Аннотация: В настоящей лекции вводится понятие систем деловой осведомленности, или систем бизнес-аналитики, рассматриваются основные требования к таким системам и архитектурные особенности таких систем. Подробно обсуждаются вопросы обеспечения информационной безопасности систем, проблемы их создания и возможные пути решения этих проблем. Показывается место хранилища данных при разработке систем бизнес-аналитики.
Цель лекции
Изучив материал настоящей лекции, вы будете знать:
- что означает термин «деловая осведомленность», или «бизнес-аналитика»;
- назначение систем бизнес-аналитики ;
- составляющие информационной безопасности систем бизнес-аналитики ;
- особенности сбора данных для систем бизнес-аналитики;
- проблемы создания систем бизнес-аналитики;
- как хранилище данных управляет системами бизнес-аналитики;
и научитесь:
- понимать бизнес-требования к системам бизнес-аналитики;
- распознавать проблемы построения систем бизнес-аналитики и находить пути их решения.
Литература: [5], [28], [40], [41], [56].
Введение
В этой лекции мы будем использовать многие понятия на интуитивном уровне, не давая им точных определений. Такие понятия будут определены в последующих лекциях.
Определение систем деловой осведомленности
Понятие деловой осведомленности
Многозначность английского слова «Intelligence» приводит к неопределенности трактовки термина «Business Intelligence» как в российских, так и в зарубежных литературных источниках, посвященных тематике использования информационных технологий для аналитической поддержки бизнеса. Английское слово «Intelligence» означает способность узнавать и понимать, готовность к пониманию, знания, переданные или приобретенные путем обучения, исследования или опыта, действие или состояние в процессе познания, разведку, разведывательные данные. В русском языке слово «интеллект» означает мыслительную способность человека.
Термин «Business Intelligence» получил широкое распространение, когда был введен в обращение аналитиками компании Gartner Group в конце 80-х годов прошлого века как «пользователецентрический процесс, включающий доступ и исследование информации, ее анализ, выработку интуиции и понимания, которые ведут к улучшенному и неформальному принятию решений». Хотя ранее этот термин, например, использовался в компании IBM в качестве внутрикорпоративного термина.
К 1996 году содержание термина было уточнено, и «Business Intelligence» стал пониматься как «инструменты для анализа данных, построения отчетов и запросов, которые могут помочь бизнес-пользователям преодолеть море данных для того, чтобы помочь синтезировать из них значимую информацию».
В русскоязычной литературе термин «Business Intelligence» переводится как «бизнес-интеллект», «интеллектуальный анализ данных«, «деловая осведомленность» или вводится просто как аббревиатура BI. В настоящем курсе мы будем использовать термины «деловая осведомленность» и «бизнес-аналитика» как синонимы.
Однако все-таки в настоящее время не существует однозначного определения термина «деловая осведомленность» (BI). Отметим следующие важные аспекты трактовки содержания данного термина.
- Деловая осведомленность понимается как процесс, методы, технологии, средства извлечения и представления знаний.
- Деловая осведомленность понимается как знания о бизнесе и для бизнеса.
Таким образом, деловая осведомленность в широком смысле слова понимается как:
- процесс превращения данных в информацию и знания о бизнесе для обеспечения принятия улучшенных и неформальных решений;
- информационные технологии сбора данных, консолидации информации и обеспечения доступа пользователей к бизнес-знаниям;
- знания о бизнесе, полученные в результате анализа данных и консолидированной информации.
Системы бизнес-аналитики
В современном мире успех компании на рынке напрямую зависит от того, как быстро менеджмент компании может распознать изменения динамики рынка и насколько своевременно может отреагировать на них с целью увеличения прибыли, исходя из существующих реалий рынка. Менеджеры компании должны отслеживать тенденции рынка, идентифицировать конкурентов и угрозы, оценивать риски, преобразовывать стратегию компании, оценивать свои ресурсы и т.д. Информация является необходимым производственным ресурсом для принятия эффективных управленческих решений.
Компании накопили значительные объемы данных и имеют доступ к еще большим объемам внешних данных. Менеджерам необходимо, чтобы эта информация была преобразована, предварительно обработана и соответствующим образом организована для быстрого доступа, анализа и принятия решений. Такой подход к данным есть, с одной стороны, создание конкурентного преимущества, а с другой стороны – требование к публикации данных для менеджеров компании. Публикация данных для менеджеров, обеспечивающая быстрый доступ к данным, выполнение анализа данных и информационную поддержку процесса принятия решений, является основной целью систем бизнес-аналитики. Бизнес-аналитика помогает компании создавать знания из всей доступной информации для принятия эффективных управленческих решений и превращения этих решений в действие.
Таким образом, ключевую роль в управлении организацией в целом и ее отдельными производственными функциями играет информация. Данные, которые доступны менеджерам и аналитикам непосредственно из корпоративных информационных систем, не унифицированы, разрозненны и в общем случае не готовы для анализа. Системы деловой осведомленности или бизнес-аналитики являются тем классом информационных систем, который позволяет превратить данные корпоративных информационных систем и данные из внешних источников в полезные для бизнеса информацию и знания, используемые в управлении, на основе которых можно принимать решения.
Информационным фундаментом для бизнес-анализа и систем бизнес-аналитики является хранилище данных. Основное требование к хранилищу данных системы бизнес-анализа состоит в том, чтобы обеспечить структурированную и организованную для решения задач бизнеса информационную среду. Как правило, такую среду лаконично представляют в виде информационной пирамиды, как показано на
рис.
4.1.
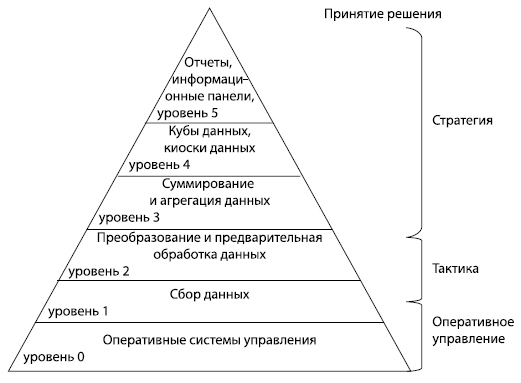
Рис.
4.1.
Информационная пирамида
Информационная пирамида формируется из нескольких уровней.
- Уровень оперативной информации. На этом уровне ИТ обеспечивают работу с данными на уровне бизнес-процедур компании. Данные в автоматизированных системах являются хорошо структурированными и детальными. С этими данными работают специалисты компании: бухгалтеры, менеджеры продаж, плановики и т.д.
- Уровень тактической информации. На этом уровне ИТ обеспечивают интеграцию данных на уровне бизнес-процессов оперативного управления производством в рамках подразделений компании. С этими данными работают руководители подразделений компании при выполнении ежедневных производственных заданий.
- Уровень стратегической информации. На этом уровне ИТ обеспечивают интеграцию данных на уровне бизнес-процессов по направлениям хозяйственной деятельности компании. С этими данными работают аналитики и руководители высшего звена компании, которые готовят стратегические решения развития и деятельности компании на рынке.
- Уровень принятия решений. На этом уровне ИТ обеспечивают интеграцию и агрегацию данных на уровне бизнес-процессов компании для руководителей высшего звена компании. Этот уровень обеспечивает информационную поддержку принятия решений.
Информационная пирамида описывает среду бизнес-аналитики, которую можно описать следующим образом. В информационную среду бизнес-аналитики поступает первичный материал — данные, которые затем перерабатываются в автоматизированных системах и информационных продуктах.
В процессе переработки происходит переход от данных к информации. ХД извлекает данные из множества транзакционных или оперативных систем, а затем интегрирует и хранит данные в специализированной БД. Например, в ХД могут приводиться в соответствие и объединяться пользовательские записи из четырех оперативных систем (приложений для обработки заказов, обслуживания, продаж и поставок). Такой процесс извлечения и интеграции преобразует данные в новый информационный продукт — информацию.
Затем пользователи, работающие с аналитическими инструментами (например, для создания запросов, отчетов, OLAP-анализа и выполнения операций интеллектуального анализа данных), обращаются к данным из ХД и анализируют ее. Таким образом, определяются тенденции, структуры и исключения. Аналитические инструменты помогают пользователям преобразовать информацию в знания.
Теперь дадим определение систем бизнес-аналитики или систем деловой осведомленности.
Определение 4.1. Система деловой осведомленности, или бизнес-аналитики (BI System) , — это система управления базой знаний предприятия, которая предоставляет ряд новых возможностей в существующей информационной системе предприятия для анализа бизнеса и управления базой знаний предприятия.
К основным функциям системы бизнес-аналитики, как правило, относят следующие.
- Управление в реальном времени бизнес-знаниями в рамках всего предприятия.
- Простой доступ к информации для сотрудников компании различных уровней.
- Рост объема перерабатываемой информации, повышение конкурентоспособности.
- Проведение более эффективного анализа доходов и расходов.
- Предоставление исполнительным директорам комплексной и более наглядной картины предприятия по всем направлениям бизнеса.
- Отслеживание ситуации как на всем предприятии в целом, так и на каких-то конкретных проблемных участках в частности.
К основным технологическим средствам реализации функциональности систем бизнес-аналитики относят:
- отчеты и средства их создания;
- специализированные средства создания отчетов;
- генераторы отчетов, встроенные в средства разработки;
- нетрадиционные средства создания отчетов;
- OLAP-средства;
- клиентские OLAP-средства;
- серверные OLAP-cредства;
- средства поиска закономерностей (Data Mining-средства) и т.д.
Система бизнес-аналитики является стержнем, вокруг которого формируются потоки стратегической бизнес-информации. Данный инструмент помогает компании принимать решения, которые будут основаны на корректной информации, полученной вовремя.
В условиях, когда рынок постоянно меняется, а конкуренция становится все жестче, руководителям крайне необходимо выявлять и анализировать имеющиеся у предприятия резервы, которые могут существенно расширить возможности бизнеса.
Предлагаемые решения в области бизнес-аналитики должны предоставлять возможность оперативно анализировать тенденции рынка, осознавать движущие силы бизнеса и, основываясь на объективной информации, быстро реагировать на изменения рыночной ситуации и принимать верные решения.
Например, одним из возможных решений может быть графический инструмент для экономического анализа, относящийся к категории OLAP-приложений (On-line Analytical Processing), который:
- позволяет регулярно проводить анализ выполнения производственной программы;
- позволяет проводить анализ отклонений финансовых показателей, таких как, например, анализ расходов по приобретению сырья и материалов;
- позволяет собирать, обобщать, анализировать и представлять данные в виде легко читаемых графиков и аналитических приложений. В сочетании с системой планирования и управления ресурсами предприятия ERP обеспечивает гибкий, многоплановый анализ бизнеса на основе операционных данных;
- позволяет создавать так называемые «информационные кубы» — виртуальные информационные центры, которые содержат аналитические данные, существенные для выявления тенденций рынка, анализа и принятия стратегических решений.
Эти многомерные «информационные кубы» собирают и хранят всю информацию о деятельности предприятия. С их помощью можно моделировать и анализировать критические аспекты бизнеса, учитывая информацию о продукции, поставщиках, потребителях, товарообороте, ценах и доходах. Анализ ведется интерактивно, в реальном времени, с помощью удобных визуальных инструментов, а не просто на основе многочисленных отчетов с тысячами страниц, таблиц и чисел.
«Кубы данных» должны быть настроены для решения ряда критически важных аспектов бизнеса, включая анализ продаж, запасов, финансов, каналов снабжения и производства.
Специальные возможности должны обеспечивать мгновенную детализацию данных и всестороннее исследование проблемы. Результирующее двух- или трехмерное представление удобно для быстрого изучения тенденций и анализа отклонений.
Типовой состав программного обеспечения систем бизнес-аналитики включает в себя не только саму систему, но и обучающие материалы, техническую документацию, а также возможность получения технической поддержки и профессиональных консультаций. Все это помогает быстро и в совершенстве освоить систему, получить максимум преимуществ ее использования:
- система для оперативного анализа;
- стандартный каталог;
- стандартные шаблоны и модели;
- стандартные отчеты;
- обучение, поддержка, документация, профессиональные консультации.
Система бизнес-аналитики должна:
- иметь единый графический интерфейс пользователя (GUI), который обеспечивает интуитивную навигацию и комфортность в работе;
- предоставлять гибкий анализ и отчетность сотрудникам различных подразделений для просмотра сводных данных, используя одни и те же разрезы деятельности в сопоставимых показателях;
- иметь открытую архитектуру и организационную масштабируемость, которые дают контролируемое, последовательное и быстрое развертывание аналитической системы во всех подразделениях предприятия;
- иметь мощную систему административного контроля, которая освобождает ИT-службу от необходимости составления многих форм отчетности, но в то же время обеспечивает контроль доступа к базам данных, конфиденциальность и мониторинг изменений;
- обеспечивать быстрое внедрение, которое способствует скорейшему получению практических результатов и ускоряет отдачу от инвестиций в программное обеспечение.
Таким образом, системы бизнес-аналитики позволяют:
- лучше анализировать структуру покупательского спроса и потребности ваших клиентов;
- использовать гибкую стратегию продаж и целевой маркетинг;
- по-новому представить на рынке возможности вашей продукции;
- выявить слабые места в цепочке поставок;
- исключить неоправданные производственные и коммерческие расходы;
- выявить стратегические тенденции в изменении ценовой структуры и номенклатуры выпускаемой продукции.
Информационная безопасность систем бизнес-аналитики
Следует отметить, что многие компании не придают значения вопросам безопасности, игнорируя тот факт, что архитектурные компоненты систем бизнес-аналитики таят в себе определенную опасность. Обеспечение безопасности среды бизнес-аналитики – не менее важная задача, чем защита оперативных приложений.
Необходимость безопасности систем оперативной обработки транзакций (On-Line Transaction Processing, OLTP) осознается большинством компаний. Особенность реализации этой задачи для OLTP-приложений заключается в том, что она хорошо поддается структуризации и является статичной (определенные приложения каждый раз одинаковым образом обращаются к определенным данным). Круг пользователей весьма ограничен — это работники с определенными бизнес-функциями, они работают с приложениями и данными, которые касаются только их поля деятельности. Кроме того, физическая структура этих приложений также остается довольно постоянной. Инструментальные средства и базовая структура данных меняются нечасто.
Среда бизнес-аналитики и ХД, наоборот, характеризуется значительной динамичностью вкупе с широкой и часто меняющейся пользовательской аудиторией, причем пользователи могут быть как внутренними, так внешними. В такой ситуации гораздо сложнее (а иногда и практически невозможно) распределить пользователей по подмножествам данных; особенно это касается аналитических приложений высокого уровня, таких как, например, решения управления эффективностью корпорации (corporate performance management), где окончательная информация формируется на основе изучения данных всего предприятия. Помимо этого, физическая структура этой среды часто является неясной: в нее устанавливается множество различных средств, а сами данные пребывают в постоянном движении (из ХД в витрины данных и на пользовательские машины в информационные панели). В результате мероприятия по обеспечению безопасности корпоративной информации обходят стороной приложения бизнес-аналитики и ХД.
Для того чтобы гарантировать защищенность среды бизнес-аналитики, компании должны в первую очередь выполнить задачи безопасности, возникающие на уровне отдельных ее компонентов (см.
рис.
4.2.).
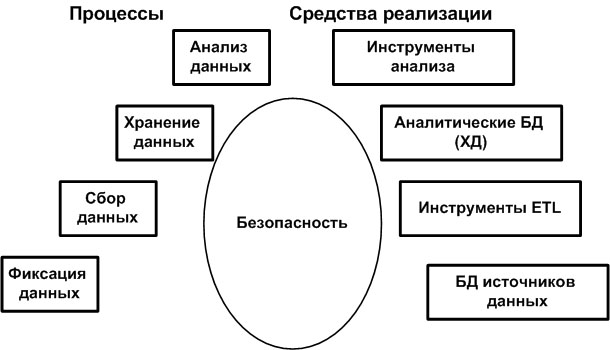
Рис.
4.2.
Оболочка решений бизнес-аналитики
Каждый из основных компонентов среды бизнес-аналитики имеет свою степень риска и для обеспечения безопасности каждого компонента потребуется реализовать различные подходы (и различные технологии). Это крайне непростая задача, и, пожалуй, наибольшую сложность представляют «пробелы» между компонентами. Ведь программная оболочка для бизнес-аналитики практически никогда не поставляется одним поставщиком или в форме одной ИТ-технологии. При этом бесшовная интеграция между компонентами невозможна. Более того, именно то, как компоненты работают друг с другом, и то, как информация проходит между ними, и образует «точки риска».
Безопасность данных
Сама суть бизнес-аналитики подталкивает бизнес-пользователей к расширению доступа к данным и контроля над ними. Поэтому необходима жесткая политика по защите информации, которая должна помочь «залатать дыры», созданные многочисленными, слабо интегрированными технологическими компонентами, а также минимизировать огромный риск, присущий человеческому фактору.
Данные в ХД, витринах данных и операционных складах данных создают условия для осуществления всей бизнес-аналитики и, как правило, включают гигантские объемы детальных, транзакционных данных. Поскольку они часто отображают длительный отрезок времени, относящейся к истории существования компании, как, например, финансовая информация, обеспечение защищенности таких данных чрезвычайно важно. При рассмотрении задач безопасности данных следует задаться следующими вопросами:
- Кто располагает доступом к ХД, витрине данных, кубам и так далее?
- Каковы рамки их доступа: одна предметная область, множество предметных областей или все предметные области?
- Каким типом доступа они обладают, например, только чтение или возможность модификации?
Топология данных в среде бизнес-аналитики влияет на возможности доступа к данным и обеспечение безопасности. Во многих компаниях результаты запросов часто загружаются на индивидуальные машины с целью дальнейшей детализации и использования. Эти данные оказываются в витринах данных, настольных БД, информационных панелях или крупноформатных электронных таблицах и быстро оказываются вне пределов инфраструктуры безопасности ИT-отдела, хотя по-прежнему сохраняют свою конфиденциальную сущность. При рассмотрении топологии данных с точки зрения безопасности необходимо изучить следующие вопросы:
- Насколько распределенной является архитектура данных, поддерживающая бизнес-аналитику?
- Имеется ли дополнительное распределение данных и если да, то каковы связанные с ним риски?
- Что делают пользователи с загружаемыми данными?
- Передают ли пользователи данные внешним партнерам?
Процесс сбора данных
Обычно процесс сбора и подготовки данных для среды бизнес-аналитики очень сложный и «непрочный». Огромное число источников данных и значительное разнообразие данных приводят к многоступенчатым процессам, в которых данные интерактивно собираются и преобразуются для загрузки в ХД. Данные, подвергающиеся как процессу сбора, так и преобразования, также образуют следующие «точки риска».
- Кто располагает доступом к средствам извлечения данных из операционных систем?
- Где находятся данные, пребывающие в процессе сбора, перед тем как оказаться в ХД, и кто имеет доступ к этой области?
- Какова логика преобразования, безопасность которой реализуется в средствах извлечения, преобразования и загрузки (ETL)?
- Если никакие средства не используются, то какова защита ETL-процессов, написанных пользователем, от несанкционированных модификаций?
Пользовательские средства формирования запросов и аналитические приложения
Программные инструменты бизнес-аналитики и аналитические приложения — это, в первую очередь, механизмы, предназначенные для доступа к данным в ХД. Такие средства часто приобретались в большом количестве с целью широкого и глубокого развертывания бизнес-аналитики по всему предприятию. Эти инструменты представляют особую ценность только для определенных пользователей и несут серьезную опасность, если попадают не в те руки.
- Кто располагает разрешением на использование средств формирования запроса и отчетности?
- Назначен ли каждому пользователю личный ID?
Появление и развитие аналитических приложений для электронной коммерции по схеме «бизнес-бизнес» (business-to-business) и «поставщик-покупатели» (business-to-consumer) усилили насущность вопросов безопасности.
- Насколько свободно ваши клиенты и поставщики обмениваются предоставленной им информацией в рамках своих предприятий?
- Предоставляют ли они ее своим внешним акционерам?
- Не может ли эта информация попасть в руки ваших конкурентов?
Политика информационной безопасности
Корпоративная политика информационной безопасности часто не затрагивает информации, которая хранится, анализируется и поставляется посредством аналитических приложений. Поскольку бизнес-аналитика расширяет доступ к информации, часто передавая ее в непосредственное распоряжение бизнес-пользователей, информация быстро оказывается вне пределов инфраструктуры безопасности ИT-отдела. Поэтому при формировании корпоративной политики информационной безопасности необходимо рассмотреть следующие вопросы:
- Учитывает ли корпоративная политика безопасности специфику ИT?
- Имеются ли области значительного риска, которые могут быть устранены посредством такой политики?
- Затрагивают ли правительственные постановления информацию, которая хранится, анализируется и представляется среде бизнес-аналитики?
- Не нарушают ли текущие или планируемые мероприятия по развертыванию среды бизнес-аналитики эти постановления?
Бизнес-аналитика
Тема 1
СОДЕРЖАНИЕ И МЕТОДЫ БИЗНЕС-АНАЛИТИКИ 1.1.АНАЛИЗ ДЕЯТЕЛЬНОСТИ ПРЕДПРИЯТИЯ КАК ОБЪЕКТ АВТОМАТИЗАЦИИ
Современный этап развития рыночных отношений в российской экономике (начало ХХI века) характеризуется началом экономического подъёма. Период времени быстрых, в значительной мере интуитивных, импровизационных, а зачастую и силовых решений меняется на зону продуманных, просчитанных выводов и решений – оперативных, инве- стиционных.
Необходимо также принимать во внимание открытость экономики России и связанной с ней конкуренции с высокоразвитыми экономическими субъектами. В регионах мира со сложившейся развитой рыночной экономикой достижение заметного повышения прибы- ли (от долей процента) связано со сложной аналитической работой с использованием новейших достижений науки: математики всех направлений, информационных техноло- гий (IT), которые питают и подкрепляют экономические науки, менеджмент, маркетинг, социологию, юриспруденцию и т. д. Начинают приобретать определяющее значение знания о протекающих хозяйственных процессах.
На успех ведения дела влияют как объективные, так и субъективные факторы. К объ- ективным факторам можно отнести закономерности протекания хозяйственных процес- сов, правовую среду, неписаные правила и традиции ведения дел, экономическую конъ- юнктуру и т. д.
Большое значение имеет и субъективный фактор, под которым понимается влияние на ход бизнес-процессов работников предприятия и в особенности лиц, принимающих ре- шения (ЛПР).
Для выработки и принятия соответствующих складывающейся обстановке решений необходима информация, которая должна удовлетворять требованиям полноты, досто- верности, своевременности (актуальности), полезности. Основополагающую роль в под- готовке принятия решений играет его обоснование по имеющейся у ЛПР информации. Её, как правило, получают из различных внутренних и внешних источников. Организа- ции собирают и хранят значительные объемы информации, например информацию о клиентах и оперативные данные, поступающие в организацию. Причем объемы и ско- рость этих информационных потоков постоянно увеличиваются. В интересах выработки адекватного решения используются внутренние информационные ресурсы, которые складываются из отражения деятельности (функционирования) объекта в документах, других видах и способах сбора, обработки, хранения информации, а также внешние по отношению к объекту информационные ресурсы, например, если это предприятие, кор- порации, отрасли, региона, а также глобальные – из средств массовой информации, спе- циальной литературы, всемирной информационной сети Internet. Таким образом, грани- цы информационного пространства как отображения деятельности предприятия и его взаимодействия с внешней средой, в рамках которого принимаются решения, выходят далеко за пределы предприятия.
Объёмы информации, необходимой и используемой при принятии решений, достига- ют десятков и сотен мегабайт и даже терабайт. Информация характеризуется многопла-
новостью, сложностью отображаемых объектов и систем, а также связей между объек- тами, явлениями и процессами, скрытостью закономерностей.
Одной из первостепенных задач при подготовке и принятии решений является анализ имеющейся в распоряжении ЛПР информации, которая является фундаментом обосно- вания решения. Все чаще организации обращаются к возможностям бизнес-аналитики как к средству, позволяющему извлекать выгоду из огромного количества информации, собранной и хранящейся в корпоративных базах данных.
Бизнес-аналитика – это средства, позволяющие организациям обработать всю посту- пающую информацию и достичь глубокого понимания ее сути, без которого не обойтись в условиях конкуренции в современной экономике. Бизнес-аналитика помогает достичь понимания взаимоотношений с клиентами и партнерами, основных показателей дея- тельности, а также добиться целостного представления о компании на всех уровнях – от руководства до рядовых сотрудников.
Для успешного развития компании необходимо видеть причины происходящих про- цессов и играть на опережение, прогнозируя развитие событий и предпринимая соответ- ствующие шаги. Поэтому потребность в инструментах анализа и визуализации данных, а также моделирования начала приобретать массовый характер. Компаниям требуются инструменты для создания полномасштабных информационно-аналитических систем корпоративного уровня, в основе которых лежит централизованное хранилище данных, а также для построения систем финансовой и управленческой отчетности, построения информационных витрин данных для различных функциональных департаментов ком- пании. Использование передовых технологий должно обеспечить осуществление опти- мальной поддержки бизнес-процессов заказчиков и эффективное решение поставленных задач.
Деятельность предприятия, другого объекта или системы отображается в информаци- онном пространстве.
Информационное пространство – это совокупность информационных объектов, ин- формационно отображающих свойства системы и протекающие в ней процессы. Оно со- стоит из различных массивов информации в виде разного рода письменных (знаковых) и фиксированных на носителях информации кодограмм, буквенно-цифровых на есте- ственном языке, устных и визуальных сообщений. Все виды сообщений передаются непосредственно потребителям информации или по каналам связи, могут быть сохране- ны в различном виде с помощью современных технических средств и по мере необходи- мости могут воспроизводиться.
Подготовка принятия решений и, соответственно, анализ происходят в этом простран- стве как среде, и производятся операции с элементами структуры этого пространства и связанных с ним других информационных пространств. Аналитик и другие лица, свя- занные с информационными процессами, используют в своей работе понятия, опреде- ляющие сущность, структуру, элементы информационного пространства, особенно при использовании современных информационных технологий.
В управлении предприятием важными компонентами являются анализ и планирование его деятельности. При этом процесс анализа сочетается с прогнозированием хода раз- личных процессов. Они могут быть контролируемыми, т. е. управляемыми субъектом, или неконтролируемыми, на которые субъект не в состоянии оказать достаточно заметно влияющее воздействие.
При анализе имеющейся информации наблюдаемые процессы можно разделить по этому признаку (влияем или не влияем на данный процесс) с дальнейшим выявлением существенных факторов, степени их влияния на рассматриваемый процесс и т. д. Такого рода анализ, сочетающийся с прогнозированием, является непременным условием эф- фективного планирования деятельности предприятия, обоснования принимаемых управ- ленческих решений.
Наблюдаемые, или исследуемые, процессы – это, в первую очередь, протекающие на предприятии (в корпорации) бизнес-процессы. Под ними подразумевают совокупность работ по выполнению какой-либо задачи предприятия. На основе анализа хода этих процессов, внешних условий, внутреннего состояния предприятия, в том числе финан- сового, делаются определённые выводы, вырабатываются или корректируются цели предприятия. В соответствии с выработанными целевыми установками ставятся задачи, осуществляется планирование мероприятий и деятельности предприятия в целом. При этом учитываются принятые критерии оценки, вырабатываются управленческие реше- ния по реализации планов. Эта часть анализа называется стратегическим анализом.
В процессе реализации планов должен осуществляться контроль и анализ хода их реа- лизации, который называют текущим анализом. Результаты его являются материалом для выработки решений по корректировке, с одной стороны, уже состоявшихся управ- ленческих решений, а с другой – по доработке самих планов или даже целевых устано- вок в случае значительных отклонений полученных показателей от запланированных, отсутствия ресурсов или в связи с какими-либо другими обстоятельствами.
В целом содержание бизнес-анализа состоит в систематизации, оценке полученных параметров в соответствии с принятой системой показателей, изучении и оценке факто- ров, влияющих на деятельность предприятия, выявлении его сильных и слабых сторон, определении возможностей и рисков.
1.2 .МЕТОДЫ БИЗНЕС-АНАЛИТИКИ
Методы бизнес-аналитики можно классифицировать по следующим признакам:
1. По целям:
− оценка состояния и результатов деятельности предприятия;
− постоянный контроль рациональности ведения хозяйственной деятельности, выяв- ление резервов для обеспечения выполнения поставленных задач;
− прогнозирование хода внутренних процессов на предприятии и внешних факторов, влияющих на его деятельность.
2. По временному фактору:
анализ, использующий прошлую информацию, отражённую в документации и на различных носителях и содержащуюся в информационной системе, – анализ фактов;
анализ на базе как прошлой, так и обращённой в будущее, то есть прогнозной ин- формации, – анализ событий и отклонений;
анализ будущей информации – по существу оценка бюджетов и планов, их альтер- натив.
3. По масштабности решаемых или обслуживаемых задач:
• стратегический анализ – сюда можно отнести оценку эффективности целей, долго- срочные прогнозы, исторические оценки процессов и явлений и т. д.;
• оперативный анализ – оценка текущего состояния, выявление узких мест и отклоне- ний;
• система раннего предупреждения.
4. По предметным областям:
• анализ в маркетинге;
• анализ производственной или основной деятельности;
• анализ в логистике;
• анализ в обеспечении ресурсами;
• анализ в финансовой сфере;
• анализ в сфере инвестиций и инноваций.
5. По методам:
• сравнительный анализ по подразделениям, предприятиям, регионам, временным периодам и т. д.;
• анализ отклонений;
• функционально-стоимостной анализ;
• анализ цепочки создания стоимости и конкурентный анализ по Портеру;
• анализ полей бизнеса (Profit Impact of Market Strategies – PIMS);
• бенчмаркинг (Beanchmarking);
• интеллектуальный анализ (Data mining).
В процессе анализа используются различные математические методы, в том числе:
− математической статистики;
− многомерного статистического анализа,
− эконометрики;
− алгебры – линейная, логики, предикатов, нечёткой логики;
− численные методы анализа.
Какой-либо конкретный аналитический процесс или аналитическая работа могут ха- рактеризоваться одновременно несколькими из перечисленных признаков.
Рассмотрим содержание некоторых методов по предметным областям и методикам проведения. Знание методов анализа необходимо в дальнейшем для сценариев OLAP и интеллектуального анализа. Это облегчает реализацию рассматриваемых ниже методик (ряд из них без использования этих средств будут мало эффективными).
Методики проведения анализа в маркетинговой деятельности
Анализ разрыва (Gap analysis) является средством долгосрочного (стратегического) планирования. Основой метода является сравнение стратегий оптимального и возможно- го развития. Составляется матрица оценок стратегий по принятым показателям, по ним строятся профили стратегий. Используются экспертные оценки по балльной качествен- ной системе.
Портфолио-анализ – подбор такого портфеля инвестиций с учётом рисков (сочетания возможных потерь и доходности), который обеспечил бы наименьшие потери с макси- мально возможными доходами.
Анализ маржинальной прибыли (МП) исследует реакцию величины маржинальной прибыли на маркетинговые мероприятия. Объектами анализа являются продукты, реги- оны, заказы, группы клиентов и т. д. Производится выявление причин убытков или рез- кого повышения прибыли, их локализация и вырабатываются предложения по ликвида-
ции «узких» мест или распространению передового опыта. Величину маржинальной прибыли распределяют по различным объектам исследования: продуктам, группам про- дуктов, продуктовым сегментам рынка, предприятиям, корпорации в целом.
Сравнительные расчёты определяют зависимость маржинальной прибыли или вы- ручки от расходов: на рекламу, послепродуктовое обслуживание клиентов, торговые из- держки, в том числе площади; других расходов на маркетинг.
Анализ обеспечения ресурсами
Общие подходы заключаются в исследовании рынков закупки товаров и анализе по- ставщиков, разделении материалов и комплектующих по номенклатуре, качеству, количе- ству, ценам у различных поставщиков. Выделяются факторы, влияющие на процесс снаб- жения, оценивается «совокупное предложение на рынке», а затем выделяются нужные или подходящие поставщики.
АВС-анализ – метод, позволяющий выделить наиболее значимые для предприятия группы товаров. Рассчитываются количество и стоимость потребляемых материалов. По итогам расчёта формируются три группы товаров: А, В и С. Товары А обладают наибольшей кумулятивной стоимостью КС (Количество единиц товара ∙ Цена ед. това- ра). Товары группы С имеют наименьшую кумулятивную стоимость. При этом соблюда- ется условие: КС группы А=50 % всей КС; совместная КС групп А и В = 90 % всей КС. Такое разделение позволяет сосредоточить внимание на направлениях, где ожидается наибольшая польза. Этот метод применяется не только в анализе обеспечения ресурса- ми.
Анализ возможных прерываний бизнес-процесса. Из-за непоступления исходных ма- териалов или необеспеченности другими ресурсами или услугами может быть нарушен производственный или другой процесс. Остановки могут быть частичными или полны- ми. Результатами их являются потери, затраты, упущенная выгода. Оцениваются факто- ры, связанные с убытками, готовностью поставщиков, подбираются альтернативы.
Определение верхних границ цен. Под ними понимают максимальную цену, которую готов заплатить покупатель, в том числе и при закупке материалов. Этот уровень зависит от потребности и значимости товара или материала для обеспечиваемого бизнес- процесса. Цена альтернативного товара-заменителя служит ориентиром верхней границы цены.
Анализ в области логистики
Логистика – это наука и практика управления продвижением (перемещением и хране- нием) товара от производителя к потребителю.
Анализ цепочек логистических процессов позволяет обеспечить руководство предпри- ятия информацией по предметам логистики и выработать соответствующие решения, осуществить согласование и оптимизацию материальных и сопутствующих им инфор- мационных потоков с другими процессами, протекающими на предприятии, и с партнё- рами. Определяются потребности в материалах, транспорте, складских площадях и т. д. исходя из планов заказов и производства. Выбирается методика управления складскими запасами по ритму или срокам поставок. Определяется потребность в поставке по мере достижения минимально допустимого объёма или по окончанию рассчитанного периода
времени, например, вычислением средней скорости потребления по прошлым периодам или по производственной мощности, темпам производственного процесса.
Анализ издержек логистических процессов выявляет места возникновения издержек, к ним относятся объекты приёма-выдачи материалов и полуфабрикатов, склады, система транспортирования, сопутствующий информационный обмен, включая документообо- рот. Далее в соответствии с принятыми в логистической цепи методами учёта определя- ются составляющие издержек. В процессе анализа оцениваются прогнозные и реальные издержки. Проводится контроль экономичности по принятой системе показателей, оце- нивается степень готовности поставок и продвижения, информационное обеспечение и другие показатели.
Финансовый анализ
Основой насчитывающей несколько десятков показателей системы оценки финансо- вого состояния предприятия являются показатели ликвидности и рентабельности, отра- жающие платежеспособность и прибыльность предприятия. Методами анализа улавли- ваются неблагоприятные или критические ситуации, принятые по результатам анализа меры обеспечивают приемлемые или оптимальные значения и соотношения показате- лей, подтверждающие выправление положения. Анализ в финансовой сфере тесно увя- зан с планированием. Каждые плановые предложения или решения должны тщательно оцениваться на предмет реализуемости планов, недопущения недостатка или избытка средств, достижения необходимой и достаточной эффективности их использования.
Методическими инструментами финансового анализа, которые заложены в программ- ные информационно-аналитические средства, являются:
• анализ потоков платежей (Cash flow analysis) – баланс притока и оттока финансо- вых средств. На его основе определяются показатели маржинальной прибыли, безубы- точности, в том числе точка безубыточности, точка закрытия предприятия, кромка без- опасности, эффект операционного рычага, коэффициент выручки. Важное значение имеет показатель работающего капитала, который должен быть положительным. Для прогнозирования критического состояния используется показатель Z-счёт Альтмана, вычисляемый по балансу и отчёту о прибылях и убытках;
• финансовая «паутина». Для поддержки принятия решений важное значение имеют графические методы представления состояния объекта, в данном случае финансового состояния. Одним из таких инструментов является этот метод, который является вариан- том многомерного графического представления данных.
Анализ инвестиций и инноваций
Расчёты, связанные с инвестициями и проектированием, представляют собой самосто- ятельное направление финансово-экономического планирования, тесно связанного с ин- женерно-технологическими исследованиями и решениями.
Задачи анализа в этой области экономической деятельности заключаются в сравни- тельных оценках альтернатив, мониторинге реализации инвестиционных и инновацион- ных проектов по принятой системе показателей. Помимо ставших традиционными фи- нансовых оценок по ряду специальных показателей используется также функционально- стоимостной анализ. В основе его лежат субъективные оценки проектов путём состав- ления иерархии целей, их взвешивания, составления таблиц функций и определения аль-
тернатив реализации функций. Производятся расчёт полезности и формирование после- довательности в матрице ценности целей. Функционально-стоимостной анализ заверша- ется анализом чувствительности полученных данных к изменению весовых коэффици- ентов целей, оценкой и выдачей результата.
Используются различные методы оценки инвестиционных и инновационных проектов в условиях неопределённости. К ним относятся:
анализ ставки дисконтирования с поправкой на риск;
метод достоверных эквивалентов с вариантами использования в качестве их матема- тического ожидания денежных потоков и состояния предпочтения;
методики принятия решений без использования численных значений вероятностей, основанные на построении и анализе матрицы стратегий и состояний природы для инве- стиционного проекта методами максимакса, максимина, минимакса и компромиссного – Гурвица;
опционный, использующий подходы, принятые при оценке ценных бумаг.
Методы стратегического анализа
Анализ стратегической позиции предприятия
Для оценки стратегической позиции предприятия используются несколько методик.
SWOT-анализ – аббревиатура английских слов strengths, weaknesses, opportunities, threats, т. е. сильные, слабые (имеются в виду стороны предприятия), возможности, опасности. На основе анализа внутренней и внешней среды, выявления ключевых фак- торов успеха, социальных аспектов строится четырёхклеточная матрица. Клетки её за- полняются соответствующими данными. Полученные данные позволяют сформировать стратегию предприятия, которая закладывается в планы, исполняется, результаты под- вергаются очередному этапу анализа.
Матрица БКГ (Бостонской консультативной группы) – схожий подход. Результаты аналитической работы представляются таким же образом. Определяются позиции пред- приятия на рынке по сравнению с ведущей фирмой в данном сегменте рынка, все направления деятельности разбиваются на четыре группы. В их отношении вырабаты- ваются соответствующие стратегии. Наработаны типовые рекомендации, суть которых сводится к поддержке перспективных, ликвидации безнадёжных направлений деятель- ности.
Матрица Мак-Кинси является развитием матрицы БКГ. Эта методика предусматрива- ет использование формализованных показателей привлекательности рынка и конкурент- ного статуса. В исходных данных используются экспертные оценки, прогнозные показа- тели.
Анализ цепочки создания стоимости и конкурентный анализ по Портеру. Им предло- жено представить совокупность выполняемых предприятием функций в виде цепочек процессов создания стоимости. В начале и конце цепочек деятельность предприятия ин- тегрируется (согласуется) с деятельностью партнёров по бизнесу.
Конкурентный анализ проводится на «поле сил», действующих на предприятии. Вы- делим пять основных сил: влияние покупателей, влияние поставщиков; возможность по- явления новых конкурентов, существование товаров-заменителей, действия конкурентов внутри отрасли. Исследуются факторы, обусловливающие эти силы, оценивается их со-
отношение. По материалам анализа вырабатывается оптимальная стратегия. Конкретных рекомендаций методика не даёт и ограничивается качественным анализом.
Анализ ситуации по слабым сигналам и оценка рисков
Методика анализа ситуации по слабым сигналам даёт рекомендации по установке
контрольных точек, определяет или устанавливает уровни нестабильности, осведомлён- ности. Предусматриваются варианты реакции на сигналы.
Оценка рисков и управление ими. Риск рассматривается как возможность потерь в виде убытков, упущенной выгоды или как степень нестабильности, непредсказуемых исходов.
Проводится качественный и количественный анализ рисков. При качественном анали- зе выявляются факторы, зоны опасности, виды рисков. Количественный анализ исполь- зует методы аналогий, Монте-Карло, экспертные, анализа чувствительности (что…, ес- ли…), сценариев.
Анализ отклонений
В комплексе аналитических работ на предприятии анализ отклонений играет довольно
существенную роль. После разработки системы целей, выбора стратегий и рассчитанных на их основе планов и бюджетов в процессе их реализации необходим контроль. В идеа- ле он должен сопровождать каждый процесс и быть непрерывным. На практике он реа- лизуется выборочно для наиболее значимых и существенных процессов с допустимой периодичностью. Выводы о степени реализации планов и бюджетов делают посредством анализа отклонений числовых и (или) качественных показателей в принятой на пред- приятии системе.
Различают абсолютные и относительные показатели. В экономической и других пред- метных областях имеется проблема знака отклонения. Иногда снижение значения пока- зателя означает «хорошо» или наоборот. Это обстоятельство необходимо учитывать, например прирост прибыли или убытков.
Селективные отклонения предусматривают сравнения во временном аспекте. Отрезок времени текущего года или другого периода сравнивается с таким же – предыдущего.
Кумулятивное отклонение получаем при сравнении значений показателей, получен- ных нарастающим итогом.
Рассматриваются отклонения «план – факт», «факт – факт» – сравнение с прошлым фактом в сопоставимом отрезке времени, «план – желаемый результат», когда сравни- вается плановый показатель с желательным с учётом изменившихся условий.
Оценку отклонений производят по допустимым пределам и по влиянию на прибыль или другой обобщающий показатель, например ROI.
В процессе анализа выявляются места и причины отклонений. Для оценки величин от- клонений может быть использована методика цепных подстановок, которая представля- ет собой совокупность формул и схем расчёта на основе цепочек создания стоимости, позволяющую в итоге вычислить отклонения по обобщающему показателю на основе имеющихся исходных данных. Для реализации этого метода необходимо реализовать на предприятии систему классификации и кодирования показателей, которая была рассмот- рена выше. В интегрированных экономических информационных системах имеются мо- дули, выполняющие подобные задачи на основе принятой в конкретном программном ин- струментальном средстве системы классификации и кодирования.
Исследование причинно-следственных связей и других интересующих лиц, принима- ющих решения (ЛПР) и аналитиков ведётся с использованием методов интеллектуально- го анализа. Анализ отклонения может быть обращён как в ретроспективу, так и в пер- спективу. Исследование ретроспективы ведётся в интересах извлечения знаний и фор- мирования на их основе выводов на перспективу.
Анализ полей бизнеса
Это исследование воздействия рыночных стратегий на прибыль для данного предпри-
ятия или отдельных полей бизнеса, или видов деятельности на базе информации о более чем 2 000 предприятиях, содержащейся в базах данных специализированных фирм. Учи- тывается взаимовлияние специфической внешней среды данного вида бизнеса и внут- ренней ситуации на предприятии. В качестве обобщающих показателей используются ROI и денежные потоки – Cash-balance.
Бенчмаркинг
Одним из условий выживаемости предприятия, что особенно актуально для нынешних
российских условий, является достижение мирового уровня рыночной привлекательности продукции или услуг. Здесь имеется в виду совокупная оценка свойств продукции, связан- ных с ней услуг, а также процессов на самом предприятии. Целью анализа является выяв- ление лучшего в отрасли или на данном поле бизнеса продукта или предприятия, выявле- ние и оценка уровня собственного отставания или опережения. Сравниваются также про- изводственные, управленческие и иные функции. На основании анализа вырабатываются меры по устранению отставания или закреплению успехов.
1.3 .ИНФОРМАЦИОННЫЙ ОБМЕН, СВЯЗАННЫЙ С АНАЛИТИЧЕСКОЙ РАБОТОЙ
Аналитическая работа на предприятии осуществляется специальной группой. Она может быть автономной или включённой в какое-либо подразделение. В последнее вре- мя создаются подразделения контроллинга, в чьи функции в качестве основной включа- ется эта деятельность. В отдельных, особо сложных ситуациях пользуются услугами консультантов. На малых предприятиях эта работа может быть возложена на одного из заместителей руководителя или эксперта.
Для уяснения функций информационно-аналитической системы необходимо изучить информационный обмен, связанный с аналитической работой. В общей постановке ана- лиз основан на переработке информации, которую аналитики должны где-то получить, и выдаче информации заинтересованным лицам или организационным единицам.
Источники информации для анализа делятся на внутренние и внешние. К внутренним источникам относятся:
− бухгалтерский учёт, включая аналитический и складской;
− статистический учёт;
− управленческий учёт;
− деловая переписка;
− материалы различных исследований и обследований, выполненных на предприятии;
− текущая документация, в том числе материалы ревизий и аудиторских проверок и
т. д.;
− зафиксированные данные опросов;
− устная информация;
− информация из баз данных, эксплуатирующихся на предприятии ЭИС и автономных автоматизированных рабочих мест (АРМ).
Из перечисленных видов учёта бухгалтерский и статистический относятся к обяза- тельным видам учёта.
К внешним источникам информации относятся:
• установочная информация из государственных органов и вышестоящих организа- ций (для зависимых предприятий) – правовые и руководящие документы, инструкции и т. д., определяющие условия функционирования;
• информация из специализированных информационных организаций и их информа- ционных хранилищ, к которым относятся различные фонды, финансовые и биржевые, и т. д.;
• библиотечные фонды и информационные хранилища;
• средства массовой и специализированной информации;
• глобальные информационные ресурсы, например сеть Internet и другие;
• данные деловой разведки и прочие возможные источники информации.
С другой стороны, служба анализа выдаёт информацию заинтересованным потребите- лям. Основной потребитель её – лица, принимающие решения (ЛПР). На предприятии потребителями её являются также службы управления предприятием. К ним относятся:
• бухгалтерская и финансовая службы;
• служба контроллинга или её подразделения, если аналитики входят в её состав;
• маркетинговое подразделение;
• служба логистики;
• технологические и производственные;
• информационная и PR;
• другие заинтересованные структуры и лица.
На предприятии должен быть установлен порядок доступа к такой информации по при- чине её особой ценности и подчас конфиденциальности.
Информация для лиц, принимающих решения, и смежных служб может представляться на бумажных носителях в виде аналитических записок, отчётов, предложений, справок и т. д. Виды и формы документов должны соответствовать российским и международным стандартам документооборота. Это не означает, что исключаются какие-либо иные фор- мы.
Тема 2
OLAP-ТЕХНОЛОГИИ
2.1. ТРЕБОВАНИЯ К ИНФОРМАЦИОННЫМ АНАЛИТИЧЕСКИМ СИСТЕМАМ
В основе концепции OLAP, или оперативной аналитической обработки данных (On- Line Analytical Processing), лежит многомерное концептуальное представление данных (Multidimensional conceptual view).
Термин OLAP введен Коддом (E. F. Codd) в 1993 году. Главная идея данной системы заключается в построении многомерных таблиц, которые могут быть доступны для за- просов пользователей. Эти многомерные таблицы, или так называемые многомерные кубы, строятся на основе исходных и агрегированных данных. И исходные, и агрегиро- ванные данные для многомерных таблиц могут храниться как в реляционных, так и в многомерных базах данных. Взаимодействуя с OLAP-системой, пользователь может осуществлять гибкий просмотр информации, получать различные срезы данных, выпол- нять аналитические операции детализации, свертки, сквозного распределения, сравнения во времени. Вся работа с OLAP-системой происходит в терминах предметной области.
В конце 90-х годов получил распространение свод требований к информационно- аналитическим системам в виде «теста FASMI» – аббревиатуры английских слов, опре- деляющих требования к OLAP-системам: Fast Analysis Shared Multidimensional Infor- mation (быстрый анализ разделяемой многомерной информации).
Рассмотрим содержание перечисленных свойств информационно-аналитической си- стемы.
Fast (быстрый) – это свойство выражается во временных требованиях к ответам си-
стемы на запросы пользователей. Ответ должен быть получен обычно за время в пределах секунды. Более сложные запросы допускается обрабатывать в течение пяти секунд, и лишь отдельные запросы допускаются с 20-секундной реакцией. Такие требования свя- заны с психофизиологичекими показателями аналитиков и ЛПР, обусловлены достиже- нием наиболее значимых результатов анализа при выполнении этих требований. Специ- альные исследования показали, что при времени ответа более 30 секунд наступает раз- дражение и возможна реакция в виде перезапуска системы.
Analysis (анализ) – возможности системы выполнять аналитические работы различно- го характера в предметной области пользователя собственными средствами, не прибегая к программированию. Для описания специфических для данного пользователя анали- тических процессов могут применяться встроенные средства в виде языков высокого уровня, электронных таблиц со встроенными функциями, графических конструкторов, визуальных средств.
Shared (разделяемый) – система должна обеспечивать необходимый уровень защиты при множественном доступе для исключения взаимных помех, несанкционированного доступа, ведь ценность результатов анализа гораздо выше исходной информации.
Multidimensional (многомерный) – определяющее требование. Средства OLAP- системы должны обеспечить работу с данными в многомерном представлении на кон- цептуальном уровне с полной поддержкой иерархий. Требование считается выполнен- ным независимо от того, какой тип базы данных используется, не устанавливаются рам- ки количества измерений.
Information (информация) – должна обеспечиваться возможность получения её из лю- бых необходимых источников. Инструментальные средства оперируют с необходимыми объёмами и структурами данных.
Свойство многомерности является наиболее характерным, отличительным от других систем свойством, в частности OLTP.
Информационное пространство, отображающее функционирование объекта (например, предприятия), многомерно. Естественно стремление аналитика и ЛПР к тому, чтобы иметь дело с моделью данных в наиболее естественном виде. Это обстоятельство приве-
ло к тому, что с помощью современных информационных технологий, имеющих широ- кие возможности интерпретации данных, были созданы соответствующие многомерные модели. Теоретические основы были заложены в трудах крупных российских учёных Ясина, Королёва и др. ещё в 70-х годах XX века. В трудах Кодда, Инмона легко узнают- ся основополагающие идеи этих и других учёных, которые были реализованы в большом числе проектов в разных предметных областях.
2.2. МНОГОМЕРНАЯ МОДЕЛЬ ДАННЫХ
В последнее десятилетие XX века основной моделью данных, использованной в мно- гочисленных инструментальных средствах создания и поддержки баз данных – СУБД, была реляционная модель. Данные в ней представлены в виде множества связанных ключевыми полями двумерных таблиц – отношений. Для устранения дублирования, противоречивости, уменьшения трудозатрат на ведение баз данных применяется фор- мальный аппарат нормализации отношений. Однако применение его связано с дополни- тельными затратами времени на формирование ответов на запросы к базам данных, хотя и экономятся ресурсы памяти.
Многомерная модель данных представляет исследуемый объект в виде многомерного куба, чаще используют трёхмерную модель. По осям или граням куба откладываются из- мерения или реквизиты-признаки. Реквизиты-основания являются наполнением ячеек куба. Пример трехмерного куба информационного пространства «Объем продаж» при- веден на рис. 1.
Многомерный куб, или, как иногда называют, пул данных, может быть представлен комбинацией трёхмерных кубов с целью облегчения восприятия и объёмного представ- ления при формировании отчётных и аналитических документов и мультимедийных презентаций по материалам аналитических работ в системе поддержки принятия реше- ний.
Многомерные данные могут быть отображены инструментами в виде СУБД на основе реляционных моделей данных, а также и специальными многомерными инструменталь- ными средствами.
Рис. 1. Трехмерный куб информационного пространства «Объем продаж»
Представление многомерных данных в рамках реляционных моделей может выпол- няться в виде трёх вариантов схем: «звезда», «снежинка», «созвездие». Линейное пред- ставление на плоскости отображено на рис. 2.
а)
б)
в)
Рис. 2. Линейное представление схем многомерных данных: а) «звезда»; б) «снежинка»; в) созвездие
Данные схемы являются системами таблиц реляционной модели.
На рис. 3 представлена схема базы данных Northwind, входящей в комплект поставки СУБД MS SQL Server и MS Access, а также варианты схем построенных на их основе кубов данных.
Рис. 3. Схема базы данных Northwind
В многомерном пуле информации создаётся большая центральная таблица, называе- мая таблица факта (fact table) (рис. 4). В ней помещаются все данные относительно ин- тересующего пользователя обобщающего показателя. Её окружают меньшие таблицы, содержащие данные по признакам, так называемые таблицы размерности, иногда их называют таблицами измерений (dimensional table) (рис. 5).
Таблицы размерности являются родительскими по отношению к таблице факта. Таб- лица факта является дочерней. Могут быть также консольные таблицы (outrigger table). Они присоединяются к таблицам размерности и детализируют отдельные атрибуты. Консольные таблицы являются родительскими по отношению к таблицам размерности.
Таблицы фактов содержат числовые или качественные (содержательные) значения.
Рис. 4. Таблица факта
При разработке базы данных по схеме «звезда» или по другой многомерной схеме необходимо тщательно проанализировать предметную область и поместить в централь- ную таблицу факта все характеризующие исследуемый объект данные, предварительно разработав систему признаков.
Консольные и таблицы размерности, а также таблица факта соединяются идентифи- цирующими связями. Первичные ключи родительских таблиц являются внешними клю- чами дочерних. Например, первичный ключ таблицы размерности является внешним ключом таблицы факта. Схема «звезда» состоит только из таблиц размерности и табли- цы факта (рис. 6).
Рис. 5. Таблица измерений
Рис. 6. Система таблиц по схеме «звезда
Развитием схемы «звезда» является схема «снежинка» (snowflake schema). Её отличает от первой схемы большое количество консольных таблиц, они имеются практически на каждой таблице размерности и могут иметь несколько уровней иерархии, как показано на рис. 7.
Рис. 7. Система таблиц по схеме «снежинка»
Схема «созвездие» (fact constellation schema) получается из нескольких таблиц фактов. В этом варианте многомерной модели через таблицы размерности сообщаются несколь- ко таблиц фактов, отображающих несколько объектов с общими атрибутами.
В схемах «снежинка» и «созвездие» применение консольных таблиц приводит к до- полнительным затратам времени на реализацию запроса. При проектировании этот фак-
тор должен учитываться. При создании многомерных моделей на основе реляционной базы данных рекомендуется создавать длинные и узкие таблицы фактов и сравнительно небольшие и широкие таблицы размерности (измерений).
Многомерные модели данных на основе многомерных СУБД отличаются отсутствием или неполнотой нормализации. Допускаются дублирование или избыточность данных. Ячейки гиперкубов, формируемые такими средствами, имеют одинаковую размерность, что приводит к избыточному расходу ресурсов системы.
2.3 ТИПЫ МНОГОМЕРНЫХ OLAP-СИСТЕМ
В рамках OLAP-технологий на основе того, что многомерное представление данных может быть организовано как средствами реляционных СУБД, так и многомерных спе- циализированных средств, различают три типа многомерных OLAP-систем:
• многомерный (Multidimensional) OLAP-MOLAP;
• реляционный (Relation) OLAP-ROLAP;
• смешанный, или гибридный (Hibrid) OLAP-HOLAP.
Выше по существу изложены сходство и различия между многомерной и реляционной моделью OLAP-систем. Сущность смешанной OLAP-системы заключается в возможности использования многомерного и реляционного подхода в зависимости от ситуации: раз- мерности информационных массивов, их структуры, частоты обращений к тем или иным записям, вида запросов и т. д.
Рассмотрим подробнее достоинства и недостатки приведённых разновидностей OLAP-систем.
Многомерные OLAP-системы
В многомерных СУБД данные организованы не в виде реляционных таблиц, а в виде упорядоченных многомерных массивов, или гиперкубов, когда все хранимые данные должны иметь одинаковую размерность, что означает необходимость образовывать мак- симально полный базис измерений. Данные могут быть организованы в виде поликубов, в этом варианте значения каждого показателя хранятся с собственным набором измере- ний, обработка данных производится собственным инструментом системы.
Достоинствами MOLAP являются:
• более быстрое, чем при ROLAP, получение ответов на запросы – затрачиваемое время на один-два порядка меньше;
• из-за ограничений SQL затрудняется реализация многих встроенных функций. К ограничениям MOLAP относятся:
• сравнительно небольшие размеры баз данных – десятки гигабайт;
• за счёт денормализации и предварительной агрегации многомерные массивы ис- пользуют в 2,5–100 раз больше памяти, чем исходные данные;
• отсутствуют стандарты на интерфейс и средства манипулирования данными;
• имеются ограничения при загрузке данных.
Исходные и многомерные данные хранятся в многомерной БД или в многомерном ло- кальном кубе. Такой способ хранения обеспечивает высокую скорость выполнения OLAP-операций, но многомерная база в этом случае чаще всего будет избыточной. Куб, построенный на ее основе, будет сильно зависеть от числа измерений. При увеличении
количества измерений объем куба будет экспоненциально расти. Иногда это может при- вести к «взрывному росту» объема данных, парализующему в результате запросы поль- зователей.
Реляционные OLAP-системы
В настоящее время в массовых средствах, обеспечивающих аналитическую работу, преобладает использование инструментов на основе реляционного подхода. В ROLAP- продуктах исходные данные хранятся в реляционных БД или в плоских локальных таб- лицах на файл-сервере. Агрегатные данные могут помещаться в служебные таблицы в той же БД. Преобразование данных из реляционной БД в многомерные кубы происходит по запросу OLAP-средства. При этом скорость построения куба будет сильно зависеть от типа источника данных, и поэтому время отклика системы порой становится неприем- лемо большим.
Достоинствами ROLAP-систем являются:
возможность оперативного анализа непосредственно содержащихся в хранилище данных, так как большинство исходных баз данных -реляционного типа;
при переменной размерности задачи выигрывают ROLAP, так как не требуется фи-
зическая реорганизация базы данных;
ROLAP-системы могут использовать менее мощные клиентские станции и серверы, причём на серверы ложится основная нагрузка по обработке сложных SQL-запросов;
уровень защиты информации и разграничения прав доступа в реляционных СУБД намного выше, чем в многомерных.
Недостатком ROLAP-систем является меньшая производительность, необходимость тщательной проработки схем базы данных, специальная настройка индексов, анализ ста- тистики запросов и учёт выводов анализа при доработках схем баз данных, что приводит к значительным дополнительным трудозатратам. Выполнение же этих условий позволя- ет при использовании ROLAP-систем добиться схожих с MOLAP-системами показате- лей в отношении времени доступа и даже превзойти в экономии памяти.
Гибридные OLAP-системы
Представляют собой сочетание инструментов, реализующих реляционную и много- мерную модели данных. При таком подходе используются достоинства первых двух подходов и компенсируются их недостатки. В наиболее развитых программных продук- тах такого назначения реализован именно этот принцип. Использование гибридной ар- хитектуры в OLAP-системах – это наиболее приемлемый путь решения проблем в при- менении программных инструментальных средств в многомерном анализе. В HOLAP- продуктах исходные данные остаются в реляционной базе, а агрегаты размещаются в многомерной. Построение OLAP-куба выполняется по запросу OLAP-средства на основе реляционных и многомерных данных. Такой подход позволяет избежать взрывного ро- ста объёма данных. При этом можно достичь оптимального времени исполнения клиент- ских запросов.
Рынок OLAP-систем
Сейчас на рынке представлено огромное многообразие OLAP-систем. Разработано не- сколько классификаций продуктов этого типа, например классификация по способу хра- нения данных, по месту нахождения OLAP-машины, по степени готовности к примене- нию. Классификацию по способу хранения данных мы уже рассмотрели: MOLAP, ROLAP, HOLAP.
Следующая классификация – по месту размещения OLAP-машины. По этому признаку OLAP-продукты делятся на OLAP-серверы и OLAP-клиенты.
В серверных OLAP-средствах вычисления и хранение агрегатных данных выполняют- ся отдельным сервером. Клиентское приложение получает только результаты запросов к многомерным кубам, которые хранятся на сервере. Некоторые OLAP-серверы поддер- живают хранение данных только в реляционных базах, другие – только в многомерных. Многие современные OLAP-серверы поддерживают все три способа хранения данных: MOLAP, ROLAP и HOLAP. Одним из самых распространенных в настоящее время сер- верных решений является OLAP-сервер корпорации Microsoft. OLAP-клиент устроен по- другому. Построение многомерного куба и OLAP-вычисления выполняются в памяти клиентского компьютера.
С помощью OLAP-сервера может быть организовано физическое хранение обрабо- танной многомерной информации, что позволяет быстро выдавать ответы на запросы пользователя. Кроме того, предусматривается преобразование данных из реляционных и других баз в многомерные структуры в режиме реального времени.
Каким образом реляционные и многомерные средства работают совместно? OLAP- продукты вливаются в существующую корпоративную инфраструктуру путем интегри- рования с реляционными системами. Администраторы баз данных либо загружают ре- ляционные данные в многомерный кэш, либо настраивают кэш для доступа к SQL- данным.
Тема 3
КОНЦЕПЦИЯ ОРГАНИЗАЦИИ ХРАНЕНИЯ ДАННЫХ
3.1. ПОНЯТИЕ ИНФОРМАЦИОННОГО ХРАНИЛИЩА
Подготовка принятия решений требует сосредоточения значительного, а подчас ко- лоссального количества информации на месте его подготовки. Естественно стремление приблизить места хранения и использования информации. Проблемы подготовки приня- тия решений разрешаются с использованием инструментальных систем поддержания принятия решения Decision Support System (DSS). В них большое место стали занимать OLAP-технологии. Проблема сбора и хранения информации выделилась как занимаю- щая особое место во всей системе управления предприятием (корпорацией) и оформи- лась в концепцию информационных хранилищ Data Warehouse (DW).
Data Warehouse выполняет задачи сбора информации из баз данных, отображающих отдельные бизнес-процессы, автоматизированных рабочих мест, информационных си- стем и других источников информации, в том числе из глобальных информационных се- тей, например Internet. Такие источники данных называют операционными базами дан- ных. Сбор информации сочетается, как правило, с доработкой исходных данных, которая заключается в проверке достоверности, устранении противоречивости, сортировке, си- стематизации, построении заданной единой структуры хранилища и т. д.
Выделим свойства информационных хранилищ:
• предметная ориентированность;
• интегрированность;
• неизменчивость;
• поддержка хронологии.
Свойство предметной ориентированности означает компоновку пулов информации по определённым предметным областям или целям, обеспечивающим подготовку и при- нятие необходимых решений в соответствующей системе DSS.
Интегрированность предусматривает сбор и доработку (предварительную обработку) информации по определённой предметной области из различных источников и превра- щение её в организованный по заданным правилам, подчинённым определённой цели, массив в виде гиперкуба или системы поликубов информации.
Неизменчивость состоит в том, что информация не подвергается частым обновлени- ям, а только в случае крайней необходимости. В основном наращивается по заданному, чётко определённому графику. Пользователь имеет только право чтения информации.
Поддержка хронологии заключается в обязательности привязки данных ко времени. Информация, содержащаяся в хранилище, рассматривается в историческом аспекте.
Используют следующие типы привязки ко времени:
• к моменту совершения события или факта;
• к моменту фиксации его информационными средствами;
• комбинированные методы, сочетающие оба подхода.
Реализация концепции Data Warehouse может быть осуществлена несколькими спосо- бами – имеются несколько вариантов концепций информационного хранилища.
3.2. КОНЦЕПЦИЯ ЦЕНТРАЛИЗОВАННОГО ХРАНИЛИЩА ДАННЫХ
Такой подход означает, что при нескольких источниках информации – операционных базах данных – создаётся единое централизованное хранилище. В первичных источни- ках информация хранится в «сыром», недоработанном виде, то есть в структуре инфор- мационного пространства данного источника информации или операционной БД. Вся поступающая в Data Warehouse информация должна быть преобразована в принятую в данном DW структуру. Передача данных из операционных БД в информационное хра- нилище, которая сопровождается доработкой, может быть организована по заданному временному графику и правилам доработки с соблюдением принципов Инмона. Допус- каются неожиданные запросы «на лету», что предъявляет более строгие требования к инструментальным средствам информационных хранилищ.
При реализации такой концепции возникает потребность в мощном компьютере. В за- висимости от масштабов предметной области это будет или персональный компьютер с предельно высокими характеристиками, особенно в части требований к объёмам памяти, или майнфрейм и даже суперкомпьютер. Необходимо наличие развитых средств теле- коммуникаций, обеспечивающих информационный обмен «операционные БД – инфор- мационное хранилище». Это требование относится к любому варианту концепции ин- формационного хранилища. Схема централизованного хранения данных приведена на рис. 8.
Центральное храни- лище данных
Операци- онная база данных 1
Операци- онная база данных 2
Операци- онная база данных N
Рис. 8. Схема централизованного хранения данных
3.3. КОНЦЕПЦИЯ РАСПРЕДЕЛЁННОГО ХРАНИЛИЩА ДАННЫХ
Возможен и имеет место противоположный подход к хранению данных на основе распределения функций информационного хранилища по местам их возникновения или группировки нескольких операционных баз данных вокруг локального или регионально- го информационного хранилища. Эти хранилища могут быть ориентированы на опреде- лённую предметную область или на регион в корпоративных структурах. Система ло- кальных хранилищ действует в качестве распределённого хранилища. Не исключается и наличие центрального хранилища, но в такой структуре требования к его размерности значительно облегчаются.
Этот подход предусматривает трансляцию каждого запроса к каждому источнику (базе данных), обработку, увязывание, согласование, компоновку извлечённых данных «на ле- ту» и предоставление их пользователю.
Такой подход при экономии ресурсов на создание крупного централизованного хра- нилища имеет ряд недостатков:
• в связи с нормализованностью данных в операционных базах и длительностью до- ступа из «центра» общее время отклика такой системы выходит за рамки допустимого;
• должны быть обеспечены постоянство нахождения в сети и открытость всех источ- ников информации, так как отсутствие какого-либо из них может сорвать весь процесс анализа;
• возможны противоречивость и несогласованность ответов из различных источников из-за различных форматов представления, разницы в темпах обновления, правила при- вязки ко времени, изменения смысловой нагрузки данных и т. д.;
• практическая невозможность комплексного исторического обзора содержащейся в разнородных источниках информации из-за различного порядка её хранения – навязать единый порядок весьма затруднительно. Схема распределённого информационного хра- нилища приведена на рис. 9.
Информаци- онное храни- лище 1
Информаци- онное храни- лище 2
Операционная база 1
Операционная база 1.n
Операцион- ная база 2
Операционная база 2.m
Информационное хранилище 3
Операционная база 3
Операционная база 3.k
Рис. 9. Схема распределённого информационного хранилища
3.4. КОНЦЕПЦИЯ АВТОНОМНЫХ ВИТРИН ДАННЫХ
Одним из вариантов организации централизованного хранения и представления ин- формации является концепция витрин данных (Data Mart). Она предложена Forrester Re- search в 1991 году.
При таком подходе информация, относящаяся к крупной предметной области, напри- мер информационному пространству крупной корпоративной системы, имеющей не- сколько достаточно самостоятельных направлений деятельности, группируется по этим направлениям в специально организованных базах данных, которые называют витрина- ми данных.
Этот подход является развитием концепции распределённого информационного храни- лища в части придания функций предметной ориентированности некоторым локальным информационным хранилищам.
Такой подход позволяет обойтись сравнительно менее ресурсоёмкими аппаратными и программными средствами, обеспечивает повышение адаптируемости системы к изме- няющимся условиям, расширяет доступность для внедрения. Пользователь предприятия или другого подразделения корпорации получает своё информационное хранилище, об- служивающее местные потребности.
3.5. КОНЦЕПЦИЯ ЕДИНОГО ИНТЕГРИРОВАННОГО ХРАНИЛИЩА И МНОГИХ ВИТРИН ДАННЫХ
В 1994 году было предложено объединить две концепции: единого интегрированного хранилища и связанных с ним и получающих из него информацию витрин данных. В та- ком варианте имеется крупное информационное хранилище агрегированной и подрабо- танной информации, которое может удовлетворить потенциальные запросы по отдель- ным направлениям деятельности.
Здесь очевидны преимущества: данные заранее агрегируются, обеспечивается единая хронология, согласованы различные форматы, устраняются противоречивость и неодно- значность данных – информация приобретает необходимую кондицию для быстрого и достаточного полного удовлетворения необходимого множества запросов.
Недостатком является необходимость применения высокопроизводительных аппарат- ных средств и специализированных многомерных или гибридных программных инстру- ментальных средств.
В таком варианте информационная аналитическая система приобретает иерархическую многоуровневую структуру, содержащую следующие уровни:
• общекорпоративное централизованное хранилище данных;
• витрины данных по направлениям деятельности;
• локальные или региональные базы и хранилища данных;
• операционные базы данных, автоматизированные рабочие места пользователей ав- тономных программ.
Пунктам концентрации информации соответствуют иерархические уровни использова- ния при подготовке, принятии и реализации решений данных, которые являются появ- ляющейся в результате функционирования предприятия (корпорации) информации:
• уровень лиц, принимающих решения, который может быть совмещён с уровнем витрин данных;
• уровень рабочих мест аналитиков и других заинтересованных пользователей.
Рассмотренные концепции охватывают лишь те стороны функционирования систем аналитики, которые относятся к организации хранения данных. Они не определяют тре- бования и подходы к выполнению анализа, способы представления данных в информа- ционном хранилище – реляционный или многомерный.
Тема 4 DATA MINING
4.1. ИСТОРИЯ DATA MINING
За последние годы, когда, стремясь к повышению эффективности и прибыльности бизнеса, при создании БД все стали пользоваться средствами обработки цифровой ин- формации, появился и побочный продукт этой активности – горы собранных данных.
Термин «Data Mining» получил свое название из двух понятий: поиска ценной инфор- мации в большой базе данных (data) и добычи горной руды (mining). Оба процесса тре-
буют или просеивания огромного количества сырого материала, или разумного исследо- вания и поиска искомых ценностей.
«Data Mining» часто переводится как добыча данных, извлечение информации, рас- копка данных, интеллектуальный анализ данных, средства поиска закономерностей, из- влечение знаний, анализ шаблонов, извлечение зерен знаний из гор данных, раскопка знаний в базах данных, информационная проходка данных, промывание данных. Поня- тие «обнаружение знаний в базах данных» (Knowledge Discovery in Databases, KDD) многие считают синонимом Data Mining.
Понятие «Data Mining», появившееся в 1978 году, приобрело высокую популярность в современной трактовке примерно с первой половины 1990-х годов. Что же такое Data Mining?
Data Mining – мультидисциплинарная область, возникшая и развивающаяся на базе таких наук, как прикладная статистика, распознавание образов, искусственный интел- лект, теория баз данных и др. (рис. 10).
Теория баз данных
Другие
дисциплины
Статистика
Машинное обу- чение
Data Mining
Визуализация
Алгоритмизация
Искусственный интеллект
Распознавание образов
Рис. 10. Data Mining как мультидисциплинарная область
Приведем краткое описание некоторых дисциплин, на стыке которых появилась тех- нология Data Mining.
Статистика – это наука о методах сбора данных, их обработки и анализа для выяв- ления закономерностей, присущих изучаемому явлению. Статистика является совокуп- ностью методов планирования, эксперимента, сбора данных, их представления и обоб- щения, а также анализа и получения выводов на основании этих данных. Она оперирует данными, полученными в результате наблюдений либо экспериментов.
Машинное обучение можно охарактеризовать как процесс получения программой но- вых знаний. Митчелл в 1996 году дал такое определение: «Машинное обучение – это наука, которая изучает компьютерные алгоритмы, автоматически улучшающиеся во время работы». Одним из наиболее популярных примеров алгоритма машинного обуче- ния являются нейронные сети.
Искусственный интеллект – научное направление, в рамках которого ставятся и ре- шаются задачи аппаратного или программного моделирования видов человеческой дея- тельности, традиционно считающихся интеллектуальными. Термин «интеллект» (intelligence) происходит от латинского intellectus, что означает ум, рассудок, разум, мыслительные способности человека. Соответственно, искусственный интеллект (AI, Artificial Intelligence) толкуется как свойство автоматических систем брать на себя от- дельные функции интеллекта человека. Искусственным интеллектом называют свойство интеллектуальных систем выполнять творческие функции, которые традиционно счита- ются прерогативой человека. Каждое из направлений, сформировавших Data Mining, имеет свои особенности.
Понятие «Data Mining» тесно связано с технологиями баз данных. Развитие техноло- гии баз данных прошло несколько этапов.
1960-е гг. В 1968 году была введена в эксплуатацию первая промышленная СУБД- система IMS фирмы IBM.
1970-е гг. В 1975 году появился первый стандарт ассоциации по языкам систем обра- ботки данных – Conference on Data System Languages (CODASYL), определивший ряд фундаментальных понятий в теории систем баз данных, которые до сих пор являются основополагающими для сетевой модели данных.
1980-е гг. В течение этого периода многие исследователи экспериментировали с но- вым подходом в направлениях структуризации баз данных и обеспечения к ним доступа. Целью этих поисков было получение реляционных прототипов для более простого мо- делирования данных. В результате в 1985 году был создан язык, названный SQL. На се- годняшний день практически все СУБД обеспечивают данный интерфейс.
1990-е гг. Появились специфичные типы данных: «графический образ», «документ»,
«звук», «карта». Типы данных для времени, интервалов времени, символьных строк с двухбайтовым представлением символов были добавлены в язык SQL. Появились техно- логии Data Mining, хранилища данных, мультимедийные базы данных и web-базы дан- ных.
Возникновение и развитие Data Mining обусловлено различными факторами, основ- ными среди которых являются следующие:
• совершенствование аппаратного и программного обеспечения;
• совершенствование технологий хранения и записи данных;
• накопление большого количества ретроспективных данных;
• совершенствование алгоритмов обработки информации.
4.2. ПОНЯТИЕ DATA MINING
Data Mining – это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей (шаблонов информации).
Суть и цель технологии Data Mining можно охарактеризовать так: это технология, ко- торая предназначена для поиска в больших объемах данных неочевидных, объективных и полезных на практике закономерностей.
Неочевидные – т. е. найденные закономерности не обнаруживаются стандартными ме- тодами обработки информации или экспертным путем.
Объективные – т. е. обнаруженные закономерности будут полностью соответствовать действительности в отличие от экспертного мнения, которое всегда является субъектив- ным.
Практически полезные – т. е. выводы имеют конкретное значение, которому можно найти практическое применение.
Знания – совокупность сведений, которая образует целостное описание, соответству- ющее некоторому уровню осведомленности об описываемом вопросе, предмете, про- блеме и т. д. Использование знаний (knowledge deployment) означает действительное применение найденных знаний для достижения конкретных преимуществ (например, в конкурентной борьбе за рынок).
Существует множество определений понятия «Data Mining». Вот некоторые из них:
• Data Mining – это процесс выделения из данных неявной и неструктурированной информации и представления ее в виде, пригодном для использования;
• Data Mining – это процесс выделения, исследования и моделирования больших объ- емов данных для обнаружения неизвестных до этого структур (patterns) с целью дости- жения преимуществ в бизнесе (определение SAS Institute);
• Data Mining – это процесс, цель которого обнаружить новые значимые корреляции, образцы и тенденции в результате просеивания большого объема хранимых данных с использованием методик распознавания образцов и применением статистических и ма- тематических методов (определение Gartner Group).
В основу технологии Data Mining положена концепция шаблонов (patterns), которые представляют собой закономерности, свойственные подвыборкам данных и выраженные в форме, понятной человеку. Построение моделей прогнозирования также является це- лью поиска закономерностей.
4.3. ОТЛИЧИЯ DATA MINING ОТ ДРУГИХ МЕТОДОВ АНАЛИЗА ДАННЫХ
Традиционные методы анализа данных (статистические методы) и OLAP в основном ориентированы на проверку заранее сформулированных гипотез (verification-driven data mining) и на «грубый» разведочный анализ, составляющий основу оперативной аналити- ческой обработки данных (On Line Analytical Processing, OLAP), в то время как одно из основных положений Data Mining – поиск неочевидных закономерностей. Инструменты Data Mining могут находить такие закономерности самостоятельно и также самостоя- тельно строить гипотезы о взаимосвязях. Преимущество Data Mining по сравнению с другими методами анализа является очевидным. Большинство статистических методов для выявления взаимосвязей в данных используют концепцию усреднения по выборке, приводящую к операциям над несуществующими величинами, тогда как Data Mining оперирует реальными значениями. OLAP больше подходит для понимания ретроспек- тивных данных, Data Mining опирается на ретроспективные данные для получения отве- тов на вопросы о будущем.
4.4. ПЕРСПЕКТИВЫ ТЕХНОЛОГИИ DATA MINING
Потенциал Data Mining дает «зеленый свет» для расширения границ применения тех- нологии. Относительно перспектив Data Mining возможны следующие направления раз- вития:
• выделение типов предметных областей с соответствующими им эвристиками, фор- мализация которых облегчит решение соответствующих задач Data Mining, относящихся к этим областям;
• создание формальных языков и логических средств, с помощью которых будут формализованы рассуждения и автоматизация которых станет инструментом решения задач Data Mining в конкретных предметных областях;
• создание методов Data Mining, способных не только извлекать из данных законо- мерности, но и формировать определенные теории, опирающиеся на эмпирические дан- ные;
• преодоление существенного отставания возможностей инструментальных средств Data Mining от теоретических достижений в этой области.
Если рассматривать будущее Data Mining в краткосрочной перспективе, то очевидно, что развитие этой технологии наиболее направлено к областям, связанным с бизнесом. Продукты Data Mining могут стать такими же обычными и необходимыми, как элек- тронная почта, и, например, использоваться для поиска самых низких цен на определен- ный товар или наиболее дешевых билетов.
Однако Data Mining таит в себе и потенциальную опасность, ведь все большее количе- ство информации становится доступным через всемирную сеть, в том числе и сведения частного характера, и все больше знаний возможно добыть из нее. Не так давно круп- нейший онлайновый магазин Amazon оказался в центре скандала по поводу полученного им патента «Методы и системы помощи пользователям при покупке товаров», который представляет собой по сути очередной продукт Data Mining, предназначенный для сбора персональных данных о посетителях магазина. Новая методика позволяет прогнозиро- вать будущие запросы на основании фактов покупок, а также делать выводы об их назначении. Цель данной методики – получение как можно большего количества ин- формации о клиентах (пол, возраст, предпочтения и т. д.).
Существуют как успешные решения, использующие Data Mining, так и неудачный опыт применения этой технологии. Области, где применение технологии Data Mining, скорее всего, будет успешным, имеют такие особенности:
• требуют решений, основанных на знаниях;
• имеют изменяющуюся окружающую среду;
• имеют доступные, достаточные и значимые данные;
• обеспечивают высокие дивиденды от правильных решений.
4.5. КЛАССИФИКАЦИЯ СТАДИЙ DATA MINING
Data Mining может состоять из двух или трех стадий.
Стадия 1. Выявление закономерностей (свободный поиск).
Стадия 2. Использование выявленных закономерностей для предсказания неизвест- ных значений (прогностическое моделирование).
В дополнение к этим стадиям иногда вводят стадию валидации, следующую за стади- ей свободного поиска. Цель валидации – проверка достоверности найденных закономер- ностей. Однако многие аналитики считают валидацию частью первой стадии, поскольку в реализации многих методов, в частности нейронных сетей и деревьев решений, преду- смотрено деление общего множества данных на обучающее и проверочное, и последнее позволяет проверять достоверность полученных результатов.
Стадия 3. Анализ исключений – стадия предназначена для выявления и объяснения аномалий, найденных в закономерностях.
Свободный поиск (Discovery)
На стадии свободного поиска осуществляется исследование набора данных с целью поиска скрытых закономерностей. Предварительные гипотезы относительно вида зако- номерностей здесь не определяются.
Закономерность (law) – существенная и постоянно повторяющаяся взаимосвязь, определяющая этапы и формы процесса становления, развития различных явлений или процессов.
Система Data Mining на этой стадии определяет шаблоны, для получения которых в системах OLAP, например, аналитику необходимо обдумывать и создавать множество запросов. Здесь же аналитик освобождается от такой работы – шаблоны ищет за него си- стема. Особенно полезно применение данного подхода в сверхбольших базах данных, где уловить закономерность путем создания запросов достаточно сложно, для этого тре- буется перепробовать множество разнообразных вариантов.
Свободный поиск представлен такими действиями:
• выявление закономерностей условной логики (conditional logic);
• выявление закономерностей ассоциативной логики (associations and affinities);
• выявление трендов и колебаний (trends and variations).
Допустим, имеется база данных кадрового агентства с данными о профессии, стаже, возрасте и желаемом уровне вознаграждения. В случае самостоятельного задания запро- сов аналитик может получить приблизительно такие результаты: средний желаемый уровень вознаграждения специалистов в возрасте от 25 до 35 лет равен 1 200 условных единиц. В случае свободного поиска система сама ищет закономерности, необходимо лишь задать целевую переменную. В результате поиска закономерностей система сфор- мирует набор логических правил «если …, то …».
Могут быть найдены, например, такие закономерности «Если возраст менее 20 лет и желаемый уровень вознаграждения более 700 условных единиц, то в 75 % случаев соис- катель ищет работу программиста» или «Если возраст более 35 лет и желаемый уровень вознаграждения более 1 200 условных единиц, то в 90 % случаев соискатель ищет руко- водящую работу». Целевой переменной в описанных правилах выступает профессия.
При задании другой целевой переменной, например возраста, получаем такие правила:
«Если соискатель ищет руководящую работу и его стаж более 15 лет, то возраст соиска- теля – более 35 лет в 65 % случаев».
Описанные действия в рамках стадии свободного поиска выполняются при помощи:
• индукции правил условной логики (задачи классификации и кластеризации, описа- ние в компактной форме близких или схожих групп объектов);
• индукции правил ассоциативной логики (задачи ассоциации и последовательности и извлекаемая при их помощи информация);
• определения трендов и колебаний (исходный этап задачи прогнозирования).
На стадии свободного поиска также должна осуществляться валидация закономерно- стей, т. е. проверка их достоверности на части данных, которые не принимали участие в формировании закономерностей. Такой прием разделения данных на обучающее и про- верочное множества часто используется в методах нейронных сетей и деревьев решений и будет описан в соответствующих лекциях.
Прогностическое моделирование (Predictive Modeling)
Вторая стадия Data Mining – прогностическое моделирование – использует результаты работы первой стадии. Здесь обнаруженные закономерности используются непосред- ственно для прогнозирования.
Прогностическое моделирование включает такие действия:
− предсказание неизвестных значений (outcome prediction);
− прогнозирование развития процессов (forecasting).
В процессе прогностического моделирования решаются задачи классификации и про- гнозирования.
При решении задачи классификации результаты работы первой стадии (индукции пра-
вил) используются для отнесения нового объекта с определенной уверенностью к одно- му из известных, предопределенных классов на основании известных значений.
При решении задачи прогнозирования результаты первой стадии (определение тренда или колебаний) используются для предсказания неизвестных (пропущенных или же бу- дущих) значений целевой переменной (переменных).
Продолжая рассмотренный пример первой стадии, можем сделать следующий вывод. Зная, что соискатель ищет руководящую работу и его стаж более 15 лет, на 65 % можно быть уверенным в том, что возраст соискателя –более 35 лет. Или же, если возраст соис- кателя более 35 лет и желаемый уровень вознаграждения – более 1 200 условных еди- ниц, на 90 % можно быть уверенным в том, что соискатель ищет руководящую работу.
Сравнивая свободный поиск и прогностическое моделирование с точки зрения логи- ки, можно отметить следующее. Свободный поиск раскрывает общие закономерности. Закономерности, полученные на этой стадии, формируются от частного к общему. В ре- зультате мы получаем некоторое общее знание о некотором классе объектов на основа- нии исследования отдельных представителей этого класса. Правило: «Если возраст со- искателя менее 20 лет и желаемый уровень вознаграждения более 700 условных еди- ниц, то в 75 % случаев соискатель ищет работу программиста». На основании частного, т. е. информации о некоторых свойствах класса – «возраст более 20 лет» и «желаемый уровень вознаграждения более 700 условных единиц» – мы делаем вывод об общем, а именно: соискатели – программисты.
Закономерности, полученные на стадии прогностического моделирования, формиру- ются от общего к частному и единичному. Здесь мы получаем новое знание о некотором объекте или же группе объектов на основании:
• знания класса, к которому принадлежат исследуемые объекты;
• знания общего правила, действующего в пределах данного класса объектов.
Знаем, что соискатель ищет руководящую работу и его стаж более 15 лет, на 65 % можно быть уверенным в том, что возраст соискателя более 35 лет.
На основании некоторых общих правил, а именно: цель соискателя – руководящая ра- бота и его стаж более 15 лет – и мы делаем вывод о единичном: возраст соискателя – бо- лее 35 лет.
Следует отметить, что полученные закономерности, а точнее, их конструкции, могут быть прозрачными, т. е. допускающими толкование аналитика, и непрозрачными, так называемыми «черными ящиками». Типичный пример последней конструкции – нейронная сеть.
Анализ исключений (forensic analysis)
На третьей стадии Data Mining анализируются исключения или аномалии, выявленные в найденных закономерностях. Действие, выполняемое на этой стадии, – выявление от- клонений (deviation detection). Для выявления отклонений необходимо определить нор- му, которая рассчитывается на стадии свободного поиска.
Вернемся к одному из примеров, рассмотренных выше. Найдено правило «Если воз- раст более 35 лет и желаемый уровень вознаграждения более 1 200 условных единиц, то в 90 % случаев соискатель ищет руководящую работу». Возникает вопрос, к чему отне- сти оставшиеся 10 % случаев.
Здесь возможны два варианта. Первый из них – существует некоторое логическое объ- яснение, которое также может быть оформлено в виде правила. Второй вариант для оставшихся 10 % – это ошибки исходных данных. В этом случае стадия анализа исклю- чений может быть использована в качестве очистки данных.
4.6. КЛАССИФИКАЦИЯ МЕТОДОВ DATA MINING
Все методы Data Mining подразделяются на две большие группы по принципу работы с исходными обучающими данными. В этой классификации верхний уровень определяется на основании того, сохраняются ли данные после Data Mining либо они дистиллируются для последующего использования.
1. Непосредственное использование данных, или сохранение данных. В этом случае ис- ходные данные хранятся в явном детализированном виде и непосредственно использу- ются на стадиях прогностического моделирования и (или) анализа исключений. Пробле- ма этой группы методов – при их использовании могут возникнуть сложности анализа сверхбольших баз данных. Методы этой группы: кластерный анализ, метод ближайшего соседа, метод k-ближайшего соседа, рассуждение по аналогии.
2. Выявление и использование формализованных закономерностей, или дистилляция шаблонов. При технологии дистилляции шаблонов один образец (шаблон) информации извлекается из исходных данных и преобразуется в некие формальные конструкции, вид которых зависит от используемого метода Data Mining. Этот процесс выполняется на стадии свободного поиска, у первой же группы методов данная стадия в принципе от- сутствует. На стадиях прогностического моделирования и анализа исключений исполь- зуются результаты стадии свободного поиска, они значительно компактнее самих баз данных. Конструкции этих моделей могут быть трактуемыми аналитиком либо нетрак- туемыми («черными ящиками»). Методы этой группы: логические методы, методы визу- ализации, методы кросс-табуляции, методы, основанные на уравнениях.
Логические методы, или методы логической индукции, включают: нечеткие запросы и анализы, символьные правила, деревья решений, генетические алгоритмы. Методы этой
группы являются, пожалуй, наиболее интерпретируемыми – они оформляют найденные закономерности в большинстве случаев в достаточно прозрачном виде с точки зрения пользователя. Полученные правила могут включать непрерывные и дискретные пере- менные. Следует заметить, что деревья решений могут быть легко преобразованы в наборы символьных правил путем генерации одного правила по пути от корня дерева до его терминальной вершины. Деревья решений и правила фактически являются разными способами решения одной задачи и отличаются лишь по своим возможностям. Кроме того, реализация правил осуществляется более медленными алгоритмами, чем индукция деревьев решений.
Методы кросс-табуляции: агенты, баесовские (доверительные) сети, кросс-табличная визуализация. Последний метод не совсем отвечает одному из свойств Data Mining – са- мостоятельному поиску закономерностей аналитической системой. Однако предостав- ление информации в виде кросс-таблиц обеспечивает реализацию основной задачи Data Mining – поисках шаблонов, поэтому этот метод можно также считать одним из методов Data Mining.
Методы на основе уравнений выражают выявленные закономерности в виде математи- ческих выражений, уравнений. Следовательно, они могут работать лишь с численными переменными и переменные других типов должны быть закодированы соответствую- щим образом. Это несколько ограничивает применение методов данной группы, тем не менее они широко используются при решении различных задач, особенно задач прогно- зирования. Основные методы данной группы: статистические методы и нейронные сети. Статистические методы наиболее часто применяются для решения задач прогнозирова- ния. Существует множество методов статистического анализа данных, среди них, например, корреляционно-регрессионный анализ, корреляция рядов динамики, выявле- ние тенденций динамических рядов, гармонический анализ.
Различают статистические методы, основанные на использовании усредненного накопленного опыта, который отражен в ретроспективных данных, и кибернетические методы, включающие множество разнородных математических подходов. Недостатком такой классификации является то, что и статистические, и кибернетические алгоритмы опираются на сопоставление статистического опыта с результатами мониторинга теку- щей ситуации. Преимуществом является удобство для интерпретации – она используется при описании математических средств современного подхода к извлечению знаний из массивов исходных наблюдений (оперативных и ретроспективных), т. е. в задачах Data Mining.
Статистические методы Data mining
Статистические методы Data mining представляют собой четыре взаимосвязанных раздела:
• предварительный анализ природы статистических данных (проверка гипотез стаци-
онарности, нормальности, независимости, однородности, оценка вида функции распре- деления, ее параметров и т. п.);
• выявление связей и закономерностей (линейный и нелинейный регрессионный ана- лиз, корреляционный анализ и др.);
• многомерный статистический анализ (линейный и нелинейный дискриминантный анализ, кластерный анализ, компонентный анализ, факторный анализ и др.);
• динамические модели и прогноз на основе временных рядов.
Арсенал статистических методов Data Mining классифицирован на четыре группы ме- тодов:
1. Дескриптивный анализ и описание исходных данных.
2. Анализ связей (корреляционный и регрессионный анализ, факторный анализ, дис- персионный анализ).
3. Многомерный статистический анализ (компонентный анализ, дискриминантный анализ, многомерный регрессионный анализ, канонические корреляции и др.).
4. Анализ временных рядов (динамические модели и прогнозирование).
Кибернетические методы Data Mining
Второе направление Data Mining – это множество подходов, объединенных идеей компьютерной математики и использования теории искусственного интеллекта.
К этой группе относятся такие методы:
• искусственные нейронные сети (распознавание, кластеризация, прогноз);
• эволюционное программирование (в т. ч. алгоритмы метода группового учета аргу- ментов);
• генетические алгоритмы (оптимизация);
• ассоциативная память (поиск аналогов, прототипов);
• нечеткая логика;
• деревья решений;
• системы обработки экспертных знаний.
Методы Data Mining также можно классифицировать по задачам (более подробно за- дачи Data Mining мы рассмотрим позже).
В соответствии с такой классификацией выделяются две группы. Первая из них – это подразделение методов Data Mining на решающие задачи сегментации (т. е. задачи клас- сификации и кластеризации) и задачи прогнозирования.
В соответствии со второй классификацией по задачам методы Data Mining могут быть направлены на получение описательных и прогнозирующих результатов.
Описательные методы служат для нахождения шаблонов или образцов, описывающих данные, которые поддаются интерпретации с точки зрения аналитика. Прогнозирующие методы используют значения одних переменных для предсказания (прогнозирования) неизвестных (пропущенных) или будущих значений других (целевых) переменных. К методам, направленным на получение прогнозирующих результатов, относятся такие методы: нейронные сети, деревья решений, линейная регрессия, метод ближайшего со- седа, метод опорных векторов и др.
