Завтра искусственный интеллект поработит Землю и станет использовать человеков в качестве смешных батареек, поддерживающих функционирование его систем, а сегодня мы запасаемся попкорном и смотрим, с чего он начинает.
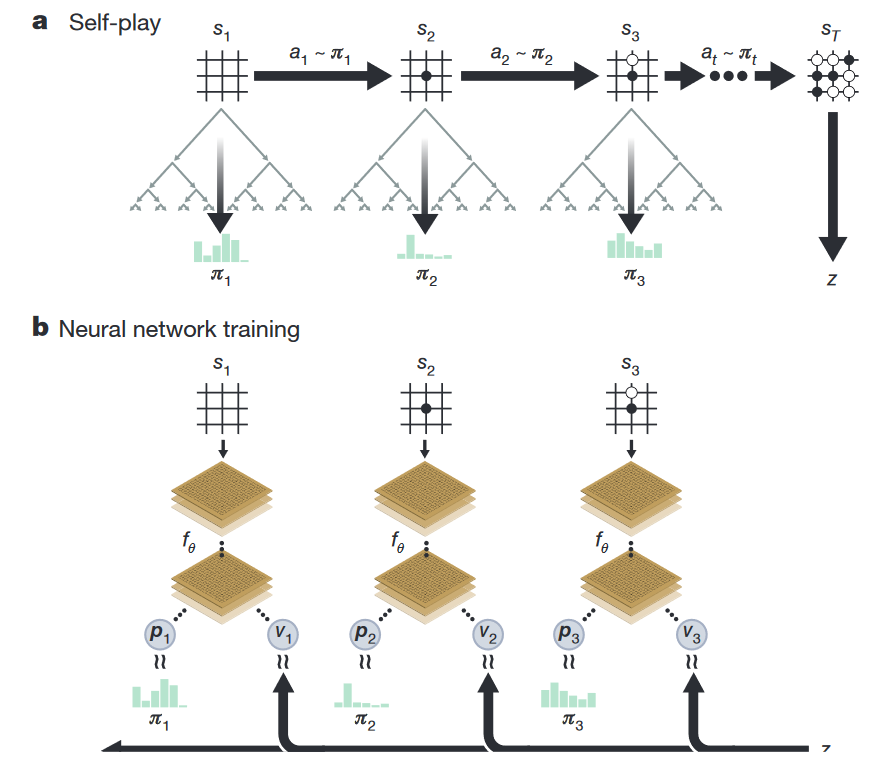
19 октября 2017 года команда Deepmind опубликовала в Nature статью, краткая суть которой сводится к тому, что их новая модель AlphaGo Zero не только разгромно обыгрывает прошлые версии сети, но ещё и не требует никакого человеческого участия в процессе тренировки. Естественно, это заявление произвело в AI-коммьюнити эффект разорвавшейся бомбы, и всем тут же стало интересно, за счёт чего удалось добиться такого успеха.
По мотивам материалов, находящихся в открытом доступе, Семён sim0nsays записал отличный стрим:
А для тех, кому проще два раза прочитать, чем один раз увидеть, я сейчас попробую объяснить всё это буквами.
Сразу хочу отметить, что стрим и статья собирались в значительной степени по мотивам дискуссий на closedcircles.com, отсюда и спектр рассмотренных вопросов, и специфическая манера повествования.
Ну, поехали.
Что такое го?
Го — это древняя (по разным оценкам, ей от 2 до 5 тысяч лет) настольная стратегическая игра. Есть поле, расчерченное перпендикулярными линиями. Есть два игрока, у одного в мешочке белые камни, у другого — чёрные. Игроки по очереди выставляют камни на пересечение линий. Камни одного цвета, окружённые по четырём направлениям камнями другого цвета, снимаются с доски:
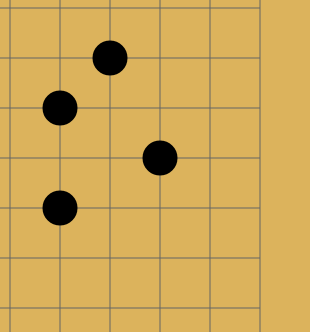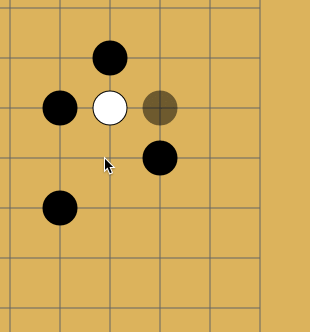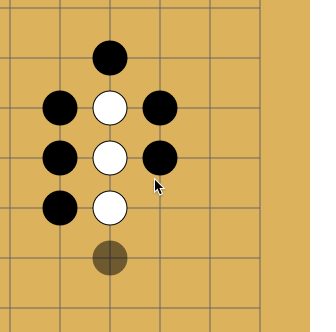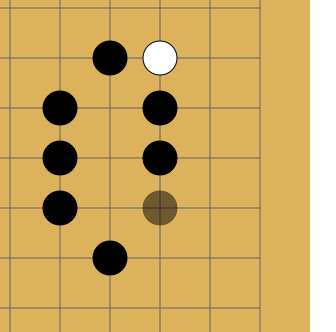
Выигрывает тот, кто к концу партии «окружит» большую по площади территорию. Там есть ещё несколько тонкостей, но базово это всё — человеку, который видит го первый раз в жизни, вполне реально объяснить правила за пять минут.
И почему это считается сложным?
Окей, давай попробуем сравнить несколько настольных игр.
Начнём с шашек. В шашках у игрока есть примерно 10 вариантов того, какой сделать ход. В 1994 году чемпион мира по шашкам был обыгран программой, написанной исследователями из университета Альберты.
Дальше шахматы. В шахматах игрок выбирает в среднем из 20 допустимых ходов и делает такой выбор приблизительно 50 раз за игру. В 1997 году Deep Blue, созданная командой IBM программа, обыграла чемпиона мира по шахматам Гарри Каспарова.
Теперь го. Профессионалы играют в го на поле размера 19х19, что даёт 361 вариант того, куда можно поставить камень. Отсекая откровенно проигрышные ходы и точки, занятые другими камнями, мы всё равно получаем выбор из более чем 200 опций, который требуется совершить в среднем 50-70 раз за партию. Ситуация осложняется тем, что камни взаимодействуют между собой, образуя построения, и в результате камень, поставленный на 35 ходу, может принести пользу только на 115. А может не принести. А чаще всего вообще трудно понять, помог нам этот ход или помешал. Тем не менее, в 2016 году программа AlphaGo обыграла сильнейшего (по меньшей мере, одного из сильнейших) игрока в мире Ли Седоля в серии из пяти игр со счётом 4:1.
Почему на победу в го потребовалось столько времени? Там так много вариантов?
Грубо говоря, да. И в шашках, и в шахматах, и в го общий принцип, по которому работают алгоритмы, один и тот же. Все эти игры попадают в категорию игр с полной информацией, значит, мы можем построить дерево всех возможных состояний игры. Поэтому мы банально строим такое дерево, а дальше просто идём по ветке, которая приводит к победе. Тонкость в том, что для го дерево получается ну очень большим из-за лютого фактора ветвления и впечатляющей глубины, и ни построить, ни обойти его за адекватное время не представлялось возможным. Именно эту проблему смогли решить ребята из DeepMind.
И как они победили?
Тут начинается интересное.
Сначала давай поговорим о том, как работали алгоритмы игры в го до AlphaGo. Все они показывали не самые впечатляющие результаты и успешно играли примерно на уровне среднего любителя, и все опирались на метод под названием Monte Carlo Tree Search — MCTS. Идея в чём (с этим важно разобраться).
У тебя есть дерево состояний — ходов. Из данной конкретной ситуации ты идёшь по какой-то из веток этого дерева, пока она не закончится. Когда ветка заканчивается, добавляешь в неё новый узел (ноду), тем самым инкрементально это дерево достраивая. А потом добавленную ноду оцениваешь, чтобы в дальнейшем определять, стоит ходить по данной ветке или не стоит, не раскрывая само дерево.
Чуть детальнее, это работает следующим образом:
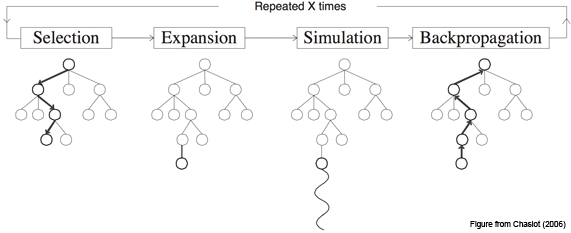
Шаг первый, Selection: у нас есть дерево позиций, и мы каждый раз совершаем ход, выбирая наилучший дочерний узел для текущей позиции.
Шаг второй, Expansion: допустим, мы дошли до конца дерева, но это ещё не конец игры. Просто создаём новую дочернюю ноду и идём в неё.
Шаг третий, Simulation: хорошо, появилась новая нода, фактически, игровая ситуация, в которой мы оказались впервые. Теперь надо её оценить, то есть понять, в хорошей мы оказались ситуации или не очень. Как это сделать? В базовой концепции — используя так называемый rollout: просто сыграть партию (или много партий) из текущей позиции и посмотреть, выиграли мы или проиграли. Получившийся результат и считаем оценкой узла.
Шаг четвёртый, Backpropagation: идём вверх по дереву и увеличиваем или уменьшаем веса всех родительских нод в зависимости от того, хороша новая нода или плоха. Пока важно понять общий принцип, мы ещё успеем рассмотреть данный этап в деталях.
В каждой ноде сохраняем два значения: оценку (value) текущей ноды и количество раз, которое мы по ней пробегали. И повторяем цикл из этих четырёх шагов много-много раз.
Как мы выбираем дочернюю ноду на первом шаге?
В самом простом варианте — берём ноду, у которой будет наивысший показатель Upper Confidence Bounds (UCB):
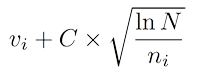
Здесь v — это value нашей ноды, n — сколько раз мы в этой ноде были, N — сколько раз были в родительской ноде, а C — просто некоторый коэффициент.
В не самом простом варианте можно усложнять формулу, чтобы получить более точные результаты, или вообще использовать какую-то другую эвристику, например, нейросеть. Об этом подходе мы тоже ещё поговорим.
Если смотреть чуть шире, перед нами классическая multi-armed bandit problem. Задача — найти такую функцию выбора узла, которая обеспечит оптимальный баланс между использованием лучших из имеющихся вариантов и исследованием новых возможностей.
Почему это работает?
Потому что с MCTS дерево решений растёт асимметрично: более интересные ноды посещаются чаще, менее интересные — реже, а оценить отдельно взятую ноду становится возможным без раскрытия всего дерева.

Это имеет какое-то отношение к AlphaGo?
В общем и целом, AlphaGo опирается на те же самые принципы. Ключевое отличие — когда на втором этапе мы добавляем новую ноду, для того, чтобы определить, насколько она хорошая, вместо rollout’ов используем нейросеть. Как мы это делаем.
(Я совсем в двух словах расскажу про прошлую версию AlphaGo, хотя на самом деле в ней хватает интересных нюансов; кто хочет подробностей — вэлком в видео в начале, там они хорошо объясняются, или в соответствующий пост на хабре, там они хорошо расписаны).
Во-первых, тренируем две сети, каждая из которых получает на вход состояние доски и говорит, какой бы ход в этой ситуации сделал человек. Почему две? Потому что одна — медленная, но работает хорошо (57% верных предсказаний, и каждый дополнительный процент даёт очень солидный бонус к итоговому результату), а вторая обладает намного меньшей точностью, зато быстрая.
Обе эти сети, медленную и быструю, мы тренируем на человеческих ходах — банально идём на сервер го, забираем партии игроков хорошего уровня, парсим и скармливаем для обучения.
Во-вторых, берём две эти натренированные «на людях» сети и начинаем играть ими сами с собой, чтобы их прокачать.

Примерно так.
В-третьих, тренируем value-сеть, которая получает на вход текущее состояние доски, а в ответ отдаёт число от -1 до 1 — вероятность выиграть, оказавшись в этой позиции в какой-то момент партии.
Таким образом, у нас есть одна медленная и точная функция, которая говорит, куда надо ходить (из шага 2), одна быстрая функция, которая делает то же самое, хоть и не так хорошо (опять же из шага 2), и третья функция, которая, глядя на доску, говорит, проиграешь ты или выиграешь, если окажешься в этой ситуации (из шага 3). Всё, теперь мы играем по MCTS и используем первую, чтобы посмотреть, в какие ноды следует соваться из текущей, вторую — чтобы очень быстро просимулировать rollout из текущей позиции, а третью — чтобы напрямую без rollout’а оценить, насколько хороша нода, в которую мы сунулись. Для итоговой value значения, выданные второй и третьей сетями, просто складываются. В результате мы и очень сильно урезаем фактор ветвления, и можем для оценки узла не лезть вниз по дереву (а если лезем, то быстро-быстро).
И это работает прям сильно лучше, чем вариант без нейросетей?
Да, внезапно этого оказывается достаточно.
В октябре 2015 AlphaGo играет с трёхкратным чемпионом Европы Fan Hui и обыгрывает его со счётом 5:0. Событие, с одной стороны, большое, потому что впервые компьютер выигрывает у профессионала в равных условиях, а с другой — не очень, потому что в мире го чемпион Европы — это примерно чемпион водокачки, и тот же Fan Hui обладает всего лишь вторым профессиональным даном (из девяти возможных). Версия AlphaGo, которая играла в этом матче, получила внутреннее название AlphaGo Fan.
А вот в марте 2016 новая версия AlphaGo играет пять партий уже с одним из лучших игроков мира Lee Sedol и выигрывает со счётом 4:1. Забавно, но сразу после игр в медиа к Ли Седолю стали относиться как к первому топ-игроку, проигравшему ИИ, хотя время расставило всё по местам и на сегодня Седоль остаётся (и, вероятно, останется навсегда) последним человеком, обыгравшим компьютер. Но я забегаю вперёд. Эта версия AlphaGo в дальнейшем стала обозначаться AlphaGo Lee.

