Аннотация: Лекция посвящена вопросам распределенной обработки данных. Рассматриваются модели типа «клиент-сервер»
При размещении БД на персональном компьютере, который не находится в сети, БД всегда используется в монопольном режиме. Даже если БД используют несколько пользователей, они могут работать с ней только последовательно, и поэтому вопросов о поддержании корректной модификации БД в этом случае здесь не стоит, они решаются организационными мерами — то есть определением требуемой последовательности работы конкретных пользователей с соответствующей БД. Однако даже в некоторых настольных БД требуется учитывать последовательность изменения данных при обработке, чтобы получить корректный результат: так, например, при запуске программы балансного бухгалтерского отчета все бухгалтерские проводки — финансовые операции должны быть решены заранее до запуска конечного приложения.
Однако работа на изолированном компьютере с небольшой базой данных в настоящий момент становится уже нехарактерной для большинства приложений. БД отражает информационную модель реальной предметной области, она растет по объему и резко увеличивается количество задач, решаемых с ее использованием, и в соответствии с этим увеличивается количество приложений, работающих с единой базой данных. Компьютеры объединяются в локальные сети, и необходимость распределения приложений, работающих с единой базой данных по сети, является несомненной.
Действительно, даже когда вы строите БД для небольшой торговой фирмы, у вас появляется ряд специфических пользователей БД, которые имеют свои бизнес-функции и территориально могут находиться в разных помещениях, но все они должны работать с единой информационной моделью организации, то есть с единой базой данных.
Параллельный доступ к одной БД нескольких пользователей, в том случае если БД расположена на одной машине, соответствует режиму распределенного доступа к централизованной БД. (Такие системы называются системами распределенной обработки данных.)
Если же БД распределена по нескольким компьютерам, расположенным в сети, и к ней возможен параллельный доступ нескольких пользователей, то мы имеем дело с параллельным доступом к распределенной БД. Подобные системы называются системами распределенных баз данных. В общем случае режимы использования БД можно представить в следующем виде (см. рис. 10.1).
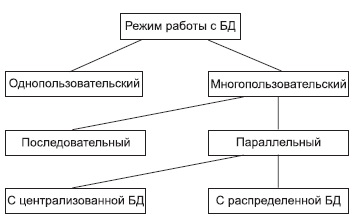
Рис.
10.1.
Режимы работы с базой данных
Определим терминологию, которая нам потребуется для дальнейшей работы. Часть терминов нам уже известна, но повторим здесь их дополнительно.
Терминология
Пользователь БД — программа или человек, обращающийся к БД на ЯМД.
Запрос — процесс обращения пользователя к БД с целью ввода, получения или изменения информации в БД.
Транзакция — последовательность операций модификации данных в БД, переводящая БД из одного непротиворечивого состояния в другое непротиворечивое состояние.
Логическая структура БД — определение БД на физически независимом уровне, ближе всего соответствует концептуальной модели БД.
Топология БД = Структура распределенной БД — схема распределения физической БД по сети.
Локальная автономность — означает, что информация локальной БД и связанные с ней определения данных принадлежат локальному владельцу и им управляются.
Удаленный запрос — запрос, который выполняется с использованием модемной связи.
Возможность реализации удаленной транзакции обработка одной транзакции, состоящей из множества SQL-запросов на одном удаленном узле.
Поддержка распределенной транзакции допускает обработку транзакции, состоящей из нескольких запросов SQL, которые выполняются на нескольких узлах сети (удаленных или локальных), но каждый запрос в этом случае обрабатывается только на одном узле, то есть запросы не являются распределенными. При обработке одной распределенной транзакции разные локальные запросы могут обрабатываться в разных узлах сети.
Распределенный запрос — запрос, при обработке которого используются данные из БД, расположенные в разных узлах сети.
Системы распределенной обработки данных в основном связаны с первым поколением БД, которые строились на мультипрограммных операционных системах и использовали централизованное хранение БД на устройствах внешней памяти центральной ЭВМ и терминальный многопользовательский режим доступа к ней. При этом пользовательские терминалы не имели собственных ресурсов — то есть процессоров и памяти, которые могли бы использоваться для хранения и обработки данных. Первой полностью реляционной системой, работающей в многопользовательском режиме, была СУБД SYSTEM R, разработанная фирмой IBM, именно в ней были реализованы как язык манипулирования данными SQL, так и основные принципы синхронизации, применяемые при распределенной обработке данных, которые до сих пор являются базисными практически во всех коммерческих СУБД.
Общая тенденция движения от отдельных mainframe-систем к открытым распределенным системам, объединяющим компьютеры среднего класса, получила название DownSizing. Этот процесс оказал огромное влияние на развитие архитектур СУБД и поставил перед их разработчиками ряд сложных задач. Главная проблема состояла в технологической сложности перехода от централизованного управления данными на одном компьютере и СУБД, использовавшей собственные модели, форматы представления данных и языки доступа к данным и т. д., к распределенной обработке данных в неоднородной вычислительной среде, состоящей из соединенных в глобальную сеть компьютеров различных моделей и производителей.
В то же время происходил встречный процесс — UpSizing. Бурное развитие персональных компьютеров, появление локальных сетей также оказали серьезное влияние на эволюцию СУБД. Высокие темпы роста производительности и функциональных возможностей PC привлекли внимание разработчиков профессиональных СУБД, что привело к их активному распространению на платформе настольных систем.
Сегодня возобладала тенденция создания информационных систем на такой платформе, которая точно соответствовала бы ее масштабам и задачам. Она получила название RightSizing (помещение ровно в тот размер, который необходим).
Однако и в настоящее время большие ЭВМ сохраняются и сосуществуют с современными открытыми системами. Причина этого проста — в свое время в аппаратное и программное обеспечение больших ЭВМ были вложены огромные средства: в результате многие продолжают их использовать, несмотря на морально устаревшую архитектуру. В то же время перенос данных и программ с больших ЭВМ на компьютеры нового поколения сам по себе представляет сложную техническую проблему и требует значительных затрат.
Модели «клиент-сервер» в технологии баз данных
Вычислительная модель «клиент—сервер» исходно связана с парадигмой открытых систем, которая появилась в 90-х годах и быстро эволюционировала. Сам термин «клиент-сервер» исходно применялся к архитектуре программного обеспечения, которое описывало распределение процесса выполнения по принципу взаимодействия двух программных процессов, один из которых в этой модели назывался «клиентом», а другой — «сервером». Клиентский процесс запрашивал некоторые услуги, а серверный процесс обеспечивал их выполнение. При этом предполагалось, что один серверный процесс может обслужить множество клиентских процессов.
Ранее приложение (пользовательская программа) не разделялась на части, оно выполнялось некоторым монолитным блоком. Но возникла идея более рационального использования ресурсов сети. Действительно, при монолитном исполнении используются ресурсы только одного компьютера, а остальные компьютеры в сети рассматриваются как терминалы. Но теперь, в отличие от эпохи main-фреймов, все компьютеры в сети обладают собственными ресурсами, и разумно так распределить нагрузку на них, чтобы максимальным образом использовать их ресурсы.
И как в промышленности, здесь возникает древняя как мир идея распределения обязанностей, разделения труда. Конвейеры Форда сделали в свое время прорыв в автомобильной промышленности, показав наивысшую производительность труда именно из-за того, что весь процесс сборки был разбит на мелкие и максимально простые операции и каждый рабочий специализировался на выполнении только одной операции, но эту операцию он выполнял максимально быстро и качественно.
Конечно, в вычислительной технике нельзя было напрямую использовать технологию автомобильного или любого другого механического производства, но идею использовать было можно. Однако для воплощения идеи необходимо было разработать модель разбиения единого монолитного приложения на отдельные части и определить принципы взаимосвязи между этими частями.
Основной принцип технологии «клиент—сервер» применительно к технологии баз данных заключается в разделении функций стандартного интерактивного приложения на 5 групп, имеющих различную природу:
- функции ввода и отображения данных (Presentation Logic);
- прикладные функции, определяющие основные алгоритмы решения задач приложения (Business Logic);
- функции обработки данных внутри приложения (Database Logic);
- функции управления информационными ресурсами (Database Manager System);
- служебные функции, играющие роль связок между функциями первых четырех групп.
Структура типового приложения, работающего с базой данных приведена на рис. 10.2.
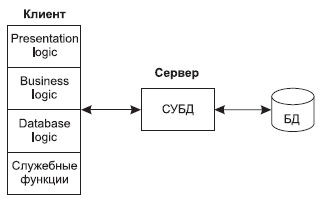
Рис.
10.2.
Структура типового интерактивного приложения, работающего с базой данных
Презентационная логика (Presentation Logic) как часть приложения определяется тем, что пользователь видит на своем экране, когда работает приложение. Сюда относятся все интерфейсные экранные формы, которые пользователь видит или заполняет в ходе работы приложения, к этой же части относится все то, что выводится пользователю на экран как результаты решения некоторых промежуточных задач либо как справочная информация. Поэтому основными задачами презентационной логики являются:
- формирование экранных изображений;
- чтение и запись в экранные формы информации;
- управление экраном;
- обработка движений мыши и нажатие клавиш клавиатуры.
Некоторые возможности для организации презентационной логики приложений предоставляет знако-ориентированный пользовательский интерфейс, задаваемый моделями CCIS (Customer Control Information System ) и IMS/DC фирмы IBM и моделью TSO (Time Sharing Option) для централизованной main-фреймовой архитектуры. Модель GUI — графического пользовательского интерфейса, поддерживается в операционных средах Microsoft’s Windows, Windows NT, в OS/2 Presentation Manager, X-Windows и OSF/Motif.
Бизнес-логика, или логика собственно приложений (Business processing Logic), — это часть кода приложения, которая определяет собственно алгоритмы решения конкретных задач приложения. Обычно этот код пишется с использованием различных языков программирования, таких как C, C++, Cobol, SmallTalk, Visual-Basic.
Логика обработки данных (Data manipulation Logic) — это часть кода приложения, которая связана с обработкой данных внутри приложения. Данными управляет собственно СУБД (DBMS). Для обеспечения доступа к данным используются язык запросов и средства манипулирования данными стандартного языка SQL.
Обычно операторы языка SQL встраиваются в языки 3-го или 4-го поколения (3GL, 4GL), которые используются для написания кода приложения.
Процессор управления данными (Database Manager System Processing) — это собственно СУБД, которая обеспечивает хранение и управление базами данных. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако для рассмотрения архитектуры приложения нам надо их выделить в отдельную часть приложения.
В централизованной архитектуре (Host-based processing) эти части приложения располагаются в единой среде и комбинируются внутри одной исполняемой программы.
В децентрализованной архитектуре эти задачи могут быть по-разному распределены между серверным и клиентским процессами. В зависимости от характера распределения можно выделить следующие модели распределений (см. рис. 10.3):
- распределенная презентация (Distribution presentation, DP);
- удаленная презентация (Remote Presentation, RP);
- распределенная бизнес-логика (Distributed Business Logic, DBL);
- распределенное управление данными (Distributed data management, DDM);
- удаленное управление данными (Remote data management, RDM).
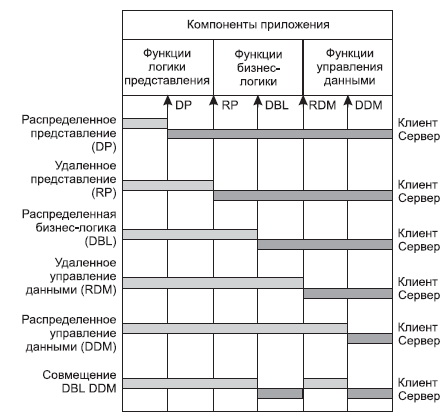
Рис.
10.3.
Распределение функций приложения в моделях «клиент—сервер»
Эта условная классификация показывет, как могут быть распределены отдельные задачи между серверным и клиенскими процессами. В этой классификации отсутствует реализация удаленной бизнес-логики. Действительно, считается, что она не может быть удалена сама по себе полностью. Считается, что она может быть распределена между разными процессами, которые в общем-то могут выполняться на разных платформах, но должны корректно кооперироваться (взаимодействовать) друг с другом.
Клиент-сервер с бизнес-логикой на клиенте
В
данных системах хранение, выборка и
поддержание непротиворечивостиданных
возлагается на сервер БД,
а вся бизнес-логика и логика представления
исполняются на клиентских машинах. Так
как все операции по манипулированию
данными осуществляются только через
сервер,производительность и сохранность
данных зависит
только от сервера БД.
Серверы БД изначально
рассчитаны на многопользовательский
режимработы,
имеют эффективные
алгоритмы кеширования данных.
Современные серверы имеют
хорошую масштабируемость.
Клиентская
часть обменивается данными с сервером
посредством SQLзапросов.
Обработка информации в клиент-серверных
системах ведется на уровне множества кортежей.
Процесс разработки разделяется
на создание БД и
написание клиентской части с бизнес-логикой.
![]() Достоинства
Достоинства
-
Высокая производительность, стабильность и надежность при
многопользовательской работе. -
Легко
организуется защита
данных (шифрование сетевого
трафика SSH,SSL) -
Универсальность языка
определения и манипулирования данными
![]() Недостатки
Недостатки
-
Более
высокая цена СУБД.
(сервер БД продается
отдельно). -
Достаточно
высокие требования к квалификации
разработчиков -
Навыки администрирования сервера БД
-
Повышенные
требования к пропускной
способности сети -
Повышенные
требования к клиентским местам (на них
выполняется слой бизнес- логики)
Выводы
При
количестве пользователей от 2 до ~50 она
является хорошим вариантом. С ростом
числа пользователей начинает сказываться
недостаточная пропускная
способность сети.
Клиент-сервер с бизнес-логикой на сервере
Используется
возможность современных серверов БД исполнять
хранимые SQL процедуры
на сервере, куда и переносится максимально
возможная часть бизнес-логики. Требования
к серверу БД возрастают,
однако резко понижаются требования к
клиентским машинам (за счет выноса с
них бизнес-логики) и к пропускной
способностисети (клиенту
передаются только данные, необходимые
пользователю).
![]() Достоинства
Достоинства
-
Пониженные,
по сравнению с предыдущим классом систем,
требования к пропускной
способности сети и
клиентским местам. -
Более
простой процесс создания бизнес-логики.
![]() Недостатки
Недостатки
-
Повышенные
требования к серверу БД.(каждый сеанс «съедает» память из
расчета предельной загрузки) -
Невысокая переносимость (мобильность)
системы на другие серверы БД.
Выводы
По
сравнению с предыдущими классами,
позволяет держать большую нагрузку.
N-уровневая
архитектура
Основными
элементами являются сервера БД,
сервер(кластер) приложений и
клиентская часть. Главная идея n-уровневой
архитектуры заключается в максимальном
упрощении клиента (тонкий клиент)
, выносе всей бизнес-логики с клиента и
сервера БД.
Тонкий клиент представляет
собой некоторый терминал типа HTML—browser или
эмуляторы X-терминала
Вся
бизнес- логика оформляется в виде набора
приложений, запускаемых на сервере
приложений под управлением ОС типа
UNIX.
Сервера БД занимаются
только проблемами хранения, добавления,
модификации и поддержаниянепротиворечивости данных.
Сервер
приложений соединен
с сервером БД при
помощи отдельного высокоскоростного сегмента сети.
![]() Достоинства
Достоинства
-
Повышенная
защищенность. -
Высокая производительность.
-
Легкость
развития и модификации. -
Легкость администрирования.
-
Возможность
создания системы с
массовым параллелизмом (серверов БД может
быть несколько, а сервером приложений
могут служить несколько соединенных
в кластер компьютеров).
![]() Недостатки
Недостатки
-
Высокая
сложность. -
Высокая
цена решения. -
В
некоторых случаях уступает по
производительности клиент-серверным
системам с бизнес-логикой на сервере.
Выводы
Единственная альтернатива для
создания ИС для очень большого количества
пользователей.
5.
Лекция: Базовые объектные архитектуры
распределенных систем. Технологии .NET,
(D)COM+, CORBA, EJB
Соседние файлы в папке РСБДтЗ
- #
- #
- #
05.03.2016269.82 Кб22Методичка РБД курсач.doc
Где наша бизнес-логика, сынок?
Время на прочтение
18 мин
Количество просмотров 77K
Спасибо небу за то, что в субботу шел дождь, и я это прочитал (а вы скажите спасибо за то, что перевел). В воскресенье, однако, светило солнце и форматирование текста было отложено.
Отдельное спасибо автору, за разрешение отдельной публикации.
Крайне занятная статья о том, что такое бизнес логика и где ей жить. Статье, кстати, уже три года. А я нередко встречаю системы, где код от данных не отделен. Может привести к реальному холивару.
Где наша бизнес логика, сынок?
Введение
За годы развития мы продвинулись от десктопа к клиент-серверной архитектуре, потом к 3-х звенной конструкции, к n-звенной, к сервис ориентированной. Во время этого процесса многие вещи изменились, но многие привычки остались. Зачастую, сопротивление изменениям происходит от привычек. Однако, во многих случаях оно процедурное. Эта статья описывает, что мы делаем неправильно и возможные решения.
О статье
То, что я здесь опишу, один из методов построения n-звенных систем с точки зрения проектирования и архитектуры. Эта статья не фокусируется на коде. Есть много методов построения n-звенных систем, это только один из них. Если вы строите систему, я надеюсь, вы найдете хороший совет, методику или шаблон использования этого подхода.
Хотя данная статья может предлагать несколько отправных точек из «стандартных методов», все в этой статье базируется на Шаблонах и Методах Microsoft и описывается в Designing Data Tier Components and Passing Data through Tiers и других документах.
Даже если вы не решитесь применять все методологии, предложенные здесь, вам следует воспользоваться хотя некоторыми из них.
Цель
Спросите любого разработчика, где должна быть бизнес логика, и получите ответ: «Конечно же в бизнес слое».
Спросите того же разработчика, где находится бизнес логика в их организации, и снова услышите: «Конечно же в бизнес слое».
У вас не должно быть не малейших сомнений на счет того где должна быть бизнес логика – в бизнес слое. Не часть бизнес логики – вся бизнес логика должна быть в бизнес слое. После прочтения данной статьи, многие разработчики поймут что то, что они считали правдой о своих системах, таковой не является.
Термины
Эти термины часто используются вместе, но в данной статье я буду использовать их так, как опишу здесь.
Звено (tier)
Когда я использую слово звено, я подразумеваю физическое звено состоящее из физического сервера или группы серверов, выполняющих одинаковую функцию и сгруппированных только для повышения емкости.
Слой (layer)
Когда я использую слово слой, я подразумеваю сегмент системы, который ограничен собственным процессом или модулем. Множество слоев может содержаться в одном звене, но любой из них должен иметь возможность быть легко перенесенным на другое звено.
Развитие проблемы
Десктоп
На настольных приложениях бизнес логика содержится на одном звене со всеми остальными слоями. Т.к. нет необходимости разделять слои, они зачастую перемешаны и не имеют четких границ.

Клиент-сервер
В клиент-серверном приложении имеются два звена, что приводит к созданию как минимум двух слоев. На начальном этапе сервер рассматривался только как удаленная база данных, и деление было как на рисунке – приложение на клиенте и данные на сервере. Обычно вся бизнес логика находилась на клиенте, перемешанная с остальными слоями, такими как пользовательский интерфейс.

Достаточно быстро стало понятно, что можно сократить нагрузку на сеть и централизовать логику для уменьшения постоянных затрат на развертывание, перенеся большую часть бизнес логики на сервер. Архитектурно сервер был хорошо подготовленным местом в клиент-серверной системе, но база данных как платформа давала мало возможностей. Базы данных были спроектированы для хранения и выдачи и в их архитектуру не были заложены возможности расширения в направлении бизнес логики. Языки хранимых процедур в базах данных были разработаны для базовых преобразований данных, чтобы поддержать то, на что не хватало SQL. Языки хранимых процедур разработали для быстрого исполнения, а не для обслуживания сложных задач бизнес логики.
Но из двух зол эта была меньшей, и часть бизнес логики переехала в хранимые процедуры. На самом деле, я готов поспорить, что бизнес логика была ужата и вбита в рамки хранимых процедур, исключительно с прагматической точки зрения. В двух звеном мире – это было не идеальным, но все-таки гораздо лучшим.

3-звенка
Когда проблема клиент-серверной архитектуры стала явной, возросла популярность 3-х звенного подхода. Наибольшей и самой тяжелой проблемой того времени было количество подключений. Сейчас многие базы данных могут обрабатывать тысячи единовременных подключений, в девяностых большинство баз данных падали где-то на 500 подключений. Сервера зачастую лицензировались по кол-ву клиентских подключений. Это все и привело к тому, что потребовалось сократить количество подключений к базе данных.
Стало популярным объединение подключений в пул, однако для реализации пула подключений в системе с множеством отдельных клиентов, необходимо внедрить третье звено между клиентом и сервером. Среднее звено так и стало называться «среднее звено». В большинстве случаев среднее звено существовало только для управления пулом соединений, но в некоторых случаях бизнес логика начала перемещаться в среднее звено потому, что языки разработки (C++, VB, Delphi, Java) гораздо лучше подходили для реализации бизнес логики, чем языки хранимых процедур. Вскоре стало очевидно, что среднее звено –это наилучшее место для бизнес логики.
Также среднее звено предоставило возможность подключения клиентов с низкими скоростями, т.к. прямое соединение с базой данных, как правило, требует широкого канала и низкой задержки.
Что такое бизнес логика?
Прежде чем я продолжу, давайте четко определим: что же такое бизнес логика. Выступая с презентациями на конференциях и внутри компании, я начал опасаться того, что не все соглашаются с тем, чем является бизнес логика, и, довольно часто, даже не до конца понимают: что она есть, а что нет.
Сервер базы данных – это уровень хранения. Базы данных разработаны для хранения, получения и обновления данных с максимально высокой эффективностью. Функционал зачастую является СУПОм (Создать, Удалить, Получить, Обновить). Некоторые базы данных СУПОм и являются, но разговор не об этом.
Базы данных разработаны для того, чтобы очень быстро обслуживать эти операции. Они не разработаны для форматирования телефонных номеров, рассчитывать оптимальное использование и пиковые нагрузки, определять географическое местоположение и маршруты грузов, и так далее. Хотя, я видел все это и много более сложные задачи, реализованные только с помощью или большой частью на хранимых процедурах.
Удалить Покупателя
И все это относится не только к сложным вещам. Давайте представим себе простую задачу и такую, которую зачастую даже не относят к бизнес логике. Задача – Удалить Покупателя. Практически во всех системах, что я видел, удаление покупателя обрабатывается исключительно хранимой процедурой. Однако в удаление покупателя довольно многие решения должны быть приняты на уровне бизнес логики. Можно ли удалить покупателя? Какие процессы должны быть запущены до и после? Какие предосторожности должны быть соблюдены? Из каких таблиц записи должны быть удалены или обновлены в последствие?
Базе данных не должно быть дела до того, что такое покупатель, она должна заботиться только об элементах, используемых для хранения покупателя. У базы данных не должно быть возможности разобраться, какие таблицы должны хранить объект покупатель, и она должна работать с таблицами не обращая внимания на объект покупатель. Задача базы данных – хранить ряды в таблицах, которые описывают покупателя. Кроме базовых ограничений вроде каскадной целостности, типов данных, индексов и пустых значений, база данных не должна иметь функционального знания о том, что же из себя представляет покупатель в бизнес слое.
Хранимые процедуры, если они есть, должны оперировать только одной таблицей; исключение – это процедуры запрашивающие выборку из нескольких таблиц для выдачи данных. В этом случае, хранимые процедуры работают как представления (view). Представления и хранимые процедуры должны использоваться для консолидации значений, но исключительно для более быстрой и эффективной работы с данными в бизнес слое.
Но даже в компаниях, гордящихся новейшими достижениями в разработках и технологиях, и в тех, что с пеной у рта кричат о всей их бизнес логике в бизнес слое, короткий анализ базы данных быстро выявляет: удалить покупателя, добавить покупателя, заблокировать покупателя, заморозить покупателя и т.д. и т.п. И не только с покупателем, но и с многими другими объектами бизнес логики.
Я часто встречал хранимые процедуры вроде этой:
sp_DeleteCustomer(x)
Select row in customer table, is Locked field
If true then throw error
Sum total of customer billing table
If balance > 0 then throw error
Delete rows in customer billing table (A detail table)
if Customer table Created field older than one year then
Insert row in survey table
Delete row in customer table
Регулярно часть бизнес логики отъезжает в бизнес слой.
Business Layer (C#, etc)
Select row in customer table, is Locked field
If true then throw error.
Sum total of customer billing table
If balance > 0 then throw error.
if Customer table Created field older than one year then
Insert row in survey table
Call sp_DeleteCustomer
sp_DeleteCustomer(x)
Delete rows in customer billing table (A detail table)
Delete row in customer table
В этом случае, часть бизнес логики была перемещена, но не вся. Некоторые таблицы обрабатываются и в слое бизнес логики. База данных не должна иметь ни малейшего представления о том, какие таблицы формируют покупателя в бизнес слое. Для всех трех операций, бизнес слой должен выдать SQL команду или вызвать три отдельные хранимые процедуры для реализации функционала в приведенной sp_DeleteCustomer.
Передав всю бизнес логику в бизнес слой, мы получим:
Business Layer (C#, etc)
Select row in customer table, is Locked field
If true then throw error.
Sum total of customer billing table
If balance > 0 then throw error.
if Customer table Created field older than one year then
Insert row in survey table
Call sp_DeleteCustomer
Delete rows in customer billing table (A detail table)
Delete row in customer table
Удаление рядов может использовать хранимую процедуру, если они из одной таблицы. Однако, в современных базах данных, использующих кэширование запросов, это является несущественным улучшением производительности. К тому же, SQL, генерируемый такими системами очень прост, т.к. он работает с одной таблицей, и потому практически не требует оптимизации. На самом деле, базе данных становится не очень хорошо от слишком большого количества загруженных хранимых процедур, а простые SQL команды на них так не действуют.
Переведя даже модификацию таблиц в бизнес слой, мы получим следующие преимущества:
- Перенос базы данных может быть осуществлен с меньшими усилиями, т.к. все эти хранимые процедуры не нужно отлаживать для каждой СУБД.
- Модификация проще, т.к. вся логика содержится в одном слое, а не в двух.
- Отладка проще – логика не размазана по двум слоям.
- Другая логика не сможет проскользнуть в хранимую процедуру только потому, что «так проще».
В виду того, что такой метод требует три успешных обращения к базе данных вместо одного, ваш узел бизнес логики должен быть подключен к базе данных по отдельному высокоскоростному сегменту, типа гигабита. Отправка 300 байт вместо 100 байт станет непринципиальной. Большинство баз данных поддерживают пакетную передачу SQL запросов, и все три запроса могут быть посланы в одном пакете, уменьшив нагрузку на сеть. Для выдачи таких запросов следует использовать слой доступа к данным, а не включать запросы прямо в код.
Некоторые администраторы баз данных и даже разработчики могут не принять этот уровень интеграции и настаивать на реализации таких пакетных обновлений в хранимых процедурах. Это выбор, который вы должны сделать, и он очень зависит от вашей базы данных и ваших приоритетов. Т.к. практически все современные базы данных используют механизмы кэширования запросов, выигрыш в производительности в большинстве случаев минимален, а четкие технологические причины не нагружать логикой хранимые процедуры есть. Если вы выберите оставить такие пакетные обновления в хранимых процедурах, вы должны быть очень осторожны, чтобы не допустить проскальзывания другой бизнес логики в хранимые процедуры, и ограничить свои хранимые процедуры СУПОвыми операциями, без каких либо условных операций и другой бизнес логики.
Форматирование
Давайте разберем еще один пример, обнаруженный мной и сеющий зерна войны среди разработчиков – является это бизнес логикой или нет. Я расскажу, почему я считаю это бизнес логикой, а не пользовательским интерфейсом или хранением. Этот пример не относится к легко реализуемому форматированию. Пример, который я буду использовать, — телефонные номера.
Каждая страна имеет свой собственный формат отображения телефонных номеров в приятной глазу манере. В некоторых странах их даже больше одной. Ниже несколько примеров:
Кипр:
+357 (25) 66 00 34
+357 (25) 660 034
+357 25 660 034
+357 2566 0034
Германия:
+49 211 123456
+49 211 1234-0
Северная Америка (США, Канада)
+1 (423) 235-2423
+1-423-235-2423
Россия:
+7 (812) 438-46-02
+7 (812) 438-4602
В Германии есть даже специальный официальный стандарт для форматирования – DIN 5008.
Конечно же, код страны отбрасывают при локальном использовании. Но давайте предположим, что у вас интернациональная система и необходимо хранить и отображать код страны. Для каждой страны мы выберем один формат отображения.
Договоримся форматировать телефоны следующим образом:
- Данные поступают в различных форматах.
- У каждой страны есть свой уникальный способ отображать телефоны.
- Форматы некоторых стран не просты и меняются в зависимости от первых цифр.
- Первые несколько цифр (обычно код страны и региона) не всегда имеют фиксированную длину. Например, в России, 812 – код города Санкт-Петербург, 495 – Москва, но некоторые регионы имеют 4 знака (3952). Это приводит и к изменению и общей длины, и формата, в зависимости от регионального кода.
- При выходе новых законов, появлении новых операторов, интеграции Евросоюза, обновления телефонных систем и еще множестве всего, форматы и длины телефонов меняются довольно часто в глобальном масштабе. За недавнее время Кипр сменил свой код страны дважды: один раз при обновление системы, второй раз из-за возросшего числа сотовых операторов. Имея сотни стран во всем мире, следует ожидать изменений на регулярной основе.
Обычно делается следующее, все не цифровые символы убираются и номер становится похожим на:
Phone: 35725660034
Иногда отделяется код страны и номер становится таким:
PhoneCountry: 357
PhoneLocal: 25660034
Кажется простым, но это еще одна задача для бизнес логики. Не все страны имеют код одинаковой длины. Коды стран могут быть от 1 до 3 знаков.
Зачастую обработка ввода (если код страны отделен) и логика отображения реализованы на клиенте, т.к. клиент написан на традиционном языке, который хорошо для этого подходит. Проблема в том, что клиенту требуется огромное количество данных для определения длины кодов стран, и потребуется обновление клиента каждый раз, когда изменился формат отображения.
Иногда форматирование осуществляется в хранимой процедуре. Проблема этого подхода в том, что языки хранимых процедур, не приспособленны для такого типа логики, и он часто приводит к багам и тормозам в работе с настоящей логики.
Еще чаще телефонные номера хранятся дважды. Один раз в чистом виде для хорошей индексации и поиска, и второй – в отформатированном для отображения. В дополнении к проблемам, описанным выше, получаем проблемы избыточных записей и обновления.
У особо изощренных экстрималов, встречающихся до смешного часто, телефонный номер хранится в том формате, в котором поступил. Проблема очевидна: телефоны нельзя быстро найти, проиндексировать или отсортировать.
Важно то, что хотя это и форматирование, оно не относится к пользовательскому интерфейсу, а попытка тотальной централизации может пристрелить базу данных. Это однозначно бизнес логика. Реализация форматирования в бизнес слое не допустит дублирования данных и будет написана на языке разработки, а не вбита в язык обработки данных.
Исключения
Некоторые пакетные обновления выполняются во много раз быстрее, будучи реализованными с помощью хранимых процедур. В большинстве случаев можно обойтись простым SQL, но некоторые типы пакетных обновлений требуют циклов и при реализации в бизнес слое создадут тысячи SQL команд. В таких редких случаях, должна быть использована хранимая процедура, даже если в ней нужно реализовать бизнес логику. Нужно обратить особое внимание на то, чтобы в ней был реализован только необходимый минимум.
Я еще вернусь в статье к этой проблеме.
Сегодняшние системы
Клиент-сервер
В клиент-серверных приложениях бизнес логика обычно имеется и на клиенте, и на сервере.
Реальное соотношение будет меняться от приложения и компании, предыдущий пример хорошо описывает клиент-серверные приложения. Большая часть бизнес логики была реализована в хранимых процедурах и представлениях в попытке централизовать бизнес логику. Однако многие бизнес правила не могут быть реализованы просто на SQL или хранимыми процедурами, или их быстрее выполнять на клиенте, так как они основываются на интерфейсе пользователя. Из-за этих противоположных факторов бизнес логика распределена между клиентом и сервером.
N-звенка
По многим причинам, которые я опишу позже в отдельной статье, при построении n-звенных систем ситуация становится только хуже в плане консолидации бизнес логики. Вместо консолидации, бизнес логика становится еще более фрагментированной.
Конечно же, каждая система имеет отличия в том, как бизнес логика распределяется по слоям, но есть одно общее для всех. Бизнес логика сейчас распределяется по трем слоям вместо двух. Далее я представлю несколько типичных сценариев.
Сценарий 1
Типичное распределение бизнес логики по n-звенной системе:

В таких случаях бизнес слой не содержит бизнес правил. Это не настоящий бизнес слой, а только форматер XML (или другого потокового формата) и адаптер наборов данных базы данных. Хотя некоторые плюсы такие как: пул соединений и изоляция БД, могут быть достигнуты, это не настоящий слой бизнес логики. Это скорее инородный физический слой без слоя логики.
Сценарий 2
Другой типичный сценарий:

Обычно некоторые бизнес правила приложения переходят в бизнес слой, но то, что было в базе данных, так в ней большей частью и остается.
При повторном использовании бизнес слоя в таких разработках бизнес правила должны повторяться и в клиентском приложении. Это сводит на нет основную цель внедрения бизнес слоя.
Также у клиентских приложений появляется возможность не выполнять бизнес правила, не реализуя их или просто игнорируя. При наличие настоящего бизнес слоя, это невозможно.
Консолидация
Вместо всего вышеперечисленного, бизнес слой должен содержать все бизнес правила.

Такая разработка имеет следующие преимущества:
- Вся бизнес логика находится в одном месте и может быть легко проверенна, отлажена и изменена.
- Нормальный язык разработки может быть использован для реализации бизнес правил. Такие языки более гибкие и более подходят для бизнес правил, чем SQL и хранимые процедуры.
- База данных становится слоем хранения и может заниматься эффективным получением и хранением данных без ограничений относящихся к слою бизнес логики или представления.
Приведенный сценарий – это цель. Однако, некоторое дублирование, особенно для проверки данных, должно быть и на клиенте. Эти правила должны быть поддержаны и бизнес слоем. Кроме этого, в некоторых системах отдельные высоко емкие операции, такие как пакетные обновления, могут привести к исключениям и должны быть размещены в базе данных. Потому более реалистичных подход представлен ниже. Обратите внимание, что вся бизнес логика должна быть реализована в бизнес слое, и те минимальные наборы, присутствующие в других слоях, являются просто дублями исключительно для повышения производительности или отключения тех или иных компонент пользовательского интерфейса.

Переезд на центральный узел
Скользкий путь
При переходе на центральный узел всегда есть искус «реализовать эту часть в хранимой процедуре». Потом «ту» и «вот эту». И скоро вы окажетесь в той же ситуации, что и были, без существенных изменений.
Хранимые процедуры должны использоваться для выполнения SQL и получения наборов данных в базах данных, которые оптимизируют хранимые процедуры лучше, чем представления. Но хранимые процедуры не должны быть использованы ни для чего другого, нежели объединения и выдачи данных. При обновлении данных она должна именно и только обновлять, но не интерпретировать данные каким-либо образом.
Есть задачи, где для повышения производительности некоторые компоненты должны быть помещены в хранимую процедуру. Но такие задачи на самом деле достаточно редки и они должны быть исключением, а не правилом. Каждое исключение должно быть проверенно и одобрено, а не просто реализовано по воле разработчика или администратора базы данных.
Дешевле
Звучит несколько странно, что покупка железа может сделать дешевле. Но при внедрении серверов среднего звена, практически никакого дополнительного ПО, кроме ОС, не требуется. А стоимость наращивания мощности сервера базы данных существенна по следующим причинам:
- Сервера баз данных, как правило, более высокого класса, чем сервера среднего звена, и стоят дороже.
- Базы данных зачастую лицензируются на процессор и добавление процессора – дорогостоящая процедура в терминах лицензий. Лицензионные сборы могут составлять от 5000 до 40000 долларов на процессор.
При переносе логики на среднее звено, вы можете существенно сократить нагрузку на базу данных и предотвратить преждевременное наращивание ее мощностей.
Проще
В добавление к стоимости, обновление среднего звена обычно проще чем обновление базы данных.
У баз данных есть врожденный предел того, на сколько они могут быть увеличены простым добавлением железа. В какой-то момент нужно начинать использовать другие технологии вроде деления, кластеризации, репликации и т.п. Но ни одна из этих технологий не является простой, и все требуют существенных вложений в железо, миграцию и сильно влияют на существующие системы.
Наращивать же сервера среднего звена гораздо проще. Как только запущен механизм распределения нагрузки, все сводится к задаче добавить новый сервер.
Топология
Давайте рассмотрим утверждения, которые я только что привел, используя следующую диаграмму. Заливка в сегментах показывает направление или важность их названия в отношении звеньев на диаграмме. Цена единицы возрастает, когда мы движемся от клиента, к среденму звену, к базе данных. Я использую слово единица для обозначения процессора или сервера, в зависимости от конфигурации.
(сверху вниз: цена единицы, средняя полоса пропускания, сложность развертывания, количество)
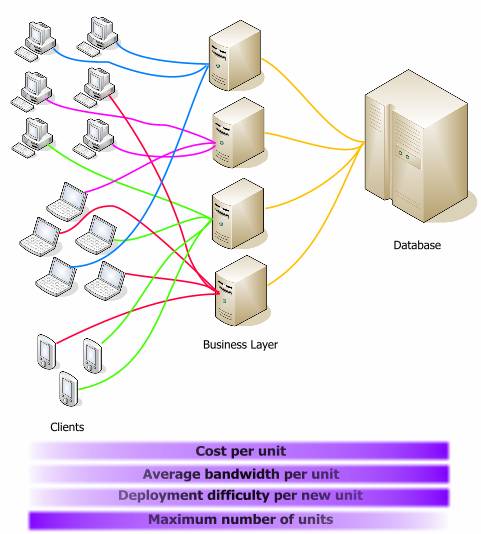
Если те же данные привести в относительных значениях, их можно легко сравнить:

Я не привел цифры на графиках потому, что они очень зависят от конфигурации сети, мощности процессоров и других факторов, уникальных для каждой организации. Каждая функция использует свои единицы измерения. Я представил лишь общее взаимоотношение измерений. Оно хорошо показывает, что среднее звено имеет емкость для роста и гораздо дешевле базы данных.
Вырасти середину
Если большая часть бизнес логики реализована в базе данных, вам будет нужна более мощная база данных.
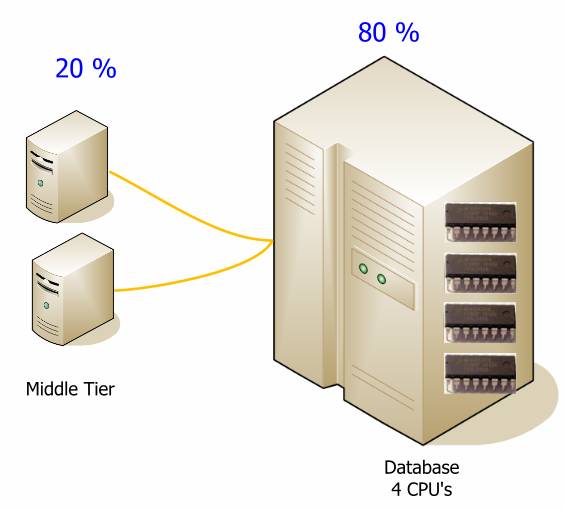
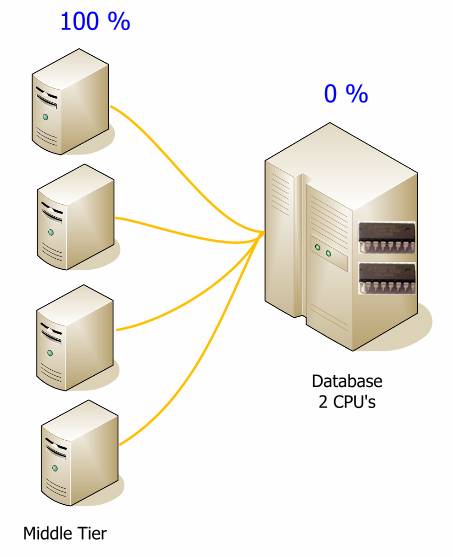
При переносе логики в среднее звено, вы можете серьезно снизить нагрузку на базу данных. Цифры представленные здесь, приведены только для демонстрации и будут меняться от системы к системе, но они могут помочь уловить идею. Хотя на следующей диаграмме и больше аппаратуры, суммарная стоимость системы будет меньше, и ее будет проще развернуть. Гораздо дешевле и проще наращивать среднее звено.
Бутылочное горлышко
Давайте посмотрим еще раз на один из предыдущих графиков:
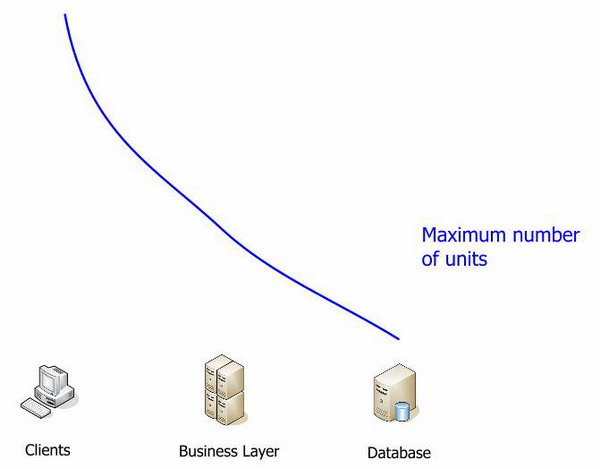
Какое единственное узкое место в системе? Какое из звеньев имеет выраженный предел наращивания? Это однозначно база данных. Все упирается в базу данных.
Потому перемещая вычисления в среднее звено, мы может отойти от границ слоя данных.
Сложности
Есть несколько сложностей для перехода в среднее звено, и не все они заключаются в том, что нужно по-разному программировать.
Привычки
Есть поговорка: «сложно избавиться от старых привычек». Это применимо и к команде. В команде вам нужно убедить не только себя, но и большинство команды.
Процедуры
Многие компании имеют устоявшиеся политики безопасности, предписывающие обеспечение безопасности в базе данных, а использование хранимых процедур в качестве представлений не дает достаточного контроля. Изменение корпоративных политик безопасности для перехода в n-звенный мир может оказаться очень сложным, если не невозможным.
В .Net безопасность, как и в новых технологиях Microsoft, ориентирована на корпоративную безопасность в среднем звене как никогда ранее, но многие компании все еще опираются на базы данных и либо не заботятся об изменениях, либо не хотят менятся.
Администраторы баз данных
Это рискованное утверждение. Настолько рискованная, что есть еще кое-что, что нужно сказать. Если вы администратор БД или разработчик, пожалуйста, не воспринимайте то, что я хочу сказать как стереотип или правду о всех администраторах баз данных. Однако, это превалирует и часто встречается. Если вы администратор БД, который не попадает под это описание – браво! Вы Президент баз данных, а не лорд баз данных.
Администраторы баз данных с работающей системой зачастую сопротивляются внесению каких-либо значительных изменений потому, что они могут сломать их систему. Многие организации имеют одного администратора и множество ассистентов. Администратор базы данных – король в своей вотчине и обладает последним словом во всем, что касается БД. И только менеджмент попытается взять верх над администратором, так тут же некомпетентный в проблемах базы данных менеджмент сдается администратору.
У многих администраторов БД очень мало знаний о том, зачем нужны изменения в сторону n-звенной архитектуры, или им просто всё равно. Для них любое звено всего лишь еще один клиент, и все для них клиент-серверная архитектура. Они заботятся лишь о работе базы данных и идут на сделку с разработчиками, только если она не доставит им каких-либо хлопот.
Администраторы баз данных не мигрируют по компаниям с такой частотой как разработчики, и многие из них руководят корпоративной базой данных на протяжении последних 10 и даже 20 лет. База данных очень важная для них вещь, и они не хотят идти ни на какие сделки. Они построили свое королевство и не хотят потерять контроль. Заставить такого администратора отдать часть безопасности и реализации можно только в серьезной битве и при поддержке менеджмента.
Другие администраторы не столь требовательны и пойдут на встречу всему, что сочтут разумным. Но во многих организациях, особенно крупных, есть сотни разработчиков и только один или парочка администраторов базы данных, и администраторы базы данных сидят на верхушке корпоративной цепочке команд.
Инструментарий
Большая часть доступных сегодня инструментов, нестабильны или не предоставляют средств реализации бизнес логики. Многие инструменты акцентированы исключительно на масштабируемость, пул соединений и изоляцию базы данных, и не нацелены на реализацию потребностей бизнес логики.
Решения
Архитектура
Я обнаружил большую пользу в регулярном аудите архитектуры системы, при котором помечается некорректное размещение бизнес логики. Чем раньше они обнаружены, тем проще и дешевле их исправить. Если у вас нет специального главного архитектора, тогда разработчики из команды могут проверять друг друга. Если что-то найдено не в том месте, разработчик может оповестить команду и тимлидера.
Обучение ассистентов
Очень полезно обучать ассистентов администратора базы данных. Администраторы так долго реализовывали бизнес логику, что для них тяжело определить: где бизнес логика, а где хранилище. Ассистенты обычно делают только то, что от них требуют, как правило, следуя указаниям администратора.
Все равно процесс затронет ассистентов. Они пишут запросы, оптимизируют их и обслуживают базу данных. Также они должны отслеживать SQL, приходящий из среднего звена, и производительность БД. Ассистенты также продолжат проектировать архитектуру БД.
Обучение менеджеров
Часто встречается сопротивление менеджмента, хотя, это скорее простое препятствие, чем сложное. Менеджменту наплевать, стала ли легче ваша работа, но их заботят накладные расходы, время разработки, преимущества для бизнеса, ну и не плохо бы им рассказать о текущих потерях.
Основное препятствие на пути изменения менеджмента будет сопротивления администратора базы данных. Так что, сдайте менеджмент с потрохами и пусть они сами разбираются с администратором.
Что еще почитать
Основой этой статьи послужили шаблоны и методы, которые я использую почти десять лет. Конечно же, они постоянно пересматриваются и обновляются, чтобы получить преимущества новых технологий и быть адаптированными к изменениям в мире.
Во время своей работы, я прочитал много материала, написанного «экспертами». Большая часть их была написана разработчиками, хорошими в создании теорий и обучении других в том как надо делать, но никогда не применявшими свои собственные методы на практике. Другие были написаны опытными разработчиками с узким кругозором, а эти знания очень зависят от конкретного приложения. Когда разработчики читают такие материалы, они становятся уверенны в том, что есть только один путь решения проблемы. Разработчикам нужно мыслить шире и понимать, что описанное решение проблемы является только направлением, а не доктриной.
Я говорю об этом только потому, что очень редко можно найти что-то реально стоящее и не попасться в эти ловушки. Один из самых лучших материалов, которые я прочитал за прошедшие годы был написан в августе 2002 и это шаблоны и методики от Microsoft. Они очень хорошо составлены и согласуются с тем, что я описал здесь и в других моих статьях.
Пожалуйста, обратите внимание на Designing data tier components and passing data through tiers.
Заключение
Изменение направления в больших компаниях является вопросом политически и высокого риска. С точки зрения разработчика проще лечь на дно и позволить другим грызть друг друга. Я сомневаюсь, что многие разработчики скажут нет своим проверенным методикам. В этой статье мне хочется дать вам несколько идей для реорганизации существующих у вас процессов, или хотя бы посмотреть на некоторые решения, которые обычно не обдумывались, более пристально.
Описанный подход наилучший для построения новых систем, или при изменении всей или части системы. На работающих системах лучше ничего не трогать до тех пор, когда какое-то обстоятельство не заставит вас заняться перестройкой.
UPD: по подсказке maovrn перенесено в «Проектирование и рефакторинг».
UPD1:
Для тех кто в танке:
1. На Хабре есть правила оформления переводов см. помощь
2. Для тех, кто не может осилить п.1. автор статьи Chad Z. Hower aka Kudzu
3. Для тех, кто читает только середину без начала и конца — статье три года. Потому, как минимум некорректно объявлять автора статьи безграмотным на основание того, что он не читал на момент публикации материалов, выпущенных после публикации.
4. Если данный апдейт вас задел — это ваши проблемы.
Содержание:

Введение
В современном мире компьютерные сети затронули практически каждую сферу деятельности человека. В свою очередь создание глобального интернета было бы невозможным без организации сообщения между отдельными участниками сети.
Со временем участники компьютерных сетей совершенствовали методы и характер взаимодействия между собой. Появлялись новые технологии и приложения, которые позволяли работать автоматизировано в информационных системах, требующих гибкую архитектуру и производительную аппаратную составляющую.
С совершенствованием аппаратной составляющей сетей развивалось и сетевое программное обеспечение. Вскоре стало необходимым совершенствование используемых технологий, а не только совершенствование программного обеспечения и аппаратной составляющей. Таким образом были созданы современные сетевые технологии. Одной из подобных технологий является технология «клиент-сервер», реализующая оптимальный и быстрый обмен информацией между участниками компьютерной сети и организующая их гибкое взаимодействие.
В текущее время тема актуальна и лежит в основе самых современных подходах организации информационных систем и их архитектуре. Именно поэтому я решил раскрыть все подробности этой модели в своей работе.
Глава 1. История возникновения модели
У истоков информационных технологий каждая вычислительная машина являлась изолированным местом хранения данных. Пользователи различных компьютеров не имел возможности совместно использовать общие данные. Это значительно снижало выгоду, получаемую от компьютеризации предприятия. Первым шагом в направлении к разделению пользователями общей информации явилось появление компьютеров с несколькими терминалами. На эти компьютеры ставились системы общего пользования, например, «Примус» или TSO для больших машин компании IBM, и группа пользователей одновременно работала с общими массивами данных.
Многотерминальные компьютеры и сейчас используются достаточно широко. Однако при использовании центральной машины с несколькими терминалами все задачи всех пользователей выполняются на одном компьютере и замедляют работу друг друга. Кроме того, на центральной машине обычно используется одна операционная система, и все задачи должны быть написаны для данной операционной системы. Таким образом многие полезные программы, реализованные для другой операционной системы, просто невозможно выполнять на данной машине. Выполнение всех задач на одной машине выдвигает очень высокие требования к оборудованию. Центральная машина должна быть быстродействующей и иметь большую оперативную и дисковую память. Поэтому, как правило, эти машины очень дороги и сложны в эксплуатации.
Терминалы в подобном подходе исполняют пассивную роль. Они в основном являются лишь способом отображения и простейшего внесения данных. Обычно производительные центральные компьютеры организовываются для исполнения сложных вычислений и оснащаются алфавитно-цифровыми терминалами. Для работы приложений, работающих с графическими данными, необходимо приобретать специализированные графические терминалы, которые довольно сложны и дороги. Кроме того, изолированные компьютеры с множеством терминалов не дают использовать данные других изолированных машин, а при неполадках центрального компьютера все его пользователи не имеют возможности вести работу до момента устранения сбоя.
Несмотря на вышеупомянутые недостатки данного подхода, мощный центральный компьютер с множеством терминалов продолжает использоваться для выполнения локальных задач, требующих значительной вычислительной мощности и не требующих использования информации с других машин или терминалов.
Наряду с многотерминальными машинами на наших глазах форсировано эволюционировали персональные компьютеры. Они имеют ряд больших преимуществ. Более значимыми среди них являются невысокая стоимость, отличные возможности работы с графической, звуковой и видео информацией, простота использования и изучения. Кроме того, сегодня персональные компьютеры широко распространились по всему миру и стоят почти в каждом офисе.
Появился ряд инструментов, сильно знакомый большинству пользователей ПК, такие как графические и текстовые редакторы, электронные таблицы, интегрированные пакеты, СУБД и т.д. Пользователи персональных компьютеров также широко используют такие оболочки, как Norton Commander, PC Tools, MS Windows. Пакеты для персональных компьютеров просты в освоении, хорошо используют все преимущества персональных компьютеров. Они облегчают работу по делопроизводству, финишную обработку информации, помогают в принятии решений.
Основным недостатком ПК является их невысокая вычислительная мощность и надежность, а также необходимость в приобретении дополнительных аппаратных средств для устранения изолированности отдельных персональных компьютеров друг от друга.
Как правило пользователям компьютеров нужны и высокая вычислительная мощность и хорошие свойства оборудования. Таким образом, где для исполнения сложных вычислений используются производительные изолированные центральные компьютеры с терминалами, их пользователям периодически приходится ходить на персональные компьютеры для редактирования текстов или исполнения задач, использующих электронные таблицы. Это делает необходимым освоить 2 разные операционные системы пользователями (на больших серверах обычно установлены OC MVS, VMS, VM, UNIX, а на ПК — MS DOS/MS Windows,OS/2 или Mac) и не решает задачи одновременного использования информации.
В ходе опроса сотрудников 300 крупнейших американских компаний, использующих ПК, выяснилось, что для 82% респондентов нужен доступ к данным более чем одного устройства (компьютер, телефон, планшет и т.д). Для эффективного решения этой задачи, ПК стали объединять в локальные сети и устанавливать на них специальные операционные системы, например, NetWare компании Novell, для одновременного использования компьютерами сети файлов, расположенных в распределенных сегментах и доменах сети. Эта технология называется файл-сервер.
Файл-серверы имели и имеют множество минусов. Они не дают в полной мере контроль за доступом к данным и их целостность. По сети файлы передаются целыми, не взирая на то, какая действительно часть необходима пользователю. Это довольно перегружает сеть и уменьшает быстродействие системы. Невысока и надежность системы на основе файл-серверов. Отказоустойчивость данной модели низкая, т.к сбой на какой либо этапе может привести к потере данных. Для обеспечения одновременного изменения данных в файле приходится выполнять полную блокировку, что также замедляет скорость работы.
Естественным желанием специалистов в сфере вычислительной техники было соединить преимущества ПК и мощных центральных компьютеров. Первым шагом в этом направлении явилось использование персональных компьютеров в качестве интеллектуальных терминалов. В таком случае в ПК, соединенном с центральным компьютером, внедряется специализированное ПО, позволяющее данному компьютеру находиться в режиме эмуляции терминала. Таким образом мы имеем модель, имеющую все достоинства архитектуры с производительным центральным компьютером, но кроме того, ПК может использоваться и отдельно, в рамках своего предназначения
В результате отсутствует необходимость в двух дисплеях на столе, однако большинство недостатков, присущих модели с центральным компьютером, все еще имеют место быть. Вдобавок, персональные компьютеры, дисплеи которых подключены с помощью интерфейса VGA, позволяют работать с графикой, однако использовать их в качестве графического терминала большой центральной машины неудобно. Задача выполняется в центральном компьютере и по проводам передаются графические образы экрана. Эти образы довольно велики и скорость смены изображения на экране может быть очень низкой.
Следующим шагом в устранении упомянутой выше проблемы стало появление модели клиент-сервер. В данной модели все компьютеры определенной сети поделены на две группы: клиенты и серверы. Компьютер-сервер — это производительная машина с большими ресурсами оперативной и долговременной памяти, мощным процессором. На нем располагается БД и выполняется сложные действия, требующая больших вычислительных ресурсов. На компьютерах-клиентах исполняется первичная обработка данных при вводе, подготовка и проверка данных, а также окончательная обработка данных после получения их с сервера. В качестве компьютеров-клиентов часто используются обычные ПК типа IBM PC или Macintosh. Плюсы модели клиент-сервер очевидны. Любой тип компьютера используется по своему предназначению, обеспечивая полное применение возможностей компьютеров.
На компьютерах-клиентах работают знакомые пользователям PC пакеты, позволяющие отображать результаты работы всей системы в удобном для анализа и принятия решений виде. На подобных ПК легко можно реализовать дружественный пользовательский интерфейс приложения, представляющий данные различного рода: графику, звук, работу с навигацией и мышью и т.д. в удобном эргономичном виде. Компьютер-клиент позволяет оптимально реализовывать ввод и первичную проверку вводимых данных. В целях компьютеров-клиентов возможно единовременно использоваться компьютеры различных типов с разными ОС.
Модель клиент-сервер дает возможность реализовать распределенную обработку, поскольку некоторая часть преобразований выполняется на компьютере-клиенте, а другая часть обрабатывается на компьютере-сервере и возвращается клиенту. Это позволяет грамотно распределить логическую работу и оптимально организовать работу приложения в целом, что позволяет увеличить одновременное число подключенных клиентов, работающих с функционалом сервера.
Обычно модель клиент-сервер организовывается для приложений, созданных с использованием систем управления базами данных (СУБД). При этом на сервере размещается ядро СУБД и выполняются наиболее сложные операции по вводу, хранению, модификации, извлечению и первичной обработке данных. Например, в реляционных БД на сервере выполняются такие трудоемкие операции, как соединение таблиц, сортировка, выполнение сложных запросов и т.д. Централизованное хранение БД позволяет облегчить работы по администрированию БД, поскольку они исполняются локально на серверах, реализовать единые для всей функциональности правила контроля целостности и непротиворечивости БД, а также реализовать контроль прав доступа к данным.
Модель клиент-сервер также позволяет увеличить скорость работы приложений в результате минимизации объема данных, транслируемых по сети. Обычно от клиента к серверу передается запрос на извлечение и обработку данных. Выполнение запроса осуществляется на сервере и обратно клиенту передаются только те данные, которые удовлетворяют критериям запроса. В случае исполнения операций вставки, удаления, модификации данных или корректировки структуры БД обратно клиенту по сети передается лишь сообщение об успешности/неуспешности исполнения операции. Программы-серверы обычно разрабатываются так, чтобы максимально полно использовать возможности конкретной вычислительной платформы (компьютер + OC) и обеспечить максимальную производительность как можно большего числа одновременно работающих пользователей.
Следующим шагом в развитии модели клиент-сервер стало реализация в сети не одного, а нескольких серверов БД. Это дало возможность перейти от работы с локальной БД к работе с удаленной БД. Причем работа с распределенной БД «прозрачна» для клиента, т.е. он работает с ней аналогично, как с локальной БД, не задумываясь о том, на каком сервере лежат его данные. Клиент инициирует запрос к одному из серверов, тот, не найдя у себя необходимой информации, автоматически переводит запрос к другим серверам.
Многосерверная архитектура сегодня видится довольно перспективной. Она позволяет заменить одну мощную центральную машину на некоторое количество менее мощных и, следовательно, более дешевых, и еще больше распараллелить обработку данных. Кроме того, такая модель взаимодействия повышает надежность системы, поскольку при выходе из строя одного из серверов все модули системы, работающие с данными других серверов, могут вести работу. При выходе из строя части локальной или глобальной сети приложение может попытаться найти альтернативный путь к нужному серверу, если подобная балансировка будет настроена. Кроме того, на локальных серверах могут храниться информация, наиболее часто используемая в текущей функциональности, что позволяет свести к минимуму передачу данных по сети от сервера к серверу.
Глава 2. Характеристика модели
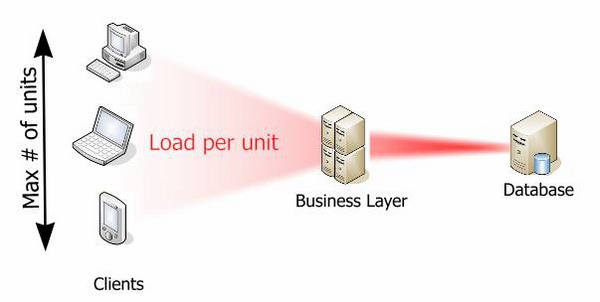
Термин «клиент-сервер» изначально использовался в архитектуре ПО, которое реализовывало распределение процесса исполнения по принципу работы двух программных процессов, один из которых в этой модели назывался «клиентом», а другой «сервером» (Рис 1). Клиентский процесс запрашивал некоторые услуги, а серверный процесс обеспечивал их выполнение. При этом задумано, что один серверный процесс может обслужить множество клиентских потоков.
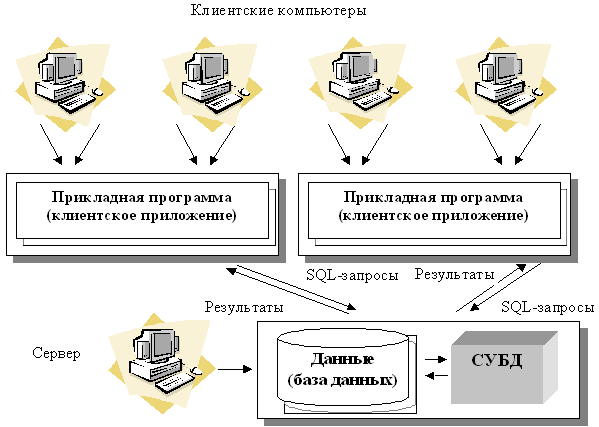
Рис 1. Модель «клиент-сервер»
Главный принцип модели «клиент-сервер» применимый к технологии баз данных содержится в распределении функцонала стандартного интерактивного приложения на пять групп, имеющих разное предназначение:
- Ввод и вывод данных (Presentation Logic);
- Бизнес логика приложения, выполняющая преобразования данных в рамках определенных бизнес-процессов (Business Logic);
- Логика на уровне базы данных (Database Logic),
- Средства управления ресурсами БД (Database Manager System);
- Служебные, мониторинговые и административные модули
Уровень презентационной логики ввода и вывода данных (Presentation Logic) как часть приложения заключается в том, что клиент приложения видит на своем экране, в ходе его работы. Сюда включаются все экранные формы интерфейса, которые пользователь видит или заполняет в ходе работы приложения, к данному уровню относится то, что показывается пользователю на экран как промежуточные итоги решения некоторых задач, либо как справочная информация. Поэтому основными задачами презентационной логики являются:
-
- формирование экранных изображений;
- чтение и запись в экранные формы информации;
- управление функционалом приложения;
- обработка движений мыши и нажатие клавиш клавиатуры.
Часть возможностей для организации презентационного уровня приложений предоставляет знако-ориентированный пользовательский интерфейс, задаваемый моделями CICS (Customer Control Information System) и IMS/DC компании IBM и моделью TSO (Time Sharing Option) для централизованной main-фреймовой архитектуры. Модель GUI — графического пользовательского интерфейса, поддерживается в операционных средах Microsoft’s Windows, Windows NT, в OS/2 Presentation Manager, X-Windows и OSF/Motif.
Уровень бизнес-логики, выполняющая преобразования данных в рамках определенных бизнес-процессов (Business processing Logic), — это часть кода приложения, которая реализует алгоритмы выполнения конкретных задач. Обычно этот код пишется с использованием различных языков программирования, таких как С#, C++, Python, PHP, Visual-Basic.
Уровень логики базы данных (Data manipulation Logic) — это часть конфигурации приложения, которая реализуется на уровне БД. Данными управляет собственно СУБД (DBMS). Для обеспечения доступа к данным используются язык запросов и средства управления данными стандартного языка SQL, PL/SQL и т.д (зависит от диалекта БД).
Средства управления ресурсами БД (Database Manager System Processing) позволяют к базе данных, которая обеспечивает хранение и управление базами данных. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако для рассмотрения архитектуры приложения нам надо их выделить в отдельную часть приложения.
В централизованной архитектуре (Host-based processing) эти части приложения располагаются в единой среде и комбинируются внутри одной исполняемой программы.
В децентрализованной архитектуре эти процессы могут быть распределены иначе между серверным и клиентским компьютерами. В зависимости от характера распределения можно выделить следующие модели распределений:
- распределенная презентация (Distribution presentation, DP);
- удаленная презентация (Remote Presentation, RP);
- распределенная бизнес-логика (Remote business logic, RBL);
- распределенное управление данными (Distributed data management, DDM);
- удаленное управление данными (Remote data management, RDA).
Это деление показывает, каким образом может быть распределение задач между серверным и клиентскими процессами. В данном случае отсутствует реализация удаленной бизнес — логики. Таким образом, получается, что она не может быть удалена сама по себе в полной мере. Считается, что она может быть распределена между разными процессами, которые в общем-то могут исполняться на разных платформах, но должны уметь правильно взаимодействовать между собой.
Глава 3. Архитектурные подходы на основе модели «клиент-сервер»
В предыдущей главе мы прояснили принципы работы двухуровневой архитектуры взаимодействия клиент-сервер, заключающийся в том, что обработка запроса происходит на одной машине без использования сторонних ресурсов. Двухзвенная архитектура предъявляет жесткие требования к производительности сервера, но в тоже время является очень надежной. Двухуровневую модель взаимодействия клиент-сервер вы можете увидеть на рисунке ниже.
Модель клиент-сервер устанавливает лишь общие принципы взаимодействия между участниками сети, детали этого взаимодействия задают различные протоколы. Данная концепция нам говорит, что нужно разделять машины в сети на клиентские, которым всегда что-то надо и на серверные, которые дают то, что надо. При этом взаимодействие всегда начинает клиент, а правила, по которым происходит взаимодействие описывает протокол.
В традиционной модели клиент-сервер приходится распределять три составляющие приложения по двум физическим машинам. Обычно ПО хранения данных располагается на сервере базы данных, интерфейс приложения с пользовательскими представлениями на машине клиента, а вот обработку данных необходимо распределять между клиентской и серверной частями. Именно в этом и заключается недостаток двухзвенной архитектуры, из которого вытекают ограничения, сильно усложняющие реализацию клиент-серверных автоматизированных систем.
При делении алгоритмов преобразования данных приходится синхронизировать поведение обеих уровней системы. Каждый разработчик должен иметь четкое представление о последних изменениях, внесенных в систему, и ориентироваться в них. Это создает дополнительные трудозатраты при внедрении клиент-серверных систем, их реализации и сопровождении, т.к приходится тратить большие усилия на настройку взаимодействия разных групп специалистов. В поставках разработчиков часто создаются противоречия, а это тормозит развитие системы и вынуждает дорабатывать уже готовые и проверенные элементы.
Развитием распределенной архитектуры информационных систем с базами данных является трехзвенная модель с сервером приложений (Рис 2). В этом случае в системе кроме сервера базы данных и клиентских компьютеров выделяется еще одна самостоятельная компонента, так называемый сервер приложений, который помещается между клиентскими подсистемами и сервером базы данных.
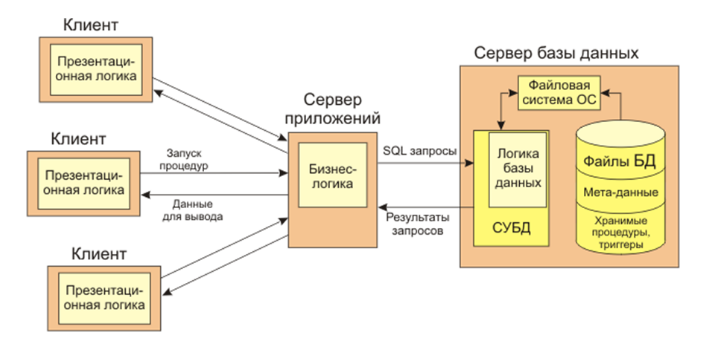
Рис. 2. Архитектура с сервером приложений
На программное обеспечение сервера приложений с клиентского звена системы перекладываются функции, реализующие бизнес-логику решаемых системой прикладных задач.
Такое распределение в первую очередь дает освобождение программного обеспечения клиентского уровня от разработки бизнес-логики приложений делает его более мобильным и масштабируемым, снижая требование к машине клиента, упрощая и унифицируя доступ и требования к пользованию автоматизированной системой вплоть до обеспечения возможности использования для доступа в приложение с помощью стандартных web-браузеров. В связи с этим подходом данное решение еще называют архитектурой с «тонким клиентом», в отличие от приведенной выше традиционной архитектуры клиент-север с гораздо тяжелее нагруженной среды клиента, получившим название «толстого клиента».
Перенос всей бизнес-логики прикладной задачи на сервер приложений значительно снижает риск проблем, связанных с модернизацией и сопровождением прикладного программного обеспечения, совместимости стороннего ПО, установленного на машине клиента и требований к уровню безопасности ПК. Процесс обновления версий приложений с «тонким клиентом» может теперь быть значительно упрощен, за счет изменений только на стороне серверной части.
Не вдаваясь в подробности, можно отметить, что такая трехзвенная архитектура, состоящая из: сервер БД, сервера приложений и машин клиентской стороны, обладает значительной гибкостью и масштабируемостью, повышает надежность системы и ее уровень безопасности.
Безусловно, использование подобной архитектуры приложения очень трудоемко в реализации и проектировании. Необходимо гарантировать надежность работы, целостность данных и их непротиворечивость, необходимые перекодировки и транслитерации, поддержку стабильного многопользовательского режима, мощные инструменты мониторинга и администрирования. Таким образом, для разработки приложений с распределенной базой данных и распределенной обработкой применяются специальные распределенные СУБД. Наиболее известными из них являются Oracle, Postgre, InterBase, SQLServer, Sybase. Наиболее промышленные из них, например, дают возможность единовременно использовать в одном приложении, работающем на сети, различные виды машин серверов и их операционных систем, сетевых протоколов и СУБД.
Во избежание неконсистентности различных элементов архитектуры, обычно выполняют преобразование данных на одной из двух физических частей — либо на стороне клиента («толстый» клиент), либо на сервере («тонкий» клиент, или архитектура, называемая «2,5 — уровневый клиент-сервер»). Каждая реализация имеет свои плюсы и минусы. В первом случае довольно сильно перегружается сеть, поскольку по ней транслируются исходные данные без предварительной обработки, в большинстве случаев избыточные. Вдобавок, усложняется сопровождение системы и ее доработки, так как изменение алгоритма вычислений или исправление ошибки влечет за собой изменение всех экземпляров программ на стороне клиентской составляющей. С другой стороны, если вся логика выполняется на стороне сервера, возникает проблема написания сложной логики, редких вещей и выполнение каких то действий на машине клиента вне приложения (к примеру, работа с принтером клиента, или запуск сторонней программы).
Не так давно модель клиент-сервер была модернизирована и доработана. Появилась архитектура, называемая равный к равному (peer to peer). Она реализована, например, в СУБД InterBase компании Borland и в СУБД Oracle Enterprise Edition 7 версии. При этом подходе все участники сети являются равноправными, т.е. они приходятся в роли и клиента и в роли сервера одновременно. Из любого сегмента сети есть возможность запросить и обновить информацию, имеющуюся на любом другом участнике сети. При такой реализации деление компьютеров на серверы и клиенты становится условным и непостоянным, но, т.к участники-серверы нуждаются в достаточно больших вычислительных ресурсов, архитектура равный к равному является ресурсоемкой задачей, а, следовательно, дорогой.
Очевидно, на сегодняшний день проще организовать работу с распределенной БД гетерогенной структуры, в которой часть узлов является и серверами и клиентами одновременно, а другая часть значится только в роли клиентов. Следует заметить, что поскольку сервер БД обеспечивает одновременную работу с данными нескольких пользователей, он должен работать в высоконагруженной или многопользовательской ОС (например, NetWare, OS/2, VMS, Unix , MVS, VM, Windows NT).
Подводя итог, сравнивая два рассмотренных архитектурных подхода можно выделить следующее:
Двухзвенная архитектура проще, так как все запросы обслуживаются одним сервером, но именно из-за этого она менее масштабируема и предъявляет повышенные требования к производительности сервера. Трехзвенная архитектура сложнее и выдвигает высокие требования к поддержке системы, но благодаря тому, что функции распределены между серверами второго и третьего уровня, эта архитектура представляет:
- Высокую степень гибкости и масштабируемости.
- Высокую отказоустойчивость (т.к. компоненты архитектуры обособлены друг от друга).
- Высокую производительность (т.к. задачи распределены между серверами и могут выполняться параллельно).
Глава 4. Программное обеспечение для реализации архитектуры клиент-сервер
В ситуации, когда имеется перечень разнотипных машин с различными операционными системами, включенных в глобальную или локальную сеть, а на этих машинах развернуты БД различных компаний, то можно построить автоматизированную систему, работающую с данными из нескольких БД. При этом в сети могут использоваться различные сетевые протоколы, СУБД могут поддерживать различные модели данных (сетевую, реляционную, иерархическую, навигационную, инвертированные списки и т. д.), а часть данных может храниться в файлах операционных систем.
Но в текущее время, когда выгода от интегрированного использования данных очевидна, а перечень компьютеров меняется все чаще, эту задачу приходится решать оперативно. Сегодня имеется несколько вариантов реализации в подобном сетевом ландшафте приложения с архитектурой клиент-сервер и обеспечить, чтобы одно и то же приложение клиента взаимодействовало с разными серверами БД, и его не требовалось дорабатывать при смене сервера БД.
Наиболее частые решения для подобных ситуаций:
1. Использование на всех компьютерах программного обеспечения одного производителя;
2. Использование на персональных компьютерах-клиентах популярных персональных СУБД с «дополнительными» пакетами для этих СУБД, позволяющими им работать с сервером БД конкретной компании;
3. Использование для разработки клиентских приложений специальных высокоуровневых инструментальных средств разработки приложений, умеющих работать с основными реляционными серверами БД;
4. Использование в качестве платформы для клиентских приложений персональных компьютеров с MS Windows, на которых работают пакеты, обеспечивающие стандарт обмена данными DDE;
5. Использование на компьютерах-клиентах и компьютерах-серверах пакетов, поддерживающих один из стандартов интерфейса клиент-сервер (ODBC, IDAPI, DAL и т.д.);
6. Использование пакетов, поддерживающих совокупность стандартов интерфейса клиент — сервер и позволяющих использовать в макрокомандах и процедурах на языке 4GL различных прикладных пакетов единый набор команд для работы с БД, файлами, почтовыми системами и т.д.;
7. Использование на компьютерах-серверах БД специальных пакетов-шлюзов;
8. Использование систем распределенных транзакций (мониторов транзакций).
Поскольку все перечисленные подходы реализованы в продуктах компании Oracle, мы, в основном, будем их иллюстрировать на примере пакетов этой компании, необходимо рассмотреть все достоинства и недостатки каждого из способов.
4.1 Использование программного обеспечения одного производителя
Самым простым способом реализации модели клиент-сервер будет использование БД, СУБД, сред разработки и сопровождения приложений, графического интерфейса и средств конечного пользователя (графические формы, текстовые редакторы, электронные таблицы, инструменты построения отчетов и т.д.), разработанных одной компанией и работающих в модели клиент-сервер. В этом случае компания-производитель сама позаботится о взаимодействии интерфейсов всех компонент и о средствах передачи запросов и данных по сети.
С другой стороны у данного подхода очень много минусов. Во-первых, доступные Вам СУБД могут не поддерживать все операционные платформы или сетевые протоколы, используемые в Вашей организации. Между разными системами и компонентами систем одного и того же поставщика тоже есть требования к совместимости. Если же подобный СУБД все-таки найдется, то Вам может оказаться недостаточно ее функциональных возможностей, или покажется слишком высокой цена, или в данном пакете будут отсутствовать необходимые Вам высокоуровневые средства разработки. Пожалуй, только СУБД Oracle, работающая более чем на 100 вычислительных платформах и со всеми коммерческими сетевыми протоколами, обладающая полным набором графических средств разработки, средств конечного пользователя, реализующая все основные функции коммерческой реляционной распределенной СУБД позволяет во многом избежать этих проблем. Большинство других СУБД работает всего на нескольких платформах, поддерживает 2-3 сетевых протокола и т.д.
Особенно много проблем возникает в том случае, если одна из машин сети — mainframe или надо использовать удаленную модемную связь. Кроме того, обычно на каждом предприятии уже имеется множество наработок, сделанных с помощью пакетов для персональных компьютеров, и есть опыт использования одной-двух СУБД для мини или больших машин. Поэтому хотелось бы сохранить наработки и возможность использования знакомой СУБД.
Немаловажной для отечественного рынка является и проблема поддержки русского языка при работе в сети, где на клиентах и серверах используются различные операционные системы с различными кодовыми таблицами. В составе СУБД должна быть компонента, автоматически перекодирующая данные при пересылке их по сети. Если для английского языка эта проблема осознана и в наиболее мощных пакетах решена, то для русского языка нам известно полномасштабные решения только для СУБД Oracle 7.
4.2 Работа приложений с сервером БД
На персональных компьютерах, обычно используемых в качестве компьютеров-клиентов существует большое количество популярных, легких в использовании СУБД. Наиболее известными из них являются СУБД dBase, FoxPro, Clarion, Clipper, Paradoх. С помощью этих СУБД разработано большое количество приложений.
Перечисленные СУБД были созданы специально для персональных компьютеров и наиболее полно используют их возможности. Вначале были созданы однопользовательские версии этих СУБД, однако потом, когда понадобилось реализовывать многопользовательские приложения, были созданы версии этих пакетов, работающие в сети.
К сожалению эти сетевые версии во многом сохранили архитектуру своих предшественников, а для реализации действительно многопользовательского промышленного приложения необходимо реализовывать специальную архитектуру СУБД. Эта архитектура реализована в таких серверах БД, как Sybase, Oracle, Informix, Ingres и т.д. Кроме того, СУБД для PC не реализуют многих функций обеспечения целостности и непротиворечивости данных, защиты данных, работы с большими БД и т.д. Поэтому многие организации, успешно создавшие и использовавшие приложения для сетевых версий персональных СУБД, при увеличении количества пользователей или объемов данных вынуждены переходить к архитектуре клиент-сервер. В противном случае время реакции системы, например, увеличивается выше допустимого уровня, что делает работу невозможной.
Производители СУБД для PC хорошо осознают эту проблему и потому разрабатывают программное обеспечение, позволяющее их СУБД работать с сервером БД конкретной компании. Обычно в качестве сервера используется одна из самых популярных и распространенных СУБД (Oracle, Informix, Inqres). Больше всего таких пакетов известно для СУБД Oracle, которая занимает около половины всего рынка серверов БД. Например, СУБД Paradox имеет компоненты SQL Link for Oracle и SQL Link for InterBase. С помощью этих пакетов приложения для Paradox будут работать с БД Oracle или InterBase.
4.3 Средства разработки приложений
Сегодня многие компании выпускают пакеты для разработки приложений, работающих с несколькими наиболее популярными реляционными СУБД. Эти пакеты поддерживают мощные языки 4 поколения и имеют диалоговые средства, автоматизирующие отдельные этапы разработки (например, генераторы форм, отчетов, меню). Эти средства имеются для различных платформ (DOS, Windows, Unix и т.д.) и позволяют быстро разрабатывать и модифицировать приложения с графическим пользовательским интерфейсом и сложной логикой обработки.
Обычно в документации, поставляемой с этими пакетами, перечислены реляционные СУБД, использующие язык SQL, с которыми могут работать приложения. Список этих СУБД достаточно постоянен. Это «большая четвертка» Oracle, Informix, Inqres, Sybase. Иногда к ним добавляются InterBase, DB2, Rdb, MS SQL Server. В качестве примеров таких пакетов можно указать JAM компании Convergent Solutions Inc., Power House компании Cognos Inc., Contessa компании Contexture Systems., SC/ADS компании Convergent Solutions Inc., Pro*IV компании McDonall Daugsas., Accel компании Unify и т.д.
Недостатки у этого подхода те же, что и при использовании Paradox, Clipper и т.д. Приложения должны либо использовать стандартный SQL (Ansi Level 1 или 2) и, следовательно, они могут работать с разными СУБД, но не используют их в полной мере, либо в приложениях явно записываются специфические операторы конкретной СУБД. При этом переход к другой СУБД требует модификации приложений. Кроме того, обычно языки и технологии СУБД и средства разработки приложений сильно различаются. Не всегда «стыковка» с конкретными СУБД выполняется качественно. Еще одним недостатком является то, что этот и предыдущий подходы не позволяют связываться между собой двум серверам БД различных компаний. Они подходят только для связи клиентов с серверами одной компании.
4.4 Клиентские приложения, поддерживающие протокол DDE
Очень часто в качестве компьютеров-клиентов используются персональные компьютеры с MS Windows. Эта дружественная графическая среда очень удобна для создания клиентских приложений. Появление операционной системы Windows NT очевидно еще больше повысит популярность приложений, работающих в этой среде. Наиболее известными среди них являются электронные таблицы Lotus 1-2-3, Excel, Quattro Pro, редактор текстов MS Word, СУБД MS Access.
Для того, чтобы приложения MS Windows могли обмениваться между собой данными, компания Microsoft разработала протокол динамического обмена данными DDE (Dynamic Data Exchange). Согласно этому протоколу одно из приложений MS Windows, называемое DDE клиентом, может посылать сообщения, запросы на выполнение действий, запросы на данные другому приложению для MS Windows, называемому DDE сервером (не следует путать DDE клиентов и серверов с клиентами и серверами в архитектуре клиент-сервер СУБД). Архитектура работы с DDE сервером приведена на рисунке 1.
Обмен между DDE клиентом и DDE сервером возможен только в том случае, если оба приложения написаны с соблюдением протокола DDE. Он регламентирует правила и набор функций, с помощью которых DDE клиент может связаться с DDE сервером, посылать ему данные, сообщения, команды, получать данные и прекращать связь. Данные между DDE клиентом и DDE сервером передаются в символьном виде, поэтому упаковкой/ распаковкой данных должны заниматься сами приложения.
Если в качестве DDE сервера используется приложение MS Windows, умеющее обмениваться данными с некоторой СУБД и пересылать на выполнение SQL-команды в эту СУБД, то любые приложения для MS Windows, поддерживающие протокол DDE, смогут работать с данной СУБД. Правда для каждой СУБД нужно иметь свой DDE сервер и язык SQL приложения должен быть понятен тем СУБД, с которыми оно будет работать. Однако, если приложение использует базовый набор команд SQL (например, SQL ANSI Level 1), то оно сможет работать без изменения с различными серверами реляционных БД.
Если приложение умеет работать c макрокомандами и поддерживает протокол DDE (а это справедливо для всех выше перечисленных пакетов для MS Windows), то очень просто настроить такое приложение на работу с одной СУБД или группой однородных реляционных СУБД. Вопросы передачи данных по сети либо должен решать сам DDE сервер, либо он может использовать транспортные средства СУБД, например SQL*NET .Примером DDE сервера для работы с СУБД Oracle является пакет Oracle for Windows компании Oracle.
Недостатком описанного подхода является то, что он справедлив только для приложений, работающих в MS Windows и написанных с соблюдением протокола DDE. Кроме того, DDE серверы существуют лишь для немногих СУБД, а возможность работы конкретного DDE клиента с другой СУБД очень сильно зависит от используемого набора предложений SQL и используемых типов данных. Скорее всего данный подход позволит Вам обеспечить работу конкретного пакета для MS Windows, например, Excel, c конкретной СУБД.
4.5 Стандарт ODBC
Все рассмотренные выше подходы не позволяли создавать клиентские приложения, не зависимые от используемого сервера БД. Каждый сервер реализовывал свое множество функций, имел свой диалект SQL и т.д. Для того, чтобы можно было создавать приложения и серверы, которые будут обмениваться командами и данными, ничего не зная друг про друга, было решено выработать стандарт интерфейса клиент-сервер. Этим занималась группа SQL-Access Group (SAG), в состав которой входили ведущие компании: — разработчики СУБД, операционных систем, компьютеров, такие как DEC, Hewlett-Packard, Bull, Inqres, Oracle, Informix, Sybase, Microsoft, Novell, Information Builders, NCR/Teradata, Tandem.
Группе удалось создать стандарт, который определяет:
- набор функций, позволяющих приложению связываться с СУБД, выполнять SQL операторы, извлекать данные из БД;
- синтаксис языка SQL, используемого в приложении и реализуемого на сервере;
- стандартный набор кодов ошибок;
- стандартный способ связи с БД и начала сеанса;
- стандартное представление типов данных.
Первую программную реализацию этого стандарта выполнила компания Microsoft, назвав ее Open Data Base Connectivity (ODBC). Эта реализация позволяет различным приложениям для MS Windows работать с различными серверами БД (удаленными и локальными) и с БД для PC.
Основная идея ODBC заключается в следующем: компания Microsoft создала динамическую библиотеку связи (DLL) для Windows, называемую Driver Manager. Кроме нее для каждого сервера разрабатывается свой драйвер (он выполнен тоже в виде DLL). Пользовательское приложение загружает и инициализирует Driver Manager и затем общается только с ним. Оно передает ему команды стандарта ODBC для связи с БД, исполнения запросов, извлечения данных и т.д. В свою очередь Driver Manager подключает необходимый для работы с данной БД драйвер. Все это программное обеспечение работает на той же машине, что и приложение в среде MS Windows.
Драйвер преобразует команды ODBC в операторы SQL конкретной СУБД. Он также преобразует данные и коды ошибок. Драйвер может работать с локальной СУБД, использовать для связи с удаленной СУБД ее транспортные средства (например, SQL*Net) или сам реализовывать связь по сети. На рисунке 2 приведена схема архитектуры ODBC.
Такая архитектура делает приложение полностью независимым от сервера. В случае подключения нового сервера или изменения версии, архитектуры, структуры команд сервера достаточно переписать (или написать) драйвер. Приложение при этом не изменяется. Приложение может одновременно работать с несколькими СУБД. Драйверы загружаются автоматически при попытке связаться с новой СУБД. Причем в приложении указывается лишь имя БД, имя пользователя и пароль. Соответствие имени БД и типа БД, имени и местонахождения подключаемого драйвера, полного имени БД и т.д. задаются в отдельном файле ODBC.INI и могут быть легко изменены без перекомпиляции приложения. Конечно при этом подразумевается, что все используемые СУБД ODBC — совместимы.
ODBC позволяет использовать в своих операторах динамически формируемые операторы SQL. Поэтому предусмотрены команды определения формы результата оператора Select (количество переменных, их тип и т.д.) Простое ODBC приложение должно работать следующим образом:
- связаться с источником данных, указав его имя и специфическую информацию, необходимую для связи;
- выполнять SQL операторы транзакции;
- завершать или откатывать транзакцию;
- завершить сеанс работы с источником.
В свою очередь выполнение SQL оператора состоит из следующих шагов:
- формирование в буфере строки оператора SQL, установка значений параметров;
- для операций выборки установление имени курсора данных оператора SQL;
- выполнение оператора;
- для операций выборки запрос формы результата, назначение переменных для хранения результата, выборка данных;
- проверка и обработка кода завершения оператора.
Microsoft ODBC успешно работает в Windows и Windows NT, сейчас разрабатываются драйверы для платформы Mac, планируется переход и на другие платформы. Однако, поскольку ODBC был первой реализацией стандарта группы SAG, он имеет и ряд недостатков. К сожалению многие пакеты под Windows не поддерживают стандарт ODBC, более того компания Borland (владелец таких пакетов, как dBASE, Paradox, QuatroPro, InterBase) создала свой собственный стандарт IDAPI, альтернативный ODBC. ODBC не обеспечивает прозрачность работы в сети. Забота об этом переложена либо на драйверы, либо на транспортные пакеты СУБД. При работе с несколькими СУБД одновременно используется несколько драйверов, функции которых частично дублируются. Драйверы при этом занимают оперативную память. ODBC не поддерживает работу с распределенной БД, не позволяет выполнять в запросе операции соединения таблиц из разных БД. ODBC пока работает только под MS Windows и не позволяет переносить ODBC совместимые приложения на другие платформы.
4.6 Стандарт IDAPI
Компания Borland разработала свой альтернативный стандарт интерфейса клиент-сервер, учитывая недостатки стандарта ODBC и свой опыт связывания Paradox и QuatroPro с Interbase. Стандарт называется IDAPI (Integrated Database Application Programming Interface) [6]. В его разработке также участвовали компании IBM, Novell, WordPerfect. Архитектура IDAPI более сложна, чем ODBC, и позволяет хорошо работать как с SQL серверами, так и с навигационными записе-ориентированными базами (см. рисунок 3). Для этого язык программного интерфейса (API) был расширен за счет добавления команд для работы с навигационными СУБД (NAV/CLI — навигационный CALL-интерфейс), а в программной реализации IDAPI кроме средств обработки SQL (Relational Engine) имеется средство обработки NAV/CLI.
Планируется реализовать IDAPI среду на нескольких платформах: DOS, OS/2, NetWare, MS Windows. Это позволит переносить приложения. IDAPI предусматривает работу с ODBC — совместными серверами, но не позволяет использовать ODBC — совместимые приложения. IDAPI также планирует поддерживать свой транспортный уровень связи клиента с сервером в сети с различными протоколами. Еще одним достоинством IDAPI является возможность работы с распределенной БД и исполнения в запросе операций соединения таблиц из разных СУБД. Пользователи IDAPI смогут работать с большими двоичными объектами (BLOB), в которых может хранится изображение и звук.
Стандарты IDAPI и ODBC во многом пересекаются и очевидно некоторые время будут конкурировать не рынке. Очевидно Microsoft вскоре учтет недостатки ODBC и реализует его версию на новых вычислительных платформах.
4.7 Поддержка группы стандартов интерфейса
Поскольку сегодня не существует единого стандарта интерфейса клиент-сервер и различные компании успешно реализуют на разных вычислительных платформах ODBC, IDAPI, DAL, PIA, DDE и другие стандарты в своих приложениях, стали появляться пакеты, позволяющие одновременно работать с одной СУБД пакетам, реализующим различные стандарты на разных вычислительных платформах.
Развитие этого подхода привело к появлению пакетов, позволяющих связать множество клиентских приложений, поддерживающих разные стандарты интерфейса, с множеством СУБД, почтовых серверов, файл-серверов, palmtop компьютеров и Personal Digital Assistants (PDA) компьютеров. Эти пакеты должны работать на разных вычислительных платформах и иметь средства для быстрого наращивания числа клиентских приложений переднего плана (front end) и числа серверов (back end). Хорошим примером такого продукта является пакет Oracle Glue компании Oracle.
Oracle Glue — это адаптируемый, переносимый, интегрированный пакет, позволяющий склеить в единую прикладную систему клиентские приложения, выполненные с помощью Visual Basic, MS Access, Excel, Amipro, Lotus 1-2-3, Authorware, MS Word, QuattroPro, Asymmetrix ToolBook и любых DDE совместимых пакетов в среде MS WINDOWS; приложения, выполненные с помощью HyperCard на MAС; приложения, выполненные с помощью WINGZ на Unix; приложения, выполненные с помощью Oracle Card или Pen Apps на перьевых компьютерах, с множеством серверов БД, файловых и почтовых серверов, среди которых: Oracle6, Oracle7, Oracle*Mail, DB2, SQL/DS, Tandem, Sybase, MS SQL Server, dBASE, Paradox, Sharp Wizard & PDA, серверы БД, к которым имеются шлюзы Oracle, серверы БД, поддерживающие стандарты ODBC, DAL, PIA, IDAPI, почтовые серверы, поддерживающие стандарты MHS, VIM, MAPI и т.д. (см. рисунок 4).
4.8 Шлюзы
Шлюз — это программное обеспечение, заставляющее сервер БД одной компании выглядеть для работающих с ним клиентов как сервер БД другой компании. Например, если на компьютер mainframe с OC MVS, где работает СУБД DB2, поставить шлюз Oracle Transparent Gateway to DB2, то все программы-клиенты, работающие с СУБД Oracle, смогут работать с СУБД DB2. Шлюз обычно ставится на том же компьютере, где работает СУБД, работу которой надо «закамуфлировать».
Большинство компаний-производителей популярных коммерческих серверов БД имеют шлюзы к серверам БД других компаний («чужим» серверам). Шлюз позволяет работать с «чужой» СУБД не только клиентским приложениям, но и серверам БД (в приведенном примере приложения Oracle и сервер БД Oracle могут работать с СУБД DB2). Это позволяет перекачивать данные между различными СУБД и, если шлюз обеспечивает поддержку двухфазного протокола фиксации изменений (2 phase commit), создавать распределенную БД, в узлах которой находятся СУБД различных компаний. Например, в распределенной СУБД Oracle один из узлов может использовать СУБД DB2 на mainframe или СУБД SQL/400 на компьютере AS/400 (где СУБД Oracle не реализована).
Шлюзы помогают интегрировать данные различных СУБД и использовать мощные инструментальные средства одних компаний для работы с данными СУБД других компаний. Кроме того, шлюзы могут «камуфлировать» не только реляционные СУБД, но и СУБД с другими моделями данных (иерархической, инвертированные списки), а также файловые системы. Используя, например, шлюз Oracle к Adabas можно работать с СУБД Adabas, имеющей специфическую модель данных, как с реляционной СУБД и использовать для работы команды языка SQL. Аналогично, шлюзы Oracle к VSAM и RMS позволяет работать с файлами с таким методом доступа как с реляционной СУБД.
Имея шлюзы к различным СУБД и файловым системам можно создавать программы, извлекающие данные одновременно из СУБД с различной моделью данных и файлов, выполнять соединения «join» этих данных и прочую обработку.
Некоторые шлюзы имеют ограниченные функции, т.е. позволяющие выполнять только чтение из «чужой” БД. Существуют также «двунаправленные» шлюзы, которые позволяют не только обращаться к «чужой» СУБД для чтения/записи, но и позволяют «чужой» СУБД самой обращаться к другим серверам БД для исполнения чтения/записи (пример таких двунаправленных шлюзов — Database Gateway компании MicroDecisionware Inc и Open Server компании Sybase).
Программное обеспечение шлюза выглядит для «чужой» СУБД, как клиент этой СУБД. Для «родного» сервера БД или «родного» клиентского приложения шлюз выглядит как свой «родной» сервер БД. При работе шлюз выполняет следующие действия:
- проверяет синтаксис и семантику поступающих SQL предложений и исполняет их;
- конвертирует синтаксис и семантику SQL «родной» СУБД в команды «чужой» СУБД или файловой системы;
- конвертирует типы данных;
- позволяет видеть и использовать каталог «чужой» СУБД, как каталог «родной» СУБД;
- транслирует коды и сообщения об ошибках «чужой» СУБД в коды и сообщения «родной» СУБД;
- возвращает данные, полученные в результате исполнения запроса на выборку данных.
Иногда шлюз может заниматься оптимизацией исполнения запроса, обеспечивать работу с удаленными процедурами RPC (remote procedure calls).
4.9 Средства обработки распределенных транзакций
Средства обработки распределенных транзакций (Distributed Transaction Processing — DTP) еще мало известны в нашей стране. Эти средства позволяют связывать разнородные компьютеры с различными операционными системами и различными СУБД в единую среду обработки приложений. Причем в этой среде поддерживается расширенная архитектура клиент-сервер.
Расширение заключается в том, что клиент может посылать серверам запросы не последовательно (синхронно), а асинхронно. При этом несколько запросов одного клиента могут одновременно выполняться различными серверными узлами сети. Это конечно позволяет ускорить обработку.
Наиболее известными сегодня средством обработки распределенных транзакций является пакет TUXEDO ETP System, Release 4.2 компании USL (Unix system Laboratories). Он позволяет связать в единую среду персональные компьютеры с MS DOS, MS Windоws, OS/2, Unix; машины среднего класса с Unix и mainframe с MVS/CICS. Приложения работают на персональных компьютерах, а различные СУБД — на Unix-компьютерах среднего класса. Кроме того, поддерживается интерактивное взаимодействие по схеме запрос/ответ с MVS/CICS процессами через протокол LU6.2.
Средства DTP практически надстраиваются над операционными системами компьютеров сети, образуя вместе с ними единую среду, в которой работают приложения и СУБД.
Приложения взаимодействуют не с СУБД, а с монитором транзакций DTP, а монитор сам выбирает нужную СУБД, запускает ее, передает ей запросы и получает результаты.
Монитор транзакций также обеспечивает выполнение распределенных транзакций (модифицирующих данные в нескольких, возможно различных СУБД) Он сам обеспечивает выполнение двухфазного протокола фиксации и откат транзакций.
Среди недостатков DTP следует указать ограниченное количество поддерживаемых сетевых протоколов и СУБД. В приложении должен использоваться SQL конкретной СУБД или стандарт SQL. Использование специфического языка интерфейса с монитором транзакций не позволяет «уйти» из среды DTP. Опыт использования систем такого класса у нас в стране ограничен (а они достаточно сложны в использовании).
Заключение
В результате исполнения курсовой работы можно сделать следующие выводы.
Модель взаимодействия, в которой один участник сети инициирует выполнение какой-либо действия или набора действий, а другой ее выполняет, называется моделью «клиент-сервер». Участники подобного взаимодействия являются соответственно клиентом и сервером. В большинстве случаев клиентом (или сервером) называют вычислительную машину или их объединение, которые представляют из себя клиентское (или серверное) программное обеспечение.
Мы живем в век информационных технологий и больших объемов данных. Никогда ранее еще за единицу времени не было возможности передать или обработать такое количество информации. Модель «клиент-сервер» позволяет централизованно организовать автоматизированные системы, выполняющие самые разнообразные задачи в каждой из сфер деятельности человека. Именно поэтому, модель «клиент-сервер» является незаменимым подходом организации архитектуры и взаимодействия современных приложений, представляющих необходимый функционал гибкого, безопасного и масштабируемого доступа к данным без которых представить современную жизнь уже невозможно.
Библиографический список
Специальная, научная и учебная литература
- Л. Калиниченко. Стандарт систем управления объектными базами данных ODMG 93: краткий обзор и оценка состояния. — СУБД, 1, 1996. 49 – 51 с.
- Д. Брюхов, В. Задорожный, Л. Калиниченко и др. Интероперабельные информационные системы: архитектуры и технологии. — СУБД, 4, 1995 , 96-113 с.
- H. Мухамедзянов, Java. Серверные приложения, — Издательство: СОЛОН — Р, 2003 , 287 с.
- Роберт Орфали, Дэн Харки, «JAVA и CORBA в приложениях клиент-сервер» , 2000, 614 с.
- Дуглас Камер, Дэвид Л. Стивенс, Сети TCP/IP, том 3. Разработка приложений типа клиент/сервер, издательство «Вильямс», 2002 г., 501 с.
- Фленов М.Е., Web-сервер глазами хакера: Проблемы безопасности Web-серверов; БХВ-Петербург, 2012 , 89 — 90 с.

- Методы кодирования данных (Классификация предназначения и методы представления кодов. Способ кодировки Хаффмана)
- Применение объектно-ориентированного подхода при проектировании информационной системы (Моделирования проектируемой системы)
- Управление поведением в конфликтных ситуациях (Стили поведения при конфликте и методы разрешения конфликтов)
- Опекунство (общая характеристика) (Понятие института опеки и попечительства)
- Отношения родителей и подростков (Теоретические аспекты детско-родительских отношений в подростковом возрасте)
- «Роль семьи в воспитании культуры речи ребенка»
- Международные стандарты гостиничного обслуживания (Анализ деятельности гостиницы Radisson Royal Hotel Mosсow)
- Роль мотивации в поведении организации (ООО «УК Уютный дом»)
- Прогнозирование и планирование потребительского рынка (город Ростов-на-Дону)
- Участие России в международных финансовых институтах (исследование международных финансовых институтов и роль России в их функционировании)
- Менеджмент человеческих ресурсов (Черты управленческого профессионализма)
- Распределенная технология обработки информации;
1. Модели клиент- сервер в технологии БД
Вычислительная модель клиент-сервер исходно связана с парадигмой открытых систем, которая появилась в 90-х годах и быстро развивалась. Термин клиент-сервер исходно применялся к архитектуре, при которой клиентский процесс запрашивает некоторые услуги, а серверный процесс обеспечивает их выполнение.
Реализация архитектуры клиент — сервер, применительно к разработке БД позволяет более полно использовать ресурсы сети. Нагрузка равномерно распределяется между компьютером сервером и компьютером клиентом, который также как и сервер обладает собственными ресурсами.
Основной принцип технологии клиент – сервер применительно к технологии БД заключается в разделении функций стандартного интерактивного приложения на 5 групп, имеющих различную природу:
· Функции ввода и отображения данных (Presentation Logic).
· Прикладные функции, определяющие основные алгоритмы решения задач приложения (Business Logic).
· Функции обработки данных внутри приложения (Database Logic).
· Функции управления информационными ресурсами (Database Manager System).
· Служебные функции, играющие роль связок между функциями первых 4-х групп.
Рекомендуемые материалы
Структура типового интерактивного приложения, работающего с БД, приведена на рисунке 2.
рис.
Презентационная логика – эта часть приложения, определяющая то, что пользователь видит на экране. Сюда относятся, интерфейсные экранные формы, а также все, что выводится пользователю на экран, как результаты решения промежуточных задач или справочная информация.
Основными задачами презентационной логики являются:
· Формирование экранных изображений;
· чтение и запись в экранные формы информации;
· управление экраном;
· обработка движений мыши и нажатия клавиш клавиатуры.
Бизнес- логика или логика приложений — это часть кода приложения, которая определяет собственно алгоритмы решения задач приложения. Обычно этот код пишется с помощью различных языков программирования: С, Соbol, Visual Basic.
Логика обработки данных — это часть кода приложения, которая связана с обработкой данных внутри приложения. Данными управляет собственно СУБД. Для обеспечения доступа к данным используются язык запросов и средства манипулирования данными языка SQL. Процессор управления данными – это собственно СУБД, которая обеспечивает хранение и управление БД.
В централизованной архитектуре эти функции располагаются в единой среде и комбинируются внутри исполняемой программы. В децентрализованной архитектуре эти задачи могут быть по-разному распределены между серверным и клиентским процессами. В зависимости от характера распределения можно выделить следующие модели распределений:
· распределенная презентация; (часть представления на клиенте, часть на сервере, на севере – все остальные части)
· удаленная презентация; (вся презентация на клиенте – все остальное на сервере)
· распределенная бизнес логика; (презентация и часть бизнес-логики на клиенте)
· распределенное управление данными; (презентация, бизнес-логика, и часть управления данными на клиенте);
· удаленное управление данными (презентационная и бизнес-логика на клиенте, остальное на сервере).
· распределенная БД.
Эта классификация показывает, как задачи могут быть распределены между серверным и клиентским процессами.
Двухуровневые модели
Двухуровневая модель предполагает распределение всех указанных функций между 2-мя процессами, которые выполняются на 2-х платформах – клиенте и сервере.
В чистом виде почти никакая модель не существует.
2. Модель удаленного доступа к данным
В этой модели презентационная логика и бизнес-логика располагаются на клиенте. На сервере располагается база данных и ядро СУБД (см. рис.3).
Обращение за сервисом управления данными происходит с помощью языка SQL. Достоинство модели – наличие большого числа готовых СУБД, имеющих SQL — интерфейсы и набор инструментальных средств, обеспечивающих создание клиентских приложений. В этой модели по сети передаются SQL-запросы, в ответ на запросы клиент получает не блоки файлов, а только данные, релевантные запросу. Основное достоинство – унификация интерфейса клиент- сервер, стандартом при общении клиента и сервера становится язык SQL. Недостатки: достаточно высокая загрузка системы передачи данных, вследствие того, что вся логика сосредоточена в приложении, а обрабатываемые данные расположены на удаленном узле.
Эти системы неудобны с точки зрения модификации и сопровождения. Даже при незначительном изменении функций системы требуется переделка всей прикладной части. Так как на клиенте расположена и презентационная логика и бизнес-логика приложения, то при повторении аналогичных функций в разных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения.
Сервер в этой модели играет пассивную роль, поэтому функции информационного управления должны выполняться на клиенте. Например, если необходимо выполнять контроль страховых запасов на складе, то каждое приложение, которое связано с изменением состояния склада, после выполнения операций модификации данных, имитирующих продажу или удаления товара со склада, должно выполнять проверку на объем остатка. В случае если он меньше страхового запаса, необходимо формировать соответствующую заявку на поставку требуемого товара. Это может вызвать необоснованный заказ дополнительных товаров несколькими приложениями.
3. Удаленная презентация (Модель сервера БД)
Модель сервера БД приведена на рисунке 4.
Рисунок 4
Модель сервера БД отличается тем, что функции компьютера клиента ограничиваются представлением информации, в то время как прикладные функции обеспечиваются приложением, находящимся на компьютере-сервере. Эта модель является более технологичной, чем модель удаленного доступа.
Для того чтобы избавиться от недостатков модели удаленного доступа, должны быть соблюдены следующие условия:
· Необходимо, чтобы БД, в каждый момент отражала текущее состояние предметной области.
· БД должна отражать некоторые правила предметной области, законы, по которым она функционирует. Например, завод может нормально функционировать только в том случае, когда имеется достаточный запас деталей определенной номенклатуры, деталь может быть запущена в производство только в том случае, если на складе имеется достаточно материала для ее изготовления и т.д.
· Необходим постоянный контроль над состоянием БД, отслеживание всех изменений и адекватная реакция на них. Например, при уменьшении товарного запаса ниже критического уровня должна быть сформирована заявка на поставку соответствующего товара.
Такую модель поддерживают большинство современных СУБД: Informix, Oracle, Sybase, MS SQL Server. Основу данной модели составляет механизм хранимых процедур как средство программирования SQL сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который называется механизмом поддержки доменной структуры. Процедуры обычно хранятся в словаре БД и разделяются несколькими клиентами. Хранимые процедуры могут выполняться в режимах интерпретации и компиляции. Клиентское приложение обращается серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, соответствующие его запросу, которые требуются либо для вывода на экран, либо для выполнения части бизнес-логики, которая расположена на клиенте. Трафик обмена информацией между клиентом и сервером заметно уменьшается.
Централизованный контроль целостности данных в модели сервера БД выполняется с использованием механизма триггеров. Триггеры также являются частью БД. Термин триггер взят из электроники и семантически точно отражает механизм отслеживания специальных событий, которые связаны с состоянием БД. Ядро СУБД проводит мониторинг всех событий, которые вызывают созданные и описанные триггеры в БД, и при наступлении соответствующего события сервер запускает соответствующий триггер. Триггер представляет собой некоторую программу, которая выполняется над БД. Триггеры могут вызывать хранимые процедуры.
В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД. И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях. Для написания хранимых процедур и триггеров используется расширения стандартного языка SQL.
Достоинства модели — возможность хорошего централизованного администрирования приложений на этапах разработки, сопровождения и модификации, а также эффективное использование вычислительных и коммуникационных ресурсов. Один из недостатков модели связан с ограничениями средств разработки хранимых процедур. Основное ограничение — сильная привязка операторов хранимых процедур к используемой СУБД. Язык написания хранимых процедур, по сути, является процедурным расширением языка SQL и не может соперничать по функциональным возможностям с традиционными языками, такими как С или Паскаль. Другой недостаток — очень большая загрузка сервера.
Если мы переложили большую часть бизнес логики приложения на сервер, то требования к клиентам в этой модели резко уменьшаются. Иногда такую модель называют моделью с тонким клиентом, в отличие от предыдущих, где на клиента возлагались гораздо более серьезные задачи.
Возможна модель распределенной бизнес-функции, в которой общая часть бизнес-функций реализована на сервере, а специфические функции обработки информации находятся на клиенте. Функции общего характера могут включать в себя стандартное обеспечение целостности данных, например, в виде хранимых процедур, а оставшиеся прикладные функции реализуют специальную прикладную обработку.
4. Модель распределенной БД
Эта модель предполагает использование мощного компьютера клиента, причем данные хранятся и на компьютере-клиенте и на компьютере-сервере. Взаимосвязь обеих БД может быть 2-х разновидностей:
а) в локальной и удаленной базах хранятся отдельные части единой БД;
б) локальная и удаленная БД являются синхронизируемыми друг с другом копиями.
Достоинство – гибкость разрабатываемых ИС позволяющих компьютеру клиенту обрабатывать и локальные и удаленные БД. Недостаток – высокие затраты при выполнении большого числа одинаковых приложений на компьютерах клиентах.
5. Модель сервера приложений
Эта модель является расширением 2-хуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Этот промежуточный уровень содержит один или несколько серверов приложений.
В этой модели компоненты делятся между тремя исполнителями:
6. Клиент обеспечивает логику представления, включая графический пользовательский интерфейс; клиент может запускать локальный код приложения клиента, который может содержать обращения к локальной БД, находящейся на компьютере- клиенте. Клиент исполняет коммуникационные функции, которые обеспечивают доступ клиенту в локальную или глобальную сеть.
7. Серверы приложений представляет собой новый дополнительный уровень архитектуры. На сервере приложений реализуется несколько прикладных функций, каждая из которых оформлена как служба предоставления услуг всем требующим этого программам. Серверов приложений может быть несколько, причем каждый из них предоставляет свой вид сервиса. Любая программа, запрашивающая услугу у сервера приложений, является для него клиентом. Поступающие к серверам от клиентов запросы помещаются в очередь.
8. Серверы БД в этой модели занимаются исключительно функциями СУБД: обеспечивают создания и ведения БД, обеспечивают функции хранилищ БД, кроме того, на них возлагаются функции создания резервных копий, восстановления БД после сбоев, управления выполнением транзакций.
Эта модель обладает большей гибкостью, чем двухуровневая модель.
9. КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Перечислите основные функции стандартного интерактивного приложения, связанного с обработкой баз данных.
8. Вскрытие штольней — лекция, которая пользуется популярностью у тех, кто читал эту лекцию.
2. Перечислите основные задачи презентационной логики.
3. Что включает в себя бизнес-логика приложения?
4. Перечислите варианты распределения функций стандартного интерактивного приложения в архитектуре клиент-сервер.
5. Назовите основные двухуровневые модели архитектуры клиент-сервер.
6. В чем заключаются особенности модели удаленного доступа к данным?
7. Какими средствами реализуется бизнес-логика при использовании модели удаленной презентации?