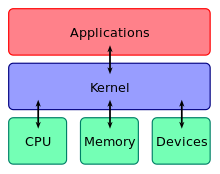
Ядро операционной системы представляет собой центральную программную часть любой системы. То есть ядро присутствует у каждой ОС: Windows, Linux и др. Оно координирует доступ сторонних программ к жизненно важным ресурсам компьютера, например:
времени работы процессора;
оперативной памяти;
внешним аппаратным устройствам, подключенным к компьютеру;
устройствам ввода и вывода информации;
и др.
Когда мы произносим слово «ядро», у большинства людей возникает ассоциация с чем-то круглым. Однако ядро операционной системы представляет собой основной программный код. Его можно представить, ассоциируя с ядром Земли. Каждый пользователь еще из курса школьной географии знает, что внутри Земли расположено ядро, а поверх ядра располагаются:
внешнее ядро,
нижняя мантия,
верхняя мантия,
земная кора, на поверхности которой живут люди.
Ядро операционной системы компьютера работает по такой же схеме. Оно расположено «глубоко внутри», а поверх него нанизывают все остальное, что в комплексе и составляет компьютерное устройство:
процессор,
оперативную память,
hard-диски,
программное обеспечение,
периферийное оборудование,
и др.
Ядро операционной системы
Ядро операционной системы — это некая программа. Каждая программа в программировании разрабатывается на основе определенной архитектуры, структуры, шаблона. Поэтому ядра могут быть представлены в нескольких архитектурах. Например:
Монолитное ядро операционной системы. Это «проверенный временем» способ организовать операционную систему. Монолитные ядра в основном применялись и применяются в UNIX-системах. Напомним, большинство дистрибутивов Linux разработаны на основе UNIX-системы. Суть его простая — ядро представляет единую программу, и все компоненты ядра находятся внутри этой программы, являясь ее частями. Отличается высокой скоростью работы, но имеет существенный недостаток — проблема в работе одного из компонентов приводит к общему сбою работоспособности ядра.
Модульное ядро операционной системы. По сути, представляет собой более «продвинутое» монолитное ядро. Подобное ядро располагает все такой же монолитной архитектурой, однако его отдельные компоненты представляют собой отдельные модули. К примеру, когда необходимо обновить какой-либо компонент монолитного ядра, происходит обновление всего ядра, так как невозможно обновить компонент отдельно. Если необходимо обновить компонент в модульном ядре, тогда происходит обновление только модуля, в котором содержится компонент. Таким образом, обновление компонентов ядра может происходит без перезагрузки операционной системы, а непосредственно во время работы устройства.
Микроядро. Микроядро — это отдельный компонент, то есть какая-то элементарная функция, которая функционирует отдельно. В модульной архитектуре все компоненты представляют собой отдельные модули, но при этом входят в состав единой программы (ядра). Микроядра работают как бы отдельно. Другими словами, это более «продвинутое» модульное ядро с более высоким показателем «модульности». Микроядра более устойчивы к проблемам в системе, чем модульное ядро, так как связь между микроядрами менее выражена, нежели между модулями.
Экзоядро. Такой тип ядра предлагает только те функции, которые нужны для взаимодействия между процессорами устройства. Эти ядра подключают все необходимые процессы из внешних библиотек, а не содержат их внутри себя. Их можно сравнить с технологией API.
Наноядро. Такой тип архитектуры использовался в первых операционных системах. Подобные ядра выполняют самые примитивные команды и задачи. Например, они обрабатывают аппаратные прерывания и отсылают информацию об этом вышестоящим программам.
Гибридное ядро. При такой архитектуре «смешиваются» различные архитектуры ядер, которые мы описали чуть выше.
Каждый вид архитектуры имеет собственные достоинства и недостатки. Большинство современных операционных систем не используют какую-то архитектуру в единственном «чистом» виде. Например, большинство Linux-дистрибутивов используют монолитные ядра с элементами модульного подхода, то есть в монолитной структуре ядра лишь часть компонентов заняла модули. Ядро операционной системы Windows также имеет гибридную архитектуру, однако здесь «смешиваются» монолитные ядра с микроядрами, но в более высоких пропорциях, чем в Linux-системах. То есть Линукс больше придерживается монолитной архитектуры, а Windows — гибридной.
«Смешивание» разных ядер дает возможность воспользоваться достоинствами разных архитектур, однако их недостатки тоже присутствуют и никуда не исчезают.
Ядро операционной системы: функции
Архитектура ядра влияет только на его внутреннее строение, производительность, обновления. Функции каждого вида ядра остаются неизменными. Например, ядро операционной системы выполняет следующие функции:
Управляет процессами. За этим выражением кроется огромная работа операционной системы. Как только пользователь запускает устройство, система начинает выполнять большое количество видимых и не видимых пользователю задач. Каждая отдельная задача представляет собой процесс, которым управляет ядро операционной системы. В этом контексте можно представить ядро регулировщиком дорожного движения на перекрестке с большим потоком автомобилей, движущихся в разных направлениях. Если «регулировщик» оплошает, тогда может наступить коллапс.
Управляет памятью. Каждому запущенному процессу необходима оперативная память. Оперативной памяти на все запущенные процессы на хватает, поэтому важно, чтобы кто-то контролировал использование оперативной памяти и в случае окончания работы одного процесса высвобождал память для запуска другого процесса. «Слежкой» за памятью занимается ядро операционной системы.
Управляет периферийными устройствами. К компьютеру могут быть подключены разные дополнительные устройства, например: клавиатура, мышь, экран, другой компьютер, модем, принтер и др. За взаимодействие между всеми устройствами отвечает ядро операционной системы, например: ввод информации с клавиатуры, вывод информации на экран, отправка документов на печать, обмен информации между компьютерными устройствами по интернету и др.
Управляет прерыванием. Запущенных процессов в системе может быть очень много. Их обработка происходит в определенной последовательности, но бывают такие процессы, которые нужно выполнить в приоритетном порядке. В этом случае необходимо прервать запущенный процесс, чтобы обработать приоритетный, а потом закончить «прерванный». Если вспомнить «регулировщика», тогда это напоминает процесс, когда движется автомобиль со специальными сигналами. «Регулировщик» вынужден остановить поток, пропустить спецавтомобиль, а потом возобновить движение потока автомобилей.
Заключение
Ядро операционной системы — это «главный» набор инструкций, благодаря которому работает компьютер. Ядро ОС означает, что оно лежит в основе работы любой операционной системы. На него накладываются все возможности ОС и все дополнительное программное обеспечение. От эффективности работы ядра зависит производительность и эффективность операционной системы. От эффективности ОС зависит работа компьютерного устройства.
The kernel is a computer program at the core of a computer’s operating system and generally has complete control over everything in the system.[1] It is the portion of the operating system code that is always resident in memory[2] and facilitates interactions between hardware and software components. A full kernel controls all hardware resources (e.g. I/O, memory, cryptography) via device drivers, arbitrates conflicts between processes concerning such resources, and optimizes the utilization of common resources e.g. CPU & cache usage, file systems, and network sockets. On most systems, the kernel is one of the first programs loaded on startup (after the bootloader). It handles the rest of startup as well as memory, peripherals, and input/output (I/O) requests from software, translating them into data-processing instructions for the central processing unit.
The critical code of the kernel is usually loaded into a separate area of memory, which is protected from access by application software or other less critical parts of the operating system. The kernel performs its tasks, such as running processes, managing hardware devices such as the hard disk, and handling interrupts, in this protected kernel space. In contrast, application programs such as browsers, word processors, or audio or video players use a separate area of memory, user space. This separation prevents user data and kernel data from interfering with each other and causing instability and slowness,[1] as well as preventing malfunctioning applications from affecting other applications or crashing the entire operating system. Even in systems where the kernel is included in application address spaces, memory protection is used to prevent unauthorized applications from modifying the kernel.
The kernel’s interface is a low-level abstraction layer. When a process requests a service from the kernel, it must invoke a system call, usually through a wrapper function.
There are different kernel architecture designs. Monolithic kernels run entirely in a single address space with the CPU executing in supervisor mode, mainly for speed. Microkernels run most but not all of their services in user space,[3] like user processes do, mainly for resilience and modularity.[4] MINIX 3 is a notable example of microkernel design. Instead, the Linux kernel is monolithic, although it is also modular, for it can insert and remove loadable kernel modules at runtime.
This central component of a computer system is responsible for executing programs. The kernel takes responsibility for deciding at any time which of the many running programs should be allocated to the processor or processors.
Random-access memory[edit]
Random-access memory (RAM) is used to store both program instructions and data.[a] Typically, both need to be present in memory in order for a program to execute. Often multiple programs will want access to memory, frequently demanding more memory than the computer has available. The kernel is responsible for deciding which memory each process can use, and determining what to do when not enough memory is available.
Input/output devices[edit]
I/O devices include such peripherals as keyboards, mice, disk drives, printers, USB devices, network adapters, and display devices. The kernel allocates requests from applications to perform I/O to an appropriate device and provides convenient methods for using the device (typically abstracted to the point where the application does not need to know implementation details of the device).
Resource management[edit]
Key aspects necessary in resource management are defining the execution domain (address space) and the protection mechanism used to mediate access to the resources within a domain.[5] Kernels also provide methods for synchronization and inter-process communication (IPC). These implementations may be located within the kernel itself or the kernel can also rely on other processes it is running. Although the kernel must provide IPC in order to provide access to the facilities provided by each other, kernels must also provide running programs with a method to make requests to access these facilities. The kernel is also responsible for context switching between processes or threads.
Memory management[edit]
The kernel has full access to the system’s memory and must allow processes to safely access this memory as they require it. Often the first step in doing this is virtual addressing, usually achieved by paging and/or segmentation. Virtual addressing allows the kernel to make a given physical address appear to be another address, the virtual address. Virtual address spaces may be different for different processes; the memory that one process accesses at a particular (virtual) address may be different memory from what another process accesses at the same address. This allows every program to behave as if it is the only one (apart from the kernel) running and thus prevents applications from crashing each other.[6]
On many systems, a program’s virtual address may refer to data which is not currently in memory. The layer of indirection provided by virtual addressing allows the operating system to use other data stores, like a hard drive, to store what would otherwise have to remain in main memory (RAM). As a result, operating systems can allow programs to use more memory than the system has physically available. When a program needs data which is not currently in RAM, the CPU signals to the kernel that this has happened, and the kernel responds by writing the contents of an inactive memory block to disk (if necessary) and replacing it with the data requested by the program. The program can then be resumed from the point where it was stopped. This scheme is generally known as demand paging.
Virtual addressing also allows creation of virtual partitions of memory in two disjointed areas, one being reserved for the kernel (kernel space) and the other for the applications (user space). The applications are not permitted by the processor to address kernel memory, thus preventing an application from damaging the running kernel. This fundamental partition of memory space has contributed much to the current designs of actual general-purpose kernels and is almost universal in such systems, although some research kernels (e.g., Singularity) take other approaches.
Device management[edit]
To perform useful functions, processes need access to the peripherals connected to the computer, which are controlled by the kernel through device drivers. A device driver is a computer program encapsulating, monitoring and controlling a hardware device (via its Hardware/Software Interface (HSI)) on behalf of the OS. It provides the operating system with an API, procedures and information about how to control and communicate with a certain piece of hardware. Device drivers are an important and vital dependency for all OS and their applications. The design goal of a driver is abstraction; the function of the driver is to translate the OS-mandated abstract function calls (programming calls) into device-specific calls. In theory, a device should work correctly with a suitable driver. Device drivers are used for e.g. video cards, sound cards, printers, scanners, modems, and Network cards.
At the hardware level, common abstractions of device drivers include:
- Interfacing directly
- Using a high-level interface (Video BIOS)
- Using a lower-level device driver (file drivers using disk drivers)
- Simulating work with hardware, while doing something entirely different
And at the software level, device driver abstractions include:
- Allowing the operating system direct access to hardware resources
- Only implementing primitives
- Implementing an interface for non-driver software such as TWAIN
- Implementing a language (often a high-level language such as PostScript)
For example, to show the user something on the screen, an application would make a request to the kernel, which would forward the request to its display driver, which is then responsible for actually plotting the character/pixel.[6]
A kernel must maintain a list of available devices. This list may be known in advance (e.g., on an embedded system where the kernel will be rewritten if the available hardware changes), configured by the user (typical on older PCs and on systems that are not designed for personal use) or detected by the operating system at run time (normally called plug and play). In plug-and-play systems, a device manager first performs a scan on different peripheral buses, such as Peripheral Component Interconnect (PCI) or Universal Serial Bus (USB), to detect installed devices, then searches for the appropriate drivers.
As device management is a very OS-specific topic, these drivers are handled differently by each kind of kernel design, but in every case, the kernel has to provide the I/O to allow drivers to physically access their devices through some port or memory location. Important decisions have to be made when designing the device management system, as in some designs accesses may involve context switches, making the operation very CPU-intensive and easily causing a significant performance overhead.[citation needed]
System calls[edit]
In computing, a system call is how a process requests a service from an operating system’s kernel that it does not normally have permission to run. System calls provide the interface between a process and the operating system. Most operations interacting with the system require permissions not available to a user-level process, e.g., I/O performed with a device present on the system, or any form of communication with other processes requires the use of system calls.
A system call is a mechanism that is used by the application program to request a service from the operating system. They use a machine-code instruction that causes the processor to change mode. An example would be from supervisor mode to protected mode. This is where the operating system performs actions like accessing hardware devices or the memory management unit. Generally the operating system provides a library that sits between the operating system and normal user programs. Usually it is a C library such as Glibc or Windows API. The library handles the low-level details of passing information to the kernel and switching to supervisor mode. System calls include close, open, read, wait and write.
To actually perform useful work, a process must be able to access the services provided by the kernel. This is implemented differently by each kernel, but most provide a C library or an API, which in turn invokes the related kernel functions.[7]
The method of invoking the kernel function varies from kernel to kernel. If memory isolation is in use, it is impossible for a user process to call the kernel directly, because that would be a violation of the processor’s access control rules. A few possibilities are:
- Using a software-simulated interrupt. This method is available on most hardware, and is therefore very common.
- Using a call gate. A call gate is a special address stored by the kernel in a list in kernel memory at a location known to the processor. When the processor detects a call to that address, it instead redirects to the target location without causing an access violation. This requires hardware support, but the hardware for it is quite common.
- Using a special system call instruction. This technique requires special hardware support, which common architectures (notably, x86) may lack. System call instructions have been added to recent models of x86 processors, however, and some operating systems for PCs make use of them when available.
- Using a memory-based queue. An application that makes large numbers of requests but does not need to wait for the result of each may add details of requests to an area of memory that the kernel periodically scans to find requests.
Kernel design decisions[edit]
Protection[edit]
An important consideration in the design of a kernel is the support it provides for protection from faults (fault tolerance) and from malicious behaviours (security). These two aspects are usually not clearly distinguished, and the adoption of this distinction in the kernel design leads to the rejection of a hierarchical structure for protection.[5]
The mechanisms or policies provided by the kernel can be classified according to several criteria, including: static (enforced at compile time) or dynamic (enforced at run time); pre-emptive or post-detection; according to the protection principles they satisfy (e.g., Denning[8][9]); whether they are hardware supported or language based; whether they are more an open mechanism or a binding policy; and many more.
Support for hierarchical protection domains[10] is typically implemented using CPU modes.
Many kernels provide implementation of «capabilities», i.e., objects that are provided to user code which allow limited access to an underlying object managed by the kernel. A common example is file handling: a file is a representation of information stored on a permanent storage device. The kernel may be able to perform many different operations, including read, write, delete or execute, but a user-level application may only be permitted to perform some of these operations (e.g., it may only be allowed to read the file). A common implementation of this is for the kernel to provide an object to the application (typically so called a «file handle») which the application may then invoke operations on, the validity of which the kernel checks at the time the operation is requested. Such a system may be extended to cover all objects that the kernel manages, and indeed to objects provided by other user applications.
An efficient and simple way to provide hardware support of capabilities is to delegate to the memory management unit (MMU) the responsibility of checking access-rights for every memory access, a mechanism called capability-based addressing.[11] Most commercial computer architectures lack such MMU support for capabilities.
An alternative approach is to simulate capabilities using commonly supported hierarchical domains. In this approach, each protected object must reside in an address space that the application does not have access to; the kernel also maintains a list of capabilities in such memory. When an application needs to access an object protected by a capability, it performs a system call and the kernel then checks whether the application’s capability grants it permission to perform the requested action, and if it is permitted performs the access for it (either directly, or by delegating the request to another user-level process). The performance cost of address space switching limits the practicality of this approach in systems with complex interactions between objects, but it is used in current operating systems for objects that are not accessed frequently or which are not expected to perform quickly.[12][13]
If the firmware does not support protection mechanisms, it is possible to simulate protection at a higher level, for example by simulating capabilities by manipulating page tables, but there are performance implications.[14] Lack of hardware support may not be an issue, however, for systems that choose to use language-based protection.[15]
An important kernel design decision is the choice of the abstraction levels where the security mechanisms and policies should be implemented. Kernel security mechanisms play a critical role in supporting security at higher levels.[11][16][17][18][19]
One approach is to use firmware and kernel support for fault tolerance (see above), and build the security policy for malicious behavior on top of that (adding features such as cryptography mechanisms where necessary), delegating some responsibility to the compiler. Approaches that delegate enforcement of security policy to the compiler and/or the application level are often called language-based security.
The lack of many critical security mechanisms in current mainstream operating systems impedes the implementation of adequate security policies at the application abstraction level.[16] In fact, a common misconception in computer security is that any security policy can be implemented in an application regardless of kernel support.[16]
According to Mars Research Group developers, a lack of isolation is one of the main factors undermining kernel security.[20] They propose their driver isolation framework for protection, primarily in the Linux kernel.[21][22]
Hardware- or language-based protection[edit]
Typical computer systems today use hardware-enforced rules about what programs are allowed to access what data. The processor monitors the execution and stops a program that violates a rule, such as a user process that tries to write to kernel memory. In systems that lack support for capabilities, processes are isolated from each other by using separate address spaces.[23] Calls from user processes into the kernel are regulated by requiring them to use one of the above-described system call methods.
An alternative approach is to use language-based protection. In a language-based protection system, the kernel will only allow code to execute that has been produced by a trusted language compiler. The language may then be designed such that it is impossible for the programmer to instruct it to do something that will violate a security requirement.[15]
Advantages of this approach include:
- No need for separate address spaces. Switching between address spaces is a slow operation that causes a great deal of overhead, and a lot of optimization work is currently performed in order to prevent unnecessary switches in current operating systems. Switching is completely unnecessary in a language-based protection system, as all code can safely operate in the same address space.
- Flexibility. Any protection scheme that can be designed to be expressed via a programming language can be implemented using this method. Changes to the protection scheme (e.g. from a hierarchical system to a capability-based one) do not require new hardware.
Disadvantages include:
- Longer application startup time. Applications must be verified when they are started to ensure they have been compiled by the correct compiler, or may need recompiling either from source code or from bytecode.
- Inflexible type systems. On traditional systems, applications frequently perform operations that are not type safe. Such operations cannot be permitted in a language-based protection system, which means that applications may need to be rewritten and may, in some cases, lose performance.
Examples of systems with language-based protection include JX and Microsoft’s Singularity.
Process cooperation[edit]
Edsger Dijkstra proved that from a logical point of view, atomic lock and unlock operations operating on binary semaphores are sufficient primitives to express any functionality of process cooperation.[24] However this approach is generally held to be lacking in terms of safety and efficiency, whereas a message passing approach is more flexible.[25] A number of other approaches (either lower- or higher-level) are available as well, with many modern kernels providing support for systems such as shared memory and remote procedure calls.
I/O device management[edit]
The idea of a kernel where I/O devices are handled uniformly with other processes, as parallel co-operating processes, was first proposed and implemented by Brinch Hansen (although similar ideas were suggested in 1967[26][27]). In Hansen’s description of this, the «common» processes are called internal processes, while the I/O devices are called external processes.[25]
Similar to physical memory, allowing applications direct access to controller ports and registers can cause the controller to malfunction, or system to crash. With this, depending on the complexity of the device, some devices can get surprisingly complex to program, and use several different controllers. Because of this, providing a more abstract interface to manage the device is important. This interface is normally done by a device driver or hardware abstraction layer. Frequently, applications will require access to these devices. The kernel must maintain the list of these devices by querying the system for them in some way. This can be done through the BIOS, or through one of the various system buses (such as PCI/PCIE, or USB). Using an example of a video driver, when an application requests an operation on a device, such as displaying a character, the kernel needs to send this request to the current active video driver. The video driver, in turn, needs to carry out this request. This is an example of inter-process communication (IPC).
Kernel-wide design approaches[edit]
Naturally, the above listed tasks and features can be provided in many ways that differ from each other in design and implementation.
The principle of separation of mechanism and policy is the substantial difference between the philosophy of micro and monolithic kernels.[28][29] Here a mechanism is the support that allows the implementation of many different policies, while a policy is a particular «mode of operation». Example:
- Mechanism: User login attempts are routed to an authorization server
- Policy: Authorization server requires a password which is verified against stored passwords in a database
Because the mechanism and policy are separated, the policy can be easily changed to e.g. require the use of a security token.
In minimal microkernel just some very basic policies are included,[29] and its mechanisms allows what is running on top of the kernel (the remaining part of the operating system and the other applications) to decide which policies to adopt (as memory management, high level process scheduling, file system management, etc.).[5][25] A monolithic kernel instead tends to include many policies, therefore restricting the rest of the system to rely on them.
Per Brinch Hansen presented arguments in favour of separation of mechanism and policy.[5][25] The failure to properly fulfill this separation is one of the major causes of the lack of substantial innovation in existing operating systems,[5] a problem common in computer architecture.[30][31][32] The monolithic design is induced by the «kernel mode»/»user mode» architectural approach to protection (technically called hierarchical protection domains), which is common in conventional commercial systems;[33] in fact, every module needing protection is therefore preferably included into the kernel.[33] This link between monolithic design and «privileged mode» can be reconducted to the key issue of mechanism-policy separation;[5] in fact the «privileged mode» architectural approach melds together the protection mechanism with the security policies, while the major alternative architectural approach, capability-based addressing, clearly distinguishes between the two, leading naturally to a microkernel design[5] (see Separation of protection and security).
While monolithic kernels execute all of their code in the same address space (kernel space), microkernels try to run most of their services in user space, aiming to improve maintainability and modularity of the codebase.[4] Most kernels do not fit exactly into one of these categories, but are rather found in between these two designs. These are called hybrid kernels. More exotic designs such as nanokernels and exokernels are available, but are seldom used for production systems. The Xen hypervisor, for example, is an exokernel.
Monolithic kernels[edit]

