Зачем нужны индексы
Индекс (англ. index) — объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному критерию путём последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. Ускорение работы с использованием индексов достигается в первую очередь за счёт того, что индекс имеет структуру, оптимизированную под поиск — например, сбалансированного дерева.
Если простым языком индекс похож на содержание книги, когда вам надо найти что-то в книге у вас два варианта:
1. Если содержания нет — просмотреть всю книгу с первой по последнюю страницу в поисках нужной главы. Повторять это для каждого запроса.
2. Зайти в содержание (индекс), найти быстро номер страницу нужной главы (адрес). Перейти на нужную страницу.
Понятно что второй способ занимает, особенно если книга большая*, намного меньше времени. А если повторять это многократно то время экономится глобально (читай — ресурсы сервера).
* — Важно! Если книга очень маленькая, то использование содержания (индекса) становится бесполезным и даже вредным, проще просмотреть две страницы и сразу выяснить искомую главу.
Как выглядят индексы в базе 1С
В файловом режим базы данных (*.1cd) индексы не увидишь, а вот если база в клиент-серверном варианте, то индексы выглядят в консоли СУБД примерно так:
Да, и тут сразу становится понятно что «индексы 1С» это на самом деле никакие не 1с индексы а обычные индексы базы данных, которые всегда существовали, 1С использует индексы также как и все остальные программы.
Как добавить индексы в 1С
В базу 1С индексы могут быть добавлены двумя способами:
1. Платформой автоматически. Независимо от действий программиста, при создании объектов метаданных в дереве (справочники, документы, регистры), одновременно с созданием в БД соотвествущей таблицы (таблиц), платформа создает и индексы для этих таблиц.
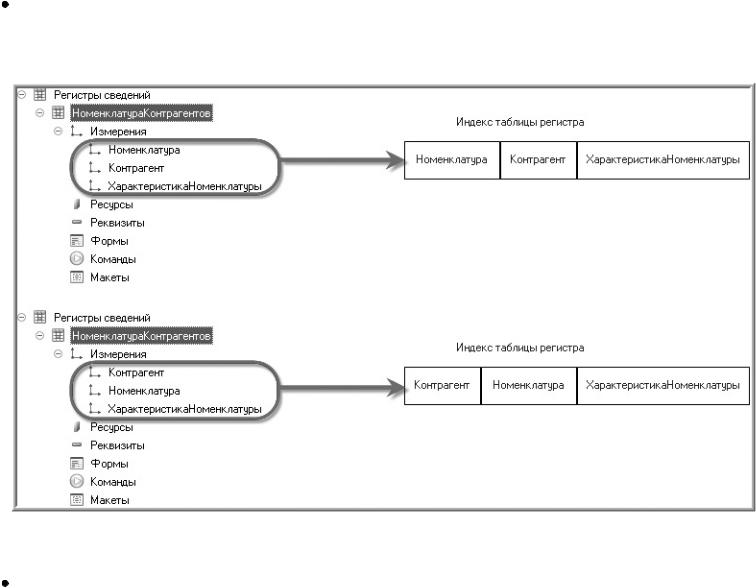
2. Явным указанием программиста. Программист может частично управлять созданием индекса, в «свойствах» реквизита для этого выделен специальный элемент «индексировать»:
Учтите, что индекс «неожиданно» может содержать при этом другие поля, так что не удивляйтесь когда решите проверить какой именно индекс создался «по настоящему» в БД. Полное описание как система поведет себя описано ниже в этой статье. Например, если в примере выше поставить «видНоменклатуры» = «индексировать»; согласно таблице ниже будет создан индекс «[ОРРХ | ОРНР1 +] Реквизит + Ссылка», т.е. составной индекс включающий одновременно несколько колонок таблицы БД.
Конкретно в этом случае не используется разделение данных и ОРРХ | ОРНР1 не будет. Значит будет создан индекс «Реквизит + Ссылка», включающий в себя целевой реквизит «вид номенклатуры» и еще колонку «ссылка», составной индекс по двум полям таблицы.
Справка 1С:
Кроме варианта «Индексировать» в данном свойстве для большинства объектов можно установить вариант «Индексировать с доп. упорядочиванием». Данный вариант предназначен, прежде всего, для использования в динамических списках.
В варианте «Индексировать» строится индекс непосредственно по реквизиту. Индекс также дополняется ссылкой, чтобы обеспечить определенный порядок записей в индексе при повторяющихся значениях реквизита.
В варианте «Индексировать с доп. упорядочиванием» индекс строится по реквизиту, а также по некоторому полю, которое обычно используется для упорядочивания объектов этого типа. Для справочника индекс в зависимости от основного представления дополняется кодом или наименованием. А для документа, индекс дополняется датой. Этот индекс также дополняется ссылкой.
Таким образом при определении варианта свойства Индексировать следует исходить из того, какие варианты выборки информации необходимо оптимизировать в первую очередь. Например, если требуется просмотр списка с отбором по реквизиту, то имеем смысл использовать вариант «Индексировать с доп. упорядочиванием». А если индекс нужен, например, только для поиска с помощью запроса объектов по данному реквизиту без упорядочивания, то лучше использовать вариант «Индексировать», чтобы создаваемые индекс требовал меньше ресурсов системы.
Есть еще один способ явно указать платформе что надо создать индекс, необходимо этот реквизит справочника включить в какой-нибудь «критерий отбора».
Внимание! Не стоит всем полям выставлять «индексировать», во первых за все надо платить, индекс замедляет запись в БД, во вторых если вы добавили индекс еще не факт что вы в него «попадете». Да-да, наличие индекса еще не гарантирует что СУБД будет его использовать, подробней ищите по словам «анализ планов запроса». Например, при создании запроса по регистру накопления (виртуальная таблица остатков), необходимо в условиях ГДЕ указывать последовательно все измерения в порядке указанном в конфигураторе (!) или дополнительно индексировать часто используемые измерения, почему? автоматически создается один единственный индекс содержащий все измерения регистра и чтобы «попасть» в индекс надо перечислять их в порядке как в индексе и без пропусков полей. Смотри Оптимизация запросов 1С.
Есть еще один способ — добавить индекс в вашем запросе, используется для временных таблиц. Во время написания запроса пишем «ИНДЕКСИРОВАТЬ ПО» после которого перечислить поля, по которым нужно построить индекс. Например:
ВЫБРАТЬ
Код,
Наименование
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ Справочник.Номенклатура
ИНДЕКСИРОВАТЬ ПО КодПоля, по которым происходит индексирование, должны находиться в списке выборки.
Можно ли обойти ограничения платформы по индексам
Ограничение платформы — 1С сама добавляет к вашему индексу дополнительные колонки, т.е. делает его составным. А вот если вы решили сделать составной индекс из нескольких реквизитов, то эта возможность наоборот отсутствует.
Частично можно обойти ограничение следующим образом. Вычислить имя таблицы, есть обработки которые показывают настоящие имена таблиц, создать запрос создания индекса, примерно такой:
CREATE UNIQUE NONCLUSTERED INDEX [_IncludeIndex] ON [dbo].[_Reference477]
(
[_Fld105061] ASC, -- Фамилия
[_Fld105062] ASC, -- Имя
[_Fld105063] ASC, -- Отчество
[_Fld11066] ASC, -- Дата рождения
[_IDRRef] ASC -- Ссылка
)
INCLUDE (
-- Включенные столбцы
[_Code], -- Код
[_Description] -- Наименование
)Выполняем его в консоли СУБД, готово индекс добавлен и будет работать.
Есть проблема, при реструктуризации базы данных (например после изменения справочника) все те индексы, что Вы создадите скриптами самостоятельно будут удалены. Вам потребуется заново запустить эти скрипты после реструктуризации, например, добавив их в Jobs на сервере СУБД на ежедневный запуск.
Внимание! Прежде чем лепить свои индексы попробуй оптимизировать код запроса средствами 1С, возможно одно добавленное условие, или смена порядка, приведет к «попаданию в индекс» и запрос ускорится в разы! Также не забывай что у тебя есть способ указать для реквизита «индексировать».
Как обслуживать индексы в базе 1С
А надо что-то делать? Ведь индексы уже созданы автоматически? Да, надо. Необходимо еженедельноежедневно и в некоторых случая частично ежечасно обновлять данные в индексах, чтобы они работали действительно эффективно. Для этого существуют стандартные команды обновления иили перестроения индекса которые необходимо отправлять СУБД. Как правило для этого создают регламентную работу на сервере СУБД и она выполняется автоматически.
В MSSQL это можно сделать одной мышью в «планах обслуживания» — создаем задачу, указываем базу — готово. Выглядит примерно так.
Чтобы не издеваться над сервером лучше выполнять это не чаще раза в сутки во время когда БД не используется. Обязательно делать бэкап базы перед выполнением.
Для ежечасного обновления информации в индексах можно использовать скрипт, который будет дефрагментировать только индексы которые в этом нуждаются, например такой
-------------------------------------------
-- НАСТРАИВАЕМЫЕ ПАРАМЕТРЫ
-- База данных для анализа
USE <BASENAME>
-------------------------------------------
-- СЛУЖЕБНЫЕ ПЕРЕМЕННЫЕ
DECLARE @object_id int; -- ID объекта
DECLARE @index_id int; -- ID индекса
DECLARE @partition_number bigint; -- количество секций если индекс секционирован
DECLARE @schemaname nvarchar(130); -- имя схемы в которой находится таблица
DECLARE @objectname nvarchar(130); -- имя таблицы
DECLARE @indexname nvarchar(130); -- имя индекса
DECLARE @partitionnum bigint; -- номер секции
DECLARE @fragmentation_in_percent float; -- процент фрагментации индекса
DECLARE @command nvarchar(4000); -- инструкция T-SQL для дефрагментации либо ренидексации
-------------------------------------------
-- ТЕЛО СКРИПТА
-- Отключаем вывод количества возвращаемых строк, это несколько ускорит обработку
SET NOCOUNT ON;
-- Удалим временные таблицы, если вдруг они есть
IF OBJECT_ID('tempdb.dbo.#work_to_do') IS NOT NULL DROP TABLE #work_to_do
-- Отбор таблиц и индексов с помощью системного представления sys.dm_db_index_physical_stats
-- Отбор только тех объектов которые:
-- являются индексами (index_id > 0)
-- фрагментация которых более 5%
-- количество страниц в индексе более 128
SELECT
object_id,
index_id,
partition_number,
avg_fragmentation_in_percent AS fragmentation_in_percent
INTO #work_to_do
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL , NULL, 'LIMITED')
WHERE index_id > 0
AND avg_fragmentation_in_percent > 5.0
AND page_count > 128;
-- Объявление Открытие курсора курсора для чтения секций
DECLARE partitions CURSOR FOR SELECT * FROM #work_to_do;
OPEN partitions;
-- Цикл по секциям
FETCH NEXT FROM partitions INTO @object_id, @index_id, @partition_number, @fragmentation_in_percent;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Собираем имена объектов по ID
SELECT @objectname = QUOTENAME(o.name), @schemaname = QUOTENAME(s.name)
FROM sys.objects AS o
JOIN sys.schemas as s ON s.schema_id = o.schema_id
WHERE o.object_id = @object_id;
SELECT @indexname = QUOTENAME(name)
FROM sys.indexes
WHERE object_id = @object_id AND index_id = @index_id;
SELECT @partition_number = count (*)
FROM sys.partitions
WHERE object_id = @object_id AND index_id = @index_id;
-- Если фрагментация менее или равна 30% тогда дефрагментация, иначе реиндексация
IF @fragmentation_in_percent < 30.0
SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REORGANIZE';
IF @fragmentation_in_percent >= 30.0
SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REBUILD';
IF @partition_number > 1
SET @command = @command + N' PARTITION=' + CAST(@partition_number AS nvarchar(10));
-- Выполняем команду
EXEC (@command);
PRINT N'Index: object_id=' + STR(@object_id) + ', index_id=' + STR(@index_id) + ', fragmentation_in_percent=' + STR(@fragmentation_in_percent);
PRINT N'Executed: ' + @command;
-- Следующий элемент цикла
FETCH NEXT FROM partitions INTO @object_id, @index_id, @partition_number, @fragmentation_in_percent;
END;
-- Закрытие курсора
CLOSE partitions;
DEALLOCATE partitions;
-- Удаление временной таблицы
DROP TABLE #work_to_do;
GO
Штатная реиндексация в 1С
В конфигураторе через меню Администрирование — Тестирование и исправление, можно попасть в форму где можно выбрать работу по реиндексации текущей базы.
Индексы таблиц базы данных создаваемые платформой 1С
В данном разделе приведен список индексов таблиц базы данных, которые создаются системой 1С:Предприятие 8. Индексы таблиц создаются неявным образом при создании объектов конфигурации, а также при тех или иных настройках объектов конфигурации. Для тех случаев, когда создание индексов зависит от настроек объектов конфигурации приведены условия создания индексов.
В приведенных ниже таблицах имена индексных полей приведены так, как они описаны в разделе документации «Таблицы запросов».
Для измерений, реквизитов и т.д. применяются условные имена Измерение1, Реквизит1 и т.д.
Для общих реквизитов, являющихся разделителями в режиме «независимо», будем использовать имена ОРНР (ОРНР1, ОРНР2, и т.д.).
Для общих реквизитов, являющихся разделителями в режиме «независимо и совместно», будем использовать имена ОРСР.
Если режим разделения не имеет значения, то для общих реквизитов, являющихся разделителями, будем использовать имена ОРР.
Если в конфигурации определены разделители, то в индексы может входит поле, которое содержит значение хэш-функции набора значений разделителей. Такое поле будем обозначать именем ОРРХ.
Те индексные поля, которые не являются обязательными приведены в квадратных скобках, а если в индексе присутствует набор однотипных полей, это описывается многоточием, например: Реквизит + Измерение1 + [Измерение2 +…].
Данным материалом следует руководствоваться при написании текстов запросов с целью оптимизации времени их исполнения.
Справочник
Основные индексы
|
Индекс |
Условие |
|---|---|
|
[ОРНР1 + … +] Ссылка (Кластерный) |
Всегда. |
|
[ОРРХ | ОРНР1 +] Код + Ссылка |
Свойство «Длина кода» не равно 0. |
|
