|
Wolfevg 0 / 0 / 0 Регистрация: 13.05.2014 Сообщений: 29 |
||||
|
1 |
||||
Как сократить время работы программы?06.08.2014, 20:21. Показов 2350. Ответов 13 Метки нет (Все метки)
Это исходный код данной задачи:http://acm.timus.ru/problem.aspx?space=1&num=1510
0 |

|
1471 / 826 / 140 Регистрация: 12.10.2013 Сообщений: 5,456 |
|
|
06.08.2014, 21:01 |
2 |
|
Как сократить время работы программы? Думаю этот код все равно переводиться в например в ассемблер, с кучей ненужных действий, если хотите ускорить любую программу то пишите на ассемблере сразу.
1 |

|
2392 / 2218 / 564 Регистрация: 28.12.2010 Сообщений: 8,662 |
|
|
06.08.2014, 22:18 |
3 |
|
Excalibur921, отличный совет! Добавлено через 5 минут
0 |

|
1471 / 826 / 140 Регистрация: 12.10.2013 Сообщений: 5,456 |
|
|
06.08.2014, 22:39 |
4 |
|
Excalibur921, отличный совет! Да, он может быть даже в разы ускорит программу. Хотя возможно это избыточно.
0 |
|
2392 / 2218 / 564 Регистрация: 28.12.2010 Сообщений: 8,662 |
|
|
06.08.2014, 22:57 |
5 |
|
Excalibur921, вопрос в том как написать эту программу на Java а не на ассемблере.
0 |
|
1471 / 826 / 140 Регистрация: 12.10.2013 Сообщений: 5,456 |
|
|
06.08.2014, 23:19 |
6 |
|
вопрос в том как написать эту программу на Java а не на ассемблере. Неправда, вот
Как сократить время работы программы? Но да, я дал просто общий совет. Добавлено через 4 минуты
0 |
|
0 / 0 / 0 Регистрация: 13.05.2014 Сообщений: 29 |
|
|
07.08.2014, 09:08 [ТС] |
7 |
|
3 Ведь у всех индексы будут разные, как все это реализовать.
0 |
|
2882 / 2294 / 769 Регистрация: 12.05.2014 Сообщений: 7,978 |
|
|
07.08.2014, 09:41 |
8 |
|
Просто я ненавижу джава, с ним сталкиваюсь с браузере с JavaScript не попутал?
0 |
|
dvano 136 / 67 / 27 Регистрация: 18.06.2014 Сообщений: 216 |
||||
|
07.08.2014, 10:01 |
9 |
|||
|
Вот моя реализация:
0 |
|
dvano 136 / 67 / 27 Регистрация: 18.06.2014 Сообщений: 216 |
||||
|
07.08.2014, 11:28 |
10 |
|||
|
Вот еще реализация на Assembler(NASM), если кому интересно:
0 |
|
dvano 136 / 67 / 27 Регистрация: 18.06.2014 Сообщений: 216 |
||||
|
07.08.2014, 11:37 |
11 |
|||
|
блин. Опечатался. Вот правильный вариант: Кликните здесь для просмотра всего текста
0 |
|
1471 / 826 / 140 Регистрация: 12.10.2013 Сообщений: 5,456 |
|
|
07.08.2014, 11:45 |
12 |
|
Вот правильный вариант: Настоящий кодер!
0 |
|
Eva Rosalene |
|||||
|
07.08.2014, 12:07
|
|||||
0 |

|
136 / 67 / 27 Регистрация: 18.06.2014 Сообщений: 216 |
|
|
07.08.2014, 17:26 |
14 |
|
Excalibur921, приблизительно 0.04 секунд. FraidZZ, больше так не буду.
0 |
ХЕЛП-Как уменьшить время исполнения программы
Реализовал Алгоритм из статьи, числа все находятся для Long.Max_VALUE , но за 13 секунд. Функция Arm проверяет принадлежность к числу Aрмстронга.
Помогите как оптимизировать код, чтобы программа быстрее работала? (4 пункт только не работает)
package com.javarush.task.task20.task2025;
import java.util.Arrays;
import java.util.*;
/*
Алгоритмы-числа
*/
public class Solution {
public static long[][] maspow = new long[20][10];
static {
for (int i = 1; i <= 19; i++) {
for (int j = 0; j <= 9; j++) {
if (i == 1) {
maspow[i][j] = j;
} else {
maspow[i][j] = maspow[1][j] * maspow[i — 1][j];
}
}
}
}
public static int dlinachisla(long N) {
long p = 10;
for (int i = 1; i < 19; i++) {
if (N < p) {
return i;
}
p *= 10;
}
return 19;
}
public static long Arm(int[] mas) {
int k = 0;
long h = 0;
long f = 0;
int lmas = mas.length;
for (int i = 0; i < lmas; i++) {
if (mas[i] == 0) {
k++;
h += maspow[lmas][mas[i]];
} else {
h += maspow[lmas][mas[i]];
}
}
if (h > 0 & (dlinachisla(h) <= lmas)) {
if (k == 0) {
if (dlinachisla(h) == lmas) {
int r4 = (int) (h % 10);
long l = 1;
for (int i = 2; i < lmas; i++) {
l = l * 10;
f += maspow[lmas][(int) ((h / l) % (10))];
}
int r1 = (int) (h / (10 * l));
f = f + maspow[lmas][r1] + maspow[lmas][r4];
if (h == f) {
return h;
} else {
return 0;
}
} else {
return 0;
}
} else {
for (int j = 0; j <= k; j++) {
h = 0;
f = 0;
int[] mas1 = new int[lmas — j];
int mas1l = mas1.length;
for (int i = lmas — 1; i >= j; i—) {
mas1[i — j] = mas[i];
h += maspow[lmas — j][mas1[i — j]];
}
if ((dlinachisla(h)) == mas1l) {
int r4 = (int) (h % 10);
long l = 1;
for (int i = 2; i <= mas1l; i++) {
l = l * 10;
f += maspow[mas1l][(int) ((h / l) % (10))];
}
f = f + maspow[mas1l][r4];
if (h == f) {
return h;
}
}
}
}
}
return 0;
}
public static long[] getNumbers(long N) {
if ((N > 0) && (N <= Long.MAX_VALUE)) {
int n = dlinachisla(N);
int[] mas = new int[n];
TreeSet<Long> ts = new TreeSet<Long>();
for (int i = 0; i < n; i++) {
mas[i] = 9;
}
int r = 0;
int ii = 1;
while (mas[n — 1] != 0) {
long p = Arm(mas);
if (p != 0 && p < N) {
ts.add(p);
}
if (mas[r] == 0) {
if (r + 1 == ii) {
if ((mas[ii] == 0) && (ii != n — 1)) {
ii++;
mas[ii]—;
for (int i = 0; i < ii; i++) {
mas[i] = mas[ii];
r = 0;
}
} else if ((mas[ii] == 0) && (ii == n — 1)) {
break;
} else if ((mas[ii] != 0)) {
mas[ii]—;
for (int i = 0; i < ii; i++) {
mas[i] = mas[ii];
r = 0;
}
}
} else {
r++;
if (mas[r] != 0) {
mas[r]—;
for (int i = 0; i < r; i++) {
mas[i] = mas[r];
}
r = 0;
}
}
} else {
mas[r]—;
}
}
long[] result1 = new long[ts.size()];
int u = 0;
for (long m : ts) {
result1[u] = m;
u++;
}
return result1;
} else {
return new long[0];
}
}
public static void main(String[] args) {
long a = System.currentTimeMillis();
System.out.println(Arrays.toString(getNumbers(Long.MAX_VALUE)));
long b = System.currentTimeMillis();
System.out.println(«memory » + (Runtime.getRuntime().totalMemory() — Runtime.getRuntime().freeMemory()) / (1024 * 1024));
System.out.println(«time = » + (b — a) / 1000);
a = System.currentTimeMillis();
System.out.println(Arrays.toString(getNumbers(100000000)));
b = System.currentTimeMillis();
System.out.println(«memory » + (Runtime.getRuntime().totalMemory() — Runtime.getRuntime().freeMemory()) / (1024 * 1024));
System.out.println(«time = » + (b — a) / 1000);
}
}
Этот веб-сайт использует данные cookie, чтобы настроить персонально под вас работу сервиса. Используя веб-сайт, вы даете согласие на применение данных cookie. Больше подробностей — в нашем Пользовательском соглашении.
