообще просто следует запомнить, что это за область и для чего она нужна. А, как ее назвать это уже на ваше усмотрение.  Кстати, если провести аналогию между процессами системы и, например, организмом человека, то SGA это мозг, а процессы это скажем руки, ноги, уши и т.д. Но всеми органами (процессами) управляет единый центр мозг (SGA), так как она координирует все процессы обработки информации происходящие в системе. Вот собственно, так и взаимодействует этот сложный «организм».
Кстати, если провести аналогию между процессами системы и, например, организмом человека, то SGA это мозг, а процессы это скажем руки, ноги, уши и т.д. Но всеми органами (процессами) управляет единый центр мозг (SGA), так как она координирует все процессы обработки информации происходящие в системе. Вот собственно, так и взаимодействует этот сложный «организм».
БД Oracle производит свое формирование следующим образом. Весь процесс делится примерно на три этапа:
- Формирование экземпляра Oracle (предустановочная стадия)
- Установка БД экземпляром (установочная стадия)
- Открытие БД (стадия открытия)
Далее по порядку. Экземпляр Oracle формируется на предустановочной стадии запуска системы. На этой стадии считывается файл параметров init.ora, запускаются фоновые процессы, и инициализируется ГСО (SGA). При этом имя экземпляра устанавливается в соответствии со значением указанным в init.ora. Следующая стадия — установочная. Значения параметров контрольного файла init.ora определяют параметры БД, устанавливаемой экземпляром. На данном этапе доступ к контрольному файлу открыт и возможна модификация данных, которые в нем хранятся. И на последней стадии собственно открывается сама База данных. Экземпляр получает исключительный доступ к файлам БД, имена которых, хранятся в контрольном файле и через него они становятся доступны пользователям БД. Фактически, если смотреть на открытие как состояние, то это скорее нормальное рабочее состояние БД. Заметим сразу, что до тех пор, пока БД не будет открыта, к ней может получить доступ только администратор БД и только через утилиту Server Manager. (В версии Oracle 9 этой утилиты нет. Её функции полностью переданы SQL*Plus. Так же, схема INTERNAL в Oracle 9 отсутствует.) Наверное, вы немного подустали уже от сухой теории, да и тот парень на галерке, по-моему, уже посапывает! Давайте разбудим его! Посмотрим, как можно управлять БД, используя утилиту Server Manager. Войдите в каталог ..Oracleora81Bin вашей учебной БД имеющей SID — proba. Затем создайте в этом каталоге bat файл с именем serverora.bat и таким содержимым:
set nls_lang=russian_cis.ru8pc866 SVRMGRL.EXE
Сразу оговорюсь, делайте это по возможности на самой машине, где установлен сервер Oracle и его экземпляр, а не с клиентской машины, так как может возникнуть ряд нюансов, на которых мы пока не будем акцентироваться. После создания файла запустите его на исполнение, вы должны увидеть примерно следующее:
Oracle Server Manager Release 3.1.5.0.0 - Production Copyright (c) Oracle Corporation 1994, 1995, 1997. Все права защищены. Oracle8i Enterprise Edition Release 8.1.5.0.0 - Production With the Partitioning and Java options PL/SQL Release 8.1.5.0.0 - Production SRVMGR>_
Введите в ответ на приглашение — internal/oracle@proba или, если вы все делаете на самом сервере — internal/oracle.
Получите в ответ:
SRVMGR> internal/oracle Связь установлена. SRVMGR>_
Затем введите на приглашение:
SRVMGR> SHUTDOWN NORMAL
Через некоторое время увидим следующее:
База данных закрыта База данных демонтирована. Экземпляр ORACLE закрыт. SRVMGR>_
Если сначала вы запустите диспетчер задач и перейдете на его закладку Performance, то будете при этом наблюдать следующую картину:
Это картинка с моего сервера, у меня два процессора и Win2000 Server. Как видно, большая часть ОЗУ очистилась, так как произошло закрытие сервера Oracle. Обратите внимание на последовательность сообщений сначала происходит закрытие БД, а затем БД демонтируется. (подобные сообщения выдавал файл-сервер Novell, только там монтировались и демонтировались тома) и в конце экземпляр БД закрывается. Кстати, если еще остановить сам сервис, занимаемой памяти станет еще меньше. Вот так с помощью Server Manager, можно остановить ваш экземпляр БД. Далее, давайте его запустим, вводим:
SRVMGR> STURTUP FORCE Получаем после нажатия Enter Экземпляр ORACLE запущен. Всего байтов System Global Area 547758028 Fixed Size 65484 байтов Variable Size 143876096 байтов Database Buffers 403742720 байтов Redo Buffers 73728 байтов База данных смонтирована. База данных открыта.
Теперь смотрите внимательно, первая строка сообщает, что экземпляр запущен! Далее пять строк дают служебную информацию и БД монтируется и открывается. Вот так ваш сервер Oracle стартует для того, чтобы начать свою работу.
Теперь хорошо видно, что объем занимаемой памяти увеличился! К утилите Server Manager мы еще вернемся, так как она выполняет еще ряд полезных функций, а пока еще раз все внимательно разберите. Да и в конце не забудьте дать команду exit:
SRVMGR> exit
Получите:
Server Manager закончил работу.
И в заключении, экземпляр в котором не установлена БД, называется не занятым (idle). Он занимает память но, не выполняет никакой работы. Это как раз примерно то, о чем я говорил выше. Экземпляр остановлен, а сервис еще нет. Хотя в вашем случае сама БД уже есть, просто она остановлена. Надеюсь, теперь понятно, что такое экземпляр, а что такое сервер БД.