[ОРРХ | ОРНР1 +] Наименование + Ссылка |
Свойство «Длина наименования» не равно 0. |
|
[ОРРХ | ОРНР1 +] Реквизит + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать». |
|
[ОРРХ | ОРНР1 +] Реквизит + Код + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина кода» не равно 0, а свойство «Основное представление» равно «В виде кода». |
|
[ОРРХ | ОРНР1 +] Реквизит + Наименование + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина наименования» не равно 0, а свойство «основное представление» равно «В виде наименования». |
|
[ОРРХ | ОРНР1 +] Реквизит |
Справочник включен в критерий отбора через реквизит «Реквизит». |
|
[ОРРХ | ОРНР1 +] PredefinedID |
Индекс по идентификатору предопределенного объекта метаданных. |
Дополнительные индексы для подчиненного справочника (вне зависимости от иерархичности справочника)
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Владелец + Ссылка |
Свойство «Длина кода» равно 0. |
|
[ОРРХ | ОРНР1 +] Владелец + Код + Ссылка |
Свойство «Длина кода» не равно 0. |
|
[ОРРХ | ОРНР1 +] Владелец + Наименование + Ссылка |
Свойство «Длина наименования» не равно 0. |
|
[ОРРХ | ОРНР1 +] Владелец + Реквизит + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать». |
|
[ОРРХ | ОРНР1 +] Владелец + Реквизит + Код + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина кода» не равно 0, а свойство «Основное представление» равно «В виде кода». |
|
[ОРРХ | ОРНР1 +] Владелец + Реквизит + Наименование + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина наименования» не равно 0, а свойство «основное представление» равно «В виде наименования». |
Дополнительные индексы для иерархического неподчиненного справочника
Если для справочника установлено свойство «Размещать группы сверху», то в индексах, наряду с полем Родитель, участвует поле ЭтоГруппа. Состав индексов соответствует приведенной ниже таблице.
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Родитель + ЭтоГруппа + Ссылка |
Свойство «Длина кода» равно 0 и свойство «Длина наименования» равно 0. |
|
[ОРРХ | ОРНР1 +] Родитель + ЭтоГруппа + Код + Ссылка |
Свойство «Длина кода» не равно 0. |
|
[ОРРХ | ОРНР1 +] Родитель + ЭтоГруппа + Наименование + Ссылка |
Свойство «Длина наименования» не равно 0. |
|
[ОРРХ | ОРНР1 +] Родитель + ЭтоГруппа + Реквизит + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать». |
|
[ОРРХ | ОРНР1 +] Родитель + ЭтоГруппа + Реквизит + Код + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина кода» не равно 0, а свойство «Основное представление» равно «В виде кода». |
|
[ОРРХ | ОРНР1 +] Родитель + ЭтоГруппа + Реквизит + Наименование + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина наименования» не равно 0, а свойство «основное представление» равно «В виде наименования». |
Для справочников без размещения групп сверху состав индексов соответствует приведенной выше таблице, но в индексы при этом не включено поле ЭтоГруппа.
Дополнительные индексы для иерархического подчиненного справочника
Если для справочника установлено свойство «Размещать группы сверху», то в индексах, наряду с полем Родитель, участвует поле ЭтоГруппа. Состав индексов соответствует приведенной ниже таблице.
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Владелец + Родитель + ЭтоГруппа + Ссылка |
Свойство «Длина кода» равно 0 и свойство «Длина наименования» равно 0. |
|
[ОРРХ | ОРНР1 +] Владелец + Родитель + ЭтоГруппа + Код + Ссылка |
Свойство «Длина кода» не равно 0. |
|
[ОРРХ | ОРНР1 +] Владелец + Родитель + ЭтоГруппа + Наименование + Ссылка |
Свойство «Длина наименования» не равно 0. |
|
[ОРРХ | ОРНР1 +] Владелец + Родитель + ЭтоГруппа + Реквизит + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать». |
|
[ОРРХ | ОРНР1 +] Владелец + Родитель + ЭтоГруппа + Реквизит + Код + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина кода» не равно 0, а свойство «Основное представление» равно «В виде кода». |
|
[ОРРХ | ОРНР1 +] Владелец + Родитель + ЭтоГруппа + Реквизит + Наименование + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина наименования» не равно 0, а свойство «основное представление» равно «В виде наименования». |
Для справочников без размещения групп сверху состав индексов соответствует приведенной выше таблице, но в индексы при этом не включено поле ЭтоГруппа.
Таблица опций справочника
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Идентификатор (Кластерный) |
Всегда. |
Документ
|
Индекс |
Условие |
|---|---|
|
[ОРНР1 + … +] Ссылка (Кластерный) |
Всегда. |
|
[ОРРХ | ОРНР1 +] Дата + Ссылка |
Всегда. |
|
[ОРРХ | ОРНР1 +] Номер + Ссылка |
Свойство «Длина номера» не равно 0. |
|
[ОРРХ | ОРНР1 +] Реквизит + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать». |
|
[ОРРХ | ОРНР1 +] Реквизит + Дата + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием». |
|
[ОРРХ | ОРНР1 +] Реквизит |
Документ включен в критерий отбора через реквизит «Реквизит». |
|
[ОРРХ | ОРНР1 +] ПрефиксНомера + Номер + Ссылка |
Свойство «Длина номера» не равно 0. |
Журнал документов
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Ссылка (Кластерный) |
Всегда. |
|
[ОРРХ | ОРНР1 +] Дата + Ссылка |
Всегда. |
|
[ОРРХ | ОРНР1 +] Графа + Ссылка |
Для графы журнала «Графа» свойство «Индексировать» установлено в значение «Индексировать». |
|
[ОРРХ | ОРНР1 +] Графа + Дата + Ссылка |
Для графы журнала «Графа» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием». |
План видов характеристик
См. описание индексов справочника с той лишь поправкой, что длина кода и длина наименования плана видов характеристик не может быть равной нулю и, кроме того, план видов характеристик не может быть подчиненным.
Таблица опций плана видов характеристик
|
Индекс |
Условие |
|---|---|
|
Идентификатор |
Всегда. |
План счетов
|
Индекс |
Условие |
|---|---|
|
[ОРНР1 + … +] Ссылка (Кластерный) |
Всегда. |
|
[ОРРХ | ОРНР1 +] Код + Ссылка |
Всегда. |
|
[ОРРХ | ОРНР1 +] Родитель + Код + Ссылка |
Всегда. |
|
[ОРРХ | ОРНР1 +] Наименование + Ссылка |
Всегда. |
|
[ОРРХ | ОРНР1 +] Родитель + Наименование + Ссылка |
Всегда. |
|
[ОРРХ | ОРНР1 +] Порядок + Ссылка |
Свойство «Длина порядка» не равно 0. |
|
[ОРРХ | ОРНР1 +] Родитель + Порядок + Ссылка |
Свойство «Длина порядка» не равно 0. |
|
[ОРРХ | ОРНР1 +] Реквизит + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать». |
|
[ОРРХ | ОРНР1 +] Родитель + Реквизит + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать». |
|
[ОРРХ | ОРНР1 +] Реквизит + Порядок + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина порядка» не равно 0. |
|
[ОРРХ | ОРНР1 +] Родитель + Реквизит + Порядок + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина порядка» не равно 0. |
|
[ОРРХ | ОРНР1 +] Реквизит + Код + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина порядка» равно 0, а свойство «Основное представление» — «В виде кода». |
|
[ОРРХ | ОРНР1 +] Родитель + Реквизит + Код + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина порядка» равно 0, а свойство «Основное представление» — «В виде кода». |
|
[ОРРХ | ОРНР1 +] Реквизит + Наименование + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина порядка» равно 0, а свойство «Основное представление» — «В виде наименования». |
|
[ОРРХ | ОРНР1 +] Родитель + Реквизит + Наименование + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием» и при этом свойство «Длина порядка» равно 0, а свойство «Основное представление» — «В виде наименования». |
|
[ОРРХ | ОРНР1 +] Реквизит |
План счетов включен в критерий отбора через реквизит «Реквизит». |
|
[ОРРХ | ОРНР1 +] PredefinedID |
Индекс по идентификатору предопределенного объекта метаданных. |
Таблица опций плана счетов
|
Индекс |
Условие |
|---|---|
|
Идентификатор |
Всегда. |
План видов расчета
См. описание основных индексов справочника.
Таблица опций плана видов расчета
|
Индекс |
Условие |
|---|---|
|
Идентификатор |
Всегда. |
План обмена
См. описание основных индексов справочника с той лишь поправкой, что длина кода и длина наименования плана обмена не может быть равной нулю.
Табличная часть
|
Индекс |
Условие |
|---|---|
|
[ОРНР1 + … +] Ссылка + Ключ (Кластерный) |
Всегда. |
|
[ОРРХ | ОРНР1 +] Реквизит + Ссылка |
Объект конфигурации включен в критерий отбора через реквизит «Реквизит» табличной части или для реквизита табличной части установлено свойство «Индексировать». |
|
[ОРРХ | ОРНР1 +] PredefinedID |
Индекс по идентификатору предопределенного объекта метаданных. |
Для всех таблиц, которые предоставляют доступ к табличным частям объектов.
Регистр сведений
Непериодический регистр сведений
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] Измерение1 + [Измерение2 +…] (Кластерный) |
Есть хоть одно измерение регистра. |
|
[ОРРХ | ОРНР1 +] ИзмерениеN + Измерение1 + [Измерение2 +…] |
Измерению «ИзмерениеN» задано свойство «Индексировать» или свойство «Ведущее» и при этом это не первое и не единственное измерение. |
|
[ОРРХ | ОРНР1 +] Реквизит + Измерение1 + [Измерение2 +…] |
Реквизиту «Реквизит» задано свойство «Индексировать». |
|
[ОРРХ | ОРНР1 +] Ресурс + Измерение1 + [Измерение2 +…] |
Ресурсу «Ресурс» задано свойство «Индексировать». |
Периодический регистр сведений
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] Период + [Измерение1 + …] |
Всегда. |
|
[ОРРХ | ОРНР1 +] Измерение1 + [Измерение2 +…] + Период (Кластерный) |
Есть хоть одно измерение регистра. |
|
[ОРРХ | ОРНР1 +] ИзмерениеN + Период + Измерение1 + [Измерение2 +…] |
Измерению «ИзмерениеN» задано свойство «Индексировать» или свойство «Ведущее» и при этом это не единственное измерение. |
|
[ОРРХ | ОРНР1 +] Реквизит + Период + [Измерение1 + …] |
Реквизиту «Реквизит» задано свойство «Индексировать». |
|
[ОРРХ | ОРНР1 +] Ресурс + Период + [Измерение1 + …] |
Ресурсу «Ресурс» задано свойство «Индексировать». |
Дополнительный индекс для регистра сведений, подчиненного регистратору
|
Индекс |
Условие и описание |
|---|---|
|
[ОРНР1 + … +] Регистратор + НомерСтроки (Кластерный) |
Всегда. |
Регистр сведений с периодичностью «По позиции регистратора»
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] Период + Регистратор + НомерСтроки |
Всегда. |
|
[ОРНР1 + … +] Регистратор + НомерСтроки |
Всегда. |
|
[ОРРХ | ОРНР1 +] Измерение1 + [Измерение2 + …] + Период + Регистратор + НомерСтроки (Кластерный) |
Есть хоть одно измерение регистра. |
|
[ОРРХ | ОРНР1 +] Измерение + Период + Регистратор + НомерСтроки |
Измерению «Измерение» задано свойство «Индексировать». |
|
[ОРРХ | ОРНР1 +] Реквизит + Период + Регистратор + НомерСтроки |
Реквизиту «Реквизит» задано свойство «Индексировать». |
|
[ОРРХ | ОРНР1 +] Ресурс + Период + Регистратор + НомерСтроки |
Ресурсу «Ресурс» задано свойство «Индексировать». |
ИтогиСрезПервых
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] Измерение1 + [Измерение2 + …] |
Есть хоть одно измерение регистра. |
|
[ОРРХ | ОРНР1 +] Реквизит + [Измерение1 + …] |
Реквизиту «Реквизит» задано свойство «Индексировать». |
|
[ОРРХ | ОРНР1 +] Ресурс + [Измерение1 + …] |
Ресурсу «Ресурс» задано свойство «Индексировать». |
ИтогиСрезПоследних
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] Измерение1 + [Измерение2 + …] |
Есть хоть одно измерение регистра. |
|
[ОРРХ | ОРНР1 +] Реквизит + [Измерение1 + …] |
Реквизиту «Реквизит» задано свойство «Индексировать» |
|
[ОРРХ | ОРНР1 +] Ресурс + [Измерение1 + …] |
Ресурсу «Ресурс» задано свойство «Индексировать» |
Регистр накопления
Основная таблица регистра
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Период + Регистратор + НомерСтроки (Кластерный) |
Всегда. |
|
[ОРНР1 + … +] Регистратор + НомерСтроки |
Всегда. |
|
[ОРРХ | ОРНР1 +] Измерение + Период + Регистратор + НомерСтроки |
Измерению «Измерение» задано свойство «Индексировать». |
|
[ОРРХ | ОРНР1 +] Реквизит + Период + Регистратор + НомерСтроки |
Реквизиту «Реквизит» задано свойство «Индексировать». |
Таблица остатков
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Период + Измерение1 + … + ИзмерениеN + [DimHash] + [Splitter] (Кластерный) |
Для регистров вида «Остатки». |
|
[ОРРХ | ОРНР1 +] Период + Измерение |
Измерению «Измерение» задано свойство «Индексировать»(начиная со второго измерения). |
Таблица оборотов
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Период + Измерение1 + … + ИзмерениеN + [DimHash] + [Splitter] (Кластерный) |
Для регистров вида «Обороты». |
|
[ОРРХ | ОРНР1 +] Период + Измерение |
Измерению «Измерение» задано свойство «Индексировать».(начиная со второго измерения). |
|
Период + DimHash |
Для регистров, где количество измерений не позволяет организовать уникальный индекс по измерениям |
Таблица опций регистра накопления
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Идентификатор (Кластерный) |
Всегда. |
Агрегаты регистра накопления
Таблица агрегатов
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Период + Измерение1 + … + ИзмерениеN (Кластерный) |
Всегда. |
