Главная / Базы данных /
Data Mining / Тест 21
Упражнение 1:
Номер 1
Data Mining это … , который должен быть интегрирован в бизнес.
Ответ:
(1) не только инструмент, но также процесс
(2) инструмент
(3) процесс
Номер 2
На каком этапе пересекается работа специалиста предметной области и специалиста по добыче данных?
Ответ:
(1) анализ бизнес-процессов
(2) анализ данных
(3) подготовка данных
(4) все ответы неверны

Номер 3
Специалист по анализу данных, который имеет, как минимум, основы статистических знаний и способен применять технологии Data Mining, а также интерпретировать полученные результаты - это...
Ответ:
(1) специалист по добыче данных
(2) специалист предметной области
(3) администратор баз данных
(4) программист
(5) все ответы неверны
Номер 4
Data Mining по стандарту CRISP-DM включает следующие фазы:
Ответ:
(1) осмысление бизнеса
(2) осмысление данных
(3) подготовка данных
(4) исследование отношений в данных
Упражнение 2:
Номер 1
Data Mining — это не только инструмент, но также процесс, который...
Ответ:
(1) должен быть интегрирован в бизнес
(2) может существовать отдельно от бизнеса
(3) должен предшествовать бизнесу
Номер 2
На каком(-их) этапе(-ах) пересекается работа администратора баз данных и специалиста по добыче данных
Ответ:
(1) анализ бизнес-процессов
(2) анализ данных
(3) сбор данных
(4) все ответы неверны
Номер 3
Специалист, имеющий знания о окружении бизнеса, процессах, заказчиках, клиентах, потребителях, а также конкурентах - это...
Ответ:
(1) специалист по добыче данных
(2) специалист предметной области
(3) администратор баз данных
(4) менеджер проекта
(5) все ответы неверны
Номер 4
Стандарт PMML относится к группе:
Ответ:
(1) стандартов по хранению и передаче моделей Data Mining
(2) стандартов, относящиеся к унификации интерфейсов
(3) стандартов, направленных на разработку надстройки над языком SQL
Упражнение 3:
Номер 1
Data Mining — это не только инструмент, но также …
Ответ:
(1) процесс, который должен быть интегрирован в бизнес
(2) процесс, который, однако, не может быть интегрирован в бизнес
(3) процесс интеграции в бизнес
Номер 2
На каком этапе пересекается работа специалиста предметной области и администратора баз данных?
Ответ:
(1) анализ бизнес-процессов
(2) анализ данных
(3) сбор данных
(4) все ответы неверны
Номер 3
Специалист, имеющий знания о том, где и каким образом хранятся данные, как получить к ним доступ, и как связать между собой эти данные - это...
Ответ:
(1) специалист по добыче данных
(2) специалист предметной области
(3) администратор баз данных
(4) программист
(5) все ответы неверны
Номер 4
Стандарт CWM (Common Warehouse Metamodel) относится к группе:
Ответ:
(1) стандартов по хранению и передаче моделей Data Mining
(2) стандартов, относящихся к унификации интерфейсов
(3) стандартов, направленных на разработку надстройки над языком SQL
Упражнение 4:
Номер 1
Анализ предметной области и интерпретация результатов, полученных в результате Data Mining - это точки соприкосновения таких специалистов как:
Ответ:
(1) специалиста предметной области
(2) специалиста по добыче данных
(3) администратора баз данных
(4) всех вместе
Номер 2
Шаги какой из методологий Data Mining здесь описаны: осмысление бизнеса; осмысление данных; подготовка данных; моделирование; оценка результатов; внедрение?
Ответ:
(1) CRISP-DM
(2) SEMMA
(3) Two Crows
Номер 3
Какой стандарт обеспечивает возможности обмена моделями данных между программным обеспечением разных разработчиков?
Ответ:
(1) PMML
(2) CWM Data Mining
(3) JDM
Упражнение 5:
Номер 1
Анализ требований к данным и сбор данных- это точки соприкосновения таких специалистов как:
Ответ:
(1) специалиста предметной области
(2) специалиста по добыче данных
(3) администратора баз данных
(4) всех вместе
Номер 2
Шаги какой из методологий Data Mining здесь описаны: отбор данных, исследование отношений в данных, модификация данных, моделирование взаимозависимостей, оценка полученных моделей и результатов?
Ответ:
(1) CRISP-DM
(2) SEMMA
(3) Two Crows
Номер 3
Какой стандарт обеспечивает поддержку наиболее распространенных прогнозных моделей, созданных при помощи алгоритмов и методов анализа данных?
Ответ:
(1) PMML
(2) CWM Data Mining
(3) JDM
Data Mining — это не только инструмент, но также процесс, который…

Какую часть мирового рынка Data Mining занимают услуги или консультации по эффективному внедрению этой технологии для решения актуальных бизнес-задач?
Технология Web mining применяет технологию Data Mining для анализа:
Специалист по анализу данных, который имеет, как минимум, основы статистических знаний и способен применять технологии Data Mining, а также интерпретировать полученные результаты — это…
Инструменты Data Mining:
Для использования технологии Data Mining …
Классификационные модели Data Mining …
Oracle Data Mining является …
Oracle Data Mining поставляется как …
Область использования Data Mining …
Правильные ответы выделены зелёным цветом.
Все ответы: Курс знакомит слушателей с технологией Data Mining, подробно рассматриваются методы, инструментальные средства и применение Data Mining. Описание каждого метода сопровождается конкретным примером его использования.
Data Mining — это процесс обнаружения в сырых данных
(1) ранее сформулированных гипотез
(2) неочевидных закономерностей
(3) практических закономерностей
(4) объективных закономерностей
(5) большого количества закономерностей
В методе опорных векторов для классификации используется …
(1) не все множество образцов, а лишь их небольшая часть, которая находится на границах
(2) все множество образцов
(3) часть образцов, которая находится вне границ
Группа синапсов нейрона – это …
(1) однонаправленные входные связи, соединенные с выходами других нейронов
(2) выходная связь данного нейрона, с которой сигнал (возбуждения или торможения) поступает на синапсы следующих нейронов
(3) один или несколько нейронов, на входы которых подается один и тот же общий сигнал
Сети без обратных связей — это …
(1) персептрон
(2) сети Хопфилда (задачи ассоциативной памяти)
(3) сети Кохонена (задачи кластерного анализа)
Спорный объект кластеризации — это объект, который по мере сходства …
(1) может быть отнесен к нескольким кластерам
(2) не может быть отнесен ни к одному кластеру
(3) может быть отнесен более чем к двум кластерам
При использовании какого метода необходимо задавать количество кластеров?
(1) метод k-средних
(2) метод ближнего соседа
(3) вся группа иерархических методов
(4) все ответы неверны
Набор называют часто встречающимся (frequent), если:
(1) его поддержка выше определенного пользователем минимального значения
(2) его поддержка ниже определенного пользователем максимального значения
(3) его поддержка равна определенному пользователем значению
Традиционные методы визуализации могут находить следующее применение:
(1) представлять пользователю информацию в наглядном виде
(2) компактно описывать закономерности, присущие исходному набору данных
(3) снижать размерность или сжимать информацию
(4) упрощать расчеты в модели
(5) восстановление пробелов в наборе данных
Существенными концепциями системы поддержки принятия решений являются:
(1) компьютерная интерактивная
(2) поддержка принятия решений
(3) слабоструктурированных и неструктурированных проблем
(4) структурированных и слабоструктурированных проблем
Для какого вида набора данных важно определение наличия сезонной компоненты:
(1) для упорядоченных данных
(2) для неупорядоченных данных
(3) для тех и других
Ошибки, которые возникают в процессе использования инструментов очистки (являющиеся двумя крайностями очистки данных) — это:
(1) решение инструментом очистки данных проблемы, которой на самом деле не существует
(2) ошибки, возникающие, когда инструменты очистки полностью упускают существующую проблему
(3) ошибки, возникающие, когда инструменты очистки не могут обнаружить существующую проблему
Данные представляют собой:
(1) факты и графики
(2) текст
(3) картинки, звуки, аналоговые или цифровые видео-сегменты
(4) все вместе
Построение моделей Data Mining осуществляется с целью:
(1) исследования или изучения моделируемого объекта и получения новых знаний, необходимых для принятия решений
(2) выбора наиболее быстродействующей модели
(3) исследования всех возможных свойств и характеристик изучаемого объекта
Data Mining это … , который должен быть интегрирован в бизнес.
(1) не только инструмент, но также процесс
(2) инструмент
(3) процесс
Существуют следующие варианты решений по внедрению инструментов Data Mining:
(1) покупка готового программного обеспечения Data Mining
(2) покупка программного обеспечения Data Mining, адаптированного под конкретный бизнес
(3) комбинация этих вариантов, в т.ч. использование различных библиотек, компонентов и инструментальные наборы для разработчиков создания встроенных приложений Data Mining
Пакет SAS Enterprise Miner особенно удобен для осуществления анализа данных в …
(1) масштабах крупных организаций
(2) масштабах средних организаций
(3) масштабах средних и небольших организаций
Архитектура системы PolyAnalyst …
(1) является однопользовательским вариантом
(2) является корпоративным решением с несколькими серверами
(3) предоставляет возможность для масштабирования системы: от однопользовательского варианта до корпоративного решения с несколькими серверами
В основу программного продукта Cognos 4Thought положена технология …
(1) нейронных сетей
(2) множественной регрессии
(3) деревьев решений
Oracle Data Mining является …
(1) опцией в Oracle Enterprise Edition
(2) самостоятельным приложением
(3) в зависимости от редакции
Постановка задачи, построение оптимальной модели, понимание модели, применение результатов. Перечисленные выше этапы являются этапами:
(1) традиционного процесса Data Mining
(2) подхода KXEN
(3) и того, и другого
(4) ни того, ни другого
Data Mining-услуги могут предоставляться …
(1) на определенных территориях
(2) в определенных предметных областях
(3) с использованием определенных методов
Какие из перечисленных ниже пунктов являются названиями стадий Data Mining?
(1) свободный поиск
(2) прогностическое моделирование
(3) анализ исключений
(4) индукция правил
В ходе решения какой из перечисленных задач устанавливаются закономерности между связанными событиями в наборе данных?
(1) задачи поиска ассоциативных правил
(2) задачи поиска последовательных ассоциативных правил
(3) задачи анализа отклонений
Классификация — это …
(1) отнесение объектов к одному из заранее известных классов
(2) отнесение объектов к одной из заранее неизвестных групп
(3) процесс формирования групп и отнесения объектов к одному из них.
Какой из параметров является основной единицей времени, на которую делается прогноз?
(1) период прогнозирования
(2) горизонт прогнозирования
(3) интервал прогнозирования
Выделите два основных направления Web Mining:
(1) Web Content Mining
(2) Web Usage Mining
(3) Web Text Mining
Характеристики измерения центральной тенденции:
(1) среднее
(2) медиана
(3) минимум
(4) дисперсия
Если зависимая переменная принимает дискретные значения, при помощи метода дерева решений решается задача:
(1) классификации
(2) численного прогнозирования
(3) классификации и численного прогнозирования
Data Mining — это процесс обнаружения в сырых данных знаний, необходимых для:
(1) принятия решений в различных сферах человеческой деятельности
(2) замены аналитика в процессе принятия решений
(3) увеличения стоимости анализа данных
Классификация методом опорных векторов считается хорошей, если область между границами …
(1) пуста
(2) минимально заполнена
(3) максимально заполнена
Нейрон имеет аксон, который представляет собой …
(1) выходную связь данного нейрона, с которой сигнал (возбуждения или торможения) поступает на синапсы следующих нейронов
(2) однонаправленные входные связи, соединенные с выходами других нейронов
(3) один или несколько нейронов, на входы которых подается один и тот же общий сигнал
Сети с обратными связями – это…
(1) персептрон
(2) сети Хопфилда (задачи ассоциативной памяти)
(3) сети Кохонена (задачи кластерного анализа)
Какой метод требует априорной информации о количестве кластеров?
(1) метод k-средних
(2) метод ближнего соседа
(3) вся группа иерархических методов
(4) все ответы неверны
Транзакция – это множество событий, которые произошли …
(1) одновременно
(2) одно за другим
(3) оба ответа неверны
Традиционные методы визуализации могут находить следующее применение:
(1) выступать только в роли вспомогательного средства при анализе данных
(2) снижение размерности или сжатие информации
(3) восстановление пробелов в наборе данных
(4) нахождение шумов и выбросов в наборе данных
(5) все ответы верны
Охарактеризуйте неструктурированные задачи
(1) имеют только качественное описание, основанное на суждениях ЛПР, количественные зависимости между основными характеристиками задачи не известны
(2) характеризуются существенными зависимостями, которые могут быть выражены количественно
(3) сочетают количественные и качественные зависимости, причем малоизвестные и неопределенные стороны задачи имеют тенденцию доминировать
(4) именно такими проблемами занимаются руководители
Если набор данных упорядочен и в нем присутствует сезонная или цикличная компонента, то каково минимальное количество данных, которое необходимо иметь для возможности анализа?
(1) данные за один сезон/цикл
(2) данные за половину сезона/цикла
(3) данные за два сезона/цикла
Ошибка Типа 1 возникает в случае, когда …
(1) инструмент очистки данных пытается решить проблему, которой на самом деле не существует
(2) инструмент очистки данных полностью упускает существующую проблему
(3) инструмент очистки данных не может обнаружить существующую проблему
Данные могут быть получены в результате:
(1) измерений
(2) экспериментов
(3) арифметических и логических операций
(4) всего вместе
Характеристиками модели являются …
(1) простота модели в сравнении с исследуемым объектом
(2) выделение в объекте наиболее существенных факторов
(3) абстрактность модели
Data Mining — это не только инструмент, но также процесс, который…
(1) должен быть интегрирован в бизнес
(2) может существовать отдельно от бизнеса
(3) должен предшествовать бизнесу
Существуют следующие варианты решений по внедрению инструментов Data Mining:
(1) разработка Data Mining-продукта на заказ сторонней компанией
(2) разработка Data Mining-продукта своими силами
(3) комбинация этих вариантов, в т.ч. использование различных библиотек, компонентов и инструментальные наборы для разработчиков создания встроенных приложений Data Mining
Разработка проектов Data Mining в SAS Enterprise Miner может выполняться:
(1) локально
(2) в архитектуре клиент-сервер
(3) возможны оба варианта
Единицей Data Mining исследования в PolyAnalyst является…
(1) дерево проекта
(2) график
(3) правило
(4) проект
Cognos 4Thought предназначен для …
(1) моделирования
(2) прогнозирования
(3) того и другого
Модуль Oracle Data Mining доступен из таких редакций:
(1) Personal Edition
(2) Standard Edition
(3) OneStandard Edition
(4) Enterprise Edition
(5) из всех перечисленных редакций
Укажите, какие из перечисленных этапов являются этапами подхода KXEN к анализу данных:
(1) постановка задачи
(2) построение оптимальной модели
(3) понимание модели
(4) применение результатов
Data Mining консультирование может включать следующие услуги:
(1) образовательные услуги
(2) услуги по разработке и внедрению программного обеспечения Data Mining
(3) услуги по адаптации программного обеспечения Data Mining
Какой из перечисленных ниже пунктов не является названием стадии Data Mining?
(1) свободный поиск
(2) прогностическое моделирование
(3) анализ исключений
(4) индукция правил
В ходе решения каких из перечисленных задач устанавливаются закономерности между событиями, связанными во времени?
(1) задачи поиска ассоциативных правил
(2) задачи поиска последовательных ассоциативных правил
(3) задачи анализа отклонений
Задачей классификации можно назвать предсказание…
(1) категориальной зависимой переменной, основываясь на выборке непрерывных и/или категориальных переменных
(2) числовой зависимой переменной, основываясь на выборке непрерывных и/или категориальных переменных
(3) порядковой зависимой переменной, основываясь на выборке непрерывных и/или категориальных переменных
Какой из параметров является числом периодов в будущем, которые покрывает прогноз?
(1) период прогнозирования
(2) горизонт прогнозирования
(3) интервал прогнозирования
Какое из перечисленных ниже направлений подразумевает автоматический поиск и извлечение качественной информации разнообразных источников Интернета, перегруженных «информационным шумом»:
(1) Web Content Mining
(2) Web Usage Mining
(3) Web Text Mining
Характеристики вариации данных:
(1) среднее
(2) медиана
(3) минимум
(4) дисперсия
Если зависимая переменная принимает непрерывные значения, то дерево решений решает задачу:
(1) классификации
(2) численного прогнозирования
(3) классификации и численного прогнозирования
Назовите факторы, обусловившие возникновение и развитие Data Mining:
(1) совершенствование аппаратного и программного обеспечения
(2) совершенствование технологий хранения и записи данных
(3) накопление большого количества ретроспективных данных
(4) совершенствование алгоритмов обработки информации
(5) необходимость замены аналитика информационной технологией
Если область между границами пуста, классификация …
(1) считается хорошей
(2) считается ненадежной
(3) невозможной
Слой нейронной сети – это …
(1) один или несколько нейронов, на входы которых подается один и тот же общий сигнал
(2) выходная связь данного нейрона, с которой сигнал (возбуждения или торможения) поступает на синапсы следующих нейронов
(3) однонаправленные входные связи, соединенные с выходами других нейронов
Сети Кохонена относятся к классу:
(1) сети с обратными связями
(2) сети без обратных связей
(3) рекуррентных сетей
Объект относится к кластеру, если …
(1) расстояние от объекта до центра кластера меньше радиуса кластера
(2) расстояние от объекта до центра кластера меньше диаметра кластера
(3) расстояние от объекта до центра кластера больше радиуса кластера
Какой метод рекомендуется использовать при небольших объемах выборки?
(1) метод k–средних
(2) метод ближнего соседа
(3) вся группа иерархических методов
(4) все ответы неверны
Поддержка ассоциативного правила определяет…
(1) количество транзакций, содержащих определенный набор данных
(2) какая вероятность того, что из события A следует событие B
(3) процент транзакций, содержащих определенный набор данных
Традиционные методы визуализации могут находить следующее применение:
(1) представлять пользователю информацию в наглядном виде
(2) компактно описывать закономерности, присущие исходному набору данных
(3) снижение размерности или сжатие информации
(4) восстановление пробелов в наборе данных
(5) все ответы верны
Охарактеризуйте слабоструктурированные задачи
(1) имеют только качественное описание, основанное на суждениях ЛПР, количественные зависимости между основными характеристиками задачи не известны
(2) характеризуются существенными зависимостями, которые могут быть выражены количественно
(3) сочетают количественные и качественные зависимости, причем малоизвестные и неопределенные стороны задачи имеют тенденцию доминировать
(4) именно такими проблемами занимаются руководители
Если набор данных не упорядочен, то количество данных, которое необходимо иметь для возможности анализа данных:
(1) не имеет значения
(2) должно быть больше одного цикла
(3) желательно, чтобы количество записей в наборе данных было значительно больше количества переменных
Ошибка Типа 2 возникает в случае, когда …
(1) инструмент очистки данных пытается решить проблему, которой на самом деле не существует
(2) инструмент очистки полностью упускает существующую проблему
(3) инструмент очистки не может обнаружить существующую проблему
Данные — это …
(1) необработанный материал, предоставляемый поставщиками данных и используемый потребителями для формирования информации на основе данных
(2) готовый материал для формирования информации
(3) синоним информации
Использование моделей Data Mining позволяет:
(1) определить наилучшее решение в конкретной ситуации
(2) определить как существенные, так и незначительные факторы
(3) оба ответа верны
Data Mining — это не только инструмент, но также …
(1) процесс, который должен быть интегрирован в бизнес
(2) процесс, который, однако, не может быть интегрирован в бизнес
(3) процесс интеграции в бизнес
Существуют следующие варианты решений по внедрению инструментов Data Mining:
(1) только покупка готового инструмента, собственная разработка системы Data Mining практически невозможна
(2) разработка Data Mining-продукта на заказ фирмой-разработчиком
(3) оба варианта неверны
Процессы в Enterprise Miner могут работать …
(1) параллельно
(2) в асинхронном режиме
(3) возможны оба варианта
Проект в PolyAnalyst объединяет в себе:
(1) только дерево проекта
(2) только графики
(3) только правила
(4) все объекты исследования
Системы Impromptu, PowerPlay, Scenario и 4Thought являются…
(1) взаимосвязанными
(2) дополняющими друг друга инструментальными средствами
(3) оба ответа верны
Oracle Data Mining поставляется как …
(1) опция в Oracle Enterprise Edition
(2) опция в Oracle Standard Edition
(3) опция в любой редакции
Выберите пропущенный этап аналитического процесса KXEN:
(1) построение и тестирование модели
(2) построение оптимальной модели
(3) построение модели
(4) тестирование модели
Data Mining консультирование может включать следующие услуги:
(1) публикация отчетности Data Mining
(2) проведение образовательных семинаров
(3) консультации пользователей и разработчиков Data Mining
На стадии свободного поиска осуществляется …
(1) выявление закономерностей
(2) использование выявленных закономерностей для предсказания неизвестных значений
(3) анализ исключений
Правильна ли такая формулировка: «Ассоциация является частным случаем последовательности с временным лагом, равным нулю»?
(1) формулировка верна
(2) нет; последовательность является частным случаем ассоциации
(3) нет; ни последовательность, ни ассоциация не являются частными случаями друг друга
Основная характеристика задачи бинарной классификации:
(1) зависимая переменная может принимать только два значения
(2) классификация осуществляется по одному признаку
(3) классификация осуществляется по двум признакам
Какой из параметров является частотой, с которой делается новый прогноз?
(1) период прогнозирования
(2) горизонт прогнозирования
(3) интервал прогнозирования
Какое из перечисленных ниже направлений подразумевает обнаружение закономерностей в действиях пользователя web-узла или их группы?
(1) Web Content Mining
(2) Web Usage Mining
(3) Web Text Mining
Какая из перечисленных характеристик не является числом, описывающим определенным способом все значения признака набора данных?
(1) среднее
(2) медиана
(3) минимум
При помощи метода деревьев решений могут решаться задачи:
(1) классификации
(2) численного прогнозирования
(3) классификации и численного прогнозирования
Закономерности, найденные в процессе использования технологии Data Mining должны обладать такими свойствами:
(1) быть очевидными
(2) быть неочевидными
(3) быть практически полезными
(4) быть объективными
(5) чем больше найдено закономерностей, тем лучше
Главная функция искусственного нейрона — …
(1) формирование выходного сигнала в зависимости от сигналов, поступающих на его входы
(2) преобразование функции активации
(3) передача входных сигналов на обработку адаптивному сумматору
Наличие блоков динамической задержки и обратных связей — характерная особенность …
(1) рекуррентных сетей
(2) сетей прямого распространения
(3) и тех, и других
Назовите характеристики кластерного анализа:
(1) не требует априорных предположений о наборе данных
(2) требует априорных предположений о наборе данных
(3) не накладывает ограничения на представление исследуемых объектов
(4) накладывает ограничения на представление исследуемых объектов
(5) позволяет анализировать показатели различных типов данных.
Назовите достоинства алгоритма кластеризации k-средних
(1) простота использования
(2) быстрота использования
(3) понятность и прозрачность алгоритма
(4) нечувствительность к выбросам
Набор ассоциативных правил представляет интерес, если его поддержка …
(1) выше определенного пользователем минимального значения
(2) ниже определенного пользователем минимального значения
(3) равна определенному пользователем значению
Нахождение шумов и выбросов в данных …
(1) возможно при помощи средств визуализации
(2) невозможно при помощи средств визуализации
(3) не является функцией визуализации
СППР — система, предназначенная для поддержки принятия решений в … проблемах различных видов человеческой деятельности, существенная концепцией которой …
(1) слабоструктурированных и неструктурированных, не обуславливает обязательного непосредственного использования ЛПР системы поддержки принятия решений
(2) структурированных и слабоструктурированных, обуславливает обязательное непосредственное использование ЛПР системы поддержки принятия решений
(3) неструктурированных и структурированных, не обуславливает обязательного непосредственного использования ЛПР системы поддержки принятия решений
Какой из перечисленных этапов является первым в процессе Data Mining?
(1) анализ предметной области
(2) подготовка данных
(3) построение модели
Оцените правильность формулировки: «Инструменты Data Mining служат средством очистки данных»
(1) формулировка верна
(2) формулировка неверна. Задача инструментов Data Mining совершенно другая.
(3) некоторые инструменты Data Mining могут быть средством очистки данных
Объект описывается как …
(1) набор атрибутов
(2) свойство, характеризующее объект
(3) поле таблицы
Создание каких моделей Data Mining означает поиск правил, которые объясняют зависимость выходных параметров от входных?
(1) моделей классификации и прогнозирования
(2) моделей кластеризации и классификации
(3) моделей правил ассоциаций
Анализ предметной области и интерпретация результатов, полученных в результате Data Mining — это точки соприкосновения таких специалистов как:
(1) специалиста предметной области
(2) специалиста по добыче данных
(3) администратора баз данных
(4) всех вместе
Для использования технологии Data Mining …
(1) возможна только покупка готового программного обеспечения, собственная разработка практически невозможна
(2) возможна как покупка готового программного обеспечения, так и разработка собственными силами
(3) наиболее правильный и выгодный вариант – использование программного обеспечения, адаптированного под конкретный бизнес
SAS Enterprise Miner относится к категории:
(1) инструментальных наборов Data Mining
(2) инструментов, решающих задачи классификации и кластеризации
(3) инструментов, решающих задачи классификации и прогнозирования
Решение каких задач предусматривают алгоритмы анализа данных в PolyAnalyst?
(1) моделирование
(2) прогнозирование
(3) кластеризация
(4) классификация
(5) текстовый анализ
(6) все ответы верны
Назовите характеристики программного продукта Cognos 4Thought:
(1) в основу продукта положена технология нейронных сетей
(2) в основу продукта положена технология самоорганизующихся сетей Кохонена
(3) позволяет строить нелинейные модели на основе неполной статистической выборки данных
(4) предназначен для моделирования и прогнозирования
(5) предназначен только для прогнозирования
Охарактеризуйте особенности работы алгоритмов, реализованных в Oracle Data Mining:
(1) они работают непосредственно с реляционными базами данных
(2) не требуют выгрузки и сохранения данных в специальных форматах
(3) требуют выгрузки и сохранения данных в специальных форматах
Какие задачи позволяет решать инструмент KXEN?
(1) задачи регрессии и классификации
(2) задачи кластеризации
(3) анализ временных рядов.
(4) поиск ассоциативных правил
(5) все ответы верны
Вариант использования адаптированного программного обеспечения Data Mining …
(1) имеет как сильные, так и слабые стороны
(2) имеет неоспоримые преимущества перед использованием готового программного обеспечения
(3) всегда проигрывает перед использованием готового программного обеспечения
Большинство аналитических методов, используемые в технологии Data mining – это …
(1) известные математические алгоритмы и методы
(2) новейшие математические алгоритмы и методы
(3) классические статистические методы
Согласно классификации по стратегиям, задачи Data Mining подразделяются на:
(1) обучение с учителем
(2) обучение без учителя
(3) дескриптивные
(4) прогнозирующие
Заполните пропуск в формулировке: «Для проведения … должны присутствовать признаки, характеризующие группу, к которой принадлежит то или иное событие или объект»
(1) классификации
(2) кластеризации
(3) классификации и кластеризации
В чем состоит основное сходство задач прогнозирования и классификации?
(1) при решении обеих задач используется двухэтапный процесс построения модели на основе обучающего набора и ее использования для предсказания неизвестных значений зависимой переменной
(2) сходство заключается в том, что при решении обеих задач предсказываются числовые значения зависимой переменной
(3) оба ответа верны
Область использования Data Mining …
(1) ничем не ограничена — она везде, где имеются какие-либо данные
(2) ничем не ограничена — она везде, не имеет значения, есть ли какие-либо данные
(3) достаточно ограничена, в большинстве случаев – это научные исследования
Размах и дисперсия являются:
(1) характеристиками измерения центральной тенденции
(2) характеристиками вариации данных
(3) определяют наличие выбросов в данных
При помощи метода деревьев решений решаются задачи …
(1) классификации и прогнозирования
(2) кластеризации и прогнозирования
(3) классификации и кластеризации
(4) кластеризации, классификации и прогнозирования
Какая из перечисленных ниже групп методов достаточно часто использует для выявления взаимосвязей в данных концепцию усреднения по выборке?
(1) Data Mining
(2) статистические методы
(3) OLAP
В основе метода опорных векторов лежит …
(1) понятие плоскостей решений
(2) предположение о взаимной независимости признаков
(3) предположение о взаимной зависимости признаков
Заполните пропуски в формулировке: «В самой распространенной конфигурации входные сигналы обрабатываются …, затем выходной сигнал сумматора поступает в … , где преобразуется функцией активации, и результат подается на …»
(1) адаптивным сумматором, нелинейный преобразователь, выход
(2) нелинейным преобразователем, адаптивный сумматор, выход
(3) входным сумматором, нелинейный преобразователь, адаптивный сумматор
Сети Кохонена относятся к классам:
(1) сети с обратными связями
(2) сети без обратных связей
(3) сети прямого распространения
Назовите характеристики кластерного анализа:
(1) позволяет сокращать размерность данных
(2) позволяет делать данные более наглядными
(3) имеет в своем арсенале около десяти алгоритмов
(4) имеет в своем арсенале около сотни алгоритмов
Назовите недостатки алгоритма быстрой кластеризации
(1) сложность использования
(2) чувствительность к выбросам
(3) алгоритм может медленно работать на больших базах данных
(4) все ответы верны
Каждый этап работы алгоритма Apriori состоит из таких шагов:
(1) формирование кандидатов
(2) кодирование кандидатов
(3) подсчет кандидатов
Компактное описание закономерностей, присущих исходному набору данных …
(1) возможно при помощи средств визуализации
(2) невозможно при помощи средств визуализации
(3) не является функцией визуализации
Назовите существенные характеристики СППР:
(1) решение принимает человек
(2) решение принимает система
(3) предназначена для решения слабоструктурированных задач
(4) предназначена для решения неструктурированных задач
(5) предназначена для решения структурированных задач
Постановка задачи …
(1) является необходимым этапом процесса Data Mining
(2) является необязательным этапом процесса Data Mining
(3) не является этапом процесса Data Mining
Согласно классификации средств очистки данных инструменты Data Mining относятся к классу …
(1) средств анализа и модернизации данных
(2) специальных средств очистки
(3) очистки специфической области
Атрибут – это:
(1) свойство, характеризующее объект
(2) строка таблицы
(3) случай или пример
Какие модели используются для классификации объектов, при условии, что набор целевых классов неизвестен?
(1) модели кластеризации
(2) модели кластеризации и классификации
(3) модели правил ассоциаций
Анализ требований к данным и сбор данных- это точки соприкосновения таких специалистов как:
(1) специалиста предметной области
(2) специалиста по добыче данных
(3) администратора баз данных
(4) всех вместе
Инструменты Data Mining могут решать …
(1) только одну задачу Data Mining
(2) несколько задач Data Mining
(3) все задачи Data Mining
(4) это зависит от конкретного инструмента
Программный продукт SAS Enterprise Miner создан специально для выявления закономерностей в …
(1) огромных массивах данных
(2) небольших массивах данных
(3) средних и малых массивах данных
Какие из перечисленных характеристик имеет пользовательский интерфейс PolyAnalyst?
(1) возможности манипулирования с данными
(2) графика для представления данных и визуализации результатов
(3) мастера создания объектов
(4) сквозная логическая связь между объектами
(5) язык символьных правил
(6) интуитивное управление через drop-down и pop-up меню
(7) все ответы верны
На каких этапах 4Thought поддерживает анализ данных?
(1) сбор данных
(2) преобразование данных
(3) исследование данных
(4) создание модели
(5) интерпретация модели
(6) применение модели
(7) на всех этапах
Oracle Data Mining является … — куда входят …
(1) опцией в Oracle Enterprise Edition, средства подготовки данных, оценки результатов применения моделей к новым наборам данных
(2) самостоятельным приложением, оценки результатов применения моделей к новым наборам данных
(3) опцией в Oracle любой редакции, средства подготовки данных, оценки результатов применения моделей к новым наборам данных
На решение каких трудностей направлен усовершенствованный аналитический процесс KXEN?
(1) трудоемкость подготовки данных
(2) сложность выбора переменных, включенных в модель
(3) требования к квалификации аналитиков
(4) сложность интерпретации полученных результатов
(5) сложность построения моделей
(6) все ответы верны
Готовые алгоритмы, полная конфиденциальность информации, техническая поддержка производителя, общение с другими пользователями пакета — это преимущества использования …
(1) готового программного обеспечения
(2) заказ готового решения у фирмы-разработчика
(3) адаптация программного обеспечения под конкретную задачу
(4) все ответы верны
Большинство методов Data mining были разработаны в рамках …
(1) теории искусственного интеллекта
(2) классического анализа данных
(3) теории баз данных
Задачи Data Mining, в зависимости от используемых моделей подразделяются на:
(1) обучение с учителем
(2) обучение без учителя
(3) дескриптивные
(4) прогнозирующие
Задачей классификации часто является предсказание …
(1) числовой зависимой переменной
(2) категориальной зависимой переменной
(3) категориальной независимой переменной
В чем состоит основное отличие задач прогнозирования и классификации?
(1) отличие заключается в этапах процесса решения задач
(2) отличие задач классификации и прогнозирования состоит в том, что в первой задаче предсказывается класс зависимой переменной, а во второй — числовые значения зависимой переменной
Выделяют такие основные сферы применения технологии Data Mining:
(1) наука
(2) бизнес
(3) исследования для правительства
(4) Web-направление
Среднее и медиана являются:
(1) характеристиками центральной тенденции
(2) характеристиками вариации данных
(3) определяют наличие выбросов в данных
Заполните пропуски в формулировке: «Если зависимая переменная принимает … значения, при помощи метода дерева решений … »
(1) дискретные, решается задача классификации
(2) дискретные, решаются задачи классификации и прогнозирования
(3) непрерывные, решаются задачи классификации и кластеризации
Какая из перечисленных дисциплин более сосредоточена на теории проверки гипотез?
(1) Data Mining
(2) статистика
(3) визуализация
Решаются ли задачи классификации и регрессии при помощи метода «ближайшего соседа»?
(1) да
(2) нет, только задачи классификации
(3) нет, только задачи регрессии
В синхронных нейронных сетях в каждый момент времени свое состояние меняет…
(1) лишь один нейрон
(2) целая группа нейронов, как правило, весь слой
(3) возможен и тот и другой вариант
Сеть Кохонена представляет собой …
(1) два слоя: входной и выходной
(2) три слоя: входной, скрытый и выходной
(3) входной, выходной и какое угодно количество скрытых слоев
Работа кластерного анализа опирается на предположения:
(1) рассматриваемые признаки объекта в принципе допускают желательное разбиение объектов на кластеры
(2) правильность выбора масштаба или единиц измерения признаков
(3) отнесение всех объектов к одному из предопределенных классов
К какой группе методов относится метод ближнего соседа?
(1) иерархический КА
(2) быстрый КА
(3) оба ответа неверны
С помощью алгоритма Apriori определите часто встречающиеся наборы в базе данных D, состоящие из трех товаров с минимальной поддержкой, равной 2
| TID | Items |
|---|---|
| 10 | a,c,d |
| 20 | b,c,e |
| 30 | a,b,c,e |
| 40 | b,e |
(1) b,c,e
(2) a,c,d
(3) a,b,c
(4) b,c,d
Способы визуального представления могут …
(1) только иллюстрировать построение модели
(2) интерпретировать полученный результат
(3) быть средством оценки качества построенной модели
Исходные данные при использовании MOLAP архитектуры хранятся:
(1) в многомерной БД или в многомерном локальном кубе
(2) в реляционных БД
(3) в плоских локальных таблицах на файл-сервере
Выберите неверную формулировку
(1) все типы грязных данных в базе данных могут быть автоматически обнаружены и очищены
(2) появление некоторых грязных данных может быть предотвращено
(3) некоторые грязные данные непригодны для автоматического обнаружения и очистки
(4) появление некоторых грязных данных невозможно предотвратить
Качественная программа очистки данных должна:
(1) исправлять неверные данные
(2) создавать небольшой по объему отчет о подозрительных записях
(3) требовать минимальных затрат на установку, обслуживание и ручные проверки
(4) исправлять абсолютно все подозрительные данные
Объектом не является:
(1) запись
(2) случай
(3) пример
(4) строка таблицы
(5) переменная
Простота модели в сравнении с исследуемым объектом является …
(1) преимуществом использования моделей
(2) недостатком использования моделей
(3) признаком невозможности использования модели
На каком этапе пересекается работа специалиста предметной области и специалиста по добыче данных?
(1) анализ бизнес-процессов
(2) анализ данных
(3) подготовка данных
(4) все ответы неверны
На рынке инструментов Data Mining в последние годы наблюдается:
(1) спад
(2) рост
(3) ситуация на рынке за последние годы почти не меняется
Позволяет ли пакет Enterprise Miner производить последовательное сравнение моделей?
(1) да
(2) нет
(3) это зависит от используемых методов
Алгоритмы анализа системы PolyAnalyst данных можно объединить в такие группы по их функциональному назначению:
(1) моделирование
(2) прогнозирование
(3) последовательность
(4) кластеризация
(5) классификация
(6) текстовый анализ
Инструмент фирмы Cognos, используемый для построения запросов любой сложности и отчетов произвольного формата пользователями, от которых не требуется навыков программирования:
(1) Cognos Impromptu
(2) Cognos Scenario
(3) Cognos PowerPlay
Deductor Studio …
(1) может функционировать без хранилища данных
(2) может получать информацию из любых других источников
(3) не может функционировать без хранилища данных
Подготовка данных в KXEN включает следующие этапы :
(1) преобразование данных
(2) оптимальное кодирование указанных атрибутов для их наилучшего анализа в рамках выбранных алгоритмов
(3) разделение атрибутов на символьные и числовые
Преимуществами использования готового программного обеспечения являются:
(1) готовые алгоритмы
(2) техническая поддержка производителя
(3) простота подготовки данных
Стадия свободного поиска представлена действиями:
(1) выявление закономерностей условной логики
(2) выявление закономерностей ассоциативной логики
(3) выявление трендов и колебаний
(4) предсказание неизвестных значений
К классу описательных задач Data Mining относятся такие задачи:
(1) прогнозирование
(2) классификация
(3) кластеризация
(4) визуализация
Задачу классификации нельзя решить с помощью…
(1) метода деревьев решений
(2) метода линейной регрессии
(3) алгоритма Apriori
В чем сходство задач классификации и прогнозирования?
(1) при решении обоих задач используется 2-х этапный процесс построения модели и ее использования для предсказания
(2) в результате решения этих задач предсказывается класс независимой переменной
(3) результат решения этих задач — предсказание будущих числовых значений зависимой переменной
При использовании какого из перечисленных ниже направлений выделяют подход, основанный на агентах, и подход, основанных на базах данных:
(1) Web Content Mining
(2) Web Usage Mining
(3) Web Text Mining
Медианой для выборки 1,2,3,7,10,__,16 является:
(1) 7,714286
(2) 7
(3) 8,5
(4) рассчитать медиану невозможно из-за пропущенных значений
Внутренний узел дерева решений называют также …
(1) узлом проверки
(2) конечным узлом
(3) вершиной
(4) листом
В процессе работы Data Mining программы пользователь может получить такие результаты:
(1) большой процент ложных, недостоверных или бессмысленных результатов
(2) только верные результаты, ложные выводы исключены
(3) только статистически достоверные результаты
Метод «ближайшего соседа»:
(1) может создавать модели и правила.
(2) может создавать модели
(3) может создавать правила
(4) не может создавать модели и правила
В асинхронных сетях в каждый момент времени свое состояние меняет …
(1) лишь один нейрон
(2) целая группа нейронов, как правило, весь слой
(3) возможен и тот и другой вариант
Наиболее распространенное применение сетей Кохонена:
(1) разведочный анализ данных
(2) обнаружение новых явлений
(3) прогнозирование числовых значений
Работа кластерного анализа опирается на следующие предположения (выберите неверный ответ):
(1) рассматриваемые признаки объекта в принципе допускают желательное разбиение объектов на кластеры
(2) правильность выбора масштаба или единиц измерения признаков
(3) отнесение всех объектов к одному из предопределенных признаков
К какой группе методов относится метод k-средних?
(1) иерархический
(2) быстрый
(3) оба ответа неверны
С помощью алгоритма Apriori определите часто встречающиеся наборы в базе данных D, состоящие из трех товаров с минимальной поддержкой, равной 2
| TID | Items |
|---|---|
| 10 | l,m,p |
| 20 | a,d,l |
| 30 | a,d,l,m |
| 40 | a,d |
(1) l,m,p
(2) a,d,l
(3) a,d,l,m
(4) a,d
Способы визуального представления могут …
(1) быть иллюстрацией построения модели
(2) помочь интерпретировать полученный результат
(3) быть средством оценки качества построенной модели
Исходные данные при использовании ROLAP архитектуры хранятся…
(1) в многомерной БД или в многомерном локальном кубе
(2) в реляционных БД или в плоских локальных таблицах на файл-сервере
(3) в реляционных БД, а агрегаты размещаются в многомерной БД
Выберите верную(-ые) формулировку(-и).
(1) все типы грязных данных в базе данных могут быть автоматически обнаружены и очищены
(2) появление некоторых грязных данных может быть предотвращено
(3) некоторые грязные данные непригодны для автоматического обнаружения и очистки
(4) появление некоторых грязных данных невозможно предотвратить
Качественная программа очистки данных должна:
(1) не затрагивать правильные данные
(2) исправлять неверные данные
(3) создавать небольшой по объему отчет о подозрительных записях
(4) требовать серьезного процесса установки и обслуживания
Преимуществом модели является возможность выделить в объекте …
(1) наиболее существенные факторы, с точки зрения цели исследования, и не отвлекаться на маловажные детали
(2) абсолютно все факторы, как существенные, так и маловажные
(3) абстрактные факторы
На каком(-их) этапе(-ах) пересекается работа администратора баз данных и специалиста по добыче данных
(1) анализ бизнес-процессов
(2) анализ данных
(3) сбор данных
(4) все ответы неверны
На рынке инструментов Business Intelligence в последние годы наблюдается:
(1) спад
(2) рост
(3) ситуация на рынке за последние годы почти не меняется
Пакет SAS Enterprise Miner обеспечивает сравнение результатов различных методов моделирования:
(1) с точки зрения статистики
(2) с точки зрения бизнеса
(3) оба варианта верны
Алгоритмы анализа системы PolyAnalyst данных можно объединить в такие группы по их функциональному назначению:
(1) моделирование
(2) прогнозирование
(3) обобщение
(4) кластеризация
(5) классификация
(6) текстовый анализ
Интеллектуальное инструментальное средство поиска (разведки) данных (Data Mining), которое позволяет руководителям выявлять скрытые тенденции и модели бизнеса и «извлекать на поверхность» его ранее неизвестные закономерности и корреляционные связи:
(1) Cognos Impromptu
(2) Cognos Scenario
(3) Cognos PowerPlay
Архитектура хранилища типа «звезда» в Deductor называется …
(1) процессом
(2) сценарием
(3) проектом
Существует ли необходимость временного или постоянного копирования данных для анализа в системе KXEN?
(1) да
(2) нет
(3) по запросу
Слабыми сторонами использования готового программного обеспечения могут быть:
(1) высокая стоимость
(2) необходимость наличия высококвалифицированных кадров
(3) сложность подготовки данных
(4) полная конфиденциальность информации
Прогностическое моделирование включает такие действия:
(1) выявление трендов и колебаний
(2) предсказание неизвестных значений
(3) прогнозирование развития процессов
К классу прогнозирующих задач Data Mining относятся такие задачи:
(1) прогнозирование
(2) классификация
(3) кластеризация
(4) визуализация
Задачи классификации решаются следующими алгоритмами:
(1) методом дерева решений
(2) методы линейной регрессии
(3) алгоритмом Apriori
Продолжите фразу: «Прогнозирование будет иметь смысл, если горизонт прогнозирования …
(1) не меньше, чем время, которое необходимо для реализации решения, принятого на основе прогноза»
(2) не больше, чем время, которое необходимо для реализации решения, принятого на основе прогноза»
(3) оба ответа верны
Какие из перечисленных ниже систем используются в подходе, основанном на агентах:
(1) интеллектуальные поисковые агенты
(2) фильтрация информации / классификация
(3) персонифицированные агенты сети
(4) многоуровневые базы данных
(5) системы web-запросов
Медианой для выборки 1,__,3,7,10,15,16,18 является:
(1) 7,714286
(2) 7
(3) 8,5
(4) рассчитать медиану невозможно из-за пропущенных значений
Конечный узел дерева решений называют также …
(1) узлом проверки
(2) узлом решения
(3) листом
Если сравнивать Data Mining, машинное обучение и статистику, какая из дисциплин сконцентрирована на едином процессе анализа данных, включает очистку данных, обучение, интеграцию и визуализацию результатов:
(1) Data Mining
(2) машинное обучение
(3) статистика
С помощью метода «ближайшего соседа» возможно решение задач:
(1) классификации и регрессии
(2) классификации и кластеризации
(3) классификации
Синхронные и асинхронные сети отличаются:
(1) принципом изменения состояния нейронов (состояние изменяется либо у одного нейрона, либо у их группы)
(2) принципом обработки информации (послойно либо всем нейронам сети)
(3) оба варианта верны
Уникальность метода самоорганизующихся карт состоит в …
(1) преобразовании n-мерного пространства в двухмерное
(2) возможности преобразования n-мерного пространства в пространство с любым количеством измерений
(3) преобразовании двухмерного пространства в n-мерное
Работа кластерного анализа опирается на предположения:
(1) рассматриваемые признаки объекта в принципе допускают желательное разбиение объектов на кластеры
(2) отнесение всех объектов к одному из предопределенных признаков
(3) о сравнимости шкал
К какой группе методов относится алгоритм PAM (partitioning around Medoids)?
(1) иерархический КА
(2) КА, основанный на разделении данных
(3) оба ответа неверны
С помощью алгоритма Apriori определите часто встречающиеся наборы в базе данных D, состоящие из трех товаров с минимальной поддержкой, равной 2
| TID | Items |
|---|---|
| 10 | k,l,m |
| 20 | l,n,o |
| 30 | k,l,n,o |
| 40 | n,o |
(1) n,l,o
(2) k,l,m
(3) k,l,n
(4) n,m,o
Исходные данные при использовании HOLAP архитектуры хранятся:
(1) в многомерной БД или в многомерном локальном кубе
(2) в реляционных БД или в плоских локальных таблицах на файл-сервере
(3) в реляционной базе, а агрегаты размещаются в многомерной
Все типы грязных данных в базе данных могут быть автоматически обнаружены и очищены
(1) формулировка неверна
(2) формулировка верна
(3) в зависимости от метода очистки данных
Качественная программа очистки данных должна иметь такие характеристики:
(1) исправлять неверные данные
(2) создавать небольшой по объему отчет о подозрительных записях
(3) требовать минимальных затрат на установку, обслуживание и ручные проверки
(4) может частично затрагивать правильные данные
Строка таблицы также известна как:
(1) запись
(2) атрибут
(3) пример
(4) переменная
Модель обладает свойством неполноты.
(1) утверждение верно
(2) утверждение неверно
(3) утверждение неверно. Модель обладает свойством упрощать объект.
На каком этапе пересекается работа специалиста предметной области и администратора баз данных?
(1) анализ бизнес-процессов
(2) анализ данных
(3) сбор данных
(4) все ответы неверны
На рынке инструментов Business Intelligence в последние годы наблюдается:
(1) значительный рост, в том числе инструментов Data Mining
(2) значительный рост только сегмента инструментов Data Mining
(3) значительный рост за исключением сегмента инструментов Data Mining
Репозитарий моделей в SAS Enterprise Miner представляет собой …
(1) систему управления моделями
(2) SAS-сервер
(3) OLTP-систему
Алгоритмы анализа системы PolyAnalyst данных можно объединить в следующие группы по их функциональному назначению:
(1) моделирование
(2) прогнозирование
(3) оценивание
(4) кластеризация
(5) классификация
(6) текстовый анализ
Инструментальное средство для оперативного анализа данных и формирования отчетов по OLAP-технологии:
(1) Cognos Impromptu
(2) Cognos Scenario
(3) Cognos PowerPlay
Последовательность действий, которые необходимо провести для анализа данных, называется в Deductor…
(1) сценарием
(2) процессом
(3) этапом
Реинжиниринг аналитического процесса KXEN …
(1) позволяет автоматизировать процесс построения моделей
(2) позволяет увеличить скорость проводимого анализа
(3) позволяет заменить аналитика
Преимущества использования адаптированного программного обеспечения Data Mining по сравнению с готовыми программными продуктами и их самостоятельным использованием является:
(1) адаптированность
(2) сложность подготовки данных
(3) наличие терминов предметной области
(4) полная конфиденциальность информации
(5) не требуется дописывать программный код
Частью какой из перечисленных стадий является валидация закономерностей?
(1) свободный поиск
(2) прогностическое моделирование
(3) анализ исключений
Продолжите фразу: «Кластеризация и классификация относятся к…
(1) стратегии обучения с учителем»
(2) стратегии обучения без учителя»
(3) к двум разным стратегиям: обучения без учителя и обучения с учителем»
Задачи классификации решаются следующими алгоритмами:
(1) нейронные сети
(2) линейной регрессии
(3) алгоритмом Apriori
Решение задачи прогнозирования …
(1) возможно без обучающей выборки данных
(2) требует некоторой обучающей выборки данных
(3) является решением задачи «обучения без учителя»
Какие из перечисленных ниже систем используются в подходе, основанном на базах данных:
(1) интеллектуальные поисковые агенты
(2) фильтрация информации / классификация
(3) персонифицированные агенты сети
(4) многоуровневые базы данных
(5) системы web-запросов
Медианой для выборки 1,2,3,__,__,15,16,18 является:
(1) рассчитать медиану невозможно из-за пропущенных значений
(2) 7
(3) 8,5
Лист дерева решений является …
(1) конечным узлом
(2) узлом проверки
(3) узлом решения
В результате использования инструментов Data Mining пользователь может …
(1) получить гипотезы о взаимосвязях в данных, самостоятельно выдвинутые инструментом Data Mining
(2) получить подтверждение или опровержение гипотез, выдвинутых пользователем
(3) проверить гипотезы о взаимосвязях в данных, самостоятельно выдвинутые пользователем инструмента Data Mining
(4) все ответы верны
Назовите метод, недостаток которого приведен ниже: «Существует сложность выбора меры «близости», от этой меры главным образом зависит объем множества записей, которые нужно хранить в памяти для достижения удовлетворительной классификации или прогноза»
(1) метод байесовской классификации
(2) метод «k-ближайших соседей»
(3) метод опорных векторов
Заполните пропуски в формулировке: «… — выходная связь нейрона, с которой сигнал (возбуждения или торможения) поступает на… следующих нейронов»
(1) аксон, синапсы
(2) синапс, аксоны
(3) аксон, точку ветвления
При … для каждого обучающего входного примера требуется знание правильного ответа или функции оценки качества ответа
(1) «обучении с учителем»
(2) «обучении без учителя»
(3) оба варианта верны
При применении кластерного анализа переменные …
(1) должны измеряться в сравнимых шкалах
(2) могут измеряться в каких угодно шкалах
(3) должны быть только числовыми
Какие методы выявляют более высокую устойчивость по отношению к шумам и выбросам, некорректному выбору метрики, включению незначимых переменных в набор, участвующий в кластеризации?
(1) неиерархические методы
(2) иерархические методы
(3) оба ответа верны
Вероятность того, что из события A следует событие B. Это — …
(1) достоверность правила
(2) поддержка правила
(3) обеспечение правила
Визуализация в виде параллельных координат является представлением информации в …
(1) двухмерном измерении
(2) трехмерном измерении
(3) более чем в трехмерном измерении
EIS (Execution Information System) или информационные системы руководства в большинстве ориентированы на …, основаны на …
(1) неподготовленного пользователя, на запросах, количество которых ограничено
(2) подготовленного пользователя, глубокой проработке данных
(3) неподготовленного пользователя, глубокой проработке данных.
Если данные являются неупорядоченными, это означает …
(1) невозможность процесса Data Mining
(2) возможность процесса Data Mining
(3) необходимость их упорядочения перед проведением анализа
Инструменты очистки данных обычно выполняют такие функции:
(1) парсинг
(2) стандартизация
(3) проверка допустимости
(4) улучшение
(5) согласование и консолидация
(6) все ответы верны
Такие данные как температура воздуха относятся к …
(1) непрерывным данным
(2) дискретным данным
(3) Оба ответа неверны
Экзогенные переменные — это переменные, которые …
(1) задаются вне модели, они известны заранее
(2) определяются по ходу расчетов в модели, они не задаются извне
(3) задаются внутри модели, они известны заранее
Шаги какой из методологий Data Mining здесь описаны: осмысление бизнеса; осмысление данных; подготовка данных; моделирование; оценка результатов; внедрение?
(1) CRISP-DM
(2) SEMMA
(3) Two Crows
Инструмент SPSS относится к категории:
(1) бесплатного программного обеспечения
(2) достаточно недорогого программного обеспечения
(3) достаточно дорогого программного обеспечения
Пакет SAS Enterprise Miner …
(1) основан на создании диаграмм процессов обработки данных
(2) основан на ручном кодировании
(3) предоставляет готовый программный код для скоринга на всех стадиях создания модели
(4) поддерживает создание различных программных сред для развертывания модели на языках SAS, C, Java и PMML
(5) все ответы верны
Какие из перечисленных модулей PolyAnalyst предназначены для построения числовых моделей и прогноза числовых переменных?
(1) полиномиальная нейронная сеть
(2) пошаговая многопараметрическая линейная регрессия
(3) метод «ближайших соседей»
(4) транзакционный анализ «корзины»
Система Cognos PowerPlay – это инструментальное средство, предназначенное для:
(1) оперативного анализа данных
(2) формирования отчетов по OLAP–технологии
(3) интеллектуального анализа данных
(4) все ответы верны
Какие компоненты входят в состав Deductor?
(1) аналитическое приложение Deductor Studio
(2) многомерное хранилище данных Deductor Warehouse
(3) лаборатория BaseGroup Labs
(4) все ответы верны
В чем заключается основная особенность инструмента KXEN?
(1) в практически полной автоматизации процесса построения моделей
(2) в возможности использования малого количества ретроспективных данных
(3) в сложности построенных моделей
(4) все ответы верны
Какое решение в большей мере требует наличия высококвалифицированных специалистов при внедрении и использования инструмента Data Mining?
(1) использование готового программного обеспечения
(2) заказ готового решения у фирмы-разработчика
(3) адаптация программного обеспечения под конкретную задачу
Какая из перечисленных ниже стадий может считаться дополнительной или частью одной из основных стадий Data mining:
(1) выявление закономерностей (свободный поиск)
(2) использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование)
(3) валидация
Заполните пропуск в формулировке: «Формирование … происходит в процессе сбора и передачи, т.е. обработки данных»
(1) знаний
(2) информации
(3) данных
Классификация относится к стратегии:
(1) обучения с учителем
(2) обучения без учителя
(3) оба ответа неверны
Временной ряд — последовательность наблюдаемых значений какого-либо признака,…
(1) упорядоченных в неслучайные моменты времени
(2) упорядоченных в случайные моменты времени
(3) не обязательно упорядоченных, но зафиксированных в неслучайные моменты времени
Технология Web mining применяет технологию Data Mining для анализа:
(1) неструктурированной информации
(2) структурированной информации
(3) неоднородной информации
(4) однородной информации
(5) распределенной и значительной по объему информации
(6) информации, содержащейся на Web-узлах
Заполните пропуск в формулировке: «Корреляционный анализ применяется для … оценки взаимосвязи двух наборов данных, представленных в безразмерном виде»
(1) количественной
(2) качественной
(3) количественной и качественной
Заполните пропуски в формулировке: «Каждая ветвь дерева, идущая от внутреннего узла, отмечена … , который может относиться лишь к одному … данного узла»
(1) атрибутами расщепления, критерию расщепления
(2) предикатом расщепления, атрибуту расщепления
(3) критерием расщепления, атрибуту расщепления
Выберите характеристику, наиболее подходящую для Data Mining
(1) подходит для понимания ретроспективных данных
(2) опирается на ретроспективные данные для получения ответов на вопросы о будущем
(3) подходит для обобщения ретроспективных данных
Метод, который делает заключения относительно данной ситуации по результатам поиска аналогий, хранящихся в базе прецедентов относится к категории …
(1) «обучение без учителя»
(2) «обучение с учителем»
(3) самообучающейся системы
Однонаправленные входные связи, соединенные с выходами других нейронов – это …
(1) синапсы
(2) аксоны
(3) слои сети
При… раскрывается внутренняя структура данных или корреляции между образцами в наборе данных
(1) обучении с учителем
(2) обучении без учителя
(3) оба варианта верны
Кластерный анализ …
(1) может применяться к совокупностям временных рядов
(2) не может применяться к совокупностям временных рядов
(3) может определять группы временных рядов со схожей динамикой
Назовите сложности иерархических методов кластеризации:
(1) ограничение объема набора данных
(2) выбор меры близости
(3) негибкость полученных классификаций
(4) наличие предположений относительно числа кластеров.
Количество транзакций, содержащих определенный набор данных. Это — …
(1) достоверность набора
(2) поддержка набора
(3) обеспечение набора
Визуализация в виде «лиц Чернова» является представлением информации в …
(1) двухмерном измерении
(2) трехмерном измерении
(3) более, чем в трехмерном измерении
DSS (Desicion Support System) ориентированы на …, основаны на …
(1) неподготовленного пользователя, на запросах, количество которых ограничено
(2) подготовленного пользователя, глубокой проработке данных
(3) неподготовленного пользователя, глубокой проработке данных
Репрезентативность выборки означает, что …
(1) выборка должна представлять как можно больше возможных ситуаций
(2) выборка должна включать более ста записей
(3) число записей выборки должно соответствовать числу переменных
К какой категории данных относится вес измеряемых объектов:
(1) непрерывным данным
(2) дискретным данным
(3) оба ответа неверны
Эндогенные переменные — это переменные, которые …
(1) задаются вне модели, они известны заранее
(2) определяются по ходу расчетов в модели, они не задаются извне
(3) задаются внутри модели, они известны заранее
Шаги какой из методологий Data Mining здесь описаны:
отбор данных, исследование отношений в данных, модификация данных, моделирование взаимозависимостей, оценка полученных моделей и результатов?
(1) CRISP-DM
(2) SEMMA
(3) Two Crows
Инструмент Weka относится к категории:
(1) бесплатного программного обеспечения
(2) достаточно недорогого программного обеспечения
(3) достаточно дорогого программного обеспечения.
Назовите характеристики, присущие SAS Enterprise Miner:
(1) имеет встроенные средства оценки моделей
(2) наличие единой среды для сравнения различных методов моделирования
(3) сравнение моделей возможно с точки зрения бизнеса
(4) сравнение моделей возможно с точки зрения статистики
(5) все ответы верны
Какие из перечисленных алгоритмов PolyAnalyst предназначены для решения задач классификации?
(1) метод «ближайших соседей»
(2) дискриминация
(3) дерево решений
(4) леса решений
Охарактеризуйте систему Cognos Scenario:
(1) интеллектуальное инструментальное средство поиска данных
(2) позволяет руководителям выявлять скрытые тенденции и модели бизнеса
(3) является средством оперативного анализа данных
(4) формирует отчеты по OLAP–технологии
При анализе данных в Deductor Studio возможны такие действия:
(1) импорт данных
(2) обработка данных
(3) визуализация
(4) экспорт данных
(5) все ответы верны
Построение модели в KXEN можно охарактеризовать как …
(1) функцию предсказательного анализа в режиме on-line в формате «вопрос-ответ»
(2) итеративный процесс
(3) набор таких шагов: подготовка модели, построение модели, тестирование модели
Достаточно высокая стоимость, невозможность добавлять свои функции, сложность подготовки данных, практическое отсутствие в интерфейсе терминов предметной области – это слабые стороны …
(1) готового программного обеспечения
(2) заказ готового решения у фирмы-разработчика
(3) адаптация программного обеспечения под конкретную задачу
(4) все ответы верны
Какая из перечисленных ниже стадий может считаться дополнительной или частью одной из основных стадий Data mining:
(1) выявление закономерностей (свободный поиск)
(2) использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование)
(3) валидация
В результате использования одних и тех же данных и различных методов…
(1) должна появляться разная информация
(2) должна появляться только одинаковая информация
(3) может появляться разная информация, это зависит от выбранных методов обработки данных
Классификация относится к:
(1) контролируемому обучению
(2) управляемому обучению
(3) обучения без учителя
Отличием анализа временных рядов от анализа случайных выборок является:
(1) предположение о равных промежутках времени между наблюдениями
(2) их хронологический порядок
(3) оба варианта верны
Согласно таксономии Web Mining выделяют основные направления:
(1) Web Content Mining и Web Usage Mining
(2) Text Mining и Call Mining
(3) Web Content Mining, Web Usage Mining, Text Mining и Call Mining
Заполните пропуск в формулировке: «Коэффициент корреляции Пирсона, который является безразмерным индексом в интервале … включительно, отражает степень … зависимости между двумя множествами данных»
(1) от -1 до 1, линейной
(2) от 0 до 1, линейной
(3) от 0 до 100, нелинейной
Внутренние узлы дерева решений называют …
(1) атрибутами расщепления
(2) предикатом расщепления
(3) критерием расщепления
Подготовка данных в процессе Data Mining является:
(1) необязательным этапом работы
(2) существенным этапом работы
(3) может вообще отсутствовать
Все переменные являются одинаково важными и статистически независимыми, т.е. значение одной переменной ничего не говорит о значении другой. Это свойства:
(1) наивной байесовской классификации
(2) метода «ближайшего соседа»
(3) метода опорных векторов
Явление переобучения характеризуется …
(1) чрезмерно точным соответствием нейронной сети конкретному набору обучающих примеров, при котором сеть теряет способность к обобщению
(2) возникновением, в случае слишком долгого обучения, недостаточного числа обучающих примеров или слишком сложной структуры нейронной сети
(3) возникновением, в случае слишком долгого обучения, слишком большого числа обучающих примеров или слишком сложной структуры нейронной сети
Правило формирования окрестности (несколько нейронов, которые окружают нейрон-победитель):
(1) сначала к окрестности принадлежит большое число нейронов, далее ее размер постепенно уменьшается
(2) сначала к окрестности принадлежит малое число нейронов, далее ее размер постепенно увеличивается
(3) размер окрестности в процессе обучения не изменяется
Процедура, которая приводит значения всех преобразованных переменных к единому диапазону значений путем выражения через отношение этих значений к некой величине, отражающей определенные свойства, это – …
(1) стандартизация
(2) нормирование
(3) оба ответа верны
Процесс последовательного укрупнения кластеров лежит в основе работы…
(1) иерархического КА
(2) быстрого
(3) всех методов
Выберите задачу, которая не решается при помощи поиска ассоциативных правил:
(1) определение товаров, которые стоит продвигать совместно
(2) выбор местоположения товара в магазине
(3) классификация клиентов фирмы на однотипные группы
(4) анализ потребительской корзины
Основные тенденции в области визуализации:
(1) разработка сложных видов диаграмм
(2) разработка более компактных видов диаграмм
(3) повышение уровня взаимодействия с визуализацией пользователя
(4) уменьшение роли пользователя
(5) все ответы верны
Предметная ориентация хранилища данных означает, что …
(1) данные объединены в категории и сохраняются соответственно областям, которые они описывают, а не применениям, их использующим
(2) данные удовлетворяют требованиям всего предприятия, а не одной функции бизнеса
(3) хранилище можно рассматривать как совокупность «исторических» данных: возможно восстановление данных в любой момент времени
Наличие дубликатов в наборе данных может быть:
(1) результатом ошибок при подготовке данных
(2) способом повышения значимости некоторых записей
(3) оба ответа верны
Специальные средства очистки служат:
(1) для работы с конкретными областями (имена и адреса)
(2) для работы по исключению дубликатов
(3) для реализации возможности сложных преобразований и большей части технологического процесса преобразования и очистки данных
Номинальная шкала – это шкала,
(1) содержащая только категории, которые не могут упорядочиваться
(2) содержащая категории, которые могут упорядочиваться
(3) содержащая только две категории
Прогнозирующие модели Data Mining …
(1) позволяют на основе выявленных закономерностей предсказывать будущее поведение объекта
(2) описывают общие закономерности предметной области
(3) решают задачи кластеризации, группировки, обобщения
(4) все ответы неверны
Специалист по анализу данных, который имеет, как минимум, основы статистических знаний и способен применять технологии Data Mining, а также интерпретировать полученные результаты — это…
(1) специалист по добыче данных
(2) специалист предметной области
(3) администратор баз данных
(4) программист
(5) все ответы неверны
Цены на инструменты Data Mining уровня предприятия находятся в диапазоне:
(1) US $10,000 и больше
(2) от $1,000 до $9,999
(3) от $1 до $999
Итогом работ по интеллектуальному анализу данных в SAS Enterprise Miner является …
(1) развертывание созданной модели
(2) сравнение моделей
(3) моделирование
Выберите характеристики математических модулей версии PolyAnalyst 4.6
(1) они выделены в отдельные динамические библиотеки
(2) они доступны из других приложений
(3) количество математических модулей равно 16
МАР-сплайны в системе STATISTICA – это …
(1) непараметрическая процедура, в работе которой не используется никаких предположений об общем виде функциональных связей между зависимыми и независимыми переменными
(2) параметрическая процедура, основанная на предположениях о виде функциональных связей между зависимыми и независимыми переменными
(3) процедура, опирающаяся на предположения о типе и накладывающая ограничения на класс зависимостей
Основные группы алгоритмов пакета Deductor:
(1) очистка данных
(2) трансформация данных
(3) сглаживание
Какой компонент KXEN используется в случаях, когда «сырые» данные содержат одновременно статическую информацию (например, возраст, пол или профессия индивида) и динамические переменные (например, шаблоны покупок или транзакции по кредитной карте)?
(1) компонент Агрегирования Событий (KXEN Event Log – KEL)
(2) компонент Согласованного Кодирования (KXEN Consistent Coder – K2C)
(3) компонент Интеллектуальной Сегментации (KXEN Smart Segmenter – K2S)
Постановка бизнес-задачи – это этап, который …
(1) формулирует конкретные бизнес-задачи, и они уже не могут быть изменены
(2) формулирует конкретные бизнес-задачи, и они не могут быть изменены в ходе прохождения именно этого цикла
(3) формулирует конкретные бизнес-задачи, и они могут быть изменены в ходе прохождения именно этого цикла
На какие две группы подразделяются методы Data Mining по принципу работы с исходными обучающими данными?
(1) непосредственное использование данных или сохранение данных
(2) выявление и использование формализованных закономерностей
(3) статистические методы
(4) кибернетические методы
Любые, неизвестные ранее сведения о каком-либо событии, сущности, процессе и т.п., являющиеся объектом некоторых операций, для которых существует содержательная интерпретация, являются…
(1) данными
(2) информацией
(3) знаниями
Множество примеров, используемое для конструирования модели, называется…
(1) обучающим множеством
(2) тестовым множеством
(3) проверочным множеством
Возможности визуализации включают:
(1) поддержку интерактивного и согласованного исследования
(2) помощь в представлении результатов
(3) формализацию задач Data Mining
Какие задачи возникают перед разработчиками при построении системы Web Mining:
(1) сбора данных
(2) использование методов персонификации
(3) анализ полученного знания
Выберите соответствующую характеристику данному варианту связи: большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), и это…
(1) наличие прямой (линейной) связи
(2) наличие отрицательной линейной связи
(3) отсутствие линейной связи
Алгоритм конструирования дерева решений …
(1) не требует от пользователя выбора из набора входных атрибутов (независимых переменных), наиболее значимых
(2) требует от пользователя выбора из набора входных атрибутов (независимых переменных), наиболее значимых
(3) на вход алгоритма можно подавать все существующие атрибуты, алгоритм сам выберет наиболее значимые среди них, и только они будут использованы для построения дерева
Инструменты Data Mining:
(1) могут самостоятельно строить гипотезы о взаимосвязях в данных
(2) не могут самостоятельно строить гипотезы о взаимосвязях в данных
(3) могут самостоятельно строить гипотезы о взаимосвязях в данных, которые обязательно подтверждаются
Использование байесовских сетей имеет следующие преимущества:
(1) позволяет избежать проблемы переучивания
(2) определяет зависимости между всеми переменными
(3) на результат классификации влияют только индивидуальные значения входных переменных
В многослойном персептроне …
(1) должен быть хотя бы один скрытый слой
(2) может быть какое угодно количество скрытых слоев, они также могут вообще отсутствовать
(3) присутствие нескольких скрытых слоев оправдано лишь в случае использования нелинейных функций активации
Обучение самоорганизующихся сетей заключается …
(1) в минимизации ошибки
(2) в подстройке весов (внутренних параметров нейросети) для наибольшего совпадения с входными данными
(3) в подстройке весов (внутренних параметров нейросети) для наибольшего совпадения с выходными данными
Иерархические дивизимные методы характеризуются …
(1) последовательным объединением исходных элементов и соответствующим уменьшением числа кластеров
(2) делением одного кластера на меньшие кластеры, в результате образуется последовательность расщепляющих групп
(3) сопоставлением фиксированного числа кластеров наблюдения кластерам так, что средние в кластере максимально возможно отличаются друг от друга
Чувствительность к выбросам – это недостаток…
(1) иерархического КА
(2) быстрого КА
(3) всех методов КА
Выберите правильное утверждение:
(1) чем больше значение поддержки правила, тем лучше правило
(2) чем ниже значение поддержки правила, тем лучше правило
(3) если поддержка правила слишком велика, в результате будут найдены правила очевидные и хорошо известные
Основные тенденции в области визуализации:
(1) разработка сложных видов диаграмм
(2) увеличение размеров и сложности структур данных, представляемых визуализацией
(3) уменьшение роли пользователя
(4) все ответы верны
Привязка ко времени хранилища данных означает, что …
(1) данные объединены в категории и сохраняются соответственно областям, которые они описывают, а не применениям, их использующим
(2) данные удовлетворяют требованиям всего предприятия, а не одной функции бизнеса
(3) хранилище можно рассматривать как совокупность «исторических» данных: возможно восстановление данных на любой момент времени
Ваши действия при обнаружении выбросов в наборе данных:
(1) их следует сразу же исключить из дальнейшего анализа
(2) оценить степень их влияния на результаты дальнейшего анализа
(3) такой набор данных вообще не поддается анализу
Когда речь идет о создании банков данных всего предприятия и, соответственно, о сплошной очистке данных, имеет смысл пользоваться следующими средствами очистки данных:
(1) универсальными системами, предназначенными для обслуживания всей базы данных целиком
(2) верификаторами имени/адреса для очистки только данных о клиентах
(3) специальными средствами очистки данных
Интервальная шкала – это шкала,
(1) содержащая категории, которые могут упорядочиваться, однако разности не имеют смысла
(2) разности между значениями которой могут быть вычислены, однако их отношения не имеет смысла
(3) содержащая только категории, которые не могут упорядочиваться
Дескриптивные модели …
(1) описывают общие закономерности предметной области
(2) осуществляют прогнозирование класса объекта
(3) решают задачи кластеризации, группировки, обобщения
(4) все ответы верны
Специалист, имеющий знания о том, где и каким образом хранятся данные, как получить к ним доступ, и как связать между собой эти данные — это…
(1) специалист по добыче данных
(2) специалист предметной области
(3) администратор баз данных
(4) программист
(5) все ответы неверны
Могут ли отличаться цены на инструменты Data Mining для различных категорий пользователей?
(1) да
(2) нет
(3) только в виде исключения
Выбор лучшей модели в пакете SAS Enterprise Miner:
(1) является автоматическим
(2) осуществляется на основе заданного пользователем критерия
(3) оба варианта неверны
Выберите характеристики математических модулей версии PolyAnalyst 4.6:
(1) они выделены в отдельные динамические библиотеки
(2) модули основаны на различных алгоритмах Data и Text Mining
(3) количество математических модулей равно 16
Охарактеризуйте систему STATISTICA:
(1) из-за сложности методов система недоступна для обычных пользователей, которые не разбираются в методах анализа данных
(2) вариант работы для обычных пользователей – в пакет встроены готовые законченные (сконструированные) модули анализа данных, предназначенные для решения наиболее важных и популярных задач
(3) в системе есть только общие методы анализа и нет готовых законченных решений
Основные группы алгоритмов пакета Deductor:
(1) трансформация данных
(2) Data Mining
(3) редактирование аномалий
Какой компонент KXEN позволяет выявить естественные группы (кластеры) в наборе данных?
(1) компонент Интеллектуальной Сегментации (KXEN Smart Segmenter – K2S)
(2) компонент Согласованного Кодирования (KXEN Consistent Coder – K2C)
(3) компонент Агрегирования Событий (KXEN Event Log – KEL
На этапе подготовки данных…
(1) специалисты компании Разработчика подготавливают данные для их дальнейшего анализа
(2) специалисты компании Заказчика подготавливают данные для их дальнейшего анализа
(3) специалисты компании Разработчика и Заказчика подготавливают данные для их дальнейшего анализа
Деревья решений относятся к группе (-ам) …
(1) статистических методов
(2) кибернетических методов
(3) логических методов
(4) методов кросс-табуляции
Совокупность фактов, закономерностей и эвристических правил, с помощью которых решается поставленная задача, – это …
(1) данные
(2) информация
(3) знания
Множество примеров, используемое для проверки работы сконструированной модели, называется…
(1) обучающим множеством
(2) тестовым множеством
(3) тренировочным множеством
Преимуществом визуализации является:
(1) простота ее использования
(2) возможность решать самые разнообразные задачи
(3) отсутствие необходимости специальной подготовки пользователя
Какая из технологий анализирует массивы неструктурированной информации и одним из ее методов является поиск подстроки в строке?
(1) Data Mining
(2) Text Mining
(3) Web Mining
Выберите соответствующую характеристику данному варианту связи: данные двух диапазонов никак не связаны (нулевая корреляция), и это…
(1) наличие прямой (линейной) связи
(2) наличие отрицательной линейной связи
(3) отсутствие линейной связи
Какие модели строят деревья решений?
(1) непараметрические модели
(2) параметрические модели
(3) и те, и другие
Оцените правильность утверждения:»Data Mining может заменить аналитика»
(1) yтверждение верно
(2) yтверждение неверно. Технология не может дать ответы на те вопросы, которые не были заданы
(3) yтверждение неверно. Технология всего лишь дает аналитику инструмент для облегчения и улучшения его работы
Назовите свойства наивной байесовской классификации:
(1) использование всех переменных и определение всех зависимостей между ними
(2) наличие предположения относительно того, что все переменные являются одинаково важными
(3) наличие предположения относительно того, что все переменные являются статистически независимыми, т.е. значение одной переменной ничего не говорит о значении другой
Ошибкой обучения нейронной сети называется …
(1) разность между желаемым и полученным на выходе сигналами
(2) целевая функция, требующая минимизации в процессе управляемого обучения нейронной сети
(3) переобучение нейронной сети
Какое количество слоев имеет сеть Кохонена?
(1) один слой: только входной
(2) два слоя: входной и выходной
(3) три слоя: входной, выходной и скрытый
(4) какое угодно количество слоев
(5) она вообще не имеет слоев
Характеристикой каких групп методов являются последовательное объединение исходных элементов и соответствующее уменьшение числа кластеров?
(1) иерархические агломеративные методы
(2) иерархические дивизимные (делимые) методы
(3) и тех, и других
Какие методы отказываются от определения числа кластеров, а строят полное дерево вложенных кластеров?
(1) иерархические методы
(2) неиерархические методы
(3) самоорганизующиеся карты
Назовите алгоритмы, при помощи которых осуществляется поиск ассоциативных правил:
(1) алгоритм AIS
(2) алгоритм SETM
(3) алгоритм Apriori
(4) алгоритм PAM
Основными тенденциями в области визуализации являются:
(1) повышение уровня взаимодействия с визуализацией пользователя
(2) уменьшения уровня взаимодействия с визуализацией пользователя
(3) сведение роли пользователя во взаимодействии в визуализацией к минимальной
MOLAP является:
(1) способом хранения данных в OLAP-системах
(2) архитектурой OLAP-серверов, при которой исходные и многомерные данные хранятся в многомерной БД или в многомерном локальном кубе
(3) методом Data Mining
(4) интеграцией Data Mining и OLAP
(5) архитектурой OLAP-серверов, при которой исходные данные хранятся в реляционных БД или в плоских локальных таблицах на файл-сервере
Качество данных – это критерий, определяющий такие качества данных как:
(1) полноту
(2) точность
(3) своевременность
(4) возможность их интерпретации
(5) все варианты верны
Автоматизированный процесс очистки данных … к ошибкам в данных, которых раннее в них не было
(1) иногда может приводить
(2) всегда приводит
(3) не может приводить
Для какой шкалы применимы только такие операции как равно и не равно?
(1) номинальная шкала
(2) порядковая шкала
(3) интервальная шкала
Назовите причины, из-за которых следует переобучать или обучать модель заново:
(1) изменились входящие данные или их поведение
(2) появились дополнительные данные для обучения
(3) изменились требования к форме и количеству выходных данных
(4) изменились цели бизнеса, которые повлияли на критерии принятия решений
(5) изменились внешнее окружение или среда
(6) все ответы верны
Какой стандарт обеспечивает возможности обмена моделями данных между программным обеспечением разных разработчиков?
(1) PMML
(2) CWM Data Mining
(3) JDM
Рынок Business Intelligence, в том числе рынок инструментов Data Mining, …
(1) насколько широк и разнообразен, что любая компания может выбрать для себя инструмент, который подойдет ей по функциональности и по возможностям бюджета
(2) является узким, и малое число компаний может позволить себе выбрать инструмент по требующейся ей функциональности
(3) является насколько узким на сегодняшний день, что лишь большие компании могут позволить себе пользоваться инструментами по требующейся им функциональности
Подход SAS к созданию информационно-аналитических систем предусматривает:
(1) возможность извлечения данных из ERP-систем
(2) возможность извлечения данных из OLTP-систем
(3) возможность извлечения данных из баз данных и других источников
(4) без применения микропрограммирования на языке управления данными ERP/OLTP-системы
(5) с применением микропрограммирования на языке управления данными ERP/OLTP-системы
Возможно ли решение задач поиска ассоциативных правил в PolyAnalyst?
(1) нет
(2) да, есть возможность поиска ассоциативных правил, но лишь в небольших базах данных
(3) да, есть такая возможность, при помощи специального алгоритма анализ возможен в очень больших данных
Опишите возможности пакета Deductor по заполнениию пропусков
(1) нет возможности заполнения пропусков
(2) есть возможность заполнения пропусков методом аппроксимации
(3) есть возможность заполнения пропусков при помощи алгоритма, подставляющего наиболее вероятные значения вместо пропущенных данных
Охарактеризуйте квалификацию, которой требуется обладать пользователю для работы с KXEN
(1) пользователю не требуется обладать специальной квалификацией и знаниями в области анализа и статистики
(2) пользователю требуется обладать специальной квалификацией и знаниями в области анализа и статистики
(3) пользователю требуется обладать специальной квалификацией и знаниями в области анализа, статистики и искусственного интеллекта
Гибкость инструмента Data Mining означает …
(1) возможность выбора наиболее удобных понятий, в терминах которых должны быть сформулированы знания или термины предметной области
(2) получение осмысленных и понятных знаний в естественной форме
(3) оба ответа верны
Регрессионный и дискриминантный анализ …
(1) относятся к статистическим методам Data mining
(2) относятся к кибернетическим методам Data mining
(3) не являются методами Data mining
У основания так называемой информационной пирамиды находится категория …
(1) данные
(2) знания
(3) информация
Кластер можно охарактеризовать как …
(1) группу объектов, имеющих общие свойства
(2) один объект, изолированный от других
(3) группу объектов, имеющую внутреннюю однородность
Параметрами прогнозирования являются:
(1) период прогнозирования
(2) горизонт прогнозирования
(3) интервал прогнозирования
(4) тренд
Web content mining подразумевает …
(1) автоматический поиск и извлечение качественной информации разнообразных источников Интернета, перегруженных «информационным шумом»
(2) обнаружение закономерностей в действиях пользователя Web-узла или их группы
(3) обнаружение последовательности просмотра страниц
Основные особенности регрессионного анализа заключаются в том, что при его помощи можно получить конкретные сведения о том:
(1) какую форму имеет зависимость между исследуемыми переменными
(2) какой характер имеет зависимость между исследуемыми переменными
(3) какую количественную взаимосвязь имеют два набора данных
Процесс создания дерева …
(1) происходит сверху вниз, т.е. является нисходящим
(2) происходит снизу вверх, т.е. является восходящим
(3) может быть как нисходящим, так и восходящим
Оцените правильность утверждения: «Извлечение полезных сведений невозможно без хорошего понимания сути данных»
(1) утверждение верно
(2) утверждение неверно. Технологии Data Mining не нужен аналитик, поэтому понимание кем-либо данных — излишне
(3) утверждение неверно. Технологии не нужно понимание данных
Назовите метод, недостаток которого приведен ниже: «Перемножать условные вероятности корректно только тогда, когда все входные переменные действительно статистически независимы»
(1) метод байесовской классификации
(2) метод «k-ближайших соседей»
(3) метод опорных векторов
Целевая функция, требующая минимизации в процессе управляемого обучения нейронной сети – это …
(1) функция ошибок
(2) ошибка обучения
(3) функция переобучения
Традиционно темно-синие участки на карте Кохонена соответствуют …
(1) наименьшим значениям показателя
(2) самым высоким значениям показателя
(3) средним значениям показателя
Деление одного кластера на меньшие кластеры, в результате чего образуется последовательность расщепляющих групп. Характеристика каких групп методов описана выше?
(1) иерархические агломеративные методы
(2) иерархические дивизимные (делимые) методы
(3) и тех, и других
Преимуществом какой группы методов кластеризации является их наглядность и возможность получить детальное представление о структуре данных
(1) иерархические методы
(2) неиерархические методы
(3) оба варианта верны
Назовите алгоритм, который не осуществляет поиск ассоциативных правил:
(1) алгоритм DHP
(2) алгоритм PAM
(3) алгоритм DIC
Назовите характеристики одной из основных тенденций в области визуализации:
(1) увеличение размеров структур данных, представляемых визуализацией
(2) усложнение структур данных, представляемых визуализацией
(3) уменьшение размеров структур данных, представляемых визуализацией
ROLAP является:
(1) архитектурой OLAP-серверов, при которой исходные данные хранятся в реляционных БД или в плоских локальных таблицах на файл-сервере
(2) интеграцией Data Mining и OLAP
(3) методом Data Mining
(4) архитектурой OLAP-серверов, при которой исходные данные остаются в реляционной базе, а агрегаты размещаются в многомерной
Существуют такие типы грязных данных:
(1) данные, которые могут быть автоматически обнаружены и очищены
(2) данные, которые не могут быть автоматически обнаружены и очищены
(3) данные, появление которых можно было предотвратить
(4) данные, появление которых невозможно было предотвратить
Согласно классификации ошибок в данных, которые возникают в результате использования средств очистки, выделяют такие их классы:
(1) ошибки, возникающие, когда инструмент очистки пытается решить проблему, которой на самом деле не существует
(2) ошибки, возникающие, когда инструменты очистки полностью упускают существующую проблему
(3) ошибки, требующие немедленного исправления
(4) ошибки, не поддающиеся исправлению
Для какой шкалы применимы только такие операции как равно, не равно, больше, меньше?
(1) номинальная шкала
(2) порядковая шкала
(3) интервальная шкала
Если модель с успехом используется определенное время, это означает, что …
(1) ее не следует считать абсолютно верной на все времена
(2) она проверена, и ее можно считать верной на все времена
(3) она уже устарела, и нужна новая модель
Какой стандарт обеспечивает поддержку наиболее распространенных прогнозных моделей, созданных при помощи алгоритмов и методов анализа данных?
(1) PMML
(2) CWM Data Mining
(3) JDM
Охарактеризуйте рынок программного обеспечения Data Mining:
(1) представлен множеством инструментов
(2) представлен достаточно небольшим количеством инструментов
(3) на нем идет постоянная конкурентная борьба за потребителя
(4) на нем практически нет конкуренции
(5) он постоянно развивается
(6) он уже достиг достаточного уровня развития и в ближайшее время предвидится спад
Подход SAS к созданию информационно-аналитических систем предусматривает:
(1) методы очистки исходных данных и их подготовки для загрузки в хранилище
(2) средства проектирования и администрирования хранилищ данных
(3) технологию физического хранения больших объемов данных.
(4) все ответы верны
Опишите возможности текстового анализа в PolyAnalyst
(1) PolyAnalyst имеет только алгоритмы, извлекающие ключевые понятия и работающие с ними
(2) PolyAnalyst имеет только алгоритмы, сортирующие тексты на классы, которые определяются пользователем с помощью языка запросов
(3) PolyAnalyst имеет и те, и другие имеет алгоритмы
Какие из представленных алгоритмов реализованы в пакете Deductor?
(1) нейронные сети
(2) автокорреляция
(3) деревья решений
(4) самоорганизующиеся карты
(5) ассоциативные правила
(6) все ответы верны
Что требуется от пользователя при работе с KXEN?
(1) данные, которые необходимо проанализировать
(2) определение типа задачи, которую нужно решить
(3) выбор лучшей модели
(4) тестирование модели
Какую часть мирового рынка Data Mining занимают услуги или консультации по эффективному внедрению этой технологии для решения актуальных бизнес-задач?
(1) менее 10% рынка
(2) около половины рынка
(3) более 75% рынка
Нечеткая логика и деревья решений …
(1) относятся к статистическим методам Data mining
(2) относятся к кибернетическим методам Data mining
(3) не являются методами Data mining
Информация, данные и знания являются:
(1) частью одного потока
(2) частями разных потоков
(3) оба ответа неверны
Изначальная предопределенность классов является характеристикой задачи …
(1) классификации
(2) кластеризации
(3) классификации и кластеризации
Период прогнозирования – это …
(1) параметр прогнозирования
(2) составляющая временного ряда
(3) характеристика временного ряда
Web Usage Mining подразумевает …
(1) автоматический поиск и извлечение качественной информации разнообразных источников Интернета, перегруженных «информационным шумом»
(2) обнаружение закономерностей в действиях пользователя Web-узла или их группы
(3) обнаружение последовательности просмотра страниц
Основные задачи регрессионного анализа включают:
(1) установление формы зависимости
(2) определение функции регрессии
(3) оценку неизвестных значений зависимой переменной
(4) все ответы верны
Процесс отсечения ветвей или замена некоторых ветвей поддеревом …
(1) происходит снизу вверх, т.е. является восходящим
(2) происходит сверху вниз, т.е. является нисходящим
(3) может быть как нисходящим, так и восходящим
На результат классификации в наивно-байесовском подходе влияют:
(1) только индивидуальные значения входных переменных
(2) комбинированное влияние пар или троек значений разных атрибутов
(3) индивидуальные значения входных переменных, комбинированное влияние пар или троек значений разных атрибутов
Многослойный персептрон – это сеть …
(1) прямого распространения сигнала (без обратных связей)
(2) обратного распространения сигнала (с обратными связями)
(3) в которой входной сигнал преобразуется в выходной, проходя последовательно через несколько слоев
Самоорганизующиеся сети в процессе обучения подстраиваются …
(1) под закономерности во входных данных
(2) под эталонное значение выхода
(3) под закономерности в выходных данных
Иерархические агломеративные методы характеризуются …
(1) последовательным объединением исходных элементов и соответствующим уменьшением числа кластеров
(2) делением одного кластера на меньшие кластеры, в результате образуется последовательность расщепляющих групп
(3) сопоставлением фиксированного числа кластеров наблюдения кластерам так, что средние в кластере максимально возможно отличаются друг от друга
Пересчет кластерных центров и перераспределение объектов между кластерными центрами – это шаги…
(1) иерархического
(2) быстрого
(3) всех методов
Достоверность ассоциативного правила определяет…
(1) количество транзакций, содержащих определенный набор данных
(2) какая вероятность того, что из события A следует событие B
(3) процент транзакций, содержащих определенный набор данных
Основные тенденции в области визуализации:
(1) разработка более компактных видов диаграмм
(2) повышение уровня взаимодействия с визуализацией пользователя
(3) увеличение размеров и сложности структур данных, представляемых визуализацией
(4) все ответы верны
Интегрированность хранилища данных означает, что …
(1) данные объединены в категории и сохраняются соответственно областям, которые они описывают, а не применениям, их использующим
(2) данные удовлетворяют требованиям всего предприятия, а не одной функции бизнеса
(3) хранилище можно рассматривать как совокупность «исторических» данных: возможно восстановление данных в любой момент времени
При наличии дубликатов в наборе данных следует использовать такой вариант их обработки:
(1) удалить всю группу записей, содержащую дубликаты
(2) заменить группу дубликатов на одну уникальную запись
(3) оба варианта можно использовать при обработке дубликатов
Инструменты ETL предназначены:
(1) для работы с конкретными областями (имена и адреса)
(2) для работы по исключению дубликатов
(3) для реализации возможности сложных преобразований и большей части технологического процесса преобразования и очистки данных
Порядковая шкала – это шкала, содержащая
(1) категории, которые могут упорядочиваться
(2) категории, которые не могут упорядочиваться
(3) только две категории
Классификационные модели Data Mining …
(1) осуществляют прогнозирование класса объекта
(2) описывают общие закономерности предметной области
(3) решают задачи кластеризации, группировки, обобщения
(4) все ответы верны
Специалист, имеющий знания о окружении бизнеса, процессах, заказчиках, клиентах, потребителях, а также конкурентах — это…
(1) специалист по добыче данных
(2) специалист предметной области
(3) администратор баз данных
(4) менеджер проекта
(5) все ответы неверны
Цены на инструменты Data Mining уровня отдела находятся в диапазоне:
(1) US $10,000 и больше
(2) от $1,000 до $9,999
(3) от $1 до $999
Скоринг в SAS – это …
(1) процесс применения модели к новым данным
(2) процесс создания модели
(3) процесс сравнения моделей
Выберите характеристики математических модулей версии PolyAnalyst 4.6:
(1) количество математических модулей равно 18
(2) они могут быть интегрированы в существующие информационные системы
(3) все модули основаны на методе нейронных сетей
Рабочее пространство STATISTICA Data Miner не включает такого элемента:
(1) сбор данных
(2) подготовка, преобразования и очистка данных
(3) анализ данных, моделирование
(4) тестирование
(5) результаты
Основные группы алгоритмов пакета Deductor:
(1) очистка данных
(2) Data Mining
(3) квантование значений
Какой компонент позволяет автоматически подготовить данные и трансформировать их в формат, подходящий для использования аналитическими приложениями KXEN?
(1) компонент Согласованного Кодирования (KXEN Consistent Coder – K2C)
(2) компонент Агрегирования Событий (KXEN Event Log – KEL)
(3) компонент Интеллектуальной Сегментации (KXEN Smart Segmenter – K2S)
На этапе первичного исследования данных …
(1) со стороны заказчика может потребоваться лишь минимальное участие
(2) со стороны заказчика может потребоваться максимальное участие
(3) всю работу осуществляет заказчик
Нейронные сети относятся к группам …
(1) статистических методов
(2) методов на основе уравнений
(3) методов кросс-табуляции
Формирование какой из перечисленных категорий происходит в процессе сбора и передачи данных, т.е. их обработки?
(1) информации
(2) знаний
(3) и того, и другого
Процесс классификации состоит из следующих этапов:
(1) конструирование модели
(2) использование модели
(3) определение вида модели
Продолжите фразу:»Визуализация …
(1) направлена исключительно на совершенствование техники анализа»
(2) может самостоятельно выполнять функции анализа»
(3) может самостоятельно выполнять функции анализа, но пользователь должен иметь специальную подготовку»
Выделите категории задач Web Mining:
(1) предварительная обработка данных для Web Mining
(2) обнаружение шаблонов и открытие знаний с использованием ассоциативных правил, временных последовательностей, классификации и кластеризации
(3) анализ полученного знания
(4) использование методов персонификации
Выберите соответствующую характеристику данному варианту связи: малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), и это…
(1) наличие прямой (линейной) связи
(2) наличие отрицательной линейной связи
(3) отсутствие линейной связи
Алгоритмы конструирования деревьев решений …
(1) имеют возможность обработки пропущенных значений вне зависимости от используемого алгоритма
(2) в принципе не могут работать с пропущенными значениями
(3) большинство алгоритмов конструирования деревьев решений имеют возможность обработки пропущенных значений
Закончите фразу: «В процессе обучения сетей Кохонена на входы подаются данные, сеть при этом подстраивается…»
(1) не под закономерности во входных данных, а под эталонное значение выхода
(2) не под эталонное значение выхода, а под закономерности во входных данных
(3) не под закономерности во входных данных, а под коэффициенты весов
Какие из перечисленных средств визуализации помогают интерпретировать полученный результат?
(1) дерево решений
(2) представление графа нейронной сети
(3) дендрограмма
Назовите основные концепции хранилища данных:
(1) предметная ориентация
(2) интегрированность
(3) привязка ко времени
(4) отсутствие привязки ко времени
(5) периодическая изменяемость данных
Метод деревьев решений применяется для решения задач …
(1) классификации
(2) кластеризации
(3) классификации и кластеризации
Характеристики визуализации:
(1) может помочь в представлении результатов Data Mining
(2) иногда может ввести пользователя в заблуждение
(3) всегда дает верное представление о данных
Обучение сетей Кохонена заключается ….
(1) не в минимизации ошибки, а в подстройке весов
(2) не в подстройке весов, а в минимизации ошибки
(3) не в подстройке весов, а в минимизации их коэффициентов
Какие из перечисленных средств визуализации служат средством оценки качества построенной модели?
(1) карты входов самоорганизующихся сетей Кохонена
(2) представление графа нейронной сети
(3) таблица сопряженности
Как называется характеристика хранилища данных описанная ниже: «Данные объединены в категории и сохраняются соответственно областям, которые они описывают, а не применениям, их использующим»
(1) предметная ориентация
(2) интегрированность
(3) привязка ко времени
(4) неизменность данных
Иерархические алгоритмы применяются для решения задач …
(1) классификации
(2) кластеризации
(3) классификации и кластеризации
Оцените правильность утверждения: «Визуализация направлена исключительно на совершенствование техники анализа»
(1) утверждение верно
(2) утверждение неверно. Визуализация не направлена на совершенствование техники анализа
(3) утверждение неверно. Визуализация может самостоятельно выполнять функции анализа
Основные меры расстояния между объектами при использовании иерархического метода КА:
(1) евклидово расстояние
(2) квадрат евклидова расстояния
(3) манхэттенское расстояние
(4) расстояние Чебышева
Data Mining по стандарту CRISP-DM включает следующие фазы:
(1) осмысление бизнеса
(2) осмысление данных
(3) подготовка данных
(4) исследование отношений в данных
Перед началом кластеризации все объекты считаются отдельными кластерами, которые в ходе алгоритма объединяются. Это характеристика…
(1) иерархического
(2) быстрого
(3) всех методов
Стандарт PMML относится к группе:
(1) стандартов по хранению и передаче моделей Data Mining
(2) стандартов, относящиеся к унификации интерфейсов
(3) стандартов, направленных на разработку надстройки над языком SQL
Дендрограмма – результат работы …
(1) дивизимного кластерного анализа
(2) быстрого кластерного анализа
(3) агломеративного кластерного анализа
Стандарт CWM (Common Warehouse Metamodel) относится к группе:
(1) стандартов по хранению и передаче моделей Data Mining
(2) стандартов, относящихся к унификации интерфейсов
(3) стандартов, направленных на разработку надстройки над языком SQL
Термин Data Mining встречается в обиходе все чаще, но иногда его путают с Big Data. РБК Тренды объясняют, как работает добыча данных, почему это целая наука и сколько зарабатывают дата-майнеры
Что такое Data Mining
Data Mining (добыча данных, интеллектуальный анализ данных, глубинный анализ данных или просто майнинг данных) — это процесс, используемый компаниями для превращения необработанных больших данных в полезную информацию. Также для этой технологии используется менее популярный термин «обнаружение знаний в данных» или KDD (knowledge discovery in databases).
Если термином Big Data обозначают все большие данные — как обработанные, так и нет, то Data Mining представляет собой процесс глубокого погружения в эти данные для извлечения ключевых знаний.

Автор термина Data Mining Григорий Пятецкий-Шапиро определял его как процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Используя программное обеспечение для поиска закономерностей в больших пакетах данных, предприятия могут выстраивать маркетинговые стратегии, управлять кредитными рисками, обнаруживать мошенничество, фильтровать спам или даже выявлять настроения пользователей.
Интеллектуальный анализ данных зависит от эффективного сбора, хранения и компьютерной обработки данных. Data Mining считается отдельной дисциплиной в области науки о данных.
Термин «интеллектуальный анализ данных» фигурировал в академических журналах еще в 1970 году, но по-настоящему популярным он стал только в 1990-х после появления интернета. Тогда компаниям потребовалось анализировать большие объемы разнородных данных, чтобы отыскать нетривиальные паттерны и научиться предсказывать поведение клиентов. Обычные модели статистики оказались неспособны справиться с этой задачей.
Первые системы Data Mining предназначались для обработки данных о продажах в супермаркетах по нескольким параметрам, включая их объем по регионам и тип продукта.
Задачи Data Mining
Модели интеллектуального анализа данных применяются для нескольких типов задач:
- прогнозирование: оценка продаж, предсказание нагрузки сервера или его времени простоя;
- риск и вероятность: выбор подходящих заказчиков для целевой рассылки, определение точки баланса для рискованных сценариев, назначение вероятностей по диагнозам или другим результатам;
- рекомендации: определение продуктов, которые будут продаваться вместе, создание рекомендательных сообщений;
- поиск последовательностей: анализ выбора заказчиков во время совершения покупок, прогнозирование их поведения;
- группирование: разделение заказчиков или событий на кластеры, анализ и прогнозирование общих черт этих кластеров.
Где применяют Data Mining
Интеллектуальный анализ данных в основном используется отраслями, обслуживающими потребителей, в том числе в сфере розничной торговли, в финансах и маркетинге. Например, у Сбера существует сервис «Сбор Аналитика», который предоставляет данные по отраслям рынка или территориям на основе анализа денежных потоков населения, продаж товаров и услуг и прочих параметров. Его могут использовать как компании, так и госорганы, чтобы оценить потенциал развития региона.
Торговля
Торговым сетям Data Mining позволяет анализировать покупательские корзины, чтобы улучшать рекламу, создавать запасы товаров на складах и планировать, как их разложить на витринах, открывать новые магазины и выявлять потребности разных категорий клиентов.
Российская сеть «Лента» проанализировала данные карт лояльности более 90% своих покупателей и поделила аудиторию на определенные сегменты по покупательскому поведению. В частности, ретейлер выделил сегмент покупающих только базовые продукты и мужчин, которые чаще приобретали только напитки и снеки. Это позволило оптимизировать ассортимент и управлять выкладкой и ценами. А Amazon в октябре 2021 года анонсировала инструмент, который предоставит продавцам доступ к информации о том, что в настоящее время ищут покупатели, и тем самым поможет упростить выбор продуктов для продажи.
Банки и телеком
Кредитным организациям Data Mining позволяет выявлять мошенничество с кредитными карточками путем анализа подобных транзакций, а также предлагать различные виды услуг разным группам клиентов. Телеком использует анализ данных, чтобы бороться со спамом и разрабатывать новые тарифы для различных групп абонентов.
Российские сотовые операторы применяют Data Mining для внутренних целей, а также предлагают анализ данных как продукт. Так, «Билайн» в 2020 году запустил новый сервис, который позволяет компаниям получить демографические данные своих клиентов путем дата-майнинга по базам, которые собирает «Вымпелком».
Страхование
Страховые компании анализируют большие объемы данных, чтобы выявлять риски и уменьшать свои потери по обязательствам, а также предлагать клиентам релевантные услуги.
Так, австралийской частной страховой компании HCF анализ больших данных позволил за четыре месяца сократить расходы на рекламные рассылки на 25%. Аналитики точно определили тех клиентов, которые с наибольшей вероятностью готовы приобрести более дорогую услугу, и сделали для них отдельную рассылку.
Производство
Предприятиям анализ больших данных позволяет согласовывать планы поставок с прогнозами спроса, а также обнаруживать проблемы производства на ранних стадиях и успешно инвестировать в бренд. Кроме того, производители могут спрогнозировать износ производственных активов и запланировать техническое обслуживание и ремонт, чтобы не останавливать линию выпуска продукции. Пример применения Data Mining в промышленности — прогнозирование качества изделия в зависимости от параметров технологического процесса.
Российская «Инфосистемы Джет» предлагает интеллектуальную систему поддержки принятия решений Jet Galatea. Она анализирует технологические инструкции и данные, поступающие с датчиков на оборудовании, а затем формирует и выдает рекомендации технологам по оптимальному ведению производственного процесса. Jet Galatea применяют в металлургии, деревообработке, агропроме и добыче полезных ископаемых, чтобы уменьшить расход сырья и увеличить объем продукции.
Социология
Анализ настроений на основе данных социальных сетей позволяет понять, как определенная группа людей относится к конкретной теме. C 2016 года российская полиция использует в некоторых регионах страны систему «Зеус». Она позволяет отслеживать поведение пользователя в соцсети и строит график окружения, устанавливая возможную связь между пользователями на базе анализа друзей, родственников, опосредованных друзей, мест проживания, общих групп, лайков и репостов.
Медицина
Системы Data Mining используются и для постановки медицинских диагнозов. Они построены на основе правил, описывающих сочетания симптомов различных заболеваний. Правила помогают выбирать средства лечения. Например, британский стартап Babylon Heath собирает всю информацию о здоровье клиентов, их образе жизни и привычках, а затем алгоритм строит гипотезы и предлагает варианты обследования, лечения и даже рекомендует конкретных врачей и клиники.
Пример общения программы Babylon Heath с клиентом
(Фото: babylonhealth.com)
Рекомендательные системы
Подобные системы предназначены для предложения товаров или услуг, которые с большой вероятностью могут быть интересными людям, а также используются для поддержки клиентов. Они работают благодаря дата-майнингу, который осуществляется в реальном времени. Проще говоря, модель постоянно обновляется. Так работают голосовые помощники Alexa от Amazon, Siri от Apple и «Алиса» от «Яндекса». В качестве примера можно привести также службу поддержки такси DiDi, где алгоритм решает до 60% запросов пользователей, поскольку чаще всего они похожи.
Технология и методы Data Mining
Выделяют несколько этапов добычи данных.
- Постановка задачи. Этот шаг включает анализ бизнес-требований, определение области проблемы, метрик, по которым будет выполняться оценка модели, а также определение задач для проекта анализа.
- Подготовка данных: объединение и очистка. Эта работа включает не только удаление ненужных данных, но и поиск в них скрытых зависимостей, определение источников самых точных данных и создание таблицы для анализа.
- Изучение данных.
- Построение моделей.
- Исследование и проверка моделей. Точность их прогнозов можно проверить при помощи специальных средств.
- Развертывание и обновление моделей. Когда модель заработала, ее нужно обновлять по мере поступления новых данных, а затем выполнять их повторную обработку.
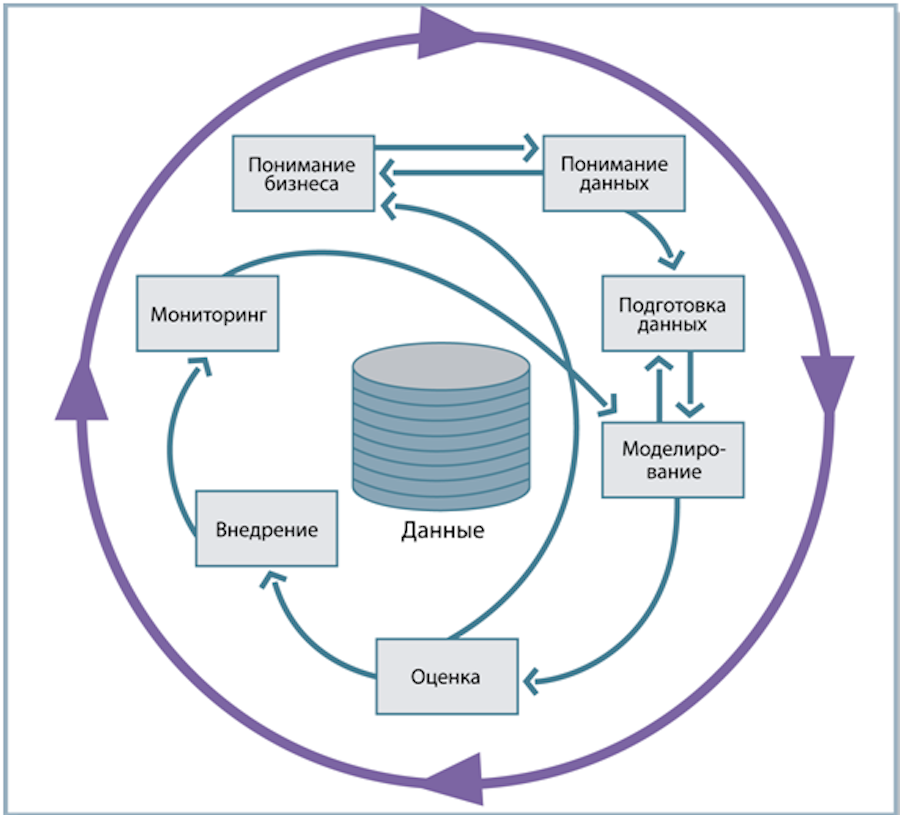
Этапы Data Mining
(Фото: predictivesolutions.ru)
Что должен знать и уметь дата-майнер
Специалист по интеллектуальной обработке данных должен иметь глубокие знания в сфере математической статистики, владеть иностранными языками, а также языками программирования. Он обрабатывает большие объемы информации и занимается поиском связей в ней. Специалист использует методики машинного обучения, создает алгоритмы, работает со статистическим анализом. Затем дата-майнер представляет организации результаты своей работы в понятном формате. Исходя из этих презентаций, компания принимает решения.
Работодатели предпочитают специалистов Data Mining с техническим, математическим или естественнонаучным образованием. Университеты предлагают соответствующие направления обучения: «Математика и компьютерные науки», «Прикладная математика и информатика», «Прикладная информатика» и «Системный анализ и управление». Кроме того, азы Data Mining можно изучить на курсах, например, Coursera.
По данным портала HeadHunter, в октябре 2021 года зарплаты дата-майнеров в России составляли от ₽28 тыс. до ₽250 тыс.
Программы для Data Mining
Существует множество программ, которые могут выполнять задачи Data Mining. Вот некоторые примеры.
- SAS Enterprise Miner — набор методов интеллектуального анализа данных, который применяется для решения таких задач, как обнаружение случаев мошенничества, минимизация финансовых рисков, оценка и прогнозирование потребностей в ресурсах, повышение эффективности маркетинговых кампаний и снижение оттока клиентов. Имеет удобный и понятный интерфейс, позволяющий пользователям самостоятельно создавать модели анализа и прогнозирования. Показывает высокую производительность даже при работе с огромным массивом разрозненных данных.
- Microsoft Analysis Services — предназначен для приложений бизнес-аналитики, анализа данных и создания отчетов. Службы доступны на разных платформах, в том числе на облаке Azure. Предусмотрен механизм для создания собственных алгоритмов и добавления их в качестве новой функции интеллектуального анализа данных.
- SAS Customer Intelligence 360 — это платформа, которая позволяет бизнесу планировать и реализовывать маркетинговые кампании, анализировать их итоги и отслеживать потоки клиентов. Она в реальном времени собирает подробную информацию о действиях клиентов на веб-страницах, в том числе анонимных пользователей, учитывая контекст. Затем платформа дает рекомендации о времени и месте размещения контента на страницах и в мобильных приложениях для конкретного клиента.
Многоканальная доставка контента в SAS Customer Intelligence 360
(Фото: blogs.sas.com)
- SAS Credit Scoring — система оценки кредитных рисков и кредитоспособности клиентов. Особенно полезна для банков, компаний финансового сектора и телекома. SAS Credit Scoring анализирует данные потенциального заемщика и представляет готовые рекомендации по выдаче кредита или предоставлению услуги с учетом возможных рисков.
- Board — сочетает функции бизнес-аналитики и корпоративного управления эффективностью. Позволяет предприятиям разрабатывать и поддерживать сложные аналитические и плановые приложения. Также инструмент удобен для составления отчетов, если есть доступ к нескольким источникам данных.
- SAS Revenue Optimization — это набор решений для оптимизации розничных цен, который позволяет определить оптимальную цену в конкретном месте и в конкретное время для формирования конкурентоспособных продаж, запуска промоакций и массовых распродаж. Применяется в ретейле.
- RapidMiner — это открытая платформа для добычи данных с возможностью глубокого обучения алгоритмов, анализа текстов и машинного обучения. RapidMiner можно использовать как на локальных серверах компании, так и в облаке. Платформа популярна в энергетике и промышленности, машиностроении и других отраслях.
Будущее Data Mining
Рынок систем Data Mining растет. Этому способствует деятельность крупных корпораций: SAS, IBM, Microsoft, Oracle и других. Ожидается, что к 2027 году объем глобального рынка расширенной аналитики вырастет на 23,1% и достигнет отметки в $56,2 млрд.
Последние тенденции в Data Mining включают развитие методов анализа с элементами виртуальной и дополненной реальности, их интеграцию с системами баз данных, добычу биологических данных для инноваций в медицине, веб-майнинг (анализ данных в интернете), анализ данных в реальном времени, а также меры по защите конфиденциальности при добыче данных. Лидеры отрасли считают, что в будущем майнинг данных будет применяться в интеллектуальных приложениях, которые будут встроены в корпоративные хранилища данных.
Главной проблемой обнаружения закономерностей в данных является время, которое требуется для перебора информационных массивов. Известные методы либо искусственно ограничивают такой перебор, либо строят целые деревья решений, которые снижают эффективность поиска. Решение этой проблемы остается главной целью разработчиков продуктов для Data Mining.
Главная /
Data Mining /
Data Mining это … , который должен быть интегрирован в бизнес.
вопрос
Правильный ответ:
не только инструмент, но также процесс
инструмент
процесс
Сложность вопроса
94
Сложность курса: Data Mining
80
Оценить вопрос
Очень сложно
Сложно
Средне
Легко
Очень легко
Спасибо за оценку!
Комментарии:
Аноним
Я завалил экзамен, какого чёрта я не нашёл этот крутой сайт с ответами по интуит до того как забрали в армию
28 ноя 2019
Аноним
Экзамен сдал и ладушки. спс
28 авг 2019
Оставить комментарий
Другие ответы на вопросы из темы базы данных интуит.
-
#
Правило формирования окрестности (несколько нейронов, которые окружают нейрон-победитель):
-
#
К какой группе методов относится метод ближнего соседа?
-
#
К какой группе методов относится метод k-средних?
-
#
Назовите алгоритмы, при помощи которых осуществляется поиск ассоциативных правил:
-
#
Стандарт CWM (Common Warehouse Metamodel) относится к группе:
Data Mining как часть рынка информационных технологий
Классификация аналитических систем
Агентство Gartner Group, занимающееся анализом рынков информационных технологий, в 1980-х годах ввело термин » Business Intelligence » (BI), деловой интеллект или бизнес-интеллект. Этот термин предложен для описания различных концепций и методов, которые улучшают бизнес решения путем использования систем поддержки принятия решений.
В 1996 году агентство уточнило определение данного термина.
Business Intelligence — программные средства, функционирующие в рамках предприятия и обеспечивающие функции доступа и анализа информации, которая находится в хранилище данных, а также обеспечивающие принятие правильных и обоснованных управленческих решений.
Понятие BI объединяет в себе различные средства и технологии анализа и обработки данных масштаба предприятия.
На основе этих средств создаются BI-системы, цель которых — повысить качество информации для принятия управленческих решений.
BI-системы также известны под названием Систем Поддержки Принятия Решений (СППР, DSS, Decision Support System). Эти системы превращают данные в информацию, на основе которой можно принимать решения, т.е. поддерживающую принятие решений.
Gartner Group определяет состав рынка систем Business Intelligence как набор программных продуктов следующих классов:
- средства построения хранилищ данных (data warehousing, ХД);
- системы оперативной аналитической обработки (OLAP);
- информационно-аналитические системы (Enterprise Information Systems, EIS);
- средства интеллектуального анализа данных (data mining);
- инструменты для выполнения запросов и построения отчетов (query and reporting tools).
Классификация Gartner базируется на методе функциональных задач, где программные продукты каждого класса выполняют определенный набор функций или операций с использованием специальных технологий.
Мнение экспертов о Data Mining
Приведем несколько кратких цитат [4] наиболее влиятельных членов бизнес-сообществ, которые являются экспертами в этой относительно новой технологии.
Руководство по приобретению продуктов Data Mining (Enterprise Data Mining Buying Guide) компании Aberdeen Group: » Data Mining — технология добычи полезной информации из баз данных. Однако в связи с существенными различиями между инструментами, опытом и финансовым состоянием поставщиков продуктов, предприятиям необходимо тщательно оценивать предполагаемых разработчиков Data Mining и партнеров.
Чтобы максимально использовать мощность масштабируемых инструментов Data Mining коммерческого уровня, предприятию необходимо выбрать, очистить и преобразовать данные, иногда интегрировать информацию, добытую из внешних источников, и установить специальную среду для работы Data Mining алгоритмов.
Результаты Data Mining в большой мере зависят от уровня подготовки данных, а не от «чудесных возможностей» некоего алгоритма или набора алгоритмов. Около 75% работы над Data Mining состоит в сборе данных, который совершается еще до того, как запускаются сами инструменты. Неграмотно применив некоторые инструменты, предприятие может бессмысленно растратить свой потенциал, а иногда и миллионы долларов».
Мнение Херба Эдельштайна (Herb Edelstein), известного в мире эксперта в области Data Mining, Хранилищ данных и CRM: «Недавнее исследование компании Two Crows показало, что Data Mining находится все еще на ранней стадии развития. Многие организации интересуются этой технологией, но лишь некоторые активно внедряют такие проекты. Удалось выяснить еще один важный момент: процесс реализации Data Mining на практике оказывается более сложным, чем ожидается.
IT-команды увлеклись мифом о том, что средства Data Mining просты в использовании. Предполагается, что достаточно запустить такой инструмент на терабайтной базе данных, и моментально появится полезная информация. На самом деле, успешный Data Mining-проект требует понимания сути деятельности, знания данных и инструментов, а также процесса анализа данных «.
Прежде чем использовать технологию Data Mining, необходимо тщательно проанализировать ее проблемы, ограничения и критические вопросы, с ней связанные, а также понять, чего эта технология не может.
Data Mining не может заменить аналитика
Технология не может дать ответы на те вопросы, которые не были заданы. Она не может заменить аналитика, а всего лишь дает ему мощный инструмент для облегчения и улучшения его работы.
Сложность разработки и эксплуатации приложения Data Mining
Поскольку данная технология является мультидисциплинарной областью, для разработки приложения, включающего Data Mining, необходимо задействовать специалистов из разных областей, а также обеспечить их качественное взаимодействие.
Квалификация пользователя
Различные инструменты Data Mining имеют различную степень «дружелюбности» интерфейса и требуют определенной квалификации пользователя. Поэтому программное обеспечение должно соответствовать уровню подготовки пользователя. Использование Data Mining должно быть неразрывно связано с повышением квалификации пользователя. Однако специалистов по Data Mining, которые бы хорошо разбирались в бизнесе, пока еще мало.
Извлечение полезных сведений невозможно без хорошего понимания сути данных
Необходим тщательный выбор модели и интерпретация зависимостей или шаблонов, которые обнаружены. Поэтому работа с такими средствами требует тесного сотрудничества между экспертом в предметной области и специалистом по инструментам Data Mining. Построенные модели должны быть грамотно интегрированы в бизнес-процессы для возможности оценки и обновления моделей. В последнее время системы Data Mining поставляются как часть технологии хранилищ данных.
Сложность подготовки данных
Успешный анализ требует качественной предобработки данных. По утверждению аналитиков и пользователей баз данных, процесс предобработки может занять до 80% процентов всего Data Mining-процесса.
Таким образом, чтобы технология работала на себя, потребуется много усилий и времени, которые уходят на предварительный анализ данных, выбор модели и ее корректировку.
Большой процент ложных, недостоверных или бессмысленных результатов
С помощью Data Mining можно отыскивать действительно очень ценную информацию, которая вскоре даст большие дивиденды в виде финансовой и конкурентной выгоды.
Однако Data Mining достаточно часто делает множество ложных и не имеющих смысла открытий. Многие специалисты утверждают, что Data Mining -средства могут выдавать огромное количество статистически недостоверных результатов. Чтобы этого избежать, необходима проверка адекватности полученных моделей на тестовых данных.
Высокая стоимость
Качественная Data Mining-программа может стоить достаточно дорого для компании. Вариантом служит приобретение уже готового решения с предварительной проверкой его использования, например на демо-версии с небольшой выборкой данных.
Наличие достаточного количества репрезентативных данных
Средства Data Mining, в отличие от статистических, теоретически не требуют наличия строго определенного количества ретроспективных данных. Эта особенность может стать причиной обнаружения недостоверных, ложных моделей и, как результат, принятия на их основе неверных решений. Необходимо осуществлять контроль статистической значимости обнаруженных знаний.
!!! Полезный материал! Сборник статей по пяти ключевым темам системного менеджмента. Скачать >
Data Mining переводится как “добыча” или “раскопка данных”. Нередко рядом с Data Mining встречаются слова “обнаружение знаний в базах данных” (knowledge discovery in databases) и “интеллектуальный анализ данных”. Их можно считать синонимами Data Mining. Возникновение всех указанных терминов связано с новым витком в развитии средств и методов обработки данных.
До начала 90-х годов, казалось, не было особой нужды переосмысливать ситуацию в этой области. Все шло своим чередом в рамках направления, называемого прикладной статистикой (см. например, [1]). Теоретики проводили конференции и семинары, писали внушительные статьи и монографии, изобиловавшие аналитическими выкладками.
Вместе с тем, практики всегда знали, что попытки применить теоретические экзерсисы для решения реальных задач в большинстве случаев оказываются бесплодными. Но на озабоченность практиков до поры до времени можно было не обращать особого внимания – они решали главным образом свои частные проблемы обработки небольших локальных баз данных.
И вот прозвенел звонок. В связи с совершенствованием технологий записи и хранения данных на людей обрушились колоссальные потоки информационной руды в самых различных областях. Деятельность любого предприятия (коммерческого, производственного, медицинского, научного и т.д.) теперь сопровождается регистрацией и записью всех подробностей его деятельности. Что делать с этой информацией” Стало ясно, что без продуктивной переработки потоки сырых данных образуют никому не нужную свалку.
Специфика современных требований к такой переработке следующие:
- Данные имеют неограниченный объем
- Данные являются разнородными (количественными, качественными, текстовыми)
- Результаты должны быть конкретны и понятны
- Инструменты для обработки сырых данных должны быть просты в использовании
Традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, откровенно спасовала перед лицом возникших проблем. Главная причина – концепция усреднения по выборке, приводящая к операциям над фиктивными величинами (типа средней температуры пациентов по больнице, средней высоты дома на улице, состоящей из дворцов и лачуг и т.п.). Методы математической статистики оказались полезными главным образом для проверки заранее сформулированных гипотез (verification-driven data mining) и для “грубого” разведочного анализа, составляющего основу оперативной аналитической обработки данных (online analytical processing, OLAP).
В основу современной технологии Data Mining (discovery-driven data mining) положена концепция шаблонов (паттернов), отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные подвыборкам данных, которые могут быть компактно выражены в понятной человеку форме. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборке и виде распределений значений анализируемых показателей. Примеры заданий на такой поиск при использовании Data Mining приведены в табл. 1.
Таблица 1. Примеры формулировок задач при использовании методов OLAP и Data Mining [2]
| OLAP | Data Mining |
| Каковы средние показатели травматизма для курящих и некурящих? | Какие факторы лучше всего предсказывают несчастные случаи? |
| Каковы средние размеры телефонных счетов существующих клиентов в сравнении со счетами бывших клиентов (отказавшихся от услуг телефонной компании)? | Какие характеристики отличают клиентов, которые, по всей вероятности, собираются отказаться от услуг телефонной компании? |
| Какова средняя величина ежедневных покупок по украденной и не украденной кредитной карточке? | Какие схемы покупок характерны для мошенничества с кредитными карточками? |
Важное положение Data Mining – нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные (unexpected) регулярности в данных, составляющие так называемые скрытые знания (hidden knowledge). К обществу пришло понимание, что сырые данные (raw data) содержат глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие самородки (рис.1).
Рисунок 1. Уровни знаний, извлекаемых из данных
В целом технологию Data Mining достаточно точно определяет Григорий Пиатецкий-Шапиро – один из основателей этого направления:
Data Mining – это процесс обнаружения в сырых данных
- ранее неизвестных
- нетривиальных
- практически полезных
- и доступных интерпретации знаний,
- необходимых для принятия решений в различных сферах
- человеческой деятельности.
G. Piatetsky-Shapiro, Knowledge Stream Partners
2. Кому это нужно”
Сфера применения Data Mining ничем не ограничена – она везде, где имеются какие-либо данные. Но в первую очередь методы Data Mining сегодня, мягко говоря, заинтриговали коммерческие предприятия, развертывающие проекты на основе информационных хранилищ данных (Data Warehousing). Опыт многих таких предприятий показывает, что отдача от использования Data Mining может достигать 1000%. Например, известны сообщения об экономическом эффекте, в 10-70 раз превысившем первоначальные затраты от 350 до 750 тыс. дол. [3]. Известны сведения о проекте в 20 млн. дол., который окупился всего за 4 месяца. Другой пример – годовая экономия 700 тыс. дол. за счет внедрения Data Mining в сети универсамов в Великобритании.
Data Mining представляют большую ценность для руководителей и аналитиков в их повседневной деятельности. Деловые люди осознали, что с помощью методов Data Mining они могут получить ощутимые преимущества в конкурентной борьбе. Кратко охарактеризуем некоторые возможные бизнес-приложения Data Mining [2].
2.1. Некоторые бизнес-приложения Data Mining
Розничная торговля
Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной покупке, используя кредитные карточки с маркой магазина и компьютеризованные системы контроля. Вот типичные задачи, которые можно решать с помощью Data Mining в сфере розничной торговли:
- анализ покупательской корзины (анализ сходства) предназначен для выявления товаров, которые покупатели стремятся приобретать вместе. Знание покупательской корзины необходимо для улучшения рекламы, выработки стратегии создания запасов товаров и способов их раскладки в торговых залах.
- исследование временных шаблонов помогает торговым предприятиям принимать решения о создании товарных запасов. Оно дает ответы на вопросы типа “Если сегодня покупатель приобрел видеокамеру, то через какое время он вероятнее всего купит новые батарейки и пленку””
- создание прогнозирующих моделей дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением, например, покупающих товары известных дизайнеров или посещающих распродажи. Эти знания нужны для разработки точно направленных, экономичных мероприятий по продвижению товаров.
!!! Полезный материал! Сборник статей по пяти ключевым темам системного менеджмента. Скачать >
Банковское дело
Достижения технологии Data Mining используются в банковском деле для решения следующих распространенных задач:
- выявление мошенничества с кредитными карточками. Путем анализа прошлых транзакций, которые впоследствии оказались мошенническими, банк выявляет некоторые стереотипы такого мошенничества.
- сегментация клиентов. Разбивая клиентов на различные категории, банки делают свою маркетинговую политику более целенаправленной и результативной, предлагая различные виды услуг разным группам клиентов.
- прогнозирование изменений клиентуры. Data Mining помогает банкам строить прогнозные модели ценности своих клиентов, и соответствующим образом обслуживать каждую категорию.
Телекоммуникации
В области телекоммуникаций методы Data Mining помогают компаниям более энергично продвигать свои программы маркетинга и ценообразования, чтобы удерживать существующих клиентов и привлекать новых. Среди типичных мероприятий отметим следующие:
- анализ записей о подробных характеристиках вызовов.Назначение такого анализа – выявление категорий клиентов с похожими стереотипами пользования их услугами и разработка привлекательных наборов цен и услуг;
- выявление лояльности клиентов. Data Mining можно использовать для определения характеристик клиентов, которые, один раз воспользовавшись услугами данной компании, с большой долей вероятности останутся ей верными. В итоге средства, выделяемые на маркетинг, можно тратить там, где отдача больше всего.
Страхование
Страховые компании в течение ряда лет накапливают большие объемы данных. Здесь обширное поле деятельности для методов Data Mining:
- выявление мошенничества. Страховые компании могут снизить уровень мошенничества, отыскивая определенные стереотипы в заявлениях о выплате страхового возмещения, характеризующих взаимоотношения между юристами, врачами и заявителями.
- анализ риска. Путем выявления сочетаний факторов, связанных с оплаченными заявлениями, страховщики могут уменьшить свои потери по обязательствам. Известен случай, когда в США крупная страховая компания обнаружила, что суммы, выплаченные по заявлениям людей, состоящих в браке, вдвое превышает суммы по заявлениям одиноких людей. Компания отреагировала на это новое знание пересмотром своей общей политики предоставления скидок семейным клиентам.
Другие приложения в бизнесе
Data Mining может применяться во множестве других областей:
- развитие автомобильной промышленности. При сборке автомобилей производители должны учитывать требования каждого отдельного клиента, поэтому им нужны возможность прогнозирования популярности определенных характеристик и знание того, какие характеристики обычно заказываются вместе;
- политика гарантий. Производителям нужно предсказывать число клиентов, которые подадут гарантийные заявки, и среднюю стоимость заявок;
- поощрение часто летающих клиентов. Авиакомпании могут обнаружить группу клиентов, которых данными поощрительными мерами можно побудить летать больше. Например, одна авиакомпания обнаружила категорию клиентов, которые совершали много полетов на короткие расстояния, не накапливая достаточно миль для вступления в их клубы, поэтому она таким образом изменила правила приема в клуб, чтобы поощрять число полетов так же, как и мили.
2.2. Специальные приложения
Медицина
Известно много экспертных систем для постановки медицинских диагнозов. Они построены главным образом на основе правил, описывающих сочетания различных симптомов различных заболеваний. С помощью таких правил узнают не только, чем болен пациент, но и как нужно его лечить. Правила помогают выбирать средства медикаментозного воздействия, определять показания – противопоказания, ориентироваться в лечебных процедурах, создавать условия наиболее эффективного лечения, предсказывать исходы назначенного курса лечения и т. п. Технологии Data Mining позволяют обнаруживать в медицинских данных шаблоны, составляющие основу указанных правил.
Молекулярная генетика и генная инженерия
Пожалуй, наиболее остро и вместе с тем четко задача обнаружения закономерностей в экспериментальных данных стоит в молекулярной генетике и генной инженерии. Здесь она формулируется как определение так называемых маркеров, под которыми понимают генетические коды, контролирующие те или иные фенотипические признаки живого организма. Такие коды могут содержать сотни, тысячи и более связанных элементов.
На развитие генетических исследований выделяются большие средства. В последнее время в данной области возник особый интерес к применению методов Data Mining. Известно несколько крупных фирм, специализирующихся на применении этих методов для расшифровки генома человека и растений.
Прикладная химия
Методы Data Mining находят широкое применение в прикладной химии (органической и неорганической). Здесь нередко возникает вопрос о выяснении особенностей химического строения тех или иных соединений, определяющих их свойства. Особенно актуальна такая задача при анализе сложных химических соединений, описание которых включает сотни и тысячи структурных элементов и их связей.
Можно привести еще много примеров различных областей знания, где методы Data Mining играют ведущую роль. Особенность этих областей заключается в их сложной системной организации. Они относятся главным образом к надкибернетическому уровню организации систем [4], закономерности которого не могут быть достаточно точно описаны на языке статистических или иных аналитических математических моделей [5]. Данные в указанных областях неоднородны, гетерогенны, нестационарны и часто отличаются высокой размерностью.
3. Типы закономерностей
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование (рис. 2).

Рисунок 2. Типы закономерностей, выявляемых методами Data Mining
Ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в супермаркете, может показать, что 65% купивших кукурузные чипсы берут также и “кока-колу”, а при наличии скидки за такой комплект “колу” приобретают в 85% случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Если существует цепочка связанных во времени событий, то говорят о последовательности. Так, например, после покупки дома в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником.
С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
!!! Полезный материал! Сборник статей по пяти ключевым темам системного менеджмента. Скачать >
Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.
Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить найти шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.
4. Классы систем Data Mining
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории баз данных и др. (рис. 3). Отсюда обилие методов и алгоритмов, реализованных в различных действующих системах Data Mining. Многие из таких систем интегрируют в себе сразу несколько подходов. Тем не менее, как правило, в каждой системе имеется какая-то ключевая компонента, на которую делается главная ставка. Ниже приводится классификация указанных ключевых компонент на основе работы [6]. Выделенным классам дается краткая характеристика.
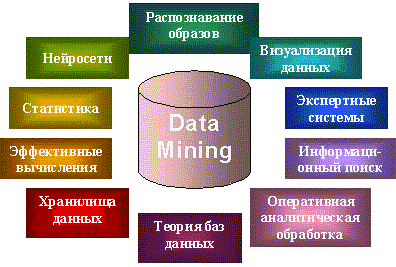
Рисунок 3. Data Mining – мультидисциплинарная область

Рисунок 4. Популярные продукты для Data Mining
4.1. Предметно-ориентированные аналитические системы
Предметно-ориентированные аналитические системы очень разнообразны. Наиболее широкий подкласс таких систем, получивший распространение в области исследования финансовых рынков, носит название “технический анализ”. Он представляет собой совокупность нескольких десятков методов прогноза динамики цен и выбора оптимальной структуры инвестиционного портфеля, основанных на различных эмпирических моделях динамики рынка. Эти методы часто используют несложный статистический аппарат, но максимально учитывают сложившуюся своей области специфику (профессиональный язык, системы различных индексов и пр.). На рынке имеется множество программ этого класса. Как правило, они довольно дешевы (обычно $300-1000).
4.2. Статистические пакеты
Последние версии почти всех известных статистических пакетов включают наряду с традиционными статистическими методами также элементы Data Mining. Но основное внимание в них уделяется все же классическим методикам – корреляционному, регрессионному, факторному анализу и другим. Самый свежий детальный обзор пакетов для статистического анализа приведен на страницах ЦЭМИ. Недостатком систем этого класса считают требование к специальной подготовке пользователя. Также отмечают, что мощные современные статистические пакеты являются слишком “тяжеловесными” для массового применения в финансах и бизнесе. К тому же часто эти системы весьма дороги – от $1000 до $15000.
Есть еще более серьезный принципиальный недостаток статистических пакетов, ограничивающий их применение в Data Mining. Большинство методов, входящих в состав пакетов опираются на статистическую парадигму, в которой главными фигурантами служат усредненные характеристики выборки. А эти характеристики, как указывалось выше, при исследовании реальных сложных жизненных феноменов часто являются фиктивными величинами.
В качестве примеров наиболее мощных и распространенных статистических пакетов можно назвать SAS (компания SAS Institute), SPSS (SPSS), STATGRAPICS (Manugistics), STATISTICA, STADIA и другие.
4.3. Нейронные сети
Это большой класс систем, архитектура которых имеет аналогию (как теперь известно, довольно слабую) с построением нервной ткани из нейронов. В одной из наиболее распространенных архитектур, многослойном перцептроне с обратным распространением ошибки, имитируется работа нейронов в составе иерархической сети, где каждый нейрон более высокого уровня соединен своими входами с выходами нейронов нижележащего слоя. На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых нужно принимать какие-то решения, прогнозировать развитие ситуации и т. д. Эти значения рассматриваются как сигналы, передающиеся в следующий слой, ослабляясь или усиливаясь в зависимости от числовых значений (весов), приписываемых межнейронным связям. В результате на выходе нейрона самого верхнего слоя вырабатывается некоторое значение, которое рассматривается как ответ – реакция всей сети на введенные значения входных параметров. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо “натренировать” на полученных ранее данных, для которых известны и значения входных параметров, и правильные ответы на них. Тренировка состоит в подборе весов межнейронных связей, обеспечивающих наибольшую близость ответов сети к известным правильным ответам.
Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей выборки. Другой существенный недостаток заключается в том, что даже натренированная нейронная сеть представляет собой черный ящик. Знания, зафиксированные как веса нескольких сотен межнейронных связей, совершенно не поддаются анализу и интерпретации человеком (известные попытки дать интерпретацию структуре настроенной нейросети выглядят неубедительными – система “KINOsuite-PR”).
Примеры нейросетевых систем – BrainMaker (CSS), NeuroShell (Ward Systems Group), OWL (HyperLogic). Стоимость их довольно значительна: $1500-8000.

Рисунок 5. Полиномиальная нейросеть
!!! Полезный материал! Сборник статей по пяти ключевым темам системного менеджмента. Скачать >
4.4. Системы рассуждений на основе аналогичных случаев
Идея систем case based reasoning – CBR – на первый взгляд крайне проста. Для того чтобы сделать прогноз на будущее или выбрать правильное решение, эти системы находят в прошлом близкие аналоги наличной ситуации и выбирают тот же ответ, который был для них правильным. Поэтому этот метод еще называют методом “ближайшего соседа” (nearest neighbour). В последнее время распространение получил также термин memory based reasoning, который акцентирует внимание, что решение принимается на основании всей информации, накопленной в памяти.
Системы CBR показывают неплохие результаты в самых разнообразных задачах. Главным их минусом считают то, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт, – в выборе решения они основываются на всем массиве доступных исторических данных, поэтому невозможно сказать, на основе каких конкретно факторов CBR системы строят свои ответы.
Другой минус заключается в произволе, который допускают системы CBR при выборе меры “близости”. От этой меры самым решительным образом зависит объем множества прецедентов, которые нужно хранить в памяти для достижения удовлетворительной классификации или прогноза [7].
Примеры систем, использующих CBR, – KATE tools (Acknosoft, Франция), Pattern Recognition Workbench (Unica, США).
4.5. Деревья решений (decision trees)
Деревья решения являются одним из наиболее популярных подходов к решению задач Data Mining. Они создают иерархическую структуру классифицирующих правил типа “ЕСЛИ… ТО…” (if-then), имеющую вид дерева. Для принятия решения, к какому классу отнести некоторый объект или ситуацию, требуется ответить на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы имеют вид “значение параметра A больше x””. Если ответ положительный, осуществляется переход к правому узлу следующего уровня, если отрицательный – то к левому узлу; затем снова следует вопрос, связанный с соответствующим узлом.
Популярность подхода связана как бы с наглядностью и понятностью. Но деревья решений принципиально не способны находить “лучшие” (наиболее полные и точные) правила в данных. Они реализуют наивный принцип последовательного просмотра признаков и “цепляют” фактически осколки настоящих закономерностей, создавая лишь иллюзию логического вывода.
Вместе с тем, большинство систем используют именно этот метод. Самыми известными являются See5/С5.0 (RuleQuest, Австралия), Clementine (Integral Solutions, Великобритания), SIPINA (University of Lyon, Франция), IDIS (Information Discovery, США), KnowledgeSeeker (ANGOSS, Канада). Стоимость этих систем варьируется от 1 до 10 тыс. долл.
Рисунок 6. Система KnowledgeSeeker обрабатывает банковскую информацию
4.6. Эволюционное программирование
Проиллюстрируем современное состояние данного подхода на примере системы PolyAnalyst – отечественной разработке, получившей сегодня общее признание на рынке Data Mining. В данной системе гипотезы о виде зависимости целевой переменной от других переменных формулируются в виде программ на некотором внутреннем языке программирования. Процесс построения программ строится как эволюция в мире программ (этим подход немного похож на генетические алгоритмы). Когда система находит программу, более или менее удовлетворительно выражающую искомую зависимость, она начинает вносить в нее небольшие модификации и отбирает среди построенных дочерних программ те, которые повышают точность. Таким образом система “выращивает” несколько генетических линий программ, которые конкурируют между собой в точности выражения искомой зависимости. Специальный модуль системы PolyAnalyst переводит найденные зависимости с внутреннего языка системы на понятный пользователю язык (математические формулы, таблицы и пр.).
Другое направление эволюционного программирования связано с поиском зависимости целевых переменных от остальных в форме функций какого-то определенного вида. Например, в одном из наиболее удачных алгоритмов этого типа – методе группового учета аргументов (МГУА) зависимость ищут в форме полиномов. В настоящее время из продающихся в России систем МГУА реализован в системе NeuroShell компании Ward Systems Group.
Стоимость систем до $ 5000.
4.7. Генетические алгоритмы
Data Mining не основная область применения генетических алгоритмов. Их нужно рассматривать скорее как мощное средство решения разнообразных комбинаторных задач и задач оптимизации. Тем не менее генетические алгоритмы вошли сейчас в стандартный инструментарий методов Data Mining, поэтому они и включены в данный обзор.
Первый шаг при построении генетических алгоритмов – это кодировка исходных логических закономерностей в базе данных, которые именуют хромосомами, а весь набор таких закономерностей называют популяцией хромосом. Далее для реализации концепции отбора вводится способ сопоставления различных хромосом. Популяция обрабатывается с помощью процедур репродукции, изменчивости (мутаций), генетической композиции. Эти процедуры имитируют биологические процессы. Наиболее важные среди них: случайные мутации данных в индивидуальных хромосомах, переходы (кроссинговер) и рекомбинация генетического материала, содержащегося в индивидуальных родительских хромосомах (аналогично гетеросексуальной репродукции), и миграции генов. В ходе работы процедур на каждой стадии эволюции получаются популяции со все более совершенными индивидуумами.
Генетические алгоритмы удобны тем, что их легко распараллеливать. Например, можно разбить поколение на несколько групп и работать с каждой из них независимо, обмениваясь время от времени несколькими хромосомами. Существуют также и другие методы распараллеливания генетических алгоритмов.
Генетические алгоритмы имеют ряд недостатков. Критерий отбора хромосом и используемые процедуры являются эвристическими и далеко не гарантируют нахождения “лучшего” решения. Как и в реальной жизни, эволюцию может “заклинить” на какой-либо непродуктивной ветви. И, наоборот, можно привести примеры, как два неперспективных родителя, которые будут исключены из эволюции генетическим алгоритмом, оказываются способными произвести высокоэффективного потомка. Это особенно становится заметно при решении высокоразмерных задач со сложными внутренними связями.
Примером может служить система GeneHunter фирмы Ward Systems Group. Его стоимость – около $1000.
4.8. Алгоритмы ограниченного перебора
Алгоритмы ограниченного перебора были предложены в середине 60-х годов М.М. Бонгардом для поиска логических закономерностей в данных. С тех пор они продемонстрировали свою эффективность при решении множества задач из самых различных областей.
Эти алгоритмы вычисляют частоты комбинаций простых логических событий в подгруппах данных. Примеры простых логических событий: X = a; X < a; X a; a < X < b и др., где X – какой либо параметр, “a” и “b” – константы. Ограничением служит длина комбинации простых логических событий (у М. Бонгарда она была равна 3). На основании анализа вычисленных частот делается заключение о полезности той или иной комбинации для установления ассоциации в данных, для классификации, прогнозирования и пр.
Наиболее ярким современным представителем этого подхода является система WizWhy предприятия WizSoft. Хотя автор системы Абрахам Мейдан не раскрывает специфику алгоритма, положенного в основу работы WizWhy, по результатам тщательного тестирования системы были сделаны выводы о наличии здесь ограниченного перебора (изучались результаты, зависимости времени их получения от числа анализируемых параметров и др.).
!!! Полезный материал! Сборник статей по пяти ключевым темам системного менеджмента. Скачать >
Автор WizWhy утверждает, что его система обнаруживает ВСЕ логические if-then правила в данных. На самом деле это, конечно, не так. Во-первых, максимальная длина комбинации в if-then правиле в системе WizWhy равна 6, и, во-вторых, с самого начала работы алгоритма производится эвристический поиск простых логических событий, на которых потом строится весь дальнейший анализ. Поняв эти особенности WizWhy, нетрудно было предложить простейшую тестовую задачу, которую система не смогла вообще решить. Другой момент – система выдает решение за приемлемое время только для сравнительно небольшой размерности данных.
Тем не менее, система WizWhy является на сегодняшний день одним из лидеров на рынке продуктов Data Mining. Это не лишено оснований. Система постоянно демонстрирует более высокие показатели при решении практических задач, чем все остальные алгоритмы. Стоимость системы около $ 4000, количество продаж – 30000.
Рисунок 7. Система WizWhy обнаружила правила, объясняющие низкую урожайность некоторых сельскохозяйственных участков
4.9. Системы для визуализации многомерных данных
В той или иной мере средства для графического отображения данных поддерживаются всеми системами Data Mining. Вместе с тем, весьма внушительную долю рынка занимают системы, специализирующиеся исключительно на этой функции. Примером здесь может служить программа DataMiner 3D словацкой фирмы Dimension5 (5-е измерение).
В подобных системах основное внимание сконцентрировано на дружелюбности пользовательского интерфейса, позволяющего ассоциировать с анализируемыми показателями различные параметры диаграммы рассеивания объектов (записей) базы данных. К таким параметрам относятся цвет, форма, ориентация относительно собственной оси, размеры и другие свойства графических элементов изображения. Кроме того, системы визуализации данных снабжены удобными средствами для масштабирования и вращения изображений. Стоимость систем визуализации может достигать нескольких сотен долларов.
Рисунок 8. Визуализация данных системой DataMiner 3D
5. Резюме
- Рынок систем Data Mining экспоненциально развивается. В этом развитии принимают участие практически все крупнейшие корпорации. В частности, Microsoft непосредственно руководит большим сектором данного рынка (издает специальный журнал, проводит конференции, разрабатывает собственные продукты).
- Системы Data Mining применяются по двум основным направлениям: 1) как массовый продукт для бизнес-приложений; 2) как инструменты для проведения уникальных исследований (генетика, химия, медицина и пр.). В настоящее время стоимость массового продукта от $1000 до $10000. Количество инсталляций массовых продуктов, судя по имеющимся сведениям, сегодня достигает десятков тысяч. Лидеры Data Mining связывают будущее этих систем с использованием их в качестве интеллектуальных приложений, встроенных в корпоративные хранилища данных.
- Несмотря на обилие методов Data Mining, приоритет постепенно все более смещается в сторону логических алгоритмов поиска в данных if-then правил. С их помощью решаются задачи прогнозирования, классификации, распознавания образов, сегментации БД, извлечения из данных “скрытых” знаний, интерпретации данных, установления ассоциаций в БД и др. Результаты таких алгоритмов эффективны и легко интерпретируются.
- Вместе с тем, главной проблемой логических методов обнаружения закономерностей является проблема перебора вариантов за приемлемое время. Известные методы либо искусственно ограничивают такой перебор (алгоритмы КОРА, WizWhy), либо строят деревья решений (алгоритмы CART, CHAID, ID3, See5, Sipina и др.), имеющих принципиальные ограничения эффективности поиска if-then правил. Другие проблемы связаны с тем, что известные методы поиска логических правил не поддерживают функцию обобщения найденных правил и функцию поиска оптимальной композиции таких правил. Удачное решение указанных проблем может составить предмет новых конкурентоспособных разработок.
!!! Полезный материал! Сборник статей по пяти ключевым темам системного менеджмента. Скачать >
Литература
- Айвазян С. А., Бухштабер В. М., Юнюков И. С., Мешалкин Л. Д. Прикладная статистика: Классификация и снижение размерности. – М.: Финансы и статистика, 1989.
- Knowledge Discovery Through Data Mining: What Is Knowledge Discovery” – Tandem Computers Inc., 1996.
- Кречетов Н.. Продукты для интеллектуального анализа данных. – Рынок программных средств, N14-15_97, c. 32-39.
- Boulding K. E. General Systems Theory – The Skeleton of Science//Management Science, 2, 1956.
- Гик Дж., ван. Прикладная общая теория систем. – М.: Мир, 1981.
- Киселев М., Соломатин Е.. Средства добычи знаний в бизнесе и финансах. – Открытые системы, ” 4, 1997, с. 41-44.
- Дюк В.А. Обработка данных на ПК в примерах. – СПб: Питер, 1997.
Автор: В.Дюк