Решаю задачу. Решение правильное, тесты проходит, но вылетает по времени выполнения.
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
byte s = sc.nextByte();
byte l1 = sc.nextByte();
byte r1 = sc.nextByte();
byte l2 = sc.nextByte();
byte r2 = sc.nextByte();
byte ans[] = new byte[2];
for (byte i = l1; i <= r1; i++) {
for(byte j = l2; j <= r2; j++) {
if(i + j == s) {
ans[0] = i;
ans[1] = j;
System.out.println(ans[0] + " " + ans[1]);
System.exit(0);
}
}
}
System.out.println(-1);
}
}
раньше использовал int вместо byte, но не помогло. Как можно уменьшить время выполнения?
Сама задача:
Задано целое число s и два диапазона целых чисел от l1 до r1, и l2 до
r2. Вам необходимо найти два целых числа x1, x2 или определить, что
таких чисел не существует, для которых выполнено x1 + x2 = s. x1 из 1
промежутка. x2 — из второго.
![]()
Эникейщик
24.8k7 золотых знаков29 серебряных знаков45 бронзовых знаков
задан 19 янв 2019 в 12:47
![]()
michael_bestmichael_best
1,5311 золотой знак9 серебряных знаков22 бронзовых знака
5
Я может чего-то недопонимаю, а зачем здесь вообще циклы?
int d = s-l1-l2; // сколько не хватает до суммы, если взяли нижние границы
int d1 = r1-l1; // сколько можно ещё выжать из первого интервала
int d2 = r2-l2; // сколько можно ещё выжать из второго интервала
if (d < 0 || d > d1+d2) return "no solution";
if (d1 >= d) return "x1="+(s-l2)+" x2="+l2; // из второго по минимуму, из первого - недостающее
return "x1="+r1+" x2="+(s-r1); // из первого по максимуму, из второго - недостающее
ответ дан 5 ноя 2019 в 4:52
![]()
Alexander PavlovAlexander Pavlov
1,8681 золотой знак6 серебряных знаков10 бронзовых знаков
5
Было много ажиотажа по поводу модного слова « масштабирование сети », и люди проходят через многие этапы реорганизации архитектуры своих приложений, чтобы заставить свои системы «масштабироваться».
Но что такое масштабирование, и как мы можем быть уверены, что можем масштабировать?
Различные аспекты масштабирования
Упомянутый выше обман главным образом связан с масштабированием нагрузки , то есть для того, чтобы система, которая работает на 1 пользователя, также работала хорошо для 10 пользователей, или 100 пользователей, или миллионов. В идеале ваша система должна быть как можно более «не имеющей состояния», чтобы оставшиеся несколько состояний могли быть перенесены и преобразованы на любом процессоре в вашей сети. Когда загрузка является вашей проблемой, задержка, вероятно, нет, поэтому все в порядке, если отдельные запросы занимают 50-100 мс. Это часто также называют масштабированием
Абсолютно другой аспект масштабирования связан с масштабированием производительности , т. Е. Чтобы убедиться, что алгоритм, который работает для 1 фрагмента информации, также будет хорошо работать для 10 частей, или 100 частей, или миллионов. Реализуется ли этот тип масштабирования лучше всего в Big O Notation . Задержка является убийцей при масштабировании производительности. Вы хотите сделать все возможное, чтобы сохранить все расчеты на одной машине. Это часто также называют расширением
Если бы было что-то вроде бесплатного ланча ( нет ), мы могли бы бесконечно комбинировать масштабирование. Во всяком случае, сегодня мы рассмотрим несколько очень простых способов улучшить ситуацию с точки зрения производительности.
Обозначение Big O
Java 7 ForkJoinPool а также параллельный Stream Java 8 помогают распараллеливать вещи, что прекрасно, когда вы развертываете свою программу Java на многоядерном процессоре. Преимущество такого параллелизма по сравнению с масштабированием между различными машинами в сети заключается в том, что вы можете почти полностью устранить эффекты задержки, поскольку все ядра могут получать доступ к одной и той же памяти.
Но не обманывайтесь эффектом параллелизма! Помните следующие две вещи:
- Параллелизм пожирает ваши ядра. Это отлично подходит для пакетной обработки, но кошмар для асинхронных серверов (таких как HTTP). Есть веские причины, по которым мы использовали однопоточную модель сервлета в последние десятилетия. Так что параллелизм помогает только при расширении.
- Параллелизм не влияет на нотацию Big O вашего алгоритма. Если ваш алгоритм
O(n log n), и вы позволяете этому алгоритму работать наcядрах, у вас все равно будет алгоритмO(n log n / c), так какcявляется незначительной константой сложности вашего алгоритма. Вы сэкономите время настенных часов, но не уменьшите сложность!
Конечно, лучший способ повысить производительность – это уменьшить сложность алгоритма. Убийца – это достижение O(1) или квази- O(1) , например, поиск HashMap . Но это не всегда возможно, не говоря уже о легкости.
Если вы не можете уменьшить свою сложность, вы все равно можете получить большую производительность, если вы настроите свой алгоритм там, где это действительно важно, если сможете найти правильные места. Предположим следующее визуальное представление алгоритма:
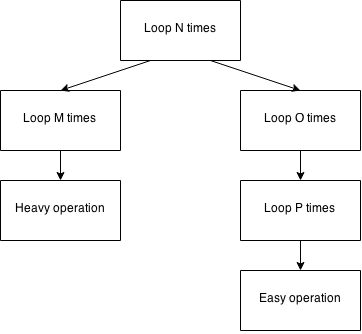
Общая сложность алгоритма составляет O(N 3 ) или O(N x O x P) если мы хотим иметь дело с отдельными порядками величины. Однако при профилировании этого кода вы можете найти забавный сценарий:
- В вашем блоке разработки левая ветвь (
N -> M -> Heavy operation) – единственная ветвь, которую вы можете видеть в своем профилировщике, поскольку значенияOиPв данных примера разработки малы. - На производстве, однако, правильная ветвь (
N -> O -> P -> Easy operationили также NOPE ) действительно вызывает проблемы. Ваша рабочая группа могла бы выяснить это с помощью AppDynamics , DynaTrace или какого-либо подобного программного обеспечения.
Без производственных данных вы можете быстро сделать выводы и оптимизировать «тяжелую работу». Вы отправляете в производство, и ваше исправление не имеет никакого эффекта.
Не существует золотых правил для оптимизации, кроме фактов, которые:
- Хорошо спроектированное приложение гораздо проще оптимизировать
- Преждевременная оптимизация не решит никаких проблем с производительностью, но сделает ваше приложение менее разработанным, что, в свою очередь, затруднит оптимизацию.
Достаточно теории. Давайте предположим, что вы нашли правильную ветвь, чтобы быть проблемой. Вполне может быть, что очень простое действие взрывается при производстве, потому что оно вызывается много раз (если N , O и P большие). Пожалуйста, прочтите эту статью в контексте проблемы на конечном узле неизбежного алгоритма O(N 3 ) . Эти оптимизации не помогут вам масштабироваться. Они помогут вам сэкономить день вашего клиента, отложив сложное улучшение общего алгоритма на потом!
Вот 10 самых простых оптимизаций производительности в Java:
1. Используйте StringBuilder
Это должно быть по умолчанию почти во всем коде Java. Старайтесь избегать оператора + . Конечно, вы можете утверждать, что это просто синтаксический сахар для StringBuilder любом случае, как в:
|
1 |
|
… который компилируется в
|
01 02 03 04 05 06 07 08 09 10 11 |
|
Но что произойдет, если позже вам понадобится изменить строку с дополнительными частями?
|
1 2 3 4 |
|
Теперь у вас будет второй StringBuilder , который просто излишне потребляет память из вашей кучи, оказывая давление на ваш GC. Напишите это вместо:
|
1 2 3 4 5 6 |
|
навынос
В приведенном выше примере это, вероятно, совершенно не имеет значения, если вы используете явные экземпляры StringBuilder или если вы полагаетесь на компилятор Java, создающий для вас неявные экземпляры. Но помните, мы в филиале NOPE . Каждый цикл ЦП, который мы тратим на такую глупость, как GC или выделение емкости по умолчанию для StringBuilder, мы теряем N x O x P раз.
Как правило, всегда используйте StringBuilder вместо оператора + . И если вы можете, сохраните ссылку StringBuilder на несколько методов, если ваша String более сложна для построения. Это то, что делает jOOQ , когда вы генерируете сложный оператор SQL. Существует только один StringBuilder который «пересекает» весь ваш SQL AST (абстрактное синтаксическое дерево)
И для громкого крика, если у вас все еще есть ссылки на StringBuffer , замените их на StringBuilder . Вам действительно никогда не нужно синхронизироваться на создаваемой строке.
2. Избегайте регулярных выражений
Регулярные выражения относительно дешевы и удобны. Но если вы находитесь в филиале NOPE , они о худшем, что вы можете сделать. Если вам абсолютно необходимо использовать регулярные выражения в разделах кода, требующих Pattern объема вычислений, по крайней мере Pattern ссылку на Pattern вместо того, чтобы постоянно компилировать ее:
|
1 2 |
|
Но если ваше регулярное выражение действительно глупо, как
|
1 |
|
… Тогда вам действительно лучше прибегнуть к обычным char[] или манипулированию на основе индекса Например, этот совершенно нечитаемый цикл делает то же самое:
|
01 02 03 04 05 06 07 08 09 10 11 12 |
|
… который также показывает, почему вы не должны делать преждевременную оптимизацию. По сравнению с версией split() это не поддерживается.
Задача: умные из ваших читателей могут найти еще более быстрые алгоритмы.
навынос
Регулярные выражения полезны, но они имеют свою цену. Если вы глубоко в ветке NOPE , вы должны избегать регулярных выражений любой ценой. Остерегайтесь различных методов JDK String, которые используют регулярные выражения, такие как String.replaceAll() или String.split() .
Вместо этого используйте популярную библиотеку, например Apache Commons Lang , для манипулирования строками.
3. Не используйте итератор ()
Теперь этот совет на самом деле не для общих случаев использования, а применим только в глубине ветви NOPE . Тем не менее, вы должны подумать об этом. Написание циклов foreach в стиле Java-5 удобно. Вы можете просто полностью забыть о внутреннем цикле и написать:
|
1 2 3 |
|
Однако каждый раз, когда вы запускаете этот цикл, если strings является Iterable , вы создаете новый экземпляр Iterator . Если вы используете ArrayList , это будет выделение объекта с 3- ints в вашей куче:
|
1 2 3 4 5 |
|
Вместо этого вы можете записать следующий эквивалентный цикл и «тратить» только одно значение int в стеке, что очень дешево:
|
1 2 3 4 5 |
|
… или, если ваш список на самом деле не меняется, вы можете даже использовать его массивную версию:
|
1 2 3 |
|
навынос
Итераторы, Iterable и цикл foreach чрезвычайно полезны с точки зрения удобочитаемости и читаемости, а также с точки зрения разработки API. Однако они создают небольшой новый экземпляр в куче для каждой отдельной итерации. Если вы выполняете эту итерацию много раз, вы должны избегать создания этого бесполезного экземпляра и вместо этого записывать итерации на основе индекса.
обсуждение
Некоторые интересные разногласия по поводу части вышеперечисленного (в частности, замена использования Iterator на access-by-index) обсуждались здесь на Reddit .
4. Не вызывайте этот метод
Некоторые методы просто дороги. В нашем примере ветки NOPE такого метода у нас нет, но у вас вполне может быть такой. Давайте предположим, что вашему драйверу JDBC нужно пройти невероятные проблемы, чтобы вычислить значение ResultSet.wasNull() . Ваш доморощенный SQL-каркасный код может выглядеть следующим образом:
|
01 02 03 04 05 06 07 08 09 10 |
|
Эта логика теперь будет вызывать ResultSet.wasNull() каждый раз, когда вы получаете int из набора результатов. Но контракт getInt() гласит:
Возвращает: значение столбца; если значение равно SQL NULL, возвращаемое значение равно 0
Таким образом, простым, но, возможно, радикальным улучшением вышесказанного будет:
|
1 2 3 4 5 6 7 8 |
|
Итак, это не просто:
навынос
Не называйте дорогие методы в алгоритме «конечными узлами», а вместо этого кэшируйте вызов или избегайте его, если это позволяет контракт метода.
5. Используйте примитивы и стек
Приведенный выше пример взят из jOOQ , в котором используется много обобщений, и поэтому он вынужден использовать типы-оболочки для byte , short , int и long – по крайней мере, прежде чем обобщения будут специализированы в Java 10 и проекте Valhalla . Но у вас может не быть этого ограничения в вашем коде, поэтому вы должны принять все меры для замены:
… этим:
Ситуация ухудшается, когда вы используете массивы:
|
1 2 |
|
… этим:
|
1 2 |
|
навынос
Когда вы глубоко в своей ветке NOPE , вы должны быть крайне осторожны с использованием типов оболочки. Скорее всего, вы создадите большое давление на свой сборщик мусора, который должен постоянно вставлять, чтобы навести порядок.
