Распознавание документов на частном примере — обзор доступных платных и бесплатных решений
Время на прочтение
6 мин
Количество просмотров 18K
Всем привет! Типичная ситуация сложилась в компании, в которой я работаю. В бухгалтерии вечный аврал, людей не хватает, все занимаются чем-то безусловно важным, но по сути бесполезным. Такое положение дел не устраивало руководство.
Если подробнее, то проблема в том, что ресурсов бухгалтерии не хватает на текущие задачи, а выделять ставки под новых людей никто не хочет. Поэтому сверху приняли решение порезать некоторые задачи и освободить время бухгалтеров для более полезных дел. Под нож попала такая работа как сканирование и распознавание документов, копирование, внесение их в прочие рутинные радости.
Так передо мной, как аналитиком, встала задача: найти решение для распознавания документа типичного для моей компании — счет-фактуры — структурировать его в имеющиеся хранилища, а также в 1С. Решение, которое будет удобным, понятным, и не влетит компании в копеечку.
Опыт получился занятным, решил поделиться тем, что удалось собрать. Возможно я что-то упустил, поэтому велком в комментарии, если есть, что добавить.
Программы сканирования документов, программы распознавания документов — не новое решение на рынке, его можно найти как в бесплатных программах, так и встроенных в системы.
Начал я с бесплатных программ:
- glmageReader
- Paperwork
- VietOCR
- CuneiForm.
В ходе распознавания нашего счета-фактуры такими программами я увидел следующее:
- В таких программах как VietOCR, Paperwork, glmageReader можно настроить хранение отсканированных документов в определенные папки, Paperwork умеет их даже сортировать, согласно меткам.
- В основном они хорошо справляются с текстом, а там, где текст распознан некорректно, в некоторых программах можно вручную изменить содержимое, прежде чем экспортировать файл.
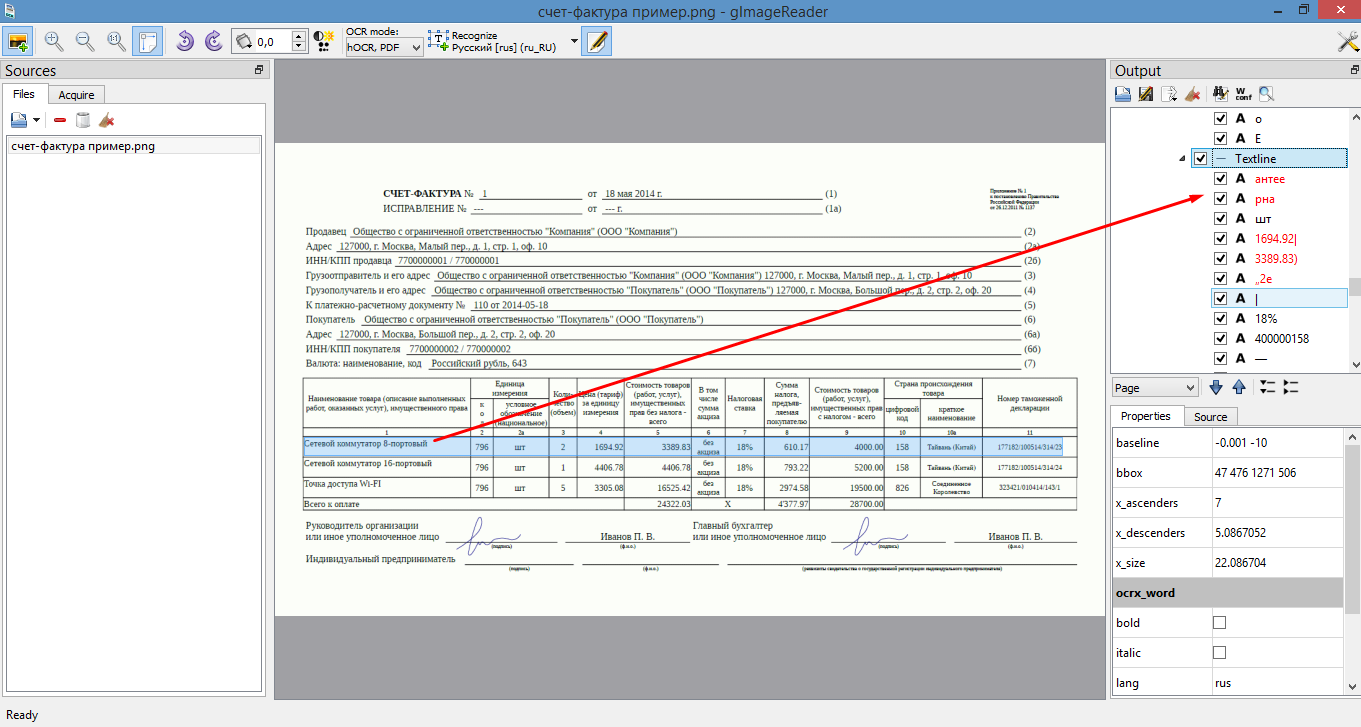
Однако есть и проблемы:
- Есть разница между работой с pdf сканами и png. Не всегда удается удачно конвертировать png в pdf.
- Большинство таких программ сложно справляются с распознаванием документов табличного вида, даже самого простого формата. В результате мы получаем распознанный текст без размеченных полей.

- Иногда неточно определяется шрифт, вследствие чего при конвертации весь распознанный текст наезжает друг на друга.
- В процессе распознавания иногда необходимо делать выравнивание по ключевым словам, с доворотами и смещением координат.
- В некоторых программах таблица распознавалась как картинка и экспортировалась в новый документ Word тоже в качестве картинки, очень урезанной, которую даже сложно разглядеть.
- При редактировании распознанного содержимого в некоторых программах возникали проблемы, менялся шрифт или сам текст.

Технология сработала достаточно хорошо, Учитывая, что программы бесплатные, описанные выше проблемы допустимы. Однако, я искал более упорядоченного решения.
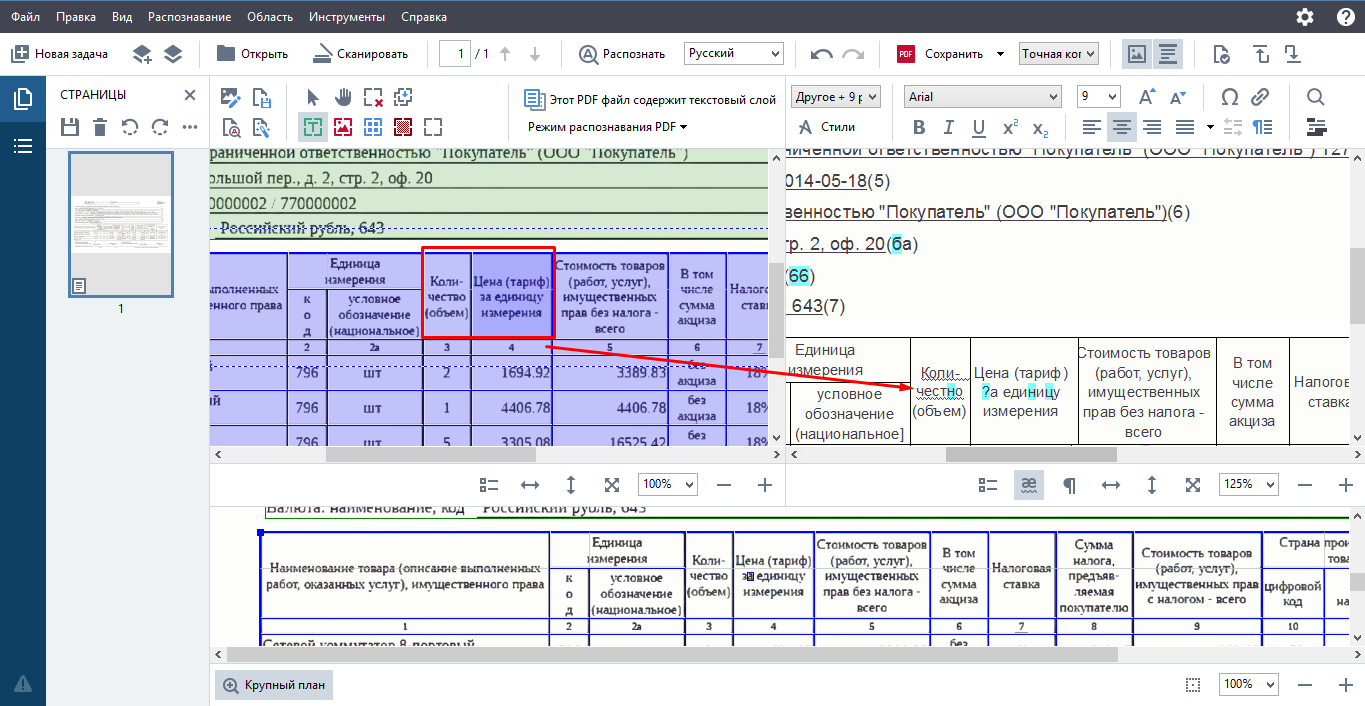
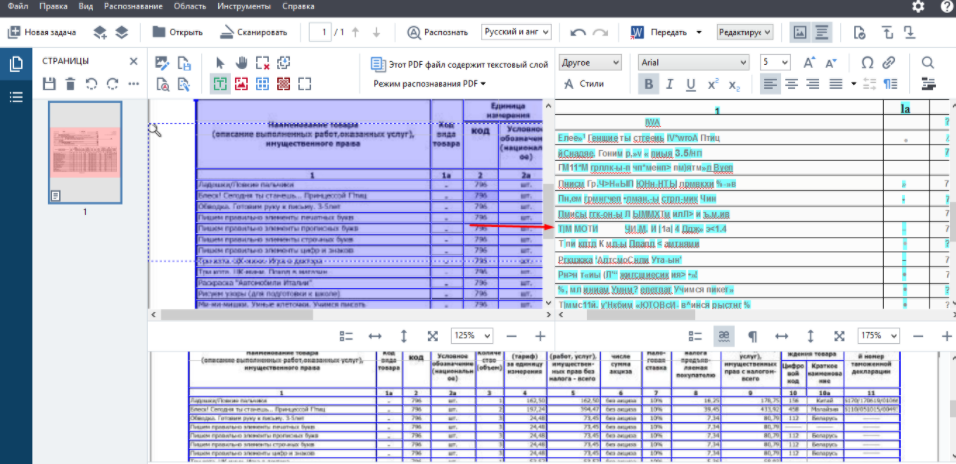
Затем я исследовал распознавание в ABBYY FineReader 15 Corporate
За 7-дневный срок триала я изучил и эту платформу.
Что отметил:
- Когда я открыл png файл, он отлично был считан и в результате удачно конвертирован в pdf без потери качества изображения и текста.
- Программа отлично знает, как отсканировать документ для редактирования текста. Причем в режиме редактирования файла формата png текст удается отредактировать без проблем, но иногда слетает разметка.
- Однако то же самое я не могу сказать про редактирование файла-скана pdf. При попытке редактирования летели слои.
- Табличный вид распознается качественно, вся структура сохраняется, меня это порадовало.
- OCR редактор хорошо распознал мой сформированный pdf счет-фактуры. Где-то пару символов требовалось поправить вручную.
- Однако, была ситуация, что почти весь подобный документ распознался с меньшей точностью и данных для изменения вручную было уйма. Думаю, здесь можно было бы решить вопрос технически, но это затратило бы больше времени.
- Здесь можно настроить автоматическую конвертацию входящих документов, которые регулярно будут тянуться из указанной папки, по указанному расписанию.
- Он позволяет сравнивать версии документов, даже если они в разных форматах. При большом потоке документов и правок в них, это очень удобно.
От использования этого софта были приятные впечатления. Однако, когда я обратился к ценнику системного решения ABBYY Flexicapture (а мне нужно именно системное), то выяснил, что решение, особенно кастомизированное, обходится в довольно круглую сумму, около 400 тыс. руб./мес. и выше за 10 тыс. страниц.
Я стал искать альтернативу. Как освободить руки сотрудника, получить качественное распознавание документов и не переживать за сохранность и структуру данных.
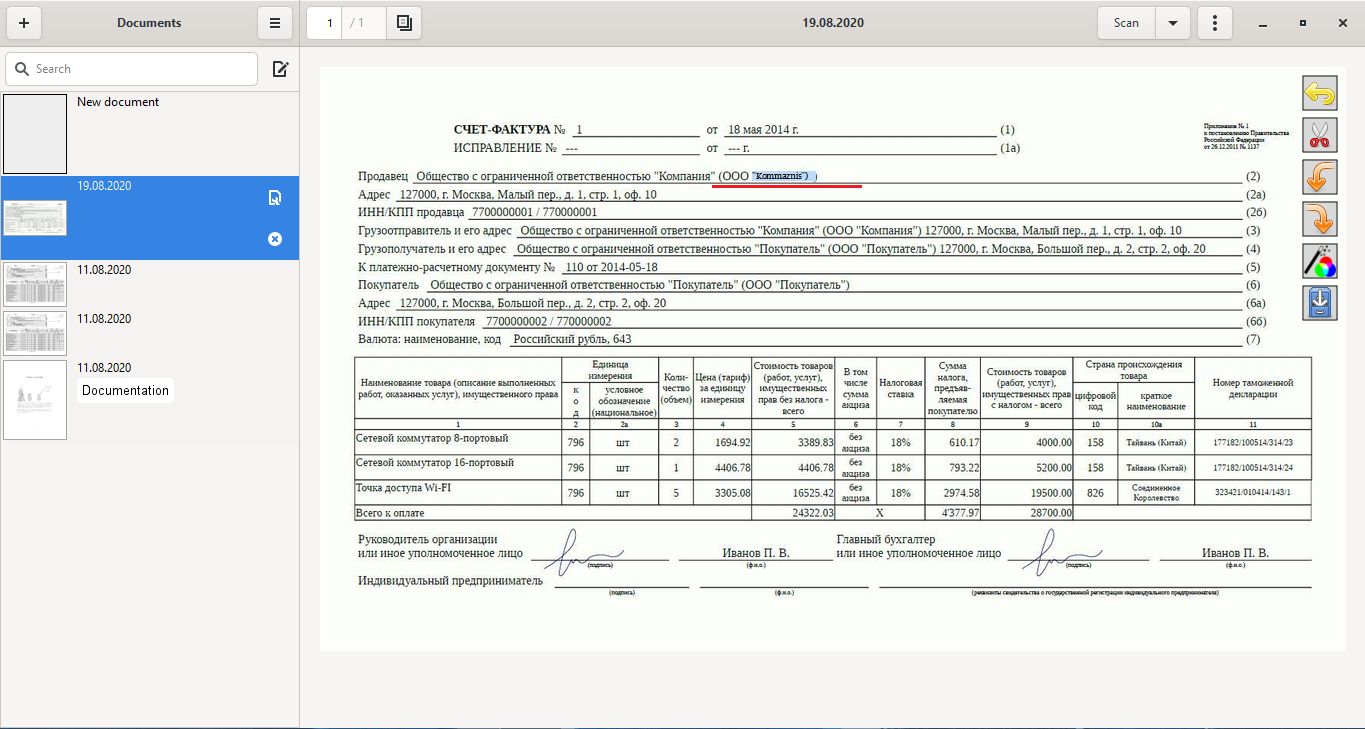
И тут я решил получше разглядеть ELMA RPA, которую я уже изучал ранее.
Вендор предлагает перекинуть значительную часть работы по экспорту данных в ERP с плеч бухгалтеров на роботов. По сути, именно это решает поставленную передо мной задачу. Чтобы познакомиться с распознаванием в этой системе, я взял у вендора триальную версию системы.
Здесь я обнаружил, что распознавание не преследует цели конвертировать полученные данные в новый документ-файл.
Здесь главная цель — распознавание реквизитов документа и их передача в другие системы/сайты/приложения. Кроме того, роботы складывают всю информацию куда надо: автоматически находят нужные папки и сохраняют в необходимых форматах.
Какие виды распознавания в системе я посмотрел:
Распознавание по шаблону
Нам предлагается на основании шаблона документа распознать подгружаемый документ. Насколько мне известно, этот вид распознавания бесплатный, внутрь зашит движок Tesseract.
Что отметил:
- Этот вид распознавания работает именно со сканами формата jpg и png, pdf он пока не рассматривает. Но продукт еще молодой, думаю, все впереди.
- Этот вид распознавания входит в бесплатную версию Community Edition
- Удобно размечен текст по блокам, которые можно сопоставить, согласно переменным, которые мы создали в контексте робота. Таким образом вручную настроить, что именно тянем в распознавание.
- Нашу счет-фактуру он распознал 50/50, некоторые слова подменил как посчитал нужным.

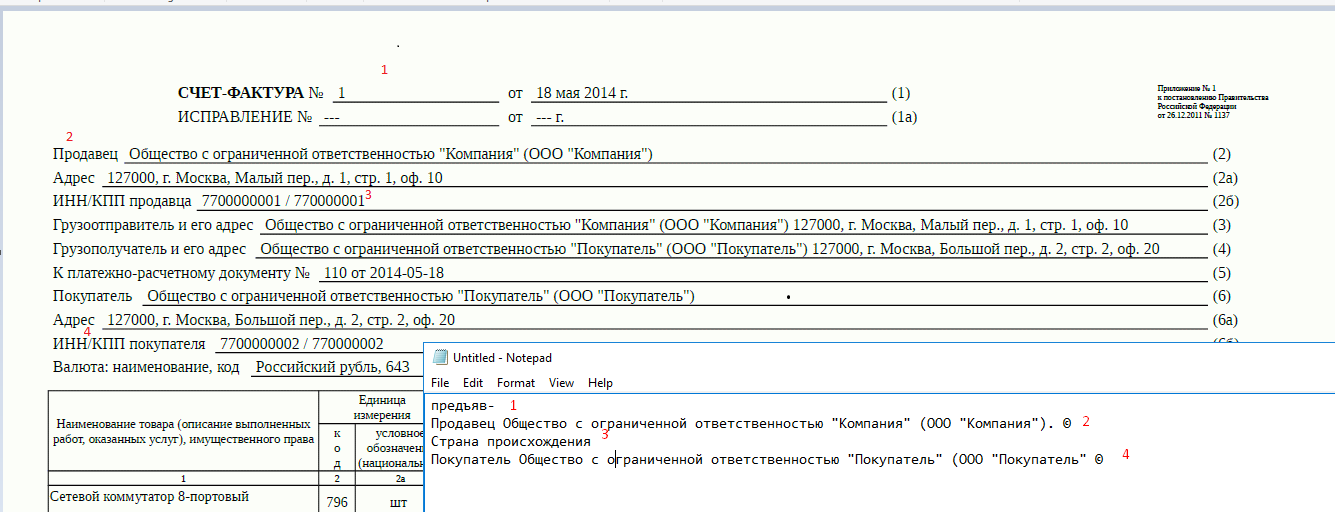
Однако, вендор на данный кейс сообщил, что этот вид распознавания адаптирован под простые документы, с текстовой структурой или с легкими формами. И посоветовал для распознавания счета-фактуры использовать другой вид распознавания — intellect lab.
Процесс тот же, загружаем шаблон и по нему распознаем. Но здесь шаблон отправляется на облачный сервер.
От сервера получаем ответ (распознает такой тип документа или нет), и если распознается, то передается структура шаблона (переменные для маппинга), для сопоставления переменных, которые необходимо будет записать в RPA процессе.
В процессе воспроизведения мы отправляем уже документ, который хотели бы распознать и получаем ответ от iLab сервера о распознавании.
Что отметил по поводу этого распознавания:
- Здесь уже распознавание работает как программа сканирования документов pdf, и при этом работает и с форматами jpg и png.
- Качество документа не влияет на эффективность распознавания. Даже документы с плохим качеством распознаются корректно.
- Счет-фактура распозналась полностью и без подмен переменных.
- Робот сумел получить скан с почты, распознать его и создать его экземпляр в 1С. То есть автоматически сохранил файл там, где мы ему задали, что, естественно, крайне удобно.
- Входит в бесплатную Community Edition в виде распознавания документа в облаке. Подходит, если используем стандартные типы (СФ, УПД, АВР и др.), и, например до 100 документов в месяц или до 500 в год. (Стоит заметить, что считаем не в страницах, а в документах непосредственно.)
Сам процесс распознавания документов довольно сложно отобразить на видео, так как это происходит в коробке, а экран пустует несколько секунд. Поэтому я сделал отдельную запись распознанных данных в блокнот для визуализации.

Соответственно, эти же данные робот записывает в 1С, создавая там новый документ:

Что удалось выяснить по ценам: Если мы, например, хотим работать масштабно именно с ilab распознаванием, то за наши 10 000 документов придется выложить:
- примерно 180 000 руб. единовременно,
- плюс, допустим, 400 000 руб. покупка робота с оркестратором
- итого: 580 000 руб.
Робот бессрочный, а 10 000 документов на какое-то время хватит. Довольно выгодно получается, как минимум в том, что заплатим за все один раз.
Что понравилось в распознавании в этой платформе в целом:
- Можно настроить получение документов по событию, а также, например из электронной почты и любых других внешних источников. У меня пока была цель настроить получение с почты.
- Все считанные данные с документа можно спокойно записать в контекстные переменные и далее их передать в необходимые системы, приложения, сайты, ВМ и т д. И я не переписываю уже ничего руками.
- Скорость обработки. 15 секунд и объект распознан, а остальной порядок действий — это счет по минутам. Если заявиться с потоковым сканированием с большим количеством документов, думаю это не составит больших временных затрат.
- Много качественного функционала в свободном доступе, для небольших компаний им можно вполне обойтись.
Итого:
- Бесплатные программы справляются с задачей распознавания документов лучше, чем я предполагал, однако за счет них значительно ускорить работу с большим объемом не удастся
- ABBYY FineReader хорошо справляется с обработкой и распознаванием документов после, однако, чтобы получить системное решение, нужны большие финансовые возможности.
- ELMA RPA удивила по качеству распознавания документов, вариативностью, а также возможностям хранения и передачи после распознавания, но стоит учесть, что продукт молодой.
Smart Document Engine
— российская система автоматического анализа и распознавания документов для десктопных, серверных и мобильных платформ.
Smart Document Engine – это программный инструмент для бизнеса и разработчиков, обеспечивающий высокоточное и высокоскоростное распознавание текстовых и иных данных первичных, деловых, уставных, бухгалтерских, налоговых, нотариальных, юридических, страховых и банковских документов, а также типовых анкет и форм строгой отчетности.
Наукоемкая технология оптического распознавания символов GreenOCR®, разработанная нашими учеными, позволяет точно распознавать текст любых документов на более чем 100 языках, включая кириллицу, латиницу, арабский, персидский, урду, японский, китайский, корейский и другие. GreenOCR® обеспечивает высокую точность распознавания печатного текста (OCR), рукопечатного и рукописного заполнения полей (ICR), а также распознавание меток и чекбоксов (OMR). Смотреть спецификацию
При использовании Smart Document Engine НЕ требуется выполнять дополнительных действий, связанных с получением согласия субъекта на обработку его персональных данных (юридическое заключение).
Легкая интеграция без нарушения привычных процессов
Smart Document Engine является уникальным инструментом, позволяющими гибко интегрировать распознавание документов в текущую деятельность компании. Программа легко и удобно встраивается в уже существующие бизнес-процессы, не нарушая привычного опыта использования. Решение доступно для интеграции с различными информационными системами, например, ECM, CRM, RPA, 1С, АБС и т.д.
Скорость
Оригинальный целочисленный конвейер обработки изображений, включающий 8- и 4-битные глубокие нейросетевые архитектуры, позволяет использовать интеллектуальное распознавание документов даже на бюджетных телефонах за счет максимального использования имеющихся аппаратных ресурсов.
Точность
Мы создали новое поколение технологий OCR, преодолевшее рубеж качества традиционных подходов за счет использования наших последних достижений в вычислительном интеллекте и глубоком обучении. Точность распознавания реквизитов документов доходит до 99.5% без участия человека.
Производительность
Высочайшая производительность достигается за счет комбинирования алгоритмов компьютерного зрения и глубокого обучения компактных нейронных сетей. Полный цикл от определения типа до распознавания всех реквизитов занимает от 2 секунд для страницы документа формата А4. Демо-версия доступна для загрузок.
Удобство
Наши передовые алгоритмы сами обнаруживают документ на кадре, автоматически определяют тип документа, находят реквизиты и распознают их. Система устойчива к различным геометрическим искажениям, шумам, перепадам освещения, дефектам печати и низкому разрешению. Загрузите демо-версию продукта и проверьте удобство технологии
Поддержка Российских платформ
Smart Document Engine — первая система распознавания документов которая нативно (без эмуляции) поддерживает Российские аппаратные платформы “Эльбрус”, “КОМДИВ” и “Байкал”, что позволяет использовать продукт в зонах максимальной ответственности и защищенности. Система Smart Document Engine обеспечивает беспрецедентный уровень безопасности обработки данных и защиту от санкционных рисков.
Многоплатформеность
Smart Document Engine поддерживает широкий класс операционных систем, включая специализированные операционные системы, предназначенные для работы с персональными данными: ОС Эльбрус, РЕД ОС, ОС Атликс, Astra Linux, Cent OS, Ubuntu, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Arch Linux и другие дистрибутивы Linux, MS Windows, macOS, ОС Аврора, iOS, Android, Sailfish Mobile OS.
Как поставляется данное программное обеспечение
С помощью Smart Document Engine SDK вы сможете добавить функциональность глубокого анализа и распознавания документов как в ваши инфраструктурные решения для автоматизации back office, так и в мобильные приложения, для максимального упрощения удаленного автоматического ввода документов.
Программа Smart Document Engine поставляется в виде автономного SDK (software development kit), содержащего все необходимые прекомпилированные библиотеки, документацию программного интерфейса и примеры интеграции для различных языков программирования. Для разработчиков подготовлен простой, но многофункциональный API (application programming interface), который позволяет внедрить распознавание документов в решения с использованием языков C++, C#, Java, Python и Objective-C для широкого круга операционных систем: iOS, Android, Linux, Windows, MacOS, в том числе Sailfish Mobile, МОС “Аврора”, ОС Эльбрус, РЕД ОС, Astra Linux, и другие. Обеспечивается поддержка следующих аппаратных платформ: x86_64, ARM v7, v8 (Aarch32, Aarch64), MIPS, Эльбрус. Имеется возможность настройки и подключения к популярным фреймворкам RPA и продуктам 1С по запросу.
Документы, распознаваемые “из коробки” включают в себя свидетельство о постановке на налоговый учет гражданина РФ (ИНН), справка о доходах физического лица установленного образца (ранее 2-НДФЛ), платежное поручение (форма 0401060), бухгалтерский баланс (форма 0710001), отчет о финансовых результатах (форма 0710002), заявления на выдачу загранпаспорта, форма АДИ-РЕГ, титульный лист устава, сертификат самозанятого, выписка ЕГРЮЛ, товарная накладная (ТОРГ-12), форма УПД, счет-фактура и другая первичка.
Наши клиенты
Тинькофф Банк
Smart Engines поставляет мобильные и серверные решения по распознаванию документов Тинькофф Банку
Альфа-Банк
Альфа-Банк распознает документы клиентов в мобильном приложении с помощью Smart ID Engine
Банк «Открытие»
Банк «Открытие» увеличит продажи кредитных продуктов за счет внедрения технологии распознавания документов Smart Engines на сайте
Газпромбанк
Газпромбанк внедрил решение Smart Engines на основе искусственного интеллекта для распознавания QR-кодов

Как ускорить ввод первички и при этом не наделать ошибок? Например, воспользоваться сервисами распознавания документов. Такие решения сегодня предлагают как производители сканеров, так и разработчики систем электронного документооборота.
Распознавание документов востребовано в компаниях, где ежедневно сотрудники обрабатывают тысячи бумажных документов. Например, это банки, организации в сфере ритейла, промышленные предприятия, холдинги.
За счет распознавания текстов сокращаются трудозатраты сотрудников на рутину и освобождается время для более важных задач.
Directum Ario One обеспечивает распознавание текста с точностью до 100%. Работает это так: объем данных, которые передает заказчик, «прогоняется» через интеллектуальную обработку и верификацию. Распознавать можно документы любой сложности, даже рукописные тексты.
Как работает распознавание документов
- Сотрудник сканирует и загружает документы в сервис распознавания, который синхронизируется с корпоративной системой.
- Далее с помощью механизмов искусственного интеллекта из скан-копии извлекаются реквизиты и другая необходимая информация.
- Облачный оператор проверяет извлеченные факты и дозаполняет данные, если необходимо.
- Когда документ полностью распознан, он выгружается непосредственно в систему или в папку, привязанную к email.
Решения для распознавания документов, которые предлагают вендоры
Автоматическая классификация, извлечение реквизитов и занесение данных в информационную систему
У некоторых компаний есть запрос на полную автоматизацию процессов внутри корпоративной системы — от распознавания скан-копии до заполнения реквизитов и отправки на согласование. С помощью такого комплексного подхода можно настроить распознавание текстов документов непосредственно под нужды организации.
Например, в АО «ОДК-Авиадвигатель» решения на базе искусственного интеллекта самостоятельно классифицируют вид документов, извлекают данные и создают электронные карточки в системе. Делопроизводитель только проверяет корректность заполнения. Временные затраты на регистрацию документа снижаются на 15-20%.
Другой пример — обработка финансовых документов в АО «Теплоэнерго». С помощью системы и ИИ в компании проходит классификация первички с точностью до 95%. При этом полнота извлечения данных составляет 87%.
Автоматическое определение ответственного
Распознанные документы классифицируются по большому количеству реквизитов, например, по контрагентам, номенклатуре. Затем благодаря системе автоматически определяется ответственный за обработку документации. Не нужно пересылать друг другу скан-копии и узнавать, что с ними делать дальше.
В госорганах Удмурткой Республики уже внедрили интеллектуальные сервисы, которые автоматически отличают спам от содержательных входящих писем и регистрируют их в системе. Далее система сама заполняет реквизиты, готовит проект резолюции и отправляет его на корректировку, а после — на согласование по заданному маршруту. Ожидается, что сервисы сэкономят до 3 млн рублей в год на обработке входящей корреспонденции.
Где хранить электронные документы после распознавания?
После распознавания документов их скан-копии обрабатываются и попадают в архив. Он находится в ИТ-инфраструктуре заказчика. У централизованного хранения электронных и отсканированных документов множество преимуществ:
- Безопасность данных. Доступ к информации регулируется: для сотрудников определенных должностей настраивают соответствующие права. Сколько по времени хранить тот или иной документ, устанавливает законодательство и непосредственно сама компания.
- Задачи под контролем. Все действия фиксируются: когда и что было отправлено, когда возвращено. Все согласования и подписания идут строго по маршруту. В любой момент можно посмотреть, где сейчас находится документ;
- Быстрый поиск. Необходимый комплект документов легко найти и выгрузить — достаточно ввести несколько параметров. В итоге время на поиск и подготовку документации сокращается в 7-12 раз.
Подробнее о распознавании нетиповых и архивных документов читайте здесь.
Появились решения, расширяющие возможности Directum RX в части интеллектуальной обработки. «Фоновая индексация документов» извлекает текстовый слой документа для удобного поиска по содержимому, а алгоритмы нечеткого поиска помогают системе точнее определять контрагента и адресата при занесении документов.
Интеллектуальная обработка документов снижает трудоемкость ручных действий сотрудников. В линейке решений Directum RX появилась «Фоновая индексация документов», а в саму систему были интегрированы алгоритмы нечеткого поиска данных с помощью Elasticsearch.
Фоновая индексация
В системе могут оставаться документы, для которых недоступен поиск по содержимому. Например, загруженные до внедрения интеллектуальных сервисов Ario или созданные из файла или других программ.
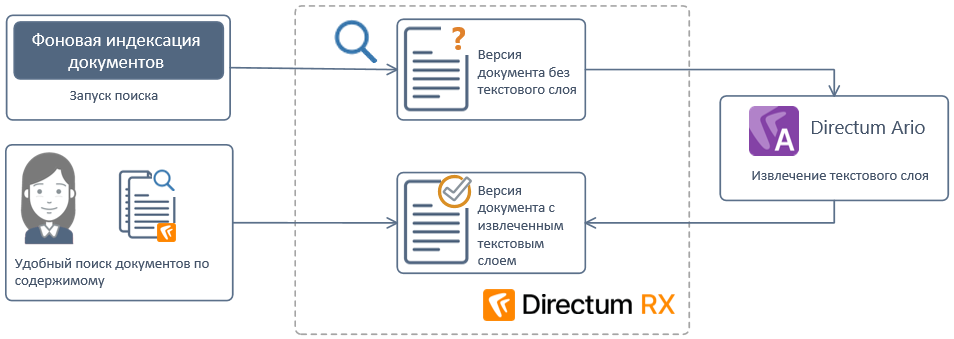
Схема работы решения «Фоновая индексация документов»
Текстовый слой извлекается автоматически и не требует участия человека. Нужно только настроить расписание процесса, виды и количество обрабатываемых за раз документов. При этом нагрузку на сетевые ресурсы можно гибко масштабировать.
В результате документы становятся доступными для поиска по содержимому, и пользователям их проще найти.
Гибкий подбор контрагента и адресата
Сервисы Ario извлекают из текста поступившего документа факты, на основании которых в системе заполняется его карточка. Бывает, что в документе не хватает реквизитов или из-за качества изображения какой-то из них не распознается.
Для таких случаев разработаны алгоритмы нечеткого поиска — они позволяют избежать ручного занесения информации:
- сервисы Ario извлекают реквизиты организации-отправителя (ИНН, КПП и наименование) и получателя (ФИО);
- если не все факты распознаны, имеющиеся данные передаются в Elasticsearch, что помогает с большей долей вероятности идентифицировать контрагента и адресата, даже если в документе, например, есть только КПП и нет ИНН.
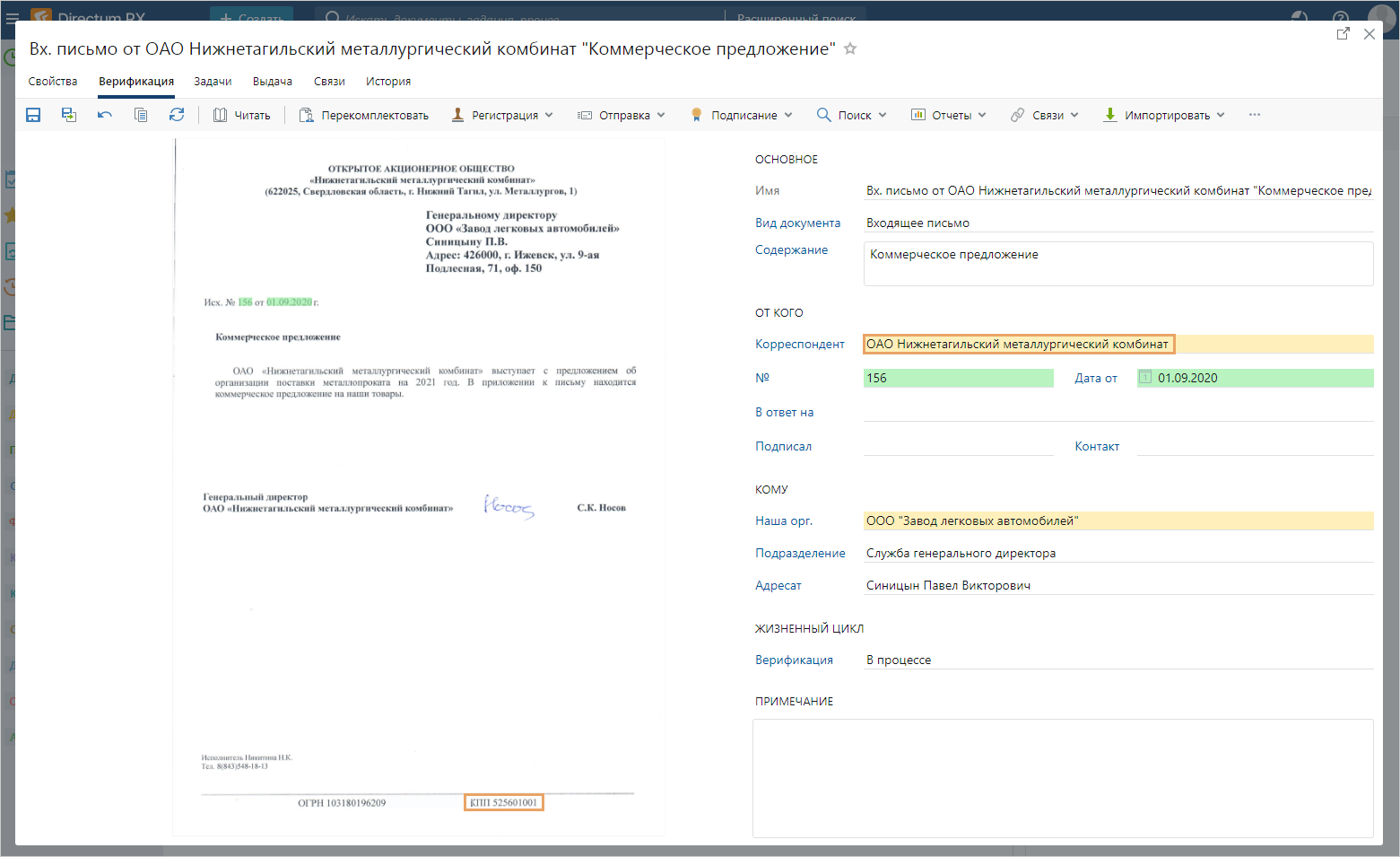
Пример автоматического подбора контрагента по КПП
В перспективе с помощью этой функциональности можно будет с высокой вероятностью заполнять любые справочные реквизиты.
Развитие и разработка новых инструментов для повышения качества и эффективности обработки документопотоков — одно из приоритетных направлений работы компании Directum.
Автоматическое заполнение реквизитов документа
Автор Kest_88, 25 мар 2016, 11:22
0 Пользователей и 1 гость просматривают эту тему.
Добрый день! Уважаемые форумчане, нужна помощь.
Имеется документ «Продажа товаров», на основании которого, формируется документ «Заявка на машину», в котором есть реквизиты «контактное лицо» и «телефон», которые в свою очередь должны браться из справочника «Клиенты».
Вопрос собственно вот в чем: как сделать, что бы реквизиты «контактное лицо» и «телефон» в документе «Заявка на машину» заполнялись автоматически? Реквизит «покупатель» заполняется на основании документа «Продажа товаров». Также необходимо, чтобы номер тел. и контактное лицо менялись в зависимости от наименования покупателя.
Заранее спасибо!
В Модуле Объекта
Процедура ОбработкаЗаполнения
Там есть основание, оттуда все и берите.
Помог? Нажми — Спасибо 
skype: Soprov1C
Помог? Нажми — Спасибо
skype: Soprov1C
Обязательным условием для успешной работы в CRM является полное, единообразное и стандартизированное заполнение реквизитов ИП и компаний клиентов.
Какие варианты заполнения реквизитов компаний и ИП встречаются в практике?
- Вручную, как у кого получится, лишь бы что было записано в карточке.
- Полуавтоматически по исторически сложившемуся стандарту и с помощью штатного ПО Битрикс24.CRM.
- В автоматическом режиме по стандарту ФНС и 1С с помощью специальных приложений.
Как работает штатный функционал ПО Битрикс24.CRM?
Менеджер открывает вкладку «компании», вручную пишет название компании и сохраняет новую учетную запись-карточку. Название компании при этом пишется как правило так как думает менеджер, в лучшем случае копируется из e-mail или с сайта.
Достаточно в поле «реквизиты» набрать поле «ИНН» компании и система осуществит автоматический поиск, вывод на экран данных нужной компании, а при сохранении перенос, сохранение реквизитов и юридического адреса в карточке созданной компании.
Штатная форма карточки реквизитов компании содержит стандартный набор полей, в которые вносятся данные компании заглавными буквами.
ВНИМАНИЕ:
Поле «реквизиты» может быть скрыто в карточке становиться доступным в режиме «изменить», а если и в этом случае его не видно, то нужно обратится к администратору портала чтобы он включил «видимость» этого поля и сделал его общедоступным.
По умолчанию штатное ПО Битрикс24.CRM записывает название компании используя шаблон (кратная ОПФ +название + ИНН) записанные заглавными буквами.
Преимущества и недостатки:
Все данные которые переносятся в карточку компании записаны заглавными буквами. При автоматической генерации счетов, актов, договоров переменные данные написанные заглавными буквами создают бросаются в глаза, выбиваются из общепринятого делового стиля, вызывают неудобства, требуют муторной ручной корректировки в каждой карточке и вызывают раздражение пользователей.
Написание названия компании принятого в Битрикс24.CRM с указанием сначала правовой формы обесценивают работу с фильтрами, быстрый поиск и структуру хранения папок документов с названиями компаний на общем диске выстраивая сортируя списки компаний по аббревиатуре.
Так как шаблон написания в Битрикс24.CRM отличается от принятого стандарта 1С, там принят обратный порядок сначала пишется название компании, а в конце указывает ОПФ то в случае обмена данными вызывает дополнительную путаницу и сложности.
Нет возможности заполнять данные банковских реквизитов по банк-клиенту.
Каждое поле банковских реквизитов в карточке компании загружается вручную.
Для заполнения реквизитов компании приходится совершать достаточно много действий.
Требуется обязательное обучение сотрудников и контроль за соблюдением ими регламента.
Приложение «БЫСТРОЕ ЗАПОЛНЕНИЕ РЕКВИЗИТОВ КОМПАНИЙ И БАНКА»
Менеджер открывает вкладку «компании» и если менеджер не знает ИНН компании которое он может записать вместо его названия, то вручную пишет условное название и сохраняет новую учетную запись-карточку.
Дальше менеджер открывает вкладку старта приложения «Автореквизиты» и в поисковой строке начинает набирать название компании. Система сама выведет список совпадений и предложит менеджеру выбрать нужную компанию из ограниченного списка. Если название компании уникальное, то в списке будет содержаться только одна запись.
Если при добавлении новой компании вместо названия сразу указывает ИНН компании, то произойдет автоматическое определение компании и загрузка данных без дальнейших усилий.
Для автоматического заполнения банковских реквизитов компании достаточно заполнить всего два поля: расчетный счет и название или БИК банка.
Важно:
Для продолжения работы с приложением нужно сразу обязательно сохранить новую карточку.
Преимущества и недостатки:
Приложение успешно эксплуатируется 2064 компаниями 35 месяцев, практически 2 года и позволяет работать с компаниями и контактами, обрабатывать все известные ОФП включая ИП.
Часто справочные системы Битрикс24.CRM, ФМС и DaData предлагают неполные или содержащие ошибки адреса. По этой причине имеется возможность после ознакомления с результатом, который подготовило приложение внести ручные и сохранить правки в поля в юридический и фактические адреса.
Полные адреса компании занесенные в формате строки в соответствующее поле автоматически раскладывается на составляющие и сохраняются в отдельных полях для дальнейшей работы с ними: Улица, дом, корпус, строение, Квартира/Офис, Город, Область, Почтовый индекс, Район и Страна.
Имеется возможность записи нескольких адресов: юридический, фактический, доставки, склады и т.д.
Заполнение банковских реквизитов происходит всего в два клика вместо обязательного заполнения каждого обязательного поля.
Процедура автозаполнения реквизитов для ИП (индивидуальных предпринимателей) полностью идентична процедуре заполнения данных для ООО и компаний с другими организационно правовыми формами. Для осуществления заполнения реквизитов для ИП важно указать только нужный шаблон.
Приложение имеет дополнительные поля и гибкие индивидуальные опции для каждой сущности включение которых позволяет не только привести и автоматически обновлять название компании приведя его к стандарту ФНС и 1С (Название + ОПФ), но и удалить из названия кавычки наличие которых приводит к некорректным результатам автоматического обмена данными.
Работает специальная опция адаптации юр. адреса под обмен с 1С.
Более 90% пользователей устраивает бесплатный сервис DaData, но в случае перехода на его платную версию приложение позволяет получать дополнительный и расширенный пакет данных о клиенте содержащий информацию об актуальных e-mail и номерах телефонов компаний.
СПРАВКА:
Существуют несоответствия при организации обмена данными между 1С и Битрикс24.CRM. Причина заключается в том, что ряд версий 1С.10 и 1С.БУХ даже последних версий не имеет выделенного шаблона ИП и по умолчанию приравнивает индивидуальных предпринимателей к физическим лицам.
В Битрикс24.CRM все ИП предприниматели, являющиеся по факту юридическими лицами, совершенно правильно обычно регистрируются в карточках компании.
Для устранения такого перекоса ряд компаний вынуждены регистрировать своих клиентов ИП в контактах. Для таких компаний приложение предоставляет возможность автоматически заполнять данные реквизитов по шаблону ИП, что в итоге позволяет проводить обмен данными с 1С и обойти описанную выше проблему. По факту данные из контактов Битрикс24.CRM будут корректно перетекать в каталог физических лиц 1С и обратно.
Сколько стоит приложение?
- Бесплатно, если у Вас оформлена и действует подписка на Маркет24.
- Если подписка на Маркет24.Битрикс не оформлена, то ее цена опубликована на официальном сайте Битрикс24.CRM и зависит от вашего используемого вами тарифа и стоимости лицензии https://www.bitrix24.ru/prices/.
- Есть 15-дневный демо-режим для бесплатного ознакомления с работой более 1 000 приложений Битрикс24.CRM.
- Ссылка на приложение
Больше деталей и новостей можно узнать на наших каналах:
- YouTube Канал
- Телеграм Канал
- Инстаграм Канал
С уважением, Лаборатория автоматизации «LOG [IN] OFF»
Если вы работаете с юридическими лицами, то вам постоянно приходится заполнять реквизиты контрагентов. И скорей всего мечтаете о волшебной кнопочке, которая заполнит все за вас. В данной статье я расскажу как реализовать автоматическое заполнение реквизитов по ИНН или любым другим данным организации.
Есть замечательный сервис DaData.ru, который умеет не только исправлять контактные данные типа ФИО, адреса, телефона и т.п., удалять дубликаты, но и ищет реквизиты организаций и ИП.
Данный сервис предоставляет доступ к API и дает бесплатно до 10 тыс. запросов в день по API-ключу. Этим мы и воспользуемся, чтобы реализовать автоматическое заполнение реквизитов по ИНН.
Получение API-ключа на Dadata.ru
Для начала необходимо зарегистрироваться на сервисе DaData. После регистрации в личном кабинете можно увидеть ваш API-ключ, который будет использоваться для запросов к сервису. А еще вам будет бонус 10 рублей на счет за использование API.

Ну а теперь можем приступить к написанию скрипта для отправки запроса и обработки ответа. Напоминаю, что писать код мы будем на Javascript.
Javascript для получения и заполнение реквизитов по ИНН
Создаем форму, в которой будет происходить заполнение реквизитов:
<div class="well well-sm col-md-6"> <div class="view"> </div> <div class="view"><p>Пожалуйста, заполняйте поля как можно более подробней. Это поможет нам быстрее и точнее отреагировать на ваше сообщение.</p></div> <form action="/ method="POST"> <div class="form-group"> <label for="company">Название компании* (реквизиты заполнятся автоматически):</label> <input class="form-control" type="text" name="company" id="company" value="" placeholder="Введите название, адрес, ИНН или ОГРН" required /> </div> <div class="form-group"> <label for="inn">ИНН:</label> <input class="form-control" type="text" name="inn" id="inn" value="" placeholder="Например, 1111111111" readonly required /> </div> <div class="form-group"> <label for="kpp">КПП:</label> <input class="form-control" type="text" name="kpp" id="kpp" value="" placeholder="Например, 111111111" readonly /> </div> <div class="form-group"> <label for="ogrn">ОГРН:</label> <input class="form-control" type="text" name="ogrn" id="ogrn" value="" placeholder="Например, 1111111111111" readonly required /> </div> <div class="form-group"> <label for="address">Адрес:</label> <input class="form-control" type="text" name="address" id="address" value="" placeholder="Невский пр., 1" required /> </div> <div class="form-group"> <label for="tel">Телефон для связи*:</label> <input class="form-control" type="text" name="tel" id="tel" value="" placeholder="Например, +7 812 111 1111" required /> </div> <div class="form-group"> <label for="email">Ваш email*:</label> <input class="form-control" type="text" name="email" id="email" value="" placeholder="Например, [email protected]" required /> </div> <div class="form-group"> <label for="url">Сайт:</label> <input class="form-control" type="text" name="url" id="url" value="" placeholder="Например, pogrommist.ru" /> </div> <div class="form-group"> <label for="comment">Дополнительные сведения:</label> <textarea class="form-control" type="text" name="comment" id="comment" rows="4" /></textarea> </div> <div class="form-group"> <div class="g-recaptcha" data-sitekey="тут ключ для капчи"></div> </div> <div class="form-group"> <button type="submit" name="addevent" class="btn btn-default">Отправить</button> </div> </form> </div>
Выглядеть наша форма будет примерно так:

Также нам понадобятся дополнительные стили и библиотеки:
<link href="https://cdn.jsdelivr.net/jquery.suggestions/17.2/css/suggestions.css" type="text/css" rel="stylesheet" /> <script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/jquery/1.10.2/jquery.min.js"></script> <!--[if lt IE 10]> <script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/jquery-ajaxtransport-xdomainrequest/1.0.1/jquery.xdomainrequest.min.js"></script> <![endif]--> <script type="text/javascript" src="https://cdn.jsdelivr.net/jquery.suggestions/17.2/js/jquery.suggestions.min.js"></script>
Теперь пишем код, который будет отправлять запросы по мере заполнения первой графы и обрабатывать ответы.
<script>
function join(arr) {
var separator = arguments.length > 1 ? arguments[1] : ", ";
return arr.filter(function(n){return n}).join(separator);
}
function typeDescription(type) {
var TYPES = {
'INDIVIDUAL': 'Индивидуальный предприниматель',
'LEGAL': 'Организация'
}
return TYPES[type];
}
function showSuggestion(suggestion) {
console.log(suggestion);
var data = suggestion.data;
if (!data)
return;
$("#type").text(
typeDescription(data.type) + " (" + data.type + ")"
);
if (data.name)
//$("#company").val(join([data.opf && data.opf.short || "", data.name.short || data.name.full], " "));
$("#inn").val(data.inn);
$("#kpp").val(data.kpp);
$("#ogrn").val(data.ogrn);
if (data.address)
$("#address").val(data.address.value);
}
$("#company").suggestions({
token: "Здесь должен быть ваш API-ключ",
type: "PARTY",
count: 5,
onSelect: showSuggestion
});
</script>
При заполнении первой графы будут предложены 5 подсказок, за это отвечает переменная «count». Максимально можно выводить до 20 подсказок. При выборе одной из них в нашем варианте будут заполняться поля «Название компании», «ИНН», «ОГРН» и «адрес».

Какие данные еще можно получить?
| Название | Описание |
|---|---|
| value | Наименование компании одной строкой (как показывается в списке подсказок) |
| unrestricted_value | Наименование компании одной строкой (полное) |
| data.address.value | Адрес одной строкой:
Стандартизован, поэтому может отличаться от записанного в ЕГРЮЛ. |
| data.address.unrestricted_value | Адрес одной строкой (полный, от региона) Стандартизован, поэтому может отличаться от записанного в ЕГРЮЛ. |
| data.address.data | Гранулярный адрес. Может отсутствовать |
| data.address.data.source | Адрес одной строкой как в ЕГРЮЛ |
| data.branch_count | Количество филиалов |
| data.branch_type | Тип подразделения
MAIN — головная организация BRANCH — филиал |
| data.inn | ИНН |
| data.kpp | КПП |
| data.ogrn | ОГРН |
| data.ogrn_date | Дата выдачи ОГРН |
| data.hid | Уникальный идентификатор в Дадате |
| data.management.name | ФИО руководителя |
| data.management.post | Должность руководителя |
| data.name.full_with_opf | Полное наименование с ОПФ |
| data.name.short_with_opf | Краткое наименование с ОПФ |
| data.name.latin | Наименование на латинице |
| data.name.full | Полное наименование |
| data.name.short | Краткое наименование |
| data.okpo | Код ОКПО (не заполняется) |
| data.okved | Код ОКВЭД |
| data.okved_type | Версия справочника ОКВЭД (2001 или 2014) |
| data.okveds | Коды ОКВЭД дополнительных видов деятельности (не заполняется) |
| data.opf.code | Код ОКОПФ |
| data.opf.full | Полное название ОПФ |
| data.opf.short | Краткое название ОПФ |
| data.opf.type | Не используется |
| data.state.actuality_date | Дата актуальности сведений |
| data.state.registration_date | Дата регистрации |
| data.state.liquidation_date | Дата ликвидации |
| data.state.status | Статус организации
ACTIVE — действующая LIQUIDATING — ликвидируется LIQUIDATED — ликвидирована |
| data.type | Тип организации
LEGAL — юридическое лицо INDIVIDUAL — индивидуальный предприниматель |
| data.capital | Уставной капитал, для организаций (не заполняется) |
| data.citizenship | Гражданство, для ИП (не заполняется) |
| data.authorities | Руководители, доверенные лица, управляющие организации (не заполняется) |
| data.documents | Документы (не заполняется) |
| data.licenses | Лицензии (не заполняется) |
| data.phones | Телефоны (не заполняется) |
| data.emails | Адреса эл. почты (не заполняется) |
| data.source | Не используется |
| data.qc | Не используется |
Данный сервис можно использовать для заполнения реквизитов контрагентов в 1С. Возможно в будущем я опишу как это реализовать в 1С:Бухгалтерия 3.0.