Diagram of a monolithic kernel
In a monolithic kernel, all OS services run along with the main kernel thread, thus also residing in the same memory area. This approach provides rich and powerful hardware access. UNIX developer Ken Thompson stated that «it is in [his] opinion easier to implement a
monolithic kernel».[34] The main disadvantages of monolithic kernels are the dependencies between system components – a bug in a device driver might crash the entire system – and the fact that large kernels can become very difficult to maintain; Thompson also stated that «It is also easier for [a monolithic kernel] to turn into a mess in a hurry as it is modified.»[34]
Monolithic kernels, which have traditionally been used by Unix-like operating systems, contain all the operating system core functions and the device drivers. A monolithic kernel is one single program that contains all of the code necessary to perform every kernel-related task. Every part which is to be accessed by most programs which cannot be put in a library is in the kernel space: Device drivers, scheduler, memory handling, file systems, and network stacks. Many system calls are provided to applications, to allow them to access all those services. A monolithic kernel, while initially loaded with subsystems that may not be needed, can be tuned to a point where it is as fast as or faster than the one that was specifically designed for the hardware, although more relevant in a general sense.
Modern monolithic kernels, such as the Linux kernel, the FreeBSD kernel, the AIX kernel, the HP-UX kernel, and the Solaris kernel, all of which fall into the category of Unix-like operating systems, support loadable kernel modules, allowing modules to be loaded into the kernel at runtime, permitting easy extension of the kernel’s capabilities as required, while helping to minimize the amount of code running in kernel space.
Most work in the monolithic kernel is done via system calls. These are interfaces, usually kept in a tabular structure, that access some subsystem within the kernel such as disk operations. Essentially calls are made within programs and a checked copy of the request is passed through the system call. Hence, not far to travel at all. The monolithic Linux kernel can be made extremely small not only because of its ability to dynamically load modules but also because of its ease of customization. In fact, there are some versions that are small enough to fit together with a large number of utilities and other programs on a
single floppy disk and still provide a fully functional operating system (one of the most popular of which is muLinux). This ability to miniaturize its kernel has also led to a rapid growth in the use of Linux in embedded systems.
These types of kernels consist of the core functions of the operating system and the device drivers with the ability to load modules at runtime. They provide rich and powerful abstractions of the underlying hardware. They provide a small set of simple hardware abstractions and use applications called servers to provide more functionality. This particular approach defines a high-level virtual interface over the hardware, with a set of system calls to implement operating system services such as process management, concurrency and memory management in several modules that run in supervisor mode.
This design has several flaws and limitations:
- Coding in kernel can be challenging, in part because one cannot use common libraries (like a full-featured libc), and because one needs to use a source-level debugger like gdb. Rebooting the computer is often required. This is not just a problem of convenience to the developers. When debugging is harder, and as difficulties become stronger, it becomes more likely that code will be «buggier».
- Bugs in one part of the kernel have strong side effects; since every function in the kernel has all the privileges, a bug in one function can corrupt data structure of another, totally unrelated part of the kernel, or of any running program.
- Kernels often become very large and difficult to maintain.
- Even if the modules servicing these operations are separate from the whole, the code integration is tight and difficult to do correctly.
- Since the modules run in the same address space, a bug can bring down the entire system.
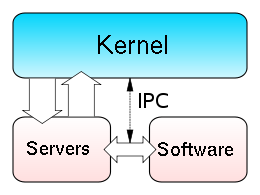
In the microkernel approach, the kernel itself only provides basic functionality that allows the execution of servers, separate programs that assume former kernel functions, such as device drivers, GUI servers, etc.
Microkernels[edit]
Microkernel (also abbreviated μK or uK) is the term describing an approach to operating system design by which the functionality of the system is moved out of the traditional «kernel», into a set of «servers» that communicate through a «minimal» kernel, leaving as little as possible in «system space» and as much as possible in «user space». A microkernel that is designed for a specific platform or device is only ever going to have what it needs to operate. The microkernel approach consists of defining a simple abstraction over the hardware, with a set of primitives or system calls to implement minimal OS services such as memory management, multitasking, and inter-process communication. Other services, including those normally provided by the kernel, such as networking, are implemented in user-space programs, referred to as servers. Microkernels are easier to maintain than monolithic kernels, but the large number of system calls and context switches might slow down the system because they typically generate more overhead than plain function calls.
Only parts which really require being in a privileged mode are in kernel space: IPC (Inter-Process Communication), basic scheduler, or scheduling primitives, basic memory handling, basic I/O primitives. Many critical parts are now running in user space: The complete scheduler, memory handling, file systems, and network stacks. Micro kernels were invented as a reaction to traditional «monolithic» kernel design, whereby all system functionality was put in a one static program running in a special «system» mode of the processor. In the microkernel, only the most fundamental of tasks are performed such as being able to access some (not necessarily all) of the hardware, manage memory and coordinate message passing between the processes. Some systems that use micro kernels are QNX and the HURD. In the case of QNX and Hurd user sessions can be entire snapshots of the system itself or views as it is referred to. The very essence of the microkernel architecture illustrates some of its advantages:
- Easier to maintain
- Patches can be tested in a separate instance, and then swapped in to take over a production instance.
- Rapid development time and new software can be tested without having to reboot the kernel.
- More persistence in general, if one instance goes haywire, it is often possible to substitute it with an operational mirror.
Most microkernels use a message passing system to handle requests from one server to another. The message passing system generally operates on a port basis with the microkernel. As an example, if a request for more memory is sent, a port is opened with the microkernel and the request sent through. Once within the microkernel, the steps are similar to system calls. The rationale was that it would bring modularity in the system architecture, which would entail a cleaner system, easier to debug or dynamically modify, customizable to users’ needs, and more performing. They are part of the operating systems like GNU Hurd, MINIX, MkLinux, QNX and Redox OS. Although microkernels are very small by themselves, in combination with all their required auxiliary code they are, in fact, often larger than monolithic kernels. Advocates of monolithic kernels also point out that the two-tiered structure of microkernel systems, in which most of the operating system does not interact directly with the hardware, creates a not-insignificant cost in terms of system efficiency. These types of kernels normally provide only the minimal services such as defining memory address spaces, inter-process communication (IPC) and the process management. The other functions such as running the hardware processes are not handled directly by microkernels. Proponents of micro kernels point out those monolithic kernels have the disadvantage that an error in the kernel can cause the entire system to crash. However, with a microkernel, if a kernel process crashes, it is still possible to prevent a crash of the system as a whole by merely restarting the service that caused the error.
Other services provided by the kernel such as networking are implemented in user-space programs referred to as servers. Servers allow the operating system to be modified by simply starting and stopping programs. For a machine without networking support, for instance, the networking server is not started. The task of moving in and out of the kernel to move data between the various applications and servers creates overhead which is detrimental to the efficiency of micro kernels in comparison with monolithic kernels.
Disadvantages in the microkernel exist however. Some are:
- Larger running memory footprint
- More software for interfacing is required, there is a potential for performance loss.
- Messaging bugs can be harder to fix due to the longer trip they have to take versus the one off copy in a monolithic kernel.
- Process management in general can be very complicated.
The disadvantages for microkernels are extremely context-based. As an example, they work well for small single-purpose (and critical) systems because if not many processes need to run, then the complications of process management are effectively mitigated.
A microkernel allows the implementation of the remaining part of the operating system as a normal application program written in a high-level language, and the use of different operating systems on top of the same unchanged kernel. It is also possible to dynamically switch among operating systems and to have more than one active simultaneously.[25]
Monolithic kernels vs. microkernels[edit]
As the computer kernel grows, so grows the size and vulnerability of its trusted computing base; and, besides reducing security, there is the problem of enlarging the memory footprint. This is mitigated to some degree by perfecting the virtual memory system, but not all computer architectures have virtual memory support.[b] To reduce the kernel’s footprint, extensive editing has to be performed to carefully remove unneeded code, which can be very difficult with non-obvious interdependencies between parts of a kernel with millions of lines of code.
By the early 1990s, due to the various shortcomings of monolithic kernels versus microkernels, monolithic kernels were considered obsolete by virtually all operating system researchers.[citation needed] As a result, the design of Linux as a monolithic kernel rather than a microkernel was the topic of a famous debate between Linus Torvalds and Andrew Tanenbaum.[35] There is merit on both sides of the argument presented in the Tanenbaum–Torvalds debate.
Performance[edit]
Monolithic kernels are designed to have all of their code in the same address space (kernel space), which some developers argue is necessary to increase the performance of the system.[36] Some developers also maintain that monolithic systems are extremely efficient if well written.[36] The monolithic model tends to be more efficient[37] through the use of shared kernel memory, rather than the slower IPC system of microkernel designs, which is typically based on message passing.[citation needed]
The performance of microkernels was poor in both the 1980s and early 1990s.[38][39] However, studies that empirically measured the performance of these microkernels did not analyze the reasons of such inefficiency.[38] The explanations of this data were left to «folklore», with the assumption that they were due to the increased frequency of switches from «kernel-mode» to «user-mode», to the increased frequency of inter-process communication and to the increased frequency of context switches.[38]
In fact, as guessed in 1995, the reasons for the poor performance of microkernels might as well have been: (1) an actual inefficiency of the whole microkernel approach, (2) the particular concepts implemented in those microkernels, and (3) the particular implementation of those concepts. Therefore it remained to be studied if the solution to build an efficient microkernel was, unlike previous attempts, to apply the correct construction techniques.[38]
On the other end, the hierarchical protection domains architecture that leads to the design of a monolithic kernel[33] has a significant performance drawback each time there’s an interaction between different levels of protection (i.e., when a process has to manipulate a data structure both in «user mode» and «supervisor mode»), since this requires message copying by value.[40]