Хорошая попытка, Ли, но нет.
После этого, в конце 2016 и начале 2017, уже следующая версия AlphaGo (AlphaGo Master) играет 60 матчей в онлайне с игроками из топовых позиций мирового рейтинга и выигрывает с общим счётом 60:0. В мае AlphaGo Master играет с топ-1 мирового рейтинга Ke Jie и обыгрывает его со счётом 3:0. Собственно, всё, противостояние человека и компьютера в го завершено.
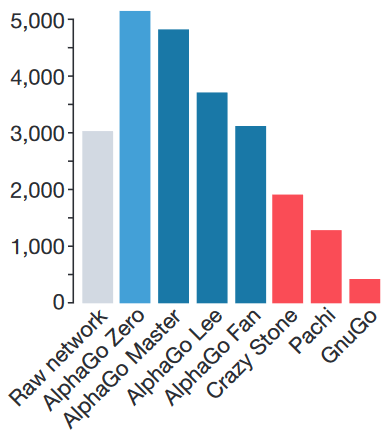
Рейтинг ELO. GnuGo, Pachi и CrazyStone — боты, написанные без использования нейросетей.
Но раз они и так всех обыграли, зачем понадобилась ещё одна сеть?
Если коротко — для красоты. У сообщества были три относительно большие претензии к AlphaGo:
1) Для стартового обучения используются игры людей. Получается, что без человеческого интеллекта искусственный интеллект не работает.
2) Много заинженеренных фич. Я опустил этот момент в своём пересказе, но в видео и в посте про AlphaGo Lee ему уделяется достаточно внимания, — обе используемые сети получают на вход значительное количество фич, придуманных людьми. Сами по себе эти фичи никакой новой информации не несут и могут быть вычислены, исходя из положения камней на доске, но вот без них сети не справляются. Например, сеть, которая определяет следующий ход, помимо непосредственно стейта получает следующее:
- сколько ходов назад был поставлен тот или иной камень;
- сколько свободных точек вокруг данного камня;
- сколько своих камней ты пожертвуешь, если сходишь в данную точку;
- легален ли вообще данный ход, то есть позволяется ли он правилами го;
- поучаствует ли камень, поставленный в эту точку, в так называемом “лестничном” построении;
и так далее — в общей сложности 48 слоёв с информацией. А “быстрой” сети, которая предсказывает вероятность победы, и вовсе отдают на вход сто с лишним тысяч заготовленных параметров. Получается, модель учится не играть в го per se, а показывать результаты в некотором заранее очень хорошо подготовленном окружении с большим количеством свойств, о которых ей рассказывает опять же человек.
3) Нужен здоровый кластер, чтобы всё это запустить.
И вот буквально месяц назад Deepmind представили новую версию алгоритма, AlphaGo Zero, в котором все эти проблемы устранены — модель учится с нуля, играя исключительно сама с собой и используя случайные веса нейросети в качестве стартовых; использует только положение камней на доске, чтобы принять решение; и сильно проще по требованиям к железу. Приятным бонусом она обыгрывает AlphaGo Lee в противостоянии из ста партий с общим счётом 100:0.
Так, и что для этого пришлось сделать?
Две большие штуки.
Во-первых, объединить две сети из прошлых версий AlphaGo в одну. Она получает состояние доски с небольшим количеством фич (я расскажу о них чуть позже), прогоняет всё это добро через свои слои, и в конце два её выхода выдают два результата: policy-выход выдаёт массив 19х19, который показывает, насколько вероятен каждый из ходов из данной позиции, а value выдаёт одно число — вероятность выиграть партию, опять же из данной позиции.
Во-вторых, поменять сам RL-алгоритм. Если раньше непосредственно MCTS использовался только во время игры, то теперь он используется сразу при тренировке. Как это работает.
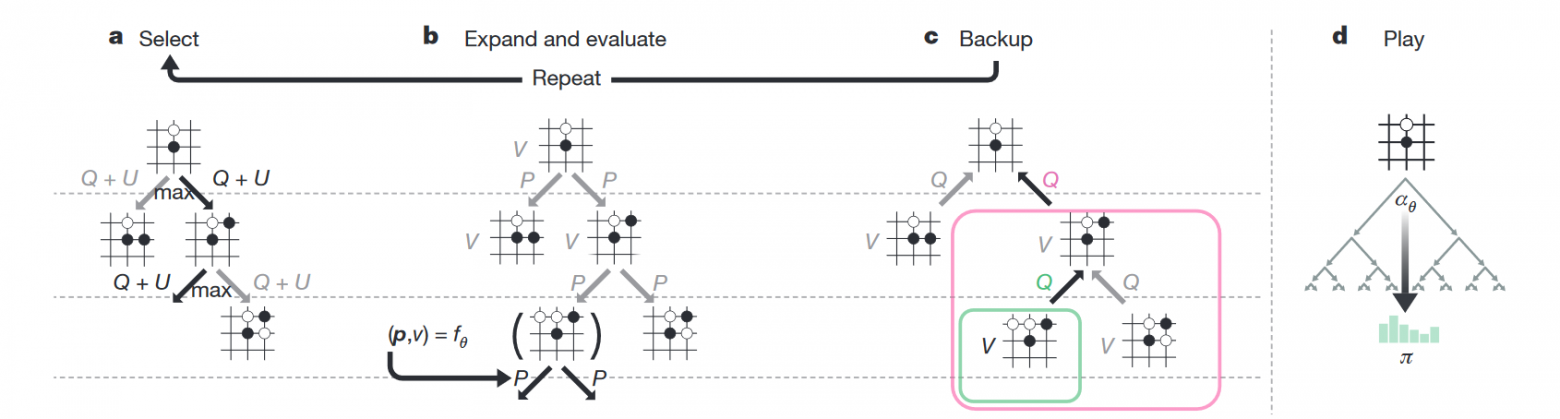
В каждой ноде дерева состояний хранится четыре значения — N (сколько раз мы ходили по этой ноде), V (value этой ноды), Q (усреднённое value всех дочерних нод этой ноды) и P (вероятность, что из всех допустимых на данном ходу нод мы выберем именно эту). Когда сеть играет сама с собой, во время каждого хода она производит следующие симуляции:
- Берёт дерево, корнем которого является текущая нода.
- Идёт в ту дочернюю ноду, где больше Q + U (U — добавка, стимулирующая поиск новых путей; она больше в начале тренировки и меньше — в дальнейшем).
- Таким нехитрым образом доходит до конца дерева — состояния, когда дочерних узлов нет, а игра ещё не закончена.
- Отдаёт это состояние на вход нейросети, в ответ получает v (value текущей ноды) и p (вероятности следующих ходов).
- Записывает v в ноду.
- Создаёт дочерние ноды с P согласно p и нулевыми N, V и Q.
- Обновляет все ноды выше текущей, которые были выбраны во время симуляции, следующим образом: N := N + 1; V := V + v; Q := V / N.
- Повторяет цикл 1-7 1600 раз.
Практика показывает, что такая симуляция выдаёт намного более сильные предсказания, нежели базовая нейросеть.
А дальше ход, который сеть действительно сделает, выбирается одним из двух способов:
— Если это реальная игра, идём туда, где больше N (выяснилось, что такая метрика оказывается самой надёжной);
— Если просто тренировка, выбираем ход из распределения Pi ~ N ^ (1/T), где T — просто некоторая температура для контроля баланса между исследованием и эффективностью.
То, что и policy, и value предсказываются одной общей сетью, даёт возможность крайне эффективно всё это запускать. Мы один раз оказались в какой-то ноде, отдали эту ноду в нашу сеть, получили некоторый результат V, все P запомнили, как изначальные веса на дочерних нодах, и всё, больше для этой ноды сеть не задействуем, сколько бы раз через неё ни ходили, а rollout’ов не запускаем вообще, считая, что предсказанный результат и так достаточно точен. Красота.
Как тренировать сеть, которая должна предсказывать и policy, и value?
Тренируется всё это дело, используя вот такой лосс:
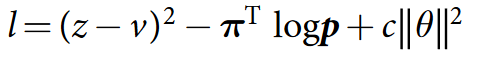
Что это, Бэрримор?
Формула состоит из трёх частей.
В первой части мы говорим, что сеть должна уметь предсказать результат, то есть z (то, с каким результатом закончилась партия) не должно отличаться от v (того value, которое она предсказала).
Во второй части в качестве лейблов для policy используем наши улучшенные вероятности. Это как reward в supervised learning’е — мы хотим как можно точнее предсказать те вероятности, которые получим, пробегаясь по дереву; очень похоже на cross-entropy loss.
Третья часть, c в конце формулы — просто регуляризатор.
Более глобально, у нас есть некоторая «наилучшая» сеть с весами А. Эта сеть A играет сама с собой 25 000 раз (используя MCTS со своими весами для оценки новых нод), и для каждого хода мы сохраняем сам стейт, распределение Pi и то, чем закончилась игра (+1 за победу и -1 за поражение). Дальше готовим батчи из 2048 случайных позиций из последних 500 000 игр, отдаём 1000 таких батчей на тренировку и получаем некоторую новую сеть с весами B, после чего сеть A играет 400 игр с сетью B — при этом обе сети используют MCTS для выбора хода, только при оценке новой ноды A, очевидно, использует свои веса, а B — свои. Если B побеждает более, чем в 55% случаев, она становится лучшей сетью, если нет — чемпион остаётся прежним. Повторять до готовности.
И ты ещё обещал рассказать про фичи, которые подаются на вход.
Ага, было такое. Итак, на вход подаётся поле 19х19, каждый пиксель которого имеет 17 каналов, итого получаем 19х19х17. 17 слоёв нужны для следующего.
Первый говорит, находится ли в данной точке твой камень или нет (1 — стоит, 0 — отсутствует), а дальнейшие семь — находился ли он тут в какой-то из предыдущих семи ходов.
Зачем это нужно
Дело в том, что в го запрещены повторения — в ряде случаев ты не можешь поставить камень туда, где он уже стоял. Как на картинке:
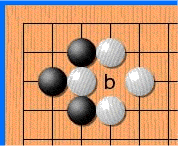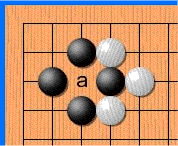
Не знаю, почему, но хабр иногда отказывается проигрывать эту гифку. Если так и произошло и ты не видишь анимации — просто кликни на неё.
Белые делают ход в точку a и забирают камень чёрных. Чёрные делают ход в точку b и забирают камень белых. Без запрета повторений оппоненты могли бы сидеть и играть последовательность a—b до бесконечности. В реальности же белые не могут сразу повторно сходить в позицию a и должны выбрать другой ход (а вот уже после какого-то иного хода сходить в позицию a разрешено). Именно для того, чтобы сеть могла научиться этому правилу, ей и передают историю. Вторая причина — в АМА на реддите разработчики рассказывали, что когда сеть видит, где в последнее время была активность, она лучше учится. По мысли это чем-то похоже на attention.
Следующие восемь слоёв — то же самое, но для камней оппонента.
Последний, семнадцатый, слой забит единицами, если ты играешь чёрными, и нулями, если играешь белыми. Это нужно, потому что при финальном подсчёте очков белые получают небольшой бонус за то, что ходят вторыми.
Вот и всё, по факту сеть действительно видит только состояние доски, но с информацией о том, камнями какого цвета она играет, и историей на восемь ходов.
А что с архитектурой?
Convolutional layer, потом 40 residual layer’ов, в конце два выхода — value head и policy head. Я не хочу останавливаться на этом подробно, кому важно — посмотрит сам, а всем остальным конкретные слои вряд ли интересны. Если резюмировать, по сравнению с версией Lee сеть стала больше, добавили batch normalization и появились residual connection. Нововведения очень стандартные, очень мейнстримовые, какого-то отдельного rocket science здесь нет.
И всё это чтобы что?
И всё это привело вот к таким результатам.
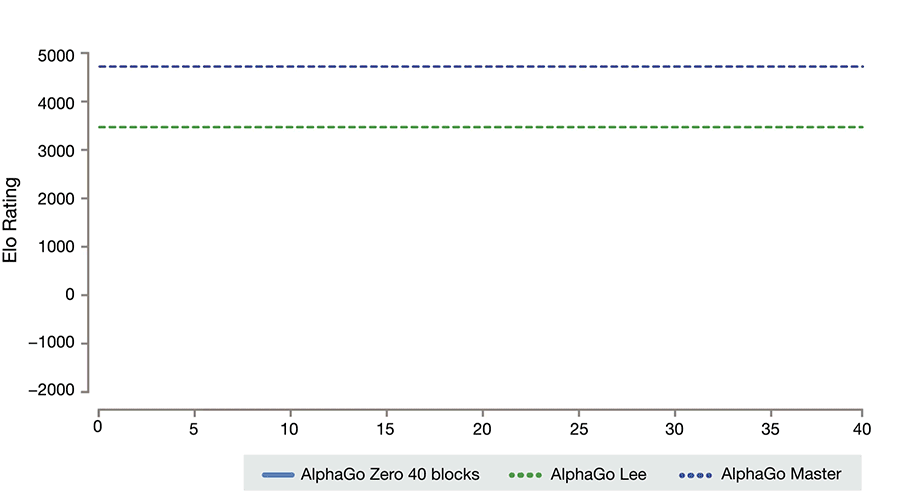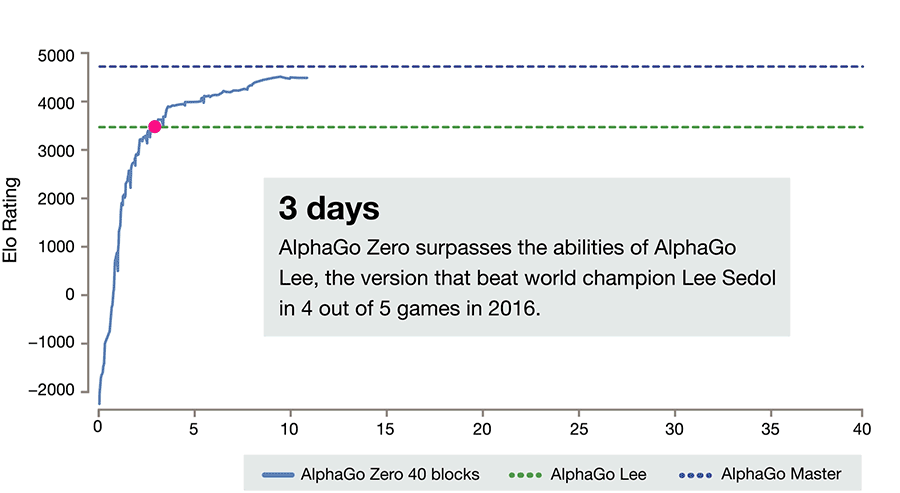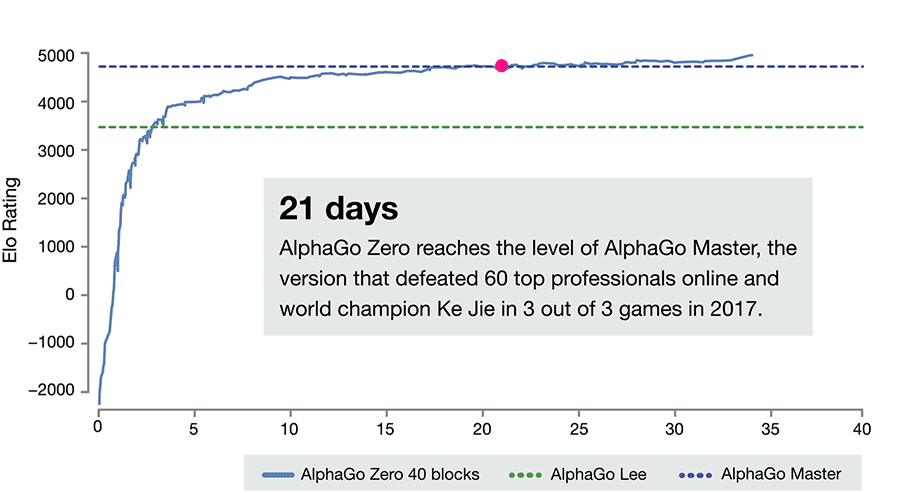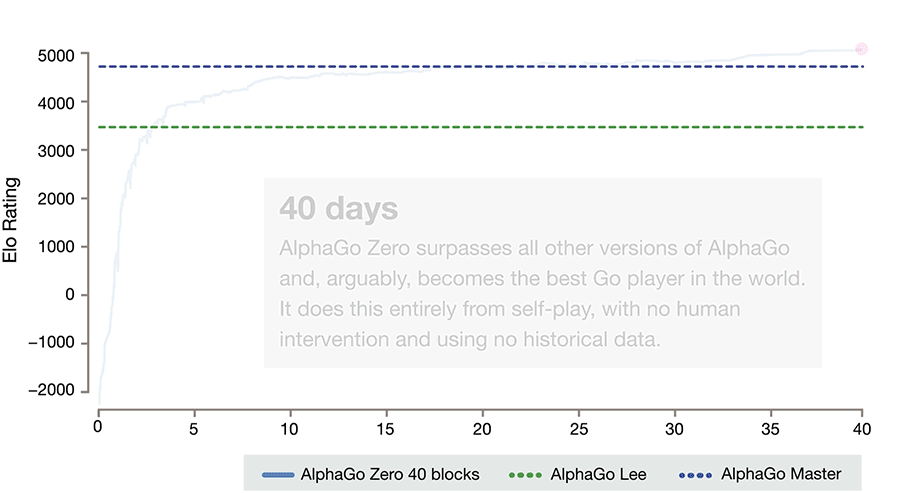
За три дня AlphaGo Zero учится обыгрывать версию Lee, за 21 — Master, а дальше отправляется в космос. После 40 дней тренировки она обыгрывает версию Lee со счётом 100:0 и версию Master со счётом 89:11. В этом свете интересно отметить, что у Master и Zero идентичный алгоритм тренировки, идентичная архитектура, а все отличия заключаются в фичах, подаваемых на вход, и том, что Zero не тренируется на играх людей. И выигрывает.
То есть всё, компьютер умнее, у человечества шансов нет?
В го — похоже, что да, мы официально в хурме. В общем случае, нет. У го есть несколько особенностей, крайне важных для текущих методов обучения:
- Всегда точно определённая среда, для которой есть идеальный и простой симулятор; никаких случайностей, никаких внешних вмешательств.
- Го — игра с полной информацией. Немножко похоже на предыдущий пункт, но тем не менее — нам известно абсолютно всё, что происходит.
В среде, жёстко ограниченной этими рамками, мы научились строить системы, эффективность которых значительно превышает человеческую. Стоит за рамки немножко выйти, и всё становится сильно сложнее. Поподробнее можно почитать в посте Andrej Karpathy.
А следующий бастион какой?
В играх — Starcraft и DotA. В обоих направлениях ведётся активная работа, но пока без прорывов сравнимого масштаба. Ждём.
Ух! Кажется, немножко понятно. Что ещё можно посмотреть по теме?
Во-первых, посмотри видео в начале этого поста, оно крутое и охватывает многие вопросы, которые я скипнул.
Во-вторых, почитай пост Семёна про AlphaGo Lee.
В-третьих, приходи в канал #data на closedcircles.com, мы там активно всё это обсуждаем.
В-четвёртых, всё, что я сейчас рассказал про AGZ, есть на одной картинке.
И давай финалочку.
Я закончу этот пост последним параграфом оригинального пейпера:
Humankind has accumulated Go knowledge from millions of games played over thousands of years, collectively distilled into patterns, proverbs and books. In the space of a few days, starting tabula rasa, AlphaGo Zero was able to rediscover much of this Go knowledge, as well as novel strategies that provide new insights into the oldest of games.
Просто подумай об этом.
Спасибо всем, у кого хватило терпения доскроллить до этого места. Отдельная благодарность пользователям sim0nsays за контент и комментарии и buriy за помощь в вычитке.
This article is about a computer program. For the film, see AlphaGo (film).
![]()
AlphaGo is a computer program that plays the board game Go.[1] It was developed by the London-based DeepMind Technologies,[2] an acquired subsidiary of Google (now Alphabet Inc.). Subsequent versions of AlphaGo became increasingly powerful, including a version that competed under the name Master.[3] After retiring from competitive play, AlphaGo Master was succeeded by an even more powerful version known as AlphaGo Zero, which was completely self-taught without learning from human games. AlphaGo Zero was then generalized into a program known as AlphaZero, which played additional games, including chess and shogi. AlphaZero has in turn been succeeded by a program known as MuZero which learns without being taught the rules.
AlphaGo and its successors use a Monte Carlo tree search algorithm to find its moves based on knowledge previously acquired by machine learning, specifically by an artificial neural network (a deep learning method) by extensive training, both from human and computer play.[4] A neural network is trained to identify the best moves and the winning percentages of these moves. This neural network improves the strength of the tree search, resulting in stronger move selection in the next iteration.
In October 2015, in a match against Fan Hui, the original AlphaGo became the first computer Go program to beat a human professional Go player without handicap on a full-sized 19×19 board.[5][6] In March 2016, it beat Lee Sedol in a five-game match, the first time a computer Go program has beaten a 9-dan professional without handicap.[7] Although it lost to Lee Sedol in the fourth game, Lee resigned in the final game, giving a final score of 4 games to 1 in favour of AlphaGo. In recognition of the victory, AlphaGo was awarded an honorary 9-dan by the Korea Baduk Association.[8] The lead up and the challenge match with Lee Sedol were documented in a documentary film also titled AlphaGo,[9] directed by Greg Kohs. The win by AlphaGo was chosen by Science as one of the Breakthrough of the Year runners-up on 22 December 2016.[10]
At the 2017 Future of Go Summit, the Master version of AlphaGo beat Ke Jie, the number one ranked player in the world at the time, in a three-game match, after which AlphaGo was awarded professional 9-dan by the Chinese Weiqi Association.[11]
After the match between AlphaGo and Ke Jie, DeepMind retired AlphaGo, while continuing AI research in other areas.[12] The self-taught AlphaGo Zero achieved a 100–0 victory against the early competitive version of AlphaGo, and its successor AlphaZero is currently perceived as the world’s top player in Go.[13][14]
History[edit]
Go is considered much more difficult for computers to win than other games such as chess, because its strategic and aesthetic nature makes it hard to directly construct an evaluation function, and its much larger branching factor makes it prohibitively difficult to use traditional AI methods such as alpha–beta pruning, tree traversal and heuristic search.[5][15]
Almost two decades after IBM’s computer Deep Blue beat world chess champion Garry Kasparov in the 1997 match, the strongest Go programs using artificial intelligence techniques only reached about amateur 5-dan level,[4] and still could not beat a professional Go player without a handicap.[5][6][16] In 2012, the software program Zen, running on a four PC cluster, beat Masaki Takemiya (9p) twice at five- and four-stone handicaps.[17] In 2013, Crazy Stone beat Yoshio Ishida (9p) at a four-stone handicap.[18]
According to DeepMind’s David Silver, the AlphaGo research project was formed around 2014 to test how well a neural network using deep learning can compete at Go.[19] AlphaGo represents a significant improvement over previous Go programs. In 500 games against other available Go programs, including Crazy Stone and Zen, AlphaGo running on a single computer won all but one.[20] In a similar matchup, AlphaGo running on multiple computers won all 500 games played against other Go programs, and 77% of games played against AlphaGo running on a single computer. The distributed version in October 2015 was using 1,202 CPUs and 176 GPUs.[4]
Match against Fan Hui[edit]
In October 2015, the distributed version of AlphaGo defeated the European Go champion Fan Hui,[21] a 2-dan (out of 9 dan possible) professional, five to zero.[6][22] This was the first time a computer Go program had beaten a professional human player on a full-sized board without handicap.[23] The announcement of the news was delayed until 27 January 2016 to coincide with the publication of a paper in the journal Nature[4] describing the algorithms used.[6]
Match against Lee Sedol[edit]
AlphaGo played South Korean professional Go player Lee Sedol, ranked 9-dan, one of the best players at Go,[16][needs update] with five games taking place at the Four Seasons Hotel in Seoul, South Korea on 9, 10, 12, 13, and 15 March 2016,[24][25] which were video-streamed live.[26] Out of five games, AlphaGo won four games and Lee won the fourth game which made him recorded as the only human player who beat AlphaGo in all of its 74 official games.[27] AlphaGo ran on Google’s cloud computing with its servers located in the United States.[28] The match used Chinese rules with a 7.5-point komi, and each side had two hours of thinking time plus three 60-second byoyomi periods.[29] The version of AlphaGo playing against Lee used a similar amount of computing power as was used in the Fan Hui match.[30] The Economist reported that it used 1,920 CPUs and 280 GPUs.[31] At the time of play, Lee Sedol had the second-highest number of Go international championship victories in the world after South Korean player Lee Changho who kept the world championship title for 16 years.[32] Since there is no single official method of ranking in international Go, the rankings may vary among the sources. While he was ranked top sometimes, some sources ranked Lee Sedol as the fourth-best player in the world at the time.[33][34] AlphaGo was not specifically trained to face Lee nor was designed to compete with any specific human players.
The first three games were won by AlphaGo following resignations by Lee.[35][36] However, Lee beat AlphaGo in the fourth game, winning by resignation at move 180. AlphaGo then continued to achieve a fourth win, winning the fifth game by resignation.[37]
The prize was US$1 million. Since AlphaGo won four out of five and thus the series, the prize will be donated to charities, including UNICEF.[38] Lee Sedol received $150,000 for participating in all five games and an additional $20,000 for his win in Game 4.[29]
In June 2016, at a presentation held at a university in the Netherlands, Aja Huang, one of the Deep Mind team, revealed that they had patched the logical weakness that occurred during the 4th game of the match between AlphaGo and Lee, and that after move 78 (which was dubbed the «divine move» by many professionals), it would play as intended and maintain Black’s advantage. Before move 78, AlphaGo was leading throughout the game, but Lee’s move caused the program’s computing powers to be diverted and confused.[39] Huang explained that AlphaGo’s policy network of finding the most accurate move order and continuation did not precisely guide AlphaGo to make the correct continuation after move 78, since its value network did not determine Lee’s 78th move as being the most likely, and therefore when the move was made AlphaGo could not make the right adjustment to the logical continuation.[40]
Sixty online games[edit]
On 29 December 2016, a new account on the Tygem server named «Magister» (shown as ‘Magist’ at the server’s Chinese version) from South Korea began to play games with professional players. It changed its account name to «Master» on 30 December, then moved to the FoxGo server on 1 January 2017. On 4 January, DeepMind confirmed that the «Magister» and the «Master» were both played by an updated version of AlphaGo, called AlphaGo Master.[41][42] As of 5 January 2017, AlphaGo Master’s online record was 60 wins and 0 losses,[43] including three victories over Go’s top-ranked player, Ke Jie,[44] who had been quietly briefed in advance that Master was a version of AlphaGo.[43] After losing to Master, Gu Li offered a bounty of 100,000 yuan (US$14,400) to the first human player who could defeat Master.[42] Master played at the pace of 10 games per day. Many quickly suspected it to be an AI player due to little or no resting between games. Its adversaries included many world champions such as Ke Jie, Park Jeong-hwan, Yuta Iyama, Tuo Jiaxi, Mi Yuting, Shi Yue, Chen Yaoye, Li Qincheng, Gu Li, Chang Hao, Tang Weixing, Fan Tingyu, Zhou Ruiyang, Jiang Weijie, Chou Chun-hsun, Kim Ji-seok, Kang Dong-yun, Park Yeong-hun, and Won Seong-jin; national champions or world championship runners-up such as Lian Xiao, Tan Xiao, Meng Tailing, Dang Yifei, Huang Yunsong, Yang Dingxin, Gu Zihao, Shin Jinseo, Cho Han-seung, and An Sungjoon. All 60 games except one were fast-paced games with three 20 or 30 seconds byo-yomi. Master offered to extend the byo-yomi to one minute when playing with Nie Weiping in consideration of his age. After winning its 59th game Master revealed itself in the chatroom to be controlled by Dr. Aja Huang of the DeepMind team,[45] then changed its nationality to the United Kingdom. After these games were completed, the co-founder of DeepMind, Demis Hassabis, said in a tweet, «we’re looking forward to playing some official, full-length games later [2017] in collaboration with Go organizations and experts».[41][42]
Go experts were impressed by the program’s performance and its nonhuman play style; Ke Jie stated that «After humanity spent thousands of years improving our tactics, computers tell us that humans are completely wrong… I would go as far as to say not a single human has touched the edge of the truth of Go.»[43]
Future of Go Summit[edit]
In the Future of Go Summit held in Wuzhen in May 2017, AlphaGo Master played three games with Ke Jie, the world No.1 ranked player, as well as two games with several top Chinese professionals, one pair Go game and one against a collaborating team of five human players.[46]
Google DeepMind offered 1.5 million dollar winner prizes for the three-game match between Ke Jie and Master while the losing side took 300,000 dollars.[47][48] Master won all three games against Ke Jie,[49][50] after which AlphaGo was awarded professional 9-dan by the Chinese Weiqi Association.[11]
After winning its three-game match against Ke Jie, the top-rated world Go player, AlphaGo retired. DeepMind also disbanded the team that worked on the game to focus on AI research in other areas.[12] After the Summit, Deepmind published 50 full length AlphaGo vs AlphaGo matches, as a gift to the Go community.[51]
AlphaGo Zero and AlphaZero[edit]
AlphaGo’s team published an article in the journal Nature on 19 October 2017, introducing AlphaGo Zero, a version without human data and stronger than any previous human-champion-defeating version.[52] By playing games against itself, AlphaGo Zero surpassed the strength of AlphaGo Lee in three days by winning 100 games to 0, reached the level of AlphaGo Master in 21 days, and exceeded all the old versions in 40 days.[53]
In a paper released on arXiv on 5 December 2017, DeepMind claimed that it generalized AlphaGo Zero’s approach into a single AlphaZero algorithm, which achieved within 24 hours a superhuman level of play in the games of chess, shogi, and Go by defeating world-champion programs, Stockfish, Elmo, and 3-day version of AlphaGo Zero in each case.[54]
Teaching tool[edit]
On 11 December 2017, DeepMind released AlphaGo teaching tool on its website[55] to analyze winning rates of different Go openings as calculated by AlphaGo Master.[56] The teaching tool collects 6,000 Go openings from 230,000 human games each analyzed with 10,000,000 simulations by AlphaGo Master. Many of the openings include human move suggestions.[56]
Versions[edit]
An early version of AlphaGo was tested on hardware with various numbers of CPUs and GPUs, running in asynchronous or distributed mode. Two seconds of thinking time was given to each move. The resulting Elo ratings are listed below.[4] In the matches with more time per move higher ratings are achieved.
| Configuration | Search threads |
No. of CPU | No. of GPU | Elo rating |
|---|---|---|---|---|
| Single[4] p. 10–11 | 40 | 48 | 1 | 2,181 |
| Single | 40 | 48 | 2 | 2,738 |
| Single | 40 | 48 | 4 | 2,850 |
| Single | 40 | 48 | 8 | 2,890 |
| Distributed | 12 | 428 | 64 | 2,937 |
| Distributed | 24 | 764 | 112 | 3,079 |
| Distributed | 40 | 1,202 | 176 | 3,140 |
| Distributed | 64 | 1,920 | 280 | 3,168 |
In May 2016, Google unveiled its own proprietary hardware «tensor processing units», which it stated had already been deployed in multiple internal projects at Google, including the AlphaGo match against Lee Sedol.[57][58]
In the Future of Go Summit in May 2017, DeepMind disclosed that the version of AlphaGo used in this Summit was AlphaGo Master,[59][60] and revealed that it had measured the strength of different versions of the software. AlphaGo Lee, the version used against Lee, could give AlphaGo Fan, the version used in AlphaGo vs. Fan Hui, three stones, and AlphaGo Master was even three stones stronger.[61]
| Versions | Hardware | Elo rating | Date | Results |
|---|---|---|---|---|
| AlphaGo Fan | 176 GPUs,[53] distributed | 3,144[52] | Oct 2015 | 5:0 against Fan Hui |
| AlphaGo Lee | 48 TPUs,[53] distributed | 3,739[52] | Mar 2016 | 4:1 against Lee Sedol |
| AlphaGo Master | 4 TPUs,[53] single machine | 4,858[52] | May 2017 | 60:0 against professional players; Future of Go Summit |
| AlphaGo Zero (40 block) | 4 TPUs,[53] single machine | 5,185[52] | Oct 2017 | 100:0 against AlphaGo Lee
89:11 against AlphaGo Master |
| AlphaZero (20 block) | 4 TPUs, single machine | 5,018
[63] |
Dec 2017 | 60:40 against AlphaGo Zero (20 block) |
Algorithm[edit]
As of 2016, AlphaGo’s algorithm uses a combination of machine learning and tree search techniques, combined with extensive training, both from human and computer play. It uses Monte Carlo tree search, guided by a «value network» and a «policy network,» both implemented using deep neural network technology.[5][4] A limited amount of game-specific feature detection pre-processing (for example, to highlight whether a move matches a nakade pattern) is applied to the input before it is sent to the neural networks.[4] The networks are convolutional neural networks with 12 layers, trained by reinforcement learning.[64]
The system’s neural networks were initially bootstrapped from human gameplay expertise. AlphaGo was initially trained to mimic human play by attempting to match the moves of expert players from recorded historical games, using a database of around 30 million moves.[21] Once it had reached a certain degree of proficiency, it was trained further by being set to play large numbers of games against other instances of itself, using reinforcement learning to improve its play.[5] To avoid «disrespectfully» wasting its opponent’s time, the program is specifically programmed to resign if its assessment of win probability falls beneath a certain threshold; for the match against Lee, the resignation threshold was set to 20%.[65]
Style of play[edit]
Toby Manning, the match referee for AlphaGo vs. Fan Hui, has described the program’s style as «conservative».[66] AlphaGo’s playing style strongly favours greater probability of winning by fewer points over lesser probability of winning by more points.[19] Its strategy of maximising its probability of winning is distinct from what human players tend to do which is to maximise territorial gains, and explains some of its odd-looking moves.[67] It makes a lot of opening moves that have never or seldom been made by humans. It likes to use shoulder hits, especially if the opponent is over concentrated.[citation needed]
Responses to 2016 victory[edit]
[edit]
AlphaGo’s March 2016 victory was a major milestone in artificial intelligence research.[68] Go had previously been regarded as a hard problem in machine learning that was expected to be out of reach for the technology of the time.[68][69][70] Most experts thought a Go program as powerful as AlphaGo was at least five years away;[71] some experts thought that it would take at least another decade before computers would beat Go champions.[4][72][73] Most observers at the beginning of the 2016 matches expected Lee to beat AlphaGo.[68]
With games such as checkers (that has been «solved» by the Chinook draughts player team), chess, and now Go won by computers, victories at popular board games can no longer serve as major milestones for artificial intelligence in the way that they used to. Deep Blue’s Murray Campbell called AlphaGo’s victory «the end of an era… board games are more or less done and it’s time to move on.»[68]
When compared with Deep Blue or Watson, AlphaGo’s underlying algorithms are potentially more general-purpose and may be evidence that the scientific community is making progress towards artificial general intelligence.[19][74] Some commentators believe AlphaGo’s victory makes for a good opportunity for society to start preparing for the possible future impact of machines with general purpose intelligence. As noted by entrepreneur Guy Suter, AlphaGo only knows how to play Go and doesn’t possess general-purpose intelligence; «[It] couldn’t just wake up one morning and decide it wants to learn how to use firearms.»[68] AI researcher Stuart Russell said that AI systems such as AlphaGo have progressed quicker and become more powerful than expected, and we must therefore develop methods to ensure they «remain under human control».[75] Some scholars, such as Stephen Hawking, warned (in May 2015 before the matches) that some future self-improving AI could gain actual general intelligence, leading to an unexpected AI takeover; other scholars disagree: AI expert Jean-Gabriel Ganascia believes that «Things like ‘common sense’… may never be reproducible»,[76] and says «I don’t see why we would speak about fears. On the contrary, this raises hopes in many domains such as health and space exploration.»[75] Computer scientist Richard Sutton said «I don’t think people should be scared… but I do think people should be paying attention.»[77]
In China, AlphaGo was a «Sputnik moment» which helped convince the Chinese government to prioritize and dramatically increase funding for artificial intelligence.[78]
In 2017, the DeepMind AlphaGo team received the inaugural IJCAI Marvin Minsky medal for Outstanding Achievements in AI. «AlphaGo is a wonderful achievement, and a perfect example of what the Minsky Medal was initiated to recognise», said Professor Michael Wooldridge, Chair of the IJCAI Awards Committee. «What particularly impressed IJCAI was that AlphaGo achieves what it does through a brilliant combination of classic AI techniques as well as the state-of-the-art machine learning techniques that DeepMind is so closely associated with. It’s a breathtaking demonstration of contemporary AI, and we are delighted to be able to recognise it with this award.»[79]
[edit]
Go is a popular game in China, Japan and Korea, and the 2016 matches were watched by perhaps a hundred million people worldwide.[68][80] Many top Go players characterized AlphaGo’s unorthodox plays as seemingly-questionable moves that initially befuddled onlookers, but made sense in hindsight:[72] «All but the very best Go players craft their style by imitating top players. AlphaGo seems to have totally original moves it creates itself.»[68] AlphaGo appeared to have unexpectedly become much stronger, even when compared with its October 2015 match[81] where a computer had beaten a Go professional for the first time ever without the advantage of a handicap.[82] The day after Lee’s first defeat, Jeong Ahram, the lead Go correspondent for one of South Korea’s biggest daily newspapers, said «Last night was very gloomy… Many people drank alcohol.»[83] The Korea Baduk Association, the organization that oversees Go professionals in South Korea, awarded AlphaGo an honorary 9-dan title for exhibiting creative skills and pushing forward the game’s progress.[84]
China’s Ke Jie, an 18-year-old generally recognized as the world’s best Go player at the time,[33][85] initially claimed that he would be able to beat AlphaGo, but declined to play against it for fear that it would «copy my style».[85] As the matches progressed, Ke Jie went back and forth, stating that «it is highly likely that I (could) lose» after analysing the first three matches,[86] but regaining confidence after AlphaGo displayed flaws in the fourth match.[87]
Toby Manning, the referee of AlphaGo’s match against Fan Hui, and Hajin Lee, secretary general of the International Go Federation, both reason that in the future, Go players will get help from computers to learn what they have done wrong in games and improve their skills.[82]
After game two, Lee said he felt «speechless»: «From the very beginning of the match, I could never manage an upper hand for one single move. It was AlphaGo’s total victory.»[88] Lee apologized for his losses, stating after game three that «I misjudged the capabilities of AlphaGo and felt powerless.»[68] He emphasized that the defeat was «Lee Se-dol’s defeat» and «not a defeat of mankind».[27][76] Lee said his eventual loss to a machine was «inevitable» but stated that «robots will never understand the beauty of the game the same way that we humans do.»[76] Lee called his game four victory a «priceless win that I (would) not exchange for anything.»[27]
Similar systems[edit]
Facebook has also been working on its own Go-playing system darkforest, also based on combining machine learning and Monte Carlo tree search.[66][89] Although a strong player against other computer Go programs, as of early 2016, it had not yet defeated a professional human player.[90] Darkforest has lost to CrazyStone and Zen and is estimated to be of similar strength to CrazyStone and Zen.[91]
DeepZenGo, a system developed with support from video-sharing website Dwango and the University of Tokyo, lost 2–1 in November 2016 to Go master Cho Chikun, who holds the record for the largest number of Go title wins in Japan.[92][93]
A 2018 paper in Nature cited AlphaGo’s approach as the basis for a new means of computing potential pharmaceutical drug molecules.[94][95]
Example game[edit]
AlphaGo Master (white) v. Tang Weixing (31 December 2016), AlphaGo won by resignation. White 36 was widely praised.
Impacts on Go[edit]
The documentary film AlphaGo[9][96] raised hopes that Lee Sedol and Fan Hui would have benefitted from their experience of playing AlphaGo, but as of May 2018 their ratings were little changed; Lee Sedol was ranked 11th in the world, and Fan Hui 545th.[97] On 19 November 2019, Lee announced his retirement from professional play, arguing that he could never be the top overall player of Go due to the increasing dominance of AI. Lee referred to them as being «an entity that cannot be defeated».[98]
See also[edit]
- Albert Lindsey Zobrist, wrote first Go program in 1968
- Chinook (draughts player), draughts playing program
- Glossary of artificial intelligence
- Go and mathematics
- Leela (software)
- Leela Zero, open-source learning Go program
- Matchbox Educable Noughts and Crosses Engine
- Samuel’s learning computer checkers (draughts)
- TD-Gammon, backgammon neural network
- Pluribus (poker bot)
- AlphaZero
- AlphaFold
References[edit]
- ^ «Artificial intelligence: Google’s AlphaGo beats Go master Lee Se-dol». BBC News. 12 March 2016. Retrieved 17 March 2016.
- ^ «DeepMind AlphaGO». DeepMind Artificial Intelligence AlphaGo.
- ^ «AlphaGo | DeepMind». DeepMind.
- ^ a b c d e f g h i Silver, David; Huang, Aja; Maddison, Chris J.; Guez, Arthur; Sifre, Laurent; Driessche, George van den; Schrittwieser, Julian; Antonoglou, Ioannis; Panneershelvam, Veda; Lanctot, Marc; Dieleman, Sander; Grewe, Dominik; Nham, John; Kalchbrenner, Nal; Sutskever, Ilya; Lillicrap, Timothy; Leach, Madeleine; Kavukcuoglu, Koray; Graepel, Thore; Hassabis, Demis (28 January 2016). «Mastering the game of Go with deep neural networks and tree search». Nature. 529 (7587): 484–489. Bibcode:2016Natur.529..484S. doi:10.1038/nature16961. ISSN 0028-0836. PMID 26819042. S2CID 515925.