Особенно полезная оптимизация может заключаться в использовании некоторого примитивного типа и создании его больших одномерных массивов и нескольких переменных-разделителей, чтобы указать, где именно ваш кодированный объект находится в массиве.
Отличная библиотека для примитивных коллекций, которые немного сложнее, чем обычные int[] это trove4j , которая поставляется с LGPL.
исключение
Из этого правила есть исключение: boolean и byte имеют достаточно мало значений для полного кэширования JDK. Ты можешь написать:
|
1 2 3 4 5 |
|
То же самое верно для низких значений других целочисленных примитивных типов, включая char , short , int , long .
Но только если вы автоматически их TheType.valueOf() или вызываете TheType.valueOf() , а не когда вы вызываете конструктор!
Никогда не вызывайте конструктор для типов оболочки, если вы действительно не хотите новый экземпляр
Этот факт также может помочь вам написать изощренную шутливую шутку Первоапрельского для ваших коллег.
От кучи
Конечно, вы также можете поэкспериментировать с библиотеками вне кучи, хотя это скорее стратегическое решение, а не локальная оптимизация.
Интересная статья на эту тему Питера Лоури и Бена Коттона: OpenJDK и HashMap… Безопасное обучение старой собаки Новые (вне кучи!) Трюки
6. Избегайте рекурсии
Современные функциональные языки программирования, такие как Scala, поощряют использование рекурсии, поскольку они предлагают средства оптимизации алгоритмов хвостовой рекурсии обратно в итеративные . Если ваш язык поддерживает такие оптимизации, у вас все может быть в порядке. Но даже в этом случае малейшее изменение алгоритма может привести к появлению ветви, которая не позволит вашей рекурсии быть хвостовой рекурсией. Надеюсь, компилятор обнаружит это! В противном случае вы могли бы тратить много кадров стека на что-то, что могло быть реализовано с использованием только нескольких локальных переменных.
навынос
Об этом особо нечего сказать, кроме: Всегда предпочитайте итерацию, а не рекурсию, когда вы глубоко в ветке NOPE
7. Используйте entrySet ()
Если вы хотите выполнить итерацию по Map и вам нужны и ключи, и значения, у вас должна быть очень веская причина написать следующее:
|
1 2 3 |
|
… а не следующее:
|
1 2 3 4 |
|
Когда вы находитесь в ветке NOPE , вам все равно следует опасаться карт, потому что множество операций доступа к карте O(1) по-прежнему являются множеством операций. И доступ тоже не бесплатный. Но, по крайней мере, если вы не можете обойтись без карт, используйте entrySet() для их итерации! В Map.Entry случае экземпляр Map.Entry есть, вам нужен только доступ к нему.
навынос
Всегда используйте entrySet() когда вам нужны и ключи, и значения во время итерации карты.
8. Используйте EnumSet или EnumMap
В некоторых случаях количество возможных ключей на карте известно заранее, например, при использовании карты конфигурации. Если это число относительно мало, вам следует рассмотреть возможность использования EnumSet или EnumSet вместо обычного HashSet или HashMap . Это легко объяснить, посмотрев на EnumMap.put() :
|
1 2 3 4 5 6 7 8 |
|
Суть этой реализации заключается в том, что у нас есть массив индексированных значений, а не хеш-таблица. При вставке нового значения все, что нам нужно сделать для поиска записи карты, это запросить у enum его постоянный порядковый номер, который генерируется компилятором Java для каждого типа enum. Если это глобальная карта конфигурации (т.е. только один экземпляр), то увеличенная скорость доступа поможет EnumMap значительно превзойти HashMap , который может использовать немного меньше динамической памяти, но который должен будет запускать hashCode() и equals() для каждого ключа ,
навынос
Enum и EnumMap – очень близкие друзья. Всякий раз, когда вы используете enum-подобные структуры в качестве ключей, подумайте над тем, чтобы сделать эти структуры перечислениями и использовать их в качестве ключей в EnumMap .
9. Оптимизируйте методы hashCode () и equals ()
Если вы не можете использовать EnumMap , хотя бы оптимизируйте методы hashCode() и equals() . Хороший метод hashCode() важен, потому что он предотвратит дальнейшие вызовы гораздо более дорогих equals() как он будет генерировать более отличные хэш-блоки для набора экземпляров.
В каждой иерархии классов у вас могут быть популярные и простые объекты. Давайте посмотрим на реализации org.jooq.Table в org.jooq.Table .
Самая простая и быстрая реализация hashCode() – это:
|
01 02 03 04 05 06 07 08 09 10 |
|
… Где name – это просто имя таблицы. Мы даже не рассматриваем схему или любое другое свойство таблицы, поскольку имена таблиц обычно достаточно различны в базе данных. Кроме того, name является строкой, поэтому оно уже имеет кэшированное значение hashCode() внутри.
Комментарий важен, потому что AbstractTable расширяет AbstractQueryPart , который является общей базовой реализацией для любого элемента AST (Abstract Syntax Tree) . Общий элемент AST не имеет никаких свойств, поэтому он не может делать какие-либо предположения оптимизированной hashCode() . Таким образом, переопределенный метод выглядит так:
|
01 02 03 04 05 06 07 08 09 10 |
|
Другими словами, весь рабочий процесс рендеринга SQL должен запускаться для вычисления хэш-кода общего элемента AST.
Вещи становятся более интересными с equals()
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
Первое: всегда (не только в ветке NOPE ) прерывать каждый метод equals() раньше, если:
-
this == argument -
this "incompatible type" argument
Обратите внимание, что последнее условие включает argument == null , если вы используете instanceof для проверки совместимости типов. Мы уже писали об этом в 10 тонких рекомендациях по кодированию Java .
Теперь, после раннего прекращения сравнения в очевидных случаях, вы можете также захотеть прервать сравнение на ранней стадии, когда сможете принимать частичные решения. Например, контракт Table.equals Table.equals() заключается в том, что для того, чтобы две таблицы считались равными, они должны иметь одинаковое имя, независимо от конкретного типа реализации. Например, эти два элемента не могут быть одинаковыми:
-
com.example.generated.Tables.MY_TABLE -
DSL.tableByName("MY_OTHER_TABLE")
Если argument не может быть равен this , и если мы можем проверить это легко, давайте сделаем это и прервем, если проверка не удалась. Если проверка прошла успешно, мы все равно можем перейти к более дорогой реализации из super . Учитывая, что большинство объектов в юниверсе не равны, мы собираемся сэкономить много времени процессора, сокращая этот метод.
некоторые объекты более равны, чем другие
В случае jOOQ большинство экземпляров действительно являются таблицами, сгенерированными генератором исходного кода jOOQ , реализация equals() которого еще более оптимизирована. Десятки других типов таблиц (производные таблицы, табличные функции, таблицы массивов, объединенные таблицы, сводные таблицы, выражения общих таблиц и т. Д.) Могут сохранять свою «простую» реализацию.
10. Думайте в наборах, а не в отдельных элементах
Наконец, что не менее важно, есть вещь, которая не связана с Java, но применима к любому языку. Кроме того, мы покидаем ветку NOPE, поскольку этот совет может просто помочь вам перейти от O(N 3 ) к O(n log n) или что-то в этом роде.
К сожалению, многие программисты думают в терминах простых локальных алгоритмов. Они решают проблему шаг за шагом, ветви за веткой, петли за петлей, метод за методом. Это императивный и / или функциональный стиль программирования. Хотя все более легко моделировать «большую картину» при переходе от чисто императивного к объектно-ориентированному (все еще обязательному) функциональному программированию, во всех этих стилях отсутствует то, что есть только в SQL, R и аналогичных языках:
Декларативное программирование.
В SQL ( и нам это нравится, так как это блог jOOQ ) вы можете объявить результат, который вы хотите получить из своей базы данных, без каких-либо алгоритмических последствий. Затем база данных может принять во внимание все доступные метаданные ( например, ограничения, ключи, индексы и т. Д. ), Чтобы выяснить наилучший возможный алгоритм.
Теоретически, это была основная идея SQL и реляционного исчисления с самого начала. На практике поставщики SQL внедряют высокоэффективные CBO (Оптимизаторы на основе затрат) только с последнего десятилетия, поэтому оставайтесь с нами в 2010-х годах, когда SQL наконец-то раскроет весь свой потенциал (это было время!)
Но вам не нужно делать SQL, чтобы думать в наборах. Наборы / коллекции / сумки / списки доступны на всех языках и в библиотеках. Основным преимуществом использования множеств является тот факт, что ваши алгоритмы станут намного более краткими. Намного легче написать:
|
1 |
|
скорее, чем:
|
01 02 03 04 05 06 07 08 09 10 |
|
Некоторые могут утверждать, что функциональное программирование и Java 8 помогут вам писать более простые и лаконичные алгоритмы. Это не обязательно правда. Вы можете перевести свой императивный цикл Java-7 в функциональную коллекцию потока Java-8, но вы все еще пишете тот же алгоритм. Написание выражения в стиле SQL отличается. Этот…
|
1 |
|
… Может быть реализовано 1000 способами с помощью механизма реализации. Как мы узнали сегодня, возможно, имеет EnumSet автоматически преобразовать два набора в EnumSet перед запуском операции INTERSECT . Возможно, мы можем распараллелить этот INTERSECT не делая низкоуровневых вызовов Stream.parallel()
Вывод
В этой статье мы поговорили об оптимизации, выполненной в ветви NOPE , т. Е. Глубоко в алгоритме высокой сложности. В нашем случае, будучи разработчиками jOOQ , мы заинтересованы в оптимизации нашей генерации SQL:
- Каждый запрос генерируется только на одном
StringBuilder - Наш шаблонизатор фактически анализирует символы вместо использования регулярных выражений
- Мы используем массивы везде, где можем, особенно при переборе слушателей
- Мы избегаем методов JDBC, которые нам не нужно вызывать
- и т.д…
jOOQ находится в «нижней части пищевой цепи», потому что это (второй) последний API, который вызывается приложениями наших клиентов до того, как вызов покинет JVM для входа в СУБД. Нахождение в нижней части пищевой цепочки означает, что каждая строка кода, которая выполняется в jOOQ, может называться N x O x P раз, поэтому мы должны с нетерпением оптимизировать.
Ваша бизнес-логика не глубоко в ветви NOPE . Но ваша собственная, доморощенная логика инфраструктуры может быть (пользовательские платформы SQL, пользовательские библиотеки и т. Д.). Они должны быть рассмотрены в соответствии с правилами, которые мы видели сегодня. Например, используя Java Mission Control или любой другой профилировщик.
I have completed this code but it seems takes longer time than its permitted
code is to generate primes between multiple two numbers.
Here is the code:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.sql.Time;
import java.util.ArrayList;
public class App {
public static boolean isPrime(int p) {
int i;
boolean t = false;
if (p == 2) {
t = true;
} else {
for (i = 2; i < p; i++) {
if (p % i == 0) {
t = false;
break;
} else {
t = true;
}
}
}
return t;
}
public static void numOfPrimes(int a, int b) {
if (a >= 1 && a <= b && b <= 1000000000 && (b - a) <= 100000) {
int i, prim = 0;
boolean t = false;
for (i = a; i <= b; i++) {
t = isPrime(i);
if (t) {
System.out.println(i + "n");
prim++;
}
}
} else {
System.out.println("bad input!!");
System.out.println("inputs must be just like (1 <= m <= n <= 1000000000, n-m<=100000) ");
}
}
public static void main(String[] args) throws IOException, NumberFormatException {
long t1 = System.currentTimeMillis();
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int t = 0, counter = 0;
String str;
try {
str = br.readLine();
t = Integer.parseInt(str);
ArrayList<String> arr = new ArrayList<String>();
while (counter < t) {
String s = br.readLine();
arr.add(s);
counter++;
System.out.println("n");
}
for (int x = 0; x < arr.size(); x++) {
StringBuffer s1 = new StringBuffer(" "), s2 = new StringBuffer("");
int q = 0, i, j;
int num1, num2;
for (i = 0; i < arr.get(x).indexOf(' '); i++) {
q++;
s1 = s1.append(arr.get(x).charAt(i));
}
String s5 = s1.toString();
for (j = q + 1; j < arr.get(x).length(); j++) {
s2 = s2.append(arr.get(x).charAt(j));
}
String s6 = s2.toString();
try {
num1 = Integer.parseInt(s5.trim());
num2 = Integer.parseInt(s6.trim());
App.numOfPrimes(num1, num2);
System.out.println("n");
} catch (NumberFormatException e) {
//Will Throw exception!
//do something! anything to handle the exception.
}
}
} catch (Exception ex) {
System.out.println("IO error ");
System.exit(1);
}
long t4 = System.currentTimeMillis();
System.out.println(t4 - t1);
}
}
I am supporting a Java messaging application that requires low latency (< 300 microseconds processing each message). However, our profiling shows that the Sun Java Virtual Machine runs slowly at first, and speeds up after the first 5,000 messages or so. The first 5,000 messages have latency of 1-4 milliseconds. After about the first 5,000, subsequent messages have ~250 microseconds latency, with occasional outliers.
It’s generally understood that this is typical behavior for a Java application. However, from a business standpoint it’s not acceptable to tell the customer that they have to wait for the JVM to «warm-up» before they see the performance they demand. The application needs to be «warmed-up» before the first customer message is processed
The JVM is Sun 1.6.0 update 4.
Ideas for overcoming this issue:
- JVM settings, such as -XX:CompileThreshold=
- Add a component to «warm-up» the application on startup, for example by sending «fake messages» through the application.
- Statically load application and JDK classes upon application startup, so that classes aren’t loaded from JARs while processing customer messages.
- Some utility or Java agent that accomplishes either or both of the above two ideas, so that I don’t have to re-invent the wheel.
NOTE: Obviously for this solution I’m looking at all factors, including chip arch, disk type and configuration and OS settings. However, for this question I want to focus on what can be done to optimize the Java application and minimize «warm up» time.
asked Sep 26, 2009 at 18:31
![]()
noahlznoahlz
10.1k7 gold badges56 silver badges75 bronze badges
9
«Warm-up» in Java is generally about two things:
(1): Lazy class loading: This can be work around by force it to load.
The easy way to do that is to send a fake message. You should be sure that the fake message will trigger all access to classes. For exmaple, if you send an empty message but your progrom will check if the message is empty and avoid doing certain things, then this will not work.
Another way to do it is to force class initialization by accessing that class when you program starts.
(2): The realtime optimization: At run time, Java VM will optimize some part of the code. This is the major reason why there is a warm-up time at all.
To ease this, you can sent bunch of fake (but look real) messages so that the optimization can finish before your user use it.
Another that you can help to ease this is to support inline such as using private and final as much as you can. the reason is that, the VM does not need to look up the inheritance table to see what method to actually be called.
Hope this helps.
answered Sep 26, 2009 at 18:56
![]()
NawaManNawaMan
24.9k10 gold badges51 silver badges77 bronze badges
1
Your problem is not class loading but «just in time» compilation.
Try -XX:CompileThreshold=1
That will force Java to compile everything the first time it runs it. It will slow down the startup of your code somewhat but not VM code (since that gets compiled when Java is installed). There is a bug open to allow Java to compile custom JARs in a similar way and save the result for later executions which would greatly reduce this overhead but there is no pressure to fix this bug any time soon.
A second option would be to send 5’000 fake messages to the app to «warm it up». Sell this as «making sure everything is set up correctly».
[EDIT] Some background info in precompiling classes: Class Data Sharing
You may want to try IBM’s version of Java since here, you can add more classes to the shared pool: Overview of class data sharing
[EDIT2] To answer concerns raised by kittylyst: It’s true that this will quickly fill up your code cache with methods that are used only once. And it might even make your whole app slower.
If you set it to a low value, the startup time of your application can become horribly slow. This is because the JIT optimization + running the compiled code is more expensive than running the code once in interpreted mode.
The main problem here is that the code is still compiled «just in time». As long as you can’t run every method that you need at least once, the app will «hickup» for a few milliseconds every time it encounters something that hasn’t been compiled before.
But if you have the RAM, your app is small or you can increase the size of the code cache and you don’t mind the slow startup time, you can give this a try. Generally, the default setting is pretty good.
![]()
answered Sep 26, 2009 at 18:46
![]()
Aaron DigullaAaron Digulla
318k106 gold badges592 silver badges816 bronze badges
11
Just run a bunch of no-op messages through the system before it’s opened for genuine customer traffic. 10k messages is the usual number.
For financial apps (e.g. FIX), this is often done by sending orders (at a price far away from last night’s close, just in case) to the market before it opens. They’ll all get rejected, but that doesn’t matter.
If the protocol you’re using is homebrew, then the next time you upgrade the libraries for it, add explicit support for a «WARMUP» or «TEST» or «SANITYCHECK» message type.
Of course, this likely won’t compile up your application-logic-specific pathways, but in a decent messaging app, the part dealing with network traffic will almost certainly be the dominant part of the stack, so that doesn’t matter.
answered May 1, 2012 at 9:00
![]()
kittylystkittylyst
5,5622 gold badges23 silver badges35 bronze badges
5
If running in Hotspot’s server mode on contemporary hardware (with 2 or more cores per CPU) and with latest version of JDK then following option can be used for speeding of warming up:
-server -XX:+TieredCompilation
answered Apr 30, 2012 at 11:47
![]()
1
Are you using the client or the server JVM? Try starting your program with:
java -server com.mycompany.MyProgram
When running Sun’s JVM in this mode, the JIT will compile the bytecode to native code earlier; because of this, the program will take longer to start, but it will run faster after that.
Reference: Frequently Asked Questions About the Java HotSpot VM
Quote:
What’s the difference between the -client and -server systems?
These two systems are different binaries. They are essentially two different compilers (JITs)interfacing to the same runtime system. The client system is optimal for applications which need fast startup times or small footprints, the server system is optimal for applications where the overall performance is most important. In general the client system is better suited for interactive applications such as GUIs. Some of the other differences include the compilation policy,heap defaults, and inlining policy.
![]()
answered Sep 26, 2009 at 18:53
![]()
JesperJesper
201k46 gold badges319 silver badges348 bronze badges
4
Old thread, I know, but I found this in the internet:
A very interesting thing is the influence of option-XX:CompileThreshold=1500 to SUN HotSpot JVM. The default is 10000 for Server VM and 1500 for Client VM. However setting it to 1500 for Server VM makes it faster than Client VM. Setting it to 100 actualy lowers the performance. And using option-Xcomp (which means that all code is compiled before usage) gives even lower performance, which is surprising.
Now you know what to do.
![]()
John Conde
216k98 gold badges453 silver badges495 bronze badges
answered Oct 17, 2012 at 17:01
![]()
markmark
841 silver badge2 bronze badges
1
Seems like your project would benefit from real time guarantees:
See: Real Time Java
answered Sep 28, 2009 at 0:04
1
Добрый вечер, коллеги.
Перевод статьи, который мы вам предложим сегодня, призван помочь ответить на вопрос: а назрела ли необходимость целой книги по оптимизации кода на Java? Надеемся, что материал не только покажется вам интересным, но и пригодится на практике. Пожалуйста, не забудьте проголосовать.
В этой статье я изложу несколько советов по оптимизации кода на Java. Я специально рассмотрю конкретные операции в реальных программах на Java. Эти советы, в сущности, применимы в конкретных сценариях, требующих высокой производительности, поэтому совершенно нет нужды писать весь код именно в такой манере, поскольку обычно выигрыш в скорости будет мизерным. Однако, на самых жарких участках разница может получиться существенной.
Пользуйтесь профилировщиком!
Прежде, чем приступать к какой-либо оптимизации, разработчик должен убедиться, что верно оценивает производительность. Может быть, тот фрагмент кода, который кажется нам тормознутым, на самом деле просто маскирует истинный источник пробуксовки, поэтому сколько бы мы не оптимизировали «явный» источник промедления, эффект будет почти нулевым. Кроме того, нужно выбрать контрольную точку, по которой можно было бы сравнивать, дает ли ваша оптимизация какой-либо эффект, и если да – то какой.
Для достижения обеих этих целей удобнее всего пользоваться профилировщиком. В нем предусмотрены инструменты, позволяющие определить, какая именно часть вашего кода выполняется медленно, сколько времени уходит на выполнение этого кода. Могу порекомендовать два профилировщика — VisualVM (бесплатный) и JProfiler (платный – но абсолютно стоит своих денег).
Вооружившись такой информацией, можете не сомневаться, что оптимизируете именно тот код, который требуется – и что эффект от вносимых вами изменений можно будет измерить
Вернемся на шаг назад и обдумаем, как подступиться к проблеме.
Прежде чем попытаться перейти к точечной оптимизации конкретного пути исполнения кода, нужно подумать, по какому пути код выполняется сейчас. Иногда избранный подход бывает фундаментально ущербным – например, вы ценой неимоверных усилий и всех мыслимых оптимизаций сможете ускорить этот код на 25%, однако, если изменить подход (подобрать иной алгоритм), выполнение кода может ускориться на порядок и даже более. Зачастую такое случается, когда резко меняются масштабы данных, которые требуется обрабатывать. Бывает несложно написать решение, которое сработает в данном конкретном случае, но для работы с реальными данными оно может оказаться непригодным.
Иногда выход бывает тривиальным – просто изменить структуру, в которой вы храните ваши данные. Вот вам воображаемый пример: если программа обычно обращается к вашим данным в произвольном порядке, а вы храните их в LinkedList, то бывает достаточно переключиться на ArrayList – и код станет выполняться гораздо быстрее. При работе с большими множествами данных и решении задач, где критична производительность, чрезвычайно важно правильно подобрать структуру данных, которая отвечает форме ваших данных и тем операциям, которые над ними осуществляются.
Всегда целесообразно оглянуться назад и обдумать: эффективен ли сам по себе тот код, который вы пытаетесь оптимизировать, либо он притормаживает лишь потому, что коряво написан, либо потому, что для него подобран не лучший путь исполнения.
Сравнение потоковых API и старого доброго цикла for
Потоки – замечательное нововведение в языке Java, при позволяющее без труда переделать барахлящие фрагменты кода, отказавшись от циклов for в пользу более универсальных многоразовых блоков кода, гарантирующих уверенное выполнение. Однако, за такие удобства приходится платить: при использовании потоков снижается производительность. К счастью, эта цена, по-видимому, не слишком высока. В случае с самыми ходовыми операциями можно получить как ускорение на несколько процентов, так и замедление на 10-30%, однако, этот момент следует иметь в виду.
В 99% случаев снижение производительности при использовании потоков более чем компенсируется благодаря тому, что код становится гораздо яснее. Но в том 1% случаев, когда поток у вас, возможно, будет использоваться в очень активном цикле, стоит задуматься о некоем компромиссе в пользу производительности. Это особенно касается приложений с высокой пропускной способностью, заставляет задуматься о том, что работа с потоковыми API сопряжена с активным выделением памяти (в этой теме на StackOverflow читаем, что каждый новый фильтр отъедает еще 88 байт памяти), поэтому давление на память может возрасти. В таком случае приходится чаще запускать сборщик мусора, что очень негативно сказывается на производительности.
С параллельными потоками – другая история. Несмотря на то, как легко с ними работать, их следует использовать лишь в редких случаях и только после того, как по результатам профилировки параллельных и последовательных операций вы убедились, что параллельная выполняется быстрее. При работе с небольшими множествами данных (размер множества данных определяется в зависимости от того, насколько затратны потоковые операции при работе над ним) издержки на распределение задач, планировку их между другими потоками, а затем сшивание результатов после того, как обработка потока закончится, несравнимо перекроет выигрыш в скорости, достигнутый благодаря распараллеливанию вычислений.
Также нужно обращать внимание, в какой именно среде выполняется ваш код. Если речь идет о сильно распараллеленном окружении (например, о сайте), то вряд ли вы ускорите его работу, добавив туда еще один поток. На самом деле, при высоких нагрузках такая ситуация может быть еще порочнее, чем непараллельное исполнение. Дело в том, что, если рабочая нагрузка по природе своей параллельна, то программа наверняка и так максимально эффективно использует оставшиеся ядра процессора – то есть, вы тратите ресурсы на разделение задач, а вычислительной мощности у вас при этом не прибавляется.
Я сделал ряд контрольных замеров. testList – это массив из 100 000 элементов, состоящий из чисел от 1 до 100 000, преобразованных в строки и затем перемешанных.
// ~1 500 оп/с
public void testStream(ArrayState state) {
List<String> collect = state.testList
.stream()
.filter(s -> s.length() > 5)
.map(s -> "Value: " + s)
.sorted(String::compareTo)
.collect(Collectors.toList());
}
// ~1 500 оп/с
public void testFor(ArrayState state) {
ArrayList<String> results = new ArrayList<>();
for (int i = 0;i < state.testList.size();i++) {
String s = state.testList.get(i);
if (s.length() > 5) {
results.add("Value: " + s);
}
}
results.sort(String::compareTo);
}
// ~8 000 оп/с
// Обратите внимание: при размере массива от 10 000 элементов и переменной нагрузке на процессор этот код выполнялся втрое медленнее testStream
public void testStreamParrallel(ArrayState state) {
List<String> collect = state.testList
.stream()
.parallel()
.filter(s -> s.length() > 5)
.map(s -> "Value: " + s)
.sorted(String::compareTo)
.collect(Collectors.toList());
}Итак: потоки очень помогают при поддержке кода и повышают его удобочитаемость, и при этом в большинстве случаев пренебрежимо влияют на производительность. Однако, необходимо учитывать возможные издержки в тех редких случаях, когда действительно требуется выжать из нагруженного цикла всю производительность до капли.
Передача даты и операции с ней
Нельзя недооценивать издержек, возникающих, например, при парсинге строки с датой в объект даты и при форматировании объекта даты в строку с датой. Представьте себе ситуацию, когда у вас есть список из миллиона объектов (это либо обычные строки, либо некие объекты, представляющие элемент в виде поля данных, подкрепленного строкой) – и весь список нужно откорректировать по заданной дате. В случае, если эта дата представлена в виде строки, потребуется сначала разобрать эту строку, чтобы преобразовать ее в объект Date, обновить объект Date, а затем вновь отформатировать его в виде строки. Если дата уже представлена в виде временной метки Unix (или в виде объекта Date, фактически, представляющего собой просто обертку вокруг временной метки Unix) – то вам останется сделать простую арифметическую операцию, сложение или вычитание.
Мои тесты показывают, что программа выполняется до 500 раз быстрее, если просто оперировать объектом даты, нежели если парсить его, преобразовывать в строку и обратно. Даже если просто исключить этап парсинга, все равно достигается стократное ускорение. Этот пример может показаться надуманным, но, уверен, вам известны случаи, когда значения даты хранились в базе данных в виде строк, а также возвращались в виде строк в откликах API
// ~800 000 оп/c
public void dateParsingWithFormat(DateState state) throws ParseException {
Date date = state.formatter.parse("20-09-2017 00:00:00");
date = new Date(date.getTime() + 24 * state.oneHour);
state.formatter.format(date);
}
// ~3 200 000 оп/с
public void dateLongWithFormat(DateState state) {
long newTime = state.time + 24 * state.oneHour;
state.formatter.format(new Date(newTime));
}
// ~400 000 000 оп/с
public long dateLong(DateState state) {
long newTime = state.time + 24 * state.oneHour;
return newTime;
}Итак, всегда учитывайте издержки, связанные с парсингом и форматированием объектов даты, и, если нет необходимости держать их в виде строк, гораздо разумнее представлять дату в виде временной метки Unix.
Операции над строками
Манипуляция над строками – это, пожалуй, одна из самых распространенных операций в любой программе. Однако, если выполнять ее неправильно, она может получиться затратной. Именно поэтому я уделяю такое внимание работе со строками в этой статье, посвященной оптимизации Java. Ниже мы рассмотрим один из самых частых подводных камней. Однако, хочу дополнительно подчеркнуть, что такие проблемы проявляются лишь при выполнении самых скоростных фрагментов кода, либо когда приходится иметь дело с существенным количеством строк. В 99% случаев ничего из показанного ниже не случится. Однако, если такая проблема возникнет, она может убийственно сказаться на производительности.
Использование String.format, когда могла бы сработать простая конкатенация
Простейший вызов String.format происходит примерно в 100 раз медленнее, чем при конкатенации значений в строку вручную. Как правило, это приемлемо, поскольку на моей машине мы здесь все равно имеем дело с миллионами операций в секунду. Однако, в случае загруженного цикла, оперирующего миллионами элементов, спад производительности может быть ощутимым.
Однако, есть один случай, когда _следует _использовать именно строковое форматирование, а не конкатенацию даже в среде с высокими требованиями к производительности – я говорю о журналировании отладочной информации. Рассмотрим два вызова, происходящих в таком контексте:
logger.debug("the value is: " + x);
logger.debug("the value is: %d", x);Второй случай (что на первый взгляд может показаться нелогичным) в продакшене, бывает, работает быстрее. Поскольку маловероятно, что на ваших продакшен-серверах будет включено журналирование отладочной информации, в первом случае программа выделяет новую строку, которая затем так и не используется (поскольку лог так и не выводится). Во втором случае требуется загрузить постоянную строку, после чего этап форматирования пропускается.
// ~1 300 000 оп/с
public String stringFormat() {
String foo = "foo";
String formattedString = String.format("%s = %d", foo, 2);
return formattedString;
}
// ~115 000 000 оп/с
public String stringConcat() {
String foo = "foo";
String concattedString = foo + " = " + 2;
return concattedString;
}Неиспользование построителя строк внутри цикла
Если вы не пользуетесь построителем строк внутри цикла, то производительность кода сильно падает. В упрощенной реализации мы наращивали бы строку внутри цикла при помощи оператора +=, прикрепляя таким образом новую часть строки к уже имеющейся. Проблема с данным подходом заключается в том, что при каждой итерации цикла будет выделяться новая строка, а старую строку на каждой итерации придется копировать в новую. Даже сама по себе эта операция затратна, не говоря уже о лишней нагрузке, связанной с дополнительной сборкой мусора, необходимой при создании и отбрасывании такого количества строк. Воспользовавшись StringBuilder, мы ограничим количество операций выделения памяти, что позволит нам сильно повысить производительность. В моих тестах таким образом удавалось ускорить программу более чем в 500 раз. Если при создании построителя строк вы можете, как минимум, достаточно уверенно предположить, какого размера будет результирующая строка, то можно ускорить код еще на 10%, заранее задав корректный размер (в таком случае не придется пересчитывать размер внутреннего буфера и избавиться от операций выделения и копирования).
Также отмечу, что (почти) всегда использую StringBuilder, а не StringBuffer. StringBuffer предназначен для работы в многопоточных средах и именно поэтому оснащен внутренней синхронизацией. Издержки за такую синхронизацию приходится нести даже в однопоточной среде. Если вам требуется наращивать строку данными, поступающими из многих потоков (допустим, в реализации с журналированием) – вот вам одна из немногих ситуаций, когда следует пользоваться именно StringBuffer, а не StringBuilder.
// ~11 операций в секунду
public String stringAppendLoop() {
String s = "";
for (int i = 0;i < 10_000;i++) {
if (s.length() > 0) s += ", ";
s += "bar";
}
return s;
}
// ~7 000 операций в секунду
public String stringAppendBuilderLoop() {
StringBuilder sb = new StringBuilder();
for (int i = 0;i < 10_000;i++) {
if (sb.length() > 0) sb.append(", ");
sb.append("bar");
}
return sb.toString();
}
Использование построителя строк вне цикла
Мне попадались в Интернете рекомендации использовать построитель строк вне цикла – и это даже кажется целесообразным. Однако, мои опыты показали, что на самом деле код при этом выполняется втрое медленнее, чем при += — даже если StringBuilder находится вне цикла. Хотя += в данном контексте и превращается в вызовы StringBuilder, выполняемые javac, код получается гораздо быстрее, чем при непосредственном использовании StringBuilder, что меня удивило.
Если у кого-нибудь есть версии, почему так происходит – поделитесь пожалуйста в комментариях.
// ~20 000 000 операций в секунду
public String stringAppend() {
String s = "foo";
s += ", bar";
s += ", baz";
s += ", qux";
s += ", bar";
s += ", bar";
s += ", bar";
s += ", bar";
s += ", bar";
s += ", bar";
s += ", baz";
s += ", qux";
s += ", baz";
s += ", qux";
s += ", baz";
s += ", qux";
s += ", baz";
s += ", qux";
s += ", baz";
s += ", qux";
s += ", baz";
s += ", qux";
return s;
}
// ~7 000 000 операций в секунду
public String stringAppendBuilder() {
StringBuilder sb = new StringBuilder();
sb.append("foo");
sb.append(", bar");
sb.append(", bar");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
return sb.toString();
}
Итак, создание строк связано с явственными издержками, поэтому в циклах следует по возможности избегать такой практики. Добиться этого легко – просто используйте StringBuilder внутри цикла.
Надеюсь, вам пригодятся изложенные здесь советы по оптимизации кода на Java. Еще раз подчеркну, что в большинстве контекстов описанные здесь приемы вам не пригодятся. Нет разницы, сколько раз в секунду вы успеете отформатировать строку – миллион раз или 80 миллионов раз, если вам требуется проделать всего несколько таких операций.
Но в тех критических случаях, когда речь действительно может идти о миллионах таких операций, восьмидесятикратное ускорение кода может сэкономить вам массу времени.
Написав эту статью, я собрал zip-архив со всеми упомянутыми здесь данными, и ниже привожу вывод после проверки всех контрольных точек. Все результаты получены на ПК с i5-6500. Код запускался с JDK 1.8.0_144, VM 25.144-b01 на Windows 10
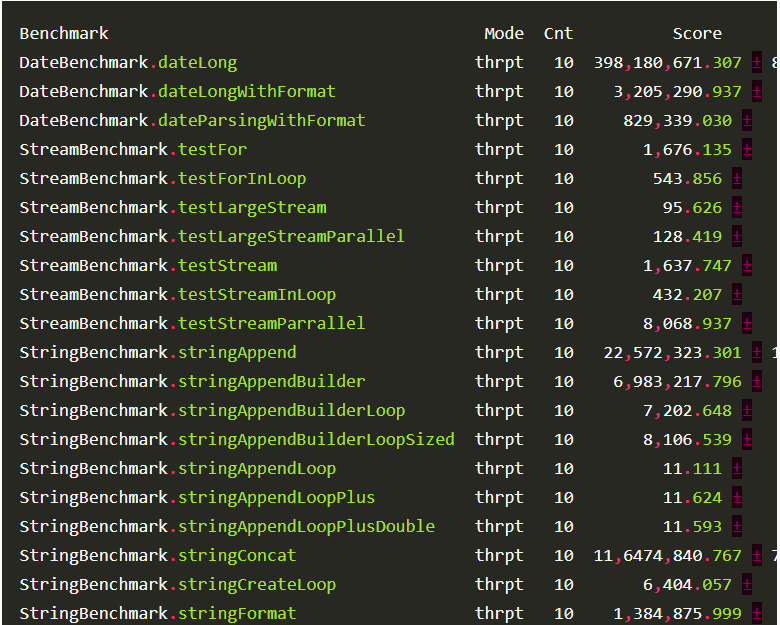
Весь код можно скачать здесь на GitHub.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Мое мнение о книге на тему Java Performance Optimization
83.06%
Думаю, давно назрел перевод такой книги
103
16.94%
Вряд ли мне пригодится
21
Проголосовали 124 пользователя.
Воздержались 30 пользователей.