The hybrid kernel approach combines the speed and simpler design of a monolithic kernel with the modularity and execution safety of a microkernel
Hybrid (or modular) kernels[edit]
Hybrid kernels are used in most commercial operating systems such as Microsoft Windows NT 3.1, NT 3.5, NT 3.51, NT 4.0, 2000, XP, Vista, 7, 8, 8.1 and 10. Apple Inc’s own macOS uses a hybrid kernel called XNU which is based upon code from OSF/1’s Mach kernel (OSFMK 7.3)[41] and FreeBSD’s monolithic kernel. They are similar to micro kernels, except they include some additional code in kernel-space to increase performance. These kernels represent a compromise that was implemented by some developers to accommodate the major advantages of both monolithic and micro kernels. These types of kernels are extensions of micro kernels with some properties of monolithic kernels. Unlike monolithic kernels, these types of kernels are unable to load modules at runtime on their own. Hybrid kernels are micro kernels that have some «non-essential» code in kernel-space in order for the code to run more quickly than it would were it to be in user-space. Hybrid kernels are a compromise between the monolithic and microkernel designs. This implies running some services (such as the network stack or the filesystem) in kernel space to reduce the performance overhead of a traditional microkernel, but still running kernel code (such as device drivers) as servers in user space.
Many traditionally monolithic kernels are now at least adding (or else using) the module capability. The most well known of these kernels is the Linux kernel. The modular kernel essentially can have parts of it that are built into the core kernel binary or binaries that load into memory on demand. It is important to note that a code tainted module has the potential to destabilize a running kernel. Many people become confused on this point when discussing micro kernels. It is possible to write a driver for a microkernel in a completely separate memory space and test it before «going» live. When a kernel module is loaded, it accesses the monolithic portion’s memory space by adding to it what it needs, therefore, opening the doorway to possible pollution. A few advantages to the modular (or) Hybrid kernel are:
- Faster development time for drivers that can operate from within modules. No reboot required for testing (provided the kernel is not destabilized).
- On demand capability versus spending time recompiling a whole kernel for things like new drivers or subsystems.
- Faster integration of third party technology (related to development but pertinent unto itself nonetheless).
Modules, generally, communicate with the kernel using a module interface of some sort. The interface is generalized (although particular to a given operating system) so it is not always possible to use modules. Often the device drivers may need more flexibility than the module interface affords. Essentially, it is two system calls and often the safety checks that only have to be done once in the monolithic kernel now may be done twice. Some of the disadvantages of the modular approach are:
- With more interfaces to pass through, the possibility of increased bugs exists (which implies more security holes).
- Maintaining modules can be confusing for some administrators when dealing with problems like symbol differences.
Nanokernels[edit]
A nanokernel delegates virtually all services – including even the most basic ones like interrupt controllers or the timer – to device drivers to make the kernel memory requirement even smaller than a traditional microkernel.[42]
Exokernels[edit]
Exokernels are a still-experimental approach to operating system design. They differ from other types of kernels in limiting their functionality to the protection and multiplexing of the raw hardware, providing no hardware abstractions on top of which to develop applications. This separation of hardware protection from hardware management enables application developers to determine how to make the most efficient use of the available hardware for each specific program.
Exokernels in themselves are extremely small. However, they are accompanied by library operating systems (see also unikernel), providing application developers with the functionalities of a conventional operating system. This comes down to every user writing their own rest-of-the kernel from near scratch, which is a very-risky, complex and quite a daunting assignment — particularly in a time-constrained production-oriented environment, which is why exokernels have never caught on.[citation needed] A major advantage of exokernel-based systems is that they can incorporate multiple library operating systems, each exporting a different API, for example one for high level UI development and one for real-time control.
Multikernels[edit]
A multikernel operating system treats a multi-core machine as a network of independent cores, as if it were a distributed system. It does not assume shared memory but rather implements inter-process communications as message-passing.[43][44] Barrelfish was the first operating system to be described as a multikernel.
History of kernel development[edit]
Early operating system kernels[edit]
Strictly speaking, an operating system (and thus, a kernel) is not required to run a computer. Programs can be directly loaded and executed on the «bare metal» machine, provided that the authors of those programs are willing to work without any hardware abstraction or operating system support. Most early computers operated this way during the 1950s and early 1960s, which were reset and reloaded between the execution of different programs. Eventually, small ancillary programs such as program loaders and debuggers were left in memory between runs, or loaded from ROM. As these were developed, they formed the basis of what became early operating system kernels. The «bare metal» approach is still used today on some video game consoles and embedded systems,[45] but in general, newer computers use modern operating systems and kernels.
In 1969, the RC 4000 Multiprogramming System introduced the system design philosophy of a small nucleus «upon which operating systems for different purposes could be built in an orderly manner»,[46] what would be called the microkernel approach.
Time-sharing operating systems[edit]
In the decade preceding Unix, computers had grown enormously in power – to the point where computer operators were looking for new ways to get people to use their spare time on their machines. One of the major developments during this era was time-sharing, whereby a number of users would get small slices of computer time, at a rate at which it appeared they were each connected to their own, slower, machine.[47]
The development of time-sharing systems led to a number of problems. One was that users, particularly at universities where the systems were being developed, seemed to want to hack the system to get more CPU time. For this reason, security and access control became a major focus of the Multics project in 1965.[48] Another ongoing issue was properly handling computing resources: users spent most of their time staring at the terminal and thinking about what to input instead of actually using the resources of the computer, and a time-sharing system should give the CPU time to an active user during these periods. Finally, the systems typically offered a memory hierarchy several layers deep, and partitioning this expensive resource led to major developments in virtual memory systems.
Amiga[edit]
The Commodore Amiga was released in 1985, and was among the first – and certainly most successful – home computers to feature an advanced kernel architecture. The AmigaOS kernel’s executive component, exec.library, uses a microkernel message-passing design, but there are other kernel components, like graphics.library, that have direct access to the hardware. There is no memory protection, and the kernel is almost always running in user mode. Only special actions are executed in kernel mode, and user-mode applications can ask the operating system to execute their code in kernel mode.
Unix[edit]
Main article: Unix
A diagram of the predecessor/successor family relationship for Unix-like systems
During the design phase of Unix, programmers decided to model every high-level device as a file, because they believed the purpose of computation was data transformation.[49]
For instance, printers were represented as a «file» at a known location – when data was copied to the file, it printed out. Other systems, to provide a similar functionality, tended to virtualize devices at a lower level – that is, both devices and files would be instances of some lower level concept. Virtualizing the system at the file level allowed users to manipulate the entire system using their existing file management utilities and concepts, dramatically simplifying operation. As an extension of the same paradigm, Unix allows programmers to manipulate files using a series of small programs, using the concept of pipes, which allowed users to complete operations in stages, feeding a file through a chain of single-purpose tools. Although the end result was the same, using smaller programs in this way dramatically increased flexibility as well as ease of development and use, allowing the user to modify their workflow by adding or removing a program from the chain.
In the Unix model, the operating system consists of two parts: first, the huge collection of utility programs that drive most operations; second, the kernel that runs the programs.[49] Under Unix, from a programming standpoint, the distinction between the two is fairly thin; the kernel is a program, running in supervisor mode,[c] that acts as a program loader and supervisor for the small utility programs making up the rest of the system, and to provide locking and I/O services for these programs; beyond that, the kernel didn’t intervene at all in user space.
Over the years the computing model changed, and Unix’s treatment of everything as a file or byte stream no longer was as universally applicable as it was before. Although a terminal could be treated as a file or a byte stream, which is printed to or read from, the same did not seem to be true for a graphical user interface. Networking posed another problem. Even if network communication can be compared to file access, the low-level packet-oriented architecture dealt with discrete chunks of data and not with whole files. As the capability of computers grew, Unix became increasingly cluttered with code. It is also because the modularity of the Unix kernel is extensively scalable.[50] While kernels might have had 100,000 lines of code in the seventies and eighties, kernels like Linux, of modern Unix successors like GNU, have more than 13 million lines.[51]
Modern Unix-derivatives are generally based on module-loading monolithic kernels. Examples of this are the Linux kernel in the many distributions of GNU, IBM AIX, as well as the Berkeley Software Distribution variant kernels such as FreeBSD, DragonflyBSD, OpenBSD, NetBSD, and macOS. Apart from these alternatives, amateur developers maintain an active operating system development community, populated by self-written hobby kernels which mostly end up sharing many features with Linux, FreeBSD, DragonflyBSD, OpenBSD or NetBSD kernels and/or being compatible with them.[52]
Classic Mac OS and macOS[edit]
Apple first launched its classic Mac OS in 1984, bundled with its Macintosh personal computer. Apple moved to a nanokernel design in Mac OS 8.6. Against this, the modern macOS (originally named Mac OS X) is based on Darwin, which uses a hybrid kernel called XNU, which was created by combining the 4.3BSD kernel and the Mach kernel.[53]
Microsoft Windows[edit]
Microsoft Windows was first released in 1985 as an add-on to MS-DOS. Because of its dependence on another operating system, initial releases of Windows, prior to Windows 95, were considered an operating environment (not to be confused with an operating system). This product line continued to evolve through the 1980s and 1990s, with the Windows 9x series adding 32-bit addressing and pre-emptive multitasking; but ended with the release of Windows Me in 2000.
Microsoft also developed Windows NT, an operating system with a very similar interface, but intended for high-end and business users. This line started with the release of Windows NT 3.1 in 1993, and was introduced to general users with the release of Windows XP in October 2001—replacing Windows 9x with a completely different, much more sophisticated operating system. This is the line that continues with Windows 11.
The architecture of Windows NT’s kernel is considered a hybrid kernel because the kernel itself contains tasks such as the Window Manager and the IPC Managers, with a client/server layered subsystem model.[54] It was designed as a modified microkernel, as the Windows NT kernel was influenced by the Mach microkernel but does not meet all of the criteria of a pure microkernel.
IBM Supervisor[edit]
Supervisory program or supervisor is a computer program, usually part of an operating system, that controls the execution of other routines and regulates work scheduling, input/output operations, error actions, and similar functions and regulates the flow of work in a data processing system.
Historically, this term was essentially associated with IBM’s line of mainframe operating systems starting with OS/360. In other operating systems, the supervisor is generally called the kernel.
In the 1970s, IBM further abstracted the supervisor state from the hardware, resulting in a hypervisor that enabled full virtualization, i.e. the capacity to run multiple operating systems on the same machine totally independently from each other. Hence the first such system was called Virtual Machine or VM.
Development of microkernels[edit]
Although Mach, developed by Richard Rashid at Carnegie Mellon University, is the best-known general-purpose microkernel, other microkernels have been developed with more specific aims. The L4 microkernel family (mainly the L3 and the L4 kernel) was created to demonstrate that microkernels are not necessarily slow.[55] Newer implementations such as Fiasco and Pistachio are able to run Linux next to other L4 processes in separate address spaces.[56][57]
Additionally, QNX is a microkernel which is principally used in embedded systems,[58] and the open-source software MINIX, while originally created for educational purposes, is now focused on being a highly reliable and self-healing microkernel OS.
See also[edit]
- Comparison of operating system kernels
- Inter-process communication
- Operating system
- Virtual memory
Notes[edit]
- ^ It may depend on the Computer architecture
- ^ Virtual addressing is most commonly achieved through a built-in memory management unit.
- ^ The highest privilege level has various names throughout different architectures, such as supervisor mode, kernel mode, CPL0, DPL0, ring 0, etc. See Ring (computer security) for more information.
References[edit]
- ^ a b «Kernel». Linfo. Bellevue Linux Users Group. Archived from the original on 8 December 2006. Retrieved 15 September 2016.
- ^ Randal E. Bryant; David R. O’Hallaron (2016). Computer Systems: A Programmer’s Perspective (Third ed.). Pearson. p. 17. ISBN 978-0134092669.
- ^ cf. Daemon (computing)
- ^ a b Roch 2004
- ^ a b c d e f g Wulf 1974 pp.337–345
- ^ a b Silberschatz 1991
- ^ Tanenbaum, Andrew S. (2008). Modern Operating Systems (3rd ed.). Prentice Hall. pp. 50–51. ISBN 978-0-13-600663-3.
. . . nearly all system calls [are] invoked from C programs by calling a library procedure . . . The library procedure . . . executes a TRAP instruction to switch from user mode to kernel mode and start execution . . .
- ^ Denning 1976
- ^ Swift 2005, p.29 quote: «isolation, resource control, decision verification (checking), and error recovery.»
- ^ Schroeder 72
- ^ a b Linden 76
- ^ Eranian, Stephane; Mosberger, David (2002). «Virtual Memory in the IA-64 Linux Kernel». IA-64 Linux Kernel: Design and Implementation. Prentice Hall PTR. ISBN 978-0-13-061014-0.
- ^ Silberschatz & Galvin, Operating System Concepts, 4th ed, pp. 445 & 446
- ^ Hoch, Charles; J. C. Browne (July 1980). «An implementation of capabilities on the PDP-11/45». ACM SIGOPS Operating Systems Review. 14 (3): 22–32. doi:10.1145/850697.850701. S2CID 17487360.
- ^ a b Schneider F., Morrissett G. (Cornell University) and Harper R. (Carnegie Mellon University). «A Language-Based Approach to Security» (PDF). Archived (PDF) from the original on 2018-12-22.
{{cite web}}: CS1 maint: uses authors parameter (link) - ^ a b c Loscocco, P. A.; Smalley, S. D.; Muckelbauer, P. A.; Taylor, R. C.; Turner, S. J.; Farrell, J. F. (October 1998). «The Inevitability of Failure: The Flawed Assumption of Security in Modern Computing Environments». Proceedings of the 21st National Information Systems Security Conference. pp. 303–314. Archived from the original on 2007-06-21.
- ^ Lepreau, Jay; Ford, Bryan; Hibler, Mike (1996). «The persistent relevance of the local operating system to global applications». Proceedings of the 7th workshop on ACM SIGOPS European workshop Systems support for worldwide applications — EW 7. pp. 133–140. doi:10.1145/504450.504477. ISBN 9781450373395. S2CID 10027108.
- ^ Anderson, J. (October 1972). Computer Security Technology Planning Study (PDF) (Report). Vol. II. Air Force Electronic Systems Division. ESD-TR-73-51, Vol. II. Archived (PDF) from the original on 2011-07-21.
- ^ Jerry H. Saltzer; Mike D. Schroeder (September 1975). «The protection of information in computer systems». Proceedings of the IEEE. 63 (9): 1278–1308. CiteSeerX 10.1.1.126.9257. doi:10.1109/PROC.1975.9939. S2CID 269166. Archived from the original on 2021-03-08. Retrieved 2007-07-15.
- ^ «Fine-grained kernel isolation». mars-research.github.io. Retrieved 15 September 2022.
- ^ Fetzer, Mary. «Automatic device driver isolation protects against bugs in operating systems». Pennsylvania State University via techxplore.com. Retrieved 15 September 2022.
- ^ Huang, Yongzhe; Narayanan, Vikram; Detweiler, David; Huang, Kaiming; Tan, Gang; Jaeger, Trent; Burtsev, Anton (2022). «KSplit: Automating Device Driver Isolation» (PDF). Retrieved 15 September 2022.
- ^ Jonathan S. Shapiro; Jonathan M. Smith; David J. Farber (1999). «EROS: a fast capability system». Proceedings of the Seventeenth ACM Symposium on Operating Systems Principles. 33 (5): 170–185. doi:10.1145/319344.319163.
- ^ Dijkstra, E. W. Cooperating Sequential Processes. Math. Dep., Technological U., Eindhoven, Sept. 1965.
- ^ a b c d e Brinch Hansen 70 pp.238–241
- ^ Harrison, M. C.; Schwartz, J. T. (1967). «SHARER, a time sharing system for the CDC 6600». Communications of the ACM. 10 (10): 659–665. doi:10.1145/363717.363778. S2CID 14550794. Retrieved 2007-01-07.
- ^ Huxtable, D. H. R.; Warwick, M. T. (1967). Dynamic Supervisors – their design and construction. pp. 11.1–11.17. doi:10.1145/800001.811675. ISBN 9781450373708. S2CID 17709902. Archived from the original on 2020-02-24. Retrieved 2007-01-07.
- ^ Baiardi 1988
- ^ a b Levin 75
- ^ Denning 1980
- ^ Nehmer, Jürgen (1991). «The Immortality of Operating Systems, or: Is Research in Operating Systems still Justified?». Lecture Notes In Computer Science; Vol. 563. Proceedings of the International Workshop on Operating Systems of the 90s and Beyond. pp. 77–83. doi:10.1007/BFb0024528. ISBN 3-540-54987-0.
The past 25 years have shown that research on operating system architecture had a minor effect on existing main stream [sic] systems.
- ^ Levy 84, p.1 quote: «Although the complexity of computer applications increases yearly, the underlying hardware architecture for applications has remained unchanged for decades.»
- ^ a b c Levy 84, p.1 quote: «Conventional architectures support a single privileged mode of
operation. This structure leads to monolithic design; any module needing protection must be part of the single operating system kernel. If, instead, any module could execute within a protected domain, systems could be built as a collection of independent modules extensible by any user.» - ^ a b «Open Sources: Voices from the Open Source Revolution». 1-56592-582-3. 29 March 1999. Archived from the original on 1 February 2020. Retrieved 24 March 2019.
- ^ Recordings of the debate between Torvalds and Tanenbaum can be found at dina.dk Archived 2012-10-03 at the Wayback Machine, groups.google.com Archived 2013-05-26 at the Wayback Machine, oreilly.com Archived 2014-09-21 at the Wayback Machine and Andrew Tanenbaum’s website Archived 2015-08-05 at the Wayback Machine
- ^ a b Matthew Russell. «What Is Darwin (and How It Powers Mac OS X)». O’Reilly Media. Archived from the original on 2007-12-08. Retrieved 2008-12-09.
The tightly coupled nature of a monolithic kernel allows it to make very efficient use of the underlying hardware […] Microkernels, on the other hand, run a lot more of the core processes in userland. […] Unfortunately, these benefits come at the cost of the microkernel having to pass a lot of information in and out of the kernel space through a process known as a context switch. Context switches introduce considerable overhead and therefore result in a performance penalty.
- ^ «Operating Systems/Kernel Models — Wikiversity». en.wikiversity.org. Archived from the original on 2014-12-18. Retrieved 2014-12-18.
- ^ a b c d Liedtke 95
- ^ Härtig 97
- ^ Hansen 73, section 7.3 p.233 «interactions between different levels of protection require transmission of messages by value«
- ^ Magee, Jim. WWDC 2000 Session 106 – Mac OS X: Kernel. 14 minutes in. Archived from the original on 2021-10-30.
- ^ «KeyKOS Nanokernel Architecture». Archived from the original on 2011-06-21.
- ^ Baumann et al., «The Multikernel: a new OS architecture for scalable multicore systems», to appear in 22nd Symposium on Operating Systems Principles (2009), http://research.microsoft.com/pubs/101903/paper.pdf
- ^ The Barrelfish operating system, http://www.barrelfish.org/.
- ^ Ball: Embedded Microprocessor Designs, p. 129
- ^ Hansen 2001 (os), pp.17–18
- ^ «BSTJ version of C.ACM Unix paper». bell-labs.com. Archived from the original on 2005-12-30. Retrieved 2006-08-17.
- ^ Corbató, F. J.; Vissotsky, V. A. Introduction and Overview of the Multics System. 1965 Fall Joint Computer Conference. Archived from the original on 2011-07-09.
- ^ a b «The Single Unix Specification». The open group. Archived from the original on 2016-10-04. Retrieved 2016-09-29.
- ^ «Unix’s Revenge». asymco.com. 29 September 2010. Archived from the original on 9 November 2010. Retrieved 2 October 2010.
- ^ Wheeler, David A. (October 12, 2004). «Linux Kernel 2.6: It’s Worth More!».
- ^ This community mostly gathers at Bona Fide OS Development Archived 2022-01-17 at the Wayback Machine, The Mega-Tokyo Message Board Archived 2022-01-25 at the Wayback Machine and other operating system enthusiast web sites.
- ^ Singh, Amit (December 2003). «XNU: The Kernel». Archived from the original on 2011-08-12.
- ^ «Windows — Official Site for Microsoft Windows 10 Home & Pro OS, laptops, PCs, tablets & more». windows.com. Archived from the original on 2011-08-20. Retrieved 2019-03-24.
- ^ «The L4 microkernel family — Overview». os.inf.tu-dresden.de. Archived from the original on 2006-08-21. Retrieved 2006-08-11.
- ^ «The Fiasco microkernel — Overview». os.inf.tu-dresden.de. Archived from the original on 2006-06-16. Retrieved 2006-07-10.
- ^ Zoller (inaktiv), Heinz (7 December 2013). «L4Ka — L4Ka Project». www.l4ka.org. Archived from the original on 19 April 2001. Retrieved 24 March 2019.
- ^ «QNX Operating Systems». blackberry.qnx.com. Archived from the original on 2019-03-24. Retrieved 2019-03-24.
Sources[edit]
- Roch, Benjamin (2004). «Monolithic kernel vs. Microkernel» (PDF). Archived from the original (PDF) on 2006-11-01. Retrieved 2006-10-12.
- Silberschatz, Abraham; James L. Peterson; Peter B. Galvin (1991). Operating system concepts. Boston, Massachusetts: Addison-Wesley. p. 696. ISBN 978-0-201-51379-0.
- Ball, Stuart R. (2002) [2002]. Embedded Microprocessor Systems: Real World Designs (first ed.). Elsevier Science. ISBN 978-0-7506-7534-5.
- Deitel, Harvey M. (1984) [1982]. An introduction to operating systems (revisited first ed.). Addison-Wesley. p. 673. ISBN 978-0-201-14502-1.
- Denning, Peter J. (December 1976). «Fault tolerant operating systems». ACM Computing Surveys. 8 (4): 359–389. doi:10.1145/356678.356680. ISSN 0360-0300. S2CID 207736773.
- Denning, Peter J. (April 1980). «Why not innovations in computer architecture?». ACM SIGARCH Computer Architecture News. 8 (2): 4–7. doi:10.1145/859504.859506. ISSN 0163-5964. S2CID 14065743.
- Hansen, Per Brinch (April 1970). «The nucleus of a Multiprogramming System». Communications of the ACM. 13 (4): 238–241. CiteSeerX 10.1.1.105.4204. doi:10.1145/362258.362278. ISSN 0001-0782. S2CID 9414037.
- Hansen, Per Brinch (1973). Operating System Principles. Englewood Cliffs: Prentice Hall. p. 496. ISBN 978-0-13-637843-3.
- Hansen, Per Brinch (2001). «The evolution of operating systems» (PDF). Archived (PDF) from the original on 2011-07-25. Retrieved 2006-10-24. included in book: Per Brinch Hansen, ed. (2001). «1 The evolution of operating systems». Classic operating systems: from batch processing to distributed systems. New York: Springer-Verlag. pp. 1–36. ISBN 978-0-387-95113-3.
- Härtig, Hermann; Hohmuth, Michael; Liedtke, Jochen; Schönberg, Sebastian; Wolter, Jean (October 5–8, 1997). «The performance of μ-kernel-based systems». Proceedings of the sixteenth ACM symposium on Operating systems principles — SOSP ’97. 16th ACM Symposium on Operating Systems Principles (SOSP’97). Saint-Malo, France. doi:10.1145/268998.266660. ISBN 978-0897919166. S2CID 1706253. Archived from the original on 2020-02-17.
{{cite conference}}: CS1 maint: date format (link), Härtig, Hermann; Hohmuth, Michael; Liedtke, Jochen; Schönberg, Sebastian (December 1997). «The performance of μ-kernel-based systems». ACM SIGOPS Operating Systems Review. 31 (5): 66–77. doi:10.1145/269005.266660. - Houdek, M. E.; Soltis, F. G.; Hoffman, R. L. (1981). «IBM System/38 support for capability-based addressing». Proceedings of the 8th ACM International Symposium on Computer Architecture. ACM/IEEE. pp. 341–348.
- The IA-32 Architecture Software Developer’s Manual, Volume 1: Basic Architecture (PDF). Intel Corporation. 2002.
- Levin, R.; Cohen, E.; Corwin, W.; Pollack, F.; Wulf, William (1975). «Policy/mechanism separation in Hydra». ACM Symposium on Operating Systems Principles / Proceedings of the Fifth ACM Symposium on Operating Systems Principles. 9 (5): 132–140. doi:10.1145/1067629.806531.
- Levy, Henry M. (1984). Capability-based computer systems. Maynard, Mass: Digital Press. ISBN 978-0-932376-22-0. Archived from the original on 2007-07-13. Retrieved 2007-07-18.
- Liedtke, Jochen (December 1995). «On µ-Kernel Construction». Proc. 15th ACM Symposium on Operating System Principles (SOSP). Archived from the original on 2007-03-13.
- Linden, Theodore A. (December 1976). «Operating System Structures to Support Security and Reliable Software». ACM Computing Surveys. 8 (4): 409–445. doi:10.1145/356678.356682. hdl:2027/mdp.39015086560037. ISSN 0360-0300. S2CID 16720589., «Operating System Structures to Support Security and Reliable Software» (PDF). Archived (PDF) from the original on 2010-05-28. Retrieved 2010-06-19.
- Lorin, Harold (1981). Operating systems. Boston, Massachusetts: Addison-Wesley. pp. 161–186. ISBN 978-0-201-14464-2.
- Schroeder, Michael D.; Jerome H. Saltzer (March 1972). «A hardware architecture for implementing protection rings». Communications of the ACM. 15 (3): 157–170. CiteSeerX 10.1.1.83.8304. doi:10.1145/361268.361275. ISSN 0001-0782. S2CID 14422402.
- Shaw, Alan C. (1974). The logical design of Operating systems. Prentice-Hall. p. 304. ISBN 978-0-13-540112-5.
- Tanenbaum, Andrew S. (1979). Structured Computer Organization. Englewood Cliffs, New Jersey: Prentice-Hall. ISBN 978-0-13-148521-1.
- Wulf, W.; E. Cohen; W. Corwin; A. Jones; R. Levin; C. Pierson; F. Pollack (June 1974). «HYDRA: the kernel of a multiprocessor operating system» (PDF). Communications of the ACM. 17 (6): 337–345. doi:10.1145/355616.364017. ISSN 0001-0782. S2CID 8011765. Archived from the original (PDF) on 2007-09-26. Retrieved 2007-07-18.
- Baiardi, F.; A. Tomasi; M. Vanneschi (1988). Architettura dei Sistemi di Elaborazione, volume 1 (in Italian). Franco Angeli. ISBN 978-88-204-2746-7. Archived from the original on 2012-06-27. Retrieved 2006-10-10.
- Swift, Michael M.; Brian N. Bershad; Henry M. Levy. Improving the reliability of commodity operating systems (PDF). Archived (PDF) from the original on 2007-07-19. Retrieved 2007-07-16.
- Gettys, James; Karlton, Philip L.; McGregor, Scott (1990). «The X window system, version 11». Software: Practice and Experience. 20: S35–S67. doi:10.1002/spe.4380201404. S2CID 26329062.
- Michael M. Swift; Brian N. Bershad; Henry M. Levy (February 2005). «Improving the reliability of commodity operating systems». ACM Transactions on Computer Systems. Association for Computing Machinery. 23 (1): 77–110. doi:10.1145/1047915.1047919. eISSN 1557-7333. ISSN 0734-2071. S2CID 208013080.
Further reading[edit]
- Andrew S. Tanenbaum, Albert S. Woodhull, Operating Systems: Design and Implementation (Third edition);
- Andrew S. Tanenbaum, Herbert Bos, Modern Operating Systems (Fourth edition);
- Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel (Third edition);
- David A. Patterson, John L. Hennessy, Computer Organization and Design (Sixth edition), Morgan Kaufmann (ISBN 978-0-12-820109-1);
- B.S. Chalk, A.T. Carter, R.W. Hind, Computer Organisation and Architecture: An Introduction (Second edition), Palgrave Macmillan (ISBN 978-1-4039-0164-4).
External links[edit]
- Detailed comparison between most popular operating system kernels
Ядро операционной системы (Kernel) — часть операционной системы:
- постоянно находящаяся в оперативной памяти;
- управляющая всей операционной системой;
- содержащая: драйверы устройств, подпрограммы управления памятью, планировщик заданий;
- реализующая системные вызовы и т.п.
Все операции, связанные с процессами, выполняются под управлением той части операционной системы, которая называется ядром. Ядро представляет собой лишь небольшую часть кода операционной системы в целом, однако оно относится к числу наиболее интенсивно используемых компонент системы. По этой причине ядро обычно резидентно размещается в основной памяти, в то время как другие части операционной системы перемещаются во внешнюю память и обратно по мере необходимости.
Одной из самых важных функций, реализованных в ядре, является обработка прерываний. В больших многоабонентских системах в процессор поступает постоянный поток прерываний. Быстрая реакция на эти прерывания играет весьма важную роль с точки зрения полноты использования ресурсов системы и обеспечения приемлемых значений времени ответа для пользователей, работающих в диалоговом режиме.
Когда ядро обрабатывает текущее прерывание, оно запрещает другие прерывания и разрешает их снова только после завершения обработки текущего прерывания. При постоянном потоке прерываний может сложиться такая ситуация, что ядро будет блокировать прерывания в течение значительной части времени, т. е. не будет иметь возможности эффективно реагировать на прерывания. Поэтому ядро обычно разрабатывается таким образом, чтобы оно осуществляло лишь минимально возможную предварительную обработку каждого прерывания, а затем передавало это прерывание на дальнейшую обработку соответствующему системному процессу, после начала работы которого ядро могло бы разрешить последующие прерывания.
Основные функция ядра:
Ядро операционной системы, как правило, содержит программы для реализации следующих функций:
- обработка прерываний;
- создание и уничтожение процессов;
- переключение процессов из состояния в состояние;
- диспетчирование ;
- приостановка и активизация процессов ;
- синхронизация процессов ;
- организация взаимодействия между процессами;
- манипулирование блоками управления процессами;
- поддержка операций ввода-вывода;
- поддержка распределения и перераспределения памяти;
- поддержка работы файловой системы ;
- поддержка механизма вызова-возврата при обращении к процедурам;
- поддержка определенных функций по ведению учета работы
- машины.
Типы архитектур ядер операционных систем:
- Монолитное ядро
- Модульное ядро
- Микроядро
- Экзоядро
- Наноядро
- Гибридное ядро
Ядро не участвует в конкуренции за ресурсы и системной задачей не является. Все необходимые ему ресурсы выделяются отдельно от других задач, фиксировано (часть оперативной памяти). Процессор предоставляется ядру вне конкуренции по прерываниям.
Источники информации:
Г. Дейтл «Введение в операционные системы» — это печатный источник информации
IT-Lexicon. Что такое Kernel
Википедия — ядро операционной системы.
-