4.7. СФЕРЫ ПРИМЕНЕНИЯ DATA MINING
Следует сразу сказать, что область использования Data Mining ничем не ограничена – она везде, где имеются какие-либо данные. Рассмотрим, где Data Mining работает и дает реальные результаты.
Выделяются два направления применения систем Data Mining как массового продукта и как инструмента для проведения уникальных исследований. На сегодняшний день наибольшее распространение технология Data Mining получила при решении бизнес- задач. Возможно, причина в том, что именно в этом направлении отдача от использова- ния инструментов Data Mining может составлять, по некоторым источникам, до 1 000 %
и затраты на ее внедрение могут достаточно быстро окупиться. Сейчас технология Data Mining используется практически во всех сферах деятельности человека, где накоплены ретроспективные данные.
Рассматрим четыре основные сферы применения технологии Data Mining подробно:
• применение Data Mining для решения бизнес-задач. Основные направления: банков- ское дело, финансы, страхование, CRM, производство, телекоммуникации, электронная коммерция, маркетинг, фондовый рынок и другие;
• применение Data Mining для решения задач государственного уровня. Основные направления: поиск лиц, уклоняющихся от налогов; средства в борьбе с терроризмом;
• применение Data Mining для научных исследований. Основные направления: меди- цина, биология, молекулярная генетика и генная инженерия, биоинформатика, астроно- мия, прикладная химия, исследования, касающиеся наркотической зависимости, и др.;
• применение Data Mining для решения web-задач. Основные направления: поисковые машины (search engines), счетчики и др.
Применение Data Mining для решения бизнес-задач
Банковское дело. Технология Data Mining используется в банковской сфере для реше- ния ряда типичных задач.
Задача «Выдавать ли кредит клиенту?» Классический пример применения Data Mining в банковском деле – решение задачи определения возможной некредитоспособ- ности клиента банка. Эту задачу также называют анализом кредитоспособности клиента или «Выдавать ли кредит клиенту?». Без применения технологии Data Mining задача ре- шается сотрудниками банковского учреждения на основе их опыта, интуиции и субъек- тивных представлений о том, какой клиент является благонадежным. По похожей схеме работают системы поддержки принятия решений и на основе методов Data Mining. Та- кие системы на основе исторической (ретроспективной) информации и при помощи ме- тодов классификации выявляют клиентов, которые в прошлом не вернули кредит.
Задача «Выдавать ли кредит клиенту?» при помощи методов Data Mining решается следующим образом. Совокупность клиентов банка разбивается на два класса (вернув- шие и не вернувшие кредит); на основе группы клиентов, не вернувших кредит, опреде- ляются основные «черты» потенциального неплательщика, при поступлении информа- ции о новом клиенте определяется его класс («вернет кредит», «не вернет кредит»).
Задача привлечения новых клиентов банка. С помощью инструментов Data Mining возможно провести классификацию на «более выгодных» и «менее выгодных» клиентов. После определения наиболее выгодного сегмента клиентов банку есть смысл проводить более активную маркетинговую политику по привлечению клиентов именно среди найденной группы.
Другие задачи сегментации клиентов. Разбивая клиентов при помощи инструментов Data Mining на различные группы, банк имеет возможность сделать свою маркетинговую политику более целенаправленной, а потому эффективной, предлагая различным груп- пам клиентов именно те виды услуг, в которых они нуждаются.
Задача управления ликвидностью банка, прогнозирование остатка на счетах клиен- тов. При прогнозировании временного ряда с информацией об остатках на счетах кли- ентов за предыдущие периоды, применяя методы Data Mining, можно получить прогноз остатка на счетах в определенный момент в будущем. Полученные результаты могут быть использованы для оценки и управления ликвидностью банка.
Задача выявления случаев мошенничества с кредитными карточками. Для выявления подозрительных операций с кредитными карточками применяются так называемые «по- дозрительные стереотипы поведения», определяемые в результате анализа банковских транзакций, которые впоследствии оказались мошенническими. Для определения подо- зрительных случаев используется совокупность последовательных операций на опреде- ленном временном интервале. Если система Data Mining считает очередную операцию подозрительной, банковский работник может, ориентируясь на эту информацию, забло- кировать операции с определенной карточкой.
Страхование. Страховой бизнес связан с определенным риском. Здесь задачи, реша- емые при помощи Data Mining, сходны с задачами в банковском деле. Информация, по- лученная в результате сегментации клиентов на группы, используется для определения групп клиентов. В результате страховая компания может с наибольшей выгодой и наименьшим риском предлагать определенные группы услуг конкретным группам кли- ентов. Задача выявление мошенничества решается путем нахождения некоего общего стереотипа поведения клиентов-мошенников.
Телекоммуникации. В сфере телекоммуникаций достижения Data Mining могут ис- пользоваться для решения задачи, типичной для любой компании, которая работает с целью привлечения постоянных клиентов, – определения лояльности этих клиентов. Необходимость решения таких задач обусловлена жесткой конкуренцией на рынке теле- коммуникаций и постоянной миграцией клиентов от одной компании в другую. Как из- вестно, удержание клиента намного дешевле его возврата, поэтому возникает необходи- мость выявления определенных групп клиентов и разработка наборов услуг, наиболее привлекательных именно для них. В этой сфере, так же, как и во многих других, важной задачей является выявление фактов мошенничества. Помимо таких задач, являющихся типичными для многих областей деятельности, существует группа задач, определяемых спецификой сферы телекоммуникаций.
Электронная коммерция. В сфере электронной коммерции Data Mining применяется для формирования рекомендательных систем и решения задач классификации посетите- лей web-сайтов. Такая классификация позволяет компаниям выявлять определенные группы клиентов и проводить маркетинговую политику в соответствии с обнаруженны- ми интересами и потребностями клиентов. Технология Data Mining для электронной коммерции тесно связана с технологией Web Mining.
Промышленное производство. Особенности промышленного производства и техно- логических процессов создают хорошие предпосылки для возможности использования технологии Data Mining в ходе решения различных производственных задач. Технологи- ческий процесс по своей природе должен быть контролируемым, а все его отклонения находятся в заранее известных пределах, т. е. здесь мы можем говорить об определенной стабильности, которая обычно не присуща большинству задач, встающих перед техно- логией Data Mining.
Основные задачи Data Mining в промышленном производстве:
• комплексный системный анализ производственных ситуаций;
• краткосрочный и долгосрочный прогноз развития производственных ситуаций;
• выработка вариантов оптимизационных решений;
• прогнозирование качества изделия в зависимости от некоторых параметров техно- логического процесса;
• обнаружение скрытых тенденций и закономерностей развития производственных процессов;
• прогнозирование закономерностей развития производственных процессов;
• обнаружение скрытых факторов влияния;
• обнаружение и идентификация ранее неизвестных взаимосвязей между производ- ственными параметрами и факторами влияния;
• анализ среды взаимодействия производственных процессов и прогнозирование из- менения ее характеристик;
• выработка оптимизационных рекомендаций по управлению производственными процессами;
• визуализация результатов анализа, подготовка предварительных отчетов и проектов допустимых решений с оценками достоверности и эффективности возможных реализа- ций.
Маркетинг. В сфере маркетинга Data Mining находит очень широкое применение. Основные вопросы маркетинга «Что продается?», «Как продается?», «Кто является по- требителем?». Широко применяются такие методы анализа для решения задач маркетин- га, как, например, сегментация потребителей. Другой распространенный набор методов для решения задач маркетинга – методы и алгоритмы поиска ассоциативных правил. Также успешно здесь используется поиск временных закономерностей.
Розничная торговля. В сфере розничной торговли, как и в маркетинге, применяются:
• алгоритмы поиска ассоциативных правил (для определения часто встречающихся наборов товаров, которые покупатели покупают одновременно). Выявление таких пра- вил помогает размещать товары на прилавках торговых залов, вырабатывать стратегии закупки товаров и их размещения на складах и т. д.;
• использование временных последовательностей, например для определения необхо- димых объемов запасов товаров на складе;
• методы классификации и кластеризации для определения групп или категорий кли- ентов, знание которых способствует успешному продвижению товаров.
Фондовый рынок. Приведем список задач фондового рынка, которые можно решать при помощи технологии Data Mining:
• прогнозирование будущих значений финансовых инструментов и индикаторов по их прошлым значениям;
• прогноз тренда (будущего направления движения – рост, падение, флэт) финансового инструмента и его силы (сильный, умеренно сильный и т. д.);
• выделение кластерной структуры рынка, отрасли, сектора по некоторому набору ха- рактеристик;
• динамическое управление портфелем;
• прогноз волатильности;
• оценка рисков;
• предсказание наступления кризиса и прогноз его развития;
• выбор активов и др.
Кроме описанных выше сфер деятельности, технология Data Mining может приме- няться в самых разнообразных областях бизнеса, где есть необходимость в анализе дан- ных и накоплен некоторый объем ретроспективной информации.
Применение Data Mining в CRM
Одно из наиболее перспективных направлений применения Data Mining – использова- ние данной технологии в аналитическом CRM.
CRM (Customer Relationship Management) – управление отношениями с клиентами. При совместном использовании этих технологий добыча знаний совмещается с «до-
бычей денег» из данных о клиентах. Важным аспектом в работе отдела маркетинга и от- дела продаж является составление целостного представления о клиентах, информация об их особенностях, характеристиках, структуре клиентской базы. В CRM используется так называемое профилирование клиентов, дающее полное представление всей необходимой информации о них. Профилирование клиентов включает следующие компоненты: сег- ментацию клиентов, прибыльность клиентов, удержание клиентов, анализ реакции кли- ентов. Каждый из этих компонентов может исследоваться при помощи Data Mining, а анализ их в совокупности как компонентов профилирования в результате может дать те знания, которые из каждой отдельной характеристики получить невозможно.
В результате использования Data Mining решается задача сегментации клиентов на ос- нове их прибыльности. Анализ выделяет те сегменты покупателей, которые приносят наибольшую прибыль. Сегментация также может осуществляться на основе лояльности клиентов. В результате сегментации вся клиентская база будет поделена на определен- ные сегменты с общими характеристиками. В соответствии с этими характеристиками компания может индивидуально подбирать маркетинговую политику для каждой группы клиентов.
Также можно использовать технологию Data Mining для прогнозирования реакции определенного сегмента клиентов на определенный вид рекламы или рекламных акций – на основе ретроспективных данных, накопленных в предыдущие периоды.
Таким образом, определяя закономерности поведения клиентов при помощи техноло- гии Data Mining, можно существенно повысить эффективность работы отделов марке- тинга, продаж и сбыта. При объединении технологий CRM и Data Mining и грамотном их внедрении в бизнес компания получает значительные преимущества перед конкурен- тами.
Исследования для правительства
В планах правительства США стоит создание системы, которая позволит отслеживать всех иностранцев, приезжающих в страну. Задача этого комплекса – начиная с погра- ничного терминала, на основе технологии биометрической идентификации личности и различных других баз данных контролировать, насколько реальные планы иностранцев соответствуют заявленным ранее (включая перемещения по стране, сроки отъезда и др.). Предварительная стоимость системы составляет более 10 млрд долларов, разработчик комплекса – компания Accenture. По данным аналитического отчета Главного контроль- ного управления американского Конгресса, правительственные ведомства США участ- вуют приблизительно в двухстах проектах на основе анализа данных (Data Mining), со- бирающих разнообразную информацию о населении. Более ста из этих проектов направ- лены на сбор персональной информации (имена, фамилии, адреса e-mail, номера соцстрахования и удостоверений водительских прав), и на основе этой информации осуществляются предсказания возможного поведения людей. Поскольку в упомянутом отчете не приведена информация о секретных отчетах, надо полагать, что общее число
таких систем значительно больше. Несмотря на пользу, которую приносят системы от- слеживания, эксперты управления, так же, как и независимые эксперты, предупреждают о значительном риске, с которым связаны подобные проекты. Причина опасений – про- блемы, которые могут возникнуть при управлении и надзоре за такими базами.
Data Mining для научных исследований
Биоинформатика. Одна из научных областей применения технологии Data Mining – биоинформатика – направление, целью которого является разработка алгоритмов для анализа и систематизации генетической информации. Полученные алгоритмы исполь- зуются для определения структур макромолекул, а также их функций с целью объясне- ния различных биологических явлений.
Медицина. Несмотря на консервативность медицины во многих ее аспектах техноло- гия Data Mining в последние годы активно применяется для различных исследований и в этой сфере человеческой деятельности. Традиционно для постановки медицинских диа- гнозов используются экспертные системы, которые построены на основе символьных правил, сочетающих, например, симптомы пациента и его заболевание. С использованием Data Mining при помощи шаблонов можно разработать базу знаний для экспертной систе- мы.
Фармацевтика. В области фармацевтики методы Data Mining также имеют достаточ- но широкое применение. Это исследование эффективности клинического применения определенных препаратов, определение групп препаратов, которые будут эффективны для конкретных групп пациентов. Актуальными здесь также являются задачи продвиже- ния лекарственных препаратов на рынок.
Молекулярная генетика и генная инженерия. В молекулярной генетике и генной инже- нерии выделяют отдельное направление Data Mining, которое называют анализом данных в микромассивах (Microarray Data Analysis, MDA).
Некоторые области применения этого направления:
• ранняя и более точная диагностика;
• новые молекулярные цели для терапии;
• улучшенные и индивидуально подобранные виды лечения;
• фундаментальные биологические открытия.
Примеры использования Data Mining – молекулярный диагноз некоторых серьезней- ших заболеваний; открытие того, что генетический код действительно может предска- зывать вероятность заболевания; открытие некоторых новых лекарств и препаратов.
Основные понятия, которыми оперирует Data Mining в областях молекулярной гене- тики и генной инженерии, – маркеры, т. е. генетические коды, которые контролируют различные признаки живого организма. На финансирование проектов с использованием Data Mining в рассматриваемых сферах выделяют значительные финансовые средства.
Химия. Технология Data Mining активно используется в исследованиях органической и неорганической химии. Одно из возможных применений Data Mining в этой сфере – вы- явление каких-либо специфических особенностей строения соединений, которые могут включать тысячи элементов.
Web Mining. Web Mining можно перевести как «добыча данных в Web». Web Intelligence, или web-интеллект, готов «открыть новую главу» в стремительном развитии электронного бизнеса. Способность определять интересы и предпочтения каждого посе- тителя, наблюдая за его поведением, является серьезным и критичным преимуществом
конкурентной борьбы на рынке электронной коммерции. Системы Web Mining могут от- ветить на многие вопросы, например, кто из посетителей является потенциальным кли- ентом web-магазина, какая группа клиентов web-магазина приносит наибольший доход, каковы интересы определенного посетителя или группы посетителей.
Технология Web Mining охватывает методы, которые способны на основе данных сай- та обнаружить новые ранее неизвестные знания и которые в дальнейшем можно будет использовать на практике. Другими словами, технология Web Mining применяет техно- логию Data Mining для анализа неструктурированной, неоднородной, распределенной и значительной по объему информации, содержащейся на web-узлах.
Можно выделить два основных направления: Web Content Mining и Web Usage Mining. Web Content Mining подразумевает автоматический поиск и извлечение качественной информации из разнообразных источников Интернета, перегруженных «информацион- ным шумом». Здесь также идет речь о различных средствах кластеризации и аннотиро-
вании документов.
Второе направление – Web Usage Mining – подразумевает обнаружение закономерно- стей в действиях пользователя web-узла или их группы.
Анализируется следующая информация:
• какие страницы просматривал пользователь;
• какова последовательность просмотра страниц.
Анализируется также, какие группы пользователей можно выделить среди общего их числа на основе истории просмотра web-узла.
Web Usage Mining включает следующие составляющие:
• предварительная обработка;
• операционная идентификация;
• инструменты обнаружения шаблонов;
• инструменты анализа шаблонов.
При использовании Web Mining перед разработчиками возника.т два типа задач. Пер- вый касается сбора данных, второй – использования методов персонификации. В резуль- тате сбора некоторого объема персонифицированных ретроспективных данных о кон- кретном клиенте система накапливает определенные знания о нем и может рекомендо- вать ему, например, определенные наборы товаров или услуг. На основе информации о всех посетителях сайта web-система может выявить определенные группы посетителей и также рекомендовать им товары или же предлагать товары в рассылках.
Задачи Web Mining можно подразделить на такие категории:
• предварительная обработка данных для Web Mining;
• обнаружение шаблонов и открытие знаний с использованием ассоциативных пра- вил, временных последовательностей, классификации и кластеризации;
• анализ полученного знания.
Text Mining. Text Mining охватывает новые методы для выполнения семантического анализа текстов, информационного поиска и управления. Синонимом понятия Text Mining является KDT (Knowledge Discovering in Text – поиск или обнаружение знаний в тексте).
В отличие от технологии Data Mining, которая предусматривает анализ упорядочен- ной в некие структуры информации, технология Text Mining анализирует большие и сверхбольшие массивы неструктурированной информации. Программы, реализующие
эту задачу, должны некоторым образом оперировать естественным человеческим языком и при этом понимать семантику анализируемого текста. Один из методов, на котором основаны некоторые Text Mining-системы, – поиск так называемой подстроки в строке.
Call Mining. «Добыча звонков» может стать популярным инструментом корпоратив-
ных информационных систем. Технология Call Mining объединяет распознавание речи, ее анализ и Data Mining. Ее цель – упрощение поиска в аудиоархивах, содержащих запи- си переговоров между операторами и клиентами. При помощи этой технологии операто- ры могут обнаруживать недостатки в системе обслуживания клиентов, находить воз- можности увеличения продаж, а также выявлять тенденции в обращениях клиентов. Среди разработчиков новой технологии Call Mining (добыча и анализ звонков) – компа- нии CallMiner, Nexidia, ScanSoft, Witness Systems. В технологии Call Mining разработаны два подхода: на основе преобразования речи в текст и на базе фонетического анализа.
Примером реализации первого подхода, основанного на преобразовании речи, являет- ся система Call Miner. В процессе Call Mining сначала используется система преобразо- вания речи, затем следует ее анализ, в ходе которого в зависимости от содержания раз- говоров формируется статистика телефонных вызовов. Полученная информация хранит- ся в базе данных, в которой возможны поиск, извлечение и обработка.
Пример реализации второго подхода – фонетического анализа – продукция компании Nexidia. При этом подходе речь разбивается на фонемы, являющиеся звуками или их со- четаниями. Такие элементы образуют распознаваемые фрагменты. При поиске опреде- ленных слов и их сочетаний система идентифицирует их с фонемами. Аналитики отме- чают, что за последние годы интерес к системам на основе Call Mining значительно воз- рос. Это объясняется тем фактом, что менеджеры высшего звена компаний, работающих в различных сферах, в т. ч. в области финансов, мобильной связи, авиабизнеса, не хотят тратить много времени на прослушивание звонков с целью обобщения информации или же выявления каких-либо фактов нарушений. Использование этих технологий повышает оперативность и снижает стоимость обработки информации.
Тема 5 ЗАДАЧИ DATA MINING
5.1. ВИДЫ ЗАДАЧ DATA MINING
Напомним, что в основу технологии Data Mining положена концепция шаблонов, представляющих собой закономерности. В результате обнаружения этих скрытых от не- вооруженного глаза закономерностей решаются задачи Data Mining. Различным типам закономерностей, которые могут быть выражены в форме, понятной человеку, соответ- ствуют определенные задачи Data Mining.
Задачи (tasks) Data Mining называют закономерностями (regularity) или техниками
(techniques).
Единого мнения относительно того, какие задачи следует относить к Data Mining, нет. Большинство авторитетных источников перечисляют следующие: классификация, кла- стеризация, прогнозирование, ассоциация, визуализация, анализ и обнаружение откло- нений, оценивание, анализ связей, подведение итогов. Наиболее распространенные зада- чи Data Mining – классификация, кластеризация, ассоциация, прогнозирование.
Классификация (Classification) – наиболее простая и распространенная задача Data Mining. В результате решения задачи классификации обнаруживаются признаки, кото- рые характеризуют группы объектов исследуемого набора данных – классы; по этим признакам новый объект можно отнести к тому или иному классу.
Для решения задачи классификации могут использоваться методы: ближайшего сосе- да (Nearest Neighbor), k-ближайшего соседа (k-Nearest Neighbor), байесовские сети (Bayesian Networks), индукция деревьев решений, нейронные сети (neural networks).
Кластеризация (Clustering) является логическим продолжением идеи классификации. Это задача более сложная; особенность кластеризации заключается в том, что классы объектов изначально не предопределены. Результатом кластеризации является разбиение объектов на группы.
Пример метода решения задачи кластеризации: обучение «без учителя» особого вида нейронных сетей – самоорганизующихся карт Кохонена.
Ассоциация (Associations). В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности между связанными событиями в наборе данных.
Отличие ассоциации от двух предыдущих задач Data Mining: поиск закономерностей
осуществляется не на основе свойств анализируемого объекта, а между несколькими со- бытиями, которые происходят одновременно. Наиболее известный алгоритм решения задачи поиска ассоциативных правил – алгоритм Apriori.
Последовательность (Sequence), или последовательная ассоциация (sequential
association), позволяет найти временные закономерности между транзакциями. Задача последовательности подобна ассоциации, но ее целью является установление законо- мерностей не между одновременно наступающими событиями, а между событиями, свя- занными во времени (т. е. происходящими с некоторым определенным интервалом во времени). Другими словами, последовательность определяется высокой вероятностью цепочки связанных во времени событий. Фактически ассоциация является частным слу- чаем последовательности с временным лагом, равным нулю. Эту задачу Data Mining также называют задачей нахождения последовательных шаблонов (sequential pattern). Правило последовательности: после события X через определенное время произойдет событие Y.
Пример. После покупки квартиры жильцы в 60 % случаев в течение двух недель при- обретают холодильник, а в течение двух месяцев в 50 % случаев приобретается телеви- зор. Решение данной задачи широко применяется в маркетинге и менеджменте, напри- мер при управлении циклом работы с клиентом (Customer Lifecycle Management).
Прогнозирование (Forecasting). В результате решения задачи прогнозирования на ос- нове особенностей исторических данных оцениваются пропущенные или же будущие значения целевых численных показателей. Для решения таких задач широко применя- ются методы математической статистики, нейронные сети и др.
Определение отклонений, или выбросов (Deviation Detection), анализ отклонений, или выбросов. Цель решения данной задачи – обнаружение и анализ данных, наиболее отли- чающихся от общего множества данных, выявление так называемых нехарактерных шаблонов.
Оценивание (Estimation) сводится к предсказанию непрерывных значений признака.
Анализ связей (Link Analysis) – задача нахождения зависимостей в наборе данных.
Визуализация (Visualization, Graph Mining). В результате визуализации создается гра- фический образ анализируемых данных. Для решения задачи визуализации используют- ся графические методы, показывающие наличие закономерностей в данных. Пример ме- тодов визуализации – представление данных в 2-D и 3-D измерениях.
Подведение итогов (Summarization) – задача, цель которой – описание конкретных групп объектов из анализируемого набора данных.
5.2. КЛАССИФИКАЦИЯ ЗАДАЧ DATA MINING
Согласно классификации по стратегиям задачи Data Mining подразделяются на следу- ющие группы:
• обучение с учителем;
• обучение без учителя;
• другие.
Категория «обучение с учителем» представлена следующими задачами Data Mining: классификация, оценка, прогнозирование.
Категория «обучение без учителя» представлена задачей кластеризации.
Задачи Data Mining в зависимости от используемых моделей могут быть дескриптив- ными и прогнозирующими. В соответствии с этой классификацией задачи Data Mining представлены группами описательных и прогнозирующих задач.
В результате решения описательных (descriptive) задач аналитик получает шаблоны, описывающие данные, которые поддаются интерпретации. Эти задачи описывают об- щую концепцию анализируемых данных, определяют информативные, итоговые, отли- чительные особенности данных. Концепция описательных задач подразумевает характе- ристику и сравнение наборов данных. Характеристика набора данных обеспечивает краткое и сжатое описание некоторого набора данных.
Сравнение обеспечивает сравнительное описание двух или более наборов данных.
Прогнозирующие (predictive) задачи основываются на анализе данных, создании моде- ли, предсказании тенденций или свойств новых или неизвестных данных.
Достаточно близким к данной классификации является подразделение задач Data Mining на следующие: исследования и открытия, прогнозирования и классификации, объяснения и описания.
Автоматическое исследование и открытие (свободный поиск). Пример задачи: обна- ружение новых сегментов рынка. Для решения данного класса задач используются мето- ды кластерного анализа.
Прогнозирование и классификация. Пример задачи: предсказание роста объемов про- даж на основе текущих значений. Методы: регрессия, нейронные сети, генетические ал- горитмы, деревья решений. Задачи классификации и прогнозирования составляют груп- пу так называемого индуктивного моделирования, в результате которого обеспечивается изучение анализируемого объекта или системы. В процессе решения этих задач на осно- ве набора данных разрабатывается общая модель или гипотеза.
Объяснение и описание. Пример задачи: характеристика клиентов по демографиче- ским данным и историям покупок. Методы: деревья решения, системы правил, правила ассоциации, анализ связей. Если доход клиента больше, чем 50 условных единиц, и его возраст более 30 лет, тогда класс клиента – первый. В интерпретации обобщенной моде-
ли аналитик получает новое знание. Группировка объектов происходит на основе их сходства.
5.3. СВЯЗЬ ПОНЯТИЙ «ДАННЫЕ», «ИНФОРМАЦИЯ», «ЗНАНИЯ», «РЕШЕНИЯ»
Главная ценность Data Mining – это практическая направленность данной технологии, путь от сырых данных к конкретному знанию, от постановки задачи к готовому прило- жению, при поддержке которого можно принимать решения. Многочисленность поня- тий, которые объединились в Data Mining, а также разнообразие методов, поддержива- ющих данную технологию, начинающему аналитику могут напомнить мозаику, части которой мало связаны между собой.
Как же мы можем связать в одно целое задачи, методы, действия, закономерности, приложения, данные, информацию, решения?
Рассмотрим два потока:
1) данные – информация – знания и решения;
2) задачи – действия и методы решения – приложения.
Эти потоки являются отображением одного процесса, результатом которого должно быть знание и принятие решения.
Принятие решений требует информации, которая основана на данных. Данные обес- печивают информацию, которая поддерживает решения, и т. д.
Рассмотренные понятия являются составной частью так называемой информационной пирамиды, в основании которой находятся данные; следующий уровень – это информа- ция; затем идет решение; завершает пирамиду уровень знания. По мере продвижения вверх по информационной пирамиде объемы данных переходят в ценность решений, т. е. ценность для бизнеса. А, как известно, целью Business Intelligence является преобра- зование объемов данных в ценность бизнеса.
Следует отметить, что уровни анализа (данные, информация, знания) практически со-
ответствуют этапам эволюции анализа данных, которая происходила на протяжении по- следних лет.
Верхний уровень – приложений – является уровнем бизнеса (если мы имеем дело с за- дачей бизнеса), на нем менеджеры принимают решения. Примеры приложений: пере- крестные продажи, контроль качества, удерживание клиентов.
Средний уровень – действий – по своей сути является уровнем информации, именно на нем выполняются действия Data Mining. На рисунке приведены такие действия: про- гностическое моделирование (было рассмотрено ранее), анализ связей, сегментация дан- ных и другие.
Нижний уровень – определения задачи Data Mining, которую необходимо решить применительно к данным, имеющимся в наличии. На рисунке приведены задачи пред- сказания числовых значений, классификация, кластеризация, ассоциация.
Рассмотрим задачу удержания клиентов (определения надежности клиентов фирмы).
Первый уровень: данные – база данных по клиентам. Есть данные о клиенте (возраст, пол, профессия, доход). Определенная часть клиентов, воспользовавшись продуктом фирмы, осталась ей верна; другие клиенты больше не приобретали продукты фирмы. На этом уровне мы определяем тип задачи – это задача классификации.
На втором уровне определяем действие – прогностическое моделирование. С помо- щью прогностического моделирования мы с определенной долей уверенности можем отнести новый объект, в данном случае, – нового клиента, к одному из известных клас- сов: постоянный клиент, или это, скорее всего, его разовая покупка.
На третьем уровне мы можем воспользоваться приложением для принятия решения.
В результате приобретения знаний фирма может существенно снизить расходы, напри- мер, на рекламу, зная заранее, каким из клиентов следует активно рассылать рекламные материалы.
Информация в аспекте Data Mining
Для бизнеса информация является исходной составляющей принятия решений. Рас- смотрим понятие информации в аспекте Data Mining. Несмотря на распространенность данного понятия мы не всегда можем точно его определить и отличить от понятия дан- ных. Информация по своей сути имеет многогранную природу. С развитием человечества, в том числе с развитием компьютерных технологий, информация обретает все новые и но- вые свойства.
Информация – любые не известные ранее сведения о каком-либо событии, сущности, процессе и т. п., являющиеся объектом некоторых операций, для которых существует содержательная интерпретация. Под операциями здесь подразумеваются восприятие, передача, преобразование, хранение и использование. Для восприятия информации необходима некоторая воспринимающая система, которая может интерпретировать ее, преобразовывать, определять соответствие определенным правилам и т. п. Таким обра- зом, понятие информации следует рассматривать только при наличии источника и полу- чателя информации, а также канала связи между ними.
Свойства информации:
• полнота информации. Это свойство характеризует качество информации и опреде- ляет достаточность данных для принятия решений, т. е. информация должна содержать весь необходимый набор данных. Например, «Продажи товара А начнут сокращаться» – эта информация неполная, поскольку неизвестно, когда именно они начнут сокращаться. Пример полной информации. «Начиная с первого квартала, продажи товара А начнут со- кращаться». Этой информации достаточно для принятия решений;
• достоверность информации. Информация может быть достоверной и недостовер-
ной. В недостоверной информации присутствует информационный шум, и чем он выше, тем ниже достоверность информации;
• ценность информации. Ценность информации не может быть абстрактной. Инфор- мация должна быть полезной и ценной для определенной категории пользователей;
• адекватность информации. Это свойство характеризует степень соответствия ин- формации реальному объективному состоянию. Адекватная информация – это полная и достоверная информация;
• актуальность информации. Информация должна быть актуальной, т. е. не устарев- шей. Это свойство информации характеризует степень соответствия информации насто- ящему моменту времени;
• ясность информации. Информация должна быть понятна тому кругу лиц, для кото- рого она предназначена;
• доступность информации. Доступность характеризует меру возможности получить определенную информацию. На это свойство информации влияют одновременно доступ- ность данных и доступность адекватных методов;
• субъективность информации. Информация носит субъективный характер, она опре- деляется степенью восприятия субъекта (получателя информации).
Требования, предъявляемые к информации в Data Mining:
• динамический характер информации. Информация существует только в момент вза- имодействия данных и методов, т. е. в момент информационного процесса. Остальное время она пребывает в состоянии данных;
• адекватность используемых методов. Информация извлекается из данных. Однако в результате использования одних и тех же данных может появляться разная информа- ция. Это зависит от адекватности выбранных методов обработки исходных данных.
Данные по своей сути являются объективными. Методы являются субъективными, в основе методов лежат алгоритмы, субъективно составленные и подготовленные. Таким образом, информация возникает и существует в момент диалектического взаимодей- ствия объективных данных и субъективных методов.
Всю информацию, возникающую в процессе функционирования бизнеса и управления им, можно классифицировать определенным образом. В зависимости от источника по- лучения информацию разделяют на внутреннюю и внешнюю (например, информация, описывающая явления, происходящие за пределами фирмы, но имеющие к ней непо- средственное отношение).
Также информация может быть классифицирована на фактическую и прогнозную. К фактической информации о бизнесе относится информация, характеризующая свер- шившиеся факты; она является точной. Прогнозная информация является рассчитывае- мой или предполагаемой, поэтому ее нельзя считать точной, она может иметь опреде- ленную погрешность.
Информация и знания
Знания – совокупность фактов, закономерностей и эвристических правил, с помощью которых решается поставленная задача.
Все чаще истинные знания образуются на основе распределенных взаимосвязей раз- нородной информации. Когда информация собрана и передана для получения явно не определенного заранее результата, то вы получаете знания. Сама по себе информация в чистом виде бессмысленна. Отсюда следует вывод, что информация – это чье-то такти- ческое знание, передаваемое в виде символов и при помощи каких-либо прикладных средств.
Знания – это абсолютное использование информации и данных совместно с потенциа- лом практического опыта людей, способностями, идеями, интуицией, убежденностью и мотивациями.
Знания имеют определенные свойства, которые отличают их от информации.
1. Структурированность. Знания должны быть «разложены по полочкам».
2. Удобство доступа и усвоения. Для человека это – способность быстро понять и за- помнить или, наоборот, вспомнить; для компьютерных знаний – средства доступа к зна- ниям.
3. Лаконичность. Лаконичность позволяет быстро осваивать и перерабатывать знания
и повышает «коэффициент полезного содержания». В данный список лаконичность была
добавлена из-за всем известной проблемы шума и мусорных документов, характерной именно для компьютерной информации Интернета и электронного документооборота.
4. Непротиворечивость. Знания не должны противоречить друг другу.
5. Процедуры обработки. Знания нужны для того, чтобы их использовать. Одно из главных свойств знаний – возможность их передачи другим и способность делать выво- ды на их основе. Для этого должны существовать процедуры обработки знаний. Способ- ность делать выводы означает для машины наличие процедур обработки и вывода и под- готовленность структур данных для такой обработки, т. е. наличие специальных форма- тов знаний.
Сопоставим и сравним понятия «информация», «данные», «знание». Для того чтобы уверенно оперировать этими понятиями, необходимо не только понимать суть этих по- нятий, но и видеть отличия между ними. Сложность понимания отличий – в их кажу- щейся синонимичности. Вспомним, что понятие Data Mining переводится на русский язык при помощи этих же трех понятий: как добыча данных, извлечение информации, раскопка знаний.
Для того чтобы прочувствовать разницу, рассмотрим применение этих трех понятий
на простом примере. Для начала сделаем попытку разобраться в этих терминах на про- стых примерах:
• студент, который сдает экзамен, нуждается в данных;
• студент, который сдает экзамен, нуждается в информации;
• студент, который сдает экзамен, нуждается в знаниях.
При рассмотрении первого варианта – студент нуждается в данных – возникает мысль, что студенту нужны данные, например для вычислений. Информацией во втором вари- анте может выступать конспект или учебник. В результате их использования студент по- лучает лишь информацию, которая в определенных случаях может перейти в знания. Третий вариант звучит наиболее логично.
Информация, в отличие от данных, имеет смысл. Понятия «информация» и «знания» являются понятиями более высокого уровня, чем «данные», которое возникло относи- тельно недавно. Понятие информации непосредственно связано с сущностью процессов внутри информационной системы, тогда так понятие «знание» скорее ориентировано на качество процессов. Понятие «знание» тесно связано с процессом принятия решений.
Несмотря на различия рассмотренные понятия не являются разрозненными и несвя- занными. Они есть часть одного потока: у истока его находятся данные, в процессе пе- редачи которых возникает информация, и в результате использования информации, при определенных условиях, возникают знания.
В процессе движения вверх по информационной пирамиде объемы данных переходят в ценность знаний. Однако большие объемы данных вовсе не означают и, тем более, не гарантируют получение знаний. Существует определенная зависимость ценности полу- ченных знаний от качества и мощности процедур обработки данных. Типичным приме- ром информации, которую нельзя превратить в знание, является текст на иностранном языке. При отсутствии словаря и переводчика эта информация вообще не имеет ценно- сти, она не может перейти в знание. При наличии словаря процесс перехода от инфор- мации к знанию возможен, но длителен и трудоемок. При наличии переводчика инфор- мация действительно переходит в знания.
Таким образом, для получения ценных знаний необходимы качественные процедуры обработки. Процесс перехода от данных к знаниям занимает много времени и стоит до- рого. Поэтому очевидно, что технология Data Mining с ее мощными и разнообразными алгоритмами является инструментом, при помощи которого, продвигаясь вверх по ин- формационной пирамиде, мы можем получать действительно качественные и ценные знания.
5.4. ЗАДАЧА КЛАССИФИКАЦИИ В DATA MINING
Классификация является наиболее простой и одновременно наиболее часто решаемой задачей Data Mining. Ввиду распространенности задач классификации необходимо чет- кое понимание сути этого понятия.
Классификация – системное распределение изучаемых предметов, явлений, процессов по родам, видам, типам по каким-либо существенным признакам для удобства их иссле- дования; группировка исходных понятий и расположение их в определенном порядке, отражающем степень этого сходства.
Классификация – упорядоченное по некоторому принципу множество объектов, кото- рые имеют сходные классификационные признаки (одно или несколько свойств), вы- бранные для определения сходства или различия между этими объектами.
Классификация требует соблюдения следующих правил:
• в каждом акте деления необходимо применять только одно основание;
• деление должно быть соразмерным, т. е. общий объем видовых понятий должен равняться объему делимого родового понятия;
• члены деления должны взаимно исключать друг друга, их объемы не должны пере- крещиваться;
• деление должно быть последовательным. Различают:
• вспомогательную (искусственную) классификацию, которая производится по внешнему признаку и служит для придания множеству предметов (процессов, явлений) нужного порядка;
• естественную классификацию, которая производится по существенным признакам, характеризующим внутреннюю общность предметов и явлений. Она является результа- том и важным средством научного исследования, т. к. предполагает и закрепляет резуль- таты изучения закономерностей классифицируемых объектов.
В зависимости от выбранных признаков, их сочетания и процедуры деления понятий классификация может быть:
простой – деление родового понятия только по признаку и только один раз до рас- крытия всех видов. Примером такой классификации является дихотомия, при которой членами деления бывают только два понятия, каждое из которых является противореча- щим другому (т. е. соблюдается принцип «А и не А»);
сложной – применяется для деления одного понятия по разным основаниям и синтеза этих простых делений в единое целое. Примером такой классификации является перио- дическая система химических элементов.
Под классификацией будем понимать отнесение объектов (наблюдений, событий) к одному из заранее известных классов.
Классификация – это закономерность, позволяющая делать вывод относительно опре- деления характеристик конкретной группы. Таким образом, для проведения классифи- кации должны присутствовать признаки, характеризующие группу, к которой принадле- жит то или иное событие или объект (обычно при этом на основании анализа уже клас- сифицированных событий формулируются некие правила).
Классификация относится к стратегии обучения с учителем (supervised learning), кото- рую также именуют контролируемым или управляемым обучением.
Задачей классификации часто называют предсказание категориальной зависимой пе- ременной (т. е. зависимой переменной, являющейся категорией) на основе выборки не- прерывных и (или) категориальных переменных. Например, можно предсказать, кто из клиентов фирмы является потенциальным покупателем определенного товара, а кто – нет, кто воспользуется услугой фирмы, а кто – нет, и т. д. Этот тип задач относится к за- дачам бинарной классификации, в них зависимая переменная может принимать только два значения (например, да или нет, 0 или 1).
Другой вариант классификации возникает, если зависимая переменная может прини- мать значения из некоторого множества предопределенных классов. Например, когда необходимо предсказать, какую марку автомобиля захочет купить клиент. В этих случа- ях рассматривается множество классов для зависимой переменной.
Классификация может быть одномерной (по одному признаку) и многомерной (по двум и более признакам).
Многомерная классификация была разработана биологами при решении проблем дис- криминации для классифицирования организмов, в которой организмы разделялись на подвиды в зависимости от результатов измерений их физических параметров. Биология была и остается наиболее востребованной и удобной средой для разработки многомер- ных методов классификации.
Рассмотрим задачу классификации на простом примере. Допустим, имеется база дан- ных о клиентах туристического агентства с информацией о возрасте и доходе за месяц. Есть рекламный материал двух видов: более дорогой и комфортный отдых и более де- шевый, молодежный отдых. Соответственно, определены два класса клиентов: класс 1 и класс 2. База данных приведена в таблице 1.
База данных клиентов туристического агентства
Таблица 1
Код
клиента
Возраст
Доход
Класс
1
18
25
1
2
22
100
1
3
30
70
1
4
32
120
1
5
24
15
2
6
25
22
1
7
32
50
2
8
19
445
2
9
22
75
1
10
40
90
2
Задача. Определить, к какому классу принадлежит новый клиент и какой из двух ви- дов рекламных материалов ему стоит отсылать. Для наглядности представим нашу базу данных в двумерном измерении (возраст и доход), в виде множества объектов, принад- лежащих классам 1 и 2. На рис. 11 приведены объекты из двух классов.
1 класс
2 класс
Рис. 11. Множество объектов базы данных в двумерном измерении
Решение нашей задачи будет состоять в том, чтобы определить, к какому классу отно- сится новый клиент, на рисунке обозначенный белой меткой.
Процесс классификации
Цель процесса классификации состоит в том, чтобы построить модель, которая ис- пользует прогнозирующие атрибуты в качестве входных параметров и получает значе- ние зависимого атрибута. Процесс классификации заключается в разбиении множества объектов на классы по определенному критерию.
Классификатором называется некая сущность, определяющая, какому из предопреде- ленных классов принадлежит объект по вектору признаков.
Для проведения классификации с помощью математических методов необходимо иметь формальное описание объекта, которым можно оперировать, используя математи- ческий аппарат классификации. Таким описанием в нашем случае выступает база дан- ных. Каждый объект (запись базы данных) несет информацию о некотором свойстве объекта.
Набор исходных данных (или выборку данных) разбивают на два множества: обуча- ющее и тестовое.
Обучающее множество (training set) – множество, которое включает данные, исполь-
зующиеся для обучения (конструирования) модели. Такое множество содержит входные и выходные (целевые) значения примеров. Выходные значения предназначены для обу- чения модели.
Тестовое множество (test set) также содержит входные и выходные значения приме- ров. Здесь выходные значения используются для проверки работоспособности модели.
Процесс классификации состоит из двух этапов: конструирования модели и ее исполь- зования.
Конструирование модели – описание множества предопределенных классов. Каждый пример набора данных относится к одному предопределенному классу. На этом этапе используется обучающее множество, на нем происходит конструирование модели. По- лученная модель представлена классификационными правилами, деревом решений или математической формулой
Использование модели – классификация новых или неизвестных значений. Оценка правильности (точности) модели: известные значения из тестового примера сравнивают- ся с результатами использования полученной модели. Уровень точности – процент пра- вильно классифицированных примеров в тестовом множестве. Тестовое множество, т. е. множество, на котором тестируется построенная модель, не должно зависеть от обуча- ющего множества. Если точность модели допустима, возможно использование модели для классификации новых примеров, класс которых неизвестен.
Методы, применяемые для решения задач классификации
Для классификации используются различные методы. Основные из них:
• классификация с помощью деревьев решений;
• байесовская (наивная) классификация;
• классификация при помощи искусственных нейронных сетей;
• классификация методом опорных векторов;
• статистические методы, в частности линейная регрессия;
• классификация при помощи метода ближайшего соседа;
• классификация CBR-методом;
• классификация при помощи генетических алгоритмов.
На рис. 12, 13 схематично приведены примеры решения задач методом линейной ре- грессии, методом деревьев решений, методом нейронных сетей.
Рис. 12. Решение задач классификации методом деревьев решений
Рис. 13. Решение задач классификации методом нейронных сетей
Точность классификации: оценка уровня ошибок
Оценка точности классификации может проводиться при помощи кросс-проверки. Кросс-проверка (Cross-validation) – это процедура оценки точности классификации на данных из тестового множества, которое также называют кросс-проверочным множе-
ством. Точность классификации тестового множества сравнивается с точностью класси- фикации обучающего множества. Если классификация тестового множества дает при- близительно такие же результаты по точности, как и классификация обучающего множе- ства, считается, что данная модель прошла кросс-проверку.
Разделение на обучающее и тестовое множества осуществляется путем деления вы- борки в определенной пропорции: например, обучающее множество – две трети данных, тестовое – одна треть данных. Этот способ следует использовать для выборок с большим количеством примеров. Если же выборка имеет малые объемы, рекомендуется приме- нять специальные методы, при использовании которых обучающая и тестовая выборки могут частично пересекаться.
Оценивание классификационных методов
Оценивание методов следует проводить исходя из следующих характеристик: ско- рость, робастность, интерпретируемость, надежность.
Скорость характеризует время, которое требуется на создание модели и ее использо- вание.
Робастность, т. е. устойчивость к каким-либо нарушениям исходных предпосылок,
означает возможность работы с зашумленными данными и пропущенными значениями в данных.
Интерпретируемость обеспечивает возможность понимания модели аналитиком. Свойства классификационных правил:
• размер дерева решений;
• компактность классификационных правил.
Надежность методов классификации предусматривает возможность работы этих ме- тодов при наличии в наборе данных шумов и выбросов.
5.5. ЗАДАЧА КЛАСТЕРИЗАЦИИ DATA MINING
Задача кластеризации сходна с задачей классификации, является ее логическим про- должением, но ее отличие в том, что классы изучаемого набора данных заранее не пред- определены. Синонимами термина «кластеризация» являются «автоматическая классифи- кация», «обучение без учителя» и «таксономия».
Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры, или классы). Если данные выборки представить как точки в призна- ковом пространстве, то задача кластеризации сводится к определению «сгущений то- чек». Цель кластеризации – поиск существующих структур. Кластеризация является описательной процедурой, она не делает никаких статистических выводов, но дает воз- можность провести разведочный анализ и изучить «структуру данных».
Само понятие «кластер» определено неоднозначно: в каждом исследовании свои кла- стеры. Переводится понятие «кластер» (cluster) как «скопление», «гроздь». Кластер можно охарактеризовать как группу объектов, имеющих общие свойства. Характеристи- ками кластера можно назвать два признака:
• внутреннюю однородность;
• внешнюю изолированность.
Вопрос, задаваемый аналитиками при решении многих задач, состоит в том, как органи- зовать данные в наглядные структуры, т. е. развернуть таксономии.
Наибольшее применение кластеризация первоначально получила в таких науках как биология, антропология, психология. Для решения экономических задач кластеризация длительное время мало использовалась из-за специфики экономических данных и явле- ний. В таблице 2 приведено сравнение некоторых параметров задач классификации и кластеризации.
Сравнение классификации и кластеризации
Таблица 2
Характеристика
Классификация
Кластеризация
Контролируе-
мость обучения
Контролируемое обучение
Неконтролируемое обу-
чение
Стратегия
Обучение с учителем
Обучение без учителя
Наличие
метки класса
Обучающее множество сопровождается
меткой, указывающей класс, к которому относится наблюдение
Метки класса обучающе-
го множества неизвестны
Основание
для классифика- ции
Новые данные классифицируются на
основании обучающего множества
Дано множество данных с
целью установления суще- ствования классов или кла- стеров данных
На рис. 14 схематически представлены задачи классификации и кластеризации.
Классификация: классы определены изначально
Кластеризация: классы не предопределены, осуществ- ляется поиск наиболее по- хожих однородных групп
Рис. 14. Сравнение задач классификации и кластеризации
Кластеры могут быть непересекающимися, или эксклюзивными (non-overlapping, exclusive), и пересекающимися (overlapping). Схематическое изображение непересекаю- щихся и пересекающихся кластеров дано на рис. 15.
Рис. 15. Непересекающиеся и пересекающиеся кластеры
Следует отметить, что в результате применения различных методов кластерного ана- лиза могут быть получены кластеры различной формы. Например, возможны кластеры
«цепочного» типа, когда они представлены длинными «цепочками» – кластеры удли- ненной формы, и т. д., а некоторые методы могут создавать кластеры произвольной формы.
Различные методы могут стремиться создавать кластеры определенных размеров (например, малых или крупных) либо предполагать в наборе данных наличие кластеров различного размера. Некоторые методы кластерного анализа особенно чувствительны к шумам или выбросам, другие – менее.
В результате применения различных методов кластеризации могут быть получены не- одинаковые результаты, это нормально и является особенностью работы того или иного алгоритма. Данные особенности следует учитывать при выборе метода кластеризации. На сегодняшний день разработано более сотни различных алгоритмов кластеризации.
Рассмотрим краткую характеристику подходов к кластеризации:
• алгоритмы, основанные на разделении данных (Partitioning algorithms), в т. ч. итера- тивные: разделение объектов на k кластеров; итеративное перераспределение объектов для улучшения кластеризации;
• иерархические алгоритмы (Hierarchy algorithms), в т. ч. агломерация – каждый объ- ект первоначально является кластером, кластеры, соединяясь друг с другом, формируют больший кластер и т. д.;
• методы, основанные на концентрации объектов (Density-based methods), т. е. на воз- можности соединения объектов; игнорируют шумы, нахождение кластеров произволь- ной формы;
• грид-методы (Grid-based methods) – квантование объектов в грид-структуры;
• модельные методы (Model-based) –использование модели для нахождения класте- ров, наиболее соответствующих данным.
Оценка качества кластеризации
Оценка качества кластеризации может быть проведена на основе следующих проце- дур:
• ручная проверка;
• установление контрольных точек и проверка на полученных кластерах;
• определение стабильности кластеризации путем добавления в модель новых пере- менных;
• создание и сравнение кластеров с использованием различных методов.
Разные методы кластеризации могут создавать разные кластеры, и это является нор- мальным явлением. Однако создание схожих кластеров различными методами также указывает на правильность кластеризации.
Процесс кластеризации
Процесс кластеризации зависит от выбранного метода и почти всегда является итера- тивным. Он может стать увлекательным процессом и включать множество эксперимен- тов по выбору разнообразных параметров, например меры расстояния, типа стандарти- зации переменных, количества кластеров и т. д. Однако эксперименты не должны быть самоцелью, ведь конечной целью кластеризации является получение содержательных сведений о структуре исследуемых данных. Полученные результаты требуют дальней- шей интерпретации, исследования и изучения свойств и характеристик объектов для возможности точного описания сформированных кластеров.
Применение кластерного анализа
Кластерный анализ применяется в различных областях. Он полезен, когда нужно классифицировать большое количество информации. Так, в медицине используется кла- стеризация заболеваний, лечения заболеваний или их симптомов, а также таксономия пациентов, препаратов и т. д. В археологии устанавливаются таксономии каменных со- оружений и древних объектов и т. д. В маркетинге это может быть задача сегментации конкурентов и потребителей. В менеджменте примером задачи кластеризации будет раз- биение персонала на различные группы, классификация потребителей и поставщиков, выявление схожих производственных ситуаций, при которых возникает брак. В социо- логии задача кластеризации – разбиение респондентов на однородные группы.
Кластерный анализ в маркетинговых исследованиях
В маркетинговых исследованиях кластерный анализ применяется достаточно широко как в теоретических исследованиях, так и практикующими маркетологами, решающими проблемы группировки различных объектов. При этом решаются вопросы о группах клиентов, продуктов и т. д.
Так, одной из наиболее важных задач при применении кластерного анализа в марке- тинговых исследованиях является анализ поведения потребителя, а именно: группировка потребителей в однородные классы для получения максимально полного представления о поведении клиента из каждой группы и о факторах, влияющих на его поведение. Важ- ной задачей, которую может решить кластерный анализ, является позиционирование, т. е. определение ниши, в которой следует позиционировать новый продукт, предлагаемый на рынке. В результате применения кластерного анализа строится карта, по которой можно определить уровень конкуренции в различных сегментах рынка и соответствую- щие характеристики товара для возможности попадания в этот сегмент. С помощью ана- лиза такой карты возможно определение новых, незанятых ниш на рынке, в которых можно предлагать существующие товары или разрабатывать новые.
Кластерный анализ также может быть удобен, например, для анализа клиентов компа- нии. Для этого все клиенты группируются в кластеры, и для каждого кластера выраба- тывается индивидуальная политика. Такой подход позволяет существенно сократить объекты анализа и в то же время индивидуально подойти к каждой группе клиентов.
В 1971 году были проведены исследования по сегментации клиентов по сфере интере- сов на основе данных, характеризующих предпочтения клиентов. В 1974 году – по иден- тификации групп семей-потребителей продуктов. В результате были разработаны стра- тегии позиционирования бренда. Основой для исследований были рейтинги, которые ре- спонденты присваивали продуктам и брендам. В 1981 году был проведен анализ поведе- ния покупателей новых автомобилей на основе данных факторных нагрузок, получен- ных при анализе набора переменных.
Несмотря на кажущуюся похожесть задач классификации и кластеризации решаются они разными способами и при помощи разных методов. Различие задач – прежде всего в исходных данных.
Классификация, являясь наиболее простой задачей Data Mining, относится к стратегии
«обучение с учителем», для ее решения обучающая выборка должна содержать значения как входных переменных, так и выходных (целевых) переменных. Кластеризация, напротив, является задачей Data Mining, относящейся к стратегии «обучение без учите- ля», т. е. не требует наличия значения целевых переменных в обучающей выборке.
Задача классификации решается при помощи различных методов, наиболее простой – линейная регрессия. Выбор метода должен базироваться на исследовании исходного набора данных. Наиболее распространенные методы решения задачи кластеризации: ме- тод k-средних (работает только с числовыми атрибутами), иерархический кластерный анализ (работает также с символьными атрибутами), метод SOM.
5.6. ЗАДАЧА ПРОГНОЗИРОВАНИЯ В DATA MINING
Задачи прогнозирования решаются в самых разнообразных областях человеческой де- ятельности, таких, как наука, экономика, производство и множество других сфер. Про- гнозирование является важным элементом организации управления как отдельными хо- зяйствующими субъектами, так и экономикой в целом.
Развитие методов прогнозирования непосредственно связано с развитием информаци- онных технологий, в частности – с ростом объемов хранимых данных и усложнением методов и алгоритмов прогнозирования, реализованных в инструментах Data Mining.
Задача прогнозирования, пожалуй, может считаться одной из наиболее сложных задач Data Mining, она требует тщательного исследования исходного набора данных и мето- дов, подходящих для анализа.
Прогнозирование (от греческого prognosis), в широком понимании этого слова, опре- деляется как опережающее отражение будущего. Целью прогнозирования является пред- сказание будущих событий.
Прогнозирование (forecasting) является одной из задач Data Mining и одновременно одним из ключевых моментов при принятии решений.
Прогностика (prognostics) – теория и практика прогнозирования.
Прогнозирование направлено на определение тенденций динамики конкретного объ- екта или события на основе ретроспективных данных, т. е. анализа его состояния в про- шлом и настоящем. Таким образом, решение задачи прогнозирования требует некоторой обучающей выборки данных.
Прогнозирование – установление функциональной зависимости между зависимыми и независимыми переменными.
Прогнозирование является распространенной и востребованной задачей во многих областях человеческой деятельности. В результате прогнозирования уменьшается риск принятия неверных, необоснованных или субъективных решений. Примеры его задач: прогноз движения денежных средств, прогнозирование урожайности агрокультуры, про- гнозирование финансовой устойчивости предприятия.
Типичной в сфере маркетинга является задача прогнозирования рынков (market forecasting). В результате решения данной задачи оцениваются перспективы развития конъюнктуры определенного рынка, изменения рыночных условий на будущие периоды, определяются тенденции рынка (структурные изменения, потребности покупателей, из- менения цен).
Обычно в этой области решаются следующие практические задачи:
• прогноз продаж товаров (например, с целью определения нормы товарного запаса);
• прогнозирование продаж товаров, оказывающих влияние друг на друга;
• прогноз продаж в зависимости от внешних факторов.
Помимо экономической и финансовой сферы задачи прогнозирования ставятся в са- мых разнообразных областях: медицине, фармакологии; популярным сейчас становится политическое прогнозирование.
В самых общих чертах решение задачи прогнозирования сводится к решению таких подзадач:
• выбор модели прогнозирования;
• анализ адекватности и точности построенного прогноза.
Сравнение задач прогнозирования и классификации
Прогнозирование сходно с задачей классификации. Многие методы Data Mining ис- пользуются для решения задач классификации и прогнозирования. Это, например, ли- нейная регрессия, нейронные сети, деревья решений (которые иногда так и называют – деревья прогнозирования и классификации).
Задачи классификации и прогнозирования имеют сходства и различия. При решении обеих задач используется двухэтапный процесс построения модели на основе обучаю- щего набора и ее использования для предсказания неизвестных значений зависимой пе- ременной.
Различие задач классификации и прогнозирования состоит в том, что в первой задаче предсказывается класс зависимой переменной, а во второй – числовые значения зависи- мой переменной, пропущенные или неизвестные (относящиеся к будущему).
Возвращаясь к примеру о туристическом агентстве, мы можем сказать, что определе- ние класса клиента является решением задачи классификации, а прогнозирование дохо- да, который принесет этот клиент в будущем году, будет решением задачи прогнозиро- вания.
Прогнозирование и временные ряды
Основой для прогнозирования служит историческая информация, хранящаяся в базе данных в виде временных рядов. Существует понятие Data Mining временных рядов (Time-Series Data Mining).
На основе ретроспективной информации в виде временных рядов возможно решение различных задач Data Mining. Рассмотрим два принципиальных отличия временного ря- да от простой последовательности наблюдений:
• члены временного ряда, в отличие от элементов случайной выборки, не являются статистически независимыми;
• члены временного ряда не являются одинаково распределенными.
Временной ряд – последовательность наблюдаемых значений какого-либо признака, упорядоченных в неслучайные моменты времени.
Отличием анализа временных рядов от анализа случайных выборок является предпо- ложение о равных промежутках времени между наблюдениями и их хронологический порядок. Привязка наблюдений ко времени играет здесь ключевую роль, тогда как при анализе случайной выборки она не имеет никакого значения.
Типичный пример временного ряда – данные биржевых торгов.
Информация, накопленная в разнообразных базах данных предприятия, является вре- менными рядами, если она расположена в хронологическом порядке и произведена в по- следовательные моменты времени.
Анализ временного ряда осуществляется с целью:
− определения природы ряда;
− прогнозирования будущих значений ряда.
В процессе определения структуры и закономерностей временного ряда предполага- ется обнаружение: шумов и выбросов, тренда, сезонной компоненты, циклической ком- поненты. Определение природы временного ряда может быть использовано как своеоб- разная «разведка» данных. Знание аналитика о наличии сезонной компоненты необхо- димо, например, для определения количества записей выборки, которое должно прини- мать участие в построении прогноза.
Шумы и выбросы будут подробно обсуждаться в последующих лекциях курса. Они усложняют анализ временного ряда. Существуют различные методы определения и фильтрации выбросов, дающие возможность исключить их с целью более качественного Data Mining.
Тренд, сезонность и цикл
Основными составляющими временного ряда являются тренд и сезонная компонента. Составляющие этих рядов могут представлять собой либо тренд, либо сезонную компо- ненту. Тренд является систематической компонентой временного ряда, которая может изменяться во времени.
Трендом называют неслучайную функцию, которая формируется под действием об- щих или долговременных тенденций, влияющих на временной ряд. Примером тенден- ции может выступать, например, фактор роста исследуемого рынка.
Автоматического способа обнаружения трендов во временных рядах не существует. Но если временной ряд включает монотонный тренд (т. е. отмечено его устойчивое воз- растание или устойчивое убывание), анализировать временной ряд в большинстве случа- ев нетрудно.
Существует большое разнообразие постановок задач прогнозирования, которое можно подразделить на две группы: прогнозирование односерийных рядов и прогнозирование мультисерийных, или взаимовлияющих, рядов.
Группа прогнозирования односерийных рядов включает задачи построения прогноза одной переменной по ретроспективным данным только этой переменной, без учета вли- яния других переменных и факторов.
Группа прогнозирования мультисерийных, или взаимовлияющих, рядов включает за- дачи анализа, где необходимо учитывать взаимовлияющие факторы на одну или не- сколько переменных.
Кроме деления на классы по односерийности и многосерийности, ряды также бывают сезонными и несезонными, т. е. подразумевается наличие или отсутствие у временного ряда такой составляющей, как сезонность, т. е. включение сезонной компоненты.
Сезонная составляющая временного ряда является периодически повторяющейся компонентой временного ряда. Свойство сезонности означает, что через примерно рав- ные промежутки времени форма кривой, которая описывает поведение зависимой пере- менной, повторяет свои характерные очертания. Свойство сезонности важно при опре- делении количества ретроспективных данных, которые будут использоваться для про- гнозирования.
Рассмотрим пример. На рис. 16 приведен фрагмент ряда, который иллюстрирует пове- дение переменной «объемы продаж товара Х» за период, составляющий один месяц. При изучении кривой, приведенной на рисунке, аналитик не может сделать предположений относительно повторяемости формы кривой через равные промежутки времени.
Рис. 16. Фрагмент временного ряда за сезонный период
Однако при рассмотрении более продолжительного ряда (за 12 месяцев), изображен- ного на рис. 17, можно увидеть явное наличие сезонной компоненты. Следовательно, о сезонности продаж можно говорить, только когда рассматриваются данные за несколько месяцев. Таким образом, в процессе подготовки данных для прогнозирования аналитику следует определить, обладает ли ряд, который он анализирует, свойством сезонности.
Рис. 17. Фрагмент временного ряда за 12 сезонных периодов
Определение наличия компоненты сезонности необходимо для того, чтобы входная информация обладала свойством репрезентативности. Ряд можно считать несезонным, если при рассмотрении его внешнего вида нельзя сделать предположений о повторяемо- сти формы кривой через равные промежутки времени. Иногда по внешнему виду кривой ряда нельзя определить, является он сезонным или нет.
Существует понятие сезонного мультиряда. В нем каждый ряд описывает поведение факторов, которые влияют на зависимую (целевую) переменную. Пример такого ряда – ряды продаж нескольких товаров, подверженных сезонным колебаниям. При сборе дан- ных и выборе факторов для решения задачи по прогнозированию в таких случаях следу- ет учитывать, что влияние объемов продаж товаров друг на друга здесь намного меньше,
чем воздействие фактора сезонности. Важно не путать понятия сезонной компоненты ряда и сезонов природы. Несмотря на близость их звучания эти понятия разнятся. Так, например, объемы продаж мороженого летом намного больше, чем в другие сезоны, од- нако это является тенденцией спроса на данный товар.
Очень часто тренд и сезонность присутствуют во временном ряде одновременно.
Пример. Прибыль фирмы растет на протяжении нескольких лет (т. е. во временном ряде присутствует тренд); ряд также содержит сезонную компоненту.
Отличия циклической компоненты от сезонной:
1) продолжительность цикла, как правило, больше, чем один сезонный период;
2) циклы, в отличие от сезонных периодов, не имеют определенной продолжительно- сти.
При выполнении каких-либо преобразований понять природу временного ряда значи- тельно проще, такими преобразованиями могут быть, например, удаление тренда и сглаживание ряда.
Перед началом прогнозирования необходимо ответить на следующие вопросы:
1. Что нужно прогнозировать?
2. В каких временных элементах (параметрах)?
3. С какой точностью прогноза?
При ответе на первый вопрос мы определяем переменные, которые будут прогнозиро- ваться. Это могут быть, например, уровень производства конкретного вида продукции в следующем квартале, прогноз суммы продажи этой продукции и т. д.
При выборе переменных следует учитывать доступность ретроспективных данных, предпочтения лиц, принимающих решения, окончательную стоимость Data Mining.
Часто при решении задач прогнозирования возникает необходимость предсказания не самой переменной, а изменений ее значений.
Второй вопрос при решении задачи прогнозирования – определение следующих пара- метров:
• периода прогнозирования;
• горизонта прогнозирования;
• интервала прогнозирования.
Период прогнозирования – основная единица времени, на которую делается прогноз. Например, мы хотим узнать доход компании через месяц. Период прогнозирования для этой задачи – месяц.
Горизонт прогнозирования – это число периодов в будущем, которые покрывает про- гноз. Если мы хотим узнать прогноз на 12 месяцев вперед с данными по каждому меся- цу, то период прогнозирования в этой задаче – месяц, горизонт прогнозирования – 12 месяцев.
Интервал прогнозирования – частота, с которой делается новый прогноз. Интервал прогнозирования может совпадать с периодом прогнозирования.
При выборе параметров необходимо учитывать, что горизонт прогнозирования дол- жен быть не меньше, чем время, которое необходимо для реализации решения, принято- го на основе этого прогноза. Только в этом случае прогнозирование будет иметь смысл.
С увеличением горизонта прогнозирования точность прогноза, как правило, снижает- ся, а с уменьшением горизонта – повышается.
Мы можем улучшить качество прогнозирования, уменьшив время, необходимое на ре- ализацию решения, для которого реализуется прогноз, и, следовательно, уменьшив при этом горизонт и ошибку прогнозирования.
При выборе интервала прогнозирования следует выбирать между двумя рисками: во- время не определить изменения в анализируемом процессе и высокой стоимостью про- гноза. При длительном интервале прогнозирования возникает риск не идентифицировать изменения, произошедшие в процессе, при коротком возрастают издержки на прогнози- рование. При выборе интервала необходимо также учитывать стабильность анализируе- мого процесса и стоимость проведения прогноза.
Точность прогноза
Точность прогноза, требуемая для решения конкретной задачи, оказывает большое влияние на прогнозирующую систему. Ошибка прогноза зависит от используемой си- стемы прогноза. Чем больше ресурсов имеет такая система, тем больше шансов полу- чить более точный прогноз. Однако прогнозирование не может полностью уничтожить риски при принятии решений. Поэтому всегда учитывается возможная ошибка прогно- зирования.
Точность прогноза характеризуется ошибкой прогноза. Наиболее распространенные виды ошибок:
• средняя ошибка (СО) вычисляется простым усреднением ошибок на каждом шаге. Недостаток этого вида ошибки – положительные и отрицательные ошибки аннулируют друг друга;
• средняя абсолютная ошибка (САО) рассчитывается как среднее абсолютных оши- бок. Если она равна нулю, то мы имеем совершенный прогноз. В сравнении со средней квадратической ошибкой эта мера «не придает слишком большого значения» выбросам;
• сумма квадратов ошибок (SSE), среднеквадратическая ошибка, вычисляется как сумма (или среднее) квадратов ошибок. Это наиболее часто используемая оценка точно- сти прогноза;
• относительная ошибка (ОО). Предыдущие меры использовали действительные зна- чения ошибок. Относительная ошибка выражает качество подгонки в терминах относи- тельных ошибок.
Виды прогнозов
Прогноз может быть краткосрочным, среднесрочным и долгосрочным.
Краткосрочный прогноз представляет собой прогноз на несколько шагов вперед, т. е. осуществляется построение прогноза не более, чем на 3 % от объема наблюдений или на 1– 3 шага вперед.
Среднесрочный прогноз – это прогноз на 3–5 % от объема наблюдений, но не более 7– 12 шагов вперед; также под этим типом прогноза понимают прогноз на один или поло- вину сезонного цикла. Для построения краткосрочных и среднесрочных прогнозов вполне подходят статистические методы.
Долгосрочный прогноз – это прогноз более, чем на 5 % от объема наблюдений. При построении данного типа прогнозов статистические методы практически не используют- ся, кроме случаев очень «хороших» рядов, для которых прогноз можно просто «нарисо- вать».
До сих пор мы рассматривали аспекты прогнозирования, так или иначе связанные с процессом принятия решения. Существуют и другие факторы, которые необходимо учи- тывать при прогнозировании.
Задача 1. Известно, что анализируемый процесс относительно стабилен во времени, изменения происходят медленно, процесс не зависит от внешних факторов.
Задача 2. Анализируемый процесс нестабилен и очень сильно зависит от внешних факторов.
Решение первой задачи должно быть сосредоточено на использовании большого ко- личества ретроспективных данных. При решении второй задачи особое внимание следу- ет обратить на оценки специалиста в предметной области – эксперта, чтобы иметь воз- можность отразить в прогнозирующей модели все необходимые внешние факторы, а также уделить время для сбора данных по этим факторам (сбор внешних данных часто намного сложнее сбора внутренних данных информационной системы).
Доступность данных, на основе которых будет осуществляться прогнозирование, – важный фактор построения прогнозной модели. Для возможности выполнения качествен- ного прогноза данные должны быть представительными, точными и достоверными.
Среди распространенных методов Data Mining, используемых для прогнозирования, отметим нейронные сети и линейную регрессию.
Выбор метода прогнозирования зависит от многих факторов, в том числе от парамет- ров прогнозирования. Выбор метода следует производить с учетом всех специфических особенностей набора ретроспективных данных и целей, с которыми он строится.
Программное обеспечение Data Mining, используемое для прогнозирования, должно обеспечивать пользователя точным и достоверным прогнозом. Однако получение такого прогноза зависит не только от программного обеспечения и методов, заложенных в его основу, но также и от других факторов, среди которых – полнота и достоверность ис- ходных данных, своевременность и оперативность их пополнения, квалификация поль- зователя.
5.7. ЗАДАЧА ВИЗУАЛИЗАЦИИ
Визуализация – это инструментарий, который позволяет увидеть конечный результат вычислений, организовать управление вычислительным процессом и даже вернуться назад к исходным данным, чтобы определить наиболее рациональное направление даль- нейшего движения.
В результате использования визуализации создается графический образ данных. При- менение визуализации помогает в процессе анализа данных увидеть аномалии, структу- ры, тренды. При рассмотрении задачи прогнозирования мы использовали графическое представление временного ряда и увидели, что в нем присутствует сезонная компонента. Выше мы рассматривали задачи классификации и кластеризации и для иллюстрации распределения объектов в двумерном пространстве также использовали визуализацию. Применение визуализации является более экономичным: линия тренда или скопление точек на диаграмме рассеивания позволяют аналитику намного быстрее определить за- кономерности и прийти к нужному решению. Таким образом, здесь идет речь об исполь- зовании в Data Mining не символов, а образов.
Главное преимущество визуализации – практически полное отсутствие необходимо- сти в специальной подготовке пользователя. При помощи визуализации ознакомиться с информацией очень легко, достаточно всего лишь бросить на нее взгляд. Визуализация данных может быть представлена в виде графиков, схем, гистограмм, диаграмм и т. д.
Роль визуализации можно описать такими ее возможностями:
• поддержка интерактивного и согласованного исследования;
• помощь в представлении результатов;
• использование глаз (зрения), чтобы создавать зрительные образы и осмысливать их. Визуализацию можно считать ключевым фактором в исследовании данных, получен-
ных при помощи инструментов Data Mining. В таких случаях говорят о визуальном Data Mining.
Методы визуализации, среди которых представления информации в одно-, двух-, трех- мерном и более измерениях, а также другие способы отображения информации, напри- мер параллельные координаты, «лица Чернова», нами будут рассмотрены ниже.
Тема 6
МЕТОДЫ ВИЗУАЛИЗАЦИИ ДАННЫХ
С возрастанием количества накапливаемых данных даже при использовании сколь угодно мощных и разносторонних алгоритмов Data Mining становится все сложнее «пе- реваривать» и интерпретировать полученные результаты. А, как известно, одно из поло- жений Data Mining – поиск практически полезных закономерностей. Закономерность может стать практически полезной, только если ее можно осмыслить и понять.
К способам визуального или графического представления данных относят графики, диа- граммы, таблицы, отчеты, списки, структурные схемы, карты и т. д. Визуализация традицион- но рассматривалась как вспомогательное средство при анализе данных, однако сейчас все больше исследований говорит о ее самостоятельной роли.
Традиционные методы визуализации могут находить следующее применение:
• представлять пользователю информацию в наглядном виде;
• компактно описывать закономерности, присущие исходному набору данных;
• снижать размерность или сжимать информацию;
• восстанавливать пробелы в наборе данных;
• находить шумы и выбросы в наборе данных.
6.1. ВИЗУАЛИЗАЦИЯ ИНСТРУМЕНТОВ DATA MINING
Каждый из алгоритмов Data Mining использует определенный подход к визуализации. Ранее мы рассмотрели ряд методов Data Mining. В ходе использования каждого из мето- дов получают определенные визуализаторы, при помощи которых интерпретируются ре- зультаты, полученные в результате работы соответствующих методов и алгоритмов:
• для деревьев решений это визуализатор дерева решений, список правил, таблица со- пряженности;
• для нейронных сетей в зависимости от инструмента это могут быть топология сети, график изменения величины ошибки, демонстрирующий процесс обучения;
• для карт Кохонена – карты входов, выходов, другие специфические карты;
• для линейной регрессии в качестве визуализатора выступает линия регрессии.
• для кластеризации – дендрограммы, диаграммы рассеивания.
Диаграммы и графики рассеивания часто используются для оценки качества работы того или иного метода. Все эти способы визуального представления или отображения данных могут выполнять одну из функций:
• являются иллюстрацией построения модели (например, представление структуры (графа) нейронной сети);
• помогают интерпретировать полученный результат;
• являются средством оценки качества построенной модели;
• сочетают перечисленные выше функции (дерево решений, дендрограмма).
Визуализация Data Mining-моделей
Первая функция (иллюстрация построения модели) по сути является визуализацией Data Mining-модели. Существует много различных способов представления моделей, но графическое ее представление дает пользователю максимальную «ценность». Пользова- тель в большинстве случаев не является специалистом в моделировании, чаще всего он эксперт в своей предметной области. Поэтому модель Data Mining должна быть пред- ставлена на наиболее естественном для него языке или, хотя бы, содержать минимальное количество различных математических и технических элементов.
Таким образом, доступность является одной из основных характеристик модели Data Mining. Несмотря на это существует и такой распространенный и наиболее простой спо- соб представления модели, как «черный ящик». В этом случае пользователь не понимает поведения той модели, которой пользуется. Однако он получает результат – выявленные закономерности. Классическим примером такой модели является модель нейронной се- ти.
Другой способ представления модели – представление ее в интуитивном, понятном виде. В этом случае пользователь действительно может понимать то, что происходит
«внутри» модели. Таким образом можно обеспечить его непосредственное участие в процессе. Такие модели обеспечивают пользователю возможность обсуждать ее логику с коллегами, клиентами и другими пользователями или объяснять ее.
Понимание модели ведет к пониманию ее содержания. В результате понимания воз- растает доверие к модели. Классическим примером является дерево решений. Построен- ное дерево решений действительно улучшает понимание модели, т. е. используемого ин- струмента Data Mining.
Кроме понимания, такие модели обеспечивают пользователя возможностью взаимо- действовать с моделью, задавать ей вопросы и получать ответы. Примером такого взаи- модействия является средство «что, если». При помощи диалога «система – пользова- тель» пользователь может получить понимание модели.
Теперь перейдем к функциям, которые помогают интерпретировать и оценить резуль- таты построения Data Mining-моделей. Это всевозможные графики, диаграммы, табли- цы, списки и т. д.
Примерами средств визуализации, при помощи которых можно оценить качество мо- дели, являются диаграмма рассеивания, таблица сопряженности, график изменения ве- личины ошибки.
Диаграмма рассеивания представляет собой график отклонения значений, прогнози- руемых при помощи модели, от реальных. Эти диаграммы используют для непрерывных
величин. Визуальная оценка качества построенной модели возможна только по оконча- нии процесса построения модели.
Таблица сопряженности используется для оценки результатов классификации. Такие таблицы применяются для различных методов классификации. Оценка качества постро- енной модели возможна только по окончании процесса построения модели.
График изменения величины ошибки демонстрирует изменение величины ошибки в процессе работы модели. Например, в процессе работы нейронных сетей пользователь может наблюдать за изменением ошибки на обучающем и тестовом множествах и оста- новить обучение для недопущения «переобучения» сети. Здесь оценка качества модели и его изменения может оцениваться непосредственно в процессе построения модели.
6.2. МЕТОДЫ ВИЗУАЛИЗАЦИИ
Методы визуализации в зависимости от количества используемых измерений принято классифицировать на две группы:
1) представление данных в одном, двух и трех измерениях;
2) представление данных в четырех и более измерениях.
Представление данных в одном, двух и трех измерениях
К этой группе методов относятся хорошо известные способы отображения информа- ции, которые доступны для восприятия человеческим воображением. Практически лю- бой современный инструмент Data Mining включает способы визуального представления из этой группы.
В соответствии с количеством измерений представления это могут быть следующие способы:
• одномерное (univariate) измерение, или 1-D;
• двумерное (bivariate) измерение, или 2-D;
• трехмерное, или проекционное (projection) измерение, или 3-D.
Следует заметить, что наиболее естественно человеческий глаз воспринимает двумер- ные представления информации. При использовании двух- и трехмерного представления информации пользователь имеет возможность увидеть закономерности набора данных:
• его кластерную структуру и распределение объектов на классы (например, на диа- грамме рассеивания);
• топологические особенности;
• наличие трендов;
• информацию о взаимном расположении данных;
• существование других зависимостей, присущих исследуемому набору данных. Если набор данных имеет более трех измерений, то возможны такие варианты:
− использование многомерных методов представления информации (они рассмотрены
ниже);
− снижение размерности до одно-, двух- или трехмерного представления. Существуют различные способы снижения размерности, один из них – факторный анализ.
Представление данных в четырех измерениях
Представления информации в четырехмерном и более измерениях недоступны для че- ловеческого восприятия. Однако разработаны специальные методы для возможности отображения и восприятия человеком такой информации.
Наиболее известные способы многомерного представления информации:
• параллельные координаты;
• «лица Чернова»;
• лепестковые диаграммы.
Параллельные координаты
В параллельных координатах переменные кодируются по горизонтали, вертикальная линия определяет значение переменной. Пример набора данных, представленного в де- картовых координатах и параллельных координатах, дан на рис. 18.
Рис. 18. Набор данных в декартовых координатах и в параллельных координатах
«Лица Чернова»
Основная идея представления информации в «лицах Чернова» состоит в кодировании значений различных переменных в характеристиках или чертах человеческого лица. Пример такого «лица» приведен на рис. 19.
Рис. 19. «Лицо Чернова»
Для каждого наблюдения рисуется отдельное «лицо». На каждом «лице» относитель- ные значения переменных представлены как формы и размеры отдельных черт лица (например, длина и ширина носа, размер глаз, размер зрачка, угол между бровями).
Анализ информации при помощи такого способа отображения основан на способно- сти человека интуитивно находить сходства и различия в чертах лица.
На рис. 20 представлен набор данных, каждая запись которого выражена в виде «лица Чернова».
Рис. 20. Пример многомерного изображения данных при помощи «лиц Чернова»
Перед использованием методов визуализации необходимо:
• проанализировать, следует ли изображать все данные или же какую-то их часть;
• выбрать размеры, пропорции и масштаб изображения;
• выбрать метод, который может наиболее ярко отобразить закономерности, прису- щие набору данных.
Многие современные средства анализа данных позволяют строить сотни типов раз- личных графиков и диаграмм, поэтому выбор метода визуализации, если он самостоя- тельно осуществляется пользователем, не так прост и легок, как может показаться на первый взгляд. Наличие большого количества средств визуализации, представленных в инструменте, который применяет пользователь, может даже вызвать растерянность.
Одну и ту же информацию можно представить при помощи различных средств. Для того чтобы средство визуализации могло выполнять свое основное назначение – пред- ставлять информацию в простом и доступном для человеческого восприятия виде, – необходимо придерживаться законов соответствия выбранного решения содержанию отображаемой информации и ее функциональному назначению. Иными словами, нужно сделать так, чтобы при взгляде на визуальное представление информации можно было сразу выявить закономерности в исходных данных и принимать на их основе решения.
Среди двумерных и трехмерных средств наиболее широко известны линейные графи- ки, линейные, столбиковые, круговые секторные и векторные диаграммы.
При помощи линейного графика можно отобразить тенденцию, передать изменения какого-либо признака во времени. Для сравнения нескольких рядов чисел такие графики наносятся на одни и те же оси координат.
Гистограмму применяют для сравнения значений в течение некоторого периода или же соотношения величин.
Круговые диаграммы используют, если необходимо отобразить соотношение частей и целого, т. е. для анализа состава или структуры явлений. Составные части целого изоб- ражаются секторами окружности. Секторы рекомендуют размещать по их величине: вверху – самый крупный, остальные – по движению часовой стрелки в порядке умень- шения их величины. Круговые диаграммы также применяют для отображения результа- тов факторного анализа, если действия всех факторов являются однонаправленными. При этом каждый фактор отображается в виде одного из секторов круга.
Выбор того или иного средства визуализации зависит от поставленной задачи (напри- мер, нужно определить структуру данных или же динамику процесса) и от характера набора данных.
6.3. КАЧЕСТВО ВИЗУАЛИЗАЦИИ
Современные аналитические средства, в том числе и Data Mining, немыслимы без ка- чественной визуализации. В результате использования средств визуализации должны быть получены наглядные и выразительные, ясные и простые изображения за счет ис- пользования разнообразных средств: цвета, контраста, границ, пропорций, масштаба и т. д.
В связи с ростом требований к средствам визуализации, а также необходимостью сравнивания их между собой в последние годы был сформирован ряд принципов каче- ственного визуального представления информации.
Принципы Тафта (Tufte’s Principles) графического представления данных высокого качества гласят:
• предоставляйте пользователю самое большое количество идей, в самое короткое время, с наименьшим количеством чернил на наименьшем пространстве;
• говорите правду о данных.
Основные принципы компоновки визуальных средств представления информации:
− лаконичности;
− обобщения и унификации;
− акцента на основных смысловых элементах;
− автономности;
− структурности;
− стадийности;
− использования привычных ассоциаций и стереотипов.
Принцип лаконичности говорит о том, что средство визуализации должно содержать лишь те элементы, которые необходимы для сообщения пользователю существенной информации, точного понимания ее значения или принятия (с вероятностью не ниже до- пустимой величины) соответствующего оптимального решения.
Кроме того, средство визуализации должно обладать высокой надежностью и скоро- стью, которая устроит пользователя, принимающего на основе этой информации реше- ния. Отдельным направлением визуализации является наглядное представление про- странственных характеристик объектов. В большинстве случаев такие средства выделя- ют на карте отдельные регионы и обозначают их различными цветами в зависимости от значения анализируемого показателя.
6.4. ОСНОВНЫЕ ТЕНДЕНЦИИ В ОБЛАСТИ ВИЗУАЛИЗАЦИИ
При помощи средств визуализации поддерживаются важные задачи бизнеса, среди ко- торых – процесс принятия решений. В связи с этим возникает необходимость перехода средств визуализации на более высокий качественный уровень, который характеризуется появлением абсолютно новых средств визуализации и взглядов на ее функции, а также развитием ряда тенденций в этой области.
Среди основных тенденций в области визуализации выделяются:
• разработка сложных видов диаграмм;
• повышение уровня взаимодействия с визуализацией пользователя;
• увеличение размеров и сложности структур данных, представляемых визуализацией.
Разработка сложных видов диаграмм. Большинство визуализаций данных построено на основе диаграмм стандартного типа (секторные диаграммы, графики рассеяния и т. д.). Эти способы являются одновременно старейшими, наиболее элементарными и распространенными. В последние годы перечень видов диаграмм, поддерживаемых ин- струментальными средствами визуализации, существенно расширился. Поскольку по- требности пользователей весьма многообразны, инструменты визуализации поддержи- вают самые различные типы диаграмм. Например, известно, что бизнес-пользователи предпочитают секторные диаграммы и гистограммы, тогда как ученых больше устраи- вают визуализации в виде графиков рассеяния и диаграмм констелляции. Пользователи, работающие с геопространственными данными, сильнее заинтересованы в картах и про- чих трехмерных представлениях данных. Электронные инструментальные панели, в свою очередь, более популярны среди руководителей, использующих бизнес- аналитические технологии для контроля показателей работы компании. Такие пользова- тели нуждаются в наглядной визуализации в виде «спидометров», «термометров» и
«светофоров».
Средства создания диаграмм и презентационной графики предназначены главным об- разом для визуализации данных. Однако возможности такой визуализации обычно встроены и во множество различных других программ и систем: в инструменты репор- тинга и OLAP, средства для Text Mining и Data Mining, а также в CRM-приложения и приложения для управления бизнесом. Для создания встроенной визуализации многие поставщики реализуют визуализационную функциональность в виде компонент, встраи- ваемых в различные инструменты, приложения, программы и web-страницы (в том чис- ле инструментальные панели и персонализированные страницы порталов).
Повышение уровня взаимодействия с визуализацией пользователя. Еще совсем недав- но большая часть средств визуализации представляла собой статичные диаграммы, предназначенные исключительно для просмотра. Сейчас широко используются динами- ческие диаграммы, уже сами по себе являющиеся пользовательским интерфейсом, в ко- тором пользователь может напрямую и интерактивно манипулировать визуализацией, подбирая новое представление информации. Например, базовое взаимодействие позво- ляет пользователю вращать диаграмму или изменять ее тип в поисках наиболее полного представления данных. Кроме того, пользователь может менять визуальные свойства, к примеру, шрифты, цвета и рамки. В визуализациях сложного типа (графиках рассеяния или диаграммах констелляции) пользователь может выбирать информационные точки с помощью мыши и перемещать их, облегчая тем самым понимание представления дан- ных.
Более совершенные методы визуализации данных часто включают диаграмму или лю- бую другую визуализацию как составной уровень. Пользователь может углубляться (drill down) в визуализацию, исследуя подробности обобщенных ею данных, или углубляться в OLAP, Data Mining или другие сложные технологии.
Сложное взаимодействие позволяет пользователю изменять визуализацию для нахож- дения альтернативных интерпретаций данных. Взаимодействие с визуализацией подра- зумевает минимальный по своей сложности пользовательский интерфейс, в котором пользователь может управлять представлением данных, «кликая» на элементы визуали- зации, «перетаскивая» и помещая представления объектов данных или выбирая пункты меню. Инструменты OLAP или Data Mining превращают непосредственное взаимодей-
ствие с визуализацией в один из этапов итерационного анализа данных. Средства Text Mining, или управления документами, придают такому непосредственному взаимодей- ствию характер навигационного механизма, помогающего пользователю исследовать библиотеки документов.
Визуальный запрос является наиболее современной формой сложного взаимодействия пользователя с данными. В нем пользователь может, например, видеть крайние инфор- мационные точки графика рассеяния, выбирать их мышкой и получать новые визуализа- ции, представляющие именно эти точки. Приложение визуализации данных генерирует соответствующий язык запроса, управляет принятием запроса базой данных и визуально представляет результирующее множество. Пользователь может сфокусироваться на ана- лизе, не отвлекаясь на составление запроса.
Увеличение размеров и сложности структур данных, представляемых визуализацией. Элементарная секторная диаграмма или гистограмма визуализируют простые последо- вательности числовых информационных точек. Однако новые усовершенствованные ти- пы диаграмм способны визуализировать тысячи таких точек и даже сложные структуры данных, например, нейронные сети. Скажем, средства OLAP (а также инструменты ге- нерации запросов и выпуска отчетов) уже давно поддерживают диаграммы для своих онлайновых отчетов. Новые визуализационные программы обновляют контент за счет периодически повторяющегося считывания данных. Фактически пользователи визуали- зационных программ, отслеживающие линейные процессы (колебания фондового рынка, показатели работы компьютерных систем, сейсмограммы, сетки полезности и др.), нуж- даются в загрузке данных в режиме реального времени или близком к нему режиме.
Пользователи инструментов Data Mining обычно анализируют очень большие наборы численных данных. Традиционные типы диаграмм для бизнеса (секторные диаграммы и гистограммы) плохо справляются с представлением тысяч информационных точек. По- этому инструменты Data Mining почти всегда поддерживают некую форму визуализации данных, способную отражать структуры и закономерности исследуемых наборов данных в соответствии с тем аналитическим подходом, который используется в инструменте.
Помимо того, что визуализация поддерживает обработку структурированных данных, она также является ключевым средством представления схем так называемых неструк- турированных данных, например текстовых документов, т. е. Text Mining. В частности, средства Text Mining могут осуществлять парсинг больших пакетов документов и фор- мировать предметные указатели понятий и тем, освещенных в этих документах. Когда предметные указатели созданы с помощью нейросетевой технологии, пользователю не- просто продемонстрировать их без некоторой формы визуализации данных. Визуализа- ция в таком случае преследует две цели: визуальное представление контента библиотеки документов и навигационный механизм, который пользователь может применять при исследовании документов и их тем.
Как показывают многие исследования, визуализация является одним из наиболее пер- спективных направлений анализа данных, в т. ч. Data Mining. В этом направлении можно выделить такие проблемы, как сложность ориентации среди огромного количества ин- струментов, предлагающих решения по визуализации, а также непризнание рядом спе- циалистов методов визуализации как полноценных средств анализа и навязывание им вспомогательной роли при использовании других методов. Однако у визуализации есть неоспоримые преимущества: она может служить источником информации для пользова-
теля, не требуя теоретических знаний и специальных навыков работы, может выступить тем языком, который объединит профессионалов из различных проблемных областей, может превратить исходный набор данных в изображение, благодаря которому у иссле- дователя могут появиться абсолютно новые, неожиданные решения.