- ^ a b c d e «Research Blog: AlphaGo: Mastering the ancient game of Go with Machine Learning». Google Research Blog. 27 January 2016.
- ^ a b c d «Google achieves AI ‘breakthrough’ by beating Go champion». BBC News. 27 January 2016.
- ^ «Match 1 – Google DeepMind Challenge Match: Lee Sedol vs AlphaGo». YouTube. 8 March 2016.
- ^ «Google’s AlphaGo gets ‘divine’ Go ranking». The Straits Times. straitstimes.com. 15 March 2016. Retrieved 9 December 2017.
- ^ a b «AlphaGo Movie». AlphaGo Movie.
- ^ «From AI to protein folding: Our Breakthrough runners-up». Science. 22 December 2016. Retrieved 29 December 2016.
- ^ a b «中国围棋协会授予AlphaGo职业九段 并颁发证书» (in Chinese). Sohu.com. 27 May 2017. Retrieved 9 December 2017.
- ^ a b Metz, Cade (27 May 2017). «After Win in China, AlphaGo’s Designers Explore New AI». Wired.
- ^ «AlphaZero Crushes Stockfish In New 1,000-Game Match». 17 April 2019.
- ^ Silver, David; Hubert, Thomas; Schrittwieser, Julian; Antonoglou, Ioannis; Lai, Matthew; Guez, Arthur; Lanctot, Marc; Sifre, Laurent; Kumaran, Dharshan; Graepel, Thore; Lillicrap, Timothy; Simonyan, Karen; Hassabis, Demis (7 December 2018). «A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play». Science. 362 (6419): 1140–1144. Bibcode:2018Sci…362.1140S. doi:10.1126/science.aar6404. PMID 30523106. S2CID 54457125.
- ^ Schraudolph, Nicol N.; Terrence, Peter Dayan; Sejnowski, J., Temporal Difference Learning of Position Evaluation in the Game of Go (PDF)
- ^ a b «Computer scores big win against humans in ancient game of Go». CNN. 28 January 2016. Retrieved 28 January 2016.
- ^ «Zen computer Go program beats Takemiya Masaki with just 4 stones!». Go Game Guru. Archived from the original on 1 February 2016. Retrieved 28 January 2016.
- ^ «「アマ六段の力。天才かも」囲碁棋士、コンピューターに敗れる 初の公式戦». MSN Sankei News. Archived from the original on 24 March 2013. Retrieved 27 March 2013.
- ^ a b c John Riberio (14 March 2016). «AlphaGo’s unusual moves prove its AI prowess, experts say». PC World. Retrieved 18 March 2016.
- ^ «Google AlphaGo AI clean sweeps European Go champion». ZDNet. 28 January 2016. Retrieved 28 January 2016.
- ^ a b Metz, Cade (27 January 2016). «In Major AI Breakthrough, Google System Secretly Beats Top Player at the Ancient Game of Go». WIRED. Retrieved 1 February 2016.
- ^ «Special Computer Go insert covering the AlphaGo v Fan Hui match» (PDF). British Go Journal. 2017. Retrieved 1 February 2016.
- ^ «Première défaite d’un professionnel du go contre une intelligence artificielle». Le Monde (in French). 27 January 2016.
- ^ «Google’s AI AlphaGo to take on world No 1 Lee Sedol in live broadcast». The Guardian. 5 February 2016. Retrieved 15 February 2016.
- ^ «Google DeepMind is going to take on the world’s best Go player in a luxury 5-star hotel in South Korea». Business Insider. 22 February 2016. Retrieved 23 February 2016.
- ^ Novet, Jordan (4 February 2016). «YouTube will livestream Google’s AI playing Go superstar Lee Sedol in March». VentureBeat. Retrieved 7 February 2016.
- ^ a b c Yoon Sung-won (14 March 2016). «Lee Se-dol shows AlphaGo beatable». The Korea Times. Retrieved 15 March 2016.
- ^ «李世乭:即使Alpha Go得到升级也一样能赢». JoongAng Ilbo (in Chinese). 23 February 2016. Retrieved 24 February 2016.
- ^ a b «이세돌 vs 알파고, ‘구글 딥마인드 챌린지 매치’ 기자회견 열려» (in Korean). Korea Baduk Association. 22 February 2016. Archived from the original on 3 March 2016. Retrieved 22 February 2016.
- ^ Demis Hassabis [@demishassabis] (11 March 2016). «We are using roughly same amount of compute power as in Fan Hui match: distributing search over further machines has diminishing returns» (Tweet). Retrieved 14 March 2016 – via Twitter.
- ^ «Showdown». The Economist. Retrieved 19 November 2016.
- ^ Steven Borowiec (9 March 2016). «Google’s AI machine v world champion of ‘Go’: everything you need to know». The Guardian. Retrieved 15 March 2016.
- ^ a b Rémi Coulom. «Rating List of 2016-01-01». Archived from the original on 18 March 2016. Retrieved 18 March 2016.
- ^ «Korean Go master proves human intuition still powerful in Go». The Korean Herald/ANN. 14 March 2016. Archived from the original on 12 April 2016. Retrieved 15 March 2016.
- ^ «Google’s AI beats world Go champion in first of five matches – BBC News». BBC Online. Retrieved 9 March 2016.
- ^ «Google AI wins second Go game against world champion – BBC News». BBC Online. Retrieved 10 March 2016.
- ^ «Google DeepMind AI wins final Go match for 4–1 series win». Engadget. Retrieved 15 March 2016.
- ^ «Human champion certain he’ll beat AI at ancient Chinese game». Associated Press. 22 February 2016. Retrieved 22 February 2016.
- ^ «In Two Moves, AlphaGo and Lee Sedol Redefined the Future». WIRED. Retrieved 12 November 2017.
- ^ «黄士杰:AlphaGo李世石人机大战第四局问题已解决date=8 July 2016» (in Chinese). Retrieved 8 July 2016.
- ^ a b Demis Hassabis (4 January 2017). «Demis Hassabis on Twitter: «Excited to share an update on #AlphaGo!»«. Demis Hassabis’s Twitter account. Retrieved 4 January 2017.
- ^ a b c Elizabeth Gibney (4 January 2017). «Google reveals secret test of AI bot to beat top Go players». Nature. 541 (7636): 142. Bibcode:2017Natur.541..142G. doi:10.1038/nature.2017.21253. PMID 28079098.
- ^ a b c «Humans Mourn Loss After Google Is Unmasked as China’s Go Master». Wall Street Journal. 5 January 2017. Retrieved 6 January 2017.
- ^ «The world’s best Go player says he still has «one last move» to defeat Google’s AlphaGo AI». Quartz. 4 January 2017. Retrieved 6 January 2017.
- ^ «横扫中日韩棋手斩获59胜的Master发话:我是阿尔法狗» (in Chinese). 澎湃新闻. 4 January 2017. Retrieved 11 December 2017.
- ^ «Exploring the mysteries of Go with AlphaGo and China’s top players». 10 April 2017.
- ^ «World No.1 Go player Ke Jie takes on upgraded AlphaGo in May». 10 April 2017.
- ^ «Ke Jie vs. AlphaGo: 8 things you must know». 27 May 2017.
- ^ Metz, Cade (23 May 2017). «Revamped AlphaGo Wins First Game Against Chinese Go Grandmaster». Wired.
- ^ Metz, Cade (25 May 2017). «Google’s AlphaGo Continues Dominance With Second Win in China». Wired.
- ^ «Full length games for Go players to enjoy». Deepmind. Retrieved 28 May 2017.
- ^ a b c d e Silver, David; Schrittwieser, Julian; Simonyan, Karen; Antonoglou, Ioannis; Huang, Aja; Guez, Arthur; Hubert, Thomas; Baker, Lucas; Lai, Matthew; Bolton, Adrian; Chen, Yutian; Lillicrap, Timothy; Fan, Hui; Sifre, Laurent; Driessche, George van den; Graepel, Thore; Hassabis, Demis (19 October 2017). «Mastering the game of Go without human knowledge» (PDF). Nature. 550 (7676): 354–359. Bibcode:2017Natur.550..354S. doi:10.1038/nature24270. ISSN 0028-0836. PMID 29052630. S2CID 205261034.
- ^ a b c d e «AlphaGo Zero: Learning from scratch». DeepMind official website. 18 October 2017. Retrieved 19 October 2017.
- ^ Silver, David; Hubert, Thomas; Schrittwieser, Julian; Antonoglou, Ioannis; Lai, Matthew; Guez, Arthur; Lanctot, Marc; Sifre, Laurent; Kumaran, Dharshan; Graepel, Thore; Lillicrap, Timothy; Simonyan, Karen; Hassabis, Demis (5 December 2017). «Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm». arXiv:1712.01815 [cs.AI].
- ^ «AlphaGo teaching tool». DeepMind.
- ^ a b «AlphaGo教学工具上线 樊麾:使用Master版本» (in Chinese). Sina.com.cn. 11 December 2017. Retrieved 11 December 2017.
- ^ McMillan, Robert (18 May 2016). «Google Isn’t Playing Games With New Chip». The Wall Street Journal. Retrieved 26 June 2016.
- ^ Jouppi, Norm (18 May 2016). «Google supercharges machine learning tasks with TPU custom chip». Google Cloud Platform Blog. Retrieved 26 June 2016.
- ^ «AlphaGo官方解读让三子 对人类高手没这种优势» (in Chinese). Sina. 25 May 2017. Retrieved 2 June 2017.
- ^ «各版alphago实力对比 master能让李世石版3子» (in Chinese). Sina. 24 May 2017. Retrieved 2 June 2017.
- ^ «New version of AlphaGo self-trained and much more efficient». American Go Association. 24 May 2017. Retrieved 1 June 2017.
- ^ «【柯洁战败解密】AlphaGo Master最新架构和算法,谷歌云与TPU拆解» (in Chinese). Sohu. 24 May 2017. Retrieved 1 June 2017.
- ^ Silver, David; Hubert, Thomas; Schrittwieser, Julian; Antonoglou, Ioannis; Lai, Matthew; Guez, Arthur; Lanctot, Marc; Sifre, Laurent; Kumaran, Dharshan; Graepel, Thore; Lillicrap, Timothy; Simonyan, Karen; Hassabis, Demis (7 December 2018). «A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play». Science. 362 (6419): 1140–1144. Bibcode:2018Sci…362.1140S. doi:10.1126/science.aar6404. PMID 30523106. S2CID 54457125 – via science.org (Atypon).
- ^ Silver, David; Schrittwieser, Julian; Simonyan, Karen; Antonoglou, Ioannis; Huang, Aja; Guez, Arthur; Hubert, Thomas; Baker, Lucas; Lai, Matthew; Bolton, Adrian; Chen, Yutian; Lillicrap, Timothy; Fan, Hui; Sifre, Laurent; Driessche, George van den; Graepel, Thore; Hassabis, Demis (19 October 2017). «Mastering the game of Go without human knowledge» (PDF). Nature. 550 (7676): 354–359. Bibcode:2017Natur.550..354S. doi:10.1038/nature24270. ISSN 0028-0836. PMID 29052630. S2CID 205261034.
AlphaGo Lee… 12 convolutional layers
- ^ Cade Metz (13 March 2016). «Go Grandmaster Lee Sedol Grabs Consolation Win Against Google’s AI». Wired News. Retrieved 29 March 2016.
- ^ a b Gibney, Elizabeth (27 January 2016). «Google AI algorithm masters ancient game of Go». Nature. 529 (7587): 445–6. Bibcode:2016Natur.529..445G. doi:10.1038/529445a. PMID 26819021.
- ^ Chouard, Tanguy (12 March 2016). «The Go Files: AI computer clinches victory against Go champion». Nature. doi:10.1038/nature.2016.19553. S2CID 155164502.
- ^ a b c d e f g h Steven Borowiec; Tracey Lien (12 March 2016). «AlphaGo beats human Go champ in milestone for artificial intelligence». Los Angeles Times. Retrieved 13 March 2016.
- ^ Connor, Steve (27 January 2016). «A computer has beaten a professional at the world’s most complex board game». The Independent. Archived from the original on 28 January 2016. Retrieved 28 January 2016.
- ^ «Google’s AI beats human champion at Go». CBC News. 27 January 2016. Retrieved 28 January 2016.
- ^ Dave Gershgorn (12 March 2016). «GOOGLE’S ALPHAGO BEATS WORLD CHAMPION IN THIRD MATCH TO WIN ENTIRE SERIES». Popular Science. Retrieved 13 March 2016.
- ^ a b «Google DeepMind computer AlphaGo sweeps human champ in Go matches». CBC News. Associated Press. 12 March 2016. Retrieved 13 March 2016.
- ^ Sofia Yan (12 March 2016). «A Google computer victorious over the world’s ‘Go’ champion». CNN Money. Retrieved 13 March 2016.
- ^ «AlphaGo: Google’s artificial intelligence to take on world champion of ancient Chinese board game». Australian Broadcasting Corporation. 8 March 2016. Retrieved 13 March 2016.
- ^ a b Mariëtte Le Roux (12 March 2016). «Rise of the Machines: Keep an eye on AI, experts warn». Phys.org. Retrieved 13 March 2016.
- ^ a b c Mariëtte Le Roux; Pascale Mollard (8 March 2016). «Game over? New AI challenge to human smarts (Update)». phys.org. Retrieved 13 March 2016.
- ^ Tanya Lewis (11 March 2016). «An AI expert says Google’s Go-playing program is missing 1 key feature of human intelligence». Business Insider. Retrieved 13 March 2016.
- ^ Mozur, Paul (20 July 2017). «Beijing Wants A.I. to Be Made in China by 2030». The New York Times. Retrieved 11 April 2018.
- ^ «Marvin Minsky Medal for Outstanding Achievements in AI». International Joint Conference on Artificial Intelligence. 19 October 2017. Retrieved 21 October 2017.
- ^ CHOE SANG-HUN (16 March 2016). «Google’s Computer Program Beats Lee Se-dol in Go Tournament». The New York Times. Retrieved 18 March 2016.
More than 100 million people watched the AlphaGo-Lee matches, Mr. Hassabis said.
- ^ John Ribeiro (12 March 2016). «Google’s AlphaGo AI program strong but not perfect, says defeated South Korean Go player». PC World. Retrieved 13 March 2016.
- ^ a b Gibney, Elizabeth (2016). «Go players react to computer defeat». Nature. doi:10.1038/nature.2016.19255. S2CID 146868978.
- ^ Zastrow, Mark (15 March 2016). «How victory for Google’s Go AI is stoking fear in South Korea». New Scientist. Retrieved 18 March 2016.
- ^ JEE HEUN KAHNG; SE YOUNG LEE (15 March 2016). «Google artificial intelligence program beats S. Korean Go pro with 4–1 score». Reuters. Retrieved 18 March 2016.
- ^ a b Neil Connor (11 March 2016). «Google AlphaGo ‘can’t beat me’ says China Go grandmaster». The Telegraph (UK). Retrieved 13 March 2016.
- ^ «Chinese Go master Ke Jie says he could lose to AlphaGo : The DONG-A ILBO». Retrieved 17 March 2016.
- ^ «…if today’s performance was its true capability, then it doesn’t deserve to play against me». M.hankooki.com. 14 March 2016. Retrieved 5 June 2018.
- ^ CHOE SANG-HUN (15 March 2016). «In Seoul, Go Games Spark Interest (and Concern) About Artificial Intelligence». The New York Times. Retrieved 18 March 2016.
- ^ Tian, Yuandong; Zhu, Yan (2015). «Better Computer Go Player with Neural Network and Long-term Prediction». arXiv:1511.06410v1 [cs.LG].
- ^ HAL 90210 (28 January 2016). «No Go: Facebook fails to spoil Google’s big AI day». The Guardian. ISSN 0261-3077. Retrieved 1 February 2016.
- ^ «Strachey Lecture – Dr Demis Hassabis». The New Livestream. Retrieved 17 March 2016.
- ^ «Go master Cho wins best-of-three series against Japan-made AI». The Japan Times Online. 24 November 2016. Retrieved 27 November 2016.
- ^ «Humans strike back: Korean Go master bests AI in board game bout». CNET. Retrieved 27 November 2016.
- ^ «Go and make some drugs The Engineer». www.theengineer.co.uk. 3 April 2018. Retrieved 3 April 2018.
- ^ Segler, Martwin H.S.; Preuss, Mike; Waller, Mark P. (29 March 2018). «Planning chemical syntheses with deep neural networks and symbolic AI». Nature. 555 (7698): 604–610. arXiv:1708.04202. Bibcode:2018Natur.555..604S. doi:10.1038/nature25978. PMID 29595767. S2CID 205264340.
- ^ «AlphaGo (2017)». Rotten Tomatoes. Retrieved 5 June 2018.
- ^ «Go Ratings». Go Ratings. Retrieved 5 June 2018.
- ^ Vincent, James (27 November 2019). «Former Go champion beaten by DeepMind retires after declaring AI invincible». The Verge. Retrieved 28 November 2019.
External links[edit]
Искусственный интеллект, который воспроизводит Go
![]() логотип AlphaGo
логотип AlphaGo
AlphaGo — это компьютерная программа, которая играет в настольную игру Go. Он был разработан DeepMind Technologies, которая позже была приобретена Google. Последующие версии AlphaGo становились все более мощными, в том числе версия, которая конкурировала под именем Master. После ухода из соревновательной игры на смену AlphaGo Master пришла еще более мощная версия, известная как AlphaGo Zero, которая была полностью самоучкой, без изучения человеческих игр. Затем AlphaGo Zero был обобщен в программу, известную как AlphaZero, которая играла в дополнительные игры, включая шахматы и сёги. На смену AlphaZero, в свою очередь, пришла программа, известная как MuZero, которая учится без обучения правилам.
AlphaGo и его последователи используют алгоритм поиска по дереву Монте-Карло для поиска своих ходов на основе знаний, ранее полученных с помощью машинного обучения, в частности с помощью искусственной нейронной сети. сеть (метод глубокого обучения ) путем обширного обучения, как на людях, так и на компьютере. Нейронная сеть обучена определять лучшие ходы и процент выигрыша этих ходов. Эта нейронная сеть улучшает поиск по дереву, что приводит к более сильному выбору хода в следующей итерации.
В октябре 2015 года, в матче против Фань Хуэй, оригинальная AlphaGo стала первой компьютерной программой Go, которая победила человека профессионального игрока в го без гандикапа на полноразмерной доске 19 × 19. В марте 2016 года он победил Ли Седола в матче из пяти игр, впервые компьютерная программа Го обыграла 9-дан профессионала без гандикапа. Хотя он проиграл Ли Седолу в четвертой игре, Ли подал в отставку в последней игре, дав окончательный счет 4 игры против 1 в пользу AlphaGo. В знак признания победы AlphaGo была удостоена почетного 9 дан от Корейской ассоциации бадук. Подготовка и испытательный матч с Ли Седолом были задокументированы в документальном фильме, также озаглавленном AlphaGo, снятом Грегом Кохом. Он был выбран Science как один из призеров Прорыв года 22 декабря 2016 года.
На саммите Future of Go в 2017 году, Мастер версия AlphaGo победила Кэ Джи, игрока номер один в мире на тот момент, в матче из трех игр, после который AlphaGo был удостоен профессионального 9-го дана Китайской ассоциацией Weiqi.
После матча между AlphaGo и Ke Jie DeepMind удалил AlphaGo, продолжив исследования ИИ в других областях. Самоучка AlphaGo Zero одержала 100–0 побед над ранней соревновательной версией AlphaGo, а его преемник AlphaZero в настоящее время считается лучшим игроком в мире в го, а также, возможно, в шахматах.
Содержание
- 1 История
- 1.1 Матч против Фан Хуэй
- 1.2 Матч против Ли Седола
- 1.3 Шестьдесят онлайн-игр
- 1.4 Future of Go Summit
- 1.5 AlphaGo Zero и AlphaZero
- 1.6 Обучающий инструмент
- 2 версии
- 3 Алгоритм
- 4 Стиль игры
- 5 Ответы на победу в 2016 году
- 5.1 AI-сообщество
- 5.2 Go-сообщество
- 6 Подобные системы
- 7 Пример игры
- 8 Воздействие на го
- 9 См. Также
- 10 Ссылки
- 11 Внешние ссылки
История
Считается, что для компьютеров выиграть в го намного сложнее, чем в других подобных играх как chess, потому что его гораздо больший коэффициент ветвления чрезмерно затрудняет использование традиционных методов ИИ, таких как альфа-бета-обрезка, обход дерева и эвристический поиск.
Спустя почти два десятилетия после того, как компьютер IBM Deep Blue победил чемпиона мира по шахматам Гарри Каспарова в матче 1997 года, сильнейшие программы Go использовали Техники искусственного интеллекта достигли только уровня любительского 5 дан и все равно не смогли победить профессионального игрока в го без гандикапа. В 2012 году программа Zen, работающая на кластере из четырех компьютеров, дважды обошла Масаки Такемия (9p ) с гандикапом в пять и четыре камня. В 2013 году Crazy Stone победил Йошио Исида (9 очков) с гандикапом в четыре камня.
Согласно DeepMind Дэвиду Сильверу, AlphaGo Исследовательский проект был сформирован примерно в 2014 году, чтобы проверить, насколько хорошо нейронная сеть, использующая глубокое обучение, может конкурировать на Go. AlphaGo представляет собой значительное улучшение по сравнению с предыдущими программами Go. В 500 играх против других доступных программ Го, включая Crazy Stone и Zen, AlphaGo, запущенная на одном компьютере, выиграла все, кроме одной. В аналогичном матче AlphaGo, запущенная на нескольких компьютерах, выиграла все 500 игр, сыгранных против других программ Go, и 77% игр, сыгранных против AlphaGo, запущенной на одном компьютере. В распределенной версии в октябре 2015 года использовалось 1202 CPU и 176 GPU.
Match против Fan Hui
В октябре 2015 года распределенная версия AlphaGo победила европейцев. Чемпион го Фань Хуэй, 2 дан (из 9 возможных) профессионал, пять к нулю. Это был первый раз, когда компьютерная программа Го обыграла профессионального игрока-человека на полноразмерной доске без гандикапа. Объявление новости было отложено до 27 января 2016 года, чтобы совпасть с публикацией в журнале Nature статьи с описанием используемых алгоритмов.
Матч против Ли Седола
AlphaGo играл за профессионального игрока в го из Южной Кореи Ли Седола, занявшего 9 дан, одного из лучших игроков в го, пять игр проходили в Four Seasons Hotel в Сеуле., Южная Корея, 9, 10, 12, 13 и 15 марта 2016 г., которые транслировались в прямом эфире. Из пяти игр AlphaGo выиграл четыре игры, а Ли выиграл четвертую игру, что сделало его единственным игроком-человеком, который победил AlphaGo во всех 74 официальных играх. AlphaGo работает на облачных вычислениях Google, а его серверы расположены в США. В матче использовались китайские правила с 7,5-балльной коми, и у каждой стороны было два часа времени на размышления плюс три 60-секундных бёёми периода. Версия AlphaGo, играющая против Ли, использовала такое же количество вычислительной мощности, как и в матче с Fan Hui. The Economist сообщил, что в ней использовалось 1920 процессоров и 280 графических процессоров. На момент игры Ли Седол был вторым по количеству побед на международных чемпионатах по го в мире после южнокорейского игрока Ли Чанхо, который удерживал титул чемпиона мира в течение 16 лет. Поскольку не существует единого официального метода ранжирования в международном рейтинге Go, рейтинг может варьироваться в зависимости от источника. Хотя иногда он и занимал первое место, некоторые источники оценивали Ли Седола как четвертого лучшего игрока в мире в то время. AlphaGo не был специально обучен противостоять Ли и не предназначался для конкуренции с какими-либо конкретными игроками-людьми.
Первые три игры были выиграны AlphaGo после отставки Ли. Однако Ли обыграл AlphaGo в четвертой игре, выиграв отставкой на 180-м ходу. AlphaGo затем продолжил одерживать четвертую победу, выиграв пятую игру отставкой.
Приз составил 1 миллион долларов США. Поскольку AlphaGo выиграла четыре из пяти и, соответственно, серию, приз будет передан благотворительным организациям, в том числе UNICEF. Ли Седол получил 150 000 долларов за участие во всех пяти играх и дополнительно 20 000 долларов за победу в игре 4.
В июне 2016 года на презентации, проведенной в университете в Нидерландах, Аджа Хуанг, один из Глубинных людей. команда, выяснила, что они устранили логическую слабость, которая возникла во время 4-й игры матча между AlphaGo и Ли, и что после 78-го хода (который многие профессионалы назвали «божественным ходом »), он сыграет так, как задумано, и сохранит преимущество черных. До 78-го хода AlphaGo лидировала на протяжении всей игры, но из-за действия Ли вычислительные мощности программы были отвлечены и запутаны. Хуанг объяснил, что политическая сеть AlphaGo по нахождению наиболее точного порядка ходов и продолжения не совсем точно указала AlphaGo на правильное продолжение после 78-го хода, поскольку его сеть ценностей не определила 78-й ход Ли как наиболее вероятный и, следовательно, время, когда это движение была сделана AlphaGo не смогла внести правильную корректировку в логическое продолжение.
Шестьдесят онлайн-игр
29 декабря 2016 года на сервере Tygem появилась новая учетная запись с именем «Magister» «(обозначенный как Magist в китайской версии сервера) из Южной Кореи начал играть в игры с профессиональными игроками. Он изменил свое имя учетной записи на «Мастер» 30 декабря, а затем переместился на сервер FoxGo 1 января 2017 года. 4 января DeepMind подтвердил, что «Магистр» и «Мастер» игрались обновленной версией AlphaGo, называется AlphaGo Master. По состоянию на 5 января 2017 года онлайн-рекорд AlphaGo Master составлял 60 побед и 0 поражений, в том числе три победы над одним из лучших игроков Го, Кэ Джи, которого заранее незаметно проинформировали, что Мастер является версией AlphaGo.. После проигрыша Мастеру Гу Ли предложил награду в размере 100000 юаней (14 400 долларов США) за первого игрока-человека, который смог победить Мастера. Мастер играл в темпе по 10 партий в день. Многие быстро заподозрили, что это ИИ-игрок из-за того, что между играми почти не отдыхали. Среди его противников было много чемпионов мира, таких как Кэ Джи, Пак Чон Хван, Юта Ияма, Туо Цзяси, Ми Юйтин, Ши Юэ, Чэнь Яое, Ли Циньчэн, Гу Ли, Чан Хао, Тан Вэйсин, Фань Тиню, Чжоу Жуйян, Цзян Вэйцзе, Чжоу Чун-сюнь, Ким Джи-сок, Кан Дон Юн, Пак Ён Хун и Вон Сон Чжин ; национальные чемпионы или занявшие второе место на чемпионатах мира, такие как Лянь Сяо, Тан Сяо, Мэн Тейлин, Данг Ифэй, Хуан Юнсун, Ян Динсинь, Гу Цзихао, Шин Джинсео, Чо Хан Сын и Ан Сонджун. Все 60 игр, кроме одной, были быстрыми играми с тремя играми по 20 или 30 секунд byo-yomi. Учитель предложил продлить байо-ёми до одной минуты, играя с Не Вэйпином, учитывая его возраст. После победы в 59-й игре Мастер обнаружил себя в чате, которым управляет доктор Аджа Хуанг из команды DeepMind, затем сменил национальность на Соединенное Королевство. После того, как эти игры были завершены, соучредитель Google DeepMind, Демис Хассабис, сказал в твите: «Мы с нетерпением ждем возможности сыграть в некоторые официальные полнометражные игры позже [2017] в сотрудничестве с Организации и эксперты го «.
Эксперты в го были впечатлены производительностью программы и ее нечеловеческим стилем игры; Кэ Цзе заявил, что «после того, как человечество потратило тысячи лет на улучшение своей тактики, компьютеры говорят нам, что люди полностью неправы… Я бы сказал, что ни один человек не коснулся края истины Го». 314>
Future of Go Summit
На саммите Future of Go, проходившем в Wuzhen в мае 2017 года, AlphaGo Master сыграл три игры с Кэ Джи, Игрок, занявший первое место в мире, а также две игры с участием нескольких ведущих китайских профессионалов, одна парная игра в го и одна против совместной команды из пяти игроков.
Google DeepMind предложила троим призы победителями в размере 1,5 миллиона долларов. -игровой матч между Кэ Цзе и Мастером проигравшей стороны взял 300 000 долларов. Мастер выиграл все три игры у Ке Цзе, после чего AlphaGo была удостоена 9-го профессионального дана китайской ассоциацией Weiqi.
После победы в трехматчевом матче против Ke Jie, лучшего мирового игрока в го, AlphaGo в отставке. DeepMind также распустил команду, которая работала над игрой, чтобы сосредоточиться на исследованиях ИИ в других областях. После Саммита Deepmind опубликовала 50 полноформатных матчей AlphaGo vs AlphaGo в качестве подарка сообществу Go.
AlphaGo Zero и AlphaZero
Команда AlphaGo опубликовала статью в журнале Nature 19 октября 2017 года представляет AlphaGo Zero, версию без человеческих данных и более сильную, чем любая предыдущая версия, побеждающая человека-чемпиона. Играя в игры против самого себя, AlphaGo Zero превзошла по силе AlphaGo Lee за три дня, выиграв 100 игр с 0, достигла уровня AlphaGo Master за 21 день и превзошла все старые версии за 40 дней.
В статье, опубликованной на arXiv 5 декабря 2017 года, DeepMind заявила, что обобщила подход AlphaGo Zero в единый алгоритм AlphaZero, который за 24 часа достиг сверхчеловеческого уровень игры в играх шахматы, сёги и Go, победив программы чемпионов мира, Stockfish, Elmo и трехдневная версия AlphaGo Zero в каждом случае.
Обучающий инструмент
11 декабря 2017 года DeepMind выпустила обучающий инструмент AlphaGo на своем веб-сайте для анализа показателей выигрыша различных Проходы на ходу, рассчитанные с помощью AlphaGo Master. Инструмент обучения собирает 6000 открытий Го из 230 000 игр для людей, каждая из которых проанализирована с помощью 10 000 000 симуляций AlphaGo Master. Многие из открытий включают предложения о перемещении человека.
Версии
Ранняя версия AlphaGo была протестирована на оборудовании с различным количеством процессоров и графических процессоров, работающий в асинхронном или распределенном режиме. Каждому ходу давалось две секунды на обдумывание. Полученные рейтинги Эло перечислены ниже. В матчах с большим количеством времени на ход достигаются более высокие рейтинги.
| Конфигурация | Поиск. нитей | No. CPU | No. графических процессоров | рейтинг Эло |
|---|---|---|---|---|
| одиночный | 40 | 48 | 1 | 2,181 |
| одиночный | 40 | 48 | 2 | 2,738 |
| одиночный | 40 | 48 | 4 | 2,850 |
| одиночный | 40 | 48 | 8 | 2,890 |
| распределенный | 12 | 428 | 64 | 2,937 |
| Распределено | 24 | 764 | 112 | 3,079 |
| Распределено | 40 | 1,202 | 176 | 3,140 |
| Распределенный | 64 | 1,920 | 280 | 3168 |
В мае 2016 года Google представила собственное запатентованное оборудование «тензорные процессоры », которые, по ее словам, уже были задействованы в нескольких внутренних проектах Google, включая матч AlphaGo против Ли Седола.
На Future of Go Summit в мае 2017 года DeepMind сообщила, что версия AlphaGo, использованная на этом саммите был AlphaGo Master, и показал, что он измерял силу различных версий программного обеспечения. AlphaGo Lee, версия, использованная против Ли, могла дать AlphaGo Fan, версию, используемую в AlphaGo против Fan Hui, три камня, а AlphaGo Master был даже на три камня сильнее.
| Версии | Аппаратное обеспечение | Рейтинг Elo | Дата | Результаты |
|---|---|---|---|---|
| AlphaGo Fan | 176 Графические процессоры, распределенные | 3144 | октябрь 2015 г. | 5: 0 против Fan Hui |
| AlphaGo Lee | 48 TPU, распределенных | 3739 | март 2016 г. | 4: 1 против Ли Седол |
| AlphaGo Master | 4 TPU, одна машина | 4858 | май 2017 г. | 60: 0 против профессиональных игроков;. Future of Go Summit |
| AlphaGo Zero (40 блоков) | 4 TPU, одна машина | 5,185 | октябрь 2017 г. | 100: 0 против AlphaGo Lee
89:11 против AlphaGo Master |
| AlphaZero (20 блоков) | 4 TPU, одиночная машина | 5,018 | декабрь 2017 г. | 60:40 против AlphaGo Zero (20 блоков) |
Алгоритм
По состоянию на 2016 год алгоритм AlphaGo использует комбинацию методов машинного обучения и древовидного поиска в сочетании с обширным обучением, как на людях, так и на компьютере. Он использует поиск по дереву Монте-Карло, руководствуясь «сетью значений» и «сетью политик», которые реализованы с использованием технологии глубокой нейронной сети. Перед отправкой в нейронные сети ко входным данным применяется ограниченный объем предварительной обработки для определения особенностей игры (например, чтобы выделить, соответствует ли ход шаблону nakade ).
Нейронные сети системы изначально были созданы на основе человеческого опыта игры. AlphaGo изначально был обучен имитировать человеческую игру, пытаясь сопоставить движения опытных игроков из записанных исторических партий, используя базу данных, содержащую около 30 миллионов ходов. Когда он достиг определенной степени мастерства, он был дополнительно обучен, настроив играть большое количество игр против других экземпляров самого себя, используя обучение с подкреплением для улучшения своей игры. Чтобы избежать «неуважительной» траты времени оппонента, программа специально запрограммирована на уход в отставку, если ее оценка вероятности победы упадет ниже определенного порога; для матча с Ли порог отставки был установлен на уровне 20%.
Стиль игры
Тоби Мэннинг, судья матча AlphaGo vs. Fan Hui, описал стиль программы как » консервативный «. Стиль игры AlphaGo решительно отдает предпочтение большей вероятности выигрыша меньшим количеством очков по сравнению с меньшей вероятностью выигрыша большим количеством очков. Его стратегия максимизации вероятности выигрыша отличается от того, что обычно делают игроки-люди, а именно максимизируют территориальные выгоды, и объясняет некоторые из его странных ходов. Он делает много вводных ходов, которые никогда или редко делались людьми, при этом избегая многих вводных ходов второй линии, которые любят делать игроки-люди. Он любит использовать удары плечом, особенно если противник чрезмерно сконцентрирован.
Ответы на победу в 2016 году
AI-сообщество
Победа AlphaGo в марте 2016 года была важная веха в исследованиях искусственного интеллекта. Ранее Go считался серьезной проблемой в машинном обучении, которая, как ожидается, будет недоступна для технологий того времени. Большинство экспертов считали, что до такой мощной программы Go, как AlphaGo, осталось не менее пяти лет; некоторые эксперты считали, что потребуется еще как минимум десять лет, прежде чем компьютеры победят чемпионов го. Большинство наблюдателей в начале матчей 2016 года ожидали, что Ли победит AlphaGo.
В таких играх, как шашки (это было «решено » игроком в шашки Чинука team), шахматы, а теперь и го, выигранный компьютерами, победы в популярных настольных играх больше не могут служить важными вехами для искусственного интеллекта, как это было раньше. Deep Blue Мюррей Кэмпбелл назвал победу AlphaGo «концом эпохи… настольные игры более или менее сделаны, и пора двигаться дальше».
По сравнению с Deep Blue или Watson лежащие в основе AlphaGo алгоритмы потенциально являются более универсальными и могут свидетельствовать о том, что научное сообщество делает успехи в направлении общего искусственного интеллекта. Некоторые комментаторы считают, что победа AlphaGo дает обществу хорошую возможность начать подготовку к возможному будущему удару машин с интеллектом общего назначения. Как отметил предприниматель Гай Сутер, AlphaGo умеет играть только в го и не обладает универсальным интеллектом; «[Оно] не могло просто проснуться однажды утром и решить, что хочет научиться обращаться с огнестрельным оружием». Исследователь ИИ Стюарт Рассел сказал, что системы ИИ, такие как AlphaGo, развиваются быстрее и становятся более мощными, чем ожидалось, и поэтому мы должны разработать методы, чтобы гарантировать, что они «остаются под контролем человека». Некоторые ученые, такие как Стивен Хокинг, предупреждали (в мае 2015 года перед матчем), что некоторый будущий самосовершенствующийся ИИ может получить реальный общий интеллект, что приведет к неожиданному захвату ИИ ; другие ученые не согласны: эксперт по искусственному интеллекту Жан-Габриэль Ганася считает, что «такие вещи, как ‘здравый смысл ‘… могут никогда не воспроизводиться», и говорит: «Я не понимаю, почему мы должны говорить о страхах. Напротив, это вселяет надежды во многих областях, таких как здоровье и освоение космоса «. Компьютерный ученый Ричард Саттон сказал: «Я не думаю, что люди должны бояться… но я действительно думаю, что люди должны обращать внимание».
В Китае AlphaGo была «Момент спутника «, который помог убедить китайское правительство сделать приоритетными и резко увеличить финансирование искусственного интеллекта.
В 2017 году команда DeepMind AlphaGo получила первый титул IJCAI Marvin Минского за выдающиеся достижения в области искусственного интеллекта. «AlphaGo — замечательное достижение и прекрасный пример того, за что была учреждена медаль Мински», — сказал профессор Майкл Вулдридж, председатель комитета по наградам IJCAI. «Что особенно впечатлило IJCAI, так это то, что AlphaGo достигает того, что он делает, благодаря блестящей комбинации классических методов искусственного интеллекта, а также современных методов машинного обучения, с которыми так тесно связан DeepMind. Это захватывающая демонстрация современного искусственного интеллекта, и мы рады, что можем удостоить его этой награды ».
Сообщество го
Го — популярная игра в Китае, Японии и Корее, а также матчи 2016 года смотрели, возможно, около ста миллионов человек по всему миру. Многие ведущие игроки в го охарактеризовали неортодоксальные игры AlphaGo как кажущиеся сомнительными ходы, которые поначалу сбивали с толку зрителей, но имели смысл в ретроспективе: «Все, кроме лучших игроков в го, создают свой стиль, подражая лучшим игрокам. AlphaGo, кажется, имеет совершенно оригинальные ходы, которые создает сама. » AlphaGo, похоже, неожиданно стал намного сильнее, даже по сравнению с матчем в октябре 2015 года, когда компьютер впервые в истории обыграл профессионала в игре Го без преимущества гандикапа. На следующий день после первого поражения Ли Чон Ахрам, ведущий корреспондент Го одной из крупнейших ежедневных газет Южной Кореи, сказал: «Прошлая ночь была очень мрачной… Многие люди пили алкоголь». Корейская ассоциация бадук, организация, которая наблюдает за профессионалами го в Южной Корее, наградила AlphaGo почетным титулом 9 дан за проявление творческих способностей и продвижение вперед в игре.
Китай Ке Цзе, 18-летний парень, общепризнанный лучшим игроком в го в то время, первоначально утверждал, что сможет победить AlphaGo, но отказался играть против него, опасаясь, что это будет «копировать мой стиль. «. По ходу матчей Кэ Цзе ходил туда-сюда, заявляя, что «весьма вероятно, что я (могу) проиграть» после анализа первых трех матчей, но вновь обретя уверенность после того, как AlphaGo обнаружила недостатки в четвертом матче.
Тоби Мэннинг, судья матча AlphaGo с Фань Хуэй, и Хаджин Ли, генеральный секретарь Международной федерации го, оба считают, что в будущем игроки в го будут получать помощь от компьютеров, чтобы узнать, что у них есть. поступили неправильно в играх и улучшили свои навыки.
После второй игры Ли сказал, что он «потерял дар речи»: «С самого начала матча я никогда не мог одержать победу в одном единственном ходу. Это было Полная победа AlphaGo «. Ли извинился за свои поражения, заявив после третьей игры, что «я недооценил возможности AlphaGo и почувствовал себя бессильным». Он подчеркнул, что поражение было «поражением Ли Седола», а не «поражением человечества». Ли сказал, что его окончательная потеря из-за машины была «неизбежной», но заявил, что «роботы никогда не поймут красоту игры так же, как мы, люди». Ли назвал свою победу в четвертой игре «бесценной победой, которую я (не променяю) ни на что».
Подобные системы
Facebook также работает над своей собственной системой игры в го darkforest, также основанный на сочетании машинного обучения и поиска по дереву Монте-Карло. Несмотря на то, что он является сильным игроком против других компьютерных программ Го, по состоянию на начало 2016 года он еще не победил профессионального игрока-человека. Darkforest проиграл CrazyStone и Zen и, по оценкам, имеет такую же силу, как CrazyStone и Zen.
DeepZenGo, система, разработанная при поддержке веб-сайта для обмена видео Dwango и Токийский университет проиграл 2–1 в ноябре 2016 г. мастеру го Чо Тикун, который является рекордсменом по наибольшему количеству побед в го в Японии.
Статья 2018 г. в Nature ссылается на подход AlphaGo в качестве основы для нового средства вычисления потенциальных молекул фармацевтического препарата.
Пример игры
AlphaGo Master (белый) v. Тан Вэйсин (31 Декабрь 2016 г.), AlphaGo победила в отставке. Ход белых 36 получил широкую похвалу.
Воздействие на го
Документальный фильм AlphaGo вселил надежды на то, что Ли Седол и Фань Хуэй извлек бы пользу из своего опыта игры в AlphaGo, но по состоянию на май 2018 года их рейтинги мало изменились; Ли Седол занял 11-е место в мире, а Фань Хи 545-е место. 19 ноября 2019 года Ли объявил о своем уходе из профессиональной игры, утверждая, что он никогда не сможет стать лучшим игроком в го из-за растущего доминирования ИИ. Ли назвал их «сущностью, которую невозможно победить».
См. Также
- Чинук (игрок в шашки), шашки игровая программа
- Глоссарий искусственного интеллект
- Го и математика
- Лила (программное обеспечение)
- TD-Gammon, нарды нейронная сеть
- Pluribus (покерный бот)
Список литературы
Внешние ссылки
| Викискладе есть материалы, связанные с AlphaGo . |
| Викицитатник содержит цитаты, связанные с: AlphaGo |
- Официальный сайт
- AlphaGo wiki по адресу Библиотека Сенсея, включая ссылки на игры AlphaGo
- страницу AlphaGo, с архивом и играми
- Оценочный рейтинг Alpha Go на 2017 год
9 марта программа AlphaGo, разработанная Google, впервые обыграла человека в Го. N+1 рассказывает, почему это стало возможно
9 марта начался матч между программой AlphaGo и одним из сильнейших игроков планеты, Ли Седолем. Еще месяц назад Седоль был совершенно уверен в своей победе, но проиграл программе в первом же раунде — неожиданно и для себя, и для наблюдавших за матчем других профессиональных игроков. На следующий день он сдал и вторую игру. Чем закончится вся серия игр, станет известно на следующей неделе. Пока же N+1 рассказывает, как устроена система машинного обучения AlphaGo и что об этой истории думают эксперты — профессиональные игроки в го и специалисты по теории игр.
Матч
«Я был уверен, что у нас есть хотя бы 10 лет в запасе. Еще пару месяцев назад мы играли с программами на форе в четыре камня — это примерно как фора в ладью в шахматах. И тут — бац! — сразу Ли Седоль повержен» — так описывает свои впечатления от матча один из самых сильных российских игроков, семикратный чемпион Европы по игре го Александр Динерштейн. «Я прогнозировал счет 5-0 в пользу Ли Седоля. И многие ведущие профессионалы были согласны с этой оценкой. Сейчас все в шоке, никто не знает, что будет».
Впрочем, не для всех такой результат оказался столь неожиданным. Судя по всему, в Google предчувствовали победу: посмотреть на игру приехали не только непосредственные авторы AlphaGo, но и топы компании — один из ключевых инженеров Джеф Дин и сам Эрик Шмидт. Корея, где игра го традиционно популярнее, чем где бы то ни было, встречала создателей алгоритма первыми полосами газет и сюжетами на телевидении.
Все профессиональные комментаторы сходятся в том, что первая игра прошла очень необычно и сильно отличалась о того, что AlphaGo демонстрировала в матче с Фань Хуэем. Среди ценителей го Ли Седоль славится активной, даже агрессивной манерой игры, которой обычно не хватает компьютерам (или так о них принято думать). И в этом матче он в полной мере пытался реализовать это свое преимущество.
Ли Седоль начал с домашней заготовки, призванной выбить AlphaGo из колеи известных партий. «Уже после семи ходов у игры не оказалось аналогов в базе профессиональных партий, — поясняет Динерштейн. —Седоль, очевидно, применил такую стратегию для того, чтобы AlphaGo думал самостоятельно и не мог скопировать ходы других профи. Это одно из преимуществ го, например, перед шахматами, где все на пол-игры расписано в справочниках».
Поначалу AlphaGo отвечала на эту стратегию консервативно, пытаясь постепенно выравнивать стратегического преимущество. «Дальше программа несколько раз сыграла пассивно, многие поверили, что Ли Седоль впереди. Это в один голос утверждали все комментаторы матча, корейские и японские профессионалы го. И тут, когда казалось, что человек легко победит, последовал сильнейший удар, вторжение в огороженную зону Ли Седоля, которую он уже считал своей территорией. Партия длилась 186 ходов, но решилась она именно этим одним единственным ударом», — поясняет Александр Динерштейн.
Речь идет о ходе номер 102 (всю партию можно просмотреть здесь). Александр Динерштейн особо подчеркивает, что никто не ожидал такого удара, ни сам Ли Седоль, ни комментаторы матча: «Получилось что-то сродни тому, как бывает у высших профессионалов в боксе: компьютер не показывал ничего особенного, защищался, играл пассивно. Но стоило человеку чуть-чуть расслабиться, как последовал удар, и партию было уже не спасти. Редко такое бывает. Иногда можно допустить с десяток ошибок и выиграть партию. А тут один красивый ход все решил. Ли Седоль был удивлен: он явно этого не ожидал и дальше просто не смог оправиться от шока».
Важно отметить, что речь не идет о «зевке» — случайной ошибке, допущенной человеком по невнимательности. Все сходятся в том, что партия была выиграна «по делу» и силы в матче равны. Если раньше Ли Седоль безоговорочно верил в свою победу со счетом 5-0 (ну от силы 4-1), то после первой партии он признался, что сейчас его шансы не более чем 50 на 50.
Вторая партия также завершилась поражением корейца. После нее даже «50 на 50» выглядят чересчур оптимистично: «Я видел сотни партий Ли Седоля, но не помню, чтобы он так совсем без шансов проигрывал. В обеих партиях, получив плохую позицию, он не смог ее даже обострить, хотя умение вытаскивать тяжелые позиции — это его конек». Что касается программы, то впечатления чемпиона Европы однозначны:
«Сегодня стало понятно, что у AlphaGo нет слабых мест, это просто монстр какой-то».
О том, что будет к концу матча, наш собеседник предсказать отказывается. «Сейчас игроки всего мира, безусловно, болеют за Ли. Может быть за очень редким исключением. Все-таки быть последней непобежденной игрой — это очень дорогого стоит. Многие приходили в го, как раз зная, что это последняя игра с полной информацией, в которой компьютеры не считались серьезными соперниками. У нас даже правила касательно электроники во время матча довольно расслабленные: всем понятно, что на высоком уровне компьютер играть в го не может, искать у него подсказки глупо. Если Ли проиграет, все это сильно изменится. Но история с DeepBlue в шахматах растянулась на несколько лет, так что у нас, я думаю, еще есть надежда», — неуверенно резюмирует Александр Динерштейн.

Обрезка и прополка
Чтобы объяснить, как команде Демиса Хассабиса, создавшей AlphaGo, удалось добиться такого впечатляющего результата, придется немного погрузится в теорию игр.
Го, как и шахматы, шашки, нарды и многие другие игры относится к играм с открытой информацией. Это значит, что оба игрока знают все о своей позиции и вариантах ходов, которые им доступны. В такой игре можно ввести функцию, которая для любой позиции на доске s возвращает оптимальный ход для игрока при условии оптимальной игры всех сторон. Иметь такую функцию v*(s) значит, собственно, математически «решить» игру (найти глобальный оптимум).
Сделать ее, казалось бы, несложно: достаточно перебрать все дерево вариантов, которое доступно игрокам. Но проблема, конечно же, в том, что в приличных играх вариантов развития событий слишком много для простого перебора. И го здесь занимает особо почетное место: число допустимых комбинаций камней на гобане (доске для игры в го) превышает число атомов во Вселенной. Так что надеяться получить истинное значение функции v*(s) для го — сейчас или в каком-то отдаленном будущем — бесполезно.
Однако задолго до того, как появились DeepBlue, AlphaGo и другие сильные алгоритмы, математики придумали несколько остроумных методов замены «настоящей» функции v*(s) на ее приблизительный аналог v(s) ≈ v*(s), который можно вычислить уже за какое-то разумное время.
Один из самых очевидных и простых способов решения этой задачи — подрезка «хилых» ветвей у дерева перебора. Он основан на том, что в игре обычно существуют позиции, которые «очевидно плохие» или «очевидно хорошие». Например, какая-то терминальная позиция в шахматах может еще не быть матом, но уже настолько плохой, что ни один игрок не найдет разумным ее доигрывать. Достижение такой позиции уже можно считать проигрышем не в даваясь в детали того, как именно он произойдет, если доводить игру до конца. Такой подход, в котором ветви дерева вариантов подрезаются и заменяются средними значениями их исходов, позволяет сократить глубину перебора.
Другие подходы основаны на сокращении ширины перебора, то есть на уменьшении числа вариантов ходов из всех разрешенных до некоторого набора популярных — на основе баз известных партий. Понятно, что такой подход позволяет существенно сократить число вариантов развития событий и, соответственно, время вычислений. Но он же делает поведение программы стереотипным, консервативным и предсказуемым — то есть как раз придает те качества, которыми известны слабые алгоритмы. В таком подходе программа фактически не пытается выиграть, а пытается угадать, как в похожей ситуации поступал игрок, матч которого она помнит. Для го, где широта возможностей велика как нигде, данная конкретная партия может стать совершенно уникальной уже за несколько ходов, и программе просто не на что будет опереться в выборе. Эту проблему можно решать, если рассматривать не доску целиком, а локальную ситуацию в отдельном фрагмента доски, где вариантов меньше, но проблемы со стереотипностью те же.
Как реально решают все эти проблемы создатели современных алгоритмов? До сих пор главным подходом к созданию игровых алгоритмов в играх, где открыта информация, но невозможен исчерпывающий перебор, были так называемые методы иерархического поиска Монте-Карло (MCTS). Работают они следующим образом. Представьте, что вы переехали в новый город и хотите выбрать для себя хороший книжный. Вы заходите в один случайно выбранный магазин, подходите к случайной полке, берете случайную книгу, открываете на случайном месте и читаете, что вам попалось на глаза. Если это хороший текст, магазин в ваших глазах получает плюс к карме, если нет — минус. Проведя несколько таких забегов вы обнаруживаете, что в одном из магазинов вы часто наталкиваетесь на слова вроде «ребятня» или «вкусняшки», а в другом более популярны «нелокальность» или «октатевхи». Постепенно становится понятно, какой из книжных вам больше подходит.
Методы иерархического поиска Монте-Карло работают по такому же принципу: из данной позиции s проводится симуляция игры до самого победного (или проигрышного — это уж как повезет) конца, причем каждый ход на каждом шаге игры выбирается случайным образом. Таким образом, проведя множество случайных симуляций можно грубо оценить выгодность позиции без исчерпывающего перебора. При этом, конечно, есть вероятность пропустить среди множества проигрышных и победные варианты, но эта вероятность уменьшается с увеличением числа симуляций. Функция v(s), полученная таким перебором, асимптотически приближается к истинной v*(s) полного перебора. И лучшие на сегодняшний день программы го основаны именно на таком подходе. Играют они довольно хорошо для любителя, но на профессиональный уровень ни одна из них до сих пор не вышла. Удалось это только AlphaGo, которая устроена иначе.
Кто здесь альфа
Многие СМИ, писавшие еще о первой победе над Фанем Хуеем, называют AlphaGo нейросетью. Это справедливо, но только отчасти. На самом деле AlphaGo — это гибридная система, где одновременно используется и иерархический поиск Монте-Карло, и новые для подобных систем нейросети.
Интересно, что гибридность AlphaGo разные комментаторы интерпретируют очень по-разному. Либо как очередную убедительную победу нейросетей и глубокого обучения над традиционным формальным подходом к искусственному интеллекту (ИИ), самым известным сторонником которого был Марвин Минский. Либо, наоборот, как признак ограниченности «чистых» нейросетей (последняя точка зрения интересно изложена здесь).
Действительно, последняя громкая победа глубокого обучения, к которой, к слову, также приложил руку Демис Хассабис, была связана с использованием «чистых» нейросетей. Речь идет о создании системы ИИ, которая смогла научиться играть в игры ATARI без использования каких-либо инструкций или сложной ручной настройки. Тогда в качестве данных для обучения программа получала только изображение игрового монитора и результат игры: победа или проигрыш. Имея эти данные, программа могла управлять игрой, например, нажимать на рычаги в пинболе. Оказалось, что длительное обучение с подкреплением без какого-либо вмешательства человека может вывести ИИ в подобной игре на уровень человека или даже выше.
Однако, такой «чисто сетевой» подход не сработал с го.
Вместо него команде Демиса Хассабиса пришлось применить гибридную архитектуру, сочетающую мощь нейросетей и традиционный метод Монте-Карло.
Как была получена эта архитектура? Инженеры Deepmind начали с создания нейросети, задачей которой было предсказать наиболее вероятный ход на основе базы сыгранных партий «человек против человека». Это сверточная нейросеть из 13 слоев, очень похожая на те, которые используются для анализа изображения и распознавания символов. Вводные данные для нее — это фактически просто картинка положения камней на доске 19 на 19 пикселей. «Сверточная» в применении к нейросети означает, что в ней используется математическая операция свертки при переходе от слоя к слою, то есть на каждом уровне по полному изображению пробегает маленькое окно, видимое в котором передается на следующий «нейрон» нейросети.
Главное преимущество нейросетей в том, что они позволяют достигать очень высоких уровней абстракции, вычленяя из изображений их, как бы сказать, чисто абстрактные черты.

Если нейросеть натренирована на распознавание котиков, то в ее первый слой просто загружается изображение, а последующие слои обрабатывают его примерно так: второй распознает контрастность пикселей, третий наличие линий, четвертый их ориентацию, пятый мохнатость, шестой ушастость, а седьмой и последний — «кóтовость».
Важно понимать, что это очень условное представление о нейросетях, поскольку никто их заранее не программирует и не знает, что и как распознает данный слой. Как раз наоборот, все это происходит само собой по мере обучения. Суть в том, что уровень абстрактности очень сильно растет по мере движения от нижних к верхним слоям.
Так вот, на первом этапе в Deepmind создали нейросеть, которая просто предсказывает наиболее вероятный ход, который сделал бы человек из данной позиции s. Результат ее работы — это фактически поле для го с расставленными вероятностными коэффициентами. Эта нейросеть SL (от supervised learning) затем была использована для того, чтобы играть против себя самой, совершенствуясь по мере обучения. Здесь был использован классический метод обучения с подкреплением: шаги, которые вели к победе, поощрялись, и сеть уже не предсказывала поведение игрока-человека, а предсказывала то, какой ход чаще ведет к победе. Идентичная по архитектуре, но уже обученная игрой против самой себя нейросеть получила название RL (от reinforcement learning).
На последнем этапе в Deepmind собрали так называемую оценочную сеть, задачей которой было численно оценить выгодность той или иной позиции на доске, то есть ответить на вопрос, насколько вероятно, что игрок выиграет, если сделает ход, приводящий к такой позиции. Результат ее работы представлял собой уже не поле с весами выгодных ходов, а единственный параметр — вероятность выигрыша.
Фактически, оценочная сеть была призвана заменить поиск веса позиции методом Монте-Карло, который применяется в других программах го. И, если бы эта нейросеть была совершенной, то есть выдаваемое ею значение v(s) приближалось к истинному v*(s), то одной ее было бы достаточно для победы над любым противником. Но это оказалось не так.
Из графиков, которые приводит команда Deepmind, видно, что «чистая нейросеть», хотя и обыгрывает «чистый Монте-Карло», все же играет на уровне хорошего любителя. Профессионального уровня удается достичь только тогда, когда одновременно используется и оценочная сеть, и «предсказательная» сеть RL, и оценки методом Монте-Карло. Для того чтобы принять решение, алгоритм сложным образом складывает их независимые оценки. В скобках отметим, что успешность того или иного подхода сильно зависит от времени, которое, согласно текущим правилам, имеется в распоряжении играющих: понятно, что чем больше времени на вычисления, тем точнее методы Монте-Карло и ниже необходимость в «быстрых и грязных» методах вроде тактической сети.

После го
В играх с совершенной информацией го всегда считалась самой сложной. И выход программ на «нечеловеческий» уровень, безусловно, маркирует качественный переход во всей области исследований искусственного интеллекта. Ушла эпоха, не иначе.
Но думать, что теперь, с созданием AlphaGo, эволюция программ остановится, а «вопрос го» будет закрыт, неправильно. На это обращает внимание другой наш собеседник, доцент кафедры высшей математики ВШЭ, эксперт по теории игр Дмитрий Дагаев: «В том-то и дело, что отступление от полного перебора означает, что мы отказывается от покорения игры. Программа может научиться играть хорошо, но она не будет знать точное решение в любой возможной позиции, а значит теоретически ее можно будет обыграть. Пали шашки — в шашки компьютер может гарантировать себе ничью, он знает наилучший ход в любой возможной позиции. В шахматах и го решение компьютеру неизвестно. Но играть против компьютера будет все сложнее и сложнее».
Это открывает простор для соревнования между алгоритмами, которые со временем могут становится все совершеннее, но при этом, в отличие от случая шашек, не смогут в обозримом будущем достичь абсолютного совершенства: «DeepBlue умеет определять, что такое неудачный ход, ориентируясь на много ходов вперед в отличие от человека. Значит, любая ошибка человека, которую можно зафиксировать на расстоянии просчета компьютера, будет мгновенно им использована. Однако если, например, DeepBlue считает на 20 ходов, то нельзя исключать, что бывают ошибки, которые можно обнаружить только просчитав все на 25 ходов. Когда появится программа, умеющая это делать, она сможет обыгрывать DeepBlue», – объясняет Дмитрий Дагаев. Впрочем, все это будет интересно уже не для живых игроков, а для архитекторов и создателей программ новых поколений.
Для тех же, кто не желает участвовать в этой гонке и вообще отказывается играть на поле, где компьютеры сильнее, есть и хорошие новости. Это существование игр с несовершенной информацией, где компьютеру будет гораздо труднее проявить себя: «Любую конечную игру с совершенной информацией понятно, как решать: запускаем алгоритм обратной индукции и все. На каждой подыгре находим наилучший ход и при дальнейших расчетах ориентируемся только на него (рациональному игроку незачем делать неоптимальные ходы). В играх с несовершенной информацией так не получится: когда мы дойдем до ситуации, в которой игрок не будет однозначно понимать текущую позицию, мы не сможем однозначно определить его наилучший ход. Значит, дальше нам тоже придется учитывать несколько вариантов развития ситуации. Рост неопределенности приведет к резкому росту вычислительной сложности», — обнадеживает Дмитрий.
Помимо этого, если говорить конкретно про покер, то там компьютер ждут и другие проблемы: «В шашках, шахматах — три исхода, в го — два. В покере исход — это заработанные деньги. Поэтому приходится решать вопросы, связанные с точностью вычислений для сравнения различных альтернатив». Пока их решать не очень получается. Последний значимый результат в этом направлении — это победа программы в очень специфическом варианте покера, ограниченном холдеме «один на один». Новость о создании такой программы быстро разлетелась в СМИ в прошлом году, но профессионалы отнеслись к ней очень скептически: в такой (очень ограниченный) вариант покера почти никто не играет, это настоящая экзотика. Так что за покером пока не пришли и его можно считать недоступным для современных алгоритмов. Когда-то такой игрой считалась и го, но что уж теперь об этом вспоминать.
В прошлом месяце человечество проиграло важную битву с искусственным интеллектом — тогда AlphaGo обыграл чемпиона по го Ки Дже со счетом 3:0. AlphaGo — это программа с искусственным интеллектом, разработанная DeepMind, частью родительской компании Google Alphabet. В прошлом году она обыграла другого чемпиона, Ли Седоля, со счетом 4:1, но с тех пор существенно набрала по очкам.

Ки Дже описал AlphaGo как «бога игры в го».
Теперь AlphaGo заканчивает играть в игры, предоставляя возможность игрокам, как и прежде, сражаться между собой. Искусственный интеллект приобрел статус «игрока из далекого будущего», до уровня которого людям придется расти очень долго.
Содержание
- 1 На старт, внимание, го
- 2 Нейробиология и искусственный интеллект
- 3 Лучшие ходы
- 4 Что дальше?
На старт, внимание, го
Го — это древняя игра на двоих, где один играет белыми фигурами, другой черными. Задача — захватить доминацию на доске, разделенной на 19 горизонтальных и 19 вертикальных линий. Компьютерам играть в го сложнее, чем в шахматы, потому что число возможных ходов в каждой позиции намного больше. Это делает просчет возможных ходов наперед — вполне возможный для компьютеров в шахматах — очень сложным в го.
Прорывом DeepMind стала разработка общего алгоритма обучения, который, в принципе, можно направить в более социально ориентированном направлении, чем го. DeepMind говорит, что группа исследователей AlphaGo пытается решить сложные проблемы вроде поиска новых лечений для заболеваний, радикального снижения энергопотребления или разработки новых революционных материалов.
«Если система ИИ доказывает, что способна обретать новое знание и стратегии в этих сферах, прорывы будут просто неописуемы. Не могу дождаться, чтобы увидеть, что будет дальше», говорит один из ученых проекта.
В будущем это грозит множеством захватывающих возможностей, но проблемы пока никуда не делись.
Нейробиология и искусственный интеллект
AlphaGo сочетает две мощных идеи на тему обучения, которые получили развитие за последние несколько десятилетий: глубокое обучение и обучение с подкреплением. Что примечательно, оба направления вышли из биологической концепции работы и обучения мозга в процессе получения опыта.
В мозге человека сенсорная информация обрабатывается в серии слоев. Например, визуальная информация сперва трансформируется в сетчатке, затем в среднем мозге, а затем проходит через различные области коры головного мозга.
В итоге появляется иерархия представений, где сперва идут простые и локализованные детали, а затем более сложные и комплексные особенности.
Эквивалент в ИИ называется глубоким обучением: глубокое, потому что включает множество слоев обработки в простых нейроноподобных вычислительных единицах.
Но чтобы выжить в этом мире, животным необходимо не только распознавать сенсорную информацию, но и действовать в соответствии с ней. Поколения ученых и психологов изучали, как животные учатся предпринимать действия, чтобы максимизировать извлекаемую выгоду и получаемую награду.
Все это привело к математическим теориям обучения с подкреплением, которое теперь можно имплементировать в системы ИИ. Самой важной из них является так называемое TD-обучение, которое улучшает действия за счет максимизации ожидания будущей награды.
Лучшие ходы

За счет сочетания глубокого обучения и обучения с подкреплением в серии искусственных нейронных сетей, AlphaGo сперва научился играть на уровне профессионального игрока в го на основе 30 миллионов ходов из игр между людьми.
Но затем он начал играть против себя, используя исход каждой игры, чтобы неумолимо оттачивать собственные решения о лучшем ходе в каждой позиции на доске. Система ценностей сети научилась прогнозировать вероятный результат с учетом любой позиции, а система благоразумия сети научилась принимать лучшее решение в каждой конкретной ситуации.
Хотя AlphaGo не мог опробовать все возможные позиции на доске, нейронные сети извлекли ключевые идеи о стратегиях, которые хорошо работают в любой позиции. Именно эти бесчисленные часы самостоятельной игры привели к улучшению AlphaGo за последний год.
К сожалению, пока еще нет известного способа выяснить у сети, что это за ключевые идеи. Мы просто можем изучать игры и надеяться, что что-то извлечем из них. Это одна из проблем использования нейронных алгоритмов: они не объясняют свои решения.
Мы по-прежнему мало понимаем о том, как обучаются биологические мозги, а нейробиология продолжает предоставлять новые источники вдохновения для ИИ. Люди могут стать экспертами в игре го, руководствуясь гораздо меньшим опытом, чем нужен AlphaGo для достижения такого уровня, поэтому пространство для улучшения алгоритмов еще есть.
Кроме того, большая часть мощности AlphaGo основана на технике метода обратного распространения ошибки, которая помогает ей исправлять ошибки. Но связь между ней и обучением в реальном мозге пока неясна.
Что дальше?
Игра го стала удобной платформой разработки для оптимизации этих алгоритмов обучения. Но многие проблемы реального мира куда беспорядочнее и имеют меньше возможностей для самообучения (например, самоуправляемые автомобили).
Существуют ли проблемы, к которым мы можем применить имеющиеся алгоритмы?
Одним из примеров может быть оптимизация контролируемых промышленных условий. Здесь задача часто состоит в том, чтобы выполнить сложную серию заданий, удовлетворить множество критериев и минимизировать затраты.
До тех пор, пока условия можно будет точно смоделировать, эти алгоритмы будут учиться и набираться опыта быстрее и эффективнее, чем люди. Можно лишь повторить слова компании DeepMind: очень хочется посмотреть, что же будет дальше.

Подразделение DeepMind компании Google разработало алгоритм искусственного интеллекта AlphaGo Zero, который без помощи людей выучил правила игры го. На это ИИ потребовалось три дня, пишет The Guardian.
AlphaGo Zero уже победил искусственный интеллект версии 2015 года, который в прошлом году выиграл у чемпиона по го из Южной Кореи Ли Се Дола. Однако применение такого алгоритма не ограничивается играми: поскольку AlphaGo Zero способен обучаться с нуля, то возможности такого ИИ можно использовать для решения реальных проблем.
Демис Хассабис
глава DeepMind
«Для нас разработка AlphaGo не заканчивалась на победе в игре го. Для нас это также был большой шаг к созданию алгоритмов общего назначения».
Многие алгоритмы искусственного интеллекта ограничены в использовании, поскольку они способны выполнять одну задачу. Например, ИИ может переводить с иностранных языков или распознавать лица. А искусственный интеллект общего назначения в теории может превзойти людей в выполнении сразу нескольких задач. Хассабис ожидает, что в ближайшие 10 лет следующие версии AlphaGo будут выполнять роль научных экспертов и работать вместе с людьми.
Предыдущие версии AlphaGo обучались в ходе нескольких тысяч партий с профессионалами в этой игре. AlphaGo Zero начал в случайном порядке размещать камни на доске, но уже через некоторое время алгоритмы обнаружили выигрышные стратегии. Программа накапливает умения с помощью обучения с подкреплением, отмечает издание.
Однако сейчас возможности применения AlphaGo Zero ограничены: ИИ может решать задачи, смоделированные на компьютере. Это исключает обучение таким навыкам, как управление транспортным средством.
В феврале 2017 года ученые из DeepMind установили условия, при которых алгоритмы с искусственным интеллектом будут сотрудничать или, напротив, будут действовать в своих интересах.
Есть новость? Присылайте на news@incrussia.ru
27 января Google объявил, что AlphaGo, искусственный интеллект разработанная дочерней компанией DeepMind, победила чемпиона Европы по футболу Фань Хуэя в матче из пяти игр.
Возможно, вы слышали об этой новости, поскольку она делает заголовки во всем мире, но почему люди так заботятся об этом? Что все это значит? Если вы не знакомы с игрой в Го или ее значением для искусственного интеллекта, вы можете чувствовать себя немного растерянным.
Не волнуйтесь, мы вас покроем. Вот все, что вам нужно знать о прорыве и о том, как он влияет на обычных людей, таких как вы и я.
Игра в Го: простая, но сложная
Go — древняя китайская стратегическая игра, в которой два игрока сражаются за захват территории. По очереди, каждый игрок — один белый, другой черный — кладет камни на пересечения сетки 19 х 19. Когда группа камней полностью окружена камнями другого игрока, они «захватываются» и удаляются с игрового поля.
В конце игры каждое пустое место «принадлежит» игроку, окружающему его. Очки каждого игрока основаны на том, сколько территории он владеет (то есть сколько пустого пространства он окружил) плюс количество фигур противника, которые были захвачены во время игры.

Хотя большинство людей, вероятно, считают шахматы королем стратегических игр, на самом деле игра Go более сложна. Согласно Википедии, существует 10 761 возможных игр в Го по сравнению с 10 120 предполагаемыми играми в Шахматы.
Эта сложность, наряду с некоторыми эзотерическими правилами и акцентом на игре по инстинкту, делает игру Go особенно сложной для компьютеров, чтобы учиться и играть на высоком уровне.
Невероятный мир игровых ИИ
По большому счету, создание искусственного интеллекта, который играет в игру, не кажется очень стоящим занятием, особенно когда IBM Watson AI уже работает над улучшением здравоохранения, и эта область нуждается в любой помощи, которую он может получить. Так почему же Google потратил так много часов и долларов на создание игрового AI?
С одной стороны, это помогает исследователям ИИ найти лучший способ научить компьютеры делать что-либо. Если вы можете научить компьютер решать, как находить лучшие ходы в игре «Шашки» или «крестики-нолики», вы можете научить другой компьютер, как рекомендовать фильмы по Netflix , мгновенно переводите речь или предсказывайте землетрясения.
Многие виды использования ИИ, которые мы видели до сих пор, выиграют от улучшенных способностей решения проблем и извлечения паттернов, которые также важны для эффективных игровых ИИ.

Deep Blue, AI чемпиона по шахматам, работал, используя огромное количество вычислительной силы и методов грубой силы, чтобы оценить все возможные последующие шаги — до 200 000 000 позиций в секунду. И хотя эта стратегия была достаточно эффективной, чтобы победить бывшего чемпиона мира по шахматам, это не совсем «человеческий» способ играть в шахматы. Это также требует от программистов «объяснять» правила игры ИИ.
Совсем недавно был разработан процесс, называемый глубоким обучением , который, по сути, проложил путь к обучению компьютеров, и это полностью изменило гонку за искусственный интеллект
Благодаря глубокому обучению компьютер может извлекать полезные шаблоны из данных — вместо того, чтобы программисты сообщали им, какие шаблоны следует искать, — и использовать эти шаблоны для оптимизации своих собственных решений. Если глубокое обучение проходит успешно, ИИ может даже обнаружить шаблоны, которые более эффективны, чем то, что мы можем распознать как людей.
Этот тип обучения был продемонстрирован в прошлом году, когда исследовательская фирма DeepMind, принадлежащая Google, продемонстрировала AI, который научился играть в 49 различных игр после того, как давали только необработанный вклад. (Вы можете видеть, как он учится играть в Breakout выше.)
Процесс такой же, как изучение видеоигры без учебника или объяснения. Вы наблюдаете некоторое время, затем пытаетесь нажимать случайные кнопки, затем начинаете разбираться, разрабатывать стратегии и, в конечном итоге, добиваться успеха.
И превзойти это сделали. В некоторых играх, таких как Video Pinball, DeepMind AI полностью уничтожил людей-противников профессионального уровня. В других играх, включая г-жу Пак-Мэн, дела обстояли значительно хуже, но в целом он показал очень впечатляющие результаты.
AlphaGo: следующий уровень ИИ
AlphaGo, компьютер, который победил Fan Hui at Go, использовал эту стратегию глубокого обучения, чтобы остаться непобежденным в пяти матчах.
Вместо того, чтобы использовать вычисления грубой силы, такие как Deep Blue, AlphaGo определил свой следующий ход, используя то, что он изучил в процессе обучения, чтобы ограничить объем потенциально эффективных ходов, а затем запустил симуляции, чтобы увидеть, какие ходы, скорее всего, приведут к положительным результатам.
Две разные нейронные сети , сеть политик и сеть ценностей, работали вместе, чтобы оценить ходы и выбрать лучший каждый ход.

Из-за сложности Го подход грубой силы по всем возможным ходам просто невозможен, как в Шахматах. Таким образом, AlphaGo опирался на знания, полученные во время этапа обучения, который состоял из наблюдения за 30 миллионами ходов, сделанных человеческими экспертами, умения предсказывать их ходы, придумывать свои собственные стратегии и играть против себя тысячи раз.
Используя обучение с подкреплением, его процессы принятия решений развивались и усиливались до тех пор, пока AlphaGo не стал лучшим ИИ для игры в гоу в мире. В 500 играх против самых продвинутых компьютеров Go он выиграл 499 из них — даже после того, как эти программы получили преимущество в четыре этапа.
И, конечно же, AlphaGo победил Фана Хуэя, действующего чемпиона Европы по Го. Победа была фактически достигнута в октябре 2015 года, но объявление было отложено, чтобы совпасть с выпуском исследовательской работы DeepMind в Nature . В марте AlphaGo возьмет на себя Ли Седола, самого доминирующего игрока в мире за последние десять лет.
Итак, что все это значит?
Почему это делает заголовки во всем мире? На самом деле по нескольким причинам.
Во-первых, многие думали, что это невозможно с современными технологиями. По большинству оценок, ИИ не победил бы игрока мирового уровня в Го, по крайней мере, еще десять лет. Ценные сети AlphaGo могут оценить любую игру в Го, в которую играют в данный момент, и предсказать возможного победителя — проблема, которая, по словам Google, « настолько сложна, что это считалось невозможным».

Во-вторых, тот факт, что было использовано глубокое и независимое обучение, очень важен. Это показывает, что современный искусственный интеллект может собирать данные, извлекать закономерности, учиться прогнозировать такие закономерности и в конечном итоге разрабатывать стратегии решения проблем, которые являются достаточно сложными и эффективными, чтобы побеждать людей мирового уровня.
И хотя победа в Go не изменит мир, тот факт, что компьютер смог выработать стратегию такого уровня, используя собственные алгоритмы обучения, очень впечатляет.
Именно это глубокое изучение заставляет исследователей ИИ по-настоящему взволноваться по поводу AlphaGo Многие считают, что самостоятельное обучение является первым шагом к созданию сильного искусственного интеллекта . Сильный ИИ относится к компьютеру, который может решать интеллектуальные задачи наравне с людьми (что невероятно сложно, во многом из-за сложности и эффективности человеческого мозга). Это тот ИИ, который вы видите во многих научно-фантастических фильмах. .

Именно по этой причине создание ИИ, которые могут вести себя по-человечески, — такая большая проблема. Извлечение шаблонов и разработка стратегий — это то, что мы делаем постоянно, и мы не используем методы грубой силы при принятии решений.
Очень сложно заставить компьютер сделать это без большого руководства, но благодаря AlphaGo мы теперь знаем, что сильный ИИ не просто возможен, но ближе, чем мы думали.
Конечно, ИИ, играющий в Го, все еще далек от общего интеллектуального ИИ. Он делает только одну вещь, которая настолько проста, насколько это возможно с помощью искусственного интеллекта — даже ИИ, играющий на Atari, смог сыграть в 49 различных игр. — но эффективное самостоятельное обучение AlphaGo может стать первым шагом к серьезному изменению парадигмы в искусственном интеллекте.
Что вы думаете?
Нет сомнений в том, что победа AlphaGo над Fan Hui важна, но стоит ли спорить о том, достойна ли она всемирных заголовков.
Как вы думаете, это большое дело? Находимся ли мы на шаг ближе к апокалипсису роботов ? Или вы не впечатлены ИИ, который может просто играть в игру? Поделитесь своими мыслями ниже и давайте поговорим об этом.
Кредиты на изображения: игра go vvoe через Shutterstock, Татьяна Белова через Shutterstock.com , Mciura через Wikimedia Commons , Zerbor через Shutterstock.com