-
March 11 2021, 04:27
- Компьютеры
- Cancel
Ядро операционной системы
— центральная часть операционной системы (ОС), обеспечивающая приложениям координированный доступ к ресурсам компьютера, таким как процессорное время, память, внешнее аппаратное обеспечение, внешнее устройство ввода и вывода информации. Также обычно ядро предоставляет сервисы файловой системы и сетевых протоколов.
Все операции, связанные с процессами, выполняются под управлением той части операционной системы, которая называется ядром. Ядро представляет собой лишь небольшую часть кода операционной системы в целом, однако оно относится к числу наиболее интенсивно используемых компонент системы. По этой причине ядро обычно резидентно размещается в основной памяти, в то время как другие части операционной системы перемещаются во внешнюю память и обратно по мере необходимости. Одной из самых важных функций, реализованных в ядре, является обработка прерываний. В больших многоабонентских системах в процессор поступает постоянный поток прерываний. Быстрая реакция на эти прерывания играет весьма важную роль с точки зрения полноты использования ресурсов системы и обеспечения приемлемых значений времени ответа для пользователей, работающих в диалоговом режиме.
Во время выполнения программы обслуживания какого-либо прерывания, ядро временно блокирует остальные требования прерываний и возобновляет их только по завершению программы обслуживания действующего прерывания. Если поток требований прерывания очень плотный, то возможно возникновение ситуации, когда ядро заблокирует какие-то прерывания на существенный временной интервал. Это означает отсутствие эффективного реагирования на требования прерываний программы. Чтобы исключить вероятность возникновения такой ситуации, ядро проектируется так, что оно выполняет только минимальную начальную обработку прерывания, а далее отсылает его для дальнейшего обслуживания в соответствующий системный процесс. После этого ядро разрешает поступление следующих запросов на прерывание программы.
Ядро имеет разные слои. Нижний уровень формирует интерфейс к системному оборудованию, например, сетевым контроллерам или контроллерам PCI Express.
Ядро — это ядро операционной системы. Это первая программа операционной системы, которая загружается в основную память для запуска работы системы. Ядро остается в основной памяти до выключения системы. Ядро в основном переводит введенные пользователем команды таким образом, чтобы компьютер понимал то, что запросил пользователь.
«Ядро (вычисления)» перенаправляется сюда. Для использования в других целях см. Ядро (значения).
В ядро это компьютерная программа в основе компьютерного Операционная система который имеет полный контроль над всем в системе.[1] Это «часть кода операционной системы, которая всегда находится в памяти»,[2] и облегчает взаимодействие между аппаратными и программными компонентами. В большинстве систем ядро - одна из первых программ, загружаемых на запускать (после загрузчик ). Он обрабатывает остальную часть запуска, а также память, периферийные устройства, и ввод, вывод (I / O) запросы от программного обеспечения, переводя их в обработка данных инструкции для центральное процессорное устройство.
Критический код ядра обычно загружается в отдельную область памяти, которая защищена от доступа с помощью прикладные программы или другие, менее важные части операционной системы. Ядро выполняет свои задачи, такие как запуск процессов, управление аппаратными устройствами, такими как жесткий диск, и обработки прерываний в этом защищенном пространство ядра. В отличие, прикладные программы например, браузеры, текстовые процессоры, аудио- или видеоплееры используют отдельную область памяти, пространство пользователя. Такое разделение предотвращает взаимодействие пользовательских данных и данных ядра друг с другом, что приводит к нестабильности и замедлению работы.[1] а также предотвращение сбоя всей операционной системы из-за неисправности прикладных программ.
Ядро интерфейс это низкий уровень слой абстракции. Когда процесс запрашивает службу к ядру, оно должно вызывать системный вызов, обычно через функцию оболочки, которая предоставляется приложениям пользовательского пространства системными библиотеками, которые встраивают ассемблерный код для входа в ядро после загрузки регистров ЦП с номером системного вызова и его параметрами (например, UNIX-подобные операционные системы выполняют эту задачу с помощью Стандартная библиотека C ).
Существуют разные конструкции архитектуры ядра. Монолитные ядра работать полностью в одном адресное пространство при выполнении ЦП в режим супервизора, в основном по скорости. Микроядра запускать большинство, но не все свои службы в пользовательском пространстве,[3] как это делают пользовательские процессы, в основном для обеспечения устойчивости и модульность.[4] МИНИКС 3 является ярким примером дизайна микроядра. Вместо этого Ядро Linux монолитный, хотя и модульный, так как может вставлять и снимать загружаемые модули ядра во время выполнения.
Этот центральный компонент компьютерной системы отвечает за «запуск» или «выполнение» программ. Ядро берет на себя ответственность за принятие решения в любой момент, какая из многих запущенных программ должна быть назначена процессору или процессорам.
Оперативная память
Оперативная память (RAM) используется для хранения как программных инструкций, так и данных.[примечание 1] Как правило, для выполнения программы в памяти должны присутствовать оба. Часто нескольким программам требуется доступ к памяти, часто требуя больше памяти, чем доступно компьютеру. Ядро отвечает за решение, какую память может использовать каждый процесс, и за определение того, что делать, если памяти недостаточно.
Устройства ввода / вывода
К устройствам ввода-вывода относятся такие периферийные устройства, как клавиатуры, мыши, дисководы, принтеры, USB устройства, сетевые адаптеры и устройства отображения. Ядро распределяет запросы от приложений на выполнение операций ввода-вывода соответствующему устройству и предоставляет удобные методы использования устройства (обычно абстрагированные до такой степени, что приложению не нужно знать детали реализации устройства).
Управление ресурсами
Ключевые аспекты, необходимые в Управление ресурсами определяют область выполнения (адресное пространство ) и механизм защиты, используемый для обеспечения доступа к ресурсам в домене.[5] Ядра также предоставляют методы для синхронизация и межпроцессного взаимодействия (МПК). Эти реализации могут быть внутри самого ядра или ядро также может полагаться на другие процессы, которые оно выполняет. Хотя ядро должно предоставлять IPC для обеспечения доступа к средствам, предоставляемым друг другом, ядра также должны предоставлять работающим программам метод для выполнения запросов на доступ к этим средствам. Ядро также отвечает за переключение контекста между процессами или потоками.
Управление памятью
Ядро имеет полный доступ к системной памяти и должно разрешать процессам безопасный доступ к этой памяти по мере необходимости. Часто первым шагом к этому является виртуальная адресация, обычно достигается пейджинг и / или сегментация. Виртуальная адресация позволяет ядру сделать данный физический адрес похожим на другой адрес, виртуальный адрес. Виртуальные адресные пространства могут быть разными для разных процессов; память, к которой один процесс обращается по конкретному (виртуальному) адресу, может отличаться от памяти, к которой другой процесс обращается по тому же адресу. Это позволяет каждой программе вести себя так, как если бы она была единственной (кроме ядра) запущенной, и, таким образом, предотвращает сбой приложений друг друга.[6]
Во многих системах виртуальный адрес программы может относиться к данным, которых в настоящее время нет в памяти. Уровень косвенного обращения, обеспечиваемый виртуальной адресацией, позволяет операционной системе использовать другие хранилища данных, например жесткий диск, чтобы сохранить то, что в противном случае осталось бы в основной памяти (баран ). В результате операционные системы могут позволить программам использовать больше памяти, чем физически доступно системе. Когда программе нужны данные, которых в настоящее время нет в ОЗУ, ЦП сообщает ядру, что это произошло, и ядро отвечает, записывая содержимое неактивного блока памяти на диск (при необходимости) и заменяя его данными, запрошенными программа. Затем программа может быть возобновлена с того места, где она была остановлена. Эта схема широко известна как пейджинг по запросу.
Виртуальная адресация также позволяет создавать виртуальные разделы памяти в двух несвязанных областях, одна из которых зарезервирована для ядра (пространство ядра ), а другой — для приложений (пространство пользователя ). Процессор не разрешает приложениям обращаться к памяти ядра, что предотвращает повреждение приложением работающего ядра. Это фундаментальное разделение пространства памяти внесло большой вклад в текущие разработки реальных ядер общего назначения и почти универсально в таких системах, хотя некоторые исследовательские ядра (например, Сингулярность ) используйте другие подходы.
Управление устройством
Для выполнения полезных функций процессам необходим доступ к периферийные устройства подключены к компьютеру, которые управляются ядром через драйверы устройств. Драйвер устройства — это компьютерная программа, которая позволяет операционной системе взаимодействовать с аппаратным устройством. Он предоставляет операционной системе информацию о том, как управлять определенным оборудованием и взаимодействовать с ним. Драйвер — важная и жизненно важная часть программного приложения. Цель разработки драйвера — абстракция; функция драйвера состоит в том, чтобы переводить требуемые ОС абстрактные вызовы функций (программные вызовы) в специфичные для устройства вызовы. По идее, устройство должно корректно работать с подходящим драйвером. Драйверы устройств используются для таких вещей, как видеокарты, звуковые карты, принтеры, сканеры, модемы и карты LAN.
На аппаратном уровне общие абстракции драйверов устройств включают:
- Прямое взаимодействие
- Использование высокоуровневого интерфейса (Видео BIOS )
- Использование драйвера устройства нижнего уровня (файловые драйверы с использованием драйверов диска)
- Моделируя работу с железом, делая при этом совсем другое
А на уровне программного обеспечения абстракции драйверов устройств включают:
- Разрешение операционной системе прямого доступа к аппаратным ресурсам
- Только реализация примитивов
- Реализация интерфейса для программного обеспечения без драйверов, такого как TWAIN
- Реализация языка (часто языка высокого уровня, такого как PostScript )
Например, чтобы показать пользователю что-то на экране, приложение отправит запрос к ядру, которое направит запрос своему драйверу дисплея, который затем отвечает за фактическое отображение символа / пикселя.[6]
Ядро должно поддерживать список доступных устройств. Этот список может быть известен заранее (например, на Встроенная система где ядро будет перезаписано при изменении доступного оборудования), настроено пользователем (обычно на старых ПК и в системах, которые не предназначены для личного использования) или обнаружено операционной системой во время выполнения (обычно называется подключи и играй ). В системах plug-and-play диспетчер устройств сначала выполняет сканирование различных аппаратные автобусы, Такие как Подключение периферийных компонентов (PCI) или универсальная последовательная шина (USB), чтобы обнаружить установленные устройства, а затем выполняет поиск соответствующих драйверов.
Поскольку управление устройством очень Операционные системы для конкретной темы, эти драйверы обрабатываются по-разному в зависимости от конструкции ядра, но в каждом случае ядро должно предоставлять Ввод / вывод чтобы позволить водителям физический доступ к своим устройствам через некоторые порт или место в памяти. При разработке системы управления устройствами необходимо принять важные решения, поскольку в некоторых проектах доступ может включать переключатели контекста, что делает операцию очень интенсивной для ЦП и легко вызывает значительные накладные расходы на производительность.[нужна цитата ]
Системные вызовы
В вычислениях системный вызов — это то, как процесс запрашивает службу у ядра операционной системы, которая обычно не имеет разрешения на запуск. Системные вызовы обеспечивают интерфейс между процессом и операционной системой. Для большинства операций, взаимодействующих с системой, требуются разрешения, недоступные для процесса на уровне пользователя, например, ввод-вывод, выполняемый с помощью устройства, присутствующего в системе, или любая форма связи с другими процессами требует использования системных вызовов.
Системный вызов — это механизм, который используется прикладной программой для запроса услуги у операционной системы. Они используют Машинный код инструкция, которая заставляет процессор менять режим. Примером может быть переход из режима супервизора в защищенный режим. Здесь операционная система выполняет такие действия, как доступ к аппаратным устройствам или блок управления памятью. Обычно операционная система предоставляет библиотеку, которая находится между операционной системой и обычными пользовательскими программами. Обычно это Библиотека C Такие как Glibc или Windows API. Библиотека обрабатывает низкоуровневые детали передачи информации ядру и переключения в режим супервизора. Системные вызовы включают закрытие, открытие, чтение, ожидание и запись.
Чтобы действительно выполнять полезную работу, процесс должен иметь доступ к службам, предоставляемым ядром. Каждое ядро реализует это по-разному, но большинство из них Библиотека C или API, который, в свою очередь, вызывает связанные функции ядра.[7]
Метод вызова функции ядра варьируется от ядра к ядру. Если используется изоляция памяти, пользовательский процесс не может напрямую вызвать ядро, поскольку это было бы нарушением правил контроля доступа процессора. Вот несколько возможностей:
- Используя программно смоделированный прерывать. Этот метод доступен на большинстве аппаратных средств и поэтому очень распространен.
- Используя вызов ворот. Шлюз вызова — это специальный адрес, который ядро хранит в списке в памяти ядра в месте, известном процессору. Когда процессор обнаруживает вызов по этому адресу, он вместо этого перенаправляет в целевое расположение, не вызывая нарушения доступа. Для этого требуется аппаратная поддержка, но оборудование для этого довольно распространено.
- Используя специальный системный вызов инструкция. Этот метод требует специальной аппаратной поддержки, которая обычно используется в архитектурах (в частности, x86 ) может не хватать. Однако к последним моделям процессоров x86 были добавлены инструкции системного вызова, и некоторые операционные системы для ПК используют их, когда они доступны.
- Использование очереди на основе памяти. Приложение, которое выполняет большое количество запросов, но не должно ждать результата каждого из них, может добавлять сведения о запросах в область памяти, которую ядро периодически сканирует для поиска запросов.
Проектные решения ядра
Защита
Важным фактором при разработке ядра является поддержка, которую оно обеспечивает для защиты от сбоев (Отказоустойчивость ) и от злонамеренного поведения (безопасность ). Эти два аспекта обычно четко не различаются, и принятие этого различия в конструкции ядра приводит к отказу от иерархическая структура защиты.[5]
Механизмы или политики, предоставляемые ядром, можно классифицировать по нескольким критериям, включая: статический (применяется на время компиляции ) или динамический (применяется в время выполнения ); упреждающее или последующее обнаружение; в соответствии с принципами защиты, которым они соответствуют (например, Деннинг[8][9]); поддерживаются ли они аппаратным обеспечением или языковыми; являются ли они более открытым механизмом или обязательной политикой; и многое другое.
Поддержка доменов иерархической защиты[10] обычно реализуется с использованием Режимы ЦП.
Многие ядра обеспечивают реализацию «возможностей», то есть объектов, которые предоставляются пользовательскому коду, которые позволяют ограниченный доступ к базовому объекту, управляемому ядром. Типичный пример — обработка файлов: файл — это представление информации, хранящейся на постоянном запоминающем устройстве. Ядро может иметь возможность выполнять множество различных операций, включая чтение, запись, удаление или выполнение, но приложению пользовательского уровня может быть разрешено выполнять только некоторые из этих операций (например, ему может быть разрешено только чтение файла). Обычная реализация этого заключается в том, что ядро предоставляет объект приложению (обычно так называемый «дескриптор файла»), для которого приложение может затем вызывать операции, достоверность которых ядро проверяет во время запроса операции. Такая система может быть расширена для охвата всех объектов, которыми управляет ядро, и даже объектов, предоставляемых другими пользовательскими приложениями.
Эффективный и простой способ обеспечить аппаратную поддержку возможностей — передать полномочия блок управления памятью (MMU) ответственность за проверку прав доступа для каждого доступа к памяти, механизм, называемый адресация на основе возможностей.[11] Большинство коммерческих компьютерных архитектур лишены таких возможностей MMU.
Альтернативный подход — моделировать возможности с использованием обычно поддерживаемых иерархических доменов. В этом подходе каждый защищенный объект должен находиться в адресном пространстве, к которому приложение не имеет доступа; ядро также поддерживает список возможностей в такой памяти. Когда приложению необходимо получить доступ к объекту, защищенному возможностью, оно выполняет системный вызов, а затем ядро проверяет, дает ли возможность приложения разрешение на выполнение запрошенного действия, и, если это разрешено, выполняет доступ для него (либо напрямую, либо или делегируя запрос другому процессу уровня пользователя). Стоимость переключения адресного пространства ограничивает практичность этого подхода в системах со сложным взаимодействием между объектами, но он используется в текущих операционных системах для объектов, к которым нечасто обращаются или которые, как ожидается, не будут работать быстро.[12][13]
Если встроенное ПО не поддерживает механизмы защиты, можно смоделировать защиту на более высоком уровне, например, моделируя возможности путем манипулирования таблицы страниц, но это влияет на производительность.[14] Однако отсутствие поддержки оборудования может не быть проблемой для систем, которые предпочитают использовать защиту на основе языка.[15]
Важным решением при проектировании ядра является выбор уровней абстракции, на которых должны быть реализованы механизмы и политики безопасности. Механизмы безопасности ядра играют решающую роль в поддержке безопасности на более высоких уровнях.[11][16][17][18][19]
Один из подходов — использовать встроенное ПО и поддержку ядра для обеспечения отказоустойчивости (см. Выше), а поверх этого построить политику безопасности от злонамеренного поведения (добавив такие функции, как криптография механизмы там, где это необходимо), делегируя некоторую ответственность компилятор. Подходы, которые делегируют соблюдение политики безопасности компилятору и / или уровню приложения, часто называют языковая безопасность.
Отсутствие многих важных механизмов безопасности в текущих основных операционных системах препятствует реализации адекватных политик безопасности в приложении. уровень абстракции.[16] Фактически, распространенное заблуждение в компьютерной безопасности состоит в том, что любая политика безопасности может быть реализована в приложении независимо от поддержки ядра.[16]
Аппаратная или языковая защита
Типичные компьютерные системы сегодня используют аппаратные правила, определяющие, каким программам и каким данным разрешен доступ. Процессор контролирует выполнение и останавливает программу, которая нарушает правило, например пользовательский процесс, который пытается выполнить запись в память ядра. В системах, в которых отсутствует поддержка возможностей, процессы изолированы друг от друга с помощью отдельных адресных пространств.[20] Вызовы из пользовательских процессов в ядро регулируются, требуя от них использования одного из описанных выше методов системного вызова.
Альтернативный подход — использование языковой защиты. В языковая система защиты, ядро разрешит выполнение только кода, созданного на надежном языке. компилятор. Затем язык может быть спроектирован таким образом, чтобы программист не мог дать ему указание сделать что-то, что нарушит требования безопасности.[15]
Преимущества этого подхода:
- Нет необходимости в отдельных адресных пространствах. Переключение между адресными пространствами — это медленная операция, которая вызывает много накладных расходов, и в настоящее время выполняется большая работа по оптимизации, чтобы предотвратить ненужные переключения в текущих операционных системах. В системе защиты на основе языка переключение совершенно не требуется, поскольку весь код может безопасно работать в одном и том же адресном пространстве.
- Гибкость. С помощью этого метода можно реализовать любую схему защиты, которая может быть выражена через язык программирования. Изменения схемы защиты (например, от иерархической системы к системе, основанной на возможностях) не требуют нового оборудования.
К недостаткам можно отнести:
- Более длительное время запуска приложения. Приложения должны быть проверены при запуске, чтобы убедиться, что они были скомпилированы правильным компилятором, или может потребоваться перекомпиляция либо из исходного кода, либо из байт-код.
- Негибкий системы типов. В традиционных системах приложения часто выполняют операции, которые не тип безопасный. Такие операции не могут быть разрешены в системе защиты на основе языка, что означает, что приложения могут нуждаться в переписывании и в некоторых случаях могут потерять производительность.
Примеры систем с языковой защитой включают: JX и Microsoft с Сингулярность.
Процессное сотрудничество
Эдсгер Дейкстра доказал, что с логической точки зрения, атомный замок и разблокировать операции, работающие с двоичными семафоры достаточно примитивов, чтобы выразить любую функциональность взаимодействия процессов.[21] Однако обычно считается, что этот подход недостаточен с точки зрения безопасности и эффективности, тогда как передача сообщений подход более гибкий.[22] Также доступен ряд других подходов (нижнего или верхнего уровня), при этом многие современные ядра обеспечивают поддержку таких систем, как Общая память и вызовы удаленных процедур.
Управление устройствами ввода-вывода
Идея ядра, в котором устройства ввода / вывода обрабатываются одинаково с другими процессами, как параллельные взаимодействующие процессы, была впервые предложена и реализована Бринч Хансен (хотя подобные идеи были предложены в 1967 г.[23][24]). В описании этого Хансеном «общие» процессы называются внутренние процессы, а устройства ввода / вывода называются внешние процессы.[22]
Как и в случае с физической памятью, предоставление приложениям прямого доступа к портам и регистрам контроллера может вызвать сбой контроллера или сбой системы. При этом, в зависимости от сложности устройства, некоторые устройства могут оказаться на удивление сложными в программировании и использовать несколько разных контроллеров. По этой причине важно предоставить более абстрактный интерфейс для управления устройством. Этот интерфейс обычно выполняется драйвер устройства или уровень аппаратной абстракции. Часто приложениям требуется доступ к этим устройствам. Ядро должно поддерживать список этих устройств, каким-то образом запрашивая их у системы. Это можно сделать через BIOS или через одну из различных системных шин (например, PCI / PCIE или USB). Когда приложение запрашивает операцию на устройстве (например, отображение символа), ядру необходимо отправить этот запрос текущему активному видеодрайверу. Видеодрайвер, в свою очередь, должен выполнить этот запрос. Это пример межпроцессного взаимодействия (МПК).
Подходы к дизайну ядра
Естественно, что перечисленные выше задачи и функции могут быть реализованы разными способами, которые отличаются друг от друга дизайном и реализацией.
Принцип разделение механизма и политики Это существенная разница между философией микро и монолитного ядра.[25][26] Здесь механизм — это поддержка, которая позволяет реализовать множество различных политик, в то время как политика — это особый «режим работы». Пример:
- Механизм: Попытки входа пользователя направляются на сервер авторизации.
- Политика: Серверу авторизации требуется пароль, который сверяется с паролями, хранящимися в базе данных.
Поскольку механизм и политика разделены, политику можно легко изменить, например, на требуют использования маркер безопасности.
В минимальное микроядро включены только самые базовые политики,[26] и его механизмы позволяют тому, что выполняется поверх ядра (оставшаяся часть операционной системы и другие приложения), решать, какие политики следует принять (например, управление памятью, планирование процессов высокого уровня, управление файловой системой и т. д.).[5][22] Вместо этого монолитное ядро имеет тенденцию включать в себя множество политик, поэтому ограничивает остальную часть системы, чтобы они полагались на них.
Пер Бринч Хансен представил аргументы в пользу разделения механизма и политики.[5][22] Неспособность должным образом выполнить это разделение является одной из основных причин отсутствия существенных инноваций в существующих операционных системах.[5] проблема, распространенная в компьютерной архитектуре.[27][28][29] Монолитный дизайн вызван архитектурным подходом к защите «режим ядра» / «режим пользователя» (технически называемый домены иерархической защиты ), что является обычным явлением в обычных коммерческих системах;[30] Фактически, каждый модуль, нуждающийся в защите, поэтому предпочтительно включен в ядро.[30] Эта связь между монолитным дизайном и «привилегированным режимом» может быть преобразована в ключевой вопрос разделения механизма и политики;[5] на самом деле архитектурный подход «привилегированного режима» объединяет механизм защиты с политиками безопасности, в то время как основной альтернативный архитектурный подход, адресация на основе возможностей, четко различает их, что, естественно, приводит к микроядерному дизайну[5] (видеть Разделение защиты и безопасности ).
Пока монолитные ядра выполнять весь свой код в одном адресном пространстве (пространство ядра ), микроядра пытаются запускать большинство своих сервисов в пользовательском пространстве, стремясь улучшить ремонтопригодность и модульность кодовой базы.[4] Большинство ядер не попадают точно в одну из этих категорий, а скорее находятся между этими двумя конструкциями. Они называются гибридные ядра. Более экзотические дизайны, такие как наноядра и экзоядра доступны, но редко используются в производственных системах. В Xen гипервизор, например, является экзоядром.
Монолитные ядра
Схема монолитного ядра
В монолитном ядре все службы ОС работают вместе с основным потоком ядра, поэтому они также находятся в одной области памяти. Такой подход обеспечивает широкий и мощный доступ к оборудованию. Некоторые разработчики, такие как UNIX разработчик Кен Томпсон, утверждают, что «проще реализовать монолитное ядро»[31] чем микроядра. Основными недостатками монолитных ядер являются зависимости между компонентами системы (ошибка в драйвере устройства может привести к сбою всей системы) и тот факт, что большие ядра могут стать очень сложными в обслуживании.
Монолитные ядра, которые традиционно использовались Unix-подобными операционными системами, содержат все основные функции операционной системы и драйверы устройств. Это традиционный дизайн систем UNIX. Монолитное ядро - это одна программа, которая содержит весь код, необходимый для выполнения каждой связанной с ядром задачи. Каждая часть, доступная большинству программ, которая не может быть помещена в библиотеку, находится в пространстве ядра: драйверы устройств, планировщик, обработка памяти, файловые системы и сетевые стеки. Многие системные вызовы предоставляются приложениям, чтобы позволить им получить доступ ко всем этим службам. Монолитное ядро, изначально загруженное подсистемами, которые могут не понадобиться, может быть настроено так, чтобы оно было таким же быстрым, как или быстрее, чем то, которое было специально разработано для оборудования, хотя и более актуально в общем смысле. Современные монолитные ядра, такие как ядра Linux (одно из ядер GNU операционная система) и FreeBSD обе из которых относятся к категории Unix-подобных операционных систем, имеют возможность загружать модули во время выполнения, что позволяет легко расширять возможности ядра по мере необходимости, помогая при этом минимизировать объем кода, выполняемого в пространстве ядра. В монолитном ядре некоторые преимущества зависят от следующих моментов:
- Поскольку используется меньше программного обеспечения, он работает быстрее.
- Поскольку это единое программное обеспечение, оно должно быть меньше как в исходной, так и в скомпилированной форме.
- Меньше кода обычно означает меньше ошибок, что может привести к меньшему количеству проблем с безопасностью.
Большая часть работы в монолитном ядре выполняется с помощью системных вызовов. Это интерфейсы, обычно хранящиеся в табличной структуре, которые обращаются к какой-либо подсистеме в ядре, например к дисковым операциям. По сути, вызовы выполняются внутри программ, а проверенная копия запроса передается через системный вызов. Значит, ехать совсем недалеко. Монолитный Linux Ядро можно сделать очень маленьким не только из-за его способности динамически загружать модули, но и из-за простоты настройки. Фактически, есть некоторые версии, которые достаточно малы, чтобы уместиться вместе с большим количеством утилит и других программ на одной дискете, и при этом обеспечивают полнофункциональную операционную систему (одной из самых популярных из которых является muLinux ). Эта способность миниатюризировать его ядро также привела к быстрому росту использования GNU /Linux в встроенные системы.
Эти типы ядер состоят из основных функций операционной системы и драйверов устройств с возможностью загрузки модулей во время выполнения. Они предоставляют богатые и мощные абстракции базового оборудования. Они предоставляют небольшой набор простых аппаратных абстракций и используют приложения, называемые серверами, для обеспечения большей функциональности. Этот конкретный подход определяет высокоуровневый виртуальный интерфейс на оборудовании с набором системных вызовов для реализации сервисов операционной системы, таких как управление процессами, параллелизм и управление памятью, в нескольких модулях, которые работают в режиме супервизора. Эта конструкция имеет несколько недостатков и ограничений. :
- Кодирование в ядре может быть сложной задачей, отчасти потому, что нельзя использовать общие библиотеки (например, полнофункциональные libc ), и потому что нужно использовать отладчик исходного уровня, например GDB. Часто требуется перезагрузка компьютера. Это не просто проблема удобства разработчиков. Когда отладка усложняется и трудности становятся сильнее, возрастает вероятность того, что код будет «глючнее».
- Ошибки в одной части ядра имеют сильные побочные эффекты; поскольку каждая функция в ядре имеет все привилегии, ошибка в одной функции может привести к повреждению структуры данных другой, совершенно не связанной части ядра или любой работающей программы.
- Ядра часто становятся очень большими и сложными в обслуживании.
- Даже если модули, обслуживающие эти операции, отделены от целого, интеграция кода будет жесткой и ее трудно сделать правильно.
- Поскольку модули работают в одном адресное пространство, ошибка может вывести из строя всю систему.
- Монолитные ядра не переносимы; следовательно, они должны быть переписаны для каждой новой архитектуры, в которой будет использоваться операционная система.
в микроядро подход, само ядро обеспечивает только базовую функциональность, которая позволяет выполнять серверы, отдельные программы, которые берут на себя прежние функции ядра, такие как драйверы устройств, серверы графического интерфейса и т. д.
Примеры монолитных ядер: AIX ядро, ядро HP-UX и ядро Solaris.
Микроядра
Микроядро (также сокращенно μK или uK) — это термин, описывающий подход к проектированию операционной системы, с помощью которого функциональность системы перемещается из традиционного «ядра» в набор «серверов», которые обмениваются данными через «минимальное» ядро. , оставляя как можно меньше в «системном пространстве» и как можно больше в «пользовательском пространстве». Микроядро, разработанное для конкретной платформы или устройства, когда-либо будет иметь только то, что ему нужно для работы. Подход с использованием микроядра заключается в определении простой абстракции над оборудованием с набором примитивов или системные вызовы для реализации минимальных сервисов ОС, таких как управление памятью, многозадачность, и межпроцессного взаимодействия. Другие службы, включая те, которые обычно предоставляются ядром, такие как сеть, реализуются в программах пользовательского пространства, называемых серверы. Микроядра легче поддерживать, чем монолитные ядра, но большое количество системных вызовов и переключатели контекста могут замедлить работу системы, потому что они обычно создают больше накладных расходов, чем обычные вызовы функций.
В пространстве ядра находятся только те части, которые действительно требуют нахождения в привилегированном режиме: IPC (межпроцессное взаимодействие), базовый планировщик или примитивы планирования, базовая обработка памяти, базовые примитивы ввода-вывода. Многие важные части теперь работают в пространстве пользователя: полный планировщик, обработка памяти, файловые системы и сетевые стеки. Микроядра были изобретены как реакция на традиционный «монолитный» дизайн ядра, в соответствии с которым все системные функции были помещены в одну статическую программу, работающую в специальном «системном» режиме процессора. В микроядре выполняются только самые фундаментальные задачи, такие как доступ к некоторому (не обязательно всему) оборудованию, управление памятью и координация передачи сообщений между процессами. Некоторые системы, использующие микроядра, — это QNX и HURD. В случае QNX и Херд пользовательские сеансы могут быть полными снимками самой системы или видами, как это называется. Сама суть архитектуры микроядра иллюстрирует некоторые ее преимущества:
- Легче поддерживать
- Патчи можно протестировать в отдельном экземпляре, а затем заменить на производственный экземпляр.
- Быстрое время разработки и возможность тестирования нового программного обеспечения без перезагрузки ядра.
- Больше настойчивости в целом, если один экземпляр выходит из строя, его часто можно заменить рабочим зеркалом.
Большинство микроядер используют передача сообщений система для обработки запросов от одного сервера к другому. Система передачи сообщений обычно работает на порт база с микроядром. Например, если отправляется запрос на дополнительную память, порт открывается с микроядром, и запрос отправляется через него. Попадая в микроядро, действия аналогичны системным вызовам. Обоснованием было то, что это принесет модульность в архитектуру системы, что повлечет за собой более чистую систему, более простую отладку или динамическое изменение, настраиваемую под нужды пользователей и большую производительность. Они являются частью таких операционных систем, как GNU Hurd, МИНИКС, MkLinux, QNX и Редокс ОС. Хотя микроядра сами по себе очень малы, в сочетании со всем необходимым для них вспомогательным кодом они, по сути, часто больше, чем монолитные ядра. Сторонники монолитных ядер также отмечают, что двухуровневая структура микроядерных систем, в которой большая часть операционной системы не взаимодействует напрямую с оборудованием, создает немалые затраты с точки зрения эффективности системы. Эти типы ядер обычно предоставляют только минимальные услуги, такие как определение адресных пространств памяти, межпроцессное взаимодействие (IPC) и управление процессами. Другие функции, такие как запуск аппаратных процессов, не обрабатываются напрямую микроядрами. Сторонники микроядер отмечают, что у этих монолитных ядер есть недостаток, заключающийся в том, что ошибка в ядре может привести к сбою всей системы. Однако с микроядром, если процесс ядра дает сбой, все еще можно предотвратить сбой системы в целом, просто перезапустив службу, вызвавшую ошибку.