Все бизнесы работают с данными — информацией, генерируемой множеством внутренних и внешних источников компании. Эти каналы данных служат органами чувств руководства, предоставляя ему информацию о том, что происходит с бизнесом и рынком. Следовательно, любое ошибочное представление, неточность или нехватка информации могут привести к искажённому восприятию ситуации на рынке и неверному пониманию внутренних операций, что в свою очередь несёт за собой ошибочные решения.
Для принятия решений на основе данных необходимо чётко видеть все аспекты своего бизнеса, даже те, о которых вы не думаете. Но как превратить неструктурированные фрагменты данных в что-то полезное? В этом вам поможет business intelligence.
Мы уже говорили о стратегии организации машинного обучения. В этой статье мы расскажем о том, как интегрировать business intelligence в существующую корпоративную инфраструктуру. Вы узнаете, как подготавливается стратегия business intelligence и интегрируются инструменты в рабочие процессы компании.
Что такое business intelligence?
Начнём с определения: business intelligence (BI) — это набор практик по сбору, структурированию, анализу и превращению сырых данных в картину бизнеса, позволяющую принимать решения. BI применяет методики и инструменты, преобразующие неструктурированные массивы данных, компилируя их в понятные отчёты или информационные дэшборды. Основное предназначение BI — создавать картину бизнеса и обосновывать принятие решений при помощи данных.

Пример интерактивного дэшборда для отдела продаж
Весь процесс business intelligence можно разделить на четыре этапа:
- Сбор данных
- Очистка/стандартизация данных
- Анализ
- Отчётность
Самая большая часть реализации BI — применение инструментов, выполняющих обработку данных. Инфраструктуру BI образуют различные инструменты и технологии. Чаще всего эта инфраструктура содержит следующие технологии хранения и обработки данных, а также формирования отчётности:
- Источники данных
- ETL (Extract, Transform, Load) или инструменты интеграции данных
- Хранилище данных
- Кубы данных Online analytical processing
- Киоски данных
- Инструменты отчётности (BI)
Чтобы узнать больше о части business intelligence, касающейся инжиниринга данных, можно прочитать нашу статью или посмотреть видео:
Business intelligence — это технологический процесс, сильно зависящий от входных данных. Технологии, используемые в BI для преобразования неструктурированных или частично структурированных данных, также могут использоваться для data mining, а также во фронтенде для работы с big data.
Business intelligence и прогнозная аналитика
Определение business intelligence часто сбивает с толку, ведь оно пересекается с другими областями знания, в частности, с прогнозной аналитикой. Серьёзной ошибкой было бы считать, что business intelligence и прогнозная аналитика (predictive analytics) — это одно и то же.
По сути, business intelligence — это методика анализа данных, отвечающая на вопросы что происходило? и что происходит?. Этот тип обработки данных также называется дескриптивной аналитикой. При помощи дескриптивной аналитики компании могут исследовать состояние рынка в своей отрасли, а также собственные внутренние процессы. Анализ исторических данных помогает выявлять слабые места и потенциал бизнеса.
Прогнозная аналитика занимается предсказаниями на основании обработки данных событий прошлого. Прогнозная аналитика не проводит анализ исторических событий, а делает прогнозы о бизнес-тенденциях будущего. Оба этих типа прогнозов основаны на анализе событий прошлого. Поэтому BI и прогнозная аналитика могут использовать для обработки данных одинаковые техники. В какой-то степени, прогнозная аналитика может считаться следующим этапом business intelligence. Подробнее об этом можно прочитать в нашей статье, посвящённой моделям зрелости аналитики.
Обе методики анализа обращаются к трём основным типам управления данными:
- Дескриптивной аналитике (BI)
- Прогнозной аналитике
- Предписывающей аналитике
Предписывающая аналитика — это третий тип, нацеленный на поиск решений задач бизнеса; он предлагает действия для их решения. В настоящее время предписывающая аналитика (prescriptive analytics) реализуется при помощи многофункциональных инструментов BI, однако эта область знаний в целом не развилась до достаточно надёжного уровня.
Весь процесс интеграции инструментов BI в вашу организацию можно разбить на знакомство сотрудников компании с business intelligence как с концепцией и на саму интеграцию инструментов и приложений. Ниже мы расскажем об основных пунктах интеграции BI и раскроем некоторые сложности.

Схема реализации business intelligence по должностям и этапам
Этап 1: ознакомление сотрудников и руководства с business intelligence
Начнём с основ. Чтобы приступить к использованию business intelligence в вашей организации, вам первым делом нужно объяснить значение BI всему руководству. Здесь важно взаимопонимание, поскольку в обработку данных будут вовлечены сотрудники различных отделов. Поэтому нужно обеспечить согласованность, чтобы никто не путал business intelligence с прогнозной аналитикой.
Ещё одно предназначение этого этапа — объяснение концепции BI основным руководителям, задействованным в управлении данными. Вам нужно определить задачу, над которой вы будете работать, задать KPI и организовать специалистов, чтобы запустить собственный проект business intelligence.
Важно заметить, что на этом этапе вы, строго говоря, будете делать допущения об источниках данных и стандартах, которые будут задаваться для управления потоком данных. На последующих этапах вы сможете проверить верность своих допущений и сформировать процесс обработки данных. Именно поэтому нужно быть готовыми к изменению каналов получения данных и структуры команды.
Задаём цели, KPI и требования
Первым важным шагом после обеспечения общего видения обстановки будет определение задачи или группы задач, которые вы будете решать с помощью business intelligence. Установка целей позволит вам определить высокоуровневые параметры BI, например:
- Какие источники данных будут использоваться? (CRM, ERP, аналитика веб-сайтов, внешние источники и так далее.)
- Какой тип данных нам нужно принимать? (Показатели продаж, отчёты, трафик веб-сайтов и так далее.)
- Кому нужен доступ к этим данным? (Высшее руководство, аналитики рынка, другие специалисты.)
- Какие типы отчётов нам нужны и как они должны быть представлены? (Электронные таблицы, диаграммы, оперативные отчёты или интерактивные дэшборды.)
- Как будет измеряться прогресс?
На этом этапе наряду с целями вам нужно продумать возможные KPI и метрики оценки для проверки успешности выполнения задачи. Это могут быть физические ограничения (выделенный на разработку бюджет) или показатели результатов работы наподобие скорости запросов или частота отчётов об ошибках.
К концу этого этапа вы уже сможете сконфигурировать исходные требования к будущему продукту. Это может быть список фич в бэклоге продукта, состоящий из user story, или упрощённая версия этого документа с требованиями. Главное здесь то, что на основании требований вы должны понять, какой тип архитектуры, фичи и возможности необходимы в ваших ПО/оборудования для BI.
Этап 2: выбор инструментов или принятие решения о разработке собственного решения
Составление документа с требованиями к системе business intelligence — ключевой момент для понимания, какой инструмент вам нужен. Крупным компаниям стоит задуматься о разработке собственной экосистемы BI, и на то есть следующие причины:
- Иногда организации корпоративного уровня не могут доверить сторонним компаниям обработку своих ценных данных.
- Инструменты BI в основном дифференцируются по обслуживанию потребностей в конкретной отрасли. Может оказаться так, что на рынке нет поставщика, предоставляющего услуги в вашей отрасли.
- Обработка больших объёмов информации или работа big data могут стать обоснованием разработки собственной BI вместо поиска поставщика, поскольку своя система повышает гибкость в выборе поставщика облачной инфраструктуры.
Более мелким компаниям рынок BI предлагает огромное количество инструментов, способных работать как встроенные, так и облачные (Software-as-a-Service) технологии. Можно найти предложения, покрывающие все или почти все потребности в анализе данных для конкретной отрасли и имеющие гибкие возможности.
Исходя из требований, типа отрасли, размера и потребностей бизнеса вы сможете принять решение о необходимости вложений в собственный инструмент BI. В противном случае, можно выбрать поставщика, который возьмёт на себя ношу реализации и интеграции.
Этап 3: сбор команды business intelligence
Далее вам нужно будет собрать группу людей из разных отделов компании, чтобы поработать над стратегией business intelligence. Зачем вообще создавать такую группу? Ответ прост: команда BI помогает собрать представителей разных отделов для упрощения коммуникации и получения предложений отделов о требуемых данных и их источниках. То есть структура команды BI должна включать в себя две основные категории людей:
Представители предметной области из разных отделов
Эти люди будут отвечать за предоставление команде доступа к источникам данных. Также они вкладывают свои знания предметной области в выбор и интерпретацию различных типов данных. Например, специалист по маркетингу может определить, являются ли ценными типами данных трафик веб-сайта, процент отказа или количество подписок на рассылку. Специалист по работе с клиентами может дать ценные советы о взаимодействии с клиентами. Кроме того, вы получите доступ к информации о маркетинге или продажах от одного человека.
Должности, относящиеся к BI
Вторая категория людей — это люди, относящиеся к BI, которые будут вести процесс разработки и принимать архитектурные, технические и стратегические решения. То есть вам необходимо назначить людей на следующие должности:
Руководитель BI. Этот человек должен обладать теоретическими, практическими и техническими знаниями для поддержки реализации стратегии и инструментов. Это может быть руководитель со знанием business intelligence и доступом к источникам данных. Руководитель BI — это человек, принимающий решения, управляющие реализацией.
Инженер BI — это технический участник команды, специализирующийся на создании, реализации и настройке систем BI. Обычно инженеры BI имеют опыт в разработке ПО и конфигурировании баз данных. Также они хорошо должны владеть методиками и техниками интеграции данных. Инженер BI может руководить отделом ИТ в реализации инструментария BI. Подробнее о специалистах по данным и их обязанностях можно узнать из нашей статьи.
Также частью команды BI должен стать аналитик данных, способный применять свои знания в валидации, обработке и визуализации данных.
Этап 4: документирование стратегии BI
Собрав команду и выбрав источники данных, требуемые для решения конкретной задачи, можно приступать к разработке стратегии BI. Документировать стратегию можно при помощи традиционных стратегических документов наподобие дорожной карты продукта. Стратегия business intelligence может включать в себя различные компоненты, зависящие от отрасли, размера компании, конкуренции и бизнес-модели. Однако рекомендуются следующие обязательные компоненты:
Источники данных
Это документация выбранных каналов источников данных. В неё должны быть включены все типы каналов, будь то руководитель, аналитика отрасли в целом или информация от сотрудников и отделов. Примерами таких каналов могут быть Google Analytics, CRM, ERP и так далее.
Отраслевые/собственные KPI
Документирование стандартных отраслевых и уникальных для вас KPI может продемонстрировать полную картину развития и потерь вашего бизнеса. В конечном итоге, инструменты BI созданы для отслеживания этих KPI, поддерживая их дополнительными данными.
Стандарты отчётности
На этом этапе нужно определить, какой тип отчётности вам требуется для удобного извлечения ценной информации. В случае собственной системы BI можно выбрать визуальное или текстовое представление. Если вы уже выбрали поставщика, возможности выбора стандартов отчётности могут быть ограничены, поскольку поставщик устанавливает собственные. В этот раздел также можно включить типы данных, с которыми вы хотите работать.
Тип потока отчётности и конечные пользователи
Конечный пользователь — это человек, который будет наблюдать за данными через интерфейс инструмента отчётности. В зависимости от конечных пользователей можно выбирать различные типы потока отчётности:
Традиционная BI. Традиционно BI проектировалась исключительно для руководства. Поскольку количество пользователей и типов данных ограничено, необходимость в полной автоматизации отсутствует. Поэтому в традиционном типе потока BI требуется технический персонал в качестве посредника между инструментом отчётности и конечным пользователем. Если конечный пользователь хочет извлечь какие-то данные, то он может сделать запрос, а технический персонал сгенерирует отчёт из требуемых данных. В таком случае отдел ИТ действует как power user — пользователь, имеющий доступ к данным и влияющий на их преобразования.
Традиционный подход предлагает более безопасный и управляемый поток данных. Однако необходимость полагаться на отдел ИТ может привести к задержкам, снижающим гибкость и скорость в случае обработки больших объёмов данных (особенно в случае big data). Если вы стремитесь к большему контролю над отчётностью и к точности отчётов, то соберите отдельную команду ИТ, которая будет заниматься запросами и формированием отчётов.
BI с самообслуживанием. Современные компании и поставщики решений используют BI с самообслуживанием. Такой подход позволяет бизнес-пользователям и руководству получать отчёты, автоматически генерируемые системой. Для автоматической отчётности не требуются power user (администраторы) из отдела ИТ, обрабатывающие каждый запрос к хранилищу данных; однако для настройки системы всё равно нужен технический персонал.
Автоматизация может снизить качество конечных отчётов и их гибкость, а также быть ограниченной тем, как спроектирована отчётность. Однако у такого подхода есть преимущество: для работы с системой не нужно постоянное участие технического персонала. Не обладающие техническими знаниями пользователи смогут создать отсчёт самостоятельно или получить доступ к выделенному разделу хранилища данных.
Этап 5: подготовка инструментов интеграции данных
Этап интеграции инструментов потребует много времени и работы отдела ИТ. Если вам требуется создание собственного решения, то придётся разработать множество различных структурных элементов архитектуры BI. В остальных случаях вы можете выбрать поставщика на рынке, предоставляющего подходящие вам реализацию и структурирование данных.
Один из базовых элементов любой архитектуры BI — это хранилище данных. Хранилище — это база данных, хранящая информацию в установленном формате, обычно структурированном, классифицированном и очищенном от ошибок. Если данные предварительно не обрабатываются, инструмент BI или отдел ИТ не смогут запросить их. Поэтому нельзя напрямую соединять хранилище данных (data warehouse) с источниками информации. Вместо этого следует использовать инструменты ETL (Extract, Transform, Load) или инструменты интеграции данных. Они предварительно обработают сырые данные из исходных источников и передадут их в хранилище за три последовательных этапа:
- Извлечение данных. Инструмент ETL получает данные из таких источников данных, как ERP, CRM, аналитика и электронные таблицы.
- Преобразование данных. После извлечения инструмент ETL начинает обработку данных. Все извлечённые данные анализируются, очищаются от дубликатов, а затем стандартизируются, сортируются, фильтруются и проверяются.
- Загрузка данных. На этом этапе преобразованные данные загружаются в хранилище.
Обычно инструменты ETL предоставляются в готовом виде вместе с инструментами BI, разработанными поставщиком. (Ниже мы рассмотрим самые популярные из них). Чтобы узнать, что нужно для очистки и подготовки данных, прочитайте нашу статью.
Этап 6: конфигурирование хранилища данных и выбор архитектурного решения
Хранилище данных
Сконфигурировав передачу данных из выбранных источников, необходимо настроить хранилище. Хранилища данных в business intelligence — это особые типы баз данных, обычно хранящие историческую информацию в форматах SQL. С одной стороны хранилища соединены с источниками данных и системами ETL, с другой — с инструментами отчётности или интерфейсами дэшбордов. Это позволяет отображать данные из различных систем в едином интерфейсе.
Однако хранилище обычно содержит огромные объёмы информации (от 100 ГБ), из-за чего ответы на запросы оказываются достаточно медленными. В некоторых случаях данные могут храниться в неструктурированном или частично структурированном виде, что приводит к высокой частоте ошибок при парсинге данных для генерирования отчёта. Для аналитики может потребоваться определённый тип данных, который ради простоты использования сгруппирован в одном пространстве хранения. Именно поэтому компании используют дополнительные технологии для предоставления ускоренного доступа к мелким тематическим блокам информации.
Существуют различные типы решений, используемых для предоставления аналитике небольших частей данных из хранилища. Самый популярный из них — это Online Analytical Processing и киоск данных. Эти технологии обеспечивают ускорение отчётности и упрощение доступа к необходимым данным.
Рекомендации: если вы не обладаете большими объёмами данных, то достаточно будет использовать простое SQL-хранилище. Дополнительные структурные элементы наподобие киоска данных потребуют больших дополнительных затрат, не обеспечивая при этом никакой ценности. Этот вариант подходит мелким бизнесам или отраслям, работающим с относительно небольшими объёмами данных.

Так как хранилище данных невелико, инструменты отчётности конечных пользователей могут напрямую выполнять запросы к ней без задержек
Хранилище данных + кубы данных Online Analytical Processing
Находящиеся в хранилище данные имеют две размерности, напоминающие обычный формат электронной таблицы (таблицы и строки). Способ хранения данных в таком хранилище также называется реляционной базой данных. Одна база данных может включать в себя тысячи типов данных, поэтому обработка запросов к хранилищу данных занимает существенное время. Чтобы удовлетворить потребности аналитика и обеспечить быстрый доступ к данным, их анализ в разных измерениях, группировать их по необходимости, используются кубы данных OLAP.
OLAP или online analytical processing (интерактивная аналитическая обработка) — это технология, обрабатывающая данные и предоставляющая к ним доступ одновременно в нескольких измерениях. Структурирование данных в кубы позволяет преодолеть ограничения хранилища данных.
Модель куба данных OLAP, представление многомерных данных
Куб данных OLAP — это структура данных, оптимизированная для быстрого анализа данных из баз данных SQL (хранилища). Исходные данные кубов из хранилища данных являются уменьшенной версией её описания. Однако структура данных предполагает, что существует больше двух измерений (формат строк и столбцов электронных таблиц). Для формирования отчёта размерности являются критически важными элементами. Например, для отдела продаж они могут быть такими:
- Специалист по продажам
- Объём продаж
- Продукт
- Регион
- Временной период
Кубы образуют многомерную базу данных информации, которую можно адаптировать, чтобы группировать информацию разными способами для ускорения создания отчётов. Кубы данных OLAP, посвящённые разным тематикам данных, образуют базы данных OLAP. Хранилище и OLAP используются совместно, поскольку кубы хранят относительно малый объём данных и применяются для удобства обработки.
Рекомендация: архитектуру «хранилище данных + кубы данных OLAP» можно считать типичной. Её могут использовать компании любого размера, которым требуются хранение данных и сложный многомерный анализ информации. Если вы не хотите перегружать хранилище запросами, то рассмотрите возможность использования архитектуры с OLAP.

Кубы данных OLAP задают специфические размерности данных для запросов данных и снижения нагрузки на основное хранилище
Технологии хранилища данных + киоска данных
Хранилище — первый и самый крупный элемент архитектуры business intelligence. Менее масштабным описанием массивов данных хранилищ является киоск данных. Киоск данных — это специализированная часть хранилища, собирающая тематически схожую информацию, относящуюся к конкретному отделу. При помощи киосков данных отделы могут получать доступ к требуемым данным, поскольку киоски предоставляют информацию, относящуюся к одной из сфер бизнеса. Это значит, что разработчикам не придётся настраивать для конечных пользователей систему запросов на основе разрешений.
Рекомендация: «хранилище данных + киоск данных» — второй по популярности архитектурный стиль, основанный на использовании киосков данных для распространения требуемой информации по отделам. Такой подход может использоваться для настройки постоянной отчётности или упрощения доступа к информации без предоставления разрешений конечным пользователям.

Киоск данных — это менее масштабное описание хранилища данных, посвящённое конкретной сфере данных
Гибридная архитектура
Корпоративным бизнесам могут требоваться различные варианты управления данными. Киоски и кубы данных — это разные технологии, но обе они используются для описания меньших объёмов информации из хранилища. Киоски данных описывают подмножество хранилища данных, относящееся к конкретной задаче, но реализовать их можно по-разному. Среди вариантов реализации есть реляционные базы данных (хранилище или любая другая база данных SQL) и многомерные структуры, по сути, являющиеся кубами данных OLAP. То есть для управления данными и их распределения по отделам организации можно использовать обе технологии.
Рекомендация: можно использовать обе технологии, поскольку они поддерживают одну концепцию, но служат разным целям. Киоски данных можно реализовать как часть хранилища данных для обеспечения безопасности, агрегирования данных или доступности. Или можно использовать киоски как описание нескольких размерностей куба данных OLAP. Однако стоит иметь в виду, что и киоски, и кубы данных OLAP потребуют отдельной настройки баз данных.

Комбинированная версия с кубами данных OLAP и киосками данных
Этап 7: реализация интерфейса конечного пользователя — инструментов и дэшбордов отчётности
Данные, упорядоченные в удобные тематически связанные блоки информации в кубах Online Analytical Processing или киосках данных представляются при помощи интерфейса пользователя инструментов BI. Именно здесь дескриптивный анализ приносит пользу конечному пользователю.
Современные инструменты BI позволяют представить требуемые данные множеством различных способов. В прошлом business intelligence могла создавать только статичные отчёты на основании событий будущего и прошлого. Сегодня BI способна создавать интерактивные дэшборды с настраиваемыми порциями информации. Однако самым популярным способом представления данных остаются шаблоны отчётности.
Наиболее ценным способом представления информации считается оперативный отчёт (ad hoc report). Оперативная отчётность позволяет пользователям углубиться в подробности стандартного отчёта, используя любые типы данных для единовременного применения. Такой тип отчётности применяется вместо ежедневных или ежемесячных отчётов в качестве более полной версии, поскольку пользователь будет извлекать данные из хранилища (куба или киоска данных) непосредственно в момент просмотра отчёта. Это гарантирует свежесть информации, представленной запрашиванием из баз данных каждого элемента информации. То есть, по сути, оперативный отчёт — это настраиваемый отчёт в реальном времени, используемый для поиска ответов на конкретный бизнес-вопрос.
Этап 8: Проведение обучения конечных пользователей
Чтобы процесс онбординга сотрудников был плавным, мы крайне рекомендуем провести обучающие сессии. Эти сессии могут принимать разный вид: если вы используете аналитический инструмент, встроенный в CRM или ERP, то можно применить практики онбординга наподобие видеоинструкций или интерактивных инструментов онбординга, последовательно проводящих пользователей через все этапы.
Если у вас нет бюджета на автоматизацию обучения, то менеджер или участники команды BI всё равно должны его провести.
Основные инструменты business intelligence на рынке
Важно упомянуть, что поставщики инструментов BI предоставляют пользователям инструменты интеграции данных, ETL, отчётности (дэшборды), а также услуги хранения. Это означает, что чаще всего вы получите полную архитектуру BI, интегрированную в вашу систему. Ниже мы расскажем о некоторых примерах поставщиков инструментов business intelligence.
Sisense
Sisense — одно из крупнейших имён на рынке business intelligence. Продукт компании обеспечивает доступ к системам анализа данных в бэкенде и фронтенде для пользователей с разным техническим уровнем. Также Sisense предлагает услуги хранения данных, то есть обеспечивает полнофункциональное решение. В качестве модели ценообразования используется ежегодная подписка, однако на её стоимость сильно влияют количество пользователей, объёмы данных и тип проекта.
Zoho Analytics
Ещё одно крупное имя в отрасли business intelligence — это Zoho Analytics. Zoho предлагает полную инфраструктуру с масштабируемым интерфейсом как для малых, так и для больших бизнесов. Среди прочих полезных функций она предлагает открытые RESTFUL API для подключения всех необходимых систем CRS и ERP, площадки совместной работы сотрудников или руководства.
Tableau
Tableau — это облачное решение BI, первым использовавшее в инструментах отчётности интерфейсы drag-and-drop. ПО Tableau тоже имеет функции совместной работы: для аналитиков можно создать единую страницу входа для доступа к дэшборду и обмена информацией. Можно выполнять запросы данных так, чтобы они передавались на мобильное устройство. В приложении Tableau можно изменять отчёты и сохранять изменения прямо через телефон.
SAP
SAP — международная компания, предлагающая множество технических решений, в том числе продукты пакет Business Objects Business Intelligence и Cloud Analytics. Первый продукт — это базовое решение для бизнесов любого размера. Платформа предоставляет услуги умных запросов и оперативной отчётности. Кроме того, дэшборд-отчётность использует формат на основе должностей, то есть любой пользователь может настроить аналитический дэшборд в зависимости от своей должности. Дополнительное преимущество заключается в простоте интеграции продуктов SAP с продуктами Microsoft Office.
BusinessQ
Решения BI компании BusinessQ разработаны специально для мелкого и среднего бизнеса. BusinessQ предлагает как отдельное веб-приложение, так и embedded-версию, встраиваемую в приложение клиента.
Domo
Платформа BI Domo — это решение, в первую очередь рассчитанное на использование в облаке и предназначенное для бизнесов любого размера. Сервис масштабируем, что позволяет ему работать и с big data, и с мелкими корпоративными базами данных. Domo обеспечивает доступ к дэшбордам реального времени, использует реализованные в кубах OLAP киоски данных, обеспечивающие многомерный анализ и разделение данных по отделам.
Qlik
Qlik — это поставщик услуг business intelligence, предоставляющий различные продукты для визуализации данных, интерактивного дэшбординга и самостоятельного создания отчётности. Инфраструктуру можно реализовать на мощностях клиента или в облаке. Кроме того, Qlik предлагает доступ к списку публичных массивов данных в качестве источников информации.
В заключение
Инструменты business intelligence существуют уже более двадцати лет. Однако внешний вид и базовая функциональность «стандартного» инструмента BI существенно изменились. Вместо простой статической отчётности каждый поставщик сегодня предлагает оперативную отчётность или интерактивные дэшборды для совместной работы аналитиков. Кроме того, для обычных задач бизнеса стандартом становится BI с самообслуживанием, позволяющая предпринимателям выполнять аналитику с меньшей тратой ресурсов. Следуя общим техническим тенденциям, в BI появились такие нововведения, как облачные платформы и мобильная отчётность BI.
Таким образом, зная основные тенденции и технологии, используемые в этой отрасли, вы сможете создать собственную систему BI или выбрать готовую; это позволит вам создавать простые для понимания отчёты для обоснования своих решений. Business intelligence больше не является привилегией высшего руководства, это инструмент совместной работы для всей организации. Подберите подходящего поставщика и используйте все необходимые функции, чтобы ваши сотрудники могли пользоваться результатами BI.
24

Кафедра информационных
систем и технологий
Тема 1. Лекция.
Основы бизнес
анализа в области разработки программного
обеспечения.
Лекция рассмотрена
и обсуждена на заседании
кафедры
информационных систем и технологий
протокол № ___ от
___. _____________ 2014 г.
Москва
– 2014 г.
Лекция 1. Основы
бизнес анализа в области разработки
программного обеспечения.
Вопросы:
1.Структура,
содержание и задачи бизнес аналитики
2.Основные
методы бизнес аналитики.
3.
Средства и инструменты бизнес аналитики.
Вопрос
1. Структура, содержание и задачи бизнес
аналитики
3 СЛАЙД
Аналитика
(др.-греч. άναλυτικά — буквально:
«искусство анализа» ) — часть искусства
рассуждения — логики, рассматривающая
учение об анализе — операции мысленного
или реального расчленения целого (вещи,
свойства, процесса или отношения между
предметами) на составные части, выполняемая
в процессе познания или предметно-практической
деятельности человека.
Ещё в IV веке до
нашей эры, ученик Платона, древнегреческий
философ Аристотель в своём труде
«Органон» назвал два известных своих
сочинения по логике словом «Аналитика»
(«Первая Аналитика» и «Вторая Аналитика»),
так как они разлагают логическое мышление
на простейшие элементы и затем от них
переходят к сложным формам мышления.
В XVIII веке
родоначальник немецкой классической
философии Иммануил Кант назвал
«аналитикой» разложение человеческой
познавательной способности.
Бизнес-анализ
(business analysis) — дисциплина выявления
потребностей в какой либо области (в
деле) и нахождения решений проблем по
удовлетворению потребностей в данной
области.
Потре́бность
— вид
функциональной или психологической
нужды или недостатка какого-либо объекта,
субъекта, индивида, социальной группы,
общества. Являясь внутренними возбудителями
активности, потребности проявляются
по-разному в зависимости от ситуации.
Бизнес-аналитика
— Business intelligence (интеллектуальные) или
сокращенно BI
— это методы и инструменты, используемые
для преобразования, хранения, анализа,
моделирования, доставки и трассировки
информации в ходе работы над задачами,
связанными с принятием решений на основе
фактических данных. При этом с помощью
этих средств лица, принимающие решения,
должны при использовании подходящих
технологий получать нужные сведения и
в нужное время.
Термин BI
«Бизнес-аналитика»
впервые появился в 1958 году в статье
исследователя из IBM Ханса Питера Луна
(Hans Peter Luhn). Он определил этот термин как:
«Возможность понимания связей между
представленными фактами».
BI-технологии
позволяют анализировать большие объёмы
информации, заостряя внимание пользователей
лишь на ключевых факторах эффективности,
моделируя исход различных вариантов
действий, отслеживая результаты принятия
тех или иных решений.
Сегодня
вместо
понятия
Business
Intelligence ( BI)
вводится
термин
Business
Analytics (BA).
При этом
BI закрепляется за одним из базовых
сегментов BA. Такая замена названий
создает определенные проблемы для их
перевода на русский язык, так как название
“бизнес-аналитика” уже прочно закрепилось
в качестве перевода BI, хотя более
адекватно подходит для BA.
В содержательном
же плане понятно, что BA — это некий более
общий круг аналитических задач, который
включает и традиционные средства BI, и
качественно новый уровень “искусства
анализа” для решения задач управления
бизнесом.
Бизнес-аналитик
— специалист,
использующий методы бизнес-анализа для
аналитики потребностей деятельности
организаций с целью определения проблем
бизнеса и предложения их решения.
Международный Институт
Бизнес-Анализа (IIBA,
International
Institute
of
Business
Analysis)
определяет бизнес-аналитика «как
посредника между заинтересованными
лицами для сбора, анализа, коммуницирования
и проверки требований по изменению
бизнес-процессов, регламентов и
информационных систем. Бизнес-аналитик
понимает проблемы и возможности бизнеса
в контексте требований и рекомендует
решения, позволяющие организации достичь
своих целей».
В России чаще всего
должность подразделяют на разновидности:
a)
Бизнес—аналитик
(классический)
По IIBA
это 2 области бизнес-анализа из 6-ти
(«Elicitation»,
«Enterprise
Analysis»).
Кратко по функционалу
это:
•Изучение структуры
и особенностей функционирования
различных бизнес-процессов компании;
•Изучение устройства
и особенностей функционирования
различных бизнес-систем;
•Выявление правил и
ограничений, которые влияют на
жизнедеятельность систем и БП;
•Проведение интервью
с сотрудниками компании;
•Проектирование и
описание схем модели «AS-IS» бизнес-процессов;
•Создание структурных
и функциональных схем-моделей различных
областей бизнес-деятельности;
b) Ведущий
бизнес—аналитик
По
IIBA это
4 области
бизнес-анализа
из
6-ти
(«Elicitation», «Enterprise Analysis», «Business Analysis
Planning & Monitoring», «Requirements Management &
Communication»).
Кратко по функционалу
это блок «А» плюс:
•Выяснение и
структурирование проблем бизнеса
(business pain-1);
•Анализ правил и
ограничений, которые влияют на
жизнедеятельность систем и БП;
•Проектирование и
описание схем модели «TO-BE» бизнес-процессов;
•Анализ ключевых
показателей производительности (работы)
групп сотрудников;
•Ознакомление и
разъяснение результатов проделанной
работы руководству;
c)
Эксперт—бизнес—аналитик
По
IIBA это
все
6 областей
бизнес-анализа
(«Elicitation», «Enterprise Analysis», «Business Analysis
Planning & Monitoring», «Requirements Management &
Communication», «Requirements Analysis», «Solution Assessment &
Validation»).
Кратко по функционалу
это блок «B» плюс:
•Предложения решений
выявленных проблем бизнеса (business pain-2);
•Предложения по «обходу
сложившейся системы»;
•Проектирование и
описание схем модели «SHOULD-BE»
бизнес-процессов;
•Предложения решений
по реструктуризации выявленных «дыр»
процессов и функций;
•Предложения решений
по повышению эффективности системы
принятия решения;
•Создание и проведение
презентаций;
•Анализ всей деятельности
организации для выявления зон, нуждающихся
в изменении;
•Ассистент в создании
стратегий;
•Участие в валидации
проектных документов, прототипов
продуктов и т.д.;
•Участие в процессе
управления изменениями;
•Поддержка участников
проекта – разработчиков, тестеров,
дизайнеров, технических писателей и
т.д.;
Термин «бизнес-аналитик»
не является устоявшимся. Распространенные
ошибки:
•Нельзя путать
бизнес-аналитика с «Системным аналитиком»
(СА, технический руководитель, системный
архитектор, технический лидер и т.д.).
Иногда СА называют Business Systems Analyst (BSA). В
принципе, эти две должности — очень тесно
работающее звено, а для IT – вообще как
разные стороны одной монеты. Но даже
для IT-сегмента их компетенции пересекаются
максимум на 30%.
•Нельзя путать
бизнес-аналитика с «Финансовым аналитиком»
(Financial Analyst, FA). Если бизнес-аналитик
занимается бизнес-процессами, то FA или
занимаются анализом деятельности
компании по отношению к рынку, или же
наоборот анализируют внутреннее
фин.состояние компании.
•Нельзя путать
бизнес-аналитика с «Аналитиком требований»
(Requirements Analyst, RA). Бизнес-аналитик формулирует
высокоуровневые требования, а аналитик
требований отвечает за разработку
детального описания проектируемой
системы. В связи с широким 1С-распространением
распространена грубая ошибка –
приравнивание бизнес-аналитика к
«Методологу 1С». В Техническом задании
бизнес-аналитик участвует на ~20% — в части
атрибутного состава бизнес-объектов и
схем потоков бизнес-объектов. Отметим,
что RA не нужно обладать глубокими
знаниями в IT и разрабатывать архитектуру
системы, так как для этого есть выделенные
должности «Архитектор» и «Проектировщик
системы». Все т.н. аналитики в любой
консалтинговой компании, занимающейся
разработкой ПО в нашей стране – это
именно аналитики требований.
Иногда еще путают
«бизнес-аналитика» с «QA Analyst» или
«Product Analyst». Т.е. все вышеперечисленные
— это принципиально разные люди. Каждый
из аналитиков точно знает круг своих
обязанностей. И на каждый тип специалиста
имеется свой вид сертификации.
Соседние файлы в папке Т1
- #
- #
#статьи
- 1 июн 2022
-

0
Главное о бизнес‑аналитике: как она работает и чем поможет компании
Каким компаниям и для чего нужна бизнес‑аналитика? Какие проблемы она решает? Чем отличается от бизнес‑анализа? Рассказывает Антон Антипин.
Иллюстрация: Kjpargeter / Pikisuperstar / Freepic / Betty1 / Cleanpng / Pixel Wizard / Reddit / Meery Mary для Skillbox Media

Рассказывает просто о сложных вещах из мира бизнеса и управления. До редактуры — пять лет в банке и три — в оценке имущества. Разбирается в Excel, финансах и корпоративной жизни.

Бизнес‑аналитик с 15‑летним стажем, эксперт в области организационного развития. Основатель и генеральный директор консалтинговой компании Business Set. Преподаёт в ВШЭ и на курсе Skillbox «Профессия Бизнес‑аналитик».
Бизнес‑аналитика — это прежде всего работа с данными, изучение показателей деятельности компании. Ей занимаются специально подготовленные специалисты — бизнес-аналитики. На основе анализа данных они помогают управленцам выявить проблемы бизнеса и найти возможности для его устойчивого развития.
В статье разберёмся:
- чем бизнес‑аналитика отличается от бизнес‑анализа;
- каким компаниям и для чего нужна бизнес‑аналитика;
- какие направления есть в бизнес‑аналитике;
- какие методы в ней используют;
- что должен уметь хороший бизнес‑аналитик и как он работает;
- как компаниям найти своего специалиста.
Специалисты до сих пор спорят, что такое бизнес‑аналитика: тождественна ли она бизнес‑анализу или представляет собой отдельную область знаний. Чтобы разобраться с этим, рассмотрим главные цели бизнес-анализа и бизнес‑аналитики.
Бизнес‑анализ — это изучение деятельности компании в широком смысле: анализ стратегии развития предприятия, его бизнес-процессов, организационной структуры и парка информационных систем, проектирование и настройка взаимодействия всего этого с бизнес‑окружением и внешней средой.
Главная цель бизнес-анализа — разработать и внедрить организационные изменения, которые позволили бы компании достичь её основных целей наилучшим образом.
Главная цель бизнес-аналитики — поддерживать управленческие решения и организационные изменения качественными, актуальными и объективными данными.
Вот три основные задачи бизнес-аналитики:
- получить данные о работе компании в виде цифр;
- обработать и структурировать эти данные — сделать их пригодными для последующего анализа;
- провести анализ данных — найти закономерности в деятельности предприятия и смоделировать прогнозы его развития в тех или иных условиях.
Таким образом, бизнес‑аналитика — это часть бизнес‑анализа, которая отвечает за сбор, обработку и анализ данных. Она является первым и необходимым этапом эффективного управления организационными изменениями.
Бизнес‑аналитика необходима всем компаниям, которые хотят принимать качественные управленческие решения. Качественными могут быть только решения, которые основываются на фактах. Бизнес‑аналитика отвечает как раз за сбор и обработку этих фактов.
Важно не просто собрать данные о деятельности предприятия, а ещё и подготовить их для управленцев:
- структурировать;
- проанализировать — выявить тенденции и тренды, влияющие на факторы;
- представить результаты анализа в наглядном виде;
- подготовить рекомендации по использованию этих данных для улучшения деятельности компании.
Через рекомендации бизнес-аналитиков менеджмент компании получает актуальную и достоверную информацию о том, что происходит в компании и за её пределами. Такой подход помогает принимать взвешенные и качественные бизнес‑решения.

Простой пример: компания продаёт сезонные товары — велосипеды или лыжи. Бизнес-аналитики точно определят кривую спроса продукции с учётом сезонных факторов, в понятном виде продемонстрируют её руководителям и дадут подробные рекомендации — что нужно предпринять, чтобы максимизировать выручку от продаж. Без бизнес-аналитики такие решения принимают вслепую — это приводит к тому, что компания упускает выгоду.
Обычно направления в бизнес-аналитике определяют через методы анализа данных: кластерный анализ, корреляционный анализ, регрессионный анализ, методы линейного программирования. В Business Set мы определили подвиды бизнес-аналитики несколько иначе.
Мы выделяем четыре направления бизнес‑аналитики. Каждое из них соответствует одному из ключевых элементов системы управления. Эти элементы:
- Стратегия развития предприятия.
- Бизнес-процессы.
- IT-архитектура.
- Организационно-ролевая структура.
Бизнес‑аналитика, необходимая для разработки стратегии. Стратегия развития — важнейший элемент системы управления предприятием. Чтобы стратегия получилась качественной, необходимо проанализировать большой объём данных и цифр. Для этого привлекают бизнес‑аналитика.
Он анализирует внешнюю маркетинговую информацию — например, как меняется покупательский спрос, как конкурентные силы влияют на бизнес. По итогам анализа бизнес-аналитик подготавливает отчёт, который ложится в основу стратегии развития предприятия.
Аналитика бизнес‑процессов компании. Бизнес-процессы — инструмент реализации стратегии предприятия. Достижение стратегических целей компании возможно только за счёт точного исполнения настроенных бизнес-процессов.
Чтобы процессы отвечали современным подходам, учитывали изменения бизнес-среды, успешно реализовывали внутренний потенциал компании, их нужно периодически обновлять. Такие изменения также подготавливают с помощью работы с данными.
Для этого анализируют значения показателей бизнес‑процессов:
- определяют факторы влияния на процессы и природу этих факторов — случайные они или нет;
- оценивают управляемость процессов: способны ли они стабильно производить качественный результат;
- оценивают их пропускную способность: какое количество запросов в единицу времени они способны обрабатывать.
По результатам анализа вырабатывают предложения по изменениям. Нужно, чтобы предлагаемые изменения помогали устранять сбои в процессах, улучшать качественные характеристики продуктов. Это позволит более точно достигать стратегических целей предприятия.
Бизнес‑аналитика, которая работает с данными по IT‑архитектуре. Сегодня ключевым фактором успеха предприятия является качественная работа его IT-сервисов. Чтобы ответить на вопрос, соответствует ли IT-архитектура предприятия потребностям бизнеса, нужно также обратиться к бизнес-аналитике — проанализировать состав и качество работы парка информационных систем компании, степень автоматизации и роботизации процессов, соответствие уровня IT-сервисов предприятия стандартам отрасли. Результаты анализа ложатся в основу решений для оптимизации IT‑архитектуры предприятия.

Аналитика данных, связанных с организационной структурой. Успешный бизнес способны делать только успешные люди. Вывод о том, насколько успешны люди компании, делают на основе анализа данных о работе подразделений, отделов, сотрудников компании. Здесь собирают и анализируют информацию о том, насколько бизнес оснащён требуемыми компетенциями, какова производительность организационных единиц, каков фактический уровень квалификации сотрудников предприятия.
Здесь также требуется изучить большой объём данных. Результаты таких исследований часто приводят к реструктуризации бизнеса или его отдельных направлений.
Как мы уже говорили выше, бизнес‑аналитика — это прежде всего работа с большими объёмами данных. Чтобы эта работа выполнялась качественно, бизнес-аналитику нужны соответствующие методические инструменты.
Вот несколько наиболее популярных инструментов.
Корреляционный и регрессионный анализ применяется для изучения зависимости между двумя и более количественными показателями: существует ли связь между ними, насколько она сильная, какого она характера. Результат такого анализа — математические формулы, которые описывают, как изменится один показатель в результате изменения другого.
Допустим, компания хочет понять, как связаны её продажи и объёмы торговли на всём рынке. Корреляционно‑регрессионный анализ покажет, что рост продаж на всём рынке на 2 млн долларов в месяц приведёт к увеличению выручки компании на 100 тысяч долларов за тот же период.
Дисперсионный и факторный анализ применяется для исследования степени влияния одной или нескольких качественных переменных на один зависимый количественный показатель. При этом качественные переменные рассматривают как причины (независимые переменные или факторы), а количественные — как следствия (зависимые переменные). Во время анализа меняют значения факторов и изучают, как это влияет на величину зависимой переменной.
Например, с помощью этого метода можно определить, как уровень продаж магазина зависит от дня недели: в этом случае дни недели будут качественными показателями, а уровень продаж — количественным.
Кластерный анализ применяется, когда нужно разбить множество цифр и показателей по однородным признакам. Он полезен, когда требуется проанализировать большое количество показателей, сгруппировать их и разобраться, как они друг с другом взаимодействуют.
Классическим примером кластерного анализа является ABC-анализ клиентской базы.
Методы описательной статистики применяются для обработки «сырых» данных. К этим методам относится обобщение и систематизация данных в виде таблиц, отображение результатов в графиках и расчёт статистических показателей: например, среднего значения, стандартного отклонения, медианы, моды, минимума и максимума значений.
Это не полный перечень методов — в арсенале любого специалиста их гораздо больше. Выбор метода зависит от задачи, стоящей перед бизнес‑аналитиком, а также от его предпочтений. Работу с этими методами лучше изучать на курсах по бизнес‑аналитике.
Бизнес‑аналитик — проводник изменений внутри компании. Он помогает бизнесу понять, что нужно изменить в процессах и других элементах системы управления, чтобы увеличить эффективность компании.

Функции бизнес‑аналитиков:
- Понять требования заинтересованных сторон к сотрудникам, структурам компании, процессам и бизнесу в целом.
- Найти проблемы и возможности компании и рассказать о них руководителю и менеджерам.
- Проанализировать проблемы и возможности, предложить решения — как защититься от первых и развить вторые.
- Защитить разработанные решения перед руководством компании. Для этого нужно подготовить графики и отчёты, аргументировать свою позицию.
- Организовать внедрение изменений в жизнь.
- Проанализировать, принесли ли изменения пользу для бизнеса.
Главный бизнес‑аналитик также должен:
- Определить подходы к бизнес‑анализу и бизнес‑аналитике в компании, выбрать методы и инструменты, понять, как и для чего их будут использовать.
- Разработать стратегию развития бизнес‑анализа в компании, распределить задачи между другими аналитиками и проконтролировать их выполнение.
Работа бизнес-аналитика в компании состоит из двух основных этапов.
Сбор данных, необходимых для анализа. Например, бизнес-аналитику нужны данные для разработки стратегии компании. Чтобы получить их, он формирует запросы в отделы компании. Предварительно он разбивает данные на четыре группы.
- Финансовые показатели — например, общую выручку, чистую прибыль — запрашивают в бухгалтерии или финансово-экономическом отделе компании.
- Клиентские показатели — выручку по целевым сегментам клиентской базы, удовлетворённость клиентов по сегментам, коэффициент конверсии, средний чек — запрашивают у коммерческого директора или руководителя отдела продаж.
- Показатели по бизнес-процессам — пропускную способность, процент брака процессов — запрашивают у владельцев ключевых бизнес-процессов компании.
- Показатели развития персонала — данные о текучке кадров, удовлетворённость персонала рабочими местами — запрашивают у директора по персоналу.
В запросах бизнес-аналитик указывает свои требования: какие показатели нужны, в каком виде, за какие периоды, по каким местам присутствия компании. После получения всех данных он приступает ко второму этапу работы.
Анализ данных и формирование отчётов. Чаще всего для этого используют обычный Microsoft Excel. Он позволяет применять все перечисленные выше методы и формировать отчёты с результатами.
В некоторых компаниях используют BI-системы. Это специальные программы, которые собирают, анализируют и обрабатывают показатели компании. В отличие от Excel, здесь всё происходит автоматически. Для этого к BI-системам подключают источники данных — например, облачные системы компании или отдельные файлы. BI-системы обрабатывают эти данные и в сжатом виде выдают наиболее важную информацию.
Одна из наиболее популярных BI-систем — Microsoft Power BI. У неё простой и интуитивно понятный интерфейс, который позволяет бизнес-аналитику очищать данные от информационного шума и собирать наглядные, удобочитаемые отчёты.
Результаты анализа аналитики передают менеджменту компании — теперь руководители могут принимать качественные управленческие решения.
Функции бизнес‑аналитика мы описали выше. Если исходить из функций, то для такого специалиста важно:
- иметь опыт общения с владельцами бизнеса и менеджерами;
- уметь работать с разными методами и инструментами анализа;
- иметь успешные кейсы по разработке и внедрению организационных изменений.

Если у компании нет возможности нанять бизнес‑аналитика на отдельную ставку, можно использовать две стратегии:
- Привлекать бизнес‑аналитиков время от времени — в зависимости от потребностей фирмы.
Как часто это будет требоваться, зависит от масштабов компании и интенсивности её деятельности. Программа-минимум — приглашать аналитика раз в год, когда нужно актуализировать стратегию. Чтобы аналитик глубже погрузился в деятельность компании, лучше привлекать его на ежеквартальной основе для проработки ключевых бизнес‑процессов компании.
- Наращивать компетенции бизнес‑аналитики внутри компании.
В идеале такими компетенциями должны обладать руководители фирмы, управленцы среднего и высшего звена, ключевые специалисты отделов. Для старта будет достаточно аналитического склада ума и навыков общения. Остальные скиллы можно получить в ходе работы, параллельно слушая курсы и лекции по бизнес‑аналитике.
- Бизнес‑аналитика — это часть бизнес‑анализа, связанная с показателями деятельности компании: с её помощью получают и обрабатывают данные, находят закономерности, строят прогнозы и создают бизнес‑решения.
- Бизнес‑аналитика нужна всем компаниям для принятия качественных управленческих решений. Без отчётов аналитиков менеджеры не увидят полной картины того, что происходит в компании и за её пределами.
- Направления бизнес‑аналитики соответствуют элементам системы управления: аналитика для разработки стратегии компании, аналитика бизнес‑процессов, аналитика IT‑сервисов и организационной структуры.
- Методы бизнес‑аналитики включают в себя сбор данных, их обработку и построение зависимостей. Чаще всего применяют корреляционно‑регрессионный, дисперсионный, кластерный анализ и методы описательной статистики. Выбор метода зависит от задач, которые стоят перед аналитиком.
- Хороший бизнес‑аналитик должен уметь определять проблемы и возможности компании, работать с методами и инструментами анализа, разрабатывать и внедрять организационные изменения. Не обязательно нанимать бизнес‑аналитика в штат — можно привлекать его раз в год или ежеквартально.
Другие материалы Skillbox Media для менеджеров
- Интервью Антона Антипина о том, чем занимается бизнес‑аналитик и сколько он зарабатывает
- Статья о диаграмме Исикавы — как искать причины проблем с помощью «рыбьих костей»
- Ответы на популярные вопросы о SERM: что делать с негативными отзывами и где взять позитив
- Статья с советами эксперта, как сохранить бизнес в условиях кризиса, — о рынке, рисках, зарплатах и возможностях
- Ответы на главные вопросы про MBA — что даёт, кого и чему учат.

Научитесь: Профессия Бизнес-аналитик
Узнать больше

Что это? Бизнес-анализ – использование методов и инструментов для выявления проблемных мест в коммерческой деятельности компании. Полученные результаты подскажут, как повысить эффективность бизнес-процессов, увеличить прибыль, исключить репутационные потери и т. д.

Как работает? Для проведения бизнес-анализа используются различные подходы и методологии. Одним из наиболее известных является мозговой штурм – групповые интеллектуальные усилия, направленные на поиск корня проблемы. Больше о сути и методах бизнес-анализа читайте в нашем материале.
В статье рассказывается:
- Что такое бизнес-анализ
- Примеры бизнес-анализа
- Цели и задачи бизнес-анализа компании
- Основы бизнес-анализа
- 10 методов бизнес-анализа
- 5 типичных ошибок бизнес-анализа
-

Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Что такое бизнес-анализ
Бизнес-анализ компании – это тщательное изучение всех направлений ее деятельности. После аналитической обработки полученных показателей можно выяснить, отклоняются ли фактические данные от плановых или средних по отрасли. На основе этого анализа руководство предприятия принимает конкретные решения, чтобы повысить эффективность производства.
Бизнес-анализ помогает выявить скрытые недостатки, закравшиеся в финансово-хозяйственную деятельность фирмы, равно как и обнаружить резервы для увеличения прибыльности предприятия. С его помощью легко планировать финансовые результаты в будущем.

Существует несколько видов бизнес-анализа:
- ресурсный анализ;
- анализ финансов;
- анализ инвестиций;
- анализ маркетинга;
- маржинальный анализ;
- анализ персонала.
Другими словами, все эти задачи и методы служат своего рода посредниками между теми, кому интересны полученные результаты. Они помогают разобраться в структуре, политике и деятельности предприятия, подсказывают решения, ведущие к достижению целей.
Понятие «бизнес-анализ» в научных кругах и в различных отраслях трактуется по-разному. Наиболее широкое распространение получили две интерпретации этого термина:
Бизнес-анализ в сфере экономики
В теории экономических дисциплин и менеджмента бизнес-анализ описывается как совокупность неких механизмов, помогающих определить точки роста компаний, выявить сложности в их работе и найти решение проблем, изменяя в дальнейшем некоторые процессы. По мнению специалистов подобная методика сближает понятия бизнес-анализа и консалтинга.
В такой интерпретации бизнес использует анализ для:
- понимания всей картины состояния бизнес-процессов в организации;
- поиска и привлечения соответствующих специалистов, способных найти выход из сложившихся проблемных ситуаций;
- перестройки бизнес-процессов с целью повышения эффективности предприятия;
- разработки универсальных принципов решения определенных задач в компании;
- оценки эффективности и других показателей поиска решения взаимосвязанных задач;
- применения инновационных технологий, внедрения современного программного обеспечения и прочего.
Скачать файл
Бизнес-анализ объединяет в себе:
- состояние рынка;
- материально-производственную базу;
- инновационные производственные, компьютерные, рекламные и другие методы;
- используемые основные и оборотные средства, финансовую поддержку и риски;
- занимаемую компанией рыночную нишу и возможные действия конкурентов;
- общественное, финансовое и политическое окружение фирмы.
В результате проведенного бизнес-анализа на свет должна появиться эффективная стратегия, с помощью которой можно будет добиться увеличения прибыли в данный момент и в долгосрочной перспективе. В конечном итоге миссия организации будет исполнена.
Бизнес-анализ в сфере информационных технологий
В области знаний по IT-технологиям и автоматизации бизнеса понятие бизнес-анализа интерпретируется как поиск «плохих» бизнес-процессов для последующего реинжиниринга. В этой сфере термины анализа бизнес-процессов и бизнес-анализа означают одно и то же.
При запуске бизнес-анализа на данном направлении деятельности происходит глубокое изучение проводимых в компании работ с точки зрения их системной взаимосвязи, в результате определяется проблемный участок, его возможные перспективы и исправление.
Чтобы объективно оценить внесенные изменения, необходимо тщательно изучить полученный процесс и замерить эффективность выполняемых работ на этом же участке после завершения реинжиниринга.
Прежде, чем внедрять инновационные технологии и вносить любые изменения в существующий рабочий процесс, директор компании должен обязательно провести бизнес-анализ деятельности своего предприятия. Особенно, когда речь идет о внедрении компьютерных технологий. Стоимость программного обеспечения может быть достаточно высокой, а некорректно проведенная установка способна нивелировать весь экономический эффект от его использования.
Примеры бизнес-анализа
Бизнес-анализ компании поможет вам получить более четкое представление о ее текущем состоянии или определить потребности вашего бизнеса. Обычно такой анализ проводится, когда надо озвучить и подтвердить те решения, которые направлены на достижение целей.
Приведем пример бизнес-анализа. Поставлена задача: на условном заводе возросло время производства продукции и на складе начали скапливаться материалы.
Бизнес-аналитик проходит по всем этапам производства с замерами времени и выясняет, что один из станков часто выходит из строя. Возникает два альтернативных решения: купить и заменить детали или приобрести новый станок. Анализ финансовой составляющей показывает, что купить новый станок будет дешевле. После замены станка скорость производства возвращается к норме.
Это типичный пример проведения бизнес-анализа, который привел к выявлению проблемы и выбору решения, в результате применения которого завод получил конкретную пользу.
Воспользоваться бизнес-анализом можно в любой компании – и выпускающей какую-то продукцию, и оказывающей разного рода услуги. Например, вы организовали посадочную страницу вашего продукта, но заметили, что продажи при этом не возросли.
При поиске проблем выяснилось, что потребители заполняют форму обратной связи – вносят номер телефона, e-mail, но не нажимают кнопку «купить». Отследили 300 человек, которые оставили свои контакты, но ни одной продажи не произошло. Запустили анализ бизнес-процессов.
Во время обсуждения ситуации рабочей группой в составе IT- специалиста, верстальщика, провайдера банка выяснилось, что кнопка «купить» не работает на устройствах Samsung и на конкретном браузере. Посадочную страницу пришлось перенастраивать под все устройства и верстать заново.
После исправления ошибок рабочая группа собирается снова, чтобы выяснить, как выполняется KPI. Но бизнес-анализ не только помогает найти и устранить ошибки, с его помощью можно изменить курс компании. Например, продукт, явно уступающий по качеству продукции конкурентов, имеет такую же цену. Тогда придется изменить ценовую политику.
Бизнес-анализ деятельности предприятия – это достаточно сложный процесс, включающий в себя проектную часть. Его задача – поставить диагноз и назначить лечение. В чем-то этот процесс схож с аудиторской проверкой организации с целью выявления ее сильных и слабых сторон, а также с оценкой рисков вероятности того, что начнется процесс постоянных изменений.
К примеру, была поставлена задача: определить стратегию развития бренда в условиях рыночной неопределенности и высокой конкуренции. Решение придет только после полного бизнес-анализа деятельности компании и ее подрядчиков.
Цели и задачи бизнес-анализа компании
Бизнес-аналитики, изучающие процессы внутри компании, пытаются добиться следующих результатов:
- сократить расходы компании;
- разрешить все проблемные ситуации в компании;
- соблюдать сроки сдачи всех проектов;
- поднять результативность всех процессов компании;
- письменно задокументировать все верные критерии.
Стоимость проекта — если выполнение проекта по каким-то причинам задерживается, то затраты на продолжение работ могут спровоцировать повышение его стоимости. В том случае, когда в контракте на проведение разработки была прописана повременная оплата труда, его стоимость однозначно вырастет. Если же в договоре цена была жестко зафиксирована, то риск удорожания работ заметно снижается.
Для собственных средств предприятия подобная задержка не так важна, поскольку оплата рабочего времени имеет фиксированное значение. Проблема появится, если придется пересчитывать ресурсы, потраченные за этот период на выполнение данного проекта.
Стоимость возможностей бывает двух видов – утерянная прибыль и нереализованное сжатие финансовых расходов. Некоторые бизнес-проекты запускают специально для привлечения новых или дополнительных инвестиций. Когда же сроки выходят, компания перестает получать эти доходы. Другие бизнес-проекты решают задачу роста результативности рабочего процесса с обязательным сокращением финансовых вложений.
Каждый месяц просрочки приводит не к снижению, а росту затрат. Подобные финансовые ситуации никем и нигде не анализируются, что нарушает точность расчета окупаемости всего проекта. И самым печальным в этом случае становится снижение прибыли.
В крупных компаниях ответственность за своевременное завершение проектных работ лежит на менеджере этого бизнес-проекта. В этом случае бизнес-аналитик после проведенных им исследований должен гарантировать, что все требования будут выполнены в заданные сроки, даже если сам проект не будет до конца завершен.

Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Уже скачали 20105 ![]()
Задокументировать верные требования. Аналитик бизнес-процесса, проводя бизнес-анализ, должен быть уверен, что его выводы смогут удовлетворить запросы пользователей. По факту он стремится рассказать о правильной программе бизнес-анализа, а чтобы закрепить эти положения, обязан зафиксировать их в соответствующих документах. Задача бизнес-аналитика – внимательно изучить все отзывы потребителей и передать их требования специалистам, которые и будут реализовывать это приложение. Если у аналитика не хватает опыта для выполнения подобной работы, то скорее всего он задокументирует совсем не те требования, которые требуются компании.
На фиксирование неверных требований в соответствующей документации будет потрачено время, которое окажет влияние и на аналитику самого проекта, и на разработку программы бизнес-анализа в целом. Чтобы реализовать неверные требования, инженеры должны будут разработать код приложения бизнес-анализа. По мнению аналитиков 10-40% требований в создаваемом программном обеспечении не соответствуют реальности или просто лишние. Чем меньше будут эти цифры, тем заметнее снизятся затраты времени и финансов.
Улучшить эффективность проектов. Получение эффективных результатов от внедрения проекта достигается одним из двух способов: ограничением процесса внесения изменений в готовые части и уменьшением сроков реализации проекта.

Переделывание — это больное место любого производства. Так называется дополнительная работа, в результате которой будут исправлены допущенные ранее ошибки и внесены недостающие критерии. Процесс переделывания может возникнуть на любом из этапов разработки программы – от проектирования алгоритма до тестирования готового продукта. Вероятность его появления можно уменьшить, если не допускать ошибок в составлении критериев и процессе моделирования программы, и, если технические и деловые сотрудники работают над бизнес-проектом с самого начала.
Сокращение продолжительности проекта – это дополнительные выгоды для компании. Те ресурсы, которые выделялись для работы над проектом ежемесячно, за счет сокращения сроков будут высвобождаться и могут быть использованы для решения других задач. Соответственно, можно будет гораздо раньше приступить к новому проекту, что предполагает увеличение прибыли.
Законы бизнес-анализа, используемые для оценки эффективности вложений, должны применяться совместно с финансовыми требованиями и показателями удовлетворения потребностей всех участников проекта.
Основы бизнес-анализа
Основу бизнес-анализа составляют:
- изучение деятельности любого предприятия как единой системы;
- оценка всех происходящих на предприятии процессов в целом;
- выбор надежных методов и процедур для решения найденных проблем;
- регулярное проведение анализа с периодичностью, установленной самим предприятием;
- количественное подтверждение выводов;
- возможность доказать все выводы проведенного анализа;
- озвучивание того, как выявленные проблемы влияют на производственные результаты;
- сопоставление аналитической информации за разные периоды проведения анализа;
- сопоставимость затрат на проведение анализа с положительным эффектом от его применения;
- повышение ответственности работников за результаты анализа.
Все проекты бизнес-анализа развиваются на основе базового цикла. Каждый проект – это последовательность действий, приводящих к конкретным результатам. Все они отличаются друг от друга, но этапы бизнес-анализа всегда следуют в заданном порядке:
- Планирование. Разработайте план проведения анализа и продумайте подходы к нему.
- Охват проекта. Поставьте перед собой бизнес-задачу и четко очертите границы ее решения, задокументируйте их. Определите в рамках проекта, какие возможности или проблемы придется решить компании.
- Выявление и анализ требований. Важнейшая задача, которая решается специалистами на уровне проекта. Аналитики должны определить реальные потребности бизнеса и найти источник всех проблем, а также оповестить об этих требованиях целевую аудиторию.
- Разработка решения. Профессионалы в бизнес-анализе всегда готовы помочь проектной команде в разработке решения.
- Построение решения. На принятие решения влияют результаты выполнения предыдущих шагов. Поэтому оно должно соответствовать тем бизнес-потребностям, что были указаны в целях проекта и бизнес-требованиях.
- Тестирование решения. По мере выработки решения необходимо привлекать к работе команду тестировщиков, которые смогут проверить результат на соответствие бизнес-потребностям.
- Внедрение решения. Аналитики не должны работать вхолостую – убедитесь в том, что бизнес использует найденное решение. Активно сотрудничайте со всеми заинтересованными сторонами проекта по мере его внедрения. Станьте агентом изменений, доказывая их необходимость и обучая системе новых пользователей.
- Проведение анализа после внедрения. После завершения разработки и внедрения принятого решения еще раз проанализируйте его и убедитесь, что оно полностью отвечает целям проекта. Если будет обнаружено несоответствие, то, возможно, придется разрабатывать новый проект для его устранения.
10 методов бизнес-анализа
Если бизнес-анализ – это ряд проектов, то методы, которыми эти проекты воплощаются в жизнь, представляют собой разного рода процессы. Они используются для разработки планов по выяснению потребностей компании, после выполнения которых результативность ее работы должна повыситься. Не существует универсального метода, потому что все компании – разные и работают в различных сферах бизнеса.


Читайте также
Предлагаем ознакомиться с топ-10 методов системы бизнес-анализа. Специалисты, которые считают себя профессионалами в этой сфере и собираются стать менеджерами проекта, должны знать если не все, то большинство из этих методов.
Моделирование бизнес-процессов (BPM)
Довольно часто моделирование применяют, чтобы разобраться в расхождениях между текущими бизнес-процессами и любым будущим процессом, к которому двигается бизнес. Метод включает в себя четыре задачи:
- Стратегическое планирование.
- Анализ созданной бизнес-модели.
- Определение и проектирование процесса.
- Технический анализ сложных бизнес-решений.
BPM применяют во многих сферах бизнеса, особенно в IT, потому что метод позволяет легко представить последовательность шагов процесса выполнения и демонстрирует его работу в разных условиях.
Мозговой штурм
Старая проверенная техника генерации новых идей, определения основных причин проблемы и поиска ее решений. Мозговой штурм – это групповая активность. Подобную технику часто используют в методах PESTLE, SWOT и других.

С помощью этого метода появляются новые бизнес-идеи, на базе которых будет проходить очередной анализ.
Могут быть решены следующие вопросы:
- Какой метод подойдет для решения проблемы в данный момент собственными силами компании?
- Какие проблемы, требующие принятия решения, стоят перед компанией?
- Что может замедлить рабочий процесс?
- Какие возможности есть у компании для разрешения проблемной ситуации?
![]()
Точный инструмент «Колесо компетенций»
Для детального самоанализа по выбору IT-профессии
![]()
Список грубых ошибок в IT, из-за которых сразу увольняют
Об этом мало кто рассказывает, но это должен знать каждый
![]()
Мини-тест из 11 вопросов от нашего личного психолога
Вы сразу поймете, что в данный момент тормозит ваш успех
Регистрируйтесь на бесплатный интенсив, чтобы за 3 часа начать разбираться в IT лучше 90% новичков.
Только до 27 марта
Осталось 17 мест
Положительный эффект от мозгового штурма будет в том случае, если заранее точно сформулировать тему, которую надо обсудить, установить лимит времени, выяснить, как к этому процессу относятся сотрудники компании. Затем определить критерии, по которым будут оцениваться идеи, и отобрать для участия в процессе тех специалистов, которым есть что сказать по теме обсуждения.
После проведения мозгового штурма надо еще раз озвучить все новые предложения и убрать схожие. В итоге сформируется перечень идей, которые в той или иной степени способны решить проблемы, возникшие перед компанией.
Плюсы: большая экономия времени – за несколько часов удается сформировать большой пакет предложений. Кроме этого, сотрудники получают возможность проявить свое творческое мышление, а иногда мозговой штурм способен даже снять напряжение в отношениях.
Минусы: результаты бизнес-анализа, проведенного методом мозгового штурма, в большой степени зависят от проявленного к нему интереса со стороны участников. Помешать проявлению активности в процессе обсуждения могут существующие взаимоотношения между членами команды. Предлагаемые идеи не стоит оспаривать, иначе процесс превратится в дебаты и не даст ожидаемого результата, время будет потрачено впустую.
Техника принятия решений CATWOE
Метод CATWOE позволяет собрать вместе мнения различных заинтересованных сторон, что дает возможность определить ведущих игроков и бенефициаров. Эту технику бизнес-аналитики используют обычно для того, чтобы оценить, как любое планируемое действие будет воспринято разными сторонами.
- Клиенты (Customers): кому выгоден данный бизнес?
- Действующие лица (Actors): кто является участником процесса?
- Процесс трансформации (Transformation Process): как происходит процесс трансформации, лежащий в основе данной системы?
- Глобальный взгляд (World View): какова общая картина происходящего?
- Владелец (Owner): кто владеет данной системой и какие у них взаимоотношения?
- Внешние факторы и ограничения (Environmental Constraints): какие ограничения существуют и как они влияют на решения?
Moscow (Must or Should, Could or Would)
Этот метод помогает расставить требования в приоритетном порядке, сравнивая их между собой. К каждому из них выдвигается вопрос о том, насколько оно необходимо. Является данный пункт обязательным для выполнения или можно его обойти? Поможет требование улучшить продукт в текущий момент времени или можно эту хорошую идею пока отложить, чтобы использовать в будущем?
MOST-анализ (Mission, Objectives, Strategies, and Tactics)
Мощная платформа для стратегического бизнес-анализа считается одним из лучших методов, помогающих определить цели организации и ее возможности. Техника как раз и строится на подробном внутреннем анализе целей предприятия и способов их достижения. Расшифруем акроним:
- Миссия (Mission): какова цель компании?
- Цели (Objectives): каковы ключевые цели, помогающие исполнить миссию?
- Стратегии (Strategies): какие существуют возможности достижения целей?
- Тактики (Tactics): какие методы организации следует взять на вооружение, чтобы осуществить стратегию?
PESTLE-анализ
PESTLE-модель (или просто PEST) помогает определить внешние факторы, влияющие на компанию, и то, как их надо учитывать при принятии бизнес-решений. Влияние может быть:
- Политическим: финансовая поддержка и субсидии, помощь со стороны государства, политика.
- Экономическим: трудовые затраты и энергоресурсы, инфляция, процентные банковские ставки.
- Социологическим: образование, культура, СМИ, уровень жизни, население.
- Технологическим: инновационные технологии информационных и коммуникационных систем.
- Юридическим: местные и национальные правительственные постановления, указы и стандарты занятости населения.
- Экологическим: состояние окружающей среды, отходы, переработка, загрязнения, погода и климат.
Все эти факторы легко поддаются изучению и анализу, в результате бизнес-аналитики приходят к более полному понимаю их влияния на концепцию развития компании. В результате разрабатываются полные и соответствующие моменту стратегии принятия решений.
SWOT-анализ
Очень популярный метод в бизнес-аналитике. С его помощью определяются сильные и слабые стороны в структуре компании, возможности и угрозы, идущие от внешних факторов. Аналитики используют эти понятия, чтобы сформулировать понятные и обоснованные решения, приводящие к грамотному распределению ресурсов и организационному улучшению. Четыре элемента SWOT:
- Сильные стороны: те качества проекта или бизнеса, которые обеспечивают конкурентное преимущество.
- Слабые стороны: свойства бизнеса, ухудшающие положение проекта или организации по сравнению со схожими проектами или конкурирующими фирмами.
- Возможности: внешние факторы, которые могут принести пользу проекту или бизнесу.
- Угрозы: элементы внешней среды, способные затормозить проект.
SWOT-анализ представляет собой универсальную технику управления бизнес-анализом, которую можно одинаково успешно применять и для быстрого, и для более глубокого анализа деятельности любой компании. С помощью SWOT-анализа можно оценивать и другие объекты – группы, функции, отдельных лиц.
Шесть шляп мышления
Эта техника рассчитана на групповой анализ, она поощряет людей высказывать различные идеи и мнения, а затем в процессе обсуждения приходить к верному решению. В «Шесть шляп» входят:
- Белая: акцент на данных и логике.
- Красная: анализ ситуации через призму интуиции, эмоций и ощущений.
- Черная: предположение отрицательных результатов, критическое мнение.
- Желтая: акцент на позитиве, оптимистичная точка зрения.
- Зеленая: креативность, новые идеи и неожиданный взгляд на привычные вещи.
- Синяя: общий план, рефлексивное мышление.
Метод шести шляп мышления очень хорошо сочетается с мозговым штурмом, давая возможность участникам высказывать и учитывать порой абсолютно противоположные точки зрения.
«5 почему»
Эту технику применяют в методологии «шесть сигм» (Six Sigma) и в бизнес-анализе. Она состоит из серии наводящих вопросов, помогающих бизнес-аналитику докопаться до первоисточника проблемы и принять верное решение. Первым ставится вопрос о причине возникновения проблемы, а затем еще четыре «почему», связанные логической цепочкой. Рассмотрим метод на примере:
- Почему клиент отказывается принимать устройства? Потому что были поставлены не те модели, что прописаны в договоре купли-продажи.
- Почему были поставлены не те модели? Потому что в базу данных была введена некорректная информация о продукте.
- Почему в базу данных попала неверная информация? Потому что из-за недостаточности средств модернизация программного обеспечения базы данных проводится крайне редко.
- Почему выделяется недостаточно средств? Потому что у наших менеджеров эта задача не стоит в числе первоочередных.
- Почему этот вопрос не входит в число приоритетных? Потому что никому не было известно, как часто возникала эта проблема.
Выводы из анализа сложившейся ситуации: необходимо вести учет всех подобных инцидентов; обязать менеджеров читать эти отчеты; выделить из бюджета средства на регулярное обновление ПО базы данных.
Анализ нефункциональных требований
Метод применим к любому проекту, в котором технологические решения менялись или создавались с нуля. С помощью бизнес-анализа специалист находит и фиксирует те характеристики, которые необходимы для новой или модернизированной системы. При этом часто возникают такие требования, как хранение данных или производительность. Анализ нефункциональных требований обычно включает в себя:
- Сбор данных
- Производительность
- Надежность
- Безопасность
5 типичных ошибок бизнес-анализа
Какие риски бизнес-анализа возникают в результате допущенных ошибок:
- Отсутствие четкой формулировки бизнес-цели
Задайте сами себе вопросы, которые помогут вам понять, насколько точно вы сформулировали цели вашей организации. В чем состоит главная цель компании? К каким результатам вы стремитесь? Если цель будет достигнута, означает ли это, что нужный результат получен? Насколько логично выглядит формулировка вашей цели?
Цель организации – это то, ради чего компания и была создана. Поэтому она должна быть четко и понятно сформулированной. Не путайте цель организации с ее интересами. Понятие цели имеет более глубокий и емкий смысл, при ее правильной формулировке компания обязательно добьется успеха.

Читайте также
- Непонимание и недооценка зависимости бизнес-анализа от качества управления
Сотрудники компании вправе знать о тех нововведениях, что собирается проводить руководство. Именно так вводится методика бизнес-анализа Business Intelligence, зависящая от того, насколько сотрудники осознают и принимают ее важность. Персонал – это часть компании, но чаще всего руководство выбирает политику ее деятельности, не ставя сотрудников в известность.
Им просто сообщают о каких-то новшествах, не учитывая их мнение по этому поводу, что зачастую приводит к конфликтам и снижению эффективности рабочего процесса. Игнорирование руководством понятного желания персонала быть в курсе всех изменений, его нежелание рассказывать о том, как бизнес-анализ поможет усовершенствовать рабочий процесс, зачастую приводит к негативным ситуациям и снижению качества работы.
- Пренебрежение нужными людьми
Если раньше многие организации считали, что с результатами бизнес-анализа достаточно ознакомить лишь некоторых сотрудников, поскольку простые рабочие ничего не решают, то сегодня ситуация изменилась. Практика ведения проектов показала, что в успешном развитии предприятия участвуют все сотрудники, поэтому информация об итогах бизнес-анализа должна быть для них доступна.

- Стремление к сокрытию информации
Если методика бизнес-анализа была выбрана неверно и оказалась малоэффективной, то это может привести к утаиванию верной информации, уменьшению скорости введения изменений, неполному использованию возможностей и в итоге – к провалу проекта. Неполная информация приводит к искажению фактов и, как следствие, появлению неверных данных, что может довести компанию до полного краха.
Новейшие информационные технологии поднимают уровень открытости данных, надо лишь, чтобы все подразделения компании осознавали необходимость их введения. Тогда каждый сотрудник сможет ознакомиться с результатами деятельности своего предприятия, вынесенными на информационные табло в виде графиков и схем. Свободный доступ к правдивой информации о компании повышает эффективность рабочего процесса.
- Медлительность
Если вы поставили за правило держать информацию о результатах бизнес-анализа в открытом доступе, то будет логичным сделать следующий шаг – использовать эти данные для эффективных действий и планирования рабочего процесса в дальнейшем. Важно понимать, что принятие решения на основе ценной информации должно пройти быстро, пока эти данные не потеряли свою актуальность.
Это в первую очередь касается руководства компании во главе с генеральным директором, которые несут ответственность за скорость принятия решений. Степень их готовности к решительным действиям отражается на эффективности работы всего коллектива. Если же возникают какие-то сомнения, то всегда можно получить подробные разъяснения от специалистов.
Если выяснилось, что руководство сомневается в эффективности какой-либо программы, то отдел, отвечающий за проведение бизнес-анализа, должен разработать комплекс мер, подтверждающий правильность выбранного решения. Этот человек может сомневаться, скрывать информацию, стать источником других проблем. Любая программа при условии точного внесения достоверных данных застрахована от ошибок.
Настоящее положение дел в компании способен показать и доказать только бизнес-анализ, основанный на современных технологиях. Важные бизнес-идеи должны подтверждаться реальными фактами. Бизнес-анализ нужен не только и не столько для получения информации, сколько для правильного планирования деятельности компании в дальнейшем.

Автор: Кирилл Забавский
Курс скачан из открытых интернет-источников. Авторские права на продукты принадлежат только их владельцам. Основная цель сайта — это предоставление пользователям бесплатного материала для самостоятельного обучения. Если вы заметили нарушение своих авторских прав, то вы можете связаться с нами для удаления вашего продукта с нашего сайта по ссылке>>>>>
С Уважением,
Администрация проекта learn-free.site «Учитесь бесплатно»
ОПИСАНИЕ
Основы Бизнес-анализа в ИТ. От А до БА. Полный онлайн-курс по основам Бизнес-анализа в ИТ. 4+ часов видео, материалов, занятий, тестов и т.д.
Ни для кого не секрет, что мир информационных технологий постоянно развивается. Системы становятся все сложнее и разнообразнее. Исходя из этого появляется необходимость в формировании некоторой прослойки между бизнесом и разработкой. Именно этой прослойкой становится Бизнес-анализ. Он помогает объединить представителей бизнеса и команду разработки. Помимо этого Бизнес-анализ позволяет увеличить вероятность успеха продукта, сформировать четкое видение конечного решения, а также составить четкие критерии успеха для всего проекта в целом.
Данный курс помогает разобраться в основах бизнес-анализа и специфике работы бизнес-аналитика в ИТ компаниях. Здесь вы сможете узнать о необходимых навыках, которыми должен обладать бизнес-аналитик, познакомитесь с основными артефактами и инструментами, которые использует бизнес-аналитик на проекте. Помимо этого, в курсе будут рассмотрены различные практические примеры из жизни Бизнес-аналитика, приведены популярные шаблоны документов и полезные лайфхаки.
В дополнительных источниках каждой лекции вы сможете найти различные документы, материалы каждой темы, а также дополнительные ссылки на информационные ресурсы. Во время прохождения курса вы сможете закрепить полученные знания с помощью различных тестовых заданий. В последнем разделе курса вы сможете найти полезный документ с дополнительной литературой и ссылками на наиболее популярные инструменты, которые используют бизнес-аналитики в своей работе.
ВАШ ПРЕПОДАВАТЕЛЬ:
Кирилл Забавский ведущий бизнес-аналитик и ресурсный менеджер в ИТ-компании, имеющий опыт работы более чем в 6 проектах в различных сферах, начиная от финансовых систем и заканчивая образовательными платформами. Помимо этого у преподавателя имеются различные международные сертификации по Бизнес-анализу, гибким методологиям и работы с требованиями.
ДЛЯ КОГО КУРС:
- Данный курс предназначен для людей, которые хотят познакомиться с основами бизнес-анализа в ИТ компании и получить структурированную информацию в начале карьеры бизнес-аналитика.
Требования
- Предварительных требований нет, хотя знакомство с основами бизнес-анализа полезно.
Чему вы научитесь:
- Кто такой бизнес-аналитик
- Навыки Бизнес-аналитика
- Виды требований
- Способы выявления требований: общение, наблюдение, опросные листы, анализ документов и функциональности систем
- Способы документирования требований: Пользовательские истории, Варианты использования и прочие
- Вайрфреймы, Прототипы и Мокапы
- Диаграммы в нотации BPMN
- Диаграммы в нотации UML
- Прочие диаграммы
- Документ об образе и границах
- Спецификация требований к ПО
- Экономическое обоснование
- Проект: участники, этапы и особенности
- Классическая методология управления проектом
- Гибкая методология управления проектом
- Гибридная методология управления проектом
- Scrum и Kanban
- Бонусный раздел с полезной информацией и документами
ВНИМАНИЕ!
СКАЧИВАЙТЕ КУРС СРАЗУ