Текущая страница: 6 (всего у книги 9 страниц) [доступный отрывок для чтения: 2 страниц]
5 Лекция 5. Распределенная обработка данных
Основные понятия.
При размещении СУБД на персональном компьютере, который не находится в сети, БД всегда используется в монопольном режиме. Даже если с ней работают несколько пользователей, они могут работать только последовательно.
Однако, как показала практика применения локальных баз данных, в большинстве случаев информация, которая в них содержится, носит многопользовательский характер, поэтому возникает необходимость разработки таких СУБД, которые обеспечили бы возможность одновременной работы пользователей с базами данных. Тем более, что все современные предприятия строят свою политику в области информационного обеспечения на основе принципов САLS-технологий.
Системы управления базами данных, обеспечивающие возможность одновременного доступа к информации различным пользователям называют системами управления распределенными базами данных. В общем случае режимы использования БД имеют вид, представленный на рисунке 5.1. Рассмотрим основные понятия, применяемые в системах управления распределенными базами данных.
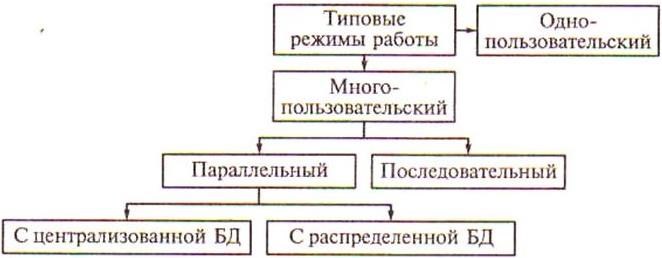
Рисунок 5.1 – Режимы работы с базами данных
Пользователь БД – программа или человек, обращающийся к базе данных.
Запрос – процесс обращения пользователя к БД с целью ввода, получения или изменения информации в БД.
Транзакция – последовательность операций модификации данных в БД, переводящая БД из одного непротиворечивого состояния в другое непротиворечивое состояние.
Логическая структура БД – определение БД на физически независимом уровне; ближе всего соответствует концептуальной модели БД.
Топология БД, или структура распределенной БД, – схема распределения физической организации базы данных в сети.
Локальная автономность означает, что информация локальной БД и связанные с ней определения данных принадлежат локальному владельцу и им управляются.
Удаленный запрос – запрос, который выполняется с использованием модемной связи.
Возможность реализации удаленной транзакции – обработка одной транзакции, состоящей из множества SQL-запросов, на одном удаленном узле.
Поддержка распределенной транзакции допускает обработку транзакции, состоящей из нескольких запросов SQL, которые выполняются на нескольких узлах сети (удаленных или локальных), но каждый запрос в этом случае обрабатывается только на одном узле.
Распределенный запрос – запрос, при обработке которого используются данные из БД, расположенные в разных узлах сети.
Системы распределенной обработки данных в основном связаны с первым поколением БД, которые строились на мультипрограммных операционных системах и использовали централизованное хранение БД на устройствах внешней памяти центральной ЭВМ и терминальный многопользовательский режим доступа. При этом пользовательские терминалы не имели собственных ресурсов, т. е. процессоров и памяти, которые могли бы использоваться для хранения и обработки данных. Первой полностью реляционной системой, работающей в многопользовательском режиме, была СУБД SYSTEM R фирмы IВМ. Именно в ней были реализованы как язык манипулирования данными SQL, так и основные принципы синхронизации, применяемые при распределенной обработке данных, которые до сих пор являются базисными практически во всех коммерческих СУБД.
Модели клиент – сервер в технологии распределенных баз данных.
Вычислительная модель клиент – сервер связана с появлением в 1990-х гг. открытых систем. Термин «клиент – сервер» применялся к архитектуре программного обеспечения, которое состояло из двух процессов обработки информации: клиентской и серверной. Клиентский процесс запрашивал некоторые услуги, а серверный процесс обеспечивал их выполнение. При этом предполагалось, что один серверный процесс может обслужить множество клиентских процессов. Учитывая что аппаратная реализация этой модели управления базами данных связана с созданием локальных вычислительных сетей предприятия, такую организацию процесса обработки информации называют архитектурой клиент – сервер.
Основной принцип технологии клиент – сервер применительно к технологии управления базами данных заключается в разделении функций стандартного интерактивного приложения на пять групп, имеющих различную природу:
– функции ввода и отображения данных (Presentation Logic);
– прикладные функции, определяющие основные алгоритмы решения задач приложения (Business Logic);
– функции обработки данных внутри приложения (Database Logic); – функции управления информационными ресурсами (Database Manager System);
– служебные функции, играющие роль связок между функциями первых четырех групп.
Структура типового приложения, работающего с базой данных в архитектуре клиент – сервер, приведена на рисунке 5.2.
Презентационная логика как часть приложения определяется тем, что пользователь видит на своем экране, когда работает приложение. Сюда относятся все интерфейсные экранные формы, которые пользователь видит или заполняет в ходе работы приложения. К этой же части относится все то, что выводится пользователю на экран как результаты решения некоторых промежуточных задач либо как справочная информация. Поэтому основными задачами презентационной логики являются:
• формирование экранных изображений;
• чтение и запись в информации экранные формы;
• управление экраном;
• обработка движений мыши и нажатие клавиш клавиатуры.
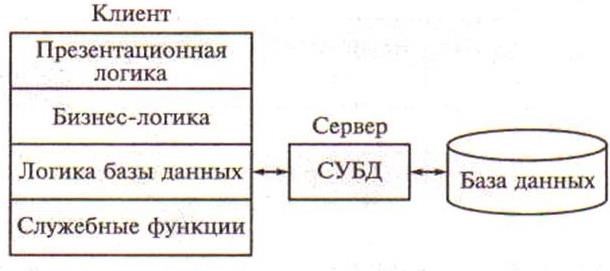
Рисунок 5.2 – Структура типового приложения, работающего с базой данных
Бизнес-логика, или логика собственно приложений – это часть кода приложения, которая определяет собственно алгоритмы решения конкретных задач приложения. Обычно этот код пишется с использованием различных языков программирования, таких как С, С++, Visual Basic и др.
Логика обработки данных – это часть кода приложения, которая непосредственно связана с обработкой данных внутри приложения. Данными управляет собственно СУБД. Для обеспечения доступа к данным используется язык SQL.
Процессор управления данными – это собственно СУБД. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако для рассмотрения архитектуры приложения их надо выделить в отдельную часть приложения.
В централизованной архитектуре эти части приложения располагаются в единой среде и комбинируются внутри одной исполняемой программы.
В децентрализованной архитектуре эти задачи могут быть по-разному распределены между серверным и клиентским процессами. В зависимости от характера распределения можно выделить следующие модели распределений:
• распределенная презентация (DR – Distribution Presentation);
• удаленная презентация (RP – Remote Presentation);
• распределенная бизнес-логика (RBL – Remote business logic);
• распределенное управление данными (DDM – Distributed data manegement);
• удаленное управление данными (RDM – Remote data manegement).
Эта условная классификации показывает, как могут быть распределены отдельные задачи между серверным и клиентскими процессами. В этой классификации отсутствует реализация удаленной бизнес-логики. Считается, что она не может быть удалена сама по себе полностью, а может быть лишь распределена между разными процессами, которые могут взаимодействовать друг с другом.
Двухуровневые модели.
Двухуровневая модель фактически является результатом распределения пяти указанных выше функций между двумя процессами, которые выполняются на двух платформах: на клиенте и на сервере. В чистом виде почти никакая модель не существует, однако рассмотрим наиболее характерные особенности каждой двухуровневой модели: модели удаленного управления данными и модели удаленного доступа к данным.
Модель удаленного управления данными. Она также называется моделью файлового сервера (FS – File Server). В этой модели презентационная логика и бизнеслогика располагаются на клиентской части. На сервере располагаются файлы с данными, и поддерживается доступ к файлам. Функции управления информационными ресурсами в этой модели находятся на клиентской части. Распределение функций в этой модели представлено на рисунке 5.3.
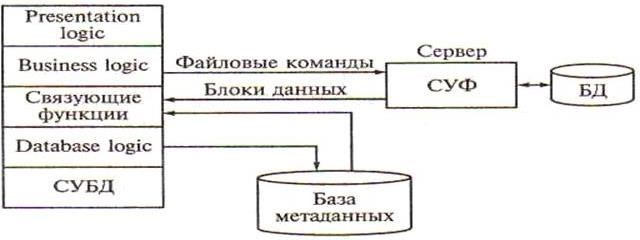
Рисунок 5.3 – модель файлового сервера
В этой модели файлы базы данных хранятся на сервере, клиент обращается к серверу с файловыми командами, а механизм управления всеми информационными ресурсами, собственно база метаданных, находится на клиенте.
Достоинство этой модели заключается в том, что приложение разделено на два взаимодействующих процесса. При этом сервер (серверный процесс) может обслуживать множество клиентов, которые обращаются к нему с запросами.
Собственно СУБД должна находиться в этой модели на клиентском компьютере.
Алгоритм выполнения клиентского запроса сводится к следующему.
1 Запрос формулируется в командах ЯМД.
2 СУБД переводит этот запрос в последовательность файловых команд.
3 Каждая файловая команда вызывает перекачку блока информации на компьютер клиента, а СУБД анализирует полученную информацию; если в полученном блоке не содержится ответ на запрос, то принимается решение о перекачке следующего блока информации, и т.д.
4 Перекачка информации с сервера на клиентский компьютер производится до тех пор, пока не будет получен ответ на запрос клиента.
Данная модель имеет следующие недостатки:
• высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов, необходимых приложению;
• узкий спектр операций манипулирования с данными, который определяется только файловыми командами;
• отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы).
Модель удаленного доступа к данным. В модели удаленного доступа (RDA – Remote Data Access) база данных хранится на сервере. На сервере же находится и ядро СУБД. На компьютере клиента располагается презентационная логика и бизнес-логика приложения. Клиент обращается к серверу с запросами на языке SQL. Структура модели удаленного доступа приведена на рисунке 5.4.
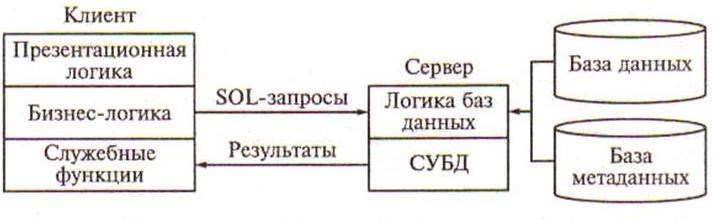
Рисунок 5.4 – Структура модели удаленного доступа к данным
Преимущества данной модели заключаются в следующем:
• перенос компонента представления и прикладного компонента на клиентский компьютер существенно разгружает сервер БД, сводя к минимуму общее число выполняемых процессов в операционной системе;
• « сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных запросов и транзакций;
• резко уменьшается загрузка сети, так как по ней от клиентов к серверу передаются не запросы на ввод-вывод в файловой терминологии, а запросы на SQL, а их объем существенно меньше. В ответ на запросы клиент получает только данные, соответствующие запросу, а не блоки файлов.
Основное достоинство RDA-модели – унификация интерфейса клиент – сервер (стандартом при общении приложения-клиента и сервера становится язык SQL).
Данная модель имеет следующие недостатки:
• запросы на языке SQL при интенсивной работе клиентской части приложения могут существенно загрузить сеть;
• так как в этой модели на клиенте располагается и презентационная логика, и бизнес-логика приложения, то при повторении аналогичных функций в разных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения. Это вызывает излишнее дублирование приложения;
• сервер в этой модели играет пассивную роль, поэтому функции управления информационными ресурсами должны выполняться на клиенте.
Модель сервера баз данных.
Для того чтобы избавиться от недостатков модели удаленного доступа, должны быть соблюдены следующие условия.
1 Необходимо, чтобы БД в каждый момент отражала текущее состояние предметной области, которое определяется не только собственно данными, но и связями между объектами данных, т.е. данные, которые хранятся в БД, в каждый момент времени должны быть непротиворечивыми.
2 БД должна отражать некоторые правила предметной области, законы, по которым она функционирует (business rules). Например, завод может нормально работать только в том случае, если на складе имеется некоторый достаточный запас (страховой запас) деталей определенной номенклатуры; деталь может быть запущена в производство только в том случае, если на складе имеется в наличии достаточно материала для ее изготовления, и т.д.
3 Необходим постоянный контроль за состоянием БД, отслеживание всех изменений и адекватная реакция на них. Например, при достижении некоторым измеряемым параметром критического значения должно произойти отключение определенной аппаратуры; при уменьшении товарного запаса ниже допустимой нормы должна быть сформирована заявка конкретному поставщику на поставку соответствующего товара и т. п.
4 Необходимо, чтобы возникновение некоторой ситуации в БД четко и оперативно влияло на ход выполнения прикладной задачи.
5 Одной из важнейших проблем СУБД является контроль типов данных. В настоящий момент СУБД контролирует синтаксически только стандартно-допустимые типы данных, т.е. такие, которые определены в DDL (data definition language) – языке описания данных, который является частью SQL. Однако в реальных предметных областях действуют данные, которые несут в себе еще и семантическую составляющую, например координаты объектов или единицы измерений.
Такую модель поддерживают большинство современных СУБД: Informix, Ingres, Sybase, Oracle, MS SQL Server. Основу данной модели составляет механизм хранимых процедур как средство программирования SQL-сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры. Модель активного сервера базы данных представлена на рисунке 5.5.
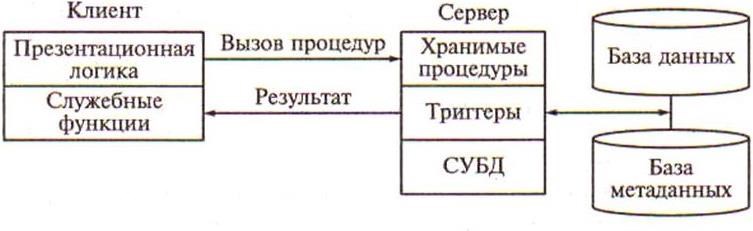
Рисунок 5.5 – Модель активного сервера базы данных
В этой модели бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика реализована в виде хранимых процедур – специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные выполненного запроса, которые требуются клиенту либо для вывода на экран, либо для выполнения части бизнес-логики. При этом трафик обмена информацией между клиентом и сервером резко уменьшается.
Централизованный контроль в модели сервера баз данных выполняется с использованием механизма триггеров. Триггеры также являются частью БД.
Термин «триггер» взят из электроники и семантически очень точно характеризует механизм отслеживания специальных событий, которые связаны с состоянием БД. Триггер в БД является неким тумблером, который срабатывает при возникновении определенного события в БД. Ядро СУБД проводит мониторинг всех событий, которые вызывают созданные и описанные триггеры в БД, и при возникновении соответствующего события сервер запускает соответствующий триггер. Каждый триггер представляет собой также некоторую программу, которая выполняется над базой данных. Триггеры могут вызывать хранимые процедуры.
Механизм использования триггеров предполагает, что при срабатывании одного триггера могут возникнуть события, которые вызовут срабатывание других триггеров.
В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД.
И хранимые процедуры, и триггеры хранятся в словаре БД. Они могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях.
Недостатком данной модели является очень большая загрузка сервера, так как он обслуживает множество клиентов и выполняет следующие функции:
• осуществляет мониторинг событий, связанных с описанными триггерами;
• обеспечивает автоматическое срабатывание триггеров при возникновении связанных с ними событий;
• обеспечивает исполнение внутренней программы каждого триггера;
• запускает хранимые процедуры по запросам пользователей;
• запускает хранимые процедуры из триггеров;
• возвращает требуемые данные клиенту;
• обеспечивает все функции СУБД (доступ к данным, контроль и поддержку целостности данных в БД, контроль доступа, обеспечение корректной параллельной работы всех пользователей с единой БД).
Если мы перенесем на сервер большую часть бизнес-логики приложений, то требования к клиентам в этой модели резко уменьшатся. Иногда такую модель называют моделью с тонким клиентом. Ранее рассмотренные модели называют моделями с толстым клиентом.
Для разгрузки сервера была предложена трехуровневая модель – модель сервера приложений.
Модель сервера приложений.
Эта модель является расширением двухуровневой модели, в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Архитектура трехуровневой модели приведена на рисунке 5.6. Этот промежуточный уровень содержит один или несколько серверов приложений.
В этой модели компоненты приложения делятся между тремя исполнителями: клиентом, сервером, сервером базы данных.
Клиент обеспечивает логику представления, включая графический пользовательский интерфейс, локальные редакторы; клиент может запускать локальный код приложения клиента, который может содержать обращения к локальной БД, расположенной на компьютере-клиенте. Клиент исполняет коммуникационные функции front – end части приложения, которые обеспечивают доступ клиенту в локальную или глобальную сеть. Дополнительно реализация взаимодействия между клиентом и сервером может включать в себя управление распределенными транзакциями, что соответствует тем случаям, когда клиент также является клиентом менеджера распределенных транзакций.
Серверы приложений составляют новый промежуточный уровень архитектуры. Серверы приложений поддерживают функции клиентов как частей взаимодействующих рабочих групп, поддерживают сетевую доменную операционную среду, хранят и исполняют наиболее общие правила бизнес-логики, поддерживают каталоги с данными, обеспечивают обмен сообщениями и поддержку запросов, особенно в распределенных транзакциях..

Рисунок 5.6 – Модель сервера приложений
Серверы баз данных в этой модели занимаются исключительно функциями СУБД: обеспечивают функции создания и ведения БД, поддерживают целостность реляционной БД, обеспечивают функции хранилищ данных (warehouse services). Кроме того, на них возлагаются функции создания резервных копий БД и восстановления БД после сбоев, управления выполнением транзакций и поддержки устаревших (унаследованных) приложений (legacy application).
Эта модель обладает большей гибкостью, чем двухуровневые модели. Наиболее заметны преимущества модели сервера приложений в тех случаях, когда клиенты выполняют сложные аналитические расчеты над базой данных, которые относятся к области OLAP-приложений (On-line analytical processing).
В этой модели большая часть бизнес-логики клиента изолирована от возможностей встроенного SQL, реализованного в конкретной СУБД, и может быть выполнена на языках программирования, таких как С, С++, СоЬо1. Это повышает переносимость системы, ее масштабируемость.
Модели серверов баз данных.
В период создания первых СУБД технология клиент – сервер только зарождалась. Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия процессов типа «клиент» и процессов типа «сервер». В современных же СУБД он является фактически основополагающим и от эффективности его реализации зависит эффективность работы системы в целом.
Рассмотрим эволюцию типов организации подобных механизмов. В основном этот механизм определяется структурой реализации серверных процессов, и часто он называется архитектурой сервера баз данных.
Первоначально, как мы уже отмечали, существовала модель, у которой управление данными (функция сервера) и взаимодействие с пользователем были совмещены в одной программе. Это можно назвать нулевым этапом развития серверов БД.
Затем функции управления данными были выделены в самостоятельную группу – сервер, однако модель взаимодействия пользователя с сервером соответствовала структуре связей между таблицами баз данных «один к одному» (рисунок 5.7), т.е. сервер обслуживал запросы только одного пользователя (клиента), а для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверов.
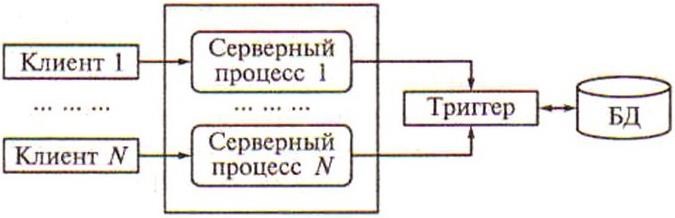
Рисунок 5.7 – Взаимодействие клиентских и серверных процессов в модели «один к одному»
Выделение сервера в отдельную программу было революционным шагом, который позволил, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем – на другую, осуществляя взаимодействие между ними по сети. Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы.
Для обслуживания большого числа клиентов на сервере должно было быть запущено большое число одновременно работающих серверных процессов, а это резко повышало требования к ресурсам ЭВМ.
Кроме того, каждый серверный процесс в этой модели запускался как независимый, поэтому если один клиент сформировал запрос, который был только что выполнен другим серверным процессом для другого клиента, то запрос выполнялся повторно. В такой модели весьма сложно обеспечить взаимодействие серверных процессов. Эта модель самая простая, и она появилась первой.
Проблемы, возникающие в информационной модели «один к одному», решаются в архитектуре систем с выделенным сервером, который способен обрабатывать запросы от многих клиентов. Сервер единственный обладает монополией на управление данными и взаимодействует одновременно со многими клиентами (рисунок 5.8). Логически каждый клиент связан с сервером отдельной нитью или потоком, по которому пересылаются запросы. Такая архитектура получила название многопотоковой односерверной.
Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей.
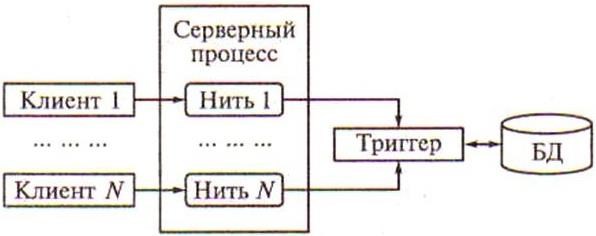
Рисунок 5.8 – Многопотоковая односерверная архитектура
Кроме того, возможность взаимодействия многих клиентов с одним сервером позволяет в полной мере использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что значительно уменьшает потребности в памяти и общее число процессов операционной системы.
Например, системой с моделью «один к одному» будет создано 100 копий процессов СУБД для 100 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобится только один серверный процесс.
Однако такое решение имеет свои недостатки. Так как серверный процесс может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три.
В некоторых системах эта проблема решается вводом промежуточного диспетчера. Подобная архитектура называется архитектурой виртуального сервера (рисунок 5. 9).
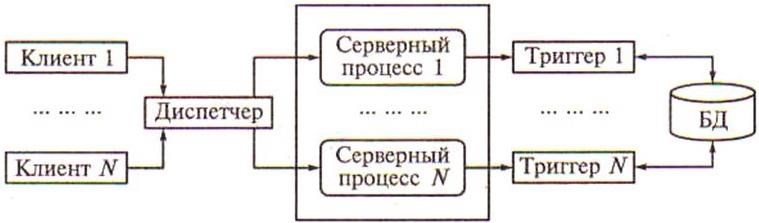
Рисунок 5.9 – Архитектура виртуального сервера
В этой архитектуре клиенты подключаются не к реальному серверу, а к промежуточному звену, называемому диспетчером, который выполняет только функции диспетчеризации запросов к серверам. В этом случае нет ограничений на использование многопроцессорных платформ. Число серверов может быть согласовано с числом процессоров в системе.
Однако и эта архитектура не лишена недостатков, потому что здесь в систему добавляется новый слой, который размещается между клиентом и сервером, что увеличивает потребность в ресурсах на поддержку баланса загрузки серверов и ограничивает возможности управления взаимодействием клиент – сервер. Вопервых, становится невозможным направить запрос от конкретного клиента конкретному серверу; во-вторых, серверы становятся равноправными, так как нет возможности устанавливать приоритеты для обслуживания запросов.
Подобная организация взаимодействия между клиентом и сервером может рассматриваться как аналог банка, где имеется несколько окон кассиров и специальный банковский служащий, администратор зала, который направляет каждого пришедшего посетителя (клиента) к свободному кассиру (актуальному серверу). Система работает нормально, пока все посетители равноправны (имеют равные приоритеты), однако стоит появиться посетителям с высшим приоритетом, которые должны обслуживаться в специальном окне, как возникают проблемы. Учет приоритета клиентов особенно важен в системах оперативной обработки транзакций, однако именно эту возможность не может предоставить архитектура систем с диспетчеризацией.
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если эти два условия выполнены, то есть основания говорить о многопотоковой архитектуре с несколькими серверами, представленной на рисунке 5.10.
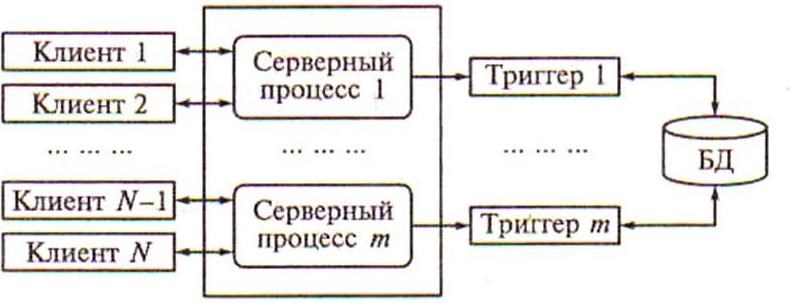
Рисунок 5.10 – Многопотоковая мультисерверная архитектура
Такую архитектуру называют также многонитиевой мулътисерверной архитектурой. Эта архитектура обеспечивает распараллеливание выполнения одного пользовательского запроса несколькими серверными процессами.
В этом случае пользовательский запрос разбивается на ряд подзапросов, которые могут выполняться параллельно, а результаты их выполнения потом объединяются в общий результат выполнения запроса. Тогда для обеспечения оперативности выполнения запросов их подзапросы могут быть направлены отдельным серверным процессам, а затем полученные результаты объединены в общий результат (рисунок 5.11).
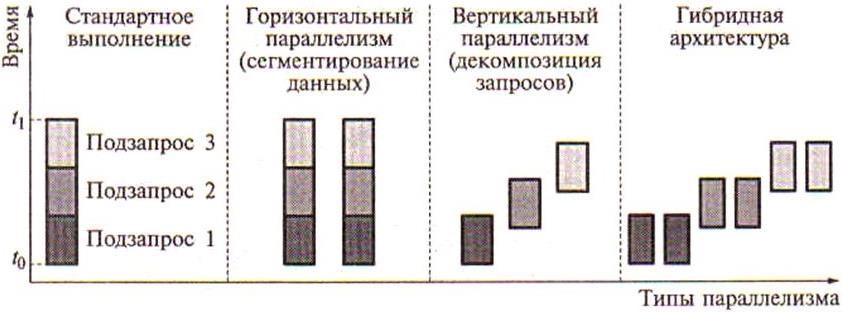
Рисунок 5.11 – Многонитевая мультисерверная архитектура
В данном случае серверные процессы не являются независимыми процессами – такими, как рассматривались ранее. Эти серверные процессы принято называть нитями. Управление нитями множества запросов пользователей требует дополнительных расходов от СУБД, однако при оперативной обработке информации в хранилищах данных такой подход наиболее перспективен.
Типы параллелизма.
Рассматривают следующие программно-аппаратные способы распараллеливания запросов: горизонтальный, вертикальный и смешанный параллелизм.
Горизонтальный параллелизм. Этот параллелизм возникает тогда, когда хранимая в БД информация распределяется по нескольким физическим устройствам хранения – нескольким дискам. При этом информация из одного отношения разбивается на части по горизонтали. Этот вид параллелизма иногда называют распараллеливанием, или сегментацией, данных. Параллельность достигается путем выполнения одинаковых операций, например фильтрации, над разными физическими хранимыми данными. Эти операции могут выполняться параллельно разными процессами – они независимы. Результат выполнения целого запроса складывается из результатов выполнения отдельных операций. Время выполнения такого запроса при соответствующем сегментировании данных существенно меньше, чем время выполнения этого же запроса традиционными способами одним процессом.
Вертикальный параллелизм. Этот параллелизм достигается конвейерным выполнением операций, составляющих запрос пользователя. Этот подход требует серьезного усложнения модели выполнения реляционных операций ядром СУБД. Он предполагает, что ядро СУБД может произвести декомпозицию запроса, базируясь на его функциональных компонентах; при этом ряд подзапросов может выполняться параллельно, с минимальной связью между отдельными шагами выполнения запроса.
Общее время выполнения подобного запроса, конечно, будет существенно меньше, чем при традиционном способе выполнения последовательности из четырех операций (рисунок 5.12).
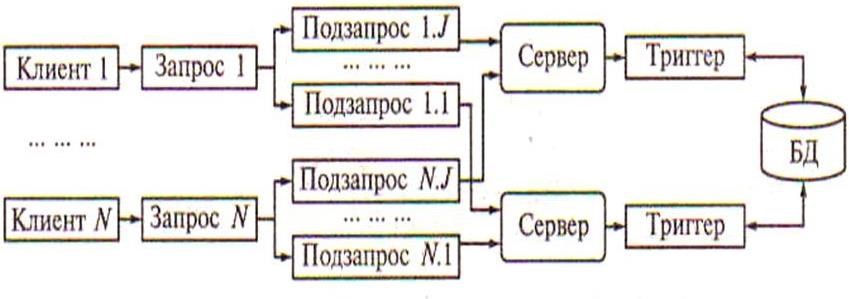
Рисунок 5.12 – Схема выполнения запроса при вертикальном параллелизме
Смешанный параллелизм. Этот параллелизм является гибридом горизонтального и вертикального параллелизма (рисунок 5.13).
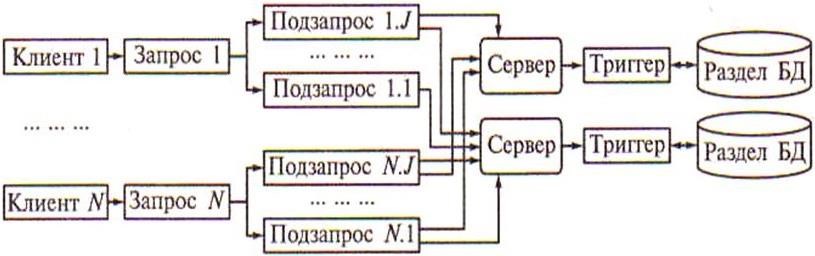
Рисунок 5.13 – Схема выполнения запроса при смешанном параллелизме
Все виды параллелизма применяются в приложениях, где они позволяют существенно сократить время выполнения сложных запросов над очень большими объемами данных.
Вопросы для самоконтроля.
1 Дайте определения следующих понятий:
• топология БД, или структура распределенной БД;
• локальная автономность;
• удаленный запрос;
• поддержка распределенной транзакции; « презентационная логика;
• бизнес-логика.
2 Какие двухуровневые модели вы знаете? Назовите их достоинства и недостатки.
3 Назовите характеристики следующих архитектур организации баз данных: « многопотоковая односерверная архитектура;
• архитектура с виртуальным сервером;
• многонитиевая мультисерверная архитектура.
4 Для чего применяют распараллеливание запросов и какие типы параллелизма вы знаете?
-
Может
ли быть реализована модель «клиент-сервер»
на одном компьютере? Приведите примеры.
Да.
Клиентский процесс запрашивал некоторые
услуги, а серверный процесс обеспечивал
их выполнение. При этом предполагалось,
что один серверный процесс может
обслужить множество клиентских процессов.
-
Где
находится СУБД в модели «файл-сервер»?
Процессор
управления данными (Database Manager System
Processing) — это собственно СУБД, которая
обеспечивает хранение и управление
базами данных. В идеале функции СУБД
должны быть скрыты от бизнес-логики
приложения, однако для рассмотрения
архитектуры приложения нам надо
их выделить в отдельную часть
приложения.
В
централизованной архитектуре (Host-based
processing) эти части приложения располагаются
в единой среде и комбинируются
внутри одной исполняемой про граммы.
В
децентрализованной архитектуре эти
задачи могут быть по-разному распределены
между серверным и клиентским
процессами. В зависимости от характера
распределения можно выделить следующие
модели распределений:
-
Каковы
основные достоинства и недостатки
модели «файл-сервер»?
Модель
удаленного управления данными также
называется моделью файлового сервера
(File Server, FS). В этой модели презентационная
логика и бизнес-логика располагаются
на клиенте. На сервере располагаются
файлы с данными и поддерживается
доступ к файлам. Функции управления
информационными ресурсами в этой
модели находятся на клиенте. Достоинства
этой модели в том, что мы уже имеем
разделение монопольного приложения
на два взаимодействующих процесса.
При этом сервер (серверный процесс)
может обслуживать множество клиентов,
которые обращаются к нему с запросами.
Собственно СУБД должна находиться
в этой модели на клиенте.
Каков
алгоритм выполнения запроса клиента?
Запрос
клиента формулируется в командах
ЯМД. СУБД переводит этот запрос
в последовательность файловых команд.
Каждая файловая команда вызывает
перекачку блока информации на клиента,
далее на клиенте СУБД анализирует
полученную информацию, и если
в полученном блоке не содержится
ответа на запрос, то принимается
решение о перекачке следующего блока
информации и т. д.
Перекачка
информации с сервера на клиента
производится до тех пор, пока не будет
получен ответ на запрос клиента.
Недостатки
этой модели:
высокий
сетевой трафик, который связан с передачей
по сети множества блоков и файлов,
необходимых приложению;
узкий
спектр операций манипулирования
с данными, который определяется
только файловыми командами;
отсутствие
адекватных средств безопасности доступа
к данным (защита только на уровне
файловой системы).
-
В
какой из двух моделей RDA
– модели или модели «файл-сервер»
больше сетевой трафик и за счет чего?
См.
пред пункт
-
Опишите
работу модели удаленного доступа.
Каковы достоинства и недостатки модели
удаленного доступа?
В
модели удаленного доступа (Remote Data Access,
RDA) база данных хранится на сервере.
На сервере же находится ядро СУБД.
На клиенте располагается презентационная
логика и бизнес-логика приложения.
Клиент обращается к серверу с запросами
на языке SQL. Структура модели удаленного
доступа приведена на рис. 6.2.
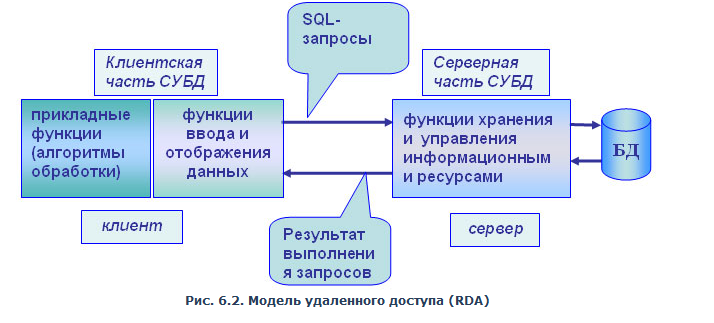
Рис.
6.2. Модель удаленного доступа (RDA)
Преимущества
данной модели:
перенос
компонента представления и прикладного
компонента на клиентский компьютер
существенно разгрузил сервер БД, сведя
к минимуму общее число процессов
в операционной системе;
сервер
БД освобождается от несвойственных
ему функций; процессор или процессоры
сервера целиком загружаются операциями
обработки данных, запросов и транзакций
(это становится возможным, если отказаться
от терминалов, не располагающих
ресурсами, и заменить их компьютерами,
выполняющими роль клиентских станций,
которые обладают собственными локальными
вычислительными ресурсами);
резко
уменьшается загрузка сети, так как
по ней от клиентов к серверу
передаются не запросы на ввод-вывод
в файловой терминологии, а запросы
на SQL, и их объем существенно
меньше. В ответ на запросы клиент
получает только данные, релевантные
запросу, а не блоки файлов, как
в FS-модели.
Основное
достоинство RDA-модели — унификация
интерфейса «клиент–сервер»,
стандартом при общении приложения-
клиента и сервера становится язык
SQL.
Недостатки
данной модели:
все-таки
запросы на языке SQL при интенсивной
работе клиентских приложений могут
существенно загрузить сеть;
так
как в этой модели на клиенте
располагается и презентационная
логика, и бизнес-логика приложения,
то при повторении аналогичных функций
в разных приложениях код соответствующей
бизнес-логики должен быть повторен для
каждого клиентского приложения —
это вызывает излишнее дублирование
кода приложений;
сервер
в этой модели играет пассивную роль,
поэтому функции управления информационными
ресурсами должны выполняться на клиенте.
Действительно, например, если нам
необходимо выполнять контроль страховых
запасов товаров на складе, то каждое
приложение, которое связано с изменением
состояния склада, после выполнения
операций модификации данных, имитирующих
продажу или удаление товара со склада,
должно выполнять проверку на объем
остатка, и в случае, если он меньше
страхового запаса, формировать
соответствующую заявку на поставку
требуемого товара. Это усложняет
клиентское приложение, с одной
стороны, а с другой — может
вызвать необоснованный заказ дополнительных
товаров несколькими приложениями.
-
Опишите
работу моделей пассивного и активного
сервера баз данных. Что является
признаком активного сервера баз данных? -
Что
такое триггер? Чем триггер отличается
от хранимой процедуры? Как клиентское
приложение может запустить триггер
базы данных?
Для
того чтобы избавиться от недостатков
модели удаленного доступа, должны быть
соблюдены следующие условия:
Необходимо,
чтобы БД в каждый момент отражала
текущее состояние предметной области,
которое определяется не только
собственно данными, но и связями
между объектами данных, т. е. данные,
которые хранятся в БД, в каждый
момент времени должны быть непротиворечивыми.
БД должна
отражать некоторые правила предметной
области, законы, по которым она
функционирует (business rules). Например, завод
может нормально работать только в том
случае, если на складе имеется
некоторый достаточный запас (страховой
запас) деталей определенной номенклатуры:
деталь может быть запущена в производство
только в том случае, если на складе
имеется в наличии достаточно материала
для ее изготовления, и т. д.
Необходим
постоянный контроль за состоянием
БД, отслеживание всех изменений
и адекватная реакция на них:
например, при достижении некоторым
измеряемым параметром критического
значения должно произойти отключение
определенной аппаратуры; при уменьшении
товарного запаса ниже допустимой нормы
должна быть сформирована заявка
конкретному поставщику на поставку
соответствующего товара.
Необходимо,
чтобы возникновение некоторой ситуации
в БД четко и оперативно влияло
на ход выполнения прикладной задачи.
Одной
из важнейших проблем СУБД является
контроль типов данных. В настоящий
момент СУБД контролирует синтаксически
только стандартно-допустимые типы
данных, т. е. такие, которые определены
в DDL (data definition language) — языке описания
данных, который является частью SQL.
Однако в реальных предметных областях
у нас действуют данные, которые несут
в себе еще и семантическую
составляющую, например координаты
объектов или единицы различных метрик,
так, рабочая неделя в отличие
от реальной имеет сразу после пятницы
понедельник.
Данную
модель поддерживают большинство
современных СУБД: Informix, Ingres, Sybase, Oracle,
MS SQL Server. Основу данной модели составляет
механизм хранимых процедур как средство
программирования SQL-сервера, механизм
триггеров как механизм отслеживания
текущего состояния информационного
хранилища и механизм ограничений
на пользовательские типы данных,
который иногда называется механизмом
поддержки доменной структуры. Модель
сервера баз данных представлена
на рис. 6.3.
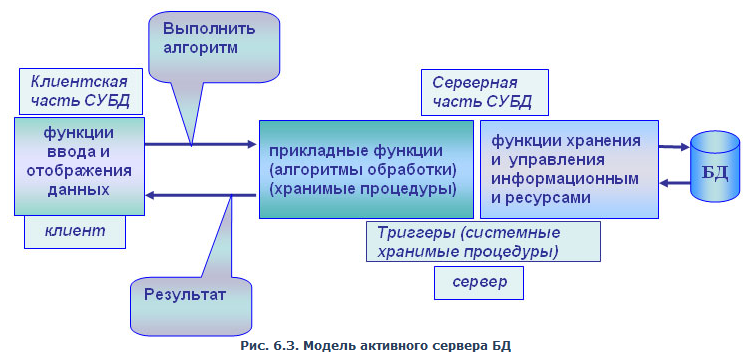
Рис.
6.3. Модель активного сервера БД
В
этой модели бизнес-логика разделена
между клиентом и сервером. На сервере
бизнес-логика реализована в виде
хранимых процедур — специальных
программных модулей, которые хранятся
в БД и управляются непосредственно
СУБД. Клиентское приложение обращается
к серверу с командой запуска
хранимой процедуры, а сервер выполняет
эту процедуру и регистрирует все
изменения в БД, которые в ней
предусмотрены. Сервер возвращает клиенту
данные, релевантные его запросу, которые
требуются клиенту либо для вывода
на экран, либо для выполнения части
бизнес-логики, которая расположена
на клиенте. Трафик обмена информацией
между клиентом и сервером резко
уменьшается.
Централизованный
контроль в модели сервера баз данных
выполняется с использованием механизма
триггеров. Триггеры также являются
частью БД.
Термин
«триггер» взят из электроники
и семантически очень точно характеризует
механизм отслеживания специальных
событий, которые связаны с состоянием
БД. Триггер в БД является как бы
некоторым тумблером, который срабатывает
при возникновении определенного события
в БД. Ядро СУБД проводит мониторинг
всех событий, которые вызывают созданные
и описанные триггеры в БД, и при
возникновении соответствующего события
сервер запускает соответствующий
триггер. Каждый триггер представляет
собой также некоторую программу, которая
выполняется над базой данных. Триггеры
могут вызывать хранимые процедуры.
Механизм
использования триггеров предполагает,
что при срабатывании одного триггера
могут возникнуть события, которые
вызовут срабатывание других триггеров.
Этот мощный инструмент требует тонкого
и согласованного применения, чтобы
не получился бесконечный цикл
срабатывания триггеров.
В
данной модели сервер является активным,
потому что не только клиент, но и сам
сервер, используя механизм триггеров,
может быть инициатором обработки данных
в БД.
И
хранимые процедуры, и триггеры
хранятся в словаре БД, они могут
быть использованы несколькими клиентами,
что существенно уменьшает дублирование
алгоритмов обработки данных в разных
клиентских приложениях.
Для
написания хранимых процедур и триггеров
используется расширение стандартного
языка SQL, так называемый встроенный SQL.
Встроенный SQL мы рассмотрим далее.
Недостатком
данной модели является очень большая
загрузка сервера. Действительно, сервер
обслуживает множество клиентов
и выполняет следующие функции:
осуществляет
мониторинг событий, связанных с описанными
триггерами;
обеспечивает
автоматическое срабатывание триггеров
при возникновении связанных с ними
событий;
обеспечивает
исполнение внутренней программы каждого
триггера;
запускает
хранимые процедуры по запросам
пользователей;
запускает
хранимые процедуры из триггеров;
возвращает
требуемые данные клиенту;
обеспечивает
все функции СУБД: доступ к данным,
контроль и поддержку целостности
данных в БД, контроль доступа,
обеспечение корректной параллельной
работы всех пользователей с единой
БД.
Если
мы переложили на сервер большую
часть бизнес-логики приложений,
то требования к клиентам в этой
модели резко уменьшаются. Иногда такую
модель называют моделью с «тонким
клиентом» в отличие от предыдущих
моделей, где на клиента возлагались
гораздо более серьезные задачи. Эти
модели называются моделями с «толстым
клиентом».
-
Каким
оператором можно предоставить право
чтения таблицы, и каким оператором
можно запретить постороннему пользователю
изменять таблицу в базе, где Вы имеете
права владельца?
Пользователи
СУБД рассматриваются
как основные действующие лица, желающие
получить доступ к данным. СУБД от имени
конкретного пользователя выполняет
операции над базой данных, т. е. добавляет
строки в таблицы (INSERT), удаляет строки
(DELETE), обновляет данные в строках
таблицы (UPDATE). Она делает это в зависимости
от того, обладает ли конкретный
пользователь правами на выполнение
конкретных операций над конкретным
объектом базы данных.
Объекты
доступа — это элементы базы данных,
доступом к которым можно управлять
(разрешать доступ или защищать от доступа).
Обычно объектами доступа являются
таблицы, однако ими могут быть и другие
объекты базы данных — формы, отчеты,
прикладные программы и т. д. Конкретный
пользователь обладает конкретными
правами доступа к конкретному объекту.
Привилегии
(priveleges) — это операции, которые
разрешено выполнять пользователю над
конкретными объектами. Например,
пользователю может быть разрешено
выполнение над таблицей операций SELECT
(ВЫБРАТЬ) и INSERT (ВКЛЮЧИТЬ).
Таким
образом, в СУБД авторизация доступа
осуществляется с помощью привилегий.
Установление и контроль привилегий —
прерогатива администратора базы данных.
Привилегии
устанавливаются и отменяются
специальными операторами языка SQL —
GRANT (РАЗРЕШИТЬ) и REVOKE (ОТМЕНИТЬ).
Оператор GRANT указывает конкретного
пользователя, который получает конкретные
привилегии доступа к указанной
таблице.
Например,
оператор GRANT SELECT, INSERT ON Bills TO bit
123 устанавливает привилегии пользователю
c логином bit 123 на выполнение
операций выбора и включения над
таблицей Bills. Как видно из примера,
оператор GRANT устанавливает соответствие
между операциями, пользователем
и объектом базы данных (таблицей
в данном случае).
-
Если
Вы не являетесь владельцем БД, можете
ли Вы запретить другим пользователям
просматривать некоторую информацию
из дано БД?
да
-
Какие
модели организации серверов БД Вы
знаете? Каковы недостатки архитектуры
сервера БД с виртуальным сервером?
В
период создания первых СУБД технология
«клиент-сервер» только зарождалась.
Поэтому изначально в архитектуре
систем не было адекватного механизма
организации взаимодействия процессов
типа «клиент» и процессов типа
«сервер». В современных же СУБД
он является фактически основополагающим
и от эффективности его реализации
зависит эффективность работы системы
в целом.
Рассмотрим
эволюцию типов организации подобных
механизмов. В основном этот механизм
определяется структурой реализации
серверных процессов, и часто называется
архитектурой сервера баз данных.
Первоначально,
как мы уже отмечали, существовала
модель, когда управление данными (функция
сервера) и взаимодействие с пользователем
были совмещены в одной программе.
Это можно назвать нулевым этапом развития
серверов БД (рис. 6.5, а).
Затем
функции управления данными были выделены
в самостоятельную группу — сервер,
однако модель взаимодействия пользователя
с сервером соответствовала парадигме
«один к одному» (рис. 6.5, б),
т. е. сервер обслуживал запросы
только одного пользователя (клиента),
и для обслуживания нескольких клиентов
нужно было запустить эквивалентное
число серверных процессов.

Рис.
6.5. Централизованная архитектура (а) и
архитектура 1:1 (б)
Выделение
сервера в отдельную программу было
революционным шагом, который позволил,
в частности, поместить сервер на одну
машину, а программный интерфейс
с пользователем — на другую,
осуществляя взаимодействие между ними
по сети (рис. 6.6). Однако необходимость
запуска большого числа серверов для
обслуживания множества пользователей
сильно ограничивала возможности такой
системы. Для обслуживания большого
числа клиентов на сервере должно
быть запущено большое количество
одновременно работающих серверных
процессов, а это резко повышало
требования к ресурсам ЭВМ, на которой
запускались все серверные процессы.
Кроме того, каждый серверный процесс
в этой модели запускался как
независимый, поэтому если один клиент
сформировал запрос, который был только
что выполнен другим серверным процессом
для другого клиента, то запрос тем
не менее выполнялся повторно. В такой
модели весьма сложно обеспечить
взаимодействие серверных процессов.
Эта модель — самая простая, и исторически
она появилась первой.

Рис.
6.6. Размещение клиента и сервера на
различных машинах
Проблемы,
возникающие в модели «один к одному»,
решаются в архитектуре систем
с выделенным сервером, который
способен обрабатывать запросы от многих
клиентов. Сервер единственный обладает
монополией на управление данными
и взаимодействует одновременно
со многими клиентами (рис. 6.7).

Рис.
6.7. Многопотоковая
односерверная архитектура
Логически
каждый клиент связан с сервером
отдельной нитью (thread), или потоком,
по которому пересылаются запросы.
Такая архитектура получила название
многопотоковой односерверной
(multi-threaded). Она позволяет значительно
уменьшить нагрузку на операционную
систему, возникающую при работе большого
числа пользователей.
Кроме
того, возможность взаимодействия с одним
сервером многих клиентов позволяет
в полной мере использовать разделяемые
объекты (начиная с открытых файлов
и кончая данными из системных
каталогов), что значительно уменьшает
потребности в памяти и общее число
процессов операционной системы. Например,
системой с архитектурой «один
к одному» будет создано 100 копий
процессов СУБД для 100 пользователей,
тогда как системе с многопотоковой
архитектурой для этого понадобится
только один серверный процесс.
Однако
такое решение имеет свои недостатки.
Так как сервер может выполняться только
на одном процессоре, возникает
естественное ограничение на применение
СУБД для мультипроцессорных платформ.
Если компьютер имеет, например, четыре
процессора, то СУБД с одним сервером
используют только один из них,
не загружая оставшиеся три. В некоторых
системах эта проблема решается вводом
промежуточного диспетчера. Подобная
архитектура называется архитектурой
виртуального сервера (virtual server) (рис. 6.8).

Рис.
6.8. Архитектура с виртуальным сервером
В
этой архитектуре клиенты подключаются
не к реальному серверу,
а к промежуточному звену, называемому
диспетчером, который выполняет только
функции диспетчеризации запросов
к актуальным серверам. В этом
случае нет ограничений на использование
многопроцессорных платформ. Количество
актуальных серверов может быть согласовано
с количеством процессоров в системе.
Однако
и эта архитектура не лишена
недостатков, потому что здесь в систему
добавляется новый слой, который
размещается между клиентом и сервером,
что увеличивает трату ресурсов
на поддержку баланса загрузки
актуальных серверов (load balancing) и ограничивает
возможности управления взаимодействием
«клиент–сервер». Во-первых,
становится невозможным направить запрос
от конкретного клиента конкретному
серверу; во-вторых, серверы становятся
равноправными — нет возможности
устанавливать приоритеты для обслуживания
запросов.
Подобная
организация взаимодействия «клиент–сервер»
может рассматриваться как аналог банка,
где имеется несколько окон кассиров,
и специальный банковский служащий —
администратор зала (диспетчер) направляет
каждого вновь пришедшего посетителя
(клиента) к свободному кассиру
(актуальному серверу). Система работает
нормально, пока все посетители равноправны
(имеют равные приоритеты), однако стоит
лишь появиться посетителям с высшим
приоритетом, которые должны обслуживаться
в специальном окне, как возникают
проблемы. Учет приоритета клиентов
особенно важен в системах оперативной
обработки транзакций, однако именно
эту возможность не может предоставить
архитектура систем с диспетчеризацией.
Современное
решение проблемы СУБД для мультипроцессорных
платформ заключается в возможности
запуска нескольких серверов базы данных,
в том числе и на различных
процессорах. При этом каждый из серверов
должен быть многопотоковым. Если эти
два условия выполнены, то есть
основания говорить о многопотоковой
архитектуре с несколькими серверами,
представленной на рис. 6.9.

Рис.
6.9. Многопотоковая мультисерверная
архитектура
Она
также может быть названа многонитиевой
мультисерверной архитектурой. Эта
архитектура связана с распараллеливанием
выполнения одного пользовательского
запроса несколькими серверными
процессами.
Существует
несколько возможностей распараллеливания
выполнения запроса. В этом случае
пользовательский запрос разбивается
на ряд подзапросов, которые могут
выполняться параллельно, а результаты
их выполнения потом объединяются
в общий результат выполнения запроса.
Тогда для обеспечения оперативности
выполнения запросов их подзапросы
могут быть направлены отдельным серверным
процессам, а потом полученные
результаты объединены в общий
результат. В данном случае серверные
процессы не являются независимыми
процессами, такими, как рассматривались
ранее. Эти серверные процессы принято
называть нитями (treads), и управление
нитями множества запросов пользователей
требует дополнительных расходов от СУБД,
однако при оперативной обработке
информации в хранилищах данных такой
подход наиболее перспективен.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Модель сервера баз данных
Для того чтобы избавиться от недостатков модели удаленного доступа, должны быть соблюдены следующие условия:
1. Необходимо, чтобы БД в каждый момент отражала текущее состояние предметной области, которое определяется не только собственно данными, но и связями между объектами данных. То есть данные, которые хранятся в БД, в каждый момент времени должны быть непротиворечивыми.
2. БД должна отражать некоторые правила предметной области, законы, по которым она функционирует (business rules). Например, завод может нормально работать только в том случае, если на складе имеется некоторый достаточный запас (страховой запас) деталей определенной номенклатуры, деталь может
3. быть запущена в производство только в том случае, если на складе имеется в наличии достаточно материала для ее изготовления, и т. д.
4. Необходим постоянный контроль за состоянием БД, отслеживание всех изменений и адекватная реакция на них: например, при достижении некоторым измеряемым параметром критического значения должно произойти отключение определенной аппаратуры, при уменьшении товарного запаса ниже допустимой нормы должна быть сформирована заявка конкретному поставщику на поставку соответствующего товара.
5. Необходимо, чтобы возникновение некоторой ситуации в БД четко и оперативно влияло на ход выполнения прикладной задачи.
6. Одной из важнейших проблем СУБД является контроль типов данных. В настоящий момент СУБД контролирует синтаксически только стандартно-допустимые типы данных, то есть такие, которые определены в DDL (data definition language) — языке описания данных, который является частью SQL. Однако в реальных предметных областях у нас действуют данные, которые несут в себе еще и семантическую составляющую, например, это координаты объектов или единицы различных метрик, например рабочая неделя в отличие от реальной имеет сразу после пятницы понедельник.
Данную модель поддерживают большинство современных СУБД: Informix, Ingres, Sybase, Oracle, MS SQL Server. Основу данной модели составляет механизм хранимых процедур как средство программирования SQL-сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры. Модель сервера баз данных представлена на рис. 10.6.
Рекомендуемые материалы

Рис. 10.6. Модель активного сервера БД
В этой модели бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика реализована в виде хранимых процедур — специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, релевантные его запросу, которые требуются клиенту либо для вывода на экран, либо для выполнения части бизнес-логики, которая расположена на клиенте. Трафик обмена информацией между клиентом и сервером резко уменьшается.
Централизованный контроль в модели сервера баз данных выполняется с использованием механизма триггеров. Триггеры также являются частью БД.
Термин «триггер» взят из электроники и семантически очень точно характеризует механизм отслеживания специальных событий, которые связаны с состоянием БД. Триггер в БД является как бы некоторым тумблером, который срабатывает при возникновении определенного события в БД. Ядро СУБД проводит мониторинг всех событий, которые вызывают созданные и описанные триггеры в БД, и при возникновении соответствующего события сервер запускает соответствующий триггер. Каждый триггер представляет собой также некоторую программу, которая выполняется над базой данных. Триггеры могут вызывать хранимые процедуры.
Механизм использования триггеров предполагает, что при срабатывании одного триггера могут возникнуть события, которые вызовут срабатывание других триггеров. Этот мощный инструмент требует тонкого и согласованного применения, чтобы не получился бесконечный цикл срабатывания триггеров.
В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД.
И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях.
Для написания хранимых процедур и триггеров используется расширение стандартного языка SQL, так называемый встроенный SQL..
Недостатком данной модели является очень большая загрузка сервера. Действительно, сервер обслуживает множество клиентов и выполняет следующие функции:
- осуществляет мониторинг событий, связанных с описанными триггерами;
- обеспечивает автоматическое срабатывание триггеров при возникновении связанных с ними событий;
- обеспечивает исполнение внутренней программы каждого триггера;
- запускает хранимые процедуры по запросам пользователей;
- запускает хранимые процедуры из триггеров;
- возвращает требуемые данные клиенту;
- обеспечивает все функции СУБД: доступ к данным, контроль и поддержку целостности данных в БД, контроль доступа, обеспечение корректной параллельной работы всех пользователей с единой БД.
Если мы переложили на сервер большую часть бизнес-логики приложений, то требования к клиентам в этой модели резко уменьшаются. Иногда такую модель называют моделью с «тонким клиентом», в отличие от предыдущих моделей, где на клиента возлагались гораздо более серьезные задачи. Эти модели называются моделями с «толстым клиентом».
Для разгрузки сервера была предложена трехуровневая модель.
Модель сервера приложений
Эта модель является расширением двухуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Архитектура трехуровневой модели приведена на рис. 10.7. Этот промежуточный уровень содержит один или несколько серверов приложений.

Рис. 10.7. Модель сервера приложений
В этой модели компоненты приложения делятся между тремя исполнителями:
- Клиент обеспечивает логику представления, включая графический пользовательский интерфейс, локальные редакторы; клиент может запускать локальный код приложения клиента, который может содержать обращения к локальной БД, расположенной на компьютере-клиенте. Клиент исполняет коммуникационные функции front-end части приложения, которые обеспечивают доступ клиенту в локальную или глобальную сеть. Дополнительно реализация взаимодействия между клиентом и сервером может включать в себя управление распределенными транзакциями, что соответствует тем случаям, когда клиент также является клиентом менеджера распределенных транзакций.
- Серверы приложений составляют новый промежуточный уровень архитектуры. Они спроектированы как исполнения общих незагружаемых функций для клиентов. Серверы приложений поддерживают функции клиентов как частей взаимодействующих рабочих групп, поддерживают сетевую доменную операционную среду, хранят и исполняют наиболее общие правила бизнес-логики, поддерживают каталоги с данными, обеспечивают обмен сообщениями и поддержку запросов, особенно в распределенных транзакциях.
- Серверы баз данных в этой модели занимаются исключительно функциями СУБД: обеспечивают функции создания и ведения БД, поддерживают целостность реляционной БД, обеспечивают функции хранилищ данных (warehouse services). Кроме того, на них возлагаются функции создания резервных копий БД и восстановления БД после сбоев, управления выполнением транзакций и поддержки устаревших (унаследованных) приложений (legacy application).
Отметим, что эта модель обладает большей гибкостью, чем двухуровневые модели. Наиболее заметны преимущества модели сервера приложений в тех случаях, когда клиенты выполняют сложные аналитические расчеты над базой данных, которые относятся к области OLAP-приложений. (On-line analytical processing.) В этой модели большая часть бизнес-логики клиента изолирована от возможностей встроенного SQL, реализованного в конкретной СУБД, и может быть выполнена на стандартных языках программирования, таких как C, C++, SmallTalk, Cobol. Это повышает переносимость системы, ее масштабируемость.
Функции промежуточных серверов могут быть в этой модели распределены в рамках глобальных транзакций путем поддержки XA-протокола (X/Open transaction interface protocol), который поддерживается большинством поставщиков СУБД.
Модели серверов баз данных
В период создания первых СУБД технология «клиент-сервер» только зарождалась. Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия процессов типа «клиент» и процессов типа «сервер». В современных же СУБД он является фактически основополагающим и от эффективности его реализации зависит эффективность работы системы в целом.
Рассмотрим эволюцию типов организации подобных механизмов. В основном этот механизм определяется структурой реализации серверных процессов, и часто он называется архитектурой сервера баз данных.
Первоначально, как мы уже отмечали, существовала модель, когда управление данными (функция сервера) и взаимодействие с пользователем были совмещены в одной программе. Это можно назвать нулевым этапом развития серверов БД.
Затем функции управления данными были выделены в самостоятельную группу — сервер, однако модель взаимодействия пользователя с сервером соответствовала парадигме «один-к-одному» (рис. 10.8), то есть сервер обслуживал запросы только одного пользователя (клиента), и для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверов.

Рис. 10.8. Взаимодействие пользовательских и клиентских процессов в модели «один-к-одному»
Выделение сервера в отдельную программу было революционным шагом, который позволил, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем — на другую, осуществляя взаимодействие между ними по сети. Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы.
Для обслуживания большого числа клиентов на сервере должно быть запущено большое количество одновременно работающих серверных процессов, а это резко повышало требования к ресурсам ЭВМ, на которой запускались все серверные процессы. Кроме того, каждый серверный процесс в этой модели запускался как независимый, поэтому если один клиент сформировал запрос, который был только что выполнен другим серверным процессом для другого клиента, то запрос тем не менее выполнялся повторно. В такой модели весьма сложно обеспечить взаимодействие серверных процессов. Эта модель самая простая, и исторически она появилась первой.
Проблемы, возникающие в модели «один-к-одному», решаются в архитектуре «систем с выделенным сервером», который способен обрабатывать запросы от многих клиентов. Сервер единственный обладает монополией на управление данными и взаимодействует одновременно со многими клиентами (рис. 10.9). Логически каждый клиент связан с сервером отдельной нитью («thread»), или потоком, по которому пересылаются запросы. Такая архитектура получила название многопотоковой односерверной («multi-threaded»).
Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей («trashing»).

Рис. 10.9. Многопотоковая односерверная архитектура
Кроме того, возможность взаимодействия с одним сервером многих клиентов позволяет в полной мере использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что значительно уменьшает потребности в памяти и общее число процессов операционной системы. Например, системой с архитектурой «один-к-одному» будет создано 100 копий процессов СУБД для 100 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобится только один серверный процесс.
Однако такое решение имеет свои недостатки. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три.
В некоторых системах эта проблема решается вводом промежуточного диспетчера. Подобная архитектура называется архитектурой виртуального сервера («vir-tual server») (рис. 10.10).
В этой архитектуре клиенты подключаются не к реальному серверу, а к промежуточному звену, называемому диспетчером, который выполняет только функции диспетчеризации запросов к актуальным серверам. В этом случае нет ограничений на использование многопроцессорных платформ. Количество актуальных серверов может быть согласовано с количеством процессоров в системе.
Однако и эта архитектура не лишена недостатков, потому что здесь в систему добавляется новый слой, который размещается между клиентом и сервером, что увеличивает трату ресурсов на поддержку баланса загрузки актуальных серверов («load balancing») и ограничивает возможности управления взаимодействием «клиент—сервер». Во-первых, становится невозможным направить запрос от конкретного клиента конкретному серверу, во-вторых, серверы становятся равноправными — нет возможности устанавливать приоритеты для обслуживания запросов.

Рис. 10.10. Архитектура с виртуальным сервером
Подобная организация взаимодействия клиент-сервер может рассматриваться как аналог банка, где имеется несколько окон кассиров, и специальный банковский служащий — администратор зала (диспетчер) направляет каждого вновь пришедшего посетителя (клиента) к свободному кассиру (актуальному серверу). Система работает нормально, пока все посетители равноправны (имеют равные приоритеты), однако стоит лишь появиться посетителям с высшим приоритетом, которые должны обслуживаться в специальном окне, как возникают проблемы. Учет приоритета клиентов особенно важен в системах оперативной обработки транзакций, однако именно эту возможность не может предоставить архитектура систем с диспетчеризацией.
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если эти два условия выполнены, то есть основания говорить о многопотоковой архитектуре с несколькими серверами, представленной на рис. 10.11.

Рис. 10.11. Многопотоковая мультисерверная архитектура
Она также может быть названа многонитевой мультисерверной архитектурой. Эта архитектура связана с вопросами распараллеливания выполнения одного пользовательского запроса несколькими серверными процессами.
Существует несколько возможностей распараллеливания выполнения запроса. В этом случае пользовательский запрос разбивается на ряд подзапросов, которые могут выполняться параллельно, а результаты их выполнения потом объединяются в общий результат выполнения запроса. Тогда для обеспечения оперативности выполнения запросов их подзапросы могут быть направлены отдельным серверным процессам, а потом полученные результаты объединены в общий результат (см. рис. 10.12). В данном случае серверные процессы не являются независимыми процессами, такими, как рассматривались ранее. Эти серверные процессы принято называть нитями (treads), и управление нитями множества запросов пользователей требует дополнительных расходов от СУБД, однако при оперативной обработке информации в хранилищах данных такой подход наиболее перспективен.

Рис. 10.12. Многонитевая мультисерверная архитектура
Типы параллелизма
Рассматривают несколько путей распараллеливания запросов.
Горизонтальный параллелизм. Этот параллелизм возникает тогда, когда хранимая в БД информация распределяется по нескольким физическим устройствам хранения — нескольким дискам. При этом информация из одного отношения разбивается на части по горизонтали (см. рис. 10.13). Этот вид параллелизма иногда называют распараллеливанием или сегментацией данных. И параллельность здесь достигается путем выполнения одинаковых операций, например фильтрации, над разными физическими хранимыми данными. Эти операции могут выполняться параллельно разными процессами, они независимы. Результат выполнения целого запроса складывается из результатов выполнения отдельных операций.

Рис. 10.13. Выполнение запроса при горизонтальном параллелизме
Время выполнения такого запроса при соответствующем сегментировании данных существенно меньше, чем время выполнения этого же запроса традиционными способами одним процессом.
Вертикальный параллелизм. Этот параллелизм достигается конвейерным выполнением операций, составляющих запрос пользователя. Этот подход требует серьезного усложнения в модели выполнения реляционных операций ядром СУБД. Он предполагает, что ядро СУБД может произвести декомпозицию запроса, базируясь на его функциональных компонентах, и при этом ряд подзапросов может выполняться параллельно, с минимальной связью между отдельными шагами выполнения запроса.
Действительно, если мы рассмотрим, например, последовательность операций реляционной алгебры:
R5=R1 [ A,C]
R6=R2 [A,B,D]
R7 = R5[A > 128]
R8 = R5[A]R6,
Информация в лекции «Глава 3. Форма и материал» поможет Вам.
то операции первую и третью можно объединить и выполнить параллельно с операцией два, а затем выполнить над результатами последнюю четвертую операцию.
Общее время выполнения подобного запроса, конечно, будет существенно меньше, чем при традиционном способе выполнения последовательности из четырех операций (см. рис. 10.13).
И третий вид параллелизма является гибридом двух ранее рассмотренных (см. рис. 10.14).

Рис. 10.14. Выполнение запроса при гибридном параллелизме
Наиболее активно применяются все виды параллелизма в OLAP-приложениях, где эти методы позволяют существенно сократить время выполнения сложных запросов над очень большими объемами данных.
К операторам определения данных относятся
- (Правильный ответ) ALTER VIEW
- (Правильный ответ) DROP INDEX
- (Правильный ответ) CREATE TABLE
- (Правильный ответ) ALTER TABLE
Система, обеспечивающая параллельный доступ к одной БД нескольких пользователей, если БД расположена на одной машине, — это
- распределенная система
- (Правильный ответ) система распределенной обработки данных
- система распределенных баз данных
Индивидуальный откат транзакции применяется в случае
- (Правильный ответ) аварийного завершения работы прикладной программы
- (Правильный ответ) взаимной блокировке транзакций при параллельном выполнении
- (Правильный ответ) завершение транзакции оператором ROLLBACK
После выполнения операции
GRANT SELECT, INSERT ON TABLE1TO USER1
- пользователь USER1 может передать пользователю USER2 права на ввод данных в таблицу TABLE1
- пользователь USER1 может передать пользователю USER2 права на удаление таблицы TABLE1
- (Правильный ответ) пользователь USER1 может делать выборку из таблицы TABLE1
- (Правильный ответ) пользователь USER1 может вводить данные в таблицу TABLE1
Транзакция — это
- (Правильный ответ) последовательность операций над БД, переводящих ее из одного непротиворечивого состояния в другое непротиворечивое состояние
- система из нескольких БД, находящихся под управлением одной СУБД
- один из типов организации СУБД
- система из нескольких СУБД, создающаяся с целью оптимизации процесса мониторинга баз данных
Технология Intranet
- полностью заменила технологию клиент-сервер
- не получила широкого распространения
- (Правильный ответ) существует совместно с технологией клиент-сервер
Алгоритмически сложные задачи работы с БД целесообразнее решать в архитектуре
- Intranet
- (Правильный ответ) клиент-сервер
- Internet
Языковая целостность БД предполагает:
- поддержку языков манипулирования данными низкого уровня
- (Правильный ответ) поддержку языков манипулирования данными высокого уровня
- отсутствие поддержки языков манипулирования данными высокого уровня
Для использовании технологии доступа к данным Intranet
- необходимо использование архитектуры клиент-сервер
- необходимо специальное ПО
- (Правильный ответ) нет необходимости в специальном ПО
Второй этап развитии баз данных связан с
- (Правильный ответ) появлением персональных компьютеров
- исчезновением больших ЭВМ
- исчезновением мини-ЭВМ
- появлением мини-ЭВМ
К третьему этапу развития БД относится
- (Правильный ответ) появление распределенных БД
- (Правильный ответ) появление многоплатформенных СУБД
- (Правильный ответ) начало работ с концепцией ООБД
Структурированный язык запросов и манипулирования данными имеет аббревиатуру
- ICQ
- (Правильный ответ) SQL
- PL
Пользователи банка данных, от которых не требуются специальные знания в области вычислительной техники — это
- разработчики и администраторы приложений
- администраторы банка данных
- (Правильный ответ) конечные пользователи
Физическая независимость при работе с данными предполагает
- возможность работы нескольких приложений с базой данных
- возможность переноса хранимой информации с одних носителей на другие без сохранения работоспособности всех приложений, работающих с данной базой данных
- (Правильный ответ) возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных
Самый верхний уровень трехуровневой системы организации БД, предложенной ANSI, называется
- (Правильный ответ) уровень внешних моделей
- концептуальный уровень
- физический уровень
Выберите верное:
- (Правильный ответ) сначала операционная система осуществляет перекачку информации из устройств хранения и пересылает ее в системный буфер, затем оповещает СУБД об окончании пересылки
- СУБД сначала просит операционную систему предоставить необходимые данные, затем в СУБД возвращается информация о местоположении данных в терминах операционной системы
- (Правильный ответ) СУБД сначала возвращается информация о местоположении данных в терминах операционной системы, затем СУБД просит операционную систему предоставить необходимые данные
- сначала операционная система оповещает СУБД об окончании пересылки информации, затем помещает информацию в системный буфер
Модель данных в контексте баз данных — это
- (Правильный ответ) некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет трактовать их как сведения, содержащие не только данные, но и связи между ними
- набор абстракций, характеризующих объект
- набор конкретных значений параметров, характеризующих объек
Понятие «данные» в контексте баз данных — это
- некоторая абстракция
- (Правильный ответ) набор конкретных значений, параметров, характеризующих объект
- набор абстракций,характеризующих объек
Дескрипторные модели согласно классификации моделей данных
- основаны на принципе организации словарей
- (Правильный ответ) самые простые из документальных моделей
- (Правильный ответ) каждому документу ставят в соответствие дескриптор-описатель
- самые сложные из документальных моделей
БМД — это
- (Правильный ответ) База Метаданных
- Банк Метаданных
- Банк Местных Данных
- База Местных Данных
Конечные пользователи банка данных — это
- (Правильный ответ) категория пользователей, от которых не требуются специальные знания в области вычислительной техники
- группа, отвечающая за оптимальную организацию банка данных
- пользователи, функционирующие во время проектирования, создания и реорганизации банка данных
Выберите верное:
- СУБД сначала просит операционную систему предоставить необходимые данные, затем — получает информацию о запрошенной части концептуальной модели
- СУБД сначала запрашивает информацию о местоположении данных на физическом уровне, затем получает информацию о запрошенной части концептуальной модели
- (Правильный ответ) СУБД сначала получает информацию о запрошенной части концептуальной модели, затем запрашивает информацию о местоположении данных на физическом уровне
В иерархической модели результатом вызова оператора GET UNIQUE Сотрудники WHERE Сотрудники.Возраст=30 будет
- данные о последнем найденном сотруднике в возрасте 30 лет
- (Правильный ответ) данные о первом найденном сотруднике в возрасте 30 лет
- список всех сотрудников в возрасте 30 лет
В иерархической модели данных «близнецы» — это
- экземпляры-потомки одного типа
- (Правильный ответ) экземпляры-потомки одного типа, связанные с одним экземпляром сегмента-предка
- экземпляры-потомки одного экземпляра сегмента-предка
Совокупность физических баз данных образует
- (Правильный ответ) концептуальную модель данных
- логическую модель данных
- физическую модель данных
- внешнюю модель данных
В иерархической модели данных конкретные значения полей данных, входящих в сегмент данных, — это
- тип сегмента
- (Правильный ответ) экземпляр сегмента
- тип данных
- экземпляр данных
В иерархической модели при описании корневого сегмента параметр FREQ определяет
- число всех подчиненных сегментов
- (Правильный ответ) число возможных экземпляров корневого сегмента
- число возможных экземпляров родительского сегмента
Для иерархической модели совокупность поддеревьев для физических баз данных, с которыми работает конкретный пользователь, — это
- (Правильный ответ) внешняя модель
- физическая модель
- концептуальная модель
- пользовательская модель
В иерархической модели данных
- поля объединяются в неориентированный древовидный граф
- (Правильный ответ) сегменты объединяются в ориентированный древовидный граф
- наборы данных объединяются в неориентированный граф
- сегменты объединяются в неориентированный древовидный граф
- агрегаты данных объединяются в ориентированный граф
В сетевой модели данных между двумя типами записей можно определить
- не больше двух наборов
- только один набор
- (Правильный ответ) любое количество наборов
В сетевой модели данных набор данных — это двухуровневый граф, связывающий отношением
- «один-ко-многим» два агрегата данных
- «один-к-одному» два типа записи
- «один-к-одному» два элемента данных
- (Правильный ответ) «один-ко-многим» два типа записи
- «многие-ко-многим» два типа записи
В физической БД иерархической модели корневой сегмент — это сегмент, который
- (Правильный ответ) не имеет родительского типа сегмента
- связан только с одним родительским сегментом
- не имеет подчиненных типов сегментов
В иерархической модели данных физические записи
- не различаются по длине
- (Правильный ответ) различаются по структуре
- не различаются по структуре
- (Правильный ответ) различаются по длине
К разделам языка описания данных в сетевой модели относится
- (Правильный ответ) описание базы данных
- (Правильный ответ) описания наборов
- (Правильный ответ) описания записей
- описания полей данных
Свойство коммутативности алгебраической операции означает, что
- (Правильный ответ) результат не зависит от порядка аргументов в операции
- результат не зависит от порядка и количества аргументов
- результат зависит от порядка аргументов в операции
Схемой отношения называется
- перечень кортежей данного отношения с указанием домена, к которому они относятся
- графическое представление отношения
- (Правильный ответ) перечень имен атрибутов данного отношения с указанием домена, к которому они относятся
Сцеплением или конкатенацией двух кортежей называется кортеж, полученный
- добавлением значений первого в конец второго
- добавлением значений второго в середину первого
- добавлением значений первого в середину второго
- (Правильный ответ) добавлением значений второго в конец первого
Основные понятия и ограничения реляционной модели впервые сформулировал
- Э. Шредер
- (Правильный ответ) Э. Кодд
- Ч. Пирс
Объединением двух отношений называется отношение, содержащее множество кортежей, принадлежащих
- (Правильный ответ) либо первому исходному отношению
- (Правильный ответ) либо второму исходному отношению
- (Правильный ответ) либо первому и второму исходным отношениям одновременно
Разностью двух отношений называется отношение, содержащее множество кортежей, принадлежащих
- второму отношению и не принадлежащих первому
- не принадлежащих ни первому отношению, ни второму
- (Правильный ответ) первому отношению и не принадлежащих второму
Средства администрирования данных включают операции
- (Правильный ответ) REVOKE
- (Правильный ответ) ALTER DATABASE
- ALTER TABLE
- (Правильный ответ) GRANT
Для удаления из строки всех последних указанных символов используется функция
- (Правильный ответ) TRIM(TRAILING символ FROM строка)
- TRIM(LEADING символ FROM строка)
- TRIM(BOTH символ FROM строка)
Для вывода всех работников предприятия, занятых в отделе обслуживания, со стажем более 10 лет из таблицы Table1 с полями ФИО, ОТДЕЛ, СТАЖ, можно воспользоваться запросом:
- SELECT ФИО FROM Table1 WHERE ОТДЕЛ=»обслуживание»
- SELECT ФИО FROM Table1 WHERE СТАЖ РАБОТЫ > 10
- (Правильный ответ) SELECT ФИО FROM Table1 WHERE ОТДЕЛ=»обслуживание» AND СТАЖ РАБОТЫ > 10
Результатом операции CHARLENGTH (строка) будет являться
- последний символ строки
- строка, разбитая на отдельные символы
- первый символ строки
- (Правильный ответ) число, отражающее длину строки
Оператор SELECT относится к группе операторов
- манипулирования данными
- (Правильный ответ) запросов
- управлении транзакциями
- управления БД
Операции COMMIT, ROLLBACK относятся к операциям
- (Правильный ответ) управления транзакциями
- запросов
- манипулирования данными
Операторы ALTER PASSWORD, DROP DATABASE, CREATE DBAREA относятся к операторам
- (Правильный ответ) администрирования данных
- запросов
- манипулирования данными
- управления транзакциями
В языке SQL/89 поддерживаются следующие типы даннх:
- (Правильный ответ) CHAR(n)
- (Правильный ответ) INTEGER
- (Правильный ответ) NUMERIC[(c,m)]
- (Правильный ответ) REAL
Для получения количества строк или непустых значений, которые выбрал запрос, применяется функци
- AVG
- SUM
- (Правильный ответ) COUNT
Словесное описание объектов предметной области и связей между ними — это
- создание даталогической модели предметной области
- создание инфологической модели предметной области
- (Правильный ответ) системный анализ предметной области
Отношение может иметь
- не более двух возможных ключей
- (Правильный ответ) несколько возможных ключей
- только один возможный ключ
Завершающим этапом проектирования БД является
- (Правильный ответ) физическое проектирование
- инфологическое проектирование
- даталогическое проектирование
- системный анализ предметной области
Согласно модели жизненного цикла БД, проектирование БД является
- не является этапом жизненного цикла БД
- последним этапом
- (Правильный ответ) первым этапом
Функциональный подход к выбору состава и структуры предметной области предполагает
- (Правильный ответ) выделение минимально необходимого набора объектов предметной области
- (Правильный ответ) заранее известные информационные потребности и функции будущих пользователей БД
- заранее неизвестные информационные потребности и функции будущих пользователей БД
Замена множества исходных отношений схемы БД множеством их проекций — суть проектирования схемы БД методом
- синтеза
- экспозиции
- (Правильный ответ) декомпозиции
- суперпозиции
Разработка процедур поддержки семантической целостности базы данных является результатом
- инфологического проектирования
- физического проектирования
- анализа предметной области
- (Правильный ответ) даталогического проектирования
Отношение находится в первой нормальной форме тогда и только тогда, когда
- в каждой строке находятся только элементарные значения атрибутов
- (Правильный ответ) на пересечении каждого столбца и каждой строки находятся только элементарные значения атрибутов
- на пересечении каждого столбца и каждой строки находятся нормализованные значения атрибутов
Корректная схема БД -это схема, в которой
- отсутствуют атрибуты отношений
- присутствуют атрибуты отношений
- отсутствуют зависимости между атрибутами отношений
- (Правильный ответ) отсутствуют нежелательные зависимости между атрибутами отношений
Важнейшими свойствами нормальных форм являются
- при переходе к следующим нормальным формам свойства предыдущих не сохраняются
- (Правильный ответ) при переходе к следующим нормальным формам свойства предыдущих сохраняются
- (Правильный ответ) каждая следующая нормальная форма улучшает свойства предыдущей
Связь между сущностью и ей же самой называется
- бинарной
- унарной
- (Правильный ответ) рекурсивной
Для ER-модели существует алгоритм ее однозначного преобразования в
- сетевую модель данных
- иерархическую модель данных
- (Правильный ответ) реляционную модель данных
Графически сущность обозначается
- кругом
- (Правильный ответ) прямоугольником
- треугольником
- стрелкой
Характеристики, определяющие свойства данного представителя класса — это
- ключи
- сущности
- (Правильный ответ) атрибуты
Разрешение связи типа многие-ко-многим при переходе к реляционной модели осуществляется с помощью
- удаления «проблемных» отношений
- введения нескольких связующих отношений
- (Правильный ответ) введения связующего отношения
В ER-модели категоризация сущностей
- обязательна
- (Правильный ответ) допускается
- запрещается
Если экземпляр одной сущности связан только с одним экземпляром другой сущности, то это связь
- один-ко-многим
- многие-к-одному
- (Правильный ответ) один-к-одному
- многие-ко-многим
Согласно правилам преобразования ER-модели в реляционную модель данных, каждой сущности ставится в соответствие
- два отношения реляционной модели
- один кортеж реляционной модели данных
- (Правильный ответ) одно отношение реляционной модели
Наличие у отношения внешнего ключа означает, что в исходной ER-модели этому отношению соответствует
- супертип
- основная сущность
- (Правильный ответ) подчиненная сущность
В реляционной модели данных поддерживаются связи между отношениями типа
- один-к-одному
- (Правильный ответ) один-ко-многим
- многие-к-многим
Поддержка семантической целостности может быть обеспечена
- (Правильный ответ) процедурно
- синтетически
- (Правильный ответ) декларативно
Декларативные ограничения целостности задаются на уровне
- (Правильный ответ) операторов создания таблиц
- операторов изменения таблиц
- операторов задания доменов
Согласно таблице истинности для логических операций с неопределенными значениями, если значение A -TRUE, а B — NULL, то конъюнкция А и B
- (Правильный ответ) TRUE
- NULL
- FALSE
Задание в разделе ограничений целостности столбца выражения NOT NULL приводит к
- (Правильный ответ) неявному порождению проверочного ограничения целостности для всей таблицы
- неявному порождению проверочного ограничения целостности только для этого столбца
- неявному порождению проверочного ограничения целостности для этого столбца и соседних с ним
Согласно таблице истинности для логических операций с неопределенными значениями, если значение A -TRUE, а B — NULL, то пересечение А и B
- FALSE
- (Правильный ответ) NULL
- TRUE
При задании ограничений уникальности столбец определяется как
- первичный ключ
- вторичный ключ
- (Правильный ответ) возможный ключ
Требование допустимости СУБД работы только с данными типа «реляционное отношение» — это поддержка
- (Правильный ответ) структурной целостности
- языковой целостности
- ссылочной целостности
- семантической целостности
Существуют следующие виды декларативных ограничений целостности
- (Правильный ответ) ограничения целостности на уровне домена
- (Правильный ответ) ограничения целостности на уровне отношения
- (Правильный ответ) ограничения целостности атрибута
- (Правильный ответ) ограничения целостности на уровне связи между отношения
Необходимость для СУБД обеспечения языков описания и манипулирования данными не ниже стандарта SQL — это требование поддержки
- структурной целостности
- ссылочной целостности
- (Правильный ответ) языковой целостности
- семантической целостности
При создании базы данных Readers в MS SQL Server 7.0 c помощью оператора CREATE DATABASE Readers
- (Правильный ответ) будет создана база данных Readers
- будет выдана ошибка, так как не указаны обязательные параметры
- будет создана база данных Library
Существуют следующие виды ограничения целостности атрибута
- (Правильный ответ) значение по кортежу
- (Правильный ответ) задание обязательности/необязательности значений
- (Правильный ответ) задание условий на значения
- (Правильный ответ) значение по умолчанию
Поддержка целостности включает в себя поддержку
- (Правильный ответ) языковой целостности
- (Правильный ответ) структурной целостности
- синтетической целостности
- (Правильный ответ) ссылочной целостности
Возможность определения текущей записи файла, а также последующей и предыдущей — следствие
- хаотичности последовательности записей
- (Правильный ответ) линейности последовательности записей
- нелинейности последовательности записей
При нахождении нужных записей «подчиненного» файла
- сначала ищется запись в «подчиненном» файле, затем в основном
- (Правильный ответ) сначала ищется запись в «основном» файле, затем в подчиненном
- сначала ищется запись в «промежуточном» файле, затем в подчиненном
В-деревья относятся к
- инвертированным спискам
- (Правильный ответ) индексным файлам
- файлам прямого доступа
- взаимосвязанным файлам
Наиболее эффективным алгоритмом поиска на упорядоченном массиве является
- (Правильный ответ) бинарный поиск
- n-арный поиск
- унарный поиск
Если структура записи индекса имеет вид: ЗНАЧЕНИЕ КЛЮЧА ПЕРВОЙ ЗАПИСИ БЛОКА-НОМЕР БЛОКА С ЭТОЙ ЗАПИСЬЮ, то файл является
- индексно-непоследовательным файлом
- (Правильный ответ) индексно-последовательным файлом
- индексно-параллельным файлом
Часть диска, физическое пространство на диске, которое ассоциировано одному процессу, называется
- (Правильный ответ) чанком
- экстентом
- кластером
Поименованная линейная последовательность записей, расположенных на внешних носителях, называется
- базой данных
- деревом данных
- (Правильный ответ) файлом
В стратегии свободного замещения разрешения коллизий для каждой записи добавляется
- (Правильный ответ) указатель на предыдущую запись в цепочке синонимов
- (Правильный ответ) указатель на последующую запись в цепочке синонимов
- указатель на последнюю запись в цепочке синонимов
В стратегии свободного замещения разрешения коллизий файловое пространство
- подразделяется на свободную и замещенную области
- подразделяется на основную область и область преполнения
- (Правильный ответ) не разделяется на области
При модификации основного файла с организацией вторичных списков осуществляются следующие дейсвия:
- (Правильный ответ) изменяется запись основного файла
- (Правильный ответ) добавляется новая ссылка на новое значение вторичного ключа
- (Правильный ответ) исключается старая ссылка на предыдущее значение вторичного ключа
В структуре хранения данных MS SQL Server физически используются следующие единицы хранения данных:
- (Правильный ответ) страница
- (Правильный ответ) блок
- (Правильный ответ) единица размещения
Запрос, при обработке которого используются данные из БД, расположенные в разных узлах сети, называется
- (Правильный ответ) распределенным
- виртуальным
- скоростным
- удаленным
В модели файлового сервера сервер может обслуживать
- не более 5 клиентов
- (Правильный ответ) множество клиентов
- только одного клиента
В модели сервера баз данных бизнес-логика приложений
- находится на клиенте
- (Правильный ответ) разделена между клиентом и сервером
- находится на сервере
Часть кода приложения, связанная с обработкой данных внутри приложения, — это
- (Правильный ответ) логика обработки данных
- бизнес-логика
- презентационная логика
Модель удаленного управления данными также называется моделью
- (Правильный ответ) файлового сервера
- файловой сущности
- удаленного сервера
- удаленного клиента
Система, обеспечивающая параллельный доступ к одной БД нескольких пользователей, если БД расположена на нескольких машинах, — это
- система распределенной обработки данных
- (Правильный ответ) система распределенных баз данных
- распределенная система
В модели файлового сервера в ответ на запрос клиент получает
- (Правильный ответ) блоки файлов
- хранимые на сервере процедуры
- только релевантные запросу данные
В модели сервера баз данных средством программирования SQL-сервера является
- (Правильный ответ) механизм хранимых процедур
- механизм передаваемых процедур
- механизм триггеров
Декомпозицией запросов называют
- гибридный параллелизм
- горизонтальный параллелизм
- (Правильный ответ) вертикальный параллелизм
Часть кода приложений, определяющая алгоритмы решения конкретных задач приложения, — это
- презентационная логика
- (Правильный ответ) бизнес-логика
- логика обработки данных
На нулевом этапе развития серверов БД
- (Правильный ответ) управление данными и взаимодействие с пользователем были совмещены в одной программе
- управление данными отсутствовало
- взаимодействие с данными отсутствовало
Распараллеливание или сегментация данных — это
- гибридный параллелизм
- вертикальный параллелизм
- (Правильный ответ) горизонтальный параллелизм
В модели сервера баз данных для отслеживания текущего состояния информационного хранилища выступает
- механизм хранимых процедур
- механизм передаваемых процедур
- (Правильный ответ) механизм триггеров
Каждая успешно завершенная транзакция должна быть зафиксирована
- в оперативной памяти
- (Правильный ответ) на внешней памяти
- в буфере
Основой обнаружения тупиковых ситуаций является построение
- графа блокировки транзакций
- (Правильный ответ) графа ожидания транзакций
- матрицы блокировки транзакций
Оператор BEGIN TRANSACTION
- сообщает об откате всей транзакции
- (Правильный ответ) сообщает о начале транзакции
- сообщает об успешном завершении транзакции
Состояние внешней памяти базы данных считается согласованным, если наборы страниц всех объектов соответствуют состоянию объекта
- только до изменения
- (Правильный ответ) до изменения или после изменения
- только после изменения
Оператор COMMIT
- прерывает транзакцию
- (Правильный ответ) означает успешное завершение транзакции
- означает ошибочное завершение транзакции
Принцип протокола журнализации WAL —
- «пиши сначала в буфер»
- (Правильный ответ) «пиши сначала в журнал»
- «не пиши в журнал»
Восстановление последнего согласованного состояния базы данных после жесткого сбоя начинается с
- выполнения в прямом направлении всех операций по журналу
- с отката всех незавершившихся транзакций
- (Правильный ответ) обратного копирования БД из архивной копии
Теневой механизм обеспечения наличия точек физической согласованности базы данных основан на использовании
- теневых индексов отображения
- таблиц теней
- (Правильный ответ) теневых таблиц отображения
Системная процедура, возвращающая все старые значения в отмененной транзакции, называется

Сравнение трёхзвенки (MVC) и варианта с переносом части бизнес-логики в СУБД(Прочитано 9101 раз)

Коллеги, наткнулся на такую вот статью на хабре Где наша бизнес-логика, сынок?
У меня на работе завязался нешуточный спор по теме, что лучше:
- Вся бизнес логика реализована в приложении на сервере приложений (IBM WebSphere);
- Часть бизнес логики реализована на уровне БД в хранимых процедурах, приложение на сервере приложений используется, в основном, в качестве GUI (view)[четырехзвенка или недотрехзвенка?];
Дополнительно стоит добавить еще такие моменты:
У нас на работе существуют две основные СУБД: Oracle — для сторонних систем и IBM DB2 — для систем, разрабатываемых своими силами. Еще есть SQL Server, но его не будем рассматривать.
Нагрузка на БД целевой системы — порядка 150000 запросов в сутки, количество пользователей, работающих с веб-интерфейсом — порядка 20 сотрудников.
У меня вопрос к тем, кто сталкивался с подобным выбором:
Какой вариант будет предпочтительнее из приведенных ниже?
- Вся бизнес логика реализована в приложении на сервере приложений (IBM WebSphere), целевая СУБД — IBM DB2;
- Часть бизнес логики реализована на уровне БД в хранимых процедурах, приложение на сервере приложений используется, в основном, в качестве GUI, целевая СУБД — IBM DB2;
- Вся бизнес логика реализована в приложении на сервере приложений (IBM WebSphere), целевая СУБД — Oracle;
- Часть бизнес логики реализована на уровне БД в хранимых процедурах, приложение на сервере приложений используется, в основном, в качестве GUI, целевая СУБД — Oracle;
« Последнее редактирование: 09 Августа 2014, 05:31:18 от Thinkler »

Записан
Vеritas odium parit
![]()
Я сварщик не настоящий, но… Из некоторых проектов вынес следующее:
1. Логика на хранимых процедурах — это дешево (в разработке), быстро (в исполнении) и дает возможность задействовать весьма приятные фишки от разработчиков СУБД.
2. Часть логики на хранимых процедурах, часть на сервере приложений — сплошные неудобства в документировании и страшный геморрой, когда дело касается развития системы через год-другой (когда большая часть «тех, кто помнит» уже разбежалась на другие проекты).
Соответственно, если надо дешево и сердито — вперед в хранилки. Если детище надо сопровождать и развивать — возможно, стоит потратиться на классическое разбиение.
Что для вас будет предпочтительнее — да кто ж знает? Кроме сугубо технических вопросов, есть еще и железно-лицензионно-проектно-организационные, которые никак обозначены. Будете ли вы разводить тучные стада представительских дибитушников, или обойдетесь парочкой ораклуш? Остались ли у вас «лишние» лицензии на СУБД, которые надо «пристроить»? Не обещал ли вам вендор скидку на мэйнфрейм (хотя под озвученную нагрузку — сомнительно)? Что у вас с доступностью персонала — кого будет больше, когда время дойдет до реализации? Что больше по душе вашем заказчику? И т.п.
P.S. 150к запросов в день и 20 активных пользователей — это мелочи. Любая из раскрученных СУБД такое (и не такое) осилит на раз.
Записан
Думаю, что лучшее место для таких обсуждений — sql.ru
Почему не рассматриваете SQL Server? Непонятно.
После 5 лет разработки ХП на Оракле, для простых систем настоятельно рекомендую рассматривать сначала более простые технологические связки, типа php + mysql.
Ну и это — покажите требования к качеству системы, тогда можно будет обсуждать более предметно.
Записан
Думаю, что лучшее место для таких обсуждений — sql.ru
— Денис, согласен, но все же решил выложить на всякий случай.
Почему не рассматриваете SQL Server? Непонятно.
— Не рассматриваю, т.к. у нас на работе существует нечто вроде стандарта организации, согласно которому
существуют две основные СУБД: Oracle — для сторонних систем и IBM DB2 — для систем, разрабатываемых своими силами.
— Это ограничение, на которое я, к сожалению (или к счастью), практически не могу сейчас повлиять. Кстати, на SQL server у меня развернуты модельные репозитории SPARX EA )))
Так что,
После 5 лет разработки ХП на Оракле, для простых систем настоятельно рекомендую рассматривать сначала более простые технологические связки, типа php + mysql
— к сожалению, не в моей компетенции.
Ну и это — покажите требования к качеству системы, тогда можно будет обсуждать более предметно.
— Вот что мне пока известно —
Нагрузка на БД целевой системы — порядка 150000 запросов в сутки, количество пользователей, работающих с веб-интерфейсом — порядка 20 сотрудников.
СУБД развернута на виртуальном сервере, параметры производительности пока что неизвестны, но известно, что при использовании СУБД DB2 периодически возникают «просадки» по производительности, чего не наблюдается, предположительно, при использовании Oracle со схожей конфигурацией платформы.
По поводу сравнения DB2 и Oracle наткнулся в форуме sql.ru на такую тему:
Oracle vs DB2
Вот такая фраза привлекла внимание:
у этих субд совершенно противоположные идиологии — оракл версионник, дб2 блокировочник
и ответ:
IBM-еры довольно много постарались для совместимости. Вплоть до того, что пустая строка может трактоваться, как NULL, а многие раньше блокирующие вещи теперь не блокируют. Нынешняя DB2 по совместимости… ну… примерно на уровне 9-го Oracle.
Читаю далее…
« Последнее редактирование: 11 Августа 2014, 12:49:35 от Thinkler »
Записан
Vеritas odium parit
![]()
IMHO
Расположение бизнес-логики. Поддерживать и развивать логику проще, если она на сервере приложений. Меньше даунтайм, проще работа в ветками кода. Это не значит, что совсем нельзя держать логику в СУБД. Это означает, что получив на начальной стадии плюс в скорости разработки в СУБД вы потом просядете на поддержке.
Чем более сложным предполагается приложение тем больше доводов за хранение логики на сервере приложений.
Нагрузка на БД целевой системы — порядка 150000 запросов в сутки, количество пользователей, работающих с веб-интерфейсом — порядка 20 сотрудников.
Может я чего не понимаю, но это совсем небольшая нагрузка. Даже для серверов 15-летней давности это было весьма и весьма подъемно. В 2001 делал тестирование производительности для некоей системы. Без всякой оптимизации, да и с неудачной архитектурой. На слабых серверах система спокойно держала более 100 запросов в секунду (запросы на чтение). В 2008 по просьбе одного из сайтов проводили оптимизацию. Сервера также были не ахти (по тем временам). Несложной манипуляцией подняли производительность с 2 500 до 5 000 запросов в секунду. И никакого Оракла. И никакого кластера.
А 20 бизнес пользователей… Ну это 2000 год и низкопроизводительные FileMaker или Acces.
Наверное, я чего то не понимаю…
Записан
Thinkler, вообще голосовалка немного странная. Это архитектурное решение. А оно зависит от разных факторов. При этом на самом деле представлено два решения, где разница в сервере БД
Записан
Записан
Эдуард, я объяснил причину ограниченности — наличия только двух вариантов СУБД, политикой компании.)))
Денис, спасибо за совет.
Записан
Vеritas odium parit
Привет, Вы узнаете про пользователь бд , Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
пользователь бд , запрос sql, логическая структура бд, топология бд, структура распределенной бд, локальная автономность ,
удаленный запрос, удаленная транзакция, поддержка распределенной транзакции , распределенный запрос , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
1.1. Термины и определения
Системы управления удаленными (распределенными) базами данных — это СУБД (СУРБД), обеспечивающие возможность одновременного доступа к информации различным пользователям.
Рассмотрим термины, применяемые в системах управления распределенными базами данных.
Архитектура БД — организация взаимодействия аппаратных средств.
Виды архитектуры БД: клиент—сервер, двухуровневая и трехуровневая клиент-сервер, файл —сервер.
Архитектура ODBC (Open DataBase Connectivity) — открытый интерфейс доступа к базам данных, т.е. взаимодействие процессора (ядра) базы данных Jet с внешними источниками данных.
Модели данных — схемы, характеризующие базы данных с разных сторон с целью определить оптимальное построение информационной системы.
Ядро базы данных — внутренняя структура СУБД, обеспечивающая доступ ко всем компонентам базы данных. В новых версиях СУБД Access называется Microsoft Data Engine (MSDE); в ранних версиях ядро базы данных называлось машина базы данных Microsoft Jet. Ядро базы данных обеспечивает поддержку символов различных алфавитов, синтаксис языка SQL и другие средства обработки различных типов данных.
пользователь бд — программа или человек, обращающийся к базе данных.
Запрос — процесс обращения пользователя к БД с целью ввести, получить или изменить информацию.
Транзакция — последовательность операций модификации данных в БД, переводящая ее из одного непротиворечивого состояния в другое непротиворечивое состояние.
логическая структура бд — определение БД на физически независимом уровне, что ближе всего соответствует концептуальной ее модели.
топология бд , или
структура распределенной бд , — схема распределения физической организации базы данных в сети.
локальная автономность — понятие, означающее, что информация локальной БД и связанные с ней определения данных принадлежат локальному владельцу и им управляются.
удаленный запрос — запрос к базам данных, находящихся на ресурсах локальной сети предприятия или сети Интернет.
Возможность реализации удаленной транзакции — обработка одной транзакции, состоящей из множества SQL-запросов, на одном удаленном узле.
поддержка распределенной транзакции — обработка транзакции, состоящей из нескольких SQL-запросов, выполняемых на нескольких узлах сети (удаленных или локальных), но каждый из которых обрабатывается только на одном узле.
распределенный запрос — запрос, при обработке которого используются данные из БД, расположенные в разных узлах сети.
Системы распределенной обработки данных в основном связаны с первым поколением БД, которые строились на мультипрограммных операционных системах, хранились на устройствах внешней памяти центральной ЭВМ и использовали терминальный многопользовательский режим доступа. При этом пользовательские терминалы не имели собственных ресурсов, т.е. процессоров и памяти, которые могли бы использоваться для хранения и обработки данных. Первой полностью реляционной системой, работающей в многопользовательском режиме, была СУБД SYSTEM R фирмы IBM. Именно в ней были реализованы как язык манипулирования данными SQL, так и основные принципы синхронизации, применяемые при распределенной обработке данных, которые до сих пор являются базисными практически во всех коммерческих СУБД.
1.2. Архитектуры клиент—сервер в технологии управления удаленными базами данных
Вычислительная модель клиент-сервер исходно связана с появлением открытых систем в 1990-х гг. Термин клиент—сервер применялся к архитектуре программного обеспечения, состоящего из двух процессов обработки информации: клиентского и серверного. Клиентский процесс запрашивал некоторые услуги, а серверный — обеспечивал их выполнение. При этом предполагалось, что один серверный процесс может обслужить множество клиентских процессов. Учитывая, что аппаратная реализация этой модели управления базами данных связана с созданием локальных вычислительных сетей предприятия, такую организацию процесса обработки информации называют архитектурой клиент—сервер.
Основной принцип модели клиент—сервер применительно к технологии управления базами данных заключается в разделении функций стандартного интерактивного приложения на пять групп, имеющих различную природу:
-
функции ввода и отображения данных (Presentation Logic);
-
прикладные функции, определяющие основные алгоритмы решения задач приложения (Business Logic);
-
функции обработки данных внутри приложения (DataBase Logic);
-
функции управления информационными ресурсами (DataBase Manager System);
-
служебные функции, играющие роль связок между функциями первых четырех групп.
Структура типового приложения, работающего с базой данных в архитектуре клиент—сервер, приведена рис. 1.1.
Как видно из рис. 1.1, клиентская часть приложения включает в себя следующие части:
-
презентационную логику;
-
бизнес-логику, или логику собственно приложений;
-
логику обработки данных;
-
процессор управления данными.
Презентационная логика (Presentation Logic) как часть приложения определяется тем, что пользователь видит на своем экране, что приложение работает. Сюда относятся все интерфейсные экранные формы, которые пользователь видит или заполняет в ходе работы приложения, а также все то, что выводится пользователю на экран в качестве результатов решения некоторых про-
Клиент

Рис. 1.1. Структура типового приложения, работающего с базой данных
межуточных задач либо как справочная информация. Следовательно, основными задачами презентационной логики являются:
-
формирование экранных изображений;
-
чтение и запись в экранные формы информации;
-
управление экраном;
-
обработка движений мыши и нажатие клавиш клавиатуры.
Бизнес-логика, или логика собственно приложений (Business
Processing Logic), — это часть кода приложения, которая определяет собственно алгоритмы решения конкретных его задач. Обычно этот код записывается с использованием различных языков программирования, таких как С, С++, Visual Basic и др.
Логика обработки данных (Data Manipulation Logic) — это часть кода приложения, которая непосредственно связана с обработкой данных внутри него. Далными управляет собственно СУБД, а для обеспечения доступа к ним используется язык SQL.
Процессор управления данными (DataBase Manager System Processing) — это собственно СУБД, которая обеспечивает хранение и управление базами данных. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако при рассмотрении архитектуры приложения мы выделим их в отдельную его часть.
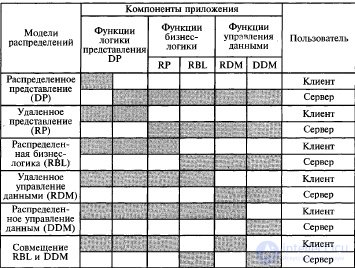
Рис . Об этом говорит сайт https://intellect.icu . 1.2. Распределение функций компонентов приложения в моделях
клиент—север
В централизованной архитектуре (Host-Based Processing) указанные части приложения располагаются в единой среде и комбинируются внутри одной исполняемой программы. В децентрализованной архитектуре эти части приложения могут быть по-разному распределены между серверным и клиентским процессами.
В зависимости от характера распределений задач можно выделить следующие их модели (рис. 1.2):
-
распределенное представление (Distribution Presentation);
-
удаленное представление (Remote Presentation);
-
распределенная бизнес-логика (Remote Business Logic);
-
удаленное управление данными (Remote Data Management);
-
распределенное управление данными (Distributed Data Management).
Эта условная классификации показывает, как могут быть распределены отдельные задачи между серверным и клиентскими процессами. В данной классификации отсутствует реализация удаленной бизнес-логики, так как считается, что она не может быть удалена полностью, а может быть лишь распределена между разными процессами, которые могут взаимодействовать друг с другом.
1.3. Двухуровневые модели
Двухуровневые модели управления БД фактически являются результатом распределения пяти указанных ранее групп функций стандартного интерактивного приложения между двумя процессами, выполняемыми на двух платформах: компьютере клиента и на сервере. В чистом виде не существует ни одна из них, однако рассмотрим наиболее характерные особенности каждой двухуровневой модели.
Модель удаленного управления данными, или модель файлового сервера (File Server — FS). В этой модели презентационная логика и бизнес-логика располагаются на клиентской части. На сервере располагаются файлы с данными и поддерживается доступ к этим файлам. Функции управления информационными ресурсами в этой модели находятся на клиентской части.
Распределение функций компонентов приложения в моделях клиент — сервер представлено на рис. 1.3.
В этой модели файлы базы данных хранятся на сервере, клиент обращается к серверу с файловыми командами, а механизм управления всеми информационными ресурсами — собственно база метаданных (выбранных данных) — находится на компьютере клиента.
Рис. 1.3. Модель файлового сервера
Д 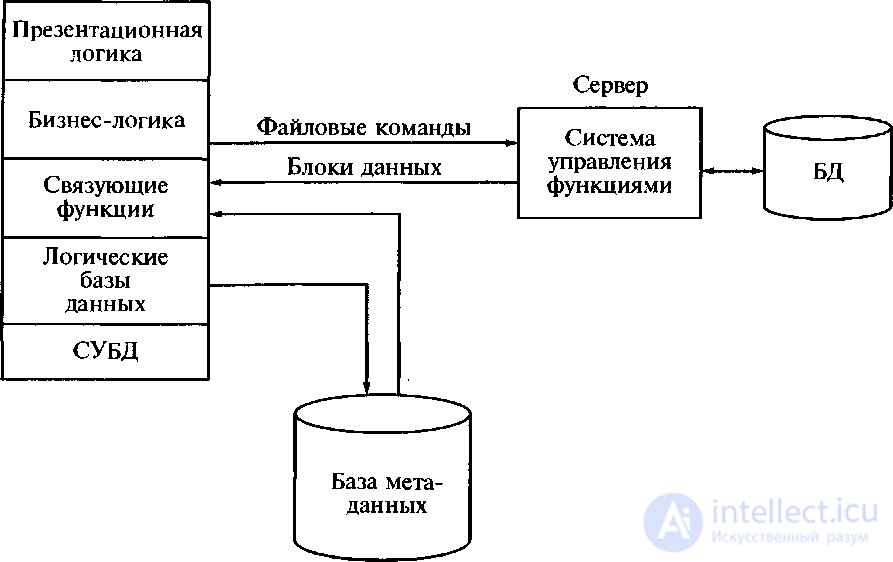 остоинство данной модели состоит в том, что приложение разделено на два взаимодействующих процесса. При этом сервер
остоинство данной модели состоит в том, что приложение разделено на два взаимодействующих процесса. При этом сервер
(серверный процесс) может обслуживать множество клиентов, которые обращаются к нему с запросами. Собственно СУБД должна находиться в этой модели на компьютере клиента.
Алгоритм выполнения клиентского запроса сводится к следующему.
-
-
Запрос формулируется в командах языка манипулирования данными (ЯМД).
-
СУБД переводит этот запрос в последовательность файловых команд.
-
Каждая файловая команда вызывает перекачку блока информации на компьютер клиента, а СУБД анализирует полученную информацию, и если в полученном блоке не содержится ответ на запрос, принимается решение о перекачке следующего блока информации и т.д.
-
Перекачка информации с сервера на клиентский компьютер производится до тех пор, пока не будет получен ответ на запрос клиента.
-
Рассмотренная модель имеет следующие недостатки:
-
высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов, необходимых приложению;
-
узкий спектр операций манипулирования с данными, определяемый только файловыми командами;
-
отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы).
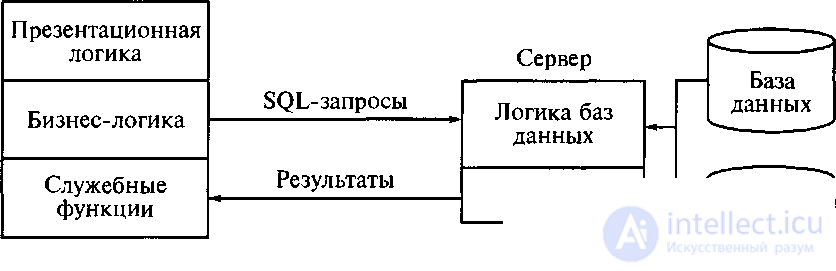
Рис. 1.4. Структура модели удаленного доступа к данным
Модель удаленного доступа к данным (Remote Data Access — RDA). В этой модели база данных хранится на сервере. Там же находится и ядро СУБД. На компьютере клиента располагаются презентационная логика и бизнес-логика приложения. Клиент обращается к серверу с запросами на языке SQL. Структура модели удаленного доступа к данным приведена на рис. 1.4.
Преимущества данной модели состоят в следующем:
-
перенос компонента представления и прикладного компонента на клиентский компьютер существенно разгружает сервер БД, сводя к минимуму общее число выполняемых процессов в операционной системе;
-
сервер БД освобождается от несвойственных ему функций, а процессор или процессоры сервера целиком загружаются операциями обработки данных запросов и транзакций;
-
резко уменьшается загрузка сети, так как по ней от клиентов к серверу передаются не запросы на ввод-вывод в файловой терминологии, а запросы на языке SQL, объем которых существенно меньше. В ответ же на эти запросы клиент получает только данные, соответствующие запросу, а не блоки файлов.
Основным достоинством модели RDA является унификация интерфейса клиент—сервер, т.е. стандартным при общении приложения клиента и сервера становится язык SQL.
Недостатки данной модели:
-
запросы на языке SQL при интенсивной работе клиентской части приложения могут существенно загрузить сеть;
-
так как в этой модели на компьютере клиента располагаются и презентационная логика, и бизнес-логика приложения, при повторении аналогичных функций в других приложениях код, соответствующей бизнес-логики, должен быть повторен для каждого клиентского приложения, что вызывает излишнее их дублирование;
-
так как сервер в этой модели играет пассивную роль, функции управления информационными ресурсами должны выполняться на компьютере клиента.Модель сервера баз данных. Для исключения недостатков модели удаленного доступа к данным необходимо выполнение следующих условий.
-
БД в каждый момент времени должна отражать текущее состояние предметной области, которое определяется не только собственно данными, но и связями между объектами данных, т.е. данные, которые хранятся в БД, в каждый момент времени должны быть непротиворечивыми.
-
БД должна отражать некоторые правила предметной области и законы, по которым она функционирует (Business Rules). Например, завод может нормально работать, только если на складе имеется достаточный (страховой) запас деталей определенной номенклатуры, а деталь может быть запущена в производство, только если на складе имеется достаточно материала для ее изготовления, и т.д.
-
Обеспечение постоянного контроля за состоянием БД, отслеживание всех изменений и адекватная реакция на них. Например, при достижении некоторым измеряемым параметром критического значения должно произойти отключение определенной аппаратуры, при уменьшении товарного запаса ниже допустимой нормы должна быть сформирована заявка конкретному поставщику на поставку соответствующего товара и т. п.
-
Возникновение некоторой ситуации в БД должно четко и оперативно влиять на ход выполнения прикладной задачи.
-
Совершенствование контроля типов данных СУБД. В настоящее время СУБД контролирует синтаксически только стандарт- но-допустимые типы данных, т. е. которые определены в DDL (Data Definition Language) — языке описания данных, являющемся частью SQL. Однако в реальных предметных областях существуют данные, которые несут в себе еще и семантическую составляющую, например координаты объектов или единицы измерений.
-
Модель сервера баз данных поддерживают большинство современных СУБД: Informix, Ingres, Sybase, Oracle, MS SQL Server. Основу данной модели составляют: механизм хранимых процедур как средство программирования SQL-сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называют механизмом поддержки доменной структуры.
Модель активного сервера базы данных представлена на рис. 1.5. В этой модели бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика реализована в виде хранимых процедур — специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все предус-
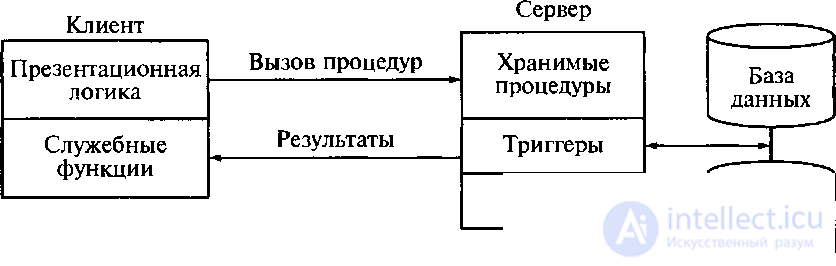
Рис. 1.5. Модель активного сервера базы данных
мотренные изменения в БД. Сервер возвращает клиенту данные выполненного запроса, которые требуются клиенту либо для вывода на экран, либо для выполнения части бизнес-логики. При этом трафик обмена информацией между клиентом и сервером резко уменьшается.
Централизованный контроль в модели сервера баз данных выполняется с использованием механизма триггеров, которые также являются частью БД.
Термин «триггер», взятый из электроники, семантически очень точно характеризует механизм отслеживания специальных событий, связанных с состоянием БД. Триггер является как бы некоторым тумблером, который срабатывает при возникновении определенного события в БД. Ядро СУБД проводит мониторинг всех событий, вызывающих созданные и описанные триггеры в БД, и при возникновении такого события сервер запускает соответствующий триггер. Каждый триггер представляет собой также некоторую программу, которая выполняется с базой данных. С помощью триггеров можно вызывать хранимые процедуры.
Механизм использования триггеров предполагает, что при срабатывании одного из них могут возникнуть события, которые вызовут срабатывание других.
В данной модели сервер является активным, так как в ней не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД.
Хранимые процедуры и триггеры хранятся в словаре БД и, следовательно, могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях.
Недостатком данной модели является очень большая загрузка сервера, так как он обслуживает множество клиентов и выполняет следующие функции:
• осуществляет мониторинг событий, связанных с выполнением разработанных триггеров;
-
обеспечивает автоматическое срабатывание триггеров при возникновении связанных с ними событий;
-
обеспечивает исполнение внутренней программы каждого триггера;
-
запускает хранимые процедуры по запросам пользователей;
-
запускает хранимые процедуры из триггеров;
-
возвращает требуемые данные клиенту;
-
обеспечивает выполнение всех функций СУБД (доступ к данным, контроль и поддержку целостности данных в БД, контроль доступа, обеспечение корректной параллельной работы всех пользователей с единой БД).
Если перенести на сервер большую часть бизнес-логики приложений, то требования к клиентам в этой модели резко уменьшатся. Иногда такую модель называют моделью с тонким клиентом, а рассмотренные ранее модели — моделями с толстым клиентом.
Модель сервера приложений. Эта трехуровневая модель, являющаяся расширением двухуровневой модели, т.е. с введенным дополнительным промежуточным уровнем между клиентом и сервером, была предложена для разгрузки сервера.
Архитектура трехуровневой модели приведена на рис. 1.6. Промежуточный уровень может содержать один или несколько серверов приложений.
В данной модели компоненты приложения делятся между тремя исполнителями: клиентом, сервером приложений и сервером базы данных.
Клиент обеспечивает логику представления, включая графический пользовательский интерфейс и локальные редакторы. Клиент может запускать локальный код приложения клиента, который может содержать обращения к локальной БД, расположенной на его компьютере. Клиент исполняет коммуникационные функции front-end части приложения, обеспечивающие ему доступ в локальную или глобальную сеть. Дополнительно реализация взаимодействия между клиентом и сервером может включать в себя управление распределенными транзакциями, что соответствует случаям, когда клиент также является клиентом менеджера распределенных транзакций.
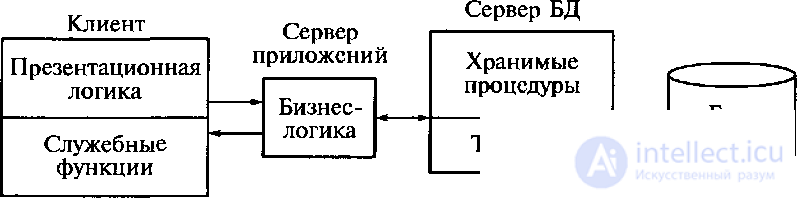
Рис. 1.6. Модель сервера приложений
Серверы приложений, составляющие новый промежуточный уровень архитектуры модели, спроектированы для исполнения общих не загружаемых функций клиентов. Серверы приложений поддерживают функции клиентов как частей взаимодействующих рабочих групп, сетевую доменную операционную среду и каталоги с данными, а также хранят и исполняют наиболее общие правила бизнес-логики, обеспечивают обмен сообщениями и поддержку запросов (особенно в распределенных транзакциях).
Серверы баз данных в этой модели занимаются исключительно функциями СУБД: обеспечивают функции создания и ведения БД, поддерживают целостность реляционной БД, обеспечивают функции хранилищ данных (warehouse services). Кроме того, на них возлагаются функции создания резервных копий БД и восстановления БД после сбоев, управления выполнением транзакций и поддержки устаревших (унаследованных) приложений (legacy application).
Данная модель обладает большей гибкостью, чем двухуровневые модели. Наиболее заметны преимущества модели сервера приложений в тех случаях, когда выполняются сложные аналитические расчеты в базе данных, относящихся к области OLAP-при- ложений (On-line analytical processing). В этой модели большая часть бизнес-логики клиента изолирована от возможностей встроенного языка SQL, реализованного в конкретной СУБД, и может быть выполнена на языках программирования С, С++, Sir.i. Talk, Cobol, что повышает переносимость системы и ее масштабируемость.
Модели серверов баз данных. При создании первых СУБД технология клиент—сервер только зарождалась, поэтому изначально в архитектуре этих систем не было адекватного механизма организации взаимодействия клиентского и серверного процессов. В современных СУБД этот механизм является фактически основополагающим и от эффективности его реализации зависит эффективность работы системы в целом.
Рассмотрим эволюцию подобных механизмов. В основном такой механизм определяется структурой реализации серверных процессов и часто называется архитектурой сервера баз данных.
Как уже отмечалось, поначалу существовала модель, в которой управление данными (функция сервера) и взаимодействие с пользователем были совмещены в одной программе. Этот этап развития серверов БД можно назвать нулевым.
Затем функции управления данными были выделены в самостоятельную группу — сервер. Однако при этом модель взаимодействия пользователя с сервером соответствовала структуре связей между таблицами баз данных «один к одному» (рис. 1.7), т.е. сервер обслуживал запросы только одного пользователя (клиента), а для обслуживания нескольких клиентов нужно было запустить соответствующее число серверов.
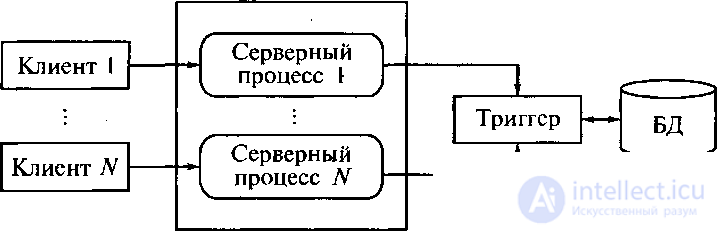
Рис. 1.7. Взаимодействие клиентских и серверных процессов в модели
«один к одному»
Выделение сервера в отдельную программу было революционным шагом, который позволил, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем — на другую и осуществлять взаимодействие между ними по сети. Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы. Для обслуживания большого числа клиентов на сервере следовало одновременно запустить в работу большое число серверных процессов, что резко повышало требования к ресурсам ЭВМ.
Кроме того, каждый серверный процесс в этой модели запускался как независимый, поэтому запрос, который только что был выполнен одним серверным процессом, при формировании его другим клиентом выполнялся повторно. В такой модели сложно обеспечить взаимодействие серверных процессов. Эта модель серверов баз данных самая простая, и исторически она появилась первой.
Проблемы, возникающие в информационной модели «один к одному», решены в архитектуре систем с выделенным сервером, который способен обрабатывать запросы от многих клиентов. В этой системе сервер единственный обладает монополией на управление данными и взаимодействует одновременно со многими клиентами (рис. 1.8). Логически каждый клиент связан с сервером от-
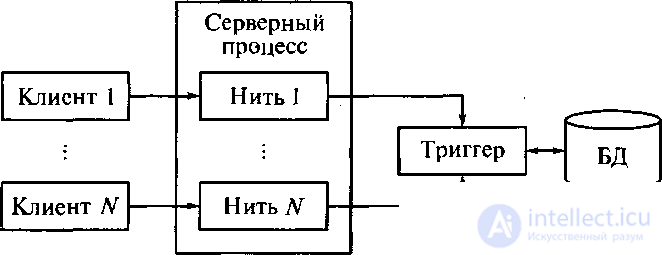
Рис. 1.8. Многопотоковая односерверная архитектура
дельной нитью (thread) или потоком, по которому пересылаются запросы. Такая архитектура, получившая название многопотоковой односерверной (multi-threaded), позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей (trashing).
Кроме того, обеспеченная в данной модели возможность взаимодействия многих клиентов с одним сервером позволяет в полной мере использовать разделяемые объекты (начиная с открытых файлов и заканчивая данными из системных каталогов), что значительно уменьшает потребность в памяти и общее число процессов операционной системы. Например, в модели «один к одному» СУБД создает 100 копий процессов для 100 пользователей, а системе с многопотоковой архитектурой для этого понадобится только один серверный процесс.
Однако такое решение имеет свои недостатки. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером использует только один из них, не загружая другие три.
Контрольные вопросы
- Дайте определения следующих терминов: архитектура ODBC, модели данных, транзакция, топология БД (или структура распределенной БД), локальная автономность, удаленный запрос, распределенный запрос, поддержка распределенной транзакции, презентационная логика, бизнес-логика, логика обработки данных, процессор управления данными.
- Какие двухуровневые модели вы знаете? Назовите их достоинства и недостатки.
См. также
- Виды баз данных
- Транзакция
- СУБД
В общем, мой друг ты одолел чтение этой статьи об пользователь бд . Работы в переди у тебя будет много. Смело пишикоментарии, развивайся и счастье окажется в ваших руках.
Надеюсь, что теперь ты понял что такое пользователь бд , запрос sql, логическая структура бд, топология бд, структура распределенной бд, локальная автономность ,
удаленный запрос, удаленная транзакция, поддержка распределенной транзакции , распределенный запрос
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Как устроены распределенные прикладные системы? Каковы наиболее важные их компоненты? Какую роль играет промежуточное программное обеспечение в разработке распределенных систем? Наконец, каковы типичные проблемы, которые могут возникнуть в процессе разработки и интеграции систем? Попытаемся ответить на эти вопросы.
В составе прикладной системы удобно выделить прикладное программное обеспечение и платформу. Формирующие (наряду с аппаратурой) платформу операционную систему, СУБД и программное обеспечение промежуточного слоя [1-4] вместе называют системным ПО.
Большинство прикладных программ можно разделить на три части: логику (алгоритмы) представления, бизнес-логику (расчетные алгоритмы и правила) и логику (алгоритмы) доступа к данным. Каждая часть вовсе не должна полностью соответствовать отдельному модулю, типу отдельной программы, нити, функции или процедуре — такое разделение весьма полезно, но не необходимо. Очень простые приложения часто способны собрать все три части в единственную программу, и подобное разделение соответствует функциональным границам.
Пользователи взаимодействуют с частью, называемой логикой представления, которая управляет доступом к приложению. Независимо от конкретных характеристик этой части системы (интерфейс командной строки, сложные графические пользовательские интерфейсы, интерфейсы через посредника) ее задача состоит в том, чтобы обеспечить средства для наиболее эффективного обмена информацией между пользователем и системой. Вот почему на стадии проектирования приложения так много внимания уделяют этому компоненту, видимому со стороны внешнего мира.
Бизнес-логика определяет, для чего, собственно, предназначено приложение. В зависимости от конкретных функциональных требований и сложности задач может быть полезным подразделить эту часть на несколько компонентов. В этом случае конкретная реализация каждого компонента может быть представлена в виде набора процедур (библиотеки), класса или классов объектов, отдельных программ. Разделение приложения по границам между программами обеспечивает естественную основу для распределения приложения на нескольких компьютерах.
Алгоритмы доступа к данным исторически рассматривались как специфический для конкретного приложения интерфейс к механизму постоянного хранения данных наподобие файловой системы или СУБД. Так, при помощи этой части программы приложение управляет соединениями с базой данных и запросами к ней (перевод специфических для конкретного приложения запросов на язык SQL, получение результатов и перевод этих результатов обратно в специфические для конкретного приложения структуры данных). К этой части относят только специфический для приложения интерфейс к СУБД, но не ее саму.
Иногда три указанные части называют слоями — от теоретической модели, которая рассматривает каждую часть приложения в терминах ее положения относительно пользователя, от «переднего слоя» (front-end, логика представления) до «заднего слоя» — (back-end, логика доступа к данным). Одна из функций «среднего слоя» (бизнес-логика) состоит в обеспечении двунаправленного преобразования между структурами данных высокого уровня переднего слоя и низкоуровневыми структурами заднего слоя. В этой модели положение каждого слоя (относительно пользователя) непосредственно связано с различными уровнями абстракции.
Рассмотрим приложение, которое производит поиск в базе данных согласно определенным пользователем критериям (рис. 1). Пользователь заполняет формы и нажимает кнопку «Поиск». Эта информация передается блоку бизнес-логики для формирования одного или более запросов. Эти запросы один за другим передаются блоку логики доступа к данным, который преобразует данные и запросы в формат, совместимый с СУБД, выполняет каждый запрос, получает результат и преобразует его в формат приложения. Наконец, он возвращает результат блоку бизнес-логики, который объединяет результаты нескольких запросов в порцию информации, передаваемую блоку логики представления; тот помещает эти данные в удобочитаемую форму и показывает ее пользователю.
Как правило, преобразования данных выполняются несколько раз. В некоторых приложениях избегают этого, используя структуры, подобные структурам СУБД, в качестве внутреннего формата представления данных. Тогда в рассматриваемом примере блок бизнес-логики может сразу же брать данные пользователя по мере получения их от блока логики представления и преобразовывать в SQL-запросы. После этого блок бизнес-логики может обращаться к базе данных непосредственно, без вовлечения специфической для приложения логики доступа к данным.
Проблема такого подхода состоит в том, что он привязывает приложение к определенному формату данных. Если приложение необходимо перенести на другую СУБД, внутренние структуры данных придется изменить. (Эта зависимость находится вне связи со специфической моделью базы данных, например, с различиями между иерархической и реляционной базами.)
Проблема обостряется еще, когда используется несколько различных по структуре представлений. В этом случае блок бизнес-логики вынужден поддерживать несколько внутренних представлений для, возможно, одних и тех же данных. Поэтому разумнее иметь один «родной» для приложения формат внутреннего представления данных. Преобразование в другой формат может выполняться, когда оно становится неизбежным (в блоке логики доступа к данным при взаимодействии с конкретной базой данных, в слое представления при взаимодействии с пользователем и т.д.).
Разделение функциональных алгоритмов на логику представления, бизнес-логику и логику доступа к данным предполагает разные уровни абстракции в различных частях приложения. Разложение же приложения на части согласно различным уровням абстракции представляет иерархию, которую можно использовать, чтобы разделить одну программу на несколько одновременно исполняемых модулей. Процесс, реализующий один или несколько уровней в этой иерархии, не должен ничего знать об уровнях, расположенных выше или ниже. Поэтому за исключением обмена информацией между процессами в различных слоях (рис. 1) каждый процесс независим и самодостаточен. Процесс на одном уровне не нуждается в прямом доступе к структурам данных, расположенным на другом уровне; следовательно, он может быть легко выделен в отдельно исполняемую программу.
Такое разделение минимизирует взаимодействие между составными элементами, уменьшая объем передаваемой информации и упрощая алгоритмы, отвечающие за связь между процессами, и потому служит основой для выделения компонентов, которые могут быть распределены на нескольких компьютерах.
Архитектуры прикладных систем
В таблице 1 перечислены наиболее часто встречающиеся архитектуры прикладных систем. Колонка «максимальное число пользователей» может рассматриваться как некоторая мера масштабируемости. Все архитектуры, кроме первой, являются архитектурами распределенных систем.
Как можно заметить, самая «древняя», централизованная архитектура обеспечивает намного более масштабируемое решение, чем две следующих. Потребовалось три поколения, прежде чем эти распределенные архитектуры смогли эффективно конкурировать с решением, ориентированным на универсальный компьютер: построить распределенную систему гораздо труднее.
Централизованная архитектура

|
Рис. 2. Централизованная архитектура. Блок «Данные» включает алгоритмы доступа к данным, СУБД и саму базу данных |
Одна мощная универсальная ЭВМ была единственной платформой, выполняющей все алгоритмы логики приложения (рис. 2). У централизованной архитектуры множество достоинств: простая разработка приложений, легкость обслуживания и управления. Именно они и обеспечили столь долгую жизнь «унаследованных» систем. Смерть универсальных ЭВМ неоднократно провозглашалась после появления четырех- и восьмиразрядных ПК в начале 80-х годов (компьютеры PET и VIC-20 компании Commodore, TRS-80 компании Radio Shack и множество других машин на базе процессоров Z-80, а также 6502 и 6800 производства Motorola). Однако они продолжали работать, переваривая десятки миллионов транзакций в день, приспосабливаясь к постоянно увеличивающимся нагрузкам.
Разделение файлов
|
|
Рис. 3. Архитектура разделения файлов |
Едва появившись, ПК принесли ожидание того, что большое число маленьких машин может заменить, а, в некоторых случаях, и превзойти по производительности универсальную ЭВМ. Архитектура разделения файлов, ставшая первым шагом к реализации этого притязания, включает множество настольных ПК и файловый сервер, связанных сетью (рис. 3). Файловый сервер загружает файлы из разделяемого местоположения, а прикладные программы исполняются полностью на настольных ПК.
Подобная архитектура была особенно популярна при использовании продуктов наподобие dBASE, FoxPro и Clipper. Первоначально сети персональных компьютеров были основаны на метафоре совместного использования файлов, потому что это было просто. Однако она хорошо работала лишь в некоторых случаях. Во-первых, все приложения должны вписаться в единственный ПК. Во-вторых, совместное использование и конфликты обновления чрезвычайно снижают производительность. Наконец, учитывая пропускную способность сети, объем данных, которые могут передаваться, также невелик. Все эти факторы крайне ограничивают число параллельных пользователей, которое способна поддерживать архитектура разделения файлов [6-8].
Клиент-сервер
|
|
Рис. 4. Ранние архитектуры клиент-сервер |
Стремление исправить архитектуру разделения файлов привело к замене файлового сервера сервером баз данных (рис. 4). Вместо передачи файлов целиком он пересылает только ответы на запросы клиентов, уменьшая нагрузку на сеть. Эта стратегия вызвала появление архитектуры клиент-сервер. Появившись в 80-х годах, она ввела понятие «клиента» (сторона, запрашивающая функции/обслуживание) и «сервера» (сторона, предоставляющая функции/обслуживание). На уровне программного обеспечения разделение на клиента и сервер является логическим: процессы клиента и сервера могут физически размещаться как на одной, так и на разных машинах. Под общим концептуальным названием скрываются три варианта архитектуры: двухзвенная, трехзвенная и многозвенная.
|
|
Рис. 5. Двухзвенная архитектура |
Самая старая — двухзвенная (рис. 5). Она разделяет приложение на две части, клиентскую и серверную. Сторона клиента содержит логику представления, а логика доступа к данным, СУБД и сама база находятся на стороне сервера.
Остаются алгоритмы бизнес-логики, которые могут быть размещены как на машине клиента вместе с логикой представления (конфигурация «толстый клиент»), так и на стороне сервера (конфигурация «тонкий клиент»), или даже могут быть разделены между ними. Конфигурация «толстый клиент» более распространена: суммарная вычислительная мощность клиентов, по крайней мере, в теории, предполагается большей, чем мощность единственного сервера. Подобный ход рассуждений привел некоторых из разработчиков к созданию приложений, где даже логика доступа к данным размещается на клиенте, оставляя серверу только поддержание самой базы данных.
Двухзвенная архитектура, особенно конфигурация «толстый клиент», имеет ряд недостатков. Например, как и в архитектуре разделения файлов, — это ограничение, вытекающее из вычислительной мощности отдельных машин клиентов. Но еще хуже имеющее фундаментальный характер ограничения на число одновременных соединений с сервером. Сервер поддерживает открытое соединение со всеми активными клиентами, даже если никакой работы нет. Это необходимо, чтобы сервер мог получать сигналы тактового импульса, что не так страшно, когда клиентов менее 100 [9-12]; однако сверх этого числа производительность начинает быстро деградировать до недопустимо низкого уровня. Хорошим примером возникновения подобной проблемы может служить работа прокси-сервера.
В некоторых прикладных системах бизнес-логику пытаются реализовать, используя хранимые процедуры. Идея состоит в том, чтобы в соответствии с «тонкой» конфигурацией клиента переместить алгоритмы бизнес-логики на серверную машину, ближе к данным, которые требуются им постоянно. Это выглядит как хорошая идея, однако только усугубляет главную проблему. Так как осуществляющие бизнес-правила процессы теперь управляются СУБД, число пользователей, которых может поддерживать такая система, ограничено максимумом возможных активных соединений с СУБД. Кроме того, от СУБД к СУБД механизмы хранимых процедур разнятся. Тем не менее, двухзвенная архитектура хорошо работает в маленьких рабочих группах [9-12]. С начала 90-х годов появилась масса инструментальных средств, упрощающих создание систем в такой архитектуре, в том числе Delphi и PowerBuilder.
|
|
Рис. 6. Трехзвенная архитектура |
С середины 90-х годов признание специалистов получила трехзвенная архитектура, которая, как и двухзвенная, поддерживала концепцию клиент-сервер, но разделила систему по функциональным границам между тремя слоями: логикой представления, бизнес-логикой и логикой доступа к данным (рис. 6). В отличие от двухзвенной архитектуры появляется дополнительное звено — «сервер приложений», целиком предназначенное для осуществления бизнес-логики.
Именно выделение бизнес-логики в отдельное звено позволяет преодолеть фундаментальные ограничения двухзвенной архитектуры. Клиенты не поддерживают постоянного соединения с базой данных, а обмениваются информацией со средним звеном только тогда, когда это необходимо. В то же время процесс среднего звена поддерживает всего несколько активных соединений с базой данных, но использует их многократно; поэтому процессы в среднем звене могут предоставлять обслуживание теоретически неограниченному числу клиентов. В сравнении со всеми другими моделями трехзвенная архитектура обладает столь многими преимуществами. Но преимущества не даются даром. Разработка прикладных программ, основанных на трехзвенной архитектуре, — более трудное дело, чем для двухзвенной архитектуры или при использовании централизованного подхода. Преодолеть возникающие проблемы помогает программное обеспечение промежуточного слоя [5-9].
Трехзвенная архитектура
Рассмотрим четыре варианта распределенных систем, основанных на трехзвенной архитектуре: с сервером приложений, с монитором обработки транзакций, с сервером передачи сообщений и с брокером объектных запросов.
Сервер приложений
|
|
Рис. 7. Трехзвенная архитектура с сервером приложений |
Клиенты (рис. 7) содержат только слой логики представления прикладного ПО, а алгоритмы бизнес-логики и логики доступа к данным перемещены в среднее звено. В этом случае сервер приложений обеспечивает «общее хранилище» бизнес-правил и процедур. Клиенты соединяются с сервером приложений и предоставляют ему данные для обработки. Совместное использование алгоритмов бизнес-логики, общих для всего приложения, обладает важными достоинствами. Помимо «утоньшения» клиента, эта стратегия ведет к созданию системы, в которой будущие обновления прикладного ПО будут производиться, главным образом, на сервере приложений, что упрощает процесс модификаций.
Обычно сервер приложений поддерживает пул ограниченного числа открытых подключений к базам данных и вместо того чтобы делать каждое подключение к базе данных выделенным для определенного клиента (как в двухзвенной архитектуре), подключения многократно используются для выполнения запросов различных клиентов.
Есть и другие преимущества. Во-первых, так как вся «важная» часть прикладной логики теперь централизована в среднем звене, нет необходимости поддерживать сложные механизмы аутентификации на стороне клиентов.
Во-вторых, аппаратная платформа, на которой выполняется сервер приложений, может быть достаточно мощной; это дает дополнительную степень масштабируемости всей прикладной системы.
В-третьих, централизованный доступ к данным в серверах приложений делает всю прикладную систему менее зависящей от конкретной СУБД.
Наконец, сервер приложений обеспечивает эффективную стратегию для интеграции. Придерживаясь того же протокола коммуникации, что и клиент, другое «внешнее» приложение может легко взаимодействовать с «чужим» сервером приложений. Эта конфигурация допускает интеграцию приложений не только на уровне данных, но и на уровне правил бизнес-логики. Это чрезвычайно важно, потому что совместное использование данных разными прикладными программами может вести к логическим противоречиям в базе данных. Типичное решение состоит в том, чтобы копировать одни и те же правила и алгоритмы в несколько прикладных программ. Но тогда очень затрудняются их поддержка и обновление — любое изменение кода должно проводиться во всех прикладных программах, которые его используют. Если же бизнес-правила сосредоточены на сервере приложений и используются совместно, то такой проблемы нет.
Мониторы обработки транзакций
Мониторы обработки транзакций (transaction processing monitor, TPM) — самый старый тип технологии распределенных систем, которая появилась в 70-х годах в среде больших универсальных ЭВМ [9-12]. Одной из первых прикладных систем была интерактивная среда поддержки, созданная компанией Atlantic Power and Light для совместного использования прикладных служб и информационных ресурсов в режимах пакетной обработки и с применением среды с разделением времени. TPM (например, IBM CICS) стали главным инструментом построения высоко масштабируемых решений для сетевых прикладных систем. Однако в начале 90-х популярность TPM начала падать; причиной стало появление продуктов категории TPM «Lite» — мониторов обработки транзакций внутри СУБД. Их функциональные возможности были близки к обычным TPM, и с возрастающей тогда популярностью двухзвенной архитектуры они первоначально обеспечили хорошее решение для создания распределенных прикладных систем.
К концу десятилетия ситуация изменилась. Оказалось, что в то время как обычный монитор транзакций может легко поддерживать тысячи пользователей, их производительность становится недопустимо низкой, когда совокупность пользователей превышает 100. Сегодня TPM снова вернулись, но теперь это технология, которая воплощает среднее звено в трехзвенной архитектуре.
Клиенты связываются с мониторами, посылая запросы на транзакции. Так как коммуникации асинхронны, после того, как запрос послан, клиент может выполнять другие задачи. Каждый запрос ставится в очередь, и монитор может обработать его позднее. Поддерживая различные схемы приоритетов, можно определить, в каком порядке запросы принимаются из очереди на обработку. Мониторы постоянно поддерживают установленное число подключений к базам данных, поэтому непосредственного соответствия между клиентами и подключениями к базе данных нет. Вместо этого мониторы мультиплексируют запросы от различных клиентов по одному и тому же подключению — точно так же, как и серверы приложений.
Одно из достоинств процессора транзакций — способность обращаться к гетерогенным источникам данных (реляционные и сетевые базы данных, плоские файлы и т.д.). Поэтому каждый TPM содержит логику доступа к данным, которая выполняет соответствующее преобразование, связанное с различными источниками.
|
|
Рис. 8. Трехзвенная архитектура с монитором обработки транзакций |
Самая простая конфигурация — клиент-A взаимодействует только с одним монитором TPM-A (рис. 8), который обеспечивает доступ к данным, расположенным на одном компьютере (Сервер Данных A). При помощи двухфазного протокола фиксации монитор может обеспечивать семантику транзакций и с несколькими базами данных. Таким образом, транзакция одного клиента будет фактически разбита между несколькими базами данных; эта ситуация показана в случае с TPM-B, который взаимодействует с источниками данных на нескольких машинах (Сервер Данных A, Сервер Данных B и Сервер Данных C). В этом случае, если подтранзакция терпит неудачу на одном из серверов, все другие подтранзакции также откатываются назад, а Клиент-B получает сообщение о таком событии.
Отношения между клиентами и мониторами, так же как и между мониторами и источниками данных, фактически являются отношениями «многие-ко-многим». Эта конфигурация часто используется, чтобы обеспечить балансировку нагрузки. Когда число пользователей увеличивается, система может запускать дополнительные экземпляры мониторов, обеспечивающих доступ к одним и тем же источникам данных.
В этой конфигурации мониторы могут также обеспечить инфраструктуру для разработки систем, способных обрабатывать ошибки. Например, как видно из рис. 8, Клиент-C и Клиент-D могут обращаться к одним и тем же источникам данных (Сервер Данных C и Сервер Данных D) либо через TPM-C, либо через TPM-D, причем каждый монитор выполняется на своем собственном компьютере. Если один из мониторов выходит из строя, то все клиенты могут переключаться на все еще работающий монитор. Система в этом случае замедлится, но будет способна обеспечить исходный набор функций.
Сервер сообщений
Вместо монитора транзакций приложение может использовать сервер сообщений. Он обладает большинством существенных преимуществ монитора транзакций. Клиенты взаимодействуют с сервером сообщения асинхронно, помещая в очередь сообщения, которые обрабатываются позднее. В свою очередь, сервер сообщений поддерживает пул доступных подключений к базе данных, которые он может использовать многократно. Но вместо предопределенных запросов, с которыми должен работать монитор, само сообщение содержит достаточно информации относительно того, что нужно с ним делать.
У каждого сообщения есть заголовок и тело. Заголовок определяет, что должно быть сделано с сообщением (скажем, выполнить бизнес-правило или хранимую процедуру, послать его в базу данных или передать его другому серверу сообщений). Последнее позволяет осуществлять коммуникации не только между клиентом и базой данных, но и между клиентами или между клиентом и базами данных, доступными через различные серверы сообщений (рис. 9).
|
|
Рис. 9. Трехзвенная архитектура с сервером сообщений |
Используя механизмы передачи с промежуточным хранением, сообщения могут обходить точки отказов по альтернативным маршрутам и дополнительным серверам сообщений. Это похоже на использование нескольких мониторов, обслуживающих одних и тех же клиентов и связанных с одними и теми же источниками данных. Но в отличие от мониторов, сообщение может быть пропущено через несколько серверов сообщений прежде чем оно, наконец, достигнет своего адресата. Более того, «интеллект», который направляет сообщение по дополнительному пути, находится не на клиенте, а на сервере сообщений. Таким образом, отказы могут оставаться полностью скрытыми от клиента.
Большинство серверов сообщений поддерживает несколько протоколов связи и выполняется на различных платформах. В результате прикладная система, построенная с серверами сообщений, может охватывать весьма сложные гетерогенные среды, состоящие из компьютеров разных платформ, различных операционных систем, сетей и протоколов коммуникаций. Ясно, что помимо создания таких переносимых приложений, серверы сообщений играют очень важную роль в интеграции, позволяя совместно использовать сообщения, данные и бизнес-правила.
Брокер объектных запросов
Брокер объектных запросов (object request broker, ORB) обеспечивает инфраструктуру, поддерживающую распределенные объекты, которыми можно управлять как и объектами, расположенными «рядом» с процессом, работающим с ними. По вызову метода (в смысле объектно-ориентированного программирования) на одном компьютере может фактически выполняться некоторый программный код другого, притом что доступ к данным в пределах распределенного объекта может потребовать получения соответствующей информации из удаленной базы данных. Все эти детали остаются скрытыми от прикладной программы [15].
Использование брокера объектных запросов в трехзвенной архитектуре очень похоже на использование сервера сообщений. Единственное различие состоит в том, что взаимодействие осуществляется на объектном уровне, а не на уровне отдельных сообщений. Эта парадигма, объединенная с мощью объектно-ориентированного программирования, делает распределенные объекты очень привлекательной стратегией для разработки распределенных систем.
|
|
Рис. 10. Трехзвенная архитектура с брокером объектных запросов |
Пример использования двух брокеров объектных запросов показан на рис. 10. Как и в случае сервера сообщения, бизнес-логика разделена между клиентами и ORB. Однако доступ к процедурам, физически расположенным на брокере, остается скрытым от клиентов при помощи распределенных объектов. Через конкретное выполнение распределенных объектов в среднем звене можно мультиплексировать запросы клиентов на одном и том же пуле подключений к базам данных. В качестве источника данных можно использовать объектно-ориентированную СУБД, однако разного рода «упаковщики» могут обеспечивать доступ к другим источникам (базы данных других типов, плоские файлы и т. п.).
Точно так же распределенные объекты могут «упаковывать» другие прикладные программы. Поэтому интеграция приложений может осуществляться не просто на уровне бизнес-правил, но на уровне объектов. Эти два подхода, однако очень похожи. Так как бизнес-правила скрыты в методах объекта, совместное использование объекта подразумевает совместное использование бизнес-правил. Но объект также содержит информацию о состоянии, поэтому он допускает интеграцию и на уровне данных.
Архитектура с пятью звеньями
Нетрудно заметить, что функция среднего звена как части архитектуры клиент-сервер в интегрированной системе должна быть значительно расширена. Во-первых, слой доступа к данным должен управлять не только данными, связанными с «родной» постоянной памятью системы (ее базой данных), но и быть способным обрабатывать информацию из внешних источников, которые представляют данные от других прикладных программ. Кроме того, рассматривая три различных уровня, на которых может проходить интеграция, и соответствующие способы, при помощи которых извлекаются эти данные, можно заключить, что сложность слоя доступа к данным непомерно велика.
Другие факторы, наподобие «упаковки» внешних прикладных программ, могут также требовать разработки локального слоя бизнес-логики. Кроме работы с бизнес-правилами, локальными для текущего приложения, он должен также знать внешние бизнес-правила, которые могут применяться к внешним (и, иногда, к локальным) данным. Вместе с расширенным (продленным) слоем доступа к данным, мы можем теперь получить чересчур «толстое» среднее звено.
Одно из возможных решений состоит в том, чтобы ввести в рассмотрение дополнительные звенья, которые помогли бы ему стать более «тонким». На рис. 11 представлено расширение трехзвенной архитектуры с сервером приложений в среднем звене. Здесь слой доступа к данным управляется звеном Универсального Доступа к данным (universal data access, UDA), показанным как четвертое звено. Он обеспечивает стандартное представление локальных данных, как и данных, постоянно находящихся в удаленных «унаследованных» системах (специализированный механизм доступа к данным унаследованных систем в четвертом звене, иногда называют legacyware — программное обеспечение доступа к унаследованным системам) или в других внешних системах (они доступны через звено бизнес-правил — businessware).
Цель состоит не просто в том, чтобы обеспечить коммуникацию между программами вообще (это задача промежуточного программного обеспечения), а в том, чтобы установить связь между прикладными программами, что включает совместное использование данных и логики. Передача данных при этом осуществляется через звено UDA (связь D), в то время как совместное использование логики реализуется связью между звеном серверов приложений и звеном бизнес-правил (связь P).
Литература
- А. Кононов, Е. Кузнецов, Онтология промежуточного ПО. // Открытые системы, 2002, № 3
- Н. Дубова, Все про промежуточное ПО. // Открытые системы, 1999, № 7-8
- Ф. Бернштейн, Middleware модель сервисов распределенной системы. // Системы управления базами данных, 1997, № 2
- Л. Розенкранц, Промежуточное ПО. // Computerworld Россия, 2000, № 39
- Е. Карташева, Средства интеграции приложений. // Открытые системы, 2000, № 1-2
- G. Schussel, Client-Server Past, Present and Future. http://news.dci.com/geos/dbsejava.htm, 1995
- S. Guengerich, G. Schussel, Rightsizing Information Systems, SAMS Publishing, 1994
- H. Edelstein, Unraveling Client-Server Architecture. DBMS, 1994, № 5: 34 (7)
- David S. Linthcum, Enterprise Application Integration, Addison-Wesley, 2000
- R. Orfali et. al., Client-Server Survival Guide, 3rd edition, Wiley Computer Publishing, 1999
- A. Berson, Client-Server Architecture, New York: McGraw-Hill, 1992
- R. M. Adler, Distributed Coordination Models for Client-Server Computing, Computer, 28, 1995, № 4
- A. Dickman, Two-Tier Versus Three-Tier Apps. Informationweek 553, 13, 1995
- J. Gallaugher, S. Ramanathan, Choosing a Client-Server Architecture. A Comparison of Two-Tier and Three-Tier Systems. Information Systems Management Magazine 13, 1996, 2
- Evans, Lacey, Harvey, Gibbons, Client-Server: A Handbook of Modern Computer Design. Prentice Hall, 1996
- Martin and Leben, Client-Server Databases: Enterprise Computing, Prentice Hall, 1996
Алексей Кононов (aik762@hotmail.com) — независимый консультант. Евгений Кузнецов (eugene.kuznetsov@hotmail.ru) — сотрудник Института проблем управления РАН (Москва).