Другие службы, предоставляемые ядром, такие как работа в сети, реализованы в программах пользовательского пространства, называемых серверы. Серверы позволяют изменять операционную систему простым запуском и остановкой программ. Например, для машины без поддержки сети сетевой сервер не запускается. Задача входа и выхода из ядра для перемещения данных между различными приложениями и серверами создает накладные расходы, которые пагубно сказываются на эффективности микроядер по сравнению с монолитными ядрами.
Однако у микроядра есть недостатки. Некоторые:
- Большой ход объем памяти
- Требуется дополнительное программное обеспечение для сопряжения, есть вероятность потери производительности.
- Ошибки обмена сообщениями может быть труднее исправить из-за более длительной поездки, которую им приходится совершать по сравнению с единственной копией в монолитном ядре.
- Управление процессами в целом может быть очень сложным.
Недостатки микроядер сильно зависят от контекста. Например, они хорошо работают для небольших одноцелевых (и критически важных) систем, потому что, если нужно запускать не так много процессов, то сложности управления процессами эффективно смягчаются.
Микроядро позволяет реализовать оставшуюся часть операционной системы как обычную прикладную программу, написанную на язык высокого уровня, а также использование разных операционных систем поверх одного и того же неизмененного ядра. Также возможно динамически переключаться между операционными системами и иметь более одной активной одновременно.[22]
Монолитные ядра против микроядер
По мере роста компьютерного ядра увеличивается размер и уязвимость его надежная вычислительная база; и, помимо снижения безопасности, существует проблема увеличения объем памяти. Это в некоторой степени смягчается за счет улучшения виртуальная память система, но не все компьютерные архитектуры есть поддержка виртуальной памяти.[32] Чтобы уменьшить нагрузку на ядро, необходимо выполнить обширное редактирование для тщательного удаления ненужного кода, что может быть очень сложно из-за неочевидных взаимозависимостей между частями ядра с миллионами строк кода.
К началу 1990-х годов из-за различных недостатков монолитных ядер по сравнению с микроядрами монолитные ядра считались устаревшими практически всеми исследователями операционных систем.[нужна цитата ] В результате дизайн Linux как монолитное ядро, а не микроядро, стало темой знаменитых дебатов между Линус Торвальдс и Эндрю Таненбаум.[33] Обе стороны аргументации, представленной в Дебаты Таненбаума и Торвальдса.
Спектакль
Монолитные ядра предназначены для размещения всего кода в одном адресном пространстве (пространство ядра ), что, по мнению некоторых разработчиков, необходимо для повышения производительности системы.[34] Некоторые разработчики также утверждают, что монолитные системы чрезвычайно эффективны, если они хорошо написаны.[34] Монолитная модель имеет тенденцию быть более эффективной[35] за счет использования общей памяти ядра, а не более медленной системы IPC в конструкции микроядра, которая обычно основана на передача сообщений.[нужна цитата ]
Производительность микроядер была низкой как в 1980-х, так и в начале 1990-х годов.[36][37] Однако исследования, в которых эмпирически измеряли производительность этих микроядер, не анализировали причины такой неэффективности.[36] Объяснение этих данных было оставлено на усмотрение «фольклора», предполагая, что они были связаны с увеличением частоты переключений с «режима ядра» на «режим пользователя», с увеличением частоты переключения. межпроцессного взаимодействия и к учащению переключатели контекста.[36]
Фактически, как предполагалось в 1995 году, причинами низкой производительности микроядер с таким же успехом могли быть: (1) фактическая неэффективность всего микроядра. подход, (2) частный концепции реализованы в этих микроядрах, и (3) конкретный выполнение этих концепций. Следовательно, оставалось изучить, будет ли решение для построения эффективного микроядра, в отличие от предыдущих попыток, применением правильных методов построения.[36]
С другой стороны, домены иерархической защиты архитектура, которая приводит к созданию монолитного ядра[30] имеет существенный недостаток производительности каждый раз, когда происходит взаимодействие между разными уровнями защиты (то есть, когда процесс должен манипулировать структурой данных как в «пользовательском режиме», так и в «режиме супервизора»), поскольку для этого требуется копирование сообщений по стоимости.[38]
В гибридное ядро Подход сочетает в себе скорость и более простую конструкцию монолитного ядра с модульностью и безопасностью выполнения микроядра.
Гибридные (или модульные) ядра
Гибридные ядра используются в большинстве коммерческих операционных систем, таких как Майкрософт Виндоус NT 3.1, NT 3.5, NT 3.51, NT 4.0, 2000, XP, Vista, 7, 8, 8.1 и 10. Apple Inc. собственный macOS использует гибридное ядро, называемое XNU который основан на коде из OSF / 1 с Ядро Маха (ОСФМК 7.3)[39] и FreeBSD с монолитное ядро. Они похожи на микроядра, за исключением того, что они включают некоторый дополнительный код в пространстве ядра для повышения производительности. Эти ядра представляют собой компромисс, который был реализован некоторыми разработчиками для учета основных преимуществ как монолитных, так и микроядер. Эти типы ядер являются расширениями микроядер с некоторыми свойствами монолитных ядер. В отличие от монолитных ядер, эти типы ядер не могут самостоятельно загружать модули во время выполнения. Гибридные ядра — это микроядра, которые имеют некоторый «несущественный» код в пространстве ядра, чтобы код выполнялся быстрее, чем в пользовательском пространстве. Гибридные ядра — это компромисс между монолитной и микроядерной конструкциями. Это подразумевает запуск некоторых служб (например, Сетевой стек или файловая система ) в пространстве ядра, чтобы снизить накладные расходы на производительность традиционного микроядра, но по-прежнему выполнять код ядра (например, драйверы устройств) в качестве серверов в пространстве пользователя.
Многие традиционно монолитные ядра теперь по крайней мере добавляют (или используют) возможности модуля. Самым известным из этих ядер является ядро Linux. Модульное ядро может иметь части, встроенные в двоичный файл ядра или двоичные файлы, которые загружаются в память по запросу. Важно отметить, что модуль с испорченным кодом может дестабилизировать работающее ядро. Многие люди сбиваются с толку при обсуждении микроядер. Можно написать драйвер для микроядра в совершенно отдельном пространстве памяти и протестировать его перед «запуском». Когда модуль ядра загружен, он получает доступ к пространству памяти монолитной части, добавляя к нему то, что ему нужно, тем самым открывая путь к возможному загрязнению. Несколько преимуществ модульного (или) гибридного ядра:
- Ускорение разработки драйверов, которые могут работать из модулей. Для тестирования перезагрузки не требуется (при условии, что ядро не дестабилизировано).
- Возможность по запросу вместо того, чтобы тратить время на перекомпиляцию всего ядра для таких вещей, как новые драйверы или подсистемы.
- Более быстрая интеграция сторонних технологий (связанных с разработкой, но, тем не менее, актуальных для себя).
Модули, как правило, взаимодействуют с ядром, используя какой-либо интерфейс модуля. Интерфейс является универсальным (хотя и специфичным для данной операционной системы), поэтому не всегда можно использовать модули. Часто драйверам устройств может потребоваться большая гибкость, чем позволяет интерфейс модуля. По сути, это два системных вызова, и часто проверки безопасности, которые нужно выполнить в монолитном ядре только один раз, теперь могут выполняться дважды. Некоторые из недостатков модульного подхода:
- При большем количестве интерфейсов существует вероятность увеличения количества ошибок (что подразумевает больше дыр в безопасности).
- Поддержка модулей может сбивать с толку некоторых администраторов при решении таких проблем, как различие символов.
Наноядра
Наноядро делегирует практически все услуги, включая даже самые простые, такие как контроллеры прерываний или таймер — к драйверы устройств сделать потребность ядра в памяти даже меньше, чем у традиционного микроядра.[40]
Экзоядра
Экзоядра — это все еще экспериментальный подход к проектированию операционных систем. Они отличаются от других типов ядер тем, что их функциональные возможности ограничиваются защитой и мультиплексированием необработанного оборудования, не предоставляя никаких аппаратных абстракций, поверх которых можно было бы разрабатывать приложения. Такое разделение аппаратной защиты и управления аппаратным обеспечением позволяет разработчикам приложений определять, как наиболее эффективно использовать доступное оборудование для каждой конкретной программы.
Сами по себе экзоядра чрезвычайно малы. Однако они сопровождаются библиотечными операционными системами (см. Также unikernel ), предоставляя разработчикам приложений функции обычной операционной системы. Основное преимущество систем на основе экзоядра состоит в том, что они могут включать в себя несколько библиотечных операционных систем, каждая из которых экспортирует свой API, например один для высокого уровня UI развития и один для в реальном времени контроль.
История развития ядра
Ядра ранних операционных систем
Строго говоря, операционная система (и, следовательно, ядро) не требуется запустить компьютер. Программы могут быть напрямую загружены и выполнены на «голом железе» машины при условии, что авторы этих программ готовы работать без какой-либо аппаратной абстракции или поддержки операционной системы. Большинство ранних компьютеров работали таким образом в 1950-х и начале 1960-х годов, которые перезагружались и перезагружались между выполнением различных программ. В конце концов, небольшие вспомогательные программы, такие как загрузчики программ и отладчики были оставлены в памяти между запусками или загружены из ПЗУ. По мере их разработки они легли в основу того, что стало ядрами ранних операционных систем. В «оголенный метал» подход все еще используется сегодня на некоторых игровые приставки и встроенные системы,[41] но в целом на более новых компьютерах используются современные операционные системы и ядра.
В 1969 г. Мультипрограммная система RC 4000 представил философию системного проектирования небольшого ядра, «на котором операционные системы для различных целей могут быть построены упорядоченным образом»,[42] то, что можно было бы назвать подходом микроядра.
Операционные системы с разделением времени
В предшествующее десятилетие Unix мощность компьютеров выросла до такой степени, что операторы компьютеров искали новые способы заставить людей проводить свободное время на своих машинах. Одним из главных достижений этой эпохи было совместное времяпровождение, в результате чего ряд пользователей получали небольшие доли компьютерного времени со скоростью, с которой, казалось, каждый из них был подключен к своей собственной, более медленной машине.[43]
Развитие систем с разделением времени привело к ряду проблем. Во-первых, пользователи, особенно в университетах, где разрабатывались системы, казалось, хотели взломать система, чтобы получить больше ЦПУ время. По этой причине, безопасность и контроль доступа стал основным направлением деятельности Мультики проект 1965 года.[44] Еще одна постоянная проблема заключалась в правильном обращении с вычислительными ресурсами: пользователи проводили большую часть своего времени, глядя на терминал и думая о том, что ввести, вместо того, чтобы фактически использовать ресурсы компьютера, а система разделения времени должна отдавать процессорное время активному пользователю. в эти периоды. Наконец, системы обычно предлагали иерархия памяти на несколько уровней, и разделение этого дорогостоящего ресурса привело к крупным разработкам в виртуальная память системы.
Amiga
В Коммодор Amiga был выпущен в 1985 году и был одним из первых — и, безусловно, наиболее успешных — домашних компьютеров с усовершенствованной архитектурой ядра. Исполнительный компонент ядра AmigaOS, exec.library, использует схему передачи сообщений микроядра, но есть и другие компоненты ядра, например graphics.library, которые имеют прямой доступ к оборудованию. Защита памяти отсутствует, а ядро почти всегда работает в пользовательском режиме. В режиме ядра выполняются только специальные действия, а приложения пользовательского режима могут запрашивать у операционной системы выполнение их кода в режиме ядра.
Unix
Основная статья: Unix
Диаграмма семейных отношений предшественник / наследник для Unix-подобный системы
На этапе проектирования Unix, программисты решили смоделировать каждый высокоуровневый устройство как файл, потому что они считали цель вычисление был преобразование данных.[45]
Например, принтеры были представлены как «файл» в известном месте — когда данные были скопированы в файл, они распечатывались. Другие системы, чтобы обеспечить аналогичную функциональность, имели тенденцию виртуализировать устройства на более низком уровне, то есть оба устройства. и файлы будут экземплярами некоторых Нижний уровень концепция. Виртуализация система на уровне файлов позволяла пользователям управлять всей системой, используя свои существующие управление файлами утилиты и концепции, значительно упрощающие работу. Как расширение той же парадигмы, Unix позволяет программистам манипулировать файлами, используя серию небольших программ, используя концепцию трубы, что позволяло пользователям выполнять операции поэтапно, подавая файл через цепочку одноцелевых инструментов. Хотя конечный результат был тем же самым, использование небольших программ таким образом резко повысило гибкость, а также простоту разработки и использования, что позволило пользователю изменять свой рабочий процесс, добавляя или удаляя программу из цепочки.
В модели Unix Операционная система состоит из двух частей: во-первых, огромного набора служебных программ, которые управляют большинством операций; во-вторых, ядро, которое запускает программы.[45] В Unix, с точки зрения программирования, разница между ними довольно тонкая; ядро — это программа, работающая в режиме супервизора,[46] который действует как загрузчик программ и контролирует небольшие служебные программы, составляющие остальную часть системы, и обеспечивает запирание и Ввод / вывод услуги для этих программ; кроме того, ядро вообще не вмешивалось в пространство пользователя.
С годами модель вычислений изменилась, и подход Unix к все как файл или поток байтов больше не был таким универсальным, как раньше. Хотя Терминал может рассматриваться как файл или поток байтов, который печатается или читается из него, то же самое не похоже на графический интерфейс пользователя. Сети возникла другая проблема. Даже если сетевое взаимодействие можно сравнить с доступом к файлам, низкоуровневая пакетно-ориентированная архитектура имеет дело с дискретными фрагментами данных, а не с целыми файлами. По мере роста возможностей компьютеров Unix становилась все более загроможденной кодом. Это также связано с тем, что модульность ядра Unix широко масштабируется.[47] Хотя в ядрах могло быть 100000 строки кода в семидесятых и восьмидесятых годах ядра вроде Linux современных преемников Unix, таких как GNU, имеют более 13 миллионов строк.[48]
Современные производные от Unix обычно основаны на монолитных ядрах, загружающих модули. Примеры этого: Ядро Linux во многих распределения из GNU, IBM AIX, так же хорошо как Распространение программного обеспечения Беркли вариантные ядра, такие как FreeBSD, СтрекозаBSD, OpenBSD, NetBSD, и macOS. Помимо этих альтернатив, разработчики-любители поддерживают активную Сообщество разработчиков операционных систем, заполненные самописными ядрами для хобби, которые в большинстве случаев разделяют многие функции с ядрами Linux, FreeBSD, DragonflyBSD, OpenBSD или NetBSD и / или совместимы с ними.[49]
Mac OS
яблоко впервые запустил классическая Mac OS в 1984 году вместе с Macintosh персональный компьютер. Apple перешла на дизайн наноядра в Mac OS 8.6. На фоне этого современные macOS (первоначально названная Mac OS X) основана на Дарвин, в котором используется гибридное ядро, называемое XNU, который был создан путем объединения 4.3BSD ядро и Ядро Маха.[50]
Майкрософт Виндоус
Майкрософт Виндоус был впервые выпущен в 1985 году как дополнение к MS-DOS. Из-за своей зависимости от другой операционной системы, первые выпуски Windows до Windows 95 считались рабочая среда (не путать с Операционная система ). Эта линейка продуктов продолжала развиваться в течение 1980-х и 1990-х годов. Windows 9x серия, добавляющая 32-битную адресацию и упреждающую многозадачность; но закончился выпуском Windows Me в 2000 г.
Microsoft также разработала Windows NT, операционная система с очень похожим интерфейсом, но предназначенная для профессиональных и бизнес-пользователей. Эта линия началась с выпуска Windows NT 3.1 в 1993 году и был представлен обычным пользователям с выпуском Windows XP в октябре 2001 г. — замена Windows 9x с совершенно другой, гораздо более сложной операционной системой. Это линия, которая продолжается с Windows 10.
В архитектура Windows NT Ядро считается гибридным, поскольку само ядро содержит такие задачи, как диспетчер окон и диспетчеры IPC, с многоуровневой моделью подсистемы клиент / сервер.[51]
IBM Supervisor
Программа надзора или руководитель — это компьютерная программа обычно является частью Операционная система, который контролирует выполнение других распорядки и регулирует график работы, ввод, вывод операции, действия при ошибке, и аналогичные функции, и регулирует поток работы в обработка данных система.
Исторически этот термин ассоциировался с IBM линия мэйнфрейм операционные системы начиная с OS / 360. В других операционных системах супервизор обычно называется ядром.
В 1970-х годах IBM дополнительно абстрагировала супервизора. государственный от оборудования, в результате гипервизор это позволило полная виртуализация, то есть возможность запускать несколько операционных систем на одном компьютере совершенно независимо друг от друга. Поэтому первая такая система получила название Виртуальная машина или же ВМ.
Развитие микроядер
Несмотря на то что Мах, разработанная в Университет Карнеги Меллон с 1985 по 1994 год является наиболее известным микроядром общего назначения, другие микроядра были разработаны с более конкретными целями. В Семейство микроядер L4 (в основном ядро L3 и L4) было создано, чтобы продемонстрировать, что микроядра не обязательно медленные.[52] Новые реализации, такие как Фиаско и Фисташковый умеют бегать Linux рядом с другими процессами L4 в отдельных адресных пространствах.[53][54]
Кроме того, QNX это микроядро, которое в основном используется в встроенные системы,[55] и программное обеспечение с открытым исходным кодом МИНИКС изначально создавались для образовательных целей, но теперь ориентированы на то, чтобы быть очень надежный и самовосстановление микроядра ОС.
Смотрите также
- Сравнение ядер операционных систем
- Межпроцессного взаимодействия
- Операционная система
- Виртуальная память
Примечания
- ^ Это может зависеть от Компьютерная архитектура
- ^ а б «Ядро». Linfo. Группа пользователей Bellevue Linux. Получено 15 сентября 2016.
- ^ Рэндал Э. Брайант; Дэвид Р. О’Халларон (2016). Компьютерные системы: взгляд программиста (Третье изд.). Пирсон. п. 17. ISBN 978-0134092669.
- ^ ср. Демон (вычисления)
- ^ а б Рох 2004
- ^ а б c d е ж грамм Вульф, 1974, стр. 337–345
- ^ а б Зильбершатц 1991
- ^ Таненбаум, Эндрю С. (2008). Современные операционные системы (3-е изд.). Прентис Холл. С. 50–51. ISBN 978-0-13-600663-3.
. . . почти все системные вызовы [вызываются] из программ C путем вызова библиотечной процедуры. . . Библиотечная процедура. . . выполняет инструкцию TRAP для переключения из пользовательского режима в режим ядра и начала выполнения. . .
- ^ Деннинг 1976
- ^ Swift 2005, стр.29 цитата: «изоляция, управление ресурсами, проверка решений (проверка) и устранение ошибок».
- ^ Шредер 72
- ^ а б Липа 76
- ^ Стефан Эраниан и Дэвид Мосбергер, Виртуальная память в ядре Linux IA-64, Prentice Hall PTR, 2002 г.
- ^ Зильбершатц и Гальвин, Концепции операционных систем, 4-е изд., Стр. 445 и 446
- ^ Хох, Чарльз; Дж. К. Браун (июль 1980 г.). «Реализация возможностей PDP-11/45». Обзор операционных систем ACM SIGOPS. 14 (3): 22–32. Дои:10.1145/850697.850701. S2CID 17487360.
- ^ а б Языковой подход к безопасности, Шнайдер Ф., Морриссетт Г. (Корнельский университет) и Харпер Р. (Университет Карнеги-Меллона)
- ^ а б c П. А. Лоскокко, С. Д. Смолли, П. А. Макельбауэр, Р. К. Тейлор, С. Дж. Тернер и Дж. Ф. Фаррелл. Неизбежность отказа: ошибочное предположение о безопасности в современных вычислительных средах В архиве 2007-06-21 на Wayback Machine. В материалах 21-й Национальной конференции по безопасности информационных систем, страницы 303–314, октябрь 1998 г. [1].
- ^ Лепро, Джей; Форд, Брайан; Хиблер, Майк (1996). «Постоянная актуальность локальной операционной системы для глобальных приложений». Труды 7-го семинара по европейскому семинару ACM SIGOPS Поддержка систем для всемирных приложений — EW 7. п. 133. Дои:10.1145/504450.504477. S2CID 10027108.
- ^ Дж. Андерсон, Исследование планирования технологий компьютерной безопасности В архиве 2011-07-21 на Wayback Machine, Air Force Elect. Системное отделение, ESD-TR-73-51, октябрь 1972 г.
- ^ * Джерри Х. Зальцер; Майк Д. Шредер (сентябрь 1975 г.). «Защита информации в компьютерных системах». Труды IEEE. 63 (9): 1278–1308. CiteSeerX 10.1.1.126.9257. Дои:10.1109 / PROC.1975.9939. S2CID 269166.
- ^ Джонатан С. Шапиро; Джонатан М. Смит; Дэвид Дж. Фарбер (1999). «EROS: система быстрых возможностей». Труды семнадцатого симпозиума ACM по принципам операционных систем. 33 (5): 170–185. Дои:10.1145/319344.319163.
- ^ Дейкстра, Э. В. Взаимодействующие последовательные процессы. Математика. Dep., Technological U., Эйндховен, сентябрь 1965 г.
- ^ а б c d е Бринч Хансен 70 с. 238–241
- ^ «SHARER, система разделения времени для CDC 6600». Получено 2007-01-07.
- ^ «Динамические супервайзеры — их конструкция и конструкция». Получено 2007-01-07.
- ^ Байарди 1988
- ^ а б Левина 75
- ^ Деннинг 1980
- ^ Юрген Нехмер «Бессмертие операционных систем, или: оправданы ли исследования операционных систем? «, Конспект лекций по информатике; Vol. 563. Труды международного семинара по операционным системам 90-х годов и не только. С. 77–83 (1991) ISBN 3-540-54987-0 [2] цитата: «Последние 25 лет показали, что исследования архитектуры операционной системы оказали незначительное влияние на существующий основной поток [sic ] системы «.
- ^ Леви 84, стр. 1 цитата: «Хотя сложность компьютерных приложений с каждым годом увеличивается, основная аппаратная архитектура приложений остается неизменной в течение десятилетий».
- ^ а б c Леви 84, стр. 1 цитата: «Обычные архитектуры поддерживают один привилегированный режим работы. Эта структура ведет к монолитной конструкции; любой модуль, нуждающийся в защите, должен быть частью единого ядра операционной системы.Если вместо этого любой модуль может выполняться в защищенном домене, системы могут быть построены как набор независимых модулей, расширяемых любым пользователем ».
- ^ «Открытые источники: голоса революции открытого исходного кода». 1-56592-582-3. 29 марта 1999 г.
- ^ Виртуальная адресация чаще всего достигается с помощью встроенного блок управления памятью.
- ^ Записи дебатов между Торвальдсом и Таненбаумом можно найти на dina.dk В архиве 2012-10-03 на Wayback Machine, groups.google.com, oreilly.com и Сайт Эндрю Таненбаума
- ^ а б Мэтью Рассел. «Что такое Дарвин (и как он работает в Mac OS X)». O’Reilly Media. цитата: «Сильно связанная природа монолитного ядра позволяет ему очень эффективно использовать базовое оборудование […] Микроядра, с другой стороны, запускают гораздо больше основных процессов в пользовательском пространстве. […] К сожалению, эти преимущества достигаются за счет того, что микроядру приходится передавать большой объем информации в пространство ядра и из него посредством процесса, известного как переключение контекста. Переключение контекста приводит к значительным накладным расходам и, следовательно, к снижению производительности ».
- ^ «Операционные системы / модели ядра — Викиверситет». en.wikiversity.org.
- ^ а б c d Liedtke 95
- ^ Härtig 97
- ^ Хансен 73, раздел 7.3 стр. 233 «взаимодействие между разными уровнями защиты требует передачи сообщений по значению«
- ^ Видео Apple WWDC (19 февраля 2017 г.). «Apple WWDC 2000, сессия 106 — Mac OS X: ядро» — через YouTube.
- ^ KeyKOS Nanokernel Архитектура В архиве 2011-06-21 на Wayback Machine
- ^ Ball: Конструкции встроенных микропроцессоров, стр. 129
- ^ Хансен 2001 (OS), стр.17–18
- ^ «BSTJ-версия документа C.ACM Unix». bell-labs.com.
- ^ Введение и обзор системы Multics, Ф. Х. Корбато и В. А. Высоцкий.
- ^ а б «Единая спецификация Unix». Открытая группа. Архивировано из оригинал на 2016-10-04. Получено 2016-09-29.
- ^ Наивысший уровень привилегий имеет разные имена в разных архитектурах, например, режим супервизора, режим ядра, CPL0, DPL0, кольцо 0 и т. Д. Кольцо (компьютерная безопасность) для дополнительной информации.
- ^ «Месть Unix». asymco.com. 29 сентября 2010 г.
- ^ Ядро Linux 2.6: оно того стоит!, Дэвид А. Уиллер, 12 октября 2004 г.
- ^ Это сообщество в основном собирается в Добросовестная разработка ОС, Доска объявлений Mega-Tokyo и другие веб-сайты энтузиастов операционных систем.
- ^ XNU: ядро В архиве 2011-08-12 на Wayback Machine
- ^ «Windows — официальный сайт ОС Microsoft Windows 10 Home и Pro, ноутбуков, ПК, планшетов и др.». windows.com.
- ^ «Семейство микроядер L4 — Обзор». os.inf.tu-dresden.de.
- ^ «Микроядро Fiasco — Обзор». os.inf.tu-dresden.de.
- ^ Золлер (инактив), Хайнц (7 декабря 2013 г.). «L4Ka — Проект L4Ka». www.l4ka.org.
- ^ «Операционные системы QNX». blackberry.qnx.com.
Рекомендации
- Рох, Бенджамин (2004). «Монолитное ядро против микроядра» (PDF). Архивировано из оригинал (PDF) на 2006-11-01. Получено 2006-10-12.
- Зильбершац, Авраам; Джеймс Л. Петерсон; Питер Б. Гэлвин (1991). Понятия операционной системы. Бостон, Массачусетс: Аддисон-Уэсли. п. 696. ISBN 978-0-201-51379-0.
- Болл, Стюарт Р. (2002) [2002]. Встроенные микропроцессорные системы: реальные проекты (первое изд.). Elsevier Science. ISBN 978-0-7506-7534-5.
- Дейтель, Харви М. (1984) [1982]. Введение в операционные системы (пересмотренное первое издание). Эддисон-Уэсли. п.673. ISBN 978-0-201-14502-1.
- Деннинг, Питер Дж. (Декабрь 1976 г.). «Отказоустойчивые операционные системы». Опросы ACM Computing. 8 (4): 359–389. Дои:10.1145/356678.356680. ISSN 0360-0300. S2CID 207736773.
- Деннинг, Питер Дж. (Апрель 1980 г.). «Почему не инновации в компьютерной архитектуре?». Новости компьютерной архитектуры ACM SIGARCH. 8 (2): 4–7. Дои:10.1145/859504.859506. ISSN 0163-5964. S2CID 14065743.
- Хансен, Пер Бринч (Апрель 1970 г.). «Ядро многопрограммной системы». Коммуникации ACM. 13 (4): 238–241. CiteSeerX 10.1.1.105.4204. Дои:10.1145/362258.362278. ISSN 0001-0782. S2CID 9414037.
- Хансен, Пер Бринч (1973). Принципы операционной системы. Englewood Cliffs: Прентис Холл. п.496. ISBN 978-0-13-637843-3.
- Хансен, Пер Бринч (2001). «Эволюция операционных систем» (PDF). Получено 2006-10-24. включено в книгу: Пер Бринч Хансен, изд. (2001). «1» (PDF). Классические операционные системы: от пакетной обработки до распределенных систем. Нью-Йорк: Springer-Verlag. С. 1–36. ISBN 978-0-387-95113-3.
- Герман Хертиг, Майкл Хохмут, Йохен Лидтке, Себастьян Шенберг, Жан Вольтер Производительность систем на основе μ-ядра, Хертиг, Германн; Хохмут, Майкл; Лидтке, Йохен; Шенберг, Себастьян (1997). «Производительность систем на основе μ-ядра». Материалы шестнадцатого симпозиума ACM по принципам операционных систем — SOSP ’97. п. 66. CiteSeerX 10.1.1.56.3314. Дои:10.1145/268998.266660. ISBN 978-0897919166. S2CID 1706253. Обзор операционных систем ACM SIGOPS, версия 31, номер 5, стр. 66–77, декабрь 1997 г.
- Ходек, М. Э., Солтис, Ф. Г., и Хоффман, Р. Л. 1981. IBM System / 38 поддерживает адресацию на основе возможностей. В материалах 8-го Международного симпозиума ACM по компьютерной архитектуре. ACM / IEEE, стр. 341–348.
- Корпорация Intel (2002) Руководство разработчика программного обеспечения с архитектурой IA-32, том 1: Базовая архитектура
- Левин, Р .; Cohen, E .; Corwin, W .; Pollack, F .; Вульф, Уильям (1975). «Разделение политики / механизма в Гидре». Симпозиум ACM по принципам операционных систем / Труды пятого симпозиума ACM по принципам операционных систем. 9 (5): 132–140. Дои:10.1145/1067629.806531.
- Леви, Генри М. (1984). Компьютерные системы на основе возможностей. Мейнард, Массачусетс: Цифровая пресса. ISBN 978-0-932376-22-0.
- Лидтке, Йохен. О конструкции µ-ядра, Proc. 15-й симпозиум ACM по принципам операционных систем (SOSP), Декабрь 1995 г.
- Линден, Теодор А. (декабрь 1976 г.). «Структуры операционной системы для поддержки безопасности и надежного программного обеспечения». Опросы ACM Computing. 8 (4): 409–445. Дои:10.1145/356678.356682. HDL:2027 / mdp.39015086560037. ISSN 0360-0300. S2CID 16720589., «Структуры операционной системы для поддержки безопасности и надежного программного обеспечения» (PDF). Получено 2010-06-19.
- Лорин, Гарольд (1981). Операционные системы. Бостон, Массачусетс: Аддисон-Уэсли. стр.161–186. ISBN 978-0-201-14464-2.
- Шредер, Майкл Д.; Джером Х. Зальцер (март 1972 г.). «Аппаратная архитектура для реализации колец защиты». Коммуникации ACM. 15 (3): 157–170. CiteSeerX 10.1.1.83.8304. Дои:10.1145/361268.361275. ISSN 0001-0782. S2CID 14422402.
- Шоу, Алан С. (1974). Логический дизайн операционных систем. Прентис-Холл. п.304. ISBN 978-0-13-540112-5.
- Таненбаум, Эндрю С. (1979). Структурированная компьютерная организация. Энглвуд Клиффс, Нью-Джерси: Прентис-Холл. ISBN 978-0-13-148521-1.
- Вульф, В.; Э. Коэн; В. Корвин; А. Джонс; Р. Левин; К. Пирсон; Ф. Поллак (июнь 1974 г.). «HYDRA: ядро многопроцессорной операционной системы» (PDF). Коммуникации ACM. 17 (6): 337–345. Дои:10.1145/355616.364017. ISSN 0001-0782. S2CID 8011765. Архивировано из оригинал (PDF) на 2007-09-26. Получено 2007-07-18.
- Baiardi, F .; А. Томази; М. Ваннески (1988). Architettura dei Sistemi di Elaborazione, том 1 (на итальянском). Франко Анджели. ISBN 978-88-204-2746-7. Архивировано из оригинал на 2012-06-27. Получено 2006-10-10.
- Свифт, Майкл М .; Брайан Н. Бершад; Генри М. Леви. Повышение надежности серийных операционных систем (PDF).
- Геттис, Джеймс; Карлтон, Филип Л .; МакГрегор, Скотт (1990). «Повышение надежности товарных операционных систем». Программное обеспечение: практика и опыт. 20: S35 – S67. Дои:10.1002 / spe.4380201404. Получено 2010-06-19.
- «Транзакции ACM в компьютерных системах (TOCS), v.23 №1, стр. 77–110, февраль 2005».
дальнейшее чтение
- Эндрю Таненбаум, Операционные системы — разработка и реализация (третье издание);
- Эндрю Таненбаум, Современные операционные системы (второе издание);
- Даниэль П. Бове, Марко Чезати, Ядро Linux;
- Дэвид А. Петерсон, Нитин Индуркхья, Паттерсон, Компьютерная организация и дизайн, Морган Коффман (ISBN 1-55860-428-6);
- Б.С. Мел, Компьютерная организация и архитектура, Макмиллан П. (ISBN 0-333-64551-0).
внешняя ссылка
- Подробное сравнение наиболее популярных ядер операционных систем
Содержание
- Во время работы компьютера в оперативной памяти постоянно находится
- Тестирование по разделу «Архитектура ЭВМ.Программное обеспечение» 10 класс.
- Как проверить оперативную память на ошибки
- Содержание
- Содержание
- Диагностика средствами Windows
- Диагностика MemTest86
- Диагностика программой TestMem5 (tm5)
- Какой программой пользоваться?
- Как найти неисправный модуль?
- Что делать, если нашли неисправный модуль памяти?
- Анатомия RAM
- Зачем же ты, RAM-ео?
- Скальпель. Зажим. Электронный микроскоп.
- Выше по рангу
- Жажда скорости
- Скорость битов
- Спасибо за службу, RAM!
Во время работы компьютера в оперативной памяти постоянно находится
Тестирование по разделу «Архитектура ЭВМ.Программное обеспечение» 10 класс.
Перед отключением компьютера информацию можно сохранить
1) в оперативной памяти
2) во внешней памяти
3) в регистрах процессора
5) в контроллере магнитного диска
Электронный блок, управляющий работой внешнего устройства, называется:
1) адаптер (контроллер)
3) регистр процессора
Наименьшая адресуемая часть памяти компьютера:
«Каталог содержит информацию о …. хранящихся в …..». Вместо многоточия вставьте соответствующее высказывание:
1) программах, оперативной памяти
2) файлах, оперативной памяти
3) программах, внешней памяти
4) файлах, внешней памяти
5) программах, процессоре
1) устройство длительного хранения информации
2) программа, управляющая конкретным внешним устройством
3) устройство ввода
4) устройство, позволяющее подсоединить к компьютеру новое внешнее
5) устройство вывода
Во время работы компьютера в оперативной памяти постоянно находится
1) ядро операционной системы
2) вся операционная система
3) прикладное программное обеспечение
4) система программирования
Информацию из оперативной памяти можно сохранить на внешнем запоминающем устройстве в виде:
Какое количество информации может обработать за одну операцию 16-разрядный процессор?
Приложение выгружается из памяти и прекращает свою работу, если
1) запустить другое приложение
2) свернуть окно приложения
3) переключиться в другое окно
4) переместить окно приложения
5) закрыть окно приложения
1) создать файл home.txt;
2) создать каталог TOWN;
3) создать каталог STREET;
4) войти в созданный каталог
5) сделать диск А: текущим.
Расположите пронумерованные команды так, чтобы был получен алгоритм, с помощью которого на пустой дискете создается файл с полным именем А: TOWN STREET home.txt.
Панель задач служит для
1) переключения между запущенными приложениями
2) завершения работы Windows
3) обмена данными между приложениями
4) запуска программ DOS
5) просмотра каталогов
Файл tetris.com находится на диске С: в каталоге GAMES, который является подкаталогом каталога DAY. Выбрать полное имя файла:
1) С: tetris.com GAMES DAY
2) С: GAMES tetris.com
3) С: DAY GAMES tetris.com
4) С: GAMES DAY tetris.com
5) С: GAMES tetris.com
«….. памяти означает, что любая информация заносится в память и извлекается из нее по …..».
Вместо многоточия вставить соответствующие высказывания:
1) Дискретность; адресам
2) Адресуемость; значениям
3) Дискретность; битам
4) Адресуемость; байтам
5) Адресуемость; адресам
В прикладное программное обеспечение входят:
1) языки программирования
2) операционные системы
3) диалоговая оболочка
4) совокупность всех программ, установленных на компьютере
5) текстовые редакторы
«Программа, хранящаяся во внешней памяти, после вызова на выполнение попадает в ….. и обрабатывается ….». Вместо многоточия вставить соответствующие высказывания:
1) устройство ввода; процессором
2) процессор; регистрами процессора
3) процессор; процессором
4) оперативная память; процессором
5) файл; процессором
Какой информационный объем займет на гибком диске текстовый файл, содержащий
В системное программное обеспечение входят:
1) языки программирования
2) операционные системы
3) графические редакторы
4) компьютерные игры
5) текстовые редакторы
«….. – это информация, обрабатываемая в компьютере программным путём». Вместо многоточия вставить соответствующее слово:
«Любая информация в памяти компьютера состоит из ….. и …».
Вместо многоточия вставить соответствующие высказывания:
2) слов; предложений
«Чистая отформатированная дискета может стать источником заражения …… «.
Вместо многоточия вставить соответствующие слова:
Источник
Как проверить оперативную память на ошибки