Таблица статистики регистра накопления
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Идентификатор + Период + Splitter (Кластерный) |
Всегда. |
|
Карта используемых измерений |
Всегда |
Таблица опций сети агрегатов
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Идентификатор (Кластерный) |
Всегда. |
Таблица буфера новых оборотов регистра накопления
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Период + Измерение1 + … + ИзмерениеN (Кластерный) |
Всегда. |
Таблица новых оборотов регистра накопления
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Период + Измерение1 + … + ИзмерениеN (Кластерный) + Splitter |
Всегда. |
Таблица кодов измерений регистра накопления
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Период + UUID измерения 1 + … + UUID измеренияN (Кластерный) |
Всегда. |
Таблица сети агрегатов
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Идентификатор + UUID измерения 1 + … + UUID измеренияN (Кластерный) |
Всегда. |
Регистр бухгалтерии
Основная таблица регистра без корреспонденции
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] Период + Регистратор + НомерСтроки (Кластерный) |
Всегда. |
|
[ОРНР1 + … +] Регистратор + НомерСтроки |
Всегда. |
|
[ОРРХ | ОРНР1 +] Счет + Период + Регистратор |
Регистру назначен план счетов. |
|
[ОРРХ | ОРНР1 +] Измерение + Период + Регистратор + НомерСтроки |
Измерению «Измерение» задано свойство «Индексировать». |
|
[ОРРХ | ОРНР1 +] Реквизит + Период + Регистратор + НомерСтроки |
Реквизиту «Реквизит» задано свойство «Индексировать». |
Основная таблица регистра с корреспонденцией
От вышеприведенного состава индексов отличается лишь тем, что вместо индекса по счету создаются два индекса по счету дебета и счету кредита.
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] СчетДт + Период + Регистратор |
Регистру назначен план счетов. |
|
[ОРРХ | ОРНР1 +] СчетКт + Период + Регистратор |
Регистру назначен план счетов. |
Таблица итогов по счету
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Период |
Поле «Счет» добавляется в случае, если регистру определен план счетов. Поле «ХэшИзмерений» добавляется, количество других полей больше 15. |
Таблица итогов между счетами
Только для регистров, поддерживающих корреспонденцию
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] |
Для не балансовых измерений. |
Таблица со значениями субконто
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Регистратор + НомерСтроки + Корреспонденция |
Всегда. |
|
[ОРРХ | ОРНР1 +] Период + Регистратор + НомерСтроки + ВидСубконто + Корреспонденция (Кластерный) |
Всегда. |
|
[ОРРХ | ОРНР1 +] ВидСубконто + Значение |
Всегда. |
Таблица опций регистра бухгалтерии
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Идентификатор (Кластерный) |
Всегда. |
Регистр расчета
Основная таблица регистра расчета
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] ПериодРегистрации + Регистратор + НомерСтроки |
Всегда. |
|
[ОРНР1 + … +] Регистратор + НомерСтроки |
Всегда. |
|
[ОРРХ | ОРНР1 +] ПериодРегистрации + [БазовоеИзмерение1 +…] |
Всегда. |
|
[ОРРХ | ОРНР1 +] [БазовоеИзмерение1 +…] + ПериодРегистрации |
Есть хоть одно базовое измерение. |
|
[ОРРХ | ОРНР1 +] ПериодДействия + [БазовоеИзмерение1 +…] |
Установлено свойство регистра расчета «ПериодДействия». |
|
[ОРРХ | ОРНР1 +] [БазовоеИзмерение1 +…] + ПериодДействия |
Установлено свойство регистра расчета «ПериодДействия» и есть хоть одно базовое измерение. |
|
[ОРРХ | ОРНР1 +] Измерение + ПериодРегистрации + Регистратор + НомерСтроки |
Измерению «Измерение» задано свойство «Индексировать». |
|
[ОРРХ | ОРНР1 +] Реквизит + ПериодРегистрации + Регистратор + НомерСтроки |
Реквизиту «Реквизит» задано свойство «Индексировать». |
Таблица перерасчета
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] Регистратор + ВидРасчета + [Измерение1 + …] |
Всегда. |
Tаблица фактических периодов действия
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] Регистратор + НомерСтроки |
Всегда. |
Таблица опций регистра расчета
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Идентификатор (Кластерный) |
Всегда. |
Последовательности
Основная таблица последовательности
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] Регистратор |
Всегда. |
|
[ОРРХ | ОРНР1 +] [Измерение1 + …] + Период + Регистратор |
Всегда. |
Таблица границ последовательности
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] [Измерение1 + …] + Период + Регистратор |
Всегда. |
Перечисления
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] Порядок + Ссылка |
Всегда. |
|
[ОРНР1 + … +] Ссылка (Кластерный) |
Всегда. |
Бизнес-процессы
Основная таблица бизнес-процесса
|
Индекс |
Условие |
|---|---|
|
[ОРНР1 + … +] Ссылка (Кластерный) |
Всегда. |
|
[ОРРХ | ОРНР1 +] Дата + Ссылка |
Всегда. |
|
[ОРРХ | ОРНР1 +] Номер + Ссылка |
Свойство «Длина номера» не равно 0. |
|
[ОРРХ | ОРНР1 +] Завершен + Дата + Ссылка |
Всегда |
|
[ОРРХ | ОРНР1 +] Стартован + Дата + Ссылка |
Всегда |
|
[ОРРХ | ОРНР1 +] ВедущаяЗадача + Ссылка |
Всегда |
|
[ОРРХ | ОРНР1 +] Реквизит + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать». |
|
[ОРРХ | ОРНР1 +] Реквизит + Дата + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием». |
|
[ОРРХ | ОРНР1 +] Реквизит |
Бизнес-процесс включен в критерий отбора через реквизит «Реквизит». |
Таблица точек маршрута бизнес-процесса
|
Индекс |
Условие и описание |
|---|---|
|
[ОРНР1 + … +] Ссылка (Кластерный) |
Всегда. |
|
[ОРРХ | ОРНР1 +] Порядок + Ссылка |
Всегда. |
Задачи
|
Индекс |
Условие |
|---|---|
|
[ОРНР1 + … +] Ссылка (Кластерный) |
Всегда. |
|
[ОРРХ | ОРНР1 +] Дата + Ссылка |
Всегда. |
|
[ОРРХ | ОРНР1 +] Номер + Ссылка |
Свойство «Длина номера» не равно 0. |
|
[ОРРХ | ОРНР1 +] Наименование + Ссылка |
Всегда |
|
[ОРРХ | ОРНР1 +] Выполнена + Наименование + Ссылка |
Всегда |
|
[ОРРХ | ОРНР1 +] Выполнена + Дата + Ссылка |
Всегда |
|
[ОРРХ | ОРНР1 +] БизнесПроцесс + ТочкаМаршрута + Ссылка |
Всегда |
|
[ОРРХ | ОРНР1 +] Выполнена + БизнесПроцесс + ТочкаМаршрута + Ссылка |
Всегда |
|
[ОРРХ | ОРНР1 +] БизнесПроцесс + Дата + Ссылка |
Всегда |
|
[ОРРХ | ОРНР1 +] Реквизит + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать». |
|
[ОРРХ | ОРНР1 +] Реквизит + Дата + Ссылка |
Для реквизита «Реквизит» свойство «Индексировать» установлено в значение «Индексировать с доп. упорядочиванием». |
|
[ОРРХ | ОРНР1 +] Реквизит |
Задача включена в критерий отбора через реквизит «Реквизит». |
Сервисы интеграции
Таблица настроек сервиса интеграции
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] (Кластерный) |
Всегда. |
Таблица очереди отправки канала сервиса интеграции
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Идентификатор сообщения (Кластерный) |
Всегда. |
|
Позиция сообщения |
Всегда. |
Таблица очереди получения канала сервиса интеграции
|
Индекс |
Условие |
|---|---|
|
[ОРРХ | ОРНР1 +] Идентификатор сообщения (Кластерный) |
Всегда. |
|
Позиция сообщения |
Всегда. |
Таблицы регистрации изменений
Таблицы регистрации изменений для различных объектов метаданных отличаются только составом и типами полей ключа данных — набора полей, однозначно определяющих данные. Для объектных типов данных (Справочник, Документ, ПланСчетов и др.) — это «Ссылка»; для регистров, подчиненных регистратору (РегистрНакопления, РегистрБухгалтерии, РегистрСведений, подчиненный регистратору и др.) — «Регистратор»; для регистров сведений, неподчиненных регистратору — поля, соответствующие изменениям, входящим в основной отбор регистра; для констант — идентификатор объекта метаданных Константы.
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ | ОРНР1 +] Узел + Номер сообщения + Ключ данных |
Всегда. |
|
[ОРРХ | ОРНР1 +] Ключ данных + Узел + Номер сообщения |
Всегда. |
Таблица списка пользователей
|
Индекс |
Условие и описание |
|---|---|
|
Уникальный идентификатор пользователя (Кластерный) |
Всегда. |
|
Идентификатор набора ролей |
Всегда. |
|
Имя пользователя ОС |
Всегда. |
|
[ОРРХ +] Имя пользователя ОС |
В конфигурации определен хотя бы один разделитель. |
|
Имя пользователя |
Всегда. |
|
[ОРРХ +] Имя пользователя |
В конфигурации определен хотя бы один разделитель. |
|
[ОРРХ +] Полное имя пользователя |
Всегда. |
|
Показывать пользователя в списке для диалога аутентификации |
Всегда. |
|
Разрешена аутентификация средствами 1С:Предприятия |
Всегда. |
Таблица истории работы пользователей
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ +] Уникальный идентификатор записи |
Всегда. |
|
[ОРРХ +] Уникальный идентификатор пользователя + Дата время |
Всегда. |
|
[ОРРХ +] Уникальный идентификатор пользователя + Хеш по URL |
Всегда. |
|
ОРРХ + ИспользованиеРазделителя1 + … |
В конфигурации определен хотя бы один разделитель. |
Таблица хранилища системных настроек
Таблица хранилища настроек отчетов
Таблица хранилища настроек вариантов отчетов
Таблица хранилища общих настроек
Таблица хранилища настроек данных форм
Таблица хранилища динамических списков
Хранилище настроек стандартного интерфейса OData
|
Индекс |
Условие и описание |
|---|---|
|
[ОРРХ +] Уникальный идентификатор пользователя + Имя предмета настройки + Имя множественной (именованной) настройки |
Всегда. |
|
ОРРХ + ИспользованиеРазделителя1 + … |
В конфигурации определен хотя бы один разделитель. |
Таблица очереди истории данных
|
Индекс |
Условие и описание |
|---|---|
|
Идентификатор объекта метаданных + Идентификатор данных + Позиция сообщения в очереди (Кластерный) |
Всегда. |
Таблица версий данных истории данных
|
Индекс |
Условие и описание |
|---|---|
|
Идентификатор данных + Номер версии данных (Кластерный) |
Всегда. |
Таблицы последних версий истории данных
|
Индекс |
Условие и описание |
|---|---|
|
[ОРР1 + … + ] + Идентификатор объекта метаданных + Идентификатор данных (Кластерный) |
Всегда. |
Таблица версий метаданных истории данных
|
Индекс |
Условие и описание |
|---|---|
|
[ОРНР1 + … + ] + Идентификатор объекта метаданных + Флаг версия метаданных сформирована при изменении настроек + Флаг версия метаданных является актуальной + Номер актуальной версии метаданных (Кластерный) |
Всегда. |
|
Идентификатор объекта метаданных + Номер актуальной версии метаданных |
Всегда. |
Таблица настроек истории данных
|
Индекс |
Условие и описание |
|---|---|
|
[ОРНР1 + … + ] + Идентификатор объекта метаданных (Кластерный) |
Всегда. |
Таблица очереди обработки после записи версии истории данных
|
Индекс |
Условие и описание |
|---|---|
|
[ОРР1 + … + ] + Идентификатор объекта метаданных + Идентификатор данных + Номер версии (Кластерный) |
Всегда. |
Копии базы данных
Таблица копий
|
Индекс |
Условие |
|---|---|
|
Идентификатор копии + Имя копии (Кластерный) |
Всегда. |
Таблица настроек копий
|
Индекс |
Условие и описание |
|---|---|
|
Идентификатор копии (Кластерный) |
Всегда. |
Таблица состояний таблиц копий
|
Индекс |
Условие и описание |
|---|---|
|
Идентификатор копии + Имя таблицы (Кластерный) |
Всегда. |
Таблица изменений в процессе первоначального копирования
|
Индекс |
Условие и описание |
|---|---|
|
Идентификатор копии + Имя таблицы (Кластерный) |
Всегда. |
Таблица объектов изменений
|
Индекс |
Условие и описание |
|---|---|
|
Идентификатор объекта (Кластерный) |
Всегда. |
Таблица с информацией по блокам первоначального копирования
|
Индекс |
Условие и описание |
|---|---|
|
Идентификатор копии + Имя таблицы + Номер блока (Кластерный) |
Всегда. |
Таблица журналов транзакций
|
Индекс |
Условие и описание |
|---|---|
|
Номер транзакции (Кластерный) |
Всегда. |
|
Идентификатор транзакции |
Всегда. |
Таблица с измененными в транзакциях таблицах
|
Индекс |
Условие и описание |
|---|---|
|
Номер транзакции + Имя таблицы (Кластерный) |
Всегда. |
|
Имя таблицы |
Всегда. |
Таблица перенесенных транзакций
|
Индекс |
Условие и описание |
|---|---|
|
Идентификатор копии + Номер транзакции (Кластерный) |
Всегда. |
You have no rights to post comments
или
— Ну у вас и запросы! — сказала база данных и повисла…
Краткий ответ на вопрос заголовка заключается в том, что это позволит выполнять запросы быстро и уменьшать негативное влияние блокировок на производительность в многопользовательском режиме.
Что такое индекс?
Подобно содержанию в книге, индекс в базе данных позволяет быстро искать конкретные сведения в таблице.
Сначала поговорим про индексы в MS SQL Server.
Индексы представляют собой структуру, позволяющую выполнять ускоренный доступ к строкам таблицы на основе значений одного или более ее столбцов.
Индекс содержит ключи, построенные из одного или нескольких столбцов таблицы или представления, и указатели, которые сопоставляются с местом хранения заданных данных.
Индексы сокращают объем данных, которые необходимо считать, чтобы возвратить результирующий набор.
Хотя индекс и связан с конкретным столбцом (или столбцами) таблицы, все же он является самостоятельным объектом базы данных.

Просто объекта «Индекс» в платформе 1С:Предприятие 8 нет.
Индексы таблиц в базе данных 1С:Предприятие создаются неявным образом при создании объектов конфигурации, а также при тех или иных настройках объектов конфигурации.
- Неявным образом индексы создаются с учетом типов полей ключа данных — набора полей, однозначно определяющих данные. Для объектных типов данных (Справочник, Документ, ПланСчетов и др.) — это «Ссылка»; для регистров, подчиненных регистратору (РегистрНакопления, РегистрБухгалтерии, РегистрСведений, подчиненный регистратору и др.) — «Регистратор»; для регистров сведений, неподчиненных регистратору — поля, соответствующие изменениям, входящим в основной отбор регистра; для констант — идентификатор объекта метаданных Константы.
- индексируются данные в «соответствии»
Явным способом включением свойства «Индексировать» реквизитов и измерений с значение «Индексировать» и «Индексировать с доп. Упорядочиванием». Вариант ««Индексировать с доп. Упорядочиванием»» включает обычно колонку «код» или «наименование» в индекс.

Еще одним явным способом можно считать добавление объекта метаданных в объект метаданных «критерий отбора».

Можно указать индекс для таблицы значений и в запросах для временных таблиц.
ВЫБРАТЬ
Код,
Наименование
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ Справочник.Номенклатура
ИНДЕКСИРОВАТЬ ПО Код
В любом случае, надо понимать, что говоря об индексах, мы фактически подразумеваем индексы СУБД, которая используется для 1С:Предприятие. Исключению составляют объекты типа Таблица значений, когда индексы находятся в RAM (оперативной памяти).
Физическая сущность индексов в MS SQL Server.
Физически данные хранятся на 8Кб страницах. Сразу после создания, пока таблица не имеет индексов, таблица выглядит как куча (heap) данных. Записи не имеют определенного порядка хранения.
Когда вы хотите получить доступ к данным, SQL Server будет производить сканирование таблицы (table scan). SQL Server сканирует всю таблицу, что бы найти искомые записи.
Отсюда становятся понятными базовые функции индексов:
— увеличение скорости доступа к данным,
— поддержка уникальности данных.
Несмотря на достоинства, индексы так же имеют и ряд недостатков. Первый из них – индексы занимают дополнительное место на диске и в оперативной памяти. Каждый раз когда вы создаете индекс, вы сохраняете ключи в порядке убывания или возрастания, которые могут иметь многоуровневую структуру. И чем больше/длиннее ключ, тем больше размер индекса. Второй недостаток – замедляются операции вставки, обновления и удаления записей.
В среде MS SQL Server реализовано несколько типов индексов:
- некластерные индексы;
- кластерные (или кластеризованные) индексы;
- уникальные индексы;
- индексы с включенными столбцами
- индексированные представления
- полнотекстовый
- XML
Некластерный индекс
Некластерные индексы – не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки.
Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя:
- информацию об идентификационном номере файла, в котором хранится строка;
- идентификационный номер страницы соответствующих данных;
- номер искомой строки на соответствующей странице;
- содержимое столбца.
Некластерных индексов может быть несколько для одной таблицы.

Некластеризованный индекс по таблице, не имеющей кластеризованного индекса

Некластеризованный индекс по таблице, имеющей кластеризованный индекс
Кластерный (кластеризованный) индекс
Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту.
Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными. Если в таблице определен некластерный индекс, то сервер должен сначала обратиться к индексу, а затем найти нужную строку в таблице. При использовании кластерных индексов следующая порция данных располагается сразу после найденных ранее данных. Благодаря этому отпадают лишние операции, связанные с обращением к индексу и новым поиском нужной строки в таблице.
Естественно, в таблице может быть определен только один кластерный индекс. Кластерный индекс может включать несколько столбцов.
Необходимо избегать создания кластерного индекса для часто изменяемых столбцов, поскольку сервер должен будет выполнять физическое перемещение всех данных в таблице, чтобы они находились в упорядоченном состоянии, как того требует кластерный индекс. Для интенсивно изменяемых столбцов лучше подходит некластерный индекс.
При создании в таблице первичного ключа (PRIMARY KEY) сервер автоматически создает для него кластерный индекс, если его не существовало ранее или если при определении ключа не был явно указан другой тип индекса.
Когда же в таблице определен еще и некластерный индекс, то его указатель ссылается не на физическое положение строки в базе данных, а на соответствующий элемент кластерного индекса, описывающего эту строку, что позволяет не перестраивать структуру некластерных индексов всякий раз, когда кластерный индекс меняет физический порядок строк в таблице.

Уникальный индекс
Уникальность значений в индексируемом столбце гарантируют уникальные индексы. При их наличии сервер не разрешит вставить новое или изменить существующее значение таким образом, чтобы в результате этой операции в столбце появились два одинаковых значения.
Уникальный индекс является своеобразной надстройкой и может быть реализован как для кластерного, так и для некластерного индекса. В одной таблице может существовать один уникальный кластерный и множество уникальных некластерных индексов.
Уникальные индексы следует определять только тогда, когда это действительно необходимо. Для обеспечения целостности данных в столбце можно определить ограничение целостности UNIQUE или PRIMARY KEY, а не прибегать к уникальным индексам. Их использование только для обеспечения целостности данных является неоправданной тратой пространства в базе данных. Кроме того, на их поддержание тратится и процессорное время.
1С:Предприятие 8 активно использует кластерные уникальные индексы. Это означает, что можно получить ошибку не уникального индекса.
Если не уникальность заключается в датах с нулевыми значениями, то проблема решается созданием базы с параметром смещения равным 2000.
«Рыба» скрипта для определения не уникальных записей:
SELECT COUNT(*) Counter, <перечисление всех полей соответствующего индекса> from <имя таблицы>
GROUP BY <перечисление всех полей соответствующего индекса>
HAVING Counter > 1
Понятие первичного и внешнего ключа
Первичный ключ (primary key) – это набор столбцов таблицы, значения которых уникально определяют строку.
Внешний ключ (foreign key) . Внешним ключом называется поле таблицы, предназначенное для хранения значения первичного ключа другой таблицы с целью организации связи между этими таблицами. Внешний ключ в таблице может ссылаться и на саму эту таблицу. Такие внешние ключи, в основном, используются для хранения древовидной структуры данных в реляционной таблице. СУБД поддерживают автоматический контроль ссылочной целостности на внешних ключах.
1С не использует внешние ключи. Ссылочная целостность обеспечивается логикой приложения.
Ограничения индексов
Индекс может быть создан на основании нескольких полей. В этом случае существует ограничение – длина ключа индекса не должна превышать 900 байтов и не более 16 ключевых столбцов. На практике это означает что при создании индекса, включающего более 16 полей, индекс усекается. Это может оказать влияние на производительность при количестве субконто составного типа более 4х.
В актуальных релизах платформы выполнена оптимизация данного случая и используется хэш по ключу полей, но это медленней «полноценных» индексов.
Статистика индексов
Microsoft SQL Server собирает статистику по индексам и полям данных, хранимых в базе. Эта статистика используется оптимизатором запроса SQL Server при выборе оптимального плана исполнения запросов на выборку или обновление данных.
При создании индекса оптимизатор запросов автоматически сохраняет данные статистики о проиндексированых столбцах.
Просмотр статистики — sp_helpstats.
Фрагментация индексов
Чрезмерная фрагментация создает проблемы для больших операций ввода-вывода. Фрагментация не должна превышать 25%. От снижения фрагментации индексов могут выиграть операции сканирования больших диапазонов данных. Для этого рекомендуется выполнять периодическую дефрагментацию индексов. Обратите внимание, что при дефрагментации индексов (по умолчанию) автоматически обновляется статистика.
Смотреть степень фрагментированности индексов можно штатными средствами СУБД или в разрезе объектов метаданных можно например с помощью бесплатного онлайн-сервиса http://www.gilev.ru/sqlsize/

Оптимизация размещения индексов
При объеме таблиц не позволяющем им «разместиться» в оперативной памяти сервера, на первое место выходит скорость дисковой подсистемы (I/O). И здесь можно обратить внимание возможность размещать индексы в отдельных файлах расположенных на разных жестких дисках.

Подробное описание действий http://technet.microsoft.com/ru-ru/library/ms175905.aspx
Использование индекса из другой файловой группы повышает производительность некластерных индексов в связи с параллельностью выполнения процессов ввода/вывода и работы с самим индексом.
Для определения размеров можно использовать выше упомянутую обработку.
Влияние индексов на блокировки
Отсутствие необходимого индекса для запроса означает перебор всех записей таблицы, что в свою очередь приводит к избыточным блокировкам, т.е. блокируются лишние записи. Кроме того, чем дольше выполняется запрос из-за отсутствующих индексов, тем больше время удержания блокировок.
Другая причина блокировок — малое количество записей в таблицах. В связи с этим SQL Server, при выборе плана выполнения запроса, не использует индексы, а обходит всю таблицу(Table Scan), блокируя целиком. Для того, чтобы избежать подобных блокировок, необходимо увеличить количество записей в таблицах до 1500-2000. В этом случае сканирование таблицы становится долее дорогостоящей операцией и SQL Server начинает использовать индексы. Конечно это можно сделать не всегда, ряд справочников как «Организации», «Склады», «Подразделения» и т.п. обычно имеют мало записей. В этих случаях индексирование не будет улучшать работу.
Эффективность индексов
Мы уже отметили в заголовке статьи, что нас интересуют влияние индексов на быстродействие запросов. Итак, индексы наиболее подходят для задач следующего типа:
- Запросы, которые указывают «узкие» критерии поиска. Такие запросы должны считывать лишь небольшое число строк, отвечающих определенным критериям.
- Запросы, которые указывают диапазон значений. Эти запросы также должны считывать небольшое количество строк.
- Поиск, который используется в операциях связывания. Колонки, которые часто используются как ключи связывания, прекрасно подходят для индексов.
- Поиск, при котором данные считываются в определенном порядке. Если результирующий набор данных должен быть отсортирован в порядке кластеризованного индекса, то сортировка не нужна, поскольку результирующий набор данных уже заранее отсортирован. Например, если кластеризованный индекс создан по колонкам lastname (фамилия), firstname (имя), а для приложения требуется сортировка по фамилии и затем по имени, то здесь нет необходимости добавлять инструкцию ORDER BY.
Правда при всей полезности индексов, есть одно очень важное НО – индекс должен быть «эффективно используемым» и должен позволять находить данные с использованием меньшего числа операций ввода-вывода и объема системных ресурсов. И наоборот, неиспользуемые (редко используемые) индексы скорее ухудшают скорость записи данных (поскольку каждая операция, изменяющая данные, должна также обновлять страницы индексов) и создают избыточный объем базы.
Покрывающим (для данного запроса), называется индекс в котором есть все необходимые поля для этого запроса. Например, если индекс создан по колонкам a, b и c, а оператор SELECT запрашивает данные только из этих колонок, то требуется доступ только к индексу.
Для того, что бы определить эффективность индекса, мы можем приблизительно оценить с помощью бесплатного онлайн-сервиса http://www.gilev.ru/querytj/ показывающий «план исполнения запроса» и используемые индексы.
![]()
получить требуемые данные.
При отсутствии индекса у таблицы, чтобы выбрать нужные записи, придется последовательно перебирать все записи таблицы и смотреть, подходит текущая запись под условия или нет. При этом выполняется сканирование всей таблицы. Это наиболее медленная операция, особенно на больших объемах данных.
При наличии индекса, неточно описывающего условия поиска, понадобится сканировать этот индекс. Конечно, сканирование индекса быстрее, чем сканирование таблицы, но не намного.
Чтобы представлять, как происходит поиск данных в таблицах, необходимо понимать, что структура индекса в СУБД представляет собой дерево значений проиндексированных полей. На первом уровне дерева находятся значения первого поля индекса, на втором – второго и так далее. Чтобы выполнить поиск данных по индексу, сначала необходимо провести поиск по значению первого поля индекса, затем – второго и так далее. Если, например, условие по первому полю индекса не указано, то индекс уже не сможет обеспечить быстрый поиск. Если указано условие по нескольким первым полям индекса, а затем одно или несколько полей индекса не задано, то индекс может быть использован только частично.
Таким образом, индексы будут использованы эффективно только в том случае, когда индекс покрывает условия запроса, то есть с самого начала содержит без пропуска поля, на которые накладываются условия.
Условия используются в следующих секциях запроса:
в предложении ГДЕ, в условии соединения таблиц ПО,
в параметрах виртуальных таблиц, в предложении ИМЕЮЩИЕ.
Для каждого условия должен существовать подходящий индекс (полностью покрывающий условия запроса), т. е. индекс, удовлетворяющий следующим требованиям:
1.Индекс должен содержать все поля, перечисленные в условии.
2.Эти поля должны находиться в самом начале индекса.
3.Эти поля должны следовать друг за другом подряд, то есть между ними не должны «вклиниваться» поля, не участвующие в условии запроса.
Что значит подходящий индекс? Рассмотрим пример.
Предположим, нам нужно получить данные об остатке товара Клавиатура на складе
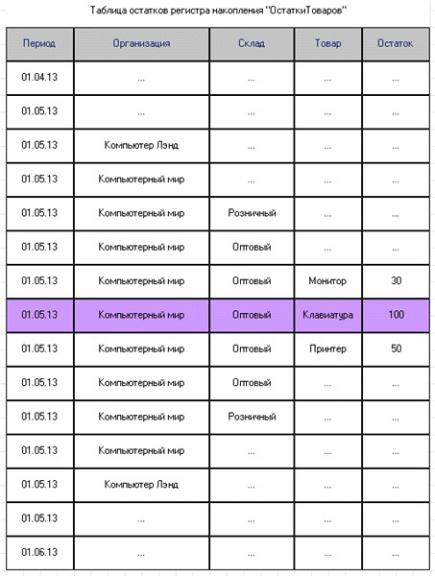
Основной в организации Компьютерный мир на 01.05.13 из регистра накопления
Остатки товаров.
В базе данных для таблицы остатков регистра накопления (без разделителей итогов) автоматически создается индекс Период + Измерение1 + Измерение2 + … + ИзмерениеN. При этом имена измерений и порядок следования их друг за другом в индексе соответствуют порядку, заданному в конфигураторе.
Регистр накопления Остатки товаров имеет измерения Организация, Склад, Номенклатура. В базе данных для таблицы остатков этого регистра накопления будет создан индекс Период + Организация + Склад + Номенклатура.
Для решения поставленной задачи в запросе к таблице остатков регистра накопления требуется задать условие отбора записей в параметрах виртуальной таблицы. Это условие отбора по полю Период (в параметре Период) и по полям Организация, Склад и Номенклатура (в параметре Условие). Таким образом, индекс удовлетворяет всем трем требованиям, описанным выше. Поэтому поиск нужных записей в таблице будет эффективным (рис. 4.1).
Рис. 4.1. Поиск записей в таблице по индексу
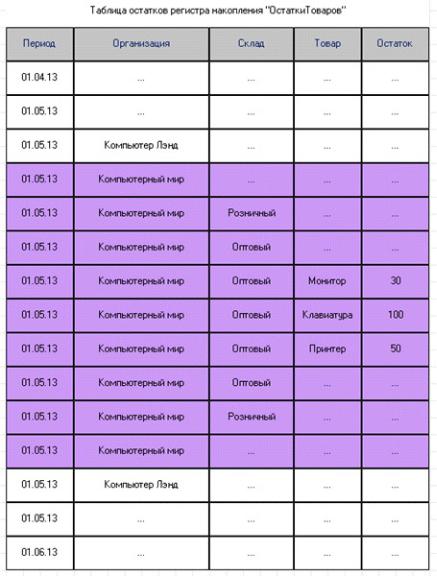
Если же изменить условие задачи, то ситуация будет другой. Например, нужно получить данные об остатке товара Клавиатура в организации Компьютерный мир на 01.05.13.
Для поиска нужных данных в таблице будут выбраны все записи, относящиеся к периоду 01.05.13 и организации Компьютерный мир. Затем последовательным перебором запрос выберет те из них, которые относятся к товару Клавиатура (рис. 4.2).
Рис. 4.2. Поиск записей в таблице путем сканирования индекса
Так происходит потому, что не выполняется третье требование к индексу – между полями условия запроса Организация и Товар «вклинивается» поле Склад. В этом случае индекс может быть использован частично, и для поиска нужных данных, скорее всего, будет применено сканирование индекса.
подробнее
Подробные рекомендации по эффективному использованию индексов будут рассмотрены в
этом разделе.
При создании таблиц, соответствующих тем или иным объектам конфигурации, платформа автоматически создает набор индексов, обеспечивающих эффективную работу с этими

таблицами. Индексов, как правило, создается несколько, для того чтобы можно было выбрать различные данные, по различным условиям. Основные индексы, создаваемые платформой:
индекс по уникальному идентификатору (ссылке) для всех объектных сущностей (справочники, документы и т. д.); индекс по регистратору (ссылке на документ) для таблиц движений регистров, подчиненных регистратору;
индекс по периоду и значениям всех измерений для итоговых таблиц регистров накопления; индекс по периоду, счету и значениям всех измерений для итоговых таблиц регистров бухгалтерии.
подробнее
Состав индексов, создаваемых платформой, можно найти в статье ИТС «Индексы таблиц
базы данных».
Посмотреть, какие индексы создаются на конкретной информационной базе, можно с помощью метода глобального контекста ПолучитьСтруктуруХраненияБазыДанных().
Но нужно понимать, что чем сложнее индекс и чем больше количество индексов в таблице, тем больше времени тратится на запись данных в эту таблицу. Поэтому нужно стремиться оптимизировать состав и количество индексов так, чтобы индексов не было слишком много и они не были слишком сложными (не содержали много полей), но при этом позволяли точно и быстро выбирать данные из таблиц по различным критериям.
Способы индексирования таблиц
Платформа не может предусмотреть индексы на все случаи жизни, так как запросы могут быть самыми разнообразными. Поэтому разработчик может дополнительно, если существует такая необходимость, указать те или иные поля, которые также должны участвовать в построении индекса.
Существуют следующие способы создания и/или изменения индексов:
изменение порядка следования измерений объектов метаданных; использование свойства Индексировать у реквизитов объектов метаданных; включение реквизитов объектов метаданных в критерий отбора.
Например, для непериодического независимого регистра сведений (при наличии хотя бы одного измерения) в базе данных автоматически создается индекс:
Измерение1 + Измерение2 + … + ИзмерениеN
При этом имена полей индекса и порядок следования их друг за другом соответствуют
заданному в конфигураторе.
Если поменять порядок следования друг за другом измерений регистра в конфигураторе, то, соответственно, изменится порядок следования полей в индексе таблицы регистра в базе данных (рис. 4.3).
Рис. 4.3. Изменение порядка следования измерений регистра в конфигураторе и полей индекса таблицы регистра в базе данных
При установке свойств измерений Ведущее и Индексировать (рис. 4.4) создается дополнительный индекс:
ИзмерениеК + Измерение1 + Измерение2 + … + ИзмерениеN.

Рис. 4.4. Свойства измерений «Ведущее» и «Индексировать»
Поэтому в случае установки свойства Ведущее для измерения Номенклатура, а затем установки свойства Индексировать для измерения ХарактеристикаНоменклатуры у
таблицы регистра в базе данных будут созданы дополнительные индексы, показанные на рис. 4.5.
Рис. 4.5. Основные и дополнительные индексы таблицы регистра при индексировании измерений
Понятно, что в некоторых случаях, чтобы не усложнять индексы, достаточно изменить порядок следования измерений регистра в конфигураторе. Например, если поставить ведущее измерение на первое место, то вместо двух индексов будет создан один.

Свойство Индексировать есть также у некоторых реквизитов объектов метаданных, например у справочников, документов и т. п. Это свойство позволяет указать системе, что нужно создать дополнительный индекс, содержащий соответствующий реквизит. Кроме значения Индексировать для большинства объектов можно установить значение
Индексировать с доп. упорядочиванием.
Например, для неиерархического неподчиненного справочника в базе данных автоматически создаются индексы:
Ссылка;
Код + Ссылка (если длина кода не равна 0); Наименование + Ссылка (если длина наименования не равна 0).
Если для реквизита справочника установить свойство Индексировать в значение
Индексировать/Индексировать с доп. упорядочиванием, для таблицы справочника в базе данных будут созданы дополнительные индексы, показанные на рис. 4.6:
Реквизит + Ссылка (если для реквизита свойство Индексировать установлено в значение Индексировать); Реквизит + Код + Ссылка (если для реквизита свойство Индексировать
установлено в значение Индексировать с доп. упорядочиванием, длина кода не равна 0 и основное представление справочника задано в виде кода);
Реквизит + Наименование + Ссылка (если для реквизита свойство Индексировать установлено в значение Индексировать с доп. упорядочиванием, длина наименования не равна 0 и основное представление справочника задано в виде наименования).
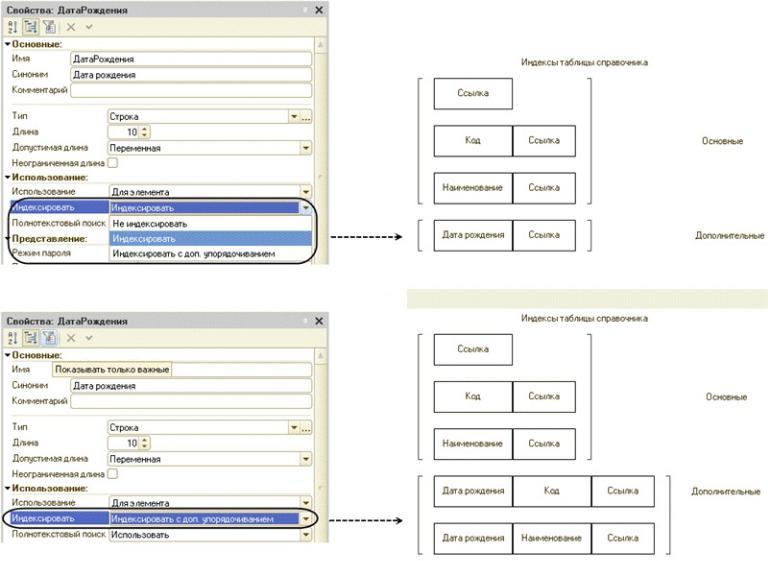
Рис. 4.6. Основные и дополнительные индексы таблицы справочника при индексировании реквизитов
Вариант индексирования Индексировать с доп. упорядочиванием предназначен, прежде всего, для использования в динамических списках. В этом случае индекс строится по реквизиту, а также по некоторому полю, которое обычно используется для упорядочивания объектов этого типа.
При выборе значения свойства Индексировать нужно исходить из того, какие варианты выборки информации необходимо оптимизировать в первую очередь. Если требуется только поиск с помощью запроса объектов по данному реквизиту без упорядочивания, то можно установить значение Индексировать, чтобы создаваемый индекс требовал меньше ресурсов системы. Если требуется просмотр списка с отбором по реквизиту, то имеет смысл использовать вариант Индексировать с доп. упорядочиванием.
Если объект конфигурации включен в критерий отбора, то создается дополнительный индекс по реквизиту, который включен в состав критерия отбора. Например, если справочник включен в критерий отбора через реквизит ДатаРождения, то у таблицы справочника будет создан дополнительный индекс по этому реквизиту (рис. 4.7).
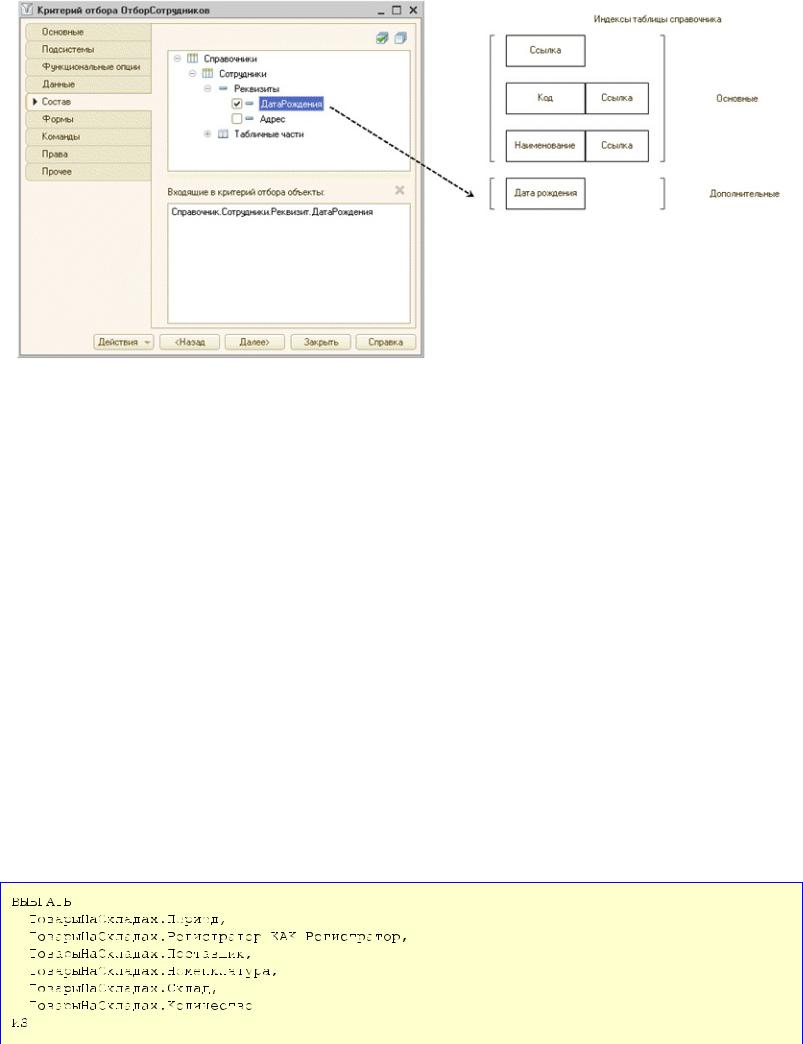
Рис. 4.7. Основные и дополнительные индексы таблицы справочника при включении реквизита в состав критерия отбора
Эффективное использование индексов
Чтобы понять, эффективно запрос использует индексы или нет, нужно посмотреть текст запроса, определить таблицы – источники запроса и выделить те поля, которые используются в условиях запроса (в предложении ГДЕ, в условии соединения таблиц ПО, в параметрах виртуальных таблиц, в предложении ИМЕЮЩИЕ).
Затем нужно сравнить их с индексами, которые создает система для исходных таблиц запроса. Если нужных для эффективного выполнения запроса индексов не хватает, следует создать дополнительные индексы описанными выше способами.
Ниже мы рассмотрим некоторые задачи по получению информации из таблиц базы данных и варианты индексирования этих таблиц, оптимальные для выполнения соответствующих запросов.
Пример 1
Пусть необходимо получить движения регистра ТоварыНаСкладах, отражающие поступления от производителей. Для этого нужно выполнить отбор движений по значению реквизита регистра ВидОперации с помощью следующего запроса (листинг 4.1).
Листинг 4.1. Отбор движений регистра накопления по значению реквизита
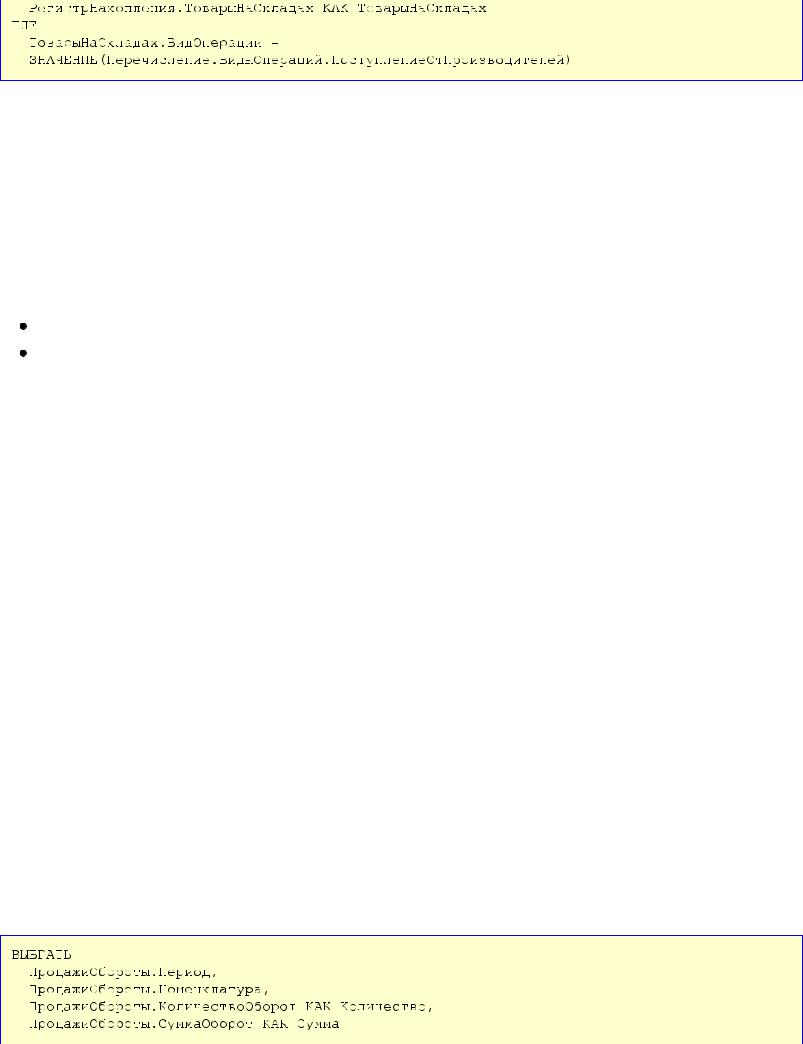
Вданном запросе источником данных является таблица движений регистра накопления остатков ТоварыНаСкладах, который имеет измерения Номенклатура и Склад, ресурс Количество и реквизиты Поставщик, ВидОперации. Измерения и реквизиты регистра не проиндексированы, т. е. свойство Индексировать для них установлено в значение Не индексировать.
Вэтом случае для таблицы движений этого регистра платформа автоматически создаст индексы:
Период + Регистратор + НомерСтроки, Регистратор + НомерСтроки.
Вусловии запроса, в предложении ГДЕ, накладывается отбор на значение реквизита регистра ВидОперации. То есть подходящий индекс, содержащий в самом начале поле, на которое накладывается условие, в таблице отсутствует.
Вэтом случае при выполнении запроса будут выбраны все записи движений регистра, а затем, путем перебора этих записей, будут получены записи с нужным значением реквизита.
Чтобы при выполнении запроса происходило обращение сразу к записям с указанным значением реквизита, для реквизита ВидОперации свойство Индексировать следует установить в значение Индексировать. В этом случае в таблице движений регистра будет создан дополнительный индекс:
ВидОперации + Период + Регистратор + НомерСтроки.
Этот индекс полностью покрывает условия запроса и позволит осуществить эффективный поиск записей в таблице движений регистра накопления.
Пример 2
Пусть необходимо получить данные о продажах товаров конкретному покупателю за указанный период с разворотом по неделям из оборотного регистра накопления Продажи. Для этого нужно выполнить следующий запрос (листинг 4.2).
Листинг 4.2. Вывод оборотов товаров по выбранному контрагенту за заданный период с периодичностью «Неделя»
Что такое реквизиты 1С?
Мы с Вами недавно обсуждали справочники 1С и документы 1С. Работа пользователя со справочниками и документами в 1С состоит из заполнения полей на форме.
Реквизиты 1С – это поля справочника и документа, которые отображаются на форме, чтобы пользователь их заполнил.

Рассмотрим подробно тему реквизитов в 1С.
Что такое Реквизиты 1С
Каждый справочник и документ 1С состоит из набора полей. Такие поля называются реквизиты 1С (для программиста 1С).
В конфигураторе, в дереве конфигурации 1С, раскройте любой справочник или документ и Вы увидите ветку Реквизиты. Это список реквизитов (полей) справочника.

Поглядите как те же реквизиты 1С выглядят на форме справочника 1С.

Каждый реквизит 1С имеет свойства, в которых указано какой вид значения хранится в реквизите (строка, число и т.п.) и как с ним будет работать пользователь.
Нажмите правой кнопкой на любой реквизит 1С и нажмите Свойства. В окне справа откроется список свойств выбранного реквизита.

Основные свойства реквизитов 1С:
- Имя – наименование реквизита 1С в языке 1С (внимание – в имени реквизитов не должно быть пробелов и знаков препинания)
- Синоним – наименование реквизита каким его увидит пользователь в режиме Предприятие
- Тип – указывает какие данные можно будет хранить в реквизите 1С, нажмите на кнопку «…», чтобы изменить тип; основные типы:
o Число — используется для цифр, а также для радиопереключателя
o Строка — может быть ограничена по длине, дело в том, что не везде возможно использование неограниченной длины
o Дата
o Булево — для того, чтобы на форме была галочка (значения Истина/Ложь или Да/Нет)
o СправочникСсылка или ДокументСсылка – выбор значения справочника или документа.
Вы можете поставить галочку Составной тип данных и тогда 1С позволит Вам выбрать несколько типов данных одновременно. В этом случае пользователю будет отображаться кнопка Т, при нажатии на которых он выберет какие данные он хотел бы ввести.
- Использование –можно сделать разные реквизиты (поля) для элемента справочника и для группы справочника
- Индексировать – требуется включать для тех реквизитов, по которым будет сортировка и поиск, однако нельзя включить для всех вообще – будет работать медленно.


Стандартные реквизиты 1С
Как Вы заметили, на форме справочника есть реквизиты 1С, которые отсутствуют в списке в конфигураторе: группа, наименование, БИК.

В форме списка справочника тоже есть реквизиты 1С, которых нет в списке: пометка удаления.

Это – стандартные реквизиты 1С. Что это такое? У каждого объекта 1С есть набор реквизитов 1С по умолчанию. У справочников это, например – код и наименование. У документов это – дата и номер.
Стандартные реквизиты 1С можно посмотреть следующим образом:
- Зайдите в редактор объекта 1С (справочника или документа), нажав на него два раза мышкой
- В открывшемся редакторе выберите закладку Данные
- Здесь Вы можете настроить стандартные реквизиты Код и Наименование справочника
- Нажмите кнопку Стандартные реквизиты 1С, чтобы посмотреть полный список.

Общие реквизиты 1С
Начиная с версии 1С 8.2.14 в 1С появился новый Объект 1С – Общие реквизиты 1С. С помощью него можно добавить реквизит (поле), который будет присутствовать сразу во множестве справочников и документов.

