This blog will help you master the fundamentals of classification machine learning algorithms with their pros and cons. You will also explore some exciting machine learning project ideas that implement different types of classification algorithms. So, without much ado, let’s dive in.
Imagine that the pandemic is over and today is a weekday. All the schools, colleges, and offices are open, and you should reach your institution by 8 A.M. You set the alarm last night and managed to wake up at 6 A.M. You have taken your bath and are now nicely dressed in your clothes. You now approach the wall hook to grab your belt, but alas! It’s not there. You start panicking and are searching for it here and there. Finally, you call out for your mother, and after 10 minutes of searching, she finds it.

And, now, on the one hand, you are happy that you have found your belt, but on the other hand, you are worried about reaching your institution late. So, on your way to the destination, you start wishing for a magical wardrobe where you could throw your stuff, and it could automatically classify things and neatly place them. We all have been through this.

Tensorflow Transfer Learning Model for Image Classification
Downloadable solution code | Explanatory videos | Tech Support
Start Project
But, if you think that such a wardrobe can’t be a reality, let me tell you that’s not true. With Artificial Intelligence, it has become possible to build what we like to call ‘smart wardrobes.’ These will allow you to access things from your wardrobe just by a single tap on your phone. Of course, you might have to explain a few characteristics of your clothing to it initially, for example, its color, size, and type. But, as the wardrobe gradually understands your dress, you will be easily able to utilize it.
Table of Contents for Classification Machine Learning
- Types of Classification Tasks in Machine Learning
- Binary Classification
- Multi-Class Classification
- Multi-Label Classification
- Imbalanced Classification
- ​How Do Classification Algorithms Work?
- ​Classification Algorithms in Machine Learning — Data Preprocessing
- Classification Algorithms in Machine Learning-Creating Testing and Training Dataset
- Classification Algorithms in Machine Learning -Selecting the Model
- ​Types of Classification Algorithms in Machine Learning
- ​Naive Bayes Classifier
- Logistic Regression
- Decision Tree Classification Algorithm
- Random Forests Classification Algorithm
- Support Vector Machines (SVMs)
- K-Nearest Neighbour Classification Algorithm
- K-Means Clustering Classification Algorithm
- ​How do you decide which classification algorithm to choose for a given business problem?
- Classification Algorithms Machine Learning Project Ideas

We expect the wardrobe to perform classification, grouping things having similar characteristics together. And there are quite a several classification machine learning algorithms that can make that happen. We will look through all the different types of classification algorithms in great detail but first, let us begin exploring different types of classification tasks.

Types of Classification Tasks in Machine Learning
In Machine Learning, most classification problems require predicting a categorical output variable called target, based on one or more input variables called features. The idea is to fit a statistical model that relates a set of features to its respective target variable to use this model to predict the output for future input observations. However, it is essential to keep in mind that predicting a single output variable will not always be the case. There are many other possible causes, and let us inspect them one by one.
There are mainly four types of classification tasks that one may come across, these are:
- Binary Classification
- Multi-Class Classification
- Multi-Label Classification
- Imbalanced Classification
Ace Your Next Job Interview with Mock Interviews from Experts to Improve Your Skills and Boost Confidence!
![]()
Binary Classification Machine Learning
This type of classification involves separating the dataset into two categories. It means that the output variable can only take two values.
Binary Classification Machine Learning Example
The task of labeling an e-mail as «spam» or «not spam.» The input variable here will be the content of the e-mail that we are trying to classify. The output variable is represented by 0 for «not spam» and 1 for «spam.»

Multi-Class Classification Machine Learning
In multi-class classification, the output variable can have more than two possible values.
Multi-Class Classification Machine Learning Example
Identifying the flower type in the case of Iris Dataset where we have four input variables: petal length, sepal length, petal width, sepal width, and three possible labels of flowers: Iris Setosa, Iris Versicolor, and Iris Virginica.

Image Source: Wikipedia Commons
Multi-Label Classification Machine Learning
This is an extraordinary type of classification task with multiple output variables for each instance from the dataset. That is, one instance can have multiple labels.
Multi-Label Classification Machine Learning Example
In Image classification, a single image may contain more than one object, which can be labeled by the algorithm, like bus, car, person, etc.

Imbalanced Classification
Imbalanced classification refers to classification problems where the instances of the dataset have a biased or skewed distribution. In other words, one class of input variables has a higher frequency than the others.
Imbalanced Classification Example: Detecting fraudulent transactions through a credit card in a transaction dataset. Usually, such transactions are remarkably less in number, and this would thus make it difficult for the machine to learn such transactions.

Get Closer To Your Dream of Becoming a Data Scientist with 70+ Solved End-to-End ML Projects
How Do Classification Algorithms Work?
To solve classification problems, we use mathematical models that are known as machine learning classification algorithms. Their task is to find how the target variables are related to input features xi to the output values, yi. In mathematical terms, estimating a function, f(xi), predicts the value of the output variable by taking the associated features as an input. We can write this as,
where y’i represents the predicted response for the output variable.
Now that we understand the task at hand, we will now move forward towards different steps that explain how classification algorithms in machine learning work.
Classification Algorithms in Machine Learning — Data Preprocessing
Before we apply any statistical algorithm to our dataset, we must thoroughly understand the input variables and output variables. In classification problems, the target is always qualitative, but sometimes, even the input values can also be categorical, for example, the gender of customers in the famous Mall Customer Dataset. And as classification algorithms are mathematically derived, one must convert all their variables into numerical values. The first step in the working of a classification algorithm is to ensure that the variables, whether input or output, have been encoded correctly.
Classification Algorithms in Machine Learning-Creating Testing and Training Dataset
After processing the dataset, the next step is to divide the dataset into two parts: the testing dataset and the training dataset. This step allows using the training dataset to make our machine learn the pattern between input and output values. On the other hand, a testing dataset tests the model’s accuracy that we will try to fit into our dataset.
Classification Algorithms in Machine Learning -Selecting the Model
Once we split the dataset into training and testing, the next task is to select the model that best fits our problem. For that, we need to be aware of the popular classification algorithms. So, let us dive into the pool of different types of classification algorithms and explore our options.
Types of Classification Algorithms in Machine Learning
There are various classification machine learning algorithms in data mining used by Data Scientists every day to gain a deeper understanding of their dataset. In this section, we will explore the popular ones in great detail. You are likely to feel like a superhero by understanding the pros and cons of classification algorithms.

Here is a list of different types of classification machine learning algorithms that you will learn about:
- Naive Bayes Classifier
- Logistic Regression
- Decision Tree
- Random Forests
- Support Vector Machines
- K-Nearest Neighbour
- K-Means Clustering
1. Naive Bayes Classifier
Naive Bayes classifier, is one of the simplest and most effective classification machine learning algorithms. Its basis is Bayes’ theorem which describes how the probability of an event is evaluated based on prior knowledge of conditions that might be related to the event. Mathematically, this theorem states-
Where P(Y|X) is the probability of an event Y, given that even X has already occurred.
P(X) is the probability of event X,
P(Y) is the probability of event Y,
P(X|Y) is the likelihood of event X given a fixed value of Y.
If X represents a feature variable and Y represents a target variable, then the Bayes Classifier will assign that label to the feature that produces the highest probability. For simplicity, consider a two-class problem where the feature variable can have only two possible values, Y=1 or Y=0. Then, the Bayes Classifier will predict class 1 if Pr(Y=1|X=x0) > 0.5, and class two otherwise.
In cases of more than one feature, we can use the following formula for evaluating the probability,
where we have assumed that the two features X1 and X2, are independent of each other. In fact, because of this assumption, the word ‘Naive’ is attached to Bayes’ classifier.
Naive Bayes Classification Algorithms Example
Consider the following dataset where a sportsperson plays or not was observed along with the weather conditions.

Data Source: Mitchell, T. M. (1997). Machine learning.
Suppose we now have to predict whether the person will play or not, given that humidity is ‘High’ and the wind is ‘Strong.’ Then, using the Bayes’ classifier, we can compute the probability as follows:
Advantages of Naive Bayes Classification Algorithm
- It is simple, and its implementation is straightforward.
- The time required by the machine to learn the pattern using this classifier is less.
- It performs well in the case where the input variables have categorical values.
- It gives good results for complex real-world problems.
- It performs well in the case of multi-class classification.
Disadvantages of Naive Bayes Classification Algorithm
- It assumes independence among feature variables which may not always be the case.
- We often refer to it as a bad estimator, and hence the probabilities are not always of great significance.
- If, during the training time, the model was not aware of any of the categorical variables and that variable is passed during testing, the model assigns 0 (zero) likelihood and thus substitutes zero probability referred to as ‘zero frequency.’ One can avoid this situation by using smoothing procedures such as Laplace estimation.
Applications of Naive Bayes Classification Algorithm
- Spam Classification: Identifying whether an e-mail is a spam or not based on the content of the e-mail
- Live Prediction System: This model is relatively fast and thus predicts the target variable in real-time.
- Sentiment Analysis: Recognising feedback on a product and classifying it as ‘positive’ or ‘negative.’
- Multi-Class Prediction: Naive Bayes works well for multi-class classification machine learning problems.
2. Logistic Regression
This algorithm is similar to Bayes’ classifier as it also predicts the probability that Y is associated with an input variable, X. It uses the logistic function,
and fits the parameters ð›ƒ0 and ð›ƒ1 using the maximum likelihood technique. This technique involves maximizing the likelihood function given by
After evaluating the two parameters, one can easily use the logistic function to predict the target variable probability p(xi) for a given input xi.
In the case of more than one feature variables (X1, X2,…, XP), the formula can be generalized as
Advantages of Logistic Regression Classification Machine Learning Algorithm
- It’s a simple model, so it takes very little time for training.
- It can handle a large number of features.
Disadvantages of Logistic Regression Classification Algorithm
- Although it has the word regression in its name, we can only use it for classification problems because of its range which always lies between 0 and 1.
- It can only be used for binary classification problems and has a poor response for multi-class classification problems
Applications of Logistic Regression Classification Algorithm
- Credit Scoring: To predict the creditworthiness(ability to pay back borrowed loan) of an individual based upon some features like annual income, account balance, etc.
- Predicting User Behaviour: Many websites use logistic regression to predict user behavior and guide them towards clicking on links that might interest them.
- Discrete Choice Analysis: Logistic regression is an excellent choice for predicting the categorical preferences of people. Examples for this could be which car to buy, which school or college to attend, etc., based on the attributes of people and the diverse options available to them.
Recommended Reading:
- The A-Z Guide to Gradient Descent Algorithm and Its Variants
- Ensemble Learning
- Types of Neural Networks​
- 5 Different Types of Neural Networks
- 15 Time Series Projects Ideas for Beginners to Practice 2021
- Exploratory Data Analysis in Python-Stop, Drop and Explore
- How to Become an Artificial Intelligence Engineer in 2021
- 8 Feature Engineering Techniques for Machine Learning
- AI Engineer Salary — The Ultimate Guide for 2021
- Logistic Regression vs Linear Regression in Machine Learning
- Correlation vs. Covariance
3. Decision Tree Classification Algorithm
This classification machine learning algorithm involves dividing a dataset into segments based on certain feature variables from the dataset. The threshold values for these divisions are usually the mean or mode of the respective feature variable (if they are numerical). As a tree can represent the set of splitting rules used to segment the dataset, this algorithm is known as a decision tree.
Look at the example below to understand it better.

The text in red represents how the dataset has been split into segments based on the output variable. The outcome is the one that has the highest proportion of a class.
Now, the question which is quite natural to ask is what criteria this algorithm uses to split the data. There are two widely used measures to test the purity of the split (a segment of the dataset is pure if it has data points of only one class).
The first one is the Gini index defined by
that measures total variance across the N classes. Another measure is cross-entropy, defined by
In both equations, pmk represents the proportion of training variables in the mth segment that belongs to the kth class.
We split the dataset into segments based on that feature, giving rise to the minimum value of entropy or Gini index.
Advantages of Decision Tree Classification Algorithm
- This algorithm allows for an uncomplicated representation of data. So, it is easier to interpret and explain it to executives.
- Decision Trees mimic the way humans make decisions in everyday life.
- They smoothly handle qualitative target variables.
- They handle non-linear data effectively.
Advantages of Decision Tree Classification Algorithm
- They may create complex trees which sometimes become irrelevant.
- They do not have the same level of prediction accuracy as compared to other algorithms.
Applications of Decision Tree Classification Algorithm
- Sentiment Analysis: It is used as a classification algorithm in text mining to determine a customer’s sentiment towards a product.
- Product Selection: Companies can use decision trees to realize which product will give them higher profits on launching.
4. Random Forests Classification Algorithm
A forest consists of a large number of trees. Similarly, a random forest involves processing many decision trees. Each tree predicts a value for the probability of target variables. We then average the probabilities to produce the final output.
We evaluate each tree as follows:
- First samples of the dataset are created by selecting data points with replacement.
- Next, we do not use all input variables to create decision trees. We use only a subset of the available ones.
- Each tree is allowed to grow to the most considerable length possible, and no pruning is involved.
Advantages of Random Forest Classification Algorithm
- It is efficient when it comes to large datasets.
- It allows estimating the significance of input variables in classification.
- It is more accurate than decision trees.
Disadvantages of Random Forest Classification Algorithm
- It is more complex when it comes to implementation and thus takes more time to evaluate.
Applications of Random Forest Classification Algorithm
- Credit Card Default: Credit card companies use random forests to predict whether the cardholder will default on their debt or not.
- Stock Market Prediction: Stock investors use it to indicate a particular stock’s trends and analyze loss and profit from it.
- Product Recommendation: One can use it to recommend products to a user based on their preferences.
5. Support Vector Machines (SVMs)
This algorithm utilizes support vector classifiers with an exciting change that makes it suitable for evaluating a non-linear decision boundary. And that becomes possible by enlarging the feature variable space using special functions called kernels. The decision boundary that this algorithm considers allows labeling the feature variable to a target variable. The mathematical function that it uses for evaluating the boundaries is given by
where K represents the kernel function, and âºi and êžµ0 beta are training parameters.
Advantages of SVM Classification Algorithm
- It makes training the dataset easy.
- It performs well when the data is high-dimensional.
Disadvantages of SVM Classification Algorithm
- It doesn’t perform well when the data has noisy elements.
- It is sensitive to kernel functions, so they have to be chosen wisely.
Applications of SVM Classification Algorithm
- Face Detection: It is used to read through images (an array of pixel numbers) and identify whether it contains a face or not based on usual human features.
- Image Classification: SVM is one of the image classification algorithms used to classify images based on their characteristics.
- Handwritten Character Recognition: We can use it to identify handwritten characters.
Time for a tea break!

Dear reader, please feel free to take a short break now to celebrate that you have learned so much about classification algorithms. FYI, till now, the algorithms that we have discussed are all instances of supervised classification algorithms. These are the algorithms that have pre-defined target variables for them in the dataset. But, in the real world, this may not always be the case. So, we will now explore unsupervised classification machine learning algorithms where the task at hand would be to learn the pattern among input features and group together similar ones.
6. K-Nearest Neighbour Classification Algorithm
KNN algorithm works by identifying K nearest neighbors to a given observation point. It then evaluates the proportions of each type of target variable using the K points and then predicts the target variable with the highest ratio. For example, consider the following case where we have to label a target value to point X. Then, if we take four neighbors around it, this model will predict that the point belongs to class with the color pink.

Advantages of K-Nearest Neighbour Classification Algorithm
- One can apply it to datasets of any distribution.
- It is easy to understand and is quite intuitive.
Disadvantages of K-Nearest Neighbour Classification Algorithm
- It is easily affected by outliers.
- It is biased towards a class that has more instances in the dataset.
- It is sometimes challenging to find the optimal number for K.
Applications of KNN Classification Algorithm
- Detecting Outliers: As the algorithm is sensitive to outlier instances, it can detect outliers.
- Identifying Similar Documents: To recognize semantically similar documents.
7. K-Means Clustering Classification Algorithm
K-Means Clustering is a clustering algorithm that divides the dataset into K non-overlapping groups. The first step for this algorithm is to specify the expected number of clusters, K. Then, the task is to divide the dataset into K clusters so that within-the-cluster variation is as tiny as possible. The algorithm proceeds as follows:
- Assign a number from 1 to K randomly to each input variable. These are initial cluster labels for the variables.
- Repeat the step until the cluster assignments remain unchanged:
- Evaluate the cluster centroid for each of the K clusters.
- Assign each input variable set to the cluster whose centroid is closest (here closest can be defined in terms of Euclidean distance)
In conclusion, this classification machine learning algorithm minimizes the sum of squares of deviations between an input point and the respective cluster centroid. The reason for naming it as K-means clustering is that step 2a) evaluates the mean of the observations belonging to a particular cluster as the cluster centroid.
Advantages of KNN Classification Algorithm
- We can apply it to large datasets.
- It is effortless to implement.
- It guarantees convergence for locating clusters.
Disadvantages of KNN Classification Algorithm
- It has a limitation as one has to provide the value for K initially.
- It is sensitive to outliers.
Applications of KNN Classification Algorithm
- Add Recommendation: Companies can identify clusters of customers who share money spending habits and present advertisements that they are more likely to buy.
- Identifying crime zones in a city: Using K-means clustering, we can identify areas more prone to criminal cases.
- Document Classification: To identify documents written on a similar topic.
Now that you are familiar with so many different classification algorithms, it is time to understand which one to use when.
How do you decide which classification algorithm to choose for a given business problem?
Below we have a list that will help you understand which classification machine learning algorithms you should use for solving a business problem.
- Problem Identification: The first and foremost thing to do would be to understand the task at hand thoroughly. If it’s a supervised classification case, you can use algorithms like Logistic Regression, Random Forest, Decision Tree, etc. On the other hand, if it is an unsupervised classification case, you should go for clustering algorithms.
- Size of the dataset: The size of the dataset is also a parameter that you should consider while selecting an algorithm. As few algorithms are relatively fast, it’ll be better to switch to those. If the size of the dataset is small, you can stick to low bias/high variance algorithms like Naive Bayes. In contrast, if the dataset is large, the number of features is high, then you should use high bias/low variance algorithms like KNN, Decision trees, and SVM.
- Prediction Accuracy: The accuracy of a model is a parameter that tests how good a classifier is. It reflects how well the predicted output value matches the correct output value. Of course, higher accuracy is desirable, but one should also check that the model does not overfit.
- Training Time: Sometimes, complex classification machine learning algorithms like SVM and Random Forests may take up a lot of time for computation. Also, higher accuracy and large datasets anyway require more time to learn the pattern. Simple algorithms like Logistic Regression are easier to implement and save time.
- Linearity of the Dataset: Not always is there a linear relationship between input variables and target variables. It is thus essential to analyze this relationship and choose the algorithm carefully as a few of them are restricted to linear datasets. The best method to check for linearity is to either fit a linear line or run a logistic regression or SVM and look for residual errors. A higher error suggests the data is non-linear and would require the implementation of complex algorithms.
- Number of Features: Sometimes, the dataset may contain unnecessarily many features, and not all of them will be relevant. One can then use algorithms like SVM, best suited for such cases, or use Principal Component Analysis to figure out which features are significant.
Classification Algorithms Machine Learning Project Ideas
Now you are entirely ready to explore some hands-on machine learning projects which implement these algorithms for solving real-world problems.
- E-Commerce Product Reviews- Pairwise Ranking and Sentiment Analysis: In this ML project, you will understand how to use machine learning algorithms for text classification in Python. You will also realize how one can use a classification problem to recognize the sentiment of a user.
- TalkingData Ad tracking Fraud Detection: This is an insightful machine learning project idea that will build your understanding of two classification algorithms, Decision Tree and Logistic Regression. You will learn about building a fraud detection system from scratch that detects whether a click on an advertisement will result in fraud or not.
- How to prepare test data for your machine learning project: This is another exciting project that will help you explore implementing a multi-class classification solution in the practical world. It will also help you realize how we use machine learning classification algorithms in Natural Language Processing (NLP) related problems.
- Predicting Loan Default: This ML project will introduce you to the application of Random Forest and Logistic Regression to predict the loan eligibility based on the data entered by him/her.
- NLP Projects — Kaggle Quora Question Pairs Solution: This NLP project implements a Random Forest classifier to identify which questions are similar.
Well, we now hope that you’ve mastered the concepts of classification algorithms and feel like a superhero.

Примеры использования различных алгоритмов машинного обучения
В машинном обучении есть много алгоритмов, которые вам нужно изучить. Понять варианты использования каждого алгоритма машинного обучения может оказаться очень сложно для новичка в области науки о данных, но это нужно сделать и это очень важно, поскольку поможет вам выбрать самый подходящий алгоритм для вашей задачи. Поэтому, если вы хотите узнать о вариантах использования различных алгоритмов машинного обучения, эта статья для вас. В этой статье я расскажу вам о вариантах использования некоторых популярных алгоритмов машинного обучения.
Примеры использования различных алгоритмов машинного обучения
Новичку в области науки о данных очень сложно определить варианты использования различных алгоритмов машинного обучения. Вот некоторые из факторов, которые могут определить вариант использования алгоритма машинного обучения:
- Допущения алгоритма;
- Тип требуемых данных;
- Тип вывода;
- Насколько для этого достаточно данных;
- Тип проблемы, для которой он подходит;
- Преимущества и недостатки алгоритма.
Многие другие факторы могут использоваться для определения вариантов использования различных алгоритмов машинного обучения. Итак, давайте рассмотрим варианты использования некоторых популярных алгоритмов машинного обучения один за другим.
Линейная регрессия
Алгоритм линейной регрессии – один из самых первых алгоритмов, которые вы изучаете при изучении машинного обучения. Как следует из названия, он используется в задачах регрессии, когда набор данных, с которым вы имеете дело, находится в линейной зависимости. Вот некоторые из вариантов использования алгоритма линейной регрессии:
- Прогнозирование продаж продукта.
- Прогнозирование спроса или цены на продукт.
- Прогнозирование увеличения прибыли с увеличением промоакций.
Логистическая регрессия
Алгоритм логистической регрессии расширяет линейную регрессию логистической функцией, которая делает его подходящим для задач, основанных на классификации. Но вы не можете использовать этот алгоритм для каких-либо задач классификации, вы можете выбрать его только для задач, основанных на бинарной классификации. Хотя вы можете использовать его для задач многоклассовой классификации, он лучше всего подходит только для задач бинарной классификации. Таким образом, некоторые из вариантов использования алгоритма логистической регрессии включают:
- Обнаружение спама
- Обнаружение кредитных рисков.
Наивный байесовский классификатор
Алгоритм наивного байесовского классификатора основан на теореме Байеса и является очень популярным алгоритмом классификации. Его можно использовать как в задачах бинарной, так и в мультиклассовой классификации. Есть три его варианта: Гауссовский (используется, когда набор данных нормально распределен), Мультиномиальный (используется в задачах многоклассовой классификации), Бернулли (используется при работе над задачами двоичной классификации). Алгоритм предпочтителен, когда ваша задача классификации основана на обработке естественного языка. Проще говоря, он предпочтительнее, когда вы хотите тренировать модели НЛП. Вот некоторые из популярных вариантов использования этого алгоритма:
- Классификация категорий новостей
- Обнаружение фейковых новостей.
- Обнаружение языка ненависти
Деревья решений
Деревья решений могут использоваться как для решения задач классификации, так и для решения задач регрессии. Но одно из преимуществ использования деревьев решений перед другими алгоритмами классификации или регрессии заключается в том, что этот алгоритм может обрабатывать нелинейные наборы данных. Если в используемом вами наборе данных есть выбросы и пропущенные значения, это не повлияет на производительность вашей модели машинного обучения. Таким образом, вы можете сказать, что это очень мощный алгоритм и его следует использовать, когда набор данных не находится в линейной зависимости.
Итак, я надеюсь, что теперь вы понимаете, какие есть варианты использования некоторых популярных алгоритмов машинного обучения. Я старался, чтобы мое объяснение было простым и понятным.
Резюме
Понимание вариантов использования каждого алгоритма машинного обучения может оказаться довольно сложным для новичка в области науки о данных, но оно очень важно, поскольку помогает вам выбрать самый подходящий алгоритм для вашей проблемы. Надеюсь, теперь вы поняли, как определять варианты использования различных алгоритмов машинного обучения. Короче говоря, просто просмотрите предположения, преимущества и недостатки алгоритмов машинного обучения, и вы поймете варианты использования алгоритмов машинного обучения.




Классификация как задача машинного обучения
39 мин на чтение
(45.884 символов)
Что такое классификация в машинном обучении?
Задача классификации на практике встречается гораздо чаще, чем регрессия. По счастливому совпадению, и решать ее в каком-то смысле гораздо проще. Формально, задача классификации состоит в предсказании какого-то дискретного значения, в противоположность регрессии — предсказанию непрерывного значения. Но в реальности задачи классификации очень непохожи на регрессионные. Задачи регрессии — часто экономические или статистические — состоят именно в прогнозировании некоторого уровня какой-то величины. Задача классификации (как, впрочем и следует из названия) сводится к отнесению конкретного объекта к одному из заранее известных классов. Вот эта “метка” — название класса — и выступает в роли целевой переменной. И, совершенно естественно, что классов может быть только конечное количество, поэтому целевая переменная — дискретная.
Классификация в машинном обучении — задача отнесения объекта по совокупности его характеристик к одному из заранее известных классов.
Важно, что классы должны быть заранее известны. Мы должны знать сколько их всего, и к какому классу относится каждый объект обучающей выборки. Если чего-то из этого мы не знаем, то это уже совершенно другая задача — кластеризация — которая относится к обучению без учителя. А для классификации в датасете должны быть приведены метки классов для каждого объекта. Иначе говорят, что датасет должен быть “размечен”. Если у нас этих данных нет, то данные надо разметить — указать для каждого объекта правильный класс.
Задачи классификации очень разнообразны. Почти любая прикладная задача машинного обучения может быть представлена в виде классификации. Например — распознавание объектов на изображении. Мы все пользуемся умными камерами в смартфонах, которые умеют автоматически определять, есть ли лицо на изображении в объективе. Вот там как раз работает алгоритм классификации, который разделяет все изображения на два класса — имеющих лицо и не имеющих. Другой пример — определение, является электронное письмо спамом или нет. Здесь так же идет разделение объектов на два класса. Или, например, выявление подозрительных банковских транзакций.
Все эти примеры имеют одну общую черту — в них идет речь о двух классах. Это примеры так называемой бинарной классификации. Такая постановка задачи действительно встречается довольно часто. И все эти задачи можно сформулировать как определение наличия или отсутствия какого-либо признака у объекта. Например, наличие лица на фото, подозрительности транзакции, и так далее. Но вообще не все задачи классификации обязаны быть бинарными. Иногда случается такое, что классов больше двух. Тогда мы говорим о задаче множественной классификации. Например, вместо распознавания конкретного объекта на изображении весьма распространена задача определения, какой именно объект изображен.
Это называется задача идентификации объекта. К задачам множественной классификации еще относятся, например, рубрикация текстов — определение тематики текста, классификация изображений, сегментация рынка, классификация товаров, и еще множество других. Более того, к задачам классификации относятся такие задачи, про которые вообще с первого взгляда непонятно, куда их относить и как их решать. Типичный пример — машинный перевод. При всей своей специфике, его тоже можно представить как задачу классификации — подбор следующего слова в тексте, соответствующего контексту и тексту на другом языке. Так как мы выбираем какое-то оптимальное значение из пусть большого, но не бесконечного количества значений — всех возможных слов языка. Так что перевод — это очень множественная, но все-таки классификация. То же можно сказать и о задаче генерации текста. Аналогично к классификации относится распознавание рукописных или сканированных текстов, преобразование речи в текст и многие другие задачи обработки естественных языков.
Кроме бинарной и множественной классификации еще выделяют одноклассовую и мультиклассовую. Одноклассовая — это когда один объект может принадлежать только одному классу. В мультиклассовой классификации каждый объект может принадлежать сразу нескольким классам. Например, текст может относиться сразу к нескольким темам. А на изображении может присутствовать сразу несколько объектов. Отдельно выделяют нечеткую классификацию — это когда объект может принадлежать некоторым классам с разной принадлежностью или вероятностью.
Некоторые прикладные задачи сводятся к элементарным задачам менее очевидным способом. Например, генерация текста, также как и машинный перевод — это всего лишь определение, какое слово должно идти следующим в переводе при известном контексте ии переводе. То есть для выбора каждого очередного слова в итоговом тексте решается задача выбора одного из сотен тысяч слов. Но тем не менее это всего лишь классификация — выбор их конечного набора вариантов. Другой пример — локация объектов на изображении. Здесь картинка разбивается на множество возможных “рамок” и для каждой из них решается задача классификации — содержит эта конкретная рамка нужное изображение или нет. Так что действительно, практически любая задача может быть переформулирована как задача классификации
Еще следует отметить, что иногда имеет смысл преобразовать задачу регрессии в классификацию. Например, рассмотрим задачу предсказания цены финансового актива. Из-за того, что на цену актива влияют множество факторов, эта задача очень сложная, ведь мы выбираем из бесконечно большого количества вариантов. Но ее можно решать по-другому. Зачастую нам не важен конкретный уровень будущего значения цены, важнее то, будет цена больше или меньше, чем текущая. В таком случае, можно заменить сложную и зачастую нерешаемую задачу предсказания уровня более простой задачей предсказания тренда. У тренда можно выделить конечное число состояний — восходящий, нисходящий или боковой. То есть мы выбираем из, например, трех вариантов — будет цена больше, меньше или примерно такая же, как текущая. Другими словами мы заменили задачу регрессии классификацией. И такой прием используется очень часто.
Выводы:
- Классификация — это задача машинного обучения, которая выражается в предсказании дискретного значения.
- Классификация — это задача обучения с учителем, поэтому в датасете должны быть “правильные ответы” — значения целевой переменной.
- Классификация — самая распространенная задача машинного обучения на практике.
- Классификация бывает бинарной и множественной, одноклассовой и мультиклассовой.
- Примеры задач классификации — распознавание объектов, генерация текстов, подбор тематики текстов, идентификация объектов на изображениях, распознавание речи, машинный перевод и так далее.
- Почти любую практическую задачу машинного обучения можно сформулировать как задачу классификации.
Как определяется задача классификации?
Итак, рассмотрим математическую формализацию задачи классификации. В такой задаче, так же как и в регрессии, на вход модели подается вектор признаков $ x^{(i)} = (x_1, x_2, … x_n)$. Как и ранее, введем искусственный признак $ x_0 = 1 $. Он нужен для удобства представления многих моделей классификации. Можете представлять его как еще один столбец в датасете, в котором во всех строчках стоят единицы.
Функция гипотезы в таком случае будет иметь точно такой же вид: $ y = h_theta (x) $. Существенное отличие в том, что целевая переменная $y$ будет принимать одно из конечного множества значений: $ y in lbrace y_1, y_2, …, y_k rbrace $, где $k$ — это количество классов. Набор данных для можно представить как множество пар, состоящих из вектора признаков и значения целевой переменной.
[{(x_1, y_1), (x_2, y_2), (x_3, y_3), …, (x_m, y_m)}]
Этот же набор данных иногда представляют как матрицу признаков (состоящую из векторов-строк для каждого объекта выборки) и вектора целевое переменной, также для каждого объекта выборки.
Сами метки классов в данных могут обозначаться как угодно, обычно текстом. В численных моделях гораздо удобнее представлять их в виде чисел. Но большинство реализаций моделей классификации прекрасно умеет работать и с нечисловыми метками классов. Поэтому условно, для удобства будем считать, что:
[y_i in {0, 1, 2, 3, …, k}]
В дальнейшем для лучшего интуитивного понимания задач и алгоритмов классификации мы будем изображать объекты из датасета в виде точек на двумерном графике. А цвет или форма точек будут показывать, какому классу они относятся. Это хорошее визуальное представление. Но следует помнить, что на практике входной вектор может иметь сколько угодно измерений. То есть в датасете может быть сколько угодно признаков у каждого объекта. Тысячу или миллион признаков невозможно изобразить на графике, но это вполне может встретиться на практике.

Источник: Papers with code.
Как мы уже говорили, классов тоже может быть произвольное количество. Но мы в начале будем рассматривать именно бинарную классификацию. Более сложные модели множественной или мультиклассовой классификации все равно строятся на основе бинарной. И на этих алгоритмах мы тоже остановимся. В такой формулировке мы будем предполагать, что $ y in lbrace 0, 1 rbrace $, где 0 обычно принимается как «отрицательный класс» и 1 как «положительный класс», но вы можете назначить этим значениям любое представление. Как мы говорили, бинарная классификация — это часто про обнаружение какого-то признака у объекта, то есть положительный класс — это объекты, у которых этот признак присутствует, а отрицательный — это объекты, у которых этого признака нет. Хотя чисто математически, нет никакой разницы, как вы обозначите классы, это скорее общепринятое соглашение, которое облегчает понимание моделей и алгоритмов.
Выводы:
- На вход модели классификации подается вектор признаков объекта.
- На выходе модель классификации предсказывает одно из конечного набора значений — метку класса объекта.
- Мы часто будем изображать классификацию на графике, но имейте в виду, что на практике это обычно многомерная задача.
- Обычно сначала рассматривается бинарная классификация, остальные типы строятся на ее основе.
- Бинарная классификация — это про наличие или отсутствие какого-либо признака у объекта.
Логистическая регрессия
Одним из самых простых и распространенных алгоритмов классификации является логистическая регрессия. Пусть название «логистическая регрессия» не вводит в заблуждение. Метод назван таким образом по историческим причинам и на самом деле является подходом к проблемам классификации, а не регрессионным задачам. В следующей главе мы рассмотрим и принципиально другие модели классификации, но именно на примере логистической регрессии проще всего понять, как работает алгоритм классификации и какие общепринятые приемы и обозначения в ней используются. Логистическая регрессия это один из самых просытх алгоритмов классификации, а что еще важнее — он очень похож и основан на уже известной нам модели линейной регрессии.
Перед рассмотрением сути метода логистической регрессии нужно задаться вопросом: почему мы не можем применить для классификации уже известные нам методы линейной регрессии? В самом деле, пусть модель предсказывает непрерывное значение, а мы будем его интерпретировать, как 0 или 1. Рассмотрим простой пример, в котором есть только один атрибут (отложен по горизонтальной оси), и на его основе мы хотим предсказать бинарное значение целевой переменной. Представим эти значения как 0 или 1 и отложим на вертикальной оси. Вот как может выглядеть датасет в таком виде:

Здесь явно наблюдается тенденция, что в имеющихся данных у положительных объектов значения атрибута выше, чем у отрицательных. Конечно, это такие идеализированные, искусственные данные, но на этом примере мы попытаемся понять главный принцип классификации. На этих данных вполне можно обучить модель парной линейной регрессии. Именно на этом датасете она может выглядеть примерно так:

Но так как нам надо предсказывать точно либо 0, либо 1, придется ввести специальное пороговое значение. Например, если модель выдает значение больше 0.5, мы предсказываем положительный класс, если меньше — то отрицательный. Это вполне нормальный способ перевести непрерывное значение в дискретное, многие реальные модели классификации этим приемом успешно пользуются. Но в этом подходе заключается проблема. Регрессионные модели по сути своей неограничены и их значение может возрастать или убывать сколько угодно. Как это может быть проблемой? Давайте предположим, что в наших данных появилась еще одна точка:

Эта новая точка никак не изменяет общую картину, она прекрасно вписывается в уже имеющееся распределение данных, ничему не противоречит. Эта точка только подтверждает общую тенденцию, что у положительных объектов более высокий уровень факторной переменной. Но давайте посмотрим, что эта новая точка сделает с нашей моделью. Если мы изобразим предыдущую линию регрессии с учетом этой новой точки то получим следующую картину:

Эта модель даст огромную ошибку в появившейся новой точке. Поэтому если мы обучим регрессионную модель заново, то алгоритм обучения регрессии вынужденно сместит линию модели вниз, вот так:

Получается, что линия регрессии очень чувствительна к расположению точек, которые никак не влияют на общую тенденцию и принцип классификации. Но из-за этих расположений старое значение порога, которое мы выбрали, ориентируясь на предыдущую модель, уже не будет разделять классы правильно. То есть нам каждый раз придется вручную подбирать значение этого самого порога.
Это очень неудобно и ненадежно. И происходит потому, что регрессионные функции как правило неограничены. Но в принципе идея использовать регрессию здравая. Надо только преобразовать нашу функцию таким образом, чтобы вместо области значений $ y in (-inf, inf) $ она имела, скажем, $ y in (0, 1) $.Это можно легко сделать, используя нелинейное преобразование. Например, так:
[h_b (x) = g(z) = frac{1}{1 + e^{-z}}]
В этой формуле $ z = X cdot vec{b}$, то есть обычная линейная комбинация значений факторов и параметров. По сути, это и есть результат работы модели линейной регрессии, но теперь эта линейная комбинация передается в нелинейное преобразование, которое ограничивает область значений и сверху и снизу. За счет этого, значение функции гипотезы будет ограничено и асимптотически приближаться к 1 при неограниченном увеличении $z$ и приближаться к 0 при неограниченном уменьшении $z$. При использовании такого преобразования график функции гипотезы будет выглядеть так:

Сама эта нелинейная функция называется логистической или сигмоидной функцией. Именно из-за ее применения вся модель называется логистической регрессией. В принципе, можно использовать и другие нелинейные функции, которые имеют ограниченную область значений, например, арктангенс. Но на практике логистическая функция используется гораздо чаще, потому что она проще и работать с ней дальше гораздо удобнее. Не забывайте, что для машинного обучения мало определить саму функцию гипотезы, надо еще составить алгоритм обучения, то есть подбора параметров. Об этом и поговорим дальше.
Кто знаком с математической статистикой знает, что логистическая функция очень похожа на функцию, которая задает нормальное распределение. Кроме того, в нейронных сетях логистическая функция часто используется в качестве функции активации. Аналогия между логистической регрессией и нейронными сетями, кстати, глубже. чем может показаться с первого взгляда. Но это предмет рассмотрения в следующих глава. А пока лишь заметим, что логистическая функция очень важна и часто используется в разных разделах математики.
В такой формулировке значение функции гипотезы $h_theta (x)$ всегда будет лежать в диапазоне от 0 до 1. Поэтому это значение может быть проинтерпретировано как вероятность того, что данный объект принадлежит к положительному классу. Например, $h_theta (x) = 0.7$ дает нам вероятность 70%, что класс данного объекта — положительный. Другими словами,
[h_b(x) = P(y=1 vert x, vec{b}) = 1 — P(y=0 vert x, vec{b})]
Вероятность того, что наше предсказание равно 0, то есть класс данного объекта — отрицательный, является просто дополнением вероятности того, что класс положительных (например, если вероятность положительного равна 70%, то вероятность отрицательного класса равна 30%).
Для практического использования логистической регрессии для классификации также необходимо выбрать значение порога. По умолчанию он берется равным 0,5. Принципиальное отличие от использования обычной линейной функции в том, что значение порога не будет так сильно зависеть от конкретного расположения точек. И поэтому не нужно каждый раз вручную подбирать его значение после каждого обучения модели. Логистическая регрессия устроена таким образом, что значение порога 0,5 всегда в среднем дает неплохие результаты классификации, и поэтому его можно использовать, не анализируя конкретное распределение точек выборки.
Выводы:
- Логистическая регрессия — это самый простой алгоритм бинарной классификации.
- Можно взять регрессионную модель и ввести пороговое значение.
- Обычная регрессия плохо работает в задачах классификации за счет своей чувствительности и неограниченности.
- Метод логистической регрессии основан на применении логистической или сигмоидной функции.
- Результат работы логистической функции часто интерпретируется как вероятность отнесения объекта к положительному классу.
- Для четкой классификации обычно выбирают некоторое пороговое значение, обычно — 0,5.
Граница принятия решений
Вернемся к пороговому значению функции гипотезы, ведь оно играет в понимании и интерпретации модели логистической регрессии. Чтобы получить дискретную классификацию, то есть конкретное значение целевой переменной 0 или 1, мы можем перевести непрерывное значение функции гипотезы, используя тот самый порог (по умолчанию, 0,5), следующим образом:
[h_b (x) ge 0.5 rightarrow y=1]
[h_b (x) lt 0.5 rightarrow y=0]
Логистическая функция $g$ ведет себя таким образом, что когда ее вход равен нулю, ее выход равен 0,5. Если входное значение больше нуля, то значение логистической функции будет больше, и наоборот. Напомним, что на вход ей подается линейная комбинация атрибутов и признаков, то есть значение линейной регрессии. Следует запомнить особые случаи значений логистической функции:
[z = 0 rightarrow h_b (x) = 0.5]
[z = -inf rightarrow h_b (x) = 0]
[z = inf rightarrow h_b (x) = 1]
Таким образом, область пространства признаков, где $z = 0$ формирует границу между областью, точки которой модель относит к положительному классу и областью, точки которой модель относит к отрицательному. Граница принятия решения — это линия, которая разделяет область, где y = 0 и где y = 1. Она создается нашей функцией гипотезы. Так как мы используем линейную функцию внутри логистической, граница принятия решений такой модели всегда будет прямой линией, плоскостью или, в общем случае, гиперплоскостью.
Граница принятия решения существует в любой модели классификации, не только в логистической регрессии. Это граница, которая отделяет область точек, классифицируемых как один определенный класс. Граница принятия решения есть и в моделях множественной классификации. Вообще, форма и сложность границы принятия решения — это одна из основных характеристик моделей машинного обучения для классификаций. Если возможно изобразить границу принятия решения графически, это всегда дает очень полное представление о работе модели. К сожалению, это можно сделать только в очень маломерных случаях, либо при использовании специальных методов, типа алгоритмов понижения размерности.
Форма границы принятия решения полностью определяется видом модели, который мы применяем. В данном случае мы имеем линейную функцию. Поэтому граница тоже может быть только линейной. Если бы мы взяли другую функцию, например, полином второй степени, то граница принятия решения была бы поверхностью второго порядка. Именно поэтому логистическая регрессия считается именно линейной моделью. Несмотря на то, что в ней используется нелинейное преобразование, граница принятия решения в этой модели всегда линейна.
А вот конкретное положение границы принятия решения зависит от значений параметров модели. И именно это мы и подбираем в ходе машинного обучения. Поэтому процесс обучения модели классификации можно представить как процесс нахождения оптимальной границы принятия решения. Отсюда, кстати, следует основное ограничение метода логистической регрессии. Она будет показывать хорошие результаты тогда, когда объекты нашей выборки могут быть разделены гиперплоскостью.

Источник: Wikimedia.
Такое свойство датасета называется линейной разделимостью. Имейте в виду, что это свойство именно данных, а не модели. На рисунке слева вы видите линейно разделимые данные, а справа — неразделимые. И логистическая регрессия хорошо работает именно на линейно разделимых данных. Поэтому важным этапом предварительного анализа данных является анализ, разделимы ли данные линейно. От этого зависит, какие модели на них будут хорошо работать.
И не забывайте, что данные у нас обычно многомерны. Это значит, что нельзя так просто нарисовать их на графике и понять визуально, разделимы они или нет. Ведь двумерный график — это лишь проекция многомерного многообразия на определенные оси. И то, что разделимо в высших размерностях может не показаться таким в проекции.
Если данные не являются линейно разделимыми, в них есть существенная нелинейная составляющая, то логистическая регрессия будет на них работать уже не так эффективно. Точно также, как линейная регрессия плохо работает, если зависимость между факторами и целевой переменной описывается нелинейной функцией. В таком случае к этим данным нужно пробовать применять другие, более сложные виды моделей. О них мы поговорим в следующих разделах.
Выводы:
- Граница принятия решений — это область, отделяющая один класс от другого.
- Форма границы принятия решения определяется видом используемой модели.
- Данные бывают линейно разделимые или нет.
- Логистическая регрессия — это линейный метод, поэтому она хорошо работает с линейно разделимыми данными.
- Если данные линейно неразделимы можно попробовать ввести в модель полиномиальные признаки.
Функция ошибки и градиентный спуск для логистической регрессии
Для использования логистической регрессии как модели машинного обучения нужно определить алгоритм обучения, то есть подбор оптимальных параметров. Для этого мы будем использовать тот же алгоритм градиентного спуска, который изучали применительно к линейной регрессии. В его основе — манипулирование функцией ошибки модели, которая показывает, насколько модель соответствует данным. К сожалению, мы уже не можем использовать ту же самую функцию ошибки, которую мы используем для линейной регрессии, потому что логистическая функция породит немонотонную производную, имеющую множество локальных оптимумов. Другими словами, это не будет выпуклая функция.
Вместо этого функция ошибки для логистической регрессии выглядит немного сложнее. Начнем ее рассматривать с самого начала. Также, как и в прошлом случае, ошибка всей модели строится как среднее из ошибок, измеренных в каждой точке данных. Это можно записать с помощью условных обозначений так:
[J(vec{b}) = frac{1}{m} sum_{i-1}^{m} Cost(h_b(x), y)]
А вот сами индивидуальные ошибки будут строиться немного по-другому. Напомним, что сейчас мы рассматриваем индивидуальные точки данных. Для начала рассмотрим случай, когда истинное значение целевой переменной равно 1, то есть данный объект принадлежит положительному классу. Тогда мы хотим, чтобы значение логистической функции было как можно ближе к 1. Чем ближе значение сигмоиды к единице, тем меньше для нас будет ошибка. В предельном случае, когда значение будет равно единице (такое невозможно, так как сигмоида только стремится к единице, но никогда не достигает ее), ошибка должна быть нулевой. А если значение сигмоиды приближается к нулю, то это значит, что ошибка растет. Чем ближе к нулю, тем больше ошибка. Если значение логистической функции равно нулю (также в пределе), то ошибка бесконечна. для моделирования такого поведения опять-таки можно использовать разные функции, но традиционно в логистической регрессии применяются логарифмы. Если взять логарифм с противоположным знаком, то мы добьемся как раз нужного эффекта. Так что если $y=1$, то ошибка в конкретной точке будет записываться так:
[Cost(h_b(x), y vert y=1) = -log(h_b(x)) = -log(frac{1}{1 + e^{-z}})]
Для противоположного случая, когда $y=0$, то есть объект принадлежит отрицательному классу, ситуация прямо противоположная. Нужно считать, что ошибка нулевая, если значение сигмоиды равно нулю, а если оно равно единице — то ошибка бесконечна. Для этого можно просто взять логарифм от $1 — g(z)$. Обратите внимание, что это имеет смысл, так как мы точно знаем, что значение сигмоиды всегда лежит от 0 до 1 (не включая концы). Поэтому нам неважно, как ведет себя функция ошибки, если ее аргумент будет какой-то другой, вне этого диапазона. Итак, для второго случая индивидуальная ошибка будет вычисляться так:
[Cost(h_b(x), y vert y=0) = -log(1 — h_b(x)) = -log(1 — frac{1}{1 + e^{-z}})]
Чем больше конкретная функция гипотезы отклоняется от реального значения $y$, тем больше получающая функция ошибки. Если гипотеза равна истинным значениям $y$, то ошибка равна 0. Это поведение функции ошибки в индивидуальной точке можно понять, посмотрев на два графика, которые иллюстрируют поведение функции ошибки в зависимости от аргумента сигмоиды, то есть линейной комбинации:

Мы можем представить два рассмотренных условных случая функции ошибки в одно выражение, используя тот факт, что истинные значения $y$ могут принимать только значения 0 или 1:
[Cost(h_b(x), y) = — y cdot log(h_b(x)) — (1 — y)(1 — log(h_b(x)))]
Обратите внимание, что когда $y$ равно 1, то второе слагаемое будет равен нулю и не повлияет на результат. Если $y$ равно 0, то, наоборот, первое слагаемое будет равен нулю и не повлияет на результат. Это математическию трюк позволяет выразить функцию в виде единой формулы, а не набора условных выражений, как в кусочных функциях. Это очень полезно и удобно для последующих манипуляций с этой функцией.
Заметим, что при такой функции ошибки она в каждой точке будет ненулевая. Идеальный случай, когда ошибка равна нулю недостижим на практике, так как значение сигмоиды только бесконечно приближается к границам (значениям 0 и 1), но никогда не может достичь их. Именно такая функция ошибки имеет несколько критичных преимуществ перед какими-нибудь другими, которые мы могли бы изобрести. Во-первых, она будет выпукла, то есть иметь один глобальный оптимум, как в случае с линейной регрессией. Во-вторых, она везде дифференцируема, так как использует только гладкие функции, мы смогли даже избавиться от кусочности, представив ее в виде одного выражения. И в-третьих, при ее дифференцировании функции логарифма и экспоненты в какой-то момент прекрасно сократятся, что значительно упростит выражение для градиента.
Доказательство того, что функция ошибки унимодальна, также как и подробное ее дифференцирование выходит за рамки данного учебника, но представляет собой неплохое упражнение по продвинутому математическому анализу для интересующихся.
Мы можем полностью сформулировать общую функцию ошибки следующим образом:
[J(vec{b}) = -frac{1}{m} sum_{i-1}^{m} y_i cdot log(h_b(x_i)) + (1 — y_i)(1 — log(h_b(x_i)))]
Теперь для полноценного определения алгоритма градиентного спуска нужно взять частные производные этой функции по всем параметрам. Продифференцировав ее найдем частную производную функции ошибки:
[frac{partial}{partial b_i} J(vec{b}) = frac{1}{m} sum_{i=1}^{m} (h_b (x_i) -y_i) x_i]
Обратите внимание, что мы получили точно такое же выражение, что и в случае с линейной регрессией. Также, как и в том случае, формула для частной производной выражена через функцию гипотезы. И опять же это не случайно. Так мы получаем, что алгоритм градиентного спуска полностью аналогичен для логистической и для линейной регрессии.
Напомним, что общая форма градиентного спуска:
[b_i := b_i -alpha frac{partial}{partial b_i} J(b)]
Подставляя выражение для частной производной получаем следующее выражение:
[b_i := b_i — frac{alpha}{m} sum_{i=1}^{m} (h_b (x) -y)x_i]
Обратите внимание, что этот алгоритм полностью идентичен тому, который мы использовали в линейной регрессии. Именно поэтому мы выразили эту формулу в терминах функции гипотезы, не раскрывая дальше $h_b(x)$. Также, как и раньше метод градиентного спуска подразумевает, что нужно обновлять все значения $b$ одновременно.
Многоклассовая классификация: один против всех
До сих пор мы рассматривали алгоритм логистической регрессии, который может решать только проблему бинарной классификации. Более того, некоторые математические выкладки активно используют тот факт, что целевая переменная может принимать только значения 0 или 1. Как же его безболезненно обобщить на случай, когда классов больше? Теперь мы рассмотрим классификацию данных более чем в двух категориях. Вместо $y = lbrace 0, 1 rbrace$ мы расширим наше определение так, чтобы
[y = lbrace 0,1 … n rbrace]
Пример набора данных для задачи множественной классификации, содержащих два признака и три класса можно увидеть на рисунке:

Алгоритм классификации в данном случае очень прост. Мы берем последовательно каждый имеющийся класс в данных, делаем его “положительным”, а все остальные — “отрицательными”, и обучаем модель, которая стремится отделить данный класс от остальных. Схематично алгоритм классификации “один против всех” можно увидеть на рисунке:

Источник: Medium.
В этом случае мы делим нашу задачу на $ n + 1 $ (потому что индекс начинается с 0) бинарных задач классификации. В каждом из них мы прогнозируем вероятность того, что $y$ является членом одного из наших классов. То есть мы обучаем сразу множество моделей, столько, сколько у нас есть классов. Так что на каждый класс в задаче будет своя собственная модель, которая для определенного объекта выдает вероятность принадлежности этого объекта к соответствующему классу. Для каждого конкретного объекта все модели выдают такой вектор вероятностей:
[h_b^{(0)} = P(y=0 vert x, vec{b});]
[h_b^{(1)} = P(y=1 vert x, vec{b});]
[…]
[h_b^{(n)} = P(y=n vert x, vec{b});]
Другими словами, построив несколько моделей бинарной классификации мы можем использовать их, чтобы получить оценки вероятности принадлежности любого объекта ко всем имеющимся классам. После этого для окончательной классификации выбирается тот класс, чья модель дала наивысший результат. Другими словами, мы с помощью нескольких моделей оцениваем, к какому классу вероятнее всего принадлежит данный объект и выбираем для окончательной классификации тот класс, чья вероятность выше остальных.
Данный метод называется “один против всех” (one vs all или one vs rest). Это название подчеркивает тот факт, что для каждого класса оценивается вероятность принадлежности объекта к нему, в сравнении с вероятностью принадлежности к любому из всех остальных классов. Надо отметить, что во всех современных программных инструментах для машинного обучения, он уже реализован и встроен в существующие методы классификации, так что разработчику не придется программировать его специально.
Кроме того, чуть позже мы познакомимся с моделями, которые сами по себе способны решать задачи множественной классификации, а значит, не требуют реализации схемы “один против всех”. Она нужна только для моделей, которые способны решать только бинарную классификацию, чтобы “приспособить” их для задач, где классов больше двух.
Обратите внимание, что формулировка данного алгоритма не предполагает использование порогового значения. Вероятности принадлежности объекта к классам могут быть любые. Нам важно выбрать среди них максимум. Даже есть все эти вероятности меньше 50%, все равно мы выберем тот класс, к которому данный объект больше всего подходит. Более того, в среднем, эти вероятности обратно пропорциональны количеству классов в задаче. То есть если в конкретной проблеме, например, 50 000 классов, то не стоит ожидать, что объект будет принадлежать одному из них с вероятностью 90%. Здесь скорее речь пойдет о выборе между 0,028% и 0,025%.
У этого алгоритма есть еще одна характерная черта. С его помощью можно решать задачи мультиклассификации. Напомним, это такие, в которых один конкретный объект может принадлежать нескольким классам одновременно. Такие задачи часто формулируются как придание объекту набора меток. Например, добавление релевантных тегов к посту в социальных сетях. Естественно, что у отдельно взятому посту можно придать достаточно много тегов. В данном случае теги служат классами, но задача мультиклассовая. Другой пример — распознавание объектов на изображении. На конкретной картинке может же быть не один объект, а несколько, произвольное количество. Так вот, при использовании алгоритма “один против всех” можно брать как итоговый не один класс с максимальной вероятностью, а сразу несколько. Стратегии отбора классов бывают разные: в одной задаче можно брать фиксированное количество лучше подходящих классов, в других — брать любое количество классов, вероятности которых больше определенного порога.
Конечно, есть у данного алгоритма и оборотная сторона. Его применение не очень целесообразно, если в задачу уж очень большое количество классов. Ведь тогда придется обучить и использовать точно такое же количество моделей. А это может быть как затратно по процессорному времени, то есть обучение будет проходить слишком медленно, так и затратно по памяти, ведь все эти модели, их параметры надо хранить для осуществления предсказания. Может, стоит рассмотреть другие виды моделей классификации, которые решают множественные задачи сами по себе.
Выводы:
- Существуют методы классификации, которые сами по себе могут решать задачи множественной классификации.
- Для тех, которые не умеют, существует алгоритм “один против всех”.
- В нем строится столько бинарных моделей, сколько классов существует в задаче.
- Данный алгоритм уже не зависит от выбора порогового значения.
- Этот алгоритм еще может решать проблемы мультиклассификации.
- Для задач с очень большим количеством классов этот алгоритм может быть неэффективен.
Практическое построение классификации
Как подготовить данные для классификации?
Для решения задач классификации в языке программирования Python с использованием sklearn остается справедливым все то, о чем мы говорили в конце предыдущей главы о подготовке данных для регрессионных задач. Так же нам нужно сформировать два массива данных — двумерный массив признаков X и одномерный массив значений целевой переменной y.
Раньше, в векторе значений целевой переменной находились сами численные значения. В данных для классификации метки классов могут обозначаться разными способами — числом, названием, аббревиатурой. Дальше мы будем подразумевать, что значения в массиве y заданы просто числами — [0, 1], если классов два (бинарная классификация), [0, 1, 2] — если классов три и так далее. Если в вашем датасете это не так и классы обозначаются как-то по другому, то обратитесь к одной из следующих глав, где мы обсуждаем преобразование и подготовку данных.
Здесь хотелось бы упомянуть еще об одной полезной функции библиотеки sklearn — процедурной генерации датасетов. Данная библиотека включает в себя несколько функций, которые используются для создания случайных наборов данных для тестирования моделей машинного обучения. В частности, существует функция make_classification, которая позволяет быстро создать случайный набор данных для классификации, обладающий определенными свойствами. Вы можете настроить количество точек, количество классов и признаков, насколько они будут линейно разделимы. Более полно информацию об этой и других функциях смотрите в официальной документации sklearn, в разделе, посвященном пакету datasets. Приведем пример использования этой функции:
1
2
3
from sklearn.datasets import make_classification
X, Y = make_classification( n_features=2)
В результате мы получаем и массив признаков и вектор значений целевой переменной. Они уже готовы для использования в моделях классификации.
Если возможно, всегда нужно стремится визуализировать данные, которые вы собираетесь анализировать. В случае с данными для классификации это немного сложнее, чем для парной регрессии, ведь нам нужно на графике как-то выделить классы. Можно воспользоваться встроенной возможностью задания цвета точек через массив вот так:
1
2
plt.scatter(X[:, 0], X[:, 1], marker="o", c=Y, s=25, edgecolor="k")
plt.show()
Обратите внимание, что в данном случае мы явно указываем, какие признаки будут расположены по осям. В данном примере мы откладываем первый столбец (с индексом 0) по горизонтальной оси, а второй (с индексом 1) — по вертикальной. Вот так это выглядит на графике:

Есть другой способ — визуализировать каждый класс отдельно. В таком случае мы можем более гибко управлять отображением разных классов — задавать явно произвольные цвета, размеры, форму маркеров точек. Обратите внимание, как в данном примере используется условная индексация одного массива (признаков) другим массивом (целевой переменной):
1
2
3
plt.scatter(X[:, 0][Y==0], X[:, 1][Y==0], marker="o", c='r', s=100)
plt.scatter(X[:, 0][Y==1], X[:, 1][Y==1], marker="x", c='b', s=100)
plt.show()
Вот так это выглядит на графике:

Помимо визуализации с данными такой структуры можно работать абсолютно так же, как и с данными для регрессии.
Как реализовать логистическую регрессию?
Рассмотрим простейшую модель логистической регрессии. Как мы увидели в этой главе, она мало чем отличается от модели линейной регрессии, поэтому возьмем за основу класс, который реализовали в предыдущей главе, посвященной задаче регрессии.
Мы будем рассматривать двумерную задачу классификации. То есть у нас будет два непрерывных признака — $x_1$ и $x_2$. Поэтому в модели будет 3 параметра — $b_0, b_1, b_2$. Еще мы предполагаем решение бинарной задачи, так как множественная классификация решается отдельным алгоритмом “один-против-всех”
Ключевым отличием метода predict будет то, что мы считаем линейную комбинацию, а затем считаем логистическую функцию от нее:
1
2
3
def predict(self, x):
x1, x2 = x
z = self.b0 + self.b1 * x1 + self.b2 * x2
Модифицируем функцию ошибки так, чтобы она соответствовала формуле логарифмической ошибки для логистической регрессии:
1
2
def error(self, X, Y):
return -sum(Y * np.log2(self.predict(X)) + (1 - Y) *(1 - np.log2(self.predict(X)))) / len(X[0])
Теперь перейдем к методу градиентного спуска. И вот здесь все останется поразительно похожим на линейную регрессию, за исключением большего количества параметров:
1
2
3
4
5
6
7
8
9
def BGD(self, X, Y):
alpha = 0.5
for _ in range(1000):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X[0]) /len(X[0])
dJ2 = sum((self.predict(X) - Y) * X[1]) /len(X[0])
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
self.b2 -= alpha * dJ2
Полностью код, реализующий метод логистической регрессии, выглядит так:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class hypothesis(object):
"""Модель логистической регрессии"""
def __init__(self):
self.b0 = 0
self.b1 = 0
self.b2 = 1
def predict(self, x):
x1, x2 = x
z = self.b0 + self.b1 * x1 + self.b2 * x2
return 1 / (1 + np.exp(-z))
def error(self, X, Y):
return -sum(Y * np.log2(self.predict(X)) + (1 - Y) *(1 - np.log2(self.predict(X)))) / len(X[0])
def BGD(self, X, Y):
alpha = 0.5
for _ in range(1000):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X[0]) /len(X[0])
dJ2 = sum((self.predict(X) - Y) * X[1]) /len(X[0])
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
self.b2 -= alpha * dJ2
Обратите внимание на задание начальных значений параметров. В данном примере мы создаем регрессию со следующими значениями параметров по умолчанию: $b_0 = 0; b_1 = 0; b_2 = 1$. Задание одного из параметров в 1 нужно будет потом, чтобы получился более понятный график модели без обучения. На практике можно задавать начальные значения всеми нулями.
Как оценить качество классификационной модели?
После создания модели логистической регрессии логичным шагом будет вывести ее на график вместе с точками данных. Проблема в том, что это не так просто, как в случае с линейной регрессией, так как мы имеем два измерения признаков плюс еще значение самой функции модели. Для того, чтобы наглядно увидеть, как сочетается значение модели с точками воспользуемся построением контурного графика.
Для начала создадим экземпляр модели с параметрами по умолчанию:
1
2
3
4
hyp = hypothesis()
print(hyp.predict((0, 0)))
J = hyp.error(X, Y)
print("initial error:", J)
Теперь надо подготовить равномерные данные для рисования функции гипотезы. Нам понадобится создать двумерную сетку. К счастью, в numpy есть необходимые элементы. Подробный разбор кода выходит за рамки данного пособия, так как использует продвинутые возможности библиотеки numpy. Если вам интересно, как работает этот код, обратитесь к документации к используемым методам:
1
2
3
4
xx, yy = np.meshgrid(
np.arange(X.min(axis=0)[0]-1, X.max(axis=0)[0]+1, 0.01),
np.arange(X.min(axis=0)[1]-1, X.max(axis=0)[1]+1, 0.01))
XX = np.array(list(zip(xx.ravel(), yy.ravel()))).reshape((-1, 2))
В данном коде мы создаем двумерную матрицу, содержащую все комбинации значений признаков в заданном диапазоне. Другими словами, мы создаем равномерную сетку в прямоугольнике от минимального до максимального значения каждого признака (отступая для красоты 1 в обоих направлениях). Попробуйте вывести получившиеся переменные, чтобы понять принцип построения данной сетки. А после мы используем матрицу XX как исходные данные для модели:
1
2
Z = hyp.predict(XX)
Z = Z.reshape(xx.shape)
Данный код выполнит предсказание модели в каждой точке нашей сетки. Эти данные мы сможем использовать для того, чтобы построить контурный график вот так:
1
2
3
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0][Y==0], X[:, 1][Y==0], marker="o", c='r', s=100)
plt.scatter(X[:, 0][Y==1], X[:, 1][Y==1], marker="x", c='b', s=100)
В итоге мы должны получить график, похожий на следующий рисунок:

На графике мы видим наши точки данных, они выглядят так же, как и в предыдущих частях. Кроме него график заполняет заливка цветом. Цвет показывает значение функции гипотезы в данной точке. Так как мы задавали начальные значения параметров модели специально, параметр $b_2 = 1$ дает нам такой ровный градиент, который увеличивается равномерно с ростом значения признака $x_1$. Конечно, такой градиент никак не учитывает положение точек. Это и логично, ведь наша модель еще не обучена. Давайте запустим градиентный спуск и увидим модель после обучения:
1
2
3
4
5
6
7
8
hyp.BGD(X, Y)
Z = hyp.predict((xx, yy))
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X.T[:, 0], X.T[:, 1], marker="o", c=Y, s=25, edgecolor="k")
plt.show()
Обратите внимание, что мы переиспользуем сетку, которую создавали на предыдущем шаге. Ведь сами значения не меняются, меняется только набор значений модели. После обучения вы должны увидеть примерно такой график:

На нем мы видим, что функция гипотезы подстроилась к точкам таким образом, чтобы для точек положительного класса (желтых) выдавать значения, близкие к единице (желтая область), а для точек отрицательного класса (черных) — значения, близкие к нулю (фиолетовая область). То есть модель стала гораздо лучше соответствовать данным. Посередине между двумя областями мы видим более узкую полоску градиента. Это область, для точек которой модель не уверена в своих предсказаниях и выдает значения, ближе к 0,5. Именно в этой полосе располагается граница принятия решения нашей модели.
Как построить простую классификацию в scikit-learn?
Так же, как и в случае с линейной регрессией, самостоятельная реализация данного метода нужна только для того, чтобы на практике прочувствовать алгоритм его работы. В реальной жизни лучше всего пользоваться существующими профессиональными реализациями. Именно поэтому мы используем sklearn. Работа с моделью классификации в этой библиотеке практически не отличается от работы с линейной регрессией. Для начала нужно импортировать нужный класс, создать его экземпляр и обучить его на имеющихся данных:
1
2
3
4
5
6
7
from sklearn import linear_model
X = X.T
reg = linear_model.LogisticRegression()
reg.fit(X, Y)
print(reg.score(X, Y))
Обратите внимание, на то, что названия методов полностью совпадают у всех моделей машинного обучения в этой библиотеке. За счет этого ей очень приятно и просто пользоваться — у всех моделей единый интерфейс.
Точно так же, как и в самостоятельной реализации мы можем использовать модель для построения предсказания по сетке и для построения контурного графика. Давайте сравним самостоятельную реализацию логистической регрессии с библиотечной:
1
2
3
4
5
6
7
Z = reg.predict(XX)
Z = Z.reshape(xx.shape)
plt.figure(figsize=(12, 9))
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0][Y==0], X[:, 1][Y==0], marker="o", c='r', s=100)
plt.scatter(X[:, 0][Y==1], X[:, 1][Y==1], marker="x", c='b', s=100)
В результате выполнения данного кода вы должны увидеть график наподобие следующего:

Обратите внимание, что граница принятия решения расположена примерно в том же месте, что и у нашей реализации. Однако полоса “неопределенности”, область, где проявляется цветовой градиент, значительно уже. На библиотечной модели ее вообще почти невозможно разглядеть. Это не значит, что наша модель обучилась хуже. Ведь наша модель все еще способна точно отделить точки обучающей выборки разных классов. Но библиотечная модель обучилась “сильнее” — она более уверенно классифицирует точки, которые ближе к границе принятия решения.
∙Применение Data Mining для решения задач государственного уровня. Основные направления: поиск лиц, уклоняющихся от налогов; средства в борьбе с терроризмом.
∙Применение Data Mining для научных исследований. Основные направления: медицина, биология, молекулярная генетика и генная инженерия, биоинформатика, астрономия, прикладная химия, исследования, касающиеся наркотической зависимости, и другие.
∙Применение Data Mining для решения Web-задач. Основные направления: поисковые машины (search engines), счетчики и другие.
Банковское дело
Технология Data Mining используется в банковской сфере для решения ряда типичных задач.
Задача «Выдавать ли кредит клиенту?»
Классический пример применения Data Mining в банковском деле — решение задачи определения возможной некредитоспособности клиента банка. Эту задачу также называют анализом кредитоспособности клиента или «Выдавать ли кредит клиенту?».
Без применения технологии Data Mining задача решается сотрудниками банковского учреждения на основе их опыта, интуиции и субъективных представлений о том, какой клиент является благонадежным. По похожей схеме работают системы поддержки принятия решений и на основе методов Data Mining. Такие системы на основе исторической (ретроспективной) информации и при помощи методов классификации выявляют клиентов, которые в прошлом не вернули кредит.
Задача «Выдавать ли кредит клиенту?» при помощи методов Data Mining решается следующим образом. Совокупность клиентов банка разбивается на два класса (вернувшие и не вернувшие кредит); на основе группы клиентов, не вернувших кредит, определяются основные «черты» потенциального неплательщика; при поступлении информации о новом клиенте определяется его класс («вернет кредит», «не вернет кредит»).
Задача привлечения новых клиентов банка.
С помощью инструментов Data Mining возможно провести классификацию на «более выгодных» и «менее выгодных» клиентов. После определения наиболее выгодного сегмента клиентов банку есть смысл проводить более активную маркетинговую политику по привлечению клиентов именно среди найденной группы.
Другие задачи сегментации клиентов.
Разбивая клиентов при помощи инструментов Data Mining на различные группы, банк имеет возможность сделать свою маркетинговую политику более целенаправленной, а потому — эффективной, предлагая различным группам клиентов именно те виды услуг, в которых они нуждаются.
Задача управления ликвидностью банка. Прогнозирование остатка на счетах клиентов.
75
Проводя прогнозирования временного ряда с информацией об остатках на счетах клиентов за предыдущие периоды, применяя методы Data Mining, можно получить прогноз остатка на счетах в определенный момент в будущем. Полученные результаты могут быть использованы для оценки и управления ликвидностью банка.
Задача выявления случаев мошенничества с кредитными карточками.
Для выявления подозрительных операций с кредитными карточками применяются так называемые «подозрительные стереотипы поведения», определяемые в результате анализа банковских транзакций, которые впоследствии оказались мошенническими. Для определения подозрительных случаев используется совокупность последовательных операций на определенном временном интервале. Если система Data Mining считает очередную операцию подозрительной, банковский работник может, ориентируясь на эту информацию, заблокировать операции с определенной карточкой.
Страхование
Страховой бизнес связан с определенным риском. Здесь задачи, решаемые при помощи Data Mining, сходны с задачами в банковском деле.
Информация, полученная в результате сегментации клиентов на группы, используется для определения групп клиентов. В результате страховая компания может с наибольшей выгодой и наименьшим риском предлагать определенные группы услуг конкретным группам клиентов.
Задача выявление мошенничества решается путем нахождения некого общего стереотипа поведения клиентов-мошенников.
Телекоммуникации
В сфере телекоммуникаций достижения Data Mining могут использоваться для решения задачи, типичной для любой компании, которая работает с целью привлечения постоянных клиентов, — определения лояльности этих клиентов. Необходимость решения таких задач обусловлена жесткой конкуренцией на рынке телекоммуникаций и постоянной миграцией клиентов от одной компании в другую. Как известно, удержание клиента намного дешевле его возврата. Поэтому возникает необходимость выявления определенных групп клиентов и разработка наборов услуг, наиболее привлекательных именно для них. В этой сфере, так же как и во многих других, важной задачей является выявление фактов мошенничества.
Помимо таких задач, являющихся типичными для многих областей деятельности, существует группа задач, определяемых спецификой сферы телекоммуникаций.
Электронная коммерция
В сфере электронной коммерции Data Mining применяется для формирования рекомендательных систем и решения задач классификации посетителей Web-сайтов. Такая классификация позволяет компаниям выявлять определенные группы клиентов и проводить маркетинговую политику в соответствии с обнаруженными интересами и потребностями клиентов. Технология Data Mining для электронной коммерции тесно связана с технологией Web Mining [28].
76
Промышленное производство
Особенности промышленного производства и технологических процессов создают хорошие предпосылки для возможности использования технологии Data Mining в ходе решения различных производственных задач. Технический процесс по своей природе должен быть контролируемым, а все его отклонения находятся в заранее известных пределах;
т.е. здесь мы можем говорить об определенной стабильности, которая обычно не присуща большинству задач, встающих перед технологией Data Mining.
Основные задачи Data Mining в промышленном производстве [29]:
∙комплексный системный анализ производственных ситуаций;
∙краткосрочный и долгосрочный прогноз развития производственных ситуаций;
∙выработка вариантов оптимизационных решений;
∙прогнозирование качества изделия в зависимости от некоторых параметров технологического процесса;
∙обнаружение скрытых тенденций и закономерностей развития производственных процессов;
∙прогнозирование закономерностей развития производственных процессов;
∙обнаружение скрытых факторов влияния;
∙обнаружение и идентификация ранее неизвестных взаимосвязей между производственными параметрами и факторами влияния;
∙анализ среды взаимодействия производственных процессов и прогнозирование изменения ее характеристик;
∙выработку оптимизационных рекомендаций по управлению производственными процессами;
∙визуализацию результатов анализа, подготовку предварительных отчетов и проектов допустимых решений с оценками достоверности и эффективности возможных реализаций.
Маркетинг
В сфере маркетинга Data Mining находит очень широкое применение.
Основные вопросы маркетинга «Что продается?», «Как продается?», «Кто является потребителем?»
В лекции, посвященной задачам классификации и кластеризации, подробно описано использование кластерного анализа для решения задач маркетинга, как, например, сегментация потребителей.
Другой распространенный набор методов для решения задач маркетинга — методы и алгоритмы поиска ассоциативных правил.
Также успешно здесь используется поиск временных закономерностей.
Розничная торговля
В сфере розничной торговли, как и в маркетинге, применяются:
77
∙алгоритмы поиска ассоциативных правил (для определения часто встречающихся наборов товаров, которые покупатели покупают одновременно). Выявление таких правил помогает размещать товары на прилавках торговых залов, вырабатывать стратегии закупки товаров и их размещения на складах и т.д.
∙использование временных последовательностей, например, для определения необходимых объемов запасов товаров на складе.
∙методы классификации и кластеризации для определения групп или категорий клиентов, знание которых способствует успешному продвижению товаров.
Фондовый рынок
Вот список задач фондового рынка, которые можно решать при помощи технологии Data Mining [30]:
∙прогнозирование будущих значений финансовых инструментов и индикаторов по их прошлым значениям;
∙прогноз тренда (будущего направления движения — рост, падение, флэт) финансового инструмента и его силы (сильный, умеренно сильный и т.д.);
∙выделение кластерной структуры рынка, отрасли, сектора по некоторому набору характеристик;
∙динамическое управление портфелем;
∙прогноз волатильности;
∙оценка рисков;
∙предсказание наступления кризиса и прогноз его развития;
∙выбор активов и др.
Кроме описанных выше сфер деятельности, технология Data Mining может применяться в самых разнообразных областях бизнеса, где есть необходимость в анализе данных и накоплен некоторый объем ретроспективной информации.
Применение Data Mining в CRM
Одно из наиболее перспективных направлений применения Data Mining — использование данной технологии в аналитическом CRM.
CRM (Customer Relationship Management) — управление отношениями с клиентами.
При совместном использовании этих технологий добыча знаний совмещается с «добычей денег» из данных о клиентах.
Важным аспектом в работе отделов маркетинга и отдела продаж является составление целостного представления о клиентах, информация об их особенностях, характеристиках, структуре клиентской базы. В CRM используется так называемое профилирование клиентов, дающее полное представление всей необходимой информации о клиентах. Профилирование клиентов включает следующие компоненты: сегментация клиентов, прибыльность клиентов, удержание клиентов, анализ реакции клиентов. Каждый из этих компонентов может исследоваться при помощи Data Mining, а анализ их в совокупности, как компонентов профилирования, в результате может дать те знания, которые из каждой отдельной характеристики получить невозможно.
78
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Classification in machine learning and statistics is a supervised learning approach in which the computer program learns from the data given to it and makes new observations or classifications. In this article, we will learn about classification in machine learning in detail. Moreover, if you want to go beyond this article and gain some hands-on experience of Machine learning under expert guidance, must visit Machine Learning Certification by Edureka!
Machine Learning Full Course – Learn Machine Learning 10 Hours | Machine Learning Tutorial | Edureka
Machine Learning Course lets you master the application of AI with the expert guidance. It includes various algorithms with applications.
The following topics are covered in this blog:
- What is Classification in Machine Learning?
- Classification Terminologies In Machine Learning
- Classification Algorithms
- Logistic Regression
- Naive Bayes
- Stochastic Gradient Descent
- K-Nearest Neighbors
- Decision Tree
- Random Forest
- Artificial Neural Network
- Support Vector Machine
- Classifier Evaluation
- Algorithm Selection
- Use Case- MNIST Digit Classification
Classification is a process of categorizing a given set of data into classes, It can be performed on both structured or unstructured data. The process starts with predicting the class of given data points. The classes are often referred to as target, label or categories.
The classification predictive modeling is the task of approximating the mapping function from input variables to discrete output variables. The main goal is to identify which class/category the new data will fall into.
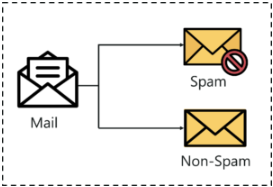
Let us try to understand this with a simple example.
Heart disease detection can be identified as a classification problem, this is a binary classification since there can be only two classes i.e has heart disease or does not have heart disease. The classifier, in this case, needs training data to understand how the given input variables are related to the class. And once the classifier is trained accurately, it can be used to detect whether heart disease is there or not for a particular patient.
Since classification is a type of supervised learning, even the targets are also provided with the input data. Let us get familiar with the classification in machine learning terminologies.
Classification Terminologies In Machine Learning
-
Classifier – It is an algorithm that is used to map the input data to a specific category.
-
Classification Model – The model predicts or draws a conclusion to the input data given for training, it will predict the class or category for the data.
-
Feature – A feature is an individual measurable property of the phenomenon being observed.
-
Binary Classification – It is a type of classification with two outcomes, for eg – either true or false.
-
Multi-Class Classification – The classification with more than two classes, in multi-class classification each sample is assigned to one and only one label or target.
-
Multi-label Classification – This is a type of classification where each sample is assigned to a set of labels or targets.
-
Initialize – It is to assign the classifier to be used for the
-
Train the Classifier – Each classifier in sci-kit learn uses the fit(X, y) method to fit the model for training the train X and train label y.
-
Predict the Target – For an unlabeled observation X, the predict(X) method returns predicted label y.
-
Evaluate – This basically means the evaluation of the model i.e classification report, accuracy score, etc.
Types Of Learners In Classification
-
Lazy Learners – Lazy learners simply store the training data and wait until a testing data appears. The classification is done using the most related data in the stored training data. They have more predicting time compared to eager learners. Eg – k-nearest neighbor, case-based reasoning.
-
Eager Learners – Eager learners construct a classification model based on the given training data before getting data for predictions. It must be able to commit to a single hypothesis that will work for the entire space. Due to this, they take a lot of time in training and less time for a prediction. Eg – Decision Tree, Naive Bayes, Artificial Neural Networks.
Build a career in Artificial Intelligence with our Post Graduate Diploma in AI ML Courses.
Classification Algorithms
In machine learning, classification is a supervised learning concept which basically categorizes a set of data into classes. The most common classification problems are – speech recognition, face detection, handwriting recognition, document classification, etc. It can be either a binary classification problem or a multi-class problem too. There are a bunch of machine learning algorithms for classification in machine learning. Let us take a look at those classification algorithms in machine learning.
Logistic Regression
It is a classification algorithm in machine learning that uses one or more independent variables to determine an outcome. The outcome is measured with a dichotomous variable meaning it will have only two possible outcomes.
The goal of logistic regression is to find a best-fitting relationship between the dependent variable and a set of independent variables. It is better than other binary classification algorithms like nearest neighbor since it quantitatively explains the factors leading to classification.
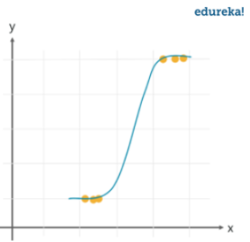
Advantages and Disadvantages
Logistic regression is specifically meant for classification, it is useful in understanding how a set of independent variables affect the outcome of the dependent variable.
The main disadvantage of the logistic regression algorithm is that it only works when the predicted variable is binary, it assumes that the data is free of missing values and assumes that the predictors are independent of each other.
Use Cases
-
Identifying risk factors for diseases
-
Word classification
-
Weather Prediction
-
Voting Applications
Learn more about logistic regression with python here.
Naive Bayes Classifier
It is a classification algorithm based on Bayes’s theorem which gives an assumption of independence among predictors. In simple terms, a Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature.
Even if the features depend on each other, all of these properties contribute to the probability independently. Naive Bayes model is easy to make and is particularly useful for comparatively large data sets. Even with a simplistic approach, Naive Bayes is known to outperform most of the classification methods in machine learning. Following is the Bayes theorem to implement the Naive Bayes Theorem.
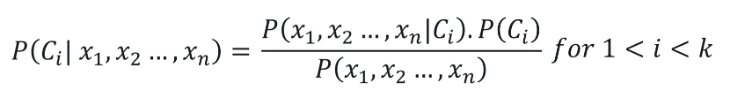
Advantages and Disadvantages
The Naive Bayes classifier requires a small amount of training data to estimate the necessary parameters to get the results. They are extremely fast in nature compared to other classifiers.
The only disadvantage is that they are known to be a bad estimator.
Use Cases
-
Disease Predictions
-
Document Classification
-
Spam Filters
-
Sentiment Analysis
Know more about the Naive Bayes Classifier here.
Stochastic Gradient Descent
It is a very effective and simple approach to fit linear models. Stochastic Gradient Descent is particularly useful when the sample data is in a large number. It supports different loss functions and penalties for classification.
Stochastic gradient descent refers to calculating the derivative from each training data instance and calculating the update immediately.
Advantages and Disadvantages
The only advantage is the ease of implementation and efficiency whereas a major setback with stochastic gradient descent is that it requires a number of hyper-parameters and is sensitive to feature scaling.
Use Cases
-
Internet Of Things
-
Updating the parameters such as weights in neural networks or coefficients in linear regression
K-Nearest Neighbor
It is a lazy learning algorithm that stores all instances corresponding to training data in n-dimensional space. It is a lazy learning algorithm as it does not focus on constructing a general internal model, instead, it works on storing instances of training data.
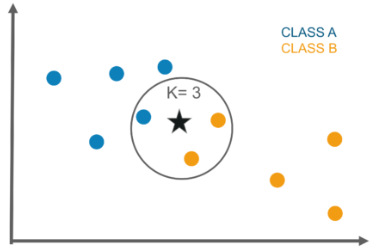
Classification is computed from a simple majority vote of the k nearest neighbors of each point. It is supervised and takes a bunch of labeled points and uses them to label other points. To label a new point, it looks at the labeled points closest to that new point also known as its nearest neighbors. It has those neighbors vote, so whichever label most of the neighbors have is the label for the new point. The “k” is the number of neighbors it checks.
Find out our Machine Learning Certification Training Course in Top Cities
| India | United States | Other Countries |
| Machine Learning Training in Hyderabad | Machine Learning Course in Dallas | Machine Learning Course in Melbourne |
| Machine Learning Certification in Bangalore | Machine Learning Course in Charlotte | Machine Learning Course in London |
| Machine Learning Course in Mumbai | Machine Learning Certification in NYC | Machine Learning Course in Dubai |
Advantages And Disadvantages
This algorithm is quite simple in its implementation and is robust to noisy training data. Even if the training data is large, it is quite efficient. The only disadvantage with the KNN algorithm is that there is no need to determine the value of K and computation cost is pretty high compared to other algorithms.
Use Cases
-
Industrial applications to look for similar tasks in comparison to others
-
Handwriting detection applications
-
Image recognition
-
Video recognition
-
Stock analysis
Know more about K Nearest Neighbor Algorithm here
Decision Tree
The decision tree algorithm builds the classification model in the form of a tree structure. It utilizes the if-then rules which are equally exhaustive and mutually exclusive in classification. The process goes on with breaking down the data into smaller structures and eventually associating it with an incremental decision tree. The final structure looks like a tree with nodes and leaves. The rules are learned sequentially using the training data one at a time. Each time a rule is learned, the tuples covering the rules are removed. The process continues on the training set until the termination point is met.
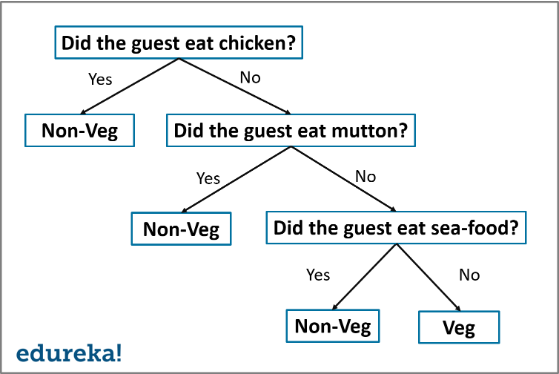
The tree is constructed in a top-down recursive divide and conquer approach. A decision node will have two or more branches and a leaf represents a classification or decision. The topmost node in the decision tree that corresponds to the best predictor is called the root node, and the best thing about a decision tree is that it can handle both categorical and numerical data.
Advantages and Disadvantages
A decision tree gives an advantage of simplicity to understand and visualize, it requires very little data preparation as well. The disadvantage that follows with the decision tree is that it can create complex trees that may bot categorize efficiently. They can be quite unstable because even a simplistic change in the data can hinder the whole structure of the decision tree.
Use Cases
-
Data exploration
-
Pattern Recognition
-
Option pricing in finances
-
Identifying disease and risk threats
Know more about decision tree algorithm here
Random Forest
Random decision trees or random forest are an ensemble learning method for classification, regression, etc. It operates by constructing a multitude of decision trees at training time and outputs the class that is the mode of the classes or classification or mean prediction(regression) of the individual trees.
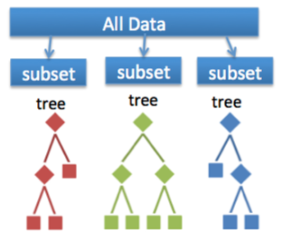
A random forest is a meta-estimator that fits a number of trees on various subsamples of data sets and then uses an average to improve the accuracy in the model’s predictive nature. The sub-sample size is always the same as that of the original input size but the samples are often drawn with replacements.
Advantages and Disadvantages
The advantage of the random forest is that it is more accurate than the decision trees due to the reduction in the over-fitting. The only disadvantage with the random forest classifiers is that it is quite complex in implementation and gets pretty slow in real-time prediction.
Use Cases
-
Industrial applications such as finding if a loan applicant is high-risk or low-risk
-
For Predicting the failure of mechanical parts in automobile engines
-
Predicting social media share scores
-
Performance scores
Know more about the Random Forest algorithm here.
Artificial Neural Networks
A neural network consists of neurons that are arranged in layers, they take some input vector and convert it into an output. The process involves each neuron taking input and applying a function which is often a non-linear function to it and then passes the output to the next layer.
In general, the network is supposed to be feed-forward meaning that the unit or neuron feeds the output to the next layer but there is no involvement of any feedback to the previous layer.
Weighings are applied to the signals passing from one layer to the other, and these are the weighings that are tuned in the training phase to adapt a neural network for any problem statement.
Advantages and Disadvantages
It has a high tolerance to noisy data and able to classify untrained patterns, it performs better with continuous-valued inputs and outputs. The disadvantage with the artificial neural networks is that it has poor interpretation compared to other models.
Use Cases
-
Handwriting analysis
-
Colorization of black and white images
-
Computer vision processes
-
Captioning photos based on facial features
Know more about artificial neural networks here
Support Vector Machine
The support vector machine is a classifier that represents the training data as points in space separated into categories by a gap as wide as possible. New points are then added to space by predicting which category they fall into and which space they will belong to.
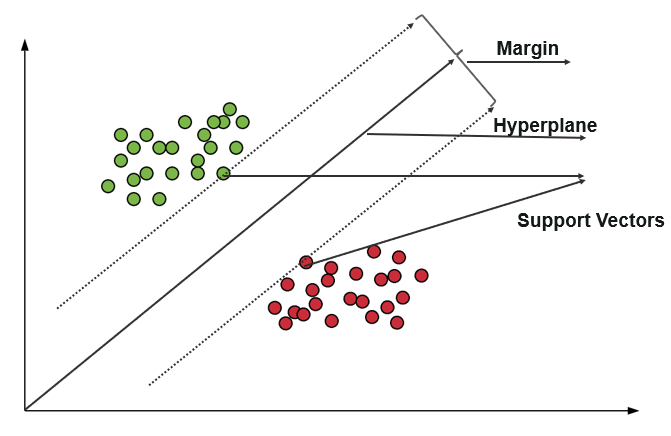
Advantages and Disadvantages
It uses a subset of training points in the decision function which makes it memory efficient and is highly effective in high dimensional spaces. The only disadvantage with the support vector machine is that the algorithm does not directly provide probability estimates.
Use cases
-
Business applications for comparing the performance of a stock over a period of time
-
Investment suggestions
-
Classification of applications requiring accuracy and efficiency
Learn more about support vector machine in python here
Classifier Evaluation
The most important part after the completion of any classifier is the evaluation to check its accuracy and efficiency. There are a lot of ways in which we can evaluate a classifier. Let us take a look at these methods listed below.
Holdout Method
This is the most common method to evaluate a classifier. In this method, the given data set is divided into two parts as a test and train set 20% and 80% respectively.
The train set is used to train the data and the unseen test set is used to test its predictive power.
Cross-Validation
Over-fitting is the most common problem prevalent in most of the machine learning models. K-fold cross-validation can be conducted to verify if the model is over-fitted at all.
In this method, the data set is randomly partitioned into k mutually exclusive subsets, each of which is of the same size. Out of these, one is kept for testing and others are used to train the model. The same process takes place for all k folds.
Classification Report
A classification report will give the following results, it is a sample classification report of an SVM classifier using a cancer_data dataset.
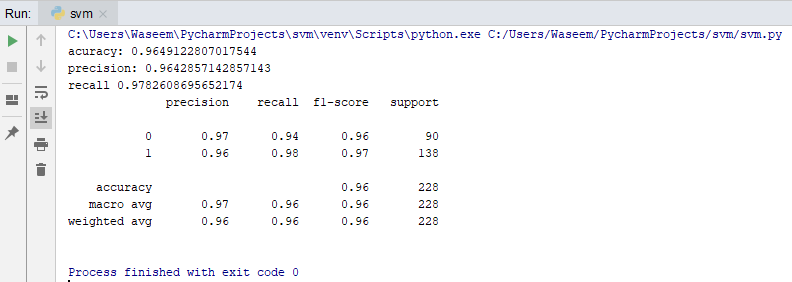
-
Accuracy
-
Accuracy is a ratio of correctly predicted observation to the total observations
-
True Positive: The number of correct predictions that the occurrence is positive.
-
True Negative: Number of correct predictions that the occurrence is negative.
-
-
F1- Score
-
It is the weighted average of precision and recall
-
- Precision And Recall
- Precision is the fraction of relevant instances among the retrieved instances, while recall is the fraction of relevant instances that have been retrieved over the total number of instances. They are basically used as the measure of relevance.
ROC Curve
Receiver operating characteristics or ROC curve is used for visual comparison of classification models, which shows the relationship between the true positive rate and the false positive rate. The area under the ROC curve is the measure of the accuracy of the model.
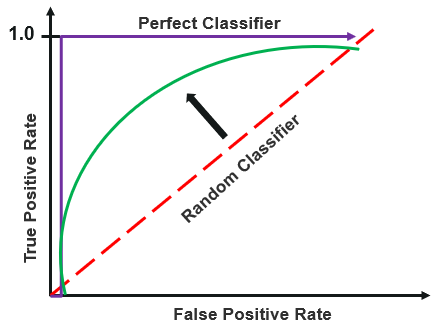
Algorithm Selection
![]()
Apart from the above approach, We can follow the following steps to use the best algorithm for the model
-
Read the data
-
Create dependent and independent data sets based on our dependent and independent features
-
Split the data into training and testing sets
-
Train the model using different algorithms such as KNN, Decision tree, SVM, etc
-
Evaluate the classifier
-
Choose the classifier with the most accuracy.
Although it may take more time than needed to choose the best algorithm suited for your model, accuracy is the best way to go forward to make your model efficient.
Let us take a look at the MNIST data set, and we will use two different algorithms to check which one will suit the model best.
Use Case
What is MNIST?
It is a set of 70,000 small handwritten images labeled with the respective digit that they represent. Each image has almost 784 features, a feature simply represents the pixel’s density and each image is 28×28 pixels.
We will make a digit predictor using the MNIST dataset with the help of different classifiers.
Loading the MNIST dataset
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784')
print(mnist)
Output: 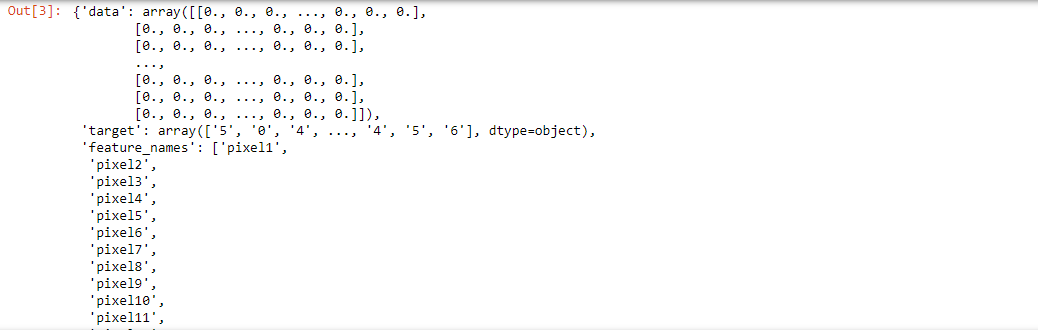
Exploring The Dataset
import matplotlib import matplotlib.pyplot as plt X, y = mnist['data'], mnist['target'] random_digit = X[4800] random_digit_image = random_digit.reshape(28,28) plt.imshow(random_digit_image, cmap=matplotlib.cm.binary, interpolation="nearest")
Output: 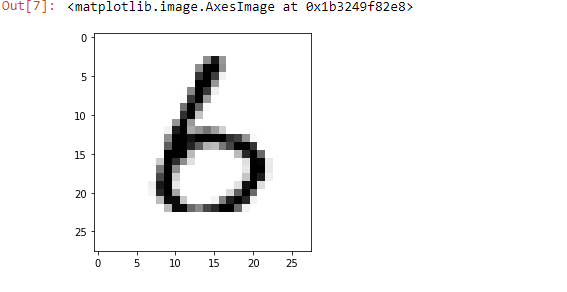
Splitting the Data
We are using the first 6000 entries as the training data, the dataset is as large as 70000 entries. You can check using the shape of the X and y. So to make our model memory efficient, we have only taken 6000 entries as the training set and 1000 entries as a test set.
x_train, x_test = X[:6000], X[6000:7000] y_train, y_test = y[:6000], y[6000:7000]
Shuffling The Data
To avoid unwanted errors, we have shuffled the data using the numpy array. It basically improves the efficiency of the model.
import numpy as np shuffle_index = np.random.permutation(6000) x_train, y_train = x_train[shuffle_index], y_train[shuffle_index]
Creating A Digit Predictor Using Logistic Regression
y_train = y_train.astype(np.int8) y_test = y_test.astype(np.int8) y_train_2 = (y_train==2) y_test_2 = (y_test==2) print(y_test_2)
Output :

from sklearn.linear_model import LogisticRegression clf = LogisticRegression(tol=0.1) clf.fit(x_train,y_train_2) clf.predict([random_digit])
Output: 
Cross-Validation
from sklearn.model_selection import cross_val_score a = cross_val_score(clf, x_train, y_train_2, cv=3, scoring="accuracy") a.mean()
Output:
Creating A Predictor Using Support Vector Machine
from sklearn import svm cls = svm.SVC() cls.fit(x_train, y_train_2) cls.predict([random_digit])
Output: 
Cross-Validation
a = cross_val_score(cls, x_train, y_train_2, cv = 3, scoring="accuracy") a.mean()
Output: 
In the above example, we were able to make a digit predictor. Since we were predicting if the digit were 2 out of all the entries in the data, we got false in both the classifiers, but the cross-validation shows much better accuracy with the logistic regression classifier instead of the support vector machine classifier.
This brings us to the end of this article where we have learned Classification in Machine Learning. I hope you are clear with all that has been shared with you in this tutorial.
Are you wondering how to advance once you know the basics of what Machine Learning is? Take a look at Edureka’s Machine Learning Python Course, which will help you get on the right path to succeed in this fascinating field. You will be prepared for the position of Machine Learning engineer.
You can also take a Machine Learning Course Masters Program. The program will provide you with the most in-depth and practical information on machine-learning applications in real-world situations. Additionally, you’ll learn the essentials needed to be successful in the field of machine learning, such as statistical analysis, Python, and data science.
Also, if you’re looking to develop the career you’re in with Deep learning, you should take a look at the Deep Learning Course. This course gives students information about the techniques, tools, and techniques they need to grow their careers.
We are here to help you with every step on your journey and come up with a curriculum that is designed for students and professionals who want to be a Python developer. The course is designed to give you a head start into Python programming and train you for both core and advanced Python concepts along with various Python frameworks like Django.
If you come across any questions, feel free to ask all your questions in the comments section of “Classification In Machine Learning” and our team will be glad to answer.
Классификация и регрессия с помощью деревьев принятия решений
Время на прочтение
5 мин
Количество просмотров 66K
Введение
В данной статье сделан обзор деревьев принятия решений (Decision trees) и трех основных алгоритмов, использующих эти деревья для построение классификационных и регрессионных моделей. В свою очередь будет показано, как деревья принятия решения, изначально ориентированные на классификацию, используются для регрессии.
Деревья принятия решений
Дерево принятия решений — это дерево, в листьях которого стоят значения целевой функции, а в остальных узлах — условия перехода (к примеру “ПОЛ есть МУЖСКОЙ”), определяющие по какому из ребер идти. Если для данного наблюдения условие истина то осуществляется переход по левому ребру, если же ложь — по правому.
Классификация
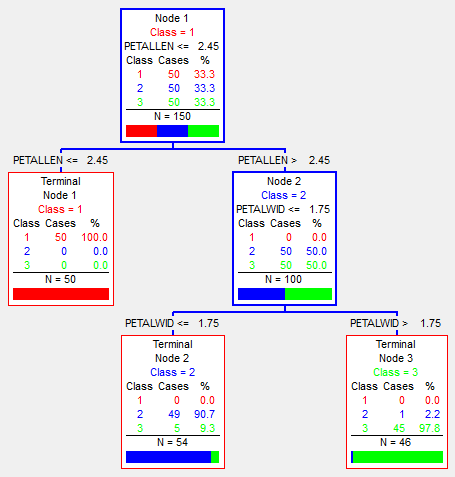
На изображении приведенном выше показано дерево классификации ирисов. Классификация идет на три класса (на изображении помечены — красным, синим и зеленым), и проходит по параметрам: длинатолщина чашелистика (SepalLen, SepalWid) и длинатолщина лепестка (PetalLen, PetalWid). Как видим, в каждом узле стоит его принадлежность к классу (в зависимости от того, каких элементов больше попало в этот узел), количество попавших туда наблюдений N, а так же количество каждого класса. Так же не в листовых вершинах есть условие перехода — в одну из дочерних. Соответственно, по этим условиям и разбивается выборка. В результате, это дерево почти идеально (6 из 150 неправильно) классифицировало исходные данные (именно исходные — те на которых оно обучалось).
Регрессия
Если при классификации в листах стоят результирующие классы, при регрессии же стоит какое-то значение целевой функции.
На выше приведенном изображении регрессионное дерево, для определения цены на землю в городе Бостон в 1978 году, в зависимости от параметров RM — количество комнат, LSTAT — процент неимущих и нескольких других параметров (более детально можно посмотреть в [4]). Соответственно, здесь в каждом узле мы видим среднее значение (Avg) и стандартное отклонение (STD) значений целевой функции наблюдений попавших в эту вершину. Общее количество наблюдений попавших в узел N. Результатом регрессии будет то значение среднего (Avg), в какой узел попадёт наблюдение.
Таким образом изначально классификационное дерево, может работать и для регрессии. Однако при таком подходе, обычно требуются большие размеры дерева, чем при классификации, что бы достигнуть хороших результатов регрессии.
Основные методы
Ниже перечислены несколько основных методов, которые используют деревья принятия решений. Их краткое описание, плюсы и минусы.
CART
CART (англ. Classification and regression trees — Классификационные и регрессионные деревья) был первым из методов, придуманный в 1983 четверкой известных ученых в области анализа данных: Leo Breiman, Jerome Friedman, Richard Olshen and Stone [1].
Суть этого алгоритма состоит в обычном построении дерева принятия решений, не больше и не меньше.
На первой итерации мы строим все возможные (в дискретном смысле) гиперплоскости, которые разбивали бы наше пространство на два. Для каждого такого разбиения пространства считается количество наблюдений в каждом из подпространств разных классов. В результате выбирается такое разбиение, которое максимально выделило в одном из подпространств наблюдения одного из классов. Соответственно, это разбиение будет нашим корнем дерева принятия решений, а листами на данной итерации будет два разбиения.
На следующих итерациях мы берем один худший (в смысле отношения количества наблюдений разных классов) лист и проводим ту же операцию по разбиению его. В результате этот лист становится узлом с каким-то разбиением, и двумя листами.
Продолжаем так делать, пока не достигнем ограничения по количеству узлов, либо от одной итерации к другой перестанет улучшаться общая ошибка (количество неправильно классифицированных наблюдений всем деревом). Однако, полученное дерево будет “переобучено” (будет подогнано под обучающую выборку) и, соответственно, не будет давать нормальные результаты на других данных. Для того, что бы избежать “переобучения”, используют тестовые выборки (либо кросс-валидацию) и, соответственно, проводится обратный анализ (так называемый pruning), когда дерево уменьшают в зависимости от результата на тестовой выборке.
Относительно простой алгоритм, в результате которого получается одно дерево принятия решений. За счет этого, он удобен для первичного анализа данных, к примеру, что бы проверить на наличие связей между переменными и другим.
 Быстрое построение модели
Быстрое построение модели
Легко интерпретируется (из-за простоты модели, можно легко отобразить дерево и проследить за всеми узлами дерева)
 Часто сходится на локальном решении (к примеру, на первом шаге была выбрана гиперплоскость, которая максимально делит пространство на этом шаге, но при этом это не приведёт к оптимальному решению)
Часто сходится на локальном решении (к примеру, на первом шаге была выбрана гиперплоскость, которая максимально делит пространство на этом шаге, но при этом это не приведёт к оптимальному решению)
RandomForest
Random forest (Случайный лес) — метод, придуманный после CART одним из четверки — Leo Breiman в соавторстве с Adele Cutler [2], в основе которого лежит использование комитета (ансамбля) деревьев принятия решений.
Суть алгоритма, что на каждой итерации делается случайная выборка переменных, после чего, на этой новой выборке запускают построение дерева принятия решений. При этом производится “bagging” — выборка случайных двух третей наблюдений для обучения, а оставшаяся треть используется для оценки результата. Такую операцию проделывают сотни или тысячи раз. Результирующая модель будет будет результатом “голосования” набора полученных при моделировании деревьев.
Высокое качество результата, особенно для данных с большим количеством переменных и малым количеством наблюдений.
Возможность распараллелить
Не требуется тестовая выборка
Каждое из деревьев огромное, в результате модель получается огромная
Долгое построение модели, для достижения хороших результатов.
Сложная интерпретация модели (Сотни или тысячи больших деревьев сложны для интерпретации)
Stochastic Gradient Boosting
Stochastic Gradient Boosting (Стохастическое градиентное добавление) — метод анализа данных, представленный Jerome Friedman [3] в 1999 году, и представляющий собой решение задачи регрессии (к которой можно свести классификацию) методом построения комитета (ансамбля) “слабых” предсказывающих деревьев принятия решений.
На первой итерации строится ограниченное по количеству узлов дерево принятия решений. После чего считается разность между тем, что предсказало полученное дерево умноженное на learnrate (коэффициент “слабости” каждого дерева) и искомой переменной на этом шаге.
Yi+1=Yi-Yi*learnrate
И уже по этой разнице строится следующая итерация. Так продолжается, пока результат не перестанет улучшаться. Т.е. на каждом шаге мы пытаемся исправить ошибки предыдущего дерева. Однако здесь лучше использовать проверочные данные (не участвовавшие в моделировании), так как на обучающих данных возможно переобучение.
Высокое качество результата, особенно для данных с большим количеством наблюдений и малым количеством переменных.
Сравнительно (с предыдущим методом) малый размер модели, так как каждое дерево ограничено заданными размерами.
Сравнительно (с предыдущим методом) быстрое время построение оптимальное модели
Требуется тестовая выборка (либо кросс-валидация)
Невозможность хорошо распараллелить
Относительно слабая устойчивость к ошибочным данным и переобучению
Сложная интерпретация модели (Так же как и в Random forest)
Заключение
Как мы увидели у каждого метода есть свои плюсы и минусы, и соответственно, в зависимости от задачи и исходных данных, при решении можно использовать один из трех методов и получить нужный результат. Однако, CART больше используется в университетах для обучения и исследований, когда необходима какая-то чёткая описательная база для решения (как в приведенном выше примере анализа цены земли в Бостоне). А для решения промышленных задач обычно используют один из его потомков — Random Forest или TreeNet.
Перечисленные методы можно найти в многих современных пакетах для анализа данных:
- Salford Predictive Modelling Suite
- SPSS
- SAS
- Пакеты анализа данных для проекта R
Список литературы
- “Classification and Regression Trees”. Breiman L., Friedman J. H., Olshen R. A, Stone C. J.
- “Random Forests”. Breiman L.
- “Stochastic Gradient Boosting”. Friedman J. H.
- http://www.cs.toronto.edu/~delve/data/boston/bostonDetail.html