Содержание
Содержание
Во время работы компьютера в оперативной памяти содержатся данные ОС, запущенных программ, а также входные, выходные и промежуточные данные, обрабатываемые процессором. Если с оперативной памятью проблемы — плохо работать будет все. Как понять, что оперативную память пора лечить или менять и проблемы именно в ней? Разбираемся.
Причин ошибок в работе оперативной памяти очень много — от неправильно заданных параметров материнской платой (настройки по умолчанию не панацея) до брака, механических дефектов памяти и разъема материнской платы, а также проблем с контроллером памяти процессора.
Одним из первых признаков неполадок в работе оперативной памяти являются синие экраны смерти (BSOD) и сопутствующие симптомы: подтормаживание, зависание, вылеты приложений с различными ошибками и просто так.
Перечисленные неполадки в работе компьютера относят в основном к симптомам общего характера. При появлении таких неявных признаков неисправности лучше всего начать диагностику компьютера именно с оперативной памяти.
Для диагностики оперативной памяти есть специальные программные средства, о которых и будет дальше идти речь.
Диагностика средствами Windows
Чтобы запустить средство диагностики памяти Windows, откройте меню «Пуск», введите «Диагностика памяти Windows» и нажмите клавишу Enter.
Вы также можете воспользоваться комбинацией клавиш Windows + R и в появившемся диалоговом окне ввести команду mdsched.exe и нажать клавишу Enter.


На выбор есть два варианта: сейчас перезагрузить компьютер и начать проверку или выполнить проверку во время следующего включения компьютера.

Как только компьютер перезагрузится, появится экран средства диагностики памяти Windows.

Ничего трогать не нужно — по завершении теста компьютер еще раз перезагрузится сам и включится в обычном режиме. Сидеть и следить за ходом проверки тоже не стоит — всю информацию с результатами проверки можно будет потом посмотреть в журнале событий операционной системы.
Результат проверки должен появиться при включении компьютера, но это происходит далеко не всегда.

Чтобы узнать результаты проверки через журнал событий. В меню поиск забиваем «просмотр событий» или можно снова воспользоваться комбинацией клавиш Windows + R и ввести команду eventvwr.msc и Enter.


Открываем журналы «Windows – Система – найти – Диагностика памяти».

Диагностика MemTest86
Данный способ несколько сложнее, так как нужно создать загрузочную флешку, но у него есть и свои положительные стороны. Он выполняет более широкий набор тестов и может найти проблемы, которые не обнаружил встроенный тест Windows.
По началу процесс создания загрузочной флешки может напугать неопытного пользователя, но здесь нет ничего сложно. Скачиваем архив, извлекаем содержимое, вставляем флешку в компьютер и запускаем файл imageUSB.exe.

Выбираем наш USB-накопитель и нажимаем Write, процесс занимает считанные минуты. Все, образ готов.


Чтобы загрузиться с созданного ранее флеш-накопителя, необходимо настроить приоритет загрузки устройств в BIOS материнской платы или, что значительно проще, воспользоваться функцией Boot Menu.
В зависимости от производителя материнской платы, клавиша для вызова функции Boot Menu может меняться, обычно это F2, Del, Esc, F12.
Соответствующую клавишу нужно нажимать сразу после включения компьютера или в момент перезагрузки компьютера, как только потух монитор (нажимать можно несколько раз, чтобы не пропустить нужный момент).
Проверка запустится автоматически, ничего трогать не нужно.



Процедура проверки будет выполняться циклически (Pass) до тех пор, пока вы не решите остановить его. Информация об ошибках будет отображаться в нижней части экрана. Когда решите закончите, нужно просто нажать клавишу Esc, чтобы выйти и перезагрузить компьютер. По-хорошему, нужно пройти минимум 5–10 циклов проверки — чем больше, чем лучше.
Диагностика программой TestMem5 (tm5)
TestMem5 — программа тестирования оперативной памяти, абсолютно бесплатная, скачать можно по ссылке.

Эта программа построена по несколько другому принципу, чем предыдущие. А именно — она настраиваемая. Сами тесты имеют довольно гибкую структуру с большим количеством настроек.
Настройкой собственной конфигурации для тестирования заниматься необязательно, есть уже несколько готовых конфигураций настроек от разных авторов. Наибольшей популярностью пользуются конфигурации от 1usmus v3 и anta777 (Экстрим – Тяжелый – Суперлайт). Процесс установки конфигураций очень прост: скачиваете нужный и помещаете в папку с программой или можно добавить через «Настроить и выйти».

Важно : Запускать tm5.exe нужно в режиме администратора ( с правами администратора).
Какой программой пользоваться?
У каждой из программа есть свои сильные и слабые стороны.
Диагностика средствами Windows — это наиболее простой способ, который уже встроен в операционную систему, его остается только запустить. Не способен найти сложные ошибки, тест короткий.
MemTest86 — старая и авторитетная программа, есть небольшие сложности с запуском. Можно использовать без установленной операционной системы.
TestMem5 — прост в использовании, проверка происходит в среде Windows, что наиболее приближено к реальным условиям использования, а не в среде DOS как Memtest86. А наличие различных конфигураций по интенсивности и времени проверки делает ее наилучшим решением для тестирования оперативной памяти как по дефолту, так и во время разгона.
Как найти неисправный модуль?
Принцип поиска неисправного модуля довольно прост:
1) Проверить правильность установки разъемов при наличии двух модулей.

2) Продуть от пыли разъемы и протереть контакты.
3) Сбросить все настройки Bios на дефолтные.
4) Проверить планки памяти вместе и по отдельности, меняя разъемы.
5) Проверить планки памяти на другой материнской плате у друга.
Что делать, если нашли неисправный модуль памяти?
Если все перечисленное не помогает избавиться от ошибок, стоит обратиться в гарантийный отдел, если товар еще на гарантии. Платный ремонт оперативной памяти обычно нецелесообразен ввиду не очень высокой цены продукта. Проще пойти и купить новый модуль на гарантии, чем заниматься восстановлением неисправного.
Сама по себе оперативная память сейчас очень редко выходит из строя и с легкостью переживает смену остальных компонентов системы. Чаще всего все ошибки, связанные с работой оперативной памяти, возникают по вине самого пользователя и из-за некорректных настроек в Bios материнской платы, а также при использовании совершенно разных планок памяти и во время разгона.
Источник
Анатомия RAM

У каждого компьютера есть ОЗУ, встроенное в процессор или находящееся на отдельной подключенной к системе плате — вычислительные устройства просто не смогли бы работать без оперативной памяти. ОЗУ — потрясающий образец прецизионного проектирования, однако несмотря на тонкость процессов изготовления, память ежегодно производится в огромных объёмах. В ней миллиарды транзисторов, но она потребляет только считанные ватты мощности. Учитывая большую важность памяти, стоит написать толковый анализ её анатомии.
Итак, давайте приготовимся к вскрытию, выкатим носилки и отправимся в анатомический театр. Настало время изучить все подробности каждой ячейки, из которых состоит современная память, и узнать, как она работает.
Зачем же ты, RAM-ео?
Процессорам требуется очень быстро получать доступ к данным и командам, чтобы программы выполнялись мгновенно. Кроме того, им нужно, чтобы при произвольных или неожиданных запросах не очень страдала скорость. Именно поэтому для компьютера так важно ОЗУ (RAM, сокращение от random-access memory — память с произвольным доступом).
Существует два основных типа RAM: статическая и динамическая, или сокращённо SRAM и DRAM.
Мы будем рассматривать только DRAM, потому что SRAM используется только внутри процессоров, таких как CPU или GPU. Так где же находится DRAM в наших компьютерах и как она работает?
Большинству людей знакома RAM, потому что несколько её планок находится рядом с CPU (центральным процессором, ЦП). Эту группу DRAM часто называют системной памятью, но лучше её называть памятью CPU, потому что она является основным накопителем рабочих данных и команд процессора.

Как видно на представленном изображении, DRAM находится на небольших платах, вставляемых в материнскую (системную) плату. Каждую плату обычно называют DIMM или UDIMM, что расшифровывается как dual inline memory module (двухсторонний модуль памяти) (U обозначает unbuffered (без буферизации)). Подробнее мы объясним это позже; пока только скажем, что это самая известная RAM любого компьютера.
Она не обязательно должна быть сверхбыстрой, но современным ПК для работы с большими приложениями и для обработки сотен процессов, выполняемых в фоновом режиме, требуется много памяти.
Ещё одним местом, где можно найти набор чипов памяти, обычно является графическая карта. Ей требуется сверхбыстрая DRAM, потому что при 3D-рендеринге выполняется огромное количество операций чтения и записи данных. Этот тип DRAM предназначен для несколько иного использования по сравнению с типом, применяемым в системной памяти.
Ниже вы видите GPU, окружённый двенадцатью небольшими пластинами — это чипы DRAM. Конкретно этот тип памяти называется GDDR5X, о нём мы поговорим позже.

Графическим картам не нужно столько же памяти, как CPU, но их объём всё равно достигает тысяч мегабайт.
Не каждому устройству в компьютере нужно так много: например, жёстким дискам достаточно небольшого количества RAM, в среднем по 256 МБ; они используются для группировки данных перед записью на диск.

На этих фотографиях мы видим платы HDD (слева) и SSD (справа), на которых отмечены чипы DRAM. Заметили, что чип всего один? 256 МБ сегодня не такой уж большой объём, поэтому вполне достаточно одного куска кремния.
Узнав, что каждый компонент или периферийное устройство, выполняющее обработку, требует RAM, вы сможете найти память во внутренностях любого ПК. На контроллерах SATA и PCI Express установлены небольшие чипы DRAM; у сетевых интерфейсов и звуковых карт они тоже есть, как и у принтеров со сканнерами.
Если память можно встретить везде, она может показаться немного скучной, но стоит вам погрузиться в её внутреннюю работу, то вся скука исчезнет!
Скальпель. Зажим. Электронный микроскоп.
У нас нет всевозможных инструментов, которые инженеры-электронщики используют для изучения своих полупроводниковых творений, поэтому мы не можем просто разобрать чип DRAM и продемонстрировать вам его внутренности. Однако такое оборудование есть у ребят из TechInsights, которые сделали этот снимок поверхности чипа:

Если вы подумали, что это похоже на сельскохозяйственные поля, соединённые тропинками, то вы не так далеки от истины! Только вместо кукурузы или пшеницы поля DRAM в основном состоят из двух электронных компонентов:

Синими и зелёными линиями обозначены соединения, подающие напряжение на МОП-транзистор и конденсатор. Они используются для считывания и записи данных в ячейку, и первой всегда срабатывает вертикальная (разрядная) линия.
Канавочный конденсатор, по сути, используется в качестве сосуда для заполнения электрическим зарядом — его пустое/заполненное состояние даёт нам 1 бит данных: 0 — пустой, 1 — полный. Несмотря на предпринимаемые инженерами усилия, конденсаторы не способны хранить этот заряд вечно и со временем он утекает.
Это означает, что каждую ячейку памяти нужно постоянно обновлять по 15-30 раз в секунду, хотя сам этот процесс довольно быстр: для обновления набора ячеек требуется всего несколько наносекунд. К сожалению, в чипе DRAM множество ячеек, и во время их обновления считывание и запись в них невозможна.
К каждой линии подключено несколько ячеек:
Строго говоря, эта схема неидеальна, потому что для каждого столбца ячеек используется две разрядные линии — если бы мы изобразили всё, то схема бы стала слишком неразборчивой.
Полная строка ячеек памяти называется страницей, а длина её зависит от типа и конфигурации DRAM. Чем длиннее страница, тем больше в ней бит, но и тем большая электрическая мощность нужна для её работы; короткие страницы потребляют меньше мощности, но и содержат меньший объём данных.
Однако нужно учитывать и ещё один важный фактор. При считывании и записи на чип DRAM первым этапом процесса является активация всей страницы. Строка битов (состоящая из нулей и единиц) хранится в буфере строки, который по сути является набором усилителей считывания и защёлок, а не дополнительной памятью. Затем активируется соответствующий столбец для извлечения данных из этого буфера.
Если страница слишком мала, то чтобы успеть за запросами данных, строки нужно активировать чаще; и наоборот — большая страница предоставляет больше данных, поэтому активировать её можно реже. И даже несмотря на то, что длинная строка требует большей мощности и потенциально может быть менее стабильной, лучше стремиться к получению максимально длинных страниц.
Если собрать вместе набор страниц, то мы получим один банк памяти DRAM. Как и в случае страниц, размер и расположение строк и столбцов ячеек играют важную роль в количестве хранимых данных, скорости работы памяти, энергопотреблении и так далее.
Например, схема может состоять из 4 096 строк и 4 096 столбцов, при этом полный объём одного банка будет равен 16 777 216 битам или 2 мегабайтам. Но не у всех чипов DRAM банки имеют квадратную структуру, потому что длинные страницы лучше, чем короткие. Например, схема из 16 384 строк и 1 024 столбцов даст нам те же 2 мегабайта памяти, но каждая страница будет содержать в четыре раза больше памяти, чем в квадратной схеме.
Все страницы в банке соединены с системой адресации строк (то же относится и к столбцам) и они контролируются сигналами управления и адресами для каждой строки/столбца. Чем больше строк и столбцов в банке, тем больше битов должно использоваться в адресе.
Для банка размером 4 096 x 4 096 для каждой системы адресации требуется 12 бит, а для банка 16 384 x 1 024 потребуется 14 бит на адреса строк и 10 бит на адреса столбцов. Стоит заметить, что обе системы имеют суммарный размер 24 бита.
Если бы чип DRAM мог предоставлять доступ к одной странице за раз, то это было бы не особо удобно, поэтому в них упаковано несколько банков ячеек памяти. В зависимости от общего размера, чип может иметь 4, 8 или даже 16 банков — чаще всего используется 8 банков.
Все эти банки имеют общие шины команд, адресов и данных, что упрощает структуру системы памяти. Пока один банк занят работой с одной командой, другие банки могут продолжать выполнение своих операций.
Весь чип, содержащий все банки и шины, упакован в защитную оболочку и припаян к плате. Она содержит электропроводники, подающие питание для работы DRAM и сигналов команд, адресов и данных.