Свойства общего реквизита 1С:
- Автоиспользование – добавляет общий реквизит 1С сразу во все справочники и документы
- Состав – позволяет добавить общий реквизит 1С только в нужные справочники и документы (автоиспользование тогда в значение Не использовать).

Как добавить реквизит 1С
Нажмем правой кнопкой на ветку Реквизиты 1С нужного справочника и выберем Добавить.

Введем нужно Имя реквизита 1С, например «АдресОфиса» и синоним «Адрес офиса». Тип оставим по умолчанию Строка, но поставим галочку Неограниченная длина.

Добавим еще один реквизит 1С точно так же, только выберем тип Булево, назовем его «РаботаетПоВыходным».
Как вывести реквизит на форму 1С (толстый клиент 1С)
Раскроем ветку Формы того же справочника. Чтобы открыть форму — выберем форму элемента и нажмем на нее два раза мышкой.

Потяните мышкой за край формы и растяните ее (необязательный пункт).

В панели конфигуратора нажмите кнопку «Размещение данных». Также можно использовать меню Форма / Размещение данных.

Вы видите – наши реквизиты на форму не выведены. Установите на них галочку. А также галочки Вставить надписи и Разместить автоматически.

Вуаля!

Как вывести реквизит на форму 1С (тонкий клиент 1С)
Раскроем ветку Формы того же справочника. Выберем форму элемента и нажмем на нее два раза мышкой.

На закладке Реквизиты раскройте строку Объект. Вы увидите список реквизитов, добавленных ранее в справочник.

Теперь просто перетяните из правого окна в левую нужный реквизит и он появится на форме.

Вуаля!

Реквизиты формы 1С
В толстом клиенте у формы есть свои собственные реквизиты. Они находятся на закладке Реквизиты.

Эти реквизиты не сохраняются в базе данных, однако их можно использовать на форме для полей, которые нужны для работы с формой.

Например, Вы добавили на форму галочку. При ее нажатии на форме что-то происходит. Значение галочки для Вас неважно (записывать его не нужно) – она используется только для переключения формы при работе с ней. В этом случае в качестве данных Вы используете не реквизит справочника, а реквизит формы.

Периодические реквизиты 1С
В 1С версии 7.7 были периодические реквизиты. Их смысл таков: значение у реквизита разное в разные даты. Например, значение на 1 сентября – одно, а на 1 октября – другое. У одного и того же реквизита.
В 1С 8 периодических реквизитов нет. Это реализуется следующим образом:
- Добавляем регистр сведений и делаете его периодическим. Период может быть – секунда, день, месяц, квартал, год.
- Добавляем измерение, у которого тип – нужный нам справочник (которому мы делаем периодический реквизит)
- Добавляем в регистр сведений нужный реквизит (или несколько). Они будут периодические.
- Теперь пользователь в форме элемента выбирает меню Перейти / ИмяСозданногоРегистра и может смотреть и изменять периодические реквизиты. Возможно вывести их на форму, но в этом случае придется дополнительно программировать.




![]() Загрузка…
Загрузка…
Дополнительные индексы для баз 1С [1130][8] AdminITD — 2019-02-18 21:02:54 |

|
Источник публикации
Автор: Юрий Пермитин
Создаем свои индексы для баз 1С. Со своей структурой и настройками!
О чем речь
Это всего лишь еще одна статья об избитой теме неплатформыенных индексов в информационных базах платформы 1С. Мы поговорим о “плохих” практиках тюнинга, которые с одной стороны запрещены лицензионным соглашением фирмы 1С, а с другой являются наиболее эффективным средством оптимизации производительности запросов. Эдакий запретный плод!
Не рекомендуется к прочтению, если к Вам относится хотя бы один из следующих пунктов:
Используется файловый режим работы информационной базы
Нет никаких проблем производительности и стабильности информационной системы
Считаете большой ошибкой выход за пределы экосистемы платформы 1С
Вы сотрудник фирмы “1С”
Все, что Вы прочитаете далее, должно остаться внутри Вашей головы и никогда не переходить в практическую плоскость. Еще раз повторяю: все что сказано далее — это плохие практики, нерекомендуемые фирмой “1С” и нарушающие ее лицензионное соглашение, противоречащие материалам подготовки к экзамену “1С:Эксперт по технологическим вопросам”, снижающие карму и просто имеющие подводные камни планетарного масштаба.
Будете читать дальше? Тогда отлично, поехали!
Зачем все это
Платформа 1С создает множество индексов самостоятельно по настройкам объектов метаданных конфигурации. Также разработчики сами могут в ограниченном режиме влиять на создание и изменение индексов. Самую полную информацию о платформенных индексах смотрите здесь.
Посмотрели? Задаетесь вопросом почему нужны еще какие-то дополнительные индексы?
Ответ на этот вопрос простой. Он даже проще, чем можно себе представить!
Индексы нужны для повышения эффективности запросов на чтение при поиске данных. При этом вариантов выборки данных, фильтров, группировок и порядка сортировки может быть огромное количество. Чем больше полей в таблице, тем больше этих вариантов. Даже чисто гипотетически трудно себе представить ситуацию, когда платформенные индексы могли бы полностью удовлетворить большую часть запросов. Частично — может быть, полностью — никогда.
Ситуация усугубляется еще и тем, что добавление индексов через свойство полей «Индексировать» в конфигураторе имеет примитивные возможности для их настройки. Фактически, Вы можете только выбрать три варианта (да и то не всегда):
- Не индексировать (с этим и так все понятно)
- Индексировать (индекс по выбранному полю + доп. поля для уникальности комбинации значений)
- Индексировать с дополнительным упорядочиванием (индекс по выбранному полю + поля упорядочивания, по которым обычно сортируют данные этой таблицы)
Повторюсь, что примеры того, как влияют эти настройки на индексы можно посмотреть здесь. Почему же этих вариантов недостаточно?
Вот Вам пару вопросов для обдумывания:
- А что если нужно создать индекс сразу по нескольким реквизитам?
- А если нужен индекс по пометке удаления?
- Как построить эффективный индекс по любому полю с типом “Булево”?
- Как добавить индексы в служебные таблицы, недоступные непосредственно в метаданных конфигурации (некоторые основные таблицы, таблицы итогов и др.?
- Можно ли сделать покрывающий индекс, чтобы исключить операции Lookup к основной таблице или кластерному индексу?
Таких вопросов можно задавать много. Вы говорите, что все это можно решить средствами платформы? Или что это все не нужно и разработчики конфигурации просто ошиблись в архитектуре. Тогда прошу напишите в комментариях Ваши решения, но у меня будет лишь пару вопросов:
- Почему бы не использовать произвольные индексы на уровне базы данных с произвольной структурой и настройками?
- Для чего тогда были придуманы фильтрованные индексы, покрывающие индексы, произвольные составные индексы, если платформа 1С их не использует?
Индекс сразу по нескольким реквизитам
Предположим, что у нас есть справочник “ФизическиеЛица” следующей структуры (некоторые поля пропущены). В самой таблице примерно 2 млн. записей.

В конфигурации есть запрос поиска физического лица по комбинации полей Фамилия + Имя + Отчество + ДатаРождения:
ВЫБРАТЬ ФизическиеЛица.Ссылка КАК Ссылка ИЗ Справочник.ФизическиеЛица КАК ФизическиеЛица ГДЕ ФизическиеЛица.Фамилия = &Фамилия И ФизическиеЛица.Имя = &Имя И ФизическиеЛица.Отчество = &Отчество И ФизическиеЛица.ДатаРождения = &ДатаРождения
Чтобы ускорить поиск и исключить операции полного сканирования таблицы справочника необходимо создать индекс. Какой бы индекс Вы создали средствами платформы?
Конечно, можно поставить свойство “Индексирование” в “Индексировать” для каждого реквизита, но что это даст? СУБД сможет использовать один индекс в каждой конкретной операции плана запроса, при этом также будет учитываться актуальность статистики. Запрос 1С конвертируется в такой SQL-запрос.
SELECT T1._IDRRef FROM dbo._Reference477 T1 WHERE ((T1._Fld1551 = @P1)) -- Разделитель данных, есть во всех типовых конфигурациях AND ((T1._Fld105061 = @P2) -- Фамилия AND (T1._Fld105062 = @P3) -- Имя AND (T1._Fld105063 = @P4) -- Отчество AND (T1._Fld11066 = @P5)) -- Дата рождения
Взгляните на план его выполнения ниже (некоторые части разбиты на несколько строк для удобства чтения).
Nested Loops(Inner Join, OUTER REFERENCES:([T1].[_IDRRef], [T1].[_Fld1551]) OPTIMIZED)
Merge Join(Inner Join,
MERGE:([T1].[_Fld1551], [T1].[_IDRRef])=([T1].[_Fld1551], [T1].[_IDRRef]),
RESIDUAL:([DB].[dbo].[_Reference477].[_Fld1551] as [T1].[_Fld1551] = [DB].[dbo].[_Reference477].[_Fld1551] as [T1].[_Fld1551]
AND [DB].[dbo].[_Reference477].[_IDRRef] as [T1].[_IDRRef] = [DB].[dbo].[_Reference477].[_IDRRef] as [T1].[_IDRRef]))
Index Seek(OBJECT:([DB].[dbo].[_Reference477].[_Reference477_ByFieldFld11066] AS [T1]),
SEEK:([T1].[_Fld1551]=[@P1] AND [T1].[_Fld11066]=[@P5]) ORDERED FORWARD)
Index Seek(OBJECT:([DB].[dbo].[_Reference477].[_Reference477_ByFieldFld105062] AS [T1]),
SEEK:([T1].[_Fld1551]=[@P1] AND [T1].[_Fld105062]=[@P3]) ORDERED FORWARD)
Clustered Index Seek(OBJECT:([DB].[dbo].[_Reference477].[_Reference477HPK] AS [T1]),
SEEK:([T1].[_Fld1551]=[DB].[dbo].[_Reference477].[_Fld1551] as [T1].[_Fld1551]
AND [T1].[_IDRRef]=[DB].[dbo].[_Reference477].[_IDRRef] as [T1].[_IDRRef]),
WHERE:([DB].[dbo].[_Reference477].[_Fld105061] as [T1].[_Fld105061]=[@P2]
Описание основных действий при выполнении плана запроса следующие:

Итог:
- 419 логических чтений
- 11 миллисекунд времени выполнения
- 16 миллисекунд CPU
- Выборка некоторых частей плана запроса отбирает 10000 записей, но в итоговый результат отбирается всего 1
4 индекса, а эффективности никакой. Создадим свой индекс с произвольными полями и нужной структурой:
CREATE UNIQUE NONCLUSTERED INDEX [_ByNameAndBirthday] ON [dbo].[_Reference477] ( [_Fld105061] ASC, -- Фамилия [_Fld105062] ASC, -- Имя [_Fld105063] ASC, -- Отчество [_Fld11066] ASC, -- Дата рождения [_IDRRef] ASC -- Ссылка )
Выполним запрос поиска еще раз и вот результат:
Index Seek(OBJECT:([DB].[dbo].[_Reference477].[_ByNameAndBirthday] AS [T1]),
SEEK:([T1].[_Fld105061]=[@P2] AND [T1].[_Fld105062]=[@P3]
AND [T1].[_Fld105063]=[@P4] AND [T1].[_Fld11066]=[@P5]),
WHERE:([DB].[dbo].[_Reference477].[_Fld1551] as [T1].[_Fld1551]=[@P1]) ORDERED FORWARD)
План запроса стал значительно проще:

Итог:
- 337 логических чтений
- 2 миллисекунд времени выполнения
- 0 миллисекунд CPU (фактически значение незначительное, поэтому не было отловлено трассировкой)
- План выполнения содержит только одну операцию “Index Seek”, которая фактически читает только 1 строку.
Пусть Вас не смущает, что запрос и в начальном варианте выполнялся быстро, ведь это только простой пример. Представьте рабочее окружение, тысячи или десятки тысяч запросов. Тогда разница даже на таких часто выполняемых запросах будет заметна!
Результаты говорят сами за себя. Создать подобный индекс средствами платформы 1С просто нет возможности. Но теперь Вы знаете, какой огромный потенциал для оптимизации у Вас есть.
Индекс по пометке удаления
Еще один наглядный пример — это индекс по пометке удаления. Средствами платформы добавить индекс по пометке удаления нет возможности, т.к. это стандартный реквизит и настройка “Индексирование” для него просто недоступна. Немного приблизим задачу к настоящей и скажем, что нужно отбирать помеченные на удаление элементы с учетом реквизита “ДатаСоздания”.
И так, платформа не даст создать такой индекс, но мы то знаем решение!
CREATE NONCLUSTERED INDEX [_ByDeletionMarkAndCreationDate] ON [dbo].[_Reference477] ( [_Marked] ASC, -- Пометка удаления [_Fld115447] ASC,-- Дата создания [_IDRRef] ASC -- Ссылка ) -- Сделаем фильтрованный индекс -- В индекс попадают только те записи, у которых установлена пометка удаления WHERE [_Marked] = 0x01
Что это за условие “WHERE”? SQL Server поддерживает фильтрованные индексы, в которых можно ограничить какие данные в него попадут. Если нужна более подробная информация, то Welcome! Самое главное, что нужно знать — фильтрованные индексы улучшают производительность, качество плана выполнения, расходы на обслуживание и хранение. Очень жаль, что платформа 1С не использует такие возможности СУБД.
Проверим новый индекс запросом:
ВЫБРАТЬ ФизическиеЛица.Ссылка КАК Ссылка ИЗ Справочник.ФизическиеЛица КАК ФизическиеЛица ГДЕ ФизическиеЛица.ПометкаУдаления И ФизическиеЛица.ДатаСоздания МЕЖДУ &НачалоПериода И &КонецПериода
И вот план запроса:
Nested Loops(Inner Join, OUTER REFERENCES:([Expr1007], [Expr1008], [Expr1009]))
Merge Interval
Concatenation
Compute Scalar(DEFINE:(([Expr1002],[Expr1003],[Expr1001])
=GetRangeWithMismatchedTypes([@P2],NULL,(22))))
Constant Scan
Compute Scalar(DEFINE:(([Expr1005],[Expr1006],[Expr1004])
=GetRangeWithMismatchedTypes(NULL,[@P3],(42))))
Constant Scan
Index Seek(OBJECT:([DB].[dbo].[_Reference477].[_ByDeletionMarkAndCreationDate] AS [T1]),
SEEK:([T1].[_Marked]=0x01 AND [T1].[_Fld115447] > [Expr1007] AND [T1].[_Fld115447] < [Expr1008]),
WHERE:([DB].[dbo].[_Reference477].[_Fld1551] as [T1].[_Fld1551]=[@P1]) ORDERED FORWARD)
То что надо! Подробно, как в прошлый раз, описывать план запроса не будем, но вот что стоит заметить: единственная значимая операция здесь — это “Index Seek”, которая как-раз и использует наш новый индекс “_ByDeletionMarkAndCreationDate”. Никаких обращений к основной таблице / кластерному индексу не выполнялось, то есть индекс полностью удовлетворяет условиям и полям выборки запроса, является покрывающим.
Итог:
- Время выполнения 7 миллисекунд
- Количество логических чтений = 459
- Время затраченное CPU 16 миллисекунд
- План запроса простейший, самая значимая часть — это поиск по индексу “_ByDeletionMarkAndCreationDate”
- Количество прочитанных строк — 3 (столько помеченных на удаление элементов за указанный период)
Для интереса создадим такой же индекс, но без фильтра по пометке удаления. Т.к. пример слишком простой, то разницы в результатах выполнения запроса мы не увидим, но размеры индексов будут разительно отличаться:
- фильтрованный индекс занимает 1 страницу и включает в себя 3 строки конечного уровня.
- полный индекс занимает 10319 страниц и содержит 2451400 строк конечного уровня.
А если не видно разницы, то зачем платить больше?
Таким же способом можно добавлять индексы для любых полей с типом “Булево” и это всегда будет эффективнее, чем добавлять индексы платформенными средствами.
Покрывающий индекс
Конечно, и мы это уже сделали в двух предыдущих примерах, где созданные некластерные индексы полностью удовлетворяли условиям и выбираемым полям в запросе.
Покрывающий индекс — это такой индекс, который полностью удовлетворяет условиям запроса. В таких случаях в планах запроса будут отсутствовать операции типа Key Lookup, “добирающие” необходимые поля из таблицы или кластерного индекса (если у таблицы нет кластерного индекса, то операция называется RID Lookup).
Можно лишь добавить, что злоупотреблять покрывающими индексами не стоит и нужно хорошо подумать, прежде чем их создавать. Но это относится вообще ко всем индексам, подходите к ним с умом. Покрывающие индексы могут создаваться либо включением необходимых полей непосредственно в индексируемые поля, либо в покрывающие поля (INCLUDE). Например, можно создать индекс по ФИО + ДатеРождения, но дополнить его полями “Наименование” и “Код”. Главное — это возможность значительно повысить производительность за счет включения в индекс всех необходимых для запроса полей без учета ограничения длины ключа и типов данных.
CREATE UNIQUE NONCLUSTERED INDEX [_IncludeIndex] ON [dbo].[_Reference477] ( [_Fld105061] ASC, -- Фамилия [_Fld105062] ASC, -- Имя [_Fld105063] ASC, -- Отчество [_Fld11066] ASC, -- Дата рождения [_IDRRef] ASC -- Ссылка ) INCLUDE ( -- Включенные столбцы [_Code], -- Код [_Description] -- Наименование )
Теперь, если выполнить запрос из предыдущего примера, но с выбором полей “Наименование” и “Код”, то новый индекс позволит выполнить его максимально эффективно.
ВЫБРАТЬ ФизическиеЛица.Ссылка КАК Ссылка, ФизическиеЛица.Наименование, ФизическиеЛица.Код ИЗ Справочник.ФизическиеЛица КАК ФизическиеЛица ГДЕ ФизическиеЛица.Фамилия = &Фамилия И ФизическиеЛица.Имя = &Имя И ФизическиеЛица.Отчество = &Отчество И ФизическиеЛица.ДатаРождения = &ДатаРождения
А теперь представьте какие возможности бы у нас были, если бы такие индексы можно было настраивать через метаданные конфигурации.
Как добавить индексы в служебные таблицы
Рассмотрим еще один пример, когда неплатформенные индексы являются единственным эффективным решением. Оговорюсь — можно будет не создавать в этом случае индекс, а делать костыли в виде дополнительных объектов метаданных, которые обрастут различными обработчиками, проверками и т.д., но это явно не лучший путь.
Итак, у нас есть регистр бухгалтерии “Хозрасчетный”. Думаю, что все с ним знакомы. В конфигурации есть запросы к физической таблице регистра нескольких видов.
ВЫБРАТЬ Хозрасчетный.Регистратор, Хозрасчетный.НомерСтроки, Хозрасчетный.СчетКт, Хозрасчетный.Сумма ИЗ РегистрБухгалтерии.Хозрасчетный КАК Хозрасчетный ГДЕ Хозрасчетный.Активность = &Активность И Хозрасчетный.СчетДт = &СчетДт И Хозрасчетный.Период МЕЖДУ &НачалоПериода И &КонецПериода
А также вот такой запрос:
ВЫБРАТЬ Хозрасчетный.Регистратор, Хозрасчетный.НомерСтроки, Хозрасчетный.СчетДт, Хозрасчетный.Сумма ИЗ РегистрБухгалтерии.Хозрасчетный КАК Хозрасчетный ГДЕ Хозрасчетный.Активность = &Активность И Хозрасчетный.СчетКт = &СчетКт И Хозрасчетный.Период МЕЖДУ &НачалоПериода И &КонецПериода
Индексов в основной таблице регистра бухгалтерии, которые бы удовлетворяли этим запросом, просто нет. Частично запросы покрываются индексом по счету ДТ и индексом по счету КТ, но с некоторыми оговорками:
- Необходимо обязательно указать фильтр по организации, чтобы фильтр по периоду работал эффективно.
- Платформенные индексы не учитывают флаг активности проводок, т.к. судя по всему изначально задумывалось, что большинство данных будет получаться из виртуальных таблиц (но это не точно
- Нет ни одного покрывающего индекса, который бы полностью удовлетворял запросам в т.ч. и по выбираемым полям.
На индексы физической таблицы регистров бухгалтерии можно влиять в ограниченном режиме с помощью настроек метаданных. Но в любом случае, включать в индексы такие поля как “Активность”, “СчетДТ”, “СчетКТ” не получится. В этом случае можно создать два неплатформенных индекса.
-- Индекс для первого запроса CREATE NONCLUSTERED INDEX [_CustomIndex1] ON [dbo].[_AccRg1595] ( [_Fld1551] ASC, -- Разделитель данных [_AccountDtRRef] ASC, -- Счет ДТ [_Period] ASC, -- Период [_Active] ASC -- Активность ) INCLUDE ( [_RecorderTRef], [_RecorderRRef], -- Регистратор [_LineNo], -- Номер строки [_AccountCtRRef], -- Счет КТ [_Fld1599] -- Сумма ) -- Индекс для второго запроса CREATE NONCLUSTERED INDEX [_CustomIndex2] ON [dbo].[_AccRg1595] ( [_Fld1551] ASC, -- Разделитель данных [_AccountCtRRef] ASC, -- Счет ДТ [_Period] ASC, -- Период [_Active] ASC -- Активность ) INCLUDE ( [_RecorderTRef], [_RecorderRRef], -- Регистратор [_LineNo], -- Номер строки [_AccountDtRRef], -- Счет КТ [_Fld1599] -- Сумма )
Подробнее на этом примере останавливаться не будем, главное было показать, что таким подходом можно оптимизировать запросы к любым таблицам, в т.ч. и служебным, которые скрыты от разработчиков 1С: таблицы итогов, некоторые части физических таблиц и др.
Например, в одной из версий платформы были проблемы с таблицами итогов среза первых и среза последних для регистров сведений. Суть проблемы была в отсутствии кластерного индекса для этих таблиц, в результате чего запросы к ним выполнялись не самым оптимальным способом. Но с помощью “магии” неплатформенных индексов эту ситуацию можно было бы быстро исправить, а так пришлось бы ждать версии 8.3.13, в которой эта проблема была решена.
Заключение
Главных подводный камень и просто неприятность при использовании описанного подхода индексации — при реструктуризации базы данных средствами платформы 1С все те индексы, что Вы создадите скриптами самостоятельно — будут удалены. Вам потребуется заново запустить эти скрипты после реструктуризации.
Тут сразу стоит оговориться, что удалены они будут только у тех таблиц, которые непосредственно и подверглись реструктуризации. Но этот факт не особо успокаивает, ведь всегда есть вероятность того, что при развертывании пакета обновления для конфигурации разработчик / администратор забудет запустить этот скрипт и на следующий день программа будет работать не как ожидалось. Ну, если это было обновление от поставщика конфигурации, то конечно всегда можно выкрутиться, что это дело именно в обновлении и в следующем релизе все поправят.
Не стоит забывать и про еще один подводный камень — это нарушение лицензионного соглашения фирмы “1С”, а именно 65 пункта, в котором явно сказано, что использовать недокументированные возможности нельзя ни при каких обстоятельствах, даже если сильно хочется. Думайте сами — решайте сами.
 |
|
|||
| Техник2___
08.11.05 — 14:53 |
Есть три варианта: Что эти все три варианта означают?
|
||
| Волшебник
Модератор 1 — 08.11.05 — 14:55 |
Возможность поиска и сортировки по реквизиту. |
||
| КонецЦикла
2 — 08.11.05 — 14:55 |
индексировать с дополнительным упорядочиванием — а это отбор что ли? |
||
| Волшебник
Модератор 3 — 08.11.05 — 14:58 |
(2) Это сортировка при отборе. |
||
|
Техник2___ 4 — 08.11.05 — 15:06 |
Спасибо. Вроде понятно |

Закон Брукера: Даже маленькая практика стоит большой теории.
![]()
Like
#0
by Техник2___
Есть три варианта: — индексировать с дополнительным упорядочиванием; Что эти все три варианта означают?
Like
#1
by Волшебник
Возможность поиска и сортировки по реквизиту.
Like
#2
by КонецЦикла
индексировать с дополнительным упорядочиванием — а это отбор что ли?
Like
#3
by Волшебник
Это сортировка при отборе.
Like
#4
by Техник2___
Спасибо. Вроде понятно 
Тэги:
Ответить:
Комментарии доступны только авторизированным пользователям
Регистрация
Похожие вопросы 1С
- ОткрытьФорму() с заполнением реквизитов документа
- запонение реквизитов документов из реквизитов справочников
- «Индексировать» и «Индексировать с доп. упорядочиванием»….?
- v8: Зачем в настройках кластера сервера 1С, предусмотрено защищенное соединение, что оно дает?
- Проверка значений реквизитов без указания реквизитов
- Индексировать или Индексировать с доп. порядочиванием
В этой группе 1С
- кто устанавливал кассовый аппарат на 1с
- Определить код родителя?
- Как написать SQL запрос на 1С при обращении к другой базе данных.
- Как из в8 обратится к ИспользоватьВладельца в 77 (OLE)?
- Как в отчете к наименованию добавить код?
- ЗУП и округление сумм к выплате.
- Как обновить конфигурацию Зарплаты и Управление Персоналом 1С.8.0
- Запрет ввода повторяющихся значений в ТЧ документа.
- Как получить значение реквизита типа справочник или перечисление (OLE)
- Как задать строку для поиска с кавычками?
- Отсутствует база распределения.
- ОФФ Прикольная фича: как легко проставить единицу хранения остатков.
- СправочникОбъект не всегда корректно записывается
- Разделить строку на подстроки
- Регистр сведений и диаграмма Ганта
- ТиС: Как отобразить поступление и реализацию услуг?
- Виснет конфигуратор при сохранении изменений.
- Подключить клиента 1С к SQL серверу
- бюджет отчет межформенный контроль где взять правила проверки
- Корректировка долга покупателя не встаёт в книгу продаж