На фотографии выше показан чип DRAM (иногда называемый модулем), изготовленный компанией Samsung. Другими ведущими производителями являются Toshiba, Micron, SK Hynix и Nanya. Samsung — крупнейший производитель, он имеет приблизительно 40% мирового рынка памяти.
Каждый изготовитель DRAM использует собственную систему кодирования характеристик памяти; на фотографии показан чип на 1 гигабит, содержащий 8 банков по 128 мегабита, выстроенных в 16 384 строки и 8 192 столбца.
Выше по рангу
Компании-изготовители памяти берут несколько чипов DRAM и устанавливают их на одну плату, называемую DIMM. Хотя D расшифровывается как dual (двойная), это не значит, что на ней два набора чипов. Под двойным подразумевается количество электрических контактов в нижней части платы; то есть для работы с модулями используются обе стороны платы.
Сами DIMM имеют разный размер и количество чипов:

На фотографии сверху показана стандартная DIMM для настольного ПК, а под ней находится так называемая SO-DIMM (small outline, «DIMM малого профиля»). Маленький модуль предназначен для ПК малого форм-фактора, например, ноутбуков и компактных настольных компьютеров. Из-за малого пространства уменьшается количество используемых чипов, изменяется скорость работы памяти, и так далее.
Существует три основных причины для использования нескольких чипов памяти на DIMM:
То есть каждому DIMM, который устанавливается в компьютер с Ryzen, потребуется восемь модулей DRAM (8 чипов x 8 бит = 64 бита). Можно подумать, что графическая карта 5700 XT будет иметь 32 чипа памяти, но у неё их только 8. Что же это нам даёт?
В чипы памяти, предназначенные для графических карт, устанавливают больше банков, обычно 16 или 32, потому что для 3D-рендеринга необходим одновременный доступ к большому объёму данных.
Один ранг и два ранга
Множество модулей памяти, «заполняющих» шину данных контроллера памяти, называется рангом, и хотя к контроллеру можно подключить больше одного ранга, за раз он может получать данные только от одного ранга (потому что ранги используют одну шину данных). Это не вызывает проблем, потому что пока один ранг занимается ответом на переданную ему команду, другому рангу можно передать новый набор команд.
Платы DIMM могут иметь несколько рангов и это особенно полезно, когда вам нужно огромное количество памяти, но на материнской плате мало разъёмов под RAM.
Так называемые схемы с двумя (dual) или четырьмя (quad) рангами потенциально могут обеспечить большую производительность, чем одноранговые, но увеличение количества рангов быстро повышает нагрузку на электрическую систему. Большинство настольных ПК способно справиться только с одним-двумя рангами на один контроллер. Если системе нужно больше рангов, то лучше использовать DIMM с буферизацией: такие платы имеют дополнительный чип, облегчающий нагрузку на систему благодаря хранению команд и данных в течение нескольких циклов, прежде чем передать их дальше.

Множество модулей памяти Nanya и один буферный чип — классическая серверная RAM
Но не все ранги имеют размер 64 бита — используемые в серверах и рабочих станциях DIMM часто размером 72 бита, то есть на них есть дополнительный модуль DRAM. Этот дополнительный чип не обеспечивает повышение объёма или производительности; он используется для проверки и устранения ошибок (error checking and correcting, ECC).
Вы ведь помните, что всем процессорам для работы нужна память? В случае ECC RAM небольшому устройству, выполняющему работу, предоставлен собственный модуль.
Шина данных в такой памяти всё равно имеют ширину всего 64 бита, но надёжность хранения данных значительно повышается. Использование буферов и ECC только незначительно влияет на общую производительность, зато сильно повышает стоимость.
Жажда скорости
У всех DRAM есть центральный тактовый сигнал ввода-вывода (I/O, input/output) — напряжение, постоянно переключающееся между двумя уровнями; он используется для упорядочивания всего, что выполняется в чипе и шинах памяти.
Если бы мы вернулись назад в 1993 год, то смогли бы приобрести память типа SDRAM (synchronous, синхронная DRAM), которая упорядочивала все процессы с помощью периода переключения тактового сигнала из низкого в высокое состояние. Так как это происходит очень быстро, такая система обеспечивает очень точный способ определения времени выполнения событий. В те времена SDRAM имела тактовые сигналы ввода-вывода, обычно работавшие с частотой от 66 до 133 МГц, и за каждый такт сигнала в DRAM можно было передать одну команду. В свою очередь, чип за тот же промежуток времени мог передать 8 бит данных.
Быстрое развитие SDRAM, ведущей силой которого был Samsung, привело к созданию в 1998 году её нового типа. В нём передача данных синхронизировалась по повышению и падению напряжения тактового сигнала, то есть за каждый такт данные можно было дважды передать в DRAM и обратно.
Как же называлась эта восхитительная новая технология? Double data rate synchronous dynamic random access memory (синхронная динамическая память с произвольным доступом и удвоенной скоростью передачи данных). Обычно её просто называют DDR-SDRAM или для краткости DDR.
Память DDR быстро стала стандартом (из-за чего первоначальную версию SDRAM переименовали в single data rate SDRAM, SDR-DRAM) и в течение последующих 20 лет оставалась неотъемлемой частью всех компьютерных систем.
Прогресс технологий позволил усовершенствовать эту память, благодаря чему в 2003 году появилась DDR2, в 2007 году — DDR3, а в 2012 году — DDR4. Каждая новая версия обеспечивала повышение производительности благодаря ускорению тактового сигнала ввода-вывода, улучшению систем сигналов и снижению энергопотребления.
DDR2 внесла изменение, которое мы используем и сегодня: генератор тактовых сигналов ввода-вывода превратился в отдельную систему, время работы которой задавалось отдельным набором синхронизирующих сигналов, благодаря чему она стала в два раза быстрее. Это аналогично тому, как CPU используют для упорядочивания работы тактовый сигнал 100 МГц, хотя внутренние синхронизирующие сигналы работают в 30-40 раз быстрее.
DDR3 и DDR4 сделали шаг вперёд, увеличив скорость тактовых сигналов ввода-вывода в четыре раза, но во всех этих типах памяти шина данных для передачи/получения информации по-прежнему использовала только повышение и падение уровня сигнала ввода-вывода (т.е. удвоенную частоту передачи данных).
Сами чипы памяти не работают на огромных скоростях — на самом деле, они шевелятся довольно медленно. Частота передачи данных (измеряемая в миллионах передач в секунду — millions of transfers per second, MT/s) в современных DRAM настолько высока благодаря использованию в каждом чипе нескольких банков; если бы на каждый модуль приходился только один банк, всё работало бы чрезвычайно медленно.
| Тип DRAM | Обычная частота чипа | Тактовый сигнал ввода-вывода | Частота передачи данных |
| SDR | 100 МГц | 100 МГц | 100 MT/s |
| DDR | 100 МГц | 100 МГц | 200 MT/s |
| DDR2 | 200 МГц | 400 МГц | 800 MT/s |
| DDR3 | 200 МГц | 800 МГц | 1600 MT/s |
| DDR4 | 400 МГц | 1600 МГц | 3200 MT/s |
Каждая новая версия DRAM не обладает обратной совместимостью, то есть используемые для каждого типа DIMM имеют разные количества электрических контактов, разъёмы и вырезы, чтобы пользователь не мог вставить память DDR4 в разъём DDR-SDRAM.

Сверху вниз: DDR-SDRAM, DDR2, DDR3, DDR4
DRAM для графических плат изначально называлась SGRAM (synchronous graphics, синхронная графическая RAM). Этот тип RAM тоже подвергался усовершенствованиям, и сегодня его для понятности называют GDDR. Сейчас мы достигли версии 6, а для передачи данных используется система с учетверённой частотой, т.е. за тактовый цикл происходит 4 передачи.
| Тип DRAM | Обычная частота памяти | Тактовый сигнал ввода-вывода | Частота передачи данных |
| GDDR | 250 МГц | 250 МГц | 500 MT/s |
| GDDR2 | 500 МГц | 500 МГц | 1000 MT/s |
| GDDR3 | 800 МГц | 1600 МГц | 3200 MT/s |
| GDDR4 | 1000 МГц | 2000 МГц | 4000 MT/s |
| GDDR5 | 1500 МГц | 3000 МГц | 6000 MT/s |
| GDDR5X | 1250 МГц | 2500 МГц | 10000 MT/s |
| GDDR6 | 1750 МГц | 3500 МГц | 14000 MT/s |
Кроме более высокой частоты передачи, графическая DRAM обеспечивает дополнительные функции для ускорения передачи, например, возможность одновременного открытия двух страниц одного банка, работающие в DDR шины команд и адресов, а также чипы памяти с гораздо большими скоростями тактовых сигналов.
Какой же минус у всех этих продвинутых технологий? Стоимость и тепловыделение.
Один модуль GDDR6 примерно вдвое дороже аналогичного чипа DDR4, к тому же при полной скорости он становится довольно горячим — именно поэтому графическим картам с большим количеством сверхбыстрой RAM требуется активное охлаждение для защиты от перегрева чипов.
Скорость битов
Производительность DRAM обычно измеряется в количестве битов данных, передаваемых за секунду. Ранее в этой статье мы говорили, что используемая в качестве системной памяти DDR4 имеет чипы с 8-битной шириной шины, то есть каждый модуль может передавать до 8 бит за тактовый цикл.
То есть если частота передачи данных равна 3200 MT/s, то пиковый результат равен 3200 x 8 = 25 600 Мбит в секунду или чуть больше 3 ГБ/с. Так как большинство DIMM имеет 8 чипов, потенциально можно получить 25 ГБ/с. Для GDDR6 с 8 модулями этот результат был бы равен 440 ГБ/с!
Обычно это значение называют полосой пропускания (bandwidth) памяти; оно является важным фактором, влияющим на производительность RAM. Однако это теоретическая величина, потому что все операции внутри чипа DRAM не происходят одновременно.
Чтобы разобраться в этом, давайте взглянем на показанное ниже изображение. Это очень упрощённое (и нереалистичное) представление того, что происходит, когда данные запрашиваются из памяти.
На первом этапе активируется страница DRAM, в которой содержатся требуемые данные. Для этого памяти сначала сообщается, какой требуется ранг, затем соответствующий модуль, а затем конкретный банк.
Чипу передаётся местоположение страницы данных (адрес строки), и он отвечает на это передачей целой страницы. На всё это требуется время и, что более важно, время нужно и для полной активации строки, чтобы гарантировать полную блокировку строки битов перед выполнением доступа к ней.
Затем определяется соответствующий столбец и извлекается единственный бит информации. Все типы DRAM передают данные пакетами, упаковывая информацию в единый блок, и пакет в современной памяти почти всегда равен 8 битам. То есть даже если за один тактовый цикл извлекается один бит, эти данные нельзя передать, пока из других банков не будет получено ещё 7 битов.
А если следующий требуемый бит данных находится на другой странице, то перед активацией следующей необходимо закрыть текущую открытую страницу (это процесс называется pre-charging). Всё это, разумеется, требует больше времени.
Все эти различные периоды между временем отправки команды и выполнением требуемого действия называются таймингами памяти или задержками. Чем ниже значение, тем выше общая производительность, ведь мы тратим меньше времени на ожидание завершения операций.
Некоторые из этих задержек имеют знакомые фанатам компьютеров названия:
| Название тайминга | Описание | Обычное значение в DDR4 |
| tRCD | Row-to-Column Delay: количество циклов между активацией строки и возможностью выбора столбца | 17 циклов |
| CL | CAS Latency: количество циклов между адресацией столбца и началом передачи пакет данных | 15 циклов |
| tRAS | Row Cycle Time: наименьшее количество циклов, в течение которого строка должна оставаться активной перед тем, как можно будет выполнить её pre-charging | 35 циклов |
| tRP | Row Precharge time: минимальное количество циклов, необходимое между активациями разных строк | 17 циклов |
Существует ещё много других таймингов и все их нужно тщательно настраивать, чтобы DRAM работала стабильно и не искажала данные, имея при этом оптимальную производительность. Как можно увидеть из таблицы, схема, демонстрирующая циклы в действии, должна быть намного шире!
Хотя при выполнении процессов часто приходится ждать, команды можно помещать в очереди и передавать, даже если память занята чем-то другим. Именно поэтому можно увидеть много модулей RAM там, где нам нужна производительность (системная память CPU и чипы на графических картах), и гораздо меньше модулей там, где они не так важны (в жёстких дисках).
Тайминги памяти можно настраивать — они не заданы жёстко в самой DRAM, потому что все команды поступают из контроллера памяти в процессоре, который использует эту память. Производители тестируют каждый изготавливаемый чип и те из них, которые соответствуют определённым скоростям при заданном наборе таймингов, группируются вместе и устанавливаются в DIMM. Затем тайминги сохраняются в небольшой чип, располагаемый на плате.

Даже памяти нужна память. Красным указано ПЗУ (read-only memory, ROM), в котором содержится информация SPD.
Процесс доступа к этой информации и её использования называется serial presence detect (SPD). Это отраслевой стандарт, позволяющий BIOS материнской платы узнать, на какие тайминги должны быть настроены все процессы.
Многие материнские платы позволяют пользователям изменять эти тайминги самостоятельно или для улучшения производительности, или для повышения стабильности платформы, но многие модули DRAM также поддерживают стандарт Extreme Memory Profile (XMP) компании Intel. Это просто дополнительная информация, хранящаяся в памяти SPD, которая сообщает BIOS: «Я могу работать с вот с такими нестандартными таймингами». Поэтому вместо самостоятельной возни с параметрами пользователь может настроить их одним нажатием мыши.
Спасибо за службу, RAM!
В отличие от других уроков анатомии, этот оказался не таким уж грязным — DIMM сложно разобрать и для изучения модулей нужны специализированные инструменты. Но внутри них таятся потрясающие подробности.
Возьмите в руку планку памяти DDR4-SDRAM на 8 ГБ из любого нового ПК: в ней упаковано почти 70 миллиардов конденсаторов и такое же количество транзисторов. Каждый из них хранит крошечную долю электрического заряда, а доступ к ним можно получить за считанные наносекунды.
Даже при повседневном использовании она может выполнять бесчисленное количество команд, и большинство из плат способны без малейших проблем работать многие годы. И всё это меньше чем за 30 долларов? Это просто завораживает.
DRAM продолжает совершенствоваться — уже скоро появится DDR5, каждый модуль которой обещает достичь уровня полосы пропускания, с трудом достижимый для двух полных DIMM типа DDR4. Сразу после появления она будет очень дорогой, но для серверов и профессиональных рабочих станций такой скачок скорости окажется очень полезным.
Источник

Александр Игоревич Фисенко
Эксперт по предмету «Информационные технологии»
Задать вопрос автору статьи
Ядро операционной системы сущность понятия
Определение 1
Ядром операционных систем называется тот их элемент, который всё время находится в оперативной памяти устройства и который выполняет функции управления всей операционной системой, включая драйверы устройств, программы, управляющие ресурсами памяти и тому подобное.
То есть все процессы и операции управляются именно ядром операционной системы. Вместе с тем, ядро это лишь незначительная составляющая кодировки всей операционной системы, но это составляющая работает практически всё время и является наиболее загруженным компонентом операционной системы. Именно поэтому ядро помещается в базовой части памяти, а другие элементы операционной системы пересылаются во внешнюю зону памяти и затем обратно при возникновении такой необходимости.
![]()
Сделаем домашку
с вашим ребенком за 380 ₽
Уделите время себе, а мы сделаем всю домашку с вашим ребенком в режиме online
Основной задачей, выполняемой ядром, считается выполнение программ обработки прерываний. В крупных операционных системах, состоящих из большого числа абонентов, центральный процессор обрабатывает, фактически, непрерывную цепочку требований прерывания программы. И немедленное реагирование на требования прерываний очень важно, так как это обеспечивает полноценную загрузку системных ресурсов и означает оптимальное время реагирования на запросы пользователей, которые работают в режиме диалога.
Во время выполнения программы обслуживания какого-либо прерывания, ядро временно блокирует остальные требования прерываний и возобновляет их только по завершению программы обслуживания действующего прерывания. Если поток требований прерывания очень плотный, то возможно возникновение ситуации, когда ядро заблокирует какие-то прерывания на существенный временной интервал. Это означает отсутствие эффективного реагирования на требования прерываний программы. Чтобы исключить вероятность возникновения такой ситуации, ядро проектируется так, что оно выполняет только минимальную начальную обработку прерывания, а далее отсылает его для дальнейшего обслуживания в соответствующий системный процесс. После этого ядро разрешает поступление следующих запросов на прерывание программы.
«Ядро операционной системы» 👇
Главные задачи, решаемые ядром
Ядро операционной системы включает в свой состав следующие программы, решающие соответствующие задачи:
- Программа обработки прерываний.
- Программа для формирования и ликвидации различных процессов.
- Программа переключения состояний процессов.
- Программа, выполняющая диспетчеризацию процессов.
- Программа для приостановки и последующей активации процесса.
- Программа синхронизации выполняемых процессов и организации обменов данными между ними.
- Программа по выполнению ввода и вывода данных.
- Программа управления функциями распределения ресурсов памяти.
- Программа поддержки файловых систем.
- Программа обеспечения вызова и возврата при работе с процедурами.
- Программа поддержки операций по учёту работ ЭВМ.
Виды структуры ядра операционной системы
Возможны следующие типы структуры (архитектуры) ядра операционной системы:
- Монолитная структура ядра.
- Модульная структура ядра.
- Микроструктура ядра.
- Экзо структура ядра.
- Нано структура ядра.
- Гибридная структура ядра.
- Комбинированная структура ядра.
Монолитное ядро формируется их обширного комплекта абстракций оборудования. Все элементы монолитного ядра работают в едином адресном формате. При такой организации операционной системы все составляющие части её ядра выступают как элементы основной программы, применяют одни и те же системы организации данных и работают друг с другом, используя непосредственный вызов процедуры. Это самый старый метод формирования операционной системы. В качестве примера можно привести UNIX. Достоинством является большая скорость выполнения операций и простота конструирования модулей. Недостатком можно считать работу ядра в едином адресном пространстве, так как неисправность в любом элементе способна блокировать работу всей системы.
Модульное ядро является современной и модифицированной версией структуры монолитного ядра операционной системы. Она отличается от классического монолитного ядра тем, что не требует общей реструктуризации ядра при различных вариациях аппаратной оснастки компьютеров. У модульных ядер есть возможность подгружать различные модули (элементы) ядра, которые поддерживают нужное аппаратное оборудование (как пример, загрузка драйвера), причём подзагрузка модуля возможна как в динамическом режиме, то есть без перезагрузки операционной системы, так и в статике, когда выполняется переконфигурирование системы и её перезагрузка.
Микроядро решает лишь самые простые задачи по управлению процессами и имеет небольшой комплект абстракций оборудования. Основная часть функций выполняется специальными процессами пользователя, которые называются сервисами. Главным признаком микроядра можно считать распределение практически всех драйверов и элементов в процессах сервиса. Часто нет возможности загрузки расширительных модулей в такое микроядро. Достоинством является нечувствительность к аппаратным сбоям, компонентных ошибках системы. Недостатком можно считать тот факт, что пересылка данных между процессами ведёт к накладным расходам.
Экзоядро –это ядро операционной системы, которое предоставляет только возможность взаимного обмена между процессами и надёжного распределения и высвобождения ресурсов.
Наноядро имеет такую структуру, при которой очень простое ядро решает лишь проблему обработки аппаратного прерывания программы, которое генерируют различные блоки компьютера. Когда обработка прерывания, например, при нажатии символа на клавиатуре, завершается, наноядро пересылает результаты программе, которая выше по рангу. При этом пересылка тоже выполняется посредством прерываний.
Гибридное ядро представляет собой модификацию микроядра, которая позволяет ускорить работу системы.
И, наконец, возможен вариант комбинированного применения вышеперечисленных вариантов построения структуры ядра